1. Introduction
The steady increase in our older adult population, coupled with older adults living longer and the requirement for more assistance, is driving caregiver demand. According to the United Nations’ World Population Prospects report, the number of people over the age of 60 is expected to be more than doubled by 2050 and more than tripled by 2100. Further, all major areas of the world will have nearly a quarter or more of their populations be 60 or over [
1]. This puts burdens on formal and informal caregivers to provide care for an average of 20 h per week [
2] for a chronically ill, disabled or aging family member or friend. Besides the demands of care-giving, there is pressure on the economic side to support the healthcare sector; the EU countries spend on average a quarter of their GDP on social protection [
3]. This highlights the needs for effective solutions to tackle the demographic and economic challenges towards a better health and social care of the older population.
Ambient assisted living (AAL) provides one of the most promising solutions with which to support the older people who wish to keep their independence as long as possible, trying to fend for themselves by having fulfilling lives in terms of everyday activities and leisure. With the introduction of new low-cost sensors, low-power wireless protocols, cloud computing, and Internet of Things (IoT) technologies, the ability to deploy tools in our daily lives has never been more available. Assisted-care and health-monitoring became more available in order to contentiously observe and keep an eye on the behaviors of the senior adults. Activities of daily living (ADLs) is a term used to represent the set of common tasks that comprise a person’s everyday requirements that influence the self-support of a senior adult in day-to-day routines. The essential list of ADLs include but are not limited to relaxing, meal preparation, eating, and sleeping. The power to perform ADLs without assistance from the others and in a constant manner provides a necessary assessment of the functional condition of the senior adult and the power to live without support at home. In a recent survey [
4], formal and informal caregivers showed an increasing interest in an accurate activity recognition and tracking.
In this paper, we use a smart environment infrastructure to observe the routines of senior adults [
5,
6,
7,
8,
9]. A smart environment is equipped with various kinds of sensors, such as infrared motion sensors (PIR), for monitoring the motions of the occupant at home. Such sensors can collect many representative details about the surroundings and its occupants. There are several potential applications for a smart environment, such as recommendation in office environments, energy preservation, home automation, surveillance, and of course assisted care of senior adults [
10,
11]. Activity learning and tracking are some of the core components of any smart environment for ADL monitoring. The purpose of an activity learning component is to identify the inhabitant activities from the low-level sensor data. The various proposed approaches in the literature include a number of large differences with respect to the primary sensing technology, the artificial intelligence approaches, and the practicality of the smart homes in which activity information is captured.
However, modeling all human activities in a supervised-based approach faces a number of challenges and obstacles. First, a large amount of sensor data must be available. The sensor data should be labeled with the actual activities (the “ground truth” labels). In real-world in-home monitoring systems, such prelabeled data are very difficult to obtain. Second, the time that is spent on activities, which are easy to annotate (e.g., sleep times), is only a fraction of an individual’s total behavioral routine. Beside that, modeling and tracking only preselected activities ignores the important insights that other activities can provide on the routine behavior and the activity context of the individual. Finally, it is very challenging to build an unintrusive sensing system to collect the data from real individuals, annotate the data with the ground truth label for training and testing purposes, and develop efficient methods to learn and accurately detect the activities. Therefore, activity discovery handles the problem of activity labels not being available using approaches based on sequence mining and clustering. Not only that, activity discovery methods can work better with mining human activities from real-life data, given its natural sequence, the continuation of disarranged patterns, and the different forms of the same pattern [
5].
The work in this paper regards activity learning on discrete, binary motion sensor data collected from real-world environments. We are mainly interested in answering questions related to the use of motion sensors. “Can the activities be automatically discovered (learned) by looking for interesting patterns in the data from the motion sensors without relying on supervised methods?” Data annotation is a very time consuming and laborious task. It is very difficult to obtain labels for all the activities in the data set. Even with the assumption of consistent predefined activities, not all individuals perform them the same way due to the complex structure of activities. Therefore, supervised methods are not practical to use. We introduce an unsupervised activity discovery algorithm that does not depend on any activity annotations in the data set.
Our framework consists of three processing steps; namely, low-level, intermediate-level, and high-level units. In the low-level processing step, the raw sensor data is preprocessed to be sampled periodically at a constant time interval. In the intermediate-level step, we use a time-based windowing approach to divide the sensor data into time intervals using two different time interval lengths. First, we use a small time interval length to extract the time duration within the detection area of each sensor. Next, we use a large time interval length to extract the time duration within the detection of each location. The small and large time intervals are processed to extract meaningful features.
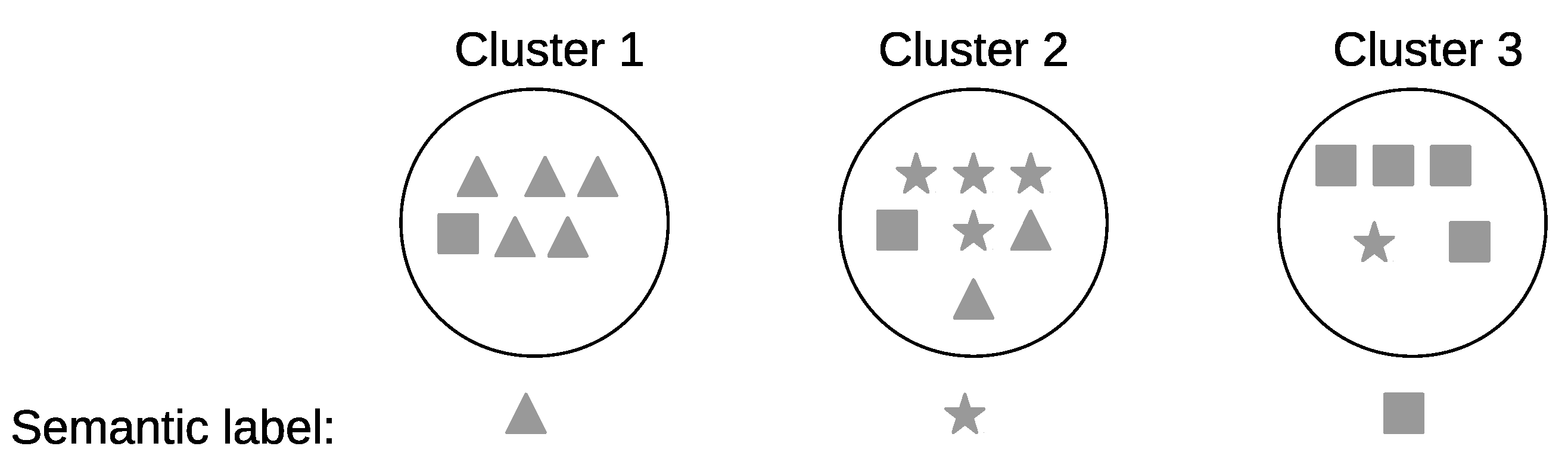
In the high-level step, we introduce several clustering algorithms and approaches to form clusters based on the statistical features encapsulated in the different time intervals. First, we perform an intra-day pattern discovery where we group similar time intervals to form the clusters within the same day using an exponential function as a similarity measure between the different time intervals. Next, we perform an inter-day pattern discovery, where we group similar clusters across all days to ensure the uniqueness of the clusters using the Earth mover’s distance (EMD) as a similarity measure between the clusters. Furthermore, the clusters are refined to have more compressed and defined characterizations. Finally, the clusters are given semantic labels in order to track the occurrences of the future activities.
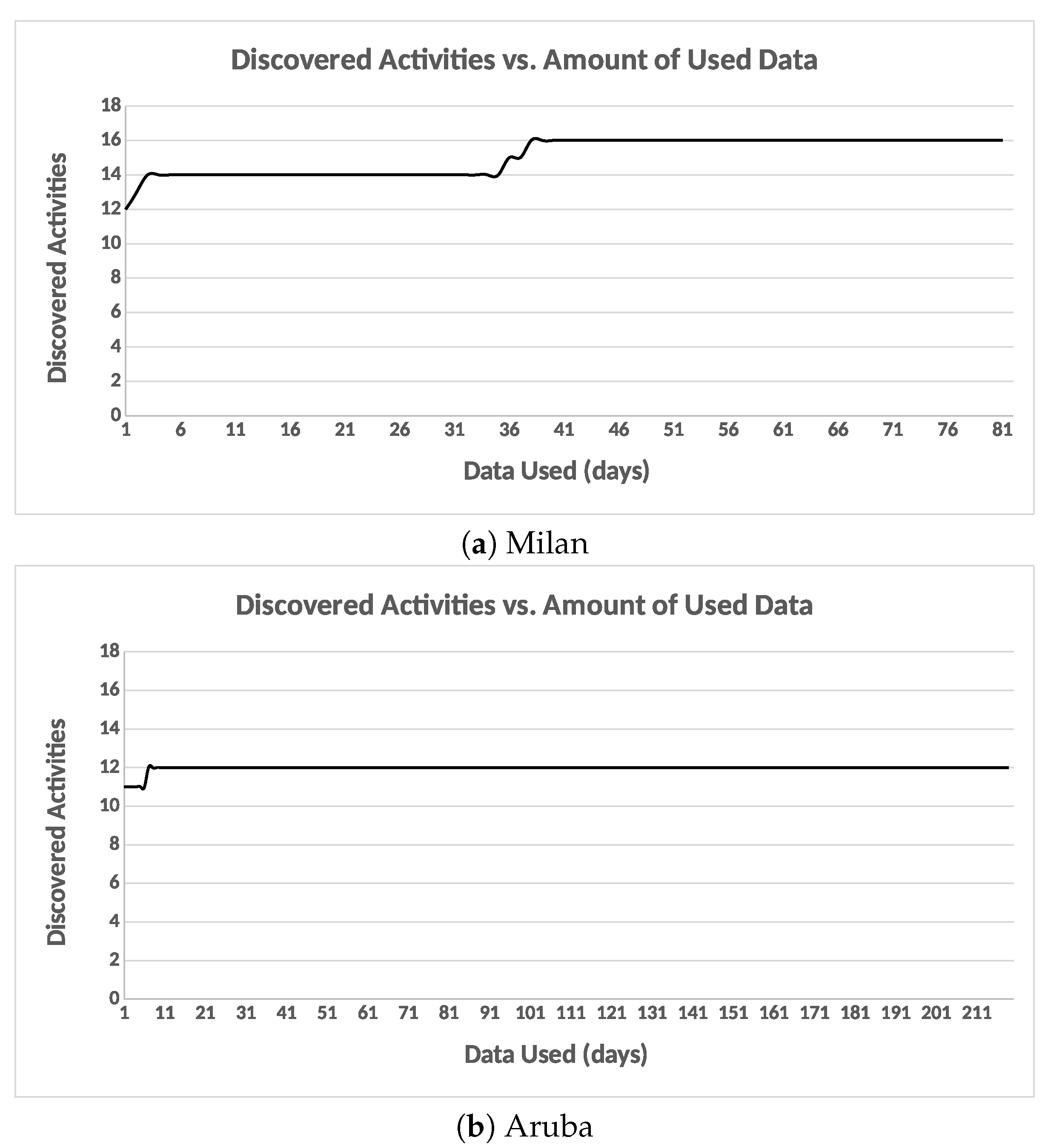
We discuss two approaches for recognizing activities using the final set of the clusters, where they are used to recognize the occurrences of the future activities from a window of sensor events. The first approach uses a model to classify the labels, while the second approach measures the similarity between the clusters’ centroids, and the test time interval within which to determine the cluster with the best similarity value, where the semantic label of that cluster is assigned. Our method handles other real-life difficulties, such as major various sensor event occurrences in different areas of the home. It completely removes the requirement to set most of the system values by the occupant, yielding to a more system-driven approach. This framework is evaluated on two public data sets captured in real-life settings from two apartments during a seven-month and a three-month periods. The data sets we use reflect the challenges of unrestricted real-life data, measured when the user is functioning in their natural home and performing their day-to-day activities with no directions or orders from the scientists.
This paper is organized as follows.
Section 2 describes the related work. In
Section 3, we introduce our proposed framework. In
Section 4, we illustrate the steps taken to preprocess the raw sensor data. In
Section 5, we discuss our approach to extract meaningful features from the raw sensor data. In
Section 6, we introduce different clustering approaches and algorithms to form clusters based on the statistical features encapsulated in the different time intervals of the sensor events. Activity recognition is presented in
Section 7. We present and discuss the experimental results in
Section 8. Finally,
Section 9 draws conclusions.
2. Related Work
A large number of works chose event-like sensors as their primary sensing technologies for data capturing, because they are computationally inexpensive, easy to install, cheap, privacy-friendly in nature, long in battery life, do not have to be carried or worn, and require minimal supervision and maintenance. This led to generating many public data sets based on event-like sensors for long duration measurements with rich information. There are still some challenges in the use of event-like sensors, such as passive infrared (PIR) sensors. First, PIR sensors produce highly bursty output, which limits PIR systems to single-person scenarios, and self-triggering due to sudden changes in environmental conditions, such as heating, ventilating, and air conditioning. Furthermore, PIR sensors may not be able to sense all motions if an obstacle is between the sensor and the moving person. Moreover, a movement can be sensed by a PIR sensor from any object that emits heat, even if the movement comes from an inorganic source. As a result, events may be generated by the motion sensor, when a printer starts printing documents in large quantities in the vicinity or if a close by baseboard heater suddenly switches on.
There are many proposed approaches toward recognizing the activities of daily living in a home setting with PIR sensors, which can be broadly categorized into two major categories: supervised and unsupervised approaches [
12,
13,
14,
15].
Among these two categories, supervised approaches are much more prevalent than unsupervised, since the task of recognizing activities of daily living can be easily formatted into a classification problem, which can be solved by a lot of mature classification algorithms. By using the sequence of PIR sensor events with their corresponding time and location information as input features, and the activity labels as ground truth, many popular machine learning algorithms, such as the naive Bayesian classifier [
16,
17], decision trees [
18], a support vector machine (SVM) [
19], and a neural network [
20], can be directly applied to activity recognition tasks [
21]. Additionally, kernel fusion is a favorable approach with which to obtain accurate results. A kernel fusion approach based on an SVM classifier is proposed in [
22], wherein the authors used four individual SVM kernel functions, wherein each kernel was designed to learn the activities in parallel. Additionally, the use of XAI models [
23] can contribute further to explaining the machine learning model results, and provide conclusions on these model behaviors and decisions about the human activity recognition problem.
Moreover, template matching methods such as k-nearest neighbors, which can be either based on Euclidean distance using location information in the sensor data or rely on edit distance with sequence details of the sensor activation events, have also been proposed for the activity recognition problem [
18,
24]. In [
25], the authors proposed a modified machine learning algorithm based on k-nearest neighbors (MkRENN) for activity recognition. In addition, because of the sequential nature of the PIR sensor data, the hidden Markov model (HMM), hierarchical hidden semi-Markov models, dynamic Bayesian networks, and many other popular graphical models have been used to model the activity transition sequence for activity recognition purposes [
24,
26,
27,
28,
29,
30,
31].
In [
32], the author explored the use of a semi-supervised machine learning algorithm to teach generalized setting activity models. The author constructed an ensemble classifier wherein the naive Bayes classifier, HMM, and conditional random field (CRF) models were the base classifiers of this ensemble, and a boosted decision tree was a top classifier. Then, a semi-supervised learning method was used to teach the final model. The final model was trained on 11 data sets. In [
33], the authors followed a similar approach, in which they constructed a neural network ensemble. A method for activity recognition is proposed in [
34] by optimizing the output of multiple classifiers with the genetic algorithm (GA). The different measurement level outputs of different classifiers, such as HMM, SVM, and CRF, were combined to form the ensemble.
Even though the majority of the surveyed activity recognition approaches are supervised methods, most of them share the same limitation: (1) the requirement for sufficient amount of labeled data in order to work well; and (2) accurate activity labels for PIR sensor data sets. For almost all of the current smart home test-beds with PIR sensors, the data collection and data labeling are two separate processes, among which the activity labeling for the collected PIR sensor data is extremely time consuming and laborious because it is usually based on direct video coding and manually labeling. Clearly, this limitation prevents the supervised approaches from being easily generalized to a real-world situation, wherein activity labels are usually not available for a huge amount of sensor data.
Intuitively, activities of daily living are mostly the occupant’s daily or weekly routines. They usually follow some similar sequences and repeat a lot, which means the interleaving connectivity and periodic or frequent patterns within the raw PIR sensor data themselves can be very useful for activity discovery and recognition purposes. Therefore, a number of unsupervised approaches have been proposed to handle the problem of activity labels not being available. Many of them are based on sequence mining algorithms, such as frequent sequence mining approaches that use different sliding windows to find frequent patterns [
35,
36,
37]; and the emerging pattern mining also known as contrast pattern-mining [
38,
39,
40] that uses significant changes and differences in the data set as features to differentiate between different activities [
41,
42,
43]. Gu et al. [
41] used the notion of emerging patterns to look for common sensor sequences that can be linked to each activity as a support for recognition.
In [
44], the author analyzed the sensor data at the location level only, and constructed a feature vector of one dimension with time series information. Xie et al. [
45] proposed a hybrid system that used an inertial sensor and a barometer to learn static activities and detect locomotion. The authors in [
46] proposed an approach based on zero-shot learning to learn human activities. Hamad et al. [
47] proposed a fuzzy windowing approach to extract temporal features for human activity recognition. Müller et al. [
48] studied several unsupervised learning methods using sensor data streams from multiple residents. Fang et al. [
49] proposed a method that depends on the integration of several hierarchical mixture models of directional statistical models with active learning strategies to build an online and active learning system for activity learning. The authors in [
50] presented a method that can track activities and detect deviations from long-term behavioral routines using binary sensors.
Some of the recent sequence mining approaches are presented in [
5,
51], wherein the authors proposed two methods; namely, discontinuous varied-order sequence mining (DVSM) and continuous varied order (COM) which can automatically discover discontinuous patterns with different event orders across their instances. In the first approach, DVSM worked best when using data collected under controlled conditions and in artificial settings. It faced difficulty mining real-life data. The DVSM method was able to discover only five activities out of ten predefined activities. In the second approach, COM was an improved version of DVSM. COM was also able to better handle real-life data by dealing with the different frequencies problem. Additionally, it was able to find a higher percentage of the frequent patterns, thereby achieving a higher recognition accuracy rate. The COM method was successfully able to discover only seven activities out of ten predefined activities. It can be noted that both methods were not able to discover all predefined activities. These methods were not able to deal with some similar activities and might mistake them with one another. Some other activities such as housekeeping were not discovered in the first place.
Other approaches include the graph-based pattern discovery method, which discovers possible activities by searching for sequence patterns that best compress the input unlabeled data [
52,
53]; activity learning and recognition based on multiple eigenspaces [
54]; activity episode mining that identifies significant episodes in sequential data by evaluating the significance values of the candidates [
14,
55]; and the hierarchical modeling method which models the occupant’s activity at different levels, such as activity, movements, and motion from top to bottom, so that level by level clustering and classification can be applied to reduce the difficulty of the overall activity discovery and recognition [
10]. In addition, techniques based on graph analysis have also been proposed to analyze and discover the occupant’s activity using PIR sensor network data sets [
15,
56,
57,
58].
The surveyed approaches consider a more simple case of the problem by not fully analyzing the real-world nature of data, such as their order or sequence, the probable interruptions (e.g., a toilet visit during a sleep time), or the differences between the same patterns. Moreover, not all the labeled activities were discovered and recognized. Differently from the standard sequence mining methods, the diverse activity patterns are expected to be detected from a continuous stream of binary data with no explicit partitioning between two following activities. As a consequence, the sensor data that represent an activity pattern can have high variations in their lengths. These problems present major challenges in discovering human activities from binary sensor data, where the sequence of the binary data can be stopped or interrupted by minor events, and can have different forms with regard to the order of the sequence, its length, its time duration, and its occurrence in specific locations.
Our method attempts to find general recurring patterns as well as pattern variations taking into consideration the erratic nature and varying order of the human activities. Our method has several advantages over the other methods. First, we use several time interval lengths in order to capture several cues and important features in the sensor data. This enables our method to handle varying frequencies for activities performed in different locations by keeping only relevant variations of patterns, and pruning other irrelevant variations. Second, we use the location as a cue in our clustering algorithms. Many of the aforementioned methods do not use this cue. The location as a cue significantly boosts the accuracy in our methods, and it has shown promising results in human activity discovery [
5]. Third, we rely on several cluster properties to measure the similarity between clusters, and this ensures a better cluster quality. Finally, our clustering algorithms eliminate the need for the user to configure the number of clusters. This results in a more automated approach overall.
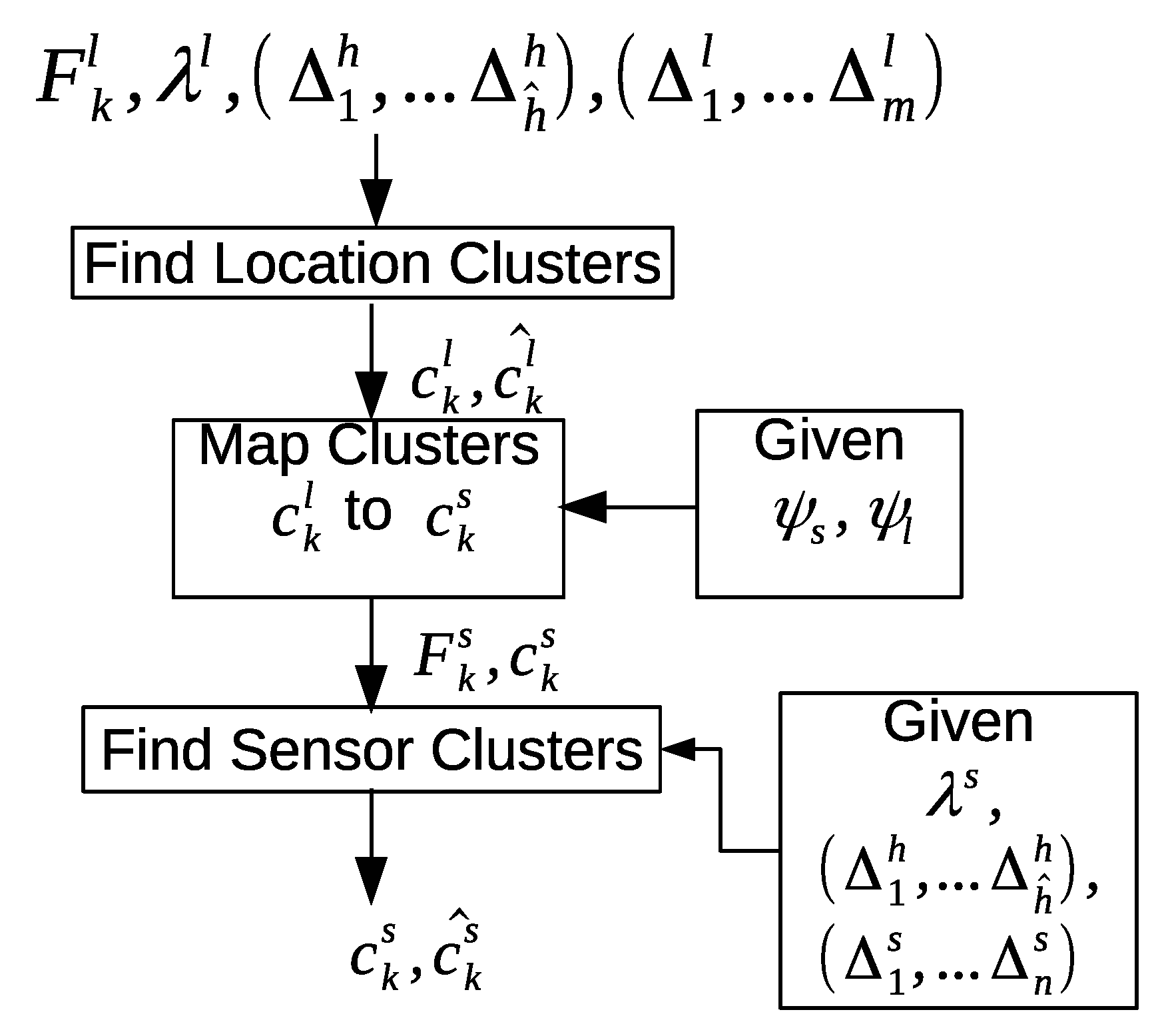
3. Our Proposed Framework
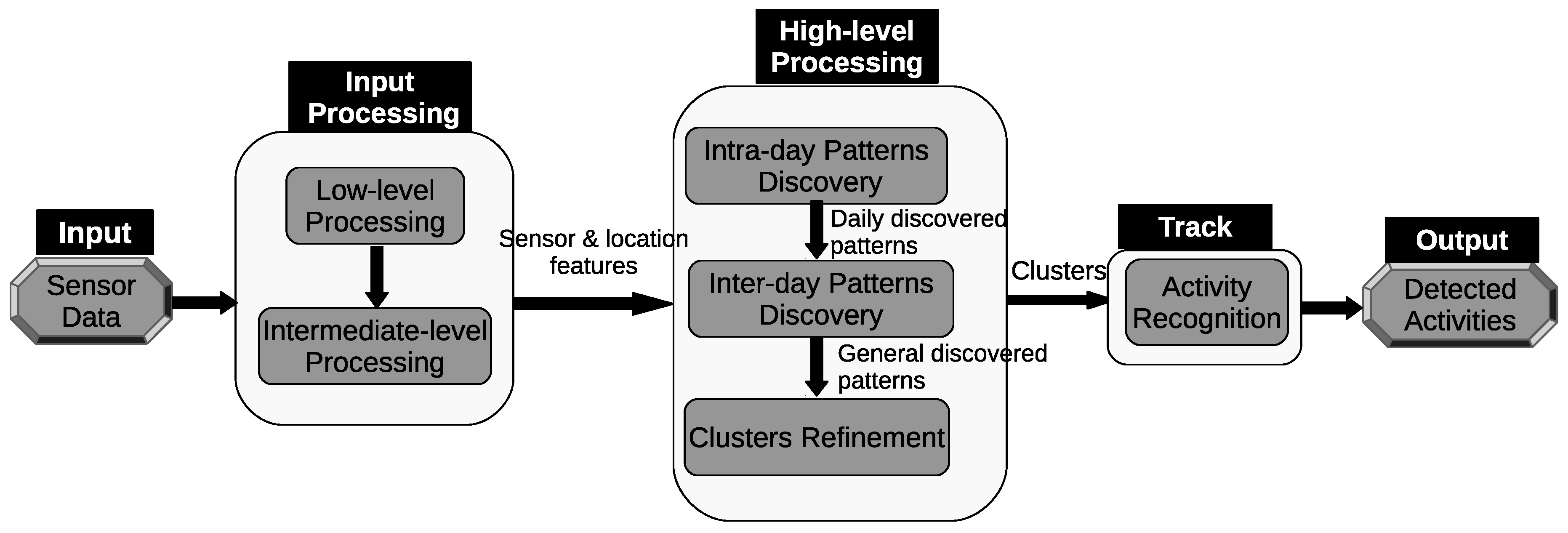
The architecture of the proposed framework can be seen in
Figure 1. The first component consists of one “low-level processing” unit and one “intermediate-level processing” unit. In the “low-level processing” unit, we assign a location label that corresponds to a room. Then, we extract useful features from the raw sensor data. Some sensors, such as motion and door sensors, generate discrete-valued messages indicating their states (e.g., on or off, open or closed). These sensors usually only generate events when there is a change in their state, typically as a result of the direct interaction with the occupant. The discrete features used in the feature vector describe the time and the location where the events occur in the home.
In the “intermediate-level processing” step, we use a time-based windowing approach with a fixed time interval length. First, we use a small time interval length to extract the time duration within the detection area of each sensor. We will refer to it as a sensor time-based window. Each index inside the window represents a particular sensor that is installed in an environment. The value of each position in the window is the time duration of a particular sensor. The time duration in a sensor time-based window is defined as the amount of time a person spends around the detection area of a sensor.
Figure 2a shows an example of a sensor time-based window. Each window has a fixed number of entries
N, where
N is the number of the sensors installed in an environment, and
is the time interval length. Each entry in the window has a time duration that a person spent within the detection area of a sensor.
Secondly, we use a large time interval length to extract the time duration within the detection of each location. We will refer to it as a location time-based window. Each index inside the window represents a particular location that exists in an environment. The value of each position in the window is the time duration of a particular location. The time duration in a location time-based window is defined as the amount of time a person spent around the detection area of a location.
Figure 2b shows an example of a location time-based window. Each window has a fixed number of entries
M, where
M is the number of the locations in an environment, and
is the time interval length. Each entry in the window has a time duration that a person spent in a location.
The high-level processing component includes three discovery steps; namely, “intra-day pattern discovery”, “inter-day pattern discovery”, and “clustering refinement”. In the “intra-day pattern discovery” step, we want to cluster similar time intervals within the same day, where each group of similar time intervals will represent a particular pattern. First, we compare the location time-based windows. Two location time-based windows are considered similar if the overall time duration difference between the locations is small (e.g., zero or less than a certain threshold). According to this criterion, the windows are clustered accordingly. Next, a mapping step is performed in order to group the sensor time-based windows according to the clusters of the location time-based windows.
Furthermore, the sensor time-based windows are clustered, so that we can compare the durations of all sensors. Using the same criterion, two sensor time-based windows are considered similar if the overall time duration difference between the sensors is small (e.g., zero or less than a certain threshold). Finally, the sensor time-based windows are clustered within a day. Each cluster will contain a group of sensor time-based windows, where all the windows share similar time durations. The similar group of windows will represent a specific pattern of behavior (e.g., sleeping, eating). Finally, a single day is segmented into several clusters, where each cluster represents a group of sensor time-based windows. We will refer to a cluster here as a pattern.
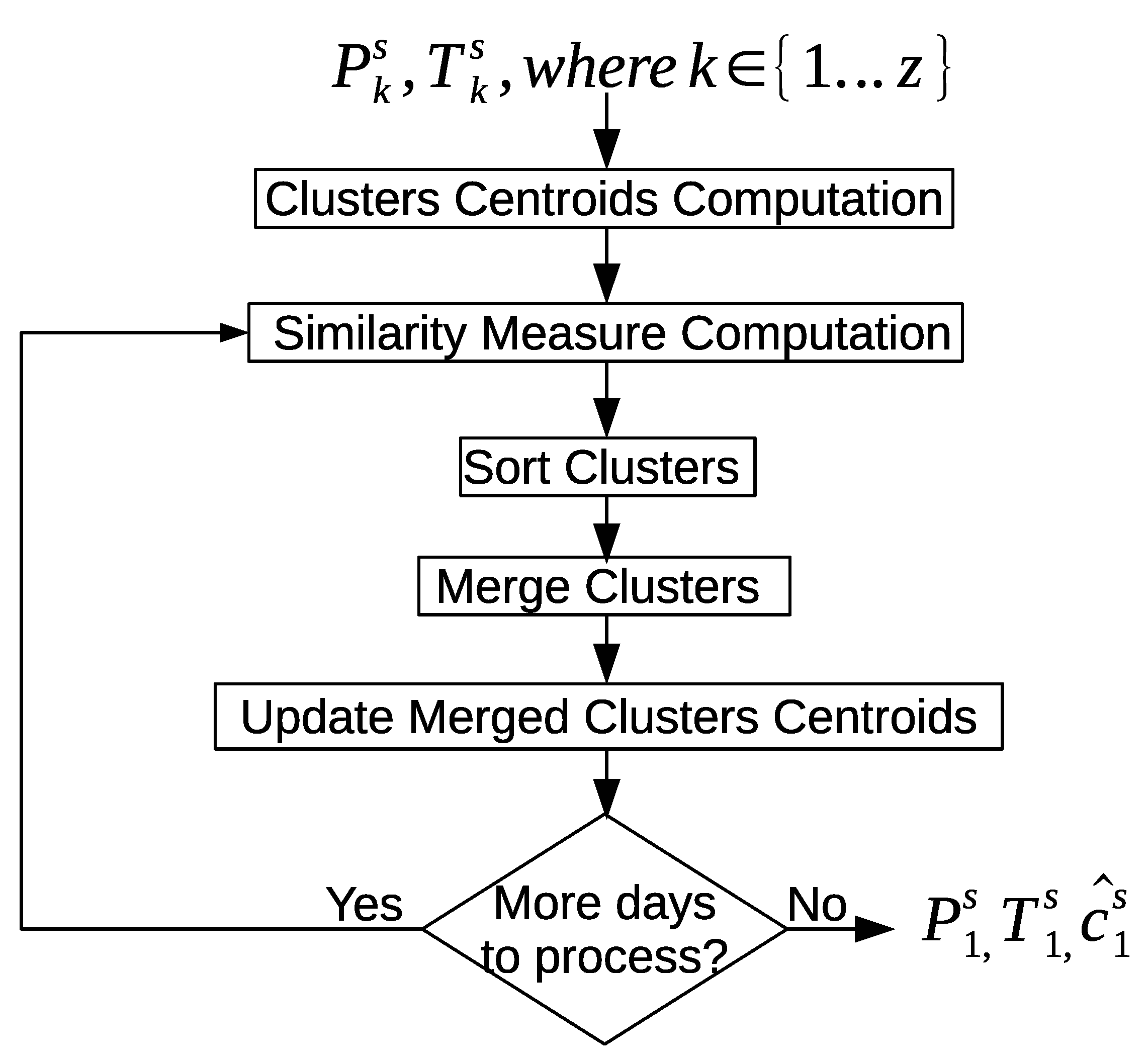
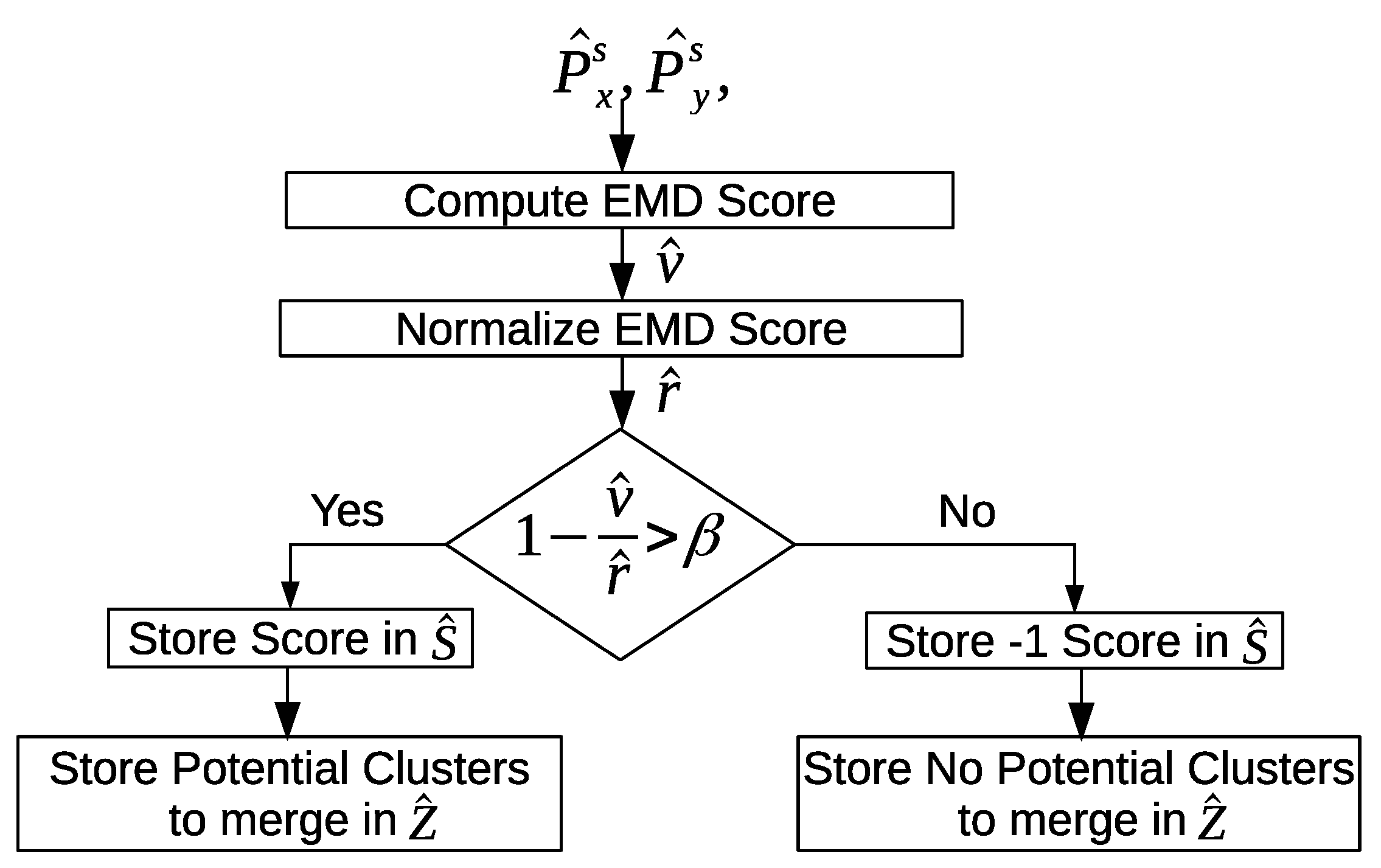
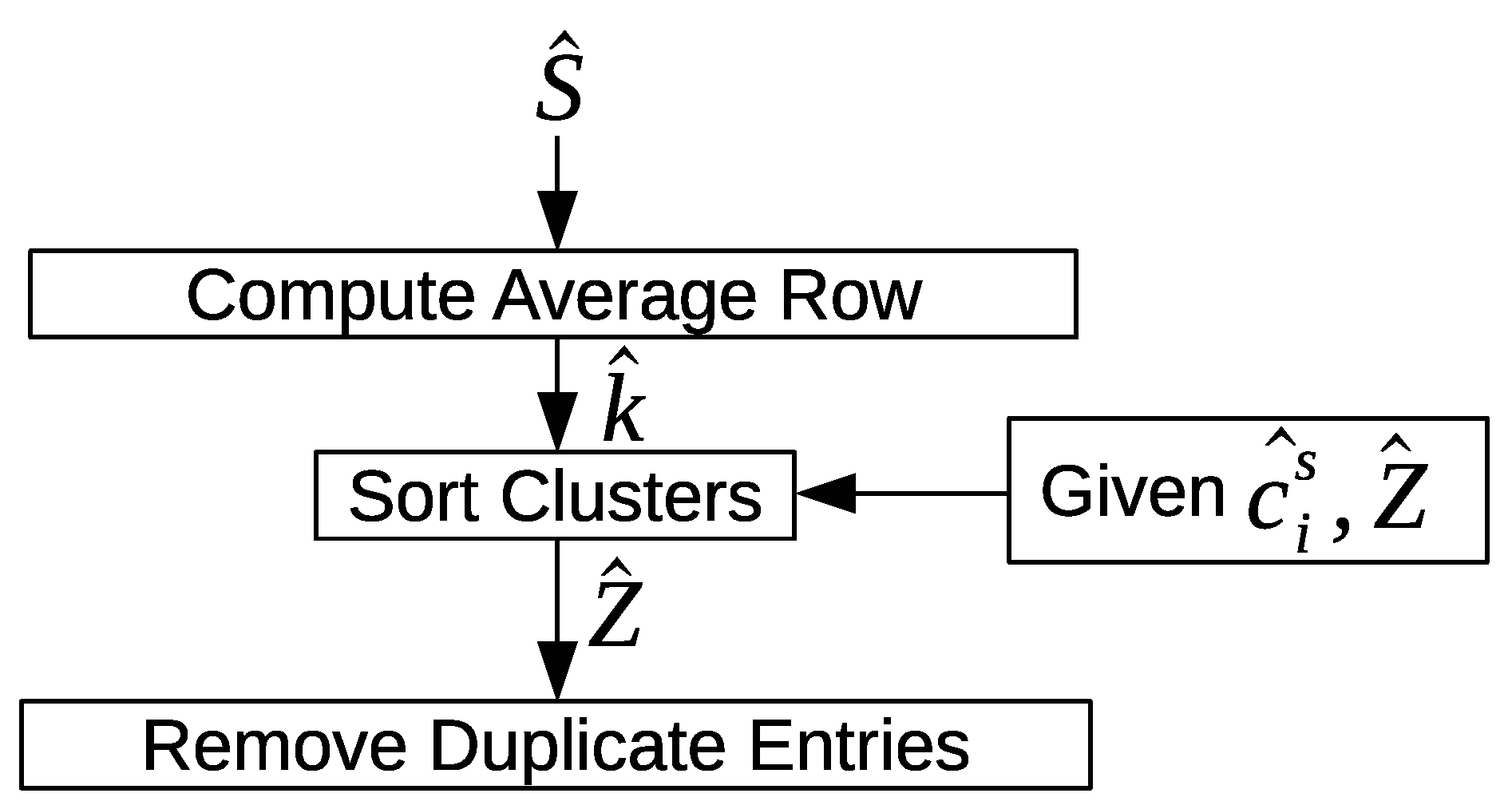
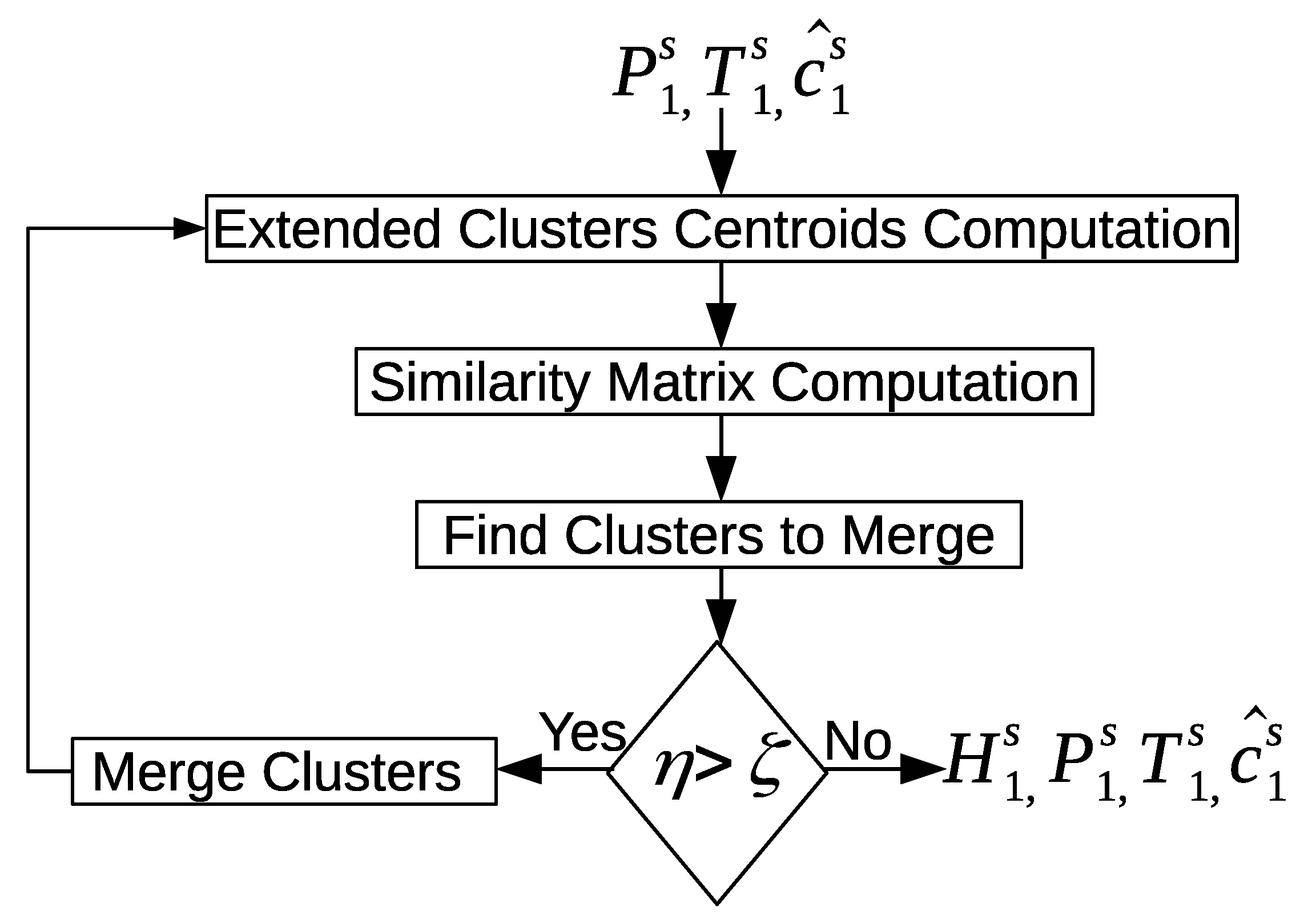
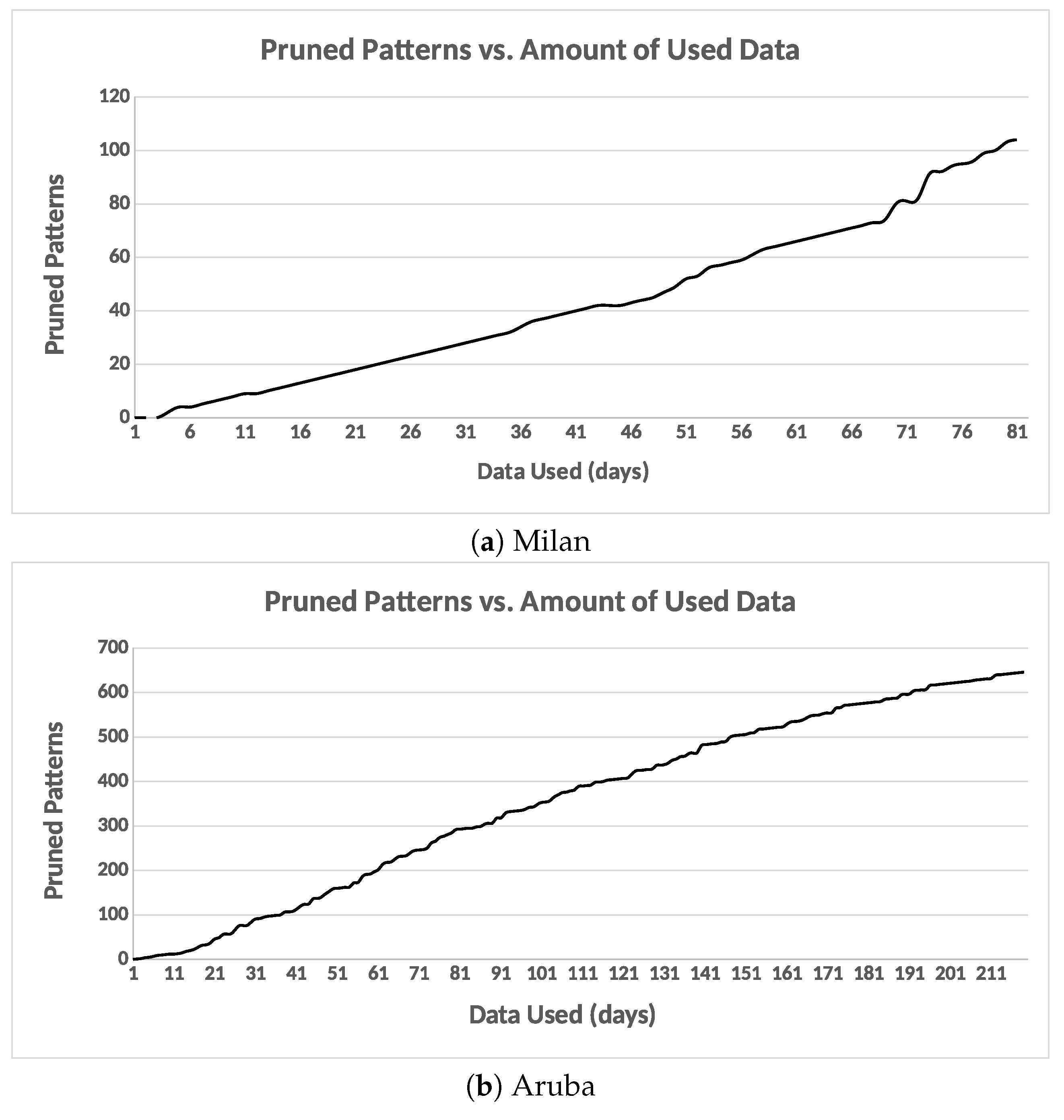
There could be similar patterns between two days or more. The discovered patterns are unique within a day but they are not unique between days. The “inter-day pattern discovery” step aims at finding the common patterns between two or more days and clusters them, and retains only the general frequent patterns and their variations across all days. We use the Earth mover’s distance (EMD) as a similarity measure for evaluating the patterns between days. In order to provide more compressed and defined characterizations of the common frequent patterns across all days, we apply an aggregate hierarchical clustering algorithm in the third step. Finally in the last component, the clusters are then used to track and recognize the occupant’s activities.
4. Low-Level Processing
The data sets used in this work consist of a series of PIR motion sensor activation events. They represent times in which an occupant or a guest moved within the detection area of one of the PIRs used in the deployment.
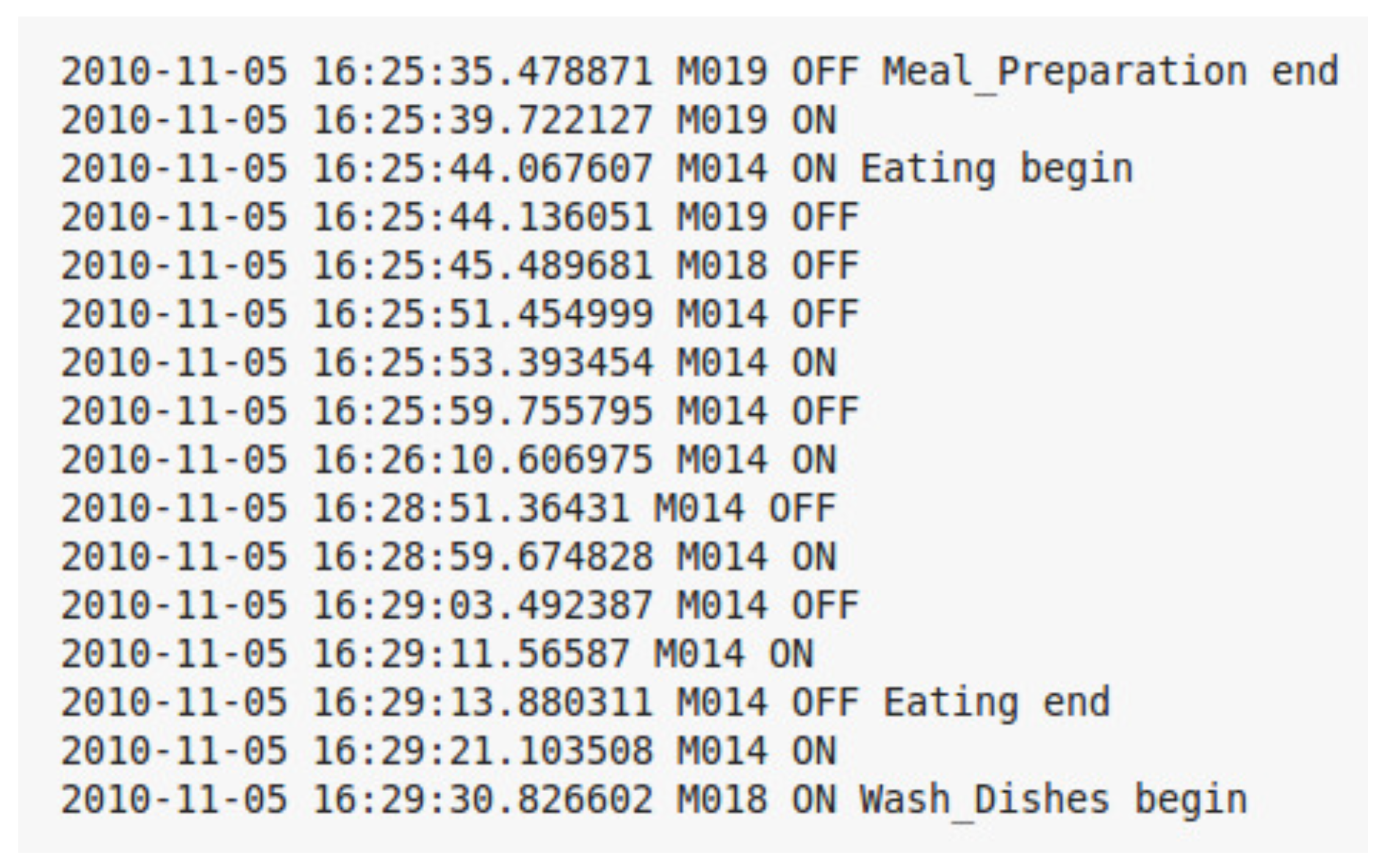
Figure 3 shows an example of several labeled sensor readings from one of the data sets. Each sensor event is described by several elements, such as a date, time of the occurrence, sensor identifier, sensor status, and associated activity label. Sensors’ identifiers starting with M represent motion sensors, and those starting with D represent door sensors. Some of the events are part of a labeled activity and others have no activity labels. The goal of an activity recognition algorithm is to predict the label of a sensor event or a sequence of sensor events.
As a first step in forming the time-based features that we will later use for the pattern discovery, we assign to each sensor event a label that corresponds to a location where the occupant is currently located. The location labeling approach was used previously in [
5,
57,
58,
59] to hypothesize that activities in a home are closely related to specific locations of a home; for example, cooking mostly occurs in the kitchen, and sleeping occurs mostly in the bedroom.
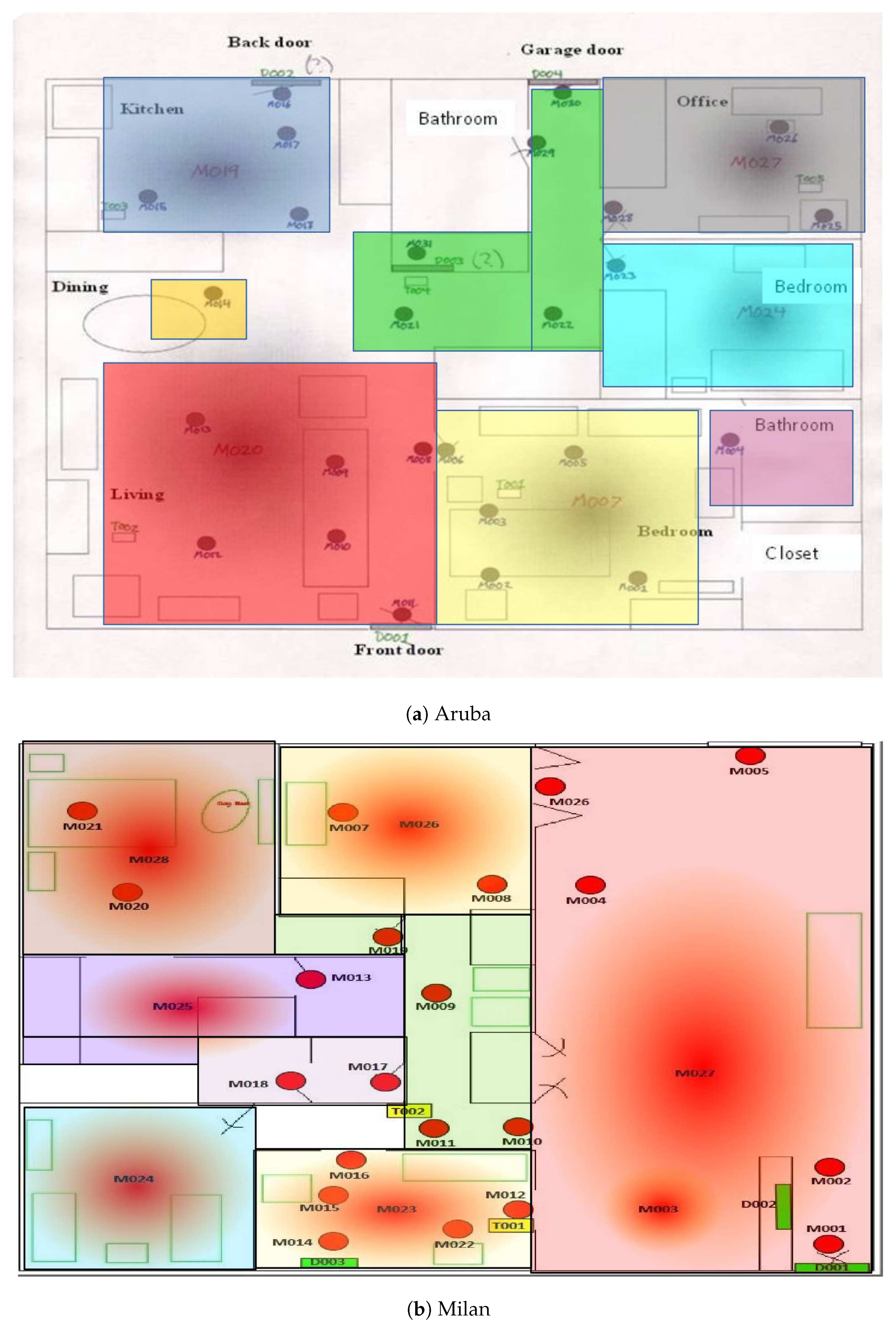
Figure 4 shows the different locations as different colored boxes overlain on the deployment map for apartment 1 and apartment 2. The two apartments are code-named “Milan” [
32] and “Aruba” [
60]. The location labels include: kitchen, dining area, living room, bedroom, guest bedroom, office, hallway, and outside.
Table 1 lists the location identifiers used. The outside of apartment is extracted using opened/closed door sensor events. Our approach of detecting outside of apartment will be explained in
Section 5.2.
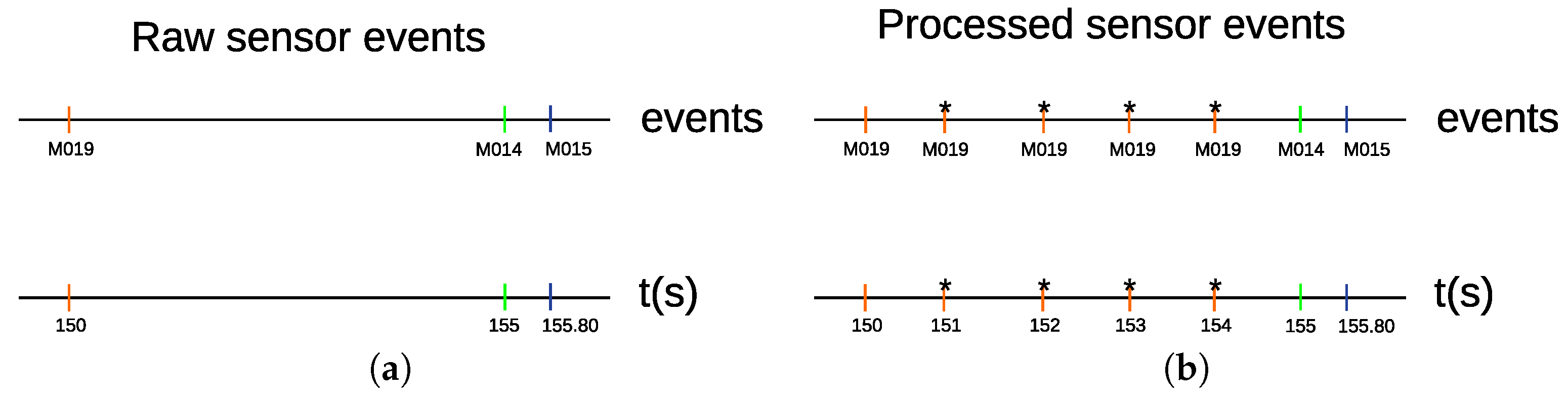
In “Milan” and “Aruba” data sets, the state of the sensor data is not sampled at a constant time interval. A sensor reports an on state, when there is a motion within its detection area. Otherwise, it reports an off state. The sensors were not configured to report their states at constant time intervals. Our method relies on a time-based segmentation approach. In this approach, it is essential for every time interval to have a constant amount of time duration data. In
Figure 5a, there are two sensors, “M019” and “M014”. The “M019” sensor triggers an event at time “150”, and the “M014” sensor triggers an event at time “155”. The “M019” sensor does not report its state at a constant time interval till “M014” triggers an event. Therefore, we need to process the time interval between “M019” and “M014”. In order to do that, we sample the interval between “M019” and “M014” at a constant time of 1 s.
Figure 5b shows the processed time interval between “M019” at time 150 and “M014” at time 155, where four “M019” events are sampled at a time interval of 1 s. The “*” sign indicates that a sensor event is sampled at a time interval of 1 s. The sensor data in “Milan” and “Aruba” data sets are processed to be sampled at a constant time interval of 1 s. Special care has to be taken for edge cases when two sensor events occur at times that are less than 1 s. For such a case, no sampling is performed. For instance, the time interval between “M014” at time 155, and “M015” at 155.80 was not sampled, as shown in
Figure 5b.
Given a sampled event at a constant time interval
where
denotes the timestamp in milliseconds,
denotes the sensor ID,
denotes the location ID, and
denotes the duration in milliseconds between two sensor events, and it is computed as follows:
We define a day instance as a sequence of
r sampled sensor events
.
Figure 6 shows examples of sensor event definitions for several sensor event outputs. The first five sensor events are activated in the kitchen, followed by the activation of the sensor events in the bathroom. It can be noted that these sensor events are sampled at a constant time interval of 1 s.
5. Intermediate-Level Processing
5.1. Feature Extraction
We use a time-based windowing approach to divide the entire sequence of the sampled sensor events into equal size time intervals. It is challenging to choose the ideal length of time interval. An interval that is too small will incorporate noise of the signal, while an interval that is too large will smooth out important details of the signal. Therefore, we use two time interval lengths. The first time interval length is small in order to capture the movement of a human being. We would like the discretization of such movement to correspond closely to the action primitives that are performed. Discretizing with a small interval might pick up any relevant activity information given the small pauses in the movement of a human being around the detection areas of the sensors. On the other hand, discretizing with a large interval length might capture long-term activity, such as relaxation or sleep that contains large pauses in the movement of a human being around the detection areas of the locations.
In the case of activity discovery using motion sensor data, no existing work presents any empirical or theoretical standing to select any time interval length. Some preprocessing steps are often employed in order to convert the raw time series data into a different representation, which makes the discovery of the patterns easier. For motion sensor data, there is no known conversion that provides better results in activity discovery, than using the raw sensor data. We define a time interval as grouping the sensor events into intervals of seconds, minutes, and hours. A longer length of time can be divided into a number of shorter periods of time, all of the same length.
We define two different time intervals lengths and , such that . The time interval length is referred to a sensor time interval length, and this is indicated by the subscript s in the symbol . The time interval length is referred to a location time interval length, and this is indicated by the subscript l in the symbol . The subscripts s and l will be used in our notation to indicate whether a feature vector belongs to a sensor or a location time interval.
Formally, the sequence of the sampled sensor events
is divided using
into windows of equal time intervals
, and the
window is represented by the sequence
. The value of the variable
changes based on the experimental setting. It is obtained through an experiential procedure by examining the impacts of the various outcomes of
on the performance of the classification system. The exact value of
will be discussed in
Section 8.
Once the sensor time interval is defined, the next step is to change this time interval into a feature vector that encapsulates its statistical figures. We execute this step by forming a constant length feature vector , explicitly encapsulating the time durations of the different sensors within the time interval. With N sensors installed in a smart home, the dimension of the vector will be N. A time duration is defined as the amount of time a person spends around the detection area of a sensor or a location. The sum of all time durations serves as a signal of how much motion and information flow are happening (or not happening) around the detection area of a sensor or a location within a time interval.
Let
be the sum of all time durations for a sensor
in
from a time interval
, and it can be computed as follows:
where
. Finally, for each sensor time interval
, we will have a corresponding sensor feature vector
, where the sum of all time duration for each sensor is computed within a time interval
.
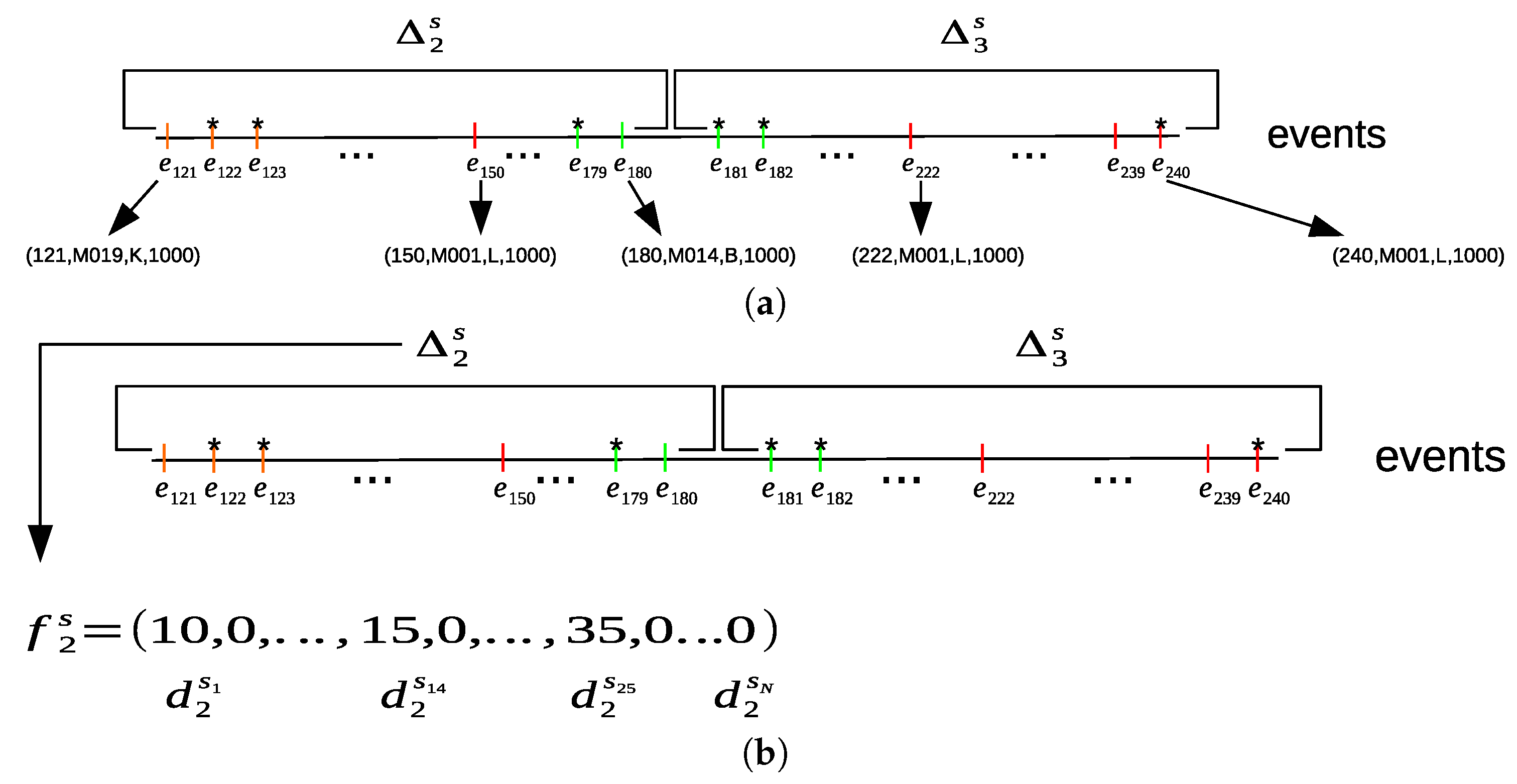
Figure 7a shows an example of dividing the sequence of the sampled sensor events into sensor time intervals. For each sensor time interval, the sum of all time durations of each sensor is computed from the sensor events within its sensor time interval to construct a sensor feature vector
, as shown in
Figure 7b.
Similarly, we use the location time interval length to divide the sequence of the sampled sensor events
into windows of an equal time intervals
, and the
window is represented by the sequence
. The value of the variable
changes based on the experimental setting. It is obtained through an experiential procedure by examining the impacts of the various outcomes of
on the performance of the classification system. The exact value of
will be discussed in
Section 8.
Once the location time interval
is defined, the next step is to change this time interval into a feature vector that encapsulates its statistical figures. We execute this step by forming a constant length feature vector
, explicitly encapsulating the time durations of the different locations within the time interval. With
M locations in a smart home, the dimension of the vector
will be
M. Let
be the sum of all time durations for location
in
from a time interval
, and it can be computed as follows:
where
. Finally, for each location time interval
, we will have a corresponding location feature vector
, where the sum of all time durations for each location is computed within a time interval
.
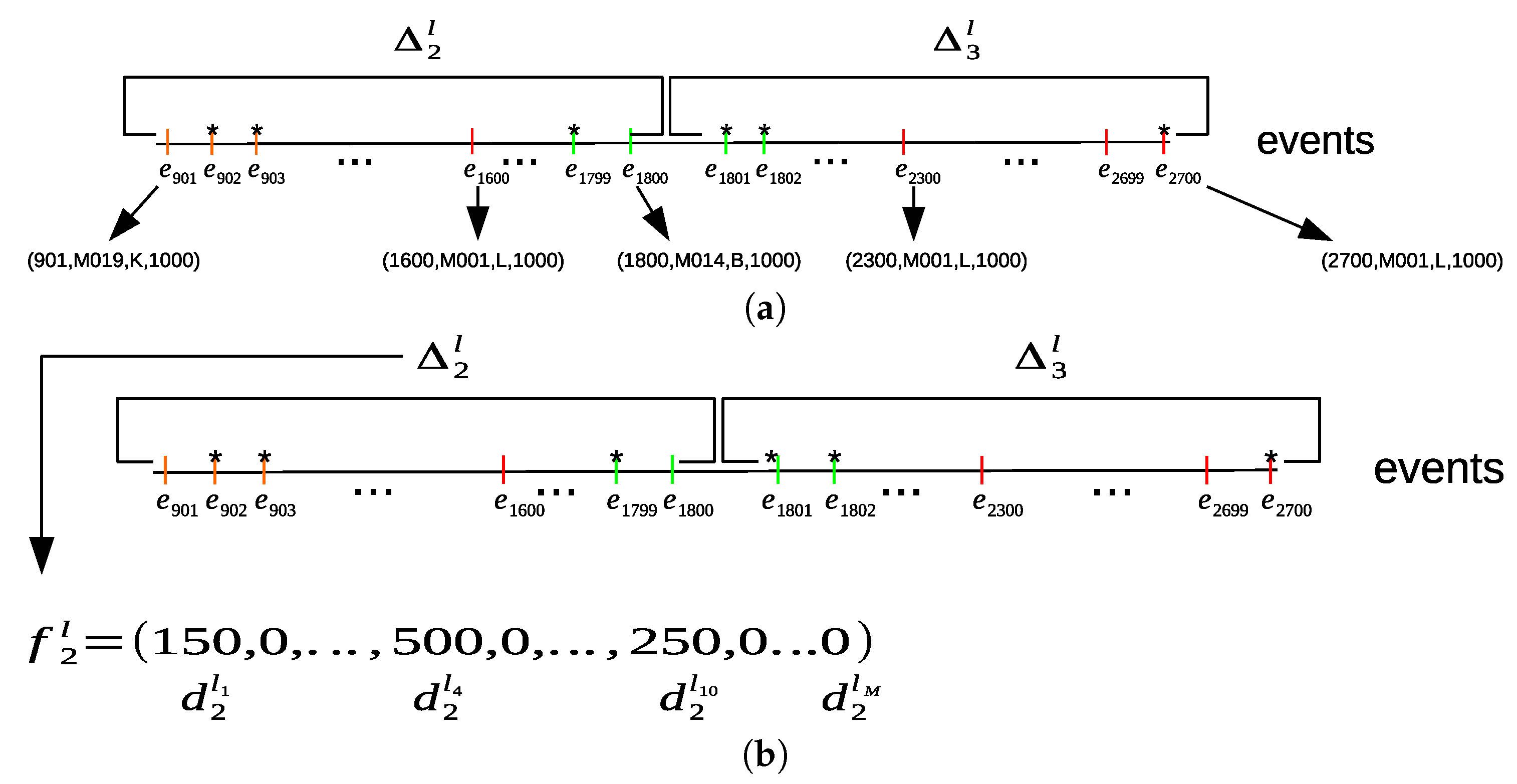
Figure 8a shows an example of dividing the sequence of the sampled sensor events into location time intervals. For each location time interval, the sum of all time durations of each location is computed from the sensor events within its location time interval to construct a location feature vector
, as shown in
Figure 8b.
Our objective in the following sections is to use the sensor feature vectors and the location feature vectors to discover the activity patterns. We introduce three levels of clustering; i.e., intra-day clustering in order to discover patterns within the same day, inter-day clustering in order to discover more general frequent patterns between days, and finally, aggregate hierarchical clustering is used to provide a more compact and precise representation of the discovered activity patterns. In the following section, we extend the definition of the sensor feature vector and the location feature vector by adding two additional feature values that represent whether an entrance to the home or exit from the home occurred.
5.2. Outside Apartment Feature Representation
In order to avoid sensor events that are far apart in time, we resorted to sampling the sensor events at a constant time interval of 1 s. As a result of the sampling, labels were assigned to all locations in the smart homes. The exit doors are located in different places in the home. There could be exit doors in the hallway, or in the kitchen, as shown in
Figure 8. Therefore, a location label is assigned to the door when it is opened or closed according to its place in the smart home.
It is important to distinguish between two activities: LEAVE_HOME and ENTER_HOME. Using the door sensor events to detect the times when a user leaves or enters a home did not yield accurate results. The door sensors may not report their state correctly and accurately when the door is opened or closed. During the closing and opening of the door multiple times, many motion sensor events could be triggered and mixed with the door sensor events in the same window, and this makes it difficult to distinguish between the two activities using a specific order of the triggered sensors in the window. Additionally, the start and the end label markers sometimes are not set correctly to the sensor event of interest (e.g., door sensor events).
We need to extend our feature vector definition to indicate when a user leaves and enters a home.
Figure 9a shows an example of the door sensor events before sampling the events. There is a gap of one and a half hours without any sensor events being reported.
Figure 9b shows an example of the door sensor events after sampling the events. The sensor events are reported periodically at a constant time interval of 1 s.
We extend the sensor feature vector by defining two additional feature values. The dimension of the vector will be . Let be the feature value, and it will be the feature value that represents the ENTER_HOME activity. Let be the feature value, and it will be the feature value that represents the LEAVE_HOME activity. The default values of and are 0. This means the user did not perform any ENTER_HOME or LEAVE_HOME activities during a time interval . Similarly, we extend the location feature vector by defining two additional feature values. The dimension of the vector will be . Let be the feature value, and it will be the feature value that represents the ENTER_HOME activity. Let be the feature value, and it will be the feature value that represents the LEAVE_HOME activity. The default values of and are 0. This means the user did not perform any ENTER_HOME or LEAVE_HOME activities during a time interval .
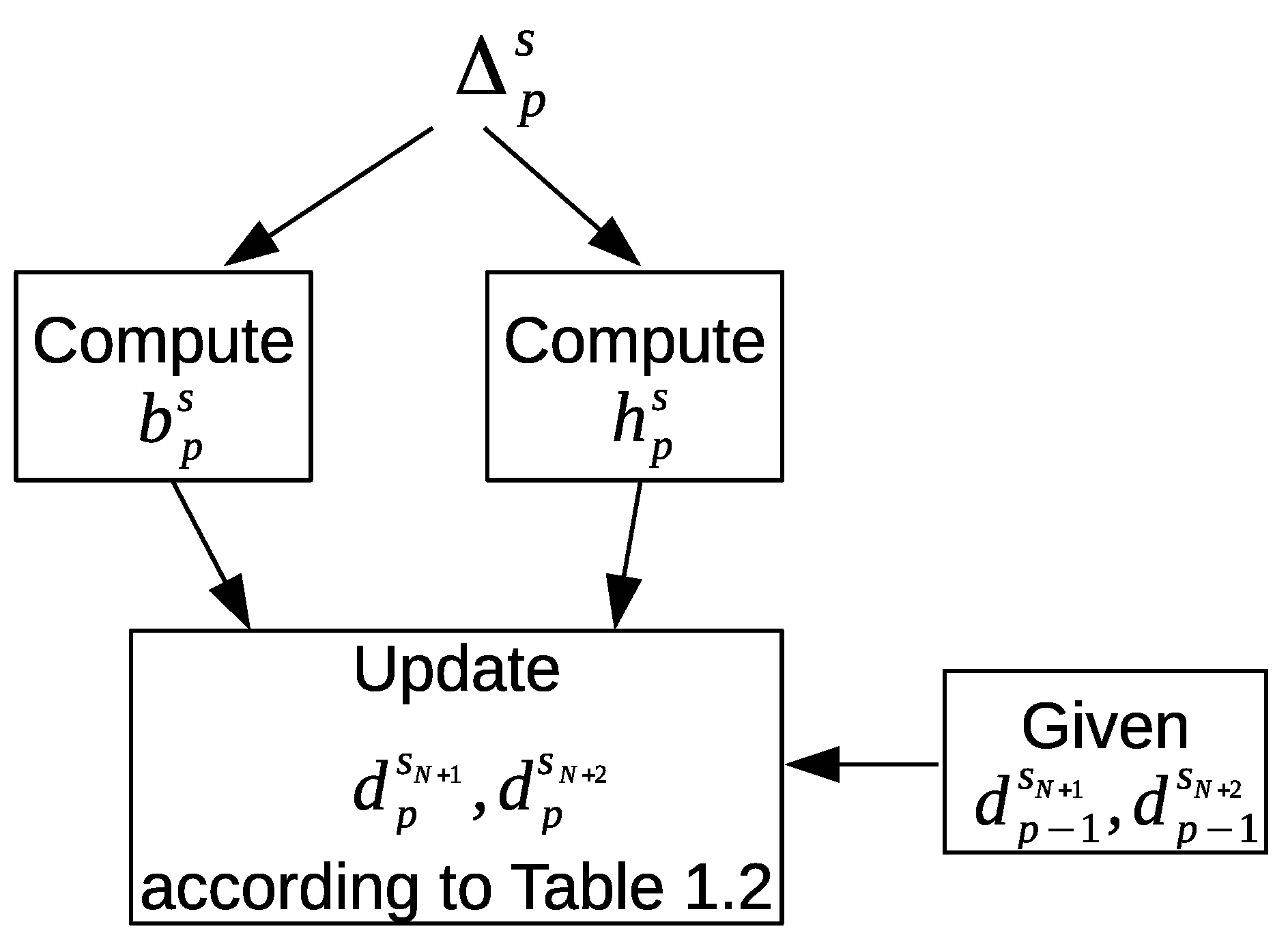
Figure 10 shows our proposed approach to update the newly introduced feature values that will represent the LEAVE_HOME and ENTER_HOME activities. First, the frequency of the motion sensor event counts
is computed for a time interval
as follows:
where
. Similarly, the frequency of the door sensor event counts
for a time interval
is computed as follows:
where
. Next, the values of
and
are updated according to the defined conditions in
Table 2 to indicate whether a sensor feature vector
represents the ENTER_HOME or LEAVE_HOME activities. Each condition in
Table 2 depends on the following information:
The values of and from the previous time interval .
The frequency of the motion sensor events , and the frequency of the door sensor events from the current time interval .
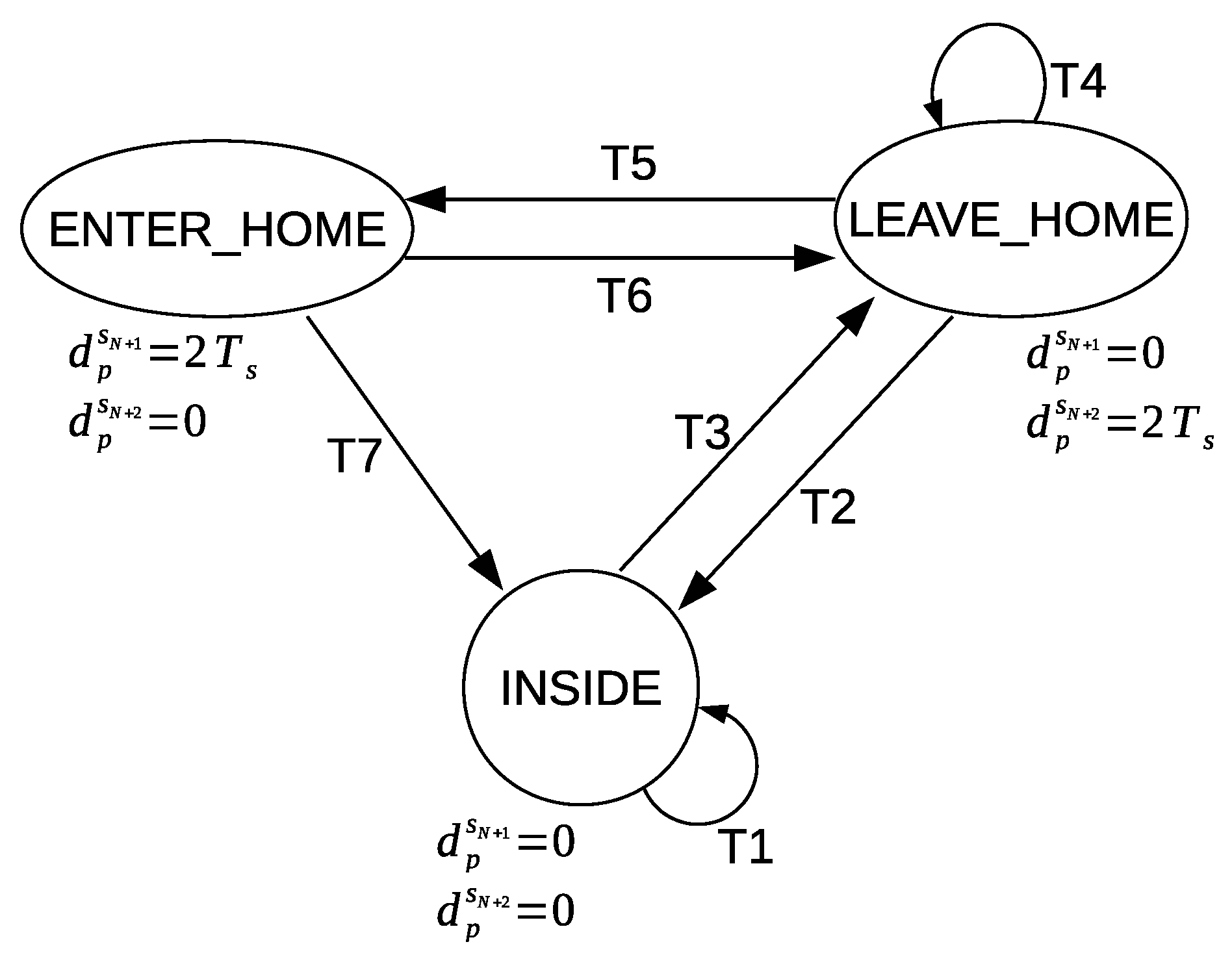
The transitions in the graphical representation of
Figure 11 are based on the defined conditions in
Table 2. The nodes represent the ENTER_HOME and LEAVE_HOME activities. The third node represents the times of no detection of the ENTER_HOME and LEAVE_HOME activities; we will refer to this node as NO_LEAVE_NO_ENTER (inside home). The values given to
and
are shown below each node. The default values of
and
are always zero unless one of the defined conditions is met; then they are updated accordingly to the given values in order to represent a corresponding ENTER_HOME activity or LEAVE_HOME activity for a sensor feature vector
.
When a sensor feature vector contains zero values for and , that means this feature vector represents a different activity than ENTER_HOME or LEAVE_HOME. A value of is assigned to , and a value of zero is assigned to in order to represent ENTER_HOME activity. On the other hand, a value of zero is assigned to , and a value of is assigned to in order to represent LEAVE_HOME activity.
A location feature vector will represent the ENTER_HOME activity or LEAVE_HOME activity by following the same approach to compute the values of and as in the sensor feature vector case.
9. Conclusions
In this paper, we proposed a framework for activity recognition from the motion sensor data in smart homes. We used a time-based windowing approach to compute features at different granularity levels. Then, we introduced an unsupervised method for discovering activities from a network of motion detectors in a smart home setting without the need for labeled training data. First, we presented an intra-day clustering algorithm to find frequent sequential patterns within a day. As a second step, we presented an inter-day clustering algorithm to find the common frequent patterns between days. Furthermore, we refined the patterns to have a more compressed and defined cluster characterizations. Finally, the clusters were given semantic labels in order to track the occurrences of the future activities.
We discussed two approaches for recognizing activities using the final set of the clusters, where they are used to recognize the occurrences of the future activities from a window of sensor events. The first approach used a model to classify the labels, while the second approach used to measure the similarity between the clusters centroids, and the test time interval to determine the cluster with the best similarity value, where the semantic label of that cluster is assigned.
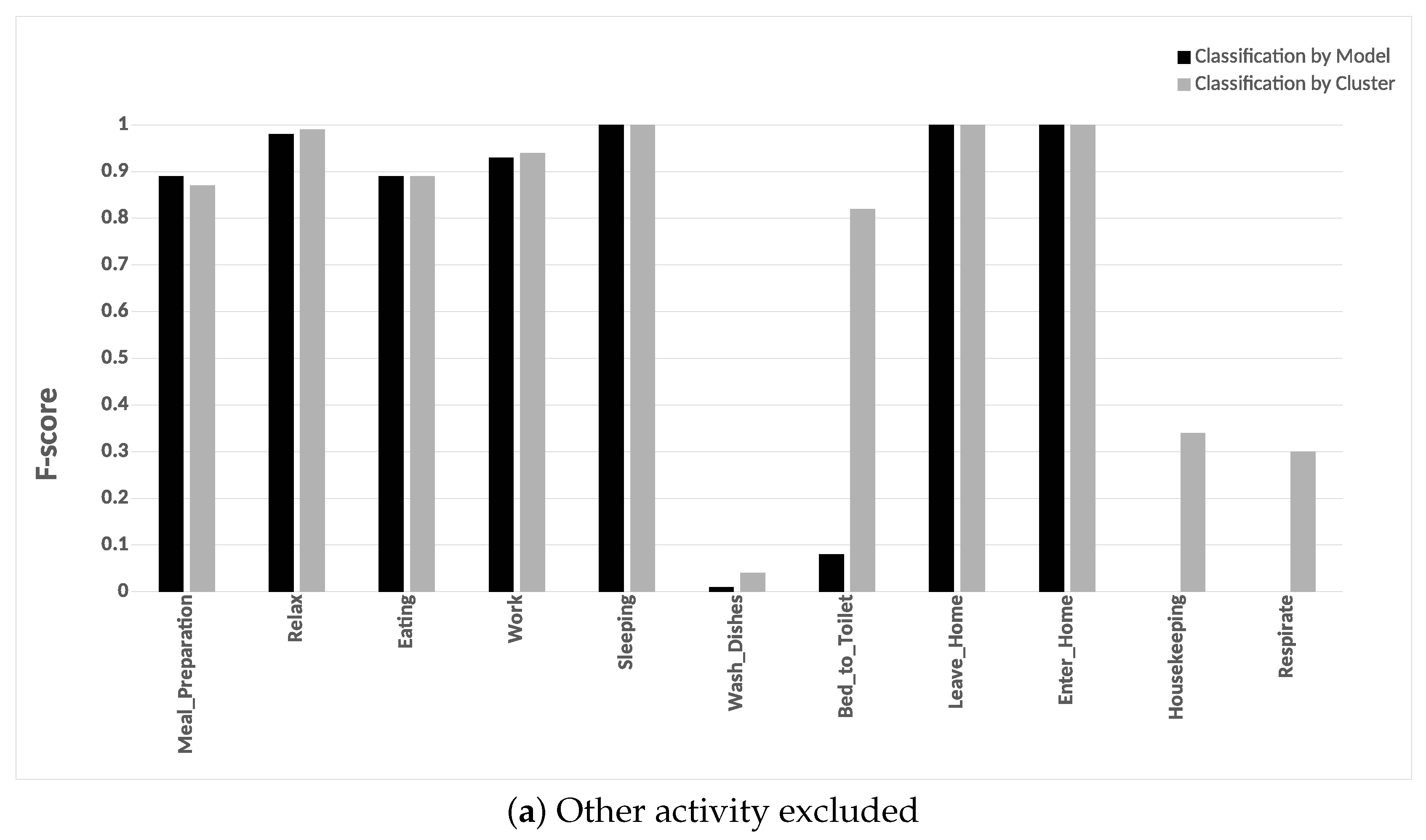
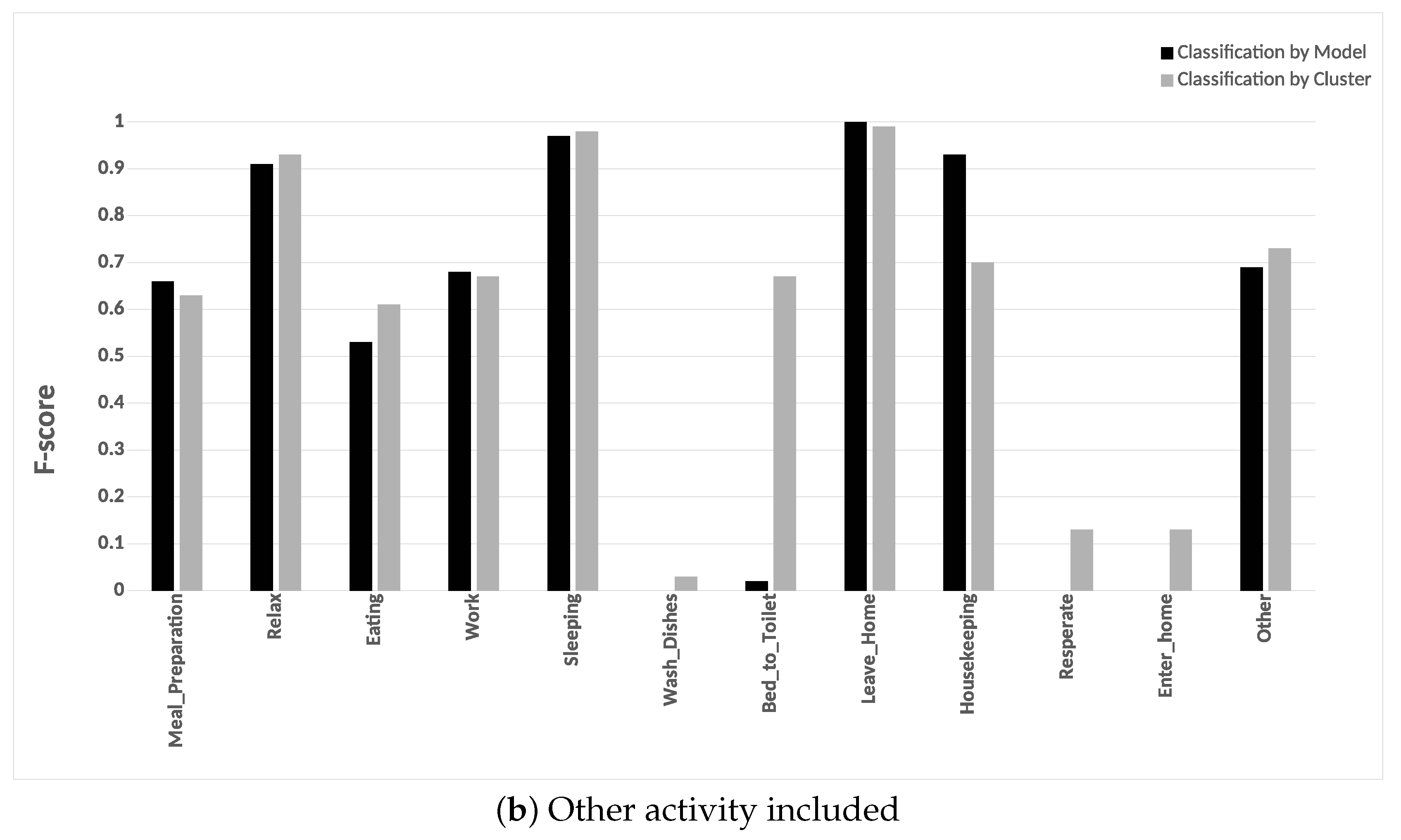
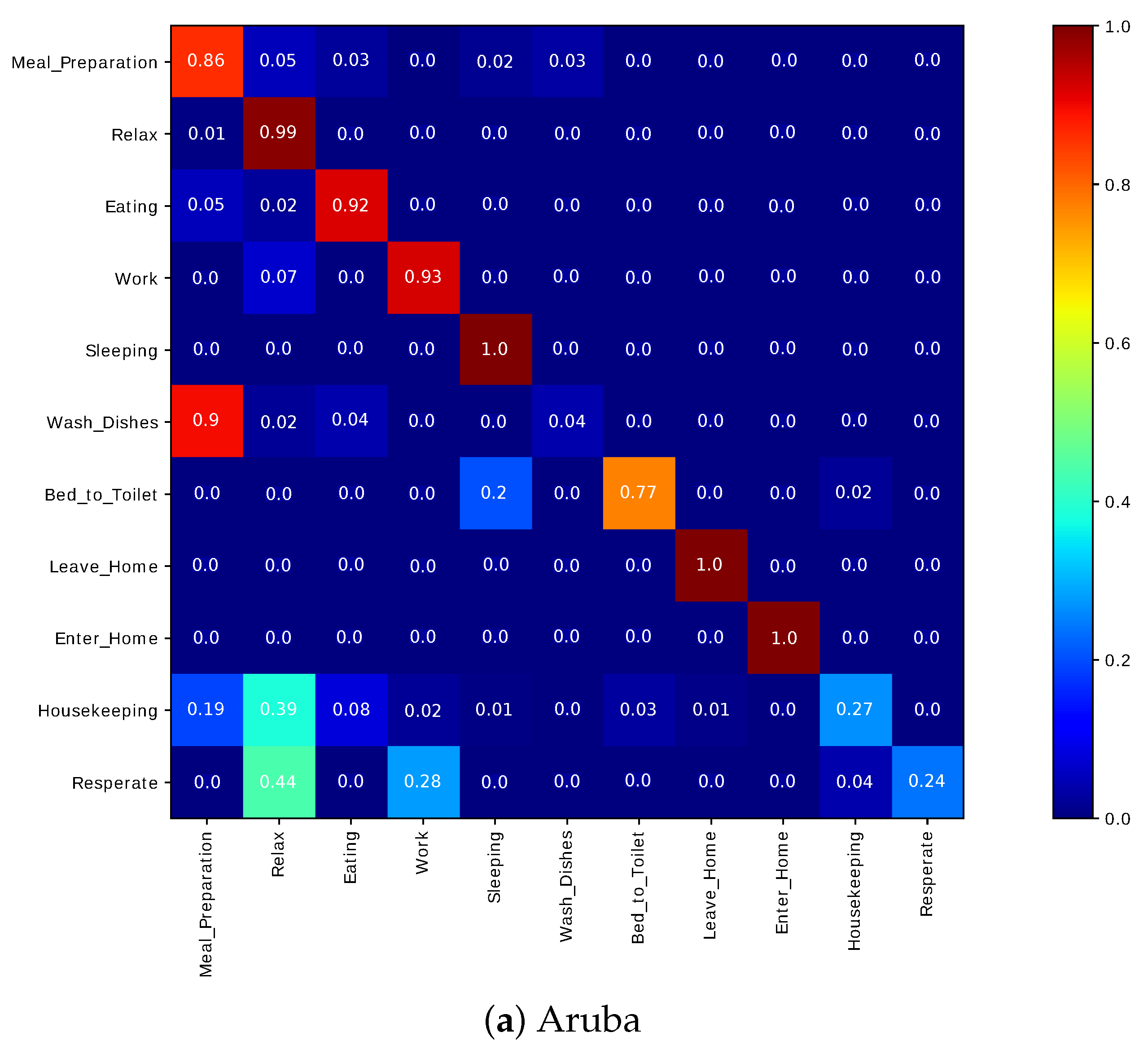
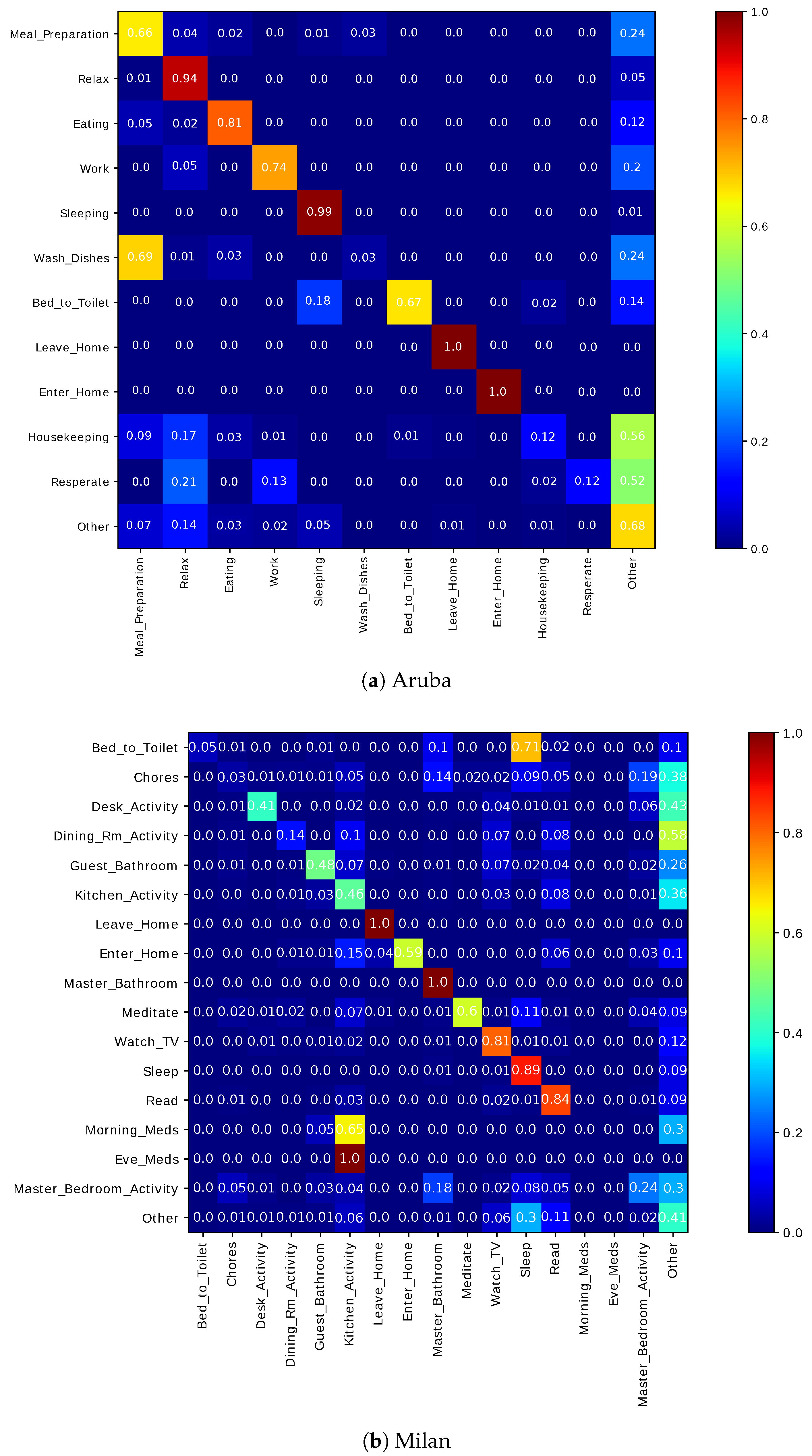
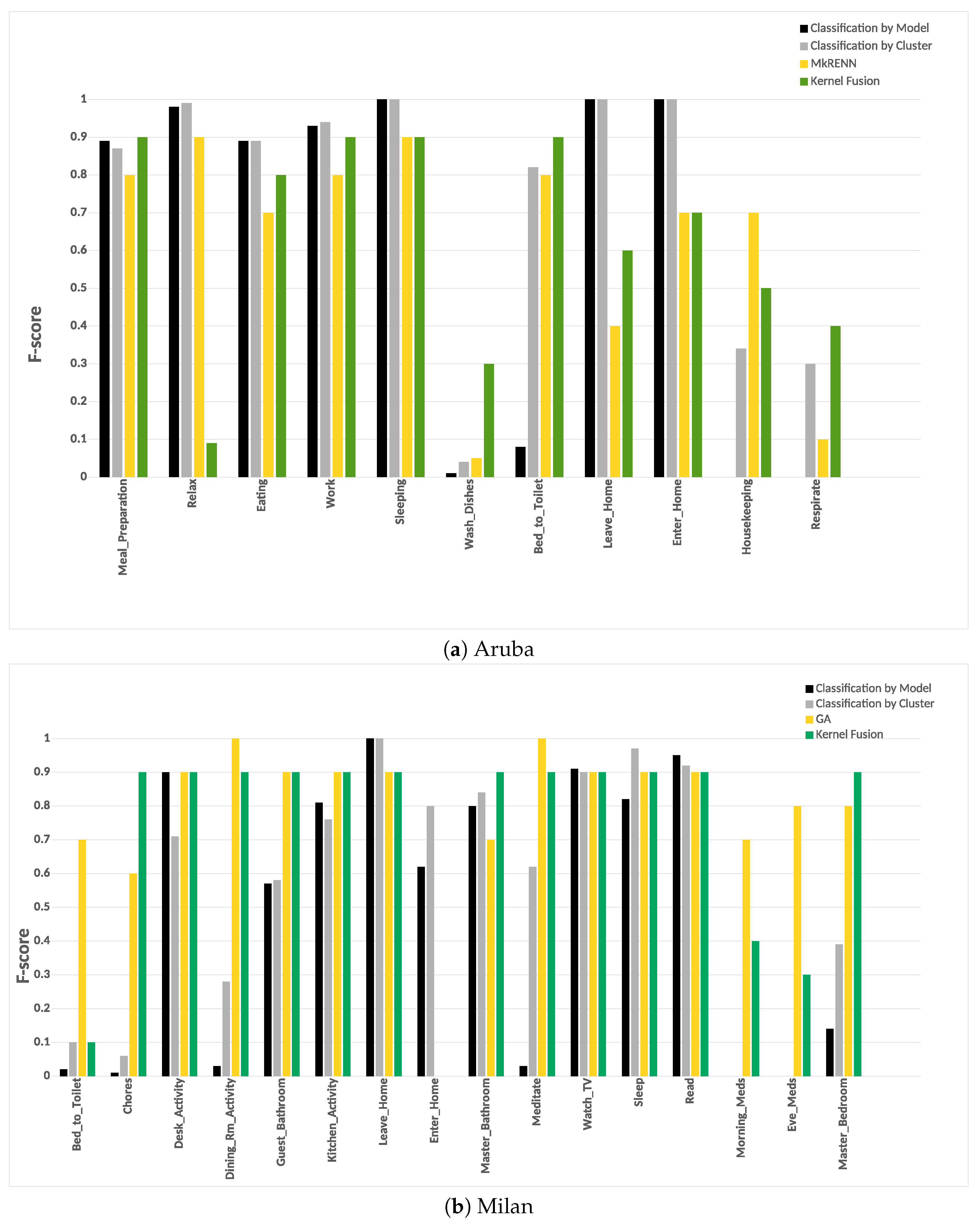
Our framework was evaluated on two public data sets captured in real-life settings from two apartments during a seven-month and a three-month periods. Experiments on the two real-world data sets revealed that the classification by cluster achieved a higher F-score and accuracy. Our experiments included evaluating the two classification approaches with and without “other activity” class. Finally, our approach achieved a higher F-score than the other approaches.
When the “other activity” class is included, there was a drop in the F-score of the individual activities of our approach, this drop was due to identifying the “other activity” class as known activities. This shows the ability of our framework to discover patterns in the “other activity” class similar to the predefined activities. One of our future goal work is to evaluate the robustness of the proposed framework on data being captured from various smart homes with more than one resident.
































{kind=link}
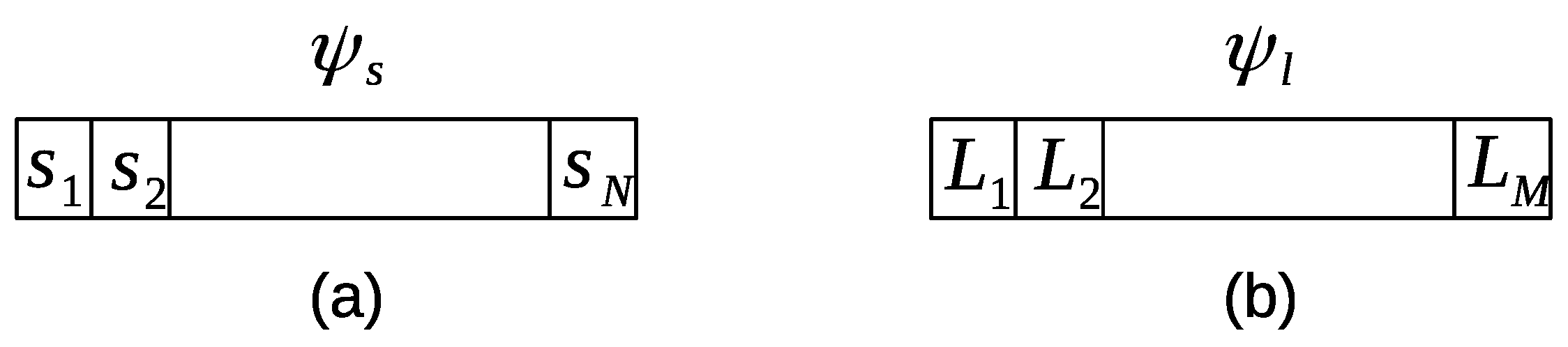{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}