
Schizophrenia Detection Using Machine Learning Approach from Social Media Content

Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Data Preprocessing
2.3. Linguistic Inquiry and Word Count (LIWC) Analysis
2.4. Topic Modeling and Analysis
2.5. Classification
2.6. Unsupervised Clustering
3. Results
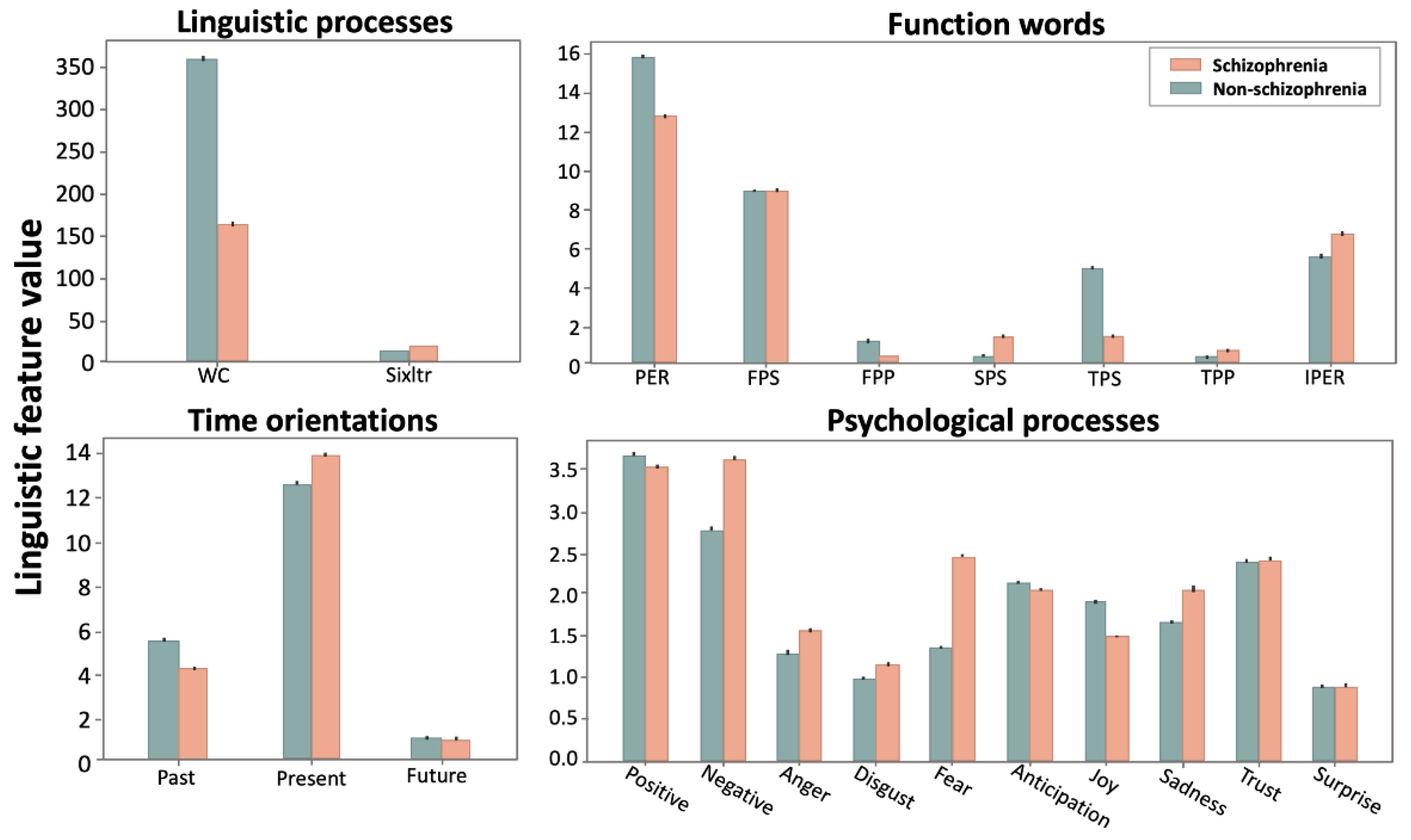
3.1. Linguistic Inquiry and Word Count (LIWC)
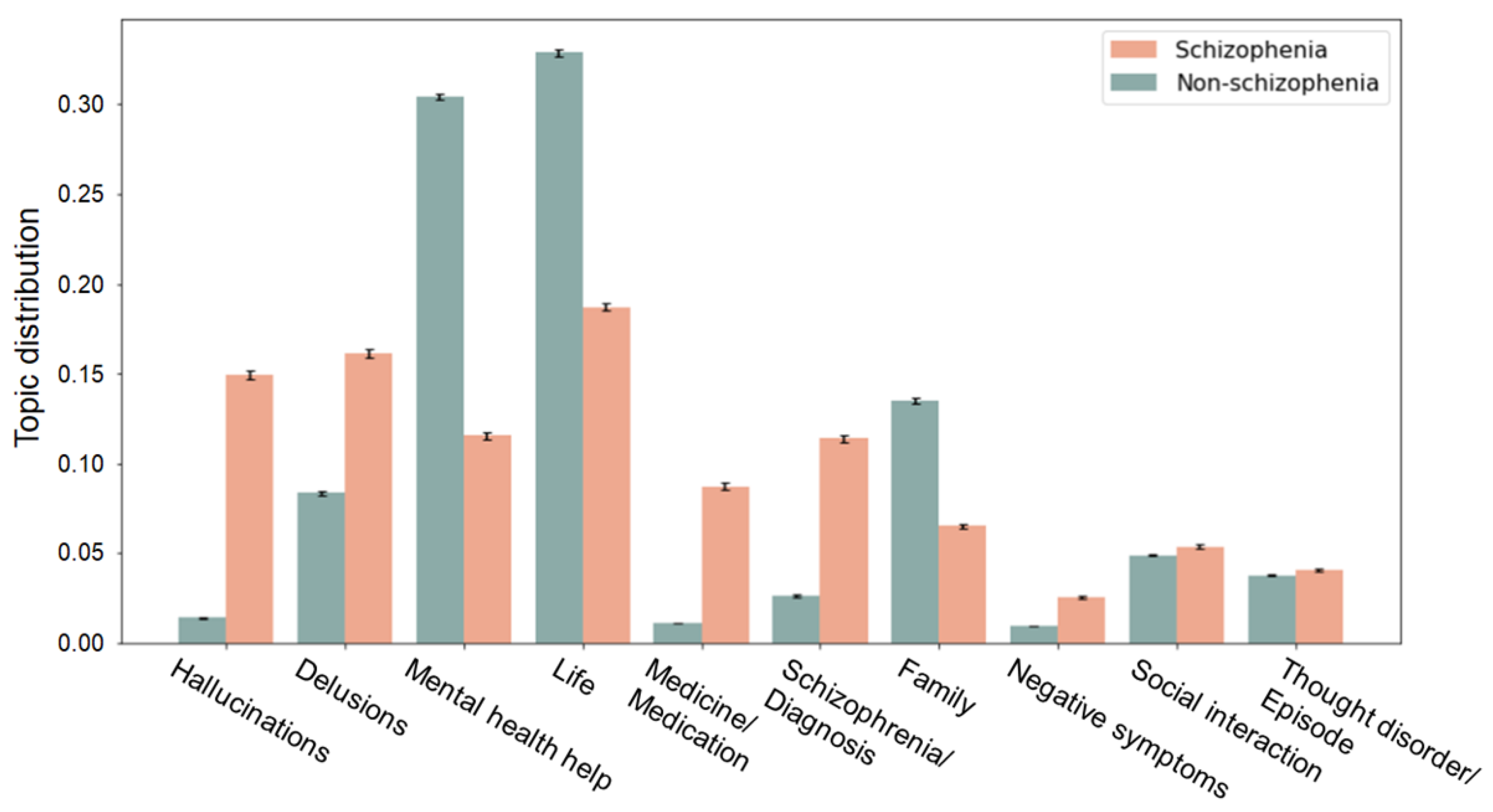
3.2. Topic Detection and Comparison
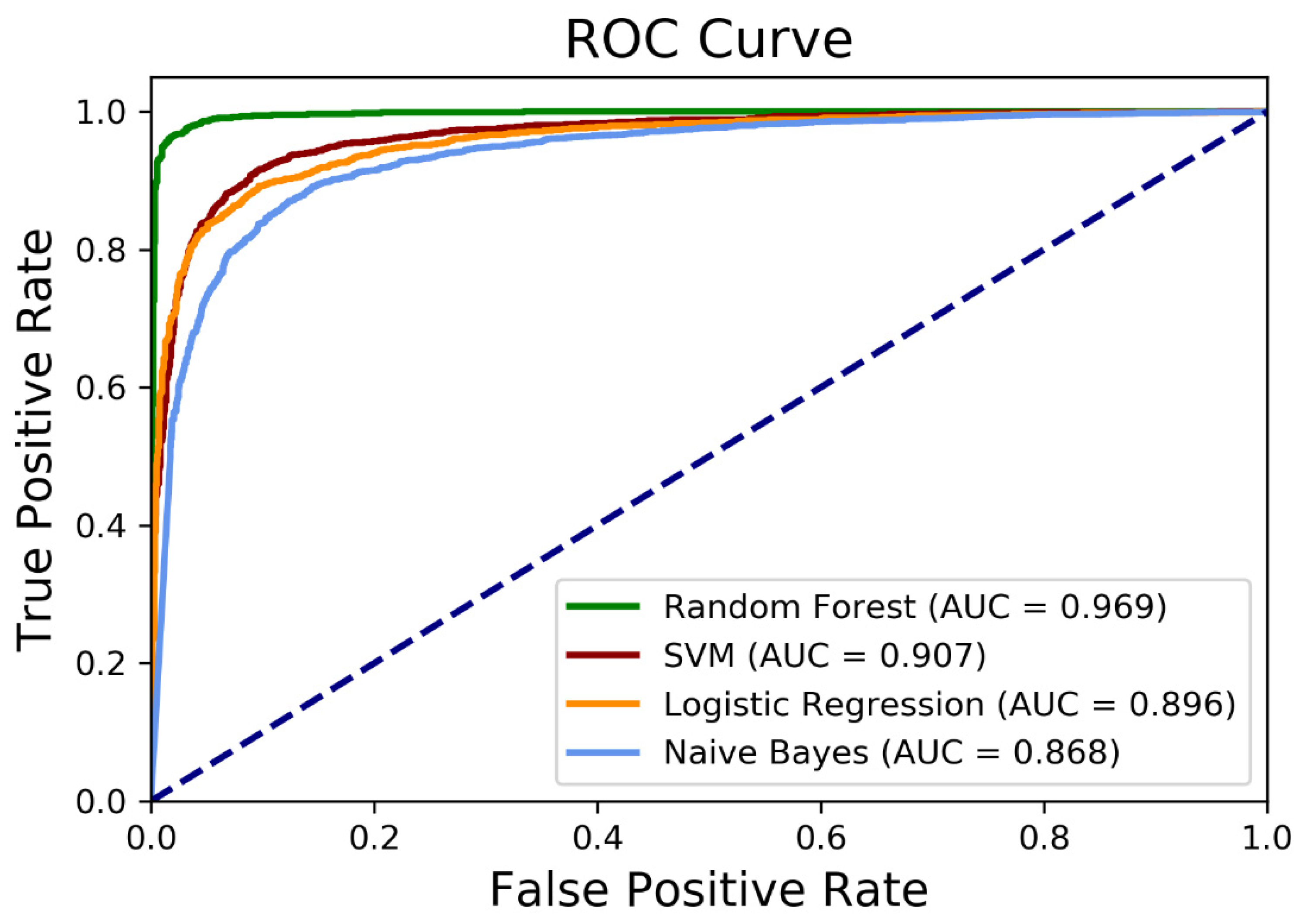
3.3. Classification
3.4. Unsupervised Clustering
4. Discussion
4.1. Linguistic Characteristics of Schizophrenia
4.2. Topic Detection and Comparison
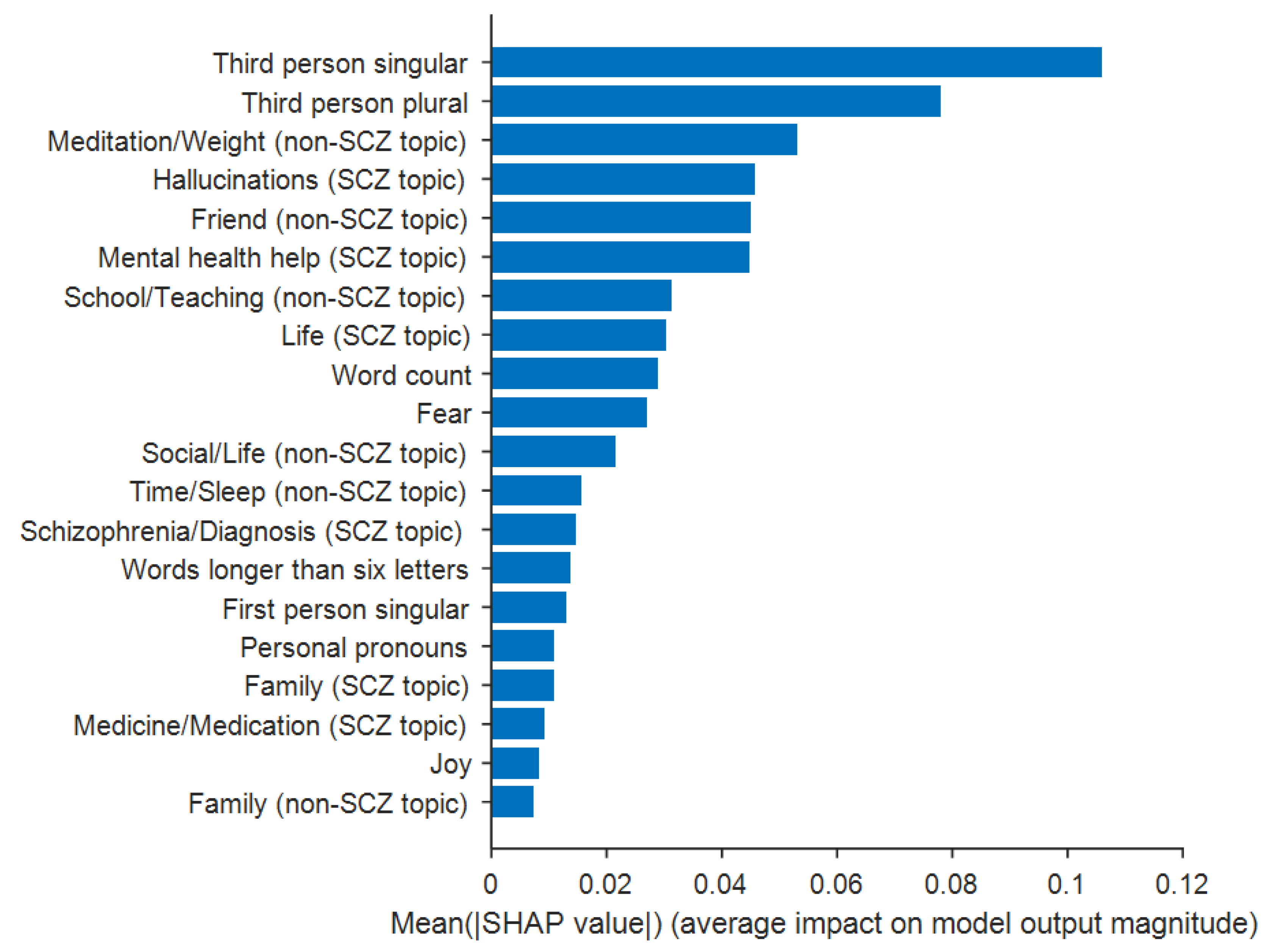
4.3. Classification and Feature Importance
4.4. Semantic Characterization of Schizophrenia
4.5. Methodological Considerations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Whiteford, H.A.; Degenhardt, L.; Rehm, J.; Baxter, A.J.; Ferrari, A.J.; Erskine, H.E.; Charlson, F.J.; Norman, R.E.; Flaxman, A.D.; Johns, N.; et al. Global burden of disease attributable to mental and substance use disorders: Findings from the global burden of disease study 2010. Lancet 2013, 382, 1575–1586. [Google Scholar] [CrossRef]
- Corcoran, C.M.; Carrillo, F.; Fernandez-Slezak, D.; Bedi, G.; Klim, C.; Javitt, D.C.; Bearden, C.E.; Cecchi, G.A. Prediction of psychosis across protocols and risk cohorts using automated language analysis. World Psychiatry 2018, 17, 67–75. [Google Scholar] [CrossRef]
- Sher, L.; Kahn, R.S. Suicide in Schizophrenia: An Educational Overview. Medicina 2019, 55, 361. [Google Scholar] [CrossRef] [Green Version]
- Buckley, P.F.; Miller, B.J.; Lehrer, D.S.; Castle, D.J. Psychiatric comorbidities and schizophrenia. Schizophr. Bull. 2009, 35, 383–402. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Johnson, G.J.; Ambrose, P.J. Neo-tribes: The power and potential of online communities in health care. Commun. ACM 2006, 49, 107–113. [Google Scholar] [CrossRef]
- Lyons, M.; Aksayli, N.D.; Brewer, G. Mental distress and language use: Linguistic analysis of discussion forum posts. Comput. Hum. Behav. 2018, 87, 207–211. [Google Scholar] [CrossRef]
- Birnbaum, M.L.; Ernala, S.K.; Rizvi, A.F.; De Choudhury, M.; Kane, J.M. A Collaborative Approach to Identifying Social Media Markers of Schizophrenia by Employing Machine Learning and Clinical Appraisals. J. Med. Internet Res. 2017, 19, e289. [Google Scholar] [CrossRef] [PubMed]
- Park, A.; Conway, M. Harnessing Reddit to Understand the Written-Communication Challenges Experienced by Individuals With Mental Health Disorders: Analysis of Texts From Mental Health Communities. J. Med. Internet Res. 2018, 20, e121. [Google Scholar] [CrossRef]
- Low, D.M.; Rumker, L.; Talkar, T.; Torous, J.; Cecchi, G.; Ghosh, S.S. Natural Language Processing Reveals Vulnerable Mental Health Support Groups and Heightened Health Anxiety on Reddit During COVID-19: Observational Study. J. Med. Internet Res. 2020, 22, e22635. [Google Scholar] [CrossRef]
- Conway, M.; O’Connor, D. Social Media, Big Data, and Mental Health: Current Advances and Ethical Implications. Curr. Opin. Psychol. 2016, 9, 77–82. [Google Scholar] [CrossRef] [Green Version]
- McMahon, F.J. Prediction of treatment outcomes in psychiatry--where do we stand ? Dialogues Clin. Neurosci. 2014, 16, 455–464. [Google Scholar]
- Chekroud, A.M.; Bondar, J.; Delgadillo, J.; Doherty, G.; Wasil, A.; Fokkema, M.; Cohen, Z.; Belgrave, D.; DeRubeis, R.; Iniesta, R.; et al. The promise of machine learning in predicting treatment outcomes in psychiatry. World Psychiatry 2021, 20, 154–170. [Google Scholar] [CrossRef]
- Nagarhalli, T.P.; Vaze, V.; Rana, N.K. Impact of Machine Learning in Natural Language Processing: A Review. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 1529–1534. [Google Scholar]
- Chancellor, S.; De Choudhury, M. Methods in predictive techniques for mental health status on social media: A critical review. NPJ Digit. Med. 2020, 3. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thorstad, R.; Wolff, P. Predicting future mental illness from social media: A big-data approach. Behav. Res. Methods 2019, 51, 1586–1600. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gkotsis, G.; Oellrich, A.; Velupillai, S.; Liakata, M.; Hubbard, T.J.; Dobson, R.J.; Dutta, R. Characterisation of mental health conditions in social media using Informed Deep Learning. Sci. Rep. 2017, 7, 45141. [Google Scholar] [CrossRef] [Green Version]
- Zomick, J.; Levitan, S.I.; Serper, M. Linguistic Analysis of Schizophrenia in Reddit Posts; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 74–83. [Google Scholar]
- Mitchell, M.; Hollingshead, K.; Coppersmith, G. Quantifying the Language of Schizophrenia in Social Media; Association for Computational Linguistics: Denver, CO, USA, 2015; pp. 11–20. [Google Scholar]
- Coppersmith, G.; Dredze, M.; Harman, C.; Hollingshead, K. From ADHD to SAD: Analyzing the Language of Mental Health on Twitter through Self-Reported Diagnoses; Association for Computational Linguistics: Denver, CO, USA, 2015; pp. 1–10. [Google Scholar]
- Loveys, K.; Crutchley, P.; Wyatt, E.; Coppersmith, G. Small but Mighty: Affective micropatterns for Quantifying Mental Health from Social Media Language; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 85–95. [Google Scholar]
- Kirinde Gamaarachchige, P.; Inkpen, D. Multi-Task, Multi-Channel, Multi-Input Learning for Mental Illness Detection Using Social Media Text; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 54–64. [Google Scholar]
- Ive, J.; Gkotsis, G.; Dutta, R.; Stewart, R.; Velupillai, S. Hierarchical Neural Model with Attention Mechanisms for the Classification of Social Media Text Related to Mental Health; Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 69–77. [Google Scholar]
- McManus, K.; Mallory, E.K.; Goldfeder, R.L.; Haynes, W.A.; Tatum, J.D. Mining Twitter Data to Improve Detection of Schizophrenia. AMIA Jt. Summits Transl. Sci. Proc. 2015, 2015, 122–126. [Google Scholar] [PubMed]
- Benton, A.; Mitchell, M.; Hovy, D. Multitask Learning for Mental Health Conditions with Limited Social Media Data; Association for Computational Linguistics: Valencia, Spain, 2017; pp. 152–162. [Google Scholar]
- Tausczik, Y.R.; Pennebaker, J.W. The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Pushshift.io Reddit API. GitHub. Available online: https://github.com/pushshift/api (accessed on 3 September 2020).
- Bird, S. NLTK: The Natural Language Toolkit. arXiv 2004, arXiv:CL/0205028. Available online: https://www.nltk.org (accessed on 3 September 2020).
- Pennebaker, J.W.; Booth, R.J.; Boyd, R.L.; Francis, M.E. LIWC 2015 Operator’s Manual; Pennebaker Conglomerates Inc.: Austin, TX, USA, 2015. [Google Scholar]
- Benoit, K.; Watanabe, K.; Wang, H.; Nulty, P.; Obeng, A.; Müller, S. quanteda: An R package for the quantitative analysis of textual data. J. Open Source Softw. 2018, 3, 774. [Google Scholar] [CrossRef] [Green Version]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Lee, W.H.; Antoniades, M.; Schnack, H.G.; Kahn, R.S.; Frangou, S. Brain age prediction in schizophrenia: Does the choice of machine learning algorithm matter? Psychiatry Res. Neuroimaging 2021, 310, 111270. [Google Scholar] [CrossRef]
- Le, N.Q.K.; Hung, T.N.K.; Do, D.T.; Lam, L.H.T.; Dang, L.H.; Huynh, T.T. Radiomics-based machine learning model for efficiently classifying transcriptome subtypes in glioblastoma patients from MRI. Comput. Biol. Med. 2021, 132, 104320. [Google Scholar] [CrossRef] [PubMed]
- Ho Thanh Lam, L.; Le, N.H.; Van Tuan, L.; Tran Ban, H.; Nguyen Khanh Hung, T.; Nguyen, N.T.K.; Huu Dang, L.; Le, N.Q.K. Machine Learning Model for Identifying Antioxidant Proteins Using Features Calculated from Primary Sequences. Biology 2020, 9, 325. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, S.; Lee, S.-I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Pearson, K. LIII. On lines and planes of closest fit to systems of points in space. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar] [CrossRef] [Green Version]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise; AAAI Press: Menlo Park, CA, USA, 1996; pp. 226–231. [Google Scholar]
- Buck, B.; Penn, D.L. Lexical Characteristics of Emotional Narratives in Schizophrenia: Relationships With Symptoms, Functioning, and Social Cognition. J. Nerv. Ment. Dis. 2015, 203, 702–708. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fineberg, S.K.; Deutsch-Link, S.; Ichinose, M.; McGuinness, T.; Bessette, A.J.; Chung, C.K.; Corlett, P.R. Word use in first-person accounts of schizophrenia. Brit. J. Psychiat. 2015, 206, 32–38. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Minor, K.S.; Bonfils, K.A.; Luther, L.; Firmin, R.L.; Kukla, M.; MacLain, V.R.; Buck, B.; Lysaker, P.H.; Salyers, M.P. Lexical analysis in schizophrenia: How emotion and social word use informs our understanding of clinical presentation. J. Psychiatr. Res. 2015, 64, 74–78. [Google Scholar] [CrossRef] [Green Version]
- APA, A.P.A. Diagnostic and Statistical Manual of Mental Disorders, 5th ed.; American Psychiatric Publishing: Arlington, VA, USA, 2013. [Google Scholar]
- De Choudhury, M.; Gamon, M.; Counts, S.; Horvitz, E. Predicting Depression via Social Media. In Proceedings of the 7th International AAAI Conference on Weblogs and Social Media, Cambridge, MA, USA, 8–11 July 2013; pp. 128–137. [Google Scholar]
- Shen, J.H.; Rudzicz, F. Detecting Anxiety through Reddit; Association for Computational Linguistics: Vancouver, BC, USA, 2017; pp. 58–65. [Google Scholar]
- Sekulic, I.; Gjurković, M.; Šnajder, J. Not Just Depressed: Bipolar Disorder Prediction on Reddit; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 72–78. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning–based Text Classification. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Iyyer, M.; Manjunatha, V.; Boyd-Graber, J.; Daumé, H., III. Deep Unordered Composition Rivals Syntactic Methods for Text Classification; Association for Computational Linguistics: Beijing, China, 2015; pp. 1681–1691. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Douze, M.; Jégou, H.; Mikolov, T. FastText.zip: Compressing text classification models. arXiv 2016, arXiv:1612.03651. Available online: https://fasttext.cc (accessed on 20 September 2020).
- Tai, K.S.; Socher, R.; Manning, C.D. Improved Semantic Representations from Tree-Structured Long Short-Term Memory Networks; Association for Computational Linguistics: Beijing, China, 2015; pp. 1556–1566. [Google Scholar]
- Zhu, X.; Sobhani, P.; Guo, H. Long short-term memory over recursive structures. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 1604–1612. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A Convolutional Neural Network for Modelling Sentences; Association for Computational Linguistics: Baltimore, MD, USA, 2014; pp. 655–665. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2016, arXiv:1408.5882. [Google Scholar]
- Peng, H.; Li, J.; He, Y.; Liu, Y.; Bao, M.; Wang, L.; Song, Y.; Yang, Q. Large-Scale Hierarchical Text Classification with Recursively Regularized Deep Graph-CNN. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1063–1072. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. Graph Convolutional Networks for Text Classification; AAAI: Menlo Park, CA, USA, 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Subreddit | Number of Posts | Description |
|---|---|---|---|
| Schizophrenia | Schizophrenia | 13,156 | Subreddit to discuss schizophrenia spectrum disorders and schizophrenia-related issues such as psychosis |
| Non-schizophrenia(Control) | Fitness | 28,660 | A place for the pursuit of physical fitness goals |
| Jokes | 83,456 | The funniest subreddit (hundreds of jokes posted each day) | |
| Meditation | 11,976 | Community for sharing experiences, stories and instruction relating to the practice of meditation | |
| Parenting | 23,489 | A place to discuss the ins and out as well as ups and downs of child-rearing | |
| Relationships | 97,038 | Community built around helping people and the goal of providing a platform for interpersonal relationship advice between people | |
| Teaching | 2950 | A place to discuss news, recourses, and tips for teachers of all levels of education |
| LIWC Variable | t-Statistic | p-Value | LIWC Variable | t-Statistic | p-Value |
|---|---|---|---|---|---|
| Linguistic processes | Psychological processes | ||||
| Word count | −74.1 | <0.001 | Positive emotion | −4.7 | <0.001 |
| Words longer than six letters | 53.7 | <0.001 | Negative emotion | 30.0 | <0.001 |
| Function words | Anger | 14.9 | <0.001 | ||
| Personal pronouns | −62.6 | <0.001 | Fear | 47.6 | <0.001 |
| First person singular | 0.02 | 0.981 | Joy | −20.8 | <0.001 |
| First person plural | −76.5 | <0.001 | Disgust | 8.8 | <0.001 |
| Second person | 37.9 | <0.001 | Sadness | 19.6 | <0.001 |
| Third person singular | −101.9 | <0.001 | Anticipation | −3.9 | <0.001 |
| Third person plural | 24.3 | <0.001 | Trust | 0.3 | 0.753 |
| Impersonal pronouns | 31.1 | <0.001 | Surprise | −0.5 | 0.616 |
| Time orientation | |||||
| Past focus | −34.7 | <0.001 | |||
| Present focus | 24.4 | <0.001 | |||
| Future focus | −0.04 | 0.965 |
| Topics | Words |
|---|---|
| Schizophrenia | |
| Hallucinations | voice, hear, like, think, hallucinate, schizophrenia, thing, people, know, head |
| Delusions | feel, like, think, thing, know, time, delusion, experience, start, people |
| Mental health help | think, friend, know, help, tell, want, people, talk, say, like |
| Life | feel, want, like, know, time, life, go, think, year, tell |
| Medicine/Medication | medic, take, med, effect, month, doctor, antipsychotic, work, ability, experience |
| Schizophrenia/Diagnosis | schizophrenia, mental, help, diagnosis, experience, discord, symptom, know, thank, people |
| Family | year, help, time, mother, live, go, sister, house, work, family |
| Negative symptoms | negative, symptom, negative symptom, like, lack, schizophrenia, good, thing, work, motivation |
| Social interaction | people, like, know, want, go, thing, game, talk, feel, life |
| Thought disorder/Episode | go, think, tell, say, start, episode, week, walk, house, like |
| Non-schizophrenia (Control) | |
| Friend | friend, like, know, talk, tell, want, say, girl, think, feel |
| Feel/Relationship | feel, relationship, want, like, time, love, year, know, thing, think |
| Social/Life | tell, say, like, know, want, thing, feel, talk, go, time |
| Friend/Home/School | friend, go, time, drink, home, come, school, week, want, night |
| Family | parent, family, year, want, live, sister, work, mother, kid, husband |
| Joke | say, look, ask, walk, go, joke, like, come, tell, fuck |
| Meditation/Weight | meditate, weight, like, body, start, lose, eat, help, mind, calorie |
| Fitness/Exercise | workout, weight, week, work, exercise, lift, train, muscle, start, like |
| Time/Sleep | time, sleep, play, like, work, room, night, game, get, go |
| School/Teaching | school, teacher, teach, https, class, people, student, learn, read, book |
| Model | Recall | Precision | F1-Score | Accuracy | AUC |
|---|---|---|---|---|---|
| Random forest (RF) | 0.94 | 0.98 | 0.96 | 0.96 | 0.97 |
| Support vector machine (SVM) | 0.91 | 0.90 | 0.91 | 0.91 | 0.91 |
| Logistic regression (LR) | 0.87 | 0.91 | 0.89 | 0.89 | 0.90 |
| Naive Bayes (NB) | 0.87 | 0.82 | 0.93 | 0.86 | 0.87 |
| Feature | Weight |
|---|---|
| Symptom | 1.12 |
| Voice | 1.00 |
| Diagnose | 0.88 |
| Psychotic | 0.72 |
| Delusions | 0.71 |
| Hallucinations | 0.68 |
| Paranoia | 0.67 |
| Medication | 0.65 |
| Psychosis | 0.61 |
| Medicine | 0.55 |
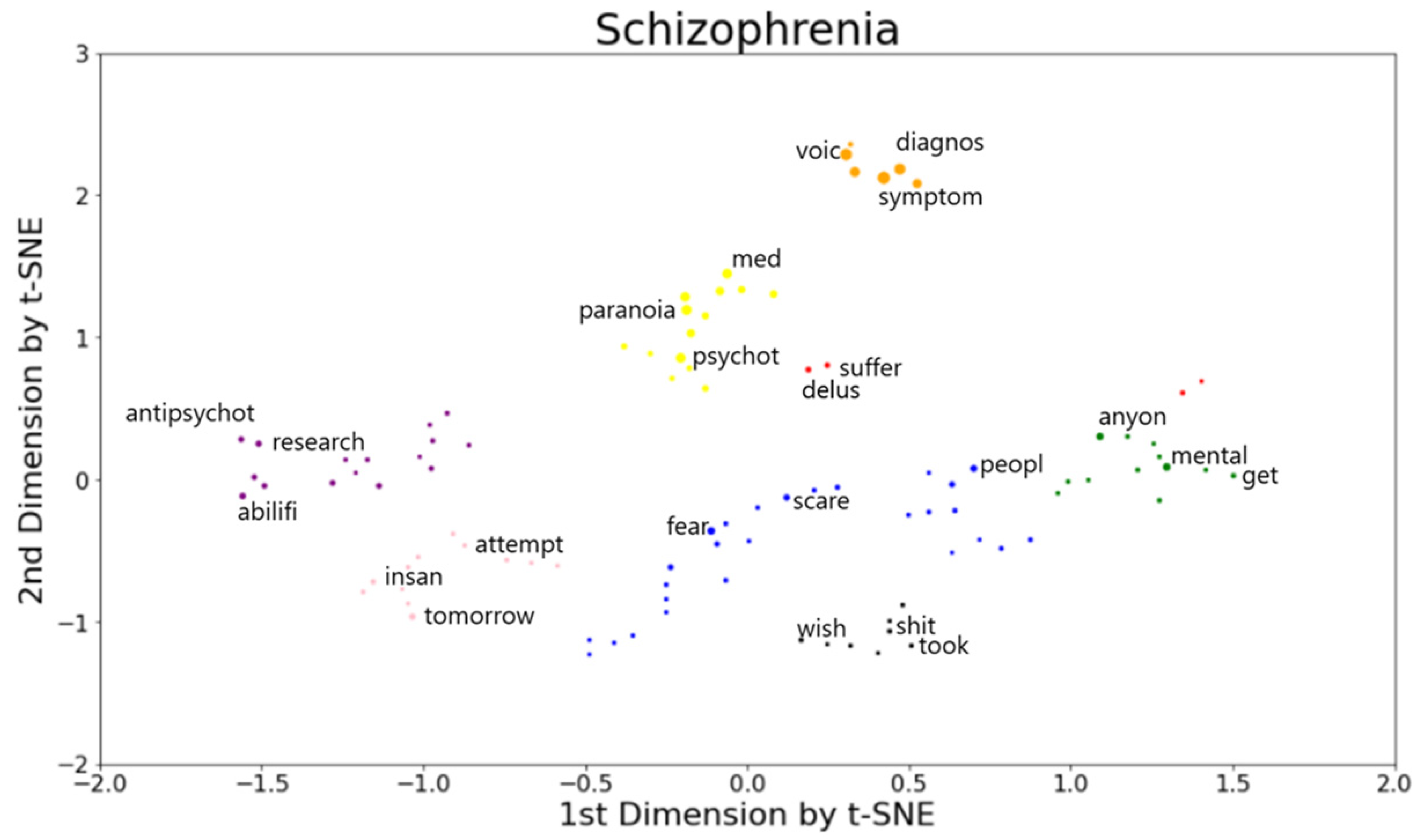
| Cluster Color | Semantic Content | Words in Cluster |
|---|---|---|
| Orange | Symptoms/Hallucinations | Symptom, voice, diagnosis, hallucination, medic, hear |
| Yellow | Symptoms/Psychosis | psychotic, paranoia, med, psychosis, episode, psychiatrist, paranoid, discord, diagnosis, heard, hospital, brain, reality, drug |
| Red | Delusions/Suffering | delusion, suffer, hi, hurt, didn’t |
| Blue | Fear | fear, people, scare, thought, remember, afraid, believe, actual, understand, life, run, mind, worry, kill, certain, head, sense, watch, action, think, beauty, twice, connect, sudden, manipulate, happen, go |
| Pink | Prognosis | tomorrow, insane, attempt, safe, fake, free, disable, isolate, patient, stuck, odd |
| Purple | Support | abilify, antipsychotic, research, delusion, condition, medicine, psych, profession, god, strange, trigger, attack, sub, music, anybody, form |
| Black | Present | shit, wish, took, today, alone, state, hell, anyway |
| Green | Mental health help | mental, anyone, get, ill, ani, read, else, help, thank, everyone, wonder, experience |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bae, Y.J.; Shim, M.; Lee, W.H. Schizophrenia Detection Using Machine Learning Approach from Social Media Content. Sensors 2021, 21, 5924. https://doi.org/10.3390/s21175924
Bae YJ, Shim M, Lee WH. Schizophrenia Detection Using Machine Learning Approach from Social Media Content. Sensors. 2021; 21(17):5924. https://doi.org/10.3390/s21175924
Chicago/Turabian StyleBae, Yi Ji, Midan Shim, and Won Hee Lee. 2021. "Schizophrenia Detection Using Machine Learning Approach from Social Media Content" Sensors 21, no. 17: 5924. https://doi.org/10.3390/s21175924
APA StyleBae, Y. J., Shim, M., & Lee, W. H. (2021). Schizophrenia Detection Using Machine Learning Approach from Social Media Content. Sensors, 21(17), 5924. https://doi.org/10.3390/s21175924