
An Automated CAD System for Accurate Grading of Uveitis Using Optical Coherence Tomography Images


 ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
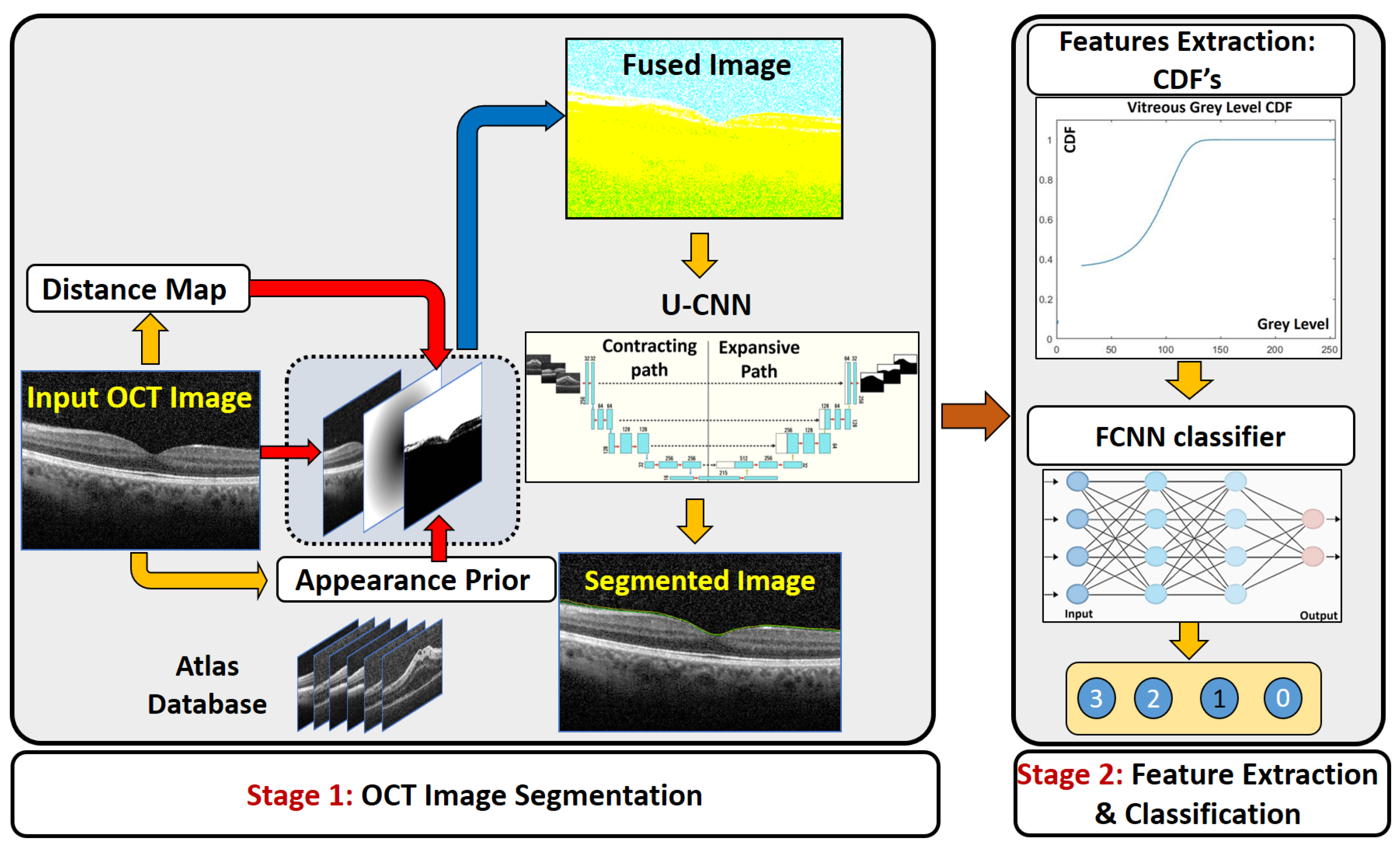
- In contrast to [16], where the OCT images were directly applied to train the U-CNN, the first stage of the proposed CAD system trains the U-CNN model using a fused image (FI) dataset, which integrates the information of the original image with a proposed distance map, and a proposed adaptive appearance map (AAP), instead of the direct original images.
- Compared to previous work, the first stage of the proposed CAD system shows superior performance in vitreous segmentation from the OCT images in spite of the great similarity between the vitreous and the background.
- The second stage of the proposed CAD system shows great performance in classification accuracy in spite of the great overlap among the extracted features from the OCT vitreous images.
2. Materials and Methods
2.1. Segmentation Stage
2.1.1. Construction of the Fused Image
2.1.2. U-Net Segmentation
2.2. Grading Stage
2.3. Performance Metrics
3. Experimental Results and Discussions
3.1. Data Set
3.2. Fused Image Construction
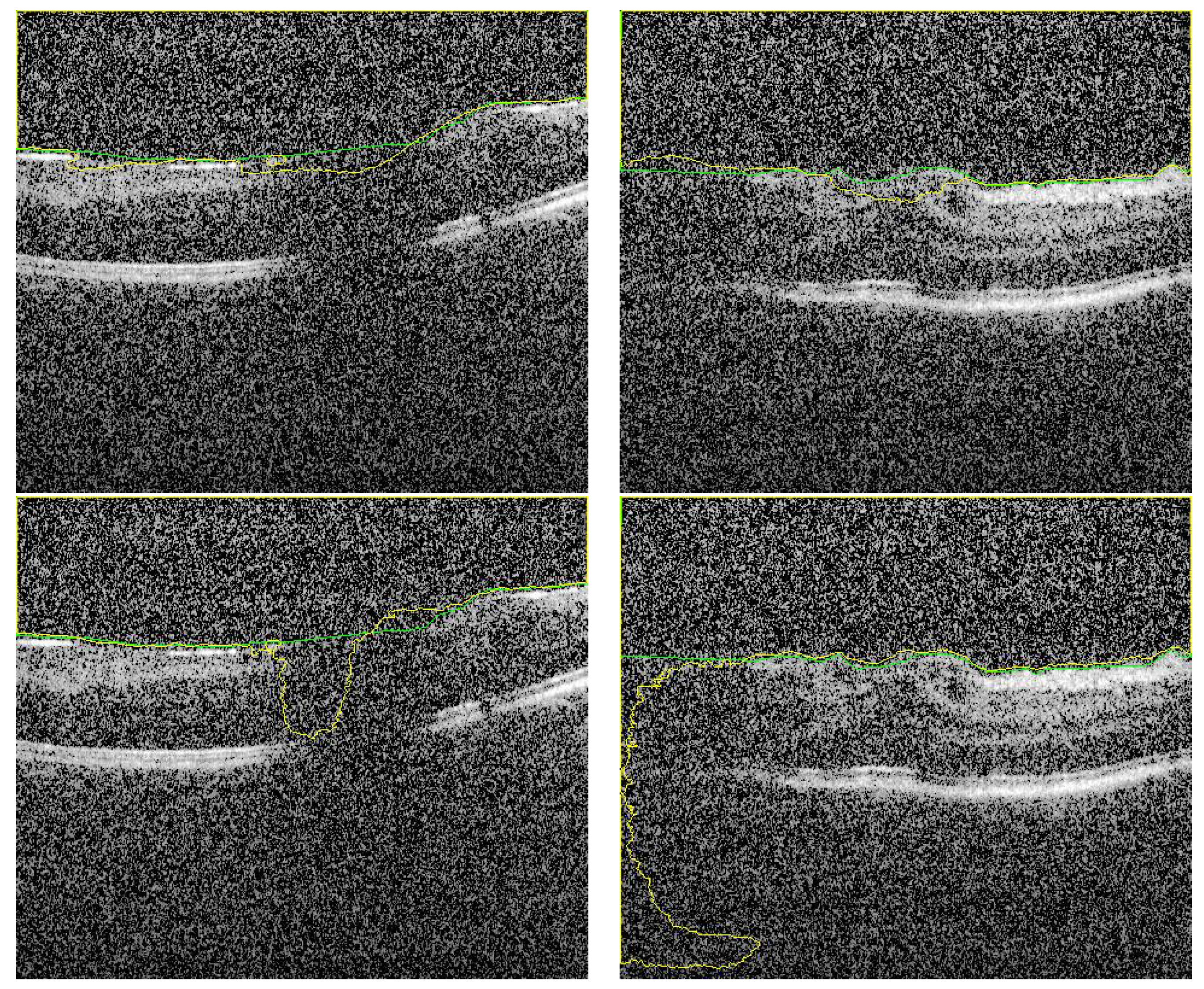
3.3. Overall Segmentation Evaluation
3.4. Ablation Study
3.5. Grading Stage
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Park, J.; Lee, K.P.; Kim, H.; Park, S.; Wijesinghe, R.E.; Lee, J.; Han, S.; Lee, S.; Kim, P.; Cho, D.W.; et al. Biocompatibility evaluation of bioprinted decellularized collagen sheet implanted in vivo cornea using swept-source optical coherence tomography. J. Biophotonics 2019, 12, e201900098. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wijesinghe, R.E.; Park, K.; Kim, P.; Oh, J.; Kim, S.W.; Kim, K.; Kim, B.M.; Jeon, M.; Kim, J. Optically deviated focusing method based high-speed SD-OCT for in vivo retinal clinical applications. Opt. Rev. 2016, 23, 307–315. [Google Scholar] [CrossRef]
- Huang, D.; Swanson, E.A.; Lin, C.P.; Schuman, J.S.; Stinson, W.G.; Chang, W.; Hee, M.R.; Flotte, T.; Gregory, K.; Puliafito, C.A.; et al. Optical coherence tomography. Science 1991, 254, 1178–1181. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barisani-Asenbauer, T.; Maca, S.M.; Mejdoubi, L.; Emminger, W.; Machold, K.; Auer, H. Uveitis-a rare disease often associated with systemic diseases and infections-a systematic review of 2619 patients. Orphanet J. Rare Dis. 2012, 7, 1–7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miserocchi, E.; Fogliato, G.; Modorati, G.; Bandello, F. Review on the worldwide epidemiology of uveitis. Eur. J. Ophthalmol. 2013, 23, 705–717. [Google Scholar] [CrossRef] [PubMed]
- Chang, J.H.M.; Wakefield, D. Uveitis: A global perspective. Ocul. Immunol. Inflamm. 2002, 10, 263–279. [Google Scholar] [CrossRef] [PubMed]
- Khan, M.; Silva, B.N.; Han, K. Efficiently processing big data in real-time employing deep learning algorithms. In Deep Learning and Neural Networks: Concepts, Methodologies, Tools, and Applications; IGI Global: Hershey, PA, USA, 2020; pp. 1344–1357. [Google Scholar]
- Pelosini, L.; Hull, C.C.; Boyce, J.F.; McHugh, D.; Stanford, M.R.; Marshall, J. Optical coherence tomography may be used to predict visual acuity in patients with macular edema. Investig. Ophthalmol. Vis. Sci. 2011, 52, 2741–2748. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- ElTanboly, A.; Ismail, M.; Shalaby, A.; Switala, A.; El-Baz, A.; Schaal, S.; Gimel’farb, G.; El-Azab, M. A computer-aided diagnostic system for detecting diabetic retinopathy in optical coherence tomography images. Med. Phys. 2017, 44, 914–923. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhang, Y.; Yao, Z.; Zhao, R.; Zhou, F. Machine learning based detection of age-related macular degeneration (AMD) and diabetic macular edema (DME) from optical coherence tomography (OCT) images. Biomed. Opt. Express 2016, 7, 4928–4940. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Murugeswari, S.; Sukanesh, R. Investigations of severity level measurements for diabetic macular oedema using machine learning algorithms. Ir. J. Med. Sci. 2017, 186, 929–938. [Google Scholar] [CrossRef] [PubMed]
- Miri, M.S.; Abràmoff, M.D.; Kwon, Y.H.; Sonka, M.; Garvin, M.K. A machine-learning graph-based approach for 3D segmentation of Bruch’s membrane opening from glaucomatous SD-OCT volumes. Med. Image Anal. 2017, 39, 206–217. [Google Scholar] [CrossRef] [PubMed]
- Rossant, F.; Ghorbel, I.; Bloch, I.; Paques, M.; Tick, S. Automated segmentation of retinal layers in OCT imaging and derived ophthalmic measures. In Proceedings of the 2009 IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Boston, MA, USA, 28 June–1 July 2009; pp. 1370–1373. [Google Scholar]
- Yazdanpanah, A.; Hamarneh, G.; Smith, B.R.; Sarunic, M.V. Segmentation of intra-retinal layers from optical coherence tomography images using an active contour approach. IEEE Trans. Med. Imaging 2010, 30, 484–496. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Waldstein, S.M.; Montuoro, A.; Gerendas, B.S.; Langs, G.; Schmidt-Erfurth, U. Automated fovea detection in spectral domain optical coherence tomography scans of exudative macular disease. Int. J. Biomed. Imaging 2016, 2016, 7468953. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hagagg, S.; Khalifa, F.; Abdeltawab, H.; Elnakib, A.; Abdelazim, M.; Ghazal, M.; Sandhu, H.; El-Baz, A. A CNN-Based Framework for Automatic Vitreous Segemntation from OCT Images. In Proceedings of the 2019 IEEE International Conference on Imaging Systems and Techniques (IST), Abu Dhabi, United Arab Emirates, 8–10 Decemer 2019; pp. 1–5. [Google Scholar]
- Invernizzi, A.; Cozzi, M.; Staurenghi, G. Optical coherence tomography and optical coherence tomography angiography in uveitis: A review. Clin. Exp. Ophthalmol. 2019, 47, 357–371. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Keane, P.A.; Balaskas, K.; Sim, D.A.; Aman, K.; Denniston, A.K.; Aslam, T.; EQUATOR Study Group. Automated analysis of vitreous inflammation using spectral-domain optical coherence tomography. Transl. Vis. Sci. Technol. 2015, 4, 4. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schlegl, T.; Waldstein, S.M.; Bogunovic, H.; Endstraßer, F.; Sadeghipour, A.; Philip, A.M.; Podkowinski, D.; Gerendas, B.S.; Langs, G.; Schmidt-Erfurth, U. Fully automated detection and quantification of macular fluid in OCT using deep learning. Ophthalmology 2018, 125, 549–558. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, C.S.; Tyring, A.J.; Deruyter, N.P.; Wu, Y.; Rokem, A.; Lee, A.Y. Deep-learning based, automated segmentation of macular edema in optical coherence tomography. Biomed. Opt. Express 2017, 8, 3440–3448. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, Y.; Carass, A.; Yun, Y.; Zhao, C.; Jedynak, B.M.; Solomon, S.D.; Saidha, S.; Calabresi, P.A.; Prince, J.L. Towards topological correct segmentation of macular OCT from cascaded FCNs. In Fetal, Infant and Ophthalmic Medical Image Analysis; Springer: Berlin/Heidelberg, Germany, 2017; pp. 202–209. [Google Scholar]
- Fang, L.; Cunefare, D.; Wang, C.; Guymer, R.H.; Li, S.; Farsiu, S. Automatic segmentation of nine retinal layer boundaries in OCT images of non-exudative AMD patients using deep learning and graph search. Biomed. Opt. Express 2017, 8, 2732–2744. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Babalola, K.O.; Patenaude, B.; Aljabar, P.; Schnabel, J.; Kennedy, D.; Crum, W.; Smith, S.; Cootes, T.; Jenkinson, M.; Rueckert, D. An evaluation of four automatic methods of segmenting the subcortical structures in the brain. Neuroimage 2009, 47, 1435–1447. [Google Scholar] [CrossRef] [PubMed]
- Hossin, M.; Sulaiman, M. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | This Paper | Haggag et al. [16] | p-Value |
|---|---|---|---|
| DC (%) | 98.8 ± 1.03 | 94.0 ± 13.0 | ≤0.0001 |
| (mm) | 0.0003 ± 0.001 | 0.0360 ± 0.086 | ≤0.0001 |
| Metrics | FCNN | Two-Level SVM Classifier |
|---|---|---|
| Accuracy (%) | 86.0 ± 1.0 | 80.0 ± 1.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Haggag, S.; Khalifa, F.; Abdeltawab, H.; Elnakib, A.; Ghazal, M.; Mohamed, M.A.; Sandhu, H.S.; Alghamdi, N.S.; El-Baz, A. An Automated CAD System for Accurate Grading of Uveitis Using Optical Coherence Tomography Images. Sensors 2021, 21, 5457. https://doi.org/10.3390/s21165457
Haggag S, Khalifa F, Abdeltawab H, Elnakib A, Ghazal M, Mohamed MA, Sandhu HS, Alghamdi NS, El-Baz A. An Automated CAD System for Accurate Grading of Uveitis Using Optical Coherence Tomography Images. Sensors. 2021; 21(16):5457. https://doi.org/10.3390/s21165457
Chicago/Turabian StyleHaggag, Sayed, Fahmi Khalifa, Hisham Abdeltawab, Ahmed Elnakib, Mohammed Ghazal, Mohamed A. Mohamed, Harpal Singh Sandhu, Norah Saleh Alghamdi, and Ayman El-Baz. 2021. "An Automated CAD System for Accurate Grading of Uveitis Using Optical Coherence Tomography Images" Sensors 21, no. 16: 5457. https://doi.org/10.3390/s21165457
APA StyleHaggag, S., Khalifa, F., Abdeltawab, H., Elnakib, A., Ghazal, M., Mohamed, M. A., Sandhu, H. S., Alghamdi, N. S., & El-Baz, A. (2021). An Automated CAD System for Accurate Grading of Uveitis Using Optical Coherence Tomography Images. Sensors, 21(16), 5457. https://doi.org/10.3390/s21165457