
An Effective Conversion of Visemes to Words for High-Performance Automatic Lipreading




Abstract
:1. Introduction
- Fewer classes are needed in comparison to the use of ASCII characters, and words which can reduce computational bottleneck;
- Pre-trained lexicons are not required. Hence, in theory, a viseme-based lipreading system can be used to classify words that may have not been presented in the training phase. This is because visemes can be classified as images where deciphered visemes can then be matched to all the possible words spoken;
- They can be applied to different languages because many different languages share the same visemes.
2. Literature Review
2.1. Implementation of a Language Model
2.2. Comparison of Viseme-to-Word Conversion Models
2.3. Syntactic and Semantic Disambiguation
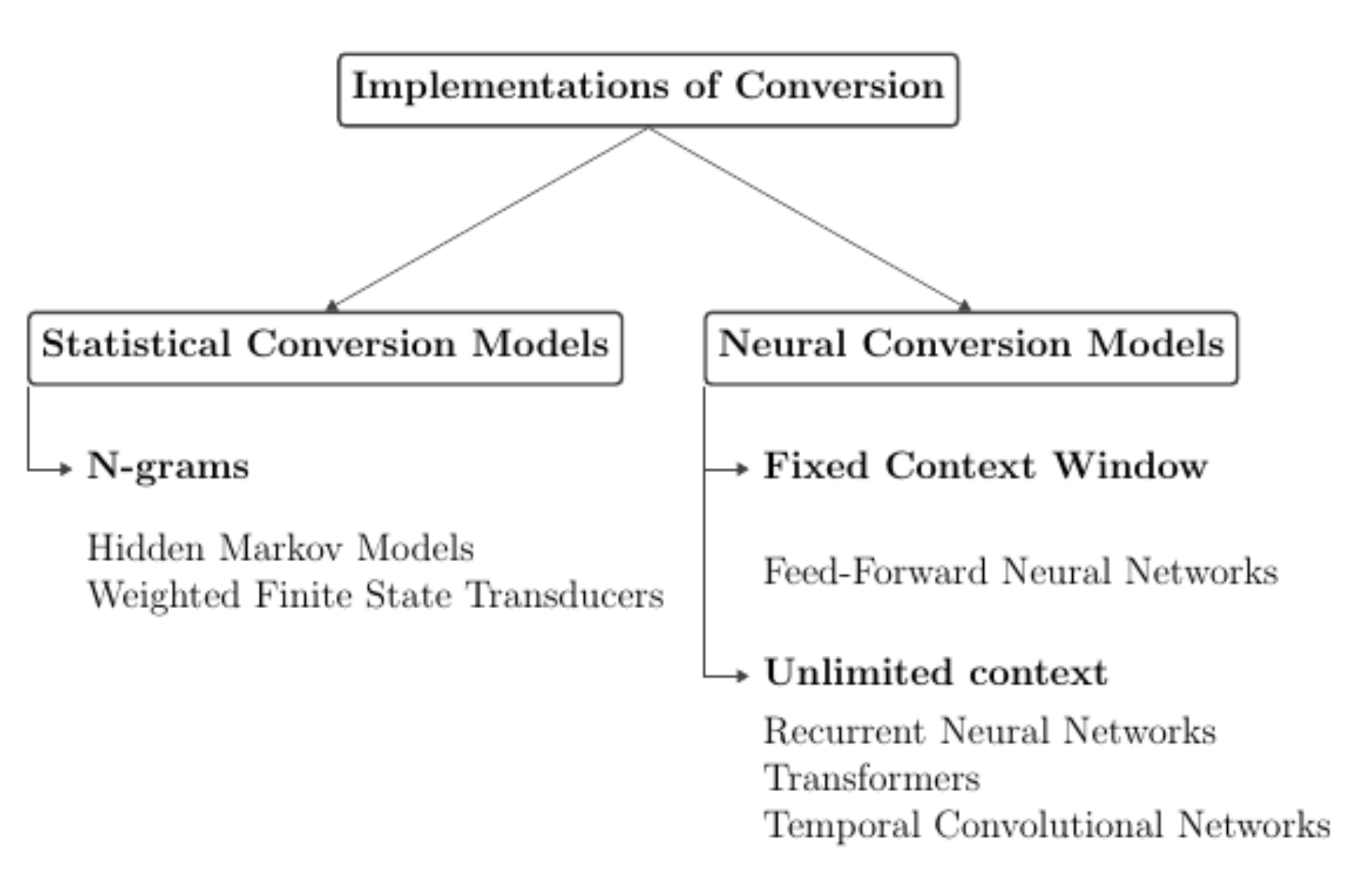
3. Methodology
- An Attention based sequence model using GRUs;
- A GPT-based iterator that uses perplexity scores;
- A Feed-Forward Neural Network;
- A Hidden Markov Model.
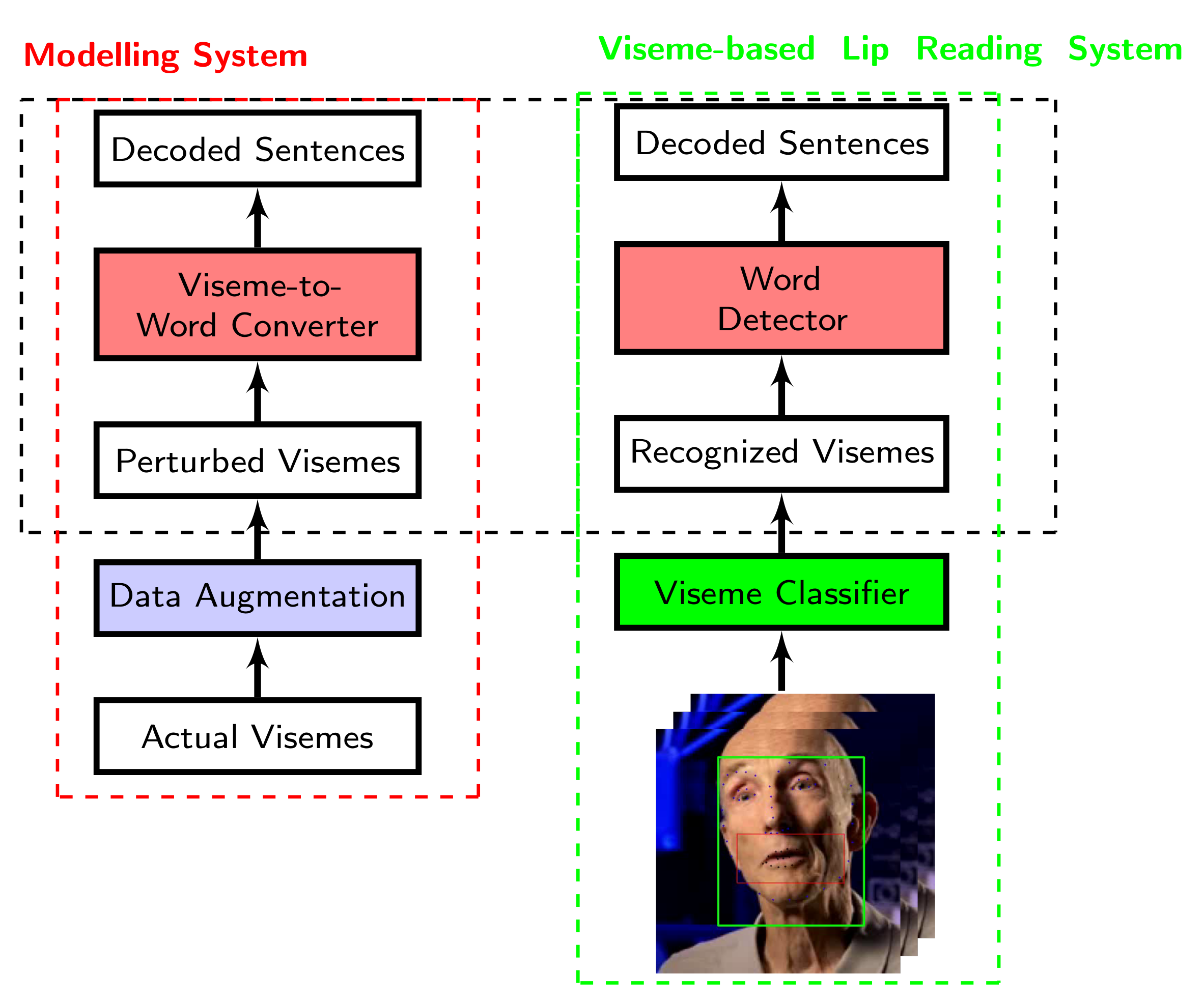
- Visemes with 100% accuracy where the identity of spoken visemes are known;
- The outputs of the viseme classifier reported in [1];
- Perturbed visemes with added noise whereby the errancy is varied.
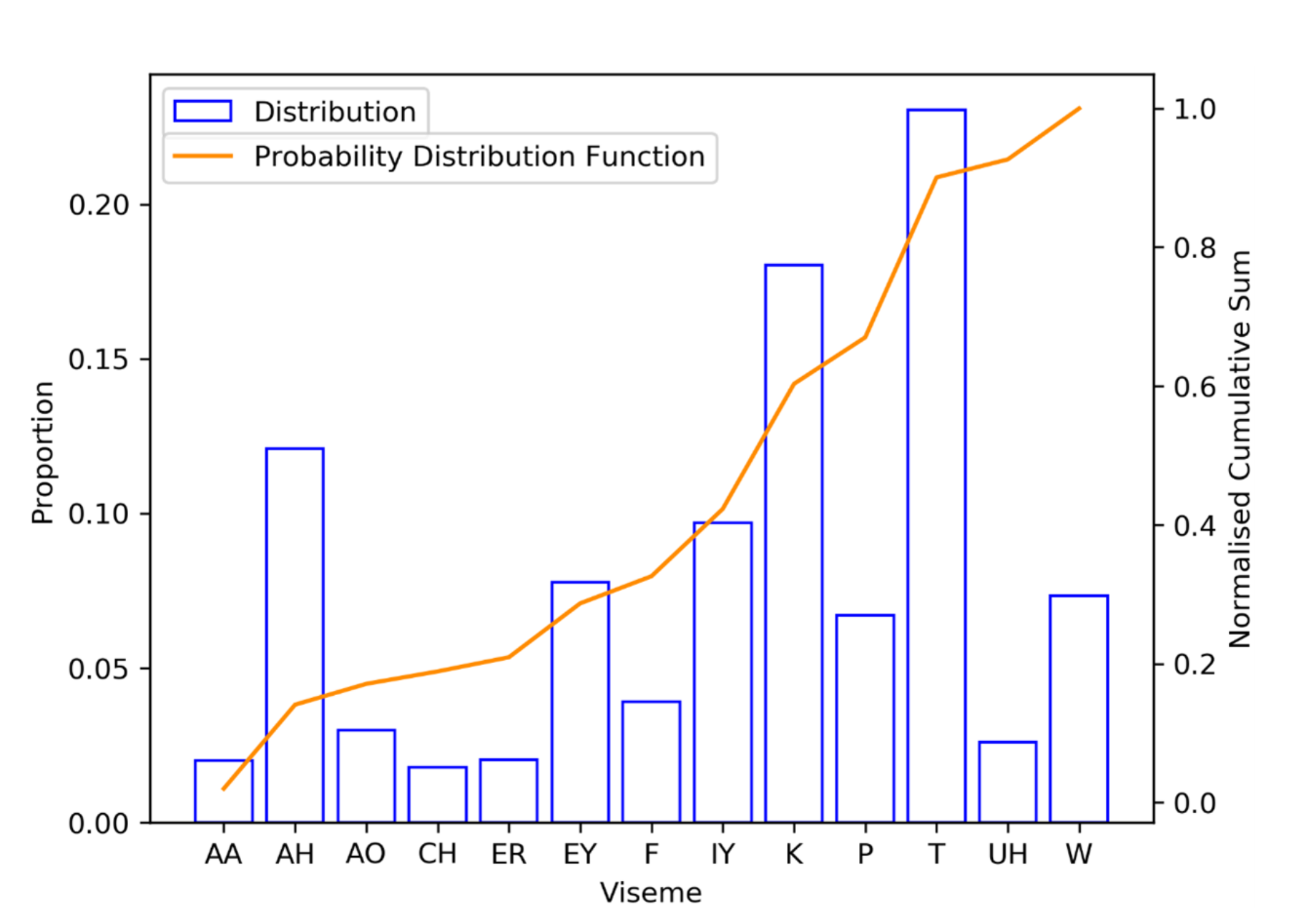
3.1. Data
3.2. Viseme Classifier
3.3. Viseme-to-Word Converters
3.3.1. Hidden Markov Model
3.3.2. Feed-Forward Neural Network
3.3.3. GPT-Based Iterator
| Algorithm 1: Rules for Sentence Prediction |
| Require: Viseme Clusters V, Beam With B, Coca Rankings C, Word Lexicon mapping L, Predicted Output O, Perplexity scores for sentences |
| if and then |
| Select 1 Word Match |
| if and then |
| Select Highest ranked word according to COCA |
| if then |
| Exhaustively combine words matching to |
| Select Combinations with lowest B Perplexity scores for |
| for For , , do |
| Perform word matches for |
| Combine sentences from with words from |
| Select Combinations with lowest B Perplexity scores |
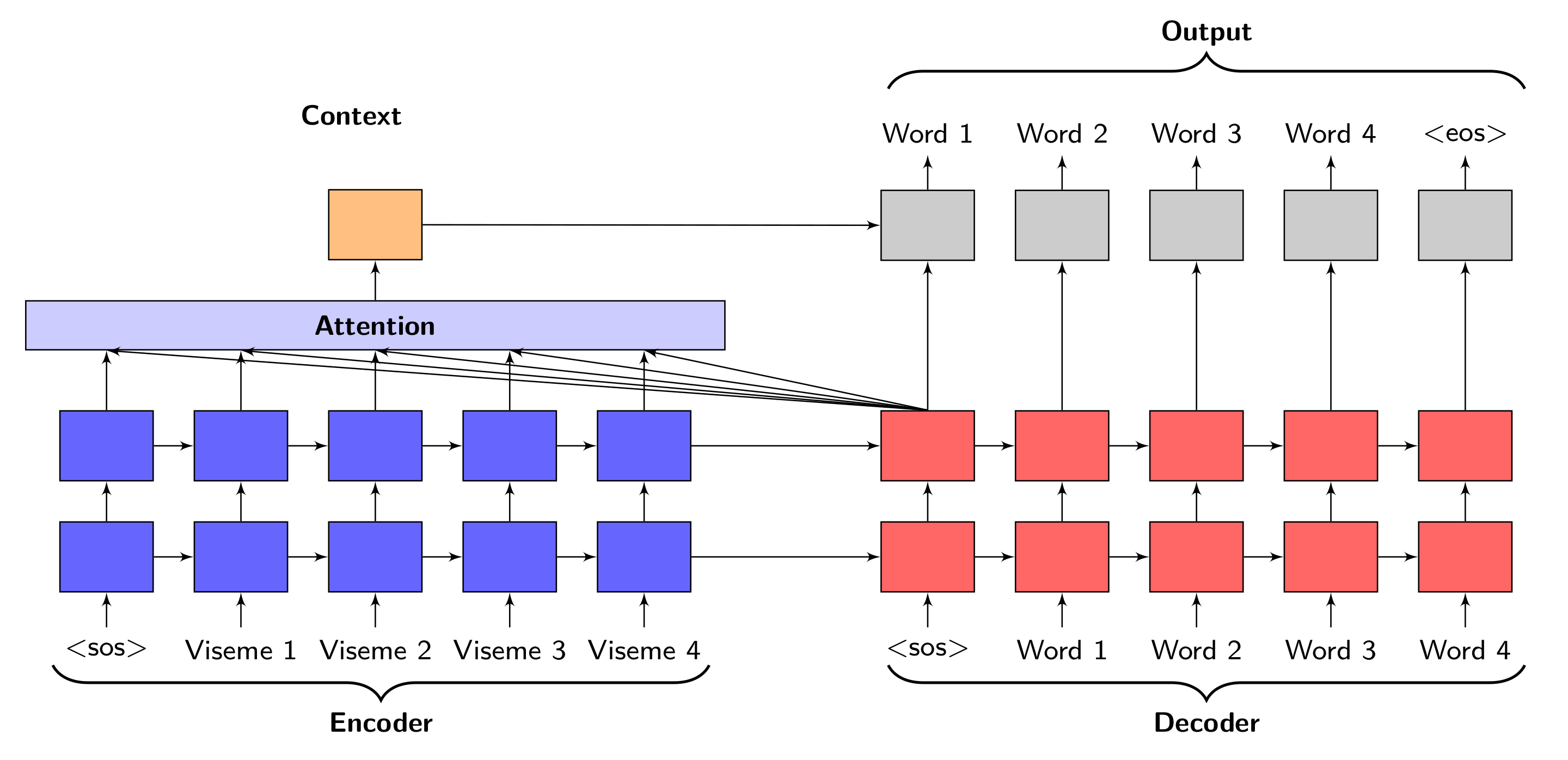
3.3.4. Attention-GRU
3.4. Data Noisification
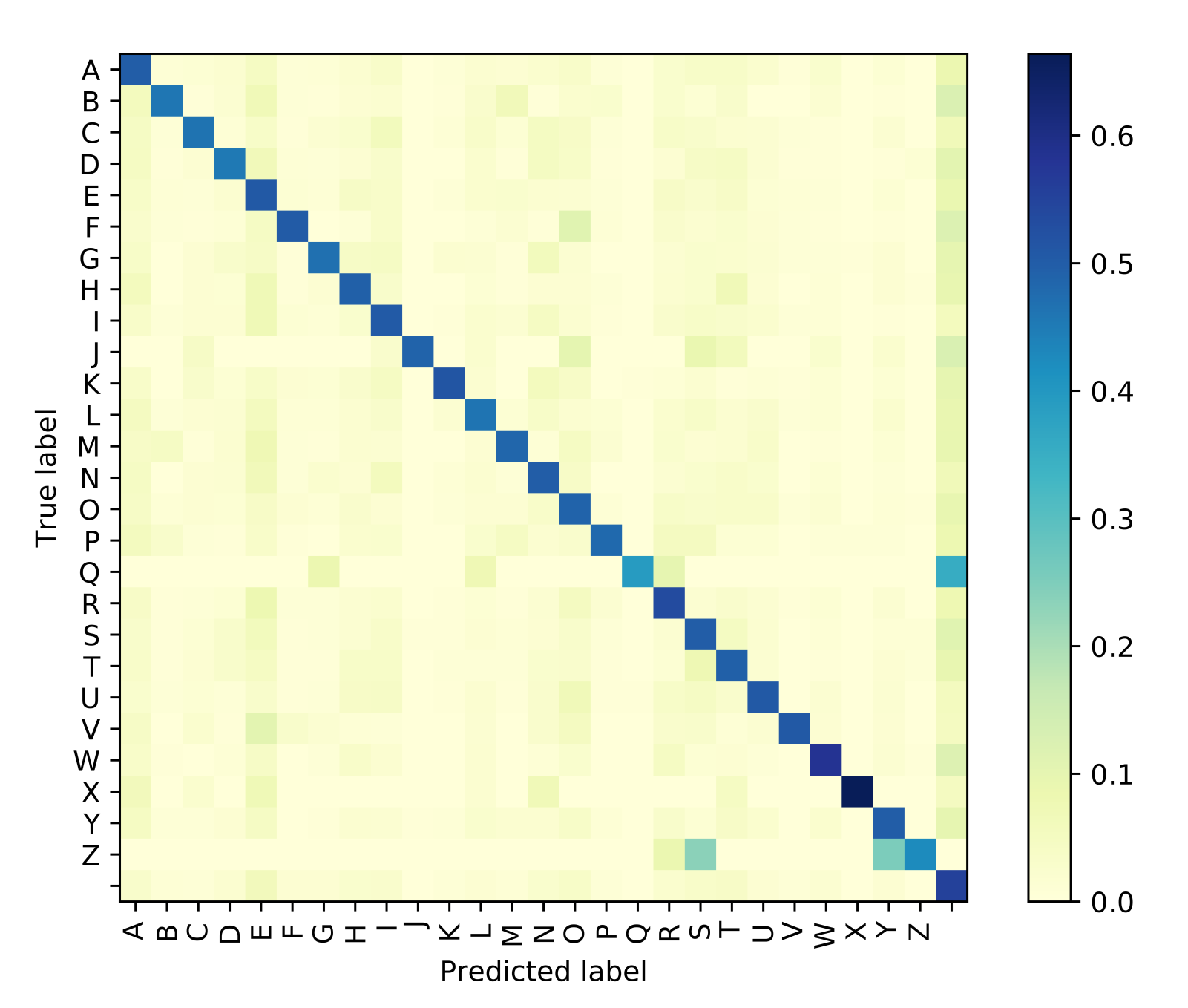
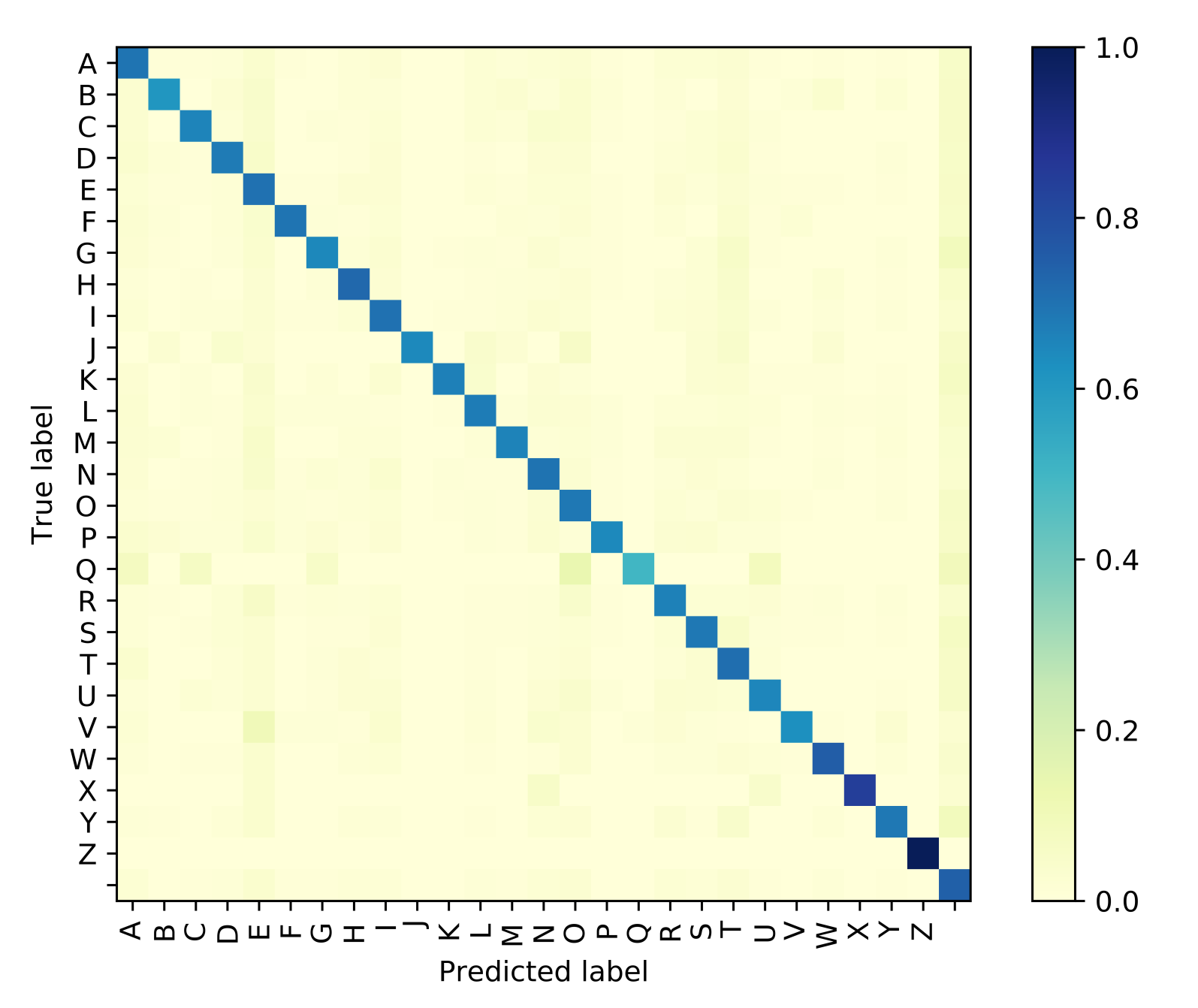
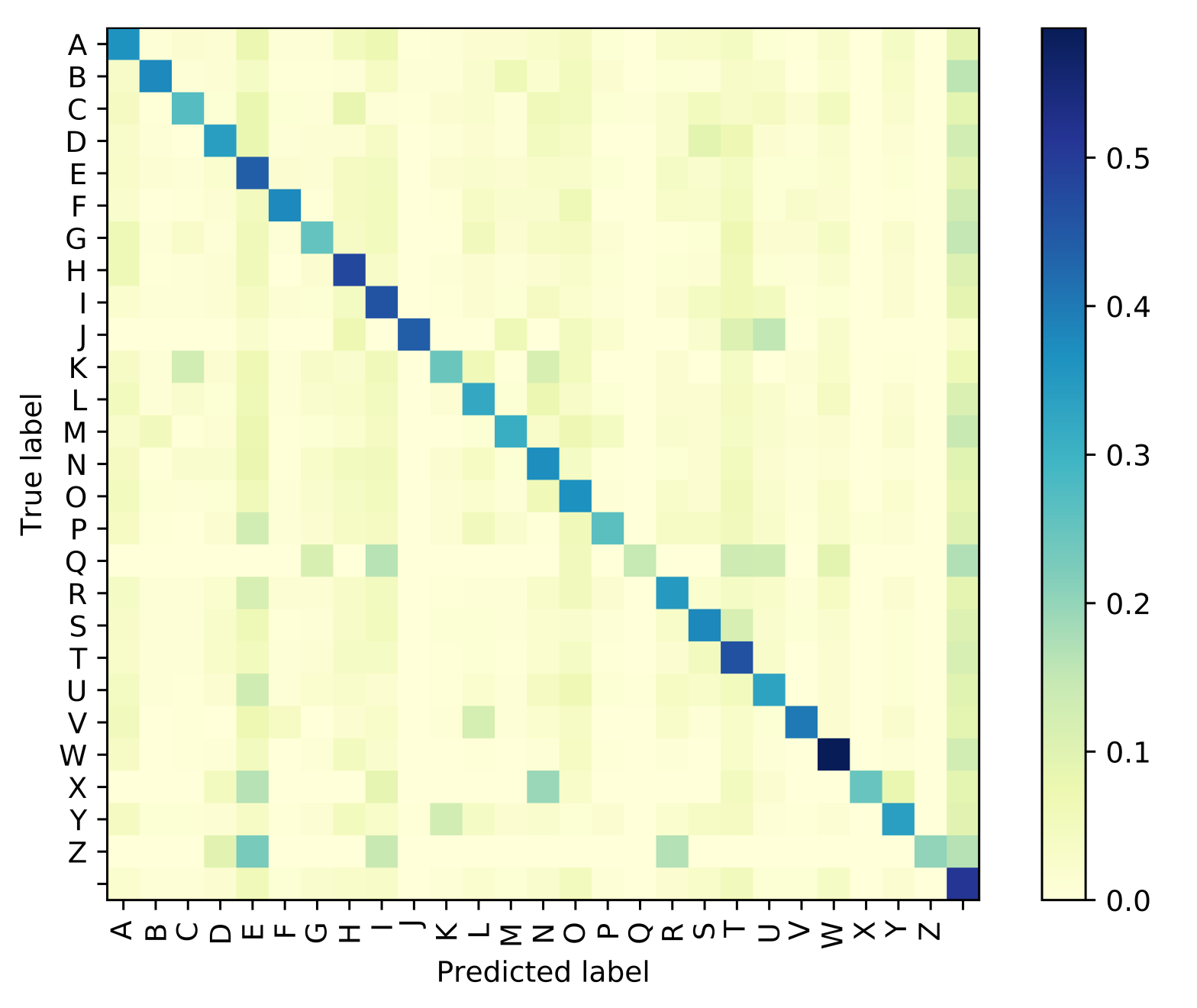
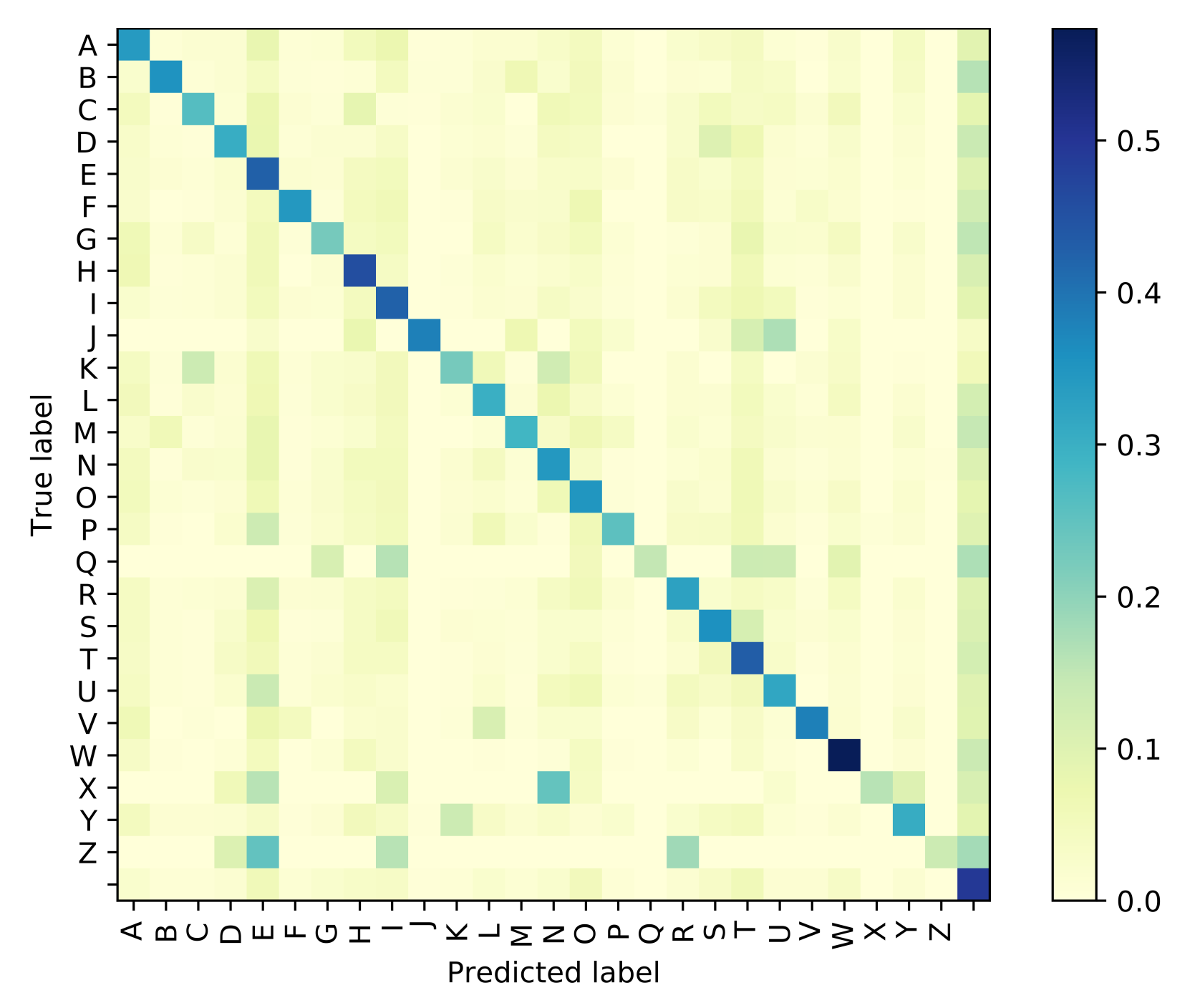
3.5. Systems Performance Measures
4. Experiment and Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fenghour, S.; Chen, D.; Guo, K.; Xiao, P. Lip Reading Sentences Using Deep Learning with Only Visual Cues. IEEE Access 2020, 8, 215516–215530. [Google Scholar] [CrossRef]
- Howell, D.; Cox, S.; Theobald, B. Visual Units and Confusion Modelling for Automatic Lip-reading. Image Vis. Comput. 2016, 51. [Google Scholar] [CrossRef] [Green Version]
- Thangthai, K.; Bear, H.L.; Harvey, R. Comparing phonemes and visemes with DNN-based lipreading. In Proceedings of the 28th British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar]
- Bear, H.L.; Harvey, R. Decoding visemes: Improving machine lip-reading. In Proceedings of the International Conference on Acoustics. Speech and Signal Processing, Shanghai, China, 20–25 March 2016. [Google Scholar]
- Lan, Y.; Harvey, R.; Theobald, B.J. Insights into machine lip reading. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, New York, NY, USA, 11–14 April 1988. [Google Scholar]
- Almajai, I.; Cox, S.; Harvey, R.; Lan, Y. Improved speaker independent lip reading using speaker adaptive training and deep neural networks. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing, Shanghai, China, 20–25 March 2016. [Google Scholar]
- Ma, P.; Petridis, S.; Pantic, M. End-to-End Audio-visual Speech Recognition with Conformers. In Proceedings of the ICASSP, Toronto, ON, Canada, 6–11 June 2021. [Google Scholar]
- Botev, A.; Zheng, B.; Barber, D. Complementary sum sampling for likelihood approximation in large scale classification. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Firth, J.R. A Synopsis of Linguistic Theory. In Studies in Linguistic Analysis; Special Volume of the Philological Society; Blackwell: Oxford, UK, 1957; pp. 1–31. [Google Scholar]
- Mohri, M.; Pereira, F.; Riley, M. Weighted finite-state transducers in speech recognition. Comput. Speech Lang. 2002, 16, 69–88. [Google Scholar] [CrossRef] [Green Version]
- Goldschen, A.J.; Garcia, O.N.; Petajan, E.D. Continuous automatic speech recognition by li-preading. In Motion-Based Recognition; Springer: Dordrecht, The Netherlands, 1997. [Google Scholar]
- Kun, J.; Xu, J.; He, B. A Survey on Neural Network Language Models. arXiv 2019, arXiv:1906.03591. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mac. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Lipton, Z. A Critical Review of Recurrent Neural Networks for Sequence Learning. arXiv 2015, arXiv:1506.00019. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modelling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Harte, N.; Gillen, E. TCD-TIMIT: An audio-visual corpus of continuous speech. IEEE Trans. Multimed. 2015, 17, 603–615. [Google Scholar] [CrossRef]
- Lan, Y.; Theobald, B.-J.; Harvey, R.; Ong, E.-J.; Bowden, R. Improving visual features for lip-reading. In Proceedings of the International Conference on Auditory-Visual Speech Processing, Stockholm, Sweden, 25–26 August 2017. [Google Scholar]
- Howell, D.L. Confusion Modelling for Lip-Reading. Ph.D. Thesis, University of East Anglia, Norwich, UK, 2015. [Google Scholar]
- JChung, S.; Zisserman, A.; Senior, A.; Vinyals, O. Lip Reading Sentences in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, International Conference on Automatic Face and Gesture Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Fenghour, S.; Chen, D.; Xiao, P. Decoder-Encoder LSTM for Lip Reading. In Proceedings of the Conference: 8th International Conference on Software and Information Engineering (ICSIE), Cairo, Egypt, 9–12 April 2019. [Google Scholar]
- Shillingford, B.; Assael, Y.; Hoffman, M.; Paine, T.; Hughes, C.; Prabhu, U.; Liao, H.; Sak, H.; Rao, K.; Bennett, L.; et al. Large-Scale Visual Speech Recognition. arXiv 2018, arXiv:1807.05162. [Google Scholar]
- Thangthai, K.; Harvey, R. Improving Computer Lipreading via DNN Sequence Discriminative Training Techniques. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017. [Google Scholar] [CrossRef] [Green Version]
- Thangthai, K.; Harvey, R.; Cox, S.; Theobald, B.J. Improving Lip-reading Performance for Robust Audiovisual Speech Recognition using DNNs. In Proceedings of the 1st Joint Conference on Facial Analysis, Animation, and Auditory-Visual Speech Processing, Vienna, Austria, 11–13 September 2015. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 1 November 2021).
- Sterpu, G.; Harte, N. Towards Lipreading Sentences with Active Appearance Models. arXiv 2018, arXiv:1805.11688. [Google Scholar]
- Peymanfard, J.; Mohammadi, M.R.; Zeinali, H.; Mozayani, N. Lip reading using ex-ternal viseme decoding. arXiv 2021, arXiv:2104.04784. [Google Scholar]
- Lamel, L.; Kassel, R.H.; Seneff, S. Speech database development: Design and analysis of the acoustic-phonetic corpus. In Proceedings of the DARPA Speech Recognition Workshop, Philadelphia, PA, USA, 21–23 February 1989. [Google Scholar]
- Zhang, B.; Xiong, D.; Su, J. A GRU-Gated Attention Model for Neural Machine Translation. IEEE Trans. Neural Netw. Learn. Syst. 2017, 31, 4688–4698. [Google Scholar] [CrossRef] [PubMed]
- Schwenk, H. Continuous space language models. Comput. Speech Lang. 2007, 21, 492–518. [Google Scholar] [CrossRef]
- Kuncoro, A.; Dyer, C.; Hale, J.; Yogatama, D.; Clark, S.; Blunsom, P. LSTMs Can Learn Syntax-Sensitive Dependencies Well, But Modeling Structure Makes Them Better. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018. [Google Scholar] [CrossRef] [Green Version]
- Linzen, T.; Dupoux, E.; Goldberg, Y. Assessing the Ability of LSTMs to Learn Syn-tax-Sensitive Dependencies. Trans. Assoc. Comput. Linguist. 2016, 4, 521–535. [Google Scholar] [CrossRef]
- Handler, A.; Denny, M.; Wallach, H.; O’Connor, B. Bag of What? Simple Noun Phrase Ex-traction for Text Analysis. In Proceedings of the First Workshop on NLP and Computational Social Science, Austin, TX, USA, 5 November 2016; pp. 114–124. [Google Scholar] [CrossRef]
- Kondrak, G. A new algorithm for the alignment of phonetic sequences. In Proceedings of the 1st North American chapter of the Association for Computational Linguistics Conference, Seattle, WA, USA, 29 April–4 May 2000. [Google Scholar]
- Afouras, T.; Chung, J.S.; Zisserman, A. LRS3-TED: A large-scale dataset for visual speech recognition. arXiv 2018, arXiv:1809.00496. [Google Scholar]
- Treiman, R.; Kessler, B.; Bick, S. Context sensitivity in the spelling of English vowels. J. Mem. Lang. 2001, 47, 448–468. [Google Scholar] [CrossRef]
- Lee, S.; Yook, D. Audio-to-Visual Conversion Using Hidden Markov Models. In Proceedings of the 7th Pacific Rim International Conference on Artificial Intelligence: Trends in Artificial Intelligence, Tokyo, Japan, 18–22 August 2002. [Google Scholar]
- Jeffers, J.; Barley, M. Speechreading (Lipreading); Charles C Thomas Publisher Limited: Sprinfield, IL, USA, 1971. [Google Scholar]
- Neti, C.; Neti, C.; Potamianos, G.; Luettin, J.; Matthews, I.; Glotin, H.; Vergyri, D.; Sison, J.; Mashari, A. Audio Visual Speech Recognition; Technical Report IDIAP: Martigny, Switzerland, 2000. [Google Scholar]
- Hazen, T.J.; Saenko, K.; La, C.; Glass, J.R. A segment based audio-visual speech recognizer: Data collection, development, and initial experiments. In Proceedings of the 6th International Conference on Multimodal Interfaces, New York, NY, USA, 14–15 October 2004. [Google Scholar]
- Bozkurt, E.; Erdem, C.E.; Erzin, E.; Erdem, T.; Ozkan, M. Comparison of phoneme and viseme based acoustic units for speech driven realistic lip animation. In Proceedings of the 3DTV Conference, Kos, Greece, 7–9 May 2007. [Google Scholar]
- Fisher, C. Confusions among visually perceived consonants. J. Speech Lang. Hear. Res. 1968, 11, 796–804. [Google Scholar] [CrossRef] [PubMed]
- DeLand, F. The Story of Lip-Reading, Its Genesis and Development; The Volta Bureau: Georgetown, WA, USA, 1931. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Po-losukhin, I. Attention Is All You Need. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Vogel, S.; Ney, H.; Tillmann, C. HMM-Based Word Alignment in Statistical Translation. In Proceedings of the COLING 1996 Volume 2: The 16th International Conference on Computational Linguistics, Copenhagen, Denmark, 5–9 August 1996; pp. 836–841. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Afouras, T.; Chung, J.S.; Zisserman, A. Deep lip reading: A comparison of models and an online application. arXiv 2018, arXiv:1806.06053. [Google Scholar]
- Wei, J.; Zou, K. EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Ataman, D.; Firat, O.; Gangi, M.; Federico, M.; Birch, A. On the Importance of Word Boundaries in Character-level Neural Machine Translation. In Proceedings of the 3rd Workshop on Neural Generation and Translation(WNGT), Hong Kong, China, 4 November 2019; pp. 187–193. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the ICML, Montreal, QC, Canada, 14–18 June 2009; pp. 41–48. [Google Scholar]
- Spitkovsky, V.I.; Alshawi, H.; Jurafsky, D. From baby steps to leapfrog: How less is more in unsupervised dependency parsing. In Proceedings of the NAACL, Los Angeles, CA, USA, 1–6 June 2010; pp. 751–759. [Google Scholar]
- Tsvetkov, Y.; Faruqui, M.; Ling, W.; Macwhinney, B.; Dyer, C. Learning the Curriculum with Bayesian Optimization for Task-Specific Word Representation Learning. arXiv 2016, arXiv:1605.03852. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Viseme Format | 1st Stage Feature Extractor | First Stage Classifier | Second Stage Classifier | Dataset | Unit Classif. Acc. (%) | Word Classif. Acc. (%) |
|---|---|---|---|---|---|---|---|
| Lan and Harvey [5] | Bigram | LDA + PCA | HMM-GMM | HMM | LiLiR | 45.67 | 14.08 |
| Almajai [6] | Bigram | LDA HMM | HMM | HMM | LiLiR | - | 17.74 |
| Almajai [6] | Bigram | LDA+MLLT | HMM | HMM | LiLiR | - | 22.82 |
| Almajai [6] | Bigram | LDA+MLLT+SAT | HMM | HMM | LiLiR | - | 37.71 |
| Almajai [6] | Bigram | LDA+MLLT+SAT | HMM | Feed-forward | LiLiR | - | 47.75 |
| Bear and Harvey [4] | Bigram | Active Appearance Model | HMM | HMM | LiLiR | 8.51 | 4.38 |
| Thangthai [3] | Bigram | Discrete Cosine Transform | CD-GMM + SAT | WFST | TCD-TIMIT | 42.48 | 10.47 |
| Thangthai [3] | Bigram | Discrete Cosine Transform | CD-DNN | WFST | TCD-TIMIT | 38.00 | 9.17 |
| Thangthai [3] | Bigram | Eigenlips | CD-GMM + SAT | WFST | TCD-TIMIT | 44.61 | 12.15 |
| Thangthai [3] | Bigram | Eigenlips | CD-DNN | WFST | TCD-TIMIT | 44.60 | 19.15 |
| Howell [2] | Bigram | Active Appearance Model | CD-HMM | HMM | RM-3000 | 52.31 | 43.47 |
| Fenghour [20] | Cluster | N/A | N/A | Encoder-Decoder LSTM | LRS2 | N/A | 72.20 |
| Fenghour [1] | Cluster | ResNet CNN | Linear Transformer | GPT-Transformer based Iterator | LRS2 | 95.40 | 64.60 |
| Visemes | <sos> | ’T’ | ’AH’ | <space> | ’T’ | ’ER’ | ’P’ | ’W’ | ’AH’ | ’T’ | <space> | ’W’ | ’AA’ | ’T’ | <eos> |
| Words | <sos> | “THE” | “SURPRISE” | “WAS” | <eos> | ||||||||||
| [pad], AA, AH, AO, CH, ER, EY, F, IY, K, P, T, UH, W, <sos>, <eos>, [space] |
| Converter | Fold No. | CER (%) | WER (%) | SAR (%) | WAR (%) |
|---|---|---|---|---|---|
| GPT-based Iterator | Fold 1 | 10.7 | 18.0 | 56.8 | 82.0 |
| GPT-based Iterator | Fold 2 | 11.4 | 19.5 | 55.1 | 80.5 |
| GPT-based Iterator | Fold 3 | 11.2 | 19.1 | 54.8 | 80.9 |
| GPT-based Iterator | Fold 4 | 12.0 | 20.3 | 54.2 | 79.7 |
| GPT-based Iterator | Fold 5 | 11.0 | 18.6 | 54.9 | 81.4 |
| GPT-based Iterator | Average | 11.3 ± 0.5 | 19.1 ± 0.9 | 55.2 ± 1.0 | 80.9 ± 0.9 |
| Attention-based GRU | Fold 1 | 6.2 | 8.8 | 74.9 | 91.2 |
| Attention-based GRU | Fold 2 | 6.9 | 9.7 | 74.2 | 90.3 |
| Attention-based GRU | Fold 3 | 7.5 | 10.6 | 73.4 | 89.4 |
| Attention-based GRU | Fold 4 | 7.4 | 10.4 | 73.4 | 89.6 |
| Attention-based GRU | Fold 5 | 7.1 | 10.2 | 73.8 | 89.8 |
| Attention-based GRU | Average | 7.0 ± 0.5 | 9.9 ± 0.7 | 73.9 ± 0.6 | 90.1 ± 0.7 |
| Feed-Forward Network | Fold 1 | 31.7 | 42.7 | 9.4 | 57.3 |
| Feed-Forward Network | Fold 2 | 32.4 | 43.4 | 8.6 | 56.6 |
| Feed-Forward Network | Fold 3 | 33.0 | 44.1 | 7.8 | 55.9 |
| Feed-Forward Network | Fold 4 | 32.8 | 43.9 | 8.1 | 56.1 |
| Feed-Forward Network | Fold 5 | 32.6 | 43.5 | 8.1 | 56.5 |
| Feed-Forward Network | Average | 32.5 ± 0.5 | 43.5 ± 0.5 | 8.4 ± 0.6 | 56.5 ± 0.5 |
| Hidden Markov Model | Fold 1 | 34.0 | 44.5 | 9.0 | 55.5 |
| Hidden Markov Model | Fold 2 | 35.3 | 46.2 | 7.8 | 53.8 |
| Hidden Markov Model | Fold 3 | 36.1 | 49.8 | 6.5 | 50.2 |
| Hidden Markov Model | Fold 4 | 35.8 | 48.0 | 8.0 | 52.0 |
| Hidden Markov Model | Fold 5 | 35.2 | 45.9 | 7.4 | 54.1 |
| Hidden Markov Model | Average | 35.3 ± 0.8 | 46.9 ± 2.1 | 7.7 ± 0.9 | 53.1 ± 2.1 |
| Converter | Fold No. | CER (%) | WER (%) | SAR (%) | WAR (%) |
|---|---|---|---|---|---|
| GPT-based Iterator | Fold 1 | 18.8 | 31.7 | 36.2 | 68.3 |
| GPT-based Iterator | Fold 2 | 19.7 | 32.5 | 34.8 | 67.5 |
| GPT-based Iterator | Fold 3 | 20.3 | 33.3 | 33.7 | 66.7 |
| GPT-based Iterator | Fold 4 | 19.4 | 32.2 | 35.3 | 67.8 |
| GPT-based Iterator | Fold 5 | 18.6 | 31.3 | 36.3 | 68.7 |
| GPT-based Iterator | Average | 19.4 ± 0.7 | 32.2 ± 0.8 | 35.3 ± 1.1 | 67.8 ± 0.8 |
| Attention-based GRU | Fold 1 | 10.2 | 15.0 | 59.2 | 85.0 |
| Attention-based GRU | Fold 2 | 10.5 | 15.4 | 59.0 | 84.6 |
| Attention-based GRU | Fold 3 | 11.2 | 16.1 | 58.2 | 83.9 |
| Attention-based GRU | Fold 4 | 10.9 | 15.8 | 58.2 | 84.2 |
| Attention-based GRU | Fold 5 | 11.5 | 16.8 | 57.6 | 83.2 |
| Attention-based GRU | Average | 10.9 ± 0.5 | 15.8 ± 0.7 | 58.4 ± 0.7 | 84.2 ± 0.7 |
| Feed-Forward Network | Fold 1 | 38.5 | 49.9 | 7.1 | 50.1 |
| Feed-Forward Network | Fold 2 | 39.4 | 51.3 | 6.3 | 48.7 |
| Feed-Forward Network | Fold 3 | 41.1 | 52.1 | 5.4 | 47.9 |
| Feed-Forward Network | Fold 4 | 39.6 | 51.6 | 6.2 | 48.4 |
| Feed-Forward Network | Fold 5 | 39.3 | 51.3 | 6.3 | 48.7 |
| Feed-Forward Network | Average | 39.6 ± 0.9 | 51.2 ± 0.8 | 6.3 ± 0.6 | 48.8 ± 0.8 |
| Hidden Markov Model | Fold 1 | 41.3 | 52.1 | 7.0 | 47.9 |
| Hidden Markov Model | Fold 2 | 42.5 | 54.2 | 6.1 | 45.8 |
| Hidden Markov Model | Fold 3 | 43.3 | 54.9 | 5.4 | 45.1 |
| Hidden Markov Model | Fold 4 | 42.6 | 54.4 | 5.8 | 45.6 |
| Hidden Markov Model | Fold 5 | 42.2 | 53.8 | 6.3 | 46.2 |
| Hidden Markov Model | Average | 42.4 ± 0.7 | 53.9 ± 1.1 | 6.1 ± 0.6 | 46.1 ± 1.1 |
| Viseme-to-Word Converter | CER (%) | WER (%) | SAR (%) | WAR (%) |
|---|---|---|---|---|
| GPT-based iterator | 23.1 | 35.4 | 33.4 | 64.6 |
| Attention-based GRU | 14.0 | 20.4 | 49.8 | 79.6 |
| Feed-Forward Network | 67.2 | 78.7 | 2.9 | 21.3 |
| Hidden Markov Model | 71.4 | 81.7 | 2.8 | 18.3 |
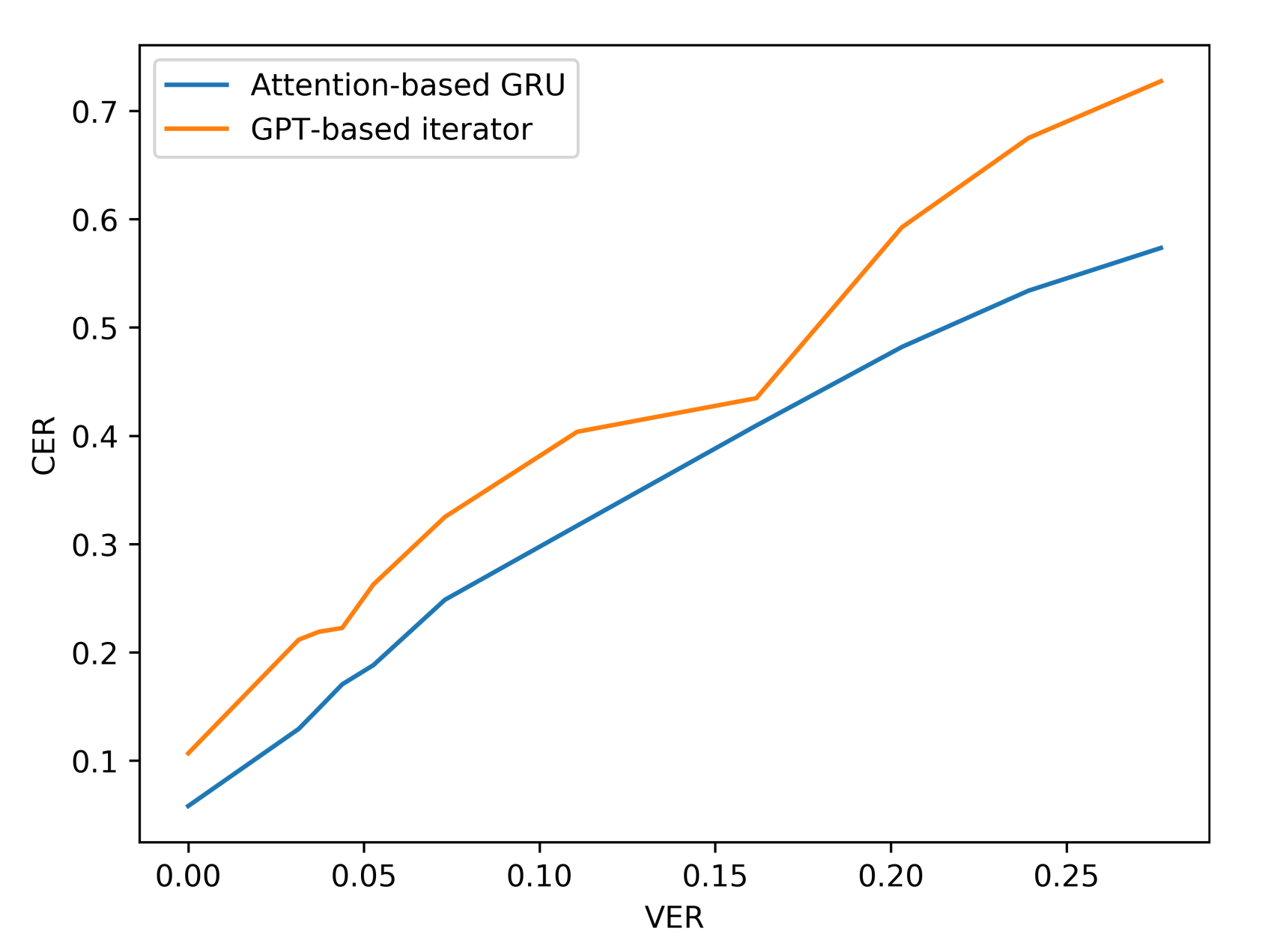
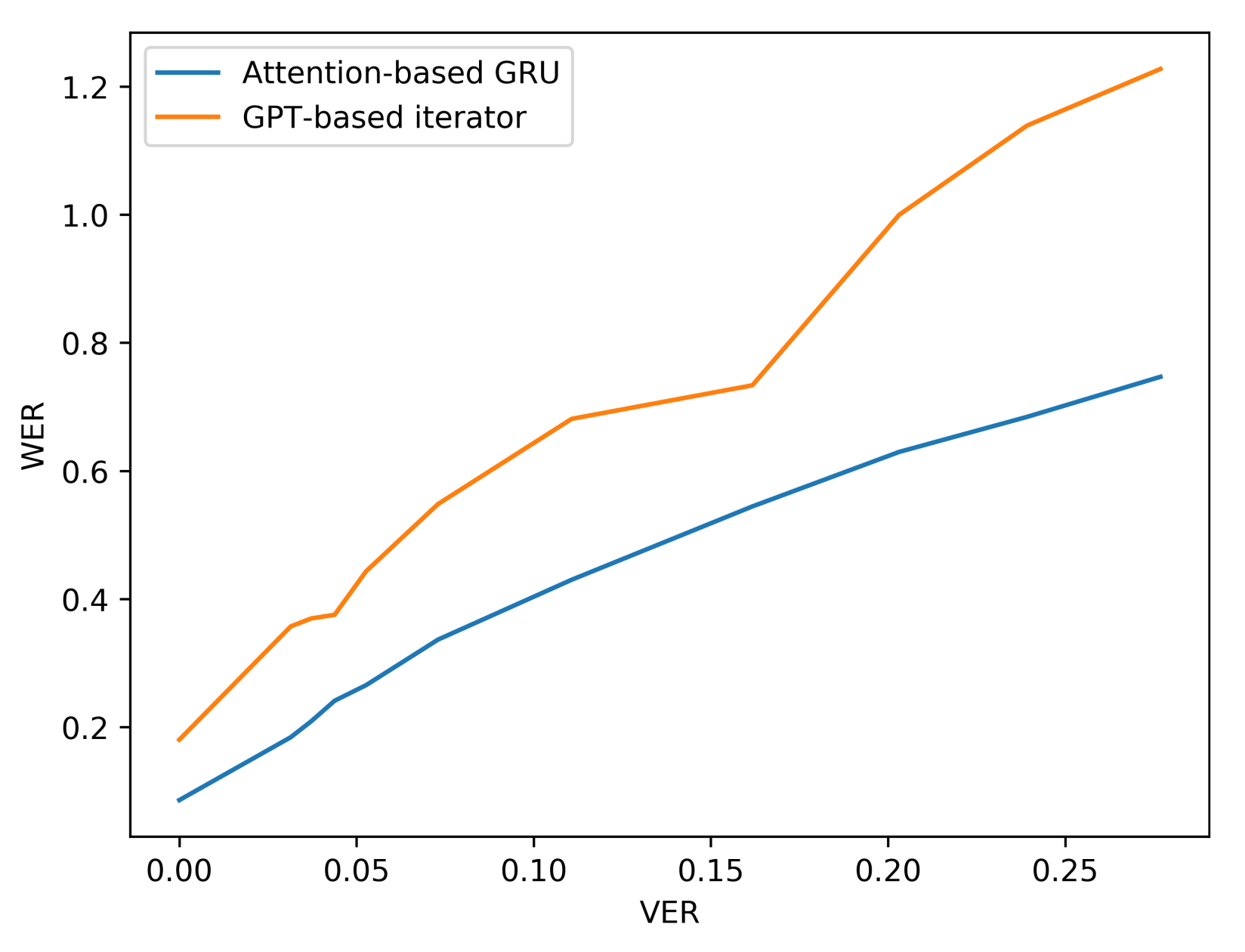
| VER (%) | Attention-Based GRU | GPT-Based Iterator | |||
|---|---|---|---|---|---|
| CER (%) | WER (%) | CER (%) | WER (%) | ||
| 0 | 0.0 | 5.8 | 8.6 | 10.7 | 18.0 |
| 5 | 3.1 | 12.9 | 18.4 | 21.2 | 35.7 |
| 6 | 3.7 | 14.8 | 20.9 | 21.9 | 37.0 |
| 7 | 4.4 | 17.1 | 24.1 | 22.3 | 37.5 |
| 8 | 5.3 | 18.8 | 26.5 | 26.3 | 44.3 |
| 10 | 7.3 | 24.9 | 33.7 | 32.5 | 54.8 |
| 15 | 11.1 | 31.7 | 43.0 | 40.4 | 68.1 |
| 20 | 16.2 | 40.9 | 54.4 | 43.5 | 73.4 |
| 25 | 20.3 | 48.2 | 63.0 | 59.2 | 100.0 |
| 30 | 23.9 | 53.4 | 68.4 | 67.5 | 113.9 |
| 35 | 27.7 | 57.2 | 74.5 | 72.7 | 122.7 |
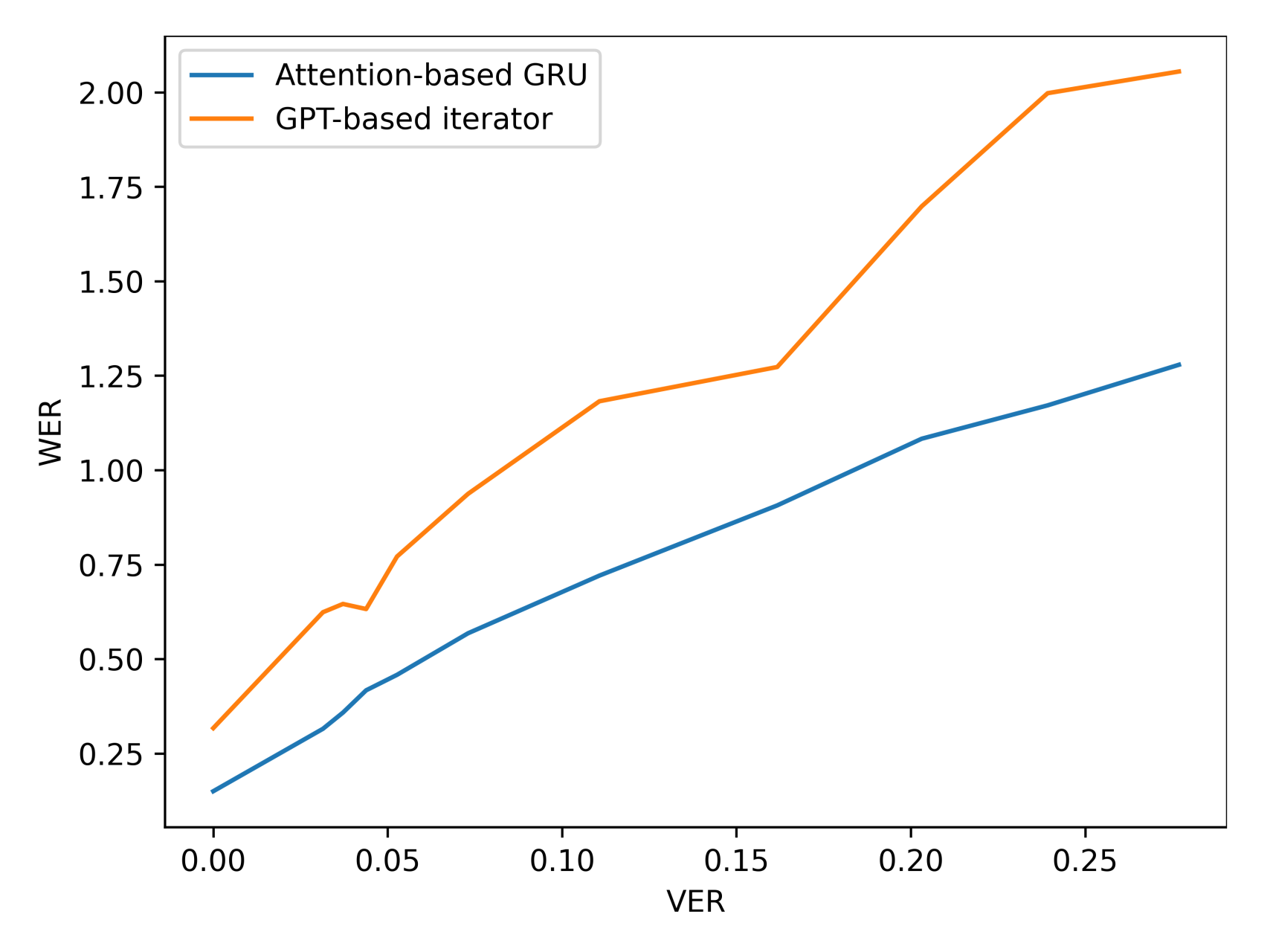
| VER (%) | Attention-Based GRU | GPT-Based Iterator | |||
|---|---|---|---|---|---|
| CER (%) | WER (%) | CER (%) | WER (%) | ||
| 0 | 0.0 | 10.2 | 15.0 | 18.8 | 31.7 |
| 5 | 2.8 | 22.5 | 31.5 | 35.5 | 62.4 |
| 6 | 3.5 | 25.0 | 35.8 | 37.6 | 64.6 |
| 7 | 4.5 | 29.8 | 41.7 | 38.0 | 63.2 |
| 8 | 5.2 | 32.8 | 45.8 | 45.6 | 77.1 |
| 10 | 7.6 | 41.5 | 56.8 | 56.9 | 93.7 |
| 15 | 11.0 | 53.6 | 72.1 | 70.6 | 118.2 |
| 20 | 16.5 | 70.8 | 90.7 | 76.1 | 127.3 |
| 25 | 20.1 | 80.8 | 108.3 | 102.0 | 169.8 |
| 30 | 23.9 | 92.9 | 117.1 | 116.4 | 199.8 |
| 35 | 27.5 | 99.3 | 127.9 | 125.7 | 205.5 |
| Actual Subtitle | Actual Visemes | Predicted Visemes | GPT-Based Iterator | Attention-Based GRU | ||
|---|---|---|---|---|---|---|
| Decoded Subtitle | Execution Time (s) | Decoded Subtitle | Execution Time (s) | |||
| WHEN THERE ISN’T MUCH ELSE IN THE GARDEN | (’W’, ’EY’, ’K’), (’T’, ’EY’, ’W’), (’IY’, ’T’, ’AH’, ’K’, ’T’), (’P’, ’AH’, ’CH’), (’EY’, ’K’, ’T’), (’IY’, ’K’), (’T’, ’AH’), (’K’, ’AA’, ’W’, ’T’, ’AH’, ’K’) | (’W’, ’EY’, ’K’), (’T’, ’EY’, ’W’), (’IY’, ’T’, ’AH’, ’K’, ’T’), (’P’, ’AH’, ’CH’), (’EY’, ’K’, ’T’), (’IY’, ’K’), (’T’, ’AH’), (’K’, ’AA’, ’W’, ’T’, ’AH’, ’K’) | WHEN THERE ISN’T MUCH ELSE IN THE GARDEN | 147.35 | WHEN THEY’RE ISN’T MUCH ELSE IN THE GARDEN | 0.08 |
| SORT OF SECOND HALF OF OCTOBER | (’T’, ’AO’, ’W’, ’T’), (’AH’, ’F’), (’T’, ’EY’, ’K’, ’AH’, ’K’, ’T’), (’K’, ’EY’, ’F’), (’AH’, ’F’), (’AA’, ’K’, ’T’, ’AO’, ’P’, ’ER’) | (’T’, ’AO’, ’W’, ’T’), (’AH’, ’F’), (’T’, ’EY’, ’K’, ’AH’, ’K’, ’T’), (’K’, ’EY’, ’F’), (’AH’, ’F’), (’AA’, ’K’, ’T’, ’AO’, ’P’, ’ER’) | SORT OF SECOND HALF OF OCTOBER | 32.86 | SORT OF SECOND HALF OF OCTOBER | 0.05 |
| WELL INTO NOVEMBER | (’W’, ’EY’, ’K’), (’IY’, ’K’, ’T’, ’UH’), (’K’, ’AO’, ’F’, ’EY’, ’P’, ’P’, ’ER’) | (’W’, ’EY’, ’K’), (’IY’, ’K’, ’T’, ’UH’), (’K’, ’AO’, ’F’, ’EY’, ’P’, ’P’, ’ER’) | RAN INTO NOVEMBER | 2.83 | WELL INTO NOVEMBER | 0.03 |
| WE CAN JUST ABOUT GET AWAY WITH IT NOW | (’W’, ’IY’), (’K’, ’EY’, ’K’), (’CH’, ’AH’, ’T’, ’T’), (’AH’, ’P’, ’EY’, ’T’), (’K’, ’EY’, ’T’), (’AH’, ’W’, ’EY’), (’W’, ’IY’, ’T’), (’IY’, ’T’,) (’K’, ’EY’) | (’W’, ’IY’), (’K’, ’EY’, ’K’), (’CH’, ’AH’, ’T’, ’T’), (’AH’, ’P’, ’EY’, ’T’), (’K’, ’EY’, ’T’), (’AH’, ’W’, ’EY’), (’W’, ’IY’, ’T’), (’IY’, ’IY’), (’K’, ’EY’) | WE CAN JUST ABOUT GET AWAY WITH IIE KAYE | 323.84 | WE CAN JUST ABOUT GET AWAY WITH IT NOW | 0.07 |
| AND IF YOU WANT WONDERFUL | (’AH’, ’K’, ’T’), (’IY’, ’F’), (’K’, ’UH’), (’W’, ’AA’, ’K’, ’T’), (’W’, ’AH’, ’K’, ’T’, ’ER’, ’F’, ’AH’, ’K’) | (’AH’, ’K’, ’T’), (’IY’, ’F’), (’K’, ’UH’), (’W’, ’AA’, ’K’, ’T’), (’W’, ’AH’, ’K’, ’T’, ’ER’, ’F’, ’AH’, ’K’) | AND IF YOU WANT WONDERFUL | 35.19 | AND IF YOU WANT WONDERFUL | 0.05 |
| FOR A BRIEF TIME | (’F’, ’AO’, ’W’), (’AH’), (’P’, ’W’, ’IY’, ’F’), (’T’, ’AH’, ’P’) | (’AO’, ’AO’, ’W’), (’AH’), (’P’, ’W’, ’IY’, ’F’), (’T’, ’AH’, ’P’) | OR A BRIEF TIME | 21.95 | FOR A BRIEF TIME | 0.05 |
| IT WILL CHANGE LIVES | (’IY’, ’T’), (’W’, ’IY’, ’K’), (’CH’, ’EY’, ’K’, ’CH’), (’K’, ’IY’, ’F’, ’T’) | (’T’, ’T’), (’W’, ’IY’, ’K’), (’CH’, ’EY’, ’K’, ’CH’), (’K’, ’IY’, ’F’, ’T’) | THS WE’LL CHANGE LIFFE’S | 27.53 | THIS WILL CHANGE LIVES | 0.05 |
| I THINK IT’S BRILLIANT | (’AH’), (’T’, ’IY’, ’K’, ’K’), (’IY’, ’T’, ’T’), (’P’, ’W’, ’IY’, ’K’, ’K’, ’AH’, ’K’, ’T’) | (’AH’), (’T’, ’IY’, ’K’), (’IY’, ’T’, ’T’), (’P’, ’W’, ’IY’, ’K’, ’K’, ’AH’, ’K’, ’T’) | EYE ’TIL IT’S PRINGLE’S | 13.24 | I THING IT’S BRILLIANT | 0.05 |
| BUT IT’S A DECENT SIZE | (’P’, ’AH’, ’T’), (’IY’, ’T’, ’T’), (’AH’), (’T’, ’IY’, ’T’, ’AH’, ’K’, ’T’), (’T’, ’AH’, ’T’) | (’P’, ’AH’, ’T’), (’IY’, ’T’, ’T’), (’AH’), (’T’, ’IY’, ’T’, ’AH’, ’K’, ’T’), (’T’, ’AH’, ’T’) | BUT IT’S I DIDN’T SUSS | 79.88 | BUT IT’S A DECENT SIZE | 0.06 |
| Actual Subtitle | Actual Visemes | Predicted Visemes | Hidden Markov Model | Feed-Forward Network | ||
|---|---|---|---|---|---|---|
| Decoded Subtitle | Execution Time (s) | Decoded Subtitle | Execution Time (s) | |||
| WHEN THERE ISN’T MUCH ELSE IN THE GARDEN | (’W’, ’EY’, ’K’), (’T’, ’EY’, ’W’), (’IY’, ’T’, ’AH’, ’K’, ’T’), (’P’, ’AH’, ’CH’), (’EY’, ’K’, ’T’), (’IY’, ’K’), (’T’, ’AH’), (’K’, ’AA’, ’W’, ’T’, ’AH’, ’K’) | (’W’, ’EY’, ’K’), (’T’, ’EY’, ’W’), (’IY’, ’T’, ’AH’, ’K’, ’T’), (’P’, ’AH’, ’CH’), (’EY’, ’K’, ’T’), (’IY’, ’K’), (’T’, ’AH’), (’K’, ’AA’, ’W’, ’T’, ’AH’, ’K’) | WHEN THEY’RE ISN’T BE JUST IN THE GARDEN | 0.07 | WHEN THEY’RE ISN’T JUST BE IN THE GARDEN | 0.08 |
| SORT OF SECOND HALF OF OCTOBER | (’T’, ’AO’, ’W’, ’T’), (’AH’, ’F’), (’T’, ’EY’, ’K’, ’AH’, ’K’, ’T’), (’K’, ’EY’, ’F’), (’AH’, ’F’), (’AA’, ’K’, ’T’, ’AO’, ’P’, ’ER’) | (’T’, ’AO’, ’W’, ’T’), (’AH’, ’F’), (’T’, ’EY’, ’K’, ’AH’, ’K’, ’T’), (’K’, ’EY’, ’F’), (’AH’, ’F’), (’AA’, ’K’, ’T’, ’AO’, ’P’, ’ER’) | SORT I’VE SECOND HALF I’VE WHICH | 0.04 | SORT I SECOND HALF OF OCTOBER | 0.05 |
| WELL INTO NOVEMBER | (’W’, ’EY’, ’K’), (’IY’, ’K’, ’T’, ’UH’), (’K’, ’AO’, ’F’, ’EY’, ’P’, ’P’, ’ER’) | (’W’, ’EY’, ’K’), (’IY’, ’K’, ’T’, ’UH’), (’K’, ’AO’, ’F’, ’EY’, ’P’, ’P’, ’ER’) | WHEN INTO NOVEMBER | 0.03 | WHEN INTO NOVEMBER | 0.04 |
| WE CAN JUST ABOUT GET AWAY WITH IT NOW | (’W’, ’IY’), (’K’, ’EY’, ’K’), (’CH’, ’AH’, ’T’, ’T’), (’AH’, ’P’, ’EY’, ’T’), (’K’, ’EY’, ’T’), (’AH’, ’W’, ’EY’), (’W’, ’IY’, ’T’), (’IY’, ’T’,) (’K’, ’EY’) | (’W’, ’IY’), (’K’, ’EY’, ’K’), (’CH’, ’AH’, ’T’, ’T’), (’AH’, ’P’, ’EY’, ’T’), (’K’, ’EY’, ’T’), (’AH’, ’W’, ’EY’), (’W’, ’IY’, ’T’), (’IY’, ’IY’), (’K’, ’EY’) | WE CAN JUST ABOUT GET AWAY WITH IT HOW | 0.07 | WE CAN JUST ABOUT GET AWAY WITH IT NOW | 0.07 |
| AND IF YOU WANT WONDERFUL | (’AH’, ’K’, ’T’), (’IY’, ’F’), (’K’, ’UH’), (’W’, ’AA’, ’K’, ’T’), (’W’, ’AH’, ’K’, ’T’, ’ER’, ’F’, ’AH’, ’K’) | (’AH’, ’K’, ’T’), (’IY’, ’F’), (’K’, ’UH’), (’W’, ’AA’, ’K’, ’T’), (’W’, ’AH’, ’K’, ’T’, ’ER’, ’F’, ’AH’, ’K’) | AND IF KNEW WANT WONDERFUL | 0.04 | AND IF YOU WANT WONDERFUL | 0.05 |
| FOR A BRIEF TIME | (’F’, ’AO’, ’W’), (’AH’), (’P’, ’W’, ’IY’, ’F’), (’T’, ’AH’, ’P’) | (’AO’, ’AO’, ’W’), (’AH’), (’P’, ’W’, ’IY’, ’F’), (’T’, ’AH’, ’P’) | FOR I THIS TYPE | 0.04 | FOR A BIG TYPE | 0.05 |
| IT WILL CHANGE LIVES | (’IY’, ’T’), (’W’, ’IY’, ’K’), (’CH’, ’EY’, ’K’, ’CH’), (’K’, ’IY’, ’F’, ’T’) | (’T’, ’T’), (’W’, ’IY’, ’K’), (’CH’, ’EY’, ’K’, ’CH’), (’K’, ’IY’, ’F’, ’T’) | THIS WILL CHANGE LIVES | 0.04 | THIS WILL CHANGE LIVES | 0.05 |
| I THINK IT’S BRILLIANT | (’AH’), (’T’, ’IY’, ’K’, ’K’), (’IY’, ’T’, ’T’), (’P’, ’W’, ’IY’, ’K’, ’K’, ’AH’, ’K’, ’T’) | (’AH’), (’T’, ’IY’, ’K’), (’IY’, ’T’, ’T’), (’P’, ’W’, ’IY’, ’K’, ’K’, ’AH’, ’K’, ’T’) | I THINK IT’S BRILLIANT | 0.04 | I THINK IT’S BRILLIANT | 0.04 |
| BUT IT’S A DECENT SIZE | (’P’, ’AH’, ’T’), (’IY’, ’T’, ’T’), (’AH’), (’T’, ’IY’, ’T’, ’AH’, ’K’, ’T’), (’T’, ’AH’, ’T’) | (’P’, ’AH’, ’T’), (’IY’, ’T’, ’T’), (’AH’), (’T’, ’IY’, ’T’, ’AH’, ’K’, ’T’), (’T’, ’AH’, ’T’) | BUT IT’S A DECENT SUSS | 0.05 | BUT IT’S A DECENT SIZE | 0.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fenghour, S.; Chen, D.; Guo, K.; Li, B.; Xiao, P. An Effective Conversion of Visemes to Words for High-Performance Automatic Lipreading. Sensors 2021, 21, 7890. https://doi.org/10.3390/s21237890
Fenghour S, Chen D, Guo K, Li B, Xiao P. An Effective Conversion of Visemes to Words for High-Performance Automatic Lipreading. Sensors. 2021; 21(23):7890. https://doi.org/10.3390/s21237890
Chicago/Turabian StyleFenghour, Souheil, Daqing Chen, Kun Guo, Bo Li, and Perry Xiao. 2021. "An Effective Conversion of Visemes to Words for High-Performance Automatic Lipreading" Sensors 21, no. 23: 7890. https://doi.org/10.3390/s21237890
APA StyleFenghour, S., Chen, D., Guo, K., Li, B., & Xiao, P. (2021). An Effective Conversion of Visemes to Words for High-Performance Automatic Lipreading. Sensors, 21(23), 7890. https://doi.org/10.3390/s21237890