
Smart Scheduling of Electric Vehicles Based on Reinforcement Learning



 and
and 
Abstract
:1. Introduction
1.1. Motivation
1.2. Related Work
1.3. Contributions of This Paper
- -
- Our algorithm recommends the charging stations at the beginning of the trip, which can be positioned along various alternative routes to the destination point. This way, users have more options to choose from and they can ensure a smoother journey, with no long queues, by slightly adjusting their itinerary so that they pass by the optimal charging stations;
- -
- The existing scientific articles in the field that studied the same concept using a Reinforcement Learning method employed a specific number of charging stations, meaning that introducing a new charging station in the grid would require the neural network to be retrained. We use the DQN to compute a score for each charging station in the grid, score that denotes the likelihood of selecting the current charging station given the car battery level and position, and the charging station’s reservations. This way we can increase the number of charging stations in the grid without having to retrain the neural network.
1.4. Methodology
1.5. Structure of the Paper
2. Reinforcement Learning Based Charging Station Selection
2.1. The DQN Algorithm for Charging Station Selection
2.1.1. The Neural Network
2.1.2. The Replay Memory
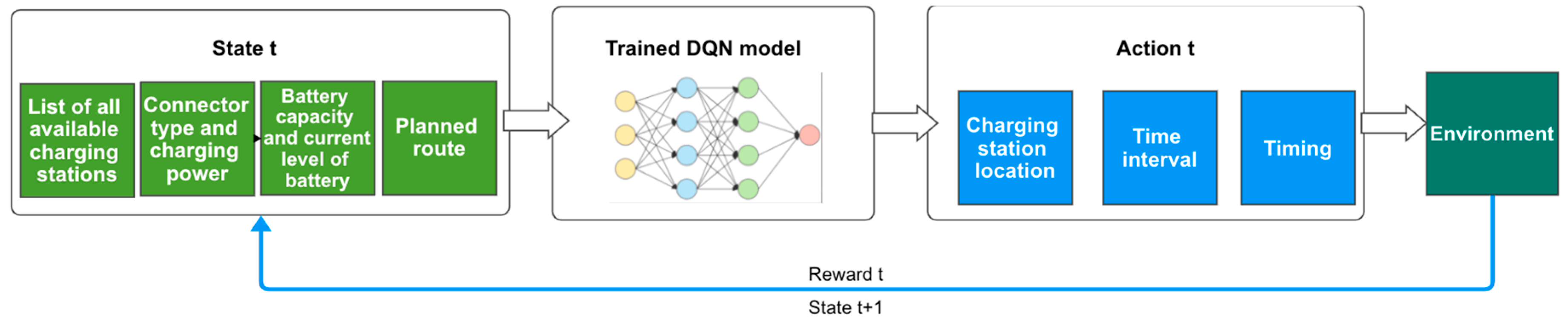
2.1.3. The Decision-Making Process
- -
- Exploration—In this phase the decision-making process is mostly random, so that the model can explore more and discover what results are yielded by different decisions. This enables the agent to improve its knowledge about each action, which is usually beneficial in the long-term. In the beginning, the agent uses this random decision-making process and starts to gradually exploit its knowledge. By the time it reaches the 10,000th iteration, this exploration process probability reaches its lowest point, where it stays for the rest of the training time. To eliminate any misinterpretation, the fact that the number of iterations is equal to the size of the replay buffer is merely a coincidence and bears no relevance in the current study;
- -
- Exploitation—In this phase the agent is exploiting its knowledge and opts for the greedy approach to get the most reward.
2.2. The Training of DQN
- Create a list of 32 random indices from 0 to the length of the Replay Memory;
- Get a list of samples from the Replay Memory based on the indices list created at step 1;
- Split the sample in state and reward lists;
- Train the neural network for one epoch using the state and reward lists as input.
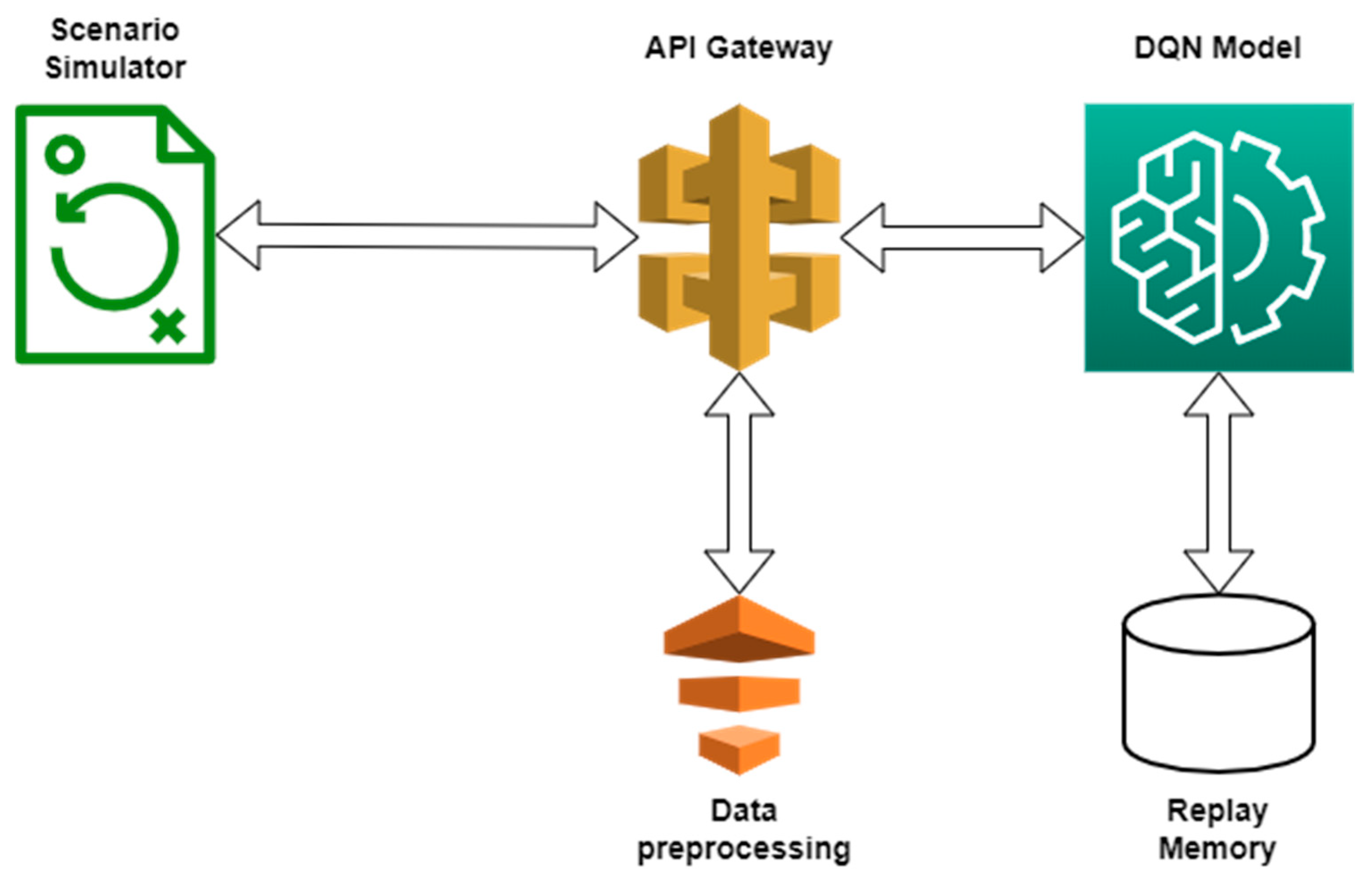
2.3. Communication Protocol between the DQN and the Scenario Generator
2.4. The Scenario Generator
2.5. The DQN Algorithm and the Scenario Generator Workflow
- A new situation is generated by the simulator and a request is made to the charging station recommendation endpoint, feeding in the information associated with the generated scenario;
- The FastApi server receives the request and maps the data in the format required by the DQN algorithm. The processed data are then fed into the DQN algorithm;
- The DQN algorithm makes a decision according to the current learning level or, with a certain probability, makes a random decision. The current scenario is then stored in the Replay Memory;
- If there are enough entries in the Replay Memory, a training dataset is generated, which is then used to train the neural network of the DQN algorithm;
- The DQN algorithm output is then passed back to the FastApi server, where another processing function is applied to map the data in a usable format;
- The data are returned as a response to the request initiated by the scenario generator and the simulation runs based on the data received;
- The value of the reward is established based on the simulation and it is then sent to the FastApi server, along with the scenario’s ID;
- Through the FastApi server, the reward reaches the Replay Memory and the scenario in question is updated.
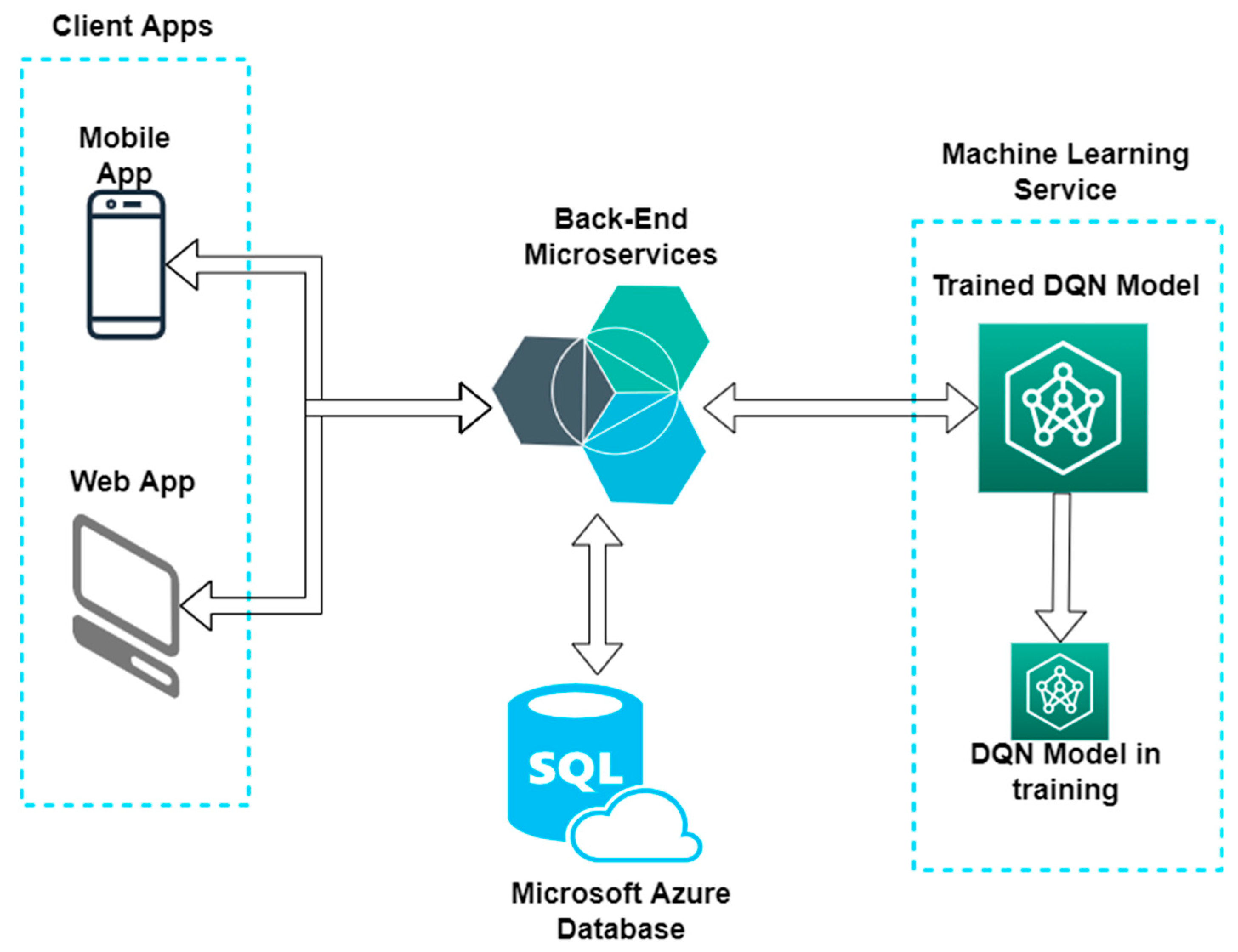
3. Case Study
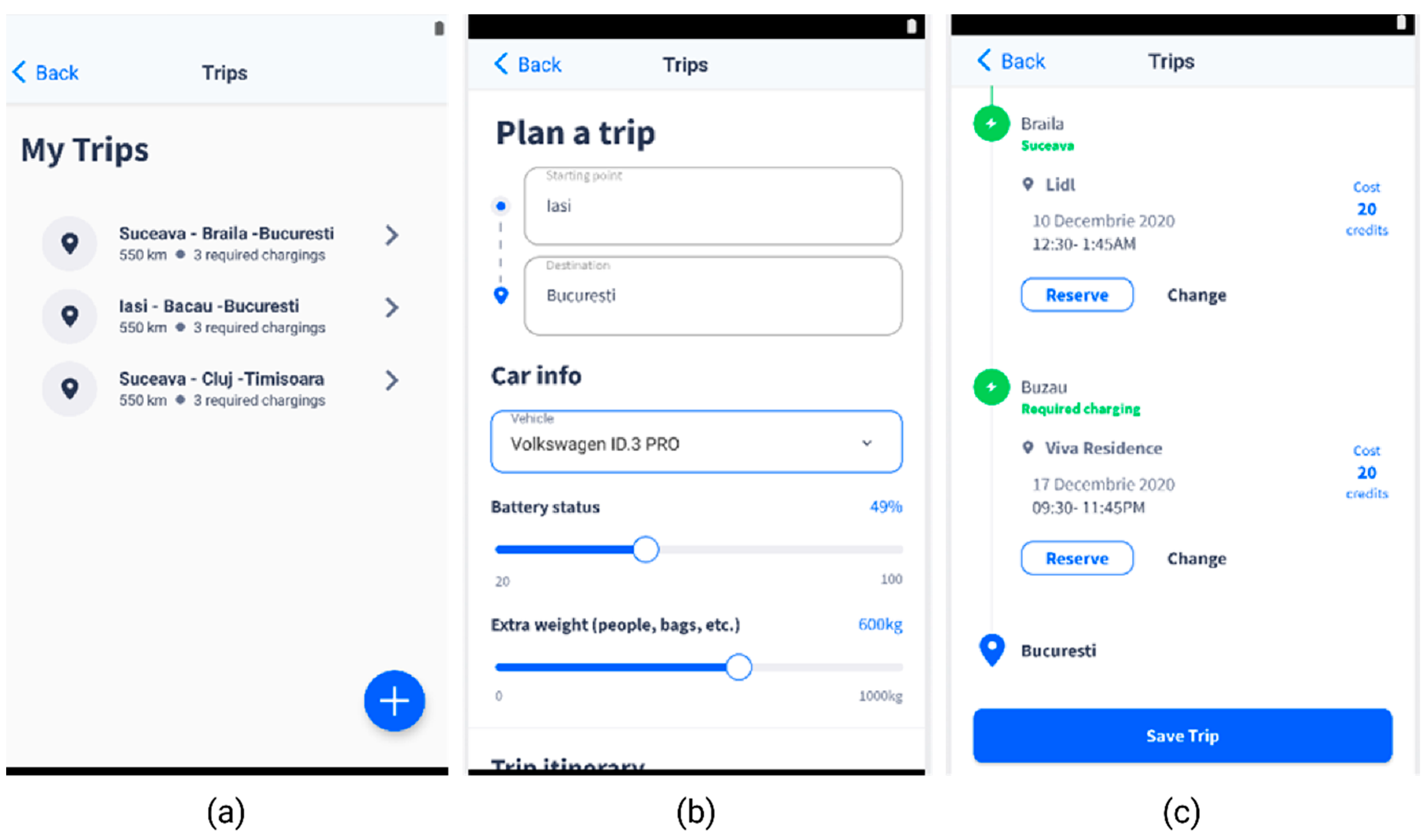
- ▪ The user sets up the starting and destination points for the trip in the mobile app, along with information about the vehicle and the battery status;
- ▪ The mobile app will call a Back-End endpoint with the data the user entered in the app;
- ▪ The Back-End will get from the database all the charging stations relevant for the data provided by the user and call the ML recommendation endpoint with the data received from database;
- ▪ The DQN model will predict the charging stations and the specific reservation time best suited for the data it gets from Back-End and sends them back as a response;
- ▪ The Back-End will send the response to the mobile app with the charging stations recommended by the DQN model;
- ▪ The mobile app will display the recommended charging stations to the user, with the option to create a reservation for the specified charging stations (Figure 4c).
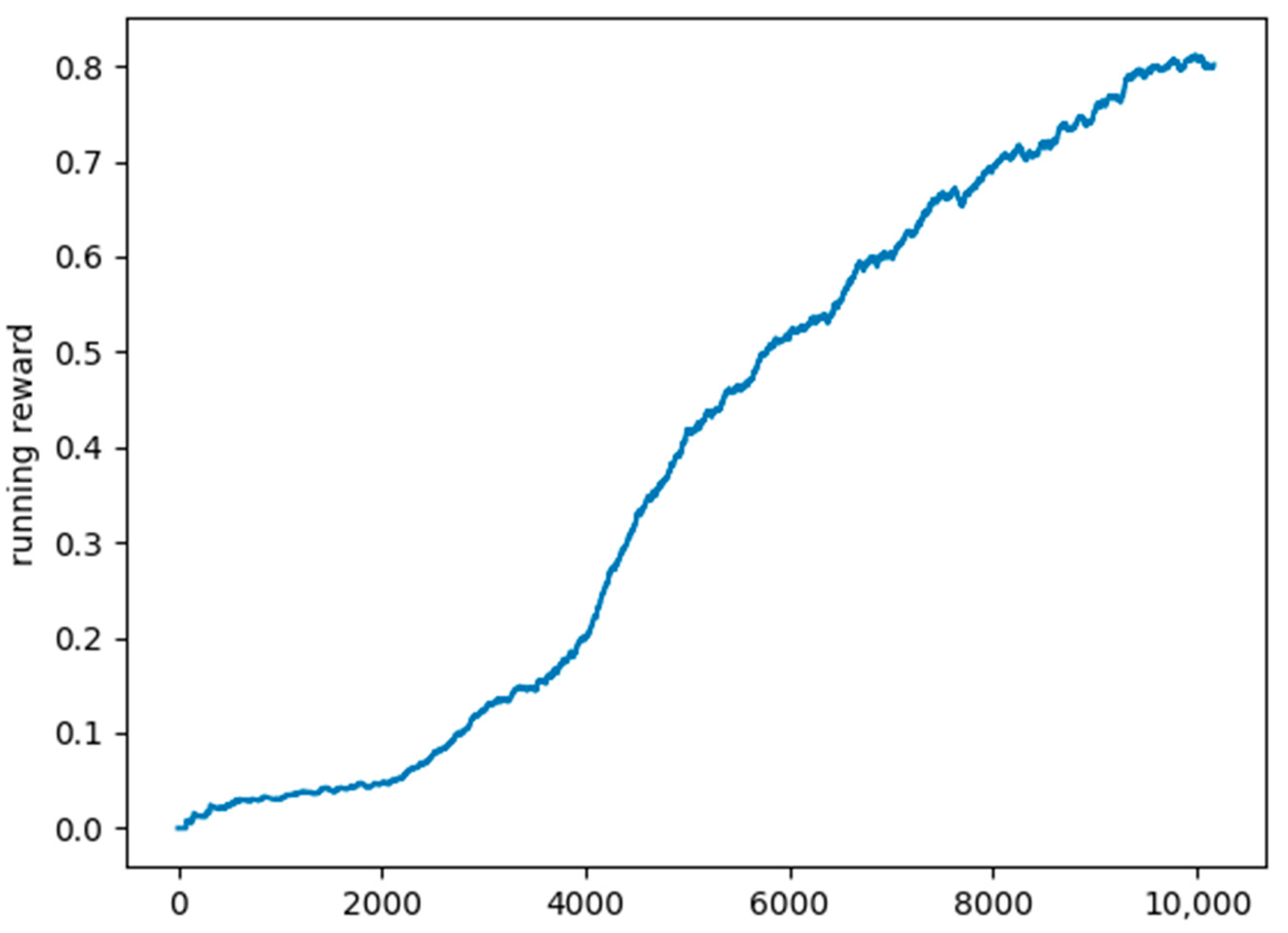
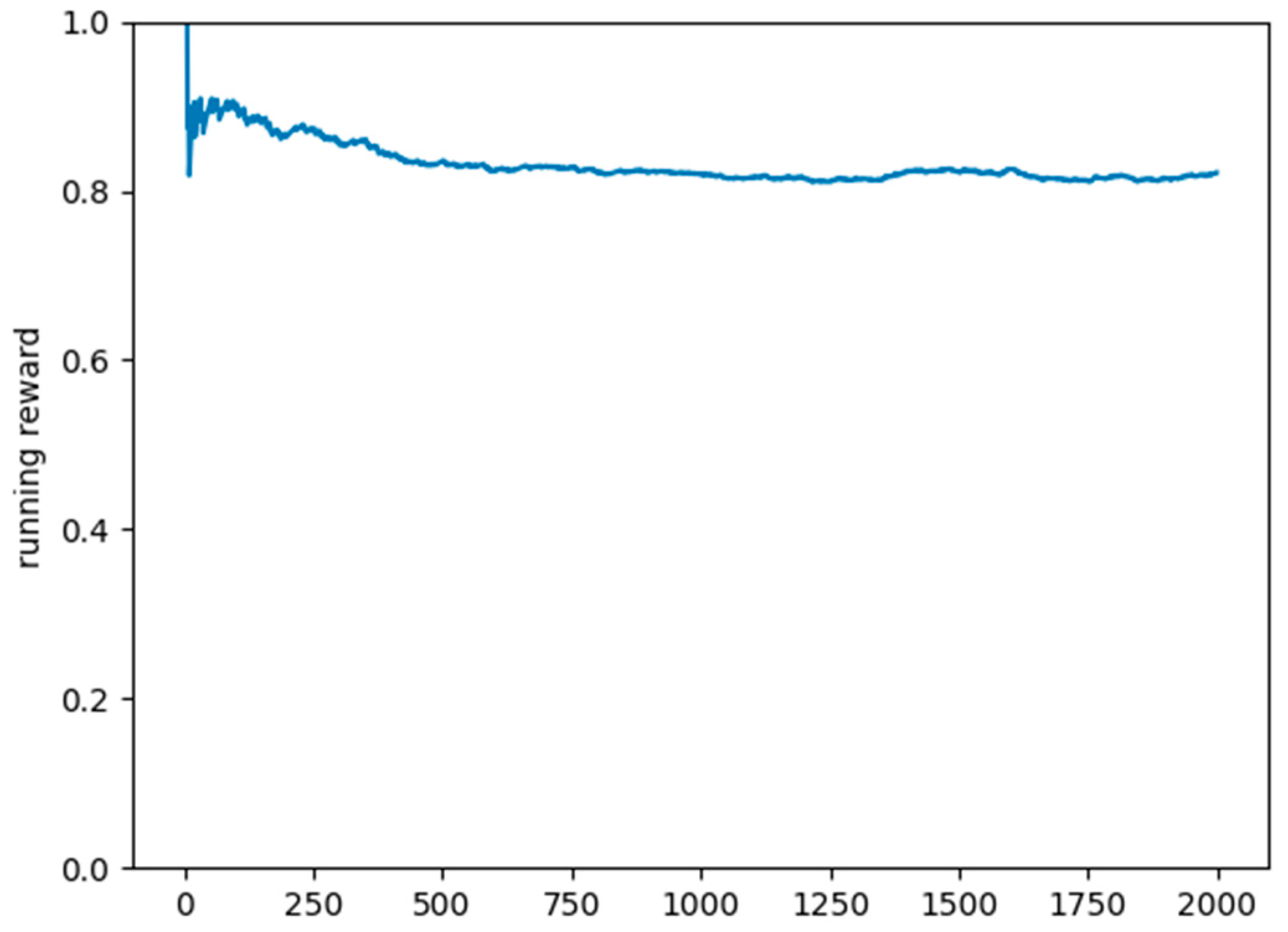
4. Results and Discussion
- ▪ Environment: Simulation of three interconnected cities, total distance of 25 km;
- ▪ Generated cars: 400 cars with a random initial position and random destination points. Once the destination point is reached, another destination point is generated. Each car sends requests to the DQN model whenever a new destination point is generated and if a charging station is returned, the vehicle’s route will be modified to reach the recommended charging station and recharge before continuing towards its original destination.
- ▪ The total distance between the current position of the car and the destination point;
- ▪ The capacity of the battery (in kW);
- ▪ The current battery level (in kW);
- ▪ The distance between the current position of the car and the charging station (in m);
- ▪ The length of the deviation from the original route and the changing station (in m);
- ▪ The charging power of the charging station per minute (in kW);
- ▪ The remaining time until the next charging slot (in minutes). A charging slot is a 30-min interval and is computed for the next 6 h starting from the current time.
5. Conclusions and Limitations
6. Future Research Directions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- World Economic Forum. Electric Vehicles for Smarter Cities: The Future of Energy and Mobility. World Economic Forum. 2018, p. 32. Available online: https://www3.weforum.org/docs/WEF_2018_%20Electric_For_Smarter_Cities.pdf (accessed on 28 January 2022).
- Wang, R.; Chen, Z.; Xing, Q.; Zhang, Z.; Zhang, T. A Modified Rainbow-Based Deep Reinforcement Learning Method for Optimal Scheduling of Charging Station. Sustainability 2022, 14, 1884. [Google Scholar] [CrossRef]
- Franke, T.; Neumann, I.; Bühler, F.; Cocron, P.; Krems, J.F. Experiencing Range in an Electric Vehicle: Understanding Psychological Barriers. Appl. Psychol. 2012, 61, 368–391. [Google Scholar] [CrossRef]
- Engel, H.; Hensley, R.; Knupfer, S.; Sahdev, S. Charging Ahead: Electric-Vehicle Infrastructure Demand; McKinsey Center for Future Mobility: New York, USA, 2018. [Google Scholar]
- Sawers, P. Google Maps Will Now Show Real-Time Availability of Electric Vehicle Charging Stations. 2019. Available online: https://venturebeat.com/2019/04/23/google-maps-will-now-show-real-time-availability-of-charging-stations-for-electric-cars/ (accessed on 1 April 2022).
- Subramanian, A.; Chitlangia, S.; Baths, V. Reinforcement learning and its connections with neuroscience and psychology. Neural Netw. 2022, 145, 271–287. [Google Scholar] [CrossRef] [PubMed]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An Introduction to Deep Reinforcement Learning. Found. Trends Mach. Learn. 2018, 11, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Mostafa, S.; Loay, I.; Ahmed, M. Machine Learning-Based Management of Electric Vehicles Charging: Towards Highly-Dispersed Fast Chargers. Energies 2020, 13, 5429. [Google Scholar] [CrossRef]
- Arwa, E. Reinforcement Learning Approaches to Power Management in Grid-tied Microgrids: A Review. In Proceedings of the 2020 Clemson University Power Systems Conference (PSC), Clemson, SC, USA, 10–13 March 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Rigas, E.S.; Ramchurn, S.D.; Bassiliades, N. Managing Electric Vehicles in the Smart Grid Using Artificial Intelligence: A Survey. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1619–1635. [Google Scholar] [CrossRef]
- Konstantina, V.; Wolfgang, K.; John, C. Smart Charging of Electric Vehicles Using Reinforcement Learning. AAAI Workshop-Technical Report. 2013, pp. 41–48. Available online: https://www.researchgate.net/publication/286726772_Smart_charging_of_electric_vehicles_using_reinforcement_learning (accessed on 24 February 2022).
- Qi, X.; Wu, G.; Boriboonsomsin, K.; Barth, M.J.; Gonder, J. Data-Driven Reinforcement Learning–Based Real-Time Energy Management System for Plug-In Hybrid Electric Vehicles. Transp. Res. Rec. J. Transp. Res. Board 2016, 2572, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Lee, S.; Choi, D.-H. Energy Management of Smart Home with Home Appliances, Energy Storage System and Electric Vehicle: A Hierarchical Deep Reinforcement Learning Approach. Sensors 2020, 20, 2157. [Google Scholar] [CrossRef] [Green Version]
- Alfaverh, F.; Denaï, M.; Sun, Y. Demand Response Strategy Based on Reinforcement Learning and Fuzzy Reasoning for Home Energy Management. IEEE Access 2020, 8, 39310–39321. [Google Scholar] [CrossRef]
- Li, H.; Wan, Z.; He, H. Constrained EV Charging Scheduling Based on Safe Deep Reinforcement Learning. IEEE Trans. Smart Grid 2020, 11, 2427–2439. [Google Scholar] [CrossRef]
- Wan, Z.; Li, H.; Danil, P. Model-Free Real-Time EV Charging Scheduling Based on Deep Reinforcement Learning. IEEE Trans. Smart Grid. 2018, 10, 5246–5257. [Google Scholar] [CrossRef]
- Abdullah, H.M.; Gastli, A.; Ben-Brahim, L. Reinforcement Learning Based EV Charging Management Systems–A Review. IEEE Access 2021, 9, 41506–41531. [Google Scholar] [CrossRef]
- Lee, J.; Lee, E.; Kim, J. Electric Vehicle Charging and Discharging Algorithm Based on Reinforcement Learning with Data-Driven Approach in Dynamic Pricing Scheme. Energies 2020, 13, 1950. [Google Scholar] [CrossRef] [Green Version]
- Wang, K.; Wang, H.; Yang, J.; Feng, J.; Li, Y.; Zhang, S.; Okoye, M.O. Electric vehicle clusters scheduling strategy considering real-time electricity prices based on deep reinforcement learning. Energy Rep. 2022, 8 (Suppl. 4), 695–703. [Google Scholar] [CrossRef]
- Wan, Y.; Qin, J.; Ma, Q.; Fu, W.; Wang, S. Multi-agent DRL-based data-driven approach for PEVs charging/discharging scheduling in smart grid. J. Frankl. Inst. 2022, 359, 1747–1767. [Google Scholar] [CrossRef]
- Mhaisen, N.; Fetais, N.; Massoud, A. Real-Time Scheduling for Electric Vehicles Charging/Discharging Using Reinforcement Learning. In Proceedings of the 2020 IEEE International Conference on Informatics, IoT, and Enabling Technologies (ICIoT), Doha, Qatar, 2–5 February 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Tuchnitz, F.; Ebell, N.; Schlund, J.; Pruckner, M. Development and Evaluation of a Smart Charging Strategy for an Electric Vehicle Fleet Based on Reinforcement Learning. Appl. Energy 2021, 285, 116382. [Google Scholar] [CrossRef]
- Ruzmetov, A.; Nait-Sidi-Moh, A.; Bakhouya, M.; Gaber, J. Towards an optimal assignment and scheduling for charging electric vehicles. In Proceedings of the 2013 International Renewable and Sustainable Energy Conference (IRSEC), Quarzazate, Morocco, 7–9 March 2013. [Google Scholar] [CrossRef]
- Qin, H.; Zhang, W. Charging scheduling with minimal waiting in a network of electric vehicles and charging stations. In Proceedings of the 8th ACM VANET 2011, Las Vegas, NV, USA, 19–23 September 2011; pp. 51–60. [Google Scholar] [CrossRef] [Green Version]
- de Weerdt, M.M.; Gerding, E.H.; Stein, S.; Robu, V.; Jennings, N.R. Intention-aware routing to minimise delays at electric vehicle charging stations. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Ser. IJCAI’13, Beijing, China, 3–9 August 2013; pp. 83–89. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Chen, W.; Huang, Z. Reinforcement Learning-Based Multiple Constraint Electric Vehicle Charging Service Scheduling. Math. Probl. Eng. 2021, 2021, 1401802. [Google Scholar] [CrossRef]
- Ma, T.; Faye, S. Multistep electric vehicle charging station occupancy prediction using hybrid LSTM neural networks. Energy 2022, 244 Pt B, 123217. [Google Scholar] [CrossRef]
- Shahriar, S.; Al-Ali, A.R.; Osman, A.H.; Dhou, S.; Nijim, M. Machine Learning Approaches for EV Charging Behavior: A Review. IEEE Access 2020, 8, 168980–168993. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Volodymyr, M.; Koray, K.; David, S.; Alex, G.; Ioannis, A.; Daan, W.; Martin, R. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. Available online: https://arxiv.org/pdf/1312.5602.pdf (accessed on 24 March 2022).
- Seno, T. Online Resource: Welcome to Deep Reinforcement Learning Part 1–DQN. 2017. Available online: https://towardsdatascience.com/welcome-to-deep-reinforcement-learning-part-1-dqn-c3cab4d41b6b (accessed on 25 February 2022).
- Lee, K.-B.; Ahmed, M.A.; Kang, D.-K.; Kim, Y.-C. Deep Reinforcement Learning Based Optimal Route and Charging Station Selection. Energies 2020, 13, 6255. [Google Scholar] [CrossRef]
- Chen, Z.; Hu, H.; Wu, Y.; Zhang, Y.; Li, G.; Liu, Y. Stochastic model predictive control for energy management of power-split plug-in hybrid electric vehicles based on reinforcement learning. Energy 2020, 211, 118931. [Google Scholar] [CrossRef]
- Liu, J.; Guo, H.; Xiong, J.; Kato, N.; Zhang, J.; Zhang, Y. Smart and Resilient EV Charging in SDN-Enhanced Vehicular Edge Computing Networks. IEEE J. Sel. Areas Commun. 2020, 38, 217–228. [Google Scholar] [CrossRef]
- Raboaca, M.S.; Meheden, M.; Musat, A.; Viziteu, A.; Creanga, A.; Vlad, V.; Filote, C.; Rață, M.; Lavric, A. An overview and performance evaluation of Open Charge Point Protocol from an electromobility concept perspective. Int. J. Energy Res. 2022, 46, 523–543. [Google Scholar] [CrossRef]
- Meheden, M.; Musat, A.; Traciu, A.; Viziteu, A.; Onu, A.; Filote, C.; Răboacă, M.S. Design Patterns and Electric Vehicle Charging Software. Appl. Sci. 2021, 11, 140. [Google Scholar] [CrossRef]
- Rata, M.; Rata, G.; Filote, C.; Raboaca, M.S.; Graur, A.; Afanasov, C.; Felseghi, A.-R. The ElectricalVehicle Simulator for Charging Station in Mode 3 of IEC 61851-1 Standard. Energies 2020, 13, 176. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Distance (m) | Battery Capacity (KW) | Current Battery Level (KW) | Distance to the Charging Station (m) | Length of the Deviation (m) | Charging Power per Minute (KWm) | Time Remaining to the Charging Slot (min) | Reward |
|---|---|---|---|---|---|---|---|
| 139 | 40 | 21 | 374 | 629 | 1 | 36 | 0 |
| 120 | 40 | 35 | 0 | 0 | 0 | 0 | 1 |
| 463 | 40 | 13 | 379 | 391 | 1 | 6 | 0.2 |
| 620 | 40 | 14 | 1130 | 1049 | 1 | 6 | 0.13 |
| 574 | 40 | 17 | 0 | 0 | 1 | 3 | 0.9 |
| 650 | 40 | 13 | 600 | 661 | 1 | 15 | 0.94 |
| 4637 | 40 | 20 | 4637 | 0 | 1 | 3 | 0.75 |
| 4587 | 40 | 17 | 5157 | 1171 | 1 | 51 | 0.89 |
| 868 | 40 | 22 | 0 | 0 | 1 | 36 | 1 |
| 6008 | 40 | 15 | 1020 | 360 | 1 | 0 | 0.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Viziteu, A.; Furtună, D.; Robu, A.; Senocico, S.; Cioată, P.; Remus Baltariu, M.; Filote, C.; Răboacă, M.S. Smart Scheduling of Electric Vehicles Based on Reinforcement Learning. Sensors 2022, 22, 3718. https://doi.org/10.3390/s22103718
Viziteu A, Furtună D, Robu A, Senocico S, Cioată P, Remus Baltariu M, Filote C, Răboacă MS. Smart Scheduling of Electric Vehicles Based on Reinforcement Learning. Sensors. 2022; 22(10):3718. https://doi.org/10.3390/s22103718
Chicago/Turabian StyleViziteu, Andrei, Daniel Furtună, Andrei Robu, Stelian Senocico, Petru Cioată, Marian Remus Baltariu, Constantin Filote, and Maria Simona Răboacă. 2022. "Smart Scheduling of Electric Vehicles Based on Reinforcement Learning" Sensors 22, no. 10: 3718. https://doi.org/10.3390/s22103718
APA StyleViziteu, A., Furtună, D., Robu, A., Senocico, S., Cioată, P., Remus Baltariu, M., Filote, C., & Răboacă, M. S. (2022). Smart Scheduling of Electric Vehicles Based on Reinforcement Learning. Sensors, 22(10), 3718. https://doi.org/10.3390/s22103718