Multiple Electric Energy Consumption Forecasting Using a Cluster-Based Strategy for Transfer Learning in Smart Building

 ,
, 
 ,
,  and
and 
Abstract
:1. Introduction
2. Related Works
2.1. Electric Energy Consumption Prediction
2.2. Time Series Prediction
3. Basic Concepts
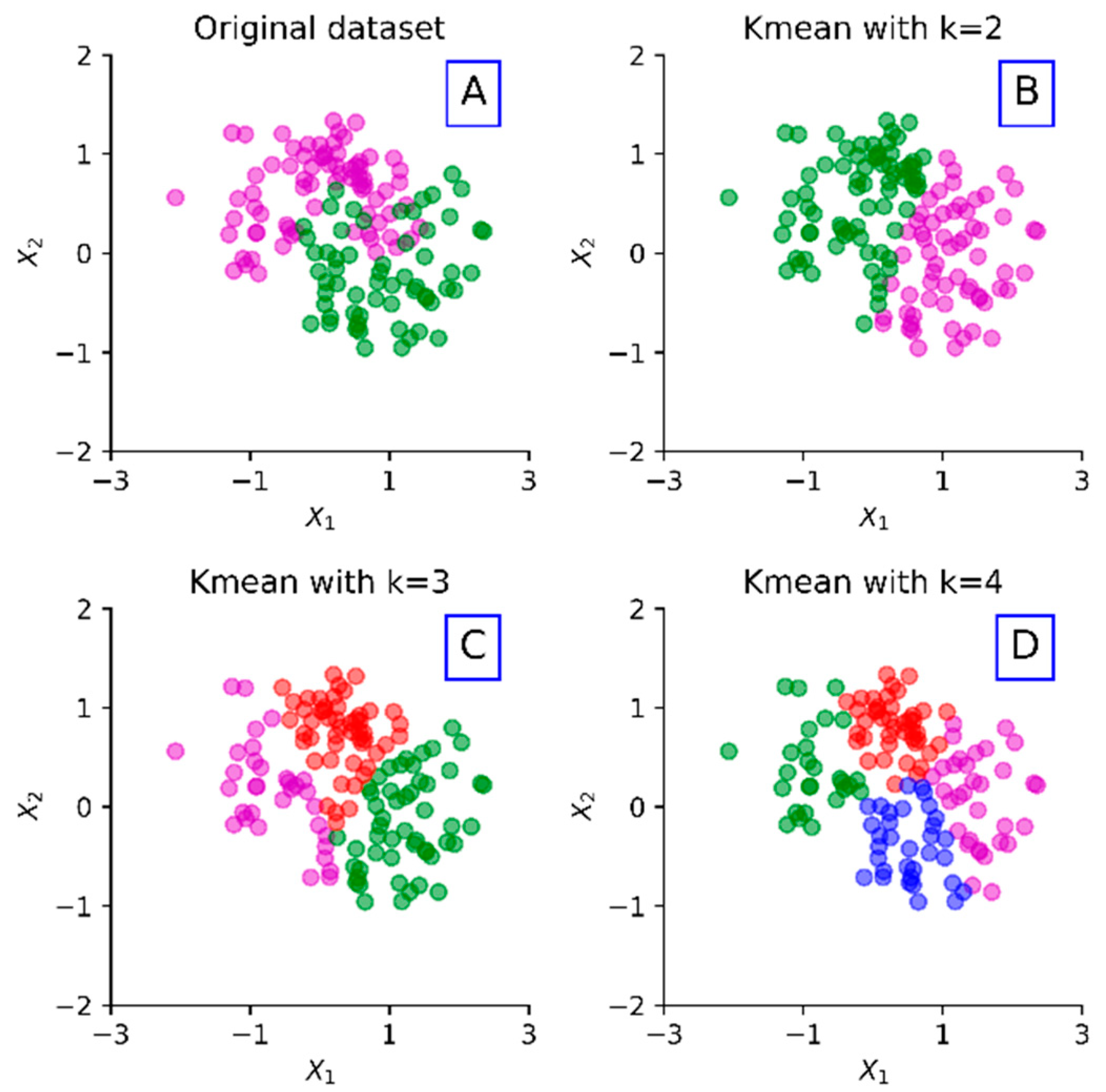
3.1. k-Means Clustering Algorithm
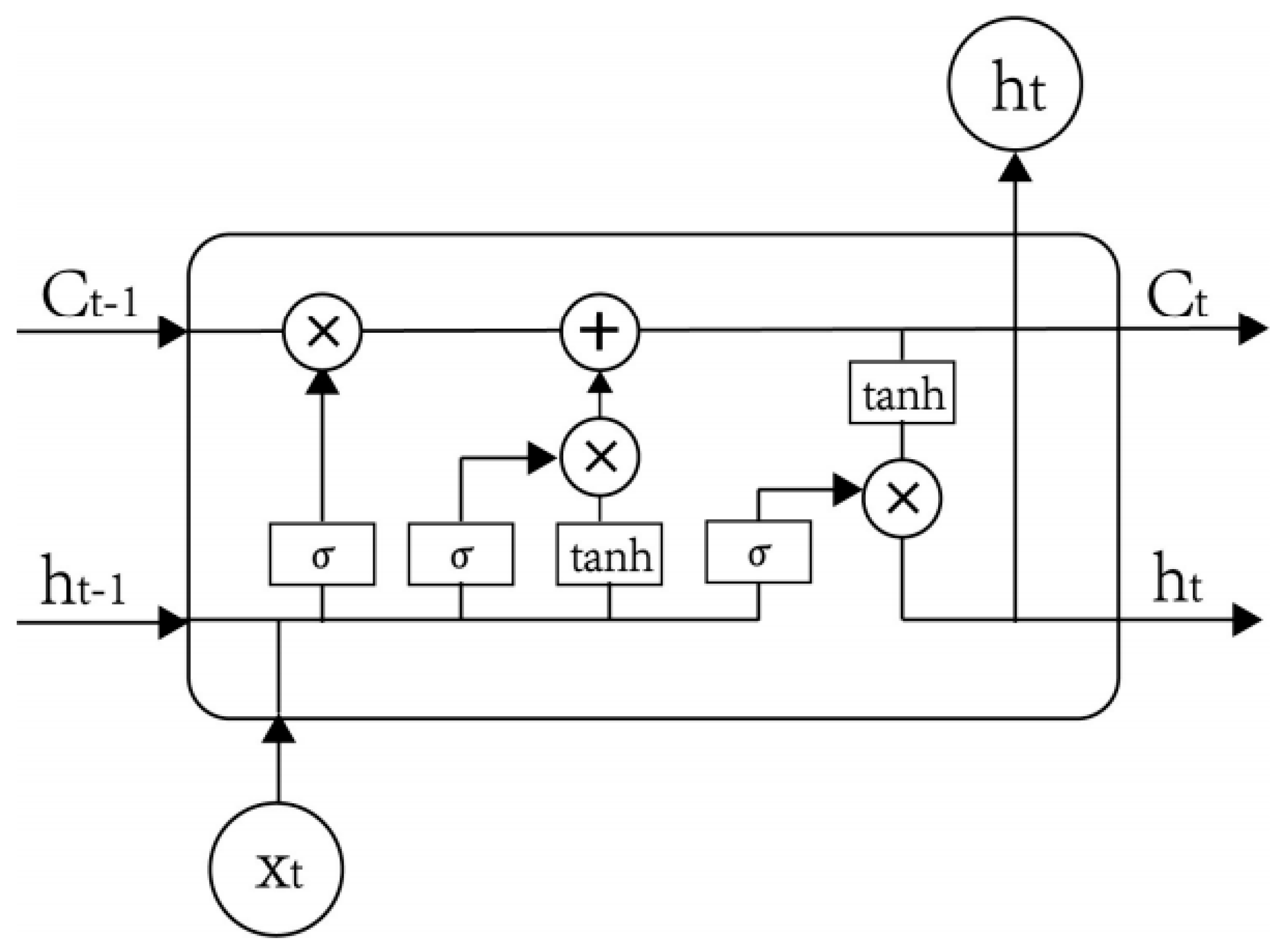
3.2. Long Short-Term Memory Networks
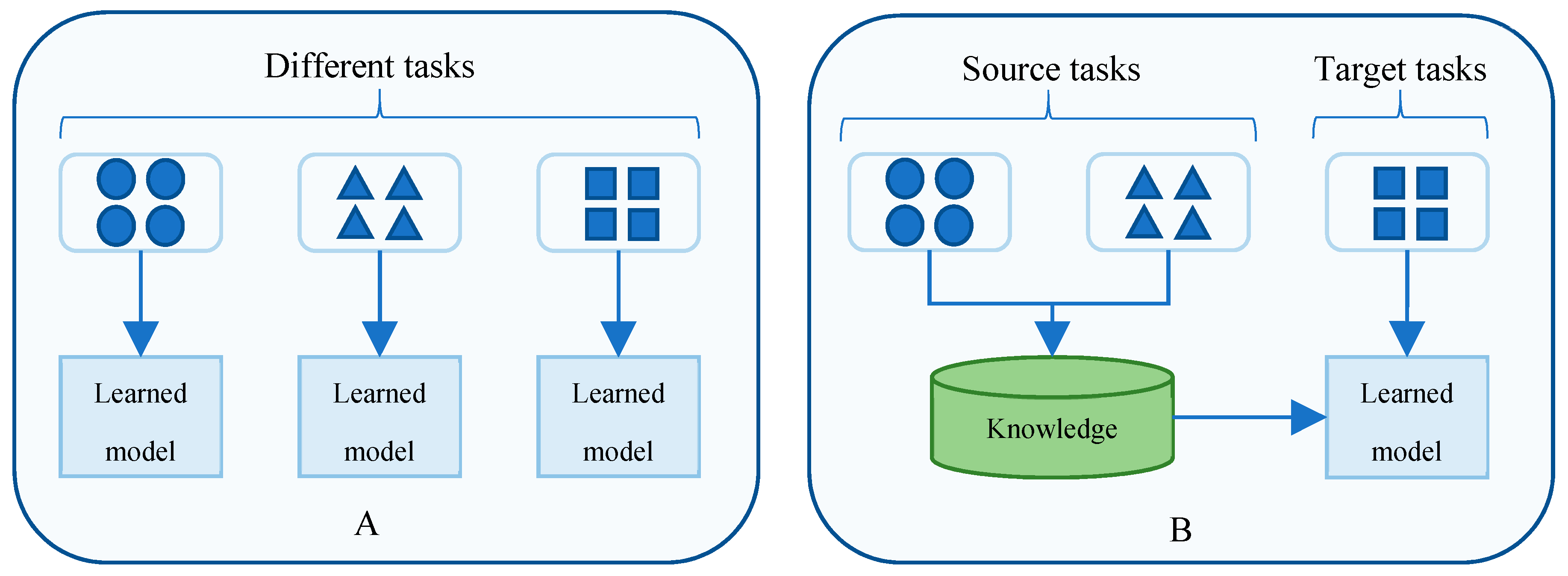
3.3. Transfer Learning
4. Materials and Methods
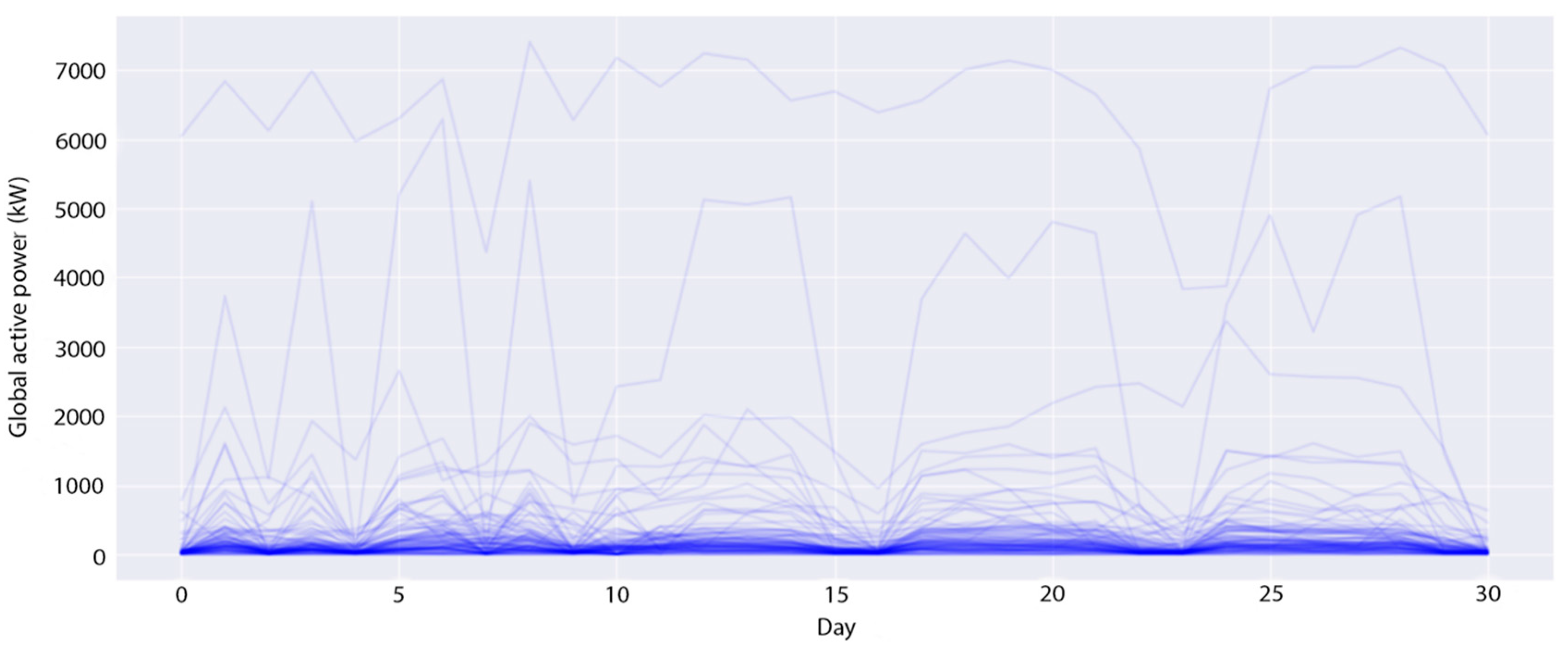
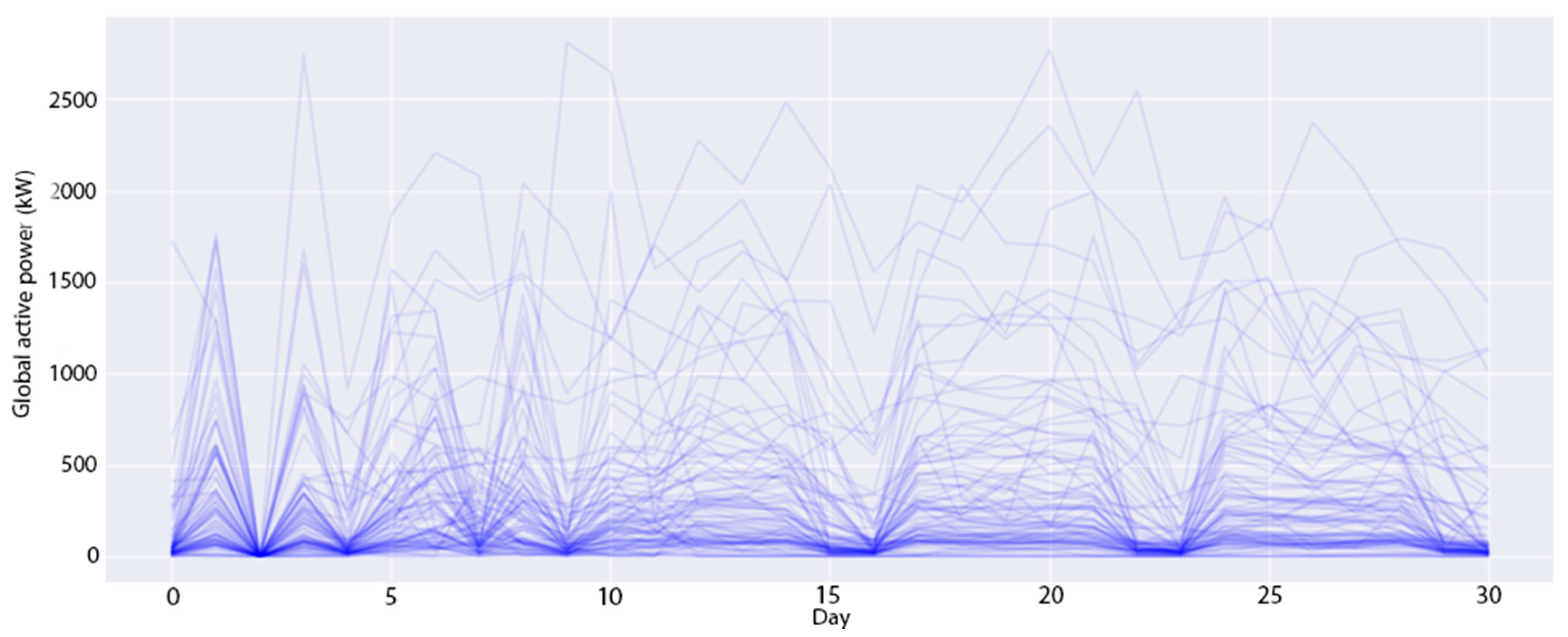
4.1. The Experimental Datasets
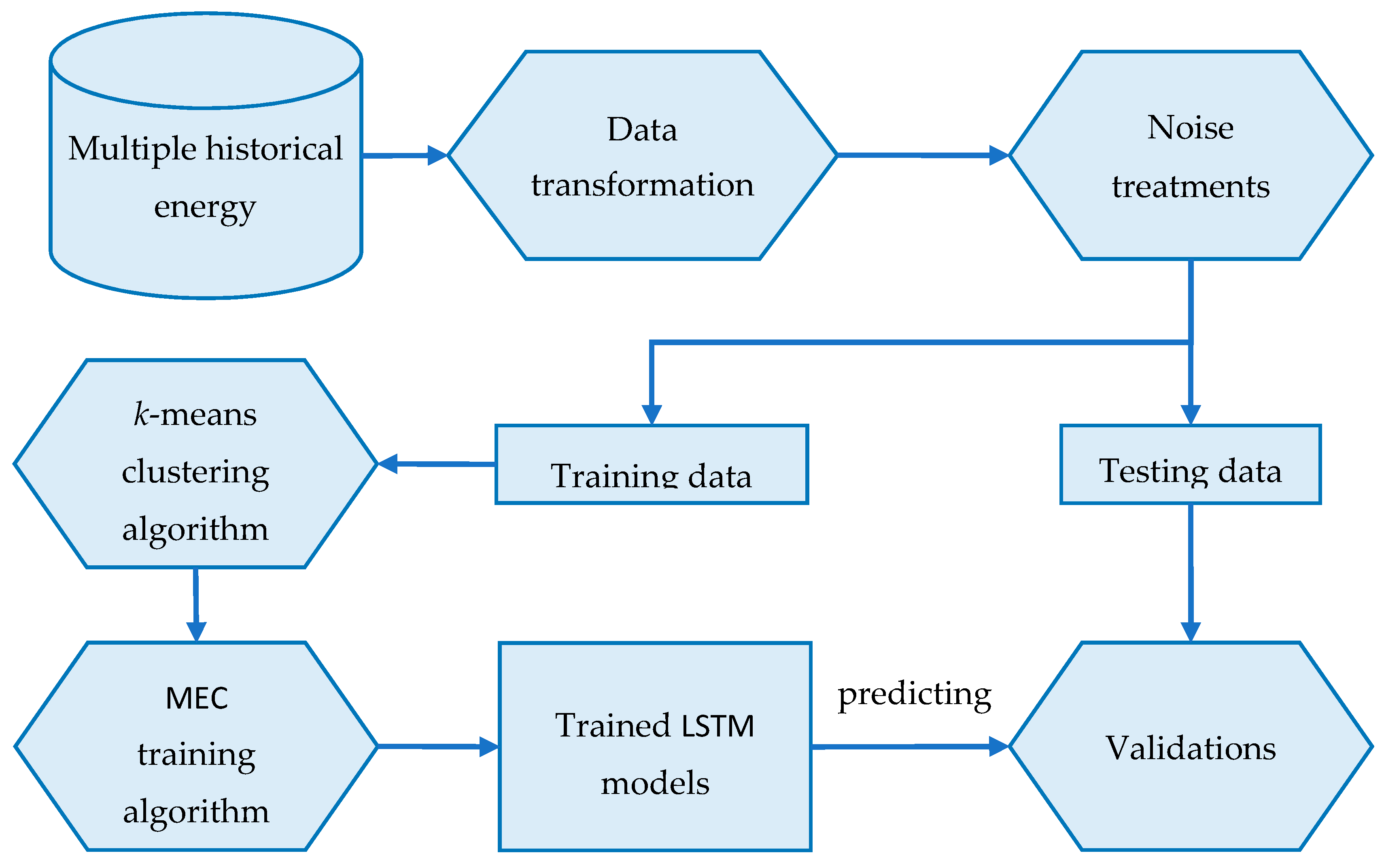
4.2. The MEC-TLL Framework
| Algorithm 1. MEC training algorithm | |
| Input: n clusters | |
| Output: n trained LSTM models | |
 | |
5. Results
5.1. Experimental Setting
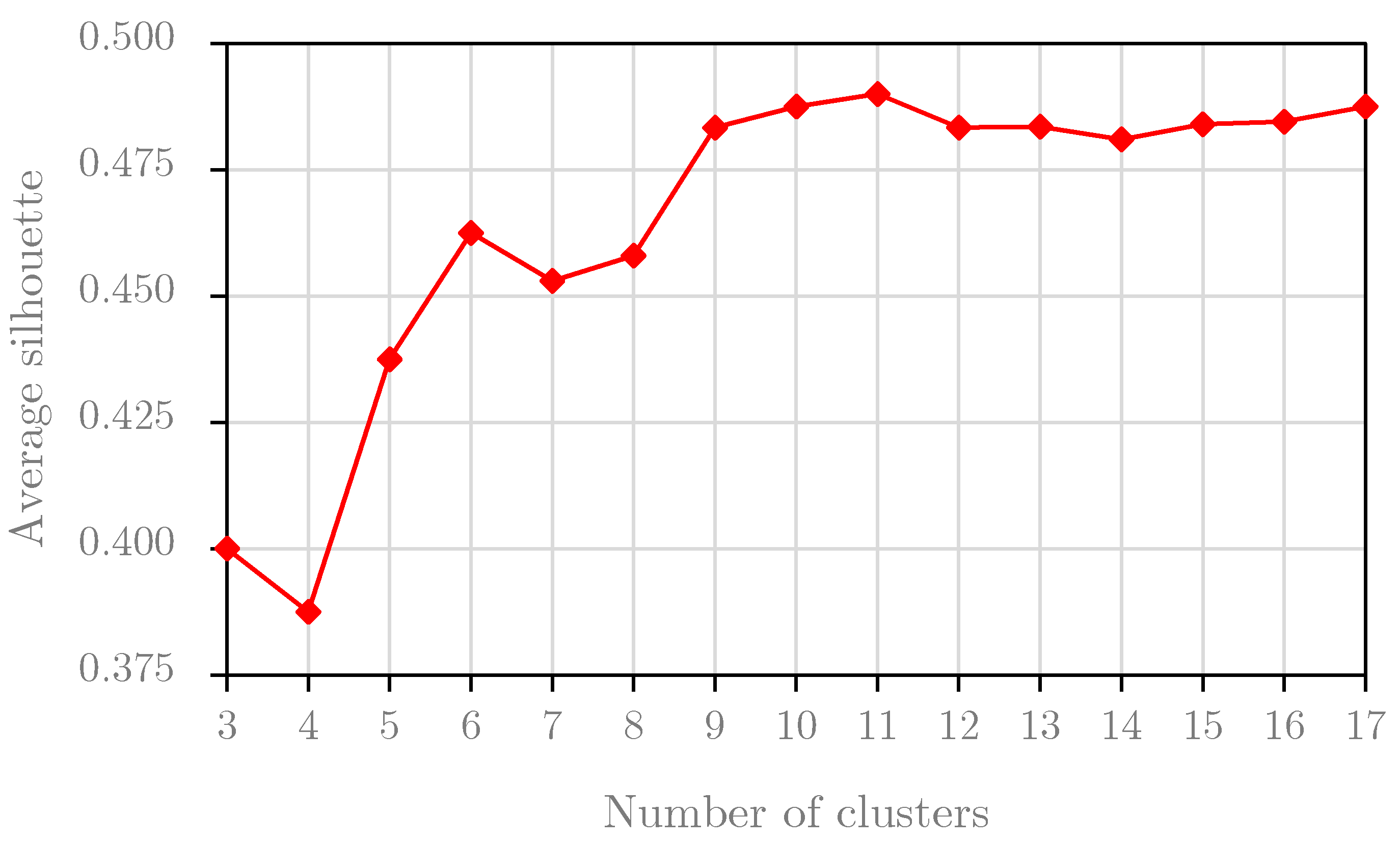
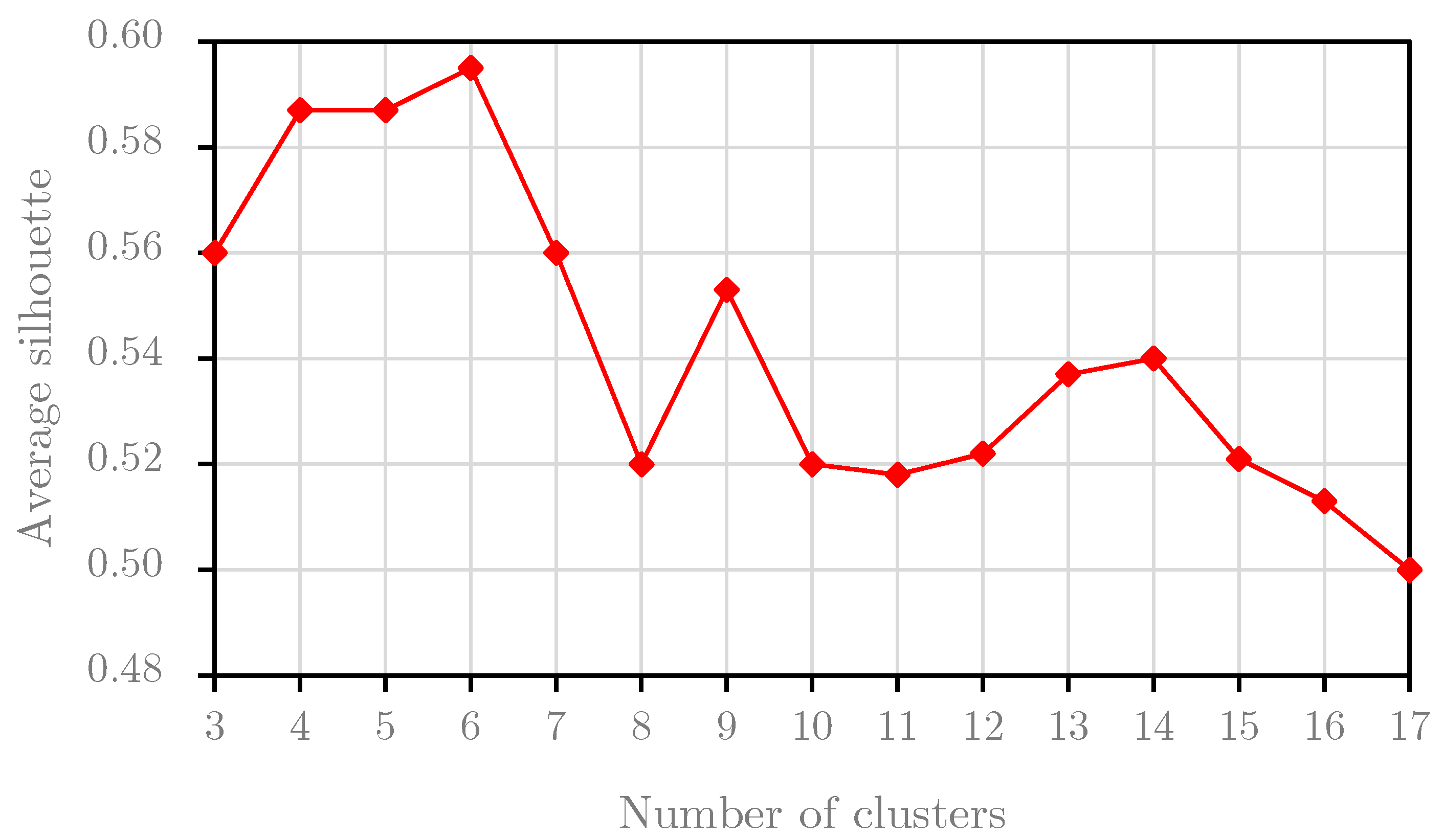
5.2. Silhouette Analysis
5.3. Experimental Results and Discussions
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Le, T.; Lee, M.Y.; Park, J.R.; Baik, S.W. Oversampling Techniques for Bankruptcy Prediction: Novel Features from a Transaction Dataset. Symmetry 2018, 10, 79. [Google Scholar] [CrossRef] [Green Version]
- Le, T.; Vo, M.T.; Vo, B.; Lee, M.Y.; Baik, S.W. A Hybrid Approach Using Oversampling Technique and Cost-Sensitive Learning for Bankruptcy Prediction. Complexity 2019, 2019, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Faris, H.; Abukhurma, R.; Almanaseer, W.; Saadeh, M.; Mora, A.M.; Castillo, P.A.; Aljarah, I. Improving financial bankruptcy prediction in a highly imbalanced class distribution using oversampling and ensemble learning: A case from the Spanish market. Prog. Artif. Intell. 2019, 9, 31–53. [Google Scholar] [CrossRef]
- Le, T.; Vo, B.; Fujita, H.; Nguyen, L.T.T.; Baik, S.W. A fast and accurate approach for bankruptcy forecasting using squared logistics loss with GPU-based extreme gradient boosting. Inf. Sci. 2019, 494, 294–310. [Google Scholar] [CrossRef]
- Nguyen, T.N.; Nguyen-Xuan, H.; Lee, J. A novel data-driven nonlinear solver for solid mechanics using time series forecasting. Finite Elements Anal. Des. 2020, 171, 103377. [Google Scholar] [CrossRef]
- Nguyen, T.N.; Lee, S.; Nguyen-Xuan, H.; Lee, J. A novel analysis-prediction approach for geometrically nonlinear problems using group method of data handling. Comput. Methods Appl. Mech. Eng. 2019, 354, 506–526. [Google Scholar] [CrossRef]
- Le, T.; Baik, S.W. A robust framework for self-care problem identification for children with disability. Symmetry 2019, 11, 89. [Google Scholar] [CrossRef] [Green Version]
- Hemanth, J.; Anitha, J.; Naaji, A.; Geman, O.; Popescu, D.E.; Son, L.H.; Hoang, L. A Modified Deep Convolutional Neural Network for Abnormal Brain Image Classification. IEEE Access 2018, 7, 4275–4283. [Google Scholar] [CrossRef]
- Vo, A.H.; Son, L.H.; Vo, M.T.; Le, T. A Novel Framework for Trash Classification Using Deep Transfer Learning. IEEE Access 2019, 7, 178631–178639. [Google Scholar] [CrossRef]
- Vo, M.T.; Nguyen, T.; Le, T. Robust head pose estimation using extreme gradient boosting machine on stacked autoencoders neural network. IEEE Access 2020, 8, 3687–3694. [Google Scholar] [CrossRef]
- Vo, T.; Nguyen, T.; Le, C.T. A hybrid framework for smile detection in class imbalance scenarios. Neural Comput. Appl. 2019, 31, 8583–8592. [Google Scholar] [CrossRef]
- Vo, T.; Nguyen, T.; Le, C.T. Race Recognition Using Deep Convolutional Neural Networks. Symmetry 2018, 10, 564. [Google Scholar] [CrossRef] [Green Version]
- Marinakis, V.; Doukas, H.; Koasidis, K.; AlBuflasa, H. From Intelligent Energy Management to Value Economy through a Digital Energy Currency: Bahrain City Case Study. Sensors 2020, 20, 1456. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fu, C.; Zhang, S.-Q.; Chao, K.-H. Energy Management of a Power System for Economic Load Dispatch Using the Artificial Intelligent Algorithm. Electronics 2020, 9, 108. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.-Y.; Cho, S.-B. Electric Energy Consumption Prediction by Deep Learning with State Explainable Autoencoder. Energies 2019, 12, 739. [Google Scholar] [CrossRef] [Green Version]
- Kim, T.-Y.; Cho, S.-B. Predicting residential energy consumption using CNN-LSTM neural networks. Energy 2019, 182, 72–81. [Google Scholar] [CrossRef]
- Djenouri, D.; Laidi, R.; Djenouri, Y.; Balasingham, I. Machine Learning for Smart Building Applications: Review and Taxonomy. ACM Comput. Surv. 2019, 52, 24:1–24:36. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Wang, S. Development of prediction models for next-day building energy consumption and peak power demand using data mining techniques. Appl. Energy 2014, 127, 1–10. [Google Scholar] [CrossRef]
- Khan, A.; Plötz, T.; Nicholson, J.; Mellor, S.; Jackson, D.; Ladha, K.; Ladha, C.; Hand, J.; Clarke, J.; Olivier, P. Occupancy monitoring using environmental & context sensors and a hierarchical analysis framework. In Proceedings of the 1st ACM Conference on Embedded Systems for Energy-Efficient Buildings - BuildSys ’14, Memphis, TN, USA, 4–6 November 2014; pp. 90–99. [Google Scholar]
- Sangogboye, F.C.; Imamovic, K.; Kjærgaard, M.B. Improving occupancy presence prediction via multi-label classification; Institute of Electrical and Electronics Engineers (IEEE): New York, NY, USA, 2016; pp. 1–6. [Google Scholar]
- Soltanaghaei, E.; Whitehouse, K. Walksense: Classifying home occupancy states using walkway sensing. In Proceedings of the BuildSys ‘16: The 3rd ACM International Conference on Systems for Energy-Efficient Built Environments, Palo Alto, CA, USA, 16–17 November 2016; pp. 167–176. [Google Scholar]
- Khalil, N.; Benhaddou, D.; Gnawali, O.; Subhlok, J. Nonintrusive Occupant Identification by Sensing Body Shape and Movement. In Proceedings of the 3rd ACM International Conference on Systems for Energy-Efficient Built Environments - BuildSys ’16 2016, Palo Alto, CA, USA, 16–17 November 2016; pp. 1–10. [Google Scholar]
- Aicha, A.N.; Englebienne, G.; Kröse, B. Unsupervised visit detection in smart homes. Pervasive Mob. Comput. 2017, 34, 157–167. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, D.; Spanos, C.J. Learning Optimization Friendly Comfort Model for HVAC Model Predictive Control. In Proceedings of the 2015 IEEE International Conference on Data Mining Workshop (ICDMW), Atlantic City, NJ, USA, 14–17 November 2015; pp. 430–439. [Google Scholar]
- Sarkar, C.; Nambi, S.A.U.; Prasad, R.V. iLTC: Achieving Individual Comfort in Shared Spaces. In Proceedings of the EWSN, Graz, Austria, 15–17 February 2016; pp. 65–76. [Google Scholar]
- Mocanu, E.; Nguyen, P.; Gibescu, M.; Kling, W. Deep learning for estimating building energy consumption. Sustain. Energy Grids Netw. 2016, 6, 91–99. [Google Scholar] [CrossRef]
- Sönmez, Y.; Güvenç, U.; Kahraman, H.T.; Yilmaz, C. A comperative study on novel machine learning algorithms for estimation of energy performance of residential buildings. In Proceedings of the 2015 3rd International Istanbul Smart Grid Congress and Fair (ICSG), Istanbul, Turkey, 29–30 April 2015; pp. 1–7. [Google Scholar] [CrossRef]
- Hartvigsson, E.; Ahlgren, E.O. Comparison of load profiles in a mini-grid: Assessment of performance metrics using measured and interview-based data. Energy Sustain. Dev. 2018, 43, 186–195. [Google Scholar] [CrossRef]
- Chou, J.-S.; Ngo, N.-T. Time series analytics using sliding window metaheuristic optimization-based machine learning system for identifying building energy consumption patterns. Appl. Energy 2016, 177, 751–770. [Google Scholar] [CrossRef]
- Yanine, F.; Sánchez-Squella, A.; Barrueto, A.; Parejo, A.; Cordova, F.; Rother, H. Grid-Tied Distributed Generation Systems to Sustain the Smart Grid Transformation: Tariff Analysis and Generation Sharing. Energies 2020, 13, 1187. [Google Scholar] [CrossRef] [Green Version]
- Parejo, A.; Sánchez-Squella, A.; Barraza, R.; Yanine, F.; Barrueto, A.; Leon, C. Design and Simulation of an Energy Homeostaticity System for Electric and Thermal Power Management in a Building with Smart Microgrid. Energies 2019, 12, 1806. [Google Scholar] [CrossRef] [Green Version]
- Hebrail, G.; Berard, A. Individual Household Electric Power Consumption Data Set. UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/datasets/individual+household+electric+power+consumption (accessed on 5 May 2020).
- Le, T.; Vo, M.; Vo, B.; Hwang, E.; Rho, S.; Baik, S.W. Improving Electric Energy Consumption Prediction Using CNN and Bi-LSTM. Appl. Sci. 2019, 9, 4237. [Google Scholar] [CrossRef] [Green Version]
- Tian, C.; Li, C.; Zhang, G.; Lv, Y. Data driven parallel prediction of building energy consumption using generative adversarial nets. Energy Build. 2019, 186, 230–243. [Google Scholar] [CrossRef]
- Yan, K.; Li, W.; Ji, Z.; Qi, M.; Du, Y. A Hybrid LSTM Neural Network for Energy Consumption Forecasting of Individual Households. IEEE Access 2019, 7, 157633–157642. [Google Scholar] [CrossRef]
- Wang, R.; Lu, S.; Feng, W. A novel improved model for building energy consumption prediction based on model integration. Appl. Energy 2020, 262, 114561. [Google Scholar] [CrossRef]
- Park, S.; Moon, J.; Jung, S.; Rho, S.; Baik, S.W.; Hwang, E. A two-stage industrial load forecasting scheme for day-ahead combined cooling, heating and power scheduling. Energies 2020, 13, 443. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Tan, Z.; Xu, C.; Chen, H.; Li, Z. Study on deep reinforcement learning techniques for building energy consumption forecasting. Energy Build. 2020, 208, 109675. [Google Scholar] [CrossRef]
- Ta, V.-D.; Liu, C.-M.; Tadesse, D.A. Portfolio Optimization-Based Stock Prediction Using Long-Short Term Memory Network in Quantitative Trading. Appl. Sci. 2020, 10, 437. [Google Scholar] [CrossRef] [Green Version]
- Liu, R.; Liu, L. Predicting housing price in China based on long short-term memory incorporating modified genetic algorithm. Soft Comput. 2019, 23, 11829–11838. [Google Scholar] [CrossRef]
- Zhang, M.; Li, X.; Wang, L. An Adaptive Outlier Detection and Processing Approach Towards Time Series Sensor Data. IEEE Access 2019, 7, 175192–175212. [Google Scholar] [CrossRef]
- Xu, Z.; Lian, J.; Bin, L.; Hua, K.; Xu, K.; Chan, H.Y. Water Price Prediction for Increasing Market Efficiency Using Random Forest Regression: A Case Study in the Western United States. Water 2019, 11, 228. [Google Scholar] [CrossRef] [Green Version]
- Lin, J.C.-W.; Shao, Y.; Zhou, Y.; Pirouz, M.; Chen, H.-C. A Bi-LSTM mention hypergraph model with encoding schema for mention extraction. Eng. Appl. Artif. Intell. 2019, 85, 175–181. [Google Scholar] [CrossRef]
- Dai, C.; Liu, X.; Lai, J. Human action recognition using two-stream attention based LSTM networks. Appl. Soft Comput. 2020, 86, 105820. [Google Scholar] [CrossRef]
- Zhao, Z.; Chen, W.; Wu, X.; Chen, P.C.Y.; Liu, J. LSTM network: A deep learning approach for short-term traffic forecast. IET Intell. Transp. Syst. 2017, 11, 68–75. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Li, Y.; Wang, J.; Tang, Z. Post Text Processing of Chinese Speech Recognition Based on Bidirectional LSTM Networks and CRF. Electron. 2019, 8, 1248. [Google Scholar] [CrossRef] [Green Version]
- Canizo, M.; Triguero, I.; Conde, A.; Onieva, E. Multi-head CNN–RNN for multi-time series anomaly detection: An industrial case study. Neurocomputing 2019, 363, 246–260. [Google Scholar] [CrossRef]
- Munusamy, S.; Murugesan, P. Modified dynamic fuzzy c-means clustering algorithm—Application in dynamic customer segmentation. Appl. Intell. 2020, 1–21. [Google Scholar] [CrossRef]
- Le, T.; Son, L.; Vo, M.T.; Lee, M.; Baik, S.W. A Cluster-Based Boosting Algorithm for Bankruptcy Prediction in a Highly Imbalanced Dataset. Symmetry 2018, 10, 250. [Google Scholar] [CrossRef] [Green Version]
- Mojarad, M.; Nejatian, S.; Parvin, H.; Mohammadpoor, M. A fuzzy clustering ensemble based on cluster clustering and iterative Fusion of base clusters. Appl. Intell. 2019, 49, 2567–2581. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Alshazly, H.; Linse, C.; Barth, E.; Martinetz, T. Ensembles of Deep Learning Models and Transfer Learning for Ear Recognition. Sensors 2019, 19, 4139. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, J.; Wu, W.; Xue, D.; Gao, P. Multi-Source Deep Transfer Neural Network Algorithm. Sensors 2019, 19, 3992. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singh, D.; Singh, P.; Sisodia, D.S. Evolutionary based ensemble framework for realizing transfer learning in HIV-1 Protease cleavage sites prediction. Appl. Intell. 2018, 49, 1260–1282. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Cheraghchi, H.S.; Zakerolhosseini, A. Toward a novel art inspired incremental community mining algorithm in dynamic social network. Appl. Intell. 2016, 46, 409–426. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR (Poster), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
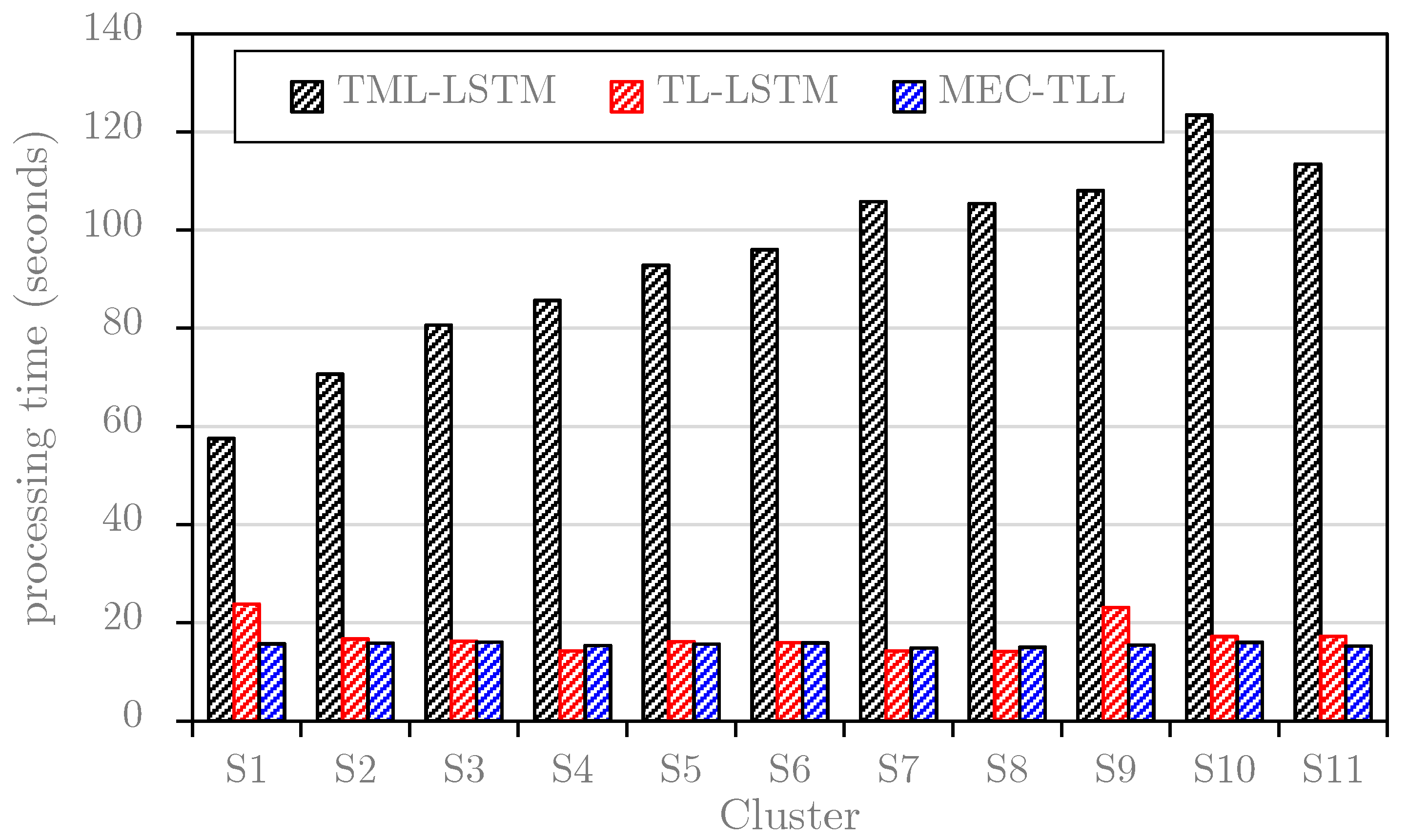
| Approaches | The Average Computational Time (Seconds) | RMSE | MAE | MAPE |
|---|---|---|---|---|
| TML-LSTM | 95.4 | 1.172 | 0.721 | 35.24 |
| TL-LSTM | 17.2 | 1.564 | 0.821 | 40.34 |
| MEC-TLL | 15.7 | 1.142 | 0.670 | 34.32 |
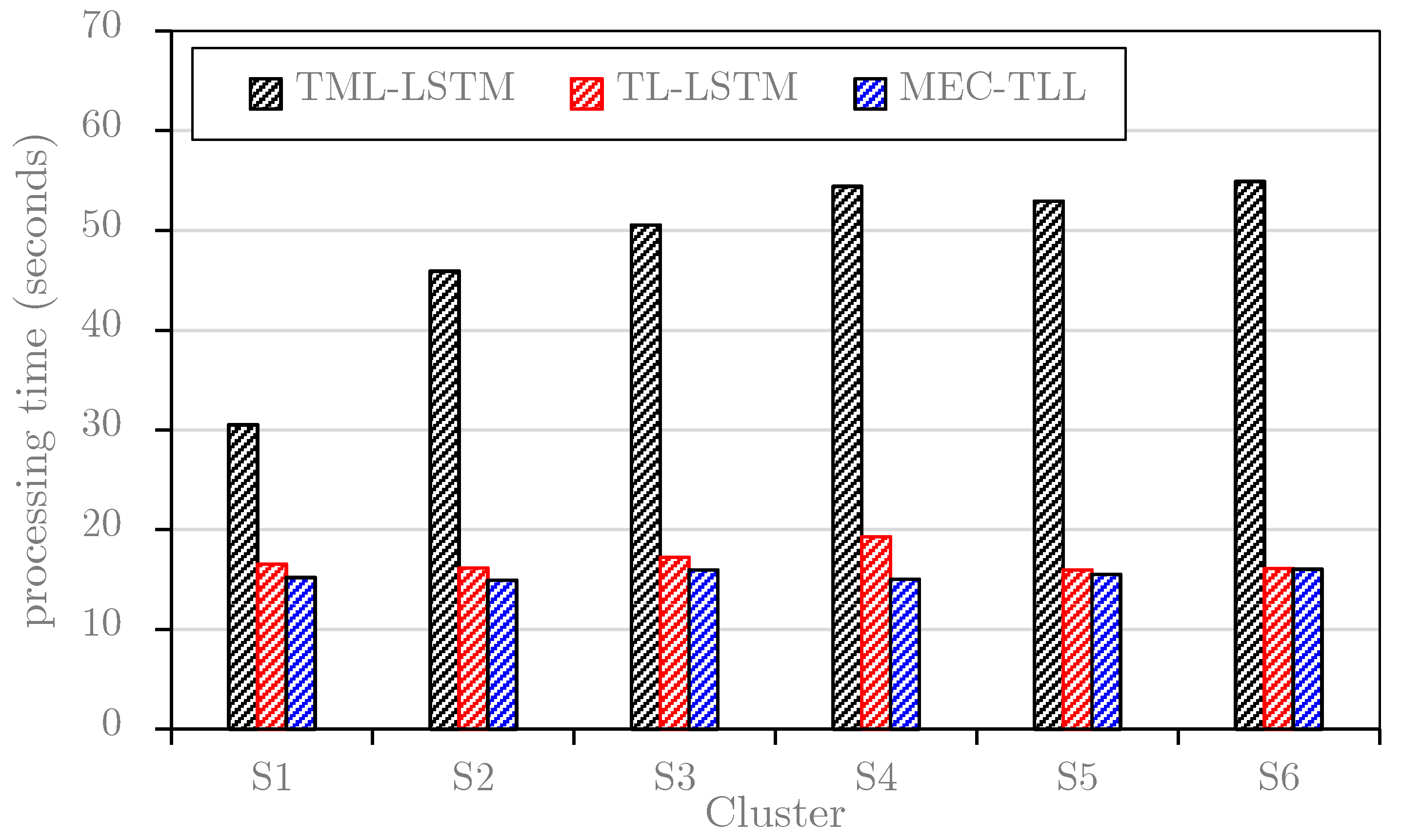
| Approaches | The Average Computational Time (Seconds) | RMSE | MAE | MAPE |
|---|---|---|---|---|
| TML-LSTM | 48.2 | 1.425 | 0.912 | 41.42 |
| TL-LSTM | 16.8 | 1.718 | 1.054 | 45.21 |
| MEC-TLL | 15.4 | 1.368 | 0.891 | 41.07 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Le, T.; Vo, M.T.; Kieu, T.; Hwang, E.; Rho, S.; Baik, S.W. Multiple Electric Energy Consumption Forecasting Using a Cluster-Based Strategy for Transfer Learning in Smart Building. Sensors 2020, 20, 2668. https://doi.org/10.3390/s20092668
Le T, Vo MT, Kieu T, Hwang E, Rho S, Baik SW. Multiple Electric Energy Consumption Forecasting Using a Cluster-Based Strategy for Transfer Learning in Smart Building. Sensors. 2020; 20(9):2668. https://doi.org/10.3390/s20092668
Chicago/Turabian StyleLe, Tuong, Minh Thanh Vo, Tung Kieu, Eenjun Hwang, Seungmin Rho, and Sung Wook Baik. 2020. "Multiple Electric Energy Consumption Forecasting Using a Cluster-Based Strategy for Transfer Learning in Smart Building" Sensors 20, no. 9: 2668. https://doi.org/10.3390/s20092668
APA StyleLe, T., Vo, M. T., Kieu, T., Hwang, E., Rho, S., & Baik, S. W. (2020). Multiple Electric Energy Consumption Forecasting Using a Cluster-Based Strategy for Transfer Learning in Smart Building. Sensors, 20(9), 2668. https://doi.org/10.3390/s20092668