Multi-TALK: Multi-Microphone Cross-Tower Network for Jointly Suppressing Acoustic Echo and Background Noise


Abstract
:1. Introduction
2. Proposed Multi-Channel Cross-Tower with Attention Mechanisms
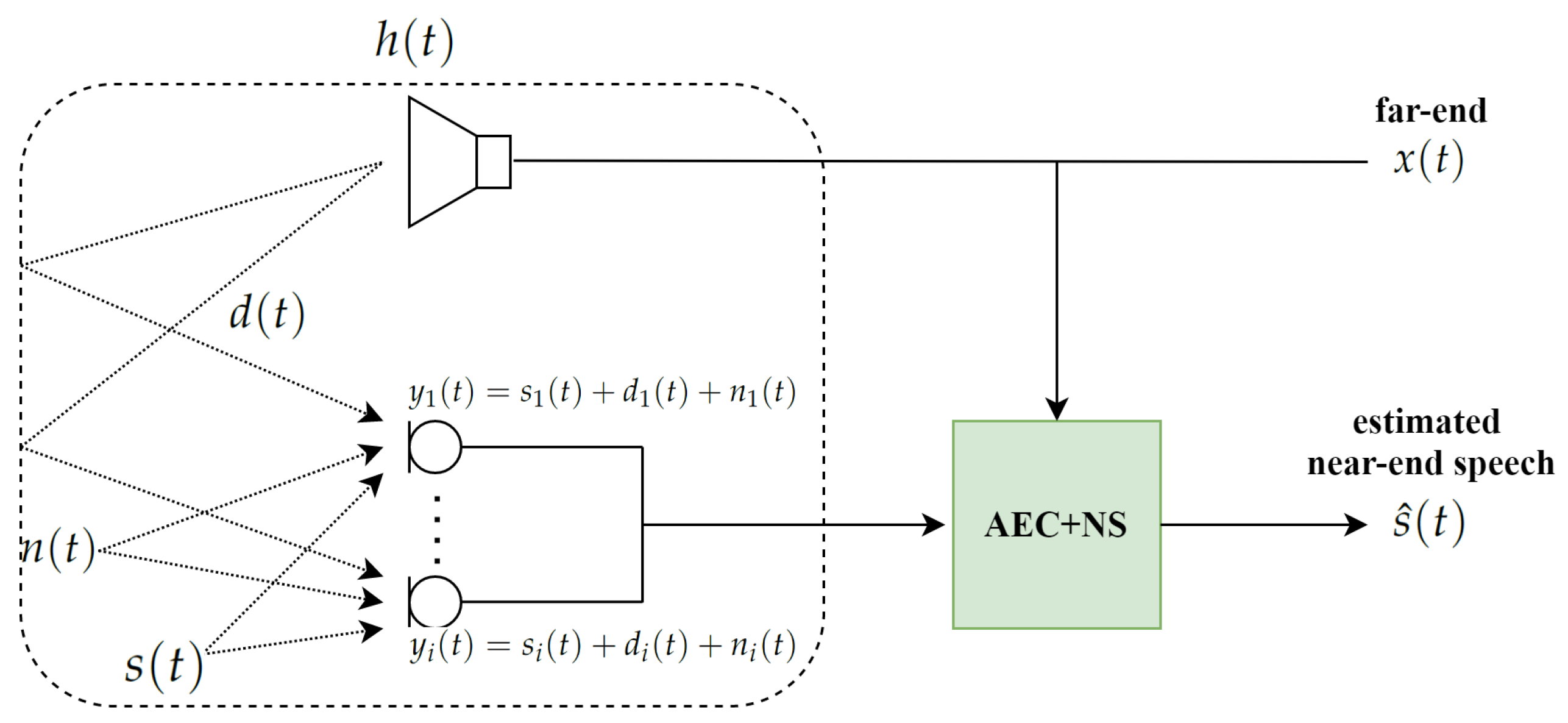
2.1. Signal Modeling
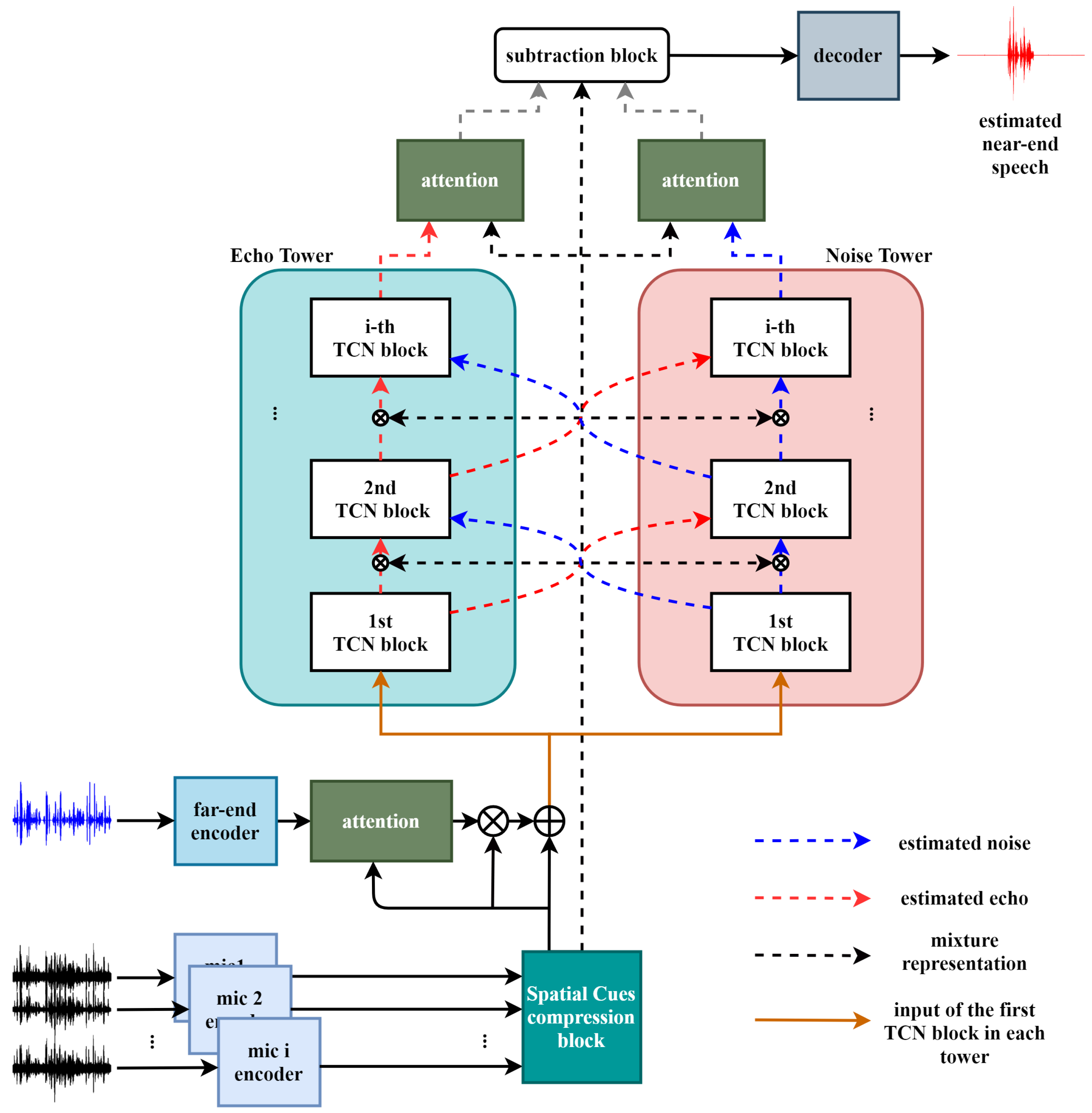
2.2. Overview of Multi-TALK
2.3. Two Different Encoders with an Attention Mechanism
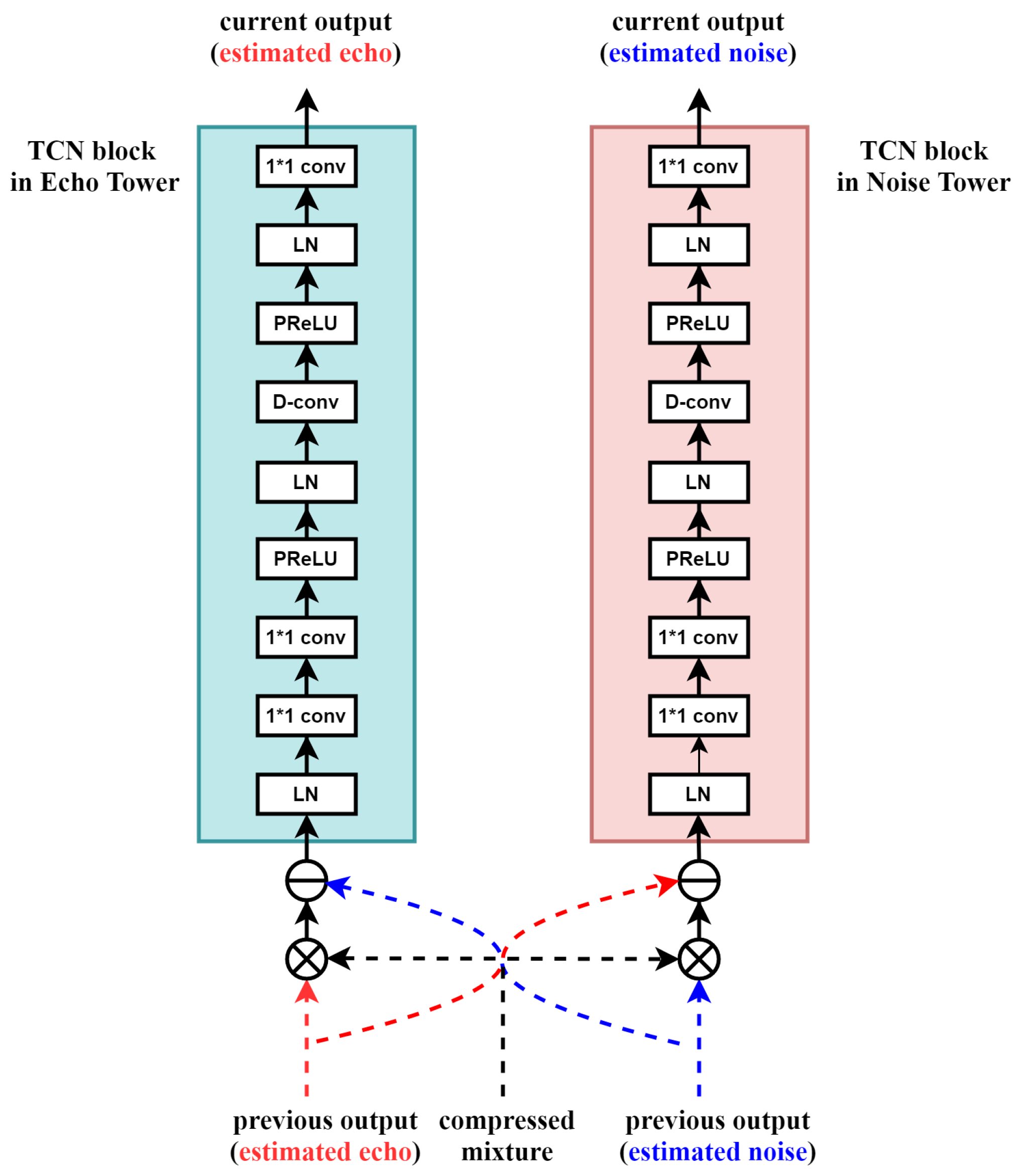
2.4. TCN Blocks in the Cross-Tower
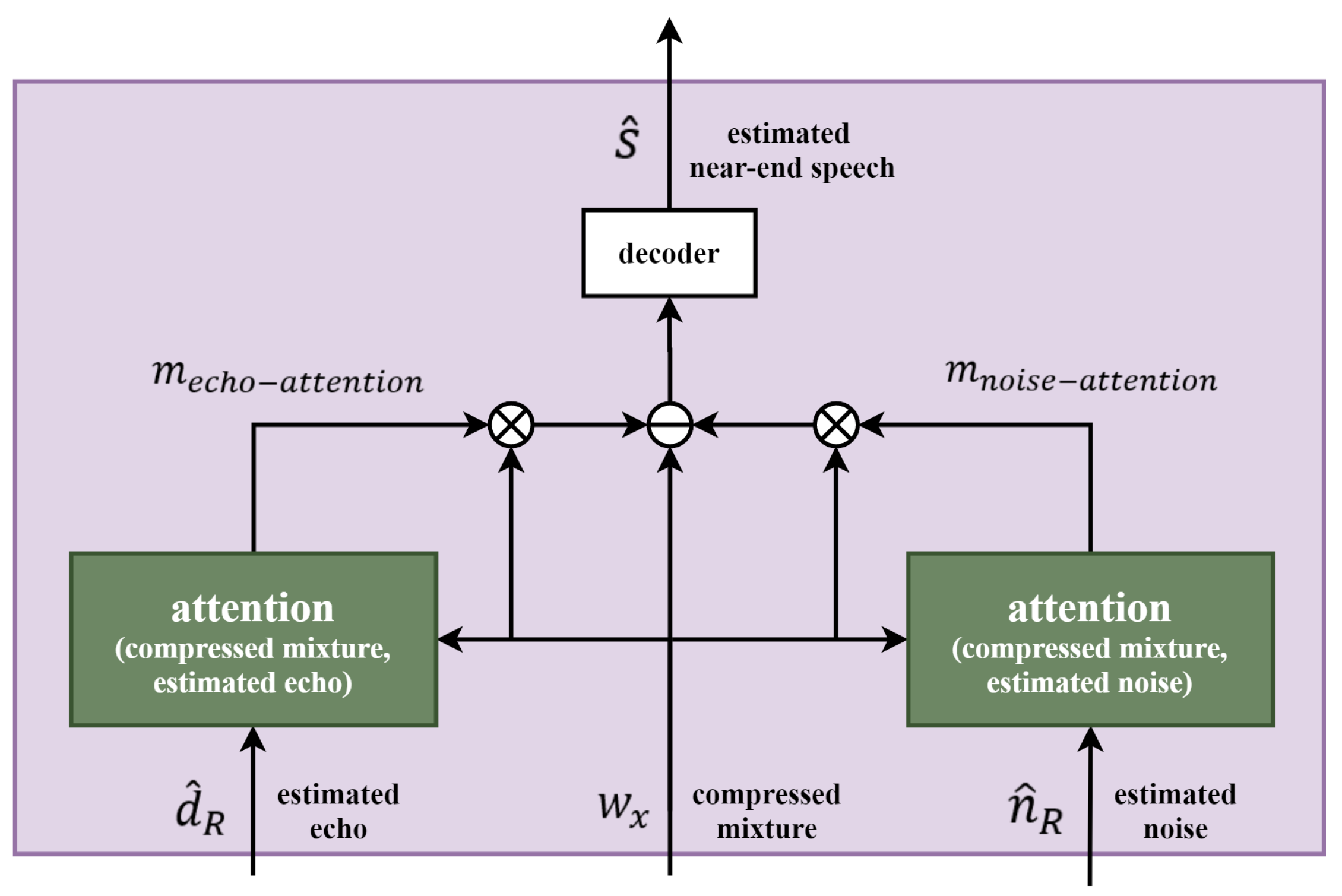
2.5. Near-End Speech Estimation in the Latent Domain with Attention Mechanisms Applied
2.6. Training Objective
3. Experiments and Simulation Results
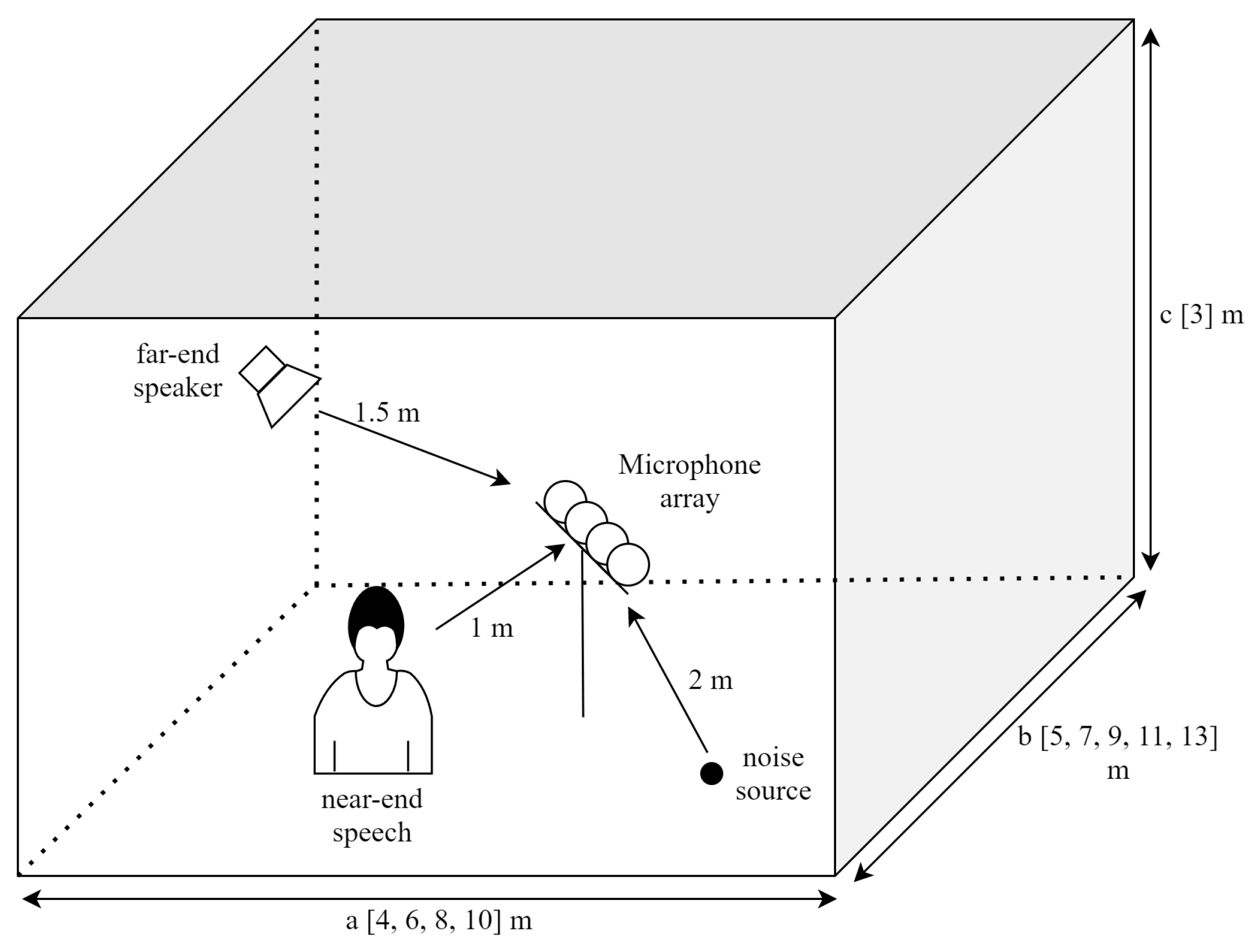
3.1. Dataset
3.2. Model Architecture
3.3. Evaluation Metrics
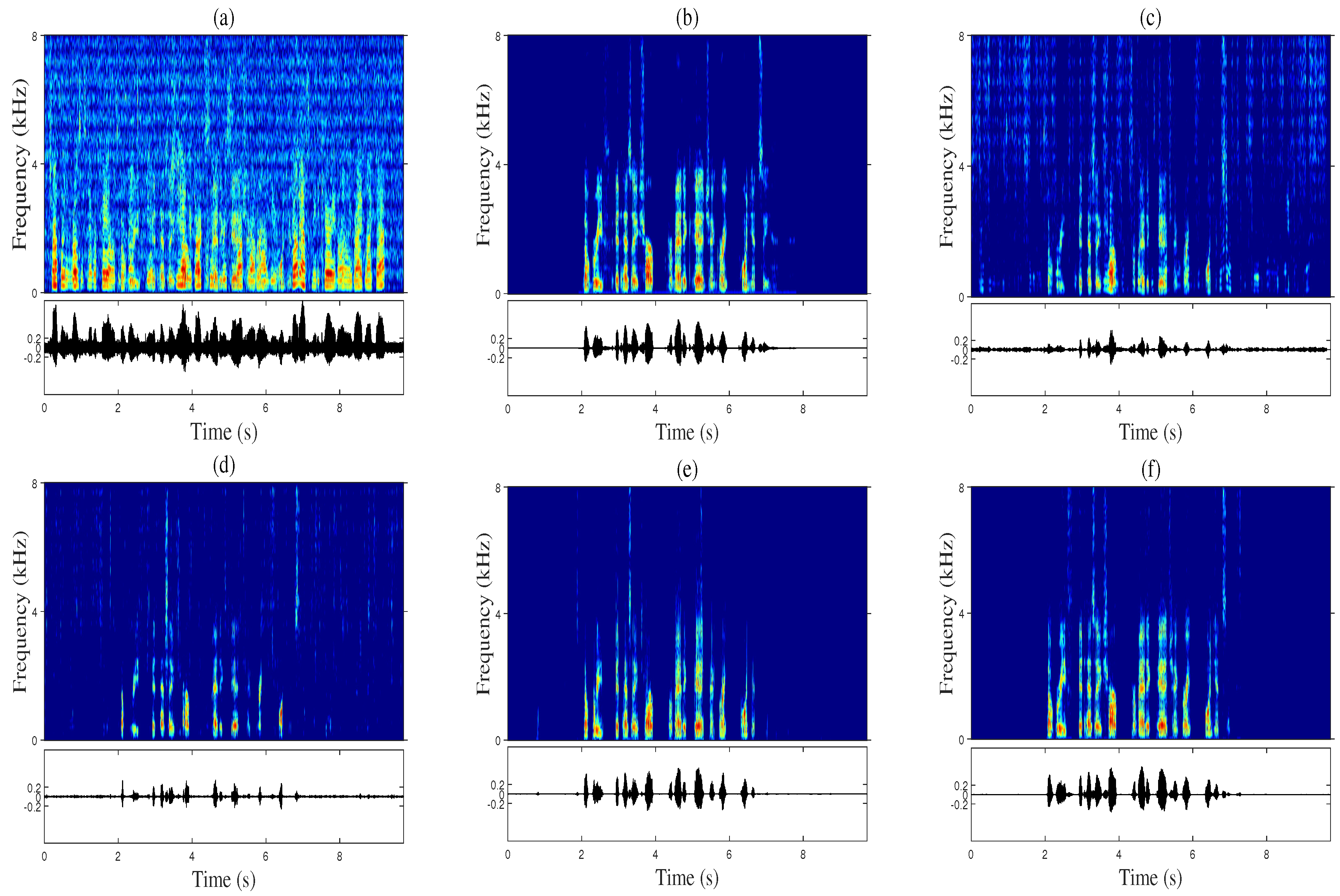
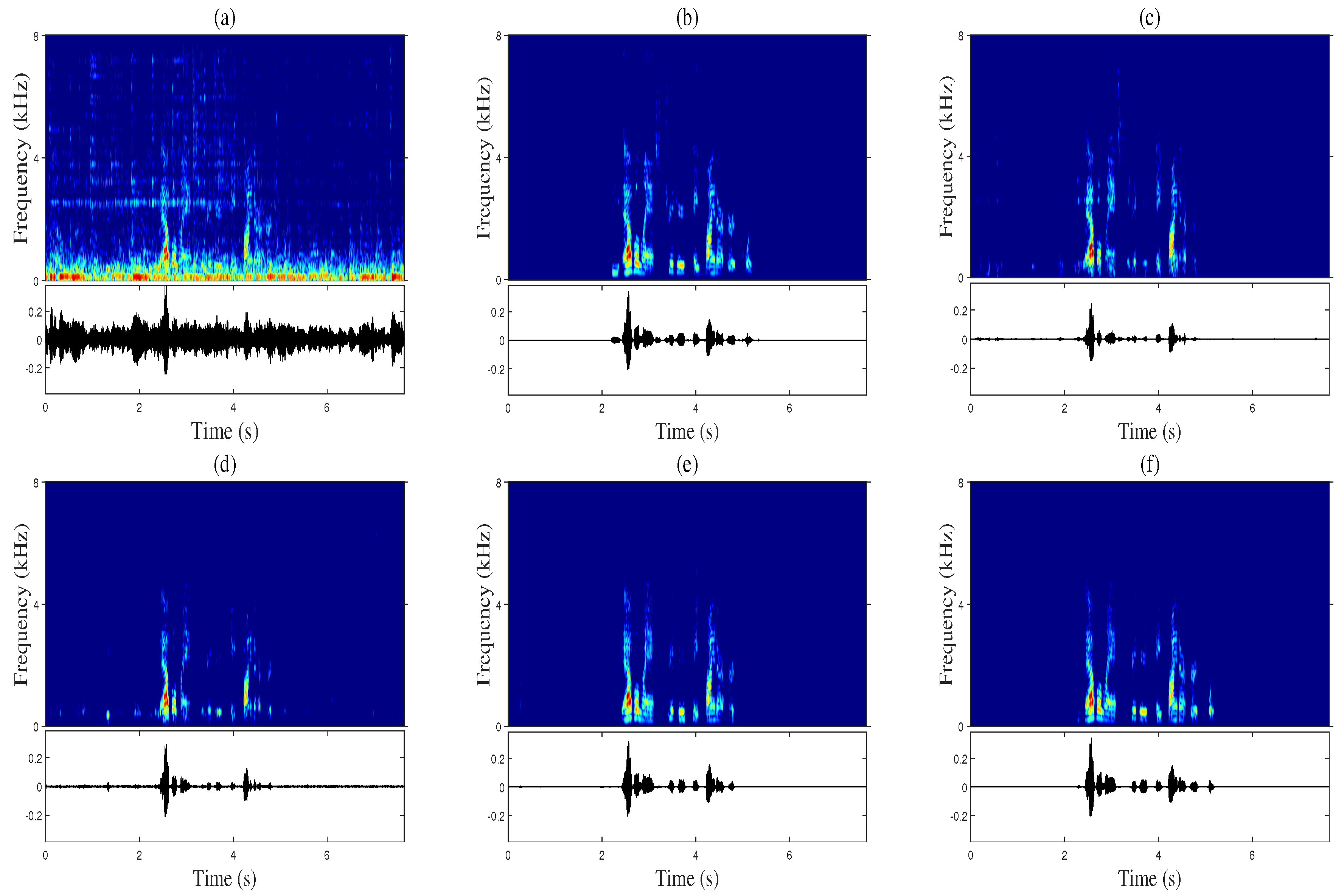
3.4. Numerical Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Benesty, J.; Amand, F.; Gilloire, A.; Grenier, Y. Adaptive filtering algorithms for stereophonic acoustic echo cancellation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Detroit, MI, USA, 9–12 May 1995; pp. 3099–3102. [Google Scholar]
- Chhetri, A.S.; Surendran, A.C.; Stokes, J.W.; Platt, J.C. Regression-based residual acoustic echo suppression. In Proceedings of the International workshop on Acoustic Echo and Noise Control (IWAENC), Eindhoven, The Netherlands, 12–15 September 2005; pp. 201–204. [Google Scholar]
- Valero, M.L.; Mabande, E.; Habets, E.A.P. Signal-based late residual echo spectral variance estimation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 5914–5918. [Google Scholar]
- Park, Y.-S.; Chang, J.-H. Double-talk detection based on soft decision for acoustic echo suppression. Signal Process. 2010, 90, 1737–1741. [Google Scholar] [CrossRef]
- Hamidia, M.; Amrouche, A. Double-talk detector based on speech feature extraction for acoustic echo cancellation. In Proceedings of the International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 17–19 September 2014; pp. 393–397. [Google Scholar]
- Kim, N.S.; Chang, J.-H. Spectral enhancement based on global soft decision. IEEE Signal Process Lett. 2000, 7, 393–397. [Google Scholar]
- Cohen, I. Noise spectrum estimation in adverse environments: Improved minima controlled recursive averaging. IEEE Trans. Speech Audio Process. 2003, 11, 466–475. [Google Scholar] [CrossRef] [Green Version]
- Park, S.J.; Cho, C.G.; Lee, C.; Youn, D.H. Integrated echo and noise canceler for hands-free applications. IEEE Trans. Circuits Syst. II 2002, 49, 188–195. [Google Scholar] [CrossRef]
- Gustafsson, S.; Martin, R.; Jax, P.; Vary, P. A psychoacoustic approach to combined acoustic echo cancellation and noise reduction. IEEE Trans. Speech Audio Process. 2002, 10, 245–256. [Google Scholar] [CrossRef]
- Lee, C.M.; Shin, J.W.; Kim, N.S. DNN-based residual echo suppression. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015; pp. 1775–1779. [Google Scholar]
- Seo, H.; Lee, M.; Chang, J.-H. Integrated acoustic echo and background noise suppression based on stacked deep neural networks. Appl. Acoust. 2018, 133, 194–201. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, D.L. Deep learning for acoustic echo cancellation in noisy and double-talk scenarios. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 3239–3243. [Google Scholar]
- Luo, Y.; Mesgarani, N. Conv-TasNet: Surpassing ideal time-frequency magnitude masking for speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luo, Y.; Mesgarani, N. Tasnet: Time domain separation network for real-time, single-channel speech separation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 696–700. [Google Scholar]
- Luo, Y.; Mesgarani, N. Real-time single-channel dereverbeation and separation with time domain audio separation network. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 342–346. [Google Scholar]
- Chen, Z.; Xiao, X.; Yoshioka, T.; Erdogan, H.; Li, J.; Gong, Y. Multi-channel overlapped speech recognition with location guided speech extraction network. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 558–565. [Google Scholar]
- Yoshioka, T.; Erdogan, H.; Chen, Z.; Alleva, F. Multi-microphone neural speech separation for far-field multi-talker speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5739–5743. [Google Scholar]
- Wang, Z.-Q.; Le Roux, J.; Hershey, J.R. Multi-channel deep clustering: Discriminative spectral and spatial embeddings for speaker-independent speech separation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 1–5. [Google Scholar]
- Drude, L.; Haeb-Umbach, R. Tight integration of spatial and spectral features for bss with deep clustering embeddings. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 2650–2654. [Google Scholar]
- Wang, Z.; Wang, D. Integrating spectral and spatial features for multi-channel speaker separation. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2718–2722. [Google Scholar]
- Chean, Y.-Y. Speech enhancement of mobile devices based on the integration of a dual microphone array and a background noise elimination algorithm. Sensors 2018, 18, 1467. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, X.; Ding, Z.; Li, W.; Liao, Q. Dual-channel cosine function based ITD estimation for robust speech separation. Sensors 2017, 17, 1447. [Google Scholar]
- Hwang, S.; Jin, Y.G.; Shin, J.W. Dual microphone voice activity detection based on reliable spatial cues. Sensors 2019, 19, 3056. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Imai, S. Cepstral analysis synthesis on the mel frequency scale. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Boston, MA, USA, 14–16 April 1983; pp. 93–96. [Google Scholar]
- Giri, R.; Isik, U.; Krishnaswamy, A. Attention Wave-U-Net for speech enhancement. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 20–23 October 2019; pp. 249–253. [Google Scholar]
- Delcroix, M.; Zmolikova, K.; Ochiai, T.; Kinoshita, K.; Araki, S.; Nakatani, T. Compact network for speakerbeam target speaker extraction. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6965–6969. [Google Scholar]
- Žmolíková, K.; Delcroix, M.; Kinoshita, K.; Ochiai, T.; Nakatani, T.; Burget, L. Černocký, SpeakerBeam: Speaker Aware Neural Network for Target Speaker Extraction in Speech Mixtures. IEEE J. Sel. Signal Process. 2019, 13, 800–814. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3239–3243. [Google Scholar]
- Vinccent, E.; Gribonval, R.; F’evotte, C. Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1462–1469. [Google Scholar] [CrossRef] [Green Version]
- Raffel, C.; McFee, B.; Humphrey, E.J.; Salamon, J.; Nieto, O.; Liang, D.; Ellis, D.P.; Raffel, C.C. mir_eval: A transparent implementation of common mir metrics. In Proceedings of the 15th International Society for Music Information Retrieval Conference. (ISMIR), Taipei, Taiwan, 27–31 October 2014. [Google Scholar]
- Kavalerov, I.; Wisdom, S.; Erdogan, H.; Patton, B.; Wilson, K.; Roux, J.L.; Hershey, J.R. Universal sound separation. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 20–23 October 2019; pp. 175–179. [Google Scholar]
- Heitkaemper, J.; Jakobeit, D.; Boeddeker, C.; Drude, L.; Haeb-Umbach, R. Demystifying TasNet: A dissecting approach. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 4–8 May 2020; pp. 6359–6363. [Google Scholar]
- Zue, V.; Seneff, S.; Glass, J. Speech database development at MIT: Timit and beyond. Speech Commun. 1990, 9, 351–356. [Google Scholar] [CrossRef]
- Snyder, D.; Chen, C.; Povey, D. Musan: A Music, Speech, and Noise Corpus. Available online: https://https://arxiv.org/pdf/1510.08484.pdf (accessed on 28 October 2015).
- Habets, E.A.P. Room impulse response generator. Tech. Univ. Eindh. Tech. Rep. 2006, 2, 1. [Google Scholar]
- Malik, S.; Enzner, G. State-space frequency domain adaptive filtering for nonlinear acoustic echo cancellation. IEEE/ACM Trans. Audio Speech Lang. Process. 2012, 20, 2065–2079. [Google Scholar] [CrossRef]
- Comminiello, D.; Scarpiniti, M.; Azpicueta-Ruiz, A.; Arenas-García, J.; Uncini, A. Functional link adaptive filters for nonlinear acoustic echo cancellation. IEEE/ACM Trans. Audio Speech Lang. Process. 2013, 21, 1502–1512. [Google Scholar] [CrossRef]
- Varga, A.; Steeneken, H.J.M. Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- ITU-T. Test signals for use in telephonometry. ITU-T Rec. P.501 2007. Available online: https://www.itu.int/rec/T-REC-P.501 (accessed on 13 November 2020).
- Reddy, C.K.; Beyrami, E.; Pool, J.; Cutler, R.; Srinivasan, S.; Gehrke, J. A scalable noisy speech dataset and online subjective test framework. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 1816–1820. [Google Scholar]
- Diederik, P.K.; Jimmy, B. Adam: A method for stochasitc optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Salt Lake City, UT, USA, 7–11 May 2001; pp. 749–752. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. A shorttime objective intelligibility measure for time-frequency weighted noisy speech. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, TX, USA, 14–19 March 2010; pp. 4214–4217. [Google Scholar]
- Enzner, G.; Vary, P. Frequency domain adaptive kalman filter for acoustic echo control in hands-free telephones. Signal Process. 2006, 86, 1140–1156. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | PESQ | ERLE | STOI | SDR |
|---|---|---|---|---|
| unprocessed | 1.60 | - | 0.527 | −2.1 |
| stacked DNN [11] | 1.81 | 24.73 | 0.590 | 4.6 |
| CRN [12] | 1.83 | 23.36 | 0.577 | 5.0 |
| Conv-TasNet [13] | 1.73 | 23.43 | 0.624 | −7.7 |
| Conv-TasNet + SDR loss | 1.79 | 27.70 | 0.631 | 6.3 |
| Conv-TasNet + SDR loss + auxiliary encoder | 1.83 | 26.77 | 0.656 | 7.5 |
| Conv-TasNet + SDR loss + auxiliary encoder (attention) | 1.87 | 30.80 | 0.682 | 8.0 |
| Multi-TALK (1 ch) | 1.94 | 32.62 | 0.690 | 8.1 |
| Multi-TALK (2 ch) | 2.43 | 41.09 | 0.801 | 10.4 |
| Multi-TALK (4 ch) | 2.50 | 45.78 | 0.811 | 11.0 |
| Algorithm | PESQ | ERLE | STOI | SDR |
|---|---|---|---|---|
| unprocessed | 1.65 | - | 0.547 | −1.8 |
| stacked DNN [11] | 1.86 | 25.97 | 0.598 | 4.4 |
| CRN [12] | 1.93 | 24.85 | 0.588 | 5.5 |
| Conv-TasNet [13] | 1.78 | 23.32 | 0.626 | −7.9 |
| Conv-TasNet + SDR loss | 1.82 | 25.47 | 0.630 | 7.0 |
| Conv-TasNet + SDR loss + auxiliary encoder | 1.83 | 28.12 | 0.646 | 7.8 |
| Conv-TasNet + SDR loss + auxiliary encoder (attention) | 1.86 | 30.04 | 0.666 | 8.0 |
| Multi-TALK (1 ch) | 1.90 | 31.61 | 0.669 | 8.2 |
| Multi-TALK (2 ch) | 2.31 | 38.00 | 0.730 | 9.9 |
| Multi-TALK (4 ch) | 2.34 | 43.94 | 0.771 | 10.6 |
| Algorithm | PESQ | STOI | SDR |
|---|---|---|---|
| unprocessed | 2.28 | 0.748 | 5.5 |
| stacked DNN [11] | 2.31 | 0.644 | 3.8 |
| CRN [12] | 1.31 | 0.549 | 5.0 |
| Conv-TasNet [13] | 2.45 | 0.778 | −8.8 |
| Conv-TasNet + SDR loss | 2.45 | 0.777 | 11.6 |
| Conv-TasNet + SDR loss + auxiliary encoder | 2.36 | 0.709 | 4.6 |
| Conv-TasNet + SDR loss + auxiliary encoder (attention) | 2.47 | 0.796 | 12.3 |
| Multi-TALK (1 ch) | 2.47 | 0.795 | 12.6 |
| Multi-TALK (2 ch) | 2.60 | 0.820 | 12.6 |
| Multi-TALK (4 ch) | 2.61 | 0.826 | 12.7 |
| Algorithm | PESQ | ERLE | STOI | SDR |
|---|---|---|---|---|
| unprocessed | 1.62 | - | 0.529 | −2.1 |
| stacked DNN [11] | 1.80 | 23.57 | 0.580 | 4.3 |
| CRN [12] | 1.21 | 19.83 | 0.410 | 2.8 |
| Conv-TasNet [13] | 1.63 | 22.14 | 0.609 | −8.3 |
| Conv-TasNet + SDR loss | 1.66 | 28.73 | 0.604 | 6.1 |
| Conv-TasNet + SDR loss + auxiliary encoder | 1.70 | 27.29 | 0.628 | 7.2 |
| Conv-TasNet + SDR loss + auxiliary encoder (attention) | 1.79 | 29.03 | 0.658 | 7.5 |
| Multi-TALK (1 ch) | 1.86 | 30.19 | 0.662 | 7.7 |
| Multi-TALK (2 ch) | 2.13 | 29.93 | 0.716 | 8.5 |
| Multi-TALK (4 ch) | 2.17 | 33.38 | 0.725 | 8.9 |
| Algorithm | PESQ | ERLE | STOI | SDR |
|---|---|---|---|---|
| unprocessed | 1.71 | - | 0.503 | −2.0 |
| stacked DNN [11] | 1.88 | 24.84 | 0.570 | 4.1 |
| CRN [12] | 1.22 | 23.84 | 0.349 | 1.8 |
| Conv-TasNet [13] | 1.47 | 19.17 | 0.534 | −8.0 |
| Conv-TasNet + SDR loss | 1.51 | 24.16 | 0.536 | 5.9 |
| Conv-TasNet + SDR loss+auxiliary encoder | 1.70 | 28.89 | 0.593 | 7.1 |
| Conv-TasNet+SDR loss+auxiliary encoder (attention) | 1.67 | 26.70 | 0.591 | 6.8 |
| Multi-TALK (1 ch) | 1.73 | 26.23 | 0.598 | 7.0 |
| Multi-TALK (2 ch) | 1.79 | 29.53 | 0.627 | 6.9 |
| Multi-TALK (4 ch) | 1.89 | 30.51 | 0.636 | 7.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.-K.; Chang, J.-H. Multi-TALK: Multi-Microphone Cross-Tower Network for Jointly Suppressing Acoustic Echo and Background Noise. Sensors 2020, 20, 6493. https://doi.org/10.3390/s20226493
Park S-K, Chang J-H. Multi-TALK: Multi-Microphone Cross-Tower Network for Jointly Suppressing Acoustic Echo and Background Noise. Sensors. 2020; 20(22):6493. https://doi.org/10.3390/s20226493
Chicago/Turabian StylePark, Song-Kyu, and Joon-Hyuk Chang. 2020. "Multi-TALK: Multi-Microphone Cross-Tower Network for Jointly Suppressing Acoustic Echo and Background Noise" Sensors 20, no. 22: 6493. https://doi.org/10.3390/s20226493
APA StylePark, S. -K., & Chang, J. -H. (2020). Multi-TALK: Multi-Microphone Cross-Tower Network for Jointly Suppressing Acoustic Echo and Background Noise. Sensors, 20(22), 6493. https://doi.org/10.3390/s20226493