1. Introduction
Nowadays, air pollution represents one of the main problems that affect the population’s quality of living, especially in densely populated areas. Low air quality can produce very harmful effects on human health, particularly on children and senior citizens [
1,
2]. Additionally, it also generates a sizable economic impact due to the increase in the cost of healthcare services.
Among air pollutants, nitrogen dioxide (NO
2) generates a great deal of concern as it is considered a critical factor for air quality demise in urban areas [
3]. This toxic gas is highly corrosive, very reactive, and possesses an intense irritating capacity [
4]. NO
2 origins are manifold: it is linked with traffic emissions and industrial operations, including combustion processes [
5]. However, it is mainly a secondary pollutant, and its primary source can be found in the oxidation reactions between nitrogen oxides (NO) and ozone (O
3) in the atmosphere [
6]. The adverse effects of exposure to nitrogen dioxide include several diseases, such as bronchitis or pneumonia [
7]. Its long-term impact on mortality is as remarkable as the effect produced by particulate matter [
8]. Additionally, it has a significant role in generating photochemical smog acid rain [
9].
Considering all the harmful effects that nitrogen dioxide may produce, it becomes essential to create accurate models to determine its future concentrations. Previous studies have addressed this purpose using two main approaches: deterministic approaches and statistical prediction. The deterministic approach employs mathematical formulations and the simulation of various physical and chemical processes, such as emission models, to predict airborne pollutants [
10,
11]. On the other hand, the statistical prediction approach creates statistical models based on historical data [
12]. Unlike deterministic models, statistical techniques are not based on understanding the processes that regulate the change mechanism of pollutant concentrations. They are centered on discovering relations among historical data. Once found, these correlations are applied to the forecasting of future pollution levels. This statistical approach has been recognized as a viable alternative to the deterministic methods and, according to Catalano and Galatioto [
13], can deliver better-performing models in short-term air pollutant concentrations. However, statistical methods are based on the assumption that the relations between variables are linear [
14]. The irruption of machine learning (ML) techniques made possible the creation of models that could detect and capture non-linear relationships between variables. As a result, ML methods have been widely adopted by researchers for air quality prediction.
Several works devoted to NO
2 time series forecasting using ML models can be found in the scientific literature in the last two decades. We can cite the work of Gardner and Dorling [
15], who addressed the modeling of hourly NO
2 concentrations using artificial neural networks (ANNs) in conjunction with meteorological data. Their results revealed how the proposed approach outperformed regression-based models. Another interesting study was undertaken by Kolehmainen et al. [
16], where ANNs were employed to predict NO
2 concentrations in Stockholm (Sweden). The authors obtained remarkable results using average NO
2 values and several meteorological variables to feed the models. Viotti et al. [
17] used ANNs for short and middle long-term forecasting of several pollutants, including NO
2. Models exhibited excellent performances with a 1-h ahead prediction horizon. As the prediction horizon increased, the model’s performance decreased but was still better than deterministic models. Kukkonen et al. [
18] evaluated the ANN model’s performance compared to other linear and deterministic models. Results brought to light how the neural network models provided better performances than the rest of the techniques tested. Aguirre-Basurko et al. [
19] predicted O
3 and NO
2 in Bilbao (Spain). The authors compared ANN and multiple linear regression models using traffic data and meteorological variables as exogenous inputs in their study. Models were tested in several prediction horizons from
t + 1 to
t + 8, and ANN models showed the best performances in nearly all the proposed cases. Kumar and Jain [
20] utilized an autoregressive moving average (ARIMA) approach to forecasting O
3, NO, NO
2, and CO with satisfactory results. Rahman et al. [
21] compared ARIMA, fuzzy logic models, and ANN models to forecast the Air Pollution Index (API) in Malaysia. The API prediction implies predicting five pollutant concentrations: PM
10, O
3, CO
2, SO
2, and NO
2. Results showed how ANN models gave the smallest forecasting errors. Bai et al. [
22] utilized ANNs in conjunction with wavelet decomposition techniques to predict several pollutants, including NO
2. The prediction horizon was set to 24 h, and results showed how the combined approach produced better results than standard ANNs. Finally, Van Roode et al. [
23] proposed a hybrid model to forecast the NO
2 concentration values with a one-hour prediction horizon in the Bay of Algeciras area (Spain). The authors employed LASSO to predict the linear part of the time series and ANN models to predict the residuals in a two-stage approach. The results confirmed that the proposed hybrid approach presented better performances than any of the particular methods employed.
Among machine learning methods, deep learning (DL) techniques have gained tremendous popularity in recent years. DL uses denser artificial neural networks combined with sequential layers and larger datasets than traditional machine learning methods. Long short-term memory networks (LSTMs) are recurrent neural networks specially designed for supervised time series learning [
24]. Several studies have employed LSTMs to forecast pollutants in the scientific literature. We can cite the work of Kök et al. [
25], where LSTMs and support vector regression (SVR) models were used to predict NO
2 and O
3 with a
t + 1 horizon. Results showed how the LSTM model outperformed the SVR model. Another interesting study was undertaken by Pardo and Malpica [
26], who proposed different LSTM models to predict NO
2 levels for
t + 8,
t + 16 and
t + 24 prediction horizons in Madrid (Spain). Finally, Rao et al. [
27] compared LSTM based recurrent neural networks and SVR applied to air quality prediction. The results showed how the LSTM approach obtained better forecasting performances than the remaining method employed for all the pollutants considered.
Despite not explicitly being devoted to nitrogen dioxide forecasting, there are two interesting works worth mentioning. Kim et al. [
28] developed a system to obtain daily PM
10 and PM
2.5 predictions in South Korea. In this work, the performances of LSTMs and chemical transport model simulations (more specifically, the Community Multiscale Air Quality (CMAQ) model) were compared. Different meteorological variables and several pollutants data (particulate matter, SO
2, NO
2 and NO
3) were employed as input variables of the LSTM models. Results showed how LSTMs were able to outperform the CMAQ predictions in most of the cases considered. In the case of the study carried out by Carnevale et al. [
29], a system to predict air quality in Milan (Italy) was proposed. This study was focused on obtaining up to 2 days ahead PM
10 and ozone concentration predictions. A two-stage procedure was followed. In the first stage, neural network predictions were obtained for a monitoring network station located in the study area using exogenous variables. In the second stage, the forecasts obtained at each station were interpolated using the cokriging technique. Additionally, a deterministic chemical transport model was also included as a secondary variable. The proposed methodology provided satisfactory results and constituted a reliable way to give the decision-makers air quality forecasting.
In the present study, ANNs and sequence-to-sequence LSTMs models are developed to forecast NO
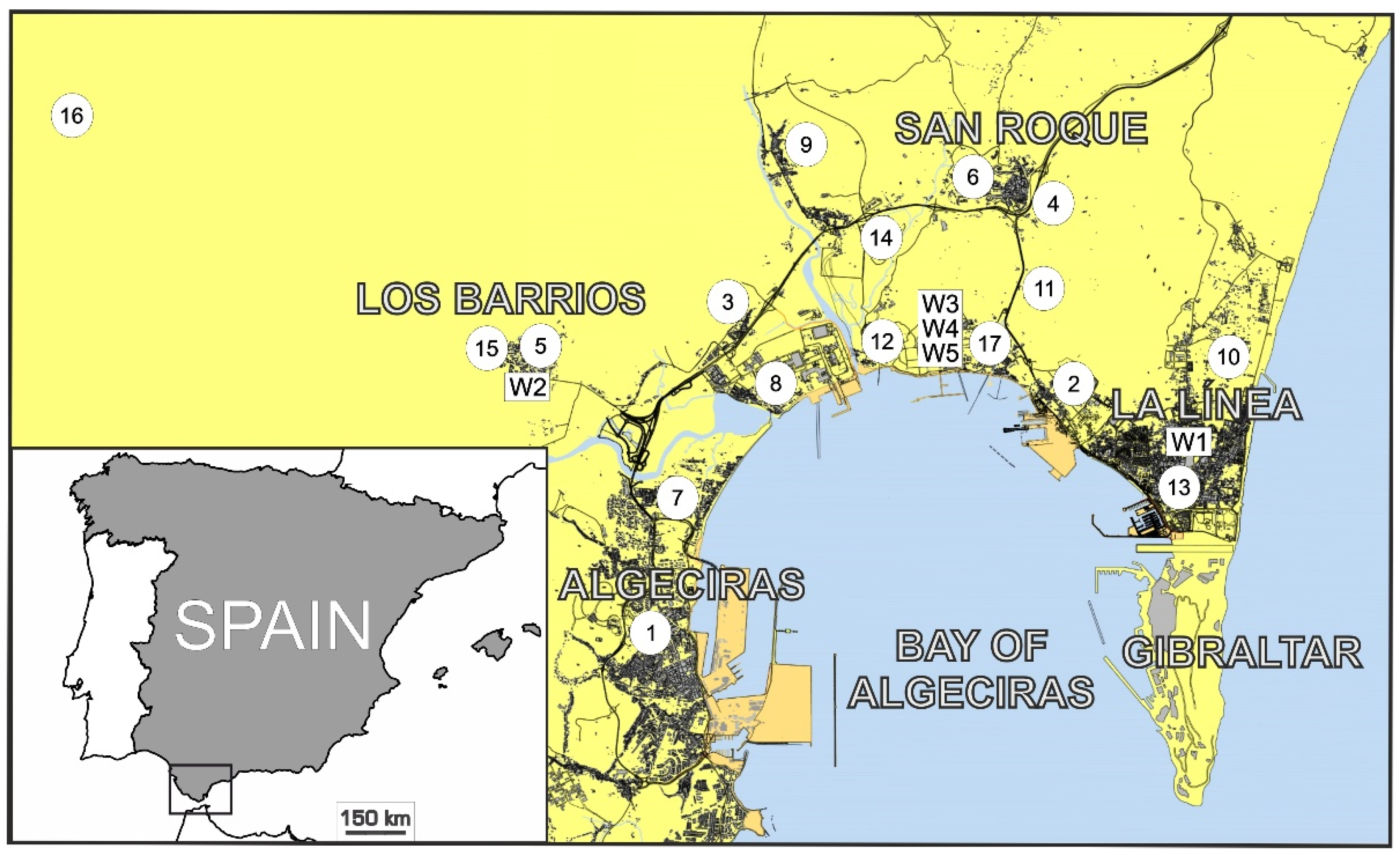
2 concentrations in a specific station of a monitoring network located in the Bay of Algeciras area (Spain). The selected station is located in Algeciras, the study area’s principal city (see
Figure 1). The primary goal is to build accurate statistical models to predict NO
2 levels with
t + 1,
t + 4, and
t + 8 prediction horizons. Two different approaches were followed to create the forecasting models. Only the NO
2 data from the selected station were employed to feed the models in the first approach. In the second approach, exogenous variables were added to the set of predictor variables. In that sense, NO
2 data from the network’s remaining stations, data from other pollutants (NO
x, SO
2, O
3) from EPS Algeciras and other stations, and several meteorological variables were included (see
Table 1). Based on the previously mentioned techniques, ANNs, standard sequence-to-sequence LSTMs, and LSTMs using a rolling window scheme in conjunction with a cross-validation procedure for time series (LSTM-CVT) were designed in both approaches. Finally, the obtained results were statistically analyzed and compared to determine the best performing model.
The rest of this paper is organized as follows.
Section 2 details the study area and the data used. The modeling methods and feature ranking techniques used in this work are depicted in
Section 3.
Section 4 describes the experimental design.
Section 5 discusses the results. Finally, the conclusions are presented in
Section 6.
2. Data and Area Description
The Bay of Algeciras is a densely populated and heavily industrialized region situated in the south of Spain. The total population of this region in 2020 is estimated at 300,000 inhabitants [
30]. It contains an oil refinery, a coal-fired power plant, a large petrochemical industry cluster, and one of the leading stainless-steel factories in Europe.
As stated in the Introduction section, this work aims to predict the NO
2 concentration levels with different time horizons in a monitoring network’s specific monitoring station. This station is EPS Algeciras (see
Figure 1). It is located in Algeciras, the study area’s most populous city. With more than 120,000 inhabitants, its air quality is severely affected by the neighboring industries’ pollutant emissions. Additionally, the Port of Algeciras Bay can be found between the top 5 ship-trading ports in Europe. The high number of import and export operations held in this port implies high numbers of heavy vehicles and vessels every year. Combustion processes related to industrial activities and dense traffic episodes favor NO
2 emissions, producing a very complicated pollution scenario (15 × 15 km
2).
As was previously indicated, NO
2 is one of the main factors of air quality decrease in urban areas. Therefore, having accurate models to predict its forthcoming concentrations becomes a critical task for environmental and governmental agencies. The proposed models can constitute a useful set of tools to predict exceedance episodes and take the corresponding corrective measures to avoid them. Additionally, the techniques presented in this article can also be applied to improve other pollutants’ predictions. These improved values can also help enhance the Air Quality Index’s [
31] forecasts for the area of study.
The data used in this work was measured by an air monitoring network deployed in the Bay of Algeciras area. It contains 17 monitoring stations and five weather stations. These weather stations are located in Los Barrios (W1), La Línea (W2), and a refinery property of the CEPSA company in different heights (W3 at 10 m, W4 at 60 m, and W5 at 15 m).
Figure 1 shows the position of the stations in the study area.
The database contains records of NO
2, NO
x, SO
2, and O
3 average hourly concentrations from January 2010 to October 2015. Several meteorological variables, measured hourly at the mentioned weather stations for the same period, are also included. The Andalusian Environmental Agency kindly provided all these measures. The complete list of variables included in the database is shown in
Table 1.
Table 2 details the correspondence between the codes used in
Figure 1 and the monitoring and weather stations. In this table, the pollutants and meteorological variables measured at each station are also indicated. It is important to note that not all pollutants are measured in all the monitoring stations.
The database was preprocessed to eliminate possible outlier values and inaccurate measures caused by instrumental errors. After that, a process to impute this database’s missing values was applied using artificial neural networks as the estimation method.
3. Methods
Different models have been created to predict the NO
2 level concentrations in this study. Two main forecasting techniques were employed: artificial neural networks and sequence-to-sequence LSTMs. Additionally, a new methodology was proposed based on the LSTM technique previously mentioned: LSTM-CVT. A concise description of these forecasting techniques is presented in
Section 3.1.
The input data for ANNs and the input sequence for LSTM-CVT have been obtained using a rolling window method. The procedure to build the new lagged variables dataset is described in
Section 3.2. Additionally, the ANN and LSTM-CVT models employ a cross-validation method for time series described in
Section 3.3.
As was stated in the Introduction section, two different approaches have been compared in this study according to the type of input variables used. In the second one, the use of exogenous variables implies a group of lagged variables for ANN and LSTM-CVT models equal to the selected window size multiplied by the total number of input variables.
Section 3.4 describes the feature ranking methods employed in this work to selects the best among these lagged variables.
3.1. Forecasting Techniques
3.1.1. Artificial Neural Networks
Artificial neural networks are a branch of machine learning techniques inspired by how the human brain operates to recognize the underlying relationships in a data set. They are made of several interconnected non-linear processing elements, called neurons. These neurons are arranged in layers, which are linked by connections, called synapses weights. ANNs can detect and determine non-linear relationships between variables. They can act as non-linear functions that map predictors and dependent variables.
Feedforward multilayer perceptron trained by backpropagation (BPNN) [
32] is the most commonly used neural network type. Its architecture includes an input layer, one or more hidden layers, and an output layer. The networks are organized in fully connected layers. Their learning process is based on information going forward to the following layers and errors being propagated backward, in a process called backpropagation. According to Hornik et al. [
33], feedforward neural networks with a single hidden layer can approach any function if they are correctly trained and contain sufficient hidden neurons. Hence, they are considered a type of universal approximators. BPNNs can be applied either to regression or classification problems [
34] where no a priori knowledge is known about the relevance of the input variables. These characteristics make them an adequate method to solve different problems of high complexity, especially non-linear mappings [
35]. However, ANNs also present some disadvantages: the inexistence of a standard approach to determine the number of hidden units and possible overfitting affecting the models.
In this work, BPNNs models have been trained using the scaled conjugate gradient backpropagation algorithm [
36] to build NO
2 forecasting models. The generalization capability of the mentioned models constitutes a crucial matter. Generalization can be defined as the network’s ability to produce good results for unseen new data [
34]. Therefore, the reduction of the generalization error becomes essential to obtain accurate prediction models. In that sense, the early stopping technique [
35,
37] was employed in the models’ training phase to reduce overfitting and avoid generalization issues. The optimal number of hidden neurons was settled by a resampling procedure using 5-fold time-series cross-validation (see
Section 3.3). The authors have successfully applied a similar resampling procedure in previous works [
38,
39,
40,
41,
42], but in this case, it has been modified to time series prediction.
3.1.2. Long Short-Term Memory Networks
Long short-term memory networks are a type of recurrent neural network proposed by Hochreiter and Schmidhuber [
43]. Some years later, they were greatly enhanced by Gers et al. [
24] by including the fundamental forget gate concept. Standard RNNs can learn past temporal patterns and correlations but are limited when dealing with long-term dependencies in sequences because of the vanishing gradient problem [
44,
45]. LSTMs overcome this situation by including a special type of unit called memory blocks in their architecture. These units allow LSTMs to decide which meaningful information must be retained, learn long-term dependencies and capture contextual information from data, making them especially suitable for time series prediction [
46].
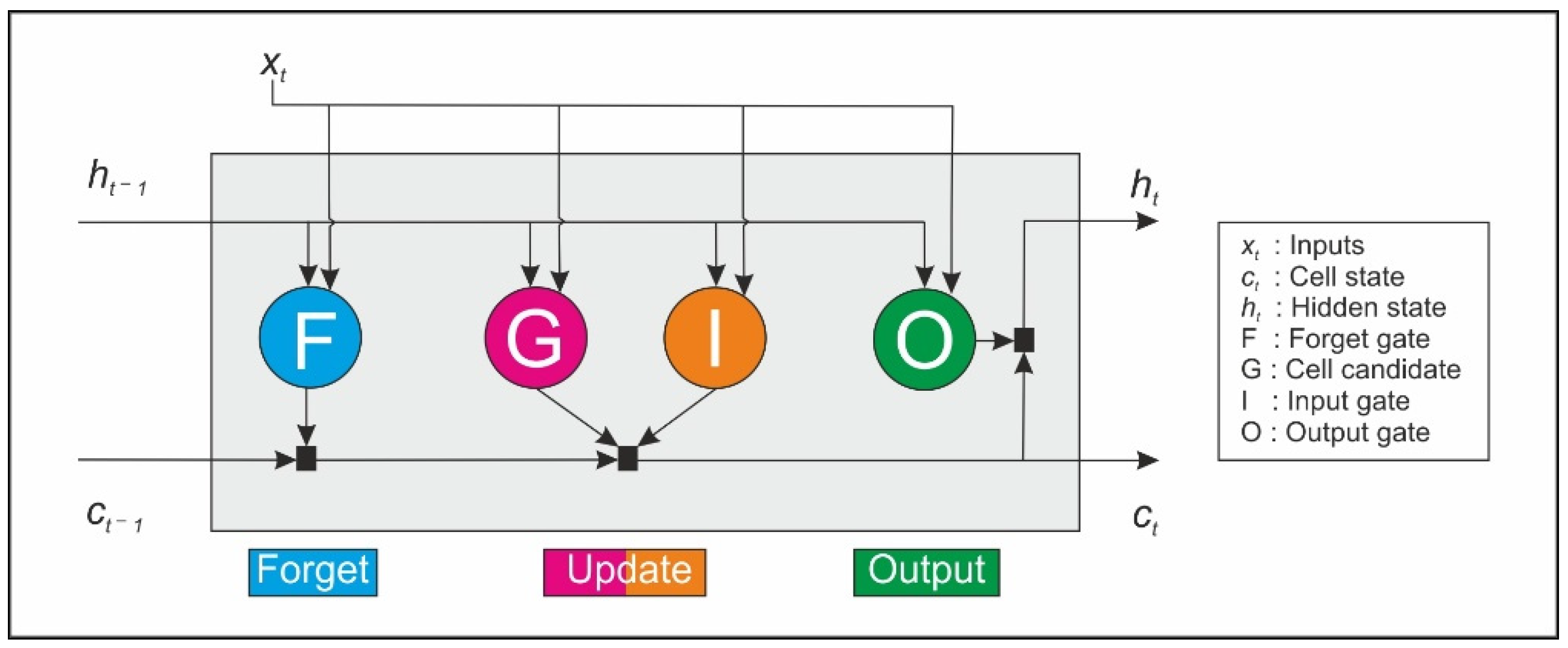
The basic architecture of the LSTM models includes an input layer, a recurrent hidden layer (LSTM layer) containing the memory blocks (also called neurons), and an output layer. One or more self-connected memory cells are included in each memory block. Additionally, three multiplicative units are also contained inside the memory blocks: input, output and forget gates. These gates provide read, write and reset capabilities, respectively, to the memory block. Additionally, they enable LSTMs to decide which meaningful information must be retained and which not relevant information must be discarded. Therefore, they allow the control of information flow and permit the memory cell to store long-term-dependencies. A schematic representation of a memory block with a single cell is shown in
Figure 2.
A typical LSTM includes several memory blocks or neurons in the LSTM layer arranged in a chain-like structure. A schematic representation of this structure is depicted in
Figure 3.
The cell state and the hidden state are the main properties of this type of network. These properties are sent forward from one memory block to the next one. At time
t, the hidden state (
ht) represents the LSTM layer’s output for this specific time step. The cell state constitutes the memory that contains the information learning from the previous timestamps. Data can be added or eliminated from this memory employing the gates. The forget gate F controls the connection of the input (
xt) and the output of the previous block (hidden state
ht−1) with the cell state received from the previous block (
ct−1). Then it selects which values from
ct−1 must be retained and which ones discarded. After that, the input gate decides which values of the cell state should be updated. The cell candidate then creates a vector of new candidate values, and the cell state is updated, producing
ct. Finally, the outputs of the memory block are calculated in the output gate. All this process can be formulated as described in Equations (1)–(5) [
47].
where
ft,
it and
ot indicate the state of the forget gate, the input gate and the output gate at time t, respectively. Additionally,
ht refers to the hidden state and
ct stands for the cell state.
Wxi,
Whi,
Wci,
Wxf,
Whf,
Wcf,
Wxc,
Whc,
Wxo,
Who and
Wco, correspond to the trainable parameters. The operator
denotes the Hadamard product, and the bias terms are represented
bi,
bf,
bc and
bo. Finally,
δ corresponds to the sigmoid function and tanh indicates the hyperbolic tangent function, which are expressed in Equations (6) and (7), respectively.
The function of the memory blocks is similar to the neurons in shallow neural networks. In that sense, in the rest of the paper, these memory blocks are referred to as LSTM neurons.
3.2. Lagged Dataset Creation
The time series were transformed into a dataset suitable for the ANN and LSMT-CVT models using a rolling window approach. Autoregressive window sizes of 24, 48 and 72 h were employed. The lagged dataset creation follows a different procedure depending on the type of input variables used: univariate time series and multivariate time series.
In the first case, only the hourly NO
2 measures from the selected station were used. New lagged variables were built based on samples of consecutive observations [
48]. Thus, the datasets were defined as
where
T indicates the number of samples,
k is the prediction horizon and
ws corresponds to the window size. Each
i-th sample (row of the dataset) was defined as an input vector
concatenated to its corresponding output value
. These new lagged datasets were split into a subset for training and a second subset for testing. The first one included the first 70% of the records and was used to train the models and determine their hyperparameters. The remaining 30% was used as the test subset. In this sense, the models’ performance was tested using unseen data from this subset.
In the second case, data from exogenous features were also included in the group of initial inputs. These time series were also transformed into new lagged datasets appropriate to feed the models using the same window sizes as the previous case. The following steps summarize this process:
For each initial variable vj, lagged variables (column vectors) were built in a similar way to the univariate case: {}.
As a second step, the group of potential input variables
Pws was created including all the previously created lagged variables
Pws = {
} where
j indicates the total number of initial variables (77 variables, see
Table 1).
Then, new datasets were created, including the potential group of variables and the output variable. These datasets were split into training (first 70% records) and test subsets (ending 30% records).
As a next step, several feature ranking methods were applied to the elements of
Pws in the training subset. The feature ranking methods applied were: mutual information, mutual information using the minimum-redundancy-maximum-relevance algorithm, Spearman’s rank correlation, a modified version of the previously mentioned algorithm using Spearman’s rank correlation, and maximal information coefficient (see
Section 3.4). The objective was to select the most relevant among the lagged variable concerning the output variable
. The selected lagged variables of the training set were included in the
set, where
fr indicates the feature ranking method applied and
per corresponds to the percentage of lagged features selected. Thus, only a small portion of the potential lagged variables was chosen to be finally included as a column in the dataset (the top 5%, top 10% and top 15% variables). Once the ranking and selection process was completed, the same selection criteria were applied to the test set, obtaining the
set.
As the final step, the final training and test datasets were defined as and . Each i-th sample (row) of these datasets was defined as an input vector which included the selected lagged variables, as well as its corresponding output value Consequently, the datasets included the selected lagged variables in separate columns and the output variable y occupying the final column.
3.3. Time Series Cross-Validation
Cross-validation is a widespread technique in machine learning. However, as was stated by Bergmeir and Benítez [
49], there exist some problems regarding dependencies and temporal evolutionary effects within the time-series data. Traditional cross-validation methods do not adequately address these issues. In the
k-fold cross-validation method [
50,
51], all the available training data is randomly divided into
k folds. The training procedure is then performed using
k − 1, folds, and the error is obtained using the remaining fold as the test set. This procedure is repeated
k times so that each fold is used as the test set once. Finally, the error estimate is obtained as the average error rate on test examples.
Bergmeir and Benítez [
49] recommend using a blocked cross-validation method for time series forecasting to overcome these shortcomings. This procedure follows the same steps as the
k-fold cross-validation method, but data is partitioned into
k sequential folds respecting the temporal order. Additionally, dependent values between the training and test sets must be removed. In this sense, an amount of lagged values equal to the window size used is removed from the borders where the training and the test sets meet.
In this work, a 5-fold blocked cross volition method was followed. This method allowed us to determine the hyperparameters of the ANN y LSTM-CVT models (in this last case, in conjunction with the Bayesian optimization technique, see
Section 4). A representation of this scheme is presented in
Figure 4 [
52].
3.4. Feature Ranking Methods
The feature ranking methods employed to select the most meaningful lag variables in the lagged dataset creation are briefly presented in this Section.
3.4.1. Mutual Information
Mutual information (MI) [
53] measures the amount of information that one vector contains about a second vector. It can determine the grade of dependency between variables. MI can be defined by Equation (8).
where
x and
y are two continuous random vectors, is their joint probability density and
p(
x) and
p(
y) are their marginal probability density. Equation (8) can be reformulated to obtain Equation (11) utilizing entropy (Equation (9)) and conditional entropy (Equation (10)).
where
S is the set of the random vector with
p(
x) > 0.
where
.
The ITE Toolbox [
54] was employed to calculate
MI throughout the present manuscript.
3.4.2. Maximal Information Coefficient
Proposed by Reshef et al. [
55], the maximal information coefficient (MIC) can reveal linear and non-linear relationships between variables and measure the strength of the relationship between them. Given two vectors,
x and
y, their MIC can be obtained employing Equation (12) [
56].
where
MI(
x,y) indicates the mutual information between
x and
y, and
nx,ny corresponds to the number of bins dividing
x and
y. This study’s MIC values were obtained through the Minepy package for Matlab [
57].
3.4.3. Spearman’s Rank Correlation Coefficient
Spearman’s rank correlation (SRC) assesses the monotonic relationship’s strength and direction between two variables. This non-parametric measure is calculated operating on the data ranks, with values ranging from [−1,1]. Given two variables
x and
y, the Spearman’s rank correlation between them can be calculated using Equation (13).
3.4.4. Minimum-Redundancy-Maximum-Relevance
Minimum-redundancy-maximum relevance (mRMR) [
58] is a feature ranking algorithm that penalizes redundant features. This algorithm aims to rank the input variables according to their balance between having maximum relevance with the target variable and minimum redundancy with the remaining features. Relevancies and redundancies are calculated using mutual information. The pseudocode of the mRMR algorithm [
59], modified to be used in regression problems, is shown in
Algorithm A1 of
Appendix A.
In this work, MI, MIC, SRC and mRMR were used to select the most relevant variables when exogenous variables were employed (see
Section 3.2). Additionally, the mRMR algorithm was also modified so that Spearman’s rank correlation was used to calculate relevancies and redundancies between variables (mRMR-SRC). Consequently, the relevance term (line 2) and the redundancy term (line 5) of the algorithm were modified, as shown in
Algorithm A2 of
Appendix A.
4. Experimental Procedure
In this study, ANNs, sequence-to-sequence LSTM and the proposed LSTM-CVT method were used to predict the NO
2 concentration levels in the EPS Algeciras monitoring station (see
Table 2 and
Figure 1). The following prediction horizons were used to create the forecasting models:
t + 1,
t + 4, and
t + 8. Additionally, two different approaches were followed in the model’s creation regarding the initial input data used: using only the NO
2 data from the EPS Algeciras station (univariate dataset) or using all the available data (exogenous dataset). This second possibility includes all the 77 variables listed in
Table 1 (NO
2 and other pollutants (NO
x, SO
2, O
3) from EPS and the remaining stations and several meteorological variables). As was mentioned in
Section 2, the database included hourly measures from January 2010 to October 2015. As the first step for both approaches, all the dataset was preprocessed and standardized.
The performance indexes utilized to evaluate the generalization capabilities of the models and their performance were the Pearson’s correlation coefficient (
ρ), the mean squared error (
MSE), the mean absolute error (
MAE) [
60] and the index of agreement (
d). Lower values of
MSE and
MAE are associated with more accurate predictions, while higher values of
d and
ρ indicate higher performance levels of the models. Their corresponding definitions are shown in Equations (14)–(17).
where
P indicates the model predicted values and
O represents the observed values.
Table 3 summarizes the characteristics of the forecasting models employed in this paper. A detailed description of the experimental procedure followed in each case is presented in the following subsections.
4.1. LSTM-UN and LSTM-EX Models
These models were built using sequence-to-sequence LSTMs. The sequence-to-sequence architecture employs an encoder-decoder structure to transform the inputs by an encoding procedure to a fixed dimensionality vector. This intermediate vector is then decoded to produce the final output sequence [
61]. In this technique, minimal assumptions are made on the sequence structure, and the LSTM models map an input sequence of values corresponding to
T time steps
to an output sequence of values
.
The univariate and exogenous datasets were split into two disjoint training and testing subsets as a first step. The training subset included the first 70% of the records and was used to train the models and determine their hyperparameters. The remaining 30% was used as the test subset. In this sense, the models’ performance was tested using unseen data from this subset.
In the case of the LSTM-UN models, the univariate datasets were used. Input and output sequences were created for the training and test subsets. The output sequences were obtained from their corresponding input sequences with values shifted by
k time steps, where
k indicates the forecasting horizon (
t + 1,
t + 4 and
t + 8 in this work). After that, the models were trained using the input and output sequences corresponding to the training subset. Bayesian optimization [
62,
63] was employed to select the optimal learning hyperparameters utilizing the bayesopt MATLAB function with 500 interactions. The root mean square error was the metric employed in this optimization process. The parameters used are shown in
Table 4.
The Adam optimizer was employed to train the LSTM models, whose architecture is detailed in
Table 5. A dropout layer [
64] was added to the standard architecture used in sequence-to-sequence regression problems. This layer aims to prevent overfitting by randomly setting input elements to zero with a given probability.
Then, the training phase’s best network was fed with the input sequence corresponding to the test subset. As a result, the NO2 predicted values were obtained. Finally, performance measures were assessed by comparing the test subset’s output sequence against these forecasted values.
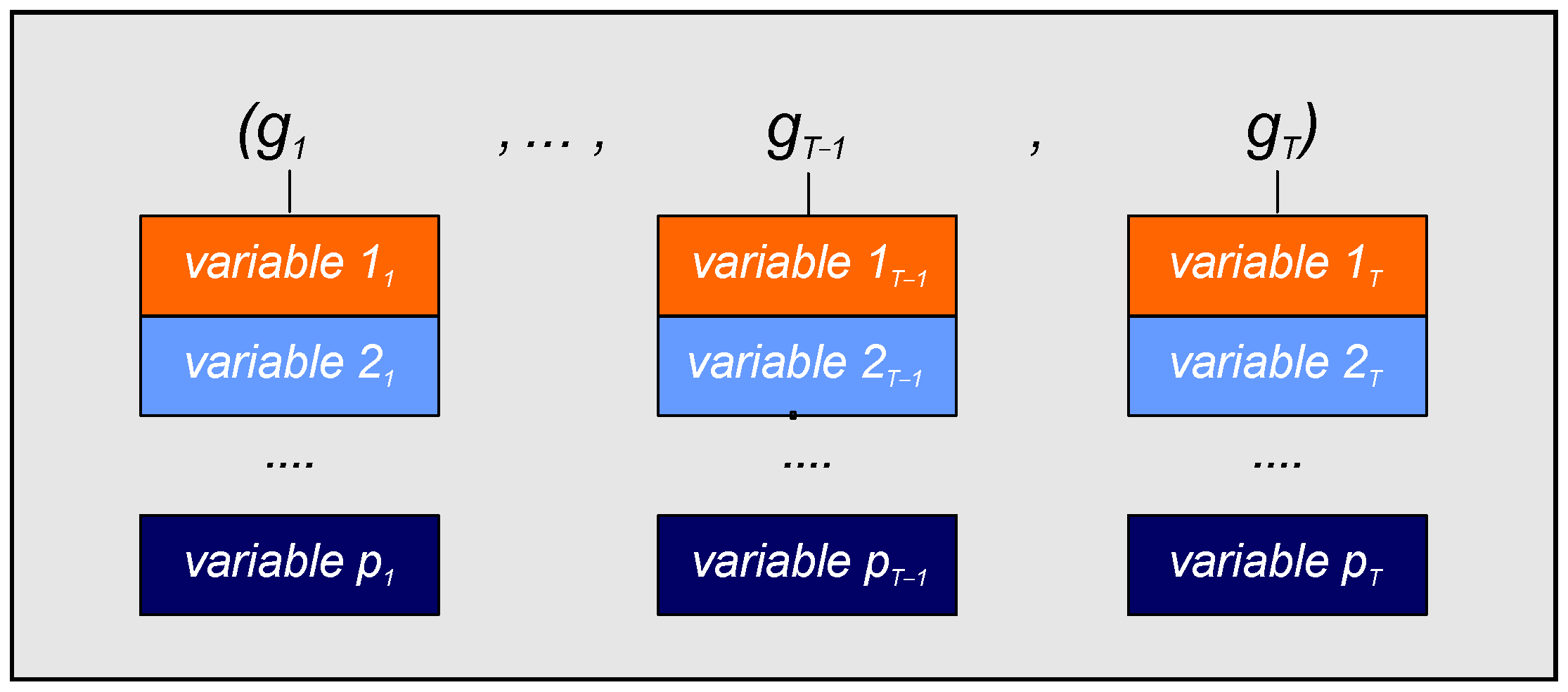
In the case of the LSTM-EX, the process followed is precisely the same as the LSTM-UN models, except for the sequences employed. Thus, the original input sequences corresponding to the training and test subsets had to be modified as these models used the exogenous datasets. Each element of a given original input sequence
x was updated to include the new exogenous variables. As a result, an exogenous input sequence
was obtained. In this new sequence, every element was a column matrix, with
and
p corresponding to the total number of variables used (see
Table 1). A graphical representation of this exogenous sequence is presented in
Figure 5.
4.2. ANN-UN and ANN-EX Models
The NO
2 forecasting models using ANNs are illustrated in this subsection. In the first step, lagged training and test datasets were created for each case, as described in
Section 3.2. BPNNs were trained using the lagged training dataset following a 5-fold fold cross-validation scheme for time series, as described in
Section 3.3. This model’s architecture included a fully connected single hidden layer and several hidden units (1 to 25). The scaled conjugate gradient backpropagation algorithm was employed in conjunction with the early stopping technique. This process was repeated 20 times, and the average results were calculated and stored.
Table 6 summarizes all the parameters used in the ANN models.
Additionally, a multi comparison procedure aimed to discover the simplest model without significant statistical differences with the best performing model was undertaken. As a first step, the Friedman test [
65] was applied to the test repetitions previously stored. This test (non-parametric alternative to ANOVA) allowed us to determine if relevant differences were present between models built using a different number of hidden units. If differences were detected, models statistically equivalent to the best performing model were found employing the Bonferroni method [
66]. Among them, the simplest model was finally selected according to Occam’s razor principle.
After that, a final BPNN model was trained using the entire lagged training dataset. The number of hidden units used was the one determined in the previous step. Once trained, the inputs of the test lagged dataset were used to feed this model. As a result, the NO2 predicted values were obtained, and performance measures were calculated comparing predicted against measured values. This process was repeated 20 times, and the average results were calculated.
4.3. LSTM-CVT-UN and LSTM-CVT-EX Models
The proposed LSTM-CVT method employed sequence-to-sequence LSTMs. However, the input data sequences used did not comprise all the
T time steps. In contrast, a rolling window approach was utilized to create lagged training and test datasets, following the procedure described in
Section 3.2.
In the case of the LSTM-CVT-UN, the univariate dataset was used to create the lagged training and test datasets. The same parameters (see
Table 4) and network architecture (see
Table 5) described in the case of the LSTM-UN were also employed in this case. The Adam optimizer was employed in the training process, and 500 interactions were used to determine the optimal hyperparameters through the Bayesian optimization algorithm. The average
MSE was the metric employed in this optimization procedure.
Each of these interactions represents a different parameter combination. Per each of them, a 5-fold fold cross-validation scheme for time series (see
Section 3.3) was applied to the lagged training dataset. Thus, this dataset was divided into five sequential folds: four of these folds acted as the training subset, while the reaming one served as the test subset. Additionally, an amount of lagged values equal to the window size was eliminated from zones where training and test subsets come together (see
Figure 4). Then, the training subset’s input and output sequences were used to train the sequence-to-sequence LSTM models. Once the model was trained, it was fed by the input sequence of the test subset, and the
MSE was calculated by comparing the predicted values against the output sequence of the test subset. This procedure was repeated five times until all the folds were employed once as the test subset. Finally, the average value of
MSE was calculated.
After the optimal parameters were found, a sequence-to-sequence final LSTM model was trained using the entire lagged training dataset. Once trained, the input sequence of the test lagged dataset was used to feed this model. As a result, the NO2 predicted values were obtained. Performance measures were calculated comparing these values against the output sequence of the test lagged dataset. This process was repeated 20 times, and the average results were calculated.
In the LSTM-EX models, the procedure followed is the same as described in LSTM-UN models. However, as the exogenous datasets were used, the input sequences of their corresponding training and test lagged datasets had to be modified. This modification was performed as described for the LSTM-EX models case (see
Section 4.1 and
Figure 5).
5. Results and Discussion
This section contains the results obtained in this study on forecasting the NO2 concentration in the EPS Algeciras monitoring station situated in the Bay of Algeciras area. All the calculations were carried out using MATLAB 2020a running on an Intel Xenon 6230 Gold workstation, equipped with 128 GB of RAM and an NVidia Titan RTX graphic card.
The performance metrics depicted in this section correspond to the final models calculated using the test subset with the ending 30% of the database’s records. The models were built employing ANNs, sequence-to-sequence LSTMs and the novel LSTM-CVT method as the forecasting techniques. Prediction horizons of
t + 1,
t + 4 and
t + 8 were established, and their performance was compared in two different scenarios depending on the dataset used (univariate or exogenous datasets, see
Section 4).
In the ANN and LSTM-CVT models, different sizes of autoregressive windows were used (24, 48 and 72 h). In the models where an exogenous dataset was used, only the top 5%, 10% or 15% lagged variables were kept (see
Section 3.2). This selection was made according to several feature ranking techniques: mutual information, mRMR, Spearman’s rank correlation, mRMR-SRC and MIC (see
Section 3.4).
Table 7 shows the average performance for the top models per each prediction horizon. In this table,
ws corresponds to the window size,
nh is the number of units in the hidden layer (neurons),
DP denotes the dropout probability,
MBS is the minibatch size,
LR corresponds to the learning rate,
L2
R is the level 2 regularization factor and
GD is the gradient decay factor. In the exogenous datasets scenario, the top models per window size are presented. Additionally,
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6 in
Appendix A show the results obtained using the univariate dataset and the top models per window size using exogenous datasets. The complete list of models built using exogenous datasets is also presented in
Table A7,
Table A8 and
Table A9 of the mentioned appendix.
A first comparison of the results based on the prediction horizon shows how performance indices worsen as the forecast horizon grows. As further in the future, the prediction goes, the accuracy of the models lowers. Thus, the best performing models go from
ρ ≈ 0.90 for
t + 1 to
ρ ≈ 0.66 for
t + 8. A comparison between the top models for each prediction horizon of
Table 7 is presented in
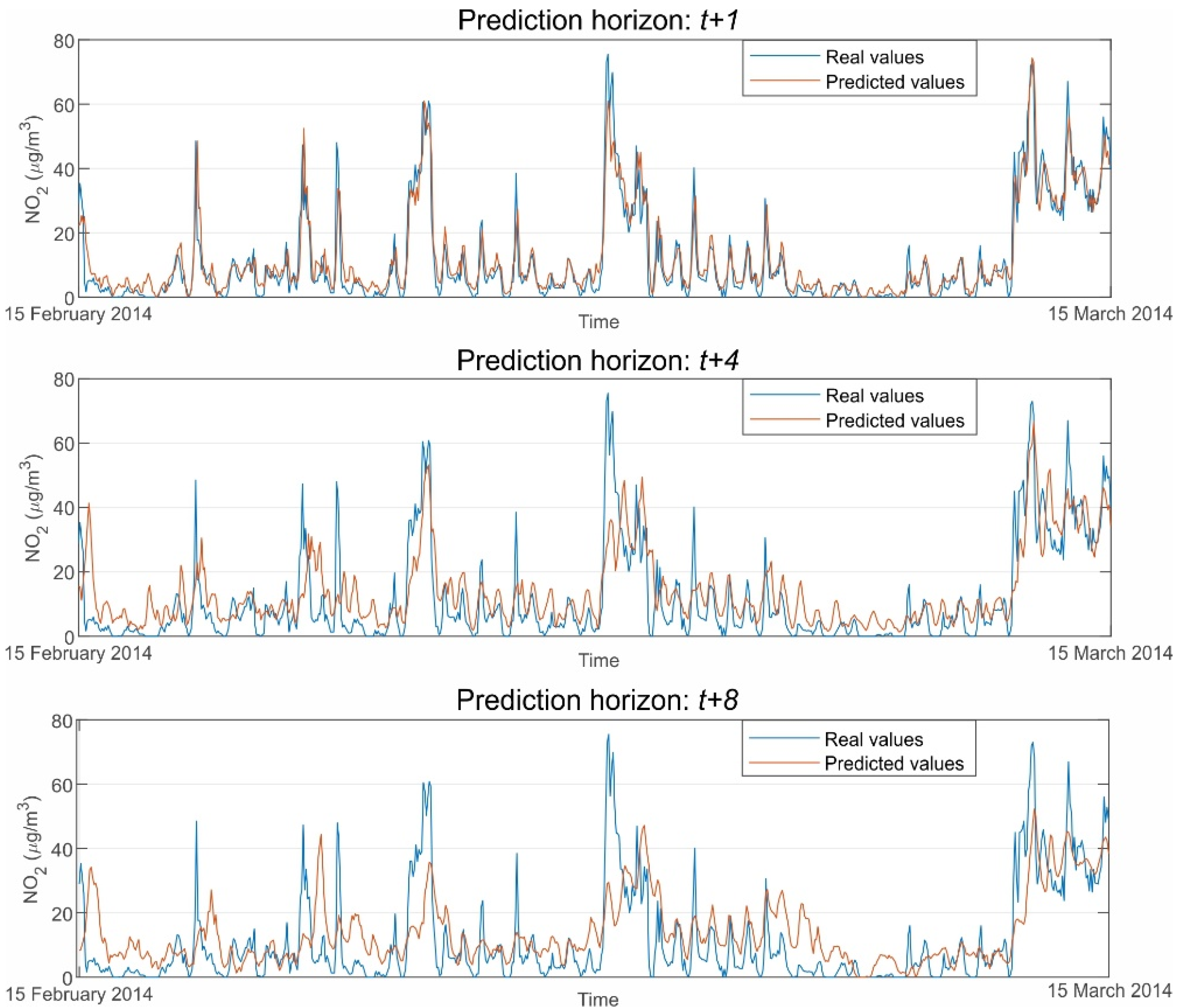
Figure 6. In this figure, observed vs. predicted values of NO
2 hourly average concentrations are depicted for the period between the 15 February 2014 and the 15 March 2014.
As can be seen, the fit and adjustment to the measured values are excellent for the best model of the t + 1 prediction horizon. However, the fit’s goodness decreases as the prediction horizons grow, confirming what was previously stated.
Another essential factor in this work is the possible influence of exogenous variables on the models’ performance. In light of the results, exogenous variables’ inclusion boosts the model’s forecasting performance, regardless of the forecasting technique used or the prediction horizon considered.
Table 8 shows the perceptual changes in
ρ and
MSE of the models from
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6 (see
Appendix A).
As can be observed, exogenous variables produce a noticeable enhancement in all the cases considered. This improvement becomes greater for t + 4 and t + 8, especially for the Pearson’s correlation coefficient. An in-depth look at the results shows how the proposed LSTM-CVT-EX models lead the prediction horizon scenarios’ performance rankings. Additionally, the LSTM-CVT and ANN best-performing models provide better performance indexes than sequence-to-sequence LSTMs in all the proposed cases. This observation emphasizes the positive effect of the lagged dataset and the time series cross-validation on the LSTM-CVT models, which internally uses sequence-to-sequence LSTMs.
The comparison of the LSTM-CVT and the ANNs models reveals that their performances are much closer than in the previous case. However, all the best performing models per prediction horizon are LSTM-CVT models. This fact can also be observed for each prediction horizon/window size combination presented in
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6.
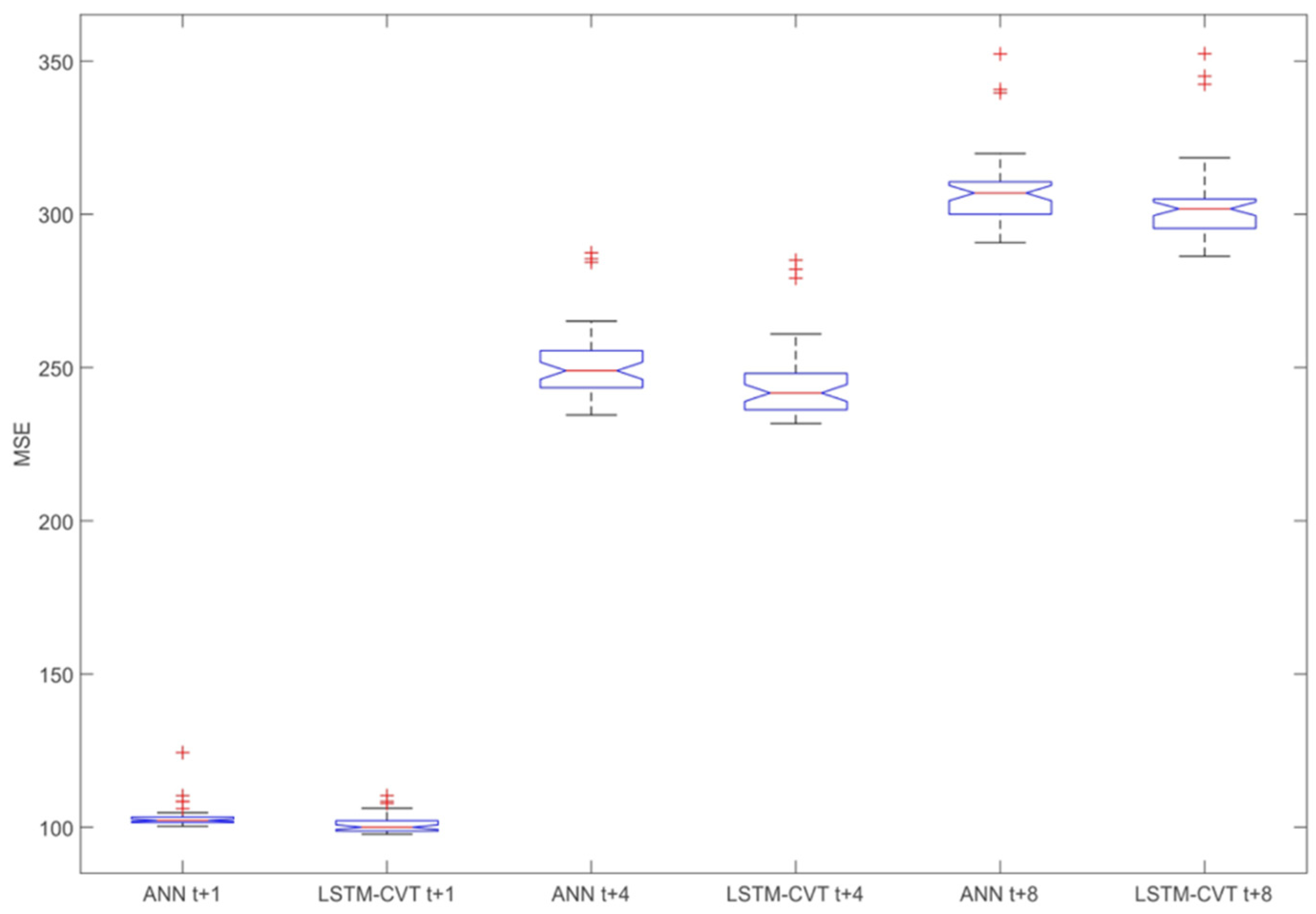
Figure 7 depicts box-plot comparisons of these models for exogenous datasets and
t + 1,
t + 4 and
t + 8 prediction horizons. For each case, their average
MSE values have been compared, including all the possible windows size, feature ranking and percentage combinations considered in this work (see
Appendix A for the complete list of cases for the exogenous datasets).
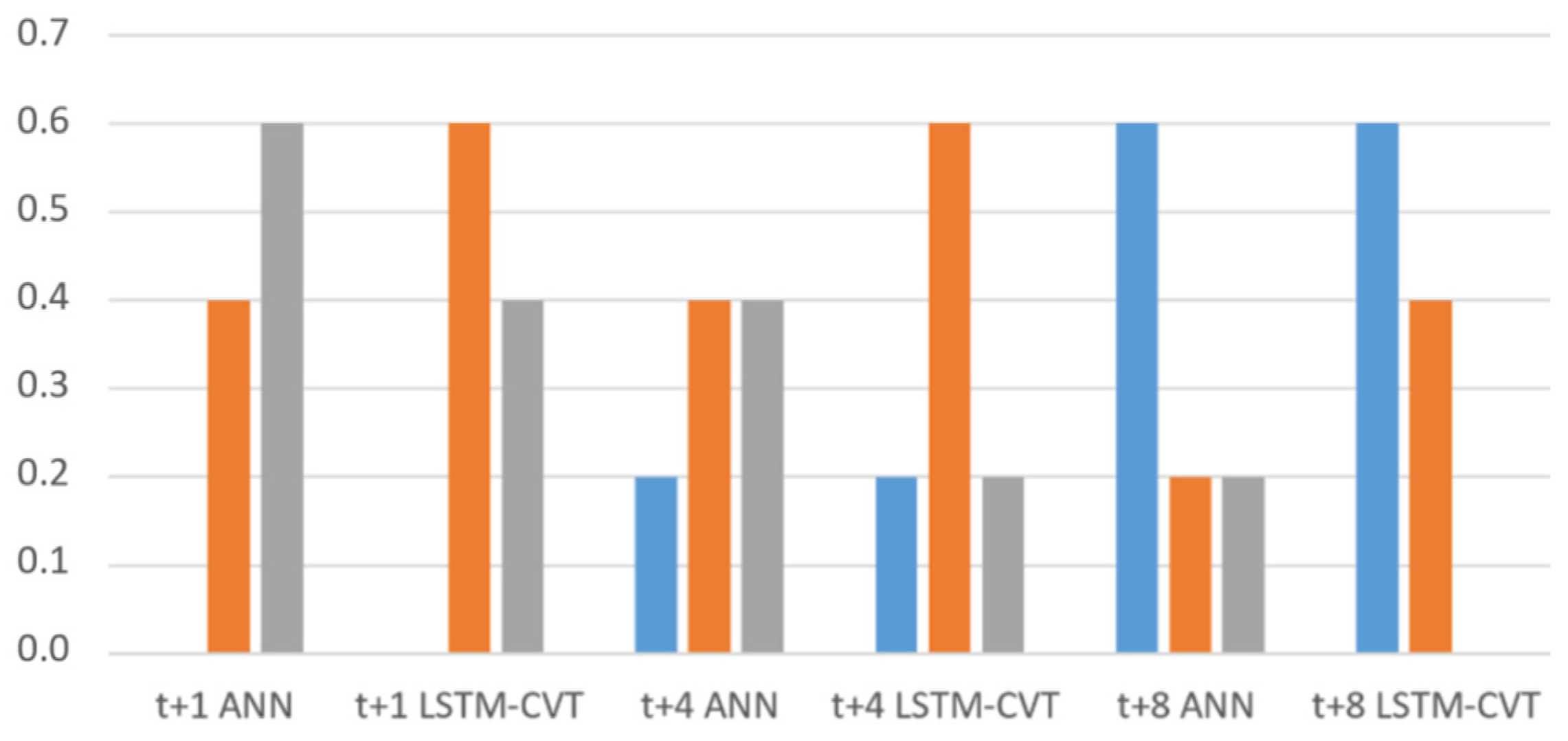
Additionally, per each parameter combination (window size + feature ranking method + percentage), ANN and LSTM-VCT models have been compared. The rates of parameter combinations where each technique provides better average
MSE values are presented in
Figure 8. The representations in
Figure 7 and
Figure 8 confirm the forecasting capability of the LSTM-CVT method as it offers a lower average
MSE than ANN models in the 85% of the total combinations considered.
Another interesting aspect is related to the window size, percentage of lagged variables selected used by the top-performing models.
Figure 9,
Figure 10 and
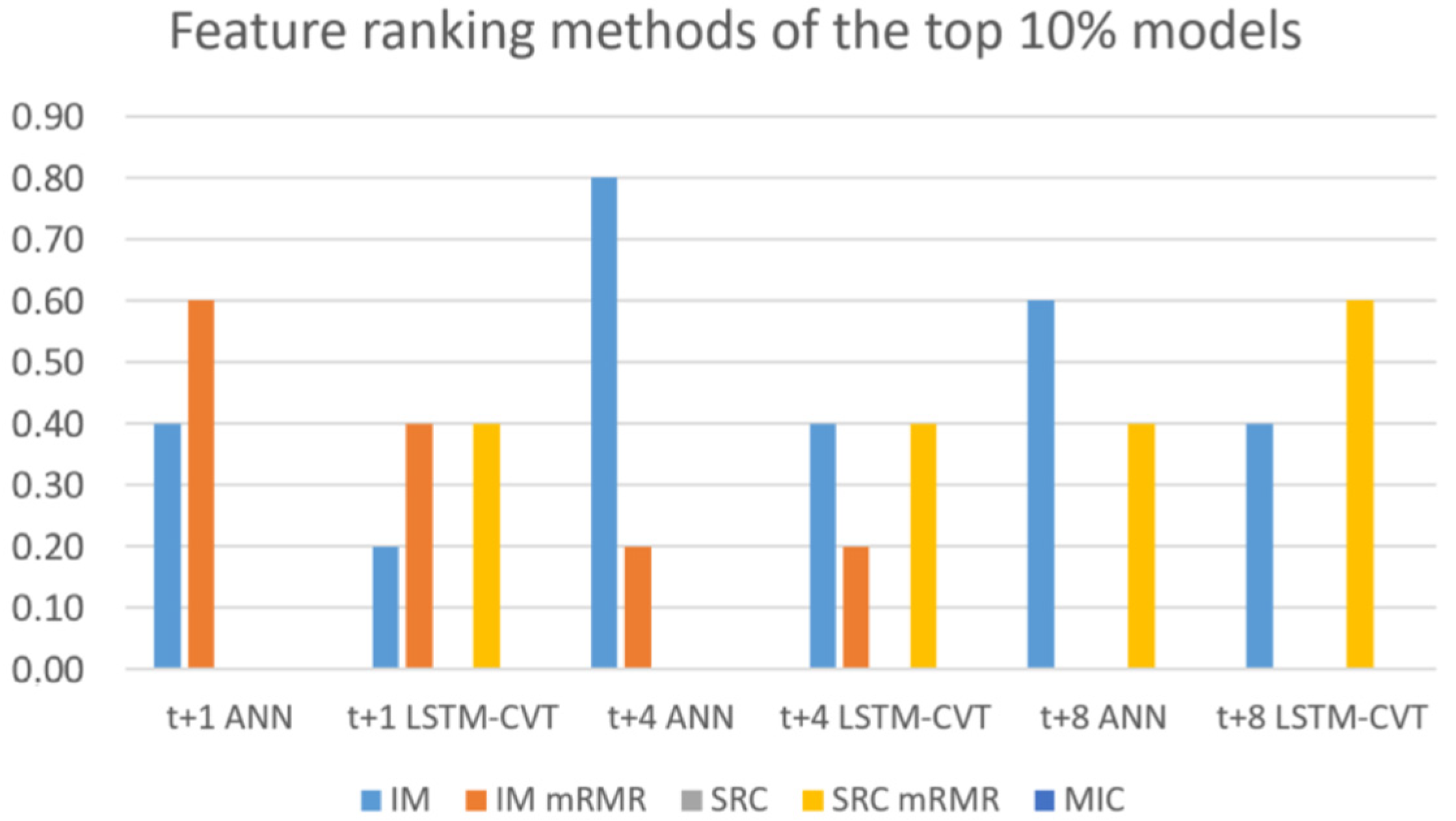
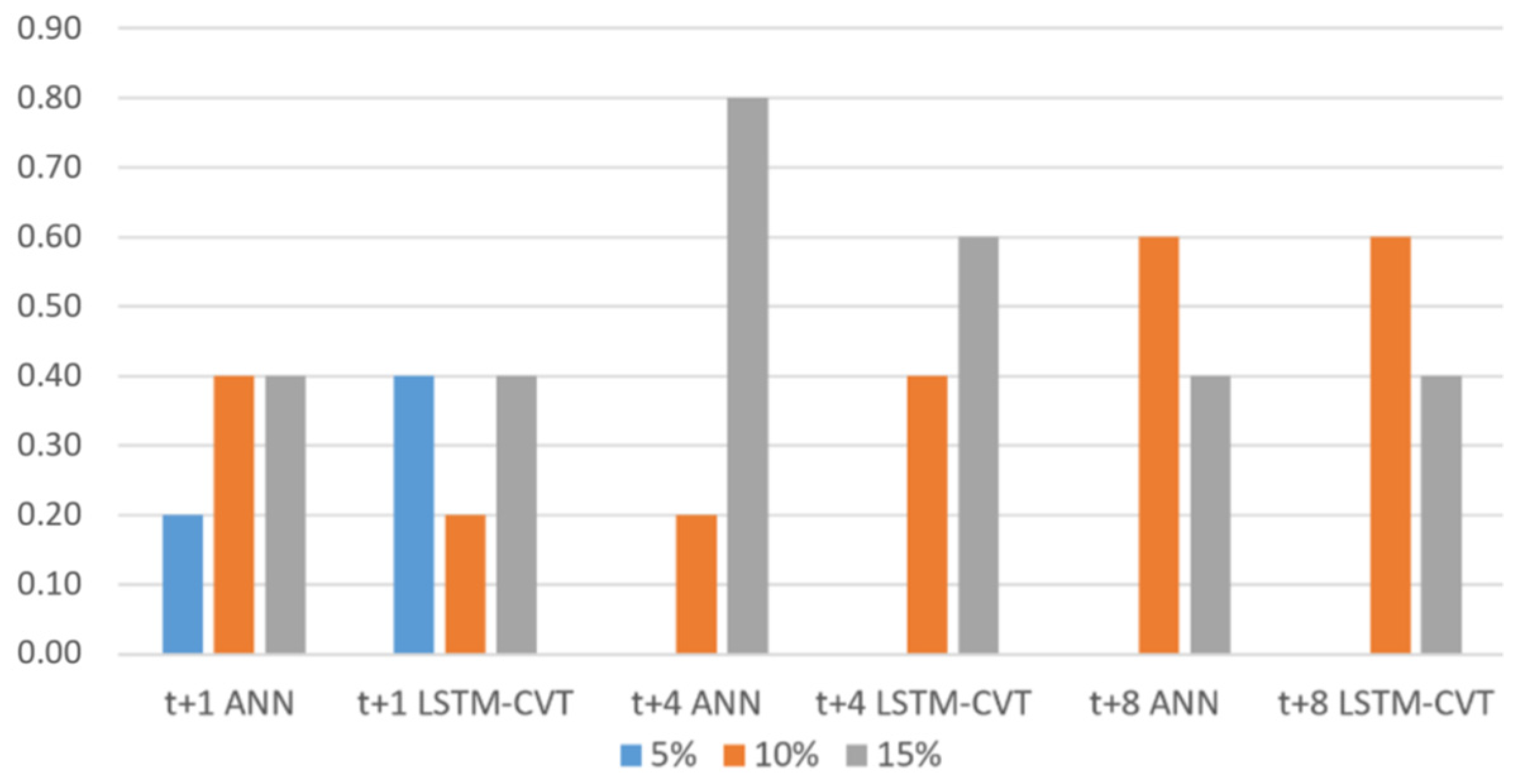
Figure 11 depicts the usage rates of their possible values for these parameters by the top 10% performing models.
As shown in
Figure 9, window sizes of 48 h are among the more employed, with an approximate usage of the 43% of the models considered. However, 72 and 24 h are also employed with use percentages of around 30%. The difference is that
t + 1 models tend to use larger window sizes (48–72 h), while
t + 8 models do the opposite (24 is the preferred window size in this prediction horizon).
Regarding the feature ranking techniques employed, it is essential to note the influence of these methods in the exogenous lagged dataset creation and, hence, the model’s future performance.
Figure 10 shows how the top-performing models only use mutual information, mRMR and mRMR-SRC. In contrast, MIC and standard Spearman’s rank correlation are not employed by these top-performing models. On the one hand, mutual information is applied by around 50% of the models. A closed look to
Figure 10 reveals that MI is especially significant in ANN models, while LSTM-CVT models use mRMR-SRC much more. Additionally, the use of mRMR decreases as the prediction horizon grows (it is not employed by any of the top-performing models in
t + 8).
Concerning the percentage of lagged variables used presented in
Figure 11, the options of 15% and 10% are used in all the cases. Their use is especially remarkable in longer time horizons. Conversely, the 5% option is only used by
t + 1 models that do not need as much information as
t + 4 or
t + 8 models to provide good forecasting results.
6. Conclusions
This paper aims to produce accurate forecasting models to predict the NO2 concentration levels at the EPS Algeciras monitoring station in the Bay of Algeciras area, Spain. The forecasting techniques employed include ANNs, LSTMs and the newly proposed LSTM-CVT method. This method merges sequence-to-sequence LSTMs with a time-series cross-validation procedure and a rolling window approach to utilize lagged datasets. Additionally, a methodology used to feed standard sequence-to-sequence LSTMs with exogenous variables was also presented. Bayesian optimization was employed to automatically determine the optimal hyperparameters of the LSTM models, including LSTM-CVT.
Three different prediction horizons (t + 1, t + 4 and t + 8) were established to test the forecasting capabilities. Additionally, two different approaches were followed regarding the input data. On the one hand, the first option used a univariate dataset with just the hourly NO2 data measured at the EPS Algeciras monitoring station. On the other hand, the second approach added exogenous features, including NO2 data from different monitoring stations, other pollutants (SO2, NOx and O3) from EPS and the remaining stations, and several meteorological variables.
The procedure used to create the ANN and LSTM-CVT exogenous models includes creating lagged datasets with different window sizes (24, 48 and 72 h). The high number of features employed made it unfeasible to use all the lagged variables produced. Hence, several feature ranking methods were presented and used to select the top 5%, 10% and 15% lagged variables into the final exogenous datasets. Consequently, 45 window size/feature ranking/percentage combinations were arranged and tested per each prediction horizon (see
Appendix A).
Exogenous datasets produced a noticeable enhancement in the model’s performance, especially for
t + 4 (
ρ ≈ 0.68 to
ρ ≈ 0.74) and
t + 8 (
ρ ≈ 0.59 to
ρ ≈ 0.66). In the case of the
t + 1 horizon, results were closer (
ρ ≈ 0.89 to
ρ ≈ 0.90). These improvements are found no matter the prediction technique used (see
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6 in
Appendix A and
Table 8). Despite the noticeable gains in the LSTM model’s performance due to exogenous features, the ANN and LSTM-CVT models’ overachieved all the sequence-to-sequence LSTM models.
The proposed LSTM-CVT method produced promising results as all the best performing models per prediction horizon employed this new methodology. This tendency can also be observed for each prediction horizon/window size combination presented in
Table A1,
Table A2,
Table A3,
Table A4,
Table A5 and
Table A6. Per each parameter combination (window size + feature ranking method + percentage), the performances of this new methodology and ANNs were compared. Results showed how the LSTM-CVT models delivered a lower average
MSE than the ANN models in 85% of the total combinations considered. Additionally, models using this methodology performed better than sequence-to-sequence LSTMs models, especially for the
t + 4 (
ρ ≈ 0.70 against
ρ ≈ 0.74) and
t + 8 (
ρ ≈ 0.63 against
ρ ≈ 0.66) prediction horizons.
The percentages of lagged features selected, the feature ranking to be employed and the optimal window sizes were also discussed. Results reveal that forecasting models using a further prediction horizon need to use more information and more exogenous variables. In contrast, models for a closer prediction horizon only need the time series data and less exogenous features.
As results indicate, the new LSTM-CVT technique could be a valuable alternative to standard LSTMs and ANNs to predict NO2 concentrations. This novel method represents an improvement against all the other methods used, which are among the most representative in NO2 time series forecasting literature. Additionally, it is also important to outline the excellent performance of the exogenous models. In the case of ANN-EX and LSTM-CVT-EX models, a new methodology using feature ranking methods was also proposed to deal with the increasing lagged variables as the window sizes grow. In this approach, the importance of the selection of the more significant lagged features becomes essential. Thus, new feature selection techniques will be tested with LSTM-CVT in future works. Furthermore, it is also necessary to highlight the Bayesian optimization procedure employed to train the sequence-to-sequence LSTM models. According to a set of limits previously established, this procedure allows an automatic search of optimal hyperparameters. As a result, the chances of finding the real optimal hyperparameters are considerably higher than other approaches followed in the scientific literature.
Finally, as stated in previous sections, nitrogen dioxide plays a principal role among air pollutants due to the study area’s inherent characteristics. The proposed models and the new methodologies presented can help to predict exceedance episodes in the NO2 concentrations. They can act as decision-making tools that allow the governmental and environmental agencies to take the necessary measures to avoid the possible harmful effects and the associated air quality demise. Additionally, these new methodologies can be applied to other pollutants forecasting and help obtain better AQI predictions in the study area.


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










