
Assessment of Non-Invasive Blood Pressure Prediction from PPG and rPPG Signals Using Deep Learning †



Abstract
:1. Introduction
2. Related Work
2.1. Deriving BP Using Parameterized Models
2.2. BP Prediction Using PPG Features
2.3. End-to-End Approaches to Predict BP
3. Materials and Methods
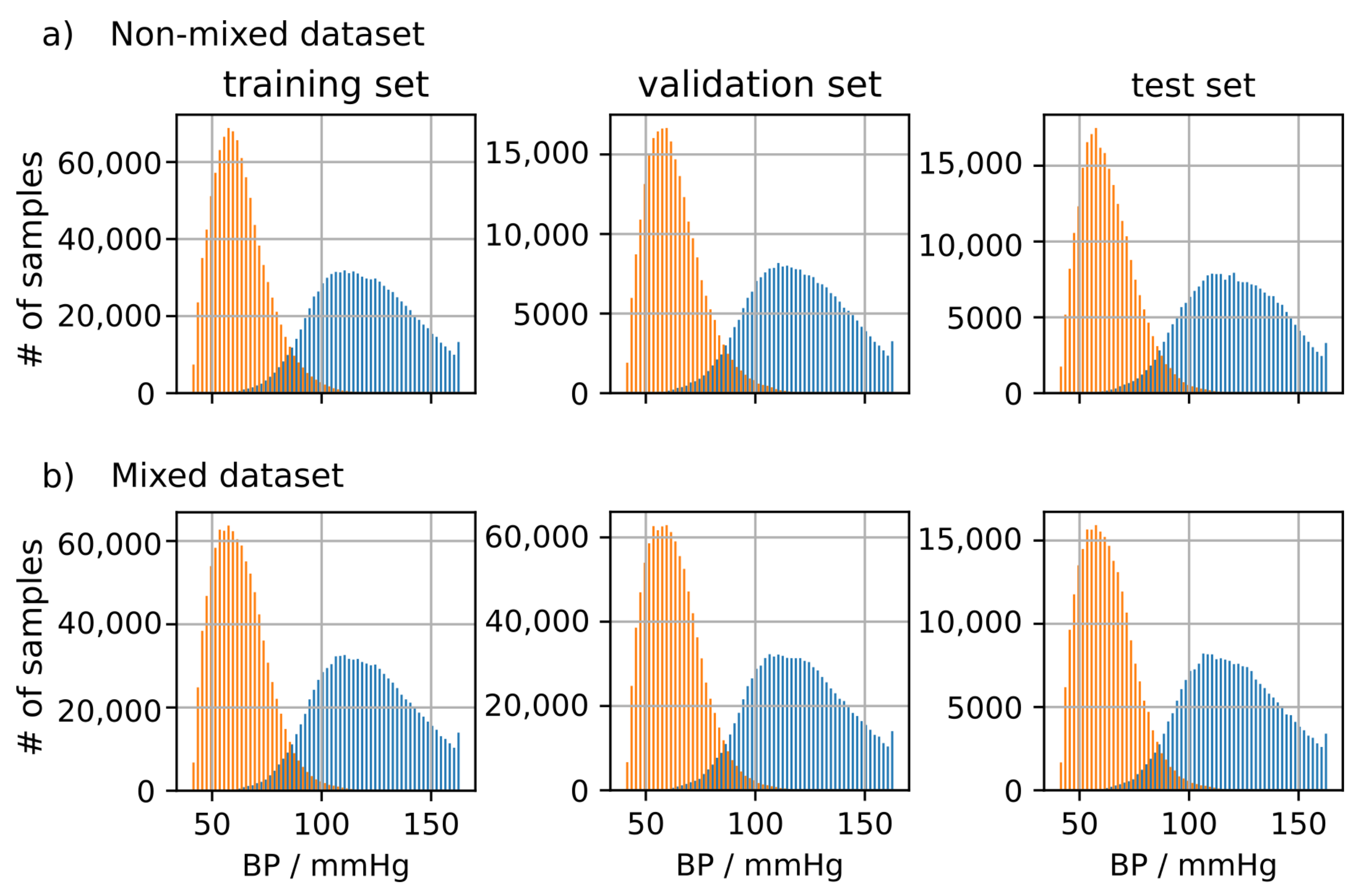
3.1. Datasets
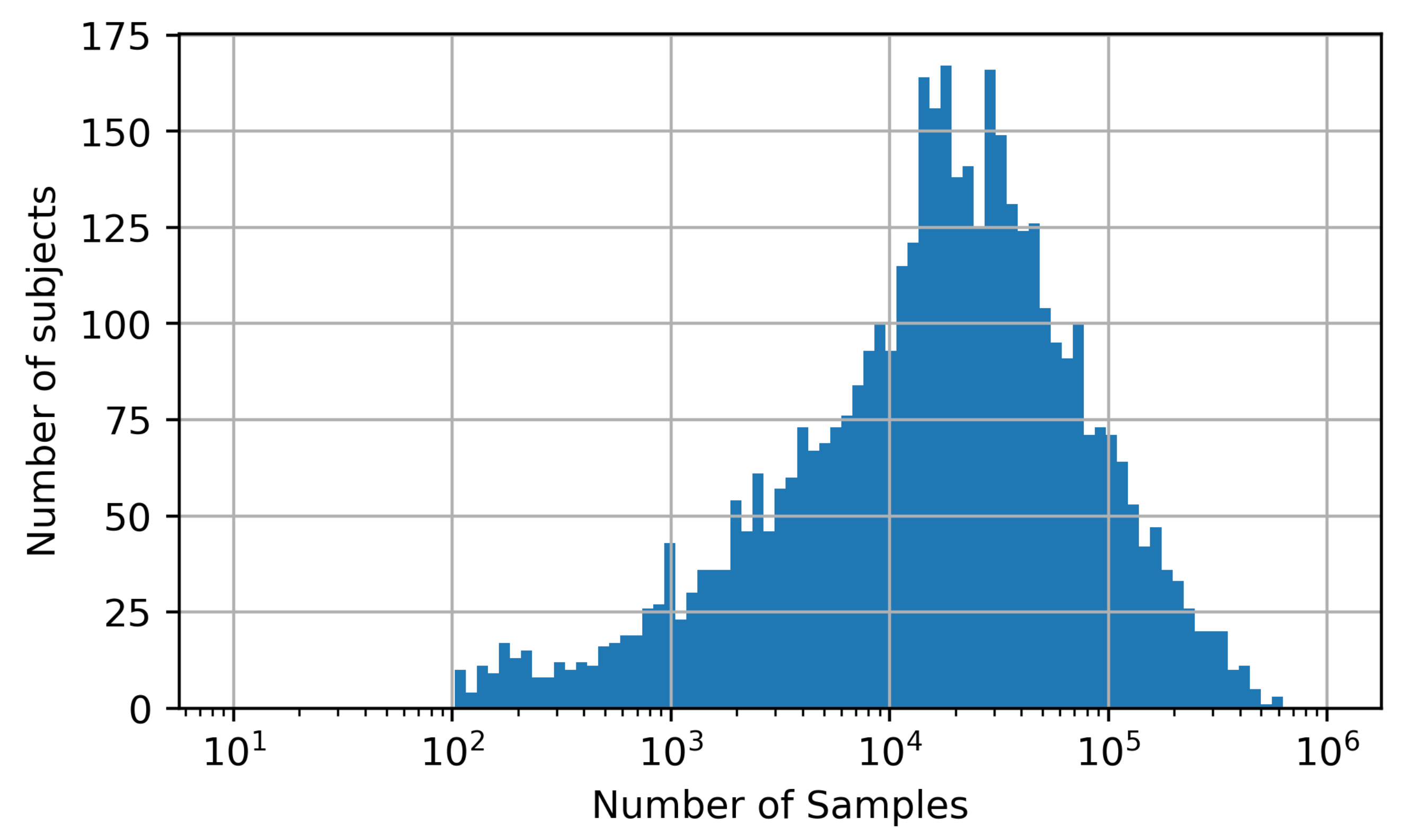
3.1.1. PPG Data
3.1.2. rPPG Data
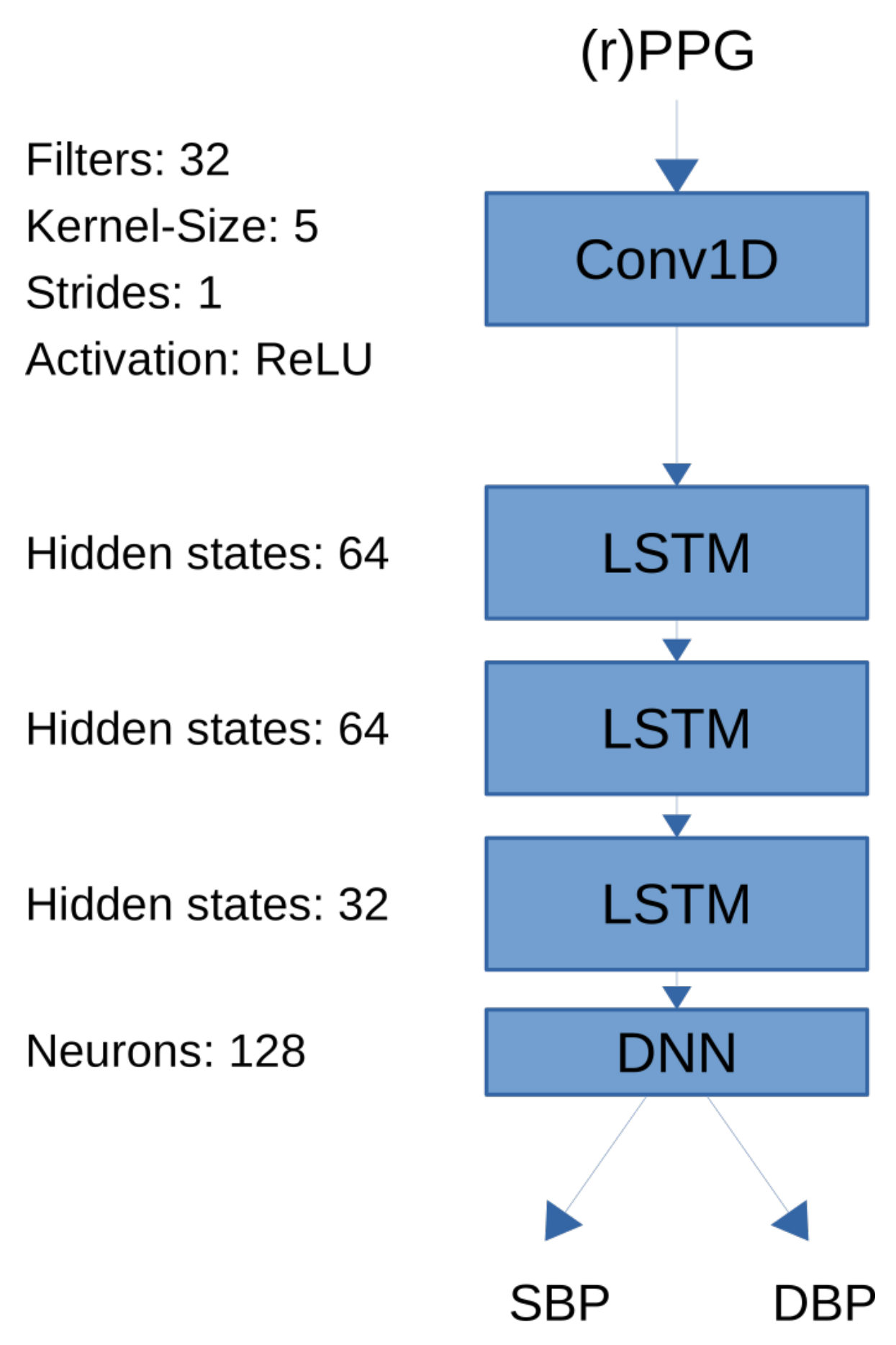
3.2. Neural Network Architectures
3.3. PPG Signal Processing
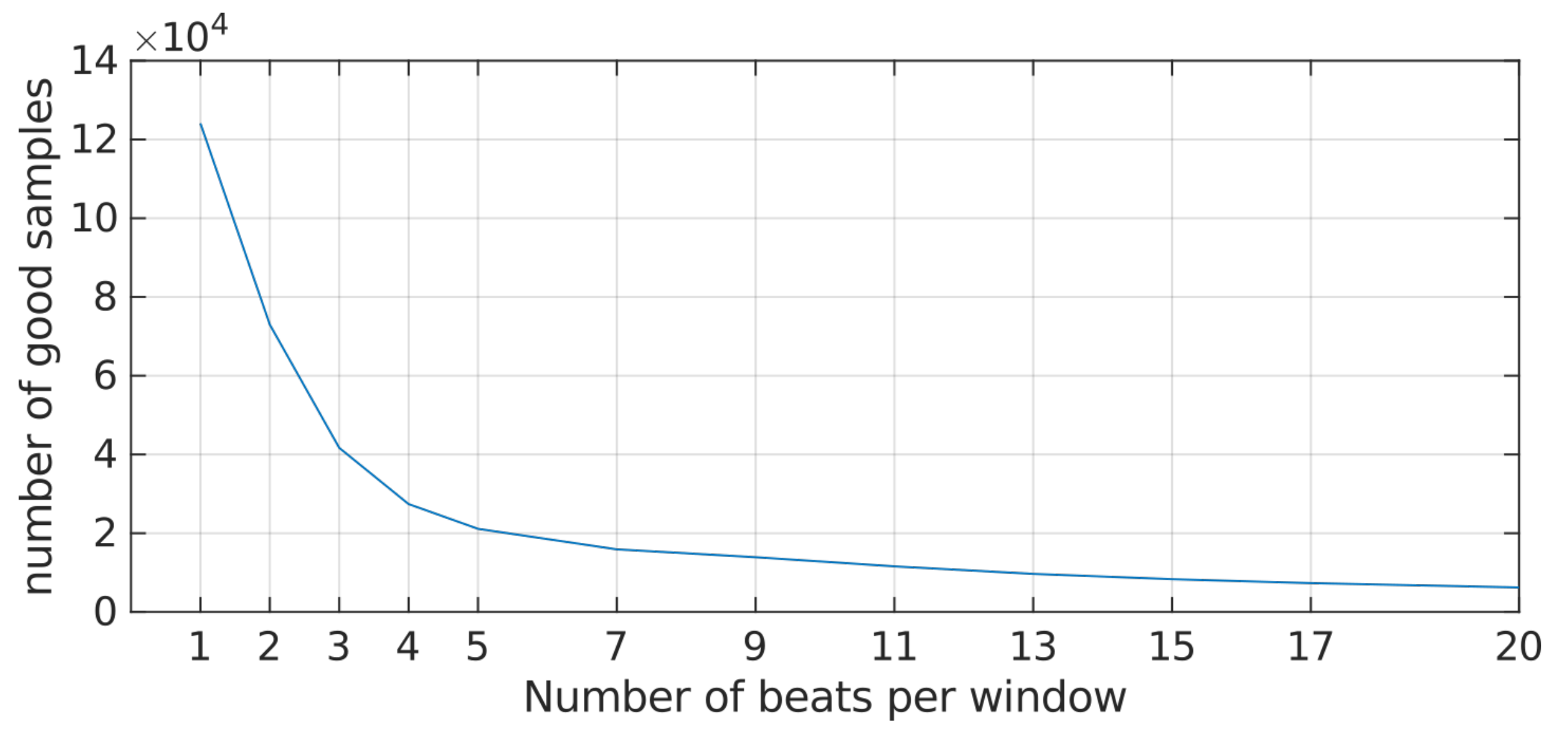
3.4. Evaluation of NN Input Sequences
3.5. PPG Based Prediction
3.5.1. Data Preprocessing
3.5.2. NN Training and Validation
3.5.3. PPG Based Personalization
3.6. rPPG Based Prediction
3.6.1. Preprocessing
3.6.2. Transfer Learning
4. Results
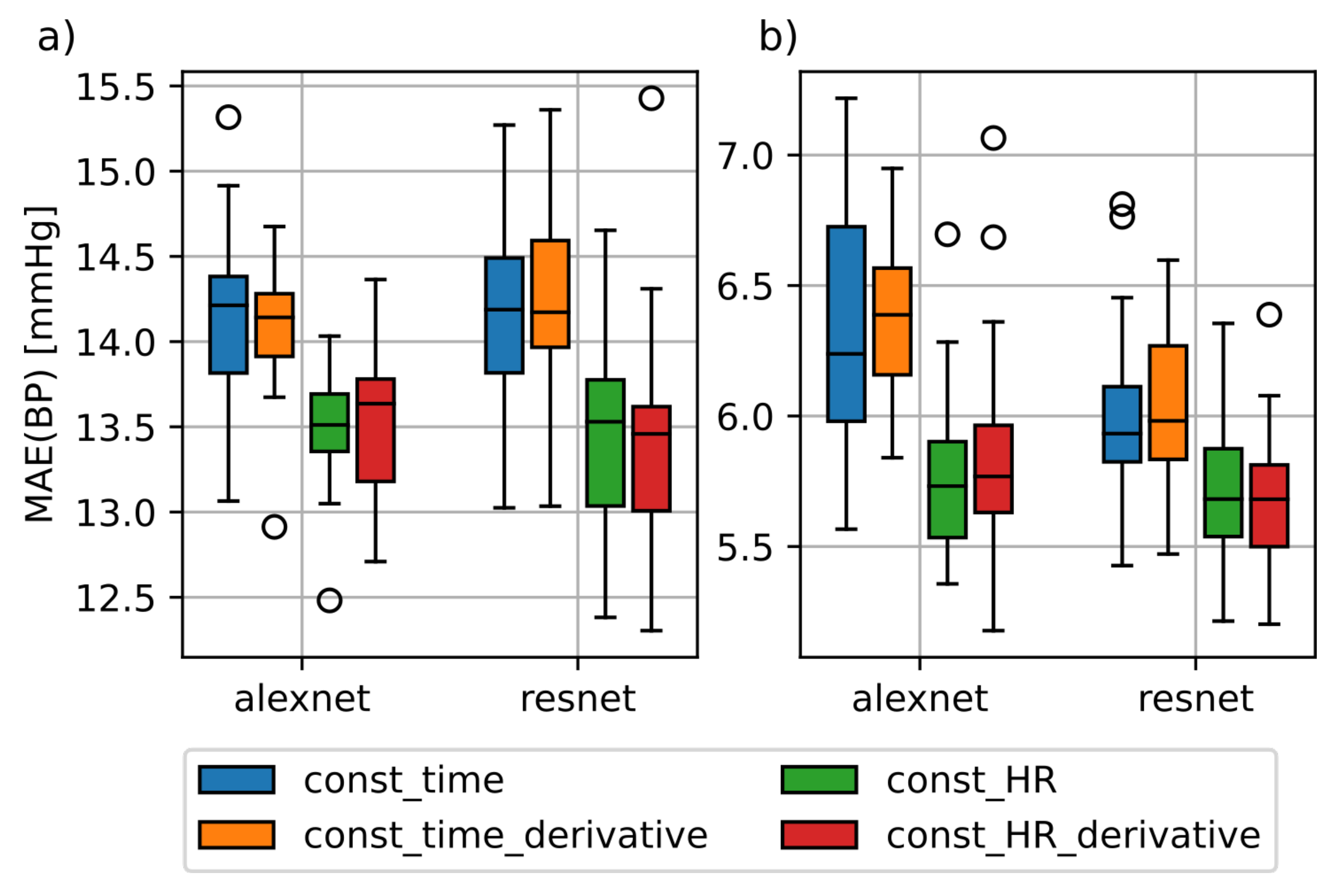
4.1. PPG Based Prediction
4.1.1. Input Signals
4.1.2. MIMIC-B Dataset
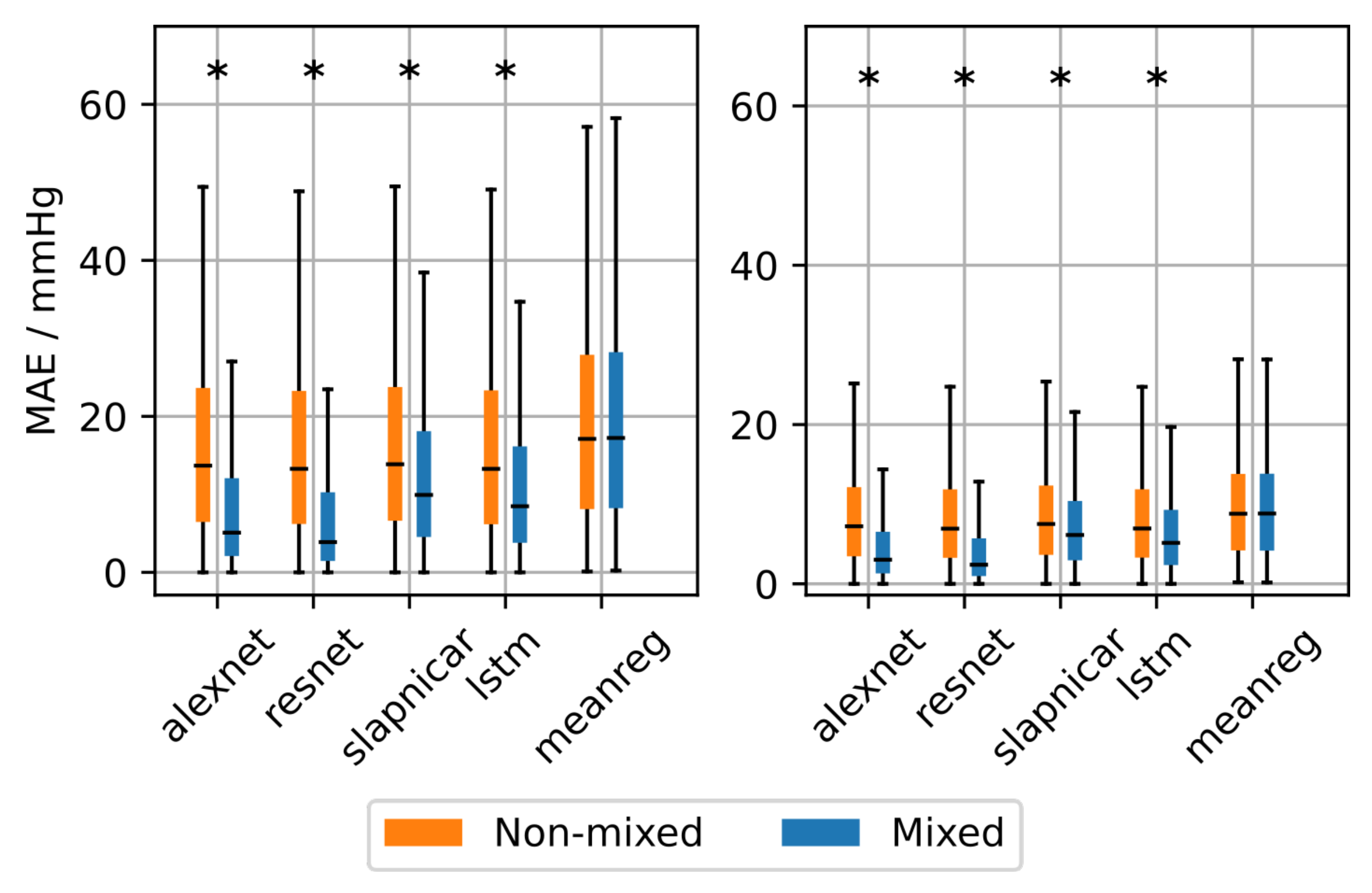
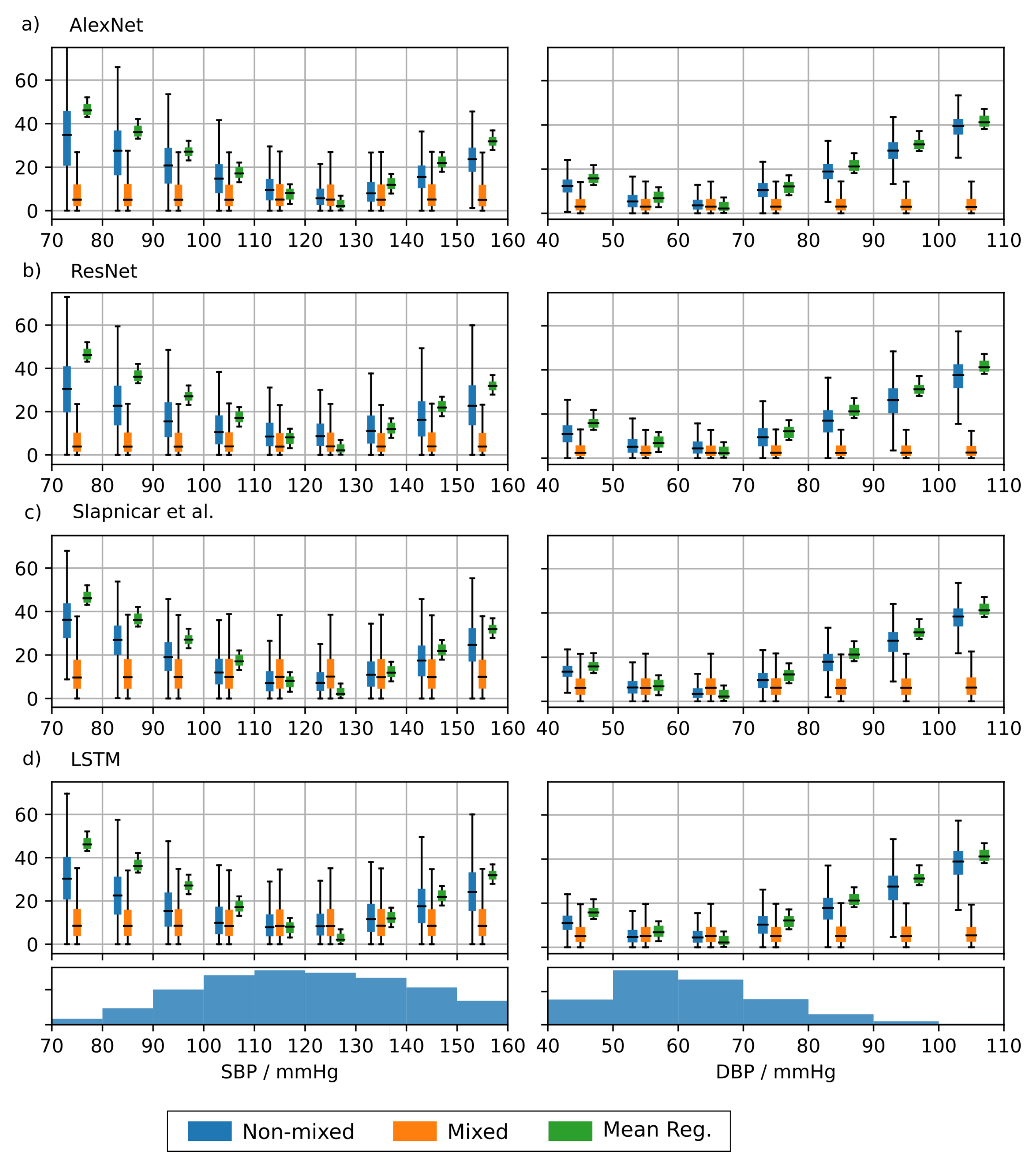
4.1.3. Predicting BP Using PPG Data
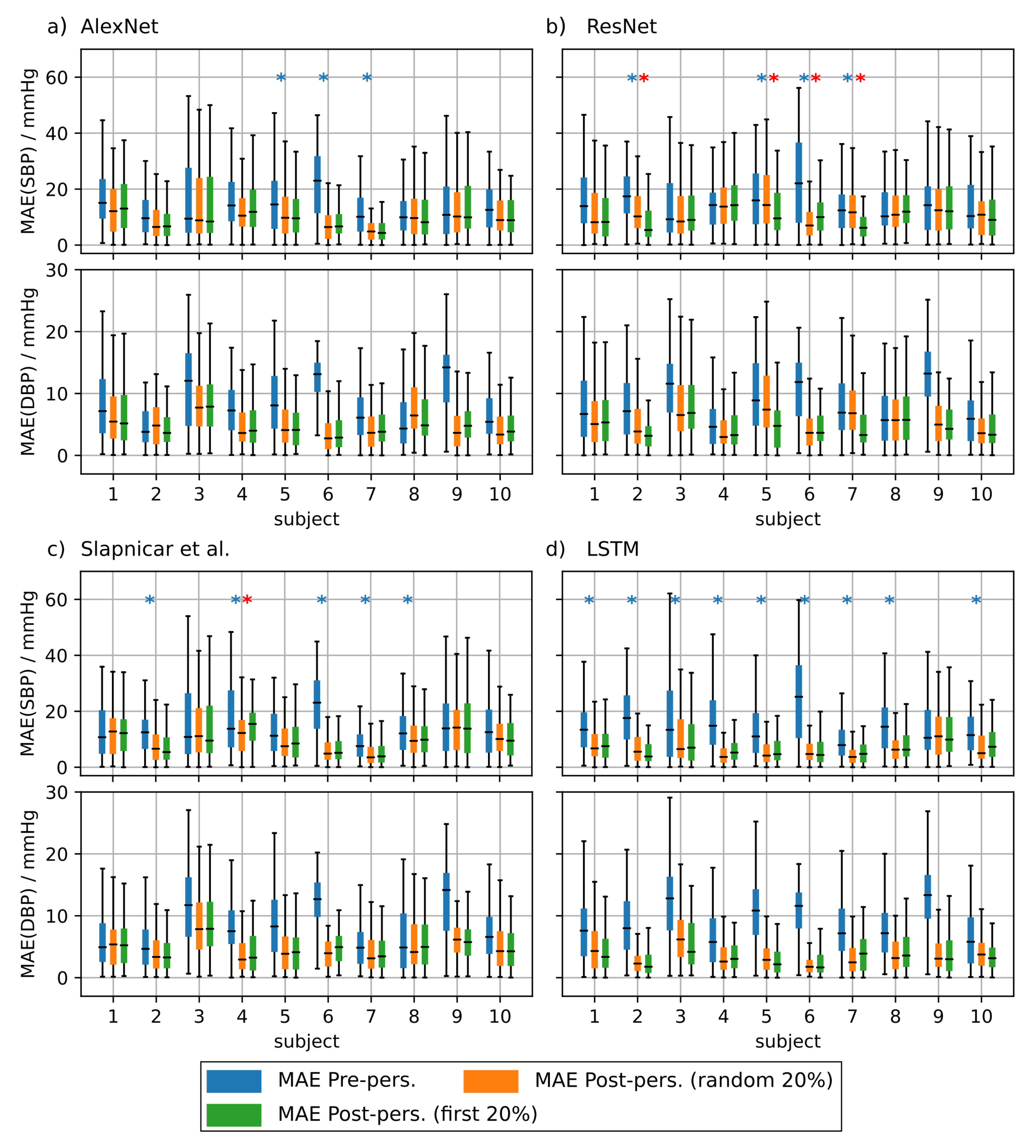
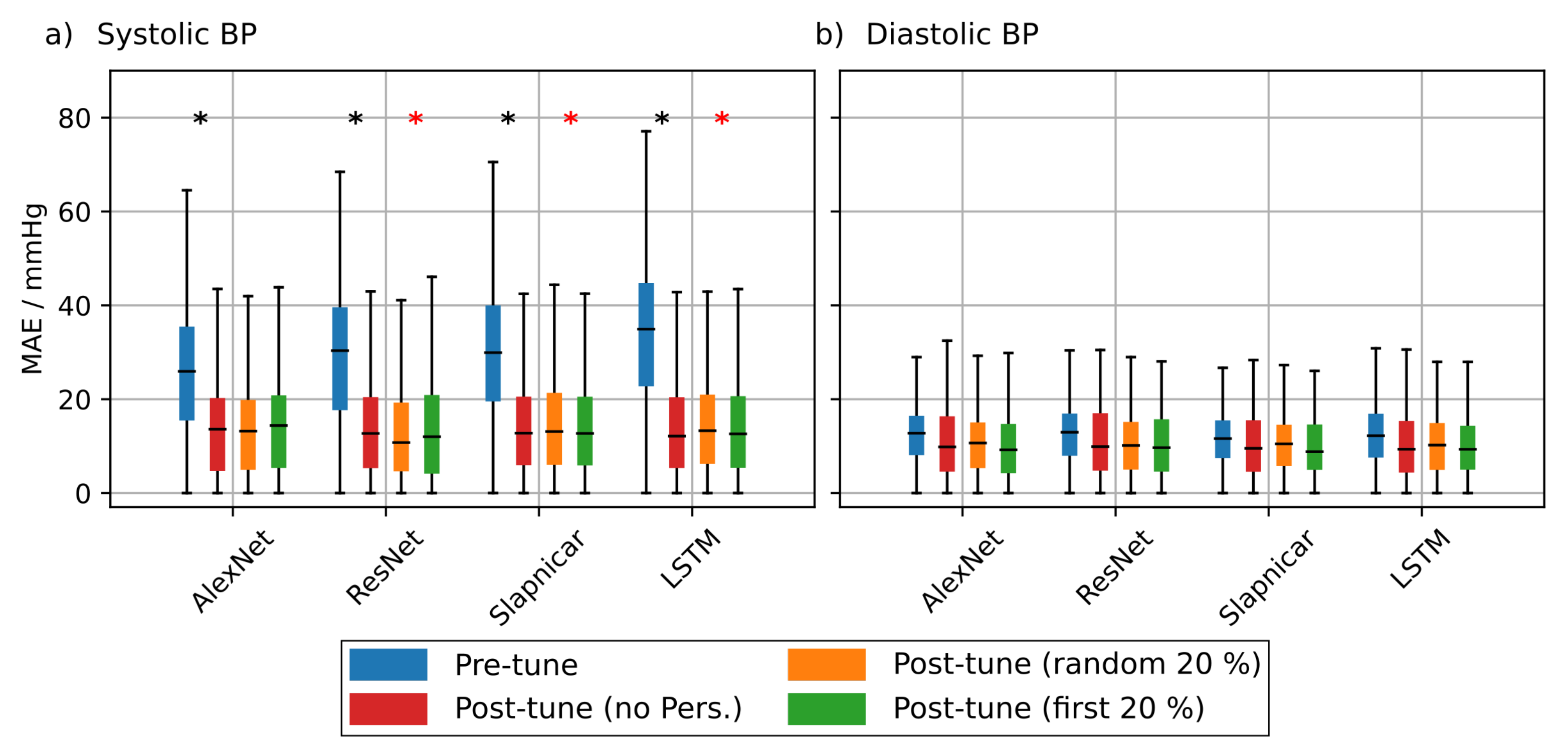
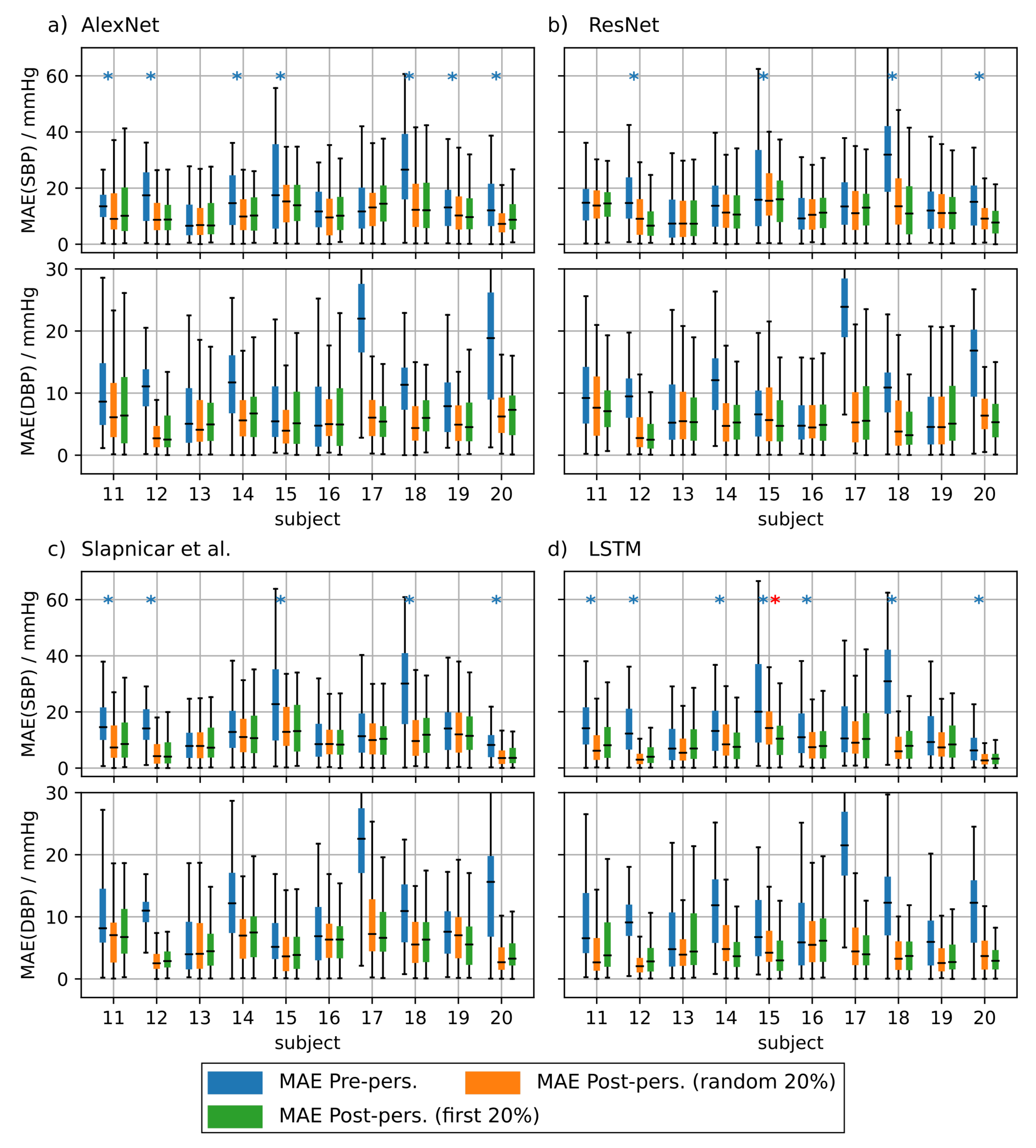
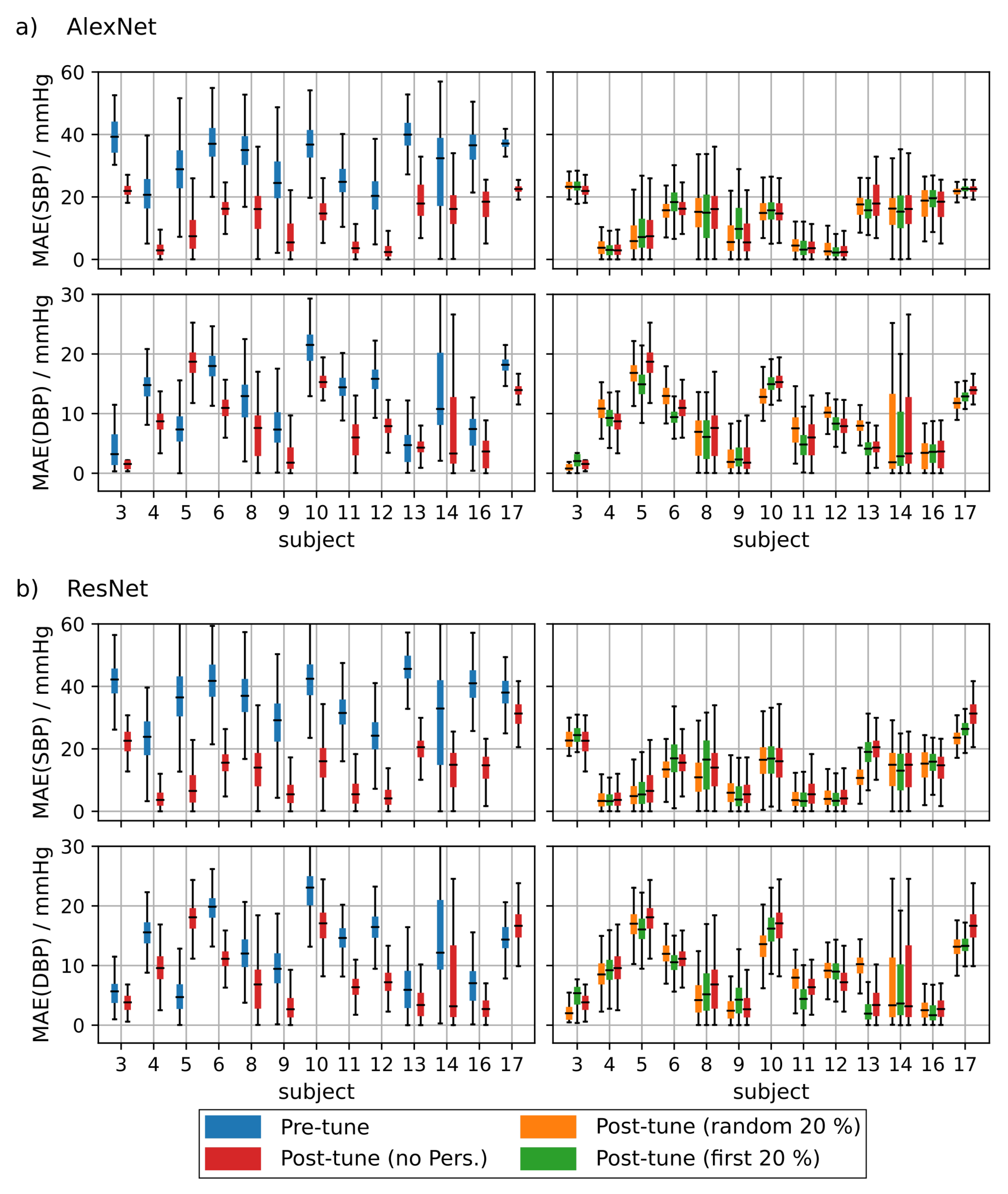
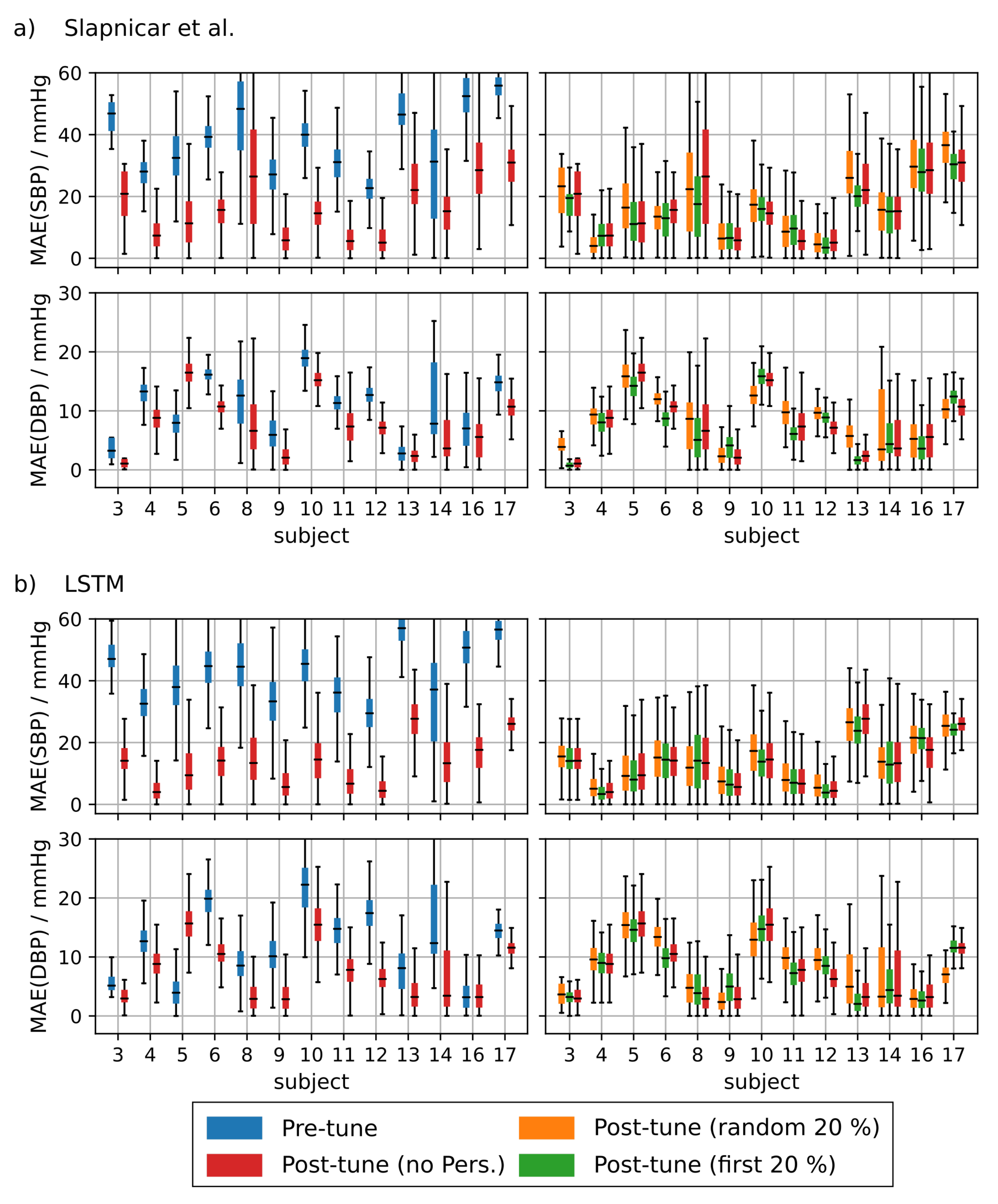
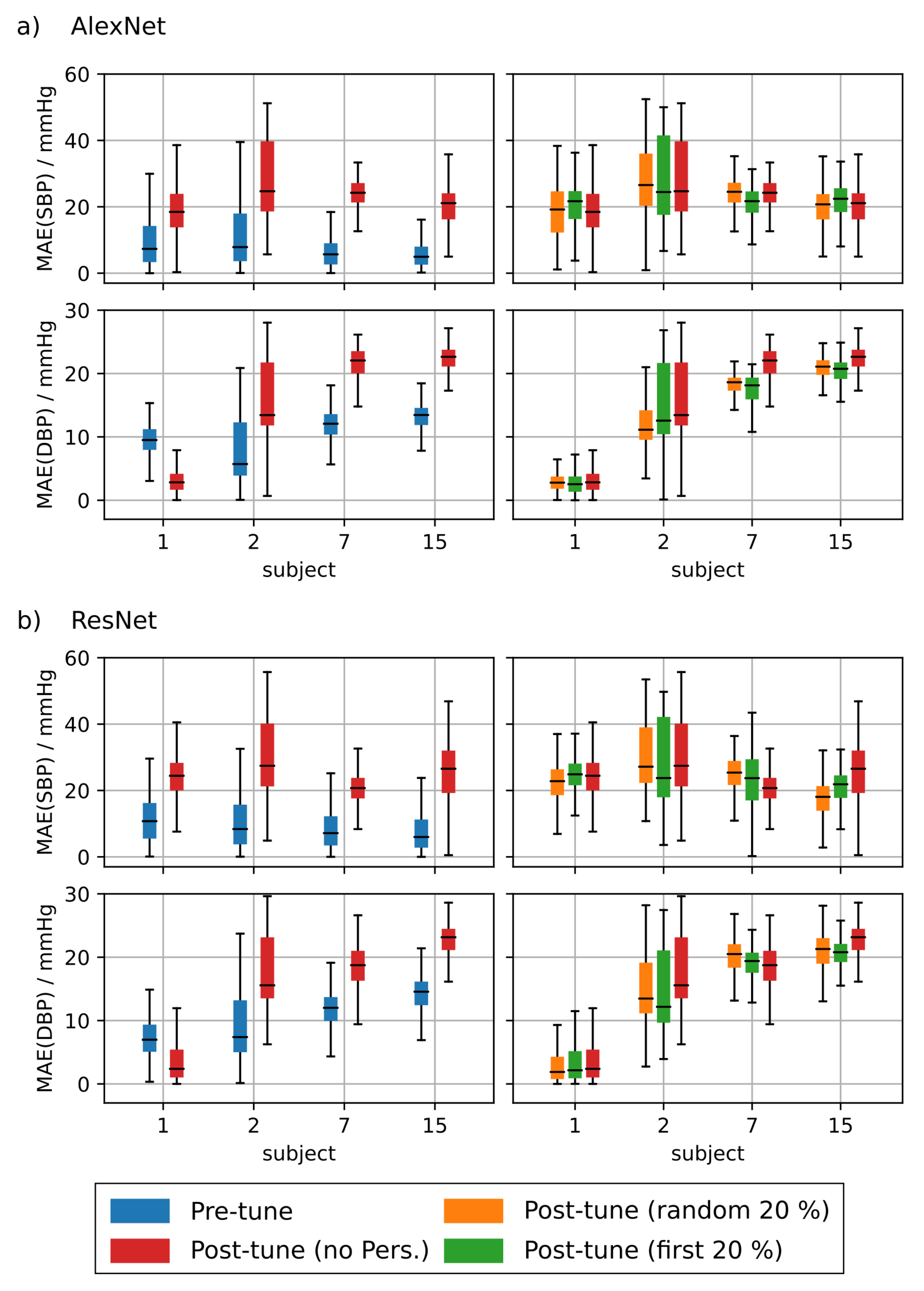
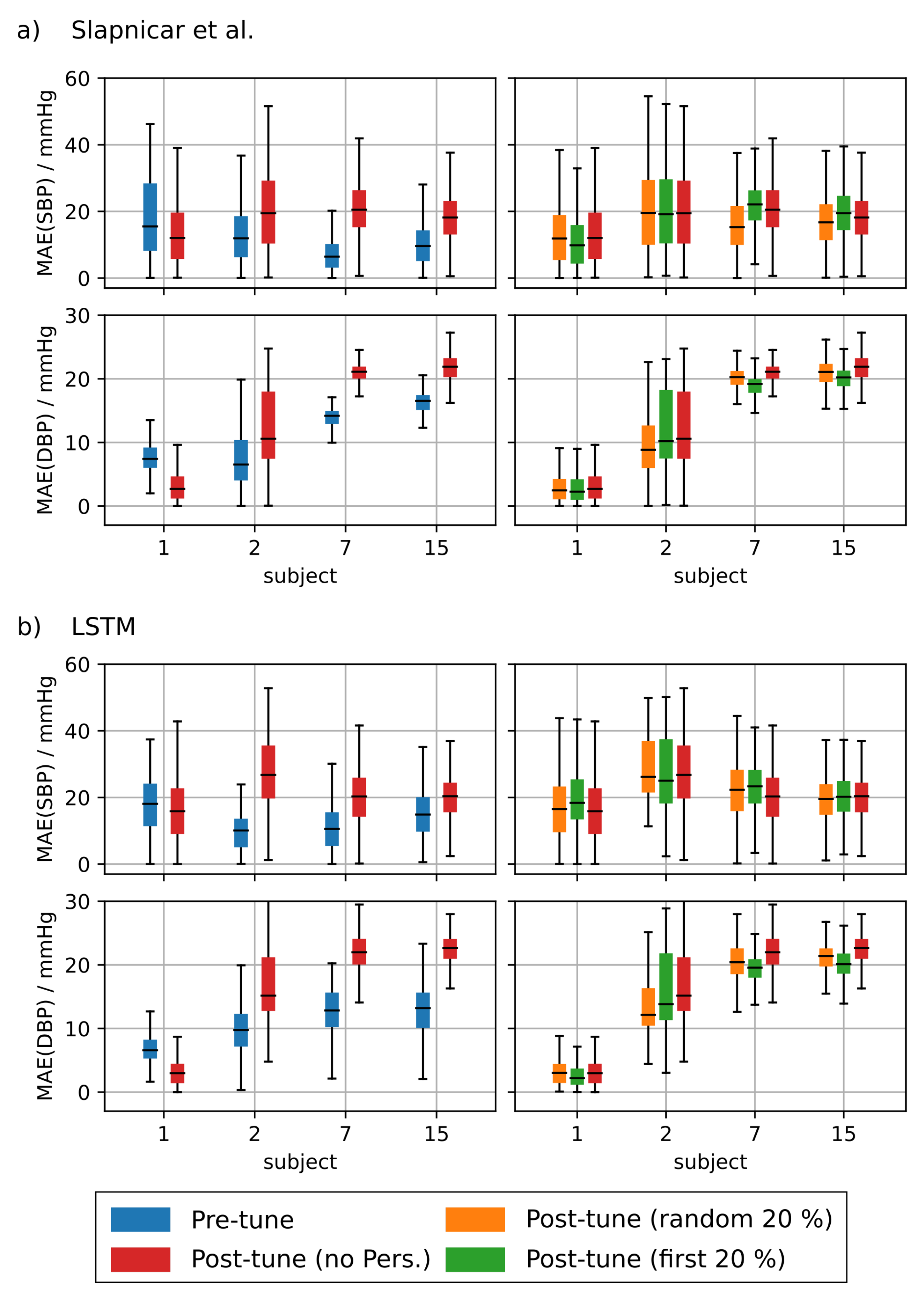
4.1.4. PPG Based Personalization
4.2. rPPG Based Prediction
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PPG | photopletysmography |
| rPPG | remote Photopletysmography |
| MAE | mean average error |
| NN | neural network |
| BP | blood pressure |
| ECG | electrocardiogram |
| ML | machine learning |
| LSTM | long short-term memory |
| PTT | pulse transit time |
| PAT | pulse arrival time |
| PWV | pulse wave velocity |
| CNN | convolutional neural network |
| SBP | systolic blood pressure |
| DBP | diastolic blood pressure |
| SNR | signa-to-noise ratio |
Appendix A





References
- Ding, X.R.; Zhao, N.; Yang, G.Z.; Pettigrew, R.I.; Lo, B.; Miao, F.; Li, Y.; Liu, J.; Zhang, Y.T. Continuous Blood Pressure Measurement From Invasive to Unobtrusive: Celebration of 200th Birth Anniversary of Carl Ludwig. IEEE J. Biomed. Health Inform. 2016, 20, 1455–1465. [Google Scholar] [CrossRef] [PubMed]
- Kumar, R.; Dubey, P.; Zafer, A.; Kumar, A.; Yadav, S. Past, Present and Future of Blood Pressure Measuring Instruments and Their Calibration. Measurement 2020, 172, 108845. [Google Scholar] [CrossRef]
- Tamura, T. Cuffless blood pressure monitors: Principles, standards and approval for medical use. IEICE Trans. Commun. 2020, 104, 580–586. [Google Scholar] [CrossRef]
- Mukherjee, R.; Ghosh, S.; Gupta, B.; Chakravarty, T. A Literature Review on Current and Proposed Technologies of Noninvasive Blood Pressure Measurement. Telemed. e-Health 2018, 24, 185–193. [Google Scholar] [CrossRef]
- Harfiya, L.N.; Chang, C.C.; Li, Y.H. Continuous Blood Pressure Estimation Using Exclusively Photopletysmography by LSTM-Based Signal-to-Signal Translation. Sensors 2021, 21, 2952. [Google Scholar] [CrossRef]
- Tanveer, M.S.; Hasan, M.K. Cuffless blood pressure estimation from electrocardiogram and photoplethysmogram using waveform based ANN-LSTM network. Biomed. Signal Process. Control 2019, 51, 382–392. [Google Scholar] [CrossRef] [Green Version]
- Su, P.; Ding, X.R.; Zhang, Y.T.; Liu, J.; Miao, F.; Zhao, N. Long-term blood pressure prediction with deep recurrent neural networks. In Proceedings of the 2018 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Las Vegas, NV, USA, 4–7 March 2018; IEEE: Las Vegas, NV, USA, 2018; pp. 323–328. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Sohn, J.; Lee, S.; Lee, J.; Kim, H.C. Estimation and Validation of Arterial Blood Pressure using Photoplethysmogram Morphology Features in conjunction with Pulse Arrival Time in Large Open Databases. IEEE J. Biomed. Health Inform. 2020, 25, 1018–1030. [Google Scholar] [CrossRef] [PubMed]
- Socrates, T.; Krisai, P.; Vischer, A.S.; Meienberg, A.; Mayr, M.; Burkard, T. Improved agreement and diagnostic accuracy of a cuffless 24-h blood pressure measurement device in clinical practice. Sci. Rep. 2021, 11, 1143. [Google Scholar] [CrossRef]
- Slapničar, G.; Mlakar, N.; Luštrek, M. Blood Pressure Estimation from Photoplethysmogram Using a Spectro-Temporal Deep Neural Network. Sensors 2019, 19, 3420. [Google Scholar] [CrossRef] [Green Version]
- Xing, X.; Sun, M. Optical blood pressure estimation with photoplethysmography and FFT-based neural networks. Biomed. Opt. Express 2016, 7, 3007–3020. [Google Scholar] [CrossRef] [Green Version]
- Schlesinger, O.; Vigderhouse, N.; Eytan, D.; Moshe, Y. Blood Pressure Estimation From PPG Signals Using Convolutional Neural Networks And Siamese Network. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Barcelona, Spain, 2020; pp. 1135–1139. [Google Scholar] [CrossRef]
- Kurylyak, Y.; Lamonaca, F.; Grimaldi, D. A Neural Network-based method for continuous blood pressure estimation from a PPG signal. In Proceedings of the 2013 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Minneapolis, MN, USA, 6–9 May 2013; IEEE: Minneapolis, MN, USA, 2013; pp. 280–283. [Google Scholar] [CrossRef]
- El Hajj, C.; Kyriacou, P.A. Cuffless and Continuous Blood Pressure Estimation From PPG Signals Using Recurrent Neural Networks. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; IEEE: Montreal, QC, Canada, 2020; pp. 4269–4272. [Google Scholar] [CrossRef]
- Hsu, Y.C.; Li, Y.H.; Chang, C.C.; Harfiya, L.N. Generalized Deep Neural Network Model for Cuffless Blood Pressure Estimation with Photoplethysmogram Signal Only. Sensors 2020, 20, 5668. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; den Brinker, A.C.; de Haan, G. Discriminative Signatures for Remote-PPG. IEEE Trans. Biomed. Eng. 2020, 67, 1462–1473. [Google Scholar] [CrossRef] [PubMed]
- Dash, A.; Ghosh, N.; Patra, A.; Choudhury, A.D. Estimation of Arterial Blood Pressure Waveform from Photoplethysmogram Signal using Linear Transfer Function Approach. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; IEEE: Montreal, QC, Canada, 2020; pp. 2691–2694. [Google Scholar] [CrossRef]
- Haddad, S.; Boukhayma, A.; Caizzone, A. Continuous PPG-Based Blood Pressure Monitoring Using Multi-Linear Regression. arXiv 2020, arXiv:2011.02231. [Google Scholar]
- Pandey, R.K.; Lin, T.Y.; Chao, P.C.P. Design and implementation of a photoplethysmography acquisition system with an optimized artificial neural network for accurate blood pressure measurement. Microsyst. Technol. 2021, 27, 2345–2367. [Google Scholar] [CrossRef]
- Han, C.; Gu, M.; Yu, F.; Huang, R.; Huang, X.; Cui, L. Calibration-free Blood Pressure Assessment Using An Integrated Deep Learning Method. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Korea, 16–19 December 2020; IEEE: Seoul, Korea, 2020; pp. 1001–1005. [Google Scholar] [CrossRef]
- Jain, M.; Deb, S.; Subramanyam, A.V. Face video based touchless blood pressure and heart rate estimation. In Proceedings of the 2016 IEEE 18th International Workshop on Multimedia Signal Processing (MMSP), Montreal, QC, Canada, 21–23 September 2016; IEEE: Montreal, QC, Canada, 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Luo, H.; Yang, D.; Barszczyk, A.; Vempala, N.; Wei, J.; Wu, S.J.; Zheng, P.P.; Fu, G.; Lee, K.; Feng, Z.P. Smartphone-Based Blood Pressure Measurement Using Transdermal Optical Imaging Technology. Circ. Cardiovasc. Imaging 2019, 12, e008857. [Google Scholar] [CrossRef] [Green Version]
- Tran, Q.V.; Su, S.F.; Tran, Q.M.; Truong, V. Intelligent Non-Invasive Vital Signs Estimation From Image Analysis. In Proceedings of the 2020 International Conference on System Science and Engineering (ICSSE), Kagawa, Japan, 31 August–3 September 2020; IEEE: Kagawa, Japan, 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Jeong, I.C.; Finkelstein, J. Introducing Contactless Blood Pressure Assessment Using a High Speed Video Camera. J. Med. Syst. 2016, 40, 77. [Google Scholar] [CrossRef]
- Sugita, N.; Yoshizawa, M.; Abe, M.; Tanaka, A.; Homma, N.; Yambe, T. Contactless Technique for Measuring Blood-Pressure Variability from One Region in Video Plethysmography. J. Med. Biol. Eng. 2019, 39, 76–85. [Google Scholar] [CrossRef]
- Takahashi, R.; Ogawa-Ochiai, K.; Tsumura, N. Non-contact method of blood pressure estimation using only facial video. Artif. Life Robot. 2020, 25, 343–350. [Google Scholar] [CrossRef]
- Finkelstein, J.; Jeong, I.C. Towards Contactless Monitoring of Blood Pressure at Rest and During Exercise Using Infrared Imaging. In Proceedings of the 2020 11th IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 28–31 October 2020; IEEE: New York, NY, USA, 2020; pp. 756–758. [Google Scholar] [CrossRef]
- Perpetuini, D.; Chiarelli, A.M.; Cardone, D.; Filippini, C.; Rinella, S.; Massimino, S.; Bianco, F.; Bucciarelli, V.; Vinciguerra, V.; Fallica, P.; et al. Prediction of state anxiety by machine learning applied to photoplethysmography data. PeerJ 2021, 9, e10448. [Google Scholar] [CrossRef]
- Pereira, T.; Tran, N.; Gadhoumi, K.; Pelter, M.M.; Do, D.H.; Lee, R.J.; Colorado, R.; Meisel, K.; Hu, X. Photoplethysmography based atrial fibrillation detection: A review. NPJ Digit. Med. 2020, 3, 3. [Google Scholar] [CrossRef] [Green Version]
- Duncan, J.S.; Insana, M.F.; Ayache, N. Biomedical Imaging and Analysis in the Age of Big Data and Deep Learning [Scanning the Issue]. Proc. IEEE 2020, 108, 3–10. [Google Scholar] [CrossRef]
- Stergiou, G.S.; Alpert, B.; Mieke, S.; Asmar, R.; Atkins, N.; Eckert, S.; Frick, G.; Friedman, B.; Graßl, T.; Ichikawa, T.; et al. A Universal Standard for the Validation of Blood Pressure Measuring Devices: Association for the Advancement of Medical Instrumentation/European Society of Hypertension/International Organization for Standardization (AAMI/ESH/ISO) Collaboration Statement. Hypertension 2018, 71, 368–374. [Google Scholar] [CrossRef]
- Dörr, M.; Weber, S.; Birkemeyer, R.; Leonardi, L.; Winterhalder, C.; Raichle, C.J.; Brasier, N.; Burkard, T.; Eckstein, J. iPhone App compared with standard blood pressure measurement—The iPARR trial. Am. Heart J. 2020, 233, 102–108. [Google Scholar] [CrossRef]
- Chandrasekhar, A.; Yavarimanesh, M.; Natarajan, K.; Hahn, J.O.; Mukkamala, R. PPG Sensor Contact Pressure Should Be Taken Into Account for Cuff-Less Blood Pressure Measurement. IEEE Trans. Biomed. Eng. 2020, 67, 3134–3140. [Google Scholar] [CrossRef]
- Allen, J.; O’Sullivan, J.; Stansby, G.; Murray, A. Age-related changes in pulse risetime measured by multi-site photoplethysmography. Physiol. Meas. 2020, 41, 074001. [Google Scholar] [CrossRef]
- Přibil, J.; Přibilová, A.; Frollo, I. Comparative Measurement of the PPG Signal on Different Human Body Positions by Sensors Working in Reflection and Transmission Modes. Eng. Proc. 2020, 2, 69. [Google Scholar] [CrossRef]
- Kamshilin, A.A.; Nippolainen, E.; Sidorov, I.S.; Vasilev, P.V.; Erofeev, N.P.; Podolian, N.P.; Romashko, R.V. A new look at the essence of the imaging photoplethysmography. Sci. Rep. 2015, 5, 10494. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moco, A.; Stuijk, S.; van Gastel, M.; de Haan, G. Impairing Factors in Remote-PPG Pulse Transit Time Measurements on the Face. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; Volume 2018, pp. 1439–14398. [Google Scholar] [CrossRef]
- Schrumpf, F.; Frenzel, P.; Aust, C.; Osterhoff, G.; Fuchs, M. Assessment of Deep Learning Based Blood Pressure Prediction From PPG and rPPG Signals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Virtual, Nashville, TN, USA, 25 June 2021; pp. 3820–3830. [Google Scholar]
- Zhang, G.; Gao, M.; Xu, D.; Olivier, N.B.; Mukkamala, R. Pulse arrival time is not an adequate surrogate for pulse transit time as a marker of blood pressure. J. Appl. Physiol. 2011, 111, 1681–1686. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wippermann, C.F.; Schranz, D.; Huth, R.G. Evaluation of the pulse wave arrival time as a marker for blood pressure changes in critically ill infants and children. J. Clin. Monit. 1995, 11, 324–328. [Google Scholar] [CrossRef]
- Callaghan, F.J.; Babbs, C.F.; Bourland, J.D.; Geddes, L.A. The relationship between arterial pulse-wave velocity and pulse frequency at different pressures. J. Med. Eng. Technol. 1984, 8, 15–18. [Google Scholar] [CrossRef]
- Gesche, H.; Grosskurth, D.; Küchler, G.; Patzak, A. Continuous blood pressure measurement by using the pulse transit time: Comparison to a cuff-based method. Eur. J. Appl. Physiol. 2012, 112, 309–315. [Google Scholar] [CrossRef]
- Senturk, U.; Polat, K.; Yucedag, I. A non-invasive continuous cuffless blood pressure estimation using dynamic Recurrent Neural Networks. Appl. Acoust. 2020, 170, 107534. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Baek, S.; Jang, J.; Yoon, S. End-to-End Blood Pressure Prediction via Fully Convolutional Networks. IEEE Access 2019, 7, 185458–185468. [Google Scholar] [CrossRef]
- Sadrawi, M.; Lin, Y.T.; Lin, C.H.; Mathunjwa, B.; Fan, S.Z.; Abbod, M.F.; Shieh, J.S. Genetic Deep Convolutional Autoencoder Applied for Generative Continuous Arterial Blood Pressure via Photoplethysmography. Sensors 2020, 20, 3829. [Google Scholar] [CrossRef]
- Esmaelpoor, J.; Moradi, M.H.; Kadkhodamohammadi, A. A multistage deep neural network model for blood pressure estimation using photoplethysmogram signals. Comput. Biol. Med. 2020, 120, 103719. [Google Scholar] [CrossRef]
- Eom, H.; Lee, D.; Han, S.; Hariyani, Y.S.; Lim, Y.; Sohn, I.; Park, K.; Park, C. End-To-End Deep Learning Architecture for Continuous Blood Pressure Estimation Using Attention Mechanism. Sensors 2020, 20, 2338. [Google Scholar] [CrossRef] [Green Version]
- Jeong, D.U.; Lim, K.M. Combined Deep CNN–LSTM Network-based Multitasking Learning Architecture for Noninvasive Continuous Blood Pressure Estimation using Difference in ECG-PPG Features. Sci. Rep. 2021, 11, 13539. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Yang, X.; Liu, X.; Fang, S.; Ma, L.; Li, L. Photoplethysmography based stratification of blood pressure using multi information fusion artificial neural network. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; IEEE: Seattle, WA, USA, 2020; pp. 1113–1119. [Google Scholar] [CrossRef]
- Lee, D.; Kwon, H.; Son, D.; Eom, H.; Park, C.; Lim, Y.; Seo, C.; Park, K. Beat-to-Beat Continuous Blood Pressure Estimation Using Bidirectional Long Short-Term Memory Network. Sensors 2020, 21, 96. [Google Scholar] [CrossRef]
- Mou, H.; Yu, J. CNN-LSTM Prediction Method for Blood Pressure Based on Pulse Wave. Electronics 2021, 10, 1664. [Google Scholar] [CrossRef]
- Johnson, A.E.; Pollard, T.J.; Shen, L.; Lehman, L.w.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Anthony Celi, L.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kachuee, M.; Kiani, M.M.; Mohammadzade, H.; Shabany, M. Cuffless Blood Pressure Estimation Algorithms for Continuous Health-Care Monitoring. IEEE Trans. Biomed. Eng. 2017, 64, 859–869. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Elgendi, M.; Fletcher, R.; Liang, Y.; Howard, N.; Lovell, N.H.; Abbott, D.; Lim, K.; Ward, R. The use of photoplethysmography for assessing hypertension. NPJ Digit. Med. 2019, 2, 60. [Google Scholar] [CrossRef] [Green Version]
- Elgendi, M. Detection of c, d, and e waves in the acceleration photoplethysmogram. Comput. Methods Programs Biomed. 2014, 117, 125–136. [Google Scholar] [CrossRef]
- Elgendi, M.; Norton, I.; Brearley, M.; Abbott, D.; Schuurmans, D. Systolic Peak Detection in Acceleration Photoplethysmograms Measured from Emergency Responders in Tropical Conditions. PLoS ONE 2013, 8, e76585. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De Haan, G.; van Leest, A. Improved motion robustness of remote-PPG by using the blood volume pulse signature. Physiol. Meas. 2014, 35, 1913–1926. [Google Scholar] [CrossRef]
- Wang, W.; den Brinker, A.C.; Stuijk, S.; de Haan, G. Algorithmic Principles of Remote PPG. IEEE Trans. Biomed. Eng. 2017, 64, 1479–1491. [Google Scholar] [CrossRef] [Green Version]
- McEniery, C.M.; Yasmin; Hall, I.R.; Qasem, A.; Wilkinson, I.B.; Cockcroft, J.R. Normal Vascular Aging: Differential Effects on Wave Reflection and Aortic Pulse Wave Velocity. J. Am. Coll. Cardiol. 2005, 46, 1753–1760. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yousef, Q.; Reaz, M.B.I.; Ali, M.A.M. The Analysis of PPG Morphology: Investigating the Effects of Aging on Arterial Compliance. Meas. Sci. Rev. 2012, 12, 266. [Google Scholar] [CrossRef] [Green Version]
- Chiarelli, A.M.; Bianco, F.; Perpetuini, D.; Bucciarelli, V.; Filippini, C.; Cardone, D.; Zappasodi, F.; Gallina, S.; Merla, A. Data-driven assessment of cardiovascular ageing through multisite photoplethysmography and electrocardiography. Med. Eng. Phys. 2019, 73, 39–50. [Google Scholar] [CrossRef]
- Dall’Olio, L.; Curti, N.; Remondini, D.; Safi Harb, Y.; Asselbergs, F.W.; Castellani, G.; Uh, H.W. Prediction of vascular aging based on smartphone acquired PPG signals. Sci. Rep. 2020, 10, 19756. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Hurley, N.C.; Ibrahim, B.; Spatz, E.; Krumholz, H.M.; Jafari, R.; Mortazavi, B.J. Developing Personalized Models of Blood Pressure Estimation from Wearable Sensors Data Using Minimally-trained Domain Adversarial Neural Networks. arXiv 2020, arXiv:2007.12802. [Google Scholar]
- Wang, W.; den Brinker, A.C. Modified RGB cameras for infrared remote-PPG. IEEE Trans. Biomed. Eng. 2020, 67, 2893–2904. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Li, X.; Zhao, G. Remote photoplethysmograph signal measurement from facial videos using spatio-temporal networks. arXiv 2019, arXiv:1905.02419. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Architecture | |||||
|---|---|---|---|---|---|---|
| AlexNet | ResNet | Slapničar | LSTM | Mean-Reg | ||
| SBP | Mixed | 8.8 | 7.7 | 12.9 | 11.6 | 19.6 |
| Non-mixed | 16.6 | 16.4 | 16.8 | 16.4 | 19.6 | |
| pre pers. (n.m.) | 15.8 | 16.2 | 15.2 | 15.7 | - | |
| pers. rand (n.m.) | 11.8 | 13.0 | 10.8 | 8.5 | - | |
| pers. first (n.m.) | 12.2 | 12.3 | 11.1 | 9.0 | - | |
| DBP | Mixed | 4.9 | 4.4 | 7.5 | 6.7 | 9.9 |
| Non-mixed | 8.7 | 8.5 | 8.8 | 8.6 | 9.8 | |
| pre pers. (n.m.) | 10.1 | 9.8 | 9.8 | 9.9 | - | |
| pers. rand (n.m.) | 6.0 | 6.3 | 5.8 | 4.5 | - | |
| pers. first (n.m.) | 6.1 | 5.8 | 5.9 | 4.6 | - | |
| MAE(SBP) [mmHg] | MAE(DBP) [mmHg] | |
|---|---|---|
| Before fine tuning | ||
| AlexNet | 28.1 | 13.8 |
| ResNet | 28.9 | 13.3 |
| Slapničar | 29.6 | 11.5 |
| LSTM | 33.5 | 12.4 |
| After fine tuning w/o personalization | ||
| AlexNet | 14.0 | 11.0 |
| ResNet | 14.1 | 11.2 |
| Slapničar | 14.8 | 10.3 |
| LSTM | 13.6 | 10.3 |
| After fine tuning with personalization (first 20%) | ||
| AlexNet | 14.2 | 10.7 |
| ResNet | 12.7 | 10.8 |
| Slapničar | 15.2 | 10.5 |
| LSTM | 14.4 | 10.5 |
| After fine tuning with personalization (random 20%) | ||
| AlexNet | 14.0 | 11.0 |
| ResNet | 14.1 | 11.2 |
| Slapničar | 14.8 | 10.3 |
| LSTM | 13.6 | 10.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schrumpf, F.; Frenzel, P.; Aust, C.; Osterhoff, G.; Fuchs, M. Assessment of Non-Invasive Blood Pressure Prediction from PPG and rPPG Signals Using Deep Learning. Sensors 2021, 21, 6022. https://doi.org/10.3390/s21186022
Schrumpf F, Frenzel P, Aust C, Osterhoff G, Fuchs M. Assessment of Non-Invasive Blood Pressure Prediction from PPG and rPPG Signals Using Deep Learning. Sensors. 2021; 21(18):6022. https://doi.org/10.3390/s21186022
Chicago/Turabian StyleSchrumpf, Fabian, Patrick Frenzel, Christoph Aust, Georg Osterhoff, and Mirco Fuchs. 2021. "Assessment of Non-Invasive Blood Pressure Prediction from PPG and rPPG Signals Using Deep Learning" Sensors 21, no. 18: 6022. https://doi.org/10.3390/s21186022
APA StyleSchrumpf, F., Frenzel, P., Aust, C., Osterhoff, G., & Fuchs, M. (2021). Assessment of Non-Invasive Blood Pressure Prediction from PPG and rPPG Signals Using Deep Learning. Sensors, 21(18), 6022. https://doi.org/10.3390/s21186022