Ship Target Automatic Detection Based on Hypercomplex Flourier Transform Saliency Model in High Spatial Resolution Remote-Sensing Images

Abstract
:1. Introduction
2. Materials and Methods
2.1. MHFT Saliency Model
2.1.1. Color Space Selection
2.1.2. Hypercomplex Fourier Transform Model
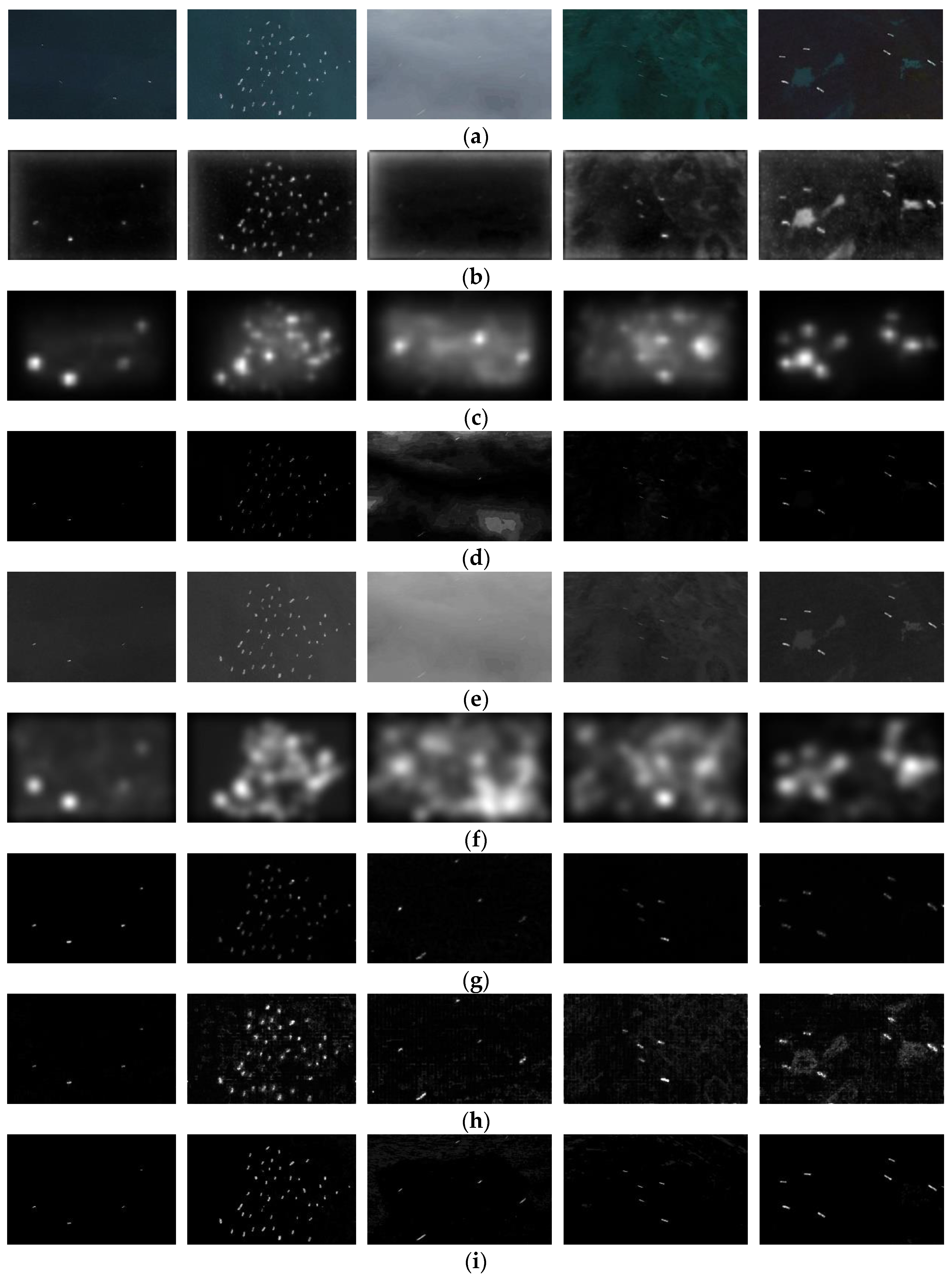
2.1.3. Experimental Results
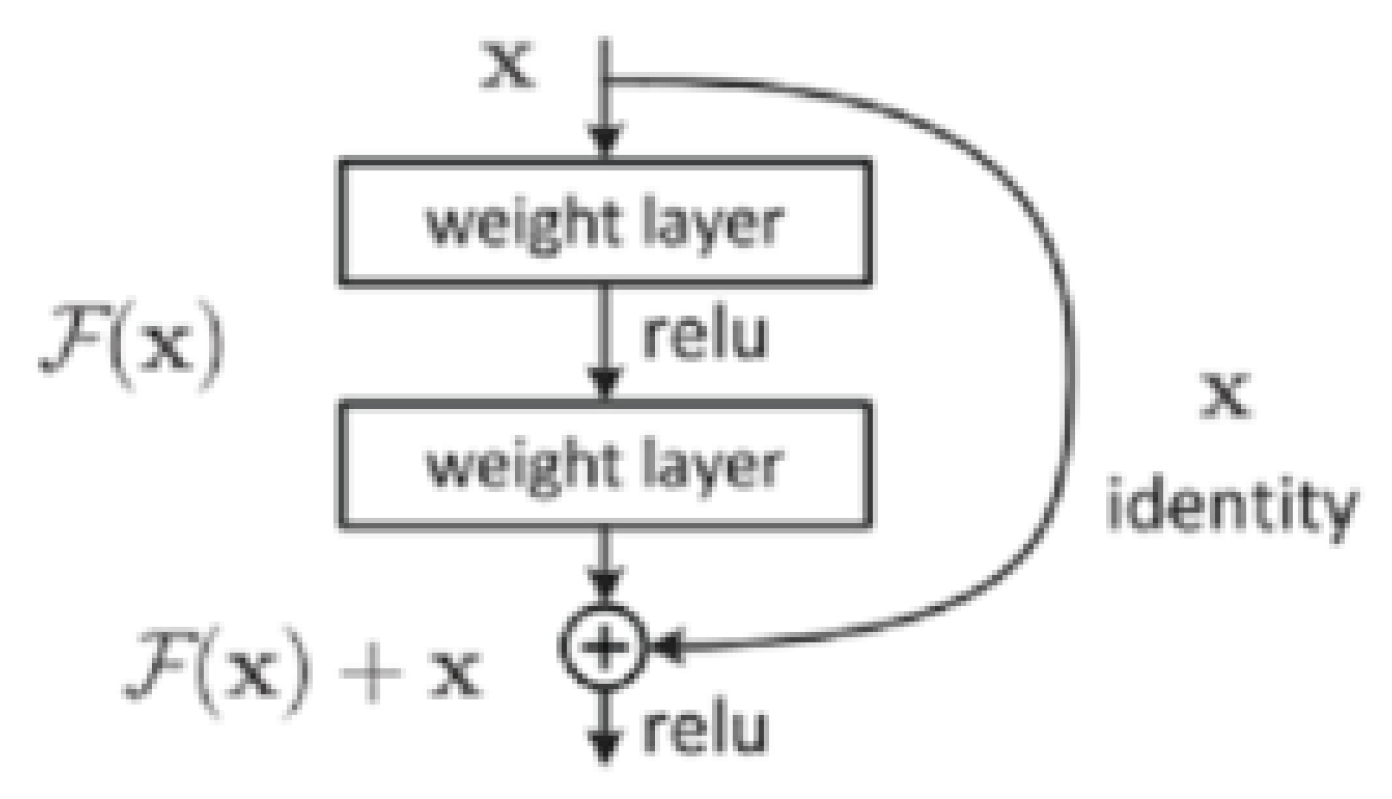
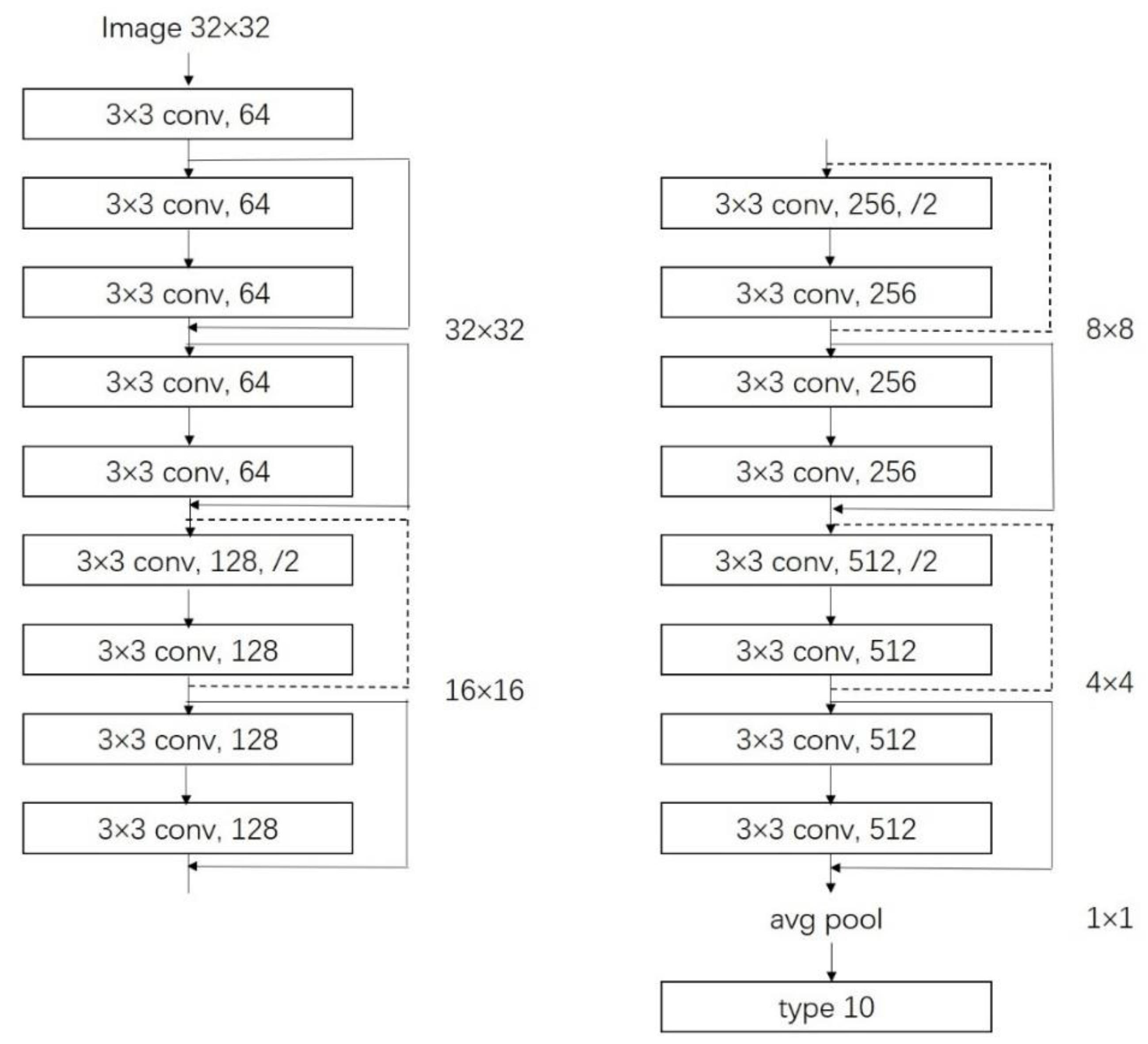
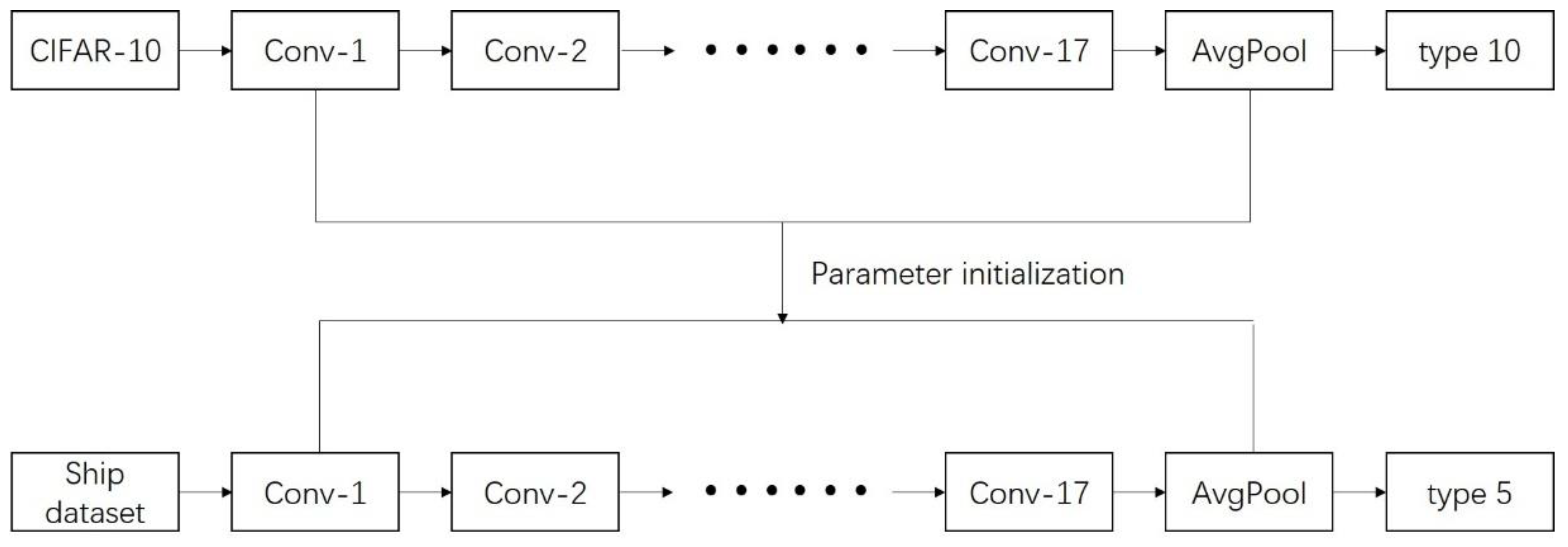
2.2. Recognition of Ship Types
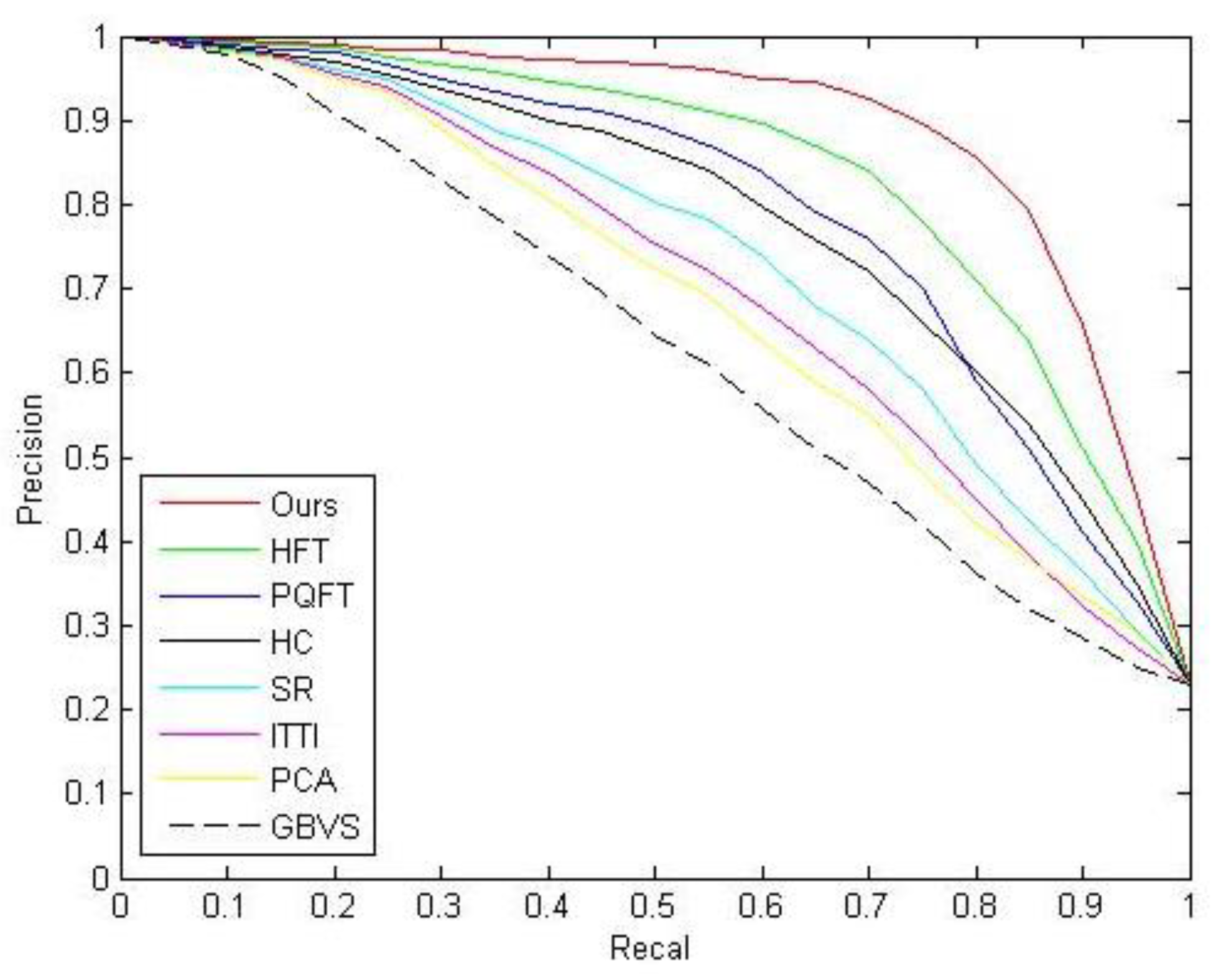
3. Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, J.; Liu, Z. Compressive sampling based on frequency saliency for remote sensing imaging. Sci. Rep. 2017. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, W.X.; Jiang, J.H.; Bao, S.L.; Tan, D.L. CISPNet: Automatic Detection of Remote Sensing Images from Google Earth in Complex Scenes Based on Context Information Scene Perception. Appl. Sci. 2019, 9, 4836. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Q.P.; Yao, L.X.; He, H.Y.; Yang, J. Target extraction method based on region of interest. Infrared Laser Eng. 2006, 20, 0240. [Google Scholar]
- Fu, K.; Li, Y.; Sun, H.; Yang, X.; Xu, G.; Li, Y.; Sun, X. A Ship Rotation Detection Model in Remote Sensing Images Based on Feature Fusion Pyramid Network and Deep Reinforcement Learning. Remote Sens. 2018, 10, 1922. [Google Scholar] [CrossRef] [Green Version]
- Bedini, L.; Righi, M.; Salerno, E. Size and Heading of SAR-Detected Ships through the Inertia Tensor. Proceedings 2018, 2, 97. [Google Scholar] [CrossRef] [Green Version]
- Guo, W.Y.; Xia, X.Z.; Wang, X.F. A remote sensing ship recognition method based on dynamic probability generative model. Expert Syst. Appl. 2014, 41, 6446–6458. [Google Scholar] [CrossRef]
- Corbane, C.; Naiman, L.; Pecoul, E. A complete processing chain for ship detection using optical satellite imagery. Int. J. Remote. Sens. 2010, 31, 5837–5854. [Google Scholar] [CrossRef]
- Yang, G.; Li, B.; Ji, S.F. Ship detection from optical satellite images based on sea surface analysis. IEEE Geosci. Remote Sens. Lett. 2014, 11, 641–645. [Google Scholar] [CrossRef]
- Li, S.; Wei, Z.H.; Zhang, C.B.; Hong, W. Target recognition using the transfer learning-based deep convolutional neural networks for SAR images. J. Univ. Chin. Acad. Sci. 2018, 35, 75–83. [Google Scholar]
- Tang, J.X.; Deng, C.W.; Huang, G.B. Compressed-domain ship detection on spaceborne optical image using deep neural network and extreme learning machine. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1174–1185. [Google Scholar] [CrossRef]
- Wang, F.C.; Zhang, M.; Gong, L.M. Fast detection algorithmfor ships under the background of ocean. Laser Infrared. 2016, 46, 602–606. [Google Scholar]
- Zhang, X.D.; He, S.H.; Yang, S.Q. Ship targets detection method based on multi-scale fractal feature. Laser Infrared. 2009, 39, 315–318. [Google Scholar]
- Yu, Y.; Yang, J. Visual Saliency Using Binary Spectrum of Walsh–Hadamard Transform and Its Applications to Ship Detection in Multispectral Imagery. Neural Process. Lett. 2017, 45, 759–776. [Google Scholar] [CrossRef]
- Sun, Y.J.; Lei, W.H.; Hu, Y.H.; Zhao, N.X.; Ren, X.D. Rapid ship detection in remote sensing images based on visual saliency model. Laser Technol. 2018, 42, 379–384. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef] [Green Version]
- Saliency based on information maximization. Available online: https://papers.nips.cc/paper/2830-saliency-based-on-information-maximization.pdf (accessed on 29 April 2020).
- Harel, J.; Koch, C.; Perona, P. Graph-based visual saliency. Adv. Neural Inf. Process. Syst. 2007, 19, 545. [Google Scholar]
- Stas, G.; Lihi, Z.M.; Ayellet, T. Context-a-ware saliency detection. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1915–1926. [Google Scholar]
- Achanta, R.; Hemami, S.; Estrada, F. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 22–24 June 2009. [Google Scholar]
- Cheng, M.M.; Zhang, G.X.; Mitra, N.J. Global contrast based salient region detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 569–582. [Google Scholar] [CrossRef] [Green Version]
- Hou, X.D.; Zhang, L. Saliency detection: A spectral residual approach. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 18–23. [Google Scholar]
- Guo, C.L.; Ma, Q.; Zhang, L.M. Spatio-temporal saliency detection using phase spectrum of quaternion Fourier transform. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 24–26. [Google Scholar]
- Du, H.; Zhang, T.; Zhang, Y. Saliency detection based on frequency domain combined with spatial domain. Chin. J. Liq. Cryst. Disp. 2016, 31, 913–920. [Google Scholar] [CrossRef]
- Li, J.; Levine, M.D.; An, X.J. Visual saliency based on scale-space analysis in the frequency domain. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 996–1010. [Google Scholar] [CrossRef] [Green Version]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Luo, H.Y.; Han, G.L.; Liu, P.X.; Wu, Y.F. Salient Region Detection Using Diffusion Process with Nonlocal Connections. Appl. Sci. 2018, 8, 2526. [Google Scholar] [CrossRef] [Green Version]
- Pang, X.M.; Min, Z.J.; Kan, J.M. Color image segmentation based on HSI and LAB color space. J. Guangxi Univ. (Nat. Sci. Ed.) 2011, 36, 976–980. [Google Scholar]
- Zhuo, Y.; Kamata, S. Hypercomplex polar Fourier analysis for color image. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 2117–2120. [Google Scholar]
- Ezequiel, L.R.; Jose, M.P. Probability density function estimation with the frequency polygon transform. Inf. Sci. 2015, 298, 136–158. [Google Scholar]
- Kazemi, F.M.; Samadi, S.; Poorreza, H.R. Vehicle recognition using curvelet transform and SVM. In Proceedings of the Fourth International Conference on Information Technology: New Generations, Las Vegas, NV, USA, 2–4 April 2007; pp. 516–521. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Krizhevsky, A. Learning multiple layers of features from tiny images. In Technical Report TR-2009; University of Toronto: Toronto, Japan, 2009. [Google Scholar]
- Carvalho, E.F.; Engel, P.M. Convolutional Sparse Feature Descriptor for Object Recognition in CIFAR-10. In Proceedings of the 2013 Brazilian Conference on Intelligent Systems, Fortaleza, Brazil, 19–24 October 2013. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Li, W.S.; Chen, X. An object recognition method combining saliency detection and bag of words model. Comput. Eng. Sci. 2017, 39, 1706–1713. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Precision | Recall | F-measure | Acc |
|---|---|---|---|---|
| ITTI | 80.72% | 42.17% | 55.40% | 54.17% |
| GBVS | 74.14% | 38.45% | 50.64% | 50.36% |
| SR | 83.25% | 43.59% | 57.56% | 59.38% |
| HC | 80.46% | 59.14% | 68.17% | 71.42% |
| PCA | 77.42% | 44.15% | 56.23% | 52.47% |
| PQFT | 84.12% | 55.34% | 66.76% | 68.17% |
| HFT | 85.58% | 68.49% | 76.09% | 73.45% |
| Ours | 91.42% | 72.47% | 80.85% | 82.36% |
| Sample Data | Learning Rate | Decay | Steps | Momentum | Batch Size |
|---|---|---|---|---|---|
| CIFAR-10 | 0.001 | 0.0001 | 120,000 | 0.9 | 128 |
| Ship dataset | 0.0001 | 0.0001 | 52,000 | 0.9 | 128 |
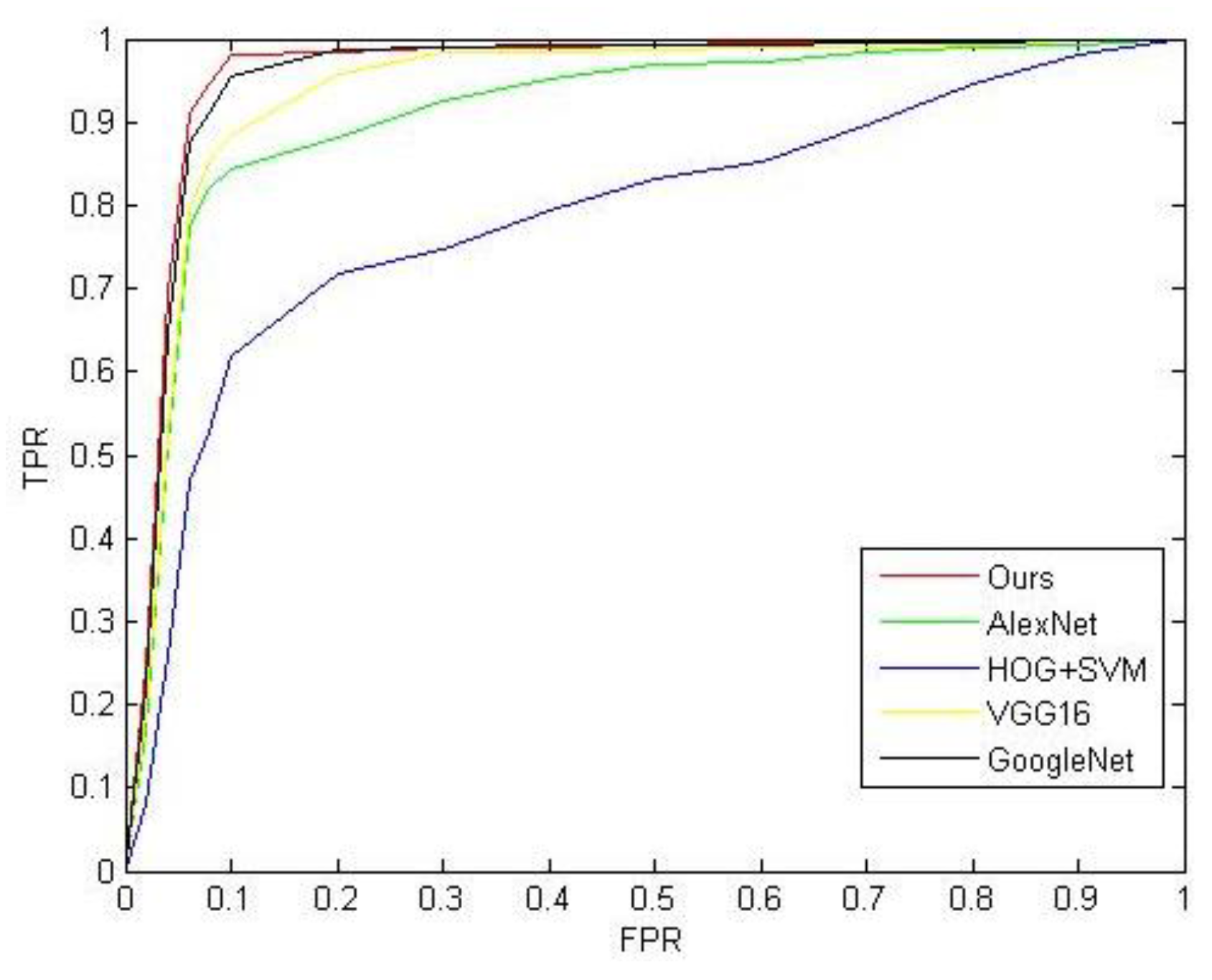
| Method | TPR | FPR |
|---|---|---|
| HOG + SVM | 89.86% | 70.60% |
| AlexNet | 91.81% | 25.40% |
| VGG16 | 95.77% | 19.60% |
| GoogleNet | 97.75% | 14.20% |
| Our model | 98.45% | 11.40% |
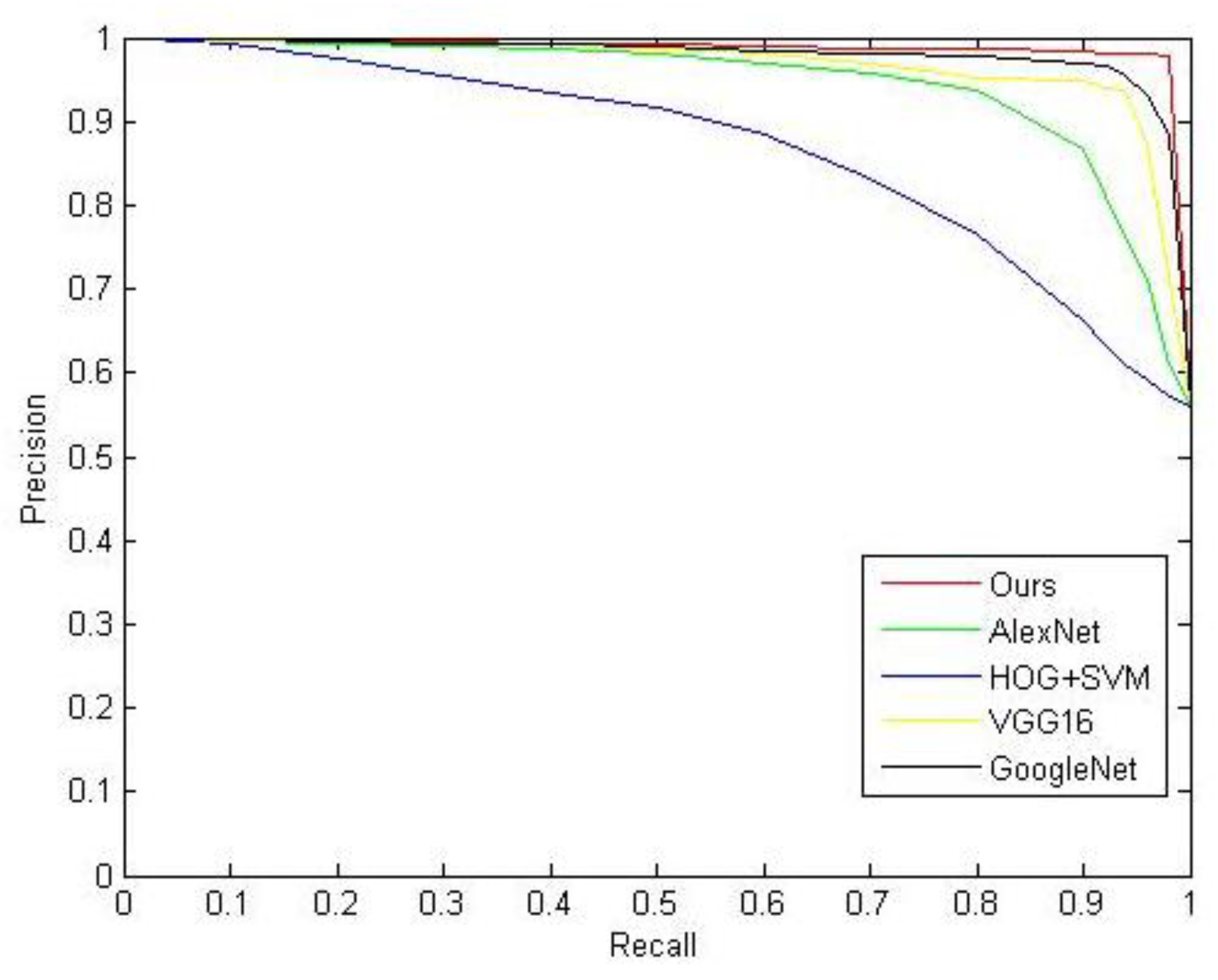
| Method | Precision | Recall | F-Measure |
|---|---|---|---|
| HOG + SVM | 64.38% | 89.86% | 75.02% |
| AlexNet | 83.70% | 91.81% | 87.57% |
| VGG16 | 87.40% | 95.77% | 91.39% |
| GoogleNet | 90.72% | 97.75% | 94.10% |
| Our model | 92.46% | 98.45% | 95.36% |
| Method | Saliency Detection(s) | Recognition Model(s) |
|---|---|---|
| Literature [35] | 0.253 | 0.835 |
| Proposed method | 0.237 | 0.047 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Guo, Y.; Yuan, H. Ship Target Automatic Detection Based on Hypercomplex Flourier Transform Saliency Model in High Spatial Resolution Remote-Sensing Images. Sensors 2020, 20, 2536. https://doi.org/10.3390/s20092536
He J, Guo Y, Yuan H. Ship Target Automatic Detection Based on Hypercomplex Flourier Transform Saliency Model in High Spatial Resolution Remote-Sensing Images. Sensors. 2020; 20(9):2536. https://doi.org/10.3390/s20092536
Chicago/Turabian StyleHe, Jian, Yongfei Guo, and Hangfei Yuan. 2020. "Ship Target Automatic Detection Based on Hypercomplex Flourier Transform Saliency Model in High Spatial Resolution Remote-Sensing Images" Sensors 20, no. 9: 2536. https://doi.org/10.3390/s20092536
APA StyleHe, J., Guo, Y., & Yuan, H. (2020). Ship Target Automatic Detection Based on Hypercomplex Flourier Transform Saliency Model in High Spatial Resolution Remote-Sensing Images. Sensors, 20(9), 2536. https://doi.org/10.3390/s20092536