1. Introduction
Hyperspectral imaging (HSI) was originally developed in the early 1970 for remote sensing applications [
1]. The invention of the first charge-coupled device (CCD) detector played a crucial role in pushing this technology forward. In recent years, the technology has been reported to have applications in many diverse fields such as forensic science [
2], pharmaceutical research [
3], agriculture [
4], and food science [
5]. HSI goes beyond traditional imaging techniques by integrating spectral and spatial information from an object [
6]. Therefore, the merits of spectroscopy and computer vision are both reflected in hyperspectral imaging. Spectroscopy identifies the analyte of interest based on its spectral signature, and imaging transforms this information into distribution maps for spatial visualization.
A key step in the successful implementation of HSI applications is the development of calibration models. For a classification task on near infrared hyperspectral imaging dataset acquired from benchtop instruments, chemometrics is currently considered as a popular tool that has been used for many years. Partial least squares discriminant analysis (PLSDA) [
7] is a supervised classification modelling method that uses the PLS algorithm to predict the belonging of a sample to a specific class. PLSDA is increasingly used in hyperspectral data analysis for classification problems due to its capability to deal with multicollinearity problem in near infrared (NIR) spectra, which occurs because of very high intercorrelation between absorbances [
8,
9]. Nevertheless, only spectral features were used as input for classification models in most cases.
Machine learning (ML) techniques have been introduced for HSI data classification [
10], which have been collected in an extensive list of detailed reviews, such as Li, et al. [
11,
12]. The ML field has experienced a significant revolution thanks to the development of new deep learning (DL) models since the early 2000s [
13], which is supported by advances in computer technology. These models have gained popularity in the development of HSI classifiers [
13,
14]. For instance, support vector machine (SVM) was applied to HSI data for strawberry ripeness evaluation achieving classification accuracy over 85%. Convolutional neural network (CNN), being the current state-of-the-art in deep learning [
15], first achieved success in the field of image recognition and has become an extremely popular tool for remotely sensed HSI data classification [
10]. More importantly, CNN models show flexibility to deal with HSI data by introducing a one-dimensional CNN for processing spectral inputs [
16], two-dimensional CNN for single or multiple wavelength images [
17], and three-dimensional CNN (3D-CNN) for an intelligent combination of spectral and spatial image data [
18,
19]. Although CNN models have been successfully implemented for remote sensing applications, they are not often applied to HSI data of food products. Earlier this year, Al-Sarayreh, et al. [
20] reported that 3D-CNN model approach applied to HSI data significantly enhanced the overall accuracy of red meat classification.
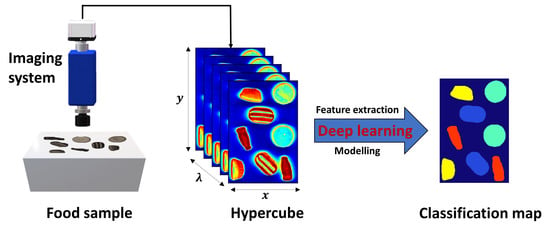
In this context, the current work aims to investigate the advantages and disadvantages of applying deep learning approaches to near infrared HSI data. The main objective is to compare CNN based modelling strategies against traditional chemometric (i.e., PLSDA) and machine learning (i.e., SVM) methods for the pixel-wise classification tasks of food products. We will apply a hybrid framework which involves first performing principal component analysis (PCA) to highlight the major spectral variation and then building 2-D CNN model from the first few PCs using spatial features. PLSDA, SVM and 3-D CNN are also applied for classifying HSI image data. The performance will be evaluated and compared in terms of efficiency and accuracy, exemplified through two case studies, i.e., classification of four sweet products and differentiation between white stripe (“myocommata”) and red muscle (“myotome”) pixels on salmon fillets.
2. Materials and Methods
2.1. Sweets Dataset
Spectral images of the sweet samples are acquired in the reflectance mode by employing a laboratory-based pushbroom hyperspectral imaging system. The main components of this system are an imaging spectrograph (Specim N17E, Spectral Imaging Ltd., Oulu, Finland) and an InGaAs camera (InGAs 12-bit SU320MS-1.7RT Sensors Unlimited, Inc., Princeton, NJ, USA). This configuration captures an image of a line across the sample, spanning the 320-pixel width of the sensor, and the spectrograph produces a spectrum for each of these pixels across the other dimension of the array, accounting for a two-dimensional image. The wavelength interval is 7 nm in the spectral range of 943–1643 nm, leading to 101 spectral bands. Direct reflectance spectra are used for subsequent data analysis.
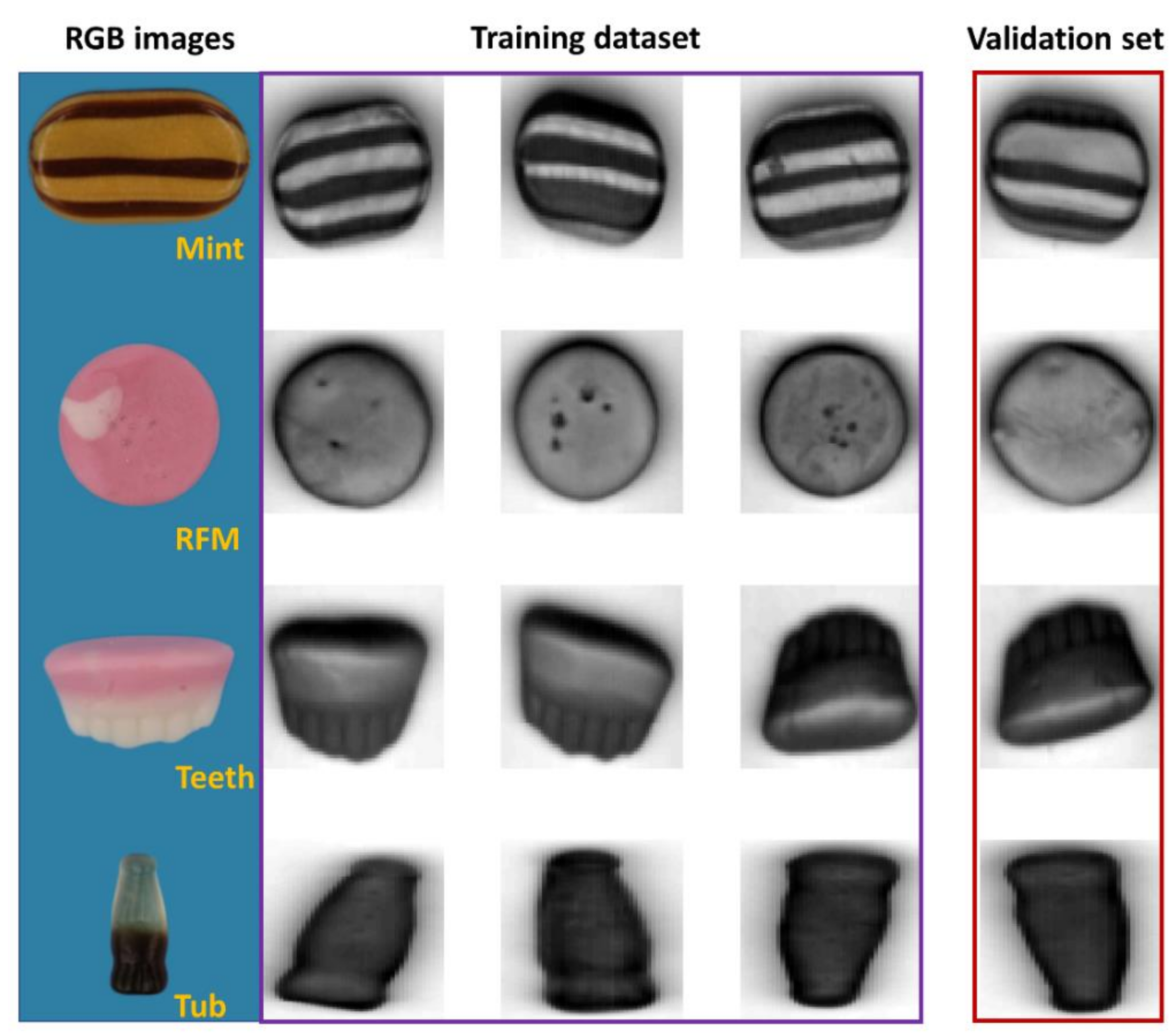
This dataset consists of NIR hyperspectral images of four different sweets with different shapes, colors, and nutritional compositions among classes. Specifically, the details of the selected four products are as follows: raspberry flavor mushroom in pink and white color with a mushroom shape, mint humbugs in brown and golden stripe with an ellipse shape, teeth and lips in pink and white color with a teeth-like appearance, and tub in brown with a cola bottle shape. These sweets, made and purchased from Tesco Ireland Ltd., are labelled as raspberry flavor mushroom (RFM), Mint, Teeth, and Tub, respectively. Sweet samples are chosen because the different spatial information among classes has great potential for improving classification performance.
Four hypercubes of each sample type are obtained with the mean image showing in
Figure 1, together with the representative red/green/blue (RGB) images captured by a computer vision system as described in Xu and Sun [
21]. As seen, the first three samples of each type are selected as the training set for model development, while the remaining one serves as the validation set, leading to 12 hypercubes consisting of 27,807 pixels for training and 4 hypercubes of 8947 pixels for validation purpose. In addition to this, the developed model is tested on two mixed images containing two samples of each material. The mean images of the mixture are shown in
Figure S1 of Supplementary Materials.
2.2. Salmon Dataset
NIR spectral images of farm-raised Atlantic salmon (Salmon salar) fillets are also collected in the reflectance configuration. The core components of the system included: an imaging spectrograph (ImSpector, N17E, Spectral Imaging Ltd., Oulu, Finland) collecting spectral images in a wavelength range of 900–1700 nm, a high performance camera with C-mount lens (Xeva 992, Xenics Infrared Solutions, Leuven, Belgium), two tungsten-halogen illuminating lamps (V-light, Lowel Light Inc., New York, NY, USA), a translation stage operated by a stepper motor (GPL-DZTSA-1000-X, Zolix Instrument Co., Beijing, China), and a computer installed with a data acquisition software (SpectralCube, Spectral Imaging Ltd., Oulu, Finland). Each fillet was individually placed on the moving table and then was scanned line by line at a speed of 2.7 cm/s adjusted to provide the same vertical and horizontal resolution (0.58 mm/pixel).
Salmon is valued as a fat-rich fish with a large proportion of lipids congregated in the white stripe of connective tissue (“myocommata”), segmenting the red-colored muscle (“myotome”) tissue in vertical blocks and presenting a zebra-like appearance [
22]. Previous study has demonstrated that the proportion of myocommata in a salmon fillet correlated well with its fat content [
23]. In this sense, it is interesting to classify the white stripe from the red muscle because the proportions of the white strip in one fillet might contain some valuable information about the fat content and/or lipid oxidation [
24]. The salmon dataset is of interest because there is spatial information on the salmon surface, yet it is unsure if this spatial information could help classification.
Overall, six salmon fillets are used with the mean images shown in
Figure 2. The first three samples are included in the training set to develop classifiers, while the fourth sample is used as the validation set and the remaining two images are considered as the test set. These salmon fillets are obtained from three different batches. As seen from
Figure 2, they are cut from different positions of fish. It can be discerned that samples are in different sizes and shapes. Some pixels with strong signals are also observed, which poses some challenges for the pixel classification. There could be due to the specular reflection of the illumination source at the salmon surface to produce regions with high-intensity values in the hyperspectral images. These regions act like a mirror and lead to saturation of CCD because of the white stripe or the existence of scales.
2.3. Background Removal
All data analysis is carried out using MATLAB (release R2019a, The MathWorks, Inc., Natick, MA, USA) incorporating functions from Deep Learning Toolbox, Statistics, and Machine Learning Toolbox, and additional functions written in-house.
Sweet samples are placed on a white tile for imaging. Background removal is carried out by subtracting a low-reflectance band from a high-reflectance band followed by a simple thresholding. In this context, the reflectance image at 1496 nm is subtracted from that of 957 nm to enhance the contrast between the sample and white tile. Afterwards, a threshold of 0.22 is applied for background removal. A binary mask for background removal is subsequently generated with all background regions set to zero.
Salmon samples are directly placed on the moving table for image acquisition. The background is removed from the salmon flesh image in the same manner. Bands 944 nm and 1450 nm are used followed by a thresholding value of 0.2. However, the selected bands and thresholding values might change depending on the segmentation result of individual hyperspectral image.
2.4. Spectral Pre-Processing
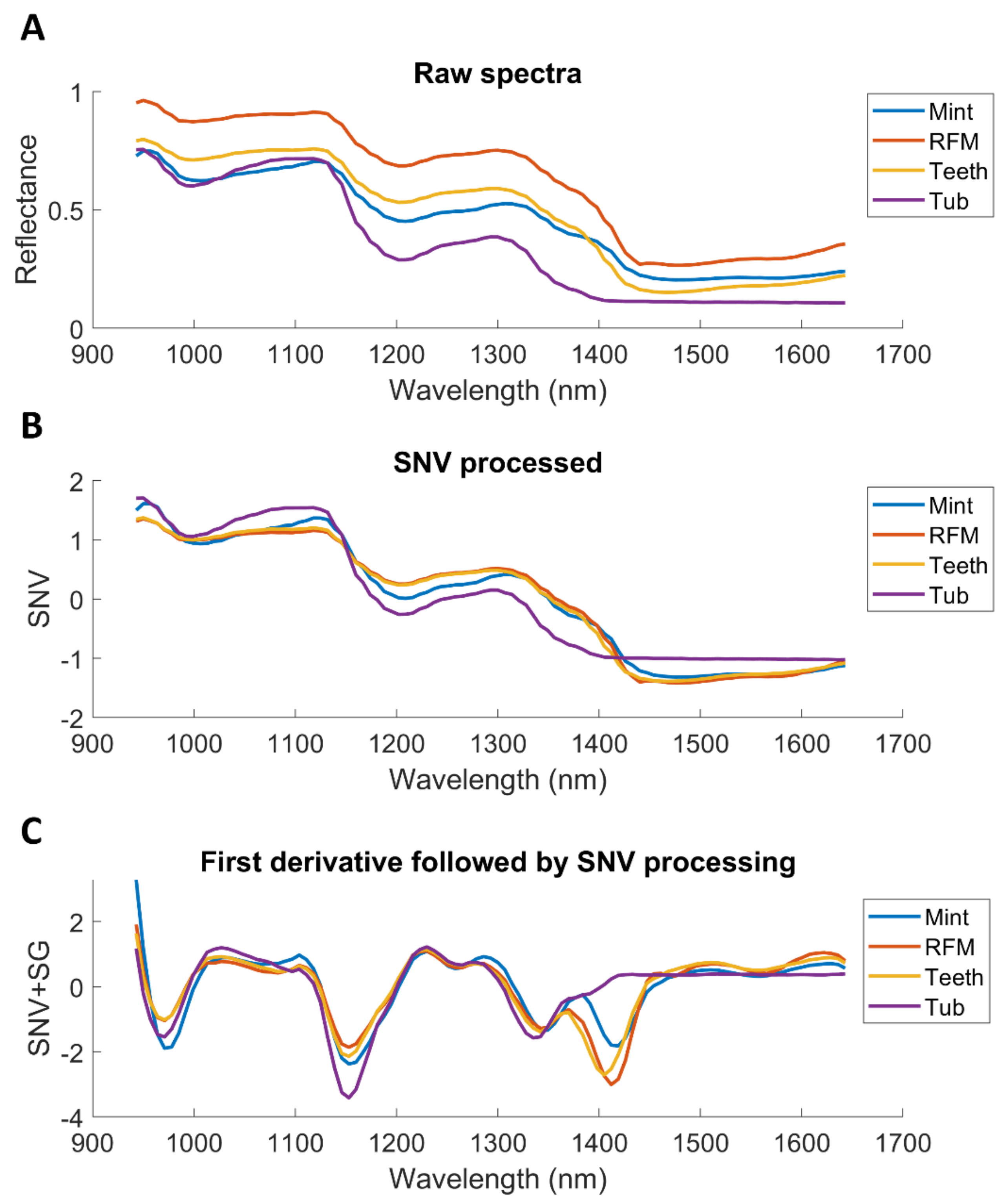
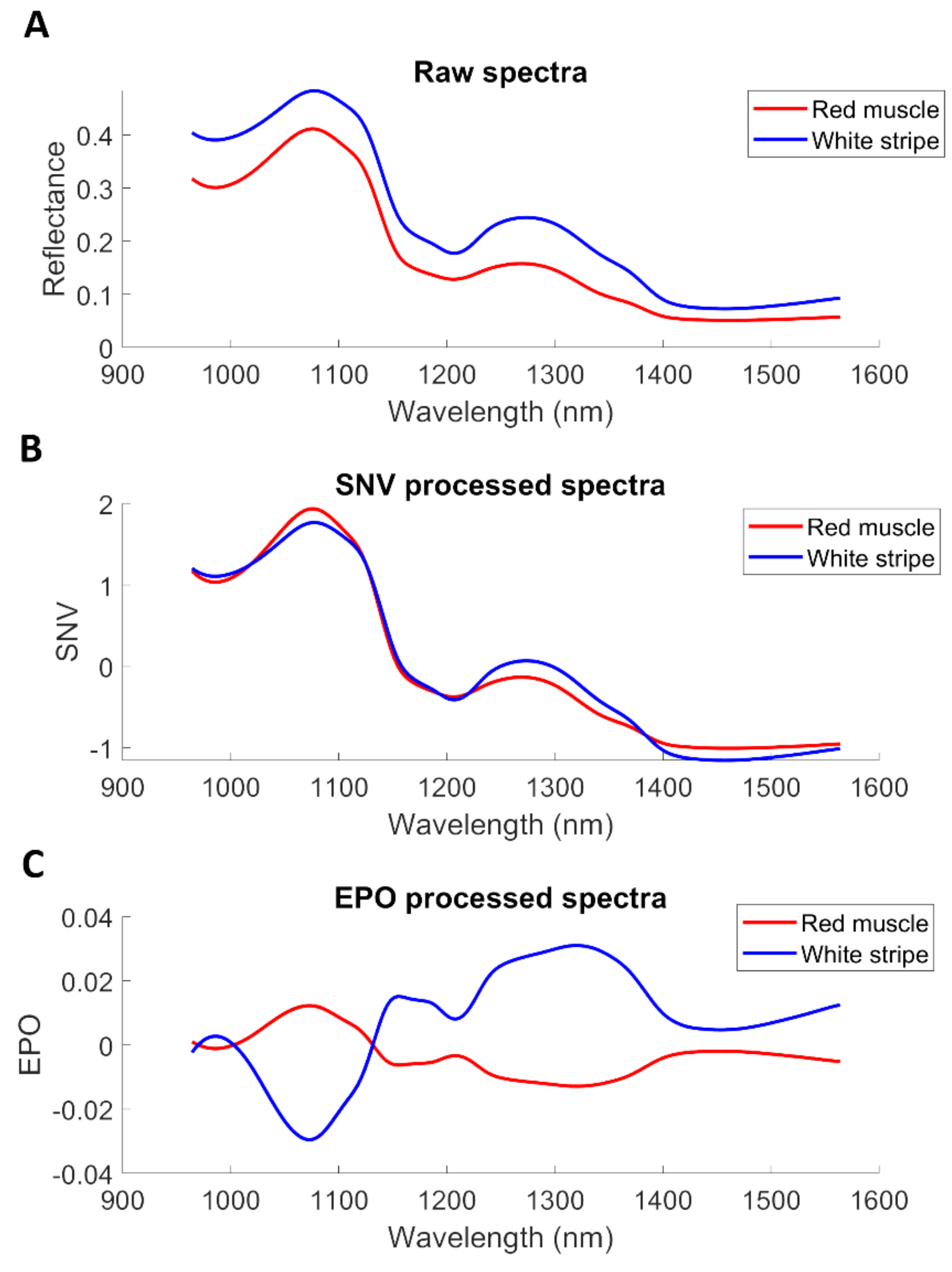
In the field of hyperspectral imaging, the most common practice is the adaptation of different pre-processing techniques [
25]. Spectral preprocessing algorithms are mathematically used to improve spectral data. It aims to correct undesired effects such as random noise, length variation of light path, and light scattering resulting from variable physical sample properties or instrumental effects. This step is generally performed prior to multivariate modelling so as to reduce, eliminate, or standardize the impact on the spectra and to greatly enhance the robustness of the calibration model [
26]. In this work, three spectral pre-processing methods are attempted comparatively, namely, standard normal variate (SNV), first derivative, and external parameter orthogonalization (EPO [
27]). SNV is a mathematical transformation method of spectra, which is used to remove slope variation and correct light scattering effects. As one of the normalization methods, SNV is performed by first calculating the standard deviation and then normalizing by this value, thus giving the sample a unit standard deviation. First derivative using Savitzky-Golay (SG) method can reduce additive effects [
28]. EPO decomposes a spectrum into two components: a useful component that has a direct relationship with the response variable, and a parasitic component that is from an external influence [
29]. By removing the parasitic component through orthogonal transformation of spectra, the calibrated spectral model can be less sensitive to the external influence.
2.5. PLSDA and SVM Modelling
Partial least squares discriminant analysis (PLSDA) [
30] and SVM are used to build classification models. It is common practice to “unfold” hypercubes such that the three-dimensional information is presented in two dimensions. Unfolding simply refers to rearranging spectra from a hypercube with three dimensions ((1) rows, (2) columns, and (3) wavelengths) to a matrix with two dimensions ((1) rows × columns against (2) wavelengths). Non-background pixels are extracted from each hypercube by unfolding and concatenated to make a two-dimensional matrix (X, i.e., a matrix where the rows represent observations and columns represent spectral features). PLSDA and SVM models are developed from X and Y (i.e., a matrix where the rows represent observations and columns represent the true classes). It is significant to select the proper number of latent variables (LVs). Inclusion of too few or too many LVs may lead to, respectively, under or over-fitting of the data and subsequently lead to poor future model performance [
31]. In this work, venetian blinds cross-validation is applied to determine the optimal number of LVs, which is performed by checking the evolution of the accuracy with the number of LVs.
Multiclass support vector machine (SVM) with the error correcting output codes (ECOC) is also implemented for comparison. The SVM is a binary classifier which can be extended by fusing several of its kind into a multiclass classifier [
32]. In this work, SVM decisions are fused using the ECOC approach, adopted from the digital communication theory [
33].
2.6. PCA-CNN Modelling
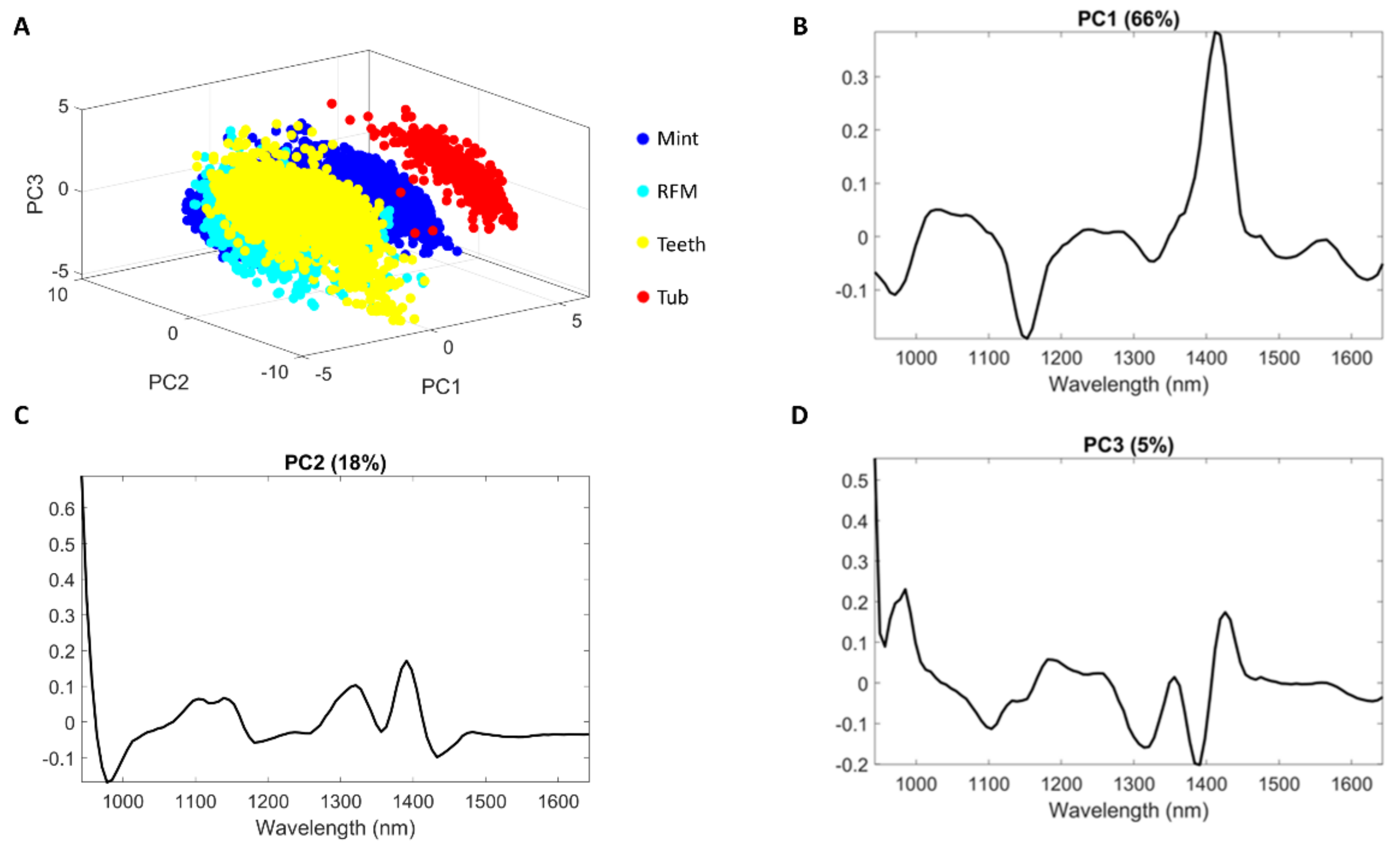
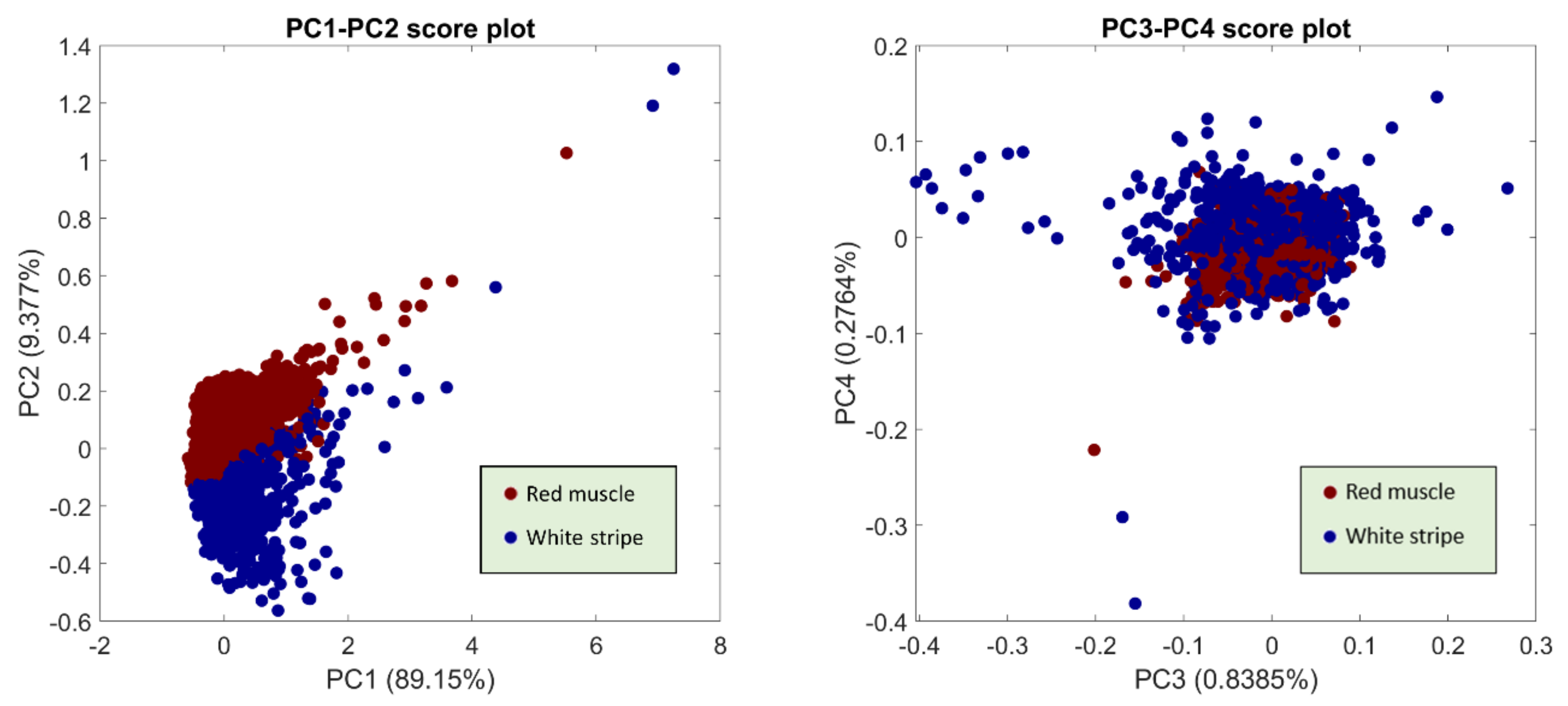
This method starts with employing PCA on the global dataset to seek for the spectral variance among different sample types. To do this, it is necessary to unfold all image cubes in the training set along the spatial axis and takes all of the pixel spectra from each hypercube (omitting the background) and then concatenates them to make a two-dimensional matrix on which PCA is performed. PCA decomposes the original data matrix into scores and loadings. Each loading is a vector which provides information on the relative importance, or the weighting, of specific wavelengths relative to each other. The first PC describes the largest variance in the dataset and each following PC describes progressively less of the variance. Therefore, instead of using all loading vectors, we can opt to just use some of the earlier loading vectors to represent the original dataset. For samples in validation and test sets, the individual hypercube is first unfolded and then projected along the PC loadings by matrix multiplication producing PC scores matrices which are subsequently re-folded to form score images.
Score images from the first few PCs are used as the input for 2-D CNN model. For a pixel-based classification of hypercube , where and are the width and the height of the image and denotes the number of spectral bands, it aims at predicting the label of each pixel within the image. Initially, the original hypercube is reduced to score images with the size of where refers to the number of selected PCs. The next step is to extract a patch for each pixel, where denotes the window size of the patch. In specific, each patch (i.e., the spatial context) is constructed surrounding a pixel, the center point of the patch. For the pixels that reside near the edge of the image, the patch includes some pixels belonging to the sample while the others belonging to the background.
In this work, the structure of the 2-D CNN consists of an input layer, a convolution (Conv) layer, a rectified linear unit (ReLU) layer, a pooling (POOL) layer, a dropout layer, a fully connected (FC) layer, a softmax layer, and an output layer. The convolutional layer convolves the input data by applying sliding convolutional filters and outputs the convolved features [
34], that is, the feature maps. Each convolutional kernel outputs a feature map corresponding to a type of extracted features. Traditional convolution moves from left to right and from top to bottom with a step of 1. Strided convolution has a larger and user-defined step size for traversing the input. All feature maps are stitched and merged by the first fully connected layer to summarize all local features. The number of neural nodes in the fully connected layer changes with the convolution kernel size, the sampling kernel size, and the number of feature maps. For a classification task, it is a common practice to place a softmax layer after the last FC layer. The softmax function is used to compute the probability that each input data pattern belongs to a certain class. The kernel size, the number of feature maps, and the spatial size (i.e., the window size of the patch) are critical parameters in CNN model. These parameters were optimized based on a systematic way of tuning one parameter and fixing it followed by the same procedure for others.
2.7. Three-Dimensional CNN Modelling
As the image formed by hyperspectral bands may have some correlations, e.g., close spectral bands may account for similar images, it is desirable to take into account spectral correlations. Although the 2-D CNN model enables to use the spatial context, it is applied without consideration of spectral correlations. To address this issue, a 3-D CNN model is proposed to extract high-level spectral-spatial features from the original 3-D hyperspectral images. A patch () for each pixel is extracted from hypercube and used as the input. The operational details of the 3-D CNN model are quite similar to those of the 2-D CNN model. Different from 2-D CNN, the convolution operator of this model is 3-D, whereas the first two dimensions are applied to capture the spatial context and the third dimension captures the spectral context. In addition to a Conv layer, a BN layer, a ReLU layer, a dropout layer, a FC layer, a softmax layer are included in the designed network structure.
2.8. Assessment of Classification Models
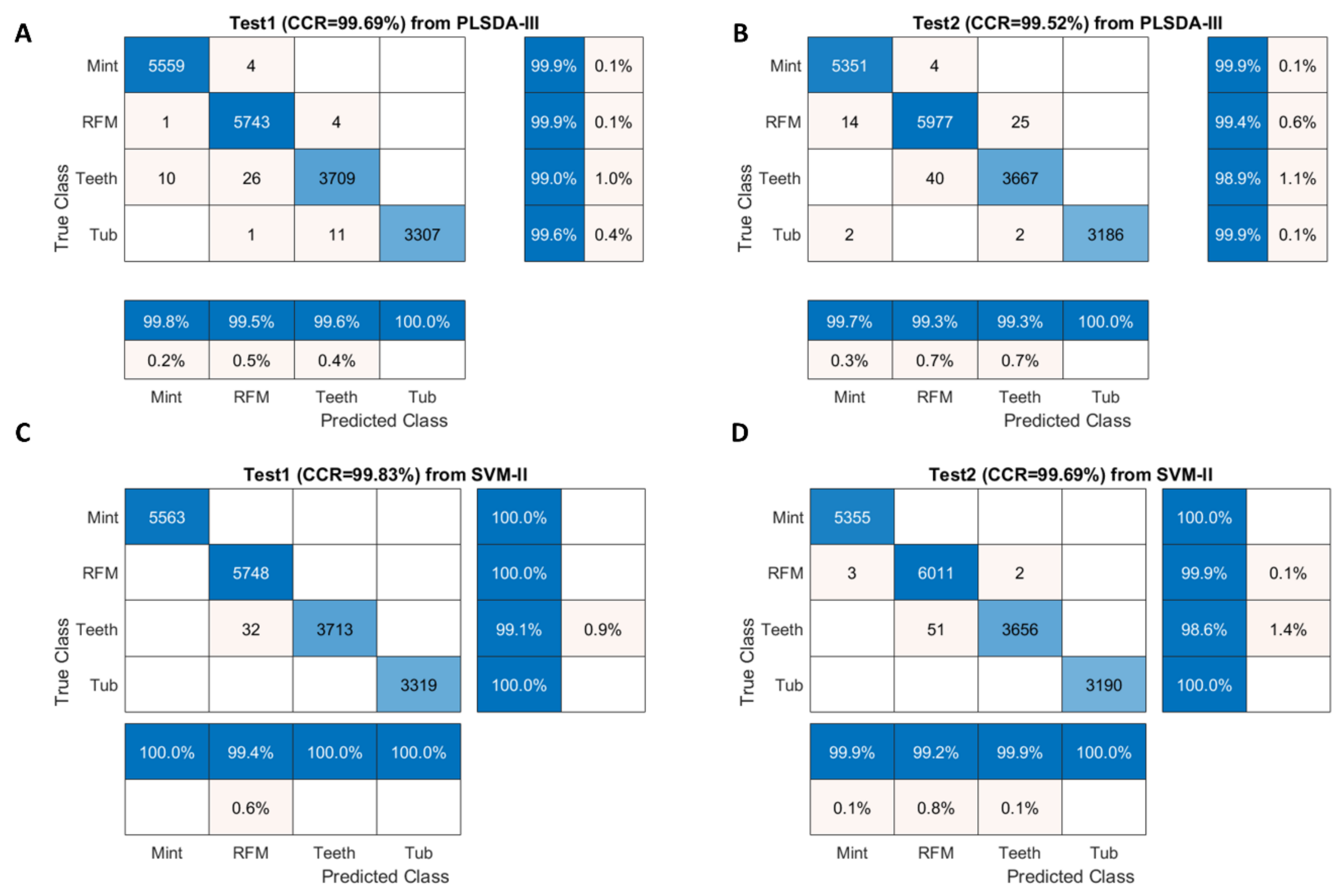
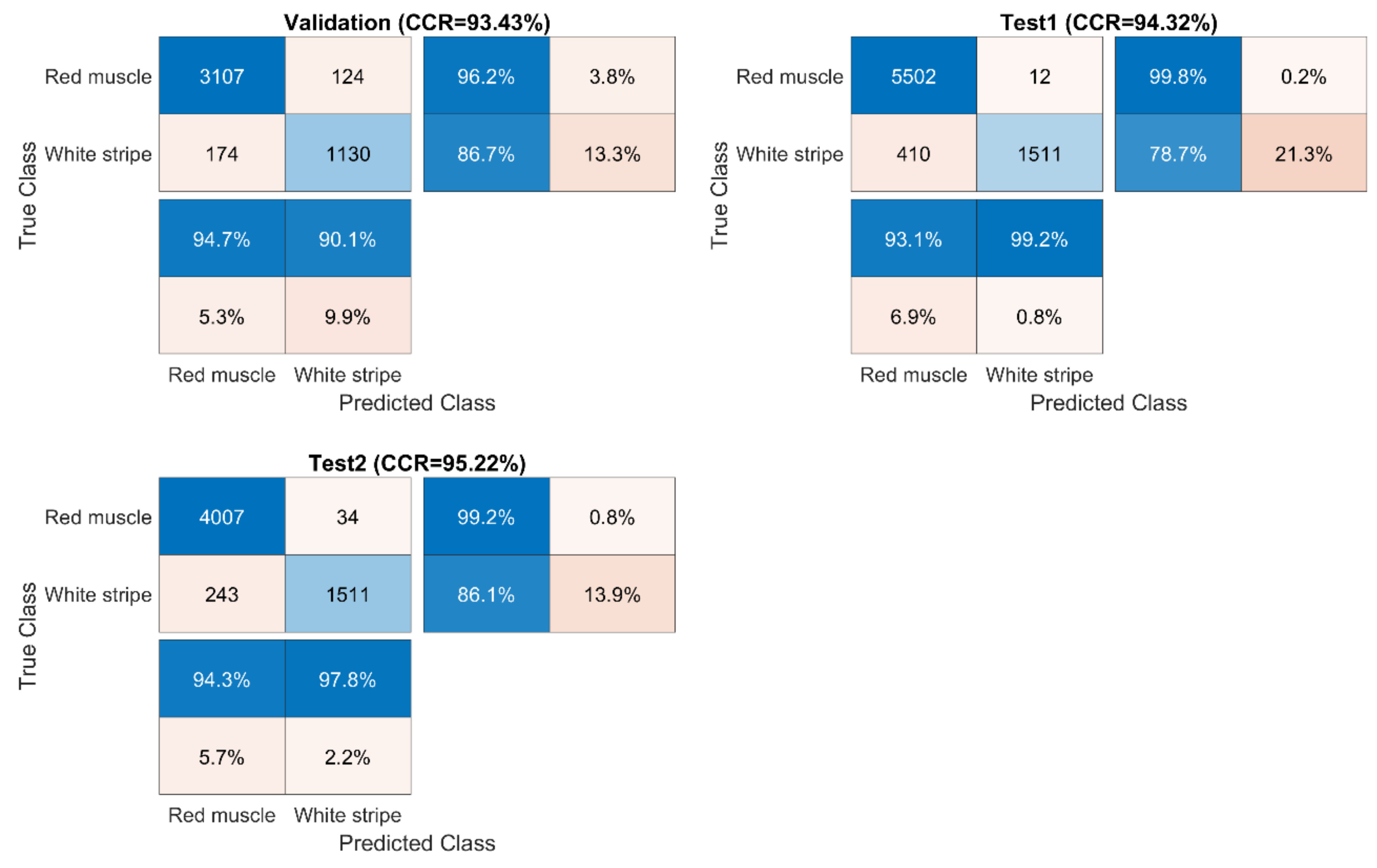
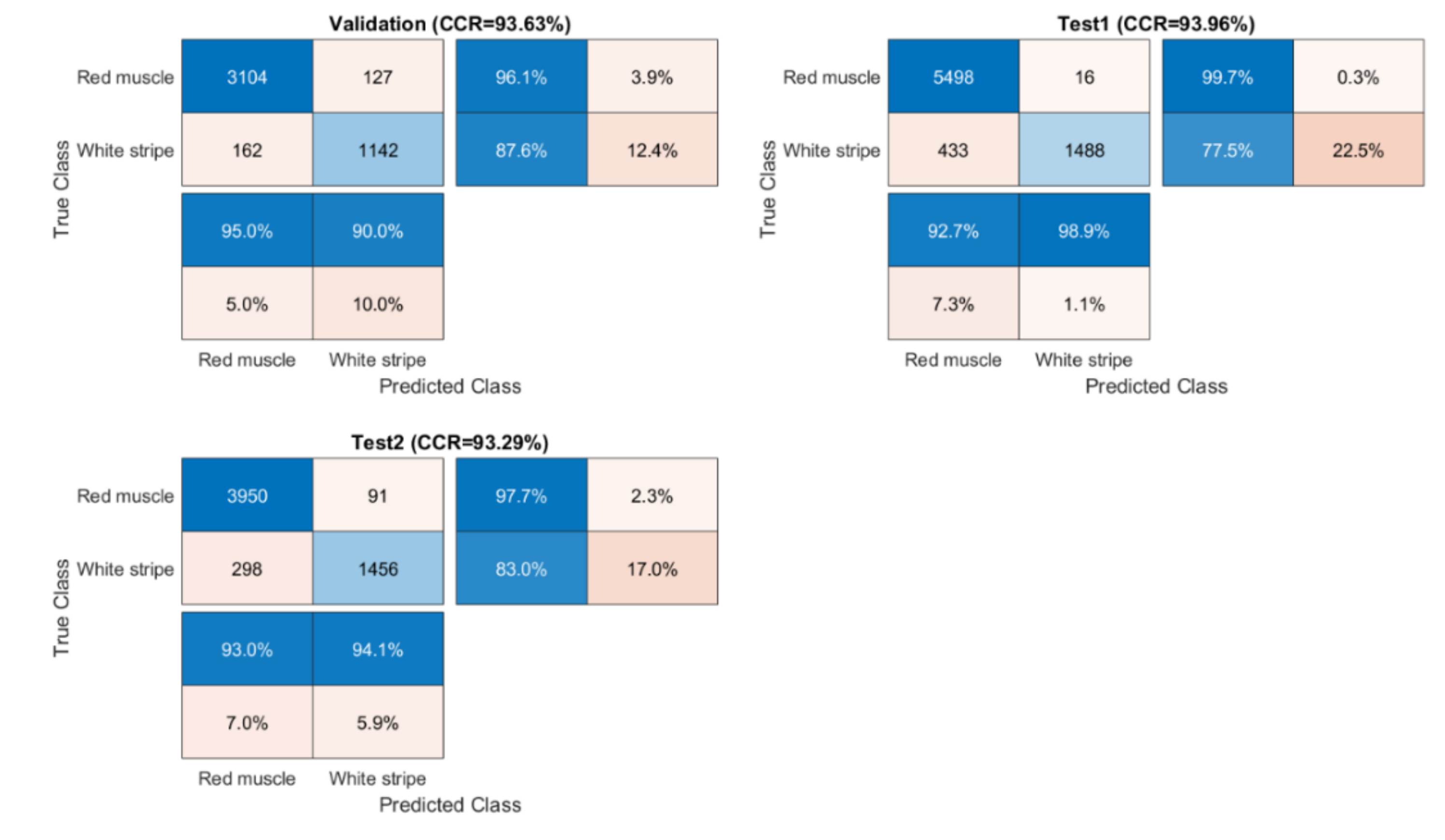
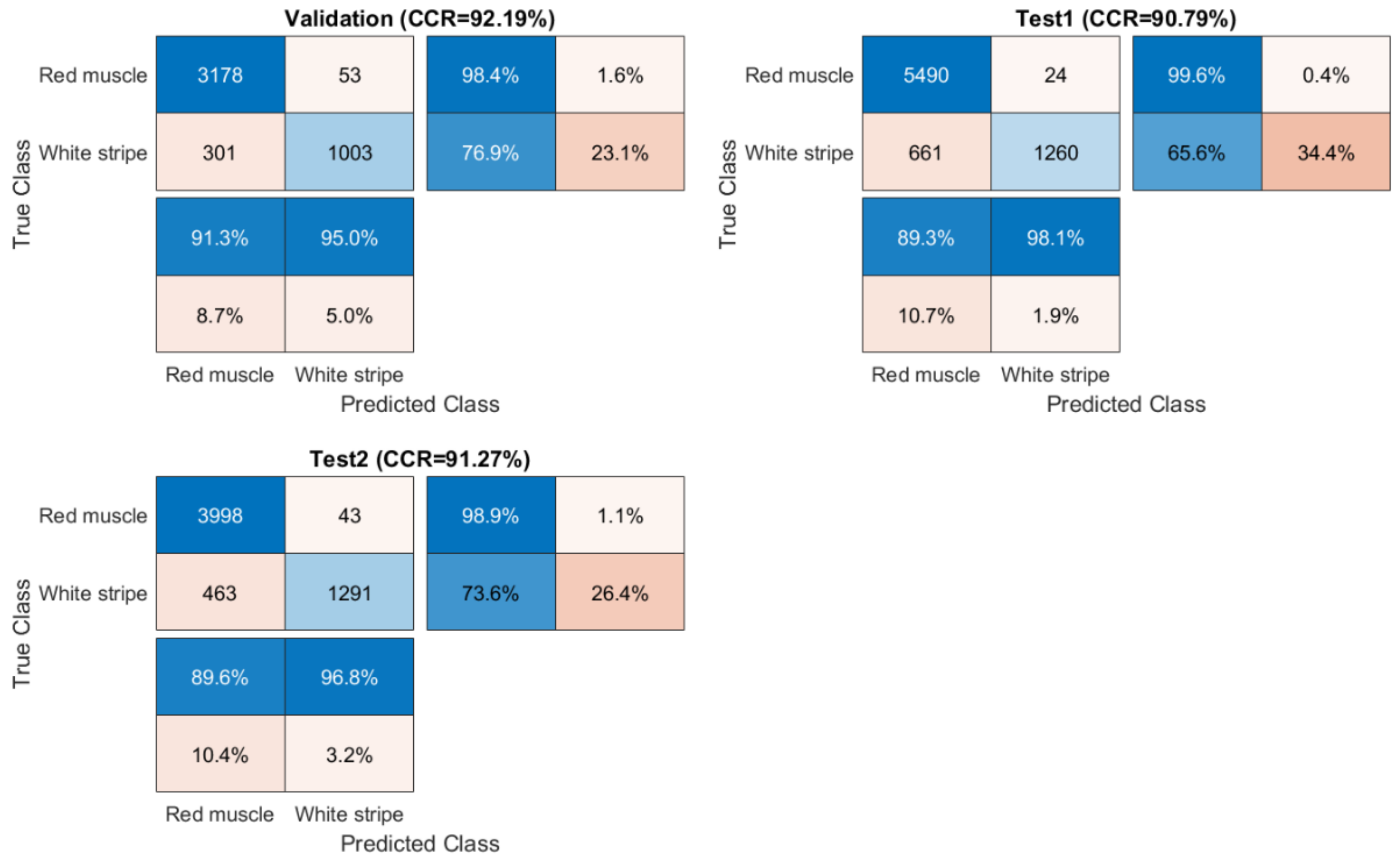
Essentially, the performance of a classifier is assessed by the data set classification accuracy index, i.e., % correct classification rate (%CCR). The ground truth for sweet samples is directly obtained by labelling after removing background (see
Section 2.3). For salmon samples, a local thresholding strategy is applied on PC2 score images to obtain ground truth. Firstly, individual score image is divided into several sub-images and then an optimal threshold value is manually selected for each sub-image. Confusion matrix, also known as an error matrix, is used to evaluate the quality of the output of the classifier for validation and test sets. The elements in the diagonal are the elements correctly classified, while the elements out of the diagonal are misclassified. We also compute the percentages of all the examples belonging to each class that are correctly and incorrectly classified and show them on the far right of the confusion matrix. These metrics are often called the recall, also known as sensitivity (or true positive rate (TPR)) and false negative rate (FNR), respectively. The row at the bottom of the confusion matrix shows the percentages of all the examples predicted to belong to each class that are correctly and incorrectly classified. These metrics are often known as the precision (or positive predictive value (PPV)) and false discovery rate (FDR), respectively. In detail, they are calculated as below:
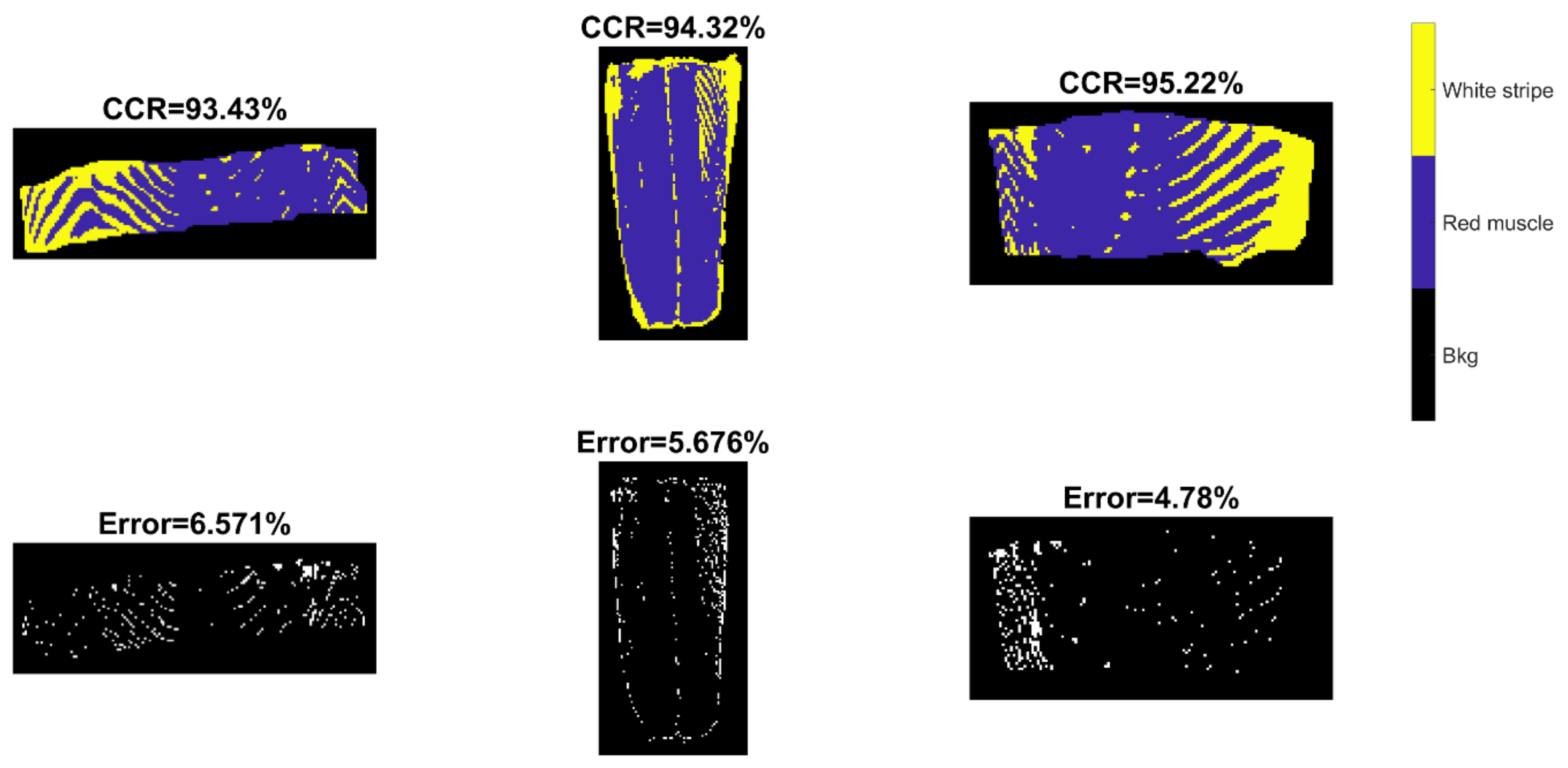
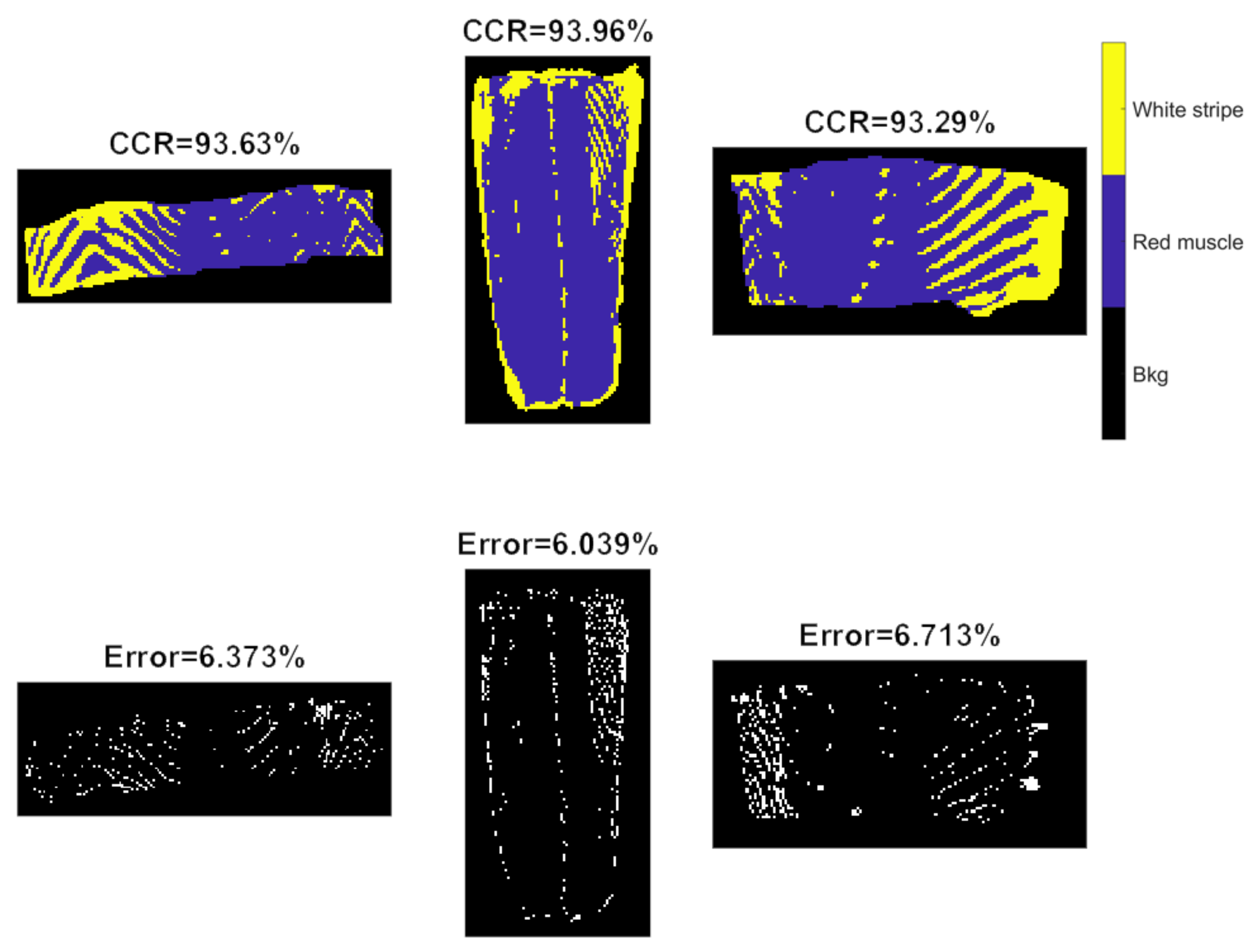
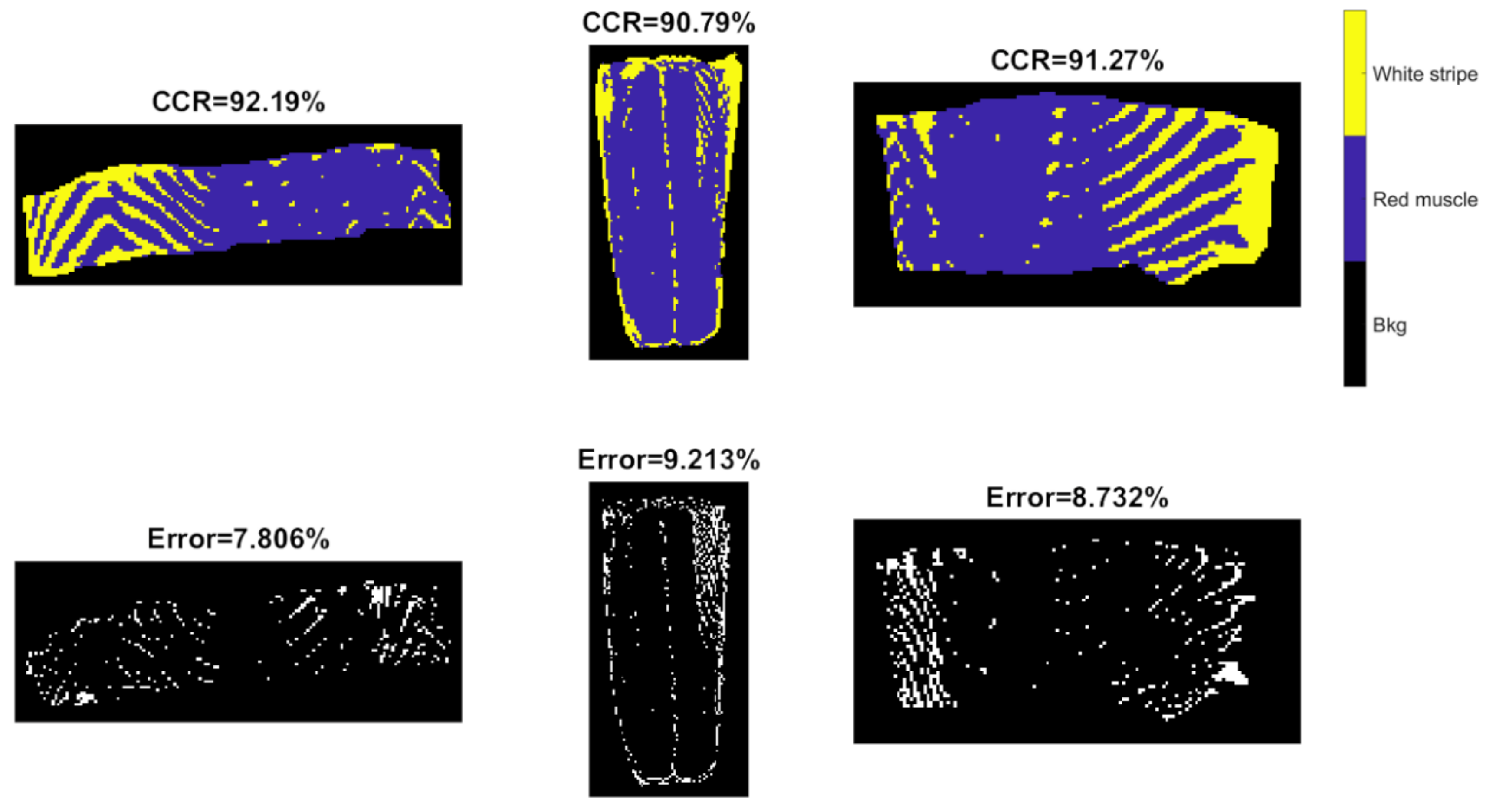
In these equations, TP, TN, FP and FN respectively refer to true positive, true negative, false positive and false negative. Desirable classification performance is characterized with higher CCR, TPR, PPV, and lower FNR and FDR. Apart from these, classification and misclassification maps are also displayed to visualize where are the correctly and incorrectly classified pixels.
4. Discussion
This work intends to compare different supervised classifiers for NIR hyperspectral imaging data acquired from benchtop instruments. Using PLSDA, the relevant sources of data variability are modelled by LVs, which are a linear combination of the original variables, and, consequently, it allows graphical visualization and understanding of the different data patterns and relations by LV scores and loadings. Theoretically, PLSDA combines dimensionality reduction and discriminant analysis into one algorithm and is especially applicable to modelling high dimensional data. Therefore, it has demonstrated great success in modelling hyperspectral imaging datasets for diverse purposes. In this work, however, PLSDA presented the inferior modelling performance in both example datasets.
For sweet samples, there are distinctive spatial patterns among classes, which could potentially contribute to the classification. PLSDA and SVM focus exclusively on the spectral domain despite the inherent spatial-spectral duality of the hyperspectral dataset. In other words, the hyperspectral data are considered not as an image but as an unordered listing of spectral vectors where the spatial coordinates can be shuffled arbitrarily without affecting classification modeling results [
37]. As we can observe from classification and misclassification maps of sweet samples, PLSDA and SVM classifiers exhibit random noise in pixel-based classification (significantly less in the CNN-based methods), because they ignore spatial-contextual information when providing a pixel prediction. Therefore, pixel-based CNN models outperform traditional chemometric technique (i.e., PLSDA) and machine learning (SVM) in terms of every aspect of classification performance for sweet samples, e.g., higher accuracy, sensitivity, and precision. On the other hand, the spectral difference is the main source for classification between white strip and red muscle classes of salmon samples. Therefore, inclusion of spatial information by applying CNN based strategies (i.e., PCA-CNN and 3-D CNN) cannot necessarily enhance model performance.
PCA-CNN and 3-D CNN both enable to use the conjunction of spatial and spectral information, therefore achieving better classification results compared to PLSDA. PCA is based on the fact that neighboring bands of hyperspectral images are highly correlated and often convey almost the same information about the object. In this sense, PCA facilitates to transform the original data so to remove the correlation among the bands. Technically, the first few PC score images may contain most of the information contained in the entire hyperspectral image data; hence, classifications using the most significant PCA bands yield the same class patterns as when entire hyperspectral data sets are used. Our two hyperspectral datasets (i.e., sweet and salmon) suggested that similar predictive capability is witnessed between these two CNN-based strategies. However, in terms of the runtime of modelling training, the PCA-CNN classifier requires much less time than 3-D CNN partly due to the computational complexity of the 3-D convolution layer. Moreover, it is observed that the number of parameters that each model needs to adjust during the training phase, being the PLSDA model with fewest parameters and the 3-D CNN the one with the most parameters to fit.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}