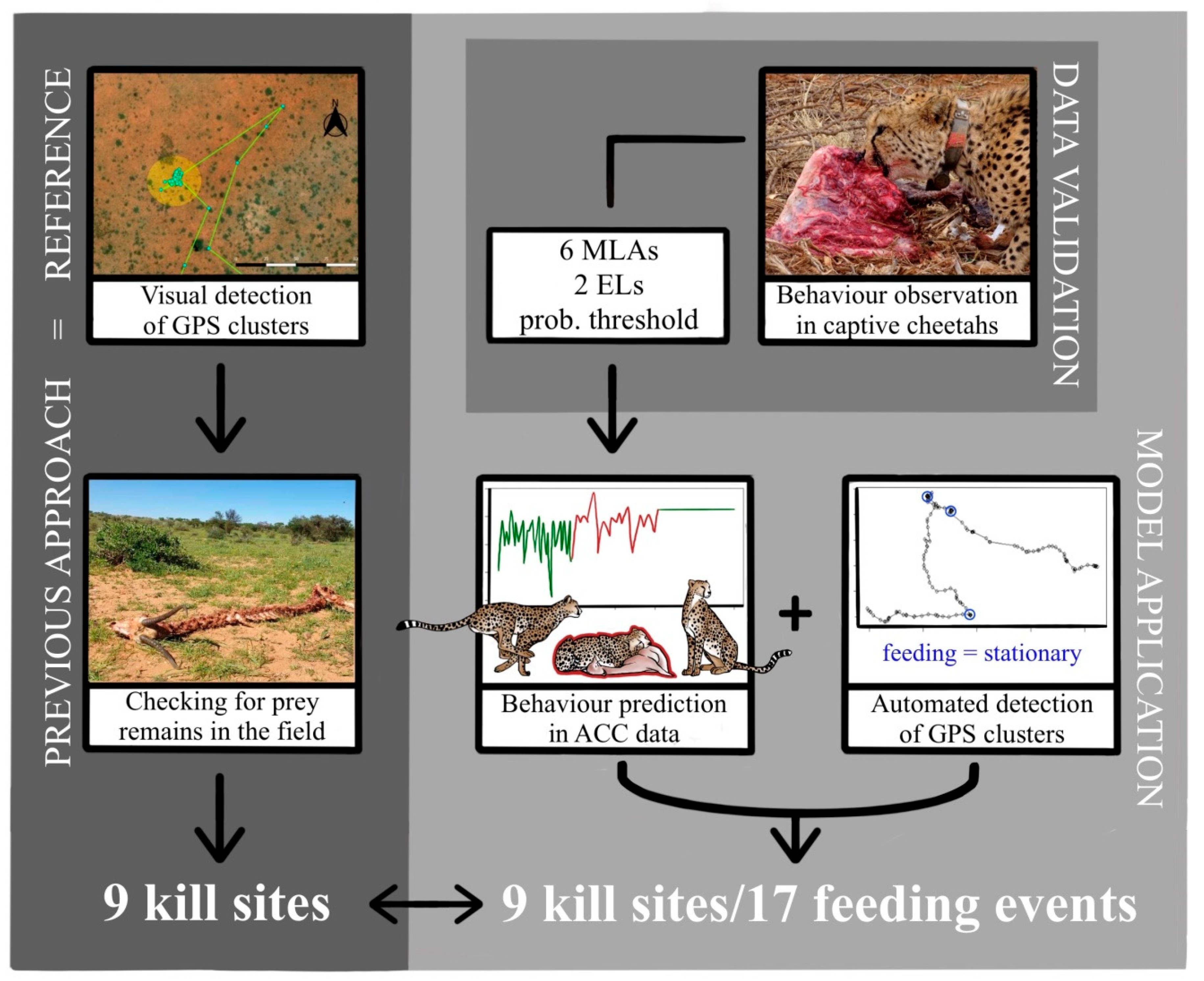
Appendix A
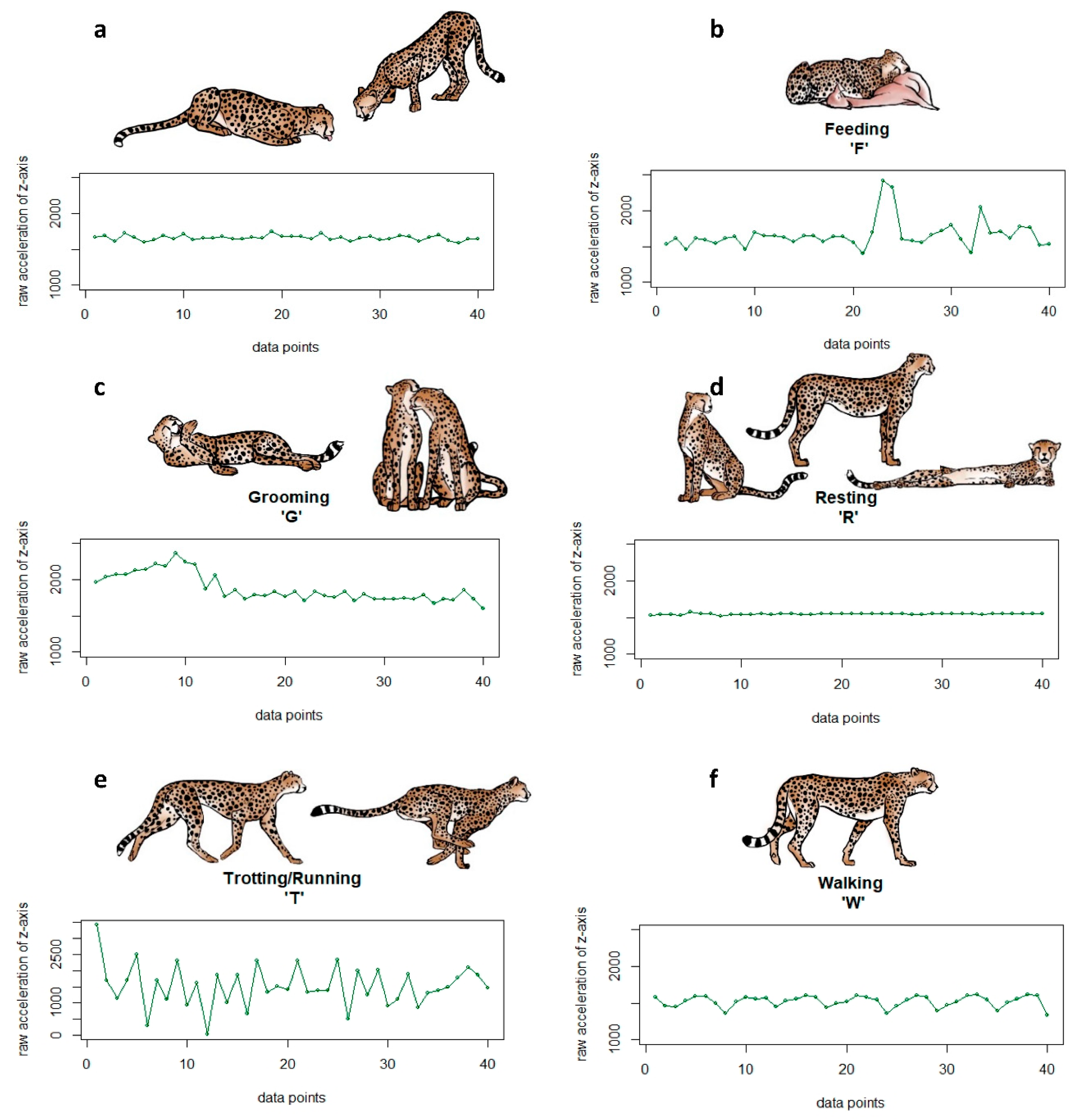
Figure A1.
Sample raw acceleration (ACC) plots of one burst for the six behaviours (a) drinking (D), (b) feeding (F), (c) grooming (G), (d) resting (R), (e) trotting/running (T), and (f) walking (W) with corresponding pictograms.
Figure A1.
Sample raw acceleration (ACC) plots of one burst for the six behaviours (a) drinking (D), (b) feeding (F), (c) grooming (G), (d) resting (R), (e) trotting/running (T), and (f) walking (W) with corresponding pictograms.
Table A1.
Output of the leave-one-out cross-validations (LOOCV) with probability thresholds for behaviour classification ranging from 0.3 to 0.8. Percentage points of performance change were determined by calculating the difference between precision and recall reached without and with the threshold. Percentage points of bursts below the probability threshold for each behaviour were calculated by dividing the number of bursts below the threshold by the total number of observed counts. Performance change and bursts below the threshold are presented as the range over all six algorithms for all ACC data (i.e., linear discriminant analysis, quadratic discriminant analysis, the k-nearest neighbour algorithm, the classification and regression tree algorithm, support vector machine algorithm and the Support Vector Machine (SVM), the range over all six algorithms for only feeding (F) data and the result for the SVM algorithm for only feeding data. The probability threshold with the best trade-off between precision increase and recall decrease and the percentage of bursts that did not exceed the probability threshold was used for the analyses. This was assessed to be the probability threshold 0.5 (bold).
Table A1.
Output of the leave-one-out cross-validations (LOOCV) with probability thresholds for behaviour classification ranging from 0.3 to 0.8. Percentage points of performance change were determined by calculating the difference between precision and recall reached without and with the threshold. Percentage points of bursts below the probability threshold for each behaviour were calculated by dividing the number of bursts below the threshold by the total number of observed counts. Performance change and bursts below the threshold are presented as the range over all six algorithms for all ACC data (i.e., linear discriminant analysis, quadratic discriminant analysis, the k-nearest neighbour algorithm, the classification and regression tree algorithm, support vector machine algorithm and the Support Vector Machine (SVM), the range over all six algorithms for only feeding (F) data and the result for the SVM algorithm for only feeding data. The probability threshold with the best trade-off between precision increase and recall decrease and the percentage of bursts that did not exceed the probability threshold was used for the analyses. This was assessed to be the probability threshold 0.5 (bold).
| Probability Threshold | Metric | Range All Algorithms, All ACC Data | Range All Algorithms, only F Data | SVM Algorithm, only F Data |
|---|
| 0.3 | Precision | 0.1–0.8 | −0.2–0.9 | 0.1 |
| Recall | −0.3–0.1 | −0.2–0.8 | 0.0 |
| Below threshold bursts | 0.0–1.1 | 0.0–0.8 | 0.1 |
| 0.4 | Precision | 0.0–4.4 | 0.0–6.1 | 0.5 |
| Recall | −2.2–0.0 | −3.3–0.0 | −0.7 |
| Below threshold bursts | 0.0–6.3 | 0.0–5.5 | 1.1 |
| 0.5 | Precision | 0.0–4.0 | 0.0–13.0 | 2.7 |
| Recall | −14.7–−0.2 | −14.2–0.0 | −2.3 |
| Below threshold bursts | 2.4–15.4 | 4.2–24.5 | 5.4 |
| 0.6 | Precision | 0.0–7.7 | 0.0–19.8 | 5.1 |
| Recall | −21.7–−0.4 | −27.7–0.0 | −9.5 |
| Below threshold bursts | 5.8–24.5 | 6.4–45.6 | 16.8 |
| 0.7 | Precision | 0.0–11.5 | 0.0–24.5 | 14.4 |
| Recall | −27.3–−0.8 | −40–0 | −32.6 |
| Below threshold bursts | 5.8–33.7 | 6.4–64.3 | 28.0 |
| 0.8 | Precision | 0.0–7.7 | −74.5–28.1 | 17.7 |
| Recall | −43.8–−1.2 | −75.4–−25.3 | −43.5 |
| Below threshold bursts | 17.7–47.2 | 37.4–81.8 | 44.3 |
By adding the probability threshold ranging from 0.3 to 0.8 to the model, precision increased for most behaviours. Drinking behaviour was never classified correctly by the LDA and CART which is why calculating changes in all algorithms was not possible resulting in 0.0 change. There was also an improvement for precision for feeding behaviour, except for the ones with a threshold of 0.3 and 0.8. The SVM algorithm performed best in correctly identifying feeding behaviour and therefore played an essential role in the determination of ‘true feeding’ in the model application. The probability threshold of 0.5 best trade-off between precision increase and recall decrease and the percentage of bursts that did not exceed the probability threshold, particularly in predicting feeding behaviour by the SVM algorithm (performance increase 2.7%) by simultaneously only missing 5.4% of true feeding bursts by labeling them as “not conclusive”. While higher thresholds showed higher precision improvements, we assessed the lower recall and percentage of feeding bursts below the probability threshold to be too high to compensate for the improvement. As a useful compromise, we decided to conduct all analyses with a probability threshold of 0.5.
Table A2.
Confusion matrix for the LDA algorithm with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
Table A2.
Confusion matrix for the LDA algorithm with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
| LDA | Expected | | | | | | |
|---|
| Predicted | | Resting | Walking | Trotting | Drinking | Feeding | Grooming |
|---|
| | resting | 2372 | 1 | 0 | 13 | 53 | 85 |
| | walking | 12 | 1583 | 28 | 73 | 217 | 19 |
| | trotting | 0 | 0 | 232 | 0 | 0 | 0 |
| | drinking | 0 | 0 | 0 | 0 | 0 | 0 |
| | feeding | 13 | 30 | 0 | 7 | 723 | 113 |
| | grooming | 7 | 3 | 0 | 0 | 3 | 33 |
| | unknown | 313 | 56 | 0 | 92 | 323 | 237 |
Table A3.
Confusion matrix for the QDA algorithm with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
Table A3.
Confusion matrix for the QDA algorithm with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
| QDA | Expected | | | | | | |
|---|
| Predicted | | Resting | Walking | Trotting | Drinking | Feeding | Grooming |
|---|
| | resting | 2464 | 0 | 0 | 11 | 6 | 9 |
| | walking | 1 | 1588 | 0 | 27 | 205 | 23 |
| | trotting | 0 | 0 | 258 | 0 | 6 | 0 |
| | drinking | 79 | 4 | 0 | 104 | 25 | 37 |
| | feeding | 27 | 66 | 1 | 17 | 941 | 150 |
| | grooming | 124 | 6 | 1 | 7 | 80 | 217 |
| | unknown | 22 | 9 | 0 | 19 | 56 | 51 |
Table A4.
Confusion matrix for the KNN algorithm with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
Table A4.
Confusion matrix for the KNN algorithm with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
| KNN | Expected | | | | | | |
|---|
| Predicted | | Resting | Walking | Trotting | Drinking | Feeding | Grooming |
|---|
| | resting | 2575 | 4 | 0 | 25 | 40 | 68 |
| | walking | 3 | 1567 | 0 | 50 | 113 | 10 |
| | trotting | 0 | 0 | 258 | 0 | 0 | 0 |
| | drinking | 4 | 0 | 0 | 23 | 1 | 0 |
| | feeding | 14 | 66 | 0 | 16 | 981 | 127 |
| | grooming | 3 | 2 | 1 | 1 | 23 | 97 |
| | unknown | 118 | 34 | 1 | 70 | 161 | 185 |
Table A5.
Confusion matrix for the CART algorithm with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
Table A5.
Confusion matrix for the CART algorithm with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
| CART | Expected | | | | | | |
|---|
| Predicted | | Resting | Walking | Trotting | Drinking | Feeding | Grooming |
|---|
| | resting | 2533 | 1 | 0 | 77 | 51 | 89 |
| | walking | 72 | 1538 | 1 | 77 | 187 | 34 |
| | trotting | 0 | 1 | 254 | 0 | 2 | 2 |
| | drinking | 0 | 0 | 0 | 0 | 0 | 0 |
| | feeding | 25 | 116 | 3 | 20 | 995 | 177 |
| | grooming | 1 | 0 | 0 | 0 | 0 | 0 |
| | unknown | 86 | 17 | 2 | 11 | 84 | 185 |
Table A6.
Confusion matrix for the RF algorithm with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
Table A6.
Confusion matrix for the RF algorithm with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
| RF | Expected | | | | | | |
|---|
| Predicted | | Resting | Walking | Trotting | Drinking | Feeding | Grooming |
|---|
| | resting | 2630 | 0 | 0 | 27 | 15 | 24 |
| | walking | 1 | 1527 | 0 | 14 | 78 | 2 |
| | trotting | 0 | 1 | 256 | 0 | 2 | 0 |
| | drinking | 5 | 3 | 0 | 70 | 2 | 5 |
| | feeding | 7 | 99 | 0 | 15 | 1027 | 129 |
| | grooming | 12 | 5 | 0 | 9 | 63 | 216 |
| | unknown | 62 | 38 | 4 | 50 | 132 | 111 |
Table A7.
Confusion matrix for the SVM algorithm with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
Table A7.
Confusion matrix for the SVM algorithm with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
| SVM | Expected | | | | | | |
|---|
| Predicted | | Resting | Walking | Trotting | Drinking | Feeding | Grooming |
|---|
| | resting | 2653 | 0 | 0 | 32 | 26 | 35 |
| | walking | 1 | 1542 | 0 | 22 | 92 | 4 |
| | trotting | 0 | 0 | 258 | 0 | 0 | 0 |
| | drinking | 3 | 3 | 0 | 68 | 2 | 10 |
| | feeding | 8 | 96 | 0 | 16 | 1087 | 173 |
| | grooming | 14 | 3 | 1 | 7 | 41 | 188 |
| | unknown | 38 | 29 | 1 | 40 | 71 | 77 |
Table A8.
Confusion matrix for the ensemble learning method “mean” with a probabillity threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
Table A8.
Confusion matrix for the ensemble learning method “mean” with a probabillity threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
| Mean | Expected | | | | | | |
|---|
| Predicted | | Resting | Walking | Trotting | Drinking | Feeding | Grooming |
|---|
| | resting | 2631 | 0 | 0 | 21 | 11 | 25 |
| | walking | 1 | 1564 | 0 | 29 | 103 | 4 |
| | trotting | 0 | 0 | 255 | 0 | 1 | 0 |
| | drinking | 1 | 0 | 0 | 33 | 0 | 0 |
| | feeding | 7 | 60 | 0 | 13 | 988 | 144 |
| | grooming | 6 | 5 | 0 | 0 | 19 | 125 |
| | unknown | 71 | 44 | 5 | 89 | 197 | 189 |
Table A9.
Confusion matrix for the ensemble learning method “majority” with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
Table A9.
Confusion matrix for the ensemble learning method “majority” with a probability threshold of 0.5. The diagonal shows all correctly predicted behaviour classes. All predictions that were below the probability threshold were labeled as unknown.
| Majority | Expected | | | | | | |
|---|
| Predicted | | Resting | Walking | Trotting | Drinking | Feeding | Grooming |
|---|
| | resting | 2650 | 0 | 0 | 30 | 28 | 39 |
| | walking | 2 | 1572 | 0 | 39 | 124 | 9 |
| | trotting | 0 | 1 | 258 | 0 | 0 | 0 |
| | drinking | 4 | 1 | 0 | 49 | 1 | 3 |
| | feeding | 9 | 79 | 1 | 17 | 1047 | 166 |
| | grooming | 8 | 4 | 1 | 2 | 26 | 141 |
| | unknown | 44 | 16 | 0 | 48 | 93 | 129 |
Table A10.
Results of the leave-one-out cross-validations (LOOCV) without (no) and with (yes) a probability threshold (PT) of 0.5 for behaviour classification for each of the six machine learning algorithms (MLA), i.e., linear discriminant analysis (LDA), quadratic discriminant analysis (QDA), the the k-nearest neighbour (KNN) algorithm, the classification and regression tree (CART) algorithm, support vector machine (SVM) algorithm and the random forest (RF) algorithm, and the two ensemble-learning approaches, i.e., the majority and mean voting. Precision (PR) across all acceleration data and for the behaviours drinking (D), feeding (F), grooming (G), resting (R), trotting/running (T) and walking (W), and recall (RE) for all behaviours are shown. PR and RE were calculated using the respective confusion matrices, with PR = TP/(TP+FP) and RE = TP/(TP+FN). TP = true positive, FP = false positive, FN = false negative.
Table A10.
Results of the leave-one-out cross-validations (LOOCV) without (no) and with (yes) a probability threshold (PT) of 0.5 for behaviour classification for each of the six machine learning algorithms (MLA), i.e., linear discriminant analysis (LDA), quadratic discriminant analysis (QDA), the the k-nearest neighbour (KNN) algorithm, the classification and regression tree (CART) algorithm, support vector machine (SVM) algorithm and the random forest (RF) algorithm, and the two ensemble-learning approaches, i.e., the majority and mean voting. Precision (PR) across all acceleration data and for the behaviours drinking (D), feeding (F), grooming (G), resting (R), trotting/running (T) and walking (W), and recall (RE) for all behaviours are shown. PR and RE were calculated using the respective confusion matrices, with PR = TP/(TP+FP) and RE = TP/(TP+FN). TP = true positive, FP = false positive, FN = false negative.
| MLA | PT | Overall | D | F | G | R | T | W |
|---|
| PR | RE | PR | RE | PR | RE | PR | RE | PR | RE | PR | RE | PR | RE |
|---|
| LDA | no | 63.1 | 60.8 | <0.01 | 0.0 | 68.6 | 69.0 | 43.6 | 18.9 | 92.2 | 91.7 | 100.0 | 89.2 | 74.2 | 96.2 |
| yes | 71.5 | 55.5 | <0.1 | 0.0 | 81.6 | 54.8 | 71.7 | 6.8 | 94.0 | 87.3 | 100 | 89.2 | 82.0 | 94.6 |
| QDA | no | 74.9 | 78.2 | 40.4 | 60.5 | 77.1 | 73.3 | 49.7 | 49.9 | 98.9 | 90.9 | 97.7 | 99.2 | 85.6 | 95.1 |
| yes | 75.5 | 76.2 | 41.8 | 56.2 | 78.2 | 71.3 | 50.0 | 44.6 | 99.0 | 90.7 | 97.8 | 99.2 | 86.1 | 94.9 |
| KNN | no | 81.8 | 72.1 | 68.1 | 26.5 | 76.2 | 80.3 | 67.2 | 34.5 | 92.5 | 97.1 | 100.0 | 99.2 | 87.0 | 94.7 |
| yes | 87.5 | 65.7 | 12.4 | 12.4 | 78.3 | 74.4 | 76.4 | 19.9 | 94.9 | 94.8 | 100 | 99.2 | 95.0 | 93.7 |
| CART | no | 65.5 | 66.0 | <0.01 | 0.0 | 74.5 | 75.4 | 47.9 | 38.0 | 92.1 | 93.2 | 98.1 | 97.7 | 80.6 | 91.9 |
| yes | 57.5 | 59.7 | <0.1 | 0.0 | 74.4 | 75.4 | 0.0 | 0.0 | 92.1 | 93.2 | 98.0 | 97.7 | 80.1 | 91.9 |
| RF | no | 83.0 | 79.1 | 69.4 | 46.5 | 77.3 | 83.0 | 62.8 | 55.9 | 96.4 | 97.8 | 98.5 | 99.2 | 93.4 | 92.1 |
| yes | 87.4 | 74.4 | 82.4 | 37.8 | 80.4 | 77.9 | 70.8 | 44.4 | 97.6 | 96.8 | 98.8 | 98.5 | 94.1 | 91.3 |
| SVM | no | 83.9 | 77.5 | 72.2 | 44.9 | 76.0 | 84.7 | 67.7 | 45.2 | 96.0 | 98.2 | 100.0 | 99.2 | 91.7 | 92.8 |
| yes | 86.9 | 74.5 | 79.1 | 36.8 | 78.8 | 82.4 | 74.0 | 38.6 | 96.6 | 97.6 | 100 | 99.2 | 92.8 | 92.2 |
| Mean | no | 84.1 | 75.5 | 73.1 | 36.8 | 76.8 | 82.3 | 71.2 | 41.1 | 95.7 | 98.5 | 99.2 | 99.2 | 88.5 | 95.1 |
| yes | 91.4 | 67.8 | 97.1 | 17.8 | 81.5 | 74.9 | 80.6 | 25.7 | 97.9 | 96.8 | 99.6 | 98.1 | 91.9 | 93.5 |
| Majority | no | 84.5 | 75.6 | 76.1 | 36.2 | 77.1 | 82.3 | 70.8 | 42.9 | 95.7 | 98.5 | 99.2 | 99.2 | 88.3 | 94.7 |
| yes | 87.9 | 70.9 | 84.4 | 26.5 | 79.4 | 79.4 | 77.5 | 29.0 | 96.5 | 97.5 | 99.6 | 99.2 | 90.0 | 94.0 |
Table A11.
Results of the per-animal cross-validations (PACV) with a probability threshold of 0.5 for the five cheetahs (M1, M2, M3, M4 and F1). Precision (PR) of the two ensemble-learning approaches (ELA), mean and majority voting, across all acceleration data and for the behaviours drinking (D), feeding (F), grooming (G), resting (R), trotting/running (T) and walking (W), and recall (RE) for all behaviours. PR and RE were calculated using the respective confusion matrices, with PR = TP/(TP + FP) and RE = TP/(TP + FN). TP = true positive, FP = false positive, FN = false negative.
Table A11.
Results of the per-animal cross-validations (PACV) with a probability threshold of 0.5 for the five cheetahs (M1, M2, M3, M4 and F1). Precision (PR) of the two ensemble-learning approaches (ELA), mean and majority voting, across all acceleration data and for the behaviours drinking (D), feeding (F), grooming (G), resting (R), trotting/running (T) and walking (W), and recall (RE) for all behaviours. PR and RE were calculated using the respective confusion matrices, with PR = TP/(TP + FP) and RE = TP/(TP + FN). TP = true positive, FP = false positive, FN = false negative.
| Test Dataset | ELA | Overall | D | F | G | R | T | W |
|---|
| PR | RE | PR | RE | PR | RE | PR | RE | PR | RE | PR | RE | PR | RE |
|---|
| M1 | Mean | 80.3 | 59.4 | 33.3 | 2.5 | 86.3 | 47.0 | 69.4 | 39.1 | 97.8 | 95.5 | 97.4 | 86.0 | 97.4 | 86.5 |
| Majority | 77.7 | 66.6 | 52.9 | 22.5 | 80.3 | 49.7 | 49.1 | 49.1 | 90.7 | 98.5 | 97.5 | 90.7 | 95.7 | 89.2 |
| M2 | Mean | 74.1 | 60.5 | <0.1 | 0.0 | 82.7 | 72.4 | 70.0 | 6.3 | 99.7 | 94.3 | 100.0 | 97.8 | 92.4 | 92.6 |
| Majority | 82.6 | 64.5 | 75.0 | 6.0 | 80.5 | 75.5 | 57.1 | 14.4 | 97.6 | 97.8 | 97.8 | 97.8 | 87.3 | 95.3 |
| M3 | Mean | 80.3 | 61.5 | <0.1 | 0.0 | 91.4 | 65.6 | 100.0 | 17.2 | 99.4 | 93.4 | 100.0 | 100.0 | 90.8 | 92.5 |
| Majority | 92.5 | 70.0 | 100.0 | 1.6 | 84.4 | 81.1 | 91.2 | 44.8 | 97.8 | 98.2 | 100.0 | 100.0 | 81.5 | 94.1 |
| M4 | Mean | 76.1 | 61.5 | <0.1 | 0.0 | 72.7 | 78.4 | 100.0 | 5.7 | 97.7 | 97.4 | 100.0 | 100.0 | 86.0 | 87.8 |
| Majority | 73.0 | 65.2 | <0.1 | 0.0 | 72.1 | 79.9 | 94.7 | 20.5 | 93.6 | 99.0 | 100.0 | 100.0 | 77.6 | 91.8 |
| F1 | Mean | 75.2 | 57.7 | <0.1 | 0.0 | 69.0 | 79.5 | 100.0 | 1.6 | 98.7 | 80.8 | 100.0 | 100.0 | 83.6 | 84.3 |
| Majority | 69.9 | 62.4 | 0.0 | 0.0 | 65.6 | 80.8 | 77.8 | 11.3 | 98.1 | 91.8 | 100.0 | 100.0 | 78.2 | 90.4 |
Discussion of
Table A11: The PACV with a probability threshold of 0.5 reached, similar to POCCV, high overall precision but lower overall recall. They ranged from 69.9% to 92.5% and from 57.5% and 70.0% for precision and recall respectively for the two ensemble learning approaches. Resting and trotting/running behaviours were predicted with very high precision and recall of up to 100%. Feeding behaviour reached precision and recall ranging from 65.6% to 91.4% and from 47.0% to 81.1% respectively. Precision for feeding was lowest in the female F1 while the M1 showed the lowest recall for feeding behaviour. Drinking and grooming showed low recall scores in all cheetahs. High precision values result from a very low rate of these behaviours being assigned to a burst at all.
Text A1: Details on data analyses
Supervised machine learning algorithms (MLAs) use feature characteristics of predictor variables calculated from a ground-truthed dataset (training dataset) with different states/behaviours, to construct a model (=training process). The model is then used for predicting the different states on another ground-truthed dataset (=testing or validating process) or on data with unknown states/behaviours (=application). References and R packages for the six supervised MLAs were as follows: linear discriminant analysis (LDA) [
51], quadratic discriminant analysis (QDA) [
16], the KNN algorithm [
31] using the R package kknn v. 1.3.1 [
52], the classification and regression tree (CART) algorithm [
16] using the package rpart v. 4.1-13 [
53], SVM algorithm [
54] using the package e1071 v. 1.6-8 [
55], and the random forest (RF) algorithm [
56] using package randomForest v. 4.6-14 [
57].
The two ensemble-learning approaches were used to improve performance classification since the six MLAs showed differences in prediction accuracy per behaviour. For the mean voting, the burst gets assigned the behaviour that has the highest mean probability of all six MLAs. For the majority voting, each burst gets assigned the behaviour which is classified most by the six MLAs. In case of no majority, i.e., a draw, the behaviour gets assigned randomly to the most classified ones.
Text A2: Calculation of resting and walking clusters
The detection of resting and walking clusters was conducted very similarly to the procedure described for the detection of feeding clusters, again using the chronological order of behaviour predictions paired with the calculated GPS clusters (see
Section 2.3). We started by determining all bursts that were identified as resting/walking by either one or both of the ensemble approaches to be bursts of ‘true resting’/’true walking’. We then again used a sliding window approach to find clusters of ‘true resting’/’true walking’ instances on the condition that the majority of bursts (at least 12 of 15) per sliding window were voted to be ‘true resting’/’true walking’. We then determined start and end time of these resting/walking clusters. Detected clusters that were at least 30 min long were then paired with their respective GPS coordinates via the timestamp. In case of the resting clusters we again assume overlaps with the already determined GPS clusters, while walking clusters are expected to be associated with missing GPS clusters, e.g., at least 2-3 coordinates that are more than 50 m apart from each other.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}


