Energy Management of Smart Home with Home Appliances, Energy Storage System and Electric Vehicle: A Hierarchical Deep Reinforcement Learning Approach


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
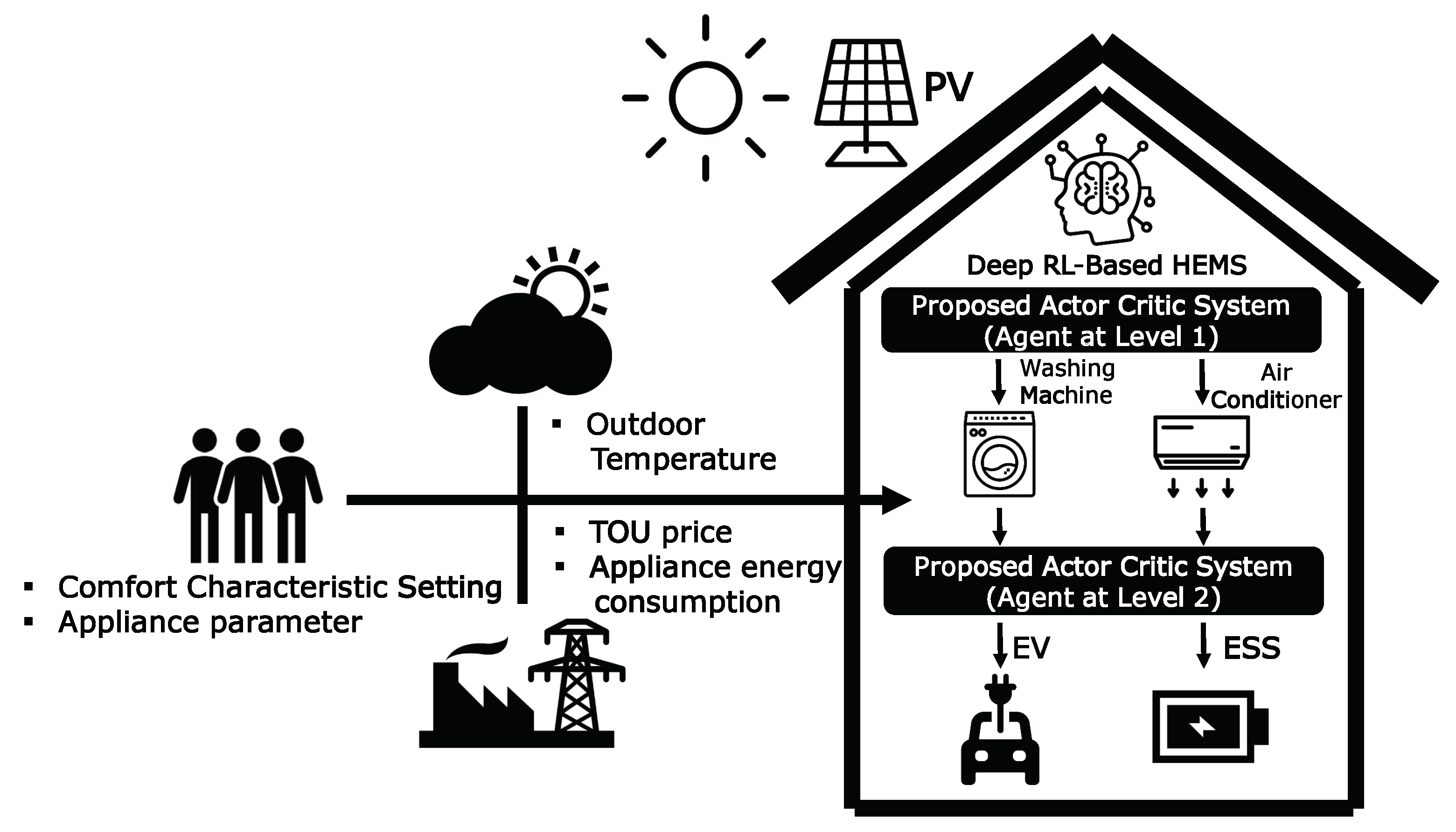
- We present a two-level distributed DRL model for optimal energy management of a smart home consisting of a first level for WM and AC, and a second level for ESS and EV. In such a model, the energy consumption scheduling at the second level is based on the aggregated energy consumption scheduled at the first level to determine the better policy of charging and discharging actions for the ESS and EV.
- Compared to the existing method using Q-learning in a discrete action space, we propose a hierarchical DRL in a continuous action space with the following two scheduling steps: (i) the controllable appliances including WM and AC are scheduled at the first level according to the consumer’s preferred appliance scheduling and comfort level; (ii) ESS and EV are scheduled at the second level, thereby resulting in optimal cost of electricity for a household.
2. Background
2.1. Types of Smart Home Appliances
- (1)
- Uncontrollable appliance (): An HEMS cannot manage the energy consumption scheduling of uncontrollable appliances such as televisions, personal computers, and lighting. Thus, an uncontrollable appliance is assumed to follow fixed energy consumption scheduling.
- (2)
- Controllable appliance (): It is an appliance for which the energy consumption scheduling is calculated by the HEMS. According to its operation characteristics, the controllable appliance is categorized into a reducible appliance () and shiftable appliance (). A representative example of a reducible appliance is an air conditioner whose energy consumption can be curtailed to reduce the cost of electricity. By the contrast, under TOU pricing, the energy consumption scheduling of a shiftable appliance can be moved from one time slot to another to minimize the cost of electricity. A shiftable appliance has two types of load: (i) a non-interruptible load (), and (ii) an interruptible load (). A shiftable appliance with an interruptible load can be interrupted at any time. For example, the HEMS must stop the discharging process and start the charging process of the ESS instantly when the PV power generation is greater than the load demand. However, the operation period of a shiftable appliance with a non-interruptible load must not be terminated by the HEMS. For example, a washing machine must finish a washing cycle prior to drying.
2.2. Traditional HEMS Optimization Approach
2.2.1. Objective Function
2.2.2. Net Energy Consumption
2.2.3. Operation Characteristics of Controllable Appliances
2.3. Reinforcement Learning Methodology
2.3.1. Reinforcement Learning
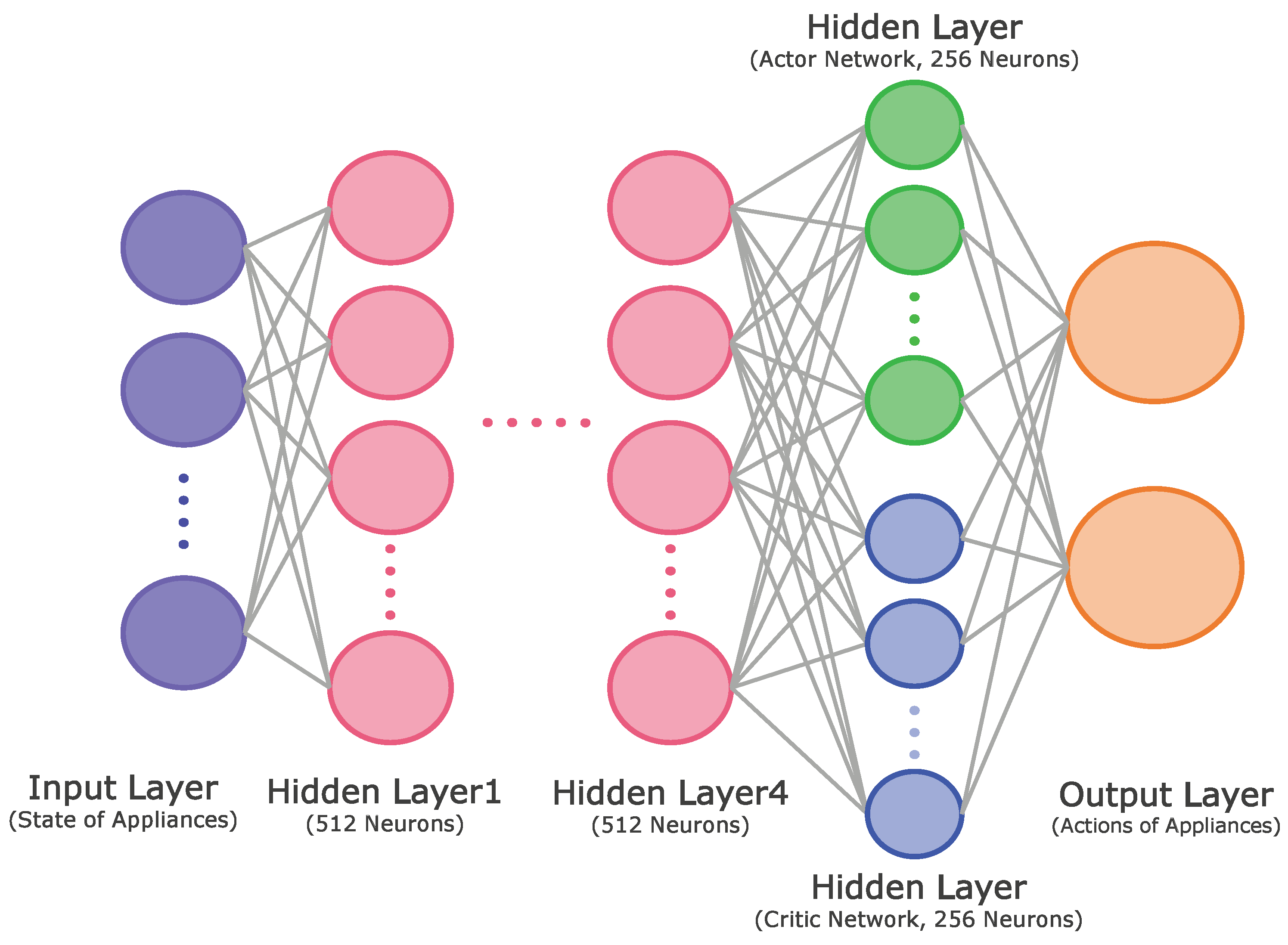
2.3.2. Actor–Critic Method
| Algorithm 1: REINFORCE method |
 |
| Algorithm 2: Actor-critic method |
 |
3. Proposed Method for DRL-Based Home Energy Management
3.1. Energy Management Model for WM and AC: Level 1
3.1.1. State Space
3.1.2. Action Space
3.1.3. Reward
3.2. Energy Management Model for ESS and EV: Level 2
3.2.1. State Space
3.2.2. Action Space
3.2.3. Reward
3.3. Proposed Actor–Critic-Based HEMS Algorithm
| Algorithm 3: Proposed actor–critic-based energy management of smart home at level 1 (or level 2). |
 |
4. Numerical Examples
4.1. Simulation Setup
- Case 1: Sunny, weekday,
- Case 2: Rainy, weekday,
- Case 3: Sunny, weekend,
- Case 4: Sunny, weekday,
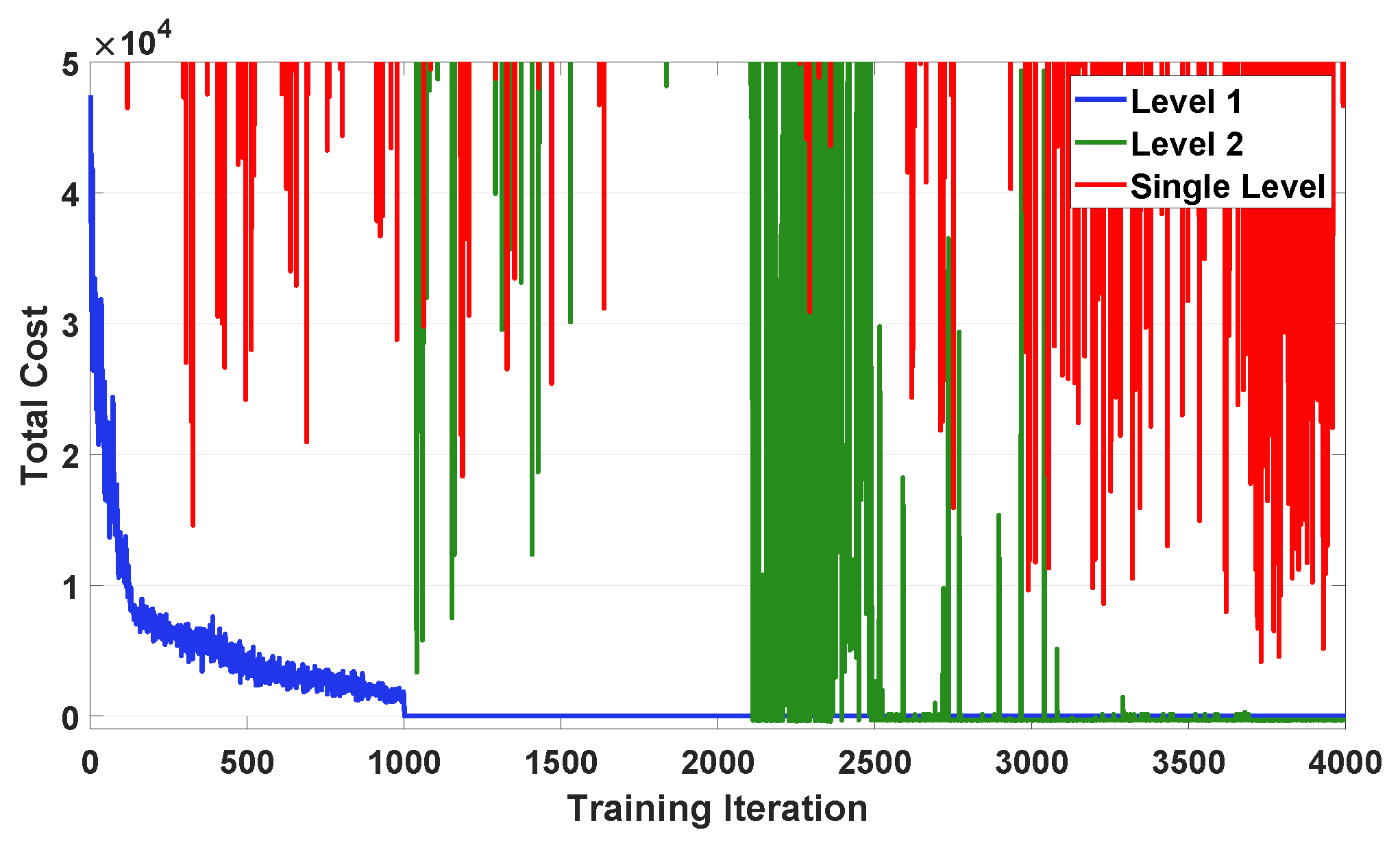
4.2. Simulation Results at Level 1
4.3. Simulation Results at Level 2
4.3.1. Case 1 vs. Case 2
4.3.2. Case 1 vs. Case 3
4.3.3. Case 1 vs. Case 4
- Through a comparison between {Case 1, Case 3, Case 4} (with PV system) and Case 2 (without PV system), we conclude that PV generation has a significant impact on the reduction of the total cost of electricity. For example, the total cost of electricity in Case 2 is 11% higher than in Case 1.
- Given that the battery capacity of the EV is approximately four times larger than that of the ESS, the EV can discharge more power than the ESS to cover the total cost of electricity. This can be verified through a comparison between {Case 1, Case 2} (in weekday) and Case 3 on weekends. In contrast, different driving patterns associated with the initial SOE of the EV significantly influence the total cost of electricity. We conclude from a comparison between Case 1 (with high SOE) and Case 4 (with low SOE) that the total cost of electricity in Case 4 is 7% higher than in Case 1. This is because the EV with low SOE needs to charge more power than with high SOE to satisfy the consumer’s preferred SOE at departure time.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- U.S. Energy Information Administration. Electricity: Detailed State Data. 2018. Available online: https://www.eia.gov/electricity/data/state/ (accessed on 26 March 2020).
- Althaher, S.; Mancarella, P.; Mutale, J. Automated demand response from home energy management system under dynamic pricing and power and comfort constraints. IEEE Trans. Smart Grid. 2015, 6, 1874–1883. [Google Scholar] [CrossRef]
- Paterakis, N.G.; Erdinc, O.; Pappi, I.N.; Bakirtzis, A.G.; Catalão, J.P.S. Coordinated operation of a neighborhood of smart households comprising electric vehicles, energy storage and distributed generation. IEEE Trans. Smart Grid. 2016, 7, 2736–2747. [Google Scholar] [CrossRef]
- Liu, Y.; Xiao, L.; Yao, G. Pricing-based demand response for a smart home with various types of household appliances considering customer satisfaction. IEEE Access 2019, 7, 86463–86472. [Google Scholar] [CrossRef]
- Wang, C.; Zhou, Y.; Wu, J.; Wang, J.; Zhang, Y.; Wang, D. Robust-Index Method for Household Load Scheduling Considering Uncertainties of Customer Behavior. IEEE Trans. Smart Grid. 2015, 6, 1806–1818. [Google Scholar] [CrossRef]
- Joo, I.-Y.; Choi, D.-H. Distributed optimization framework for energy management of multiple smart homes with distributed energy resources. IEEE Access 2017, 5, 2169–3536. [Google Scholar] [CrossRef]
- Mhanna, S.; Chapman, A.C.; Verbic, G. A Fast Distributed Algorithm for Large-Scale Demand Response Aggregation. IEEE Trans. Smart Grid. 2016, 7, 2094–2107. [Google Scholar] [CrossRef] [Green Version]
- Rajasekharan, J.; Koivunen, V. Optimal Energy Consumption Model for Smart Grid Households With Energy Storage. IEEE J. Sel. Topics Signal Process. 2014, 8, 1154–1166. [Google Scholar] [CrossRef] [Green Version]
- Ogata, Y.; Namerikawa, T. Energy Management of Smart Home by Model Predictive Control Based on EV state Prediction. In Proceedings of the 12th Asian Control Conference (ASCC), Kitakyushu-shi, Japan, 9–12 June 2019; pp. 410–415. [Google Scholar]
- Hou, X.; Wang, J.; Huang, T.; Wang, T.; Wang, P. Smart Home Energy Management Optimization Method Considering ESS and PEV. IEEE Access 2019, 5, 144010–144020. [Google Scholar] [CrossRef]
- Erdinc, O.; Paterakis, N.G.; Mendes, T.D.P.; Bakirtzis, A.G.; Catalão, J.P.S. Smart household operation considering bi-directional EV and ESS utilization by real-time pricing-based DR. IEEE Trans. Smart Grid. 2015, 6, 1281–1291. [Google Scholar] [CrossRef]
- Tushar, M.H.K.; Zeineddine, A.W.; Assi, C. Demand-side Management by Regulating Charging and Discharging of the EV, ESS, and Utilizing Renewable Energy. IEEE Trans. Ind. Informat. 2018, 14, 117–126. [Google Scholar] [CrossRef]
- Floris, A.; Meloni, A.; Pilloni, V.; Atzori, L. A QoE-aware approach for smart home energy management. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, R.P.; Wang, C.; Groot, M.D.; Zeng, Z. Consumer operational comfort level based power demand management in the smart grid. In Proceedings of the 3rd IEEE PES Innovative Smart Grid Technologies Europe (ISGT Europe), Berlin, Germany, 14–17 October 2012; pp. 14–17. [Google Scholar] [CrossRef]
- Kuzlu, M. Score-based intelligent home energy management (HEM) algorithm for demand response applications and impact of HEM operation on customer comfort. IET Gener. Transm. Distrib. 2015, 9, 627–635. [Google Scholar] [CrossRef]
- Li, M.; Jiang, C.-W. QoE-aware and cost-efficient home energy management under dynamic electricity prices. In Proceedings of the IEEE ninth International Conference on Ubiquitous and Future Networks (ICUFN 2017), Milan, Italy, 4–7 July 2017; pp. 498–501. [Google Scholar] [CrossRef]
- Li, M.; Li, G.-Y.; Chen, H.-R.; Jiang, C.-W. QoE-Aware Smart Home Energy Management Considering Renewables and Electric Vehicles. Energies 2018, 11, 2304. [Google Scholar] [CrossRef] [Green Version]
- Leitao, J.; Gil, P.; Ribeiro, B.; Cardoso, A. A Survey on Home Energy Management. IEEE Access 2020, 8, 5699–5722. [Google Scholar] [CrossRef]
- Cononnioni, M.; D’Andrea, E.; Lazzerini, B. 24-Hour-Ahead Forecasting of Energy Production in Solar PV Systems. In Proceedings of the 2011 International Conference on Intelligent Systems Design and Application, Cordoba, Spain, 22–24 November 2011; pp. 410–415. [Google Scholar] [CrossRef]
- Chow, S.; Lee, E.; Li, D. Short-Term Prediction of Photovoltaic Energy Generation by Intelligent Approach. Energy Build. 2012, 55, 660–667. [Google Scholar] [CrossRef]
- Zaouali, K.; Rekik, R.; Bouallegue, R. Deep Learning Forecasting Based on Auto-LSTM Model for Home Solar Power Systems. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications, Exeter, UK, 28–30 June 2018; pp. 235–242. [Google Scholar] [CrossRef]
- Megahed, T.F.; Abdelkader, S.M.; Zakaria, A. Energy Management in Zero-Energy Building Using Neural Network Predictive Control. IEEE Internet Things J. 2019, 6, 5336–5344. [Google Scholar] [CrossRef]
- Ryu, S.; Noh, J.; Kim, H. Deep Neural Network Based Demand Side Short Term Load Forecasting. Energies 2016, 10, 3. [Google Scholar] [CrossRef]
- Baghaee, S.; Ulusoy, I. User comfort and energy efficiency in HVAC systems by Q-learning. In Proceedings of the 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Lee, S.; Choi, D.-H. Reinforcement Learning-Based Energy Management of Smart Home with Rooftop PV, Energy Storage System, and Home Appliances. Sensors. 2019, 19, 3937. [Google Scholar] [CrossRef] [Green Version]
- Lu, R.; Hong, S.H.; Yu, M. Demand Response for Home Energy Management using Reinforcement Learning and Artificial Neural Network. IEEE Trans. Smart Grid. 2019, 10, 6629–6639. [Google Scholar] [CrossRef]
- Alfaverh, F.; Denai, M.; Sun, Y. Demand Response Strategy Based on Reinforcement Learning and Fuzzy Reasoning for Home Energy Management. IEEE Access 2020, 8, 39310–39321. [Google Scholar] [CrossRef]
- Wan, Z.; Li, H.; He, H. Residential Energy Management with Deep Reinforcement Learning. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Wei, T.; Wang, Y.; Zhu, Q. Deep Reinforcement Learning for Building HVAC Control. In Proceedings of the 54th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ding, X.; Du, W.; Cerpa, A. OCTOPUS: Deep Reinforcement Learning for Holistic Smart Building Control. In Proceedings of the 6th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, New York, NY, USA, 13–14 November 2019; pp. 326–335. [Google Scholar] [CrossRef]
- Zhang, C.; Kuppannagari, S.R.; Kannan, R.; Prasanna, V.K. Building HVAC Scheduling Using Reinforcement Learning via Neural Network Based Model Approximation. In Proceedings of the 6th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, New York, NY, USA, 13–14 November 2019; pp. 287–296. [Google Scholar] [CrossRef] [Green Version]
- Le, D.V.; Liu, Y.; Wang, R.; Tan, R.; Wong, Y.-W.; Wen, Y. Control of Air Free-Cooled Data Centers in Tropics via Deep Reinforcement Learning. In Proceedings of the 6th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, New York, NY, USA, 13–14 November 2019; pp. 306–315. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the 2014 International Conference on Machine Learning (ICML), Beijing, China, 21–26 June 2014; pp. 1–9. [Google Scholar]
- Tesau, C.; Tesau, G. Temporal Difference Learning and TD-Gammon. Commun. ACM 1995, 38, 58–68. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- National Renewable Energy Laboratory. Building Energy Optimization Tool (BEopt). Available online: https://beopt.nrel.gov/home (accessed on 26 March 2020).











© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Choi, D.-H. Energy Management of Smart Home with Home Appliances, Energy Storage System and Electric Vehicle: A Hierarchical Deep Reinforcement Learning Approach. Sensors 2020, 20, 2157. https://doi.org/10.3390/s20072157
Lee S, Choi D-H. Energy Management of Smart Home with Home Appliances, Energy Storage System and Electric Vehicle: A Hierarchical Deep Reinforcement Learning Approach. Sensors. 2020; 20(7):2157. https://doi.org/10.3390/s20072157
Chicago/Turabian StyleLee, Sangyoon, and Dae-Hyun Choi. 2020. "Energy Management of Smart Home with Home Appliances, Energy Storage System and Electric Vehicle: A Hierarchical Deep Reinforcement Learning Approach" Sensors 20, no. 7: 2157. https://doi.org/10.3390/s20072157
APA StyleLee, S., & Choi, D. -H. (2020). Energy Management of Smart Home with Home Appliances, Energy Storage System and Electric Vehicle: A Hierarchical Deep Reinforcement Learning Approach. Sensors, 20(7), 2157. https://doi.org/10.3390/s20072157