1. Introduction
Voice modality is central to most creatures, particularly in human interactions among themselves. It is envisaged that it is also sensible that social robots communicate with humans through voice. There are three related yet different challenges that researchers are currently engaged towards realization of voice as a medium through which robots and humans interact: Who is speaking? What is being said? Which language is being spoken? This paper is concerned with the first question. Humans are better in person recognition by face than voice [
1]. However, in machines, voice modality provides unique features in biometric person identification systems as opposed to face, fingerprint, gait, or iris. The speech signal is captured dynamically over a period of few seconds; therefore, variation in speaker’s model can be monitored [
2]. Another advantage of using speech signal is the availability of numerous devices such as microphones, cellphone, and soundcards that can be used to capture the speech signal [
3]. Moreover, there are many scenarios of social human–robot interactions where all the above mentioned biometric modalities are not simultaneously available due to limitation of robot’s sensory system or the occlusion of target person by static or dynamic objects such as furniture and other persons who share the same environment with the social robot. These situations may arise in many social settings like homes, hospitals, airports, etc.
Speaker recognition systems can be classified into text-dependent speaker recognition and text-independent speaker recognition. The former system is employed when the speaker is cooperative and willing to pronounce fixed utterances as an authentication password or prompted by the system to pronounce pre-defined phrases that have been already registered in the system during the enrolment process. This scenario is readily used in speaker authentication systems where they extract signature(s) from a fixed utterance pronounced by an unknown speaker and verify if this utterance corresponds to the claimed identity. Even though the text-independent speaker recognition can be used as a speaker verification system, the system demonstrates its advantages in other applications where the speaker needs to be identified from unconstrained utterances as in the case of identifying a speaker by a social robot in a social human–robot interaction scenario. Constrained utterances used in text-dependent speaker recognition systems limit the functionality of the system in some applications such as social robot, speaker diarisation, intelligent answering machine with personalized caller greeting, and forensic investigation of telephone conversations. A speaker identification system for social human–robot interaction, which is the main motivation of this research, should be able to extract a voice signature from unconstrained utterances while maintains its performance at challenging scenarios including various low signal-to-noise ratio and short length of utterance as well as different types of noise. However, most of the state-of-the-art speaker recognition systems, including those based on deep learning algorithms, have achieved significant performance on verification tasks which are not suitable for social human–robot interaction [
4,
5,
6]. In speaker diarisation, which is a key feature for social robots, also known as “who spoke when”, a speech signal is partitioned into homogenous segments according to speaker identity [
7]. Hence, the speaker identity must be induced by extracting features from unconstrained utterances that may be short and not have been used in the training stage.
The background speaker model is used in speaker recognition literature extensively as a way to enhance the robustness and computational efficiency of speaker recognition system [
3]. Unlike other biometrics (such as face, fingerprint, iris, and hand geometry), voice biometrics is prone to substantial variability. There are many factors contributing to this variability including but not limited to changes in vocal tract and how a speaker produces speech (intrinsic-based source of variations), variation of speech signal capturing and transmission (external-based source of variations), and variation in languages and dialects spoken that are used in conversation (conversation-based source of variation). In situations referred to as within-speaker variability, the same person does not utter the same words in the same way. These conditions could arise due to physiological reasons (e.g., illness, being intoxicated, or aging), emotional states (e.g., anger, happiness, and sadness), or a combination of both. In most cases, the physiological and emotional changes happen naturally and not intended to circumvent the system. Within-speaker variability is considered as one of the main challenges that must be addressed by speaker identification systems that are prevalent in social robot applications such as a robot companion, a robot caregiver, or a robot personal assistant. Additionally, a person may intentionally alter his/her voice, an important factor contributing to within-speaker variability, to elude the system [
8]. In addition, the performance of a speaker recognition system is affected by the technology used to capture, transmit, and save the speech signal. These scenarios are referred to as the channel variation effects, and the environmental, or background distortion. A significant research effort has been devoted to address this multifarious source of variations [
9]. However, most of the research efforts focus on addressing the external-based sources of variation; considerable progress has been achieved in addressing the background noise (by using additive noise known as signal-to-noise ratio) and the channel variations (by using channel compensation techniques) [
10]. Most of the feature extraction methods used in speaker recognition systems rely on spectral characteristic of the speech signal which is highly affected by a person’s health, age, and emotional state; the intrinsic-based source of variations. As such, this poses a huge challenge to speaker recognition systems particularly those intended for social robots. Among the ideal features of a speaker recognition systems are low discriminant power within-speaker variability, high discriminant power between-speaker variability, robust against the aforementioned source of variations (i.e., intrinsic-, external-, and conversation-based source of variations), easy to extract, and difficult to impersonate [
3]. A significant research effort has been devoted to develop feature vectors that possess some of the above characteristics [
11]. However, to the best of the authors knowledge no particular feature extraction method is robust against all sources of variations and all types of noises. In a parallel development, a large body of research has aimed at developing different speaker modeling, normalization, and adaption techniques that employ these feature vectors in order to increase the robustness of the speaker recognition system against the aforementioned source of variations [
3].
Motivated by the above challenges, particularly those related to social robot applications, and noting that there is no single speaker recognition model that is universally applicable in different types of noise, different signal-to-noise ratios, and variable utterance lengths scenarios, and the absence of a “crystal ball” for speaker modeling, normalization, and adaptation, we propose a sophisticated architecture of speaker identification system for social robots. The proposed architecture encapsulates heterogeneous classifiers that employ prosodic and short-term spectral features in a two-stage classifier in order to integrate the advantages of using complementary features and different classifier models (generative and discriminative) in developing a robust speaker recognition system for social robots. The architecture utilizes gender information to cluster the population in the dataset into two groups (male and female) as well as deriving a speaker model from the gender-dependent model to provide strong coupling and improve recognition rate of the base classifier. Additionally, the system exploits the knowledge based-system (IF-THEN fuzzy rules), which is derived from the performance of the trained base classifier on limited size development set, to overcome the problem of limited size speech dataset which contains short utterances distorted with different types of noise.
The rest of the paper is organized as follows: in
Section 2, we review the relevant literature and underscore the current state-of-the-art in speaker recognition systems. We also highlight the main challenges in speaker recognition. We present the detailed architecture of the proposed system in
Section 3. The proposed methodology is evaluated via simulation studies in
Section 4. The paper is concluded with a summary of the findings and the main characteristics of the present method in
Section 5.
2. Related Works
Humans have the ability to recognize another person’s voice seamlessly without conscious effort. It is understood that various aspects of a person’s voice characteristics are implicitly and explicitly involved in the recognition process including spectral characteristics, prosody (syllable stress, intonation patterns, speaking rate and rhythm), and conversation-level features (lexicon and language). Analogous to humans, automatic speaker recognition systems employ various voice proprieties to recognize a person from his/her voice. These can be categorized into (1) short-term spectral features; (2) voice-based and prosodic features; (3) high-level features. The short-term spectral features are computed based on short frames in the range of 10–20 ms and can be seen as descriptors of vocal tract characteristics. Since this category of features require a small amount of data to be extracted, they fit well with real-time applications as in the case of speaker identification in social settings [
11]. In social human–robot interactions, fast response which is prone to some degree of error is considered better than accurate but delayed response (i.e., humans prefer fast response with some level of error better than accurate but delayed response) [
12]. Additionally, short-term spectral features are easy to extract and are text and language independent. Most of the automatic speaker recognition systems that have been developed in the last two decades employ short-term spectral features including mel-frequency cepstral coefficients (MFCC), linear predictive cepstral coefficients (LPCCs), line spectral frequencies (LSFs), perceptual linear prediction (PLP) coefficients, and gammatone frequency cepstral coefficients (GFCC), to name a few [
11]. However, none of these features are robust to the above multifarious source of variations and background noise but may cooperate and complement each other [
13,
14]. A new feature extraction method has been proposed to construct features that have the advantages of cochleagram robustness and mel-spectrogram voiceprint richness [
15]. mel-spectrogram and cochleagram are combined in two ways to construct two features, named MC-spectrogram and MC-cube. MC-spectrogram is constructed by superimposed mel-spectrogram and cochleagram on each other while MC-cube is constructed by mapping mel-spectrogram and cochleagram to a cube as harmonic mean. Several research studies suggest extension of MFCC features, which is based on mel-spectrogram, for speaker recognition system. The recognition rate has been improved by 4% by including delta derivatives of MFCC namely delta MFCC and delta-delta [
16]. The best performance achieved was 94% recognition rate with MFCC feature vector having 18 coefficients. In [
17], the 18 MFCC feature vector has been modified by adding two features. Observing and tracking spectral maxima in the energy spectrum of the speech signal were the key factor in calculating the two additional features. Adopting the modified MFCC feature vector has improved the recognition accuracy by 2.43% approximately. A huge research effort has been devoted to developing speaker modeling, including Gaussian mixture model (GMM) [
18], GMM supervector with support vector machine (SVM) [
19], and i-vector system [
20,
21], deep learning systems [
6,
22,
23], normalization [
24,
25] and channel compensation techniques [
26], and adaptation techniques [
27,
28] to reduce the effect of these variations on the performance of the speaker recognition system. Impressive progress has been achieved in addressing external-based source of variations, particularly channel variations and environmental and background distortion [
9]. However, the performance of the state-of-the-art speaker recognition systems dramatically deteriorates when short utterances are used for training/testing particularly with low SNR [
29,
30]. In spite of the fact that deep neural networks (DNNs) provide a state-of-the-art tool for acoustic modeling, DNNs are data sensitive, and limited speech data as well as data-mismatch problems can deteriorate their performance [
4,
5,
31].
In the last five years, deep learning methods have been demonstrated to outperform most of the classical speech and speaker recognition systems such as GMM-Universal Background Model (UBM), SVM, and
i-vector [
32,
33]. However, deep learning systems require huge speech databases to be labeled and trained; theses databases also need to include phonetically rich sentences or at least phonetically balanced sentences [
31]. In addition, most of speaker recognition systems that were developed based on deep learning techniques have been applied to text-dependent speaker verification tasks [
4]. Hence, training deep learning systems on limited data is a difficult task and may not necessarily lead to speaker recognition systems with state-of-the-art performance. The above-mentioned challenges which are frequently encountered in some of the social robot applications such as social robots for people with developmental disabilities, elderly care housing and assisted living, nursing robots [
34,
35,
36] hinder the direct application of deep learning systems. In such scenarios, collecting large databases is time-consuming, strenuous, inconvenient, expensive, and may be an impossible task as in the case of people with speech impairments. The key advantage of deep learning systems that they can recognize a large number of subjects may not justify their adaptation for speaker recognition for social robots as social robots need to interact with a limited number of persons.
Some research studies suggest that the performance of GMM-UBM system is close to
i-vector based system in short duration utterance and over perform it in very short utterances (less than 2 s) [
37]. Another challenge that needs more work to address is intrinsic-based source of variations [
9] and synthesis and conversion spoofing attacks [
38]; voice conversion and statistical parametric speech synthesizers that may use spectral-based representation similar to the one used in speaker recognition systems that employ spectral features.
The high-level features use a speaker’s lexicon (i.e., the kind of words that a speaker frequently uses in his/her conversations) to extract a signature that characterizes a speaker. Some research studies show that this category of features is robust against channel variation and background noise, but it requires substantial computational cost and is difficult to extract [
3,
39]. Additionally, this category is language and text dependent, needs a lot of training data, and is easier to impersonate. The pros and cons of the prosodic features category sit in the middle of the scale between high-level feature and short-term spectral feature. Researchers suggest that the prosodic features carry less discriminant power than short-term spectral features but are complementary [
3]. However, due to the nature of prosody, which reflects the differences in speaking styles such as rate, rhythm, and intonation pattern. This category shows more resistance to voice synthesis and conversion spoofing attacks, but it is valuable to human impersonation. Employing this feature in speaker recognition systems provides robustness to adversarial attacks to which most deep speaker recognition systems are prone to [
40]. One can argue that a speaker recognition system that employs short-term spectral and prosodic features is more robust than those systems that employ only one type of these features. A reasonable research effort has been devoted to fuse prosodic and spectral features in order to improve the accuracy and robustness of the recognition of a speaker age, gender, and identity [
41,
42,
43]. However, most of these systems adopt either fusion at score level for prosodic-based system and spectral-based system or fusion at feature level by stacking prosodic-based feature representation with spectral-based feature representation. Fusion at score and feature level has been demonstrated in [
44]; the fusion at score level was presented as a fusion of the outputs of two prosodic-based classifiers and the output of one cepstral-based classifier while fusion at feature level was performed by stacking cepstral
i-vector with a combination of the two prosodic
i-vector representation. Some prosodic features, particularly pitch frequency F0, have demonstrated excellent performance in gender classification tasks [
45]. Gender information can be used to enhance the GMM-based speaker recognition system in two ways. First, adaptation of speaker-dependent GMM from gender-dependent GMM-UBM is computationally efficient and demonstrates stronger coupling than adaptation of speaker-dependent GMM from gender-independent GMM-UBM [
27]. Second, Reynolds et al. [
46] demonstrated that increasing the population size degrades the recognition accuracy of GMM-based speaker identification systems. Therefore, exploiting gender information to cluster speaker population into two groups reduces the population size and consequently improves the recognition accuracy of GMM-based speaker identification systems [
47]. Constructing cluster-based GMM for speaker populations improves the performance of speaker recognition systems as demonstrated in [
48]. A combination of prosodic features are exploited to cluster speaker populations into male and female groups to enhance the performance of emotional speech classification systems [
49]. Adopting a gender-dependent parameterizations approach to construct a GMM-based speaker recognition system improves the performance of the system, namely equal error rate and half total error rate.
The contribution of this study within this context is presentation of a novel architecture of a speaker identification system for social robots that employs prosodic features as well as two types of spectral-based features (MFCC and GFCC) in order to enhance the overall recognition accuracy of the system. The system works in two stages; in the first stage, a binary classifier exploits the superiority of prosodic features to infer gender information and reduce the size of gallery set by clustering the speaker population into two groups. In the second stage, the outputs of four classifiers are fused in a novel way to improve the overall performance of the system; particularly in the case of short duration utterances and low SNR which is a common condition in speaker identification in social settings.
3. Overview of the Proposed Architecture
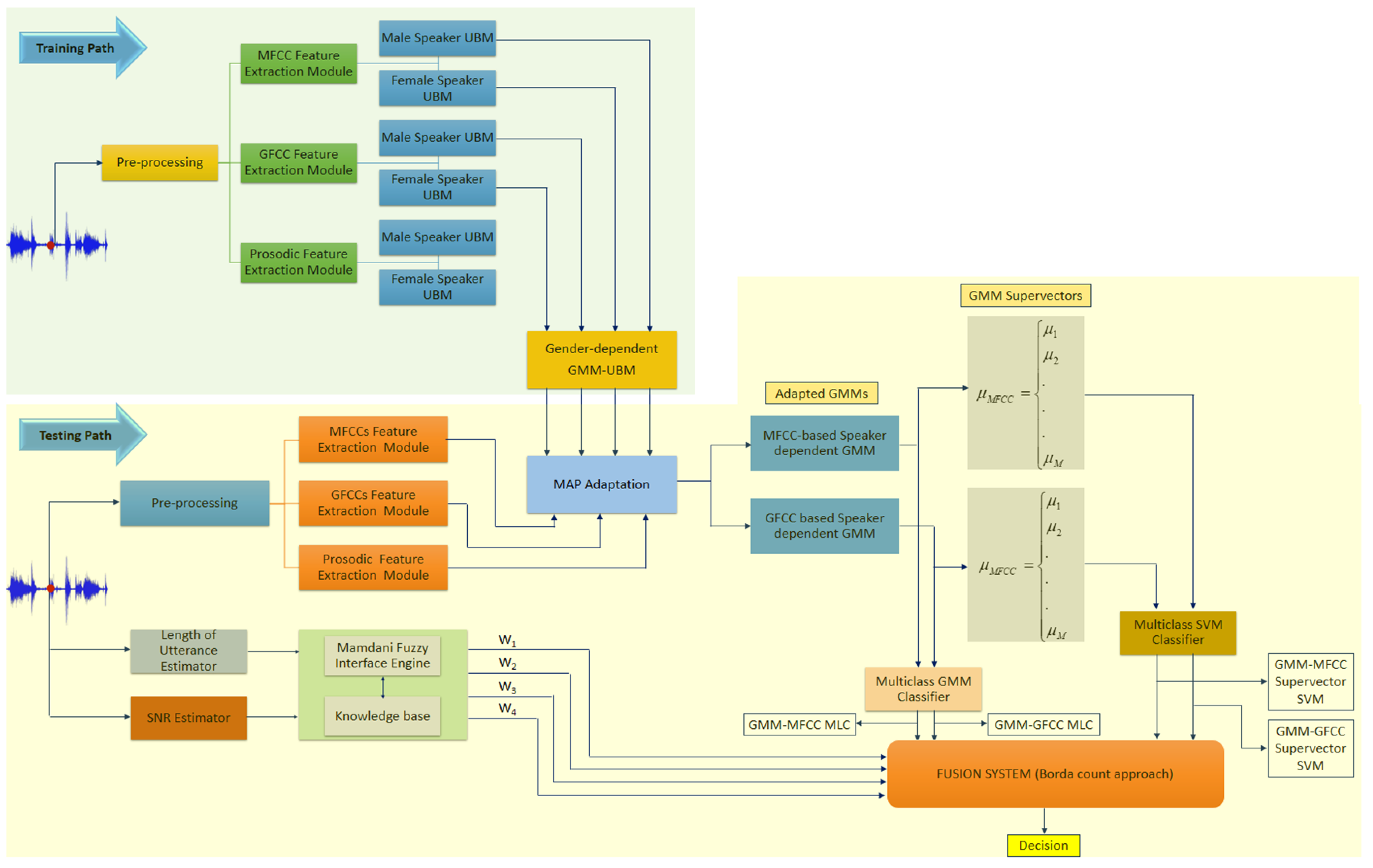
The proposed architecture of the speaker recognition system consists of two classifiers working in a quasi-parallel fashion. The overall architecture of the system is depicted in
Figure 1. The upper section represents the enrollment process (training path), whereas the lower part elaborates the recognition process (testing path). The function of the feature extraction module is to transform the speaker’s utterances into feature vectors that contain his/her specific characteristics. As shown in
Figure 1, the feature extraction module is common to both enrolment process (training) and identification process (testing). In the enrolment process, the speaker’s model is trained by the feature vectors that were extracted from speech utterances by a target speaker and labeled accordingly. The recognition process is performed by extracting feature vectors from an unknown speaker’s utterance which in turn is used to build the unknown speaker model. This model is subsequently matched to one of the labeled speaker models that were constructed during the enrolment process. One may infer that the feature extraction processes for both classifiers are initiated in parallel and at the same time. However, the second classifier requires gender information as well as MFCC and GFCC feature vectors in order to complete the identification process. The first classifier is a binary SVM classifier that uses prosodic feature to determine the gender of the speaker. The second classifier, which is a combination of GMM-based classifier and GMM supervector-based SVM classifiers, employs MFCCs and GFCCs feature as well as gender information to determine the identity of the speaker. In order to compute the GMM supervectors for both types of feature vectors (i.e., MFCCs and GFCCs supervectors), speaker’s gender must be known. As shown in
Figure 1, a binary SVM relies upon prosodic features to determine the gender of the speaker who utters a speech.
The proposed speaker identification system works in two stages: first, the prosodic feature vector is used to determine if an utterance originated from a male or a female speaker. A binary SVM is trained using a prosodic feature vector to classify the utterance into two classes (males and females). The proposed architecture incorporates the outcome of the first stage (gender classification) into the second stage where MFCCs and GFCCs feature vectors that are extracted from the same utterance are used to derive speaker-dependent GMM from a pre-trained gender-dependent GMM-UBM. The gender-dependent GMM-UBM is trained by utterances originating from specific gender groups of speakers (male or female group). The speaker-dependent GMM derived from gender-dependent GMM-UBM shows excellent coupling to the gender-dependent GMM-UBM and requires low computational power and less time as compared with the model derived from gender-independent GMM-UBM (i.e., the GMM-UBM is trained by utterances from male and female speakers). The resultant speaker-dependent GMMs are used to create GMM-supervectors by stacking the mean vectors of the speaker-dependent GMMs. As shown in
Figure 1, four classifiers were developed by employing GMMs and GMM-supervectors. Two of these classifiers are generative-based classifier. The first one is a maximum likelihood classifier (MLC) that employs GMMs trained by MFCC feature vectors and the second classifier is an MLC that employs GMMs trained by GFCC feature vectors. The third and the fourth classifiers are discriminative-based classifiers; namely, SVM that employs GMM-supervectors derived from GMM trained by MFCC and GFCC feature vectors, respectively.
Fusion at score level was adopted to combine the outputs of all the aforementioned classifiers into a single score, namely the weighted Borda count method (please see:
https://en.wikipedia.org/wiki/Borda_count, accessed on 12 July 2021). In this study, the weighted Borda count method is a plausible choice as it does not require transforming all the scores of the base classifier into a common domain (i.e., no normalization process). Additionally, the fusion system exploits the classes ranking information of the base classifiers on the development set to compute the weights for the base classifiers (more details in
Section 3.3). Borda count method uses the match scores of the base classifiers to arrange the classes in descending order. Then, for each class, the Borda count is represented as the sum of the number of classes ranked below it by the respective classifier. The higher the magnitude of Borda count for a class, the greater the degree of agreement by the base classifiers that the test sample belongs to that class [
49]. We propose a novel way to account for the Borda count for each classifier by a Mamdani fuzzy inference system [
50]. Since we know that certain classifiers are more likely to outperform others at specific conditions, the weight factors are computed via Mamdani fuzzy inference system to exploit the individual classifier capabilities at those conditions.
The fuzzy inference system employs the knowledge about the recognition rate trend of the aforementioned classifiers when they are evaluated on development set. This information is used to derive a set of rules in the form of IF-THEN fuzzy rules based on Mamdani fuzzy inference engine in order to compute the weighting factors for all the aforementioned classifiers such that the overall recognition rate is improved. Here, we employed the recognition rate of each classifier as a function of length of utterance and the signal-to-noise ratio (SNR). Then, for each combination of the length of utterance and the SNR, a respective rule is derived taking into consideration that each classifier is weighted by a factor proportional to its recognition rate. Additionally, the fuzzy rules consider the selected classifiers to be combined to complement each other from the perspectives of feature types and classifier model with priority to feature type.
In the testing path, the feature extraction modules of all feature vectors used by the two classifiers (i.e., speaker’s gender and identity classification) are initiated at the same time. Thus, there is no noticeable delay caused by this architecture (i.e., the second classifier needs the output of the first classifier (i.e., male or female) as one of its inputs in order to identify a speaker).
3.1. Feature Extraction Modules
The proposed system exploits two groups of voice-based features to identify a speaker, namely prosodic features and spectral features. The GFCC and MFCC features are adopted as spectral features. The modular representation of GFCCs and MFCCs feature extraction methods are depicted in
Figure 2 and
Figure 3, respectively. As shown in these figures, both MFCCs and GFCCs share the same stages except the type of the filter-banks that are applied to the resultant frequency domain signal from fast Fourier transform (FFT) and the compression operation. The MFCCs feature extraction method applies mel filter-bank after FFT stage and followed by logarithmic compression and discrete cosine transform (
Section 3.1.1). On the other hand, in the GFCCs feature extraction method, the gammatone filter-bank is applied to the resultant frequency domain signal from FFT before loudness compression and discrete cosine transform take place (
Section 3.1.2). The prosodic feature vector characterizes four areas of prosody including pitch, loudness, voice quality, and formant. Pitch and loudness information were represented as statistical measure of fundamental frequency (F0) and energy, respectively. Harmonics-to-noise ratio (HNR), jitter, and shimmer represent voice quality measurements while the first three formants characterize the fourth category of prosodic information. The complete details about prosodic feature vector are discussed in
Section 3.1.3.
3.1.1. MFCCs Feature Extraction Module
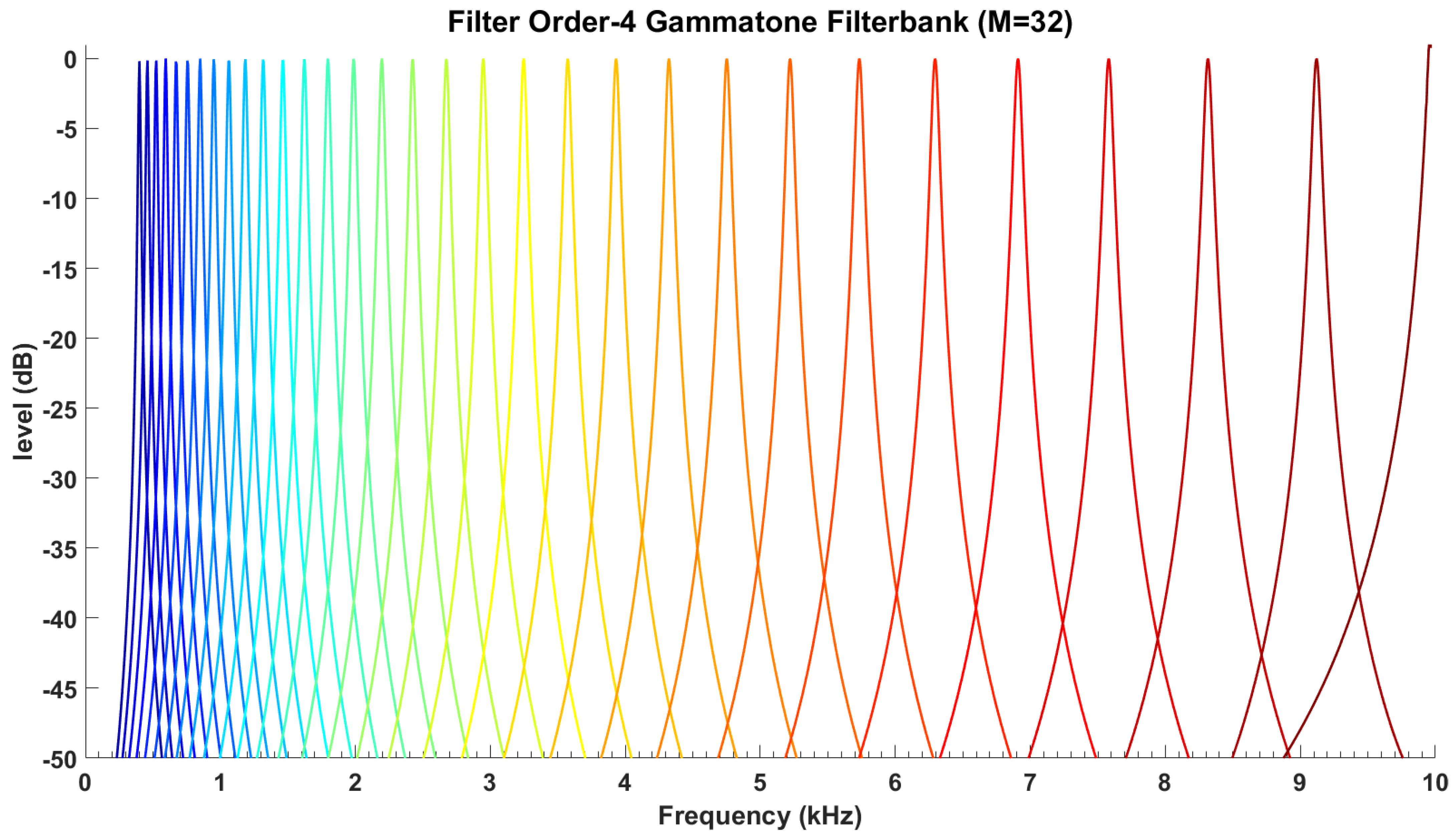
MFCCs feature vector is determined in accordance with the notion that the frequency range of human spoken words is generally limited to 1000 Hz. Therefore, MFCCs employ linearly spaced filters at below this threshold frequency and logarithmic spaced filters at above this frequency. This implies that the filter-bank selected the most appropriate frequency range of interest, i.e., more filters in the narrow bandwidths below 1000 Hz and fewer number of filters at outside this range as shown in
Figure 4.
Figure 2 demonstrates that the first step in the extraction process is to boost the input speech signal as:
where
is the input speech signal,
is the boosted speech signal. The interval of the pre-emphasized factor is selected within the range
. Subsequently, we apply a smooth window function (hamming windows) to the pre-emphasized speech signal
:
We then transform the resulting time-domain signal to frequency domain via the ubiquitous fast Fourier transform (FFT). As expected, the FFT process generates a fluctuating spectrum. Thus, in order to ensure that the FFT spectrum extracts the most relevant information for speaker recognition, we design the filter-bank based on the mel scale.
Figure 5 shows the output of the mel-frequency filter-banks. Here, we apply logarithmic compression and discrete cosine transform as in (3) to obtain the MFCCs. The main objective of the discrete cosine transform is to transform log mel spectrum into time domain.
where
is the output of an M-channel filter-bank,
is the index of the cepstral coefficient. For the purpose of this project, we retained the 12 lowest
excluding the 0th coefficient.
3.1.2. GFCCs Feature Extraction Module
The GFCCs feature vector is computed in the same way as MFCCs feature vector as shown in
Figure 3. The key difference between the GFCCs and MFCCs is that the GFCCs feature extraction uses a bio-inspired gammatone filter-bank to extract the most discriminant information from FFT spectrum, which was originally designed to model the human auditory spectral response, particularly modeling the auditory processing at the cochlea. Like MFCCs, the speech signal is pre-emphasized first and followed by Windowing and FFT stages. Then, the gammatone filter-bank is applied to the resultant FFT spectrum. The impulse response of each filter in gammatone filter-bank can be represented as in (4) [
51].
Since
is constant,
and
are fixed for the entire filter-bank. The frequency selectivity of gammatone filter-bank is mainly defined by central frequency,
, and the filter’s bandwidth
. A suggested method to compute the central frequency and the filter’s bandwidth is by using an approximation to the bandwidth of human auditory filter at the cochlea. Equivalent rectangular bandwidth (ERB), which represents the bandwidth of series rectangular filters that are used to model the human cochlea, can be used to compute the filter’s bandwidth and its central frequencies. Moore [
52] modeled the human auditory system using ERB as:
The idea of ERB is adopted by Patterson et al. [
53], to estimate the bandwidth and the center frequencies of the gammatone filter. It has been suggested that the two parameters of gammatone filter (the bandwidth,
and order of the filter,
) should be set as
and
in order to attain a filter with good match to human auditory filter.
As suggested by Moore [
52], the center frequencies of the gammatone filter are equally spaced on the ERB frequency scale. The relationship between the number of ERBs to the center frequencies,
, can be expressed as:
The ERB scale, which is approximately logarithmic, is defined as the number of ERBs below each frequency. This scale correlates the center frequencies with
distribution of frequency energy of speech signal. In other words, the frequency-dependent bandwidth of gammatone filter produces a narrower filter at low frequencies and a broader filter at high frequencies as shown in
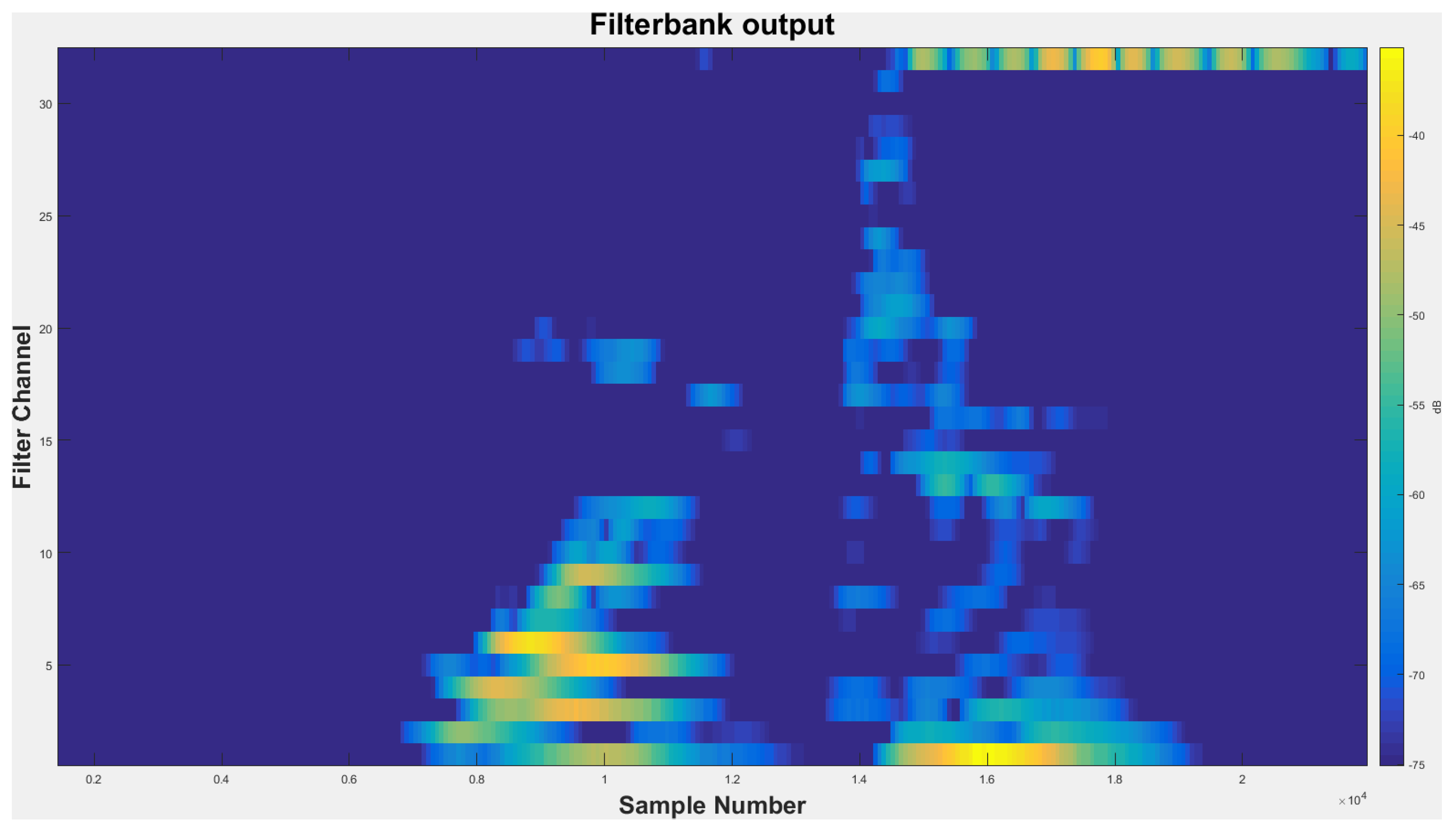
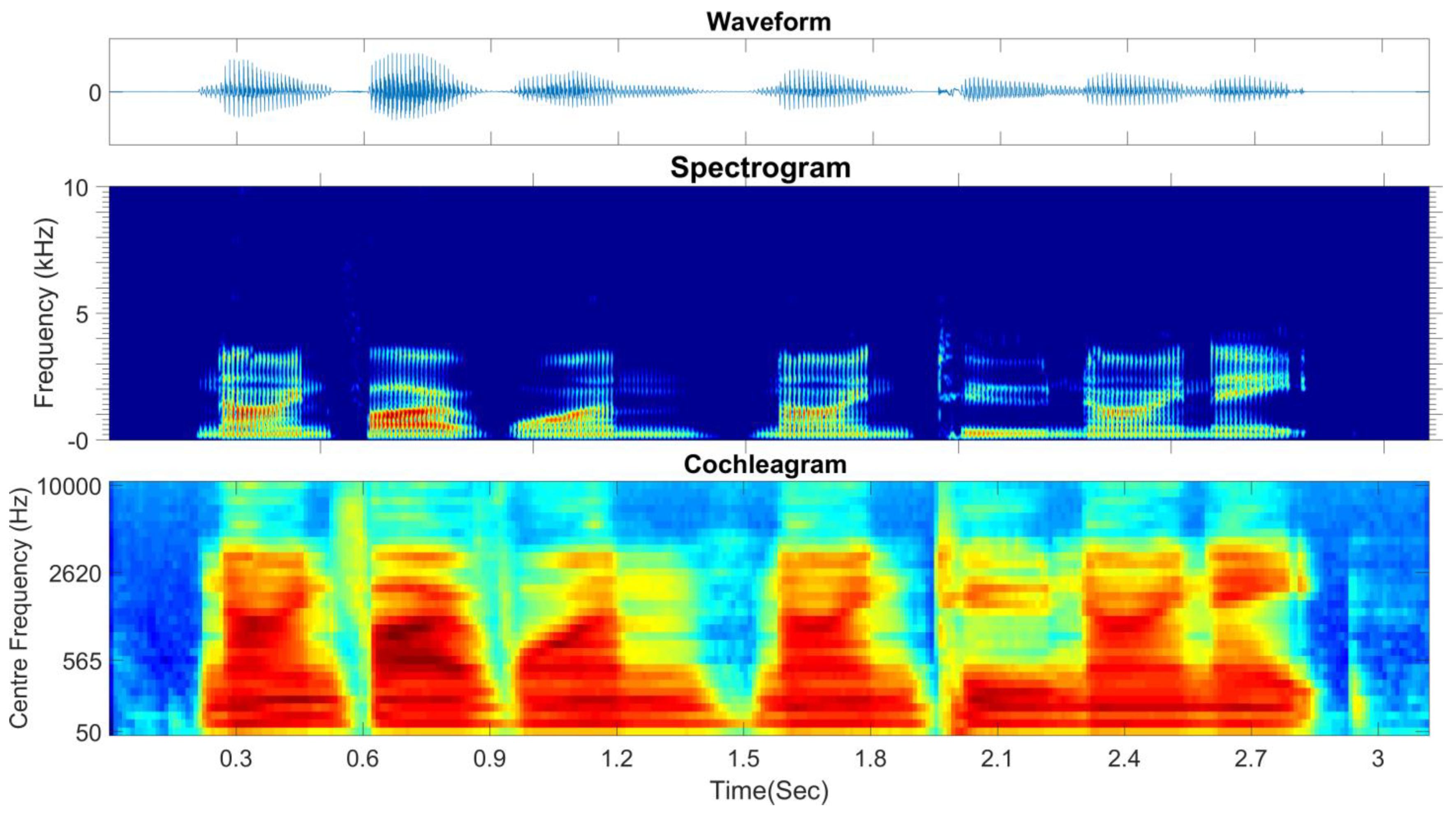
Figure 6 (fourth-order gammatone filter-bank with 32-channel outputs). In this study, the fourth-order gammatone filter-bank with 64-channel outputs is used to extract the GFCCs feature vectors. The GFCCs feature vectors are obtained by applying a cubic root operation (loudness-compression) and then de-correlating the feature components by applying a discrete cosine transform. Additionally, we retained the 22 lowest coefficients excluding the 0th coefficient. The gammatone filter-bank response (termed the cochleagram) and typical spectrogram in response to a sample of speech signal from TIDIGITS are depicted in
Figure 7.
3.1.3. The Prosodic Feature Extraction Module
It has been documented that 90% of speaker recognition systems have employed short-term spectral features such as MFCC, LPCC, and GFCC which have been found to carry high power discriminant information for the speaker recognition task [
11]. While the short-term spectral features span short frames of about 10–30 ms and contain information correlating to timber and resonance proprieties of vocal tract, the prosodic features span longer frames of about 10 to hundreds of milliseconds and correlate with non-segmental aspect of speech such as intonation, stress, rate and rhythmic organization of the speech. Since prosodic features span over long segments like syllables, words, and utterances, it is believed to contain complementary information and have more robustness for channel and background distortion. Different combinations of the prosodic parameters have been used widely for language and emotion identification, age and gender classification, and speaker authentication. The fundamental frequency (F0) is the most important parameter among these prosodic parameters. Here, selection of prosodic features from previous works of [
42,
54,
55] was adopted as feature vectors for first-stage classifier (gender classification). Particularly, various statistical measures of fundamental frequency (F0), spectral centroid (SC), spectral flatness measure (SFM), Shannon entropy (SE), harmonics-to-noise ratio (HNR), jitter and shimmer, and the first three formants were adopted to construct one prosodic feature vector. Individually, these features are correlated with pitch accents and boundary tones, the approximate location of formants, the flatness of the spectrum, the degree of randomness of spectral probability density, the amount of noise in the speech signal, the overall periodicity of speech signal, variability of fundamental frequency, voice pathologies, and psychological characteristics of vocal tract (length, shape, and volume), respectively. HNR and the first three formant frequencies are calculated with the VoiceSauce feature extraction tool [
55]. SC, SFM, and SE are computed with MIR toolbox [
56]. Absolute jitter and shimmer measurements were extracted by using Praat voice analysis software [
57]. The complete list of features and the corresponding statistical measures that were applied to construct the prosodic feature vector are listed in
Table A1 (
Appendix A).
3.2. Speaker Modeling (Classification Algorithms)
In this section, for the sake of completeness of the paper, we consider popular classification algorithms that are widely used in speech recognition and speaker identification.
3.2.1. Gaussian Mixture Model
The well-known GMM approach was adopted to construct the first two classifiers; namely GMM-MFCC MLC and GMM-GFCC MLC. We extracted the feature vectors for the MFCC and GFCC from the speech data of all speakers in training data (gallery set). For each of these feature vectors, two speaker-independent world models (a well-known UBM) were created; the first UBM is trained by the feature vector extracted from female speakers and the second UBM is trained by the feature vector that is extracted from male speakers. The UBM is estimated by training M-component GMM with the standard expectation–maximization (EM) algorithm [
28]. The UBM represents speaker-independent distribution of the feature vectors. In this study, we employ 256-compnenent GMM to build the UBM. The UBM is represented by a GMM with 256-compnents, denoted by
, that is characterized by its probability density function as:
The model is estimated by a weighted linear combination of D-variate Gaussian density function
, each parameterized by a mean
vector,
, mixing weights, which are constrained by
,
, and a
covariance matrix,
as:
The training of UBM is to estimate the parameters of 256-component GMM,
, from the training samples. Subsequently, for each speaker in the gallery set, we apply maximum a posteriori (MAP) to estimate the specific GMM from UBM-GMM. Since the UBM represents speaker-independent distribution of the feature vectors, the adaptation approach facilitates the fast-scoring as there is a strong coupling between speaker’s model and the UBM. Here, the gender-dependent UBMs were constructed to provide stronger coupling and faster scoring than that of gender-independent UBM. It should also be noted that all or some of GMM’s parameters (
can be adapted by a Maximum A Posteriori (MAP) approach. Here, we adapted only the mean
to represent specific speaker’s model. Now, let us assume a group of speakers
represented by GMMs
. The goal is to find the speaker identity
whose model has the maximum a posteriori probability for a given observation
(MFCC or GFCC feature vector). We calculate the posteriori probability of all observations
in probe set against all speaker models
in gallery set as (9). As
vary from 1 to number of speakers in gallery set and number of utterances in probe set, respectively, the result from (9) is
matrix.
Assuming equal prior probabilities of a speaker, the terms
and
are constant for all speaker, thus both terms can be ignored in (9). Since each subject in the probe set is represented as
, thus by using logarithmic and assuming independence between observations, calculation of posteriori probability
can be simplified as (10). The outputs of the two GMM-based classifiers (GMM-MFCC MLC and GMM-GFCC MLC) were computed using (10).
3.2.2. GMM Supervector and Support Vector Machine
One of the challenges of exploiting information in voice modality is that the utterances are manifested with varying time durations. The dimension of feature vectors depends on the time duration of these utterances; hence the resultant feature vectors from feature extraction modules (i.e., MFCC, GFCC, prosodic) have variable dimensions. Since most of the discriminant classifiers including SVM require fixed length feature vector as input, the speaker recognition research community has discovered a way to represent these time-varying utterances as a fixed-length feature vectors. The method relies upon using the parameters of speaker-dependent GMM. A speaker can be modeled as M-component GMM either by adapting a specific speaker model from UBM-GMM using MAP or by training M-component GMM with EM algorithm independently from UBM-GMM. Deriving a speaker-dependent model by adaptation approach provides a good coupling between a speaker model and UBM-GMM. Since the UBM-GMM represents a distribution of all speakers in the galley set, this coupling is desirable. Additionally, the adaptation approach reduces the computational cost of building a speaker-dependent model and facilitates real-time response.
In speaker recognition literature, supervector refers to a fixed length feature vector constructed by combining many smaller-dimensional vectors into a higher-dimensional vector. In this study, GMM supervector is constructed by concatenating d-dimensional mean vector of the M-component speaker-dependent model that is adapted from pre-trained UBM-GMM. The resultant GMM supervector with dimension is fed to SVM. The dimension of the MFCC-GMM supervector is () and the dimension of the GFCC-GMM supervector is (). Principal component analysis is applied to reduce the dimension of thesesupervector before being fed to SVM. We refer to the two classifiers that were trained by MFCC-GMM supervector and GFCC-GMM supervector as MFCC-GMM supervector SVM and GFCC-GMM supervector SVM, respectively.
SVM is one of the most powerful discriminative classifiers with excellent generalization performance to classify any unseen data. Basically, SVM is a supervised binary classifier that aims to separate the two classes by modeling a decision boundary as hyperplane; hence, adopting SVM to solve speaker verification is sensible. In speaker verification, the task is to determine if a given utterance matches or does not match a target model (claimant identity). In the training stage, all training feature vectors that are extracted from the target speaker’s voice samples are represented as one class and the second class is represented by all training feature vectors that are extracted from the background “impostor” speaker’s voice samples. SVM maps the training vector to high-dimensional space and finds an optimum hyperplane that separates the two classes (i.e., target speaker and impostor) with maximum margin. Since speaker identification is a multiclass classification problem, the well-known method One-Vs-All (OVA) SVM is adopted to extend the binary SVM to accommodate the multiclass classification task. Adopting the OVA approach, which requires constructing as many binary SVM classifier as the number of classes, fits our framework of integrating the outputs of various classifiers. The output of SVM should be represented as score vector that can be interpreted either as the degree of match between a given utterance and every speaker’s voice signature in gallery set or as the probability that a given utterance originates from every speaker in the gallery set. The outputs of multiclass SVM that are constructed by the OVA approach can be expressed as probabilistic outputs; hence, the OVA is adopted to construct multiclass SVM classifier. The probabilistic outputs are used to rank the classes and compute the Borda count value for each class.
In the proposed speaker recognition system, there is no need to unify and transform the outputs of the base classifiers to common domain. However, the outputs of the base classifiers should be expressed as scores (represent the degree of support) that are used to rank all the classes in descending order. The outputs of SVM, which are mostly expressed as a label for the predicted class that a test sample is assigned to (for example, the output of binary classifier is either +1 or −1), are not compatible with our fusion system. Therefore, the method suggested by Platt [
58] is used to estimate probabilistic outputs for SVM classifier. The discriminative function of binary SVM can be expressed as (11) [
59]:
where
is either
, and represents ideal output,
is support vector,
is bias,
is kernel function,
is weight,
. The kernel function satisfies the Merce condition, so that
can be expressed as (12):
where
is a mapping from input space (feature vector space) to high-dimensional space. Here, a radial basis function is selected as SVM kernel function and 3-fold cross validation was adopted to find best parameters for it. Mapping input feature vectors to high-dimensional space by using “kernel trick” which implicitly transforms the input vectors to high-dimensional space without explicit computation of dot product in high-dimensional space. Hence, all the dot products in SVM computations are replaced with kernel function
This implies that SVM optimizes a decision boundary (hyperplane) between the two classes in high-dimensional space without explicit computation of
. For more information about adopting SVM in speaker recognition, the reader may refer to [
60], and to [
59,
61] for more in-depth information about the SVM and kernel functions.
3.3. Fusion System
A large number of biometric authentication systems have adopted fusion of information at the score level to improve the overall performance of authentication systems. These systems employ various biometric modalities, different classification architectures, and feature extraction approaches. The key is not only to generate a set of feature vectors that complement each other but also to develop classifiers with satisfactory performance in diverse and challenging conditions. Here, the scores of the four classifiers (GMM-MFCC MLC, GMM-GFCC MLC, GMM-MFCC supervector SVM, and GMM-GFCC supervector SVM) are integrated using weighted Borda count method. It is worth noting that these classifiers represent both generative and discriminative approaches which intuitively can be seen as highlighting similarities and differences between classes, respectively. The weight factors are computed on the fly using a Fuzzy rule-based inference engine. The knowledge base of the fuzzy inference system is represented as IF-THEN fuzzy rules. These rules are derived by studying the recognition rate of the aforementioned classifiers as a function of SNR and the length of utterance.
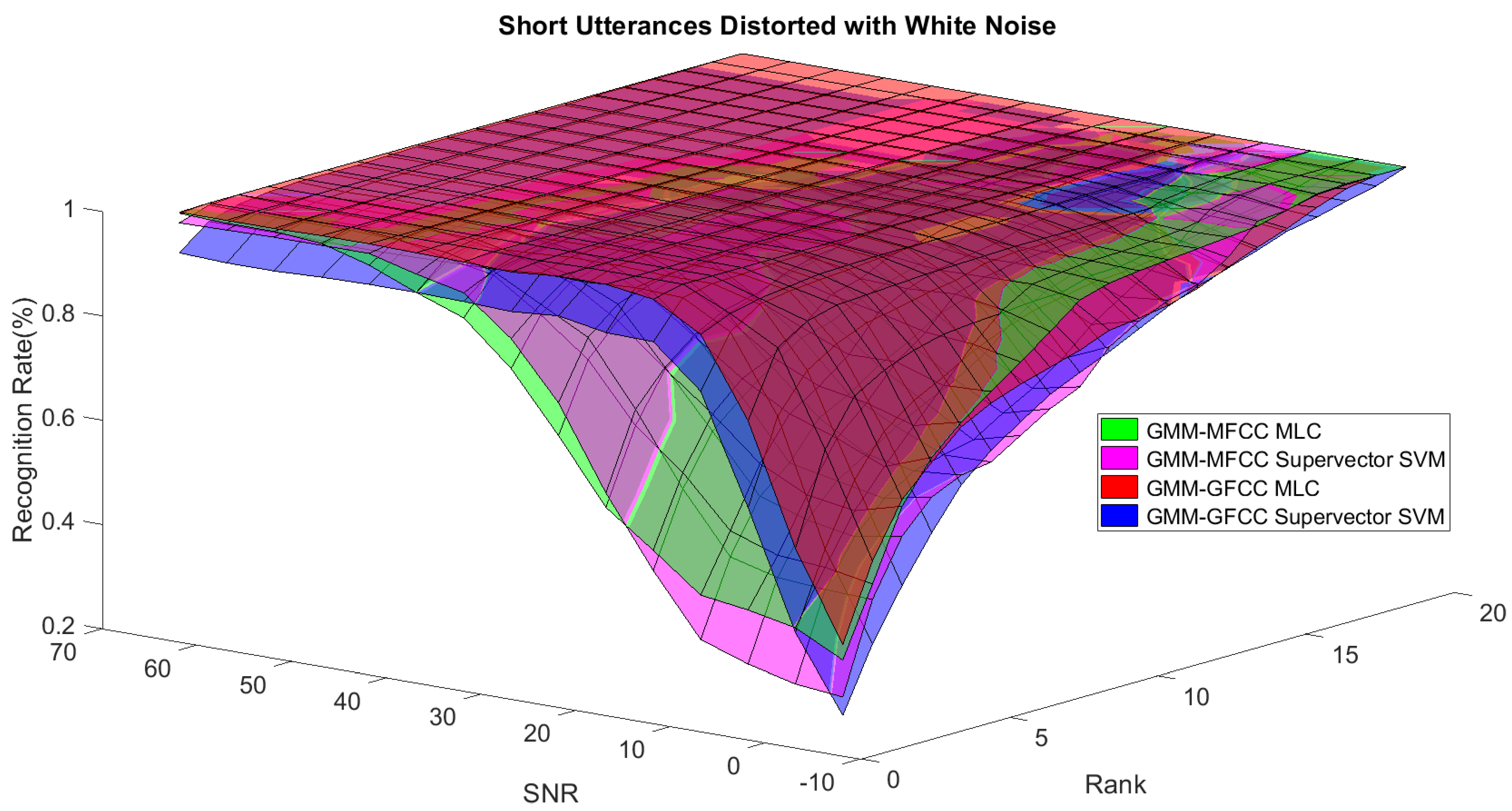
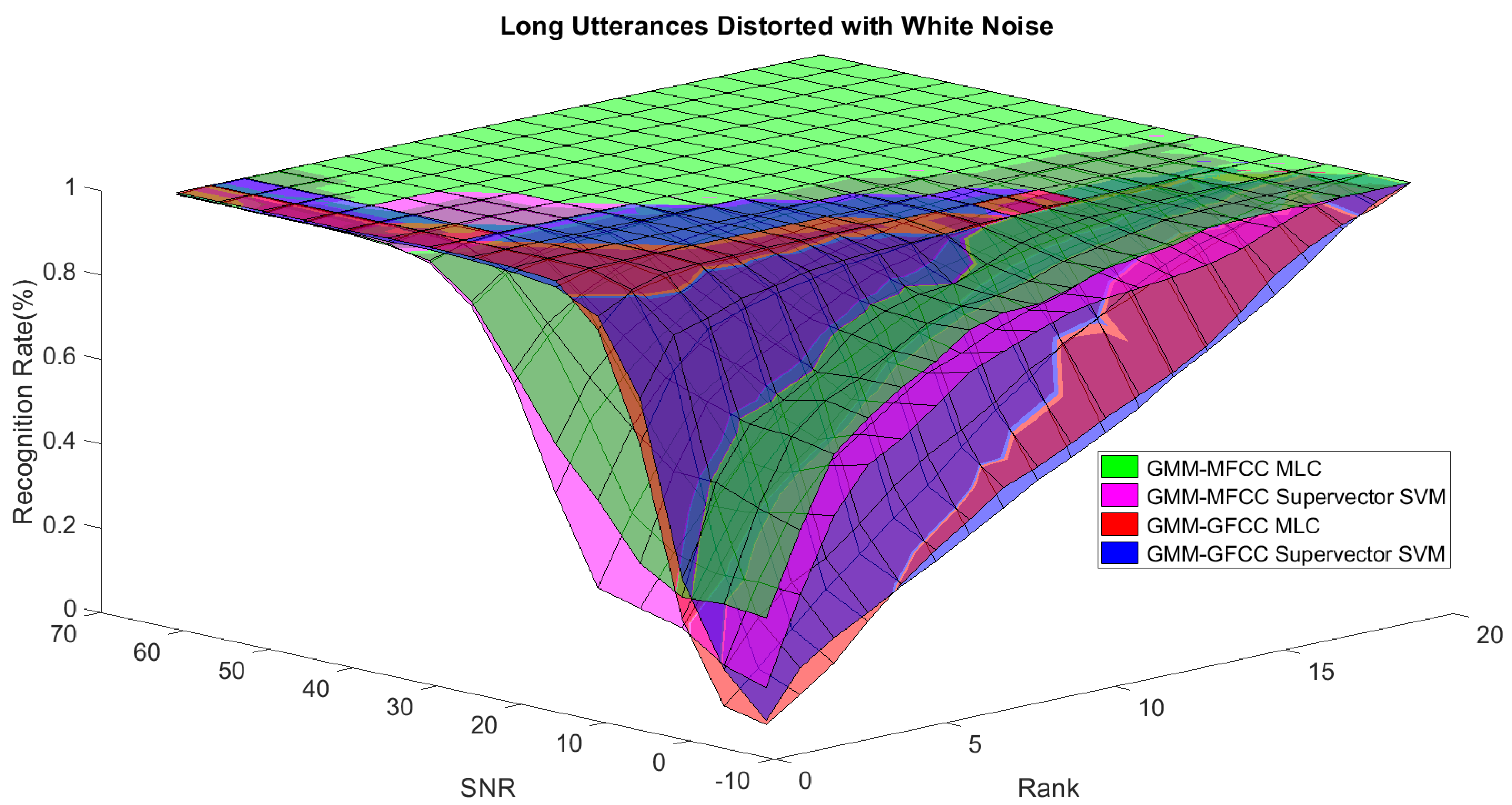
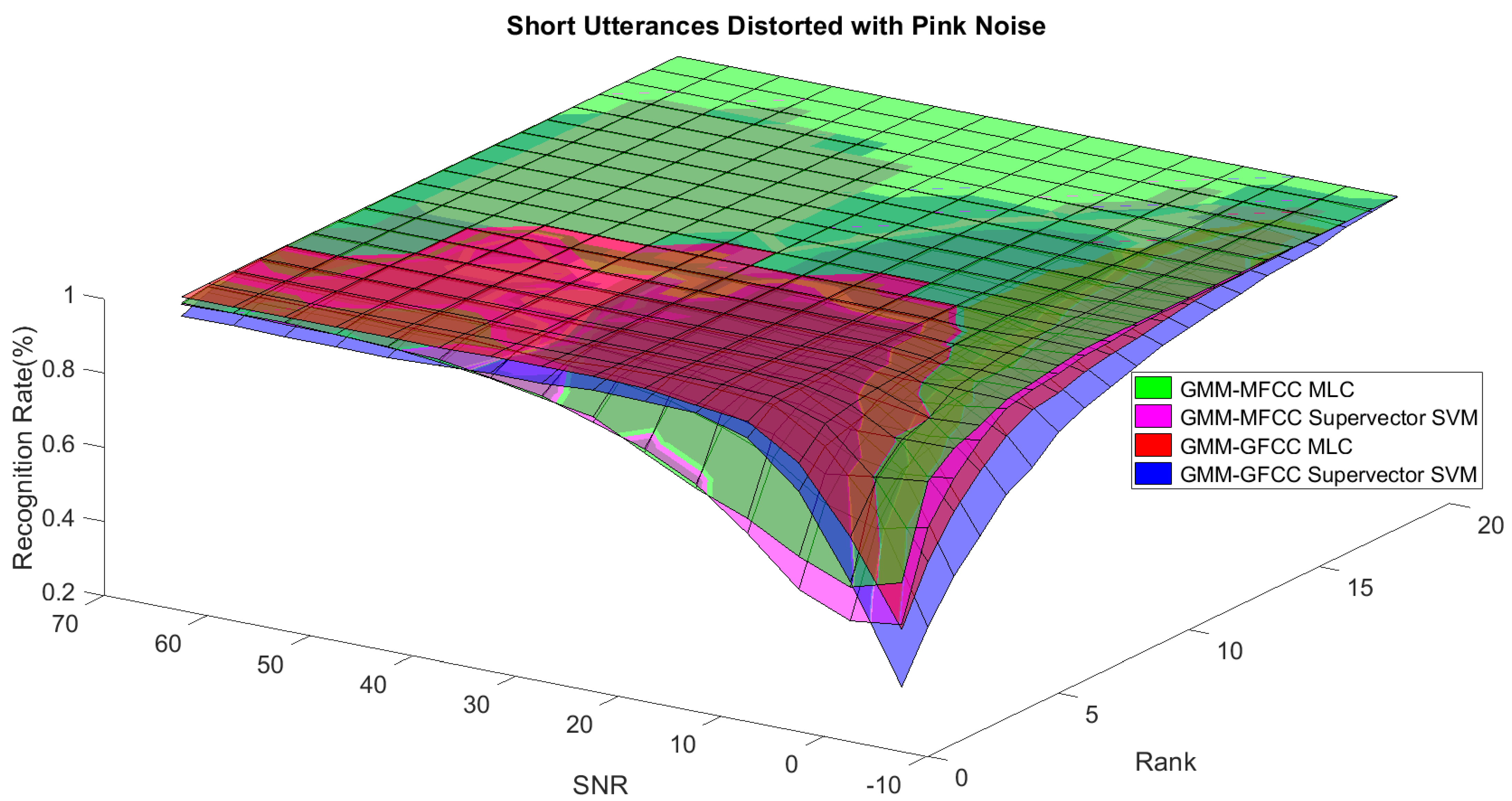
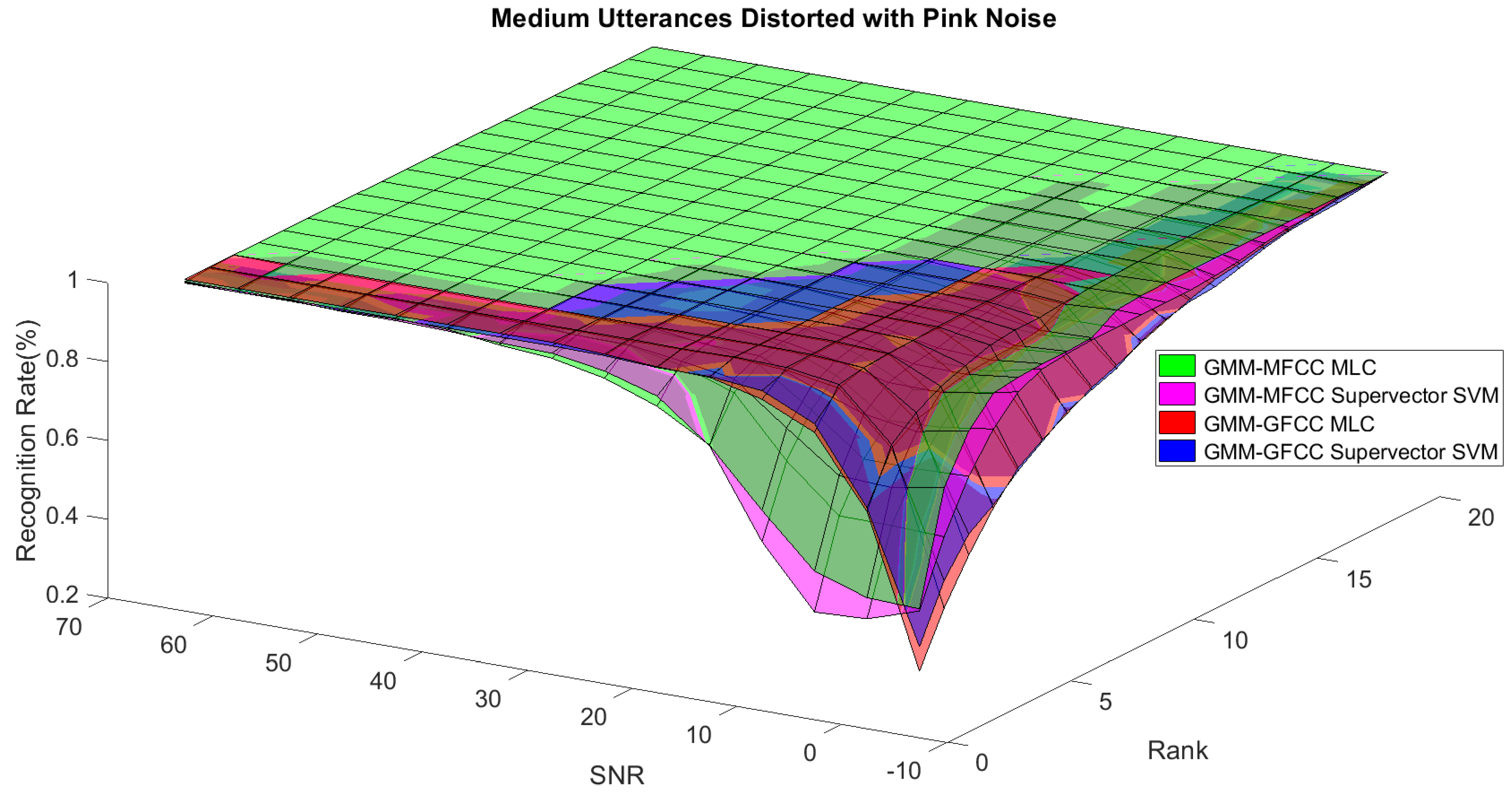
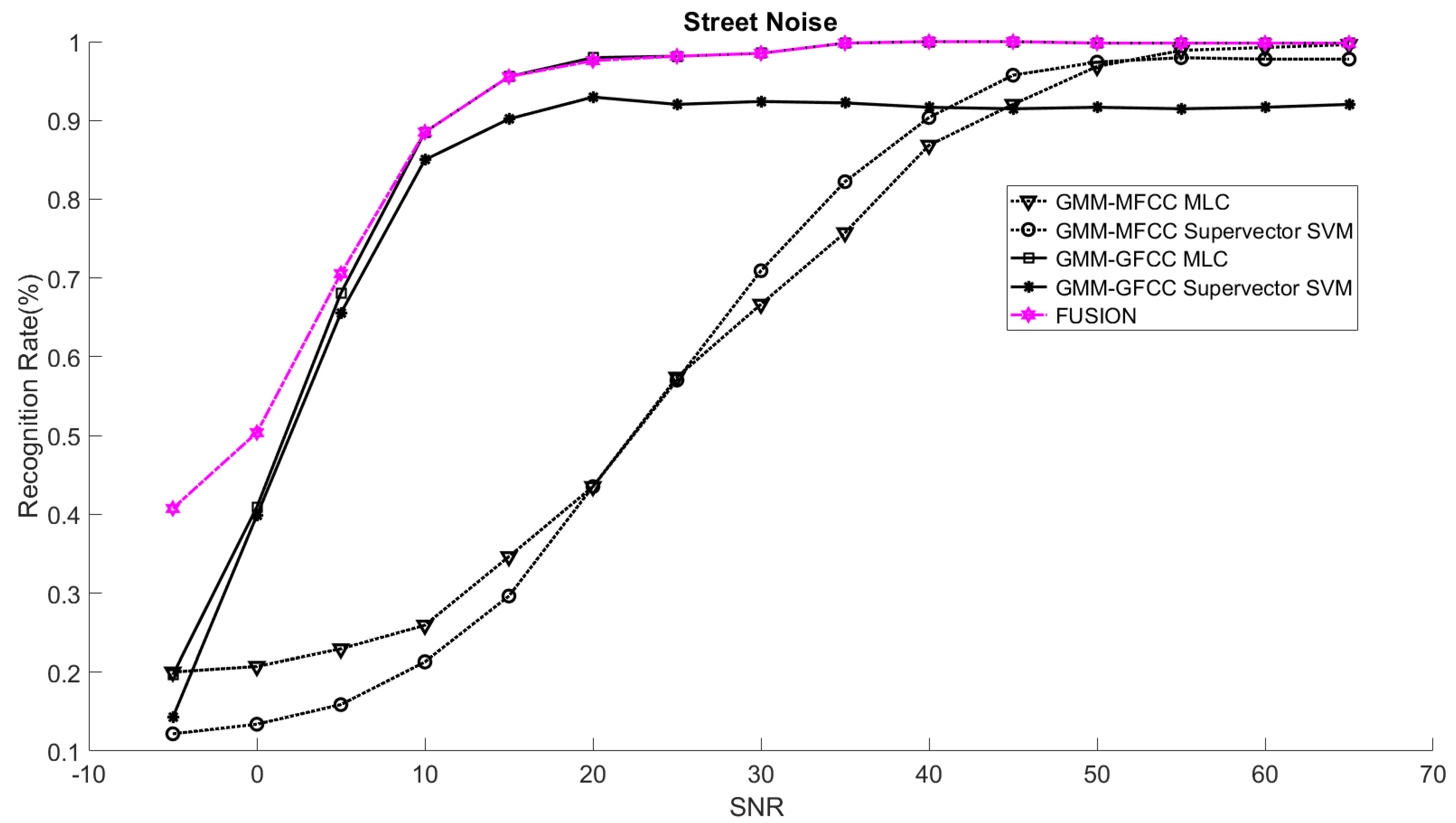
In order to study the recognition behavior for individual classifiers as a function of SNR and the length of utterance, the TIDIGITS corpus [
62] was divided into three equal sets; training set, development set, and testing set. The training set was used to train individual classifiers independently. All utterances in development set and testing set were distorted by three types of noise: white Gaussian noise, pink and street noise with SNR range from −5 to 50 dB, in increments of 5 dB. Additionally, all utterances in the development set were categorized into three groups (short, medium, long) based on the length of utterance. Then, the recognition rates of these trained classifiers were computed on each group and depicted as a function of SNR and rank. Each group (i.e., short, medium, long) contains utterances with range of time duration. Additionally, the estimation of SNR is prone to error. Thus, we fuzzified SNR and length of utterance by designing membership functions for each of them empirically as depicted in
Figure 8 and
Figure 9, respectively. The SNR and length of utterance represent inputs of the fuzzy inference system and the weight factors represent the outputs of the fuzzy inference system as shown in
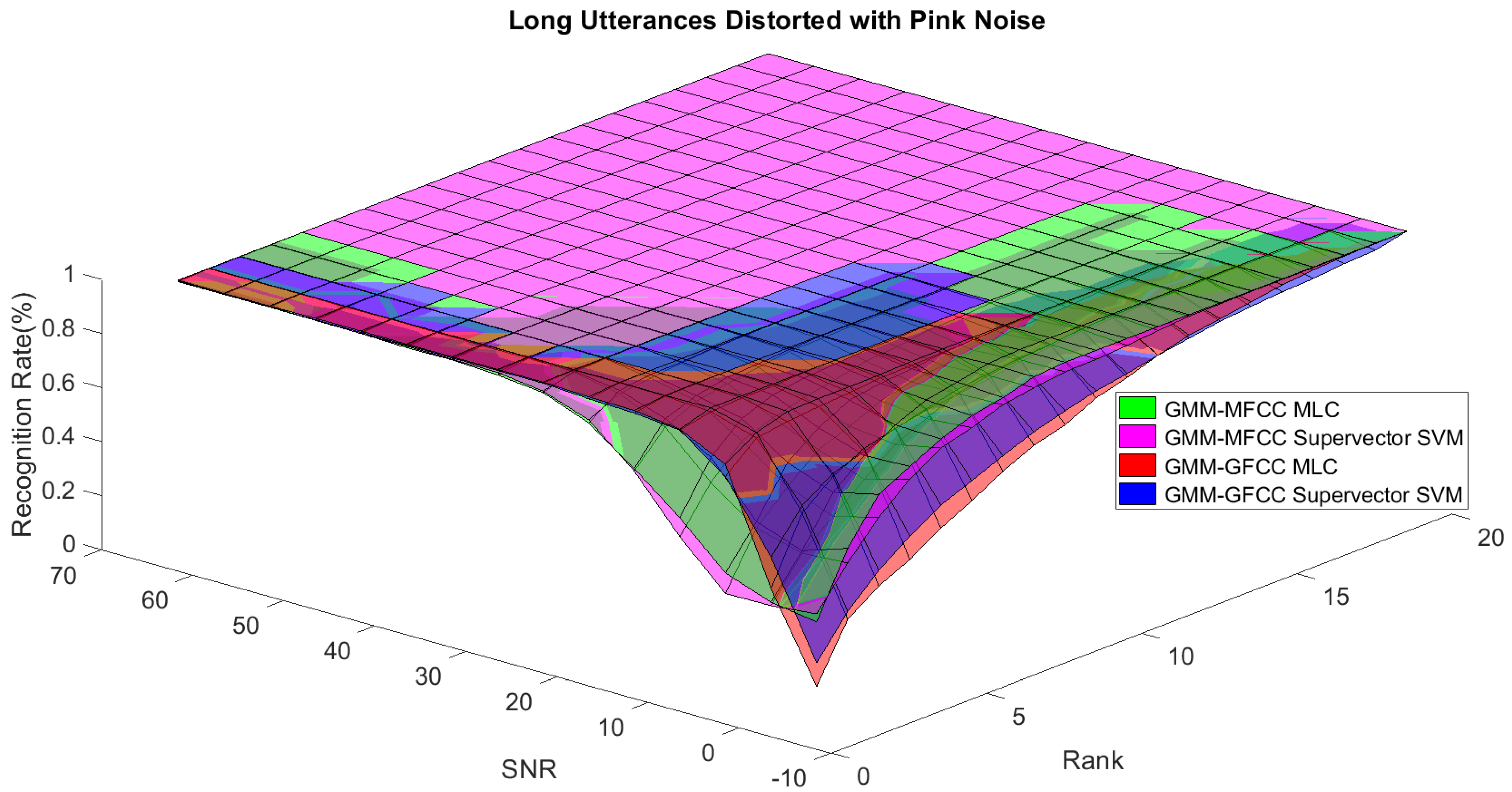
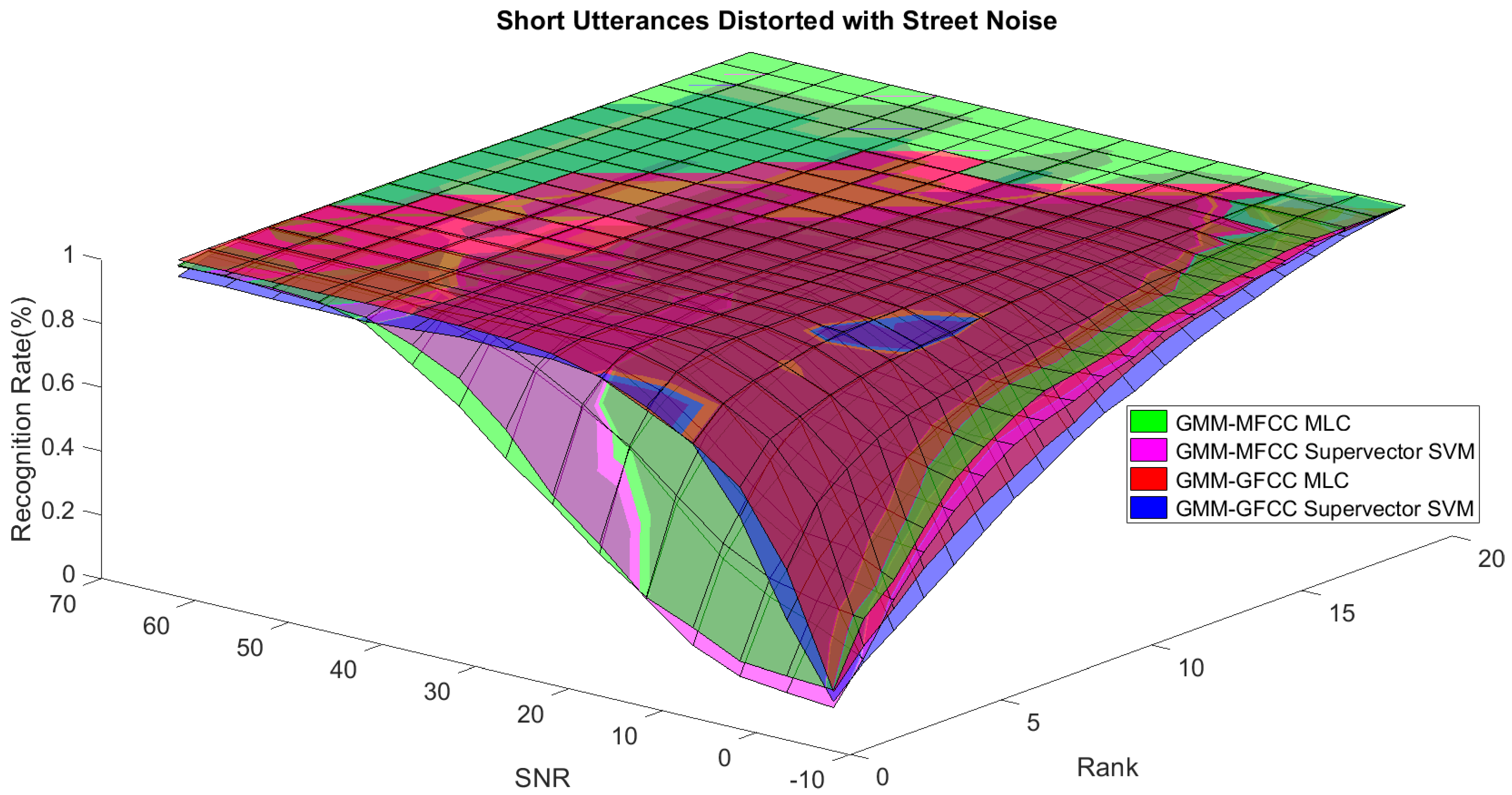
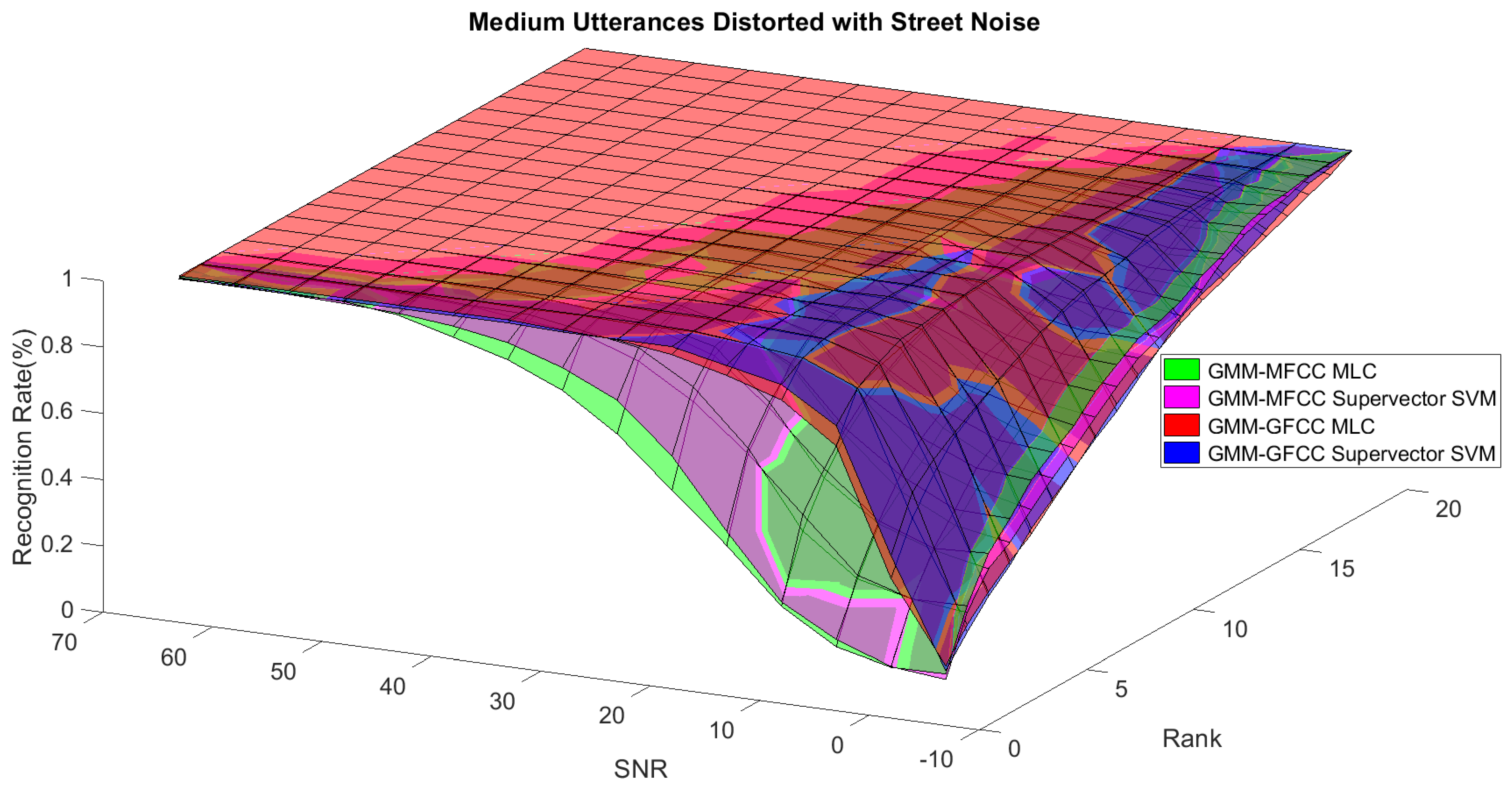
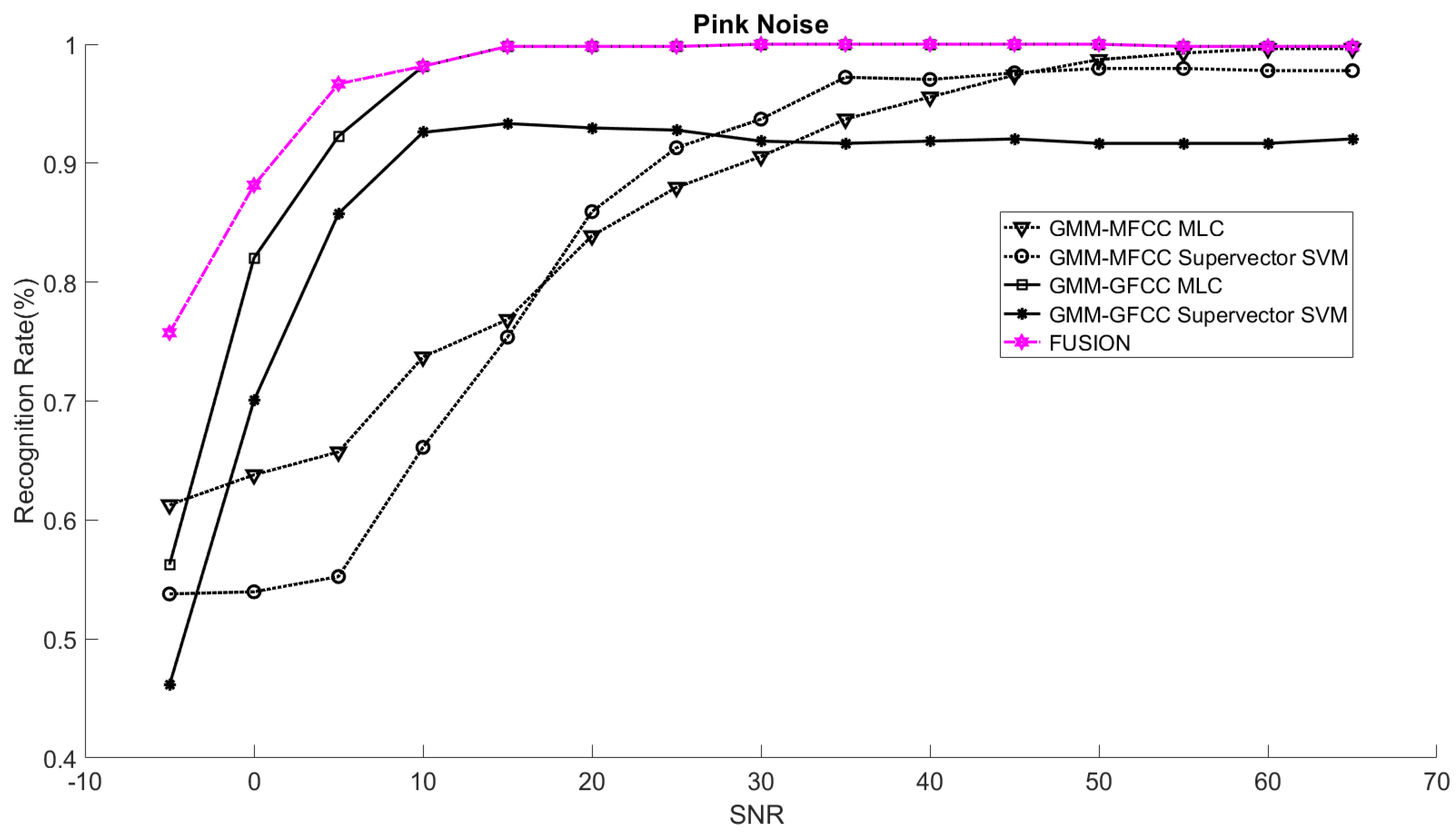
Figure 1. The statistical measures of time duration of all utterances (i.e., min, max, mean) in each group were used to facilitate determining the parameters of membership function of length of utterance. The SNR membership function parameters were determined empirically based on the performance of the base classifiers on different noise levels. For each type of noise, a set of parameters was selected relying upon the performance of the base classifiers. The knowledge base, which is represented as IF-THEN fuzzy rules, is derived from the performance of the base classifiers on the development set that categorized into three groups and distorted with three types of noise (white, pink, street). The performance of base classifiers on a combination of the three types of noise with three categories of length of utterance (i.e., total of nine groups from the development set) are depicted in
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16,
Figure 17 and
Figure 18. For each type of noise, a set of IF-THEN rules are derived relying upon the performance of the base classifiers shown in
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16,
Figure 17 and
Figure 18. These figures depict the relationship between the recognition rate of the system and SNR at various ranks. Since each of the base classifiers return a ranked list of candidates based on their match scores, recognition rate of each classifier can be calculated at different rank. When recognition rate is calculated considering the top ranked candidate (i.e., the candidate with best score is the correct class), it is called rank-1 recognition rate. Additionally, when recognition rate is calculated considering the first and second top ranked candidates (i.e., the correct class is among the two top candidates), it called rank-2 recognition rate and so on. The Borda count method uses ranking information to determine the winner class, thus, change in recognition rates of the base classifiers with respect to rank (rank axis in
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15,
Figure 16,
Figure 17 and
Figure 18) is exploited in deriving IF-THEN rules. The rules are derived such that more weight is given to the base classifier that demonstrates a big improvement in recognition rate with respect to rank axis. For example, by studying the performance of the base classifiers on utterances distorted with white noise (
Figure 10,
Figure 11 and
Figure 12), we can derive the following rules:
If the length of utterance is short and signal-to-noise ratio is very low (i.e., SNR range from −5 to 5), then the weight of GMM-MFCC MLC is high and the weight of GMM-GFCC MLC is very high and the weight of GMM-MFCC supervector SVM is very low and the weight of GMM-GFCC supervector SVM is low.
If the length of utterance is medium and signal-to-noise ratio is very low (i.e., SNR range from 5 to 15), then the weight of GMM-MFCC MLC is very high and the weight of GMM-GFCC MLC is low and the weight of GMM-MFCC supervector SVM is high and the weight of GMM-GFCC supervector SVM is very low.
If the length of utterance is short and signal-to-noise ratio is low (i.e., SNR range from 5 to 15), then the weight of GMM-MFCC MLC is low and the weight of GMM-GFCC MLC is very high and the weight of GMM-MFCC supervector SVM is very low and the weight of GMM-GFCC supervector SVM is high.
Considering five membership functions for input 2 (signal-to-noise ratio) and three membership functions for input 1 (length of utterance), 15 IF-THEN rules are derived for each type of noise. One of the shortcomings of this approach is that for each type of noise, a set of IF-THEN fuzzy rules need to be derived.
5. Conclusions
In the absence of a unique robust speaker identification system that demonstrates superior performance for applications where the system is expected to perform in challenging scenarios such as different types of environmental noise, at different levels of environmental noise (low SNR to high SNR), and with only access to short utterances (at test time), the plausible contention is to integrate the advantages of using a multi-feature speaker recognition system with a multi-classifier speaker recognition system. In this study, two types of speech-based features (short-term spectral and prosodic features) and three powerful classifier systems (SVM, GMM, and GMM supervector-based SVM classifiers) are incorporated within an elegant architecture to identify the speaker and his/her gender as a byproduct. Exploiting prosodic features to cluster the population into two groups reduces the population size and builds a strong coupling between the speaker-dependent model and the UBM. The reduction in population size as well as deriving the speaker-dependent model from the gender-dependent model, improves the recognition rates of the base classifiers and reduces the computational cost. The recognition rates of the base classifiers (namely GMM-MFCC MLC, GMM-GFCC MLC, GMM-MFCC supervector SVM, and GMM-GFCC supervector SVM), were improved by maximum (64.62%, 141.62%, 56.85%, and 119.35%), (35.23%, 41.05%, 31.49%, and 77.85%), and (52.32%, 103.60%, 33.33%, and 105%) when evaluated on short utterances distorted with white noise, pink noise, and street noise, respectively. Moreover, combining the base classifiers at score level by assigning weights proportional to their performance at different conditions (combinations of SNR and length of utterance), improve the overall recognition rate of the proposed speaker recognition system particularly at low SNR and short utterance.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




















