Configuration-Invariant Sound Localization Technique Using Azimuth-Frequency Representation and Convolutional Neural Networks



Abstract
:1. Introduction
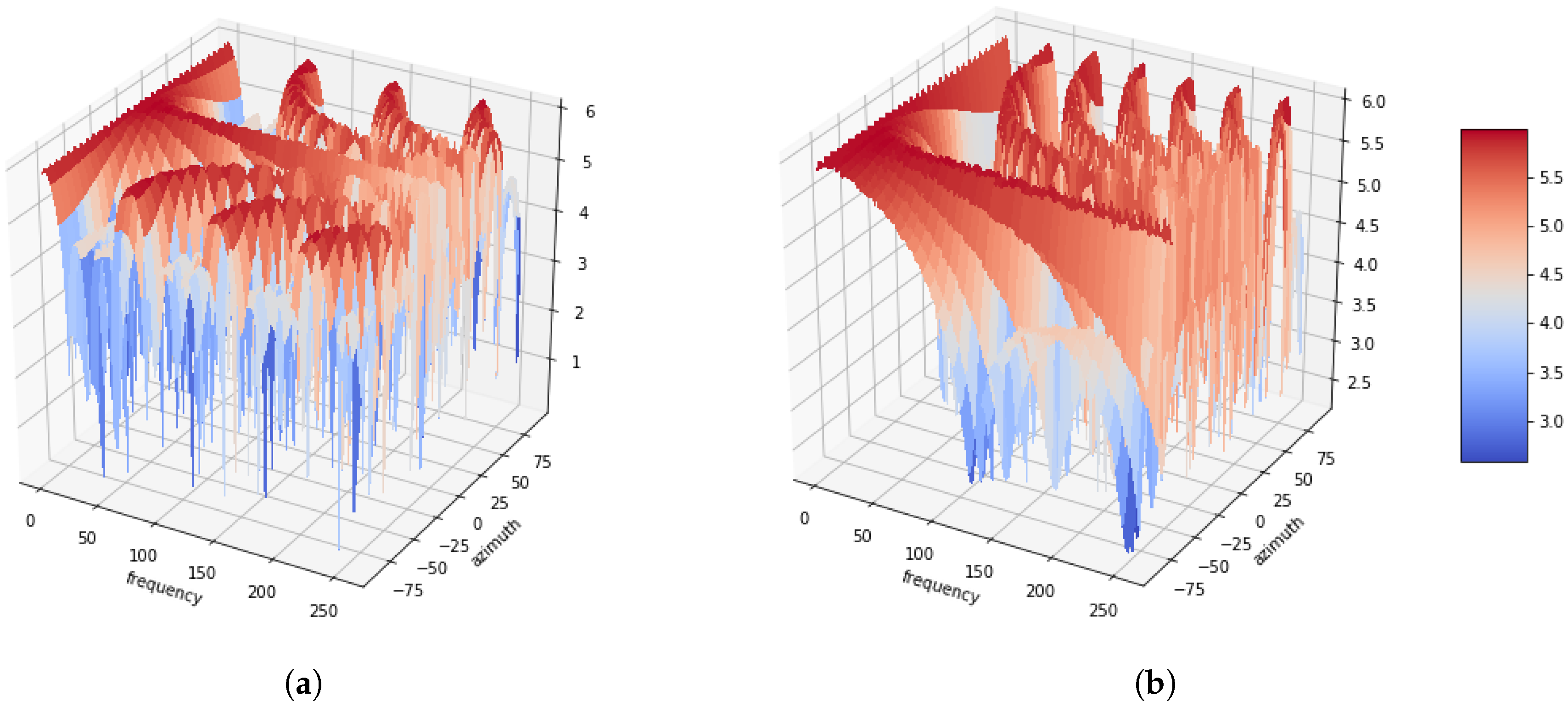
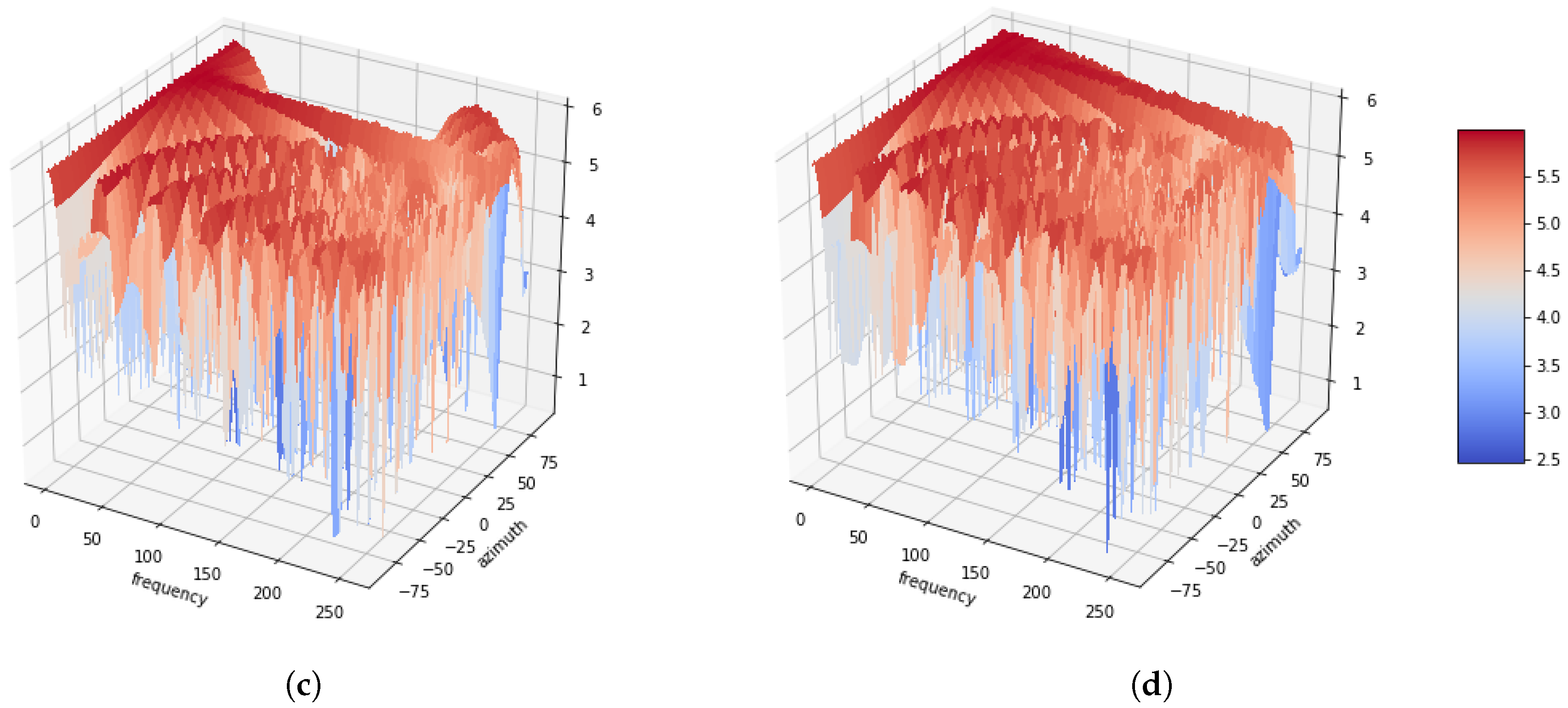
2. Azimuth-Frequency Representation from Sound Signal
3. Sound Localization using Convolutional Neural Network
3.1. Dataset
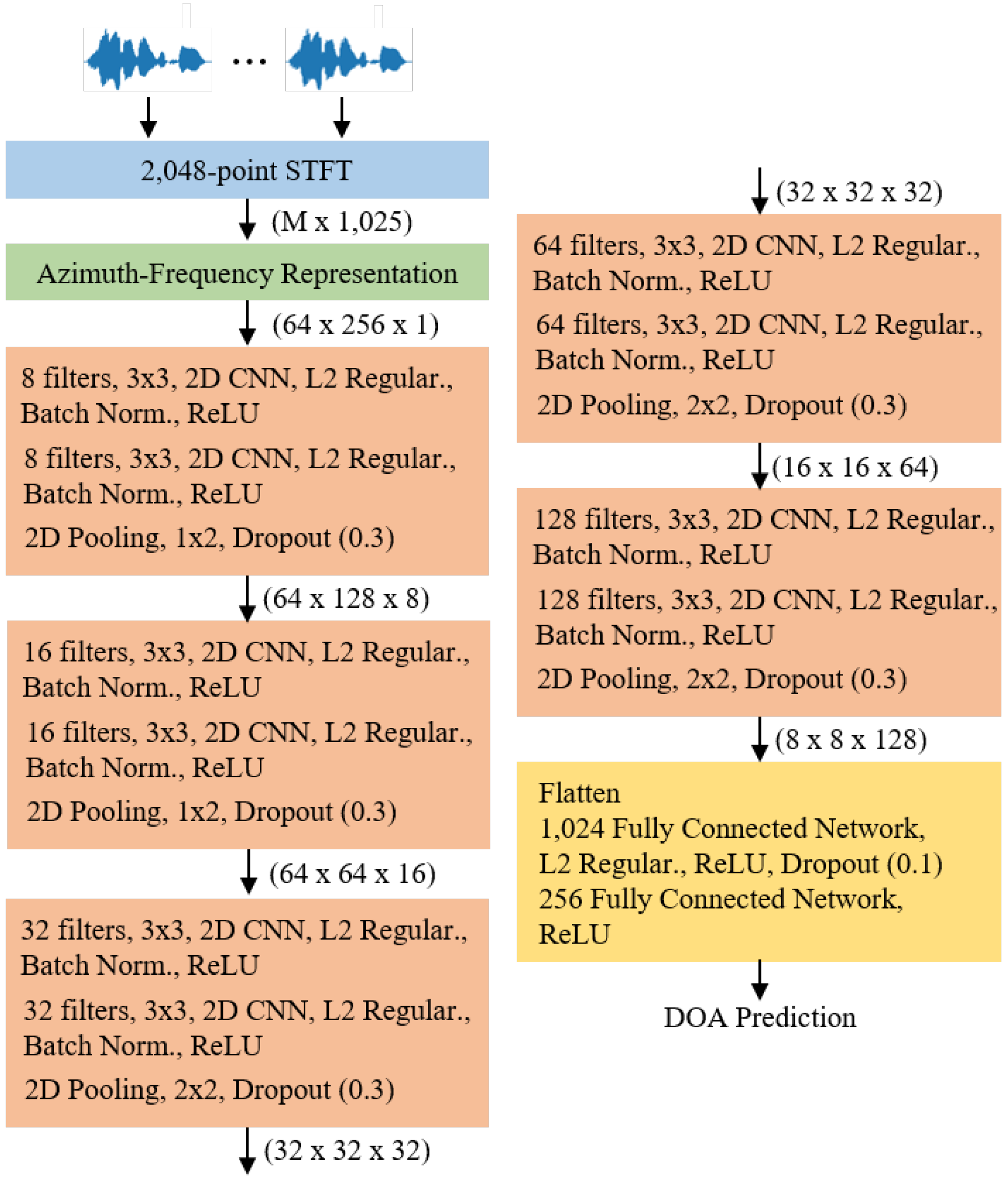
3.2. Neural Network
3.2.1. Architecture
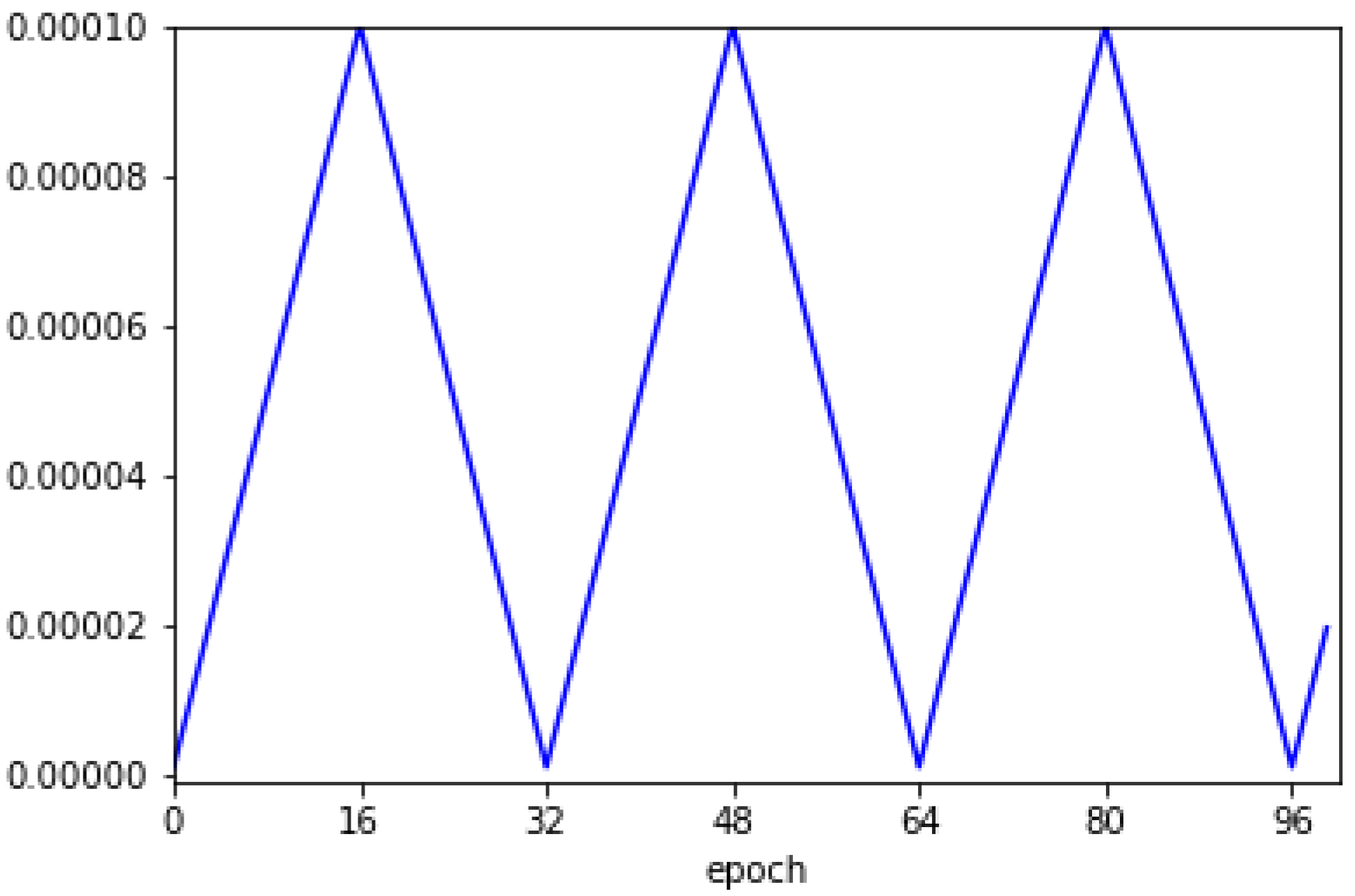
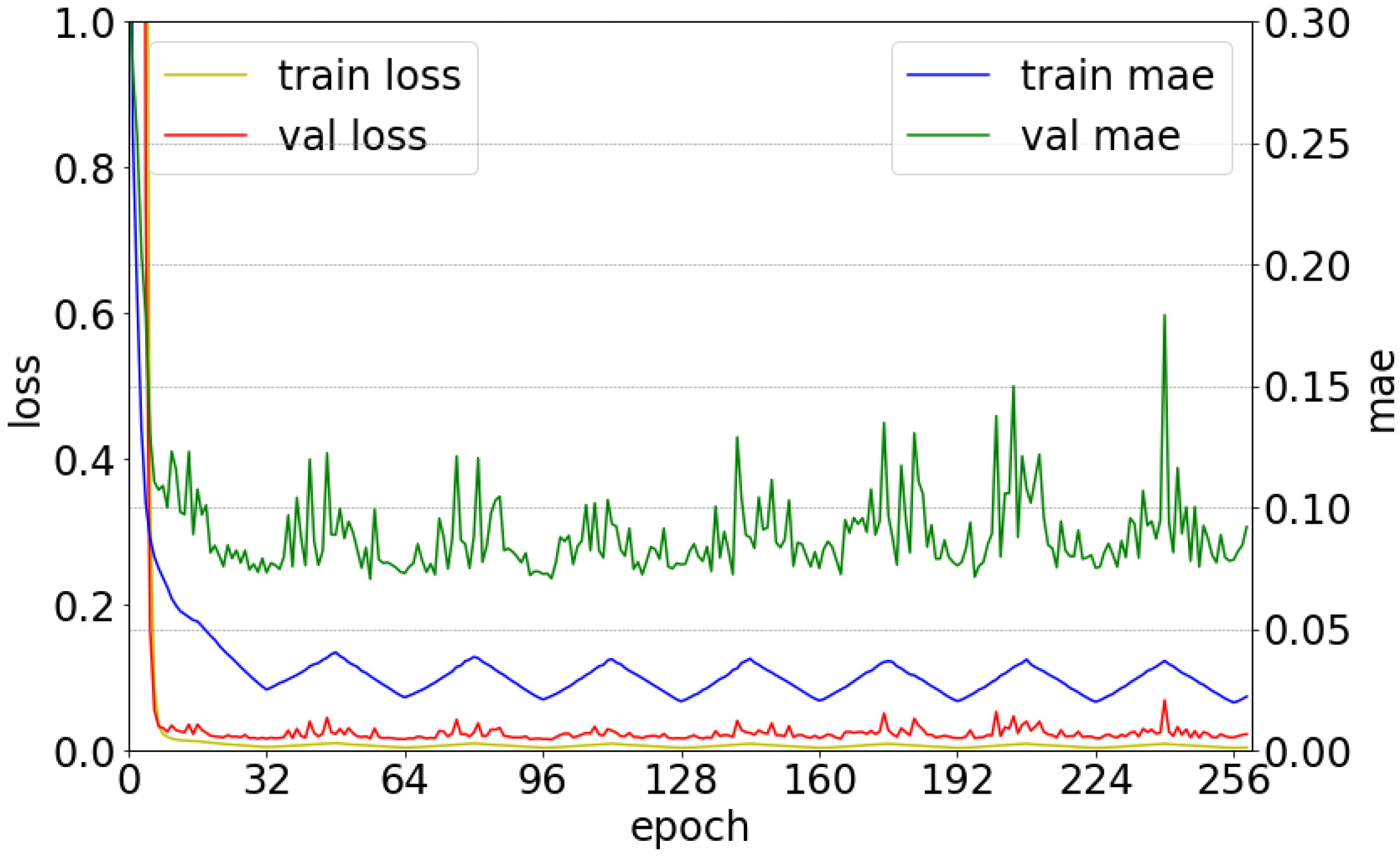
3.2.2. Training Method
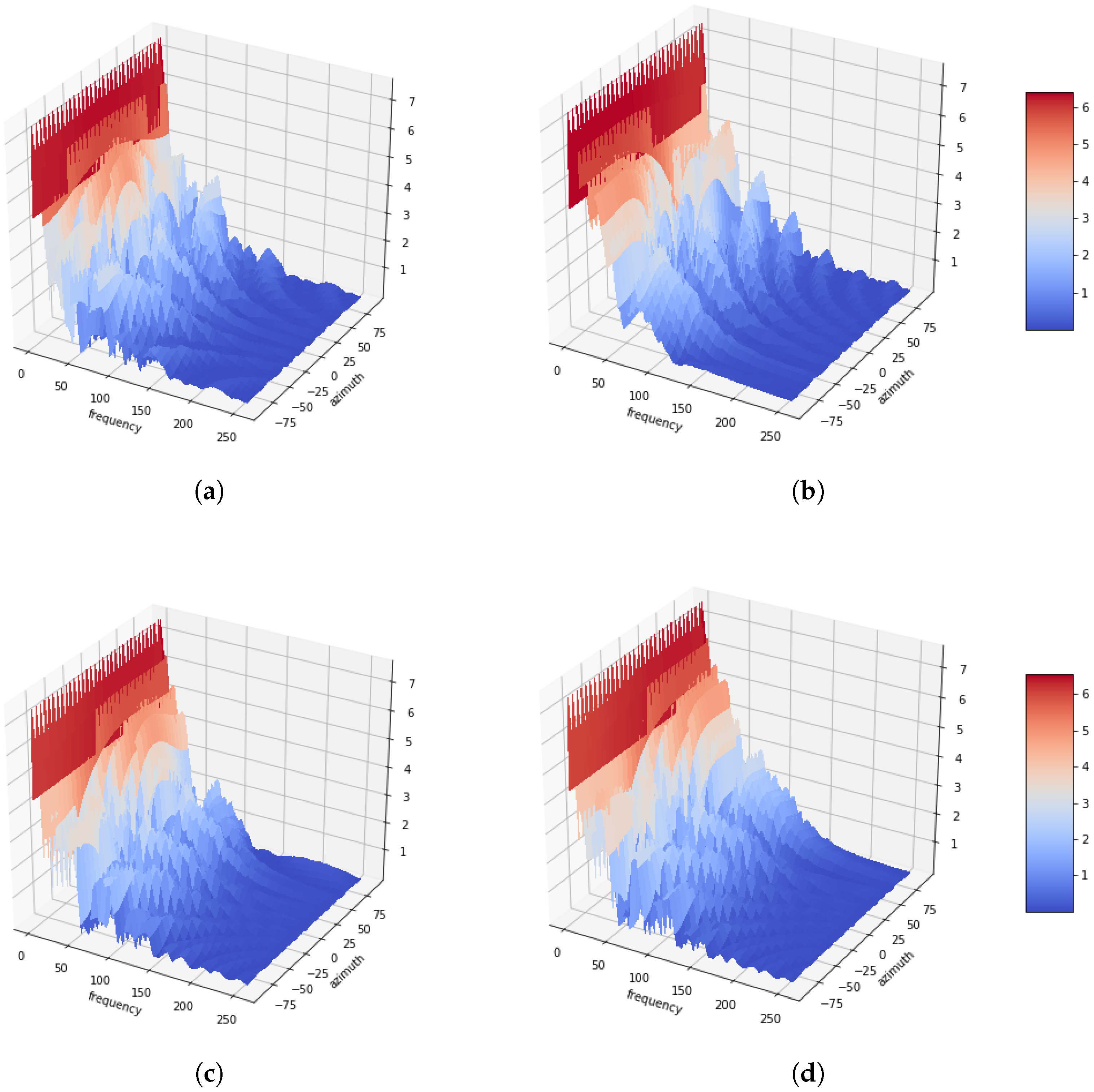
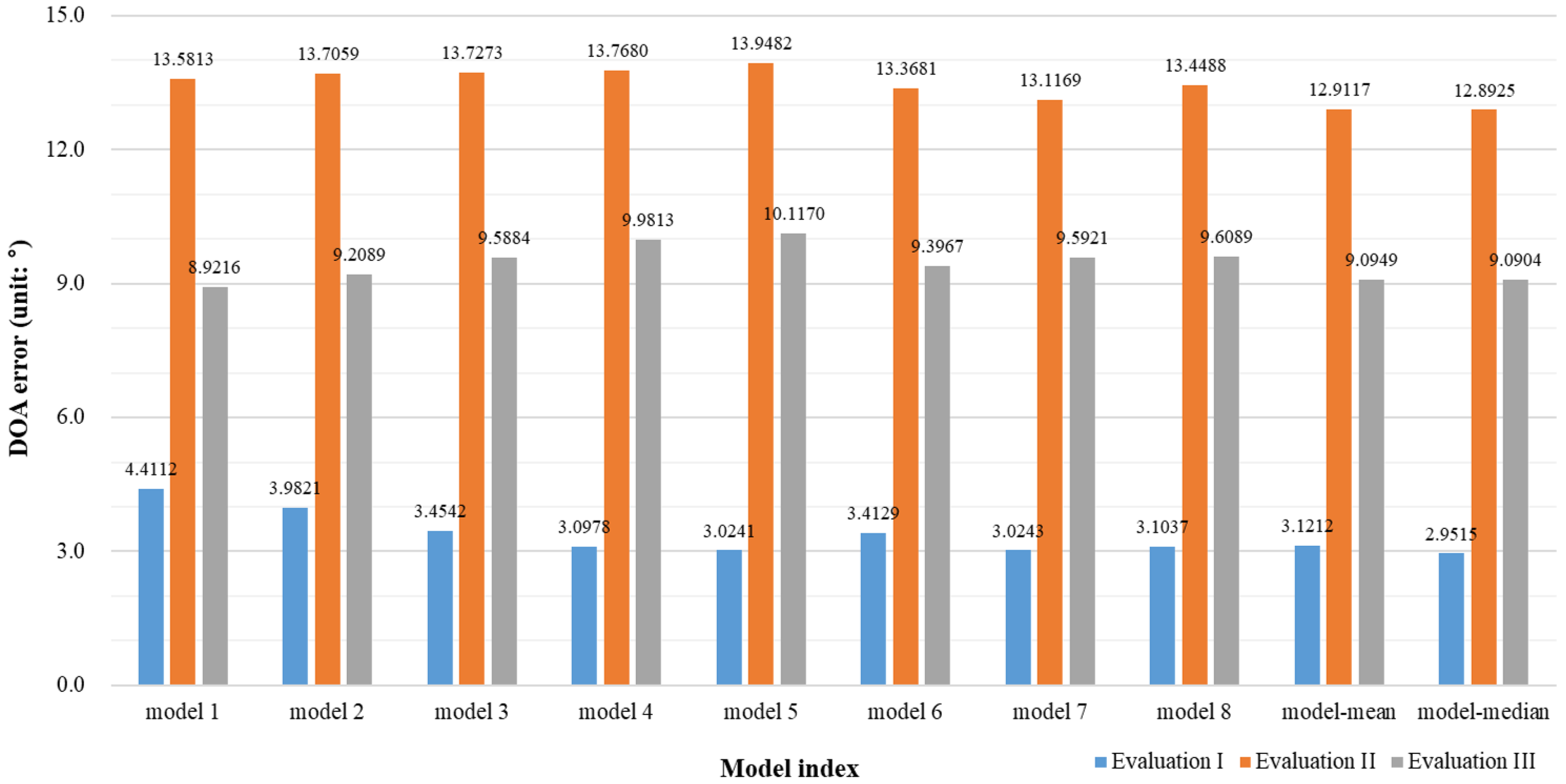
4. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Johnson, D.H.; Dudgeon, D.E. Array Signal Processing: Concepts and Techniques; Prentice Hall: Upper Saddle River, NJ, USA, 1992. [Google Scholar]
- Knapp, C.H.; Carter, G.C. The generalized correlation method for estimation of time delay. IEEE Trans. Acoust. Speech Signal Process. 1976, 24, 320–327. [Google Scholar] [CrossRef] [Green Version]
- DiBiase, J.H. A high-accuracy, low-latency technique for talker localization in reverberant environments using microphone arrays. Ph.D. Thesis, Brown University, Providence, RI, USA, 2000. [Google Scholar]
- Schmidt, R. Multiple emitter location and signal parameter estimation. IEEE Trans. Antennas Propag. 1986, 34, 276–280. [Google Scholar] [CrossRef] [Green Version]
- Takeda, R.; Komatani, K. Sound source localization based on deep neural networks with directional activate function exploiting phase information. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016. [Google Scholar] [CrossRef]
- Chakrabarty, S.; Habets, E.A.P. Broadband DOA estimation using convolutional neural networks trained with noise signals. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 15–18 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Chakrabarty, S.; Habets, E.A.P. Multi-speaker localization using convolutional neural network trained with noise. In Proceedings of the Neural Information Processing Systems (NeurIPS), Long Beach, LA, USA, 4–9 December 2017. [Google Scholar]
- Adavanne, S.; Politis, A.; Virtanen, T. Direction of arrival estimation for multiple sound sources using convolutional recurrent neural network. In Proceedings of the European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018. [Google Scholar] [CrossRef] [Green Version]
- Adavanne, S.; Politis, A.; Nikunen, J.; Virtanen, T. Sound event localization and detection of overlapping sources using convolutional recurrent neural networks. IEEE J. Sel. Top. Signal Process. 2018, 13, 34–48. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Allen, J.B.; Berkley, D.A. Image method for efficiently simulating small-room acoustics. J. Acoust. Soc. Am. 1979, 65, 943–950. [Google Scholar] [CrossRef]
- Bauer, B.B. Phasor analysis of some stereophonic phenomena. IRE Trans. Audio 1962, AU-10, 18–21. [Google Scholar] [CrossRef]
- Barry, D.; Lawlor, B. Sound source separation: Azimuth discrimination and resynthesis. In Proceedings of the International Conference on Digital Audio Effects (DAFX), Naples, Italy, 5–8 October 2004. [Google Scholar]
- Chun, C.J.; Kim, H.K. Frequency-dependent amplitude panning for the stereophonic image enhancement of audio recorded using two closely spaced microphones. Appl. Sci. 2016, 6, 39. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Krogh, A.; Hertz, J.A. A simple weight decay can improve generalization. In Proceedings of the Neural Information Processing Systems (NeurIPS), San Mateo, CA, USA, 2–5 December 1991; pp. 950–957. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Han, W.; Wu, C.; Zhang, X.; Sun, M.; Min, G. Speech enhancement based on improved deep neural networks with MMSE pretreatment features. In Proceedings of the International Conference on Signal Processing (ICSP), Chengdu, China, 6–10 November 2016. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J.L. ADAM: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. arXiv 2017, arXiv:1506.01186v6. [Google Scholar]
- Maclin, R.; Opitz, D. Popular ensemble methods: An empirical study. J. Artif. Intell. Res. 1999, 11, 169–198. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with warm restarts. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Scheibler, R.; Bezzam, E.; Dokmanić, I. Pyroomacoustics: A Python package for audio room simulations and array processing algorithms. arXiv 2017, arXiv:1710.04196v1. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Microphones | Spacing between Microphones (m) | Distance from Source to Microphone (m) | Position of Microphone Origin (m) | Room Size (m) | Reflection Coefficient | Number of Images | |
|---|---|---|---|---|---|---|---|
| 4 | 0.03 | 1.5 | [4, 1, 1.5] | [8, 6, 3.5] | 0.7 | 12 | |
| 2 | 0.03 | 1.2 | [3.5, 2, 1.4] | [7, 5, 3.3] | 0.8 | 15 | |
| 4 | 0.04 | 1.4 | [6, 1.5, 1.6] | [12, 6, 3.8] | 0.85 | 13 | |
| 8 | 0.03 | 1.8 | [5, 2.5, 1.7] | [10, 8, 4.2] | 0.72 | 15 |
| Speech I (Two Males, Two Females) | Speech II (One Male, One Female) | Speech III (One Male, One Female) | |
|---|---|---|---|
| Training | - | Evaluation I | |
| - | Validation | Evaluation II | |
| - | - | Evaluation III |
| Units (°) | Conventional | Proposed | ||
|---|---|---|---|---|
| MUSIC | SRP-PHAT | Mean | Median | |
| Evaluation I ( and ) | 30.4253 | 30.8505 | 3.1212 | 2.9515 |
| Evaluation II () | 31.1670 | 23.3249 | 12.9117 | 12.8925 |
| Evaluation III () | 21.5451 | 13.1966 | 9.0949 | 9.0904 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chun, C.; Jeon, K.M.; Choi, W. Configuration-Invariant Sound Localization Technique Using Azimuth-Frequency Representation and Convolutional Neural Networks. Sensors 2020, 20, 3768. https://doi.org/10.3390/s20133768
Chun C, Jeon KM, Choi W. Configuration-Invariant Sound Localization Technique Using Azimuth-Frequency Representation and Convolutional Neural Networks. Sensors. 2020; 20(13):3768. https://doi.org/10.3390/s20133768
Chicago/Turabian StyleChun, Chanjun, Kwang Myung Jeon, and Wooyeol Choi. 2020. "Configuration-Invariant Sound Localization Technique Using Azimuth-Frequency Representation and Convolutional Neural Networks" Sensors 20, no. 13: 3768. https://doi.org/10.3390/s20133768
APA StyleChun, C., Jeon, K. M., & Choi, W. (2020). Configuration-Invariant Sound Localization Technique Using Azimuth-Frequency Representation and Convolutional Neural Networks. Sensors, 20(13), 3768. https://doi.org/10.3390/s20133768