1. Introduction
Table tennis or ping pong is a complex sport, requiring various psychomotor skills for different techniques and movements. It is widely known for its multiple shot techniques, spins and playing styles, played at a fast pace [
1]. For beginners, it is essential to master the four fundamental strokes (forehand drive, backhand drive, forehand push, backhand push), before moving on to more complicated techniques [
2]. The most fundamental technique is the forehand drive or forehand stroke, categorised into two types; (1) short-stroke and (2) long-stroke. A short-stroke is executed based on the rotation of the body to the left/forward, from the hips (based on the right-handed player), in which the endpoint of the bat shouldn’t be over the body. Otherwise, the stroke is long and considered to be one of the common beginner mistakes [
3]. From an expert’s perspective, a long stroke is considered to be an advanced technique which requires the fundamentals, such as the short forehand stroke to be mastered first.
To learn the technique, beginners need to repeatedly practice the stroke to the extent that muscle memory is trained, which automates them. Doing so allows the player to execute the stroke without any mental effort, and thus he/she can focus on more complex aspects of performance. This requires repeated deliberate practice, a conscious form of practice, which necessitates constant feedback from the mentor [
4]. A beginner needs continuous feedback on various attributes of the skills such as the body movement and strokes during repeated practice, from the mentor in order to improve. However, the mentor’s inability to be around all the time will adversely affect the beginners’ progress requiring longer duration to master the skill. Moreover, the beginners could also develop improper techniques that, once automated, are difficult to change [
5]. Limbu et al. [
6], in their work, have pursued to address this issue by using sensors to record expert models and use the expert model to train beginners. In line with their work, this study aims to address this issue of shortage of mentors for training in table tennis by using sensors to complement mentors in providing immediate real-time feedback to the beginners.
In a high-quality training facility, such sessions are supported by sports training technologies that use expensive sensors and equipment, which are unavailable to the general population. However, smartphone devices, which are widely available for the general population, are equipped with high-tech sensors, such as the accelerometer and gyroscope that can collect data in real time. These sensors in smartphone devices can be used to measure and monitor body motion to provide feedback during table tennis practice and, therefore, can be potentially used for training [
7,
8,
9]. The majority of smartphone devices have built-in sensors that measure acceleration, orientation, and various environmental conditions. These sensors provide raw data with high precision and accuracy. In addition, they are also capable of monitoring three-dimensional device movement or positioning or monitoring changes in the ambient environment (Android Sensors Overview—
https://developer.android.com/guide/topics/sensors/sensors_overview, last accessed on 20 March 2021). Data from smartphones have been used to predict human activities such as movement [
10,
11] and fall detection [
12]. Another external sensor used for training psychomotor skills is Microsoft Kinect [
13,
14,
15]. The Kinect is an external infrared sensor that is used to track skeletal points of the human body and their movements, which can also be useful in the case of table tennis. These aforementioned devices can be used simultaneously, enabling the collection and analysis of the multimodal data for providing feedback during table tennis training.
We define multimodal data as the data from various sensors that represent more than one modality with the intention to capture an experience as close to human perception. Multimodal data often provide a better understanding of an activity that it represents. Educational researchers in the field of technology-enhanced learning and artificial intelligence (AI) are increasingly using multimodal data for training machine learning (ML) models that enhance, out of many others, psychomotor learning [
16]. The spread of smartphones, wearable sensors, and depth cameras has made the collection and use of multimodal data feasible for the general population. In recent years, the multimodal interaction approach has become increasingly popular and widely adopted in the learning science and learning analytics domains. This can be observed by the rising interest in Multimodal Learning Analytics (MMLA), an integration of a sensor-based approach with learning analytics to better understand the learning behaviour of a student. Similarly, multiple sensors, and thereof multimodal data, are increasingly being used to facilitate multimodal learning environments, which we term as Multimodal Learning Experience (MLX). Furthermore, with multimodal data, AI/ML can better understand the students’ actions, such as psychomotor activities, and thus provide better feedback during MLX.
In this paper, we first explore how multimodal data and ML approaches can be applied for automatic mistake detection in table tennis. To do so, we prototyped the Table Tennis Tutor (T3), a multi-sensor, intelligent tutoring system consisting of a smartphone with its built-in sensors and a Microsoft Kinect. We, with the prototype, investigated whether the smartphone sensors by themselves are able to classify forehand table tennis strokes as accurately as the Kinect, using the Kinect data as a baseline for performance comparison. Then, we investigated how the teachers conceptualised a system for providing real-time feedback to the beginners, by conducting an expert interview with a table tennis coach. As such, we investigated the following research questions:
- RQ1
Can we use the sensor data from the smartphone to classify forehand strokes in table tennis training, as accurately as external sensors, for example, Microsoft Kinect?
- RQ2
How do table tennis coaches conceptualise a real-time system that provides immediate feedback to the beginners during training sessions?
The paper is structured as follows: in
Section 2, we present related studies that utilise sensors for the collection of multimodal data to help improve the learning outcome and to what extent they are used in the pyschomotor domain. In
Section 3, we describe the methodology of this study. In
Section 4, we report the results of the the study, followed by a discussion of the results in
Section 5. Finally, we explain the findings of the study in
Section 6, limitations of the study in
Section 7, and possible future work in
Section 8.
3. Method
The study reported here evaluates the stroke detection system of the T3 to train table tennis using smartphone sensors. To achieve this, a workflow consisting of steps for collecting and processing the data recommended by [
29] is followed. First, we explore whether the smartphone sensors alone could classify forehand table tennis strokes as accurately as the Kinect, using the Kinect data as a baseline for performance comparison. Then, we investigate how the teachers conceptualise a computer system that provides real-time feedback to beginners by conducting an expert interview with a table tennis coach.
3.1. Participants
Due to the COVID-19 lockdown regulations, the research team was limited from acquiring enough participants in this research. After multiple search attempts and time constraints, we managed to obtain only one participant for collecting the data and one coach for the expert interview.
For RQ1, we managed to acquire only a single male participant from the Open University of The Netherlands who has approximately 19 years of experience in playing table tennis casually. With his years of experience and sufficient knowledge, we used him to collect data for training the model. We asked him to execute the correct forehand strokes and mimic the incorrect forehand strokes repetitively. The study was not conducted in a professional playground but rather in a casual office play area with an Olympic-sized standard tennis table and balls. Due to the limited amount of balls and lack of self-serving machines, we had a volunteer to serve and return the incoming balls for longer rallies to allow efficient recordings.
Due to COVID, we could not conduct the interview (RQ2) physically. Therefore, we decided to do the it online. We contacted 13 table tennis clubs in Germany, the Netherlands, and Malaysia to help us acquire the coaches for our study. Out of these, only one female coach from the University Sports of the University of Saarland (Germany) agreed to take part in the study. The coach has 21 years of playing experience and roughly four years of coaching experience. The coach was briefed, gave her consent, and agreed with the video data recording. The data collected were fully anonymised.
3.2. Smartphone Placement Study
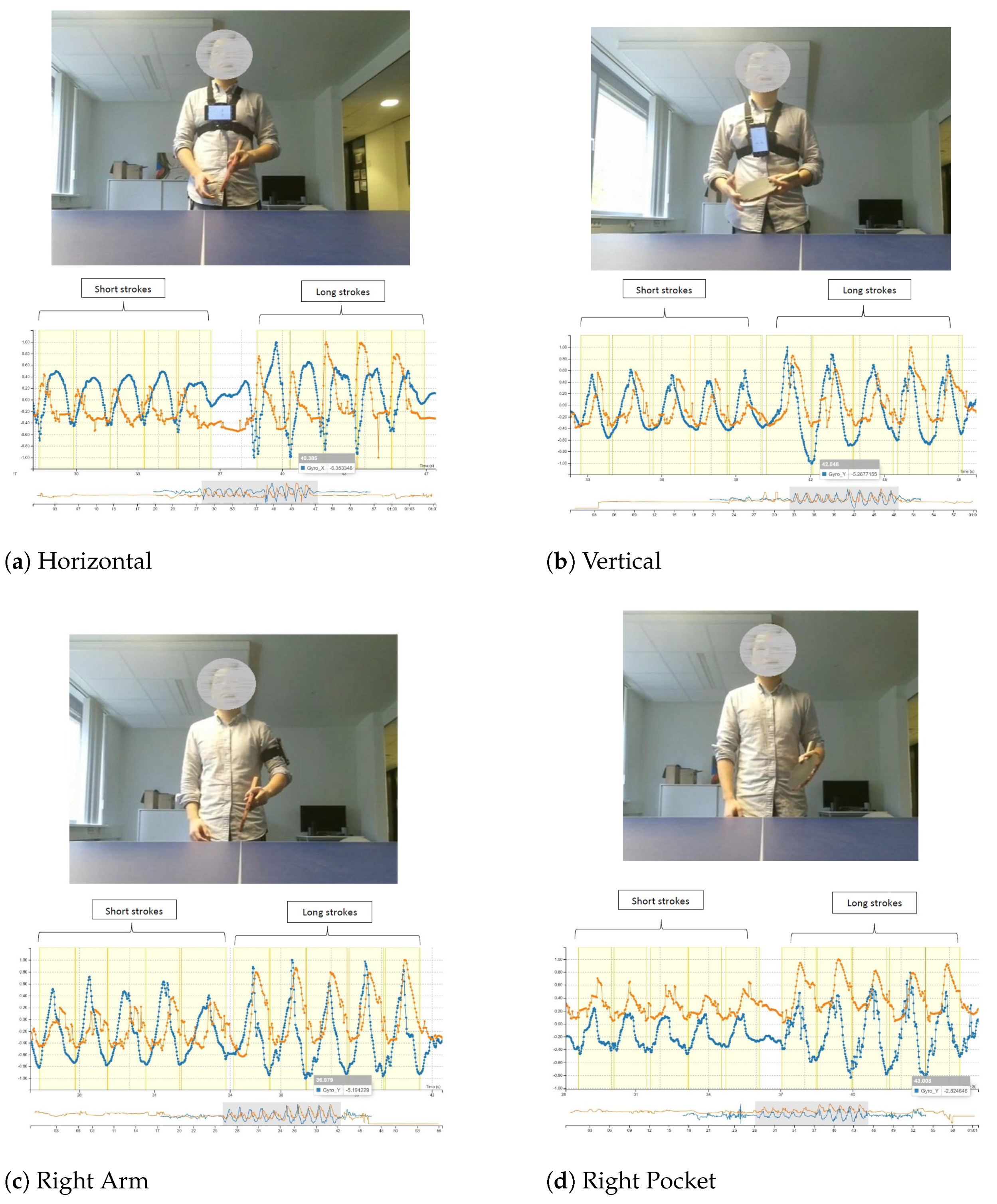
Before proceeding with RQ1, we assumed that the placement of the smartphone would likely result in a differing quality of data collected. Therefore, to figure out an ideal position for the smartphone to be placed during the training, we conducted this initial study. For this study, we considered the chest area (horizontally and vertically), arm, and pocket. These particular positions were chosen according to the recommendation of the participant about the key motion points during the execution of the forehand stroke. We excluded the wrist due to the size and weight of the device as it can be inconvenient and unnatural to the user to practice with the device strapped to the hand [
7].
The positions mentioned above, except the pocket, need additional accessories to hold the smartphone device. Therefore, a harness and mobile strap are used for the chest and arm, respectively. These methods have been used for helping patients with rehabilitation exercises, which involve body motions [
9]. On the other hand, placing the smartphone in the pocket has been widely utilised for recognising human activities [
11]. Additionally, we were focused on providing a proof of concept within a casual table tennis playing scenario. Therefore, we do not consider the implications of having a smartphone in a loose-fitting dress commonly used in table tennis.
For the arm and pocket, the right side was initially selected because the participant was right-handed. Sets of data were collected with these four positions and compared visually by the research team using the Visual Inspection Tool (VIT) [
30] (VIT—
https://github.com/dimstudio/visual-inspection-tool, last accessed on 25 March 2021), an existing annotation toolkit, by observing the data plots from the time series to explore the similarity in terms of patterns when the participant performs the strokes. The visualised results for this study are shown in
Figure 1.
Based on
Figure 1, the first five peaks’ annotations represent short strokes performed by the participant. Long strokes were mimicked by the participant and annotated as the last five peaks. By analysing these visually, we observed that the data points for the horizontally-placed smartphone (see
Figure 1a) have a unique plot pattern as compared to the other three. Hence, we excluded this position. However, for the other three positions, the plot patterns are relatively similar to each other. Reasonably, we chose the right pocket as we won’t need extra accessories to hold the smartphone, which could introduce additional inconvenience for the participant to perform the stroke. For the Kinect, we positioned the device in the middle of the tennis table (see
Figure 2) in order to capture the participant’s upper body joints, which are vital for identifying the strokes.
3.3. Data Collection Setup
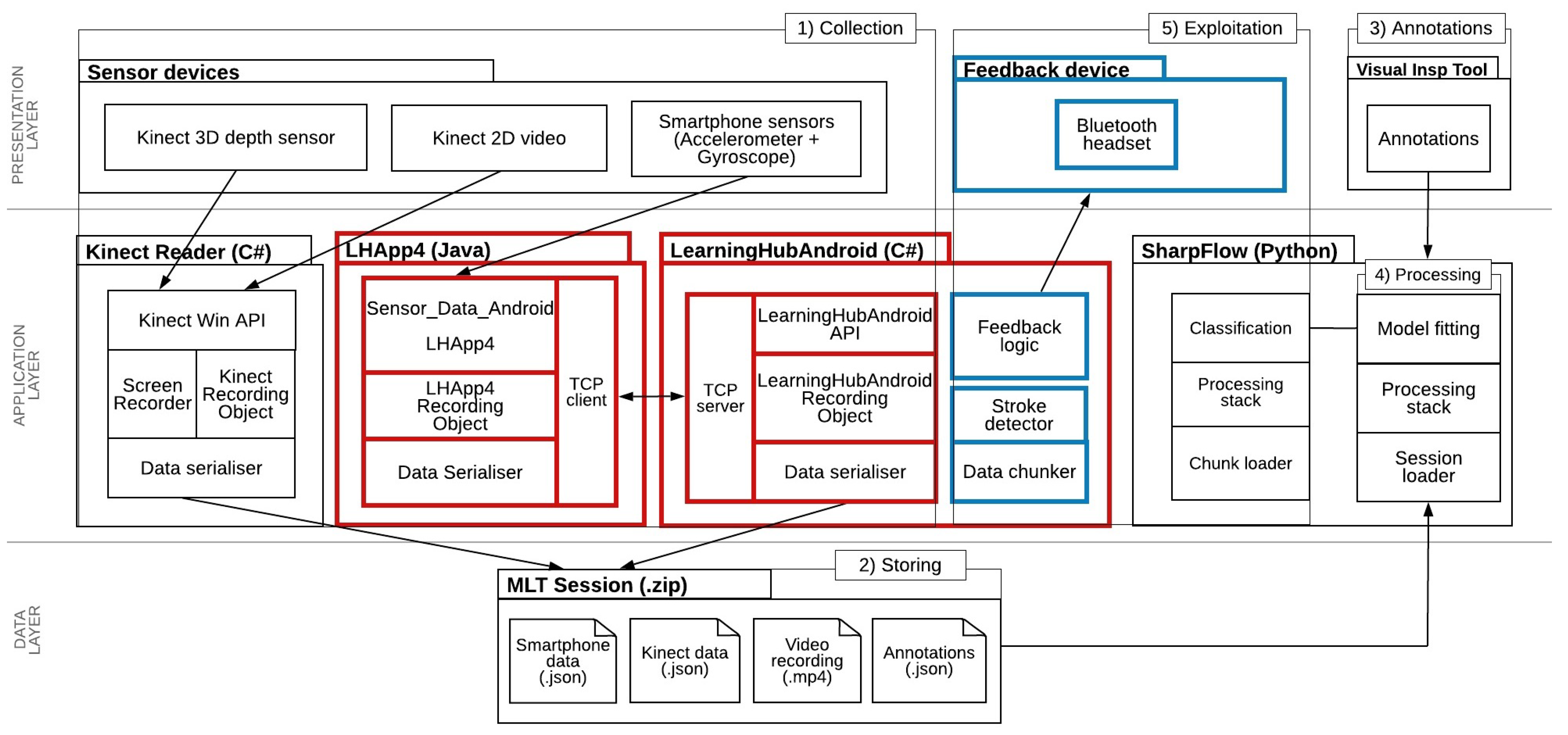
Figure 2 shows the setup used for collecting multimodal data in the case of table tennis training. It consists of the following devices/sensors:
In order to collect data from the participant in a systematic manner, we adopted the Multimodal Learning Analytics (MMLA) Pipeline [
29], a workflow for the collection, storage, annotation, analysis, and exploitation of multimodal data for supporting learning. We developed the LHAPP4 (LHAPP4—
https://github.com/khaleelasyraaf/Sensor_Data_Android.git, last accessed on 19 April 2021), a smartphone application that sends data wirelessly to the LearningHubAndroid. The LearningHubAndroid (LearningHubAndroid—
https://github.com/khaleelasyraaf/LearningHubAndroid.git, last accessed on 19 April 2021) is a Windows application that receives the data from the clients such as the LHAPP4 via WLAN, which then forwards the data to the laptop that runs the Multimodal Learning Hub (LearningHub) [
31]. The LearningHub is a custom-made sensor fusion framework designed to collect sensor data in real-time from different sensor applications and generate synchronised recordings in the form of zip files. The LearningHub is designed for short activities—a session should not be more than 10 min. It uses a client–server architecture with a master node controlling and receiving updates from multiple sensor or data provider applications. Each data provider application retrieves data updates from a single device, stores it into a list of frames, and, at the end of the recordings, sends the list of frames to the LearningHub. In this way, the LearningHub allows collecting data from various sensor streams produced at different frequencies.
We used existing components for the Kinect (Kinect Reader), which was also connected to the LearningHub for data collection. Additionally, we used the Visual Inspection Tool (VIT) [
30] for data annotation and Sharpflow [
17] for data analysis. These components above enabled the implementation of the MMLA Pipeline.
In the T3, the LearningHub was used together with three data provider applications, the LearningHubAndroid, the Kinect reader, and a screen recorder. The smartphone data provider consists of two applications: LHAPP4 and LearningHubAndroid. Thus, using these applications, we collected accelerometer and gyroscope data represented as
x,
y, and
z-axes, each directional and rotational, for a total of six attributes. The Kinect Reader collected data from the participant’s upper body joints (i.e., head, hands, shoulders, elbows, and spine) that are visible to the Kinect camera represented as three-dimensional points in space and position features for a total of 40 attributes. We excluded the lower body joints (i.e., knees and ankles) due to the obstruction of the table. The screen recorder captured the video of the participant performing the forehand strokes through the point of view of the Kinect device itself.
Figure 3 provides an overview of the setup, including the tools and sensors used. Highlighted in red are the new components introduced by this research. In blue are the future works for the T3. In the following sections, we describe how we utilised these components in this research.
3.4. Data Collection Procedure
After all the applications were ready, the participant was handed over the smartphone, which he places inside his right pocket. The participant stood on the side where the Kinect is positioned while the assistant played from the other side. The assistant served the participant, after which the two started practising short strokes or long strokes based on the intentions of data to be collected. The data were collected in multiple instances, as the LearningHub does not support long-duration recordings, and being focused consistently is mentally and physically tiring for the participant during practice. We recorded multiple sessions with the participant performing the short strokes and the long strokes repetitively. The participant dataset resulted in a total of 33 sessions and 510 recorded strokes.
3.5. Data Storing
The LearningHub uses a custom data format of Meaningful Learning Task (MLT-JSON session file) for data storing and exchange. The MLT session comes as a compressed folder including (1) one or multiple time-synchronised sensor recordings (JSON files); and (2) one video/audio of the recorded performance. The compressed folder consists of data of total attributes from smartphone and Kinect sensors which are serialised into JSON files with the following properties: an applicationId, an applicationName, and a list of frames (see Listing 1 and Listing 2). These frames have a timestamp and a sensor attribute with their corresponding values. Furthermore, an MP4 file with the recorded video of a session is added. In our case, each session produced a compressed file of roughly 15 Mb.
Listing 1.
Example of the JSON string from the LearningHubAndroid containing a RecordingObject frame for each of the DataProvider Applications.
Listing 1.
Example of the JSON string from the LearningHubAndroid containing a RecordingObject frame for each of the DataProvider Applications.
Listing 2.
Example of the JSON string from the Kinect Reader containing a RecordingObject frame for each of the DataProvider Applications.
Listing 2.
Example of the JSON string from the Kinect Reader containing a RecordingObject frame for each of the DataProvider Applications.
3.6. Data Annotation
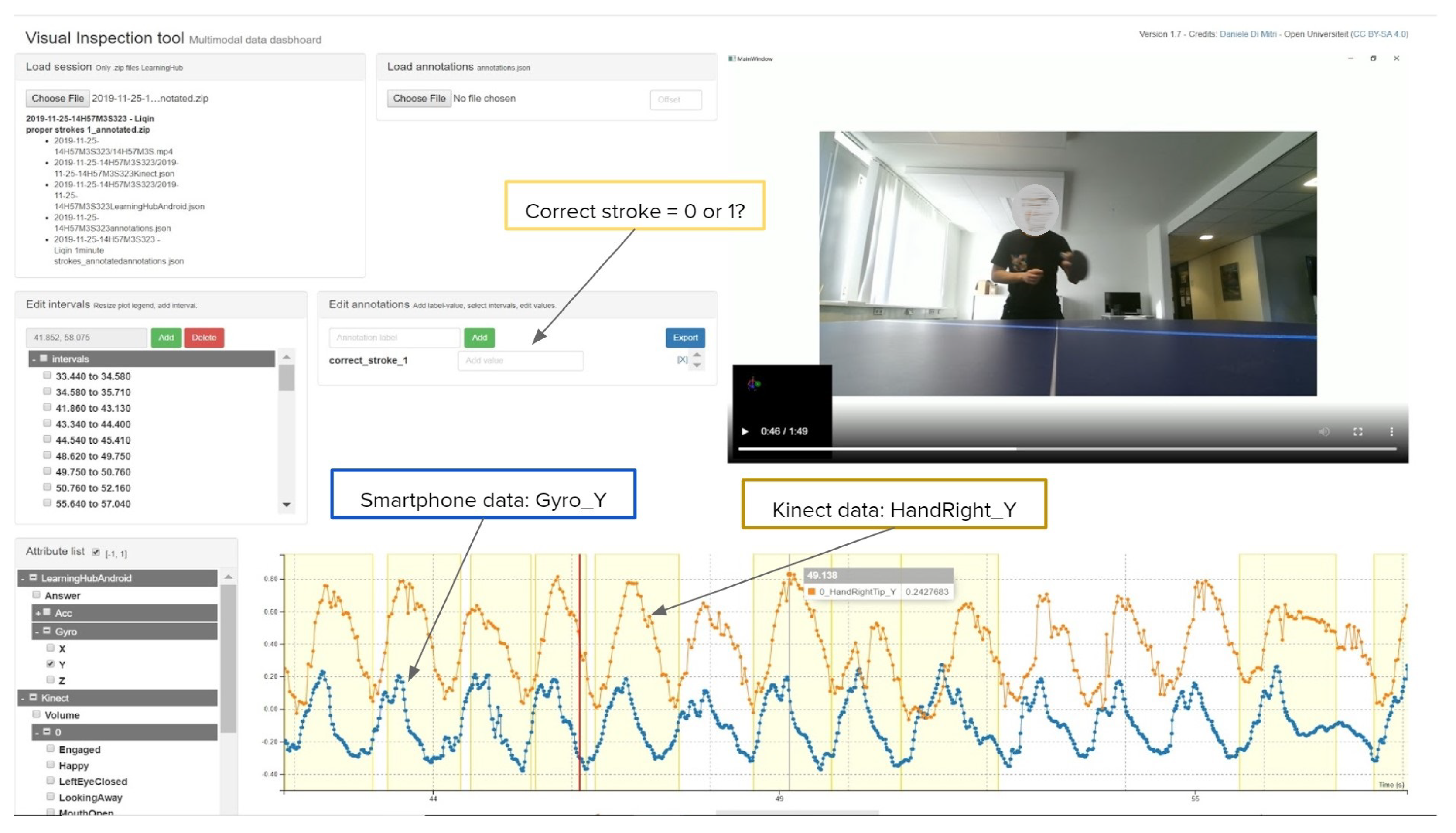
The annotations were synchronised with the recorded sessions using the VIT [
30], a web application prototype that allows manual and semi-automatic data annotation of MLT-JSON session files generated by the LearningHub. The VIT allows for specifying custom time-based intervals and assigned properties in those intervals.
Figure 4 shows the screenshot of the VIT used for the detection of strokes in a single session. For each of the 33 sessions recorded, the annotation file was loaded and synchronised manually with the guidance of the sensor data plots and the video recordings. We added the time-intervals to portions of sensor recordings. We used the binary classification approach, where either the stroke is correctly executed (Class 1) or incorrectly executed (Class 0) as labels for the machine learning classification (see Listing 3. Thus, a total number of 510 strokes (260 short strokes + 250 long strokes) were annotated. Subsequently, we downloaded the annotated sessions with the exclusion of the video files, which are vital for the next step, the analysis of data for the classification of strokes.
Listing 3.
Example of the annotation file.
Listing 3.
Example of the annotation file.
3.7. Data Analysis
We used Sharpflow (SharpFlow—
https://github.com/dimstudio/SharpFlow/, last accessed on 19 April 2021), a data analysis toolkit for time-series classification using deep and Recurrent Neural Networks (RNNs). In this study, the model used for the classification is the LSTM [
32], a special kind of RNN capable of learning over long sequences of data. In the training phase, the entire MLT-JSON sessions with the inclusion of their annotations are loaded into the memory and transformed into two Pandas DataFrames (Pandas DataFrame—
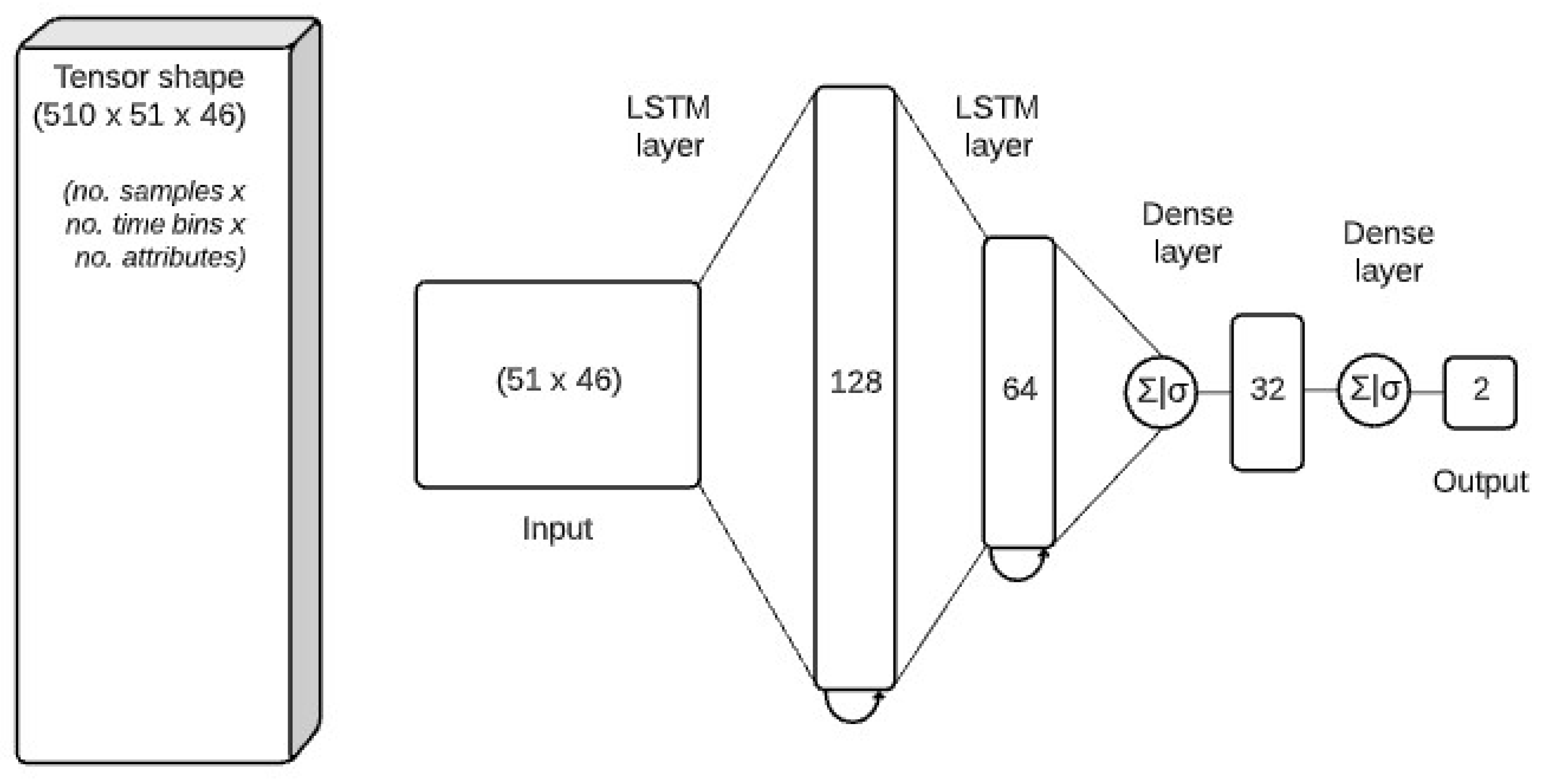
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.html, last accessed on 20 March 2021) containing: (1) the sensor data, and (2) the annotations. Since the sensor data from two devices came with different sampling frequencies, the sensor data frame had a great number of missing values. To minimise this issue, each stroke was resampled into a fixed number of time-bins that correspond to the median length of each sample. Hence, a tensor of shape (# samples ×# bins × # attributes) was obtained. Using random shuffling, the dataset was split into 85% for training and 15% for testing. A part of the training set (15%) was used as a validation set. Additionally, we applied feature scaling using min-max normalisation with a range of –1 and 1. The scaling was fitted on the training set and applied on both validation and test sets. The implementation of the LSTM model was made using PyTorch, an open-source Torch library designed to enable rapid research on machine learning models. The architecture of the model (see
Figure 5) was based on Di Mitri et al. [
17], a sequence of two stacked LSTM layers followed by two dense layers:
- –
a first LSTM with input shape 51 × 46 (#intervals × #attributes) and 128 hidden units;
- –
a second LSTM with 64 hidden units;
- –
a fully connected layer with 32 units with a sigmoid activation function;
- –
a fully connected layer with a single target class (correct_stroke) with a sigmoid activation function;
The original code from Di Mitri et al. [
17] remains unchanged, but the configuration was fitted to our dataset (see Listing 4). Since the output of the model consists of a binary class, we use a binary cross-entropy loss for optimisation and training for 30 epochs using an Adam optimiser with a learning rate of 0.01. The number of 30 epochs was chosen after acknowledging the overfitting turning point, i.e., the point when validation loss values stop increasing.
The LSTM network was trained and validated three times: (1) considering just the smartphone data as the input of the model, (2) just the Kinect data, and (3) smartphone and Kinect data combined.
Listing 4.
Code snippet for training the LSTM network.
Listing 4.
Code snippet for training the LSTM network.
3.8. Expert Interview
Since we managed to acquire only one table tennis coach, only one session was held. The whole session lasted around 40 min. During the session, we presented a set of questions with three blocks: (1) Demographic, (2) Training sessions, and (3) Design Feedback Requirements. Before proceeding to block (3), we described our study’s idea and the potential of a computer system that can help beginners improve their performance by providing feedback in real-time. We, therefore, provided an example by showing a short video of the Omron Forpheus (Omron Forpheus—
https://www.omron.com/global/en/technology/information/forpheus/index.html, last accessed on 20 March 2021), an AI ping pong robot that is able to assist table tennis players during training by providing immediate feedback.
The first block explores the coach’s background in the table tennis domain. To be more specific, we asked about her experience of playing table tennis and coaching beginners. Next, we investigated the training drills prepared by the coach for beginners and how she assisted them during training sessions (e.g., rectifying common mistakes, type of feedback). The last block explores the coach’s conceptualisation towards a computer system that can assist the beginners during training sessions by providing feedback in real time.
4. Results
4.1. RQ1—Neural Networks’ Results
The dataset transformed into a tensor of shape (510, 51, 46) where 510 are the learning samples (260 short strokes + 250 long strokes), 46 the attributes from both smartphone and Kinect (6 and 40 attributes respectively), and 51 the fixed number of time updates (time-bins) for each attribute. Each stroke being annotated with three classes: smartphone sensors alone, Kinect sensors alone, and both sensors together. The distribution of classes is the short stroke (correct_stroke) with the binary classification of 0 and 1.
Every time a random split is done between training and validation, the results retrieved were different. The intuitive explanation is that the deficiency of the whole collected dataset, which is small in size. Therefore, we used cross-validation for the resampling procedure to evaluate the model on limited data. The procedure has a single parameter called “k” that refers to the number of groups that a given data sample is to be split into. As such, the procedure is called k-fold cross-validation. When a specific value for “k” is chosen, it may be used in place of “k” in reference to the model. In our case, it was 10-fold cross-validation. Consequently, k-fold cross-validation used limited data to estimate how the model is expected to perform in general when used to make predictions on data not used during the training of the model.
Table 1 shows the results of LSTM reporting for each target class with accuracy, precision, and recall. In the context of our study, accuracy is about how close the attempts are to the target, which is the short-stroke/correct stroke, and precision is about how close they are to each other. Recall identifies positive results to get a true positive rate.
In
Table 1, we observed that the performance of the smartphone alone only achieved 51% of accuracy, which is poor as compared to the Kinect, which performs slightly better but still bad at 64% of accuracy, whereas the combination of both devices achieved similar results to the Kinect alone but with better precision at 73%. We observed that, by adding the number of attributes, the model improves.
4.2. RQ2—Expert Interview Results
The first block focuses on the background of the coach. Our only sample has 21 years of playing experience and roughly four years of coaching experience. The coach pointed out that, in general, beginners need more attention than advanced players during training sessions. Due to this, she prepared various training drills intended for the beginners, which leads to the second block.
Such drills include training the fundamental skills (i.e., forehand and backhand) repetitively before moving onto more advanced skills. Techniques observed, such as the execution of the strokes, the proper way of holding the racket and the movements. Doing these incorrectly considered common beginner mistakes that the coach has noticed in general. Hence, the coach preferred a personalised session with one beginner as she would be able to concentrate on the beginner’s performance and provide feedback instantly. In such a case, when the coach is not available during the training session, she suggested that the beginners should video record their performances to analyse them afterwards or watch and learn how the advanced players would perform the desired techniques.
For the last block, we explained the T3 and the potential of a computer system that can help beginners improve their performance by providing real-time feedback. Generally, the coach agreed but suggested that beginners should start with their table tennis class with human coaches for at least five sessions, which subsequently the computer system would complement their progress. Additionally, using the smartphone, the coach admitted that the system could be an alternative plan for beginners to practice when she is not available during the training session. As for the type of feedback, the coach preferred audio or sonification but not in real-time as it could be increasingly irritating for beginners when they make mistakes consecutively. Therefore, similar to our initial plan, she preferred an automated feedback system that fires if there are more than five mistakes detected in the last ten strokes, which would suit better. Furthermore, the coach thought that placing the smartphone in the pocket would affect the beginner’s performance.
Subsequently, we asked the coach what she would like the most and least about the system. For the former, she described that the system would improve and motivate the beginners’ performance when she, as the coach, is not around. As for the latter, since the fundamental techniques involve mostly on body motions, she mentioned that the system could be unfriendly and unnatural to disabled people, particularly those on wheelchairs. Lastly, when asked if she would include such a system in her training program, she agreed that this would help her teach more beginners concurrently and observe their performance better from far away.
6. Conclusions
In this paper, we explored an approach for classifying the forehand table tennis strokes using multimodal data and neural networks. We designed the T3, a multi-sensor setup consisting of a smartphone device with built-in motion sensors and the Kinect depth camera sensor. We validated the collected multimodal data three times, observing the performances of (1) only smartphone sensors, (2) only the Kinect, and (3) both devices combined. We observed, within our context, that smartphone sensors by themselves are unable to perform better than the Kinect. In addition, it is likely that the smartphone sensors are able to classify the strokes by complete chance due to 51% of accuracy. However, the performance improves when both of the devices are combined. Of course, our study is by no means comprehensive and many limitations exist (see
Section 7), which prevents us from drawing a conclusion for our results. Therefore, in this limited study, we conclude, as many other studies have, that more sensors are needed, in addition to the smartphone sensors for classifying forehand stroke in table tennis more accurately.
Our intention with the fore-mentioned technology was to use it to provide feedback to the employees. To facilitate this further, we organised an expert interview with a table tennis coach to explore the coach’s perception of a computer-based training system that provides feedback when mistakes are detected during training. The coach expressed her doubt about these technologies, especially AI, since they are relatively new and not widely adopted. However, the coach agrees that the system could indeed help beginners train their fundamental techniques and act as a support to further improve the learning outcome.
7. Limitations
Several shortcomings were encountered during the study from multiple perspectives. Primarily, the global pandemic of COVID-19 has restricted our objectives from collecting more data samples from the participant. Therefore, the LSTM results retrieved were poor due to the insufficiency of data (only 260 short strokes and 250 long strokes). Moreover, the Kinect only recorded the upper half of the participant’s body. Full-body tracking could have resulted in higher accuracy for the Kinect. The data from the various placements of the smartphone were manually visually judged, which could have led to unknown inaccuracies.
In addition, since strokes’ execution relies mainly on the body motion, other players with different body structures or playing styles would introduce additional uncertainty, which may affect the system’s accuracy. Furthermore, the COVID-19 limitations prevented us from conducting a user study, which was initially planned for beginners with the inclusion of a real-time feedback system. We, therefore, changed our approach into organising online expert interviews for the collection of qualitative data as an alternative. However, despite doing so, we managed to acquire only one coach after multiple search attempts.
Ideally, in our study, placing the smartphone device in the pocket helps the participant perform the strokes conveniently. However, having it inside for a long continuous session could turn out to be increasingly inconvenient due to its bulkiness. In addition, players typically wear loose shorts during the game, which removes the possibility to use the smartphone in actual club based training. A long session was also not possible due to the limitations of the LearningHub, which is only designed for short activities, and the mental and physical effort required to constantly perform short strokes repeatedly. A further limitation is the use of only one smartphone device. Newer smartphones provide more built-in sensors, and in some cases, the sensor layouts could differ from the smartphone used for this study.
8. Future Work
Despite not achieving the expected results, we think that T3 still has unexplored potential. Thus, several ideas and improvements should be further explored before this system can be used in training. The combination of the smartphone and Kinect shows the highest accuracy and precision, leading to more accurate and effective feedback. Thus, including wearable technology such as a smartwatch will potentially improve the accuracy of the system. In addition, using a smartwatch mitigates a bulky smartphone’s limitations while performing the strokes, which enables the expert or beginner to execute the stroke naturally.
This approach can also be applied in a more distinctive scenario for disabled table tennis players on wheelchairs, as suggested by the table tennis coach in our expert interview. Their strokes’ execution could differ from the regular players due to the limited movements, especially from their lower body parts. This means that the coach needs to put more time and effort into training them, as they require personal attention. Hence, our approach will likely be beneficial for helping disabled players improve their table tennis skills.
Further work could include further exploitation of data. With sufficient data samples, it is possible to improve the accuracy of the a single device or gain higher accuracy with multiple sensors. This will prove beneficial for implementing an automated (auditory) feedback system to intervene the beginners when incorrect techniques are detected. A follow-up user study should also be conducted to investigate the effectiveness of provided feedback interventions for beginners during table tennis training. Furthermore, since our study focuses on classifying the most fundamental table tennis technique, the identification of the other three strokes (forehand push, backhand drive, and backhand push) could also be further explored. This gives the flexibility to the beginners to improve their overall fundamental techniques at their own pace.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








