A Visual Sensing Concept for Robustly Classifying House Types through a Convolutional Neural Network Architecture Involving a Multi-Channel Features Extraction



Abstract
:1. Introduction
2. Related Works
3. Our Novel Method/Model
- Images, which do not contain a house but only some additional information like garden or trees, make the house classification difficult. Such images are not appropriate for use for a house classification endeavor.
- Some images are (maybe) captured from a very poor angle of the house and thus the house is not well recognizable on them.
- Some house classes have strong similarities with other classes; this is a potential source of misclassification amongst them.
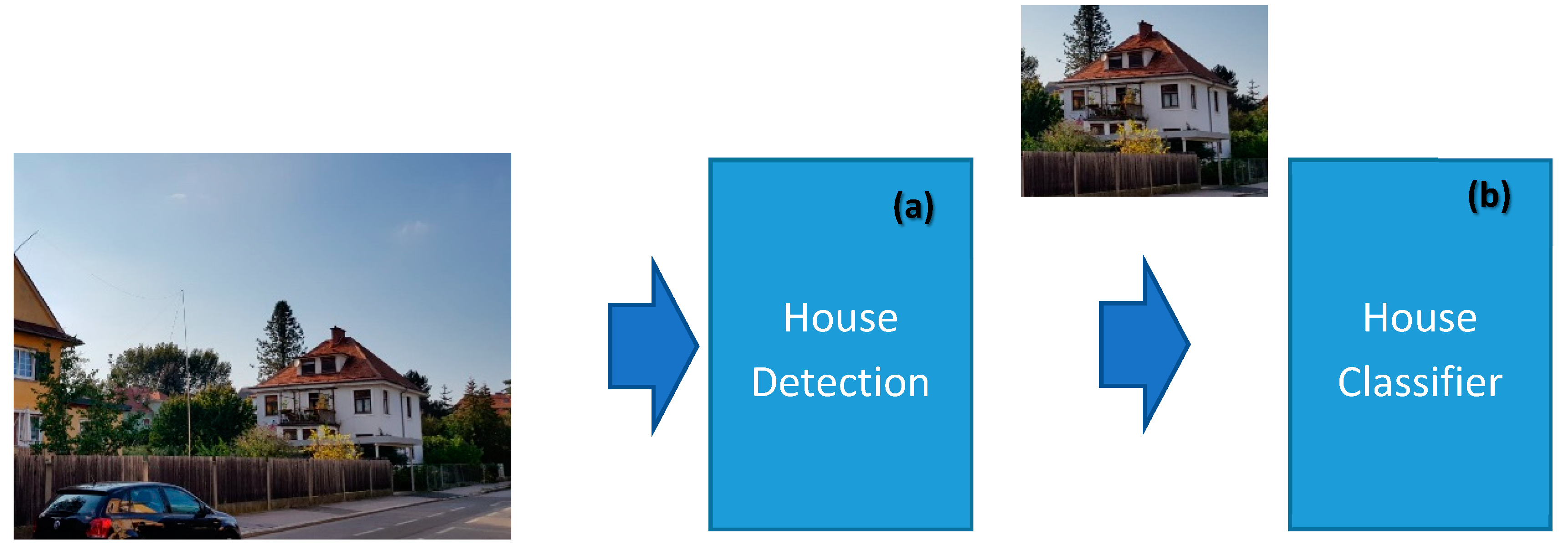
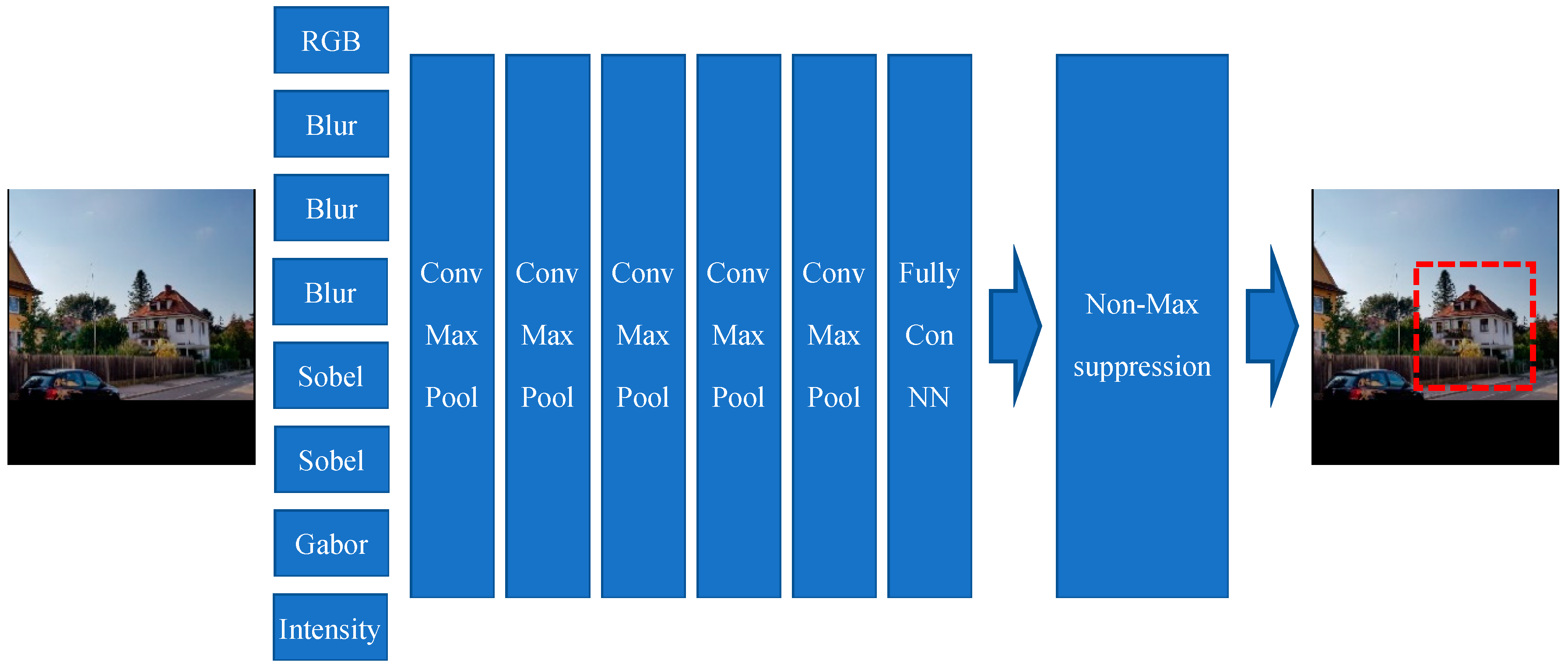
3.1. House Detection
3.2. House Classification
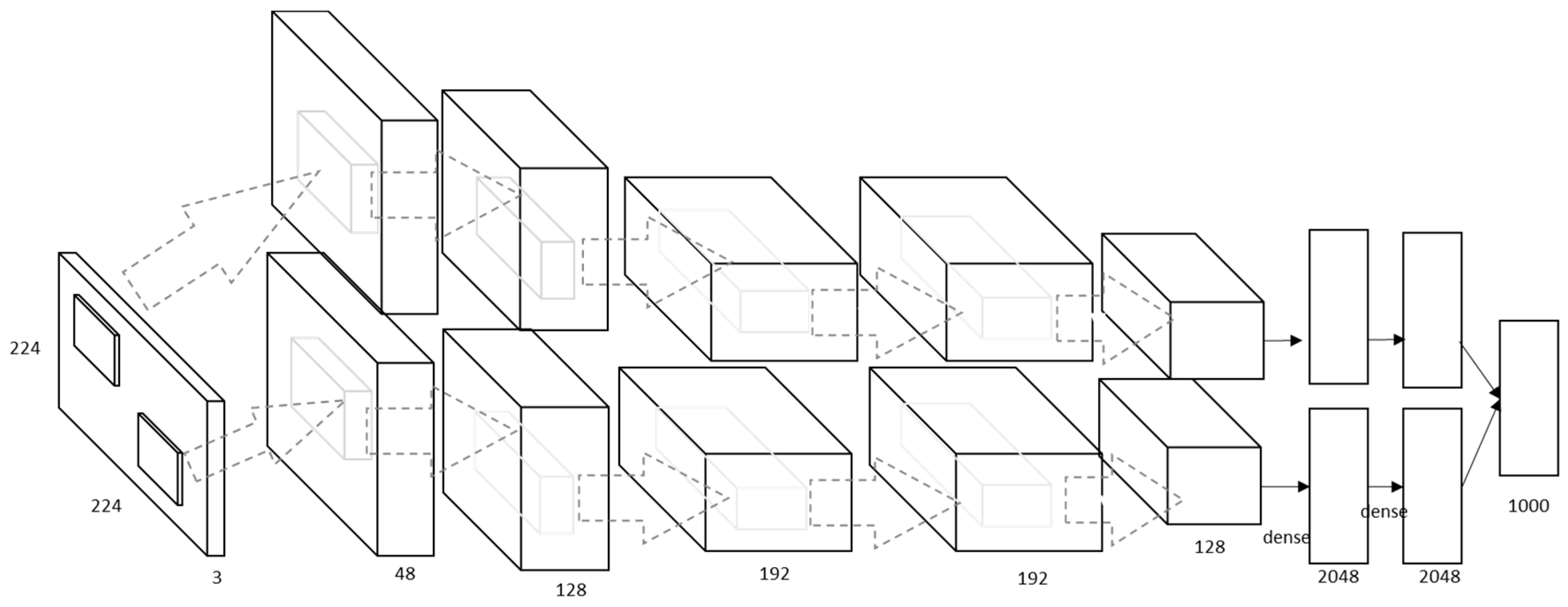
3.2.1. Model I
3.2.2. Model II
3.2.3. Model III
4. Results Obtained and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Luo, F.; Huang, Y.; Tuc, W.; Liu, J. Local manifold sparse model for image classification. Neurocomputing 2020, 382, 162–173. [Google Scholar] [CrossRef]
- Klinger, T.; Rottensteiner, F.; Heipke, C. A Dynamic Bayes Network for visual Pedestrian Tracking. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 40, 145–150. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.-C. The Feature Extraction Based on Texture Image Information for Emotion Sensing in Speech. Sensors 2014, 14, 16692–16714. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, M.Y.; Liao, W.; Yang, C.; Cao, Y.; Rosenhahn, B. Security Event Recognition For Visual Surveillance. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 19–26. [Google Scholar]
- Kang, J.; Körner, M.; Wang, Y.; Taubenböck, H.; Zhu, X.X. Building instance classification using street view images. ISPRS J. Photogramm. Remote Sens. 2018, 145, 44–59. [Google Scholar] [CrossRef]
- Zhang, Y. Optimisation of building detection in satellite images by combining multispectral classification and texture filtering. ISPRS J. Photogramm. Remote Sens. 1999, 54, 50–60. [Google Scholar] [CrossRef]
- Mukhina, K.D.; Visheratin, A.A.; Mbogo, G.; Nasonov, D. Forecasting of the Urban Area State Using Convolutional Neural Networks. In Fruct Association; IEEE: Bologna, Italy, 2018. [Google Scholar]
- Ho, Y.; Wookey, S. The Real-World-Weight Cross-Entropy Loss Function: Modeling the Costs of Mislabeling. IEEE Access 2020, 8, 4806–4813. [Google Scholar] [CrossRef]
- Cao, J.; Su, Z.; Yu, L.; Chang, D.; Li, X.; Ma, Z. Softmax Cross Entropy Loss with Unbiased Decision Boundary for Image Classification. In Chinese Automation Congress; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Peng, Y.; Cai, J.; Wu, T.; Cao, G.; Kwok, N.; Zhou, S.; Peng, Z. A hybrid convolutional neural network for intelligent wear particle classification. Tribol. Int. 2019, 138, 166–173. [Google Scholar] [CrossRef]
- Machot, F.A.; Ali, M.; Mosa, A.H.; Schwarzlmüller, C.; Gutmann, M.; Kyamakya, K. Real-time raindrop detection based on cellular neural networks for ADAS. Real-Time Raindrop Detect. Based Cell. Neural Netw. ADAS 2019, 16, 931–943. [Google Scholar] [CrossRef] [Green Version]
- Gulshan, V.; Peng, L.; Coram, M. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef]
- Esteva, A.; Kuprel, B.; Novoa, R.; Ko, J.; Swetter, S.; Blau, H.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Sharma, N.; Jain, V.; Mishra, A. An Analysis of Convolutional Neural Networks For Image Classification. Procedia Comput. Sci. 2018, 132, 377–384. [Google Scholar] [CrossRef]
- Wang, Q.Z.X. Street view image classification based on convolutional neural network. In IAEAC; IEEE: Chongqing, China, 2017. [Google Scholar]
- Ahn, J.; Park, J.; Park, D.; Paek, J.; Ko, J. Convolutional neural network-based classification system design with compressed wireless sensor network images. PLoS ONE 2018, 13, e0196251. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Chen, T.; Yu, L.; Lai, C. Image Classification Based on the Boost Convolutional Neural Network. IEEE Access 2018, 1, 1–10. [Google Scholar] [CrossRef]
- Xu, X.; Li, W.; Ran, Q.; Du, Q.; Gao, L.; Zhang, B. Multisource Remote Sensing Data Classification Based on Convolutional Neural Network. IEEE Trans. Geosci. Remote Sens. 2017, 99, 937–949. [Google Scholar] [CrossRef]
- Wenhui, Y.; Fan, Y. Lidar Image Classification Based on Convolutional Neural Networks. In Proceedings of the 2017 International Conference on Computer Network, Electronic and Automation (ICCNEA), Xi’an, China, 23–25 September 2017. [Google Scholar]
- Shahid, S.; Shahjahan, M. A new approach to image classification by convolutional neural network. In Proceedings of the 2017 3rd International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 7–9 December 2017. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Wang, W.; Lu, X.; Song, J.; Chen, C. A two-column convolutional neural network for facial point detection. In ICPIC; IEEE: Shanghai, China, 2017; pp. 169–173. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014. [Google Scholar]
- Hu, Y.; Li, C.; Dan, H.; Yu, W. Gabor Feature Based Convolutional Neural Network for Object Recognition in Natural Scene. In Proceedings of the 2016 3rd International Conference on Information Science and Control Engineering (ICISCE), Beijing, China, 8–10 July 2016. [Google Scholar]
- Hosseini, S.; Lee, S.; Kwon, H.; Koo, H.; Cho, N. Age and gender classification using wide convolutional neural network and Gabor filter. In Proceedings of the 2018 International Workshop on Advanced Image Technology (IWAIT), Chiang Mai, Thailand, 7–9 January 2018. [Google Scholar]
- Nguyen, V.; Lim, K.; Le, M.; Bui, N. Combination of Gabor Filter and Convolutional Neural Network for Suspicious Mass Classification. In Proceedings of the 2018 22nd International Computer Science and Engineering Conference (ICSEC), Chiang Mai, Thailand, 21–24 November 2018. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Buhmann, M.D. Radial basis functions. Acta Numer. 2000, 9, 138. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.; Salakhutdinov, R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 5786. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E.; Pereira, F.; Burges, C.J.C.; Bottou, L.; Weinberger, K.Q. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Kumar, J.; Ye, P.; Doermann, D. Learning document structure for retrieval and classification. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012. [Google Scholar]
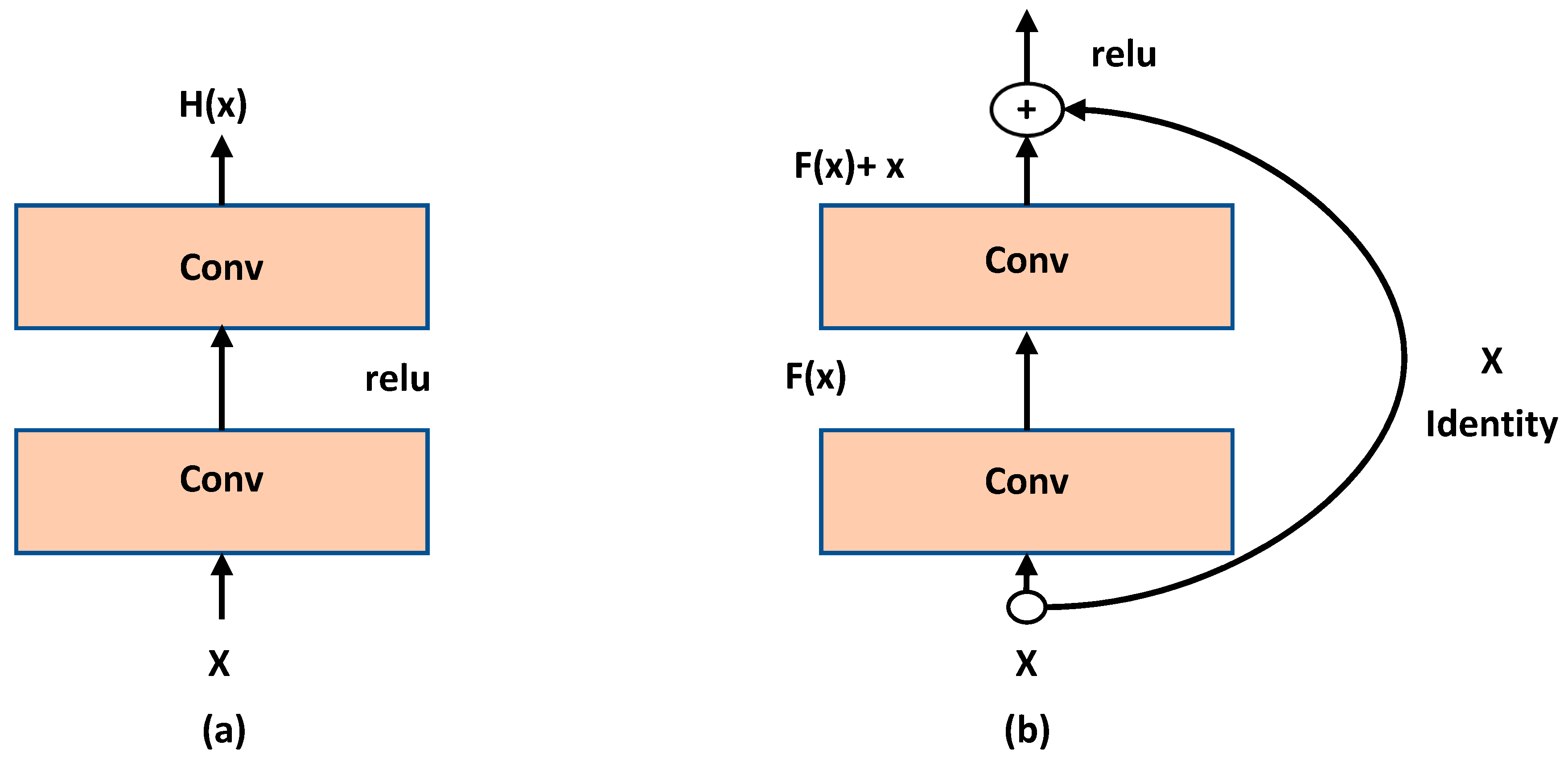
- He, K.; Zhang, X.; Ren, J.S.S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. arXiv 2017, arXiv:1709.01507. [Google Scholar]
- Römer, C.; Plümer, L. Identifying Architectural Style in 3D City Models with Support Vector Machines. Photogramm. Fernerkund. Geoinf. 2010, 5, 371–384. [Google Scholar] [CrossRef]
- Mathias, M.; Martinovic, A.; Weissenberg, J.; Haegler, S.; Van Gool, L. Automatic architectural style recognition. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2011, 1, 171–176. [Google Scholar] [CrossRef] [Green Version]
- Shalunts, G.; Haxhimusa, Y.; Sablatnig, R. Architectural Style Classification of Building Facade Windows. In International Symposium on Visual Computing; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
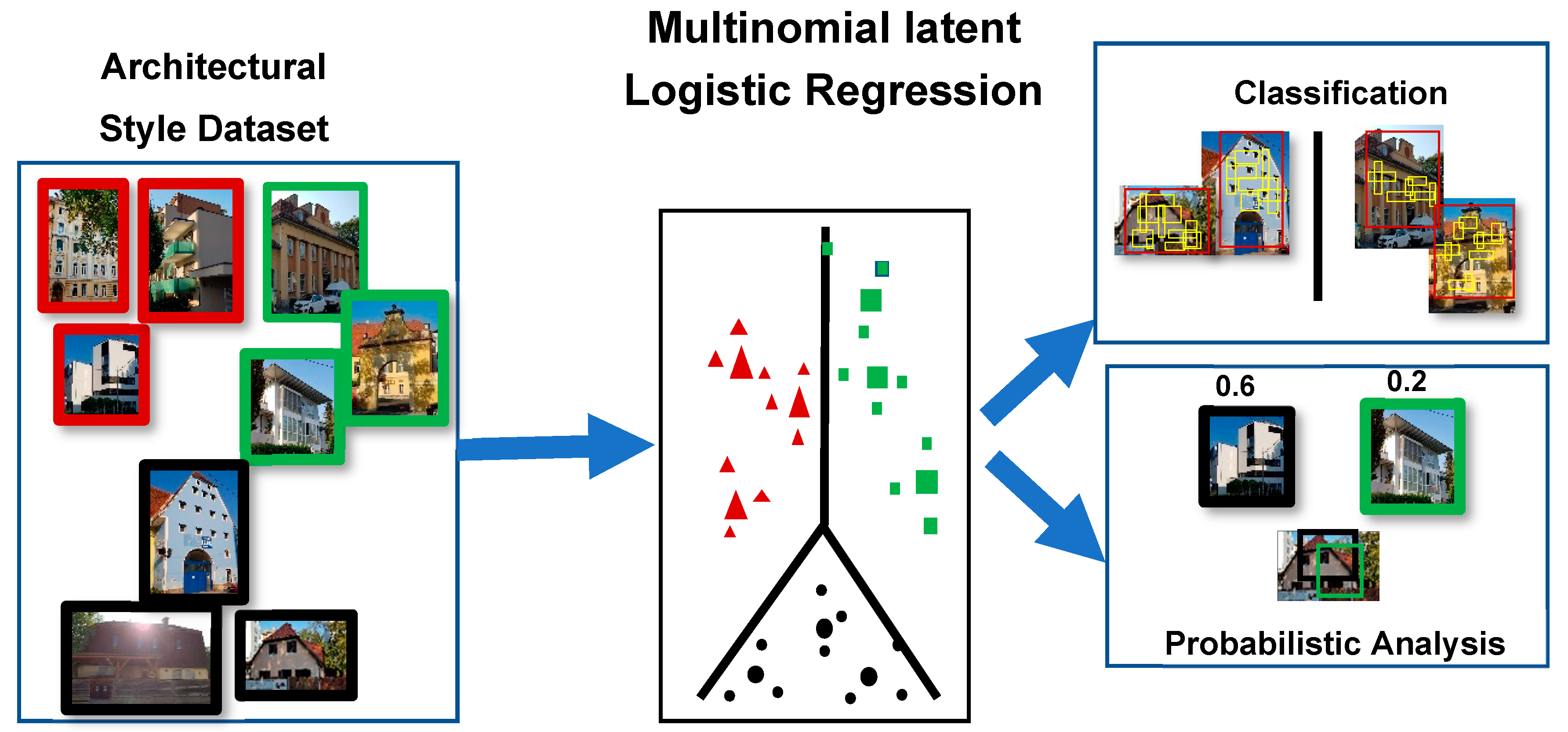
- Xu, Z.; Zhang, Y.; Tao, D.; Wu, J.; Tsoi, A. Architectural Style Classification Using Multinomial Latent Logistic Regression. In Computer Vision – ECCV; Springer: Cham, UK, 2014. [Google Scholar]
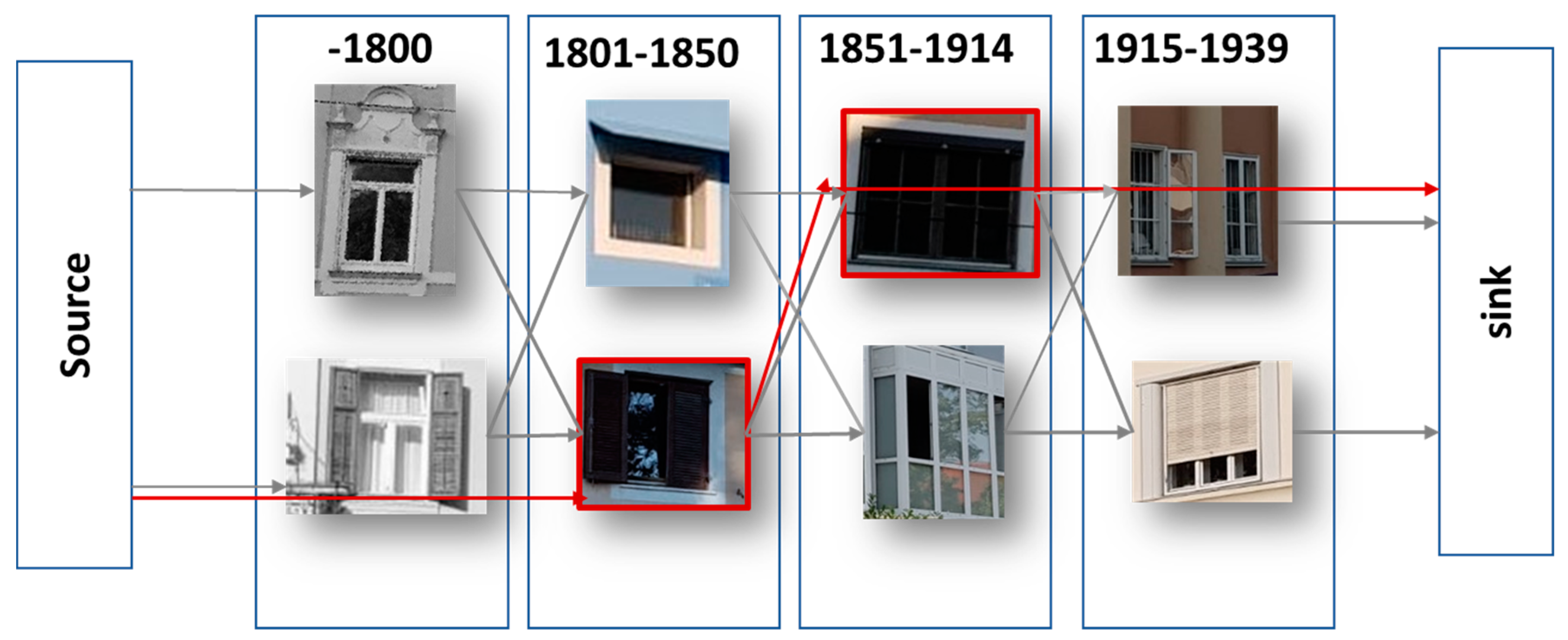
- Lee, S.; Maisonneuve, N.; Crandal, D.; Efros, A.; Sivic, J. Linking Past to Present: Discovering Style in Two Centuries of Architecture. In Proceedings of the 2015 IEEE International Conference on Computational Photography (ICCP), Houston, TX, USA, 24–26 April 2015. [Google Scholar] [CrossRef] [Green Version]
- Obeso, A.M.; Benois-Pineau, J.; Ramirez, A.; Vázquez, M. Architectural style classification of Mexican historical buildings using deep convolutional neural networks and sparse features. J. Electron. Imaging 2016, 26, 11. [Google Scholar] [CrossRef]
- Pesto, C.; Classifying US Houses by Architectural Style Using Convolutional Neural Networks. Stanford University. Available online: http://cs231n.stanford.edu/reports/2017/pdfs/126.pdf (accessed on 10 June 2019).
- Qi, W.; Su, H.; Aliverti, A. A Smartphone-Based Adaptive Recognition and Real-Time Monitoring System for Human Activities. IEEE Trans. Hum. Mach. Syst. 2020, 50, 414–423. [Google Scholar] [CrossRef]
- Su, H.; Qi, W.; Yang, C.; Sandoval, J.; Ferrigno, G.; de Momi, E. Deep neural network approach in robot tool dynamics identification for bilateral teleoperation. IEEE Robot. Autom. Lett. 2020, 5, 2943–2949. [Google Scholar] [CrossRef]
- Su, H.; Hu, Y.; Karimi, H.R.; Knoll, A.; Ferrigno, G.; de Momi, E. Improved recurrent neural network-based manipulator control with remote center of motion constraints: Experimental results. Neural Netw. 2020, 131, 291–299. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | CNN Model without Multi-Layer Channels (Figure 13) | CNN Model with Multi-Channel Features (Figure 14) | CNN Model with Multi-Channel Features (Figure 15) |
|---|---|---|---|
| NMI | 79.5% | 84.59% | 88.19% |
| Model | CNN without Multi-Layer Channels (Figure 13) | CNN with Multi-Channel Features (Figure 15, Top-1) | CNN with Multi-Channel Features (Figure 15, Top-2) |
|---|---|---|---|
| Accuracy | 86.5% | 94.5% | 96.4% |
| Precision | 86.6% | 94.2% | 96.9% |
| F1 Score | 86.7% | 94.0% | 96.1% |
| Recall | 87.7% | 93.9% | 95.9% |
| Model | Mathias (Involving SVM) [35] | Montoya Obesso (Involving CNN) [39] | ResNet-18 [40] | ResNet-34 [40] | CNN without Multi-Layer Channels (Figure 13) | CNN with Multi-Channel Features (Figure 15, Top-1) | CNN with Multi-Channel Features (Figure 15, Top-2) |
|---|---|---|---|---|---|---|---|
| Accuracy | 77.1% | 88.1% | 78.1% | 79.8% | 86.5% | 94.5% | 96.4% |
| Precision | 76.9% | 87.7% | 78.0% | 80.1% | 86.6% | 94.2% | 96.9% |
| F1-Score | 76.5% | 87.9% | 77.8% | 77.8% | 86.7% | 94.0% | 96.1% |
| Recall | 75.3% | 88.2% | 77.9% | 75.8% | 87.7% | 93.9% | 95.9% |
| Memory Usage | 200 MB | 100 MB | 24 MB | 34 MB | 20 MB | 67 MB | 67 MB |
| Processing Time | 100 ms | 12 ms | 11 ms | 12 ms | 9 ms | 10 ms | 10 ms |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tavakkoli, V.; Mohsenzadegan, K.; Kyamakya, K. A Visual Sensing Concept for Robustly Classifying House Types through a Convolutional Neural Network Architecture Involving a Multi-Channel Features Extraction. Sensors 2020, 20, 5672. https://doi.org/10.3390/s20195672
Tavakkoli V, Mohsenzadegan K, Kyamakya K. A Visual Sensing Concept for Robustly Classifying House Types through a Convolutional Neural Network Architecture Involving a Multi-Channel Features Extraction. Sensors. 2020; 20(19):5672. https://doi.org/10.3390/s20195672
Chicago/Turabian StyleTavakkoli, Vahid, Kabeh Mohsenzadegan, and Kyandoghere Kyamakya. 2020. "A Visual Sensing Concept for Robustly Classifying House Types through a Convolutional Neural Network Architecture Involving a Multi-Channel Features Extraction" Sensors 20, no. 19: 5672. https://doi.org/10.3390/s20195672
APA StyleTavakkoli, V., Mohsenzadegan, K., & Kyamakya, K. (2020). A Visual Sensing Concept for Robustly Classifying House Types through a Convolutional Neural Network Architecture Involving a Multi-Channel Features Extraction. Sensors, 20(19), 5672. https://doi.org/10.3390/s20195672