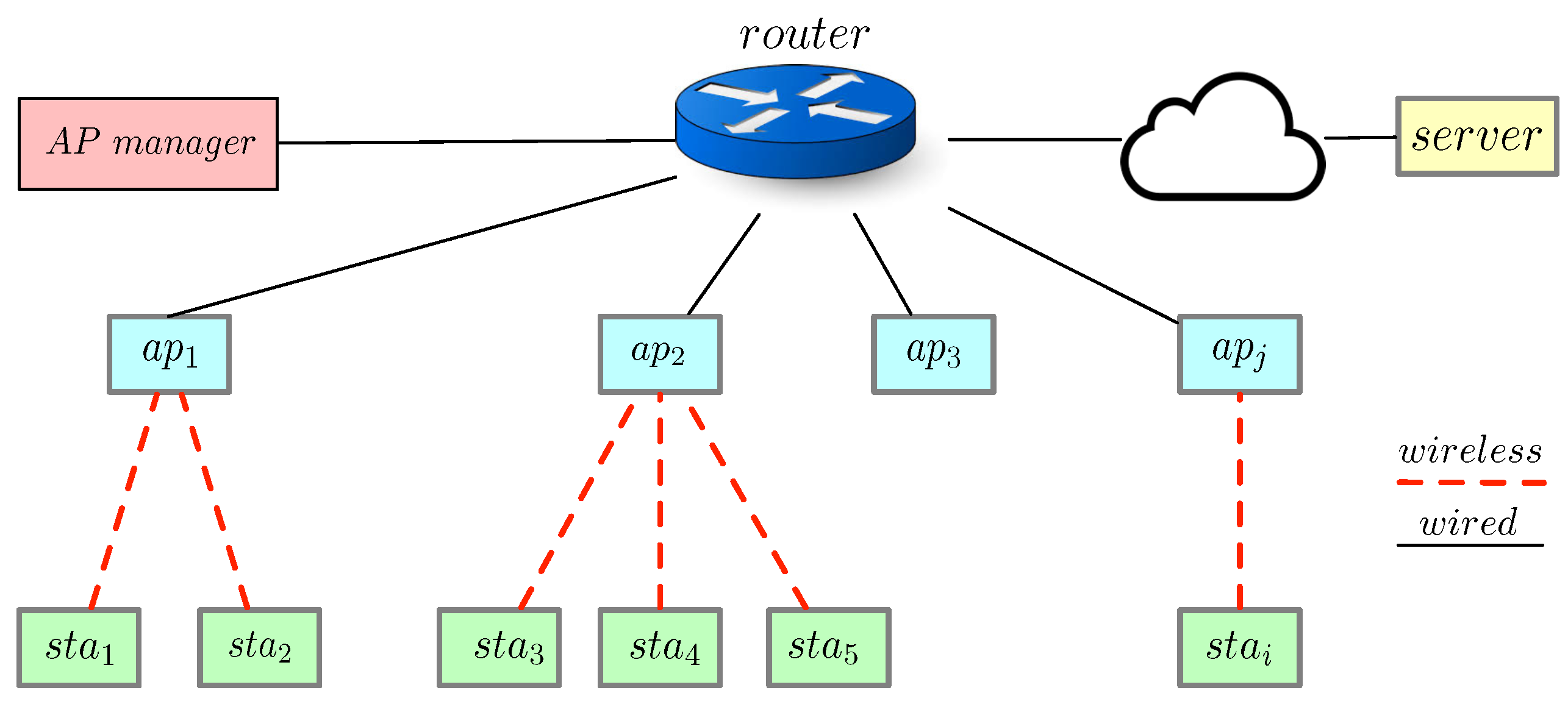
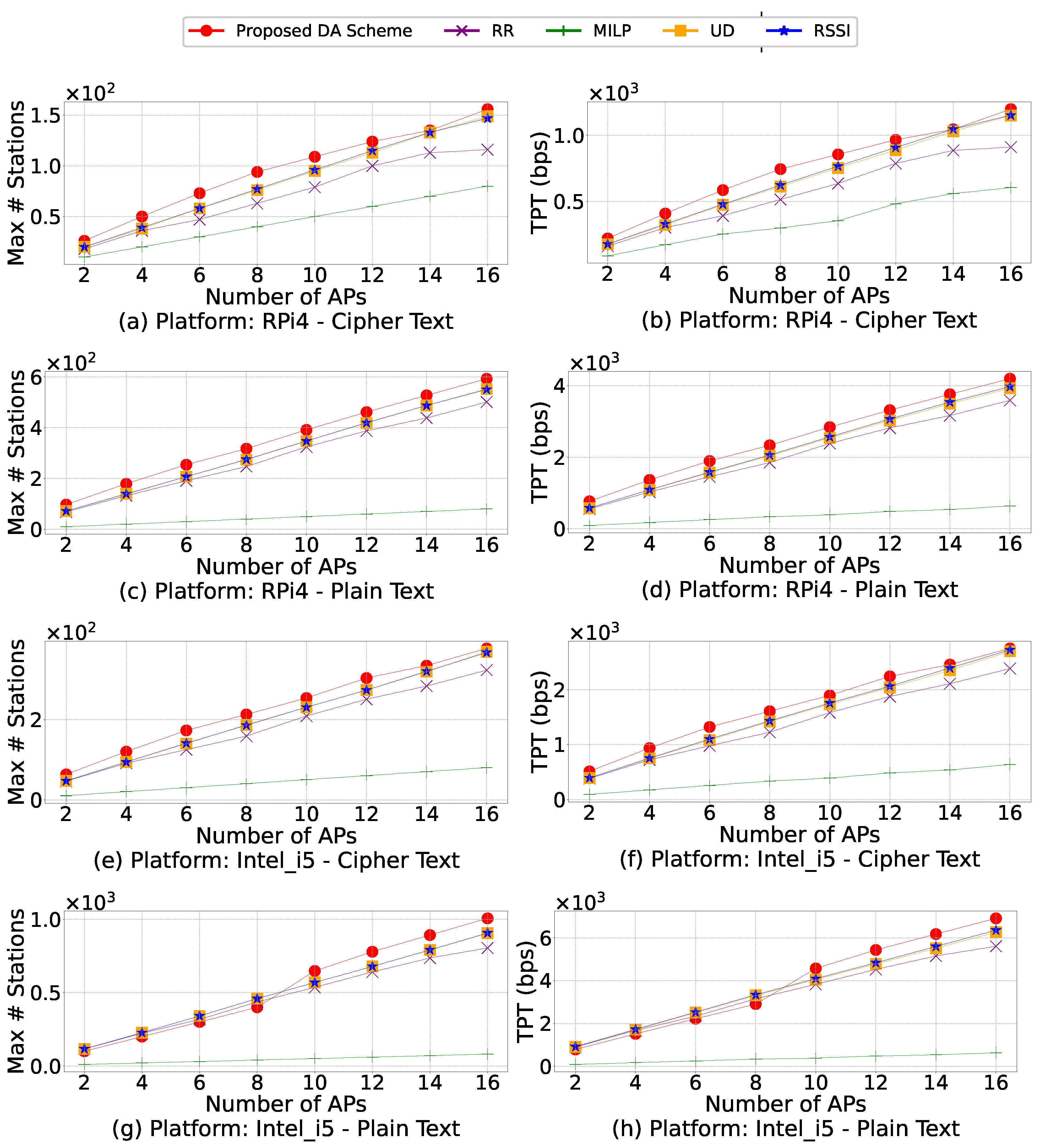
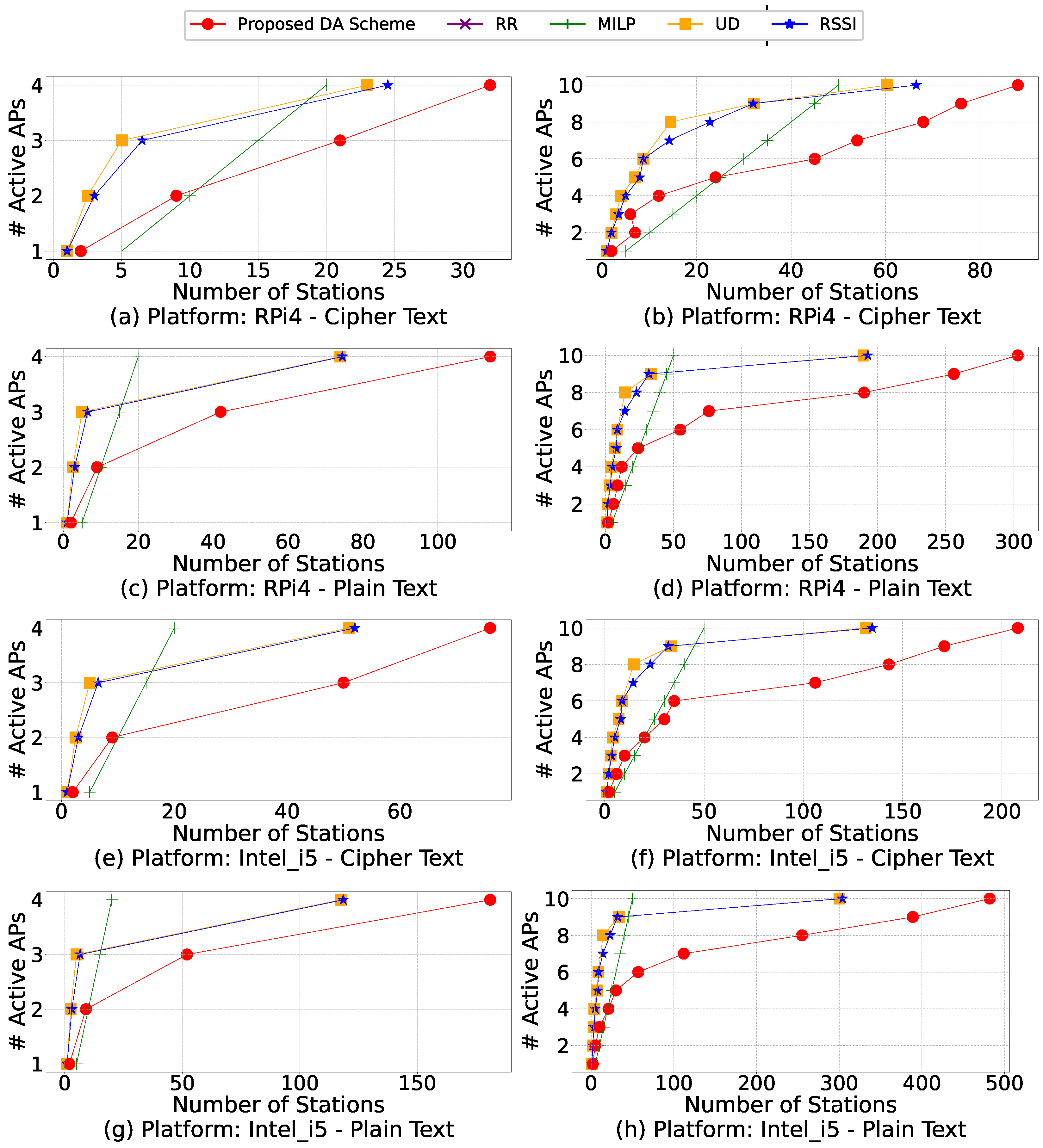
In an extensive network where multiple APs are available, an IoT station can be associated with different APs, requiring a process to identify the most appropriate AP. We define such a device association (DA) process as an optimization problem of mapping n stations to no more than m given APs. The maximum network throughput can be achieved with the minimum number of APs involved. More importantly, we assume that each AP has limited capacity to facilitate offloading and set such limitations as constraints in our problem formulation. Such an assumption differentiates this work from most existing ones. Furthermore, finding the best association is an NP-hard problem. To address this problem, we propose an efficient DA scheme that can adapt to the dynamics of large-scale networks.
4.1. Association Problem Formulation
We formulate the constraints for optimized association using several backbone formulas and quantities. In this study, the stations usually operate in the context of IoT and thus transmit messages reporting different status types to the AP. Each station provides information about its demand when it first joins the network. Such demand remains fixed throughout a station’s lifespan.
In particular, we mathematically formulate the optimization model as a multi-objective problem involving two components: (1a) maximizing the total network throughput, and (1b) minimizing the number of active (required) APs. The key symbols are summarized in
Table 2.
There are multiple constraints considered in the model. The constraint (1c) ensures that every station is associated with exactly one AP. The constraint (1d) guarantees that the signal received from any station has to be above a certain threshold in order for the AP to sense and process that signal, as dictated by IEEE 802.11 standards. The constraint (1e) makes sure that the received signal by the station from the AP has to be above a certain threshold (minimum RSSI threshold) in order to ensure proper transmitting and successful association. These are typical constraints considered by existing studies for device association.
Beyond the above constraints, we propose a security constraint (1f) to control the maximum number of stations transmitting sensitive data that an AP can serve. We assume that a station may have its own security level requirement (i.e., marked as ). A higher value of indicates a higher security requirement and thus more computation complexity. The sum of these quantities across all stations served by an individual AP cannot exceed a certain threshold, , which can be customized based on the network’s security conditions. A smaller value can help limit not only the security overhead on each AP, but also the number of stations associated with a single AP. Therefore, in case the AP is compromised, fewer stations are impacted.
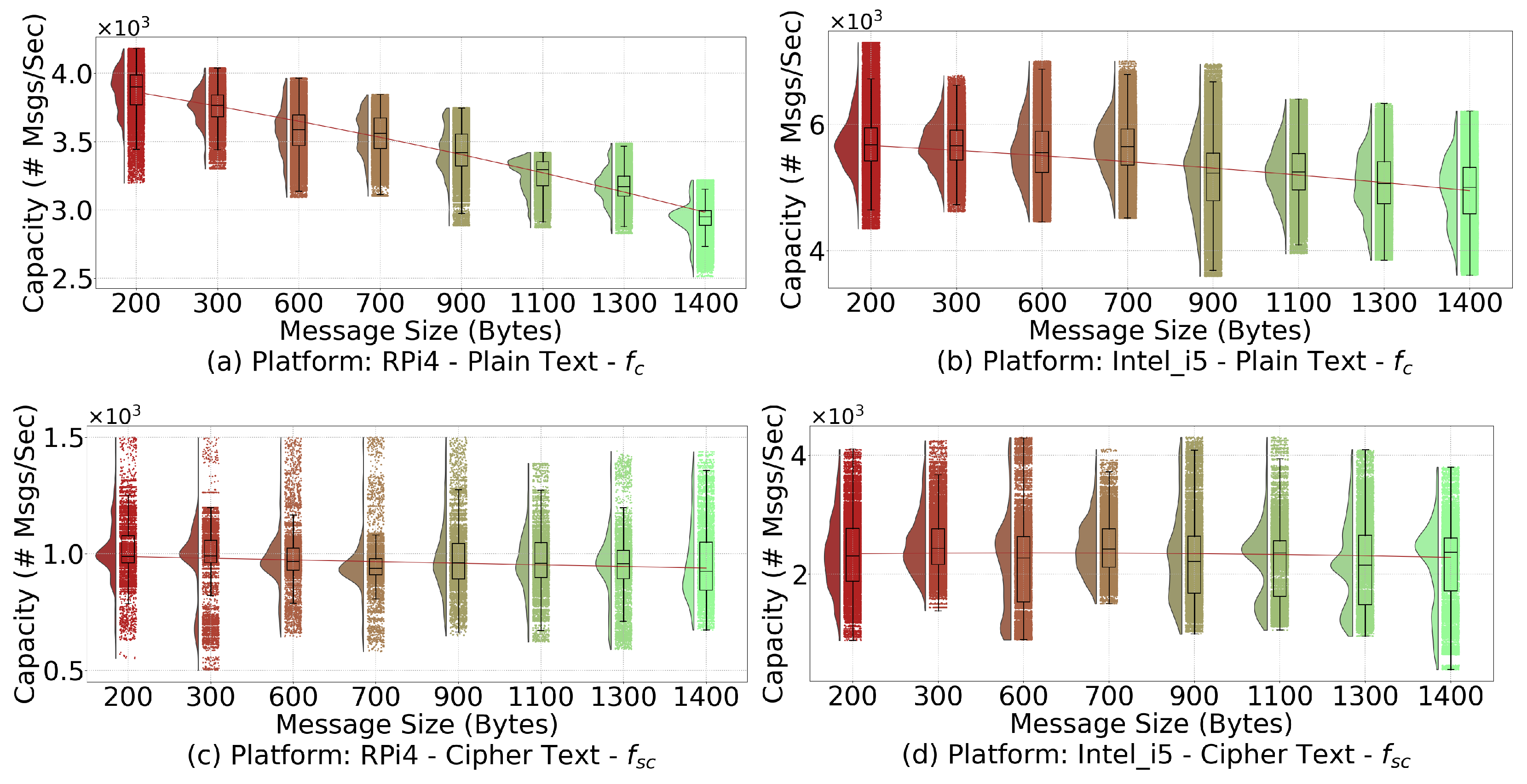
We propose the constraint (1g) to consider the APs’ computation and communication capacities. In particular, we consider that different types of messages (i.e., represented by
k with size
) may require different computation/communication resources. The function
f, which returns the maximum number of messages that can be processed by an AP per second, can be implemented as either
or
to represent different scenarios. Specifically, the function
mainly focuses on plaintext messages that are not encrypted. On the other hand, the function
mainly focuses on encrypted messages for secure communications. Since additional computation is required for continuous encryption and decryption, the AP can only process a smaller number of messages, leading to smaller return values for
when the inputs are the same. Both of these functions are customized functions. Therefore, in this study, we quantitatively evaluate their function based on a real testbed, which is discussed more in
Section 5.
Furthermore, some key parameters involved in these constraints are calculated as follow: first, the received signal strength indicator (RSSI) at
, represented by
, is calculated by subtracting the total path loss, measured in dB, from
’s transmission power
[
39]. On the other hand,
refers to the received signal strength at
from station
, which is calculated by subtracting the total path loss from
’s transmission power
. Without losing generality, we simply assume that all nodes in the network have the same transmission power and use omnidirectional antennas. The total path loss is calculated as
, where
represents the path loss at a reference point
;
is the path loss exponent; and
is a zero-mean Gaussian distributed random variable (in dB) [
40]. It should be noted that
is used only when there is a shadowing effect, and will be set as zero if the shadowing effect is not considered.
Second, we calculate the transmission rate between the station
and the AP
(marked as
). Based on the Shannon–Hartley theorem [
40], the transmission rate
can be calculated by multiplying the binary logarithm of
with
, the channel bandwidth. In reality, the actual rate may also be affected by the chosen modulation and coding scheme (MCS).
Specifically, for a given uplink connection from
to
,
of the
can be calculated as
In Equation (
3),
refers to the value of additive white Gaussian noise (AWGN). The function
returns the cumulative interference produced by all other transmitting stations that interfere with station
for a given
. ‘Transmitting stations’ refers to all stations in the entire network, including those associated with other APs.
The function
is described in detail by Algorithm 1 where
and
are the input (
is associated with
) and the interference value is the output. Given an arbitrary station
, associated with any AP
such that
, if
interferes and transmits concurrently with
, then
is 1, else
is 0. When
is 1, the interference value is incremented by
.
| Algorithm 1: Procedure describing function in Equation (3) |
![Sensors 21 06433 i001]() |
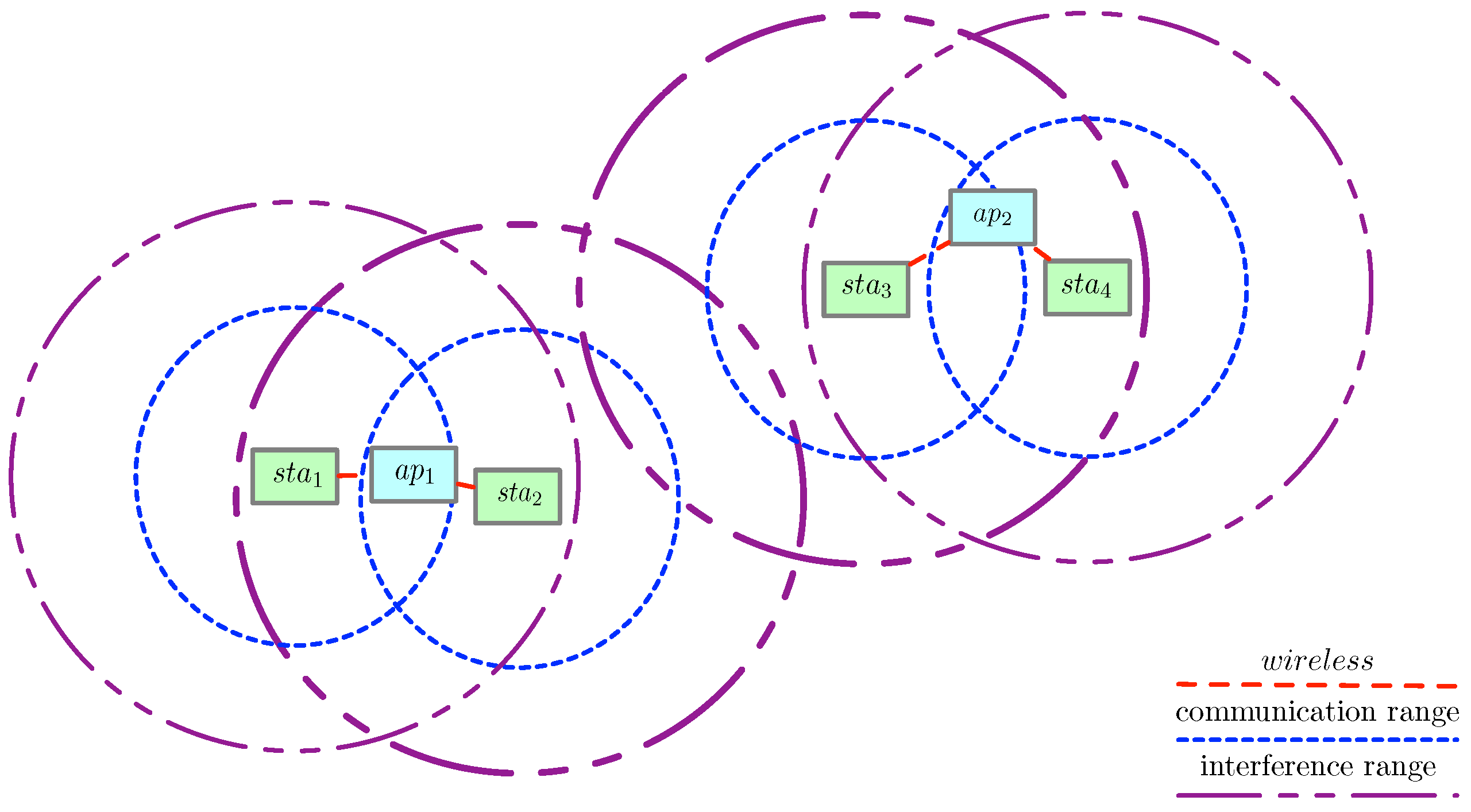
An illustration of our assumed communication and interference model is shown in
Figure 5. As an example, Algorithm 1 can be used to compute the interference of
between
and
. Assuming that
equals 1, meaning
and
are interfering with each other and transmitting at the same time, the function
returns
. Therefore, the denominator of
is
. As another example, we compute the interference of
between
and
. In this case, the function
returns 0 as none of the stations from
interferes with
, therefore the denominator of
is only
.
The interference calculated by the function can be treated as AWGN. The reason is that the interference is not dominated by only a few interferers. For example, if every AP has one station associated, the interference per station will be impacted by all the stations in the network, as all stations will be transmitting concurrently. On the other hand, in a network with only one AP and multiple associated stations, there is zero interference from other stations when a station transmits.
Once
is determined, we can use the Shannon–Hartley theorem to calculate
. To formulate our first objective (1a), used as a common quantitative measure for DA scheme comparison, we employ
. The second objective (1b) of our DA optimization problem is to minimize the number of APs needed. The resulting resource consumption reduction on both stations and APs is significant, as measured in the form of energy and time later in
Section 5.
4.2. Proposed DA Scheme
In this study, we adopt genetic algorithms (GAs), an effective approach to resolve optimization problems, to associate stations with APs. This method allows us to add a wide range of dynamic network constraints flexibly to yield a well-optimized association solution. Some of the classic problems that GAs can solve effectively include bin allocation, knapsack, and traveling salesman [
41,
42,
43]. To the best of our knowledge, this is the first study to adopt GAs to address the WiFi station association problem. In particular, we revise the default GA by setting the optimization goal as maximizing network throughput and minimizing the number of APs. Furthermore, several core functions of the GA, including
fitness, crossover, and
mutation, have been revised to fit our specific device association needs.
The basic working mechanism of the GA is as follows. Inspired by how genetics work, a GA program begins with a set of variables that internally resemble the chromosomes storing human genetic information. This involves an initial set of individuals representing candidate solutions. A feasibility function checks if an individual satisfies a list of constraints before declaring it valid. Invalid individuals are disposed of, while valid individuals’ fitness values are evaluated. For every generation, either crossover or mutation occurs at a configurable probability. Crossover occurs on valid individuals by the mate function to create child individuals for the next generation. Additionally, a certain number of individuals are subject to mutation, a process that helps add more diversity into the system by producing more interesting individuals. Finally, only a small percentage of the entire valid population is selected for the next generation using the select function, which chooses the individuals that best satisfy an objective function out of the subset mentioned above. The entire process is repeated for a given number of generations. Ultimately, the entire population evolves, but only the best individuals are selected as the final solution in the hall of fame, which keeps track of the individuals with the greatest fitness at any given time. Pareto efficiency is used as the criterion to select the best individuals for the hall of fame. One crucial characteristic, and perhaps weakness, of GAs is that there has to be a clear way to evaluate the fitness of a potential solution.
To adopt the GA, we format the association problem modeled in
Section 4.1 by representing each candidate association solution (i.e., individual in the GA) as a binary matrix. In this matrix, each row represents a specific AP, and each column represents a specific station. If an entry at (
) is 1, it means
is connected to
. In this matrix format, a specific candidate association solution can be easily compared and evaluated for fitness.
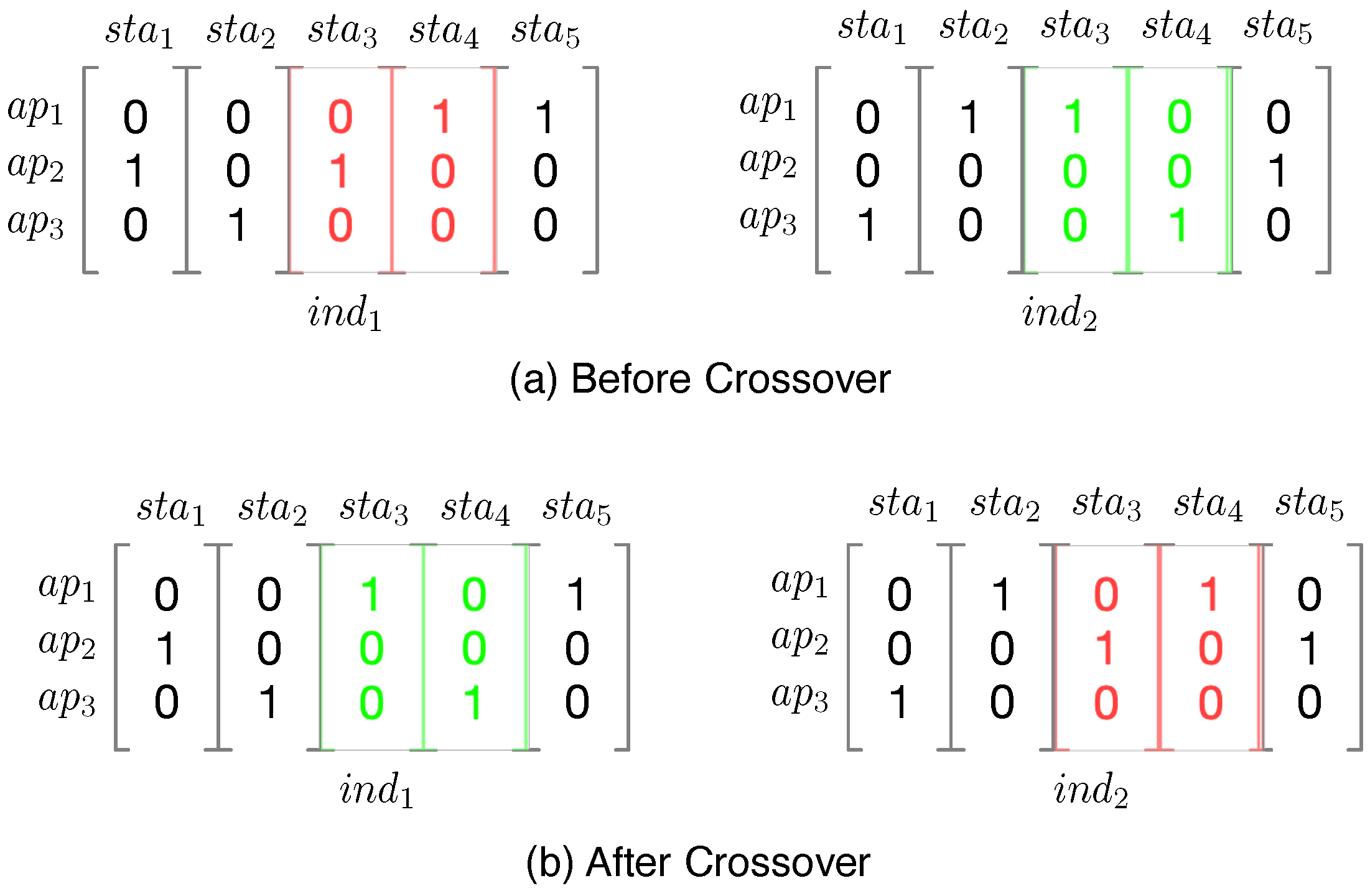
We illustrate the crossover process implemented in this study in
Figure 6. Specifically, during the crossover, two individuals, which are binary matrices, are considered as inputs. Let us consider the crossover operation on two individuals, called
and
, respectively. During this process, a particular range of consecutively numbered stations is chosen at random, which are then swapped between both individuals. For example, if
and
are chosen to be swapped, then at the end of the crossover process, the two individuals will be transformed through the swapping of columns (
and
) and become two new individuals.
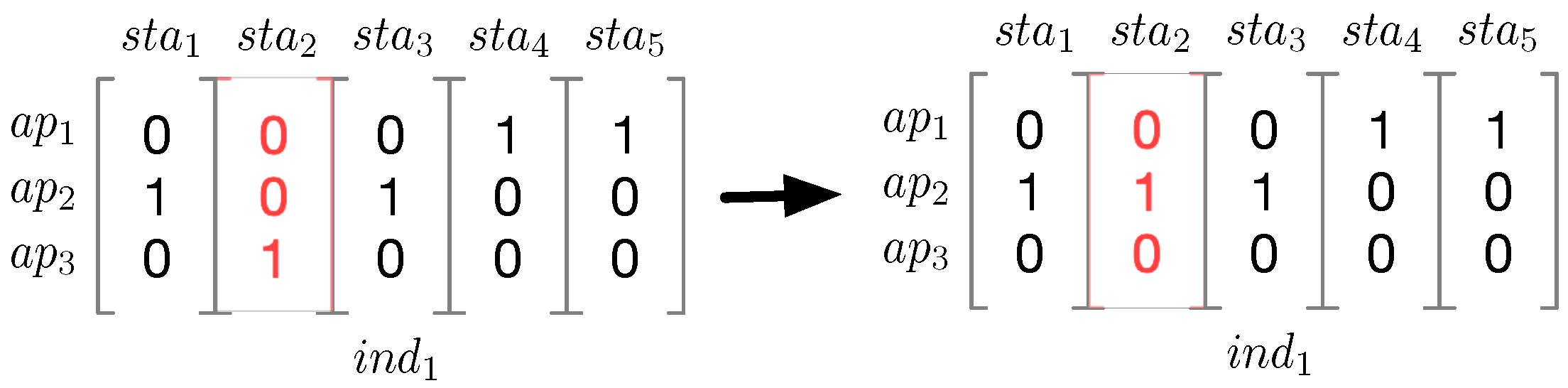
In addition, we also tailor the mutation function for our association problem, as depicted in
Figure 7. During mutation, which takes an individual as an input, a station is chosen at random to be associated with another AP, which is also randomly selected. For example, an
can experience a mutation, in which
is selected through randomness to change its associated AP.
The purpose of crossover and mutation is to introduce more randomness into the population to ensure that the evolutionary process is not trapped in a suboptimal solution.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}