Benchmark-Based Reference Model for Evaluating Botnet Detection Tools Driven by Traffic-Flow Analytics




Abstract
:1. Introduction
- In-depth literature review on malware recognition and the supervised learning methods most frequently used for botnet detection. Stressing their challenges on the current landscape as well.
- Understanding the behavior of botnets by analyzing the patterns involving the communication between bots and C&C server. Those expressed as network flow-based metrics.
- A comprehensive comparative methodology based on the selected supervised models by focusing the analysis on eight botnet families.
- Providing a detailed parameterization of the machine learning models, underpinning their optimal calibration and their testing and prediction results in the aftermath.
- An extended experimentation following the principles outlined above, along with a comprehensive discussion on the baseline accuracy achieved by similar proposals.
- Establishing a preliminary set of reference supervised algorithms with the potential of serving as benchmarking elements for further research.
2. State of the Art
2.1. Graph Mining for Malware Detection
2.2. Machine Learning Techniques
2.3. Deep Learning Methods
2.4. Data-Driven Intrusion Detection Approaches
2.5. Research Gaps on Comparative Assessment
3. Methodology
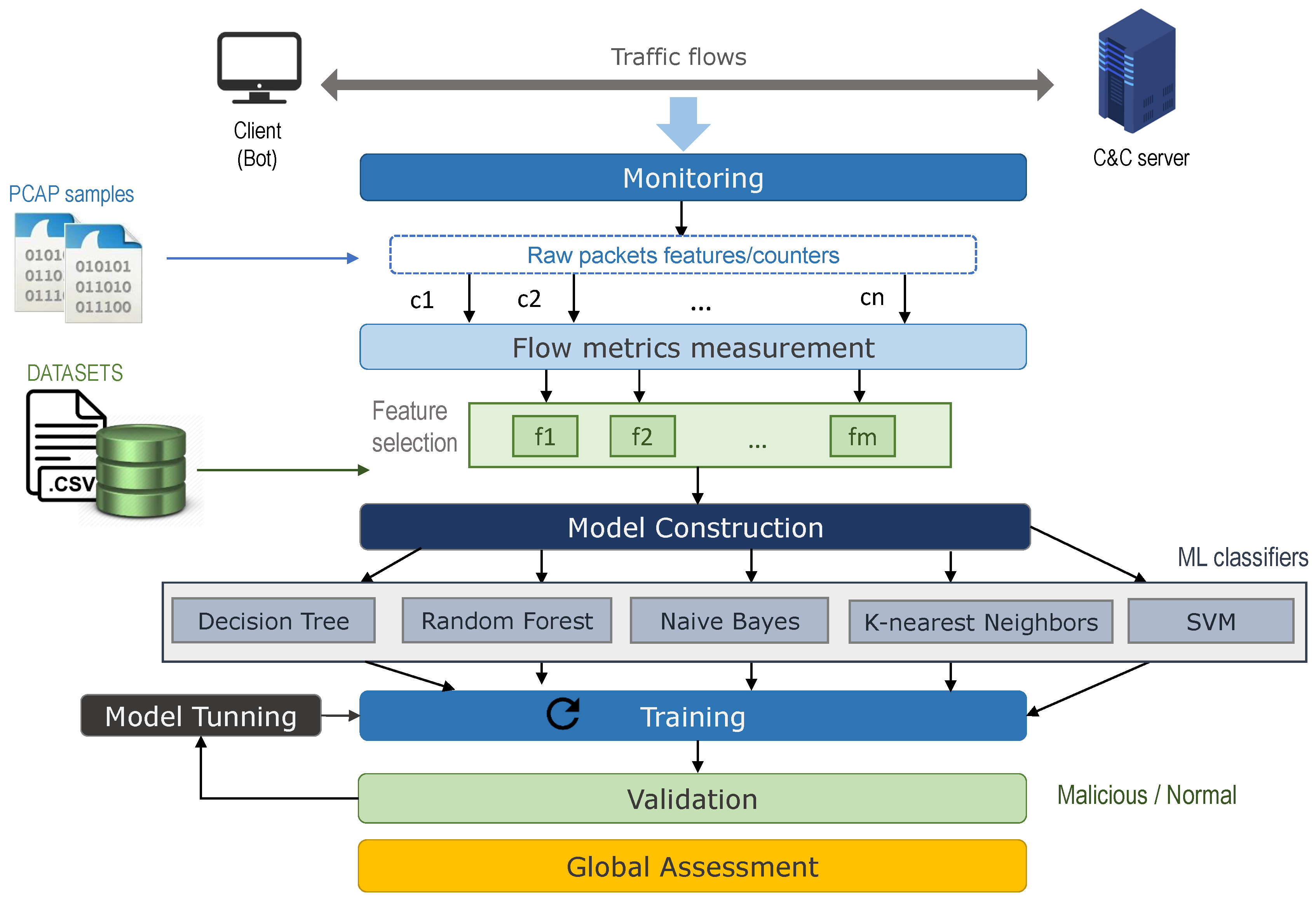
3.1. Processing Stages
3.1.1. Collecting Network Traffic Samples
3.1.2. Flow Metrics Measurement
3.1.3. Model Implementation
3.1.4. Training
3.1.5. Validation
3.1.6. Global Assessment
3.2. Datasets of Botnet Traffic
3.2.1. Cse-Cic-Ids2018 Dataset
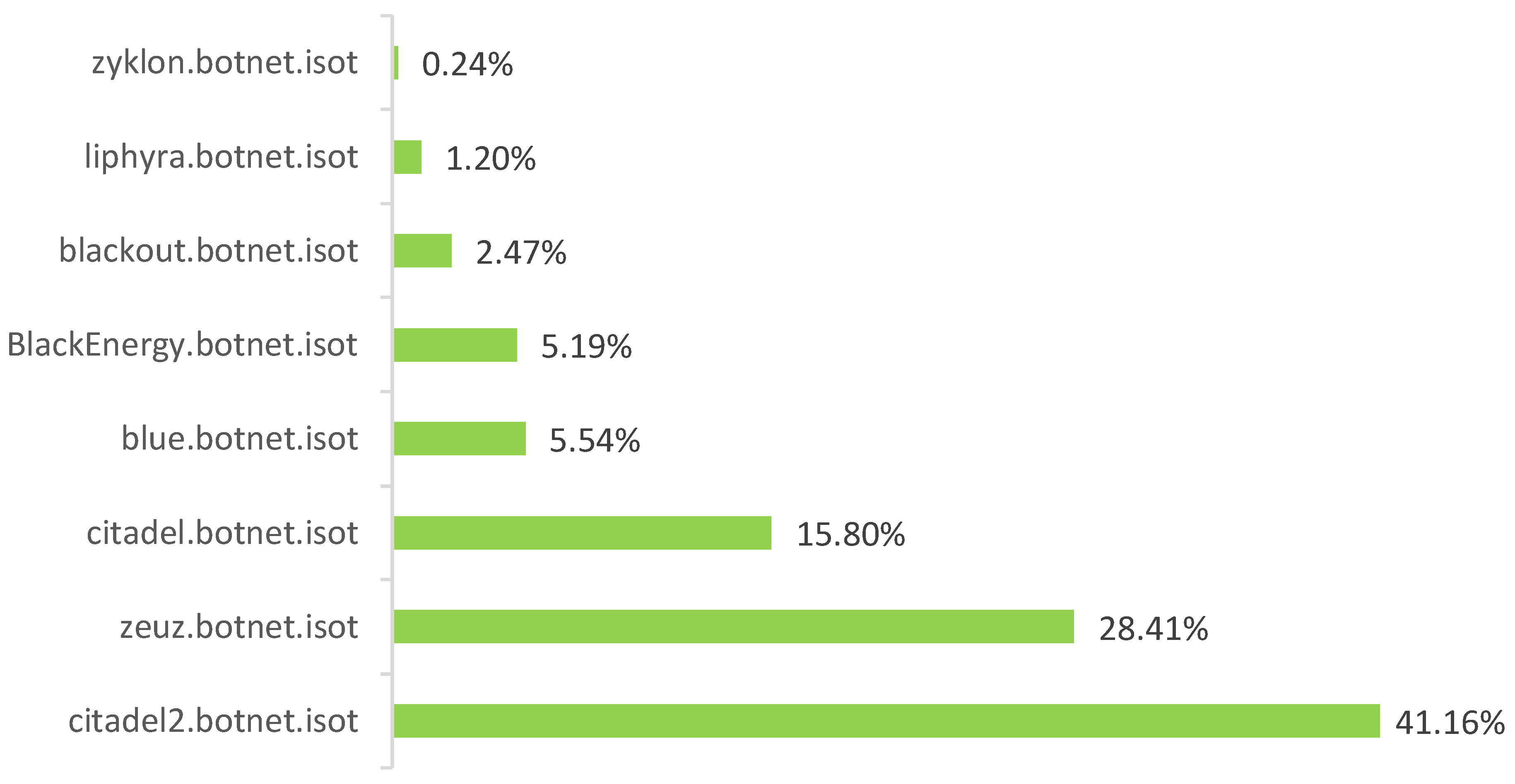
3.2.2. Isot Http Botnet Dataset
3.3. Flow-Metrics Measurement
3.4. Feature Selection
3.4.1. Behavioral and Contextual Features
3.4.2. Exploratory Data Analysis
3.5. Machine Learning Models Construction
3.5.1. Decision Tree Implementation
3.5.2. Gaussian Naive Bayes Implementation
3.5.3. Random Forest Implementation
3.5.4. K-Nearest Neighbors Implementation
3.5.5. Support Vector Machine Implementation
3.5.6. Grid Search Implementation
3.6. Execution Environment
4. Results
4.1. Cic-Aws-2018 Dataset
4.2. Isot Http Botnet Dataset
4.3. Isot Http Botnet and Cic-Aws-2018 Comparison
4.4. Cross-Validation Results
4.5. Prediction Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments

Conflicts of Interest
Appendix A. Initial Hyperparameters

{kind=link}
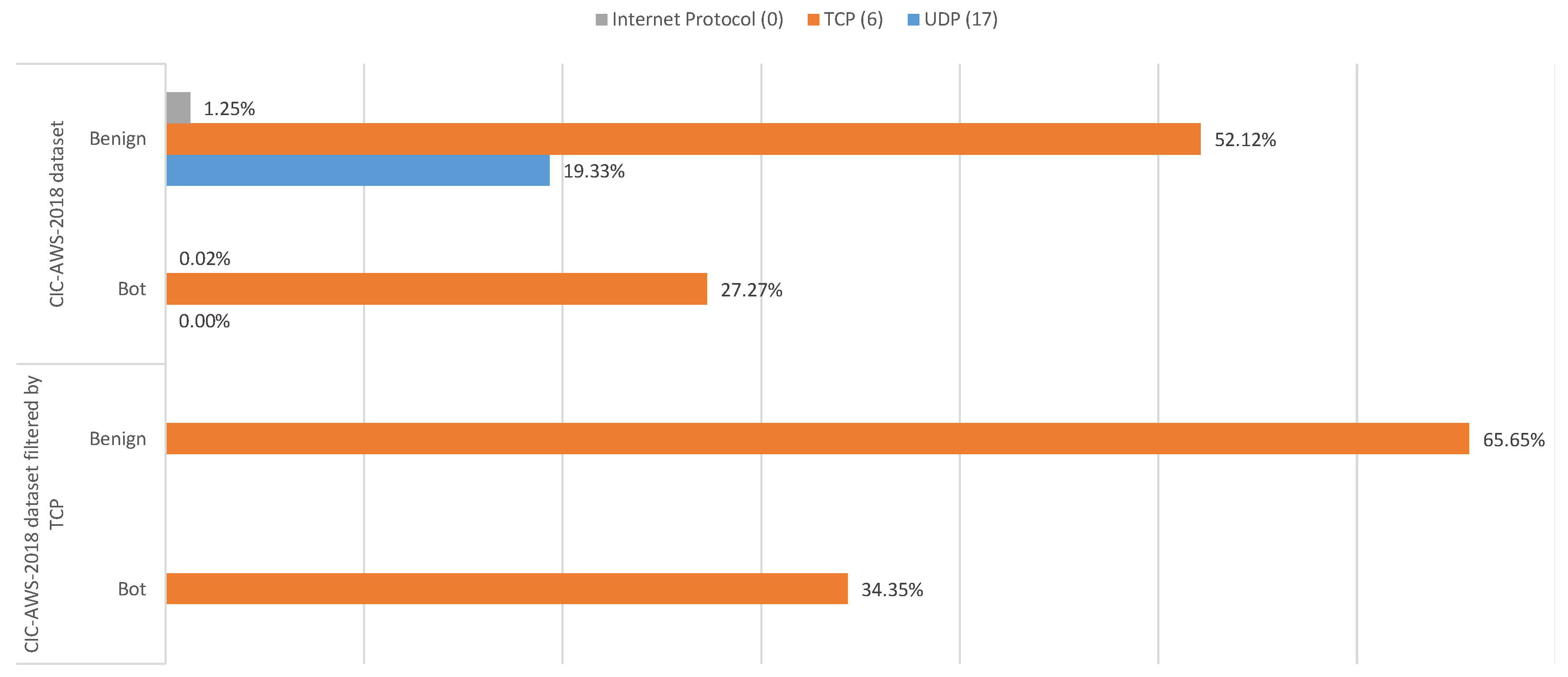{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Model | CIC-AWS-2018 | ISOT HTTP Botnet | |||
|---|---|---|---|---|---|
| Original | Filtered by TCP | Original | Minority and Majority Class | ||
| KNN | Algorithm used to compute nearest neighbors | KD tree | KD tree | KD tree | KD tree |
| Number of neighbors to use | 2 | 2 | 1 | 1 | |
| Leaf size | 30 | 30 | 30 | 30 | |
| Weight function used in prediction | Uniform | Uniform | Uniform | Uniform | |
| SVM | Regularization parameter C | 175 | 175 | 175 | 175 |
| Estimate class weights for unbalanced datasets | — | — | — | Balanced | |
| Penalty | l2 | l2 | l2 | l2 | |
| multi-class strategy | One-vs-rest | One-vs-rest | One-vs-rest | One-vs-rest | |
| Select the algorithm to either solve the dual or primal optimization problem | False | False | False | False | |
| Tolerance for stopping criteria | |||||
| Maximum number of iterations to be run | 12,000 | 12,000 | 12,000 | 12,000 | |
| Kernel type to be used in algorithm | Linear | Linear | Linear | Linear | |
| DT | Maximum tree depth | 51 | 14 | 51 | 35 |
| Estimate class weights for unbalanced datasets | — | — | — | Balanced | |
| Number of features for best split | 19 | 19 | 20 | 20 | |
| Function to measure split quality | GINI | GINI | GINI | GINI | |
| Strategy used to choose split at each node | Best | Best | Best | Best | |
| Min. Number of samples required to be at leaf node | 1 | 1 | 1 | 1 | |
| Min. Number of samples required to split | 2 | 2 | 2 | 2 | |
| RF | Use bootstrap samples when building trees | True | True | True | True |
| Estimate class weights for unbalanced datasets | — | — | — | Balanced | |
| Function to measure split quality | GINI | GINI | GINI | GINI | |
| Maximum tree depth | 35 | 22 | 35 | 35 | |
| Number of features for best split | 19 | 19 | 20 | 20 | |
| Min. number of samples required to be at leaf node | 1 | 1 | 1 | 1 | |
| Min. number of samples required to split | 2 | 2 | 2 | 2 | |
| Number of trees in forest | 12 | 12 | 12 | 12 | |
| NGB | Smoothing variable | ||||
Appendix B. Inherent Hyperparameters and Values
| Detection Model | CIC-AWS-2018 Filtered by TCP Using GS | ISOT HTTP Botnet Using GS | ||
|---|---|---|---|---|
| Original | Minority and Majority Classes | |||
| KNN | Algorithm used to compute nearest neighbors | [‘kd_tree’, ‘ball_tree’, ‘brute’] | [‘kd_tree’, ‘ball_tree’, ‘brute’] | [‘kd_tree’, ‘ball_tree’, ‘brute’] |
| Metric | minkowski | minkowski | minkowski | |
| Leaf size | [30,50,80] | [30,50,70] | [30,50,70] | |
| Number of neighbors to use | [4,10,2] | [4,10,2] | [2,10,1] | |
| SVM | Regularization parameter C | [10,100,175] | [10,100,175] | 10 |
| Estimate class weights for unbalanced datasets | — | — | Balanced | |
| Penalty parameter | l2 | l2 | l2 | |
| Tolerance for stopping criteria | [,,] | [,,] | [,] | |
| Maximum number of iterations to be run | 12000 | 12000 | 12000 | |
| Kernel type to be used in algorithm | Linear | Linear | Linear | |
| DT | Maximum tree depth | [20,30,14] | [20,30,10] | [20,35,10] |
| Estimate class weights for unbalanced datasets | — | — | Balanced | |
| Number of features for best split | 19 | 20 | 20 | |
| Min. Number of samples required to be at leaf node | [10,20,2] | [10,20,2] | [10,20,1] | |
| Min. Number of samples required to split | [10,20,2] | [10,20,2] | [10,20,2] | |
| RF | Maximum tree depth | [22,51,10] | [20,50,10] | [20,35,10] |
| Estimate class weights for unbalanced datasets | — | — | Balanced | |
| Number of features for best split | 19 | 20 | 20 | |
| Min. Number of samples required to be at leaf node. | [10,20,30] | [10,20,30] | [10,20,1] | |
| Min. Number of samples required to split | [10,20,30] | [10,20,30] | [10,20,2] | |
| Number of trees in forest | 25 | 12 | 12 | |
| NBG | Smoothing Variable | [,,] | [,,] | [,,] |
References
- Binsalleeh, H.; Ormerod, T.; Boukhtouta, A.; Sinha, P.; Youssef, A.; Debbabi, M.; Wang, L. On the analysis of the Zeus botnet crimeware toolkit. In Proceedings of the PST 2010: 2010 8th International Conference on Privacy, Security and Trust, Ottawa, ON, Canada, 17–19 August 2010; pp. 31–38. [Google Scholar] [CrossRef]
- Lazo Canazas, G. Cibercrimen: Conociendo al Enemigo Invisible; ASIS Capítulo 222: Lima, Perú, 2018. [Google Scholar]
- Méndez-García, V.; Jiménez-Ramírez, P.; Meléndez-Ramírez, M.; Torres-Martínez, F.M.; Llamas-Contreras, R.; González, H. Comparative analysis of banking malware. In Proceedings of the 2014 IEEE Central America and Panama Convention, CONCAPAN 2014, Panama City, Panama, 12–14 November 2014. [Google Scholar] [CrossRef]
- ENISA. Threat Landscape Report 2018. Available online: https://www.enisa.europa.eu/publications (accessed on 18 January 2020).
- Feily, M. A Survey of Botnet and Botnet Detection. In Proceedings of the 2009 Third International Conference on Emerging Security Information, Systems and Technologies, Athens, Greece, 18–23 June 2009; pp. 268–273. [Google Scholar] [CrossRef]
- Venkatesh, G.K.; Nadarajan, R.A. HTTP botnet detection using adaptive learning rate multilayer feed-forward neural network. In Proceedings of the IFIP International Workshop on Information Security Theory and Practice, Egham, UK, 20–22 June 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7322 LNCS, pp. 38–48. [Google Scholar] [CrossRef]
- Su, S.C.; Chen, Y.R.; Tsai, S.C.; Lin, Y.B. Detecting P2P Botnet in Software Defined Networks. Secur. Commun. Netw. 2018, 2018, 4723862. [Google Scholar] [CrossRef] [Green Version]
- Xu, Z.; Zhang, J.; Gu, G.; Lin, Z. POSTER: Automatic generation of vaccines for malware immunization. In Proceedings of the ACM Conference on Computer and Communications Security, Raleigh, NC, USA, 16–18 October 2012; ACM: New York, NY, USA, 2012; pp. 1037–1039. [Google Scholar] [CrossRef]
- Bilge, L.; Balzarotti, D.; Robertson, W.; Kirda, E.; Kruegel, C. Disclosure: Detecting botnet command and control servers through large-scale NetFlow analysis. In Proceedings of the ACM International Conference Proceeding Series 28th Annual Computer Security Applications Conference, Orlando, FL, USA, 3–7 December 2012; ACM: New York, NY, USA, 2012; pp. 129–138. [Google Scholar] [CrossRef]
- Maestre Vidal, J.; Sotelo Monge, M. Framework for Anticipatory Self-Protective 5G Environments. In Proceedings of the 14th International Conference on Availability, Reliability and Security, Canterbury, UK, 26–29 August 2019; ACM: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Vidal, J.M.; Monge, M.A.S. A novel Self-Organizing Network solution towards Crypto-ransomware Mitigation. In Proceedings of the 13th International Conference on Availability, Reliability and Security, Hamburg, Germany, 27–30 August 2018; ACM: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Vidal, J.M.; Orozco, A.; Villalba, L. Adaptive artificial immune networks for mitigating DoS flooding attacks. Swarm Evol. Comput. 2018, 38, 94–108. [Google Scholar] [CrossRef]
- Calvo Ortega, G. Botnets: La Amenaza Fantasma. 2018. Available online: https://pdfs.semanticscholar.org/80e4/0811e200a7becc608b4640b775908b7642e9.pdf?_ga=2.224492762.1111219674.1597115399-2026261475.1589343590 (accessed on 18 January 2020).
- Ieracitano, C.; Adeel, A.; Morabito, F.C.; Hussain, A. A novel statistical analysis and autoencoder driven intelligent intrusion detection approach. Neurocomputing 2020, 387, 51–62. [Google Scholar] [CrossRef]
- Srihari, S.; Govindaraju, V. Pattern Recognition. In Encyclopedia of Computer Science; John Wiley and Sons Ltd.: West Sussex, UK, 2003; pp. 1375–1382. [Google Scholar]
- Gonzalez-Cuautle, D.; Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, L.K.; Portillo-Portillo, J.; Olivares-Mercado, J.; Perez-Meana, H.M.; Sandoval-Orozco, A.L. Synthetic minority oversampling technique for optimizing classification tasks in botnet and intrusion-detection-system datasets. Appl. Sci. 2020, 10, 794. [Google Scholar] [CrossRef] [Green Version]
- Apruzzese, G.; Colajanni, M.; Ferretti, L.; Guido, A.; Marchetti, M. On the effectiveness of machine and deep learning for cyber security. In Proceedings of the 2018 10th International Conference on Cyber Conflict (CyCon), Tallinn, Estonia, 29 May–1 June 2018; pp. 371–390. [Google Scholar]
- Singh, M.; Singh, M.; Kaur, S. Issues and challenges in DNS based botnet detection: A survey. Comput. Secur. 2019, 86, 28–52. [Google Scholar] [CrossRef]
- Wuchner, T.; Cislak, A.; Ochoa, M.; Pretschner, A. Leveraging compression-based graph mining for behavior-based malware detection. IEEE Trans. Dependable Secur. Comput. 2019, 16, 99–112. [Google Scholar] [CrossRef]
- Bou-Harb, E.; Debbabi, M.; Assi, C. Big Data Behavioral Analytics Meet Graph Theory: On Effective Botnet Takedowns. IEEE Netw. 2017, 31, 18–26. [Google Scholar] [CrossRef]
- Sahu, M.K.; Ahirwar, M.; Shukla, P.K. Improved malware detection technique using ensemble based classifier and graph theory. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence and Communication Technology, CICT, Ghaziabad, India, 13–14 February 2015; pp. 150–154. [Google Scholar] [CrossRef]
- Wei, L.; Luo, W.; Weng, J.; Zhong, Y.; Zhang, X.; Yan, Z. Machine learning-based malicious application detection of android. IEEE Access 2017, 5, 25591–25601. [Google Scholar] [CrossRef]
- Gadelrab, M.S.; ElSheikh, M.; Ghoneim, M.A.; Rashwan, M. BotCap: Machine learning approach for botnet detection based on statistical features. Int. J. Commun. Netw. Inf. Secur. 2018, 10, 563–579. [Google Scholar]
- Yerima, S.Y.; Sezer, S. DroidFusion: A Novel Multilevel Classifier Fusion Approach for Android Malware Detection. IEEE Trans. Cybern. 2019, 49, 453–466. [Google Scholar] [CrossRef]
- Zhou, Q.; Pezaros, D. Evaluation of Machine Learning Classifiers for Zero-Day Intrusion Detection—An Analysis on CIC-AWS-2018 dataset. arXiv 2019, arXiv:1905.03685. [Google Scholar]
- Alenazi, A.; Traore, I.; Ganame, K.; Woungang, I. Holistic Model for HTTP Botnet Detection Based on DNS Traffic Analysis. In Proceedings of the International Conference on Intelligent, Secure, and Dependable Systems in Distributed and Cloud Environments, Vancouver, BC, Canada, 26 October 2017; Springer: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Khan, R.U.; Zhang, X.; Kumar, R.; Sharif, A.; Golilarz, N.A.; Alazab, M. An adaptive multi-layer botnet detection technique using machine learning classifiers. Appl. Sci. 2019, 9, 2375. [Google Scholar] [CrossRef] [Green Version]
- Cakir, B.; Dogdu, E. Malware classification using deep learning methods. In Proceedings of the ACMSE 2018 Conference, Richmond, KY, USA, 29–31 March 2018. [Google Scholar] [CrossRef]
- Tran, D.; Mac, H.; Tong, V.; Tran, H.A.; Nguyen, L.G. A LSTM based framework for handling multiclass imbalance in DGA botnet detection. Neurocomputing 2018, 275, 2401–2413. [Google Scholar] [CrossRef]
- Sarker, I.H.; Abushark, Y.B.; Alsolami, F.; Khan, A.I. IntruDTree: A Machine Learning Based Cyber Security Intrusion Detection Model. Symmetry 2020, 12, 754. [Google Scholar] [CrossRef]
- Maestre Vidal, J.; Sotelo Monge, M.; Martinez Monterrubio, M. EsPADA: Enhanced Payload Analyzer for malware Detection robust against Adversarial threats. Future Gener. Comput. Syst. 2020, 104, 159–173. [Google Scholar] [CrossRef]
- Abdel Wahab, O.; Bentahar, J.; Otrok, H.; Mourad, A. Resource-Aware Detection and Defense System Against Multi-Type Attacks in the Cloud: Repeated Bayesian Stackelberg Game. IEEE Trans. Dependable Secur. Comput. 2019, 1, 1. [Google Scholar] [CrossRef]
- Wahab, O.A.; Bentahar, J.; Otrok, H.; Mourad, A. Optimal Load Distribution for the Detection of VM-Based DDoS Attacks in the Cloud. IEEE Trans. Serv. Comput. 2020, 13, 114–129. [Google Scholar] [CrossRef]
- Monge, M.A.S.; Vidal, J.M.; Pérez, G.M. Detection of economic denial of sustainability (EDoS) threats in self-organizing networks. Comput. Commun. 2019, 145, 284–308. [Google Scholar] [CrossRef]
- Sotelo Monge, M.; Maestre Vidal, J. Entropy-based economic denial of sustainability detection. Entropy 2019, 19, 649. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Hou, J.; Meng, S.; Long, H. GLIDE: A Game Theory and Data-Driven Mimicking Linkage Intrusion Detection for Edge Computing Networks. Complexity 2020, 2020, 7136160. [Google Scholar] [CrossRef]
- Sotelo Monge, M.; Herranz Gonzalez, A.; Lorenzo Fernandez, B.; Maestre Vidal, D.; Rius Garcia, G.; Maestre Vidal, J. Traffic-flow analysis for source-side DDoS recognition on 5G environments. J. Netw. Comput. Appl. 2019, 136, 114–131. [Google Scholar] [CrossRef]
- University of New Brunswick. IDS 2018 | Datasets | Research | Canadian Institute for Cybersecurity | UNB; University of New Brunswick: Fredericton, NB, Canada, 2018. [Google Scholar]
- Chaabouni, N.; Mosbah, M.; Zemmari, A.; Sauvignac, C.; Faruki, P. Network Intrusion Detection for IoT Security Based on Learning Techniques. IEEE Commun. Surv. Tutor. 2019, 21, 2671–2701. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Maglaras, L. DeliveryCoin: An IDS and Blockchain-Based Delivery Framework for Drone-Delivered Services. Computers 2019, 8, 58. [Google Scholar] [CrossRef] [Green Version]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward generating a new intrusion detection dataset and intrusion traffic characterization. In Proceedings of the ICISSP 2018—4th International Conference on Information Systems Security and Privacy, Madeira, Portugal, 22–24 January 2018; Volume 2018, pp. 108–116. [Google Scholar] [CrossRef]
- Alenazi, A.; Traore, I.; Ganame, K.; Woungang, I. ISOT HTTP Botnet Dataset. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10618. [Google Scholar]
- Iana. Service Name and Transport Protocol Port Number Registry; Iana: Marina del Rey, CA, USA, 2020.
- Scikit Learn Developers. Linear SVC v0.23.1 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVC.html (accessed on 15 June 2020).







| Type | Feature Name | Description |
|---|---|---|
| Descriptive metrics | Label (Output) | The class that is assigned to the different malware samples. |
| Src_Port | Source port number | |
| Dst Port | Destination port number | |
| Protocol | Transport protocol | |
| Behavioural metrics | Flow_Duration | Flow duration in microseconds |
| Tot_Fwd_Pkts | Total number of packets transmitting in forward direction | |
| Tot_Bwd_Pkts | Total number of packets transmitting in backward direction | |
| TotLen_Bwd_Pkts | Total size of packets transmitting in forward direction. | |
| TotLen_Fwd_Pkts | Total size of packets transmitting in backward direction. | |
| Fwd Pkt Len Max | Maximum packet size in the forward direction | |
| Fwd Pkt Len Min | Mínimum packet size in the forward direction | |
| Fwd_Pkt_Len_Mean | Average size of packet transmitting in forward direction. | |
| Bwd_Pkt_Len_Mean | Average size of packet transmitting in backward direction. | |
| Flow_Byts/s | Number of bytes per second. | |
| Flow_Pkts/s | Number of flow packets per second | |
| Fwd_Pkts/s | Flow packet rate transferred in forward direction per second | |
| Bwd_Pkts/s | Flow packet rate transferred in backward direction per second | |
| Subflow_Fwd_Byts | Average number of bytes in a subflow in forward direction. | |
| Subflow_Bwd_Byts | Average number of bytes in a subflow in backward direction. | |
| Subflow_Bwd_Pkts | Average number of packets in a subflow in forward direction. | |
| Subflow_Fwd_Pkts | Average number of packets in a subflow in backward direction. |
| ML Models | CIC-AWS-2018 (TCP) | ISOT HTTP Dataset | |||
|---|---|---|---|---|---|
| Original | Minority Class | Majority Class | |||
| KNN | Algorithm used to compute nearest neighbors | KD tree | Brute | KD tree | Ball Tree |
| Number of neighbors to use | 2 | 1 | 1 | 1 | |
| Leaf size | 30 | 30 | 30 | 30 | |
| Weight function used in prediction | Uniform | Uniform | Uniform | Uniform | |
| SVM | Regularization parameter C | 10 | 10 | 10 | 10 |
| Estimated class weights for unbalanced datasets | Balanced | Balanced | |||
| Penalty | l2 | l2 | l2 | l2 | |
| multi-class strategy | One-vs-rest | One-vs-rest | One-vs-rest | One-vs-rest | |
| Select the algorithm to either solve the dual or primal optimization problem | False | False | False | False | |
| Tolerance for stopping criteria | |||||
| Maximum number of iterations to be run | 12,000 | 12,000 | 12,000 | 12,000 | |
| Kernel type to be used in algorithm | Linear | Linear | Linear | Linear | |
| DT | Maximum tree depth | 20 | 35 | 20 | 35 |
| Estimated class weights for unbalanced datasets | Balanced | Balanced | |||
| Number of features for best split | 19 | 20 | 20 | 20 | |
| Function to measure split quality | GINI | GINI | GINI | GINI | |
| Strategy used to choose split at each node | Best | Best | Best | Best | |
| Min. Number of samples required to be at leaf node | 2 | 10 | 1 | 20 | |
| Min. Number of samples required to split | 10 | 10 | 2 | 10 | |
| RF | Use bootstrap samples when building trees | True | True | True | True |
| Estimated class weights for unbalanced datasets | Balanced | Balanced | |||
| Function to measure split quality | GINI | GINI | GINI | GINI | |
| Maximum tree depth | 22 | 10 | 35 | 35 | |
| Number of features for best split | 19 | 20 | 20 | 20 | |
| Min. Number of samples required to be at leaf node | 10 | 2 | 1 | 1 | |
| Min. Number of samples required to split | 10 | 2 | 2 | 10 | |
| Number of trees in forest | 12 | 25 | 12 | 12 | |
| NGB | Smoothing variable | ||||
| Metric | Type | Random Forest | Random Forest + GS | Decision Tree | Decision Tree + GS | K-nearest Neighbors | K-nearest Neighbors + GS |
|---|---|---|---|---|---|---|---|
| Precision | Benign | 99.998% | 99.998% | 99.998% | 99.998% | 99.985% | 99.986% |
| Bot (Zeus and Ares) | 100.00% | 100.00% | 100.00% | 100.00% | 99.982% | 99.979% | |
| Recall | Benign | 100.00% | 100.00% | 100.00% | 100.00% | 99.991% | 99.989% |
| Bot (Zeus and Ares) | 99.996% | 99.996% | 99.996% | 99.996% | 99.972% | 99.974% | |
| Accuracy | 99.999% | 99.999% | 99.999% | 99.999% | 99.984% | 99.984% |
| Metric | Type | Gaussian Naïve Bayes | Gaussian Naïve Bayes + GS | Support Vector Machines (SVM) | Support Vector Machines (SVM) + GS |
|---|---|---|---|---|---|
| Precision | Benign | 99.962% | 99.025% | 99.940% | 99.943% |
| Bot (Zeus and Ares) | 77.855% | 79.780% | 86.972% | 86.904% | |
| Recall | Benign | 85.197% | 87.019% | 92.143% | 92.186% |
| Bot (Zeus and Ares) | 99.939% | 98.355% | 99.895% | 99.898% | |
| Accuracy | 90.245% | 90.901% | 94.812% | 94.821% |
| Metric | Botnet | Random Forest | Random Forest + GS | Decision Tree | Decision Tree + GS | K-Nearest Neighbors | K-Nearest Neighbors + GS |
|---|---|---|---|---|---|---|---|
| Precision | Blackout | 100.000% | 100.000% | 100.000% | 100.000% | 93.019% | 93.019% |
| Blue | 47.069% | 74.235% | 39.230% | 74.510% | 35.771% | 35.696% | |
| Liphyra | 33.993% | 100.000% | 18.992% | 100.000% | 13.729% | 13.729% | |
| Black Energy | 96.982% | 98.725% | 97.135% | 99.236% | 91.174% | 91.174% | |
| Zeus | 82.626% | 81.948% | 83.255% | 81.967% | 74.941% | 74.936% | |
| Zyklon | 94.595% | 100.000% | 88.136% | 97.938% | 53.061% | 53.061% | |
| Citadel | 54.314% | 57.923% | 53.342% | 58.855% | 51.930% | 51.980% | |
| Citadel2 | 79.709% | 81.212% | 79.319% | 79.116% | 73.756% | 73.831% | |
| Recall | Blackout | 100.000% | 99.916% | 100.000% | 99.916% | 82.857% | 82.857% |
| Blue | 29.105% | 21.524% | 38.055% | 21.080% | 36.538% | 36.501% | |
| Liphyra | 16.694% | 11.994% | 18.314% | 11.994% | 13.128% | 13.128% | |
| Black Energy | 96.302% | 96.419% | 96.341% | 96.030% | 86.454% | 86.454% | |
| Zeus | 90.594% | 97.376% | 83.553% | 97.017% | 77.337% | 77.337% | |
| Zyklon | 81.395% | 79.845% | 80.620% | 73.643% | 20.155% | 20.155% | |
| Citadel | 54.355% | 57.114% | 55.702% | 49.455% | 51.956% | 52.033% | |
| Citadel2 | 79.832% | 81.346% | 78.288% | 84.183% | 73.248% | 73.293% | |
| Accuracy | 76.604% | 79.115% | 74.696% | 78.893% | 69.025% | 69.054% |
| Metric | Botnet | Gaussian Naive Bayes | Gaussian Naive Bayes + GS | Support Vector Machine (SVM) | Support Vector Machine (SVM) + GS |
|---|---|---|---|---|---|
| Precision | Blackout | 4.792% | 100.000% | 100.000% | 100.000% |
| Blue | 9.030% | 28.155% | 0.000% | 0.000% | |
| Liphyra | 2.665% | 4.048% | 0.000% | 0.000% | |
| BlackEnergy | 6.061% | 100.000% | 100.000% | 100.000% | |
| Zeus | 20.000% | 69.687% | 72.822% | 72.817% | |
| Zyklon | 0.431% | 0.130% | 0.000% | 0.000% | |
| Citadel | 30.620% | 2.941% | 51.473% | 51.473% | |
| Citadel2 | 60.610% | 93.803% | 65.014% | 65.014% | |
| Recall | Blackout | 1.261% | 99.916% | 99.916% | 99.916% |
| Blue | 33.876% | 99.408% | 0.000% | 0.000% | |
| Liphyra | 70.178% | 99.514% | 0.000% | 0.000% | |
| BlackEnergy | 0.156% | 91.787% | 91.903% | 91.865% | |
| Zeus | 0.115% | 49.183% | 87.116% | 87.116% | |
| Zyklon | 0.775% | 0.775% | 0.000% | 0.000% | |
| Citadel | 7.094% | 0.192% | 4.708% | 4.708% | |
| Citadel2 | 60.803% | 44.917% | 91.008% | 91.008% | |
| Accuracy | 28.812% | 46.389% | 70.014% | 70.012% |
| DS Division | Metric | Botnet | Random Forest + GS | Decision Tree + GS | K-Nearest Neighbors + GS | Gaussian Naïve Bayes + GS | Support Vector Machine + GS |
|---|---|---|---|---|---|---|---|
| Minority Classes | Precision | Blackout | 100.000% | 99.918% | 89.426% | 100.000% | 100.000% |
| Blue | 99.963% | 99.963% | 91.844% | 100.000% | 99.925% | ||
| Liphyra | 100.000% | 100.000% | 80.692% | 100.000% | 100.000% | ||
| Black Energy | 99.883% | 99.883% | 94.065% | 95.784% | 98.522% | ||
| Zyklon | 100.000% | 98.230% | 56.061% | 15.152% | 75.194% | ||
| Recall | Blackout | 99.918% | 99.918% | 89.426% | 99.836% | 99.836% | |
| Blue | 100.000% | 99.963% | 95.034% | 99.216% | 99.216% | ||
| Liphyra | 100.000% | 100.000% | 75.085% | 99.831% | 100.000% | ||
| Black Energy | 100.000% | 99.922% | 93.918% | 94.776% | 98.752% | ||
| Zyklon | 97.368% | 97.368% | 32.456% | 21.930% | 85.088% | ||
| Accuracy | 99.944% | 99.902% | 91.042% | 96.554% | 98.995% | ||
| Majority Classes | Precision | Zeus | 94.811% | 94.834% | 87.478% | 71.367% | 88.972% |
| Citadel | 52.542% | 50.973% | 53.525% | 32.890% | 48.898% | ||
| Citadel2 | 88.973% | 93.050% | 75.854% | 95.242% | 92.074% | ||
| Recall | Zeus | 97.927% | 98.268% | 88.975% | 49.297% | 94.164% | |
| Citadel | 79.055% | 88.244% | 54.173% | 97.012% | 96.946% | ||
| Citadel2 | 69.977% | 65.007% | 74.599% | 45.763% | 54.157% | ||
| Accuracy | 81.044% | 80.437% | 75.731% | 56.266% | 75.413% |
| Dataset | ML Detection Model | Accuracy |
|---|---|---|
| Dataset CIC-AWS-2018 (filtered by TCP) | Random Forest | 99.999% |
| Decision Tree | 99.999% | |
| K-nearest neighbors | 99.984% | |
| Gaussian Naïve Bayes | 90.901% | |
| Support Vector Machine (SVM) | 94.821% | |
| ISOT HTTP Botnet Dataset | Random Forest | 79.115% |
| Decision Tree | 78.893% | |
| K-nearest neighbours | 69.054% | |
| Gaussian Naïve Bayes | 46.389% | |
| Support Vector Machines (SVM) | 70.012% | |
| ISOT HTTP Botnet Dataset | Random Forest | 99.944% |
| Decision Tree | 99.902% | |
| K-nearest neighbours | 91.042% | |
| Gaussian Naïve Bayes | 96.554% | |
| Support Vector Machines (SVM) | 98.995% | |
| ISOT HTTP Botnet Dataset | Random Forest | 81.044% |
| Decision Tree | 80.437% | |
| K-nearest neighbours | 75.731% | |
| Gaussian Naïve Bayes | 56.266% | |
| Support Vector Machines (SVM) | 75.413% |
| Configuration Type | ML Model | CIC-AWS-2018 (TCP) | ISOT HTTP Botnet | ||
|---|---|---|---|---|---|
| Original | Minority Class | Majority Class | |||
| Base | Random Forest | 99.999% | 76.737% | 99.909% | 80.976% |
| Decision Tree | 99.999% | 74.705% | 99.916% | 80.388% | |
| K-Nearest Neighbors | 99.984% | 68.336% | 88.934% | 74.768% | |
| Gaussian Naïve Bayes | 90.236% | 28.563% | 29.919% | 46.877% | |
| Support Vector Machine | 94.843% | 69.864% | 97.624% | 75.209% | |
| Grid Search | Random Forest | 99.998% | 79.199% | 99.909% | 81.073% |
| Decision Tree | 99.998% | 79.077% | 99.916% | 80.620% | |
| K-Nearest Neighbors | 99.983% | 68.340% | 88.934% | 74.765% | |
| Gaussian Naïve Bayes | 90.893% | 46.483% | 96.557% | 56.462% | |
| Support Vector Machine | 94.797% | 69.864% | 97.711% | 75.695% | |
| Detection Models | Without GS | With GS | Expected Class | ||
|---|---|---|---|---|---|
| Predicted Class | Success Probability | Predicted Class | Success Probability | ||
| Random Forest | Benign | 100.00% | Benign | 100.00% | Benign |
| Decision Tree | Benign | 100.00% | Benign | 100.00% | |
| KNN | Benign | 100.00% | Benign | 100.00% | |
| Naive Bayes | Benign | 100.00% | Benign | 100.00% | |
| SVM | Benign | 100.00% | Benign | 100.00% | |
| Random Forest | Bot | 100.00% | Bot | 100.00% | Bot |
| Decision Tree | Bot | 100.00% | Bot | 100.00% | |
| KNN | Bot | 100.00% | Bot | 100.00% | |
| Naive Bayes | Bot | 100.00% | Benign | 100.00% | |
| SVM | Benign | 64.850% | Benign | 64.680% | |
| Detection Model | Without GS | With GS | Expected Class | ||
|---|---|---|---|---|---|
| Predicted Class | Success Probability | Predicted Class | Success Probability | ||
| Random Forest | Blackout | 100.000% | Blackout | 100.000% | Blackout |
| Decision Tree | Blackout | 100.000% | Blackout | 100.000% | |
| KNN | Blackout | 100.000% | Blackout | 100.000% | |
| Naive Bayes | Liphyra | 69.210% | Blackout | 100.000% | |
| SVM | Blackout | 43.670% | Blackout | 43.670% | |
| Random Forest | Blue | 51.770% | Zeus | 74.420% | Blue |
| Decision Tree | Blue | 100.000% | Zeus | 74.840% | |
| KNN | Blue | 100.000% | Blue | 100.000% | |
| Naive Bayes | Liphyra | 59.490% | Blue | 100.000% | |
| SVM | Zeus | 59.410% | Zeus | 59.410% | |
| Random Forest | Liphyra | 100.000% | Liphyra | 100.000% | Liphyra |
| Decision Tree | Liphyra | 100.000% | Liphyra | 100.000% | |
| KNN | Liphyra | 100.000% | Liphyra | 100.000% | |
| Naive Bayes | Blue | 52.190% | Liphyra | 100.000% | |
| SVM | Citadel2 | 48.670% | Citadel2 | 48.670% | |
| Random Forest | Black Energy | 100.000% | Black Energy | 100.000% | Black Energy |
| Decision Tree | Black Energy | 100.000% | Black Energy | 100.000% | |
| KNN | Black Energy | 100.000% | Black Energy | 100.000% | |
| Naive Bayes | Citadel | 44.770% | Black Energy | 99.920% | |
| SVM | Black Energy | 54.400% | Black Energy | 54.400% | |
| Random Forest | Zeus | 84.290% | Zeus | 74.600% | Zeus |
| Decision Tree | Zeus | 100.000% | Zeus | 74.840% | |
| KNN | Zeus | 100.000% | Zeus | 100.000% | |
| Naive Bayes | Liphyra | 60.660% | Blue | 100.000% | |
| SVM | Zeus | 60.050% | Zeus | 60.050% | |
| Random Forest | Zyklon | 100.000% | Zyklon | 100.000% | Zyklon |
| Decision Tree | Zyklon | 100.000% | Zyklon | 100.000% | |
| KNN | Citadel | 100.00% | Citadel | 100.00% | |
| Naive Bayes | Blue | 56.840% | Citadel | 99.980% | |
| SVM | Zeus | 50.130% | Zeus | 50.130% | |
| Random Forest | Citadel | 100.000% | Citadel | 98.690% | Citadel |
| Decision Tree | Citadel | 100.000% | Citadel | 99.550% | |
| KNN | Citadel | 100.000% | Citadel | 100.000% | |
| Naive Bayes | Citadel | 91.950% | Liphyra | 100.000% | |
| SVM | Citadel2 | 45.779% | Citadel2 | 45.779% | |
| Random Forest | Citadel2 | 100.000% | Citadel2 | 100.000% | Citadel2 |
| Decision Tree | Citadel2 | 100.000% | Citadel2 | 100.000% | |
| KNN | Citadel2 | 100.000% | Citadel2 | 100.000% | |
| Naive Bayes | Citadel2 | 74.860% | Zyklon | 99.940% | |
| SVM | Citadel2 | 88.030% | Citadel2 | 88.030% | |
| Detection Model | Without GS | With GS | Expected Class | ||
|---|---|---|---|---|---|
| Predicted Class | Success Probability | Predicted Class | Success Probability | ||
| Random Forest | Blackout | 100.000% | Blackout | 100.000% | Blackout |
| Decision Tree | Blackout | 100.000% | Blackout | 100.000% | |
| KNN | Blackout | 100.000% | Blackout | 100.000% | |
| Naive Bayes | Liphyra | 62.620% | Blackout | 100.000% | |
| SVM | Blackout | 70.700% | Blackout | 71.460% | |
| Random Forest | Blue | 100.000% | Blue | 100.000% | Blue |
| Decision Tree | Blue | 100.000% | Blue | 100.000% | |
| KNN | Blue | 100.000% | Blue | 100.000% | |
| Naive Bayes | Blue | 50.530% | Blue | 100.000% | |
| SVM | Blue | 96.690% | Blue | 96.760% | |
| Random Forest | Liphyra | 100.000% | Liphyra | 100.000% | Liphyra |
| Decision Tree | Liphyra | 100.000% | Liphyra | 100.000% | |
| KNN | Liphyra | 100.000% | Liphyra | 100.000% | |
| Naive Bayes | Blue | 60.630% | Liphyra | 100.000% | |
| SVM | Liphyra | 94.780% | Liphyra | 94.040% | |
| Random Forest | Black Energy | 100.000% | Black Energy | 100.000% | Black Energy |
| Decision Tree | Black Energy | 100.000% | Black Energy | 100.000% | |
| KNN | Black Energy | 100.000% | Black Energy | 100.000% | |
| Naive Bayes | Blue | 72.350% | Black Energy | 100.000% | |
| SVM | Black Energy | 72.740% | Black Energy | 72.980% | |
| Random Forest | Zyklon | 100.000% | Zyklon | 100.000% | Zyklon |
| Decision Tree | Zyklon | 100.000% | Zyklon | 100.000% | |
| KNN | Zyklon | 100.000% | Zyklon | 100.000% | |
| Naive Bayes | Blue | 69.090% | Black Energy | 99.500% | |
| SVM | Zyklon | 95.320% | Zyklon | 95.520% | |
| Detection Model | Without GS | With GS | Expected Class | ||
|---|---|---|---|---|---|
| Predicted Class | Success Probability | Predicted Class | Success Probability | ||
| Random Forest | Zeus | 100.000% | Zeus | 100.000% | Zeus |
| Decision Tree | Zeus | 100.000% | Zeus | 100.000% | |
| KNN | Zeus | 100.000% | Zeus | 100.000% | |
| Naive Bayes | Citadel | 99.900% | Citadel | 100.000% | |
| SVM | Zeus | 93.260% | Zeus | 92.810% | |
| Random Forest | Citadel | 100.000% | Citadel | 100.000% | Citadel |
| Decision Tree | Citadel | 100.000% | Citadel | 100.000% | |
| KNN | Citadel | 100.000% | Citadel | 100.000% | |
| Naive Bayes | Citadel | 91.950% | Citadel | 100.000% | |
| SVM | Citadel | 52.020% | Citadel | 52.510% | |
| Random Forest | Citadel2 | 100.000% | Citadel2 | 100.000% | Citadel2 |
| Decision Tree | Citadel2 | 100.000% | Citadel2 | 100.000% | |
| KNN | Citadel2 | 100.000% | Citadel2 | 100.000% | |
| Naive Bayes | Citadel2 | 74.860% | Citadel2 | 99.080% | |
| SVM | Citadel2 | 82.500% | Citadel2 | 80.140% | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huancayo Ramos, K.S.; Sotelo Monge, M.A.; Maestre Vidal, J. Benchmark-Based Reference Model for Evaluating Botnet Detection Tools Driven by Traffic-Flow Analytics. Sensors 2020, 20, 4501. https://doi.org/10.3390/s20164501
Huancayo Ramos KS, Sotelo Monge MA, Maestre Vidal J. Benchmark-Based Reference Model for Evaluating Botnet Detection Tools Driven by Traffic-Flow Analytics. Sensors. 2020; 20(16):4501. https://doi.org/10.3390/s20164501
Chicago/Turabian StyleHuancayo Ramos, Katherinne Shirley, Marco Antonio Sotelo Monge, and Jorge Maestre Vidal. 2020. "Benchmark-Based Reference Model for Evaluating Botnet Detection Tools Driven by Traffic-Flow Analytics" Sensors 20, no. 16: 4501. https://doi.org/10.3390/s20164501
APA StyleHuancayo Ramos, K. S., Sotelo Monge, M. A., & Maestre Vidal, J. (2020). Benchmark-Based Reference Model for Evaluating Botnet Detection Tools Driven by Traffic-Flow Analytics. Sensors, 20(16), 4501. https://doi.org/10.3390/s20164501