Quality Control of PET Bottles Caps with Dedicated Image Calibration and Deep Neural Networks


Abstract
:1. Introduction
2. Materials and Methods
2.1. The Dataset
- good cap
- faulty cap
- dirty cap
- missing cap
- unknown
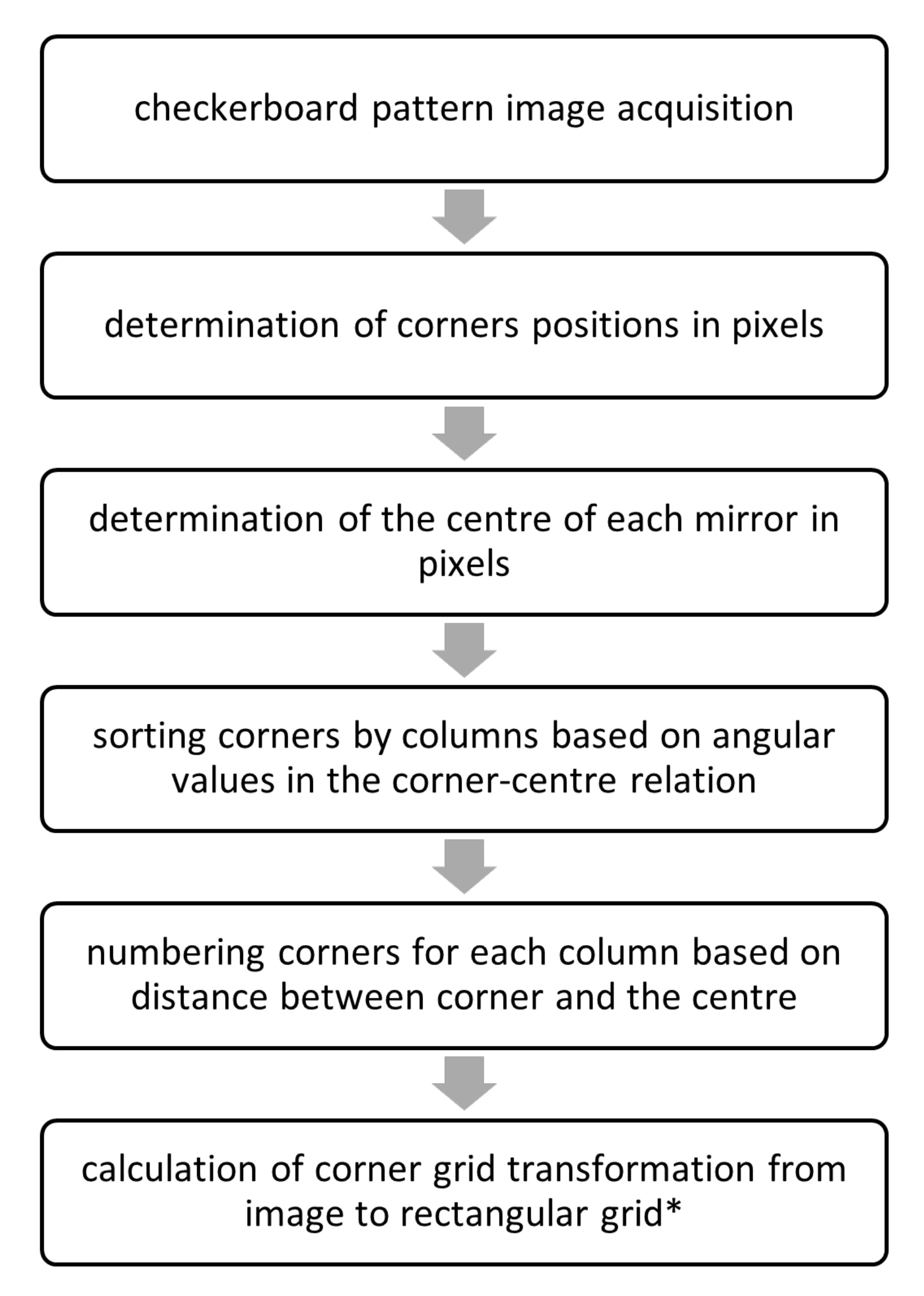
2.2. Calibration Procedure
2.3. Deep Learning Models
Training and Evaluation
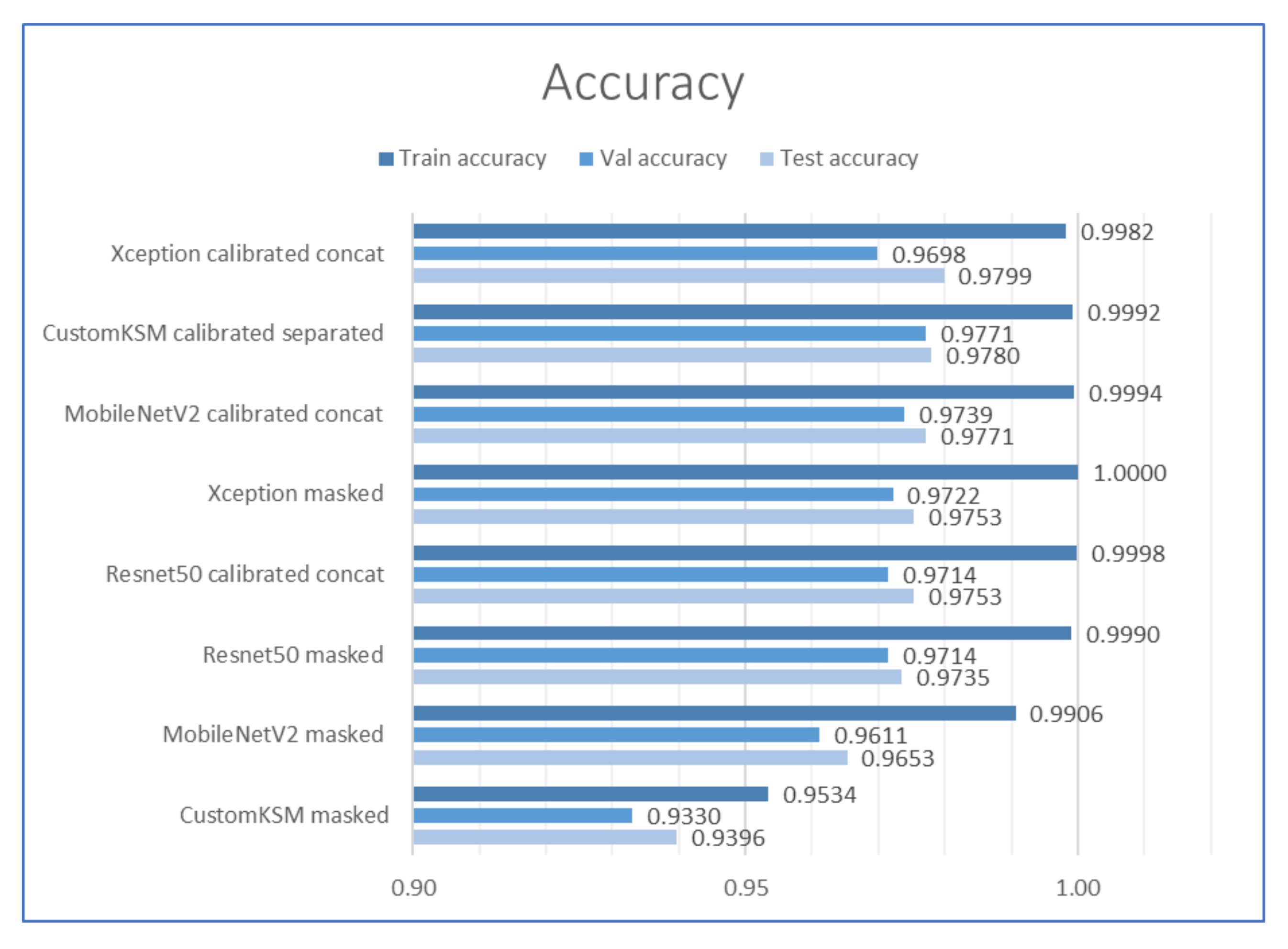
2.4. Comparison of the Accuracy of the Selected Models
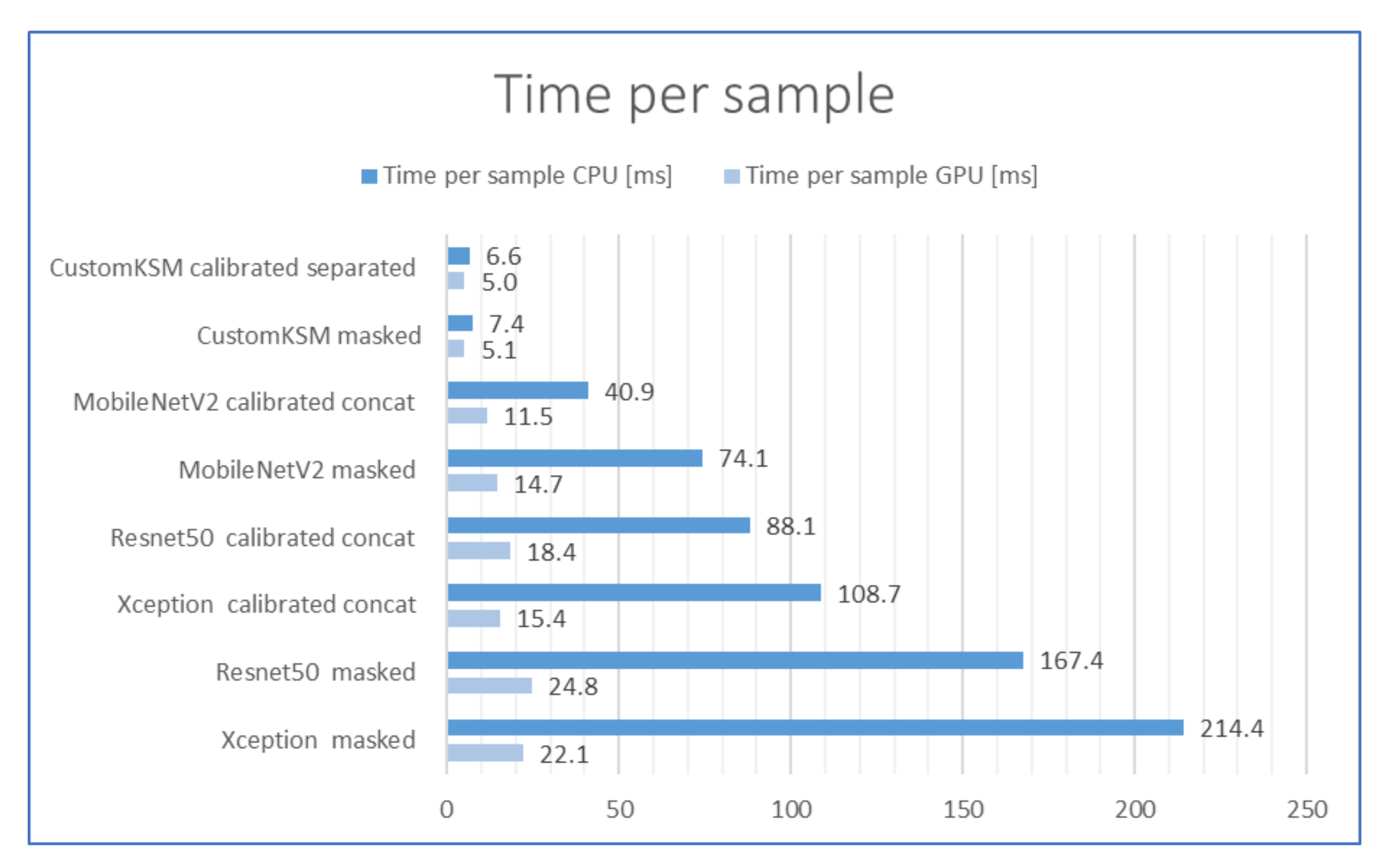
2.5. Comparison of the Inference Times
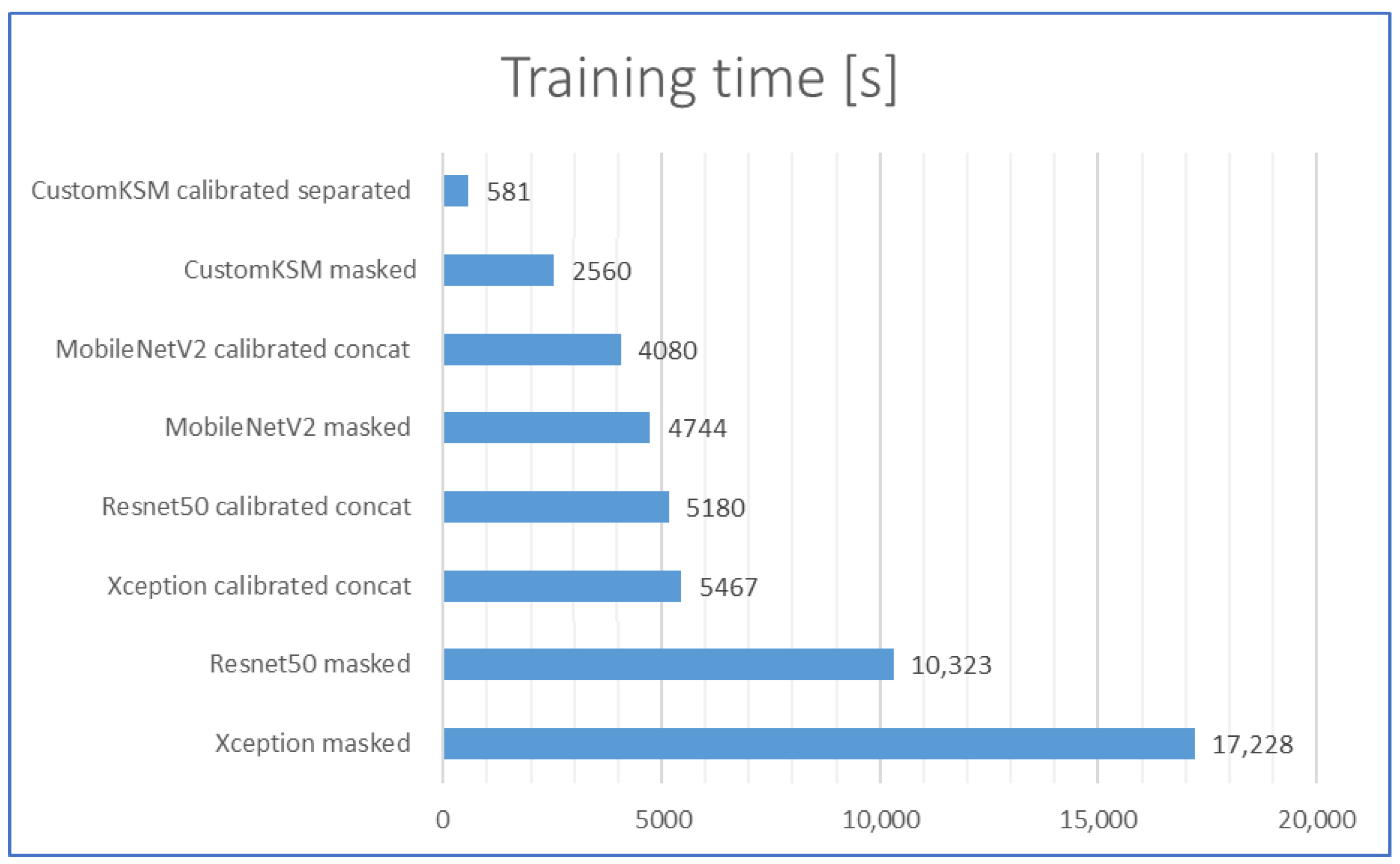
2.6. Comparison of the Training Times and Training Performance
3. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krones. A Collaborative Research Effort between Industry Week Custom Research and Kronos Incorporated: The Future of Manufacturing: 2020 and Beyond; Technical Report; Krones: Bavaria, Germany, 2016. [Google Scholar]
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M.; Dario, P. Visual-Based Defect Detection and Classification Approaches for Industrial Applications—A SURVEY. Sensors 2020, 20, 1459. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Golnabi, H.; Asadpour, A. Design and application of industrial machine vision systems. Robot. Comput. Integr. Manuf. 2007, 23, 630–637. [Google Scholar] [CrossRef]
- Batchelor, B.G. Machine Vision Handbooks; Springer: London, UK, 2012. [Google Scholar]
- Brosnan, T.; Sun, D.W. Improving quality inspection of food products by computer vision—A review. J. Food Eng. 2004, 61, 3–6. [Google Scholar] [CrossRef]
- Patel, K.; Kar, A.; Jha, S.; Khan, M. Machine vision system: A tool for quality inspection of food and agricultural products. J. Food Sci. Technol. 2012, 49, 123–141. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wilson, A.; Ben-Tal, G.; Heather, J.; Oliver, R.; Valkenburg, R. Calibrating cameras in an industrial produce inspection system. Comput. Electron. Agric. 2017, 140, 386–396. [Google Scholar] [CrossRef]
- Lins, R.G.; Kurka, P.R.G. Architecture for multi-camera vision system for automated measurement of automotive components. In Proceedings of the 2013 IEEE International Systems Conference (SysCon), Orlando, FL, USA, 15–18 April 2013; pp. 520–527. [Google Scholar] [CrossRef]
- Ferguson, M.; Ak, R.; Lee, Y.T.T.; Law, K.H. Detection and Segmentation of Manufacturing Defects with Convolutional Neural Networks and Transfer Learning. arXiv 2018, arXiv:1808.02518. [Google Scholar] [CrossRef] [PubMed]
- Weimer, D.; Scholz-Reiter, B.; Shpitalni, M. Design of deep convolutional neural network architectures for automated feature extraction in industrial inspection. CIRP Ann. 2016, 65, 417–420. [Google Scholar] [CrossRef]
- Zhao, L.; Li, F.; Zhang, Y.; Xu, X.; Xiao, H.; Feng, Y. A Deep-Learning-based 3D Defect Quantitative Inspection System in CC Products Surface. Sensors 2020, 20, 980. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Ma, Y.; Zhang, L.; Gao, R.; Wu, D. Deep Learning for Smart Manufacturing: Methods and Applications. J. Manuf. Syst. 2018, 48, 144–156. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Zhang, W.; Li, X.; Jia, X.D.; Ma, H.; Luo, Z.; Li, X. Machinery fault diagnosis with imbalanced data using deep generative adversarial networks. Measurement 2020, 152, 107377. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Li, X.; Ding, Q. Deep residual learning-based fault diagnosis method for rotating machinery. ISA Trans. 2019, 95, 295–305. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Chen, S.; Wang, Y.; Huan, W. Review of Research on Lightweight Convolutional Neural Networks. In Proceedings of the 2020 IEEE 5th Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 12–14 June 2020; pp. 1713–1720. [Google Scholar] [CrossRef]
- von Rueden, L.; Mayer, S.; Beckh, K.; Georgiev, B.; Giesselbach, S.; Heese, R.; Kirsch, B.; Pfrommer, J.; Pick, A.; Ramamurthy, R.; et al. Informed Machine Learning—A Taxonomy and Survey of Integrating Knowledge into Learning Systems. arXiv 2020, arXiv:1903.12394. [Google Scholar]
- Prabuwono, A.S.; Usino, W.; Yazdi, L.; Basori, A.H.; Bramantoro, A.; Syamsuddin, I.; Yunianta, A.; Allehaibi, K.; Allehaibi, S. Automated Visual Inspection for Bottle Caps Using Fuzzy Logic. TEM J. 2019, 8, 107–112. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Malowany, K.; Malesa, M. Device for Controlling Outer Surfaces and Geometry of Objects on Production Lines, Using Circular Observation in Full 360-Degree Circumferential Range. Polish Patent Pat. 229618, 15 March 2018. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Itseez. Open Source Computer Vision Library. 2015. Available online: https://github.com/itseez/opencv (accessed on 1 September 2020).
- Harris, C.; Stephens, M. A combined corner and edge detector. In Proceedings of the Fourth Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; pp. 147–151. [Google Scholar]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Forcinio, H. Improving Visual Inspection. BioPharm Int. 2018, 31, 32–35. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Training | Validation | Test |
|---|---|---|---|
| good cap | 2058 | 515 | 460 |
| faulty cap | 794 | 198 | 176 |
| dirty cap | 1830 | 458 | 410 |
| missing cap | 186 | 46 | 42 |
| unknown | 25 | 6 | 5 |
| Parameter | Value |
|---|---|
| learning rate | 0.001 * |
| cost function | categorical_crossentropy |
| optimizer | adam |
| metrics | categorical_accuracy |
| epochs | 100 |
| Augmentation | Range |
|---|---|
| Shift y | (−5, 5) |
| Brightness | (0.8, 1.2) |
| Model | Modes | Weights | Accuracy | Training Time [s] | Inference Time [ms] | ||||
|---|---|---|---|---|---|---|---|---|---|
| Calibrated | Input | Train | Val | Test | CPU | GPU | |||
| CustomKSM | Yes | Separated | From scratch | 0.9992 | 0.9771 | 0.978 | 348 | 5.1 | 4.4 |
| CustomKSM | No | - | From scratch | 0.9534 | 0.9330 | 0.9396 | 2560 | 7.4 | 5.1 |
| MobileNetV2 | No | - | ImageNet | 0.9906 | 0.9611 | 0.9653 | 4744 | 74.1 | 14.7 |
| MobileNetV2 | Yes | Concat | ImageNet | 0.9994 | 0.9739 | 0.9771 | 4080 | 40.9 | 11.5 |
| Resnet50 | No | - | ImageNet | 0.999 | 0.9714 | 0.9735 | 10,323 | 167.4 | 24.8 |
| Resnet50 | Yes | Concat | ImageNet | 0.9998 | 0.9714 | 0.9753 | 5180 | 88.1 | 18.4 |
| Xception | No | - | ImageNet | 1 | 0.9722 | 0.9753 | 17,228 | 214.4 | 22.1 |
| Xception | Yes | Concat | ImageNet | 0.9982 | 0.9698 | 0.9799 | 5467 | 108.7 | 15.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malesa, M.; Rajkiewicz, P. Quality Control of PET Bottles Caps with Dedicated Image Calibration and Deep Neural Networks. Sensors 2021, 21, 501. https://doi.org/10.3390/s21020501
Malesa M, Rajkiewicz P. Quality Control of PET Bottles Caps with Dedicated Image Calibration and Deep Neural Networks. Sensors. 2021; 21(2):501. https://doi.org/10.3390/s21020501
Chicago/Turabian StyleMalesa, Marcin, and Piotr Rajkiewicz. 2021. "Quality Control of PET Bottles Caps with Dedicated Image Calibration and Deep Neural Networks" Sensors 21, no. 2: 501. https://doi.org/10.3390/s21020501
APA StyleMalesa, M., & Rajkiewicz, P. (2021). Quality Control of PET Bottles Caps with Dedicated Image Calibration and Deep Neural Networks. Sensors, 21(2), 501. https://doi.org/10.3390/s21020501