Transfer Learning for Wireless Fingerprinting Localization Based on Optimal Transport


Abstract
:1. Introduction
2. Related Works
2.1. Wireless Fingerprinting Localization
2.2. Transfer Learning in the Wireless Fingerprinting Localization
2.3. Optimal Transport
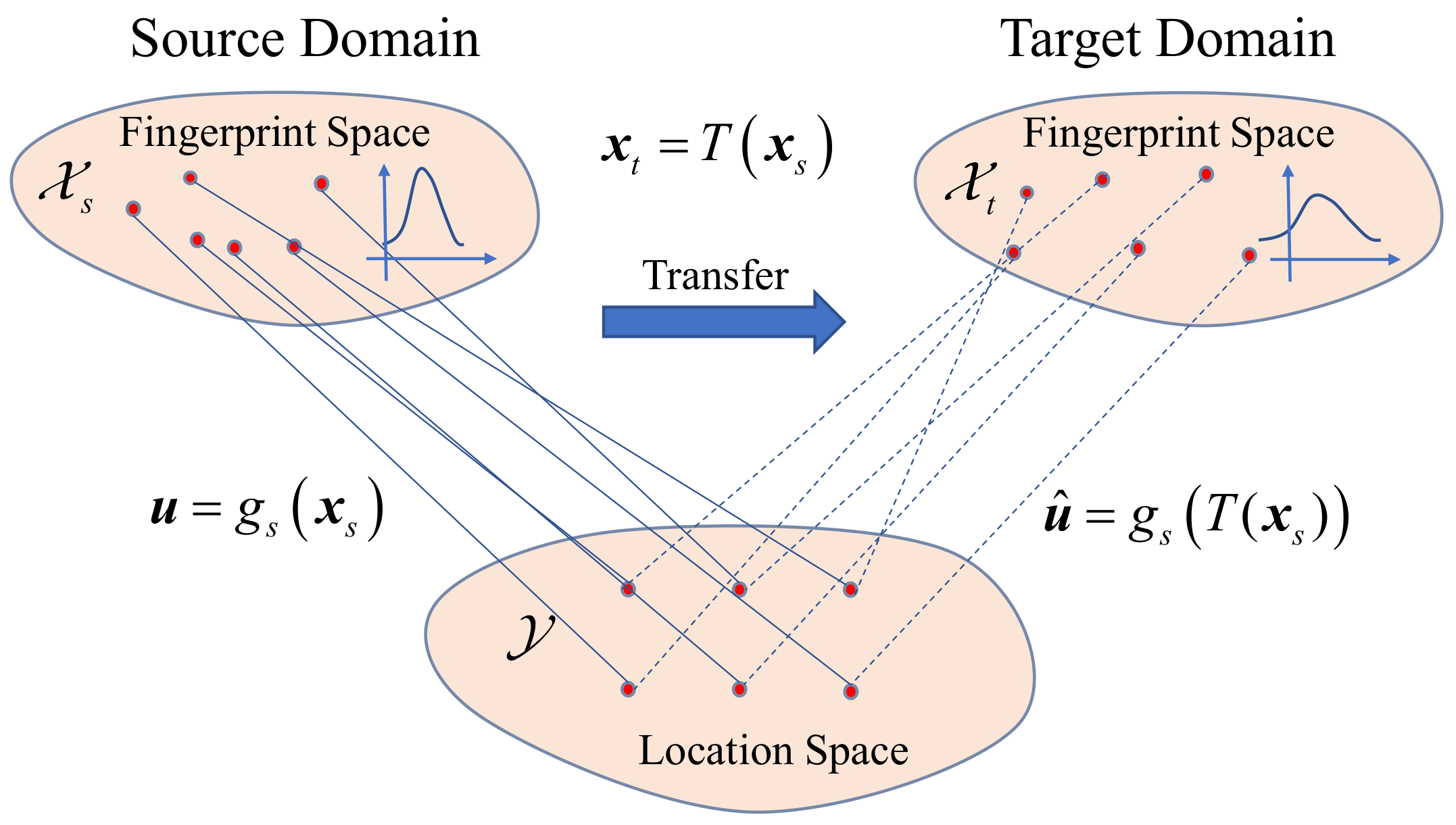
3. Problem Description
- Class imbalance hypothesis: the distribution of labels in the two fields is different, i.e., , but the conditional probability distribution of the feature is the same, i.e., .
- Covariance offset hypothesis: the marginal distribution of the two domains is different, that is, , but the conditional probability distribution of the label is the same, that is, (equivalent to the learning function ).
- The channel parameters on one or more links are changed;
- The channel parameters of a local region are changed.
4. Transfer Learning for Fingerprinting Localization
4.1. Transfer Component Analysis
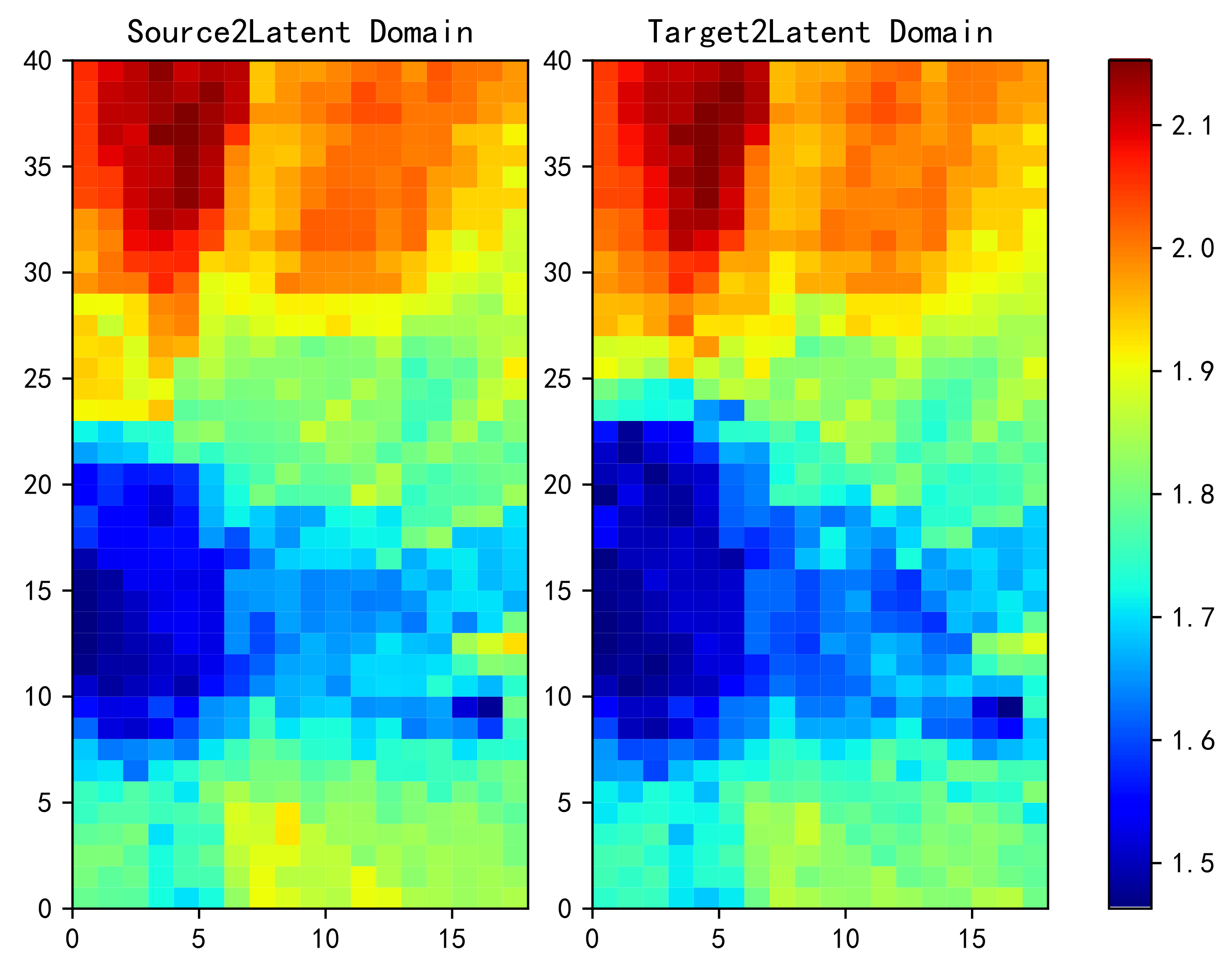
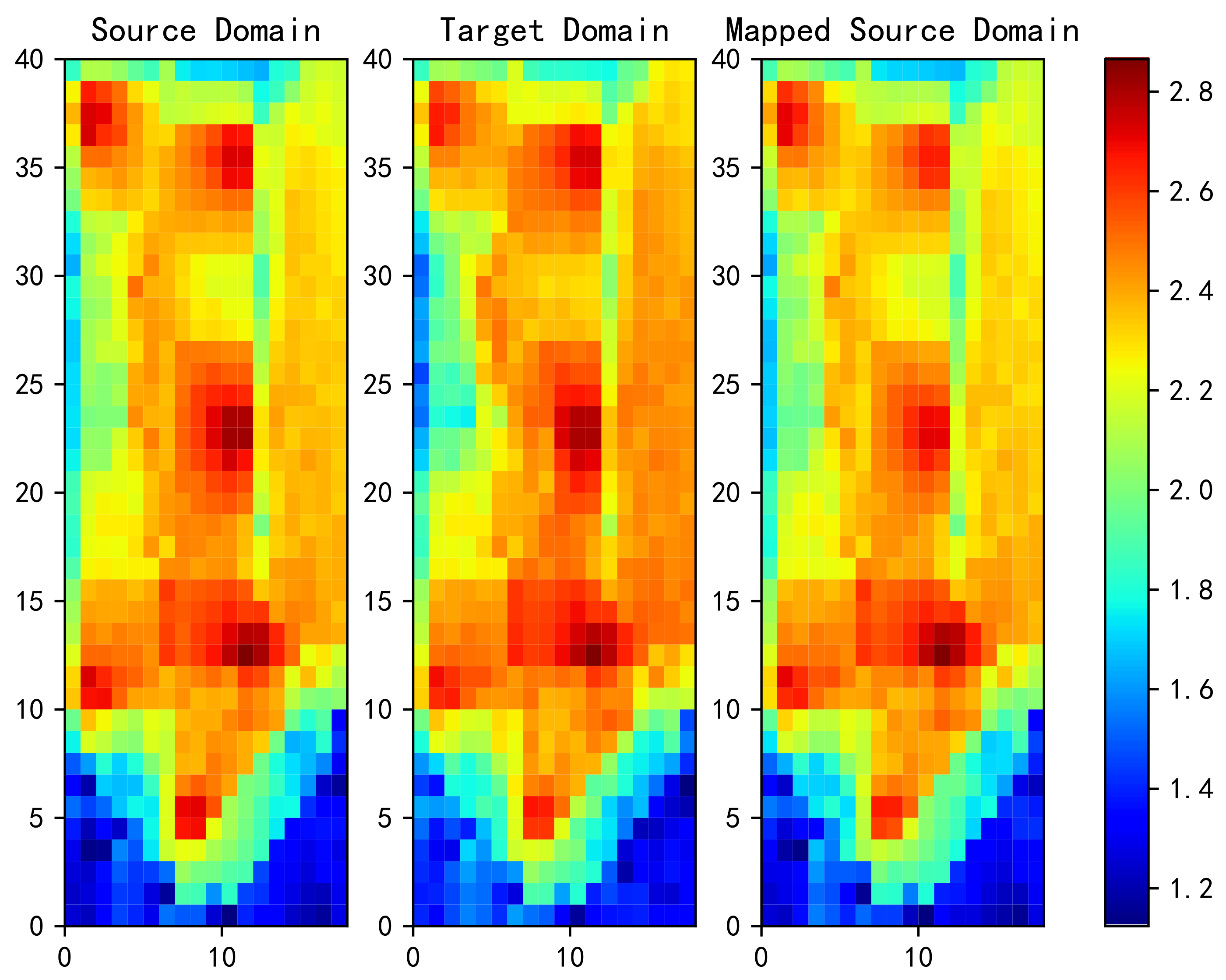
4.2. Optimal Transport For Fingerprint Transfer Learning
4.2.1. Basic Method
- The probability measures and are estimated using and .
- Find a transport map T, from to .
- The labeled sample is transported with T, and then the target domain estimator is trained with the transformed samples.
4.2.2. Laplacian Regularization
4.2.3. Joint Estimation of Transport Map and Transformation Function
4.2.4. Data Preprocessing and Optimization Algorithm
5. Wireless Fingerprint Channel Model
5.1. Free Space Loss Model
5.2. Multi-Wall Model
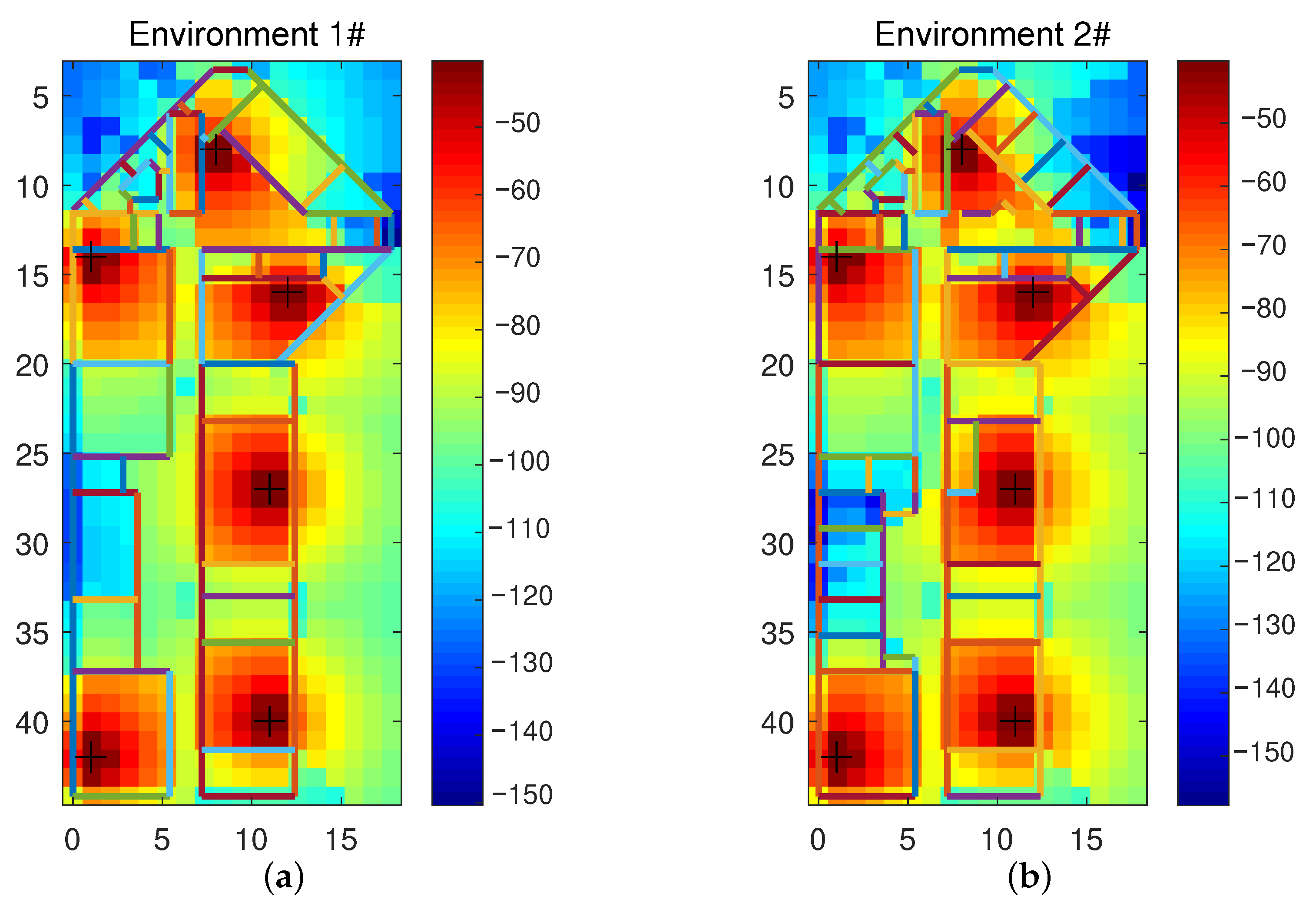
6. Experiments
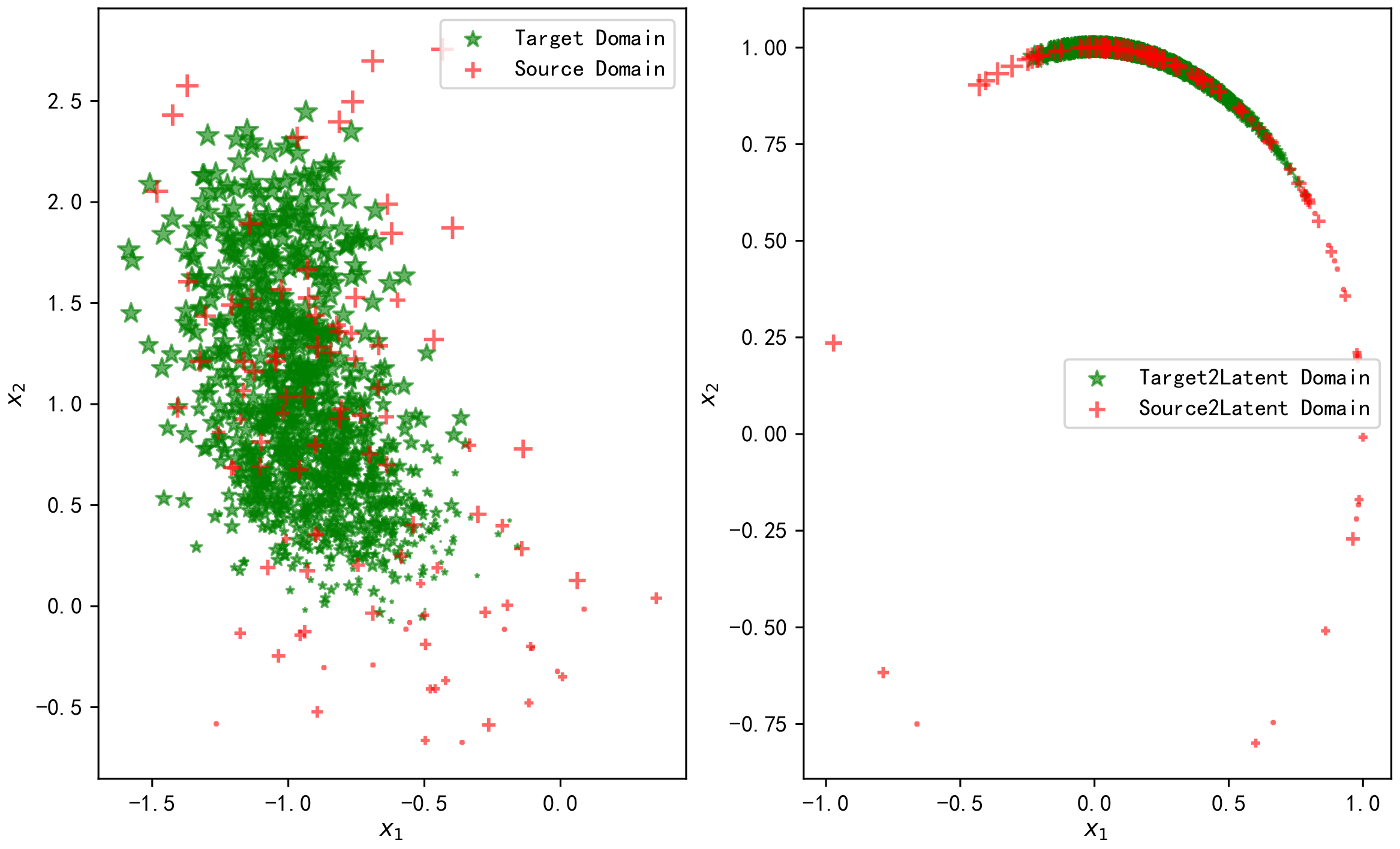
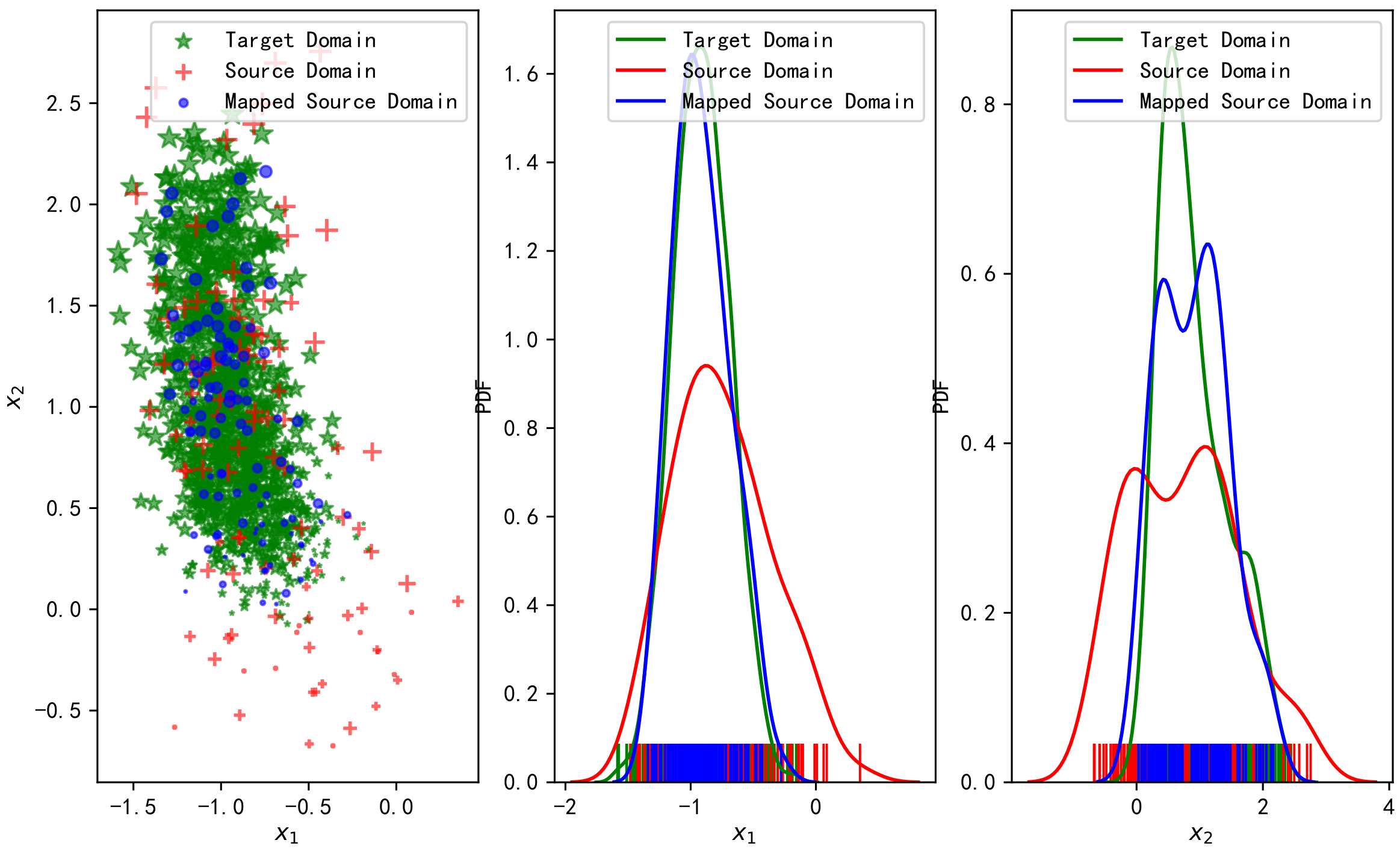
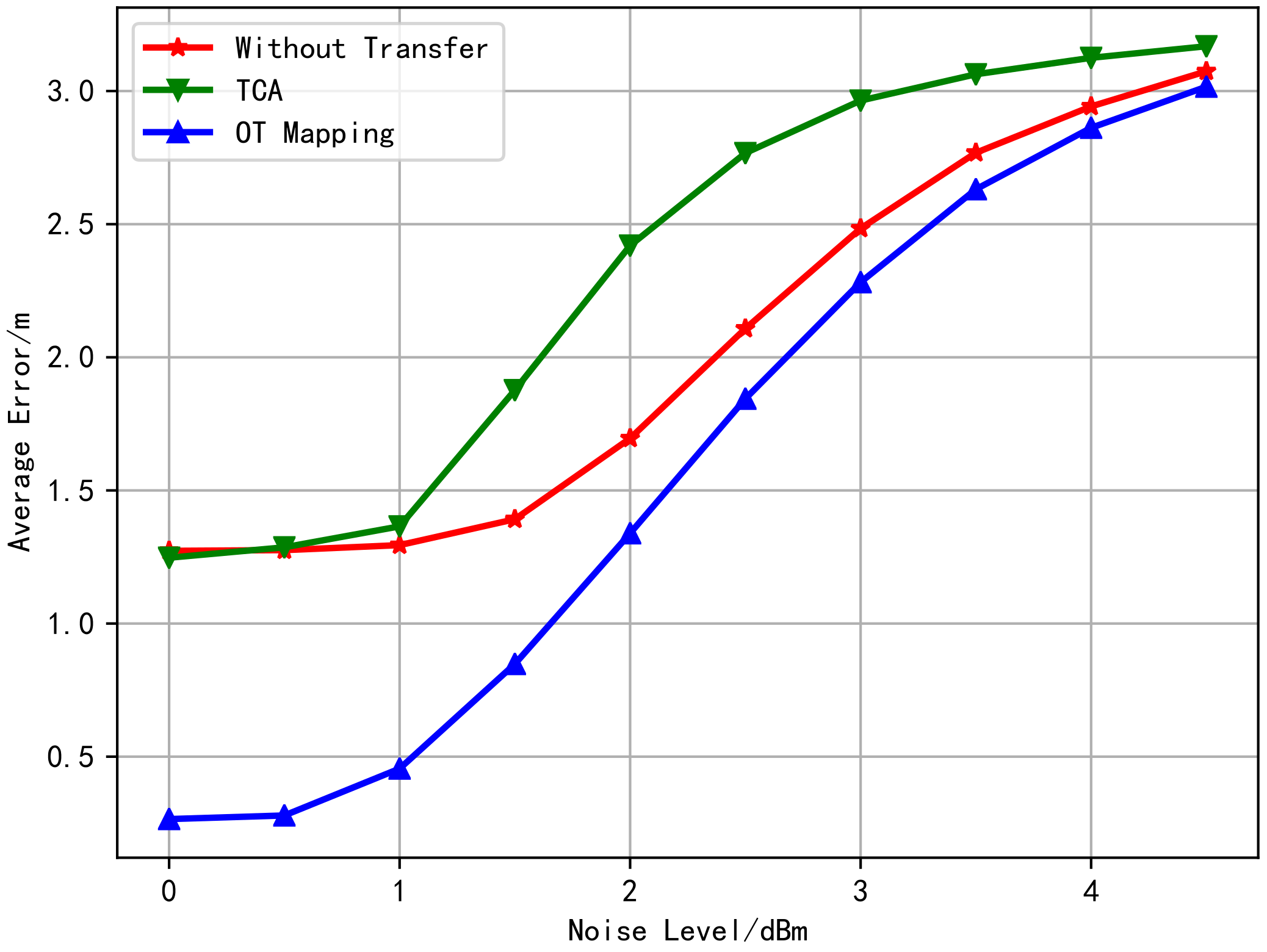
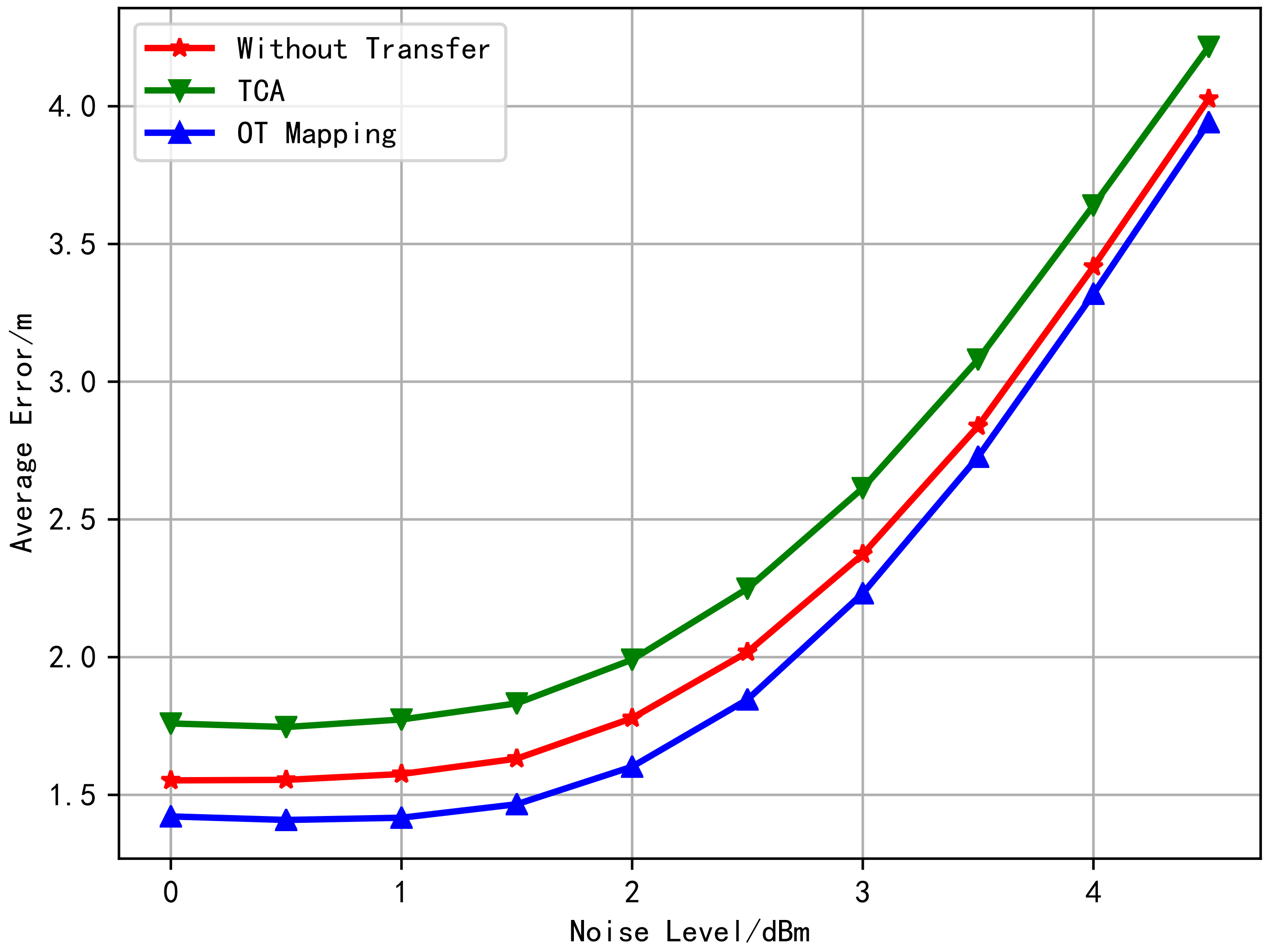
6.1. Free Space Channel Model RSS FL Transfer Learning Simulation
6.2. Multi-Wall Model of RSS FL Transfer Learning Simulation
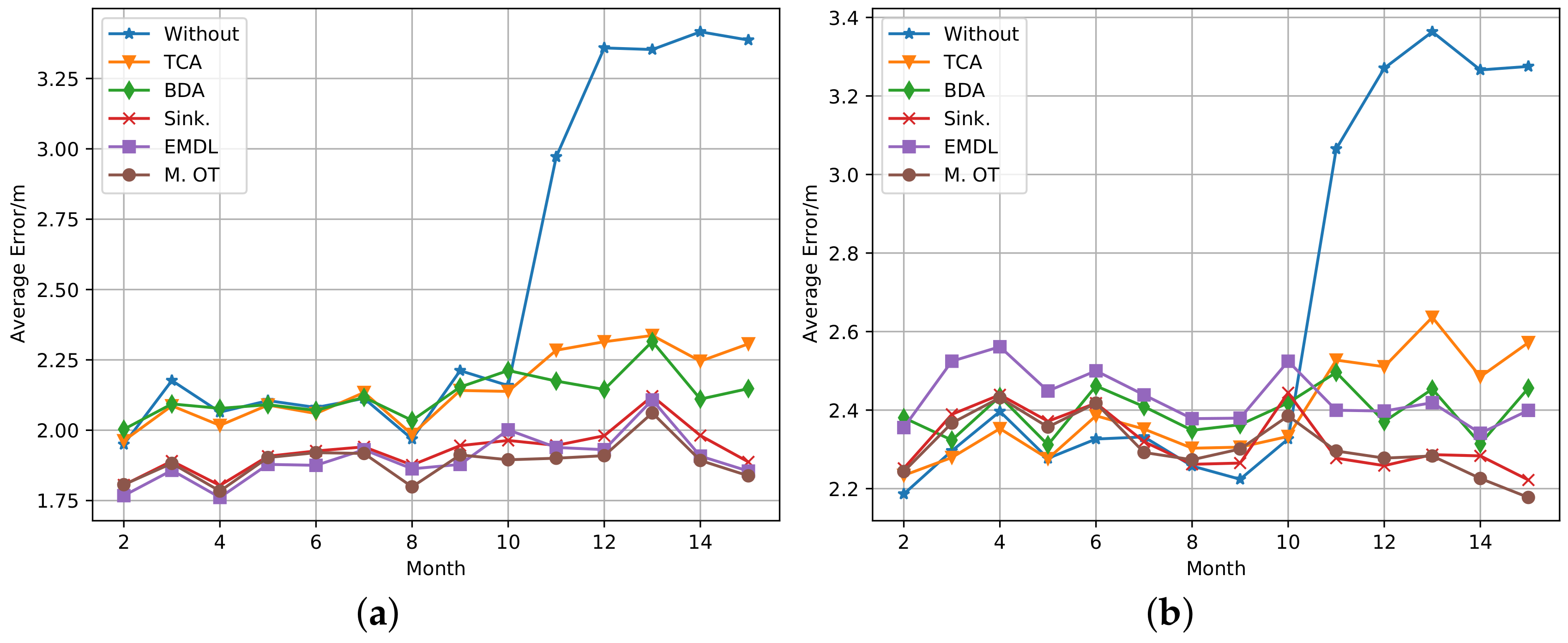
6.3. Measured Data Experiment
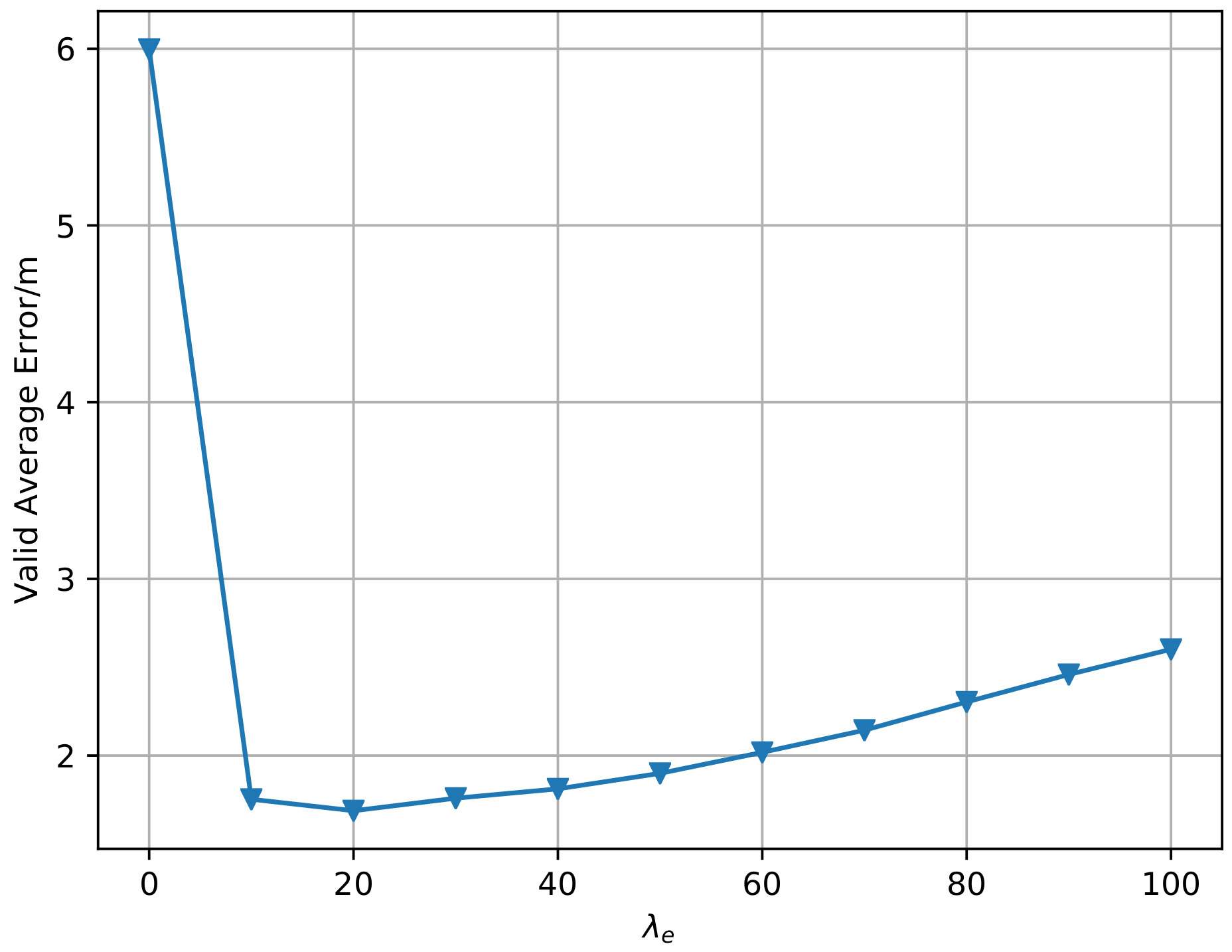
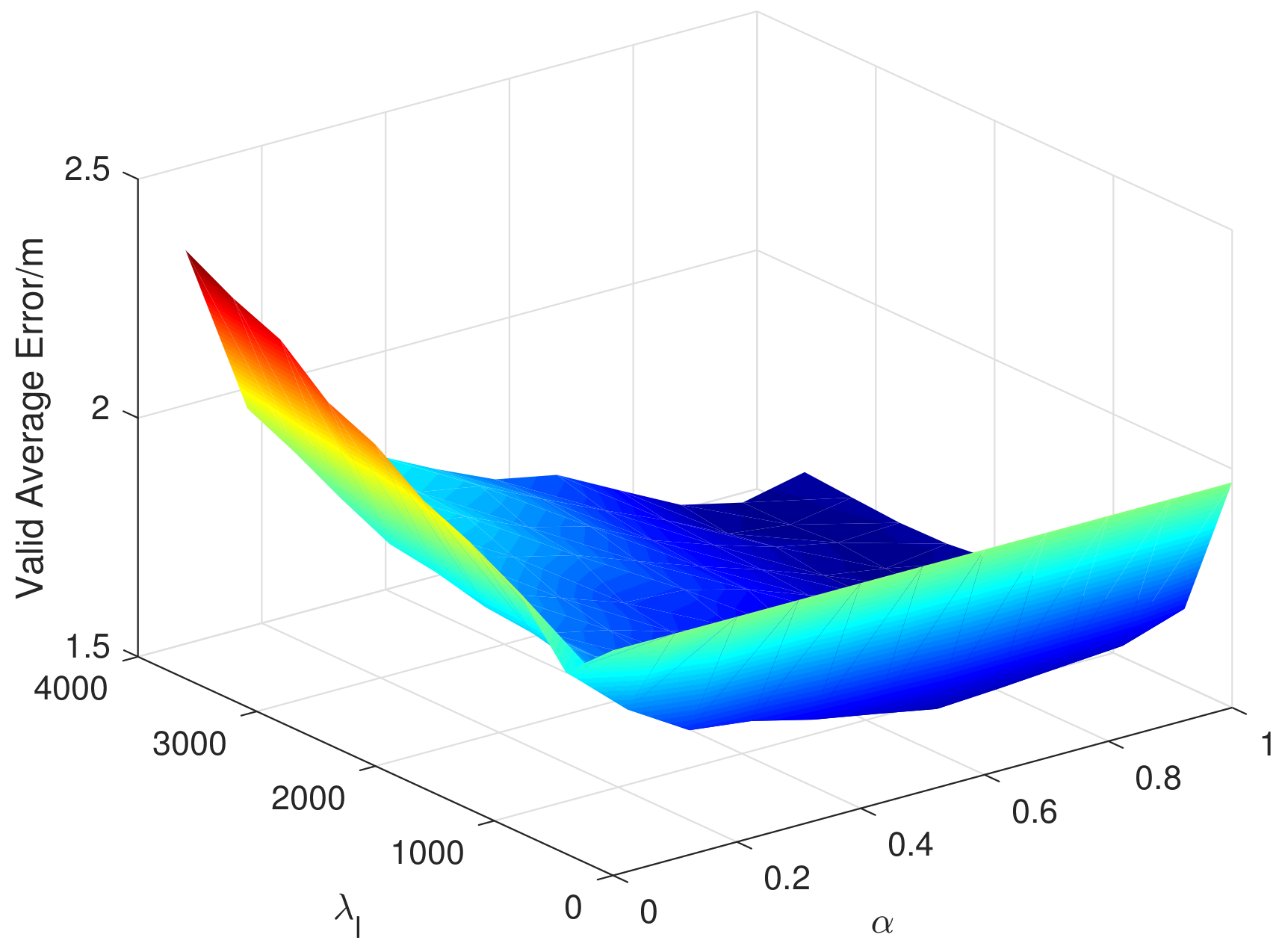
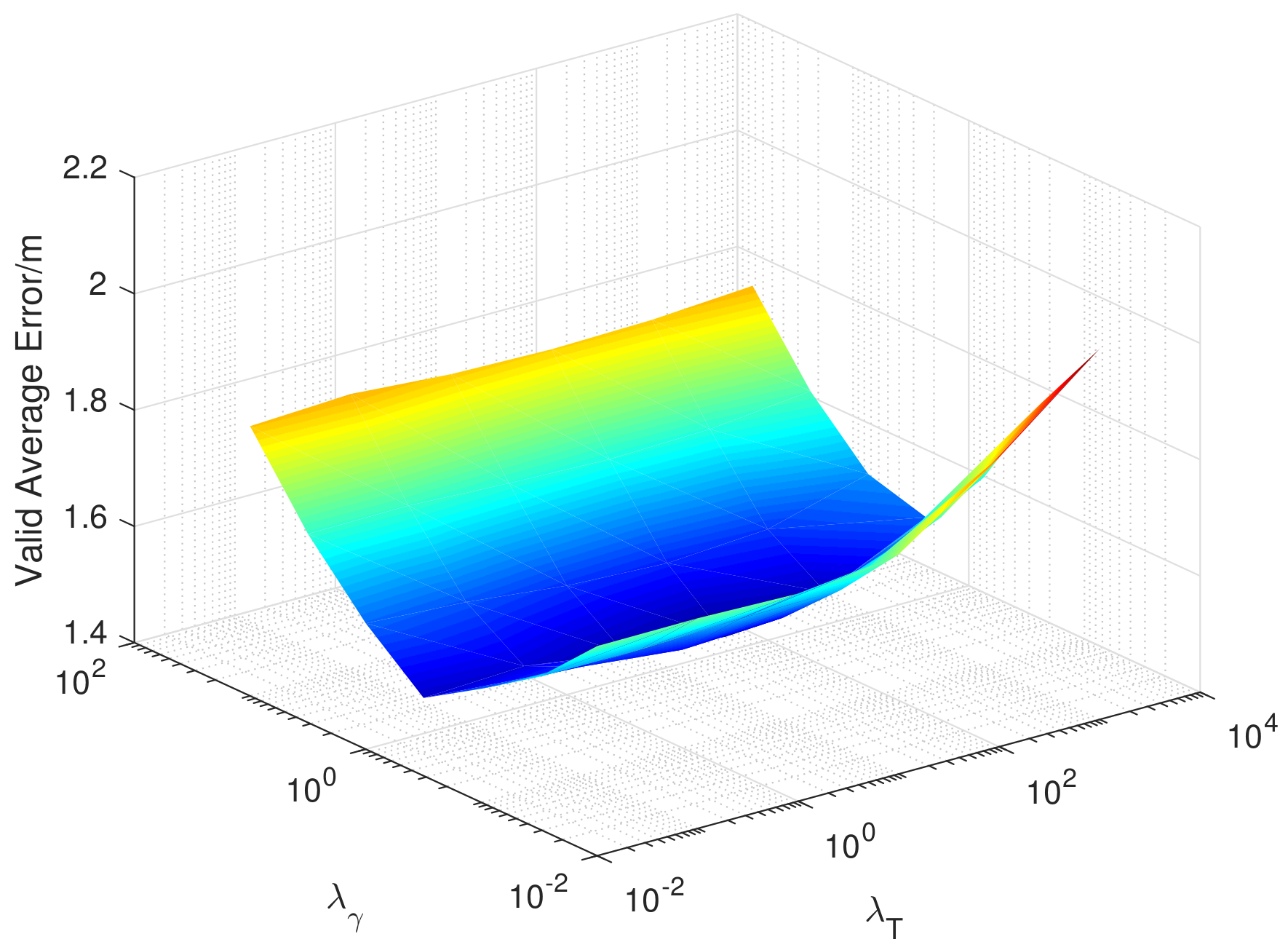
6.4. Super Parameters
7. Discussion
- What conditions the location fingerprints can be positively transferred under?
- How good the generalization bound can be reached in the transfer learning of FL?
- What causes the difference between the simulation model and the real data?
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wang, B.; Xu, Q.; Chen, C.; Zhang, F.; Liu, K.J.R. The Promise of Radio Analytics: A Future Paradigm of Wireless Positioning, Tracking, and Sensing. IEEE Signal Process. Mag. 2018, 35, 59–80. [Google Scholar] [CrossRef]
- Kokkinis, A.; Kanaris, L.; Liotta, A.; Stavrou, S. RSS Indoor Localization Based on a Single Access Point. Sensors 2019, 19, 3711. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hao, Z.; Yan, Y.; Dang, X.; Shao, C. Endpoints-Clipping CSI Amplitude for SVM-Based Indoor Localization. Sensors 2019, 19, 3689. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, C.; Qin, N.; Xue, Y.; Yang, L. Received Signal Strength-Based Indoor Localization Using Hierarchical Classification. Sensors 2020, 20, 1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuan, Z.; Zha, X.; Zhang, X. Adaptive Multi-Type Fingerprint Indoor Positioning and Localization Method Based on Multi-Task Learning and Weight Coefficients K-Nearest Neighbor. Sensors 2020, 20, 5416. [Google Scholar] [CrossRef] [PubMed]
- Shrey, S.B.; Hakim, L.; Kavitha, M.; Kim, H.W.; Kurita, T. Transfer Learning by Cascaded Network to identify and classify lung nodules for cancer detection. In International Workshop on Frontiers of Computer Vision; Springer: Singapore, 2020. [Google Scholar]
- Hudson, A.; Gong, S. Transfer Learning for Protein Structure Classification at Low Resolution. arXiv 2020, arXiv:2008.04757. [Google Scholar]
- Ye, H.; Tan, Q.; He, R.; Li, J.; Ng, H.T.; Bing, L. Feature Adaptation of Pre-Trained Language Models across Languages and Domains with Robust Self-Training. arXiv 2020, arXiv:2009.11538. [Google Scholar]
- Zhu, Q.; Xu, Y.; Wang, H.; Zhang, C.; Han, J.; Yang, C. Transfer Learning of Graph Neural Networks with Ego-graph Information Maximization. arXiv 2020, arXiv:2009.05204. [Google Scholar]
- Zhu, Y.; Xi, D.; Song, B.; Zhuang, F.; Chen, S.; Gu, X.; He, Q. Modeling Users’ Behavior Sequences with Hierarchical Explainable Network for Cross-domain Fraud Detection. Proc. Web Conf. 2020, 928–938. [Google Scholar] [CrossRef]
- Safari, M.S.; Pourahmadi, V.; Sodagari, S. Deep UL2DL: Channel Knowledge Transfer from Uplink to Downlink. arXiv 2018, arXiv:1812.07518. [Google Scholar]
- Yin, J.; Yang, Q.; Ni, L.M. Learning Adaptive Temporal Radio Maps for Signal-Strength-Based Location Estimation. IEEE Trans. Mob. Comput. 2008, 7, 869–883. [Google Scholar] [CrossRef] [Green Version]
- Pan, S.J.; Kwok, J.T.; Yang, Q.; Pan, J.J. Adaptive Localization in a Dynamic WiFi Environment through Multi-View Learning. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), Vancouver, BC, Canada, 22–26 July 2007. [Google Scholar]
- Zheng, V.; Xiang, E.; Yang, Q.; Shen, D. Transferring Localization Models over Time. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), Chicago, IL, USA, 13–17 July 2008. [Google Scholar]
- Sun, Z.; Chen, Y.; Qi, J.; Liu, J. Adaptive Localization through Transfer Learning in Indoor Wi-Fi Environment. In Proceedings of the 2008 Seventh International Conference on Machine Learning and Applications, San Diego, CA, USA, 11–13 December 2008. [Google Scholar]
- Zheng, V.; Pan, S.; Yang, Q.; Pan, J. Transferring MultiDevice Localization Models Using Latent Multi-Task Learning. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), Chicago, IL, USA, 13–17 July 2008. [Google Scholar]
- Pan, S.J.; Shen, D.; Yang, Q.; Kwok, J.T. Transferring Localization Models Across Space. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), Chicago, IL, USA, 13–17 July 2008. [Google Scholar]
- Guo, X.; Wang, L.; Li, L.; Ansari, N. Transferred Knowledge Aided Positioning via Global and Local Structural Consistency Constraints. IEEE Access 2019, 7, 32102–32117. [Google Scholar] [CrossRef]
- Peyré, G.; Cuturi, M. Computational Optimal Transport: With Applications to Data Science. Found. Trends® Mach. Learn. 2019, 11, 355–607. [Google Scholar] [CrossRef]
- Bahl, P.; Padmanabhan, V.N. RADAR: An in-building RF-based user location and tracking system. In Proceedings of the IEEE INFOCOM 2000. Conference on Computer Communications. Nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies (Cat. No.00CH37064), Tel Aviv, Israel, 26–30 March 2000. [Google Scholar]
- Lin, T.; Fang, S.; Tseng, W.; Lee, C.; Hsieh, J. A Group-Discrimination-Based Access Point Selection for WLAN Fingerprinting Localization. IEEE Trans. Veh. Technol. 2014, 63, 3967–3976. [Google Scholar] [CrossRef]
- Yim, J. Introducing a decision tree-based indoor positioning technique. Expert Syst. Appl. 2008, 34, 1296–1302. [Google Scholar] [CrossRef]
- Yu, L.; Laaraiedh, M.; Avrillon, S.; Uguen, B. Fingerprinting localization based on neural networks and ultra-wideband signals. In Proceedings of the 2007 International Symposium on Signals, Systems and Electronics, Montreal, QC, Canada, 30 July–2 August 2007. [Google Scholar]
- Youssef, M.; Agrawala, A. The Horus WLAN Location Determination System. In Proceedings of the 3rd International Conference on Mobile Systems Applications, and Services, Seattle, WA, USA, 6–8 June 2005; Association for Computing Machinery: New York, NY, USA, 2005. [Google Scholar] [CrossRef]
- Mirowski, P.; Whiting, P.; Steck, H.; Palaniappan, R.; MacDonald, M.; Hartmann, D.; Ho, T.K. Probability kernel regression for WiFi localisation. J. Locat. Based Serv. 2012, 6, 81–100. [Google Scholar] [CrossRef]
- Xiao, Z.; Wen, H.; Markham, A.; Trigoni, N. Lightweight map matching for indoor localisation using conditional random fields. In Proceedings of the 13th International Symposium on Information Processing in Sensor Networks IPSN 2014, Berlin, Germany, 15–17 April 2014. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [Green Version]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer Feature Learning with Joint Distribution Adaptation. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013. [Google Scholar]
- Wang, J.; Chen, Y.; Feng, W.; Yu, H.; Huang, M.; Yang, Q. Transfer Learning with Dynamic Distribution Adaptation. ACM Trans. Intell. Syst. Technol. 2020, 11. [Google Scholar] [CrossRef] [Green Version]
- Courty, N.; Flamary, R.; Tuia, D.; Rakotomamonjy, A. Optimal Transport for Domain Adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1853–1865. [Google Scholar] [CrossRef]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Pereira, F. Analysis of Representations for Domain Adaptation. In Proceedings of the 19th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 4–9 December 2006. [Google Scholar] [CrossRef]
- Borgwardt, K.M.; Gretton, A.; Rasch, M.J.; Kriegel, H.P.; Schölkopf, B.; Smola, A.J. Integrating structured biological data by Kernel Maximum Mean Discrepancy. Bioinformatics 2006, 22, e49–e57. [Google Scholar] [CrossRef] [Green Version]
- Dantzig, G.B. Application of the simplex method to a transportation problem. Act. Anal. Prod. Alloc. 1951, 13, 359–373. [Google Scholar]
- Knight, P.A. The Sinkhorn–Knopp Algorithm: Convergence and Applications. Siam J. Matrix Anal. Appl. 2008, 30, 261–275. [Google Scholar] [CrossRef] [Green Version]
- Reich, S. A non-parametric ensemble transform method for Bayesian inference. arXiv 2012, arXiv:1210.0375. [Google Scholar]
- Perrot, M.; Courty, N.; Flamary, R.; Habrard, A. Mapping Estimation for Discrete Optimal Transport. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, December 2016. [Google Scholar] [CrossRef]
- Bredies, K.; Lorenz, D.A.; Maass, P. A generalized conditional gradient method and its connection to an iterative shrinkage method. Comput. Optim. Appl. 2009, 42, 173–193. [Google Scholar] [CrossRef]
- Tseng, P. Convergence of a Block Coordinate Descent Method for Nondifferentiable Minimization. J. Optim. Theory Appl. 2001, 109, 475–494. [Google Scholar] [CrossRef]
- Flamary, R.; Courty, N. POT Python Optimal Transport Library. Available online: https://buildmedia.readthedocs.org/media/pdf/pot/autonb/pot.pdf (accessed on 6 December 2020).
- Wang, Z.; Dai, Z.; Póczos, B.; Carbonell, J. Characterizing and Avoiding Negative Transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Patwari, N.; Hero, A.O.; Perkins, M.; Correal, N.S.; O’Dea, R.J. Relative location estimation in wireless sensor networks. IEEE Trans. Signal Process. 2003, 51, 2137–2148. [Google Scholar] [CrossRef] [Green Version]
- De Luca, D.; Mazzenga, F.; Monti, C.; Vari, M. Performance Evaluation of Indoor Localization Techniques Based on RF Power Measurements from Active or Passive Devices. Eurasip J. Appl. Signal Process. 2006, 2006, 074796. [Google Scholar] [CrossRef] [Green Version]
- Knott, M.; Smith, C.S. On the optimal mapping of distributions. J. Optim. Theory Appl. 1984, 43, 39–49. [Google Scholar] [CrossRef]
- Mansour, Y.; Mohri, M.; Rostamizadeh, A. Domain Adaptation: Learning Bounds and Algorithms. arXiv 2009, arXiv:0902.3430. [Google Scholar]
- Mendoza-Silva, G.; Richter, P.; Torres-Sospedra, J.; Lohan, E.; Huerta, J. Long-Term WiFi Fingerprinting Dataset for Research on Robust Indoor Positioning. Data 2018, 3, 3. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AP | AP1 | AP2 | ||
|---|---|---|---|---|
| /dBm | /dBm | |||
| source domain | 50 | 1 | 80 | 3 |
| target domain | 40 | 1 | 100 | 4 |
| Month | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | 11 | 12 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C.5 | Without | 1.59 | 1.67 | 1.72 | 1.75 | 1.76 | 1.76 | 1.61 | 1.79 | 1.76 | 2.76 | 3.29 | 3.23 | 3.36 | 3.32 |
| TCA | 1.63 | 1.63 | 1.63 | 1.75 | 1.75 | 1.76 | 1.61 | 1.79 | 1.76 | 2.01 | 1.99 | 1.97 | 1.91 | 1.99 | |
| BDA | 1.69 | 1.68 | 1.76 | 1.76 | 1.73 | 1.78 | 1.67 | 1.79 | 1.88 | 1.89 | 1.76 | 1.95 | 1.76 | 1.79 | |
| EMDL | 1.42 | 1.45 | 1.42 | 1.45 | 1.47 | 1.48 | 1.45 | 1.54 | 1.48 | 1.6 | 1.49 | 1.75 | 1.47 | 1.48 | |
| Sink. | 1.34 | 1.34 | 1.34 | 1.43 | 1.44 | 1.46 | 1.36 | 1.44 | 1.47 | 1.49 | 1.45 | 1.54 | 1.34 | 1.43 | |
| M. OT | 1.44 | 1.44 | 1.44 | 1.45 | 1.5 | 1.47 | 1.42 | 1.47 | 1.45 | 1.5 | 1.45 | 1.61 | 1.42 | 1.44 | |
| C.8 | Without | 2.93 | 3.24 | 3.08 | 3.2 | 3.07 | 3.2 | 2.78 | 3.2 | 3.19 | 4.3 | 4.6 | 4.67 | 4.64 | 4.57 |
| TCA | 2.98 | 3.18 | 3.04 | 3.19 | 3.1 | 3.21 | 2.96 | 3.19 | 3.15 | 3.39 | 3.39 | 3.51 | 3.24 | 3.39 | |
| BDA | 3.08 | 3.2 | 3.08 | 3.19 | 3.09 | 3.12 | 2.95 | 3.19 | 3.2 | 3.19 | 3.23 | 3.51 | 3.15 | 3.16 | |
| EMDL | 2.76 | 2.82 | 2.72 | 2.9 | 2.89 | 2.85 | 2.78 | 2.86 | 2.96 | 2.9 | 3.08 | 3.39 | 3.04 | 2.78 | |
| Sink. | 2.7 | 2.81 | 2.72 | 2.78 | 2.76 | 2.95 | 2.78 | 2.78 | 2.98 | 3 | 2.98 | 3.46 | 2.86 | 2.76 | |
| M. OT | 2.73 | 2.85 | 2.64 | 2.81 | 2.96 | 2.81 | 2.64 | 2.78 | 2.89 | 2.81 | 2.92 | 3.24 | 2.82 | 2.73 | |
| Month | 02 | 03 | 04 | 05 | 06 | 07 | 08 | 09 | 10 | 11 | 12 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C.5 | Without | 1.99 | 2.06 | 2.2 | 2.06 | 2.19 | 2.19 | 1.99 | 1.97 | 2.15 | 2.83 | 3.29 | 3.29 | 3.25 | 3.25 |
| TCA | 2.02 | 1.97 | 2.19 | 2.08 | 2.22 | 2.19 | 2.06 | 2.16 | 2.15 | 2.31 | 2.22 | 2.37 | 2.22 | 2.26 | |
| BDA | 2.06 | 2.06 | 2.15 | 2.08 | 2.22 | 2.2 | 2.16 | 2.19 | 2.16 | 2.31 | 2.19 | 2.16 | 2.15 | 2.19 | |
| EMDL | 2.02 | 2.19 | 2.16 | 2.19 | 2.2 | 2.15 | 2.02 | 2.02 | 2.2 | 2.08 | 1.9 | 1.99 | 2.02 | 1.97 | |
| Sink. | 2.2 | 2.26 | 2.26 | 2.22 | 2.26 | 2.22 | 2.19 | 2.19 | 2.22 | 2.2 | 2.19 | 2.2 | 2.19 | 2.19 | |
| M. OT | 2.08 | 2.19 | 2.16 | 2.19 | 2.22 | 2.06 | 1.97 | 2.15 | 2.2 | 2.15 | 1.97 | 2.06 | 2.02 | 1.9 | |
| C.8 | Without | 3.12 | 3.33 | 3.47 | 3.31 | 3.21 | 3.36 | 3.22 | 3.2 | 3.25 | 4.35 | 4.49 | 4.73 | 4.66 | 4.64 |
| TCA | 3.21 | 3.32 | 3.51 | 3.32 | 3.4 | 3.51 | 3.4 | 3.36 | 3.4 | 3.62 | 3.65 | 3.95 | 3.61 | 3.78 | |
| BDA | 3.58 | 3.48 | 3.67 | 3.43 | 3.55 | 3.52 | 3.48 | 3.52 | 3.56 | 3.62 | 3.51 | 3.67 | 3.36 | 3.65 | |
| EMDL | 3.25 | 3.51 | 3.6 | 3.34 | 3.48 | 3.47 | 3.21 | 3.25 | 3.6 | 3.22 | 3.39 | 3.39 | 3.48 | 3.2 | |
| Sink. | 3.43 | 3.67 | 3.82 | 3.51 | 3.55 | 3.52 | 3.47 | 3.51 | 3.75 | 3.47 | 3.55 | 3.58 | 3.47 | 3.47 | |
| M. OT | 3.2 | 3.51 | 3.6 | 3.4 | 3.47 | 3.25 | 3.32 | 3.36 | 3.55 | 3.25 | 3.51 | 3.4 | 3.22 | 3.09 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, S.; Luo, Y.; Wan, Q. Transfer Learning for Wireless Fingerprinting Localization Based on Optimal Transport. Sensors 2020, 20, 6994. https://doi.org/10.3390/s20236994
Bai S, Luo Y, Wan Q. Transfer Learning for Wireless Fingerprinting Localization Based on Optimal Transport. Sensors. 2020; 20(23):6994. https://doi.org/10.3390/s20236994
Chicago/Turabian StyleBai, Siqi, Yongjie Luo, and Qun Wan. 2020. "Transfer Learning for Wireless Fingerprinting Localization Based on Optimal Transport" Sensors 20, no. 23: 6994. https://doi.org/10.3390/s20236994
APA StyleBai, S., Luo, Y., & Wan, Q. (2020). Transfer Learning for Wireless Fingerprinting Localization Based on Optimal Transport. Sensors, 20(23), 6994. https://doi.org/10.3390/s20236994