Author Contributions
J.B. contributed with respect to conceptualization, investigation, methodology, software, validation, writing—original draft, and writing—review and editing. R.B. contributed with respect to conceptualization, formal analysis, funding acquisition, methodology, project administration, resources, software, supervision, validation, visualization, writing—original draft, and writing—review and editing. C.M. contributed with respect to conceptualization, data curation, investigation, funding acquisition, and writing—review and editing. Z.L. contributed with respect to methodology, software, and validation. C.L. contributed with respect to resources and supervision. All authors have read and agreed to the published version of the manuscript.
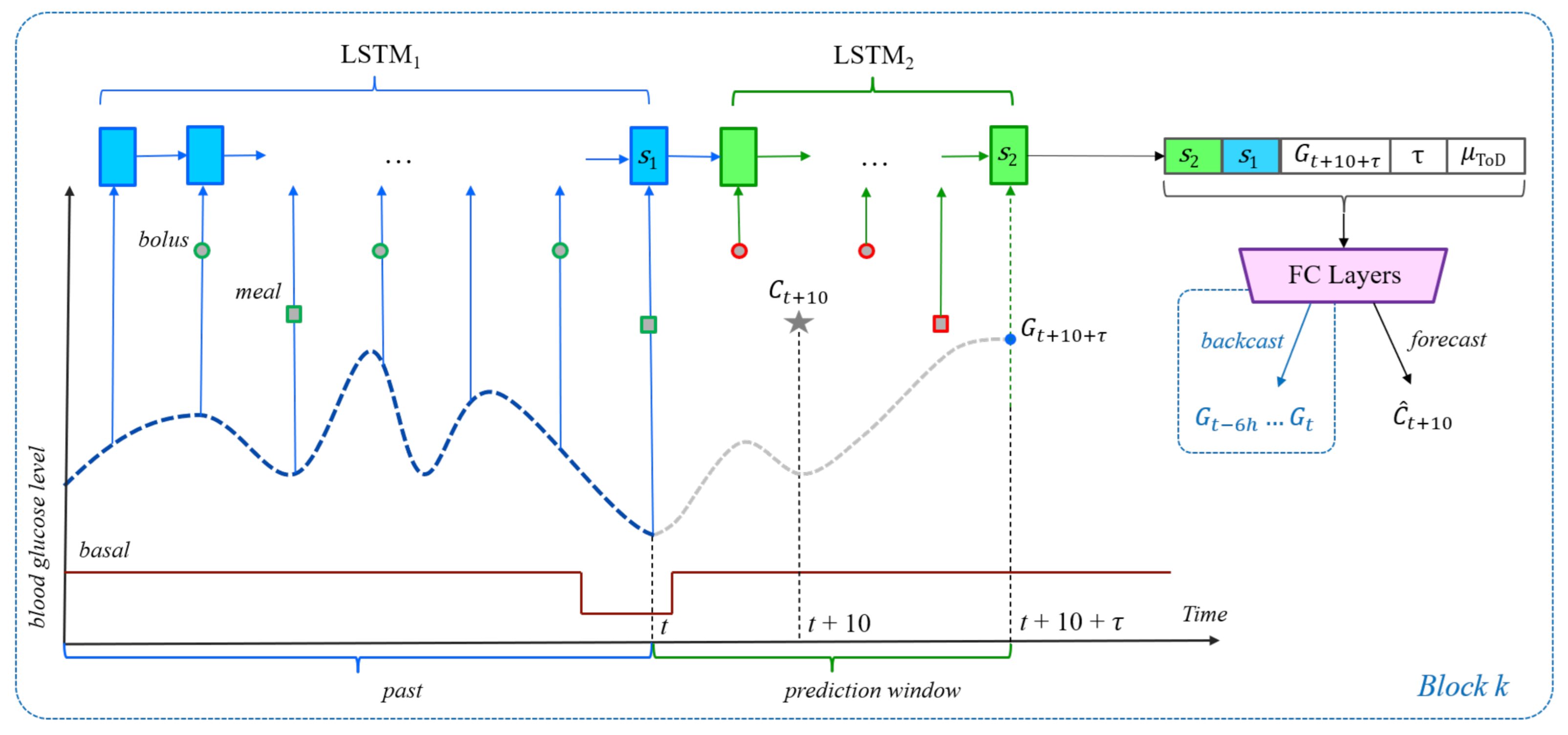
Figure 1.
The neural network architecture for the carbohydrate recommendation scenario. The dashed blue line plots BG levels, while the solid red line represents the basal rate of insulin. The gray star represents the meal event at time . Other meals are represented by squares, whereas boluses are represented by circles. Meals and boluses with a red outline can appear only in unrestricted examples. The blue units receive input from time steps in the past. The green units receive input from time steps in the prediction window. The purple block stands for the fully connected layers of the FCN that computes the prediction.
Figure 1.
The neural network architecture for the carbohydrate recommendation scenario. The dashed blue line plots BG levels, while the solid red line represents the basal rate of insulin. The gray star represents the meal event at time . Other meals are represented by squares, whereas boluses are represented by circles. Meals and boluses with a red outline can appear only in unrestricted examples. The blue units receive input from time steps in the past. The green units receive input from time steps in the prediction window. The purple block stands for the fully connected layers of the FCN that computes the prediction.
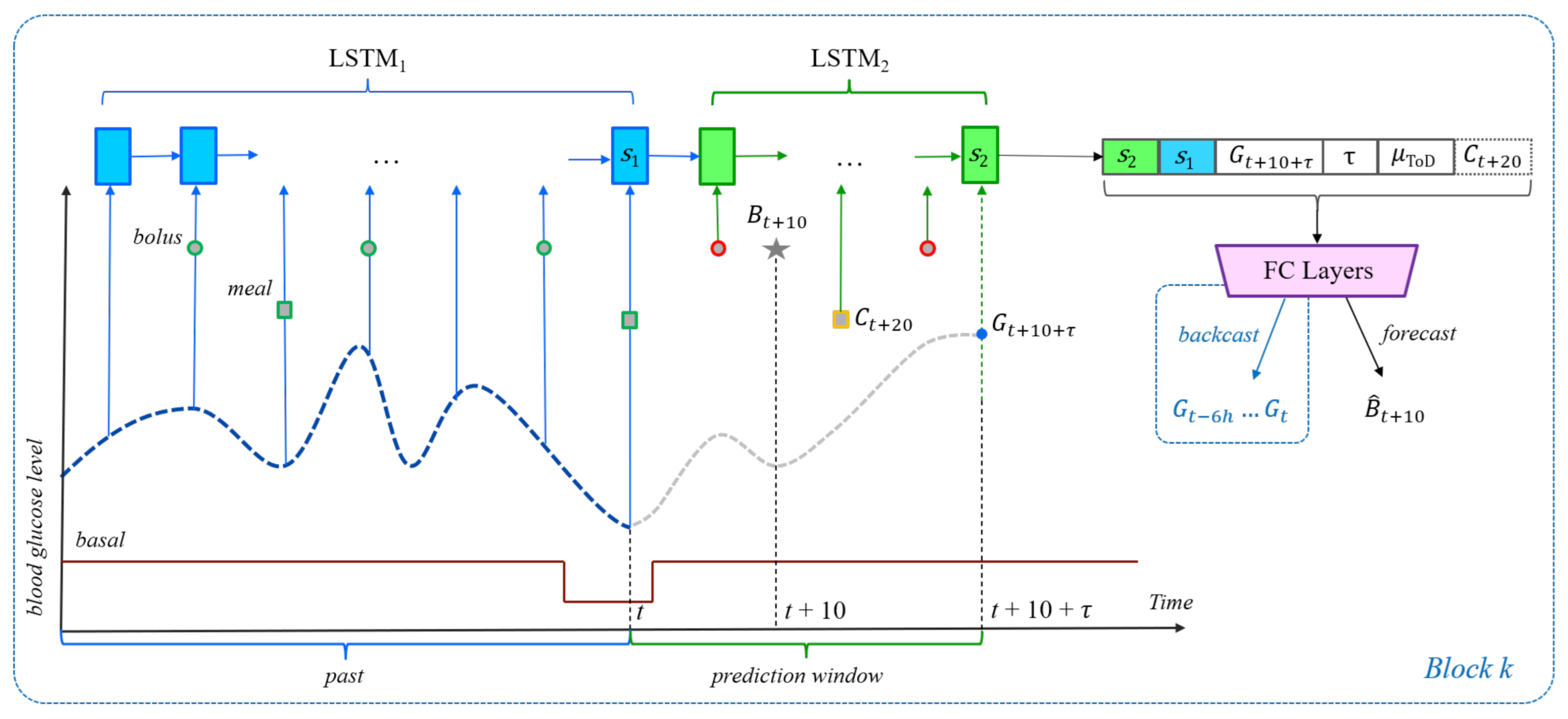
Figure 2.
The general neural network architecture for the bolus and bolus given carbs recommendation scenarios. The architecture itself is similar to that shown in
Figure 1. The gray star now represents the bolus at time
. For the bolus recommendation scenario, the events outlined in red or orange are not allowed in inertial examples. However, in the bolus given carbs scenario, the meal event
shown with the yellow outline is an important part of each example, be it inertial or unrestricted. As such, in this scenario, the dashed
becomes part of the input to the FCN.
Figure 2.
The general neural network architecture for the bolus and bolus given carbs recommendation scenarios. The architecture itself is similar to that shown in
Figure 1. The gray star now represents the bolus at time
. For the bolus recommendation scenario, the events outlined in red or orange are not allowed in inertial examples. However, in the bolus given carbs scenario, the meal event
shown with the yellow outline is an important part of each example, be it inertial or unrestricted. As such, in this scenario, the dashed
becomes part of the input to the FCN.
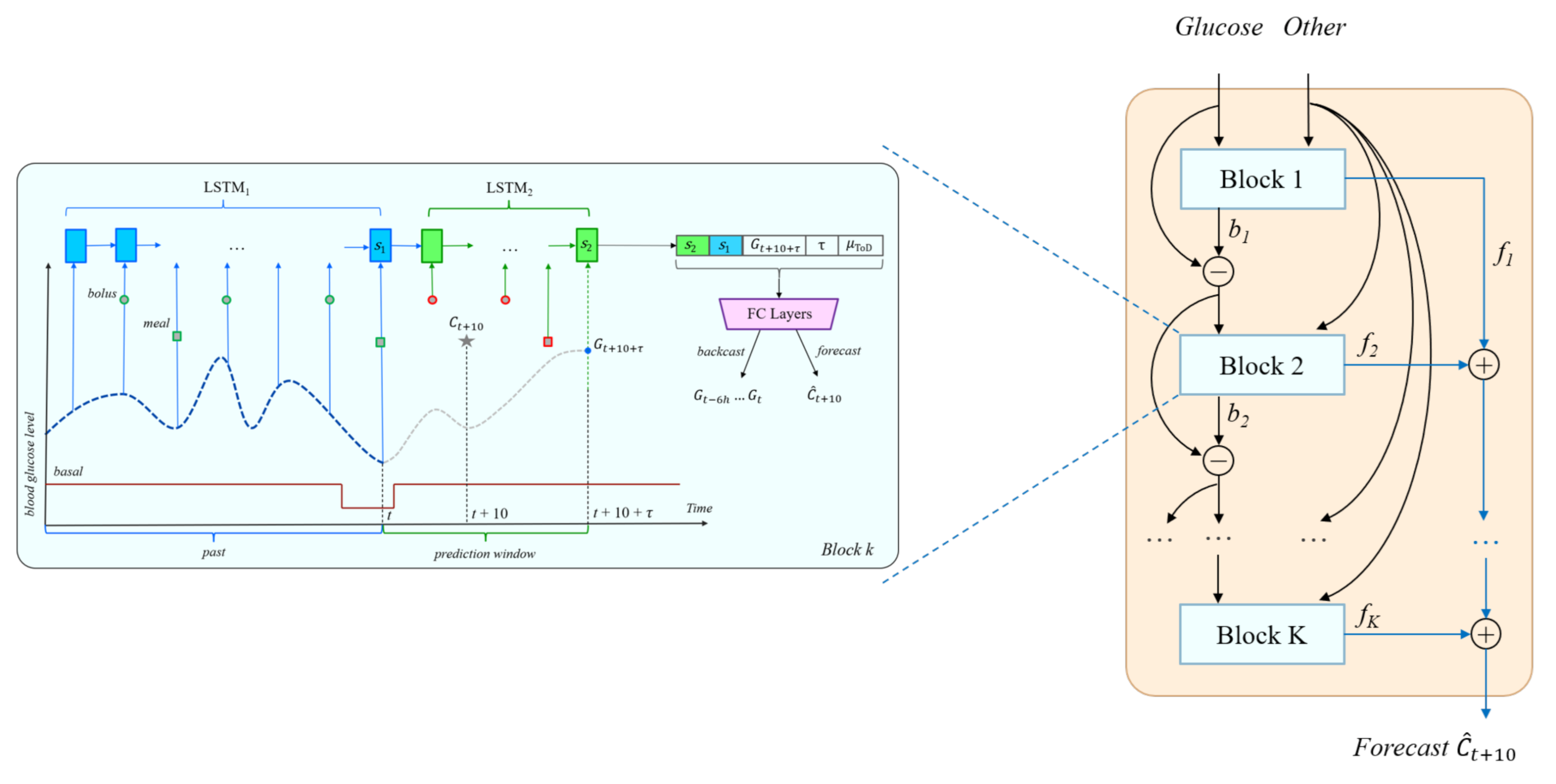
Figure 3.
The N-BEATS inspired deep residual architecture for carbohydrate recommendation. A similar architecture is used for bolus and bolus given carbs recommendations.
Figure 3.
The N-BEATS inspired deep residual architecture for carbohydrate recommendation. A similar architecture is used for bolus and bolus given carbs recommendations.
Figure 4.
Boxplots showing the absolute error per subject for each recommendation scenario achieved by the N-BEATS.best model in the inertial scenario. The orange lines within each box represent the median absolute errors, while the red crosses represent the average absolute errors. The green circles represent outliers. To avoid stretching the figures, outliers were clipped at 25 for the Carbs scenario, 8 for the Bolus scenario, and 5 for the Bolus scenario. The number of clipped outliers is shown next to the subject’s largest outlier. Above the top line is shown, for each subject, the percentage of test examples that are outliers.
Figure 4.
Boxplots showing the absolute error per subject for each recommendation scenario achieved by the N-BEATS.best model in the inertial scenario. The orange lines within each box represent the median absolute errors, while the red crosses represent the average absolute errors. The green circles represent outliers. To avoid stretching the figures, outliers were clipped at 25 for the Carbs scenario, 8 for the Bolus scenario, and 5 for the Bolus scenario. The number of clipped outliers is shown next to the subject’s largest outlier. Above the top line is shown, for each subject, the percentage of test examples that are outliers.
Table 1.
Per subject and total meal and carbohydrate per meal statistics: Minimum, Maximum, Median, Average, and Standard Deviation (StdDev). Carbs refers to all carbohydrate intake events; Carbs refers to carbohydrate intakes without a bolus. Statistics are shown for the 2018 subset, the 2020 subset, and for the entire OhioT1DM dataset.
Table 1.
Per subject and total meal and carbohydrate per meal statistics: Minimum, Maximum, Median, Average, and Standard Deviation (StdDev). Carbs refers to all carbohydrate intake events; Carbs refers to carbohydrate intakes without a bolus. Statistics are shown for the 2018 subset, the 2020 subset, and for the entire OhioT1DM dataset.
| | Carbs Per Meal (g) |
|---|
| Subject | Carbs | Carbs | Minimum | Maximum | Median | Average | StdDev |
|---|
| 559 | 215 | 83 | 8.0 | 75.0 | 30.0 | 35.5 | 15.5 |
| 563 | 225 | 28 | 5.0 | 84.0 | 31.0 | 33.8 | 18.0 |
| 570 | 174 | 39 | 5.0 | 200.0 | 115.0 | 106.1 | 41.5 |
| 575 | 297 | 122 | 1.0 | 110.0 | 40.0 | 40.0 | 22.0 |
| 588 | 268 | 73 | 2.0 | 60.0 | 20.0 | 22.7 | 14.6 |
| 591 | 264 | 60 | 3.0 | 77.0 | 28.0 | 31.5 | 14.1 |
| 2018 Total | 1443 | 405 | 1.0 | 200.0 | 33.0 | 41.5 | 32.7 |
| 540 | 234 | 14 | 1.0 | 110.0 | 40.0 | 50.2 | 29.8 |
| 544 | 206 | 41 | 1.0 | 175.0 | 60.0 | 68.7 | 36.3 |
| 552 | 271 | 25 | 3.0 | 135.0 | 26.0 | 36.7 | 29.3 |
| 567 | 207 | 5 | 20.0 | 140.0 | 67.0 | 67.0 | 21.5 |
| 584 | 233 | 44 | 15.0 | 78.0 | 60.0 | 54.6 | 11.6 |
| 596 | 300 | 277 | 1.0 | 64.0 | 25.0 | 25.1 | 14.0 |
| 2020 Total | 1451 | 406 | 1.0 | 175.0 | 42.0 | 48.2 | 29.5 |
| Combined Total | 2894 | 811 | 1.0 | 200.0 | 39.0 | 44.9 | 31.3 |
Table 2.
Per subject and total boluses and insulin units statistics: Minimum, Maximum, Median, Average, and Standard Deviation (StdDev). Bolus refers to all bolus events; Bolus refers to bolus events associated with a meal. Statistics are shown for the 2018 subset, the 2020 subset, and for the entire OhioT1DM dataset.
Table 2.
Per subject and total boluses and insulin units statistics: Minimum, Maximum, Median, Average, and Standard Deviation (StdDev). Bolus refers to all bolus events; Bolus refers to bolus events associated with a meal. Statistics are shown for the 2018 subset, the 2020 subset, and for the entire OhioT1DM dataset.
| | Insulin Per Bolus (u) |
|---|
| Subject | Bolus | Bolus | Minimum | Maximum | Median | Average | StdDev |
|---|
| 559 | 186 | 132 | 0.1 | 9.3 | 3.6 | 3.7 | 1.9 |
| 563 | 424 | 197 | 0.1 | 24.7 | 7.8 | 8.0 | 4.2 |
| 570 | 1345 | 132 | 0.2 | 12.1 | 1.3 | 1.8 | 2.1 |
| 575 | 271 | 175 | 0.1 | 12.8 | 4.4 | 4.1 | 3.0 |
| 588 | 221 | 195 | 0.4 | 10.0 | 3.5 | 4.3 | 2.3 |
| 591 | 331 | 204 | 0.1 | 9.4 | 2.9 | 3.1 | 1.8 |
| 2018 Total | 2758 | 1035 | 0.1 | 24.7 | 1.9 | 3.5 | 3.4 |
| 540 | 521 | 220 | 0.1 | 11.4 | 2.0 | 3.0 | 2.8 |
| 544 | 264 | 149 | 0.7 | 22.5 | 5.0 | 6.5 | 4.9 |
| 552 | 426 | 246 | 0.1 | 16.0 | 2.8 | 3.9 | 3.3 |
| 567 | 366 | 202 | 0.2 | 25.0 | 11.4 | 12.0 | 5.8 |
| 584 | 311 | 188 | 0.1 | 16.2 | 9.1 | 7.3 | 3.1 |
| 596 | 230 | 0 | 0.2 | 7.6 | 3.3 | 3.0 | 1.5 |
| 2020 Total | 2118 | 1169 | 0.1 | 25.0 | 4.0 | 5.8 | 5.0 |
| Combined Total | 4876 | 2204 | 0.1 | 25.0 | 2.9 | 4.5 | 4.3 |
Table 3.
Inertial (I) examples by recommendation scenario and prediction horizon. Carbs refers to all carbohydrate intake events; Carbs refers to carbohydrate intakes without a bolus.
Table 3.
Inertial (I) examples by recommendation scenario and prediction horizon. Carbs refers to all carbohydrate intake events; Carbs refers to carbohydrate intakes without a bolus.
| | CarbsRecommendation | CarbsRecommendation |
| Horizon | Training | Validation | Testing | TotalI | Training | Validation | Testing | TotalI |
| 1192 | 340 | 331 | 1863 | 265 | 53 | 40 | 358 |
| 1156 | 334 | 321 | 1811 | 255 | 51 | 40 | 346 |
| 1121 | 318 | 315 | 1754 | 243 | 50 | 40 | 333 |
| 1057 | 301 | 293 | 1651 | 226 | 44 | 34 | 304 |
| 975 | 279 | 278 | 1532 | 200 | 40 | 31 | 271 |
| All 13 horizons | 14,343 | 4103 | 4007 | 22,453 | 3100 | 620 | 486 | 4206 |
| | Bolus Recommendation | Bolus Recommendation |
| Horizon | Training | Validation | Testing | TotalI | Training | Validation | Testing | TotalI |
| 461 | 160 | 143 | 764 | 856 | 267 | 271 | 1394 |
| 416 | 142 | 124 | 682 | 833 | 259 | 258 | 1350 |
| 368 | 124 | 104 | 596 | 816 | 253 | 249 | 1318 |
| 303 | 102 | 96 | 501 | 790 | 243 | 243 | 1276 |
| 271 | 90 | 86 | 447 | 743 | 234 | 229 | 1206 |
| All 13 horizons | 4732 | 1606 | 1423 | 7761 | 10,514 | 3269 | 3249 | 17,032 |
Table 4.
Unrestricted (U) examples by recommendation scenario, also showing, in the last column, the total number of non-inertial () examples. Carbs refers to all carbohydrate intake events; Carbs refers to carbohydrate intakes without a bolus.
Table 4.
Unrestricted (U) examples by recommendation scenario, also showing, in the last column, the total number of non-inertial () examples. Carbs refers to all carbohydrate intake events; Carbs refers to carbohydrate intakes without a bolus.
| Scenario | Training | Validation | Testing | Total U | Total |
|---|
| Carbs | 17,937 | 5106 | 4943 | 27,986 | 5533 |
| Carbs | 4140 | 853 | 624 | 5617 | 1411 |
| Bolus | 19,640 | 6279 | 6136 | 32,055 | 24,294 |
| Bolus | 12,052 | 3784 | 3816 | 19,652 | 2620 |
Table 5.
Results with pre-processing of meals (pre) vs. original raw data for meal events (raw), for the carbohydrate recommendation scenario Carbs on unrestricted examples. pre refers to using all pre-processed meals (shifted original meals and added meals), whereas pre does not use meals added by the pre-processing procedure. We show results for different combinations of pre-processing options during Training and evaluation on Validation data, e.g., the first row indicates raw data were used during both training and evaluation. The symbol indicates a p-value < 0.03 when using a one-tailed t-test to compare against the results without pre-processing (raw).
Table 5.
Results with pre-processing of meals (pre) vs. original raw data for meal events (raw), for the carbohydrate recommendation scenario Carbs on unrestricted examples. pre refers to using all pre-processed meals (shifted original meals and added meals), whereas pre does not use meals added by the pre-processing procedure. We show results for different combinations of pre-processing options during Training and evaluation on Validation data, e.g., the first row indicates raw data were used during both training and evaluation. The symbol indicates a p-value < 0.03 when using a one-tailed t-test to compare against the results without pre-processing (raw).
| | Pre-Processing | |
|---|
| | Training | Validation | RMSE | MAE |
|---|
| N-BEATS.mean | raw | raw | 13.42 | 10.32 |
| pre | pre | 9.38 | 6.59 |
| pre | pre | 8.84 | 6.16 |
| N-BEATS.best | raw | raw | 12.32 | 9.28 |
| pre | pre | 8.48 | 5.90 |
| pre | pre | 8.12 | 5.53 |
Table 6.
Results with pre-processing of meals (pre) vs. original raw data for meal events (raw), for the Bolus recommendation scenario on unrestricted examples. All meals (shifted or added) are used for the pre-processed data. The symbol indicates a p-value < 0.01 when using a one-tailed t-test to compare against the results without pre-processing (raw).
Table 6.
Results with pre-processing of meals (pre) vs. original raw data for meal events (raw), for the Bolus recommendation scenario on unrestricted examples. All meals (shifted or added) are used for the pre-processed data. The symbol indicates a p-value < 0.01 when using a one-tailed t-test to compare against the results without pre-processing (raw).
| | Pre-Processing | RMSE | MAE |
|---|
| N-BEATS.mean | raw | 1.85 | 1.41 |
| pre | 1.30 | 0.92 |
| N-BEATS.best | raw | 1.81 | 1.32 |
| pre | 1.22 | 0.84 |
Table 7.
Performance of the LSTM- and N-BEATS-based models, with (+) and without (−) the final state of LSTM as part of the input to the FC Layers.
Table 7.
Performance of the LSTM- and N-BEATS-based models, with (+) and without (−) the final state of LSTM as part of the input to the FC Layers.
| LSTM.mean | RMSE | MAE | | N-BEATS.mean | RMSE | MAE |
|---|
| Carbs | | 10.14 | 7.56 | | Carbs | | 10.27 | 7.58 |
| 8.99 | 6.57 | | | | 8.84 | 6.16 |
| Bolus | | 1.33 | 0.97 | | Bolus | | 1.33 | 0.85 |
| 1.41 | 1.03 | | | | 1.30 | 0.92 |
Table 8.
N-BEATS-based model results, with a separate vs. joint final fully connected layer for computing backcast and forecast values.
Table 8.
N-BEATS-based model results, with a separate vs. joint final fully connected layer for computing backcast and forecast values.
| N-BEATS.mean | RMSE | MAE |
|---|
| Carbs | separate | 8.77 | 6.48 |
| joint | 8.84 | 6.16 |
| Bolus | separate | 1.32 | 0.94 |
| joint | 1.30 | 0.92 |
Table 9.
Tuned hyper-parameters for the LSTM-based models.
Table 9.
Tuned hyper-parameters for the LSTM-based models.
| | Hyper-Parameters |
|---|
| Scenario | Examples | FC Layers | Dropout |
|---|
| Carbs | Inertial | 3 | 0.1 |
| Unrestricted | 3 | 0.1 |
| Bolus | Inertial | 3 | 0.0 |
| Unrestricted | 2 | 0.3 |
| Bolus | Inertial | 2 | 0.2 |
| Unrestricted | 2 | 0.5 |
Table 10.
Tuned hyper-parameters for the N-BEATS-based models.
Table 10.
Tuned hyper-parameters for the N-BEATS-based models.
| | Hyper-Parameters |
|---|
| Scenario | Examples | Blocks | FC Layers | Dropout |
|---|
| Carbs | Inertial | 5 | 2 | 0.3 |
| Unrestricted | 3 | 3 | 0.3 |
| Bolus | Inertial | 5 | 4 | 0.2 |
| Unrestricted | 4 | 4 | 0.2 |
| Bolus | Inertial | 5 | 4 | 0.5 |
| Unrestricted | 3 | 5 | 0.2 |
Table 11.
Results for each recommendation scenario, for both classes of examples. The simple † indicates a p-value < 0.05 when using a one-tailed t-test to compare against the baseline results; the double indicates statistical significance for comparison against the baselines as well as against the competing neural method; the indicates significant with respect to the Global Average baseline only.
Table 11.
Results for each recommendation scenario, for both classes of examples. The simple † indicates a p-value < 0.05 when using a one-tailed t-test to compare against the baseline results; the double indicates statistical significance for comparison against the baselines as well as against the competing neural method; the indicates significant with respect to the Global Average baseline only.
| | Inertial | Unrestricted |
| CarbsRecommendation | RMSE | MAE | RMSE | MAE |
| Global Average | 20.90 | 17.30 | 20.68 | 17.10 |
| ToD Average | 20.01 | 15.78 | 19.82 | 15.68 |
| LSTM.mean | 11.55 | 7.81 | 10.99 | 7.40 |
| LSTM.best | 10.95 | 7.50 | 10.50 | 7.31 |
| N-BEATS.mean | 9.79 | 6.45 | 10.34 | 7.04 |
| N-BEATS.best | 9.92 | 6.56 | 10.07 | 6.75 |
| | Inertial | Unrestricted |
| CarbsRecommendation | RMSE | MAE | RMSE | MAE |
| Global Average | 15.92 | 13.71 | 14.66 | 12.19 |
| ToD Average | 15.55 | 13.45 | 14.27 | 11.93 |
| LSTM.mean | 14.02 | 11.47 | 14.70 | 12.27 |
| LSTM.best | 13.75 | 10.92 | 14.94 | 12.57 |
| N-BEATS.mean | 13.76 | 11.42 | 13.69 | 11.09 |
| N-BEATS.best | 14.52 | 11.78 | 14.17 | 11.47 |
| | Inertial | Unrestricted |
| BolusRecommendation | RMSE | MAE | RMSE | MAE |
| Global Average | 2.40 | 2.13 | 2.84 | 2.30 |
| ToD Average | 2.21 | 1.86 | 2.71 | 2.17 |
| LSTM.mean | 1.75 | 1.35 | 1.53 | 1.10 |
| LSTM.best | 1.70 | 1.30 | 1.50 | 1.05 |
| N-BEATS.mean | 1.56 | 1.20 | 1.49 | 1.04 |
| N-BEATS.best | 1.65 | 1.26 | 1.51 | 1.03 |
| | Inertial | Unrestricted |
| BolusRecommendation | RMSE | MAE | RMSE | MAE |
| Global Average | 3.00 | 2.35 | 3.04 | 2.39 |
| ToD Average | 2.87 | 2.21 | 2.90 | 2.25 |
| LSTM.mean | 1.02 | 0.73 | 1.00 | 0.73 |
| LSTM.best | 0.94 | 0.67 | 1.00 | 0.72 |
| N-BEATS.mean | 0.89 | 0.65 | 1.11 | 0.82 |
| N-BEATS.best | 0.85 | 0.61 | 1.06 | 0.78 |
Table 12.
Comparison between models trained on all prediction horizons vs. one prediction horizon , when evaluated on the prediction horizon . The symbol indicates a p-value < 0.05 when using a one-tailed t-test to compare against the one prediction horizon results.
Table 12.
Comparison between models trained on all prediction horizons vs. one prediction horizon , when evaluated on the prediction horizon . The symbol indicates a p-value < 0.05 when using a one-tailed t-test to compare against the one prediction horizon results.
| | CarbsRecommendation |
| | | | | | | Average |
| | Trained on | RMSE MAE | RMSE MAE | RMSE MAE | RMSE MAE | RMSE MAE | RMSE MAE |
| N-BEATS.mean | One | 9.74 | 6.72 | 10.24 | 6.89 | 10.06 | 6.85 | 10.52 | 7.19 | 9.82 | 6.73 | 10.08 | 6.88 |
| All | 9.96 | 6.57 | 9.98 | 6.56 | 9.84 | 6.50 | 9.55 | 6.30 | 9.37 | 6.22 | 9.74 | 6.43 |
| N-BEATS.best | One | 9.92 | 6.70 | 10.39 | 6.90 | 10.21 | 6.88 | 10.62 | 7.18 | 9.92 | 6.66 | 10.21 | 6.86 |
| All | 9.84 | 6.50 | 9.94 | 6.56 | 10.02 | 6.57 | 9.76 | 6.34 | 9.43 | 6.08 | 9.80 | 6.41 |
| | BolusRecommendation |
| | | | | | | Average |
| | Trained on | RMSE MAE | RMSE MAE | RMSE MAE | RMSE MAE | RMSE MAE | RMSE MAE |
| N-BEATS.mean | One | 1.82 | 1.42 | 1.57 | 1.24 | 1.51 | 1.24 | 1.37 | 1.10 | 1.40 | 1.17 | 1.53 | 1.23 |
| All | 1.75 | 1.33 | 1.61 | 1.24 | 1.47 | 1.17 | 1.38 | 1.10 | 1.28 | 1.03 | 1.50 | 1.17 |
| N-BEATS.best | One | 1.77 | 1.37 | 1.54 | 1.21 | 1.51 | 1.23 | 1.38 | 1.10 | 1.34 | 1.11 | 1.51 | 1.20 |
| All | 1.72 | 1.28 | 1.75 | 1.33 | 1.58 | 1.23 | 1.45 | 1.12 | 1.44 | 1.13 | 1.59 | 1.22 |
| | BolusRecommendation |
| | | | | | | Average |
| | Trained on | RMSE MAE | RMSE MAE | RMSE MAE | RMSE MAE | RMSE MAE | RMSE MAE |
| N-BEATS.mean | One | 0.98 | 0.73 | 0.91 | 0.69 | 0.91 | 0.69 | 0.95 | 0.74 | 0.93 | 0.72 | 0.94 | 0.71 |
| All | 0.95 | 0.68 | 0.87 | 0.65 | 0.86 | 0.65 | 0.87 | 0.65 | 0.86 | 0.64 | 0.88 | 0.65 |
| N-BEATS.best | One | 0.94 | 0.69 | 0.91 | 0.69 | 0.92 | 0.68 | 0.93 | 0.71 | 0.91 | 0.70 | 0.92 | 0.69 |
| All | 0.94 | 0.66 | 0.84 | 0.62 | 0.82 | 0.59 | 0.82 | 0.61 | 0.83 | 0.61 | 0.85 | 0.62 |








{kind=link}
{kind=link}
{kind=link}
{kind=link}