The hardware platform on which the experiments were run featured an Intel Core i7 @ 3.40 GHz × 8 CPU equipped with 32 GB DDR4 RAM.
4.3. Results on Oxford5k
To avoid the burden of operating a full grid search on the parameters of the GA, which would dramatically reduce the efficiency of our approach, we followed a greedy exploration of the space of the GA parameters, proceeding in what our experience suggested could be a reasonable order of relevance. This means we first set sensible “average” initial values for the other parameters and studied the dependence of the results on the number of generations (see
Table 1); we then set the number of generations as the one providing the best results in the previous test and tuned population size (see
Table 2) keeping the other parameters constant, and so on for the following parameters (
Table 3,
Table 4 and
Table 5).
The initial configuration of the GA was:
= 50,
,
,
. The number of generations and the population size have been set to different values in the range {10, …, 100}
(int), considering a potential maximum budget of 5000 fitness computations. As shown in
Table 1 and
Table 2, the best configurations correspond to the largest numbers of fitness computations (
,
and
,
). Since these configurations lead to the same mAP (
), the other parameters of the GA have been modified starting from the configuration that requires the lowest computation load (
,
).
Table 3 shows that the retrieval accuracy reaches its best value for a crossover probability (
) equal to
(
). Instead, for the mutation probability (
), the best results have been achieved with values
(
) and
(
), as shown in
Table 4. Considering the mutation probability for each gene (
), the highest mAP has been achieved with a value of
(
).
Therefore, as shown in
Table 5, the best set of parameters for the genetic algorithm thus obtained is:
,
,
,
,
. The corresponding configuration obtained for the diffusion parameters is:
,
,
,
,
,
,
.
Finally, since, on the one hand, we had obtained the same results as with 50 individuals and, on the other hand, running a larger number of iterations offers better chances to converge to the optimal solution, we also tested the final configuration changing the number of iterations to 100 (, , and ), obtaining a further slight improvement (). The corresponding configuration obtained for the diffusion parameters is: , , , , , , .
Given the stochastic nature of the GA, five independent runs of the algorithm have been executed to assess the repeatability of the results, obtaining an average mAP of . The results we obtained were very similar in all the runs, with a standard deviation very close to 0 (). The maximum mAP we obtained was equal to while the minimum was equal to . These results suggested there was no need to extend the number of runs to validate the procedure more robustly from a statistical viewpoint, considering also that the final results seem to be not too sensitive to small changes in the parameter settings. Instead, we have run 30 independent repetitions of the final optimization step to evaluate the statistical significance of the results we describe in the following.
Table 6 reports the results of different optimization techniques applied to image retrieval based on an approximate kNN graph and diffusion. For each method, the table shows the mAP of the best configuration found and the corresponding computational time needed for the optimization. In order to fairly compare the methods, all the experiments have been allowed to perform the same number of fitness evaluations.
Random search [
24], which is a global search technique, has sampled, in this case, 5 k or 10 k configurations modifying all the parameters according to a uniform statistical distribution. We also performed a grid search on 5 k or 10 k different parameter settings in which the values of the configurations were sampled according to a grid with pre-set step values. With the term “Manual configuration”, we refer to a setting of the diffusion parameters taken from the literature [
10] without subjecting it to any further optimization method. It represents the baseline solution for the problem and it is also the one which obtains the worst final results.
A metaheuristic such as a GA which, in a sufficiently long time, can converge to any possible combination of values within its search space is, in principle, preferable to a grid search. The latter is constrained to exploring a pre-set number of possible solutions, a large part of which would generally lie in poorly performing regions of the diffusion parameter space, which a smarter search would rule out after few evaluations. On the other hand, as we showed above, a GA needs some parameter tuning to perform at its best and, even after tuning, it cannot guarantee that, within a given time or fitness evaluation budget, its result will be better than those of a similarly computationally demanding grid search. However, if we observe the computational time reported in the tables for a grid search and a GA with equal budget in terms of number of settings to test, we observe that the GA converges to its best solution in a much shorter time. In fact, since the complexity of evaluating a parameter set is virtually the same whatever the context, the shorter time taken by the GA to converge indicates that it reaches a termination condition before using the whole budget. In addition, when the GA is close to convergence, it usually happens that some individuals in the population are identical. In that case, their fitness is evaluated only once for all of them, which also reduces convergence time.
This makes the complexity of a grid search comparable to testing a few settings of the GA, which, as we will see in the end, would be probably enough to find the optimal setting. A parallel version of the GA, distributed over five parallel processes during fitness evaluation, achieves the same result as the single-CPU GA execution in a much shorter time (6295 s).
In terms of model complexity, considering the minimum relative computation load that the application of genetic operators require with respect to a fitness evaluation, a complexity of O() can be attributed to a GA, where is the number of fitness evaluations. In terms of intrinsic memory allocation, a GA only needs to memorize the population and some punctual statistics, which is negligible with respect to the memory occupied by the data. We have compared the methods we have taken into consideration by assigning to each of them the same maximum budget in terms of fitness evaluations. In this regard, one can observe that DEAP checks the diversity (number of different individuals) of the population and computes only once the fitness of equal individuals that tend to be more and more as the population converges towards the optimum. This fact allows the GA to perform fewer fitness evaluations than the budget even when the MaxGen termination condition is chosen. The application of the termination conditions further reduces the number of fitness evaluations causing only a marginal performance decrease.
The final and most important outcome in favor of the GA is that, in all previously-reported experiments, the latter, in whatever configuration, has always performed better than manual configuration and random search and very closely to the grid search. The only exceptions are a few settings with very low values for some of the GA parameters, which were tested only to estimate a lower bound for their magnitude, below which it is actually unreasonable to go. Oddly enough, since the GA was tuned on Oxford5k, this dataset was the only one on which the best result of the GA did not clearly outperform the grid search. That happens, instead, on the other datasets, even without any further refinement of the GA settings, i.e., taking the settings computed on Oxford5k as a default configuration.
As described in
Section 3.3, we evaluated several stopping criteria for the GA. These termination conditions were based on the best fitness value obtained up to that generation or on the average or standard deviation of the fitness values of the population over subsequent generations. These trends are shown in
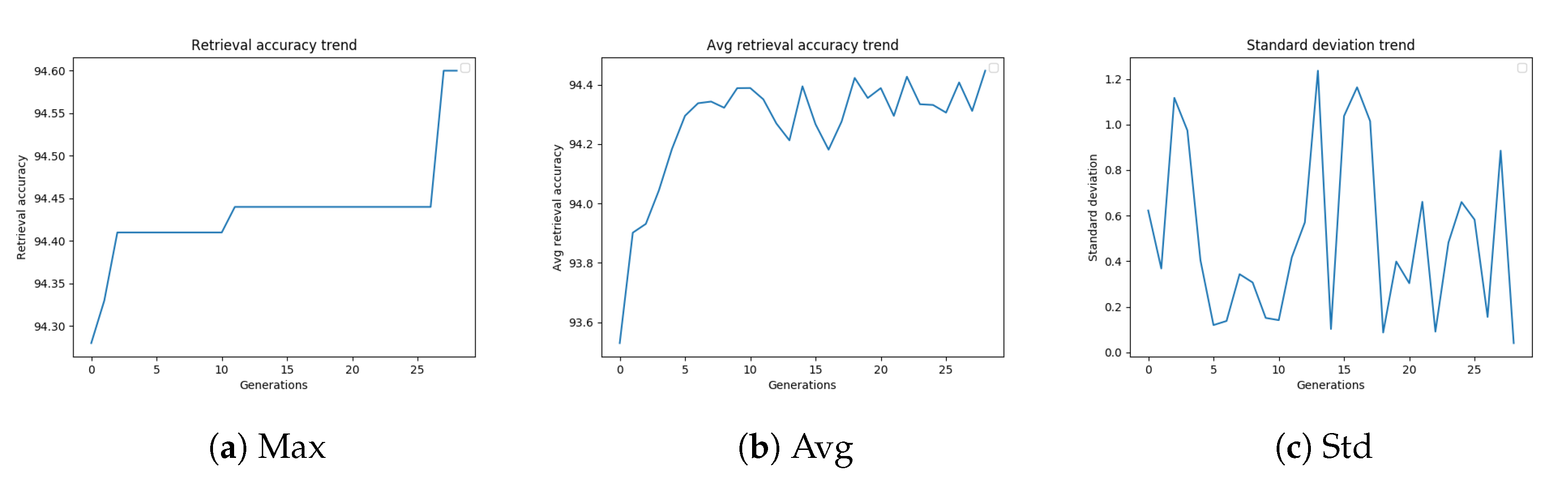
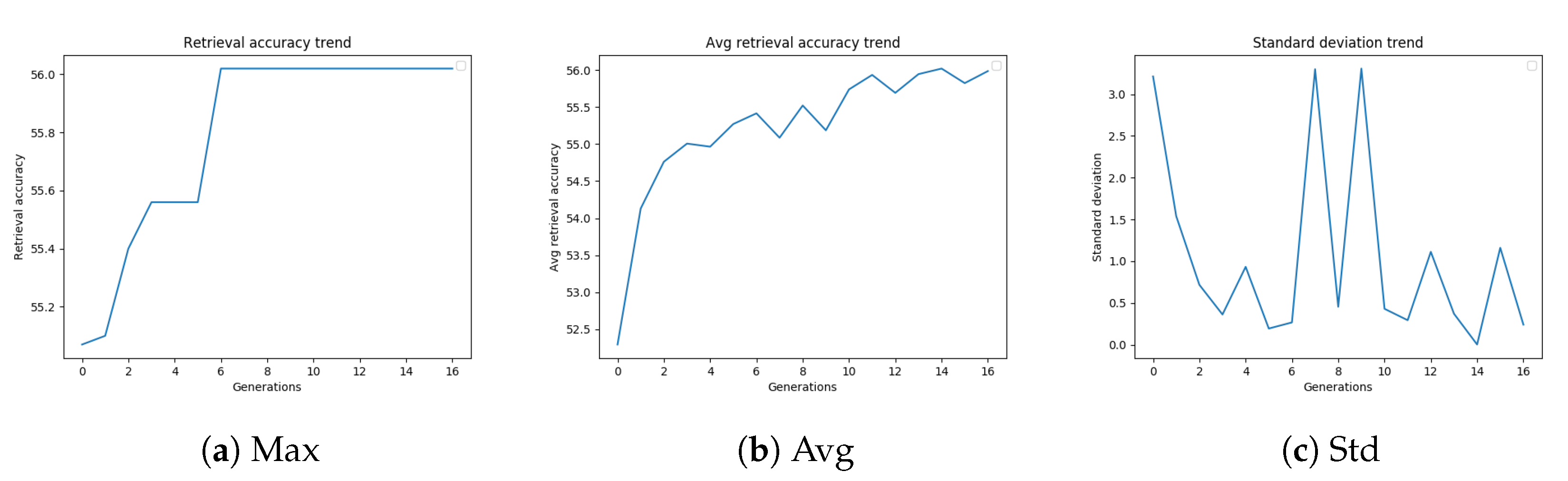
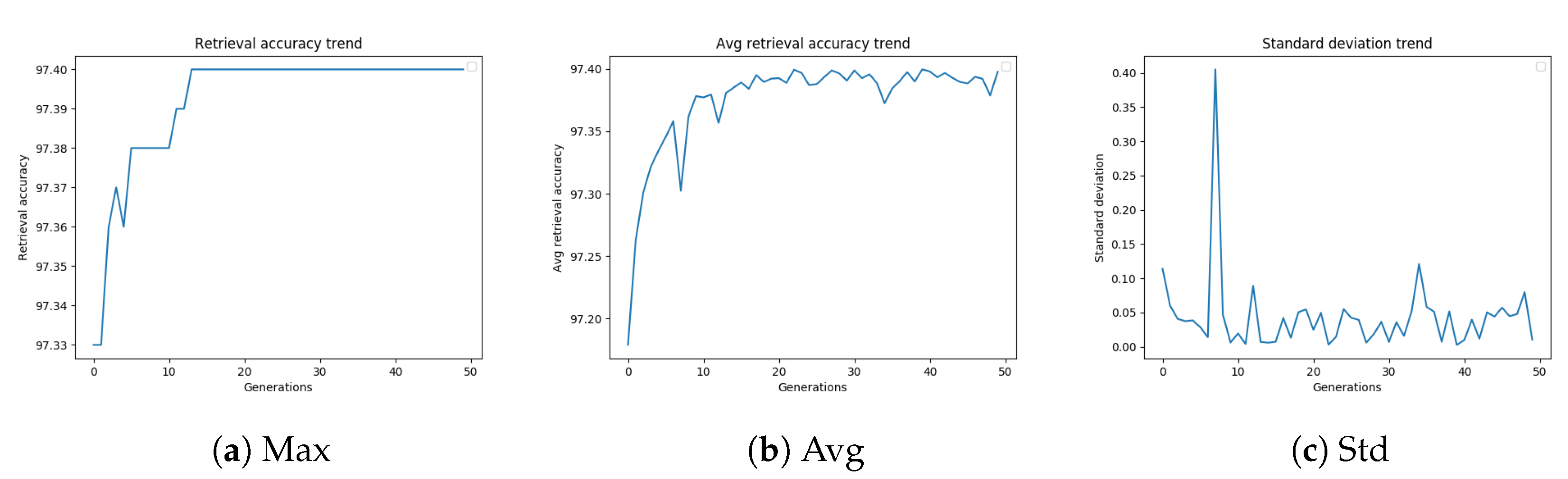
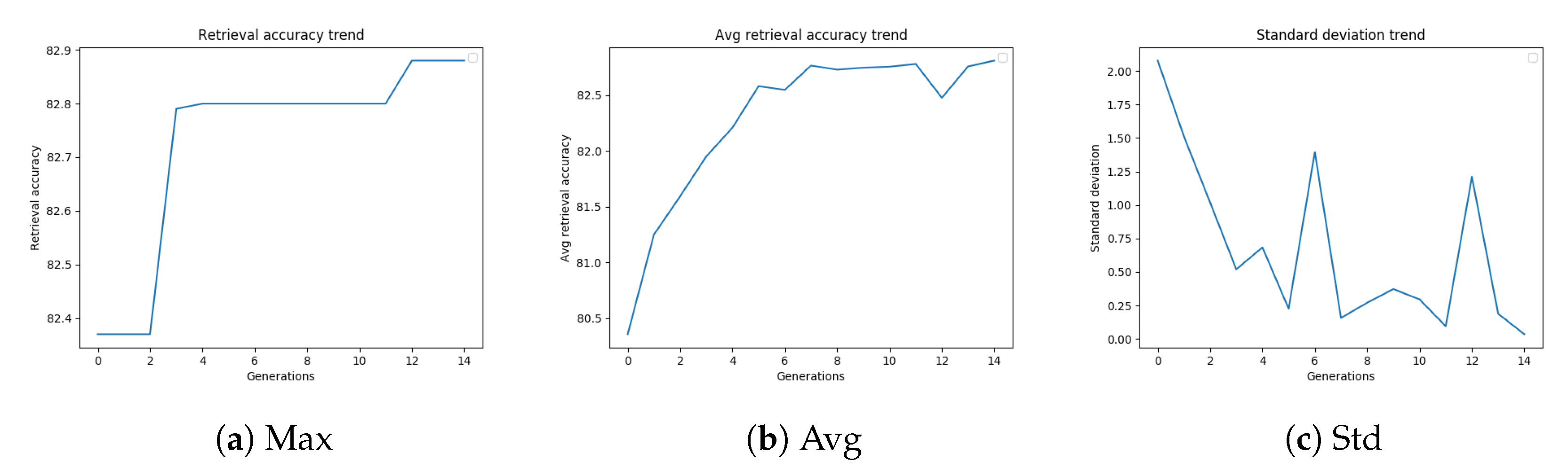
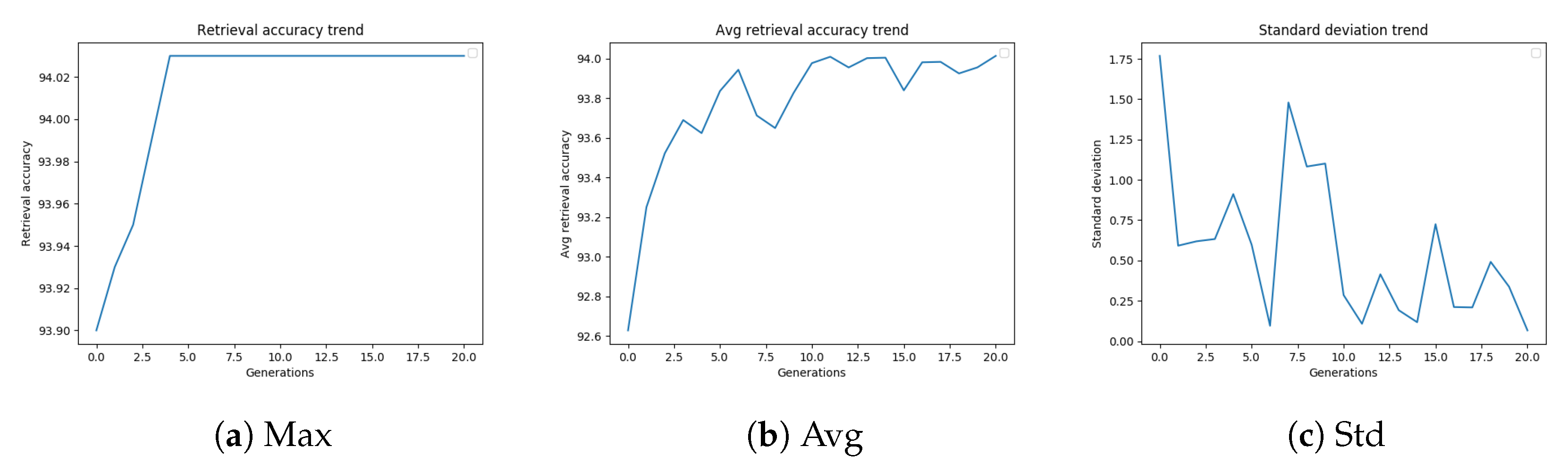
Figure 4a–c, and are related to the GA configuration, which led to the best-performing settings of the diffusion parameters.
Figure 4a shows the retrieval accuracy trend of a genetic algorithm on Oxford5k. The best fitness value increases with the number of generations. As shown in
Figure 4b, also the average retrieval accuracy generally tends to increase with the generations, but this trend is less stable. The standard deviation trend of the mAP values of the population, shown in
Figure 4c, is probably strongly affected by the outcome of mutations, considering that the population is quite small.
Table 7 summarizes the results obtained using the GA termination conditions described in
Section 3.3. The “maximum number of generations” (“Max Gen”) criterion achieves the best retrieval accuracy (
%), but it takes longer than the other techniques. The “Standard deviation” criterion is very fast, with a somewhat poorer performance (
%), while the “Best-Worst” termination condition reaches a mAP equal to
% in 4206 s, which probably represents the best trade-off between execution time and solution quality. It is worth noting that the results corresponding to the different stopping criteria have been all obtained running the parallel GA implementation.
Collecting the statistics over 30 runs of the stochastic methods we take into consideration (GA with different termination conditions, random search), and performing Wilkinson’s rank sum test (p < 0.05), we can reinforce the conclusions reported above, which apply also to the other datasets, as follows:
The improvement in terms of both mAP and execution time introduced by all GA-based methods with respect to a random search (Tables 6, 8, 10, 12 and 14) are always statistically significant.
Regarding the comparison between the different termination conditions (Tables 7, 9, 11, 13 and 15), the statistical significance of the difference between the best-performing algorithm and the others is robustly correlated with the value of the difference. In the case of Oxford5k, performing the whole budget of 5000 evaluations (MaxGen) yields significantly better results than all other termination conditions (even if by a relatively small gap). Obviously, that advantage is compensated by a significantly higher time needed to run the experiments, since the other methods can stop the optimization process when a sensible condition is reached.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}