Deep Temporal Convolution Network for Time Series Classification




Abstract
:1. Introduction
2. Network with Temporal Context
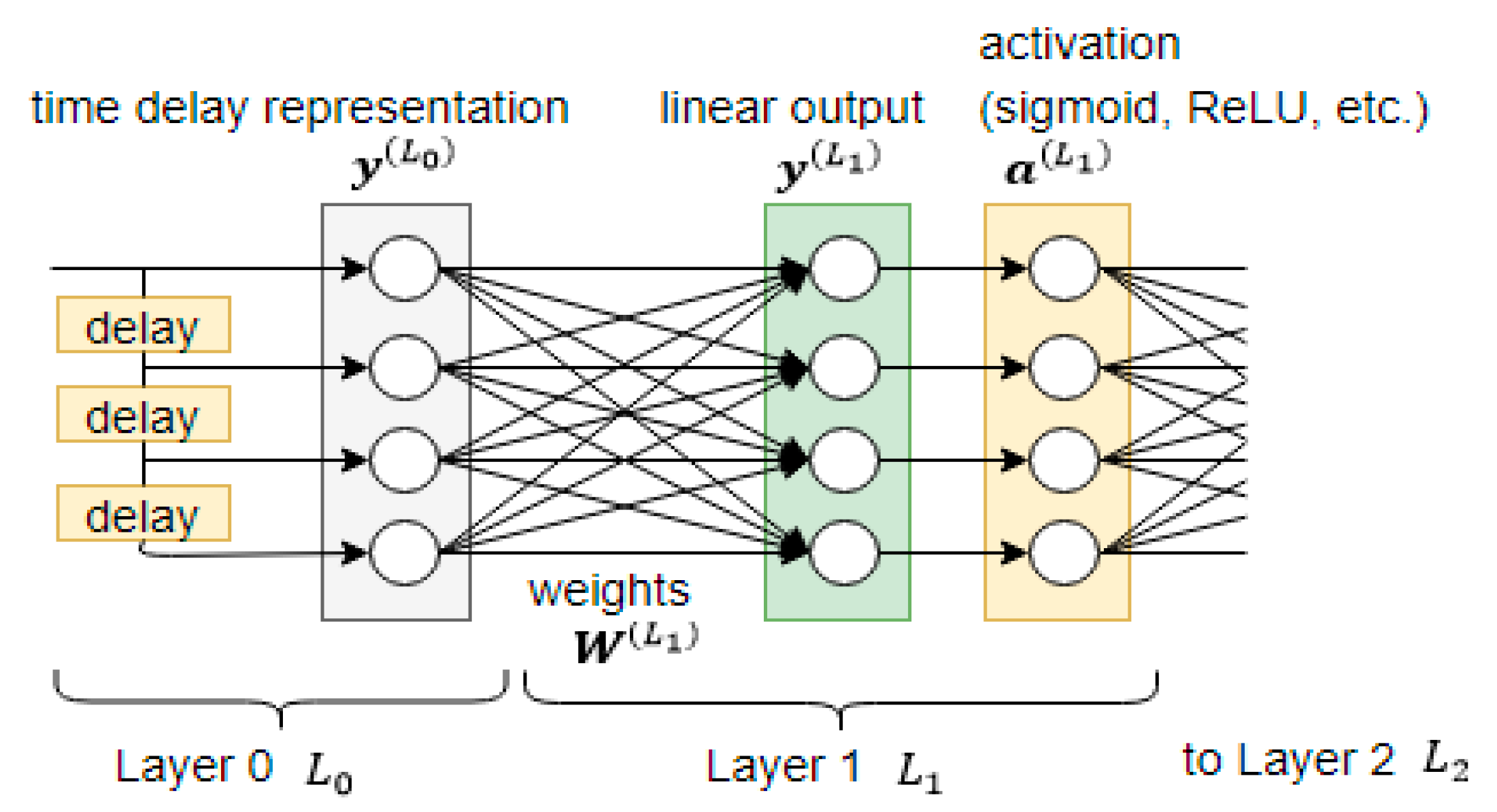
2.1. Representation of Temporal Context
2.2. Distribution of Temporal Context
2.3. Learning with Many Layers
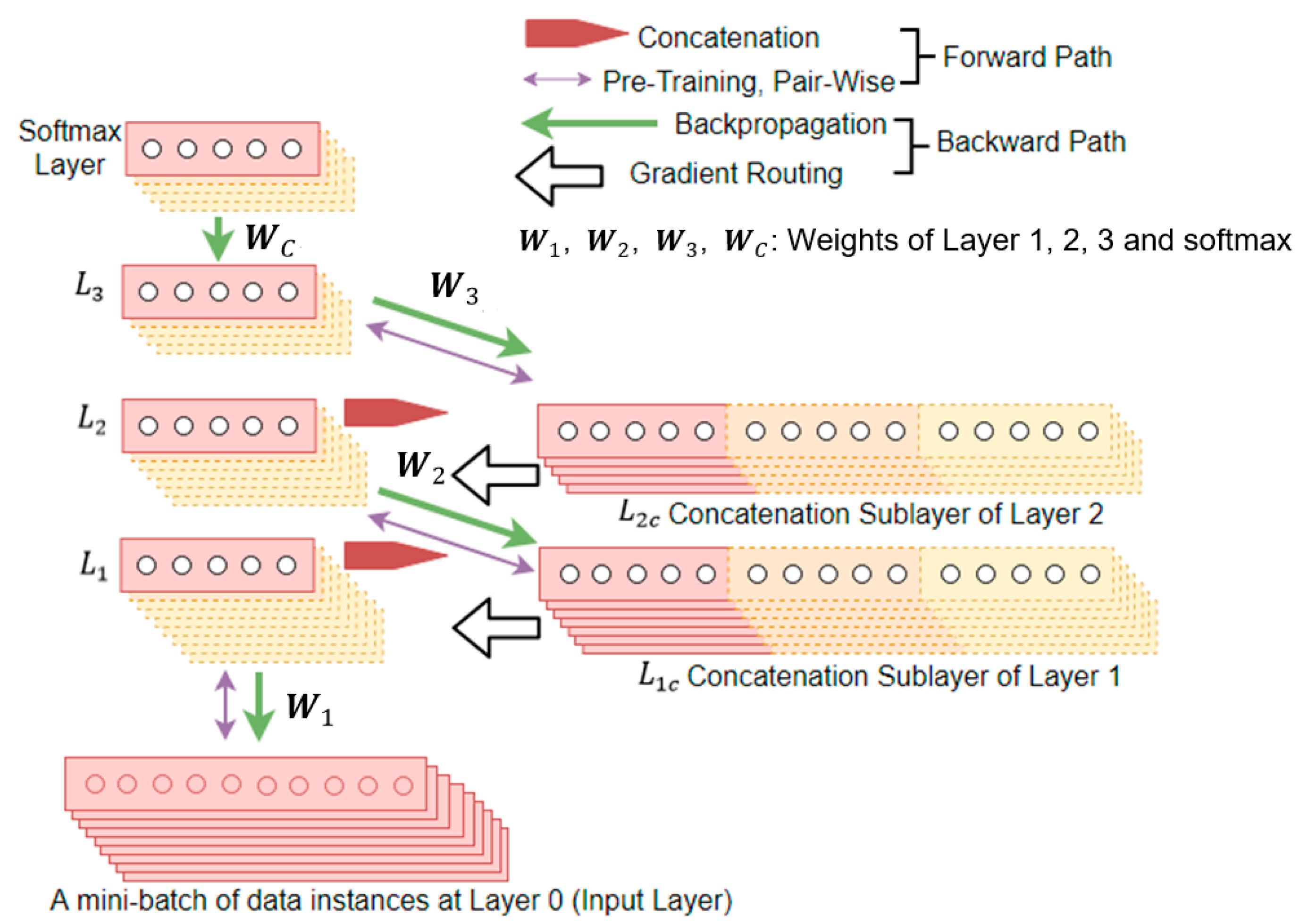
3. Proposed Methodology
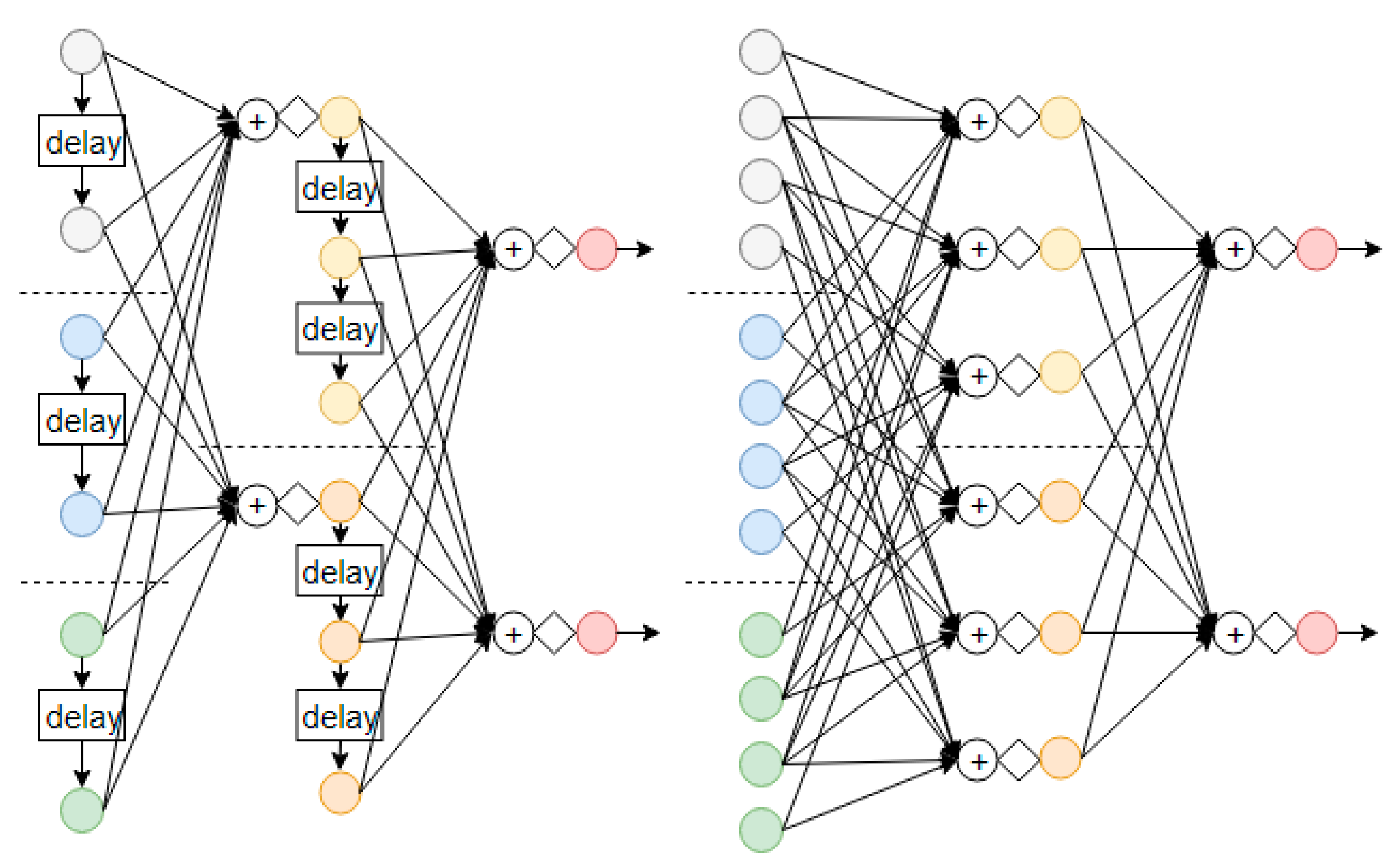
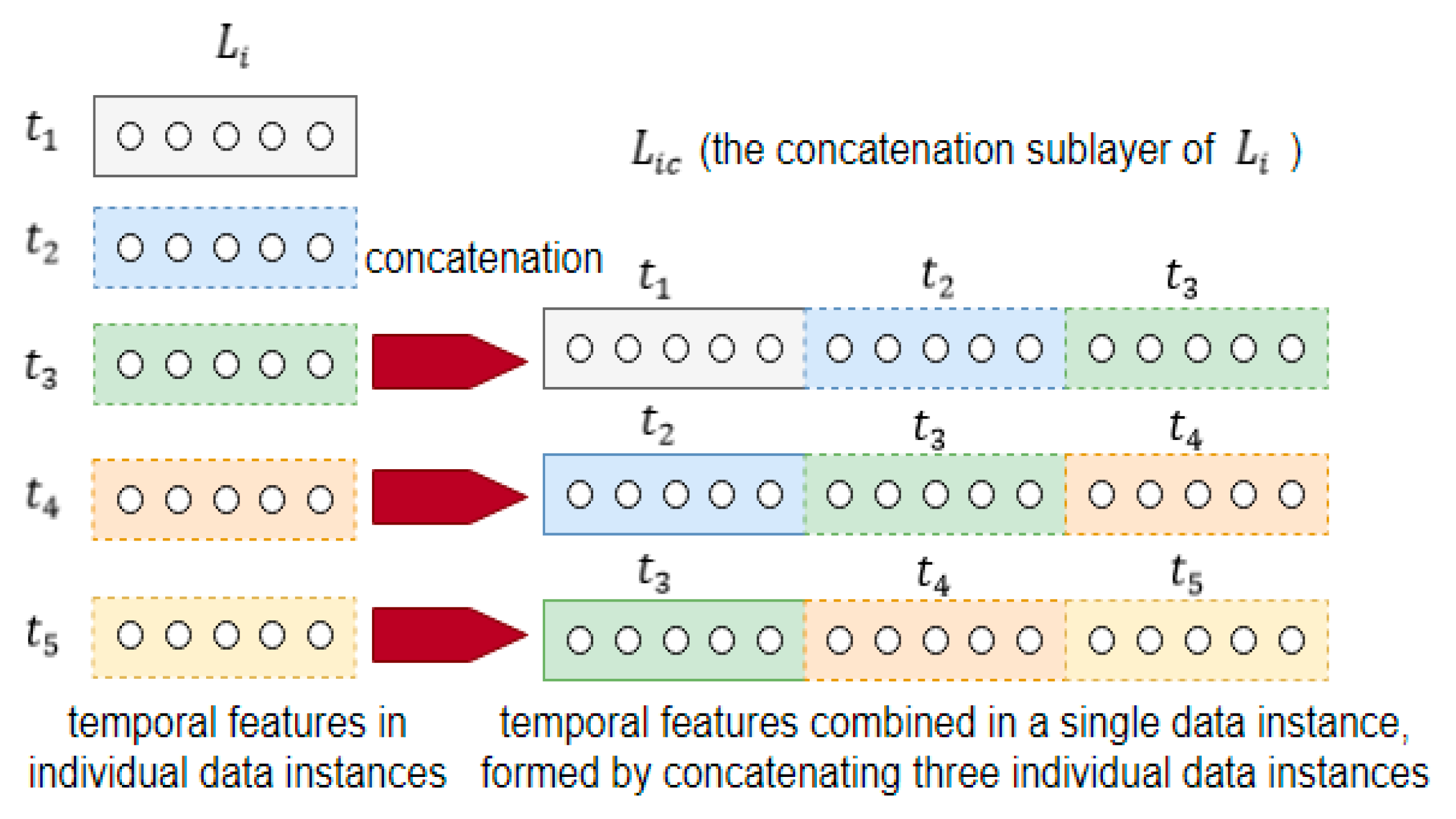
3.1. Concatenate the Temporal Context
3.2. Preparing the Data
- (1)
- Maintain short-term temporal order within a mini-batch
- (2)
- Create mini-batches that overlap with their neighbors
- (3)
- Pool the count of the target labels through the deeper layers
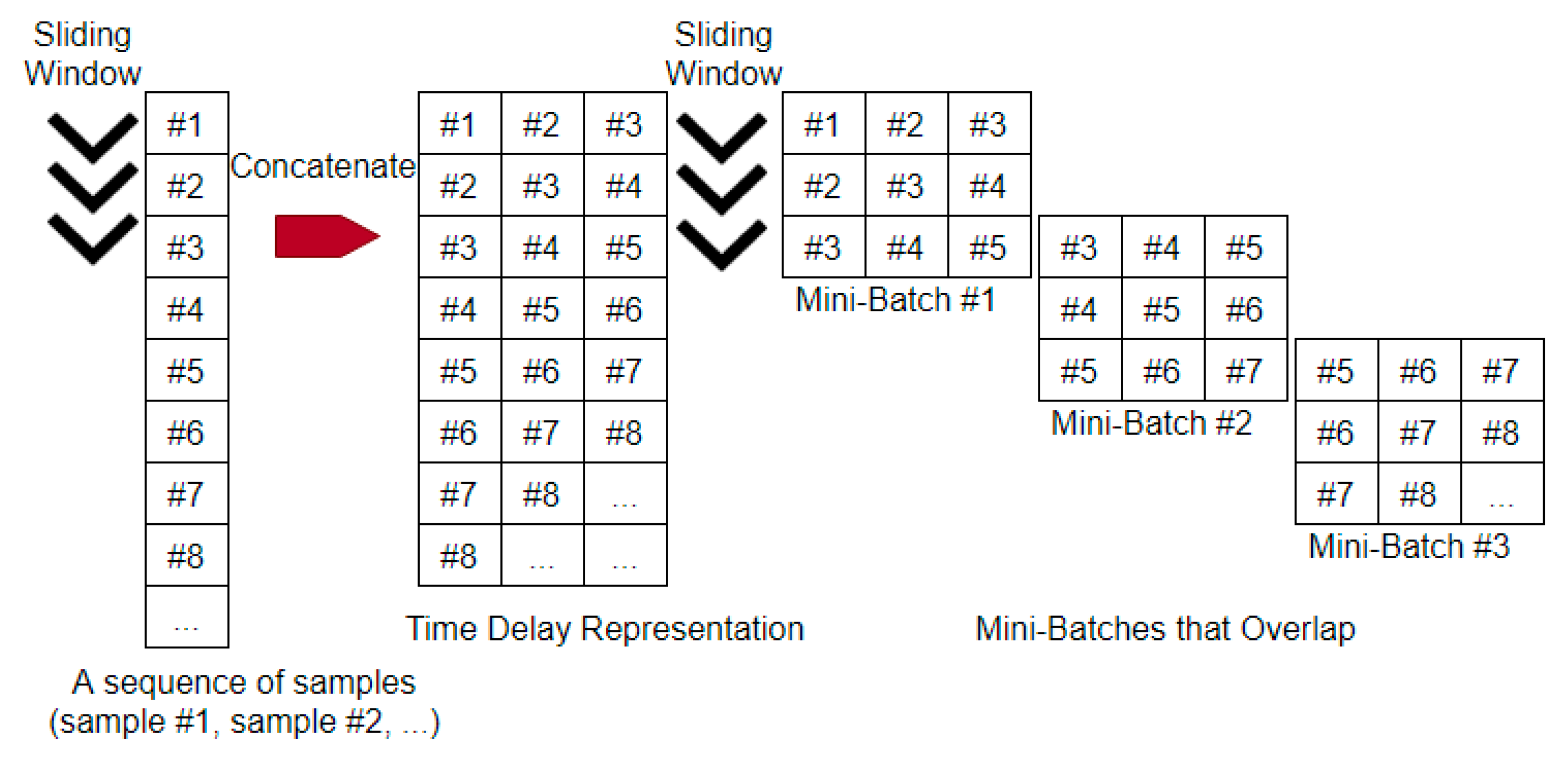
3.2.1. Short-Term Temporal Order
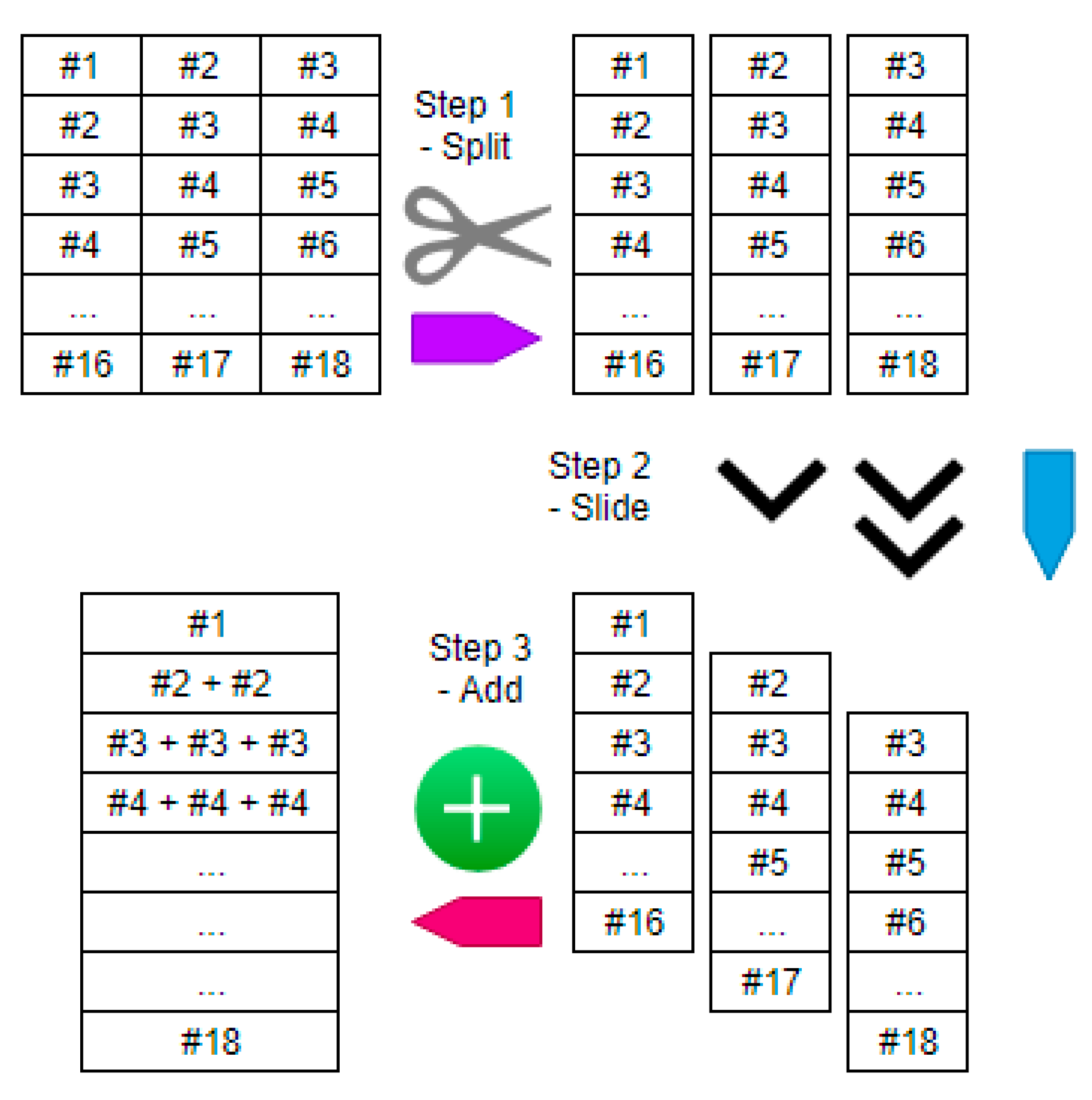
3.2.2. Mini-Batches That Overlap
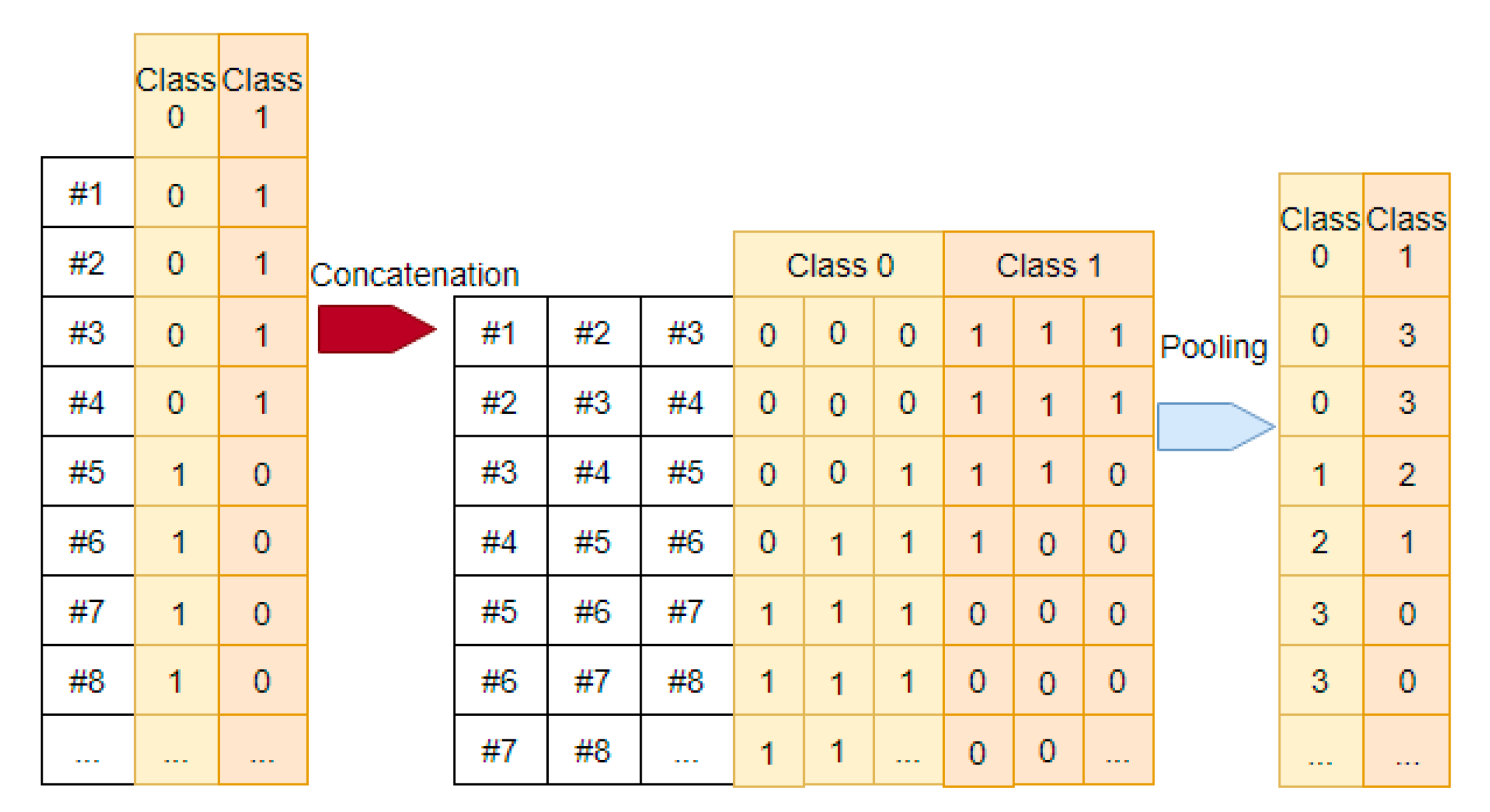
3.2.3. Pool Target Labels through the Deeper Layers
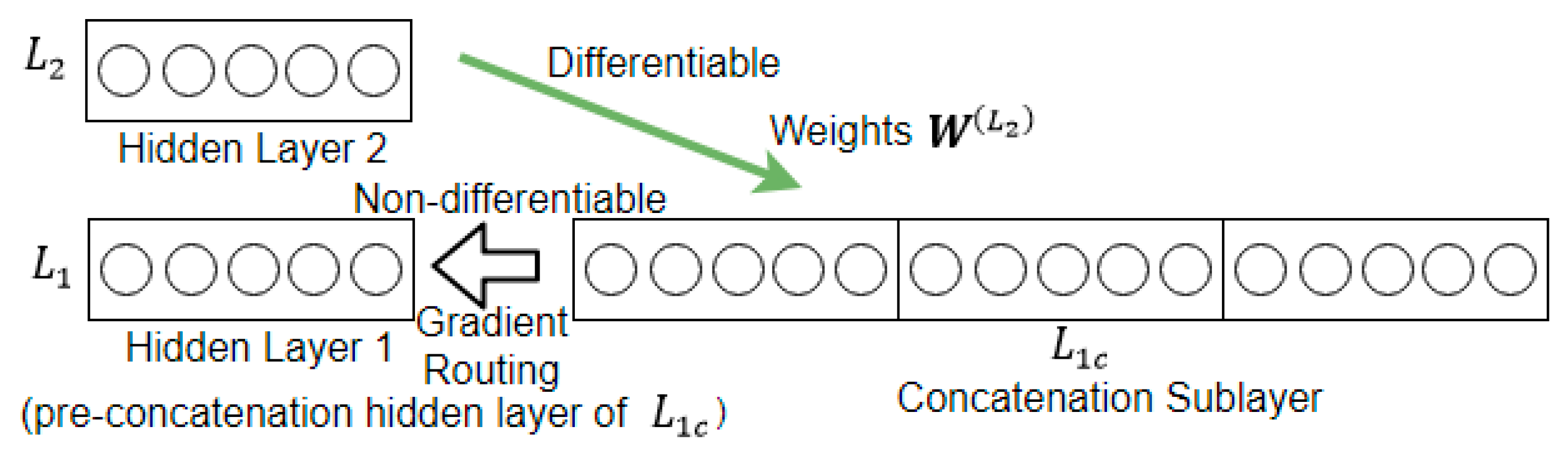
3.2.4. Learn by Backpropagation with Gradient Routing
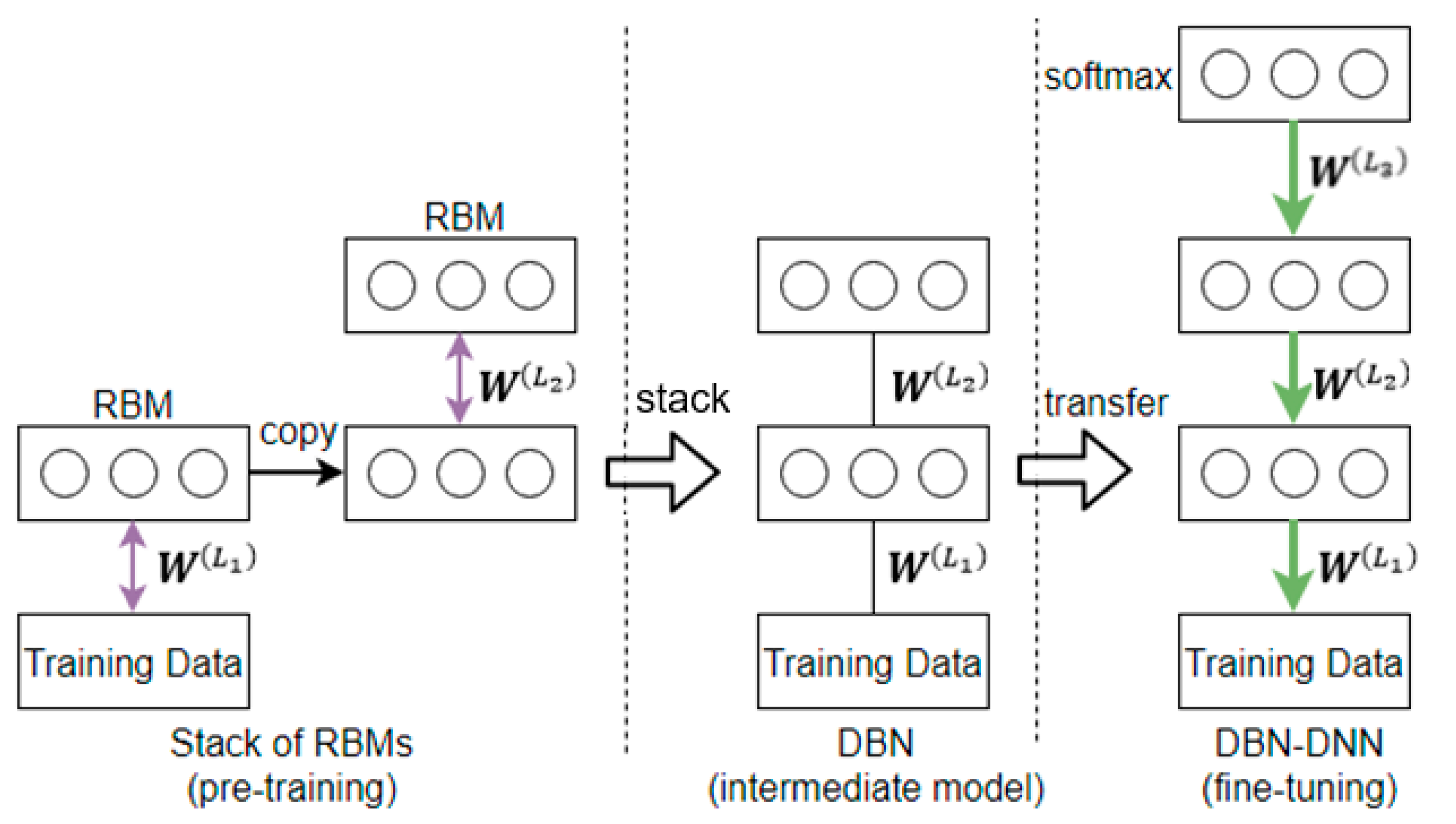
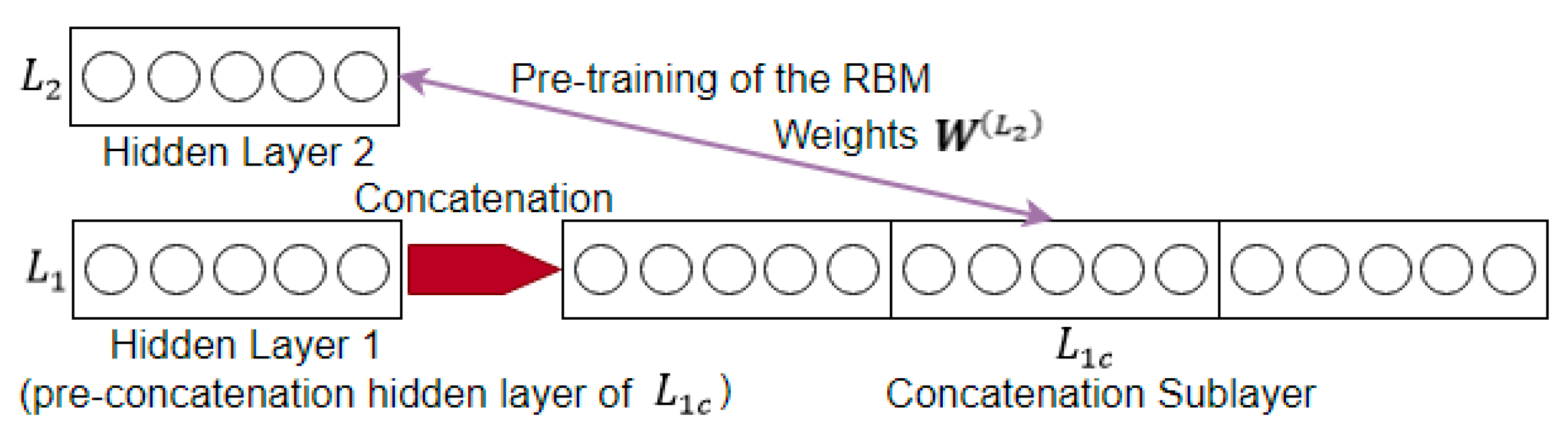
Pretraining
Backpropagation with Gradient-Routing
4. Data Experiments and Results
4.1. Spot Checking of the Eye State Data Set
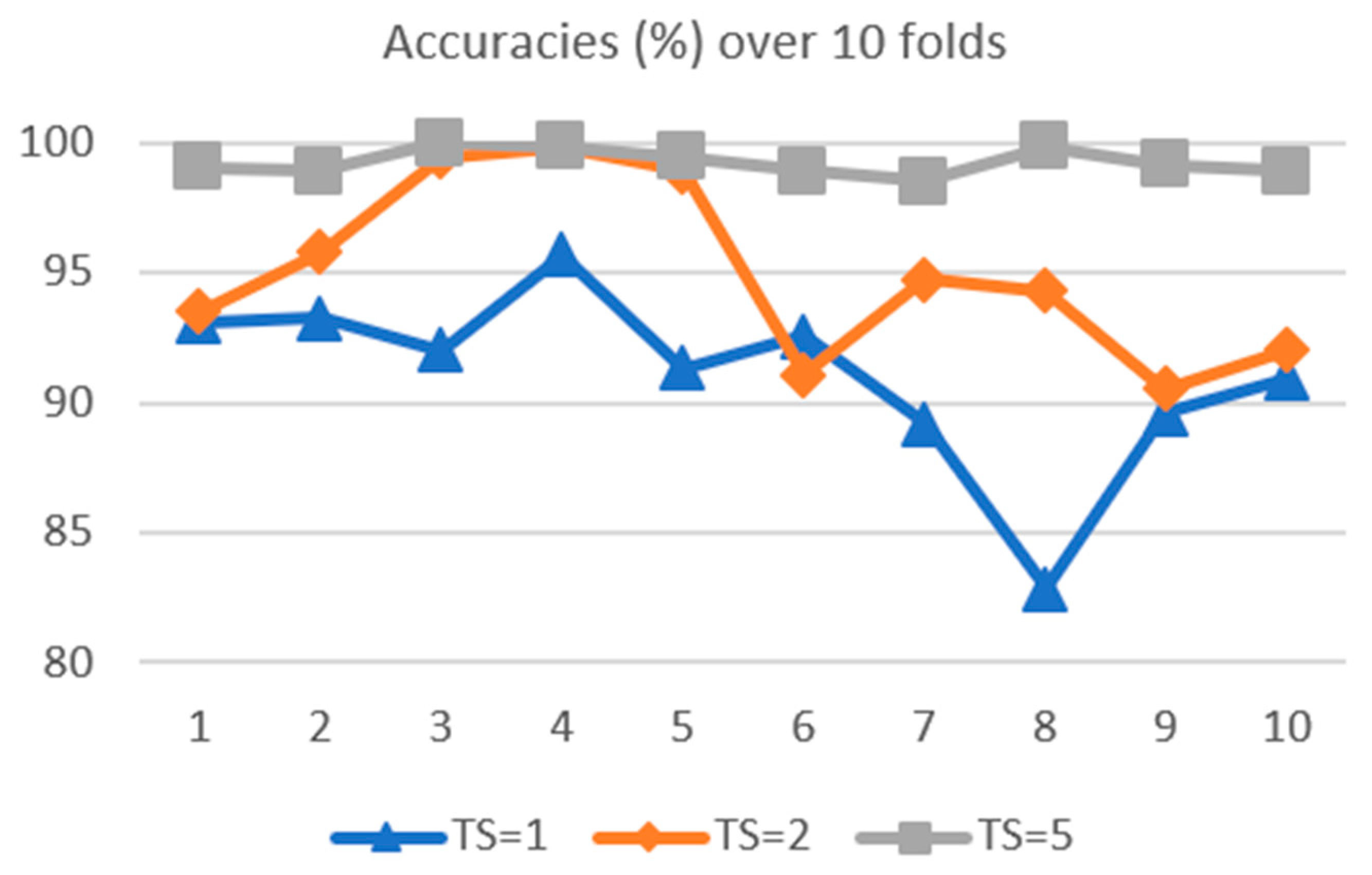
4.2. 10-Fold Validation of the Eye State Data Set with the Proposed Network, at TS = 1, 2, and 5
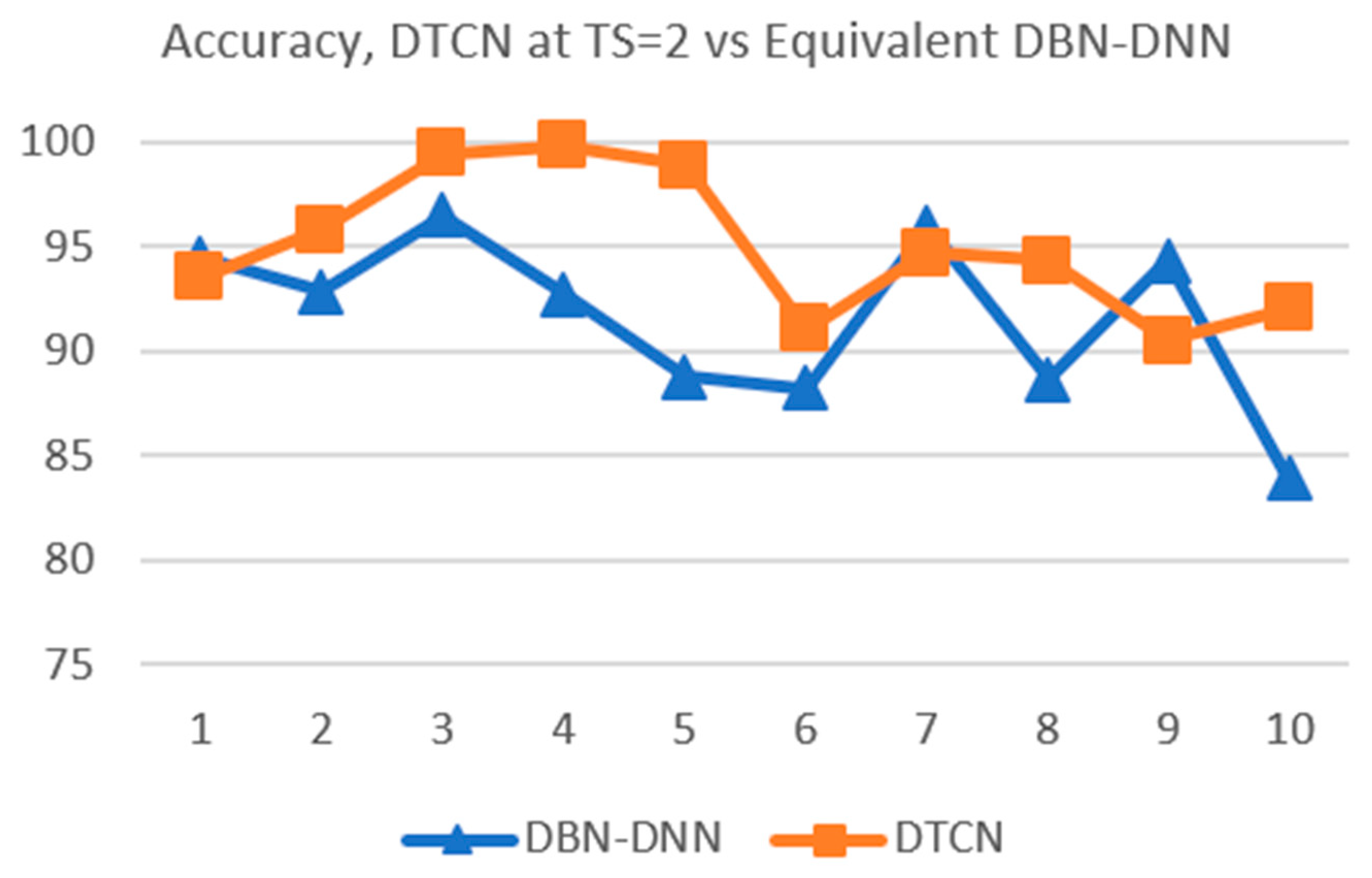
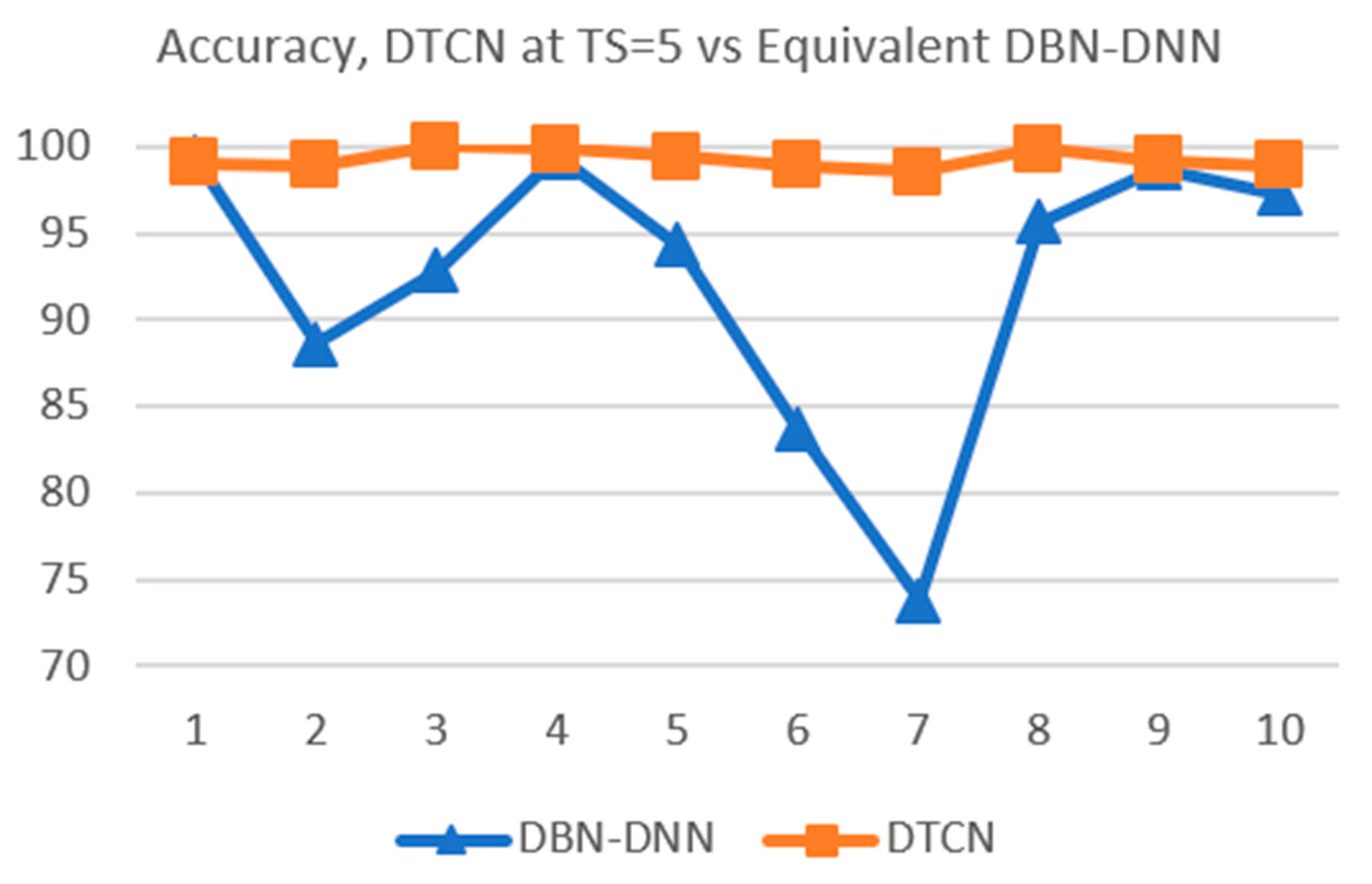
4.3. Comparing with Equivalent DBN-DNN
4.4. Human Activity Recognition
4.5. 10-Fold Validation of the HAR Data Set with the Proposed Network, at TS = 1, 2, and 5
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition Using Smartphones. In Proceedings of the ESANN 2013 Proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013; pp. 24–26. [Google Scholar]
- Andrzejak, R.G.; Lehnertz, K.; Mormann, F.; Rieke, C.; David, P.; Elger, C.E. Indications of nonlinear deterministic and finite-dimensional structures in time series of brain electrical activity: Dependence on recording region and brain state. Phys. Rev. E 2001, 64, 8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clifford, G.D.; Liu, C.; Moody, B.; Springer, D.; Silva, I.; Li, Q.; Mark, R.G. Classification of Normal/Abnormal Heart Sound Recordings: The PhysioNet/Computing in Cardiology Challenge 2016. Comput. Cardiol. 2016, 43, 3–6. [Google Scholar]
- Hu, B.; Gao, B.; Woo, W.L.; Ruan, L.; Jin, J.; Yang, Y.; Yu, Y. A Lightweight Spatial and Temporal Multi-Feature Fusion Network for Defect Detection. IEEE Trans. Image Process. 2021, 30, 472–486. [Google Scholar] [CrossRef] [PubMed]
- Woo, W.L.; Koh, B.H.D.; Gao, B.; Nwoye, E.O.; Wei, B.; Dlay, S.S. Early Warning of Health Condition and Visual Analytics for Multivariable Vital Signs. In Proceedings of the ACM International Conference Proceeding Series, Sanya, China, 24 April 2020. [Google Scholar]
- Gao, B.; Li, X.; Woo, W.L.; Tian, G.Y. Physics-Based Image Segmentation Using First Order Statistical Properties and Genetic Algorithm for Inductive Thermography Imaging. IEEE Trans. Image Process. 2018, 27, 2160–2175. [Google Scholar] [CrossRef] [PubMed]
- Woo, W.L. Future trends in I&M: Human-machine co-creation in the rise of AI. IEEE Instrum. Meas. Mag. 2020, 23, 71–73. [Google Scholar] [CrossRef]
- Längkvist, M.; Karlsson, L.; Loutfi, A. A review of unsupervised feature learning and deep learning for time-series modeling. Pattern Recognit. Lett. 2014, 42, 11–24. [Google Scholar] [CrossRef] [Green Version]
- Lütkepohl, H. New Introduction to Multiple Time Series Analysis; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Fairman, F. Introduction to dynamic systems: Theory, models and applications. Proc. IEEE 2008, 69, 1173. [Google Scholar] [CrossRef]
- Rabiner, L.; Juang, B. An introduction to hidden Markov models. IEEE ASSP Mag. 1986, 3, 4–16. [Google Scholar] [CrossRef]
- Gao, B.; Lu, P.; Woo, W.L.; Tian, G.; Zhu, Y.; Johnston, M. Variational Bayesian Subgroup Adaptive Sparse Component Extraction for Diagnostic Imaging System. IEEE Trans. Ind. Electron. 2018, 65, 8142–8152. [Google Scholar] [CrossRef]
- Lim, C.L.P.; Woo, W.L.; Dlay, S.S.; Gao, B.; Lim, C.L.P. Heartrate-Dependent Heartwave Biometric Identification With Thresholding-Based GMM–HMM Methodology. IEEE Trans. Ind. Informatics 2019, 15, 45–53. [Google Scholar] [CrossRef] [Green Version]
- Geler, Z.; Kurbalija, V.; Ivanović, M.; Radovanović, M. Weighted kNN and constrained elastic distances for time-series classification. Expert Syst. Appl. 2020, 162, 113829. [Google Scholar] [CrossRef]
- Keogh, E.; Ratanamahatana, C.A. Exact indexing of dynamic time warping. Knowl. Inf. Syst. 2005, 7, 358–386. [Google Scholar] [CrossRef]
- Soleimani, G.; Abessi, M. DLCSS: A new similarity measure for time series data mining. Eng. Appl. Artif. Intell. 2020, 92, 103664. [Google Scholar] [CrossRef]
- Jiang, W. Time series classification: Nearest neighbor versus deep learning models. SN Appl. Sci. 2020, 2, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Oregi, I.; Pérez, A.; Del Ser, J.; Lozano, J.A. On-line Elastic Similarity Measures for time series. Pattern Recognit. 2019, 88, 506–517. [Google Scholar] [CrossRef]
- Lines, J.; Bagnall, A. Time series classification with ensembles of elastic distance measures. Data Min. Knowl. Discov. 2015, 29, 565–592. [Google Scholar] [CrossRef]
- Bagnall, A.; Lines, J.; Hills, J.; Bostrom, A. Time-series classification with COTE: The collective of transformation-based ensembles. In Proceedings of the 2016 IEEE 32nd International Conference on Data Engineering, ICDE 2016, Helsinki, Finland, 16–20 May 2016. [Google Scholar]
- Tan, C.W.; Petitjean, F.; Webb, G.I. FastEE: Fast Ensembles of Elastic Distances for time series classification. Data Min. Knowl. Discov. 2020, 34, 231–272. [Google Scholar] [CrossRef]
- Wei, B.; Hamad, R.A.; Yang, L.; He, X.; Wang, H.; Gao, B.; Woo, W.L. A Deep-Learning-Driven Light-Weight Phishing Detection Sensor. Sensors 2019, 19, 4258. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Logenthiran, T.; Phan, V.T.; Woo, W.L. A novel smart energy theft system (SETS) for IoT-based smart home. IEEE Internet Things J. 2019, 6, 5531–5539. [Google Scholar] [CrossRef]
- Ruan, L.; Gao, B.; Wu, S.; Woo, W.L. DeftectNet: Joint loss structured deep adversarial network for thermography defect detecting system. Neurocomputing 2020, 417, 441–457. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Marius-Constantin, P.; Balas, V.E.; Perescu-Popescu, L.; Mastorakis, N. Multilayer perceptron and neural networks. In World Scientific and Engineering Academy and Society (WSEAS); Periodicals: Stevens Point, WI, USA, 2009. [Google Scholar]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- Zheng, Y.; Liu, Q.; Chen, E.; Ge, Y.; Zhao, J.L. Exploiting multi-channels deep convolutional neural networks for multivariate time series classification. Front. Comput. Sci. 2016, 10, 96–112. [Google Scholar] [CrossRef]
- Geng, Y.; Luo, X. Cost-sensitive convolutional neural networks for imbalanced time series classification. Intell. Data Anal. 2019, 23, 357–370. [Google Scholar] [CrossRef]
- Jaeger, H.; Haas, H. Harnessing Nonlinearity: Predicting Chaotic Systems and Saving Energy in Wireless Communication. Science 2004, 304, 78–80. [Google Scholar] [CrossRef] [Green Version]
- Munz, E.D. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift Sergey. Nervenheilkunde 2017, 37, 448–456. [Google Scholar]
- Liu, T.; Chen, M.; Zhou, M.; Du, S.S.; Zhou, E.; Zhao, T. Towards understanding the importance of shortcut connections in residual networks. arXiv 2019, arXiv:1909.04653. [Google Scholar]
- Ebrahimzadeh, Z.; Zheng, M.; Karakas, S.; Kleinberg, S. Deep learning for multi-scale changepoint detection in multivariate time series. arXiv 2019, arXiv:1905.06913. [Google Scholar]
- Koh, B.H.D.; Woo, W.L. Multi-View Temporal Ensemble for Classification of Non-Stationary Signals. IEEE Access 2019, 7, 32482–32491. [Google Scholar] [CrossRef]
- Lim, C.L.P.; Woo, W.L.; Dlay, S.S.; Wu, D.; Gao, B. Deep Multiview Heartwave Authentication. IEEE Trans. Ind. Informatics 2019, 15, 777–786. [Google Scholar] [CrossRef]
- Jin, J.; Gao, B.; Yang, S.; Zhao, B.; Luo, L.; Woo, W.L. Attention-Block Deep Learning Based Features Fusion in Wearable Social Sensor for Mental Wellbeing Evaluations. IEEE Access 2020, 8, 89258–89268. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.-A.; Petitjean, F. InceptionTime: Finding AlexNet for time series classification. Data Min. Knowl. Discov. 2020, 1–27. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1–9. [Google Scholar]
- Mhaskar, H.; Liao, Q.; Poggio, T. When and Why Are Deep Networks Better than Shallow Ones? In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-1); AAAI Press: San Francisco, CA, USA, 2017; pp. 2343–2349. [Google Scholar]
- Lin, H.W.; Tegmark, M.; Rolnick, D. Why Does Deep and Cheap Learning Work So Well? J. Stat. Phys. 2017, 168, 1223–1247. [Google Scholar] [CrossRef] [Green Version]
- Masters, D.; Luschi, C. Revisiting small batch training for deep neural networks. arXiv 2018, arXiv:1804.07612. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Manzagol, P.-A.; Vincent, P.; Bengio, S. Why Does Unsupervised Pre-training Help Deep Learning? J. Mach. Learn. Res. 2010, 11, 625–660. [Google Scholar]
- Chauvin, Y.; Rumelhart, D.E. Backpropagation: Theory, Architectures, and Applications; Psychology Press: East Sussex, UK, 1995. [Google Scholar]
- Keogh, E.; Chu, S.; Hart, D.; Pazzani, M. An online algorithm for segmenting time series. In Proceedings of the 2001 IEEE International Conference on Data Mining, San Jose, CA, USA, 29 November–2 December 2001. [Google Scholar]
- Waibel, A.; Hanazawa, T.; Hinton, G.; Shikano, K.; Lang, K. Phoneme recognition using time-delay neural networks. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 328–339. [Google Scholar] [CrossRef]
- Jin, C.; Schenkel, M.; Carlile, S. Neural system identification model of human sound localization. J. Acoust. Soc. Am. 2000, 108, 1215–1235. [Google Scholar] [CrossRef]
- Jane, Y.N.; Nehemiah, H.K.; Arputharaj, K. A Q-backpropagated time delay neural network for diagnosing severity of gait disturbances in Parkinson’s disease. J. Biomed. Informatics 2016, 60, 169–176. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Networks 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G.E.; Hinton, G.E. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 17–19 June 2013; Volume 28, pp. 1139–1147. [Google Scholar]
- AFischer, A.; Igel, C. An introduction to restricted Boltzmann machines. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy Layer-Wise Training of Deep Networks. In Advances in Neural Information Processing Systems 19; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Bengio, Y.; Delalleau, O. Justifying and Generalizing Contrastive Divergence. Neural Comput. 2009, 21, 1601–1621. [Google Scholar] [CrossRef]
- Cariani, P. Neural timing nets. Neural Netw. 2001, 14, 737–753. [Google Scholar] [CrossRef]
- Keskar, N.S.; Nocedal, J.; Tang, P.T.P.; Mudigere, D.; Smelyanskiy, M. On large-batch training for deep learning: Generalization gap and sharp minima. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017—Conference Track Proceedings, Toulon, France, 10 February 2017. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. ReLU. In Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011. [Google Scholar]
- EDua, D.; Karra Taniskidou, E. UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]; University of California, School of Information and Computer Science: Irvine, CA, USA, 2017. [Google Scholar]
- Oliver, R.; Suendermann, D. A First Step towards Eye State Prediction Using EEG. 2013. Available online: http://www.oeft.com/su/pdf/aihls2013.pdf (accessed on 11 December 2020).
- Kotsiantis, S.B. Supervised machine learning: A review of classification techniques. Informatica (Ljubljana) 2007, 31, 249–268. [Google Scholar]
- Geman, S.; Bienenstock, E.; Doursat, R. Neural Networks and the Bias/Variance Dilemma. Neural Comput. 1992, 4, 1–58. [Google Scholar] [CrossRef]
- Ayinde, B.O.; Inanc, T.; Zurada, J.M. On correlation of features extracted by deep neural networks. arXiv 2019, arXiv:1901.10900. [Google Scholar]
- Sontag, E.D. VC dimension of neural networks. NATO ASI Ser. F Comput. Syst. Sci. 1998, 168, 69–96. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Without Windowing | With Windowing | p-Value | |
|---|---|---|---|
| LR | 37.76% (19.38%) | 36.44% (15.87%) | 0.563 |
| KNN | 51.03% (13.33%) | 53.81% (16.29%) | 0.204 |
| CART | 50.67% (8.90%) | 52.05% (8.48%) | 0.516 |
| MLP | 50.38% (14.36%) | 53.78% (17.48%) | 0.453 |
| Without Windowing | With Windowing | p-Value | |
|---|---|---|---|
| LR | 64.10% (0.771%) | 62.20% (2.141%) | 0.058 |
| KNN | 96.35% (0.413%) | 95.80% (1.023%) | 0.148 |
| CART | 83.93% (1.034%) | 75.67% (2.597%) | 0.000 |
| MLP | 95.20% (0.503%) | 97.43% (1.117%) | 0.001 |
| No. of Nodes | |
|---|---|
| Input layer, | 224 |
| First hidden layer, | 20 |
| Second hidden layer, | 20 |
| Third hidden layer, | 20 |
| Softmax layer, | 2 |
| Time Steps | Fold No. | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| 93.11 | 93.24 | 92.03 | 95.68 | 91.35 | 92.57 | 89.19 | 82.84 | 89.59 | 90.95 | |
| 93.51 | 95.81 | 99.46 | 99.86 | 98.92 | 91.08 | 94.73 | 94.32 | 90.54 | 92.03 | |
| 99.05 | 98.92 | 100.0 | 99.86 | 99.46 | 98.92 | 98.51 | 99.86 | 99.19 | 98.92 | |
| Time Step | Mean | Std Dev |
|---|---|---|
| 91.05% | 3.44% | |
| 95.03% | 3.42% | |
| 99.27% | 0.50% |
| No. of Nodes in Equivalent DBN-DNN | ||
|---|---|---|
| Input layer | 224 | 224 |
| First hidden layer | 23 | 31 |
| Second hidden layer | 23 | 31 |
| Third hidden layer | 20 | 20 |
| Softmax layer | 2 | 2 |
| Total No. of Parameters | 6181 | 8565 |
| Fold No. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Eqv | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 94.46 | 92.84 | 96.49 | 92.70 | 88.78 | 88.24 | 95.95 | 88.65 | 94.32 | 83.92 | |
| 99.32 | 88.65 | 92.84 | 99.46 | 94.32 | 83.65 | 73.78 | 95.68 | 98.78 | 97.30 | |
| Mean | Std Dev | |
|---|---|---|
| Eqv | 91.64% | 4.06% |
| Eqv | 92.38% | 8.26% |
| Class | Description | |
|---|---|---|
| Basic Activity | 1 | Walking |
| 2 | Walking Upstairs | |
| 3 | Walking Downstairs | |
| 4 | Sitting | |
| 5 | Standing | |
| 6 | Laying | |
| Transitional Activity | 7 | Stand to Sit |
| 8 | Sit to Stand | |
| 9 | Sit to Lie | |
| 10 | Lie to Sit | |
| 11 | Stand to Lie | |
| 12 | Lie to Stand |
| Algorithm | Accuracy (in Percentage), 10-Fold Validated |
|---|---|
| logistic regression | 64.822 (1.309) |
| k-nearest neighbor | 77.009 (1.035) |
| CART | 72.836 (1.465) |
| MLP | 87.868 (0.870) |
| ensemble | 85.29 (0.95) |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | Fold 6 | Fold 7 | Fold 8 | Fold 9 | Fold 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 97.78 | 97.64 | 97.88 | 98.16 | 97.5 | 97.59 | 96.98 | 96.51 | 97.36 | 97.08 | |
| 99.83 | 99.96 | 99.91 | 99.91 | 99.96 | 99.83 | 99.91 | 99.83 | 99.87 | 99.87 | |
| 98.78 | 98.64 | 98.88 | 98.16 | 98.5 | 98.59 | 97.98 | 98.51 | 98.36 | 98.08 |
| Time Step | Mean | Std Dev |
|---|---|---|
| TS = 1 | 97.45% | 0.48% |
| TS = 2 | 99.89% | 0.05% |
| TS = 5 | 98.45% | 0.30% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koh, B.H.D.; Lim, C.L.P.; Rahimi, H.; Woo, W.L.; Gao, B. Deep Temporal Convolution Network for Time Series Classification. Sensors 2021, 21, 603. https://doi.org/10.3390/s21020603
Koh BHD, Lim CLP, Rahimi H, Woo WL, Gao B. Deep Temporal Convolution Network for Time Series Classification. Sensors. 2021; 21(2):603. https://doi.org/10.3390/s21020603
Chicago/Turabian StyleKoh, Bee Hock David, Chin Leng Peter Lim, Hasnae Rahimi, Wai Lok Woo, and Bin Gao. 2021. "Deep Temporal Convolution Network for Time Series Classification" Sensors 21, no. 2: 603. https://doi.org/10.3390/s21020603
APA StyleKoh, B. H. D., Lim, C. L. P., Rahimi, H., Woo, W. L., & Gao, B. (2021). Deep Temporal Convolution Network for Time Series Classification. Sensors, 21(2), 603. https://doi.org/10.3390/s21020603