
Deep Learning-Based Concrete Surface Damage Monitoring Method Using Structured Lights and Depth Camera

Abstract
:1. Introduction
2. Deep Learning-Based Damage Detection
2.1. Recapitulation of Faster RCNN
2.2. Damage Identification Model Based on Faster RCNN
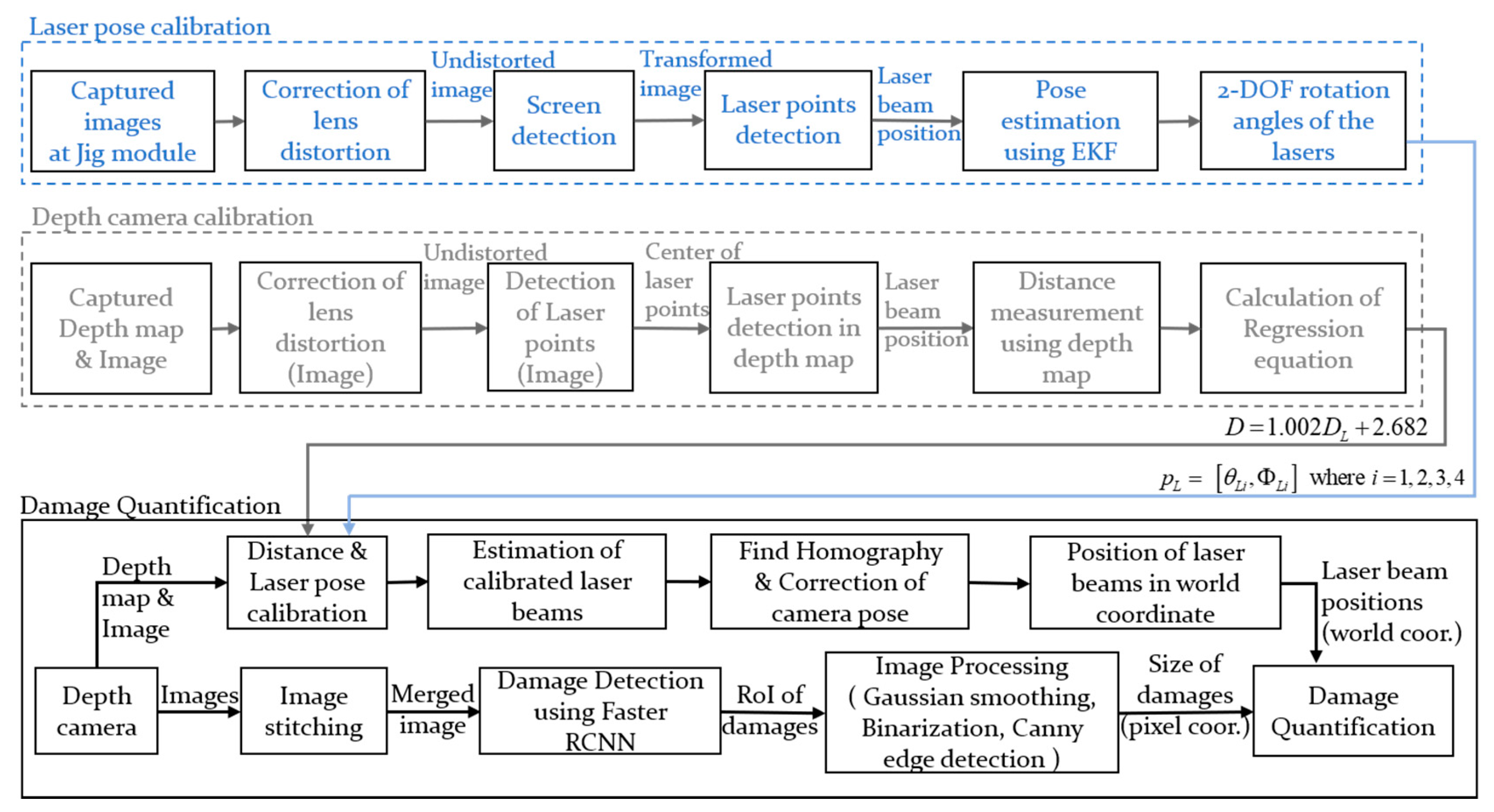
3. Damage Quantification Using Structured Lights and a Depth Camera
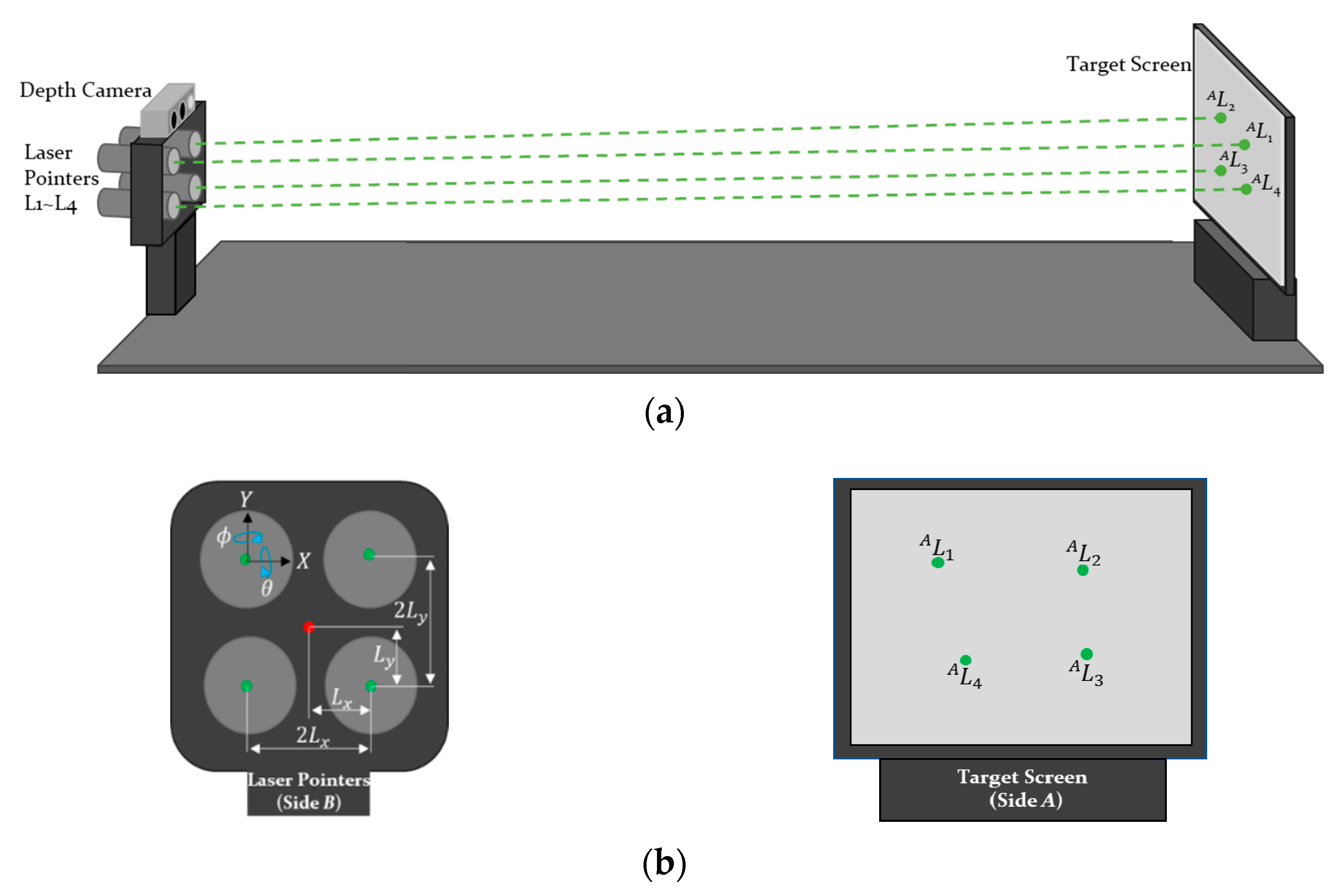
3.1. Calibration of the Structured Light
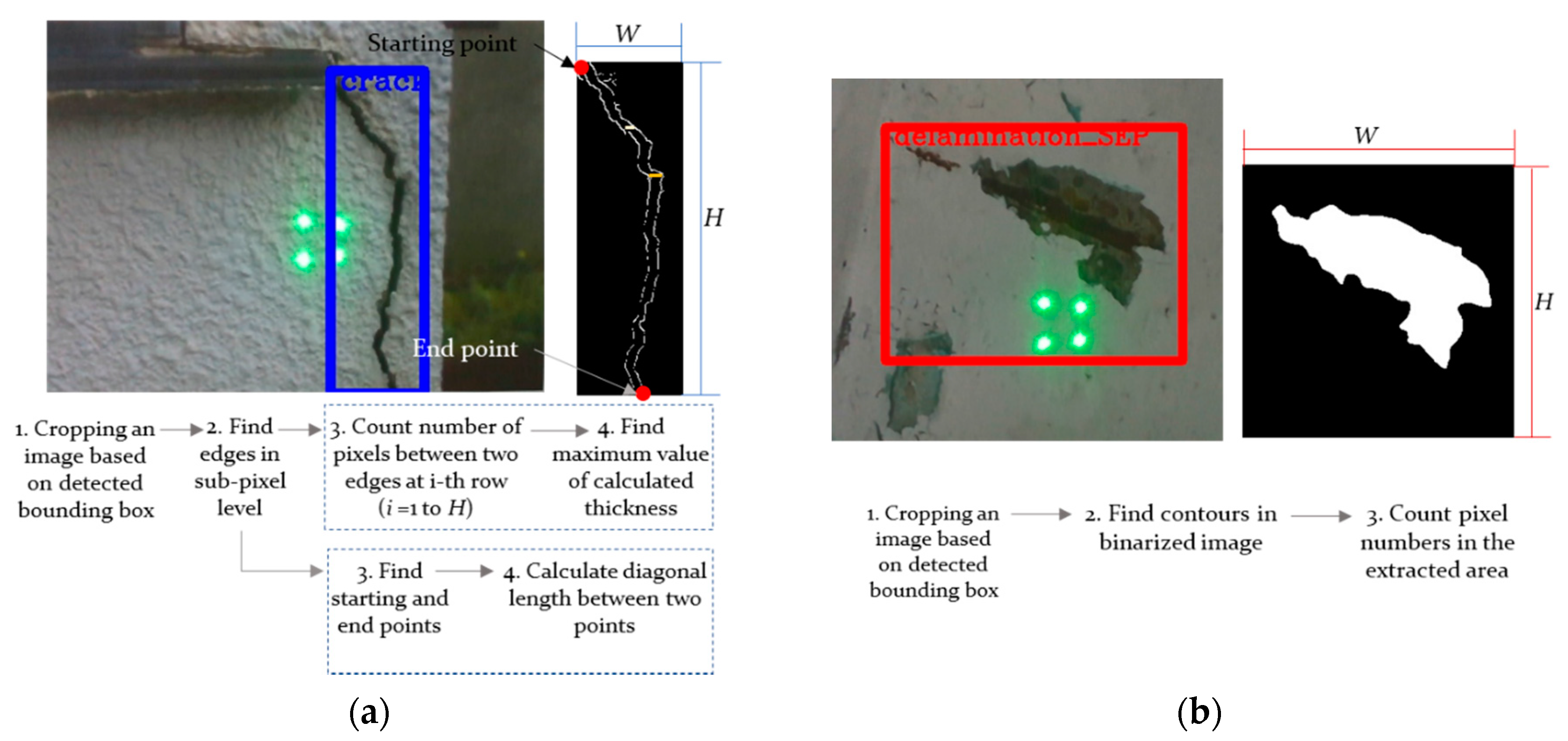
3.2. Damage Quantification Via Structured Lights and A Depth Camera
4. Experimental Test
4.1. Experimental Setup
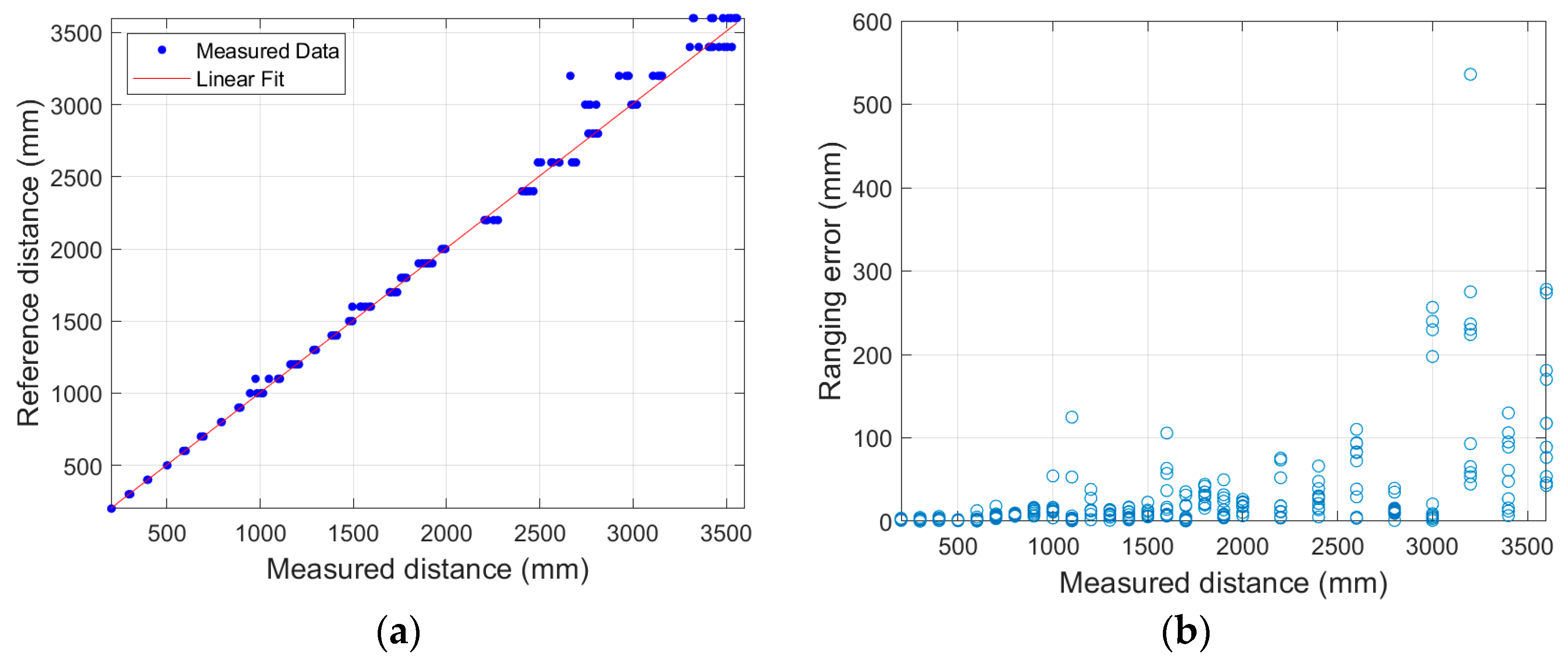
4.2. Experimental Results
4.3. Discussions on the Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jahanshahi, M.R.; Kelly, J.S.; Masri, S.F.; Sukhatme, G.S. A survey and evaluation of promising approaches for automatic image-based defect detection of bridge structures. Struct. Infrastruct. Eng. 2009, 5, 455–486. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of edge-detection techniques for crack identification in bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef]
- Lattanzi, D.; Miller, G.R. Robust automated concrete damage detection algorithms for field applications. J. Comput. Civ. Eng. 2014, 28, 253–262. [Google Scholar] [CrossRef]
- Nishikawa, T.; Yoshida, J.; Sugiyama, T.; Fujino, Y. Concrete crack detection by multiple sequential image filtering. Comput. Civ. Infrastruct. Eng. 2012, 27, 29–47. [Google Scholar] [CrossRef]
- Cha, Y.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput. Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Cha, Y.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous structural visual inspection using region-based deep learning for detecting multiple damage types. Comput. Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Kim, I.-H.; Jeon, H.; Baek, S.-C.; Hong, W.-H.; Jung, H.-J. Application of crack identification techniques for an aging concrete bridge inspection using an unmanned aerial vehicle. Sensors 2018, 18, 1881. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, S.E.; Eem, S.-H.; Jeon, H. Concrete crack detection and quantification using deep learning and structured light. Constr. Build. Mater. 2020, 252, 119096. [Google Scholar] [CrossRef]
- Kim, B.; Cho, S. Image-based concrete crack assessment using mask and region-based convolutional neural network. Struct. Control Health Monit. 2019, 26, e2381. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional Networks and Applications in Vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Lecture Notes in Computer Science, Computer Vision–ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7310–7311. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A survey of transfer learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. Available online: https://arxiv.org/abs/1602.07261 (accessed on 14 April 2021).
- Moon, T.K.; Stirling, W.C. Mathematical Methods and Algorithms for Signal Processing; Prentice Hall: Hoboken, NJ, USA, 2000; ISBN 0201361868. [Google Scholar]
- Keselman, L.; Iselin Woodfill, J.; Grunnet-Jepsen, A.; Bhowmik, A. Intel Realsense Stereoscopic Depth Cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 1–10. [Google Scholar]
- Brown, M.; Lowe, D.G. Automatic panoramic image stitching using invariant features. Int. J. Comput. Vis. 2007, 74, 59–73. [Google Scholar] [CrossRef] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Average Precision | Average Recall | F1 Score |
|---|---|---|---|
| 0.764815 | 0.93339 | 0.744322 | 0.828203 |
| Type of Cracks (Reference Value) | Thickness (T) | Length (L) | ||||||
|---|---|---|---|---|---|---|---|---|
| w/o Calibration | w Calibration | w/o Calibration | w Calibration | |||||
| Meas (mm) | Error (%) | Meas (mm) | Error (%) | Meas (mm) | Error (%) | Meas (mm) | Error (%) | |
| Shear crack (T: 1.6, W: 323.0) | 1.58 | 1.25 | 1.61 | 0.63 | 316.57 | 1.99 | 322.59 | 0.13 |
| Settlement crack (T: 3.5, W: 864.0) | 2.16 | 38.29 | 3.55 | 1.43 | 618.84 | 28.38 | 884.04 | 2.32 |
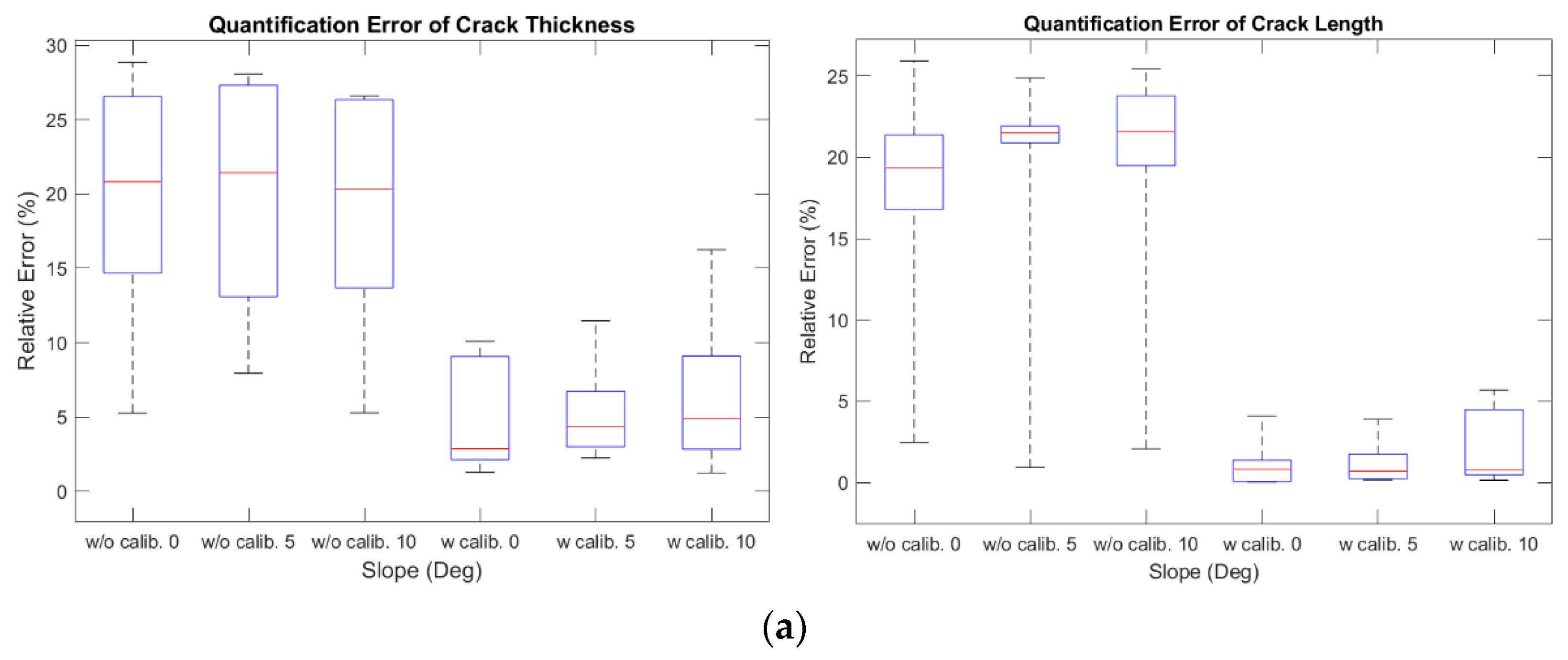
| Slope (Deg.) | Number of Samples | Min | Max | Median | First Quartile | Third Quartile | ||
|---|---|---|---|---|---|---|---|---|
| Crack thickness | Without calibration | 0 | 10 | 5.25 | 28.84 | 20.82 | 14.68 | 26.56 |
| 5 | 10 | 7.93 | 28.06 | 21.42 | 13.07 | 27.31 | ||
| 10 | 10 | 5.26 | 26.60 | 20.33 | 13.68 | 26.33 | ||
| With calibration | 0 | 10 | 1.27 | 10.09 | 2.85 | 2.11 | 9.07 | |
| 5 | 10 | 2.24 | 11.46 | 4.35 | 2.99 | 6.73 | ||
| 10 | 10 | 1.22 | 16.25 | 4.87 | 2.83 | 9.11 | ||
| Crack length | Without calibration | 0 | 10 | 2.47 | 25.92 | 19.34 | 16.79 | 21.38 |
| 5 | 10 | 0.93 | 24.88 | 21.50 | 20.90 | 21.92 | ||
| 10 | 10 | 2.09 | 25.44 | 21.59 | 19.49 | 23.79 | ||
| With calibration | 0 | 10 | 0.03 | 4.09 | 0.83 | 0.07 | 1.39 | |
| 5 | 10 | 0.16 | 3.89 | 0.71 | 0.24 | 1.76 | ||
| 10 | 10 | 0.15 | 5.69 | 0.78 | 0.49 | 4.49 | ||
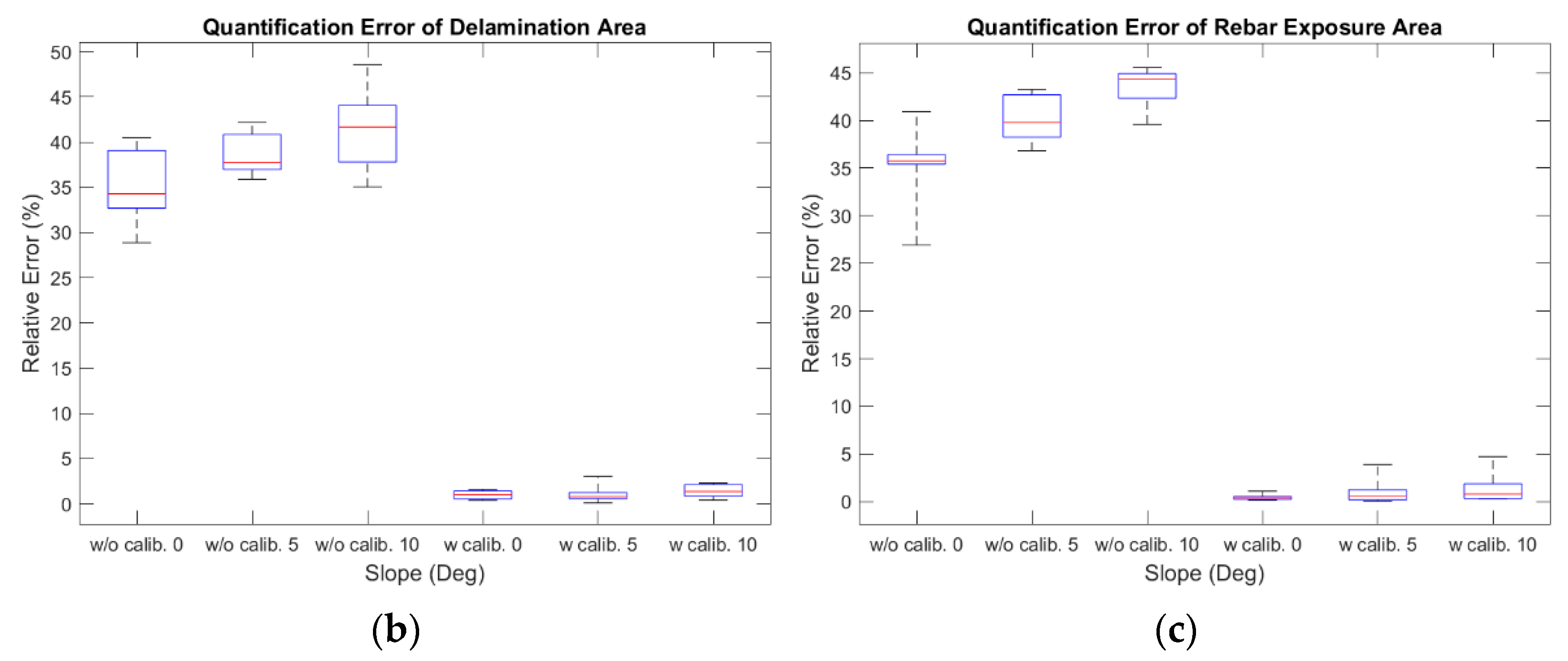
| Delamination area | Without calibration | 0 | 9 | 28.86 | 40.46 | 34.28 | 32.68 | 39.08 |
| 5 | 9 | 35.89 | 42.22 | 37.77 | 36.96 | 40.85 | ||
| 10 | 9 | 35.04 | 48.55 | 41.68 | 37.81 | 44.06 | ||
| With calibration | 0 | 9 | 0.38 | 1.59 | 1.01 | 0.53 | 1.41 | |
| 5 | 9 | 0.09 | 3.02 | 0.77 | 0.56 | 1.24 | ||
| 10 | 9 | 0.39 | 2.28 | 1.35 | 0.84 | 2.11 | ||
| Rebar exposure area | Without calibration | 0 | 7 | 26.93 | 40.91 | 35.73 | 35.40 | 36.40 |
| 5 | 7 | 36.83 | 43.25 | 39.78 | 38.25 | 42.69 | ||
| 10 | 7 | 39.59 | 45.54 | 44.31 | 42.34 | 44.90 | ||
| With calibration | 0 | 7 | 0.15 | 1.09 | 0.40 | 0.23 | 0.53 | |
| 5 | 7 | 0.05 | 3.87 | 0.55 | 0.19 | 1.24 | ||
| 10 | 7 | 0.28 | 4.73 | 0.79 | 0.28 | 1.88 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bang, H.; Min, J.; Jeon, H. Deep Learning-Based Concrete Surface Damage Monitoring Method Using Structured Lights and Depth Camera. Sensors 2021, 21, 2759. https://doi.org/10.3390/s21082759
Bang H, Min J, Jeon H. Deep Learning-Based Concrete Surface Damage Monitoring Method Using Structured Lights and Depth Camera. Sensors. 2021; 21(8):2759. https://doi.org/10.3390/s21082759
Chicago/Turabian StyleBang, Hyuntae, Jiyoung Min, and Haemin Jeon. 2021. "Deep Learning-Based Concrete Surface Damage Monitoring Method Using Structured Lights and Depth Camera" Sensors 21, no. 8: 2759. https://doi.org/10.3390/s21082759
APA StyleBang, H., Min, J., & Jeon, H. (2021). Deep Learning-Based Concrete Surface Damage Monitoring Method Using Structured Lights and Depth Camera. Sensors, 21(8), 2759. https://doi.org/10.3390/s21082759