
Photographic Reproduction and Enhancement Using HVS-Based Modified Histogram Equalization



Abstract
:1. Introduction
2. Related Works and Research Motivation
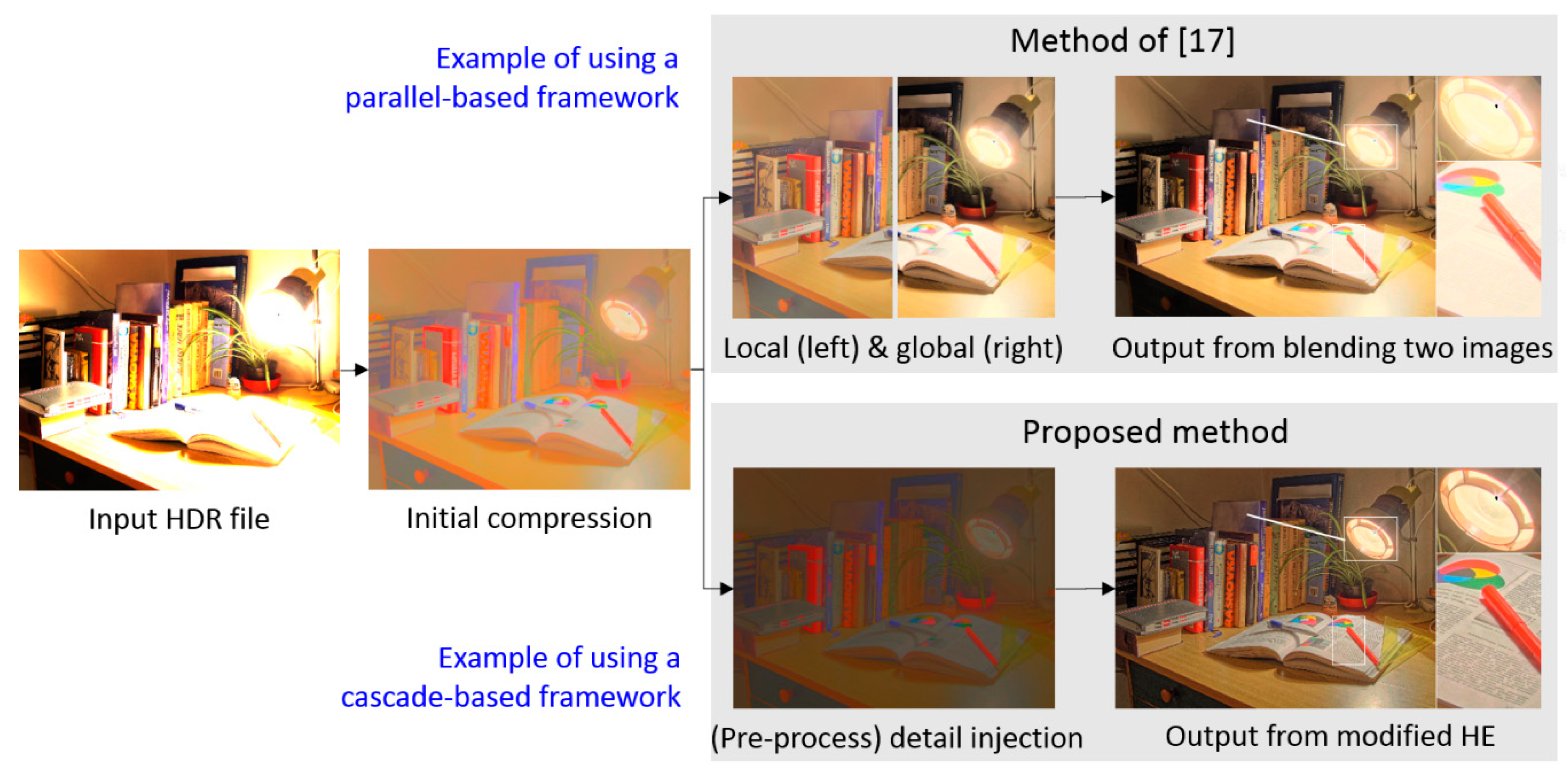
- Motivation for this study: Recently, the hybrid-based approach seems to be a promising solution to the photographic reproduction problem. However, as mentioned in the above two paragraphs, there is still room for improvement. As shown in Figure 1, the algorithm of [23] presents a typical parallel-architecture-type hybrid reproduction framework, in which the image information content is used to separately enhance each pixel in global contrast and in local details to different extents, following which a weighted fusion is performed. However, if the tone reproduction process involves this type of parallel architecture and fusion, the resultant images might bias to one of the global and local characteristics. Consequently, the parallel-architecture-based method sacrifices either the global tone naturalness or the local details more or less.
- Contribution of this study: In view of the shortcoming of the parallel-architecture-based method, this work presents a cascaded-architecture-type reproduction method. Despite having the advantage of computational efficiency, photographic reproduction methods using a monotonic transfer function are typically vulnerable to detail loss (i.e., loss of the local features), especially in the bright and dark areas. In this study, we demonstrate a practical reproduction method and demonstrate that even though it applies the monotonic transfer function (i.e., the proposed HVS-based modified histogram equalization), it is able to preserve the global contrast and even enhance the local details in bright and dark areas simultaneously. To adopt the histogram equalization scheme in photographic reproduction, the histogram configuration is reallocated according to two HVS characteristics: the just noticeable difference and the threshold versus intensity curve. The experimental results demonstrate the effectiveness of the proposed method in terms of different evaluations.
3. Proposed Approach
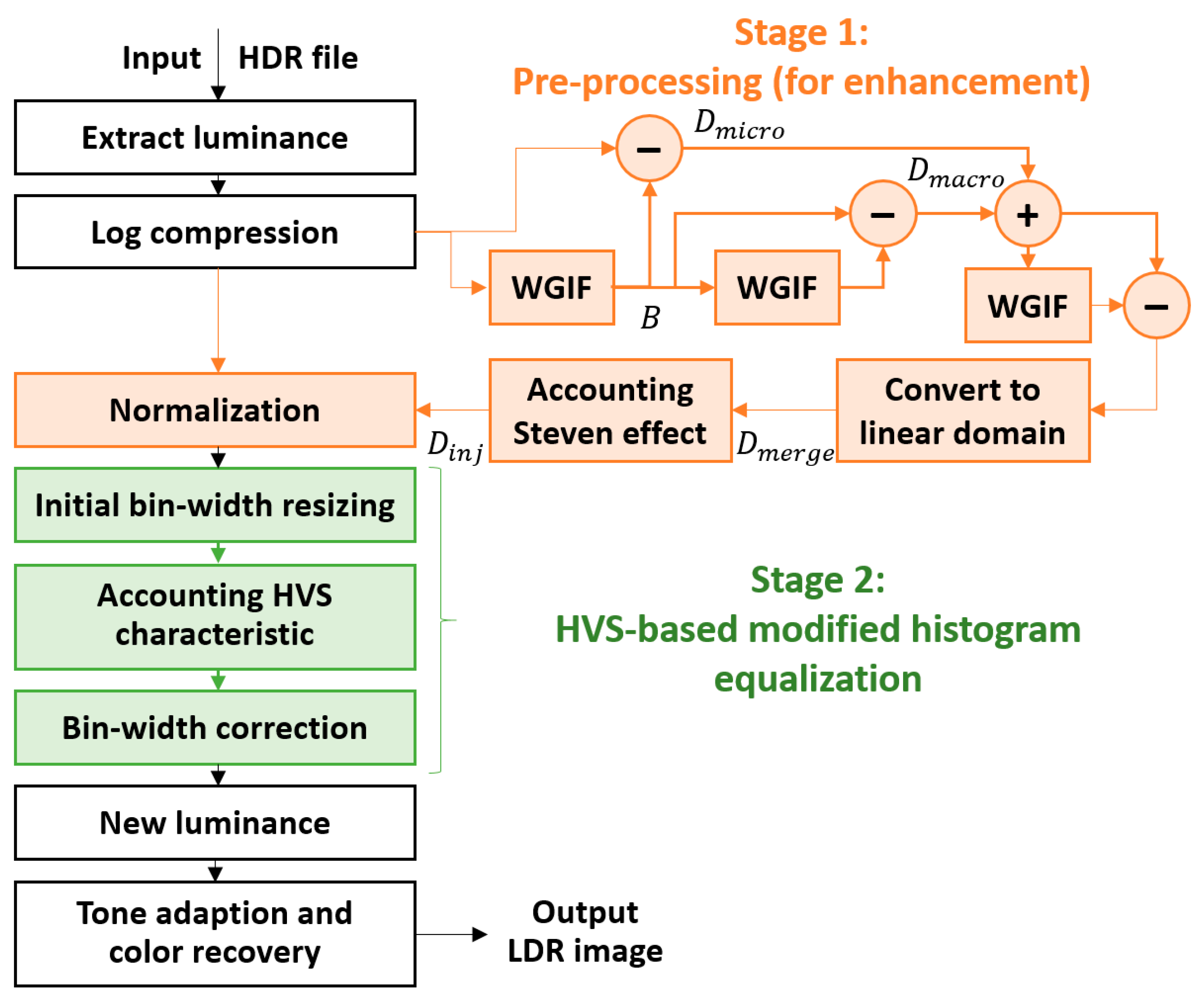
3.1. Luminance Extraction and Initial Log Compression
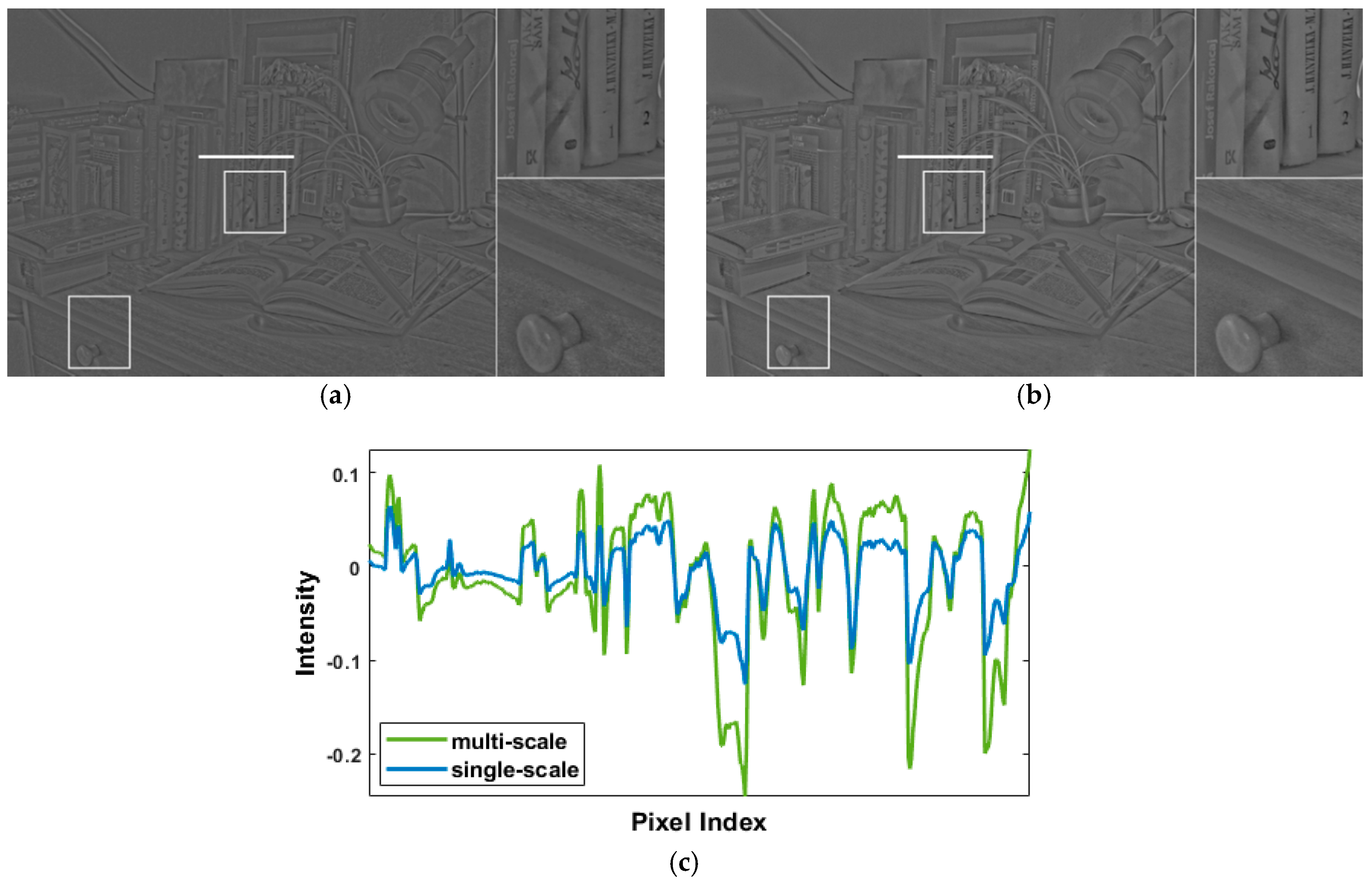
3.2. Pre-Processing for Detail Enhancement
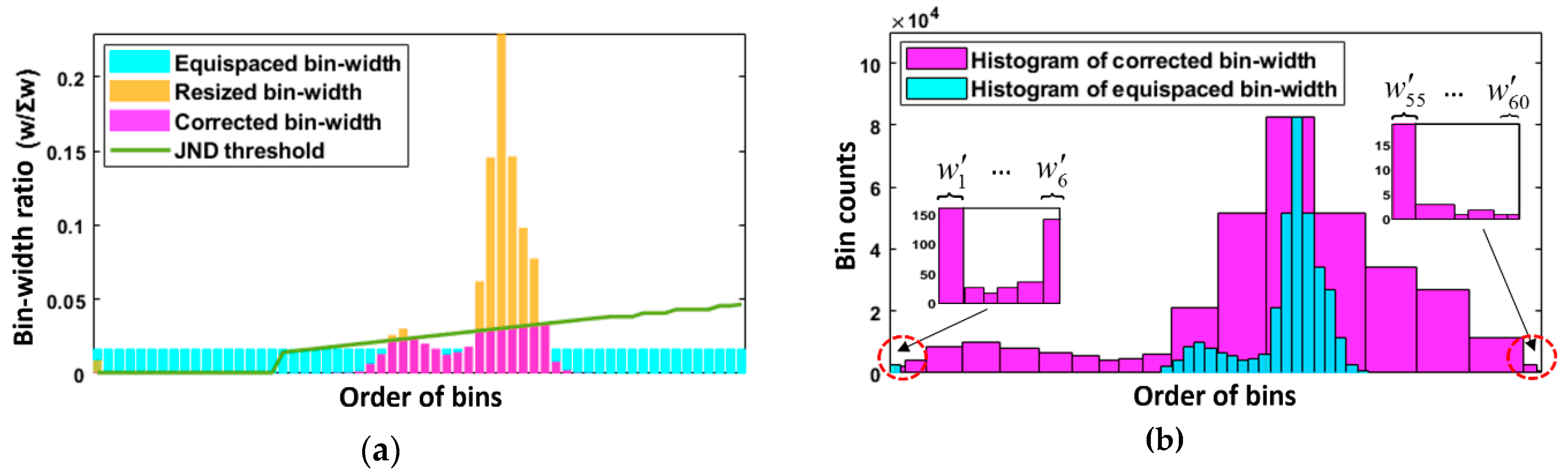
3.3. HVS-Based Modified Histogram Equalization
3.4. Luminance Adaptation and Color Recovery
4. Experimental Results and Discussions
4.1. Self-Evaluation
4.2. Subjective Analysis
4.3. Objective Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Wang, J.; Huang, L.; Zhang, Y.; Zhu, Y.; Ni, J.; Shi, Y. An effective steganalysis algorithm for histogram-shifting based reversible data hiding. Comput. Mater. Contin. 2020, 64, 325–344. [Google Scholar] [CrossRef]
- Hu, J.; Lei, Z.; Li, X.; He, Y.; Zhou, J. Ultrasound speckle reduction based on histogram curve matching and region growing. Comput. Mater. Contin. 2020, 65, 705–722. [Google Scholar] [CrossRef]
- Mamoun, M.E.; Mahmoud, Z.; Kaddour, S. Efficient analysis of vertical projection histogram to segment arabic handwritten characters. Comput. Mater. Contin. 2019, 60, 55–66. [Google Scholar] [CrossRef] [Green Version]
- Huang, D.; Gu, P.; Feng, H.; Lin, Y.; Zheng, L. Robust visual tracking models designs through kernelized correlation filters. Intell. Autom. Soft Comput. 2020, 26, 313–322. [Google Scholar] [CrossRef]
- Liu, K. The data classification query optimization method for english online examination system based on grid image analysis. Intell. Autom. Soft Comput. 2020, 26, 749–754. [Google Scholar] [CrossRef]
- Xia, Z.; Lu, L.; Qiu, T.; Shim, H.J.; Chen, X.; Jeon, B. A privacy-preserving image retrieval based on ac-coefficients and color histograms in cloud environment. Comput. Mater. Contin. 2019, 58, 27–43. [Google Scholar] [CrossRef] [Green Version]
- Lenzen, L.; Christmann, M. Subjective viewer preference model for automatic HDR down conversion. In Proceedings of the IS&T International Symposium on Electronic Imaging, Burlingame, CA, USA, 1–2 February 2017; pp. 191–197. [Google Scholar]
- Jung, C.; Xu, K. Naturalness-preserved tone mapping in images based on perceptual quantization. In Proceedings of the 2017 IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 2403–2407. [Google Scholar]
- Khan, I.R.; Rahardja, S.; Khan, M.M.; Movania, M.M.; Abed, F. A tone- mapping technique based on histogram using a sensitivity model of the human visual system. IEEE Trans. Ind. Electron. 2018, 65, 3469–3479. [Google Scholar] [CrossRef]
- Lee, D.H.; Fan, M.; Kim, S.; Kang, M.; Ko, S. High dynamic range image tone mapping based on asymmetric model of retinal adaptation. Signal Process. Image Commun. 2018, 68, 120–128. [Google Scholar] [CrossRef]
- Gu, B.; Li, W.; Zhu, M.; Wang, M. Local edge-preserving multiscale decomposition for high dynamic range image tone mapping. IEEE Trans. Image Process. 2013, 22, 70–79. [Google Scholar] [CrossRef] [PubMed]
- Barai, N.R.; Kyan, M.; Androutsos, D. Human visual system inspired saliency guided edge preserving tone-mapping for high dynamic range imaging. In Proceedings of the 2017 IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 1017–1021. [Google Scholar]
- Mezeni, E.; Saranovac, L.V. Enhanced local tone mapping for detail preserving reproduction of high dynamic range images. J. Vis. Commun. Image Represent. 2018, 53, 122–133. [Google Scholar] [CrossRef]
- Fattal, R.; Lischinski, D.; Werman, M. Gradient domain high dynamic range compression. ACM Trans. Graph. 2002, 21, 249–256. [Google Scholar] [CrossRef] [Green Version]
- Mantiuk, R.; Myszkowski, K.; Seidel, H. A perceptual framework for contrast processing of high dynamic range images. ACM Trans. Appl. Percept. 2006, 3, 286–308. [Google Scholar] [CrossRef]
- Reinhard, E.; Stark, M.; Shirley, P.; Ferwerda, J. Photographic tone reproduction for digital images. ACM Trans. Graph. 2002, 21, 267–276. [Google Scholar] [CrossRef] [Green Version]
- Ferradans, S.; Bertalmio, M.; Provenzi, E.; Caselles, V. An analysis of visual adaptation and contrast perception for tone mapping. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2002–2012. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Benzi, M.; Escobar, M.; Kornprobst, P. A bio-inspired synergistic virtual retina model for tone mapping. Comput. Vis. Image Underst. 2018, 168, 21–36. [Google Scholar] [CrossRef] [Green Version]
- Raffin, M.; Guarnieri, G. Tone mapping and enhancement of high dynamic range images based on a model of visual perception. In Proceedings of the 10th IASTED International Conference on Computer Graphics and Imaging, Anaheim, CA, USA, 6 February 2008; pp. 190–195. [Google Scholar]
- Artusi, A.; Akyuz, A.; Roch, B.; Michael, D.; Chrysanthou, Y.; Chalmers, A. Selective local tone mapping. In Proceedings of the 2017 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 2309–2313. [Google Scholar]
- Yang, K.; Li, H.; Kuang, H.; Li, C.; Li, Y. An adaptive method for image dynamic range adjustment. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 640–652. [Google Scholar] [CrossRef]
- Miao, D.; Zhu, Z.; Bai, Y.; Jiang, G.; Duan, Z. Novel tone mapping method via macro-micro modeling of human visual system. IEEE Access 2019, 7, 118359–118369. [Google Scholar] [CrossRef]
- Ok, J.; Lee, C. HDR tone mapping algorithm based on difference compression with adaptive reference values. J. Vis. Commun. Image Represent. 2017, 43, 61–76. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, J.; Zhu, Z.; Yao, W.; Wu, S. Weighted guided image filtering. IEEE Trans. Image Process. 2015, 24, 120–129. [Google Scholar] [CrossRef]
- Stevens, J.C.; Stevens, S.S. Brightness function: Effects of adaptation. J. Opt. Soc. Am. 1963, 53, 375–385. [Google Scholar] [CrossRef]
- Kuang, J.; Johnson, G.M.; Fairchild, M.D. iCAM06: A refined image appearance model for HDR image rendering. J. Vis. Commun. Image Represent. 2007, 18, 406–414. [Google Scholar] [CrossRef]
- Ward, G. Defining dynamic range. In Proceedings of the ACM SIGGRAPH 2008, Los Angeles, CA, USA, 11 August 2008; pp. 1–3. [Google Scholar]
- Gao, S.; Tan, M.; He, Z.; Li, Y. Tone Mapping Beyond the Classical Receptive Field. IEEE Trans. Image Process. 2020, 29, 4174–4187. [Google Scholar] [CrossRef]
- Anyhere Database. Available online: http://www.anyhere.com/ (accessed on 30 August 2020).
- Paris, S.; Hasinoff, S.W.; Kautz, J. Local Laplacian filters: Edge-aware image processing with a Laplacian pyramid. ACM Trans. Graph. 2011, 30, 68. [Google Scholar] [CrossRef]
- HDR-Eye Database. Available online: https://www.epfl.ch/labs/mmspg/downloads/hdr-eye/ (accessed on 18 August 2020).
- Cai, J.; Gu, S.; Zhang, L. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef] [PubMed]
- Yeganeh, H.; Wang, Z. Objective quality assessment of tone mapped images. IEEE Trans. Image Process. 2013, 22, 657–667. [Google Scholar] [CrossRef] [PubMed]
- Nafchi, H.Z.; Shahkolaei, A.; Moghaddam, R.F.; Cheriet, M. FSITM: A feature similarity index for tone-mapped images. IEEE Signal Process. Lett. 2015, 22, 1026–1029. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Gu, K.; Wang, S.; Zhai, G.; Ma, S.; Yang, X.; Lin, W.; Zhang, W.; Gao, W. Blind quality assessment of tone-mapped images via analysis of information, naturalness and structure. IEEE Trans. Multimed. 2016, 18, 432–443. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Name | D | No. | Name | D | No. | Name | D |
|---|---|---|---|---|---|---|---|---|
| 1 | Apartment_float_o15C | 4.7 | 12 | StillLife_o7C1 | 6.1 | 23 | rend04 | 4.5 |
| 2 | AtriumNight_oA9D | 4.1 | 13 | Tree_oAC1 | 4.4 | 24 | rend05_o87A | 3.3 |
| 3 | Desk_oBA2 | 5.2 | 14 | bigFogMap_oDAA | 3.6 | 25 | rend06_oB1D | 3.6 |
| 4 | Display1000_float_o446 | 3.4 | 15 | dani_belgium_oC65 | 4.1 | 26 | rend07 | 8.9 |
| 5 | Montreal_float_o935 | 3.1 | 16 | dani_cathedral_oBBC | 4.1 | 27 | rend08_o0AF | 3.7 |
| 6 | MtTamWest_o281 | 3.4 | 17 | dani_synagogue_o367 | 2.0 | 28 | rend09_o2F3 | 3.9 |
| 7 | Spheron3 | 5.8 | 18 | memorial_o876 | 4.8 | 29 | rend10_oF1C | 5.0 |
| 8 | SpheronNice | 4.7 | 19 | nave | 6.0 | 30 | rend11_o972 | 4.1 |
| 9 | SpheronPriceWestern | 2.8 | 20 | rend01_oBA3 | 3.0 | 31 | rend12 | 8.9 |
| 10 | SpheronNapaValley_oC5D | 3.2 | 21 | rend02_oC95 | 4.1 | 32 | rend13_o7B0 | 4.1 |
| 11 | SpheronSiggraph2001_oF1E | 4.5 | 22 | rend03_oB12 | 3.2 | 33 | rosette_oC92 | 4.4 |
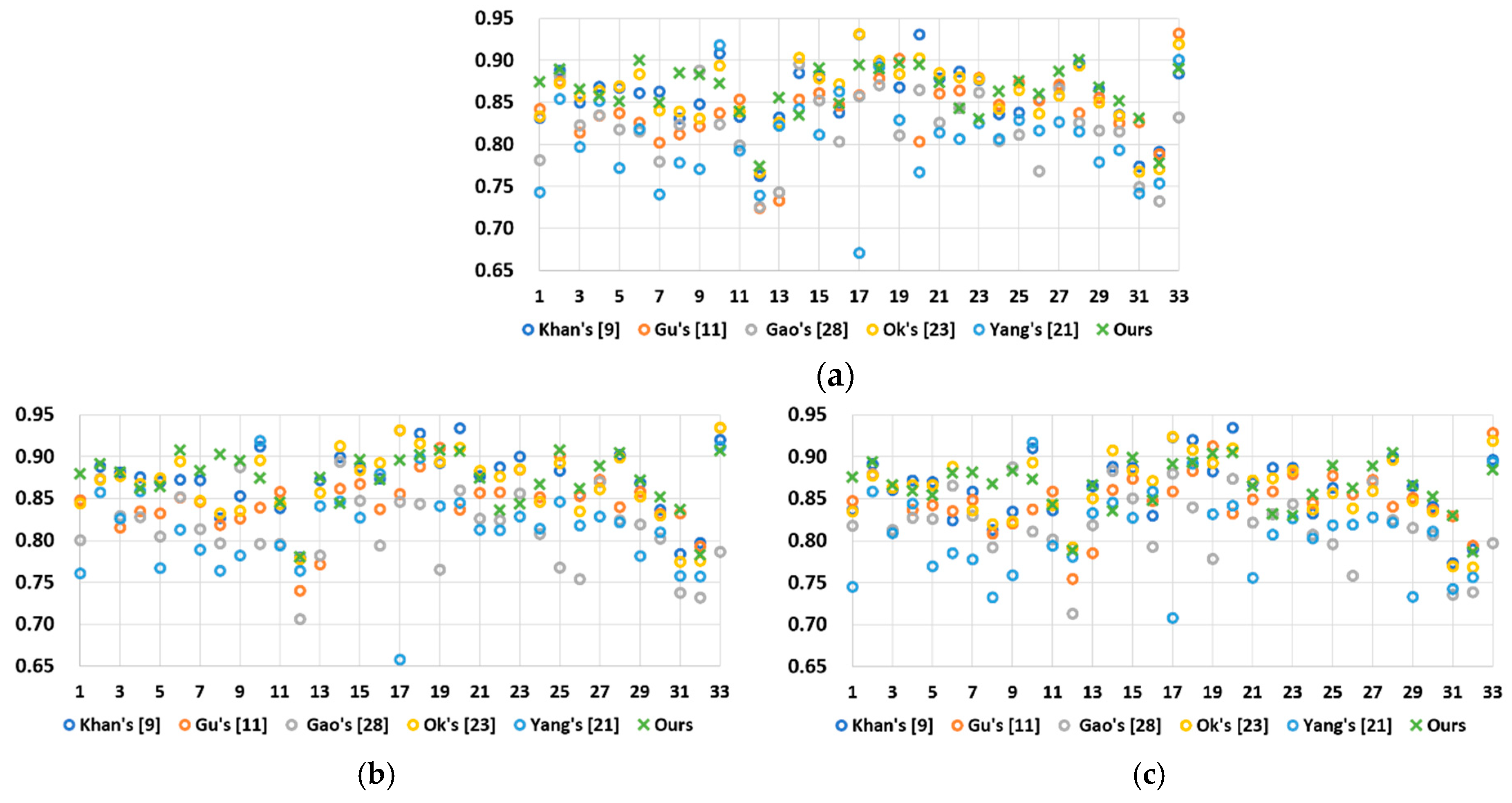
| Image | Khan et al. [9] | Gu et al. [11] | Gao et al. [28] | Ok et al. [23] | Yang et al. [21] | Our Method |
|---|---|---|---|---|---|---|
| Apartment_float_o15C | 0.8631 | 0.8132 | 0.7151 | 0.8543 | 0.6364 | 0.8850 |
| AtriumNight_oA9D | 0.9058 | 0.8809 | 0.8726 | 0.8982 | 0.8928 | 0.8972 |
| Desk_oBA2 | 0.8727 | 0.8526 | 0.8677 | 0.8700 | 0.8146 | 0.8885 |
| Display1000_float_o446 | 0.8676 | 0.8643 | 0.8325 | 0.8626 | 0.8375 | 0.8925 |
| Montreal_float_o935 | 0.8344 | 0.7532 | 0.7163 | 0.8416 | 0.5951 | 0.8297 |
| MtTamWest_o281 | 0.9275 | 0.8758 | 0.8228 | 0.8900 | 0.7278 | 0.9231 |
| Spheron3 | 0.8707 | 0.7543 | 0.7658 | 0.8160 | 0.6619 | 0.8144 |
| SpheronNice | 0.7029 | 0.6892 | 0.7090 | 0.7380 | 0.5530 | 0.8004 |
| SpheronPriceWestern | 0.8226 | 0.7663 | 0.9204 | 0.8088 | 0.6084 | 0.8321 |
| SpheronNapaValley_oC5D | 0.9228 | 0.8802 | 0.6868 | 0.9185 | 0.9226 | 0.9437 |
| SpheronSiggraph2001_oF1E | 0.8086 | 0.7950 | 0.6970 | 0.8329 | 0.6764 | 0.8251 |
| StillLife_o7C1 | 0.7907 | 0.6368 | 0.7063 | 0.7636 | 0.6164 | 0.8093 |
| Tree_oAC1 | 0.8760 | 0.7691 | 0.7115 | 0.8604 | 0.8512 | 0.9044 |
| bigFogMap_oDAA | 0.9391 | 0.8468 | 0.9290 | 0.9354 | 0.9058 | 0.9117 |
| dani_belgium_oC65 | 0.8974 | 0.8571 | 0.8381 | 0.8763 | 0.8065 | 0.8931 |
| dani_cathedral_oBBC | 0.8786 | 0.8775 | 0.8105 | 0.8963 | 0.9014 | 0.9098 |
| dani_synagogue_o367 | 0.9735 | 0.8617 | 0.7212 | 0.9677 | 0.4546 | 0.9263 |
| memorial_o876 | 0.8742 | 0.8575 | 0.8565 | 0.8709 | 0.9061 | 0.8949 |
| nave | 0.8678 | 0.8276 | 0.7522 | 0.8498 | 0.8632 | 0.8554 |
| rend01_oBA3 | 0.8030 | 0.7738 | 0.7610 | 0.7966 | 0.7197 | 0.7880 |
| rend02_oC95 | 0.8930 | 0.8569 | 0.8621 | 0.8772 | 0.8021 | 0.8961 |
| rend03_oB12 | 0.8624 | 0.8275 | 0.7643 | 0.8561 | 0.8165 | 0.8443 |
| rend04 | 0.8763 | 0.8177 | 0.8461 | 0.8619 | 0.8489 | 0.8782 |
| rend05_o87A | 0.8709 | 0.7872 | 0.7453 | 0.8666 | 0.7833 | 0.8730 |
| rend06_oB1D | 0.9303 | 0.9097 | 0.7550 | 0.9405 | 0.9158 | 0.9210 |
| rend07 | 0.7663 | 0.7567 | 0.6885 | 0.7513 | 0.7883 | 0.7725 |
| rend08_o0AF | 0.9016 | 0.8580 | 0.8294 | 0.8799 | 0.7656 | 0.9032 |
| rend09_o2F3 | 0.9246 | 0.8594 | 0.7642 | 0.9138 | 0.7668 | 0.8830 |
| rend10_oF1C | 0.7600 | 0.7147 | 0.6884 | 0.7459 | 0.6070 | 0.7914 |
| rend11_o972 | 0.8577 | 0.8156 | 0.7164 | 0.8594 | 0.7961 | 0.8814 |
| rend12 | 0.5836 | 0.6174 | 0.5058 | 0.6174 | 0.5517 | 0.6533 |
| rend13_o7B0 | 0.8426 | 0.7045 | 0.5385 | 0.7790 | 0.5367 | 0.7138 |
| rosette_oC92 | 0.8710 | 0.8782 | 0.7525 | 0.8754 | 0.8743 | 0.8898 |
| Total number of highest scores | 11 | 0 | 1 | 3 | 2 | 16 |
| Image | Khan et al. [9] | Gu et al. [11] | Gao et al. [28] | Ok et al. [23] | Yang et al. [21] | Our Method |
|---|---|---|---|---|---|---|
| Apartment_float_o15C | 0.1924 | 0.5574 | 0.3266 | 0.2325 | 0.0057 | 0.5819 |
| AtriumNight_oA9D | 0.9231 | 0.7408 | 0.9952 | 0.7588 | 0.4333 | 0.8941 |
| Desk_oBA2 | 0.9384 | 0.2219 | 0.3414 | 0.9309 | 0.4161 | 0.8246 |
| Display1000_float_o446 | 0.9716 | 0.4511 | 0.5147 | 0.8960 | 0.6954 | 0.6767 |
| Montreal_float_o935 | 0.6796 | 0.5863 | 0.4827 | 0.8802 | 0.0239 | 0.7591 |
| MtTamWest_o281 | 0.4447 | 0.6260 | 0.7823 | 0.8542 | 0.3297 | 0.9689 |
| Spheron3 | 0.3273 | 0.3470 | 0.2161 | 0.4647 | 0.0439 | 0.6419 |
| SpheronNice | 0.2154 | 0.1818 | 0.3802 | 0.3833 | 0.0275 | 0.7614 |
| SpheronPriceWestern | 0.2384 | 0.2410 | 0.6440 | 0.3327 | 0.0479 | 0.8732 |
| SpheronNapaValley_oC5D | 0.9703 | 0.3161 | 0.2192 | 0.8007 | 0.9722 | 0.3494 |
| SpheronSiggraph2001_oF1E | 0.2263 | 0.7610 | 0.3065 | 0.3685 | 0.0315 | 0.3866 |
| StillLife_o7C1 | 0.6606 | 0.5661 | 0.2309 | 0.7384 | 0.9072 | 0.5474 |
| Tree_oAC1 | 0.9983 | 0.3090 | 0.7160 | 0.9311 | 0.6864 | 0.8580 |
| bigFogMap_oDAA | 0.5713 | 0.5591 | 0.5973 | 0.8172 | 0.0593 | 0.1685 |
| dani_belgium_oC65 | 0.9092 | 0.8164 | 0.4998 | 0.8853 | 0.3094 | 0.9810 |
| dani_cathedral_oBBC | 0.8907 | 0.4703 | 0.2326 | 0.9974 | 0.7204 | 0.6609 |
| dani_synagogue_o367 | 0.6486 | 0.3386 | 0.7619 | 0.7761 | 0.1128 | 0.5031 |
| memorial_o876 | 0.8038 | 0.2666 | 0.1767 | 0.5786 | 0.2629 | 0.4157 |
| nave | 0.8101 | 0.9358 | 0.1432 | 0.8677 | 0.2235 | 0.9027 |
| rend01_oBA3 | 0.9663 | 0.0343 | 0.3516 | 0.8414 | 0.1096 | 0.6820 |
| rend02_oC95 | 0.8984 | 0.7131 | 0.2555 | 0.9860 | 0.2098 | 0.7876 |
| rend03_oB12 | 0.9457 | 0.7657 | 0.5551 | 0.9428 | 0.1120 | 0.4781 |
| rend04 | 0.9364 | 0.7112 | 0.4196 | 0.8794 | 0.1153 | 0.2038 |
| rend05_o87A | 0.5791 | 0.9096 | 0.4179 | 0.6624 | 0.3368 | 0.7149 |
| rend06_oB1D | 0.3676 | 0.8107 | 0.0208 | 0.5004 | 0.0254 | 0.8606 |
| rend07 | 0.9799 | 0.8005 | 0.1296 | 0.8766 | 0.3345 | 0.9331 |
| rend08_o0AF | 0.8867 | 0.9878 | 0.8208 | 0.9087 | 0.4212 | 0.9290 |
| rend09_o2F3 | 0.7016 | 0.2394 | 0.2692 | 0.7260 | 0.0892 | 0.8307 |
| rend10_oF1C | 0.9318 | 0.9896 | 0.4474 | 0.9447 | 0.1939 | 0.9357 |
| rend11_o972 | 0.8177 | 0.7983 | 0.6267 | 0.7643 | 0.4156 | 0.8490 |
| rend12 | 0.0845 | 0.6519 | 0.0758 | 0.1048 | 0.0364 | 0.4317 |
| rend13_o7B0 | 0.1980 | 0.2979 | 0.1393 | 0.2174 | 0.0635 | 0.2142 |
| rosette_oC92 | 0.8591 | 0.8581 | 0.1490 | 0.9440 | 0.7351 | 0.5430 |
| Total number of highest scores | 8 | 7 | 1 | 6 | 2 | 9 |
| Image | Khan et al. [9] | Gu et al. [11] | Gao et al. [28] | Ok et al. [23] | Yang et al. [21] | Our Method |
|---|---|---|---|---|---|---|
| Apartment_float_o15C | 0.8279 | 0.8837 | 0.8133 | 0.8344 | 0.7033 | 0.9074 |
| AtriumNight_oA9D | 0.9653 | 0.9316 | 0.9667 | 0.9389 | 0.8839 | 0.9588 |
| Desk_oBA2 | 0.9587 | 0.8316 | 0.8601 | 0.9569 | 0.8595 | 0.9463 |
| Display1000_float_o446 | 0.9621 | 0.8795 | 0.8818 | 0.9499 | 0.9127 | 0.9246 |
| Montreal_float_o935 | 0.9094 | 0.8711 | 0.8424 | 0.9418 | 0.6981 | 0.9204 |
| MtTamWest_o281 | 0.8950 | 0.9121 | 0.9220 | 0.9511 | 0.8178 | 0.9763 |
| Spheron3 | 0.8582 | 0.8292 | 0.8058 | 0.8685 | 0.7283 | 0.8978 |
| SpheronNice | 0.8269 | 0.8113 | 0.8217 | 0.8422 | 0.7117 | 0.9125 |
| SpheronPriceWestern | 0.9764 | 0.8585 | 0.9267 | 0.9505 | 0.9766 | 0.9382 |
| SpheronNapaValley_oC5D | 0.7866 | 0.7747 | 0.7824 | 0.8311 | 0.6845 | 0.8815 |
| SpheronSiggraph2001_oF1E | 0.8203 | 0.9109 | 0.8038 | 0.8558 | 0.7284 | 0.8570 |
| StillLife_o7C1 | 0.8941 | 0.8311 | 0.7260 | 0.8984 | 0.8770 | 0.8809 |
| Tree_oAC1 | 0.9681 | 0.8261 | 0.8792 | 0.9543 | 0.9151 | 0.9554 |
| bigFogMap_oDAA | 0.9197 | 0.8933 | 0.9214 | 0.9574 | 0.8042 | 0.8352 |
| dani_belgium_oC65 | 0.9610 | 0.9366 | 0.8808 | 0.9520 | 0.8370 | 0.9702 |
| dani_cathedral_oBBC | 0.9534 | 0.8864 | 0.8222 | 0.9733 | 0.9338 | 0.9267 |
| dani_synagogue_o367 | 0.9409 | 0.8580 | 0.8892 | 0.9593 | 0.6725 | 0.9049 |
| memorial_o876 | 0.9393 | 0.8424 | 0.8225 | 0.9031 | 0.8546 | 0.8813 |
| nave | 0.9386 | 0.9460 | 0.7848 | 0.9422 | 0.8348 | 0.9489 |
| rend01_oBA3 | 0.9434 | 0.7592 | 0.8320 | 0.9235 | 0.7663 | 0.8967 |
| rend02_oC95 | 0.9583 | 0.9208 | 0.8414 | 0.9667 | 0.8149 | 0.9427 |
| rend03_oB12 | 0.9570 | 0.9208 | 0.8692 | 0.9548 | 0.7954 | 0.8788 |
| rend04 | 0.9594 | 0.9097 | 0.8689 | 0.9472 | 0.8052 | 0.8345 |
| rend05_o87A | 0.9032 | 0.9308 | 0.8397 | 0.9155 | 0.8357 | 0.9254 |
| rend06_oB1D | 0.8816 | 0.9498 | 0.7482 | 0.9081 | 0.7947 | 0.9601 |
| rend07 | 0.9348 | 0.9058 | 0.7617 | 0.9154 | 0.8367 | 0.9299 |
| rend08_o0AF | 0.9589 | 0.9618 | 0.9297 | 0.9563 | 0.8463 | 0.9654 |
| rend09_o2F3 | 0.9370 | 0.8372 | 0.8166 | 0.9379 | 0.7748 | 0.9457 |
| rend10_oF1C | 0.9261 | 0.9206 | 0.8275 | 0.9237 | 0.7503 | 0.9357 |
| rend11_o972 | 0.9370 | 0.9224 | 0.8665 | 0.9294 | 0.8541 | 0.9480 |
| rend12 | 0.7145 | 0.8385 | 0.6829 | 0.7319 | 0.6874 | 0.8134 |
| rend13_o7B0 | 0.8236 | 0.8044 | 0.7127 | 0.8099 | 0.6910 | 0.7897 |
| rosette_oC92 | 0.9467 | 0.9485 | 0.7863 | 0.9602 | 0.9289 | 0.9022 |
| Total number of highest scores | 9 | 3 | 1 | 7 | 1 | 12 |
| Metric | Khan et al. [9] | Gu et al. [11] | Gao et al. [28] | Ok et al. [23] | Yang et al. [21] | Our Method |
|---|---|---|---|---|---|---|
| TMQI-Q | 0.912 | 0.880 | 0.834 | 0.916 | 0.807 | 0.912 |
| TMQI-S | 0.856 | 0.807 | 0.762 | 0.848 | 0.752 | 0.858 |
| TMQI-N | 0.684 | 0.572 | 0.401 | 0.721 | 0.288 | 0.671 |
| BRISQUE | 25.230 | 25.420 | 24.283 | 26.200 | 26.050 | 24.100 |
| BTMQI | 3.646 | 3.656 | 5.010 | 4.249 | 4.978 | 3.202 |
| FSITMr_TMQI | 0.860 | 0.840 | 0.820 | 0.860 | 0.806 | 0.864 |
| FSITMg_TMQI | 0.872 | 0.848 | 0.813 | 0.867 | 0.816 | 0.873 |
| FSITMb_TMQI | 0.863 | 0.847 | 0.819 | 0.861 | 0.807 | 0.865 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.-Y.; Hua, K.-L.; Tsai, Y.-C.; Wu, J.-H. Photographic Reproduction and Enhancement Using HVS-Based Modified Histogram Equalization. Sensors 2021, 21, 4136. https://doi.org/10.3390/s21124136
Chen Y-Y, Hua K-L, Tsai Y-C, Wu J-H. Photographic Reproduction and Enhancement Using HVS-Based Modified Histogram Equalization. Sensors. 2021; 21(12):4136. https://doi.org/10.3390/s21124136
Chicago/Turabian StyleChen, Yung-Yao, Kai-Lung Hua, Yun-Chen Tsai, and Jun-Hua Wu. 2021. "Photographic Reproduction and Enhancement Using HVS-Based Modified Histogram Equalization" Sensors 21, no. 12: 4136. https://doi.org/10.3390/s21124136
APA StyleChen, Y. -Y., Hua, K. -L., Tsai, Y. -C., & Wu, J. -H. (2021). Photographic Reproduction and Enhancement Using HVS-Based Modified Histogram Equalization. Sensors, 21(12), 4136. https://doi.org/10.3390/s21124136