
Self-Erasing Network for Person Re-Identification


Abstract
:1. Introduction
- (1)
- We designed an end-to-end multi-branch self-erasing network to overcome background interference and extract sufficient local information;
- (2)
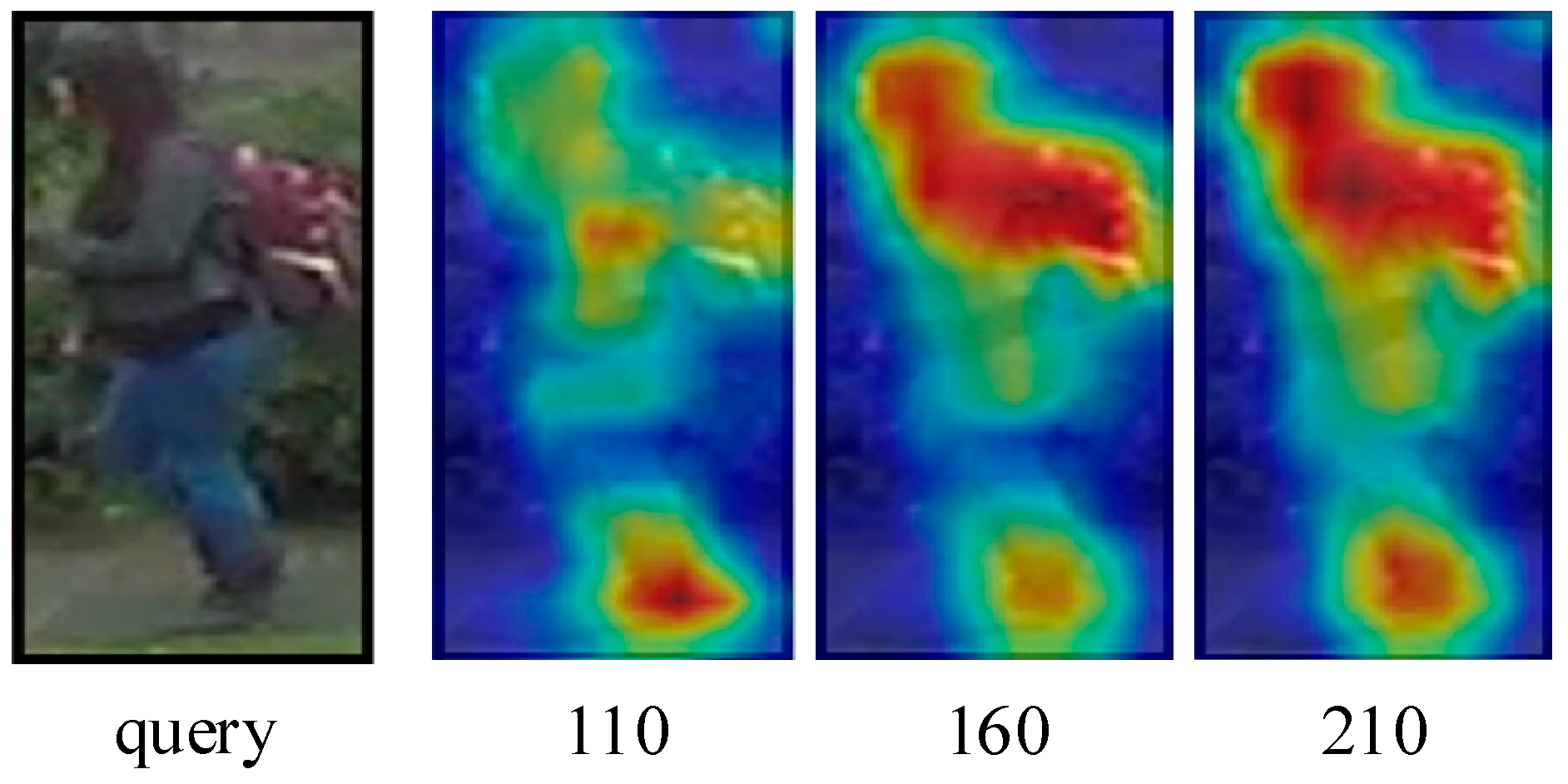
- Through the visualization of activation maps, we found that fully digging out a more comprehensive feature representation of a person helps to improve the discriminability of the model.
- (3)
- Extensive experiments show that the proposed model has certain advantages over recent state-of-the-art methods.
2. Related Work
3. Proposed Method
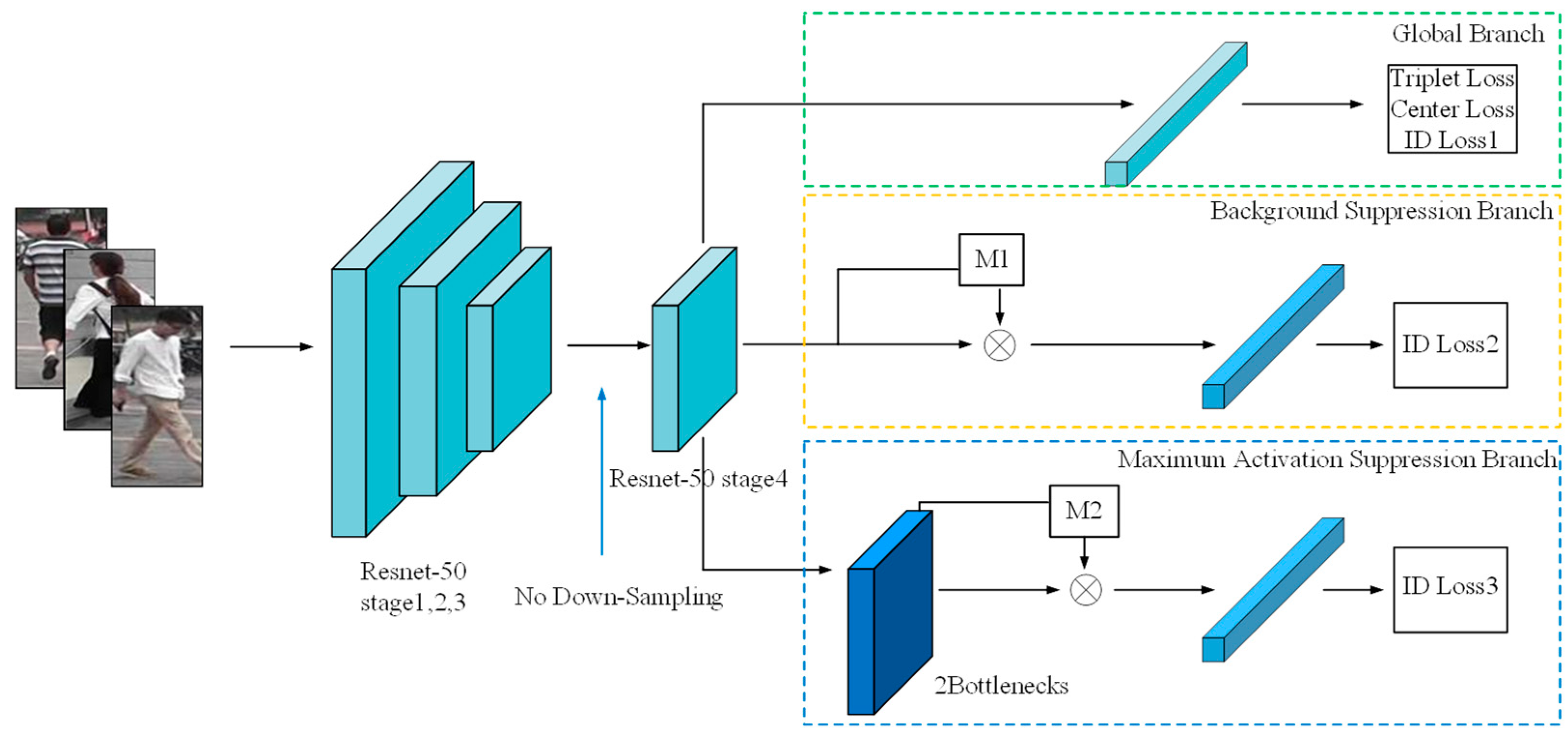
3.1. Network Architecture
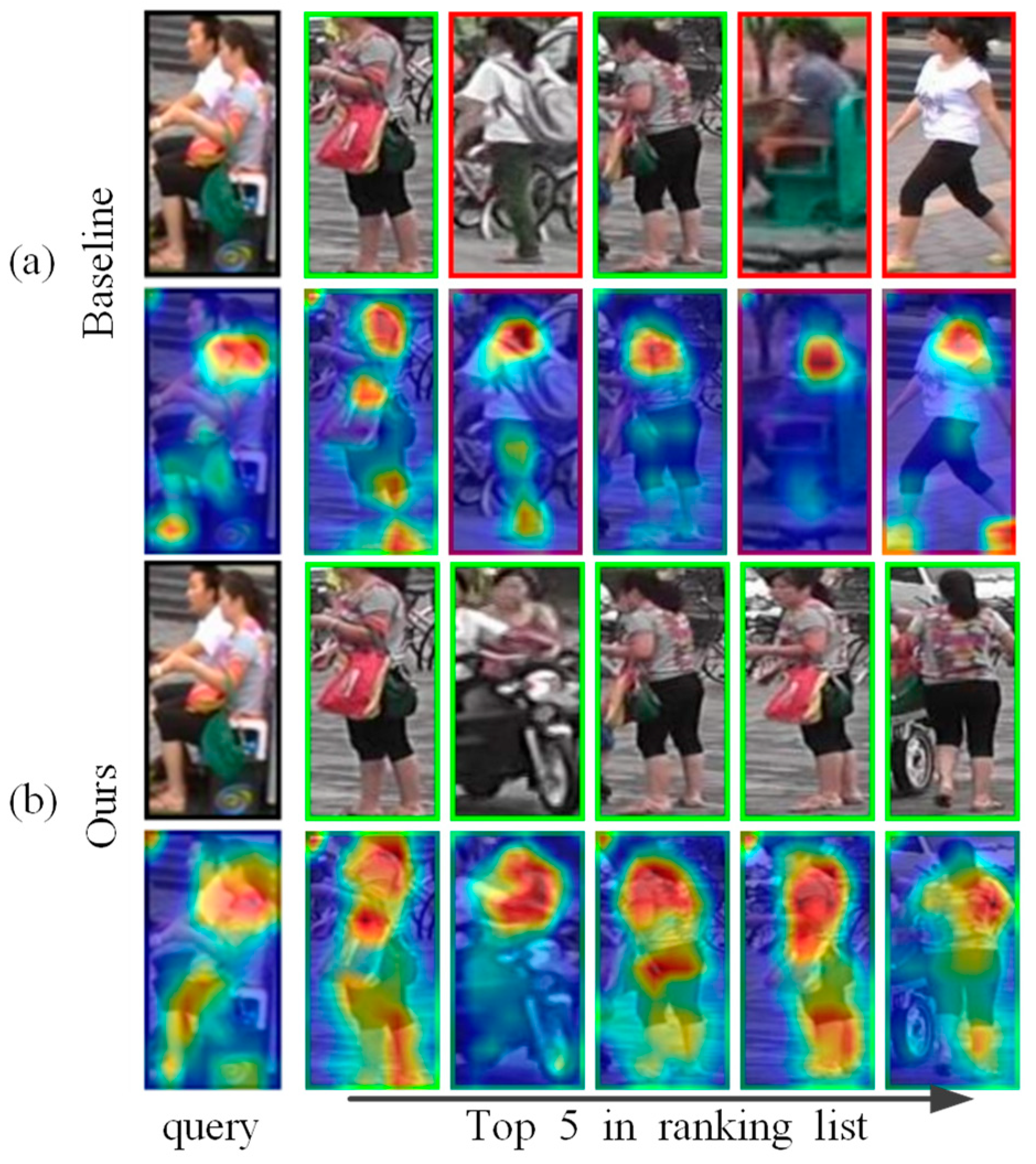
3.2. Self-Erasing Network
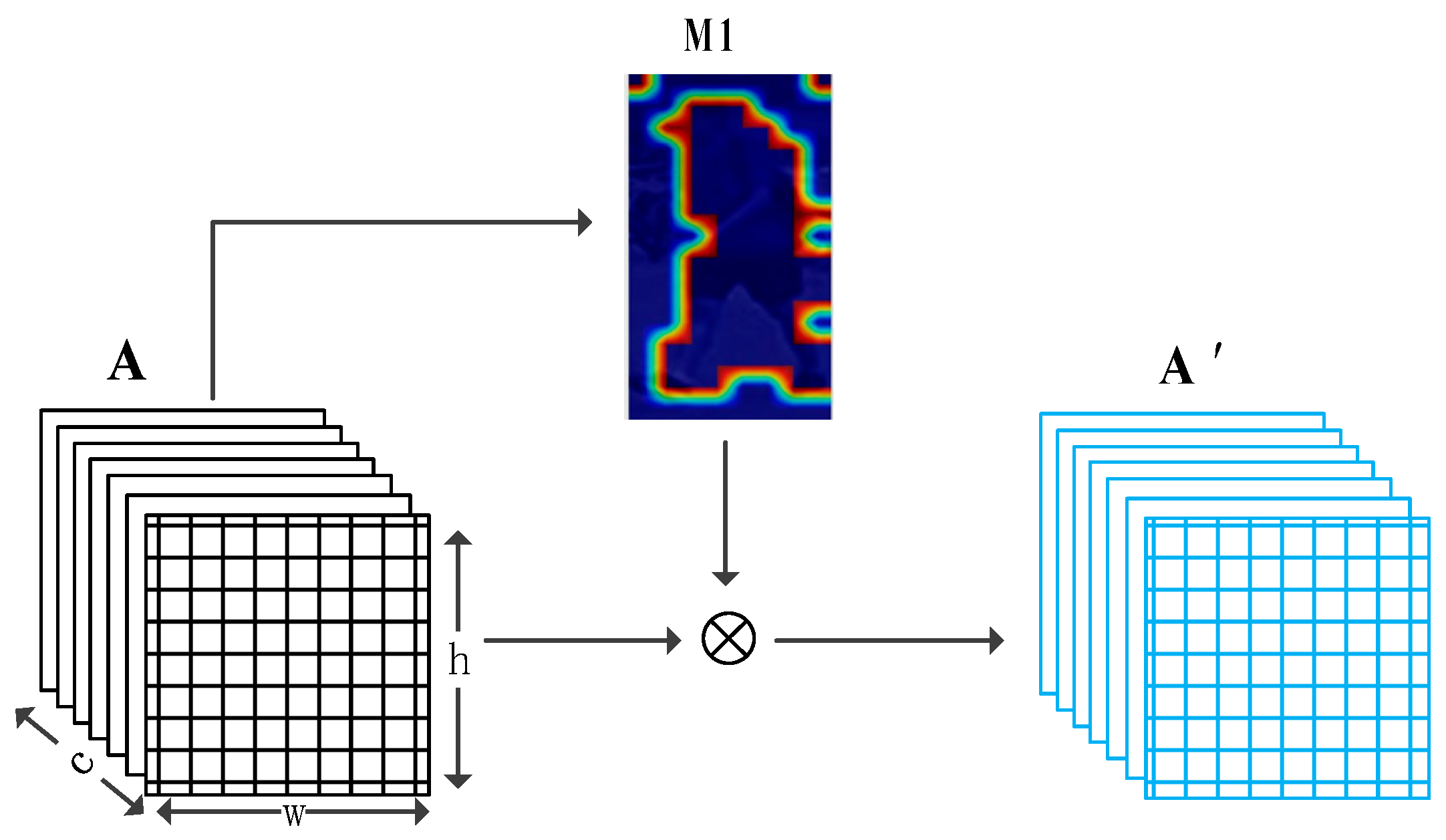
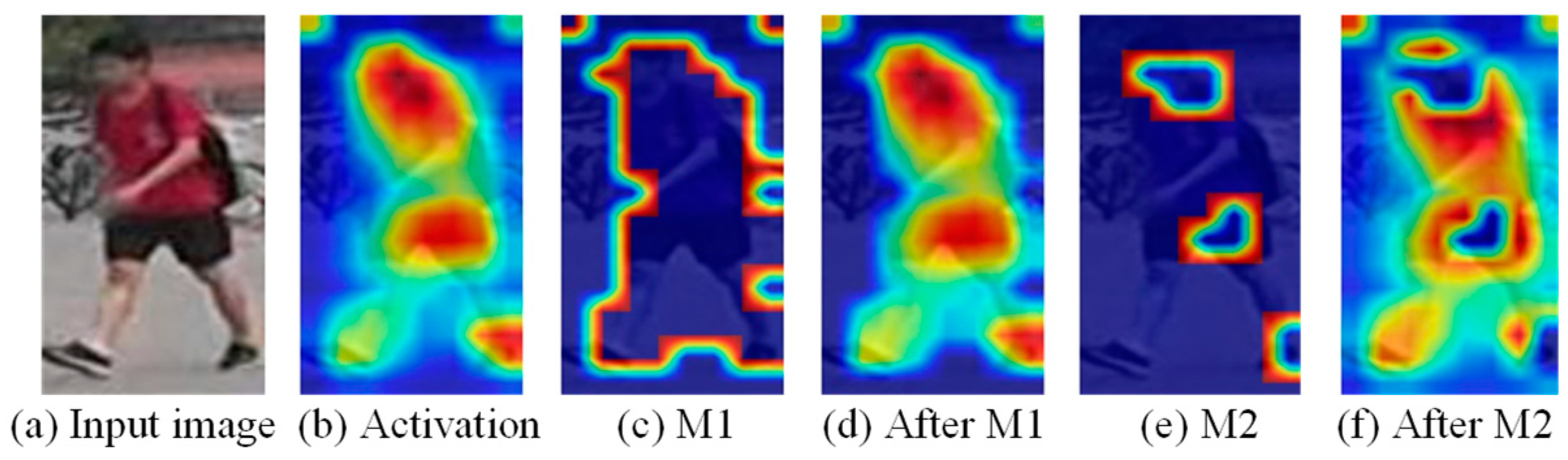
3.2.1. Background Suppression Branch
3.2.2. Maximum Activation Suppression Branch
3.3. Loss Function
4. Experimental Results
4.1. Implementation Details
4.2. Datasets and Evaluation Metrics
4.2.1. Datasets
4.2.2. Evaluation Metrics
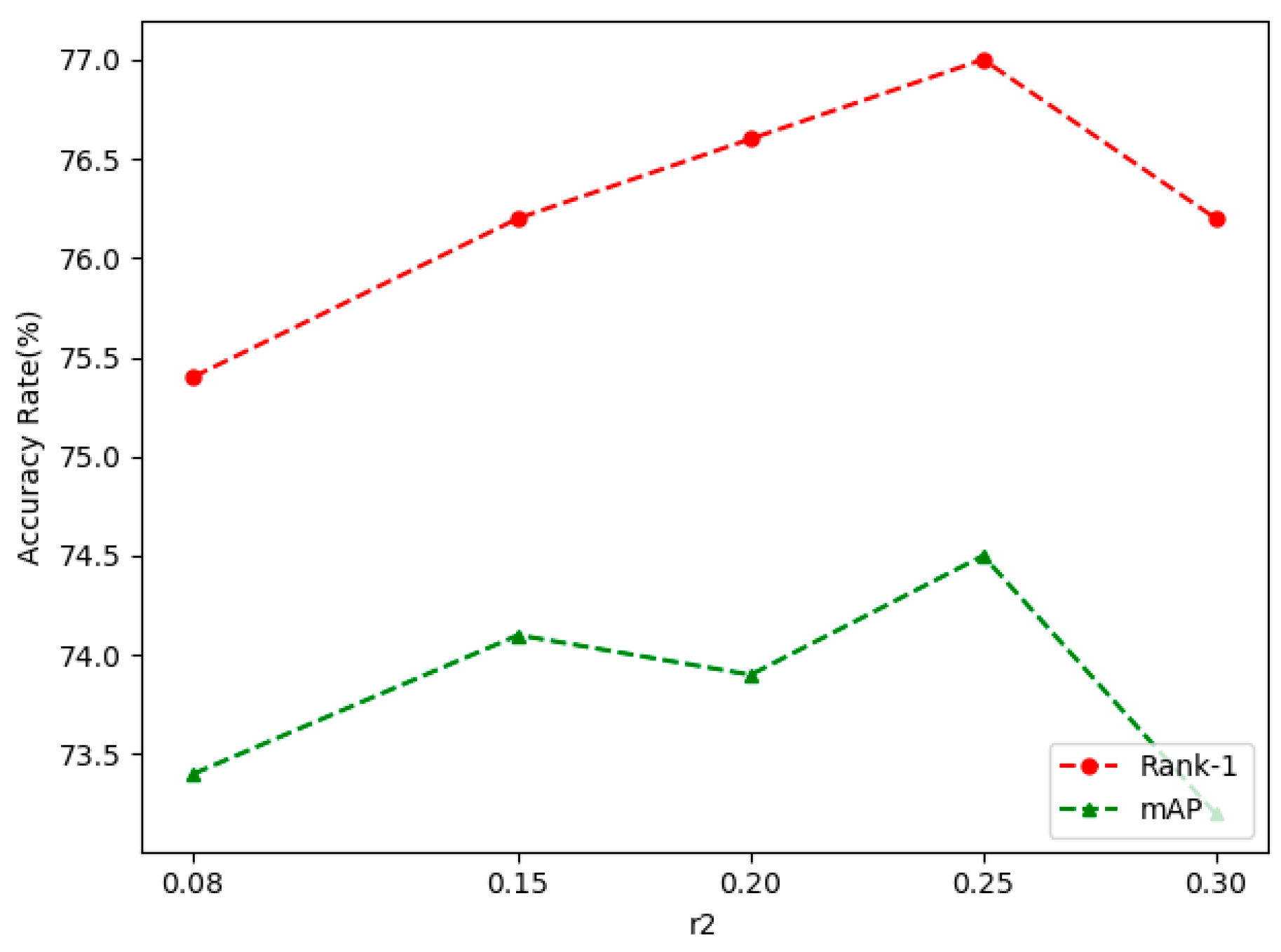
4.3. Ablation Study
4.4. Comparison with State-of-the-Art
4.5. Limitations
4.6. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| Acronyms | Full Form |
| BDB | Batch Drop-Block |
| FCN | Fully Convolutional Networks |
| GAN | Generative Adversarial Network |
| HA-CNN | Harmonious Attention Network |
| HPM | Horizontal Pyramid Matching |
| MGCAM | Mask-Guided Contrastive Attention Model |
| PCB | Part-based Convolutional Baseline |
| ReID | Person re-identification |
References
- Wang, Y.; Wang, L.; You, Y.; Zou, X.; Chen, V.; Li, S.; Huang, G.; Hariharan, B.; Weinberger, K.Q. Resource aware person re-identification across multiple resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8042–8051. [Google Scholar]
- Tan, H.; Xiao, H.; Zhang, X.; Dai, B.; Lai, S.; Liu, Y.; Zhang, M. MSBA: Multiple Scales, Branches and Attention Network with Bag of Tricks for Person Re-Identification. IEEE Access 2020, 8, 63632–63642. [Google Scholar] [CrossRef]
- Wu, D.; Wang, C.; Wu, Y.; Huang, D. Attention deep model with multi-scale deep supervision for person re-identification. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 70–78. [Google Scholar] [CrossRef]
- Qian, X.; Fu, Y.; Jiang, Y.G.; Xiang, T.; Xue, X. Multi-scale deep learning architectures for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5399–5408. [Google Scholar]
- Zhang, X.; Luo, H.; Fan, X.; Xiang, W.; Sun, Y.; Xiao, Q.; Jiang, W.; Zhang, C.; Sun, J. Alignedreid: Surpassing human-level performance in person re-identification. arXiv 2017, arXiv:1711.08184. [Google Scholar]
- Hou, R.; Ma, B.; Chang, H.; Gu, X.; Shan, S.; Chen, X. Interaction-and-aggregation network for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9317–9326. [Google Scholar]
- Cai, H.; Wang, Z.; Cheng, J. Multi-scale body-part mask guided attention for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 1555–1564. [Google Scholar]
- Xia, B.N.; Gong, Y.; Zhang, Y.; Poellabauer, C. Second-order non-local attention networks for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3760–3769. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 480–496. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-scale feature learning for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3702–3712. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13001–13008. [Google Scholar]
- Ni, X.; Fang, L.; Huttunen, H. AdaptiveReID: Adaptive L2 Regularization in Person Re-Identification. arXiv 2020, arXiv:2007.07875. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3754–3762. [Google Scholar]
- Dai, Z.; Chen, M.; Gu, X.; Zhu, S.; Tan, P. Batch dropblock network for person re-identification and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3691–3701. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 19–21 June 2018; pp. 2285–2294. [Google Scholar]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning discriminative features with multiple granularities for person re-identification. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 26 October 2018; pp. 274–282. [Google Scholar]
- Wang, H.; Fan, Y.; Wang, Z.; Jiao, L.; Schiele, B. Parameter-free spatial attention network for person re-identification. arXiv 2018, arXiv:1811.12150. [Google Scholar]
- Fu, Y.; Wei, Y.; Zhou, Y.; Shi, H.; Huang, G.; Wang, X.; Yao, Z.; Huang, T. Horizontal pyramid matching for person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, Hawaii, 27 January–1 February 2019; Volume 33, pp. 8295–8302. [Google Scholar]
- Su, C.; Zhang, S.; Xing, J.; Gao, W.; Tian, Q. Deep attributes driven multi-camera person re-identification. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland; pp. 475–491. [Google Scholar]
- Quispe, R.; Pedrini, H. Improved person re-identification based on saliency and semantic parsing with deep neural network models. Image and Vis. Comput. 2019, 92, 103809. [Google Scholar] [CrossRef] [Green Version]
- Zheng, L.; Huang, Y.; Lu, H.; Yang, Y. Pose-invariant embedding for deep person re-identification. IEEE Trans. Image Process. 2019, 28, 4500–4509. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hou, Q.; Jiang, P.T.; Wei, Y.; Cheng, M.M. Self-erasing network for integral object attention. arXiv 2018, arXiv:1810.09821. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-guided contrastive attention model for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1179–1188. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer. arXiv 2016, arXiv:1612.03928. [Google Scholar]
- Luo, H.; Jiang, W.; Gu, Y.; Liu, F.; Liao, X.; Lai, S.; Gu, J. A strong baseline and batch normalization neck for deep person re-identification. IEEE Trans. Multimed. 2019, 22, 2597–2609. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland; pp. 499–515. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland; pp. 17–35. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. DeepReID: Deep Filter Pairing Neural Network for Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 152–159. [Google Scholar]
- Zhang, Z.; Lan, C.; Zeng, W.; Zeng, W.; Chen, Z. Densely semantically aligned person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 667–676. [Google Scholar]
- Chen, Q.; Zhang, W.; Fan, J. Cluster-level Feature Alignment for Person Re-identification. arXiv 2020, arXiv:2008.06810. [Google Scholar]
- Sun, H.; Chen, Z.; Yan, S.; Xu, L. Mvp matching: A maximum-value perfect matching for mining hard samples, with application to person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6737–6747. [Google Scholar]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Lee, K.M. Part-aligned bilinear representations for person re-identification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 402–419. [Google Scholar]
- Yang, W.; Huang, H.; Zhang, Z.; Chen, X.; Huang, K.; Zhang, S. Towards rich feature discovery with class activation maps augmentation for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1389–1398. [Google Scholar]
- Quan, R.; Dong, X.; Wu, Y.; Zhu, L.; Yang, Y. Auto-reid: Searching for a part-aware convnet for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 3750–3759. [Google Scholar]
- Zheng, Z.; Yang, X.; Yu, Z.; Zheng, L.; Yang, Y.; Kaut, j. Joint discriminative and generative learning for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2138–2147. [Google Scholar]
- Wang, G.; Yang, S.; Liu, H.; Wang, Z.; Yang, Y.; Wang, S.; Yu, G.; Zhou, E.; Sun, J. High-order information matters: Learning relation and topology for occluded person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 6449–6458. [Google Scholar]
- Chen, B.; Deng, W.; Hu, J. Mixed high-order attention network for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 371–381. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Training ID | Training Image | Gallery ID | Gallery Image | Camera | Resolution |
|---|---|---|---|---|---|---|
| Market1501 | 751 | 12936 | 750 | 19732 | 6 | fixed |
| DukeMTMC-ReID | 702 | 16522 | 1110 | 17661 | 8 | vary |
| CUHK03(D) | 767 | 7365 | 700 | 5332 | 10 | vary |
| Method | Market1501 | DukeMTMC-ReID | CUHK03(L) | CUHK03(D) | ||||
|---|---|---|---|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | Rank-1 | mAP | Rank-1 | mAP | |
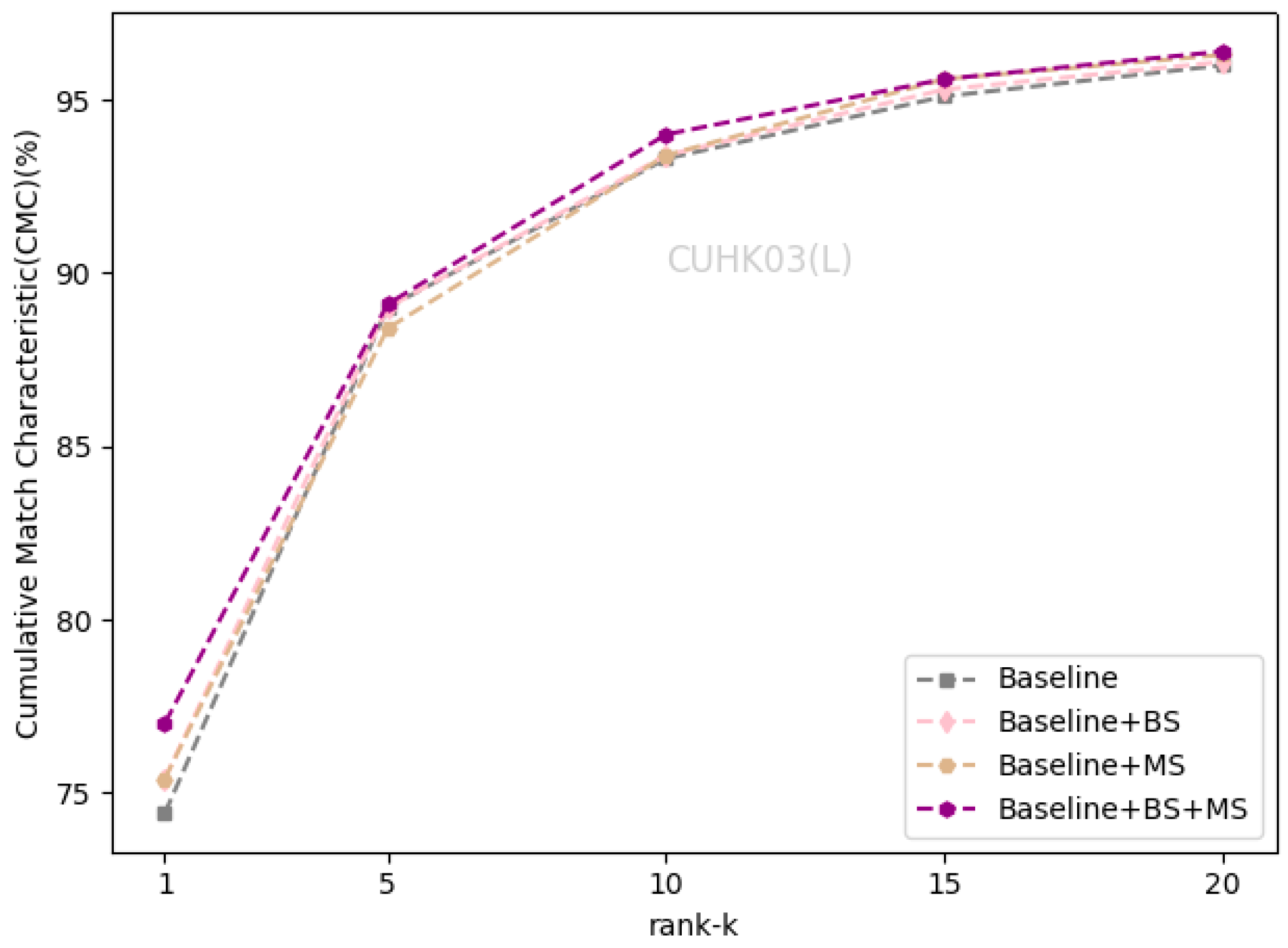
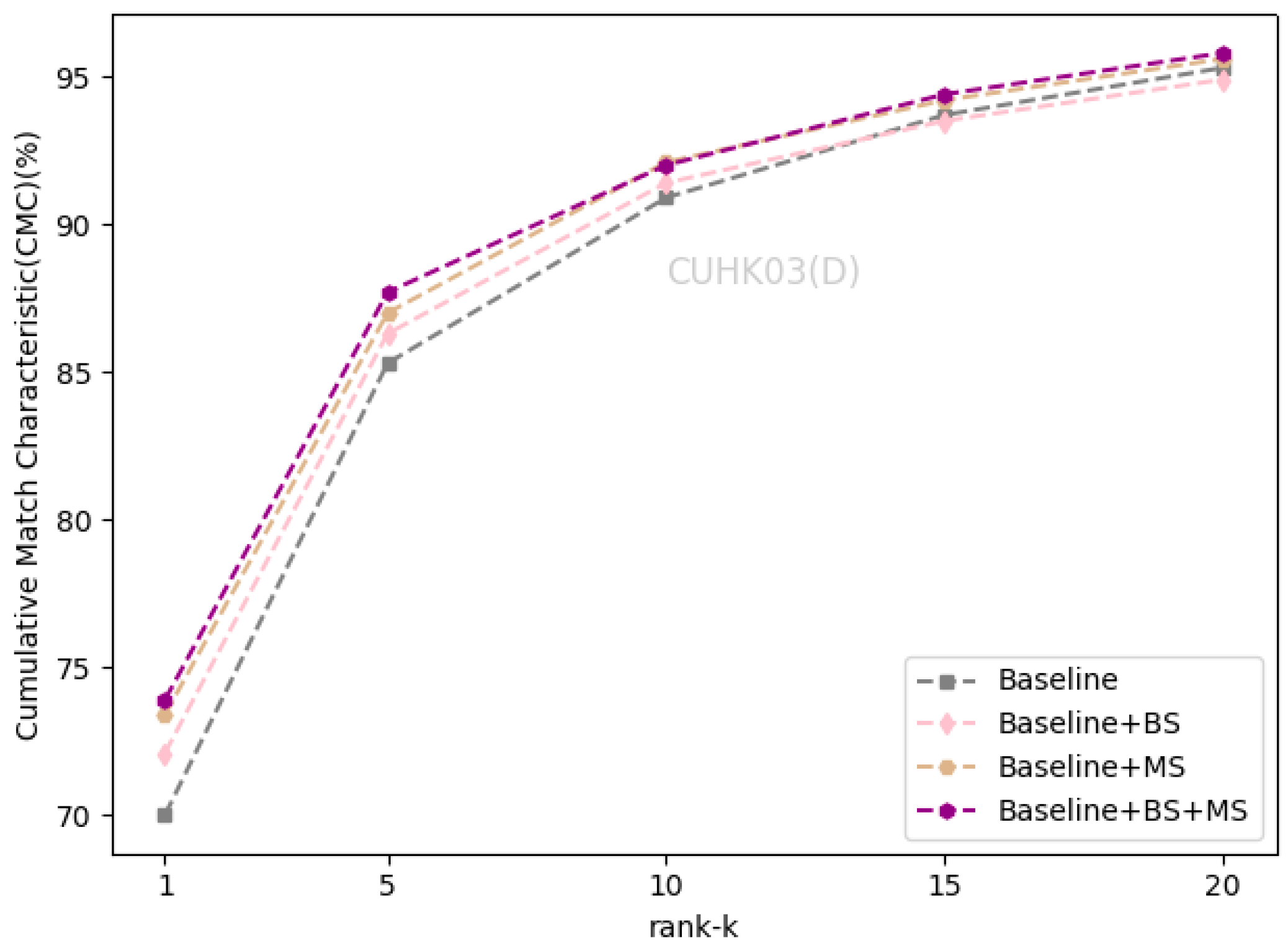
| Baseline | 94.2 | 86.2 | 86.4 | 76.4 | 74.4 | 72.7 | 70 | 67.9 |
| +BS | 94.8 | 87.2 | 88.1 | 77.6 | 75.4 | 73.1 | 72.1 | 69.1 |
| +MS | 95 | 87.5 | 88.3 | 77.9 | 75.4 | 73.4 | 73.4 | 71.2 |
| +BS+MS | 95.2 | 88.1 | 89 | 78.5 | 77 | 74.5 | 73.9 | 71 |
| Method | Source | Market1501 | DukeMTMC-ReID | ||||
|---|---|---|---|---|---|---|---|
| Rank-1 | mAP | Score | Rank-1 | mAP | Score | ||
| MVP [35] | ICCV2019 | 91.4 | 80.5 | 86 | 83.4 | 70.0 | 76.7 |
| CAMA [37] | CVPR2019 | 94.7 | 84.5 | 89.6 | 85.8 | 72.9 | 79.4 |
| Auto-ReID [38] | ICCV2019 | 94.5 | 85.1 | 89.8 | 88.5 | 75.1 | 81.8 |
| OSNet [10] | CVPR2019 | 94.8 | 84.9 | 89.9 | 86.6 | 74.8 | 80.7 |
| DGNet [39] | CVPR2019 | 94.8 | 86 | 90.4 | 86.6 | 74.8 | 80.7 |
| DSA-reID [33] | CVPR2019 | 95.7 | 87.6 | 91.7 | 86.2 | 74.3 | 80.3 |
| HOReID [40] | CVPR2020 | 94.2 | 84.9 | 89.6 | 86.9 | 75.6 | 81.3 |
| CLFA [34] | CVPR2020 | 95.4 | 88.0 | 91.7 | 88.3 | 79.1 | 83.7 |
| Ours | - | 95.2 | 88.1 | 91.7 | 89 | 78.5 | 83.8 |
| Method | Source | L | D | ||||
|---|---|---|---|---|---|---|---|
| Rank-1 | mAP | Score | Rank-1 | mAP | Score | ||
| Auto-ReID [38] | ICCV2019 | 73.0 | 77.9 | 75.5 | 73.3 | 69.3 | 71.3 |
| CAMA [37] | CVPR2019 | 70.1 | 66.5 | 68.3 | 66.6 | 64.2 | 65.4 |
| P2-Net [36] | ICCV2019 | 78.3 | 73.6 | 76 | 74.9 | 68.9 | 71.9 |
| OSNet [10] | CVPR2019 | - | - | - | 72.3 | 67.8 | 70.1 |
| MHN [41] | CVPR2019 | 77.2 | 72.4 | 74.8 | 71.7 | 65.4 | 68.6 |
| CLFA [34] | CVPR2020 | 76.3 | 74.5 | 75.4 | 72.3 | 70.3 | 71.3 |
| Ours | - | 77 | 74.5 | 75.8 | 73.9 | 71 | 72.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, X.; Lin, Y.; Zhang, C.; Zhang, J. Self-Erasing Network for Person Re-Identification. Sensors 2021, 21, 4262. https://doi.org/10.3390/s21134262
Fan X, Lin Y, Zhang C, Zhang J. Self-Erasing Network for Person Re-Identification. Sensors. 2021; 21(13):4262. https://doi.org/10.3390/s21134262
Chicago/Turabian StyleFan, Xinyue, Yang Lin, Chaoxi Zhang, and Jia Zhang. 2021. "Self-Erasing Network for Person Re-Identification" Sensors 21, no. 13: 4262. https://doi.org/10.3390/s21134262
APA StyleFan, X., Lin, Y., Zhang, C., & Zhang, J. (2021). Self-Erasing Network for Person Re-Identification. Sensors, 21(13), 4262. https://doi.org/10.3390/s21134262