
Real-Time Abnormal Object Detection for Video Surveillance in Smart Cities



Abstract
:1. Introduction
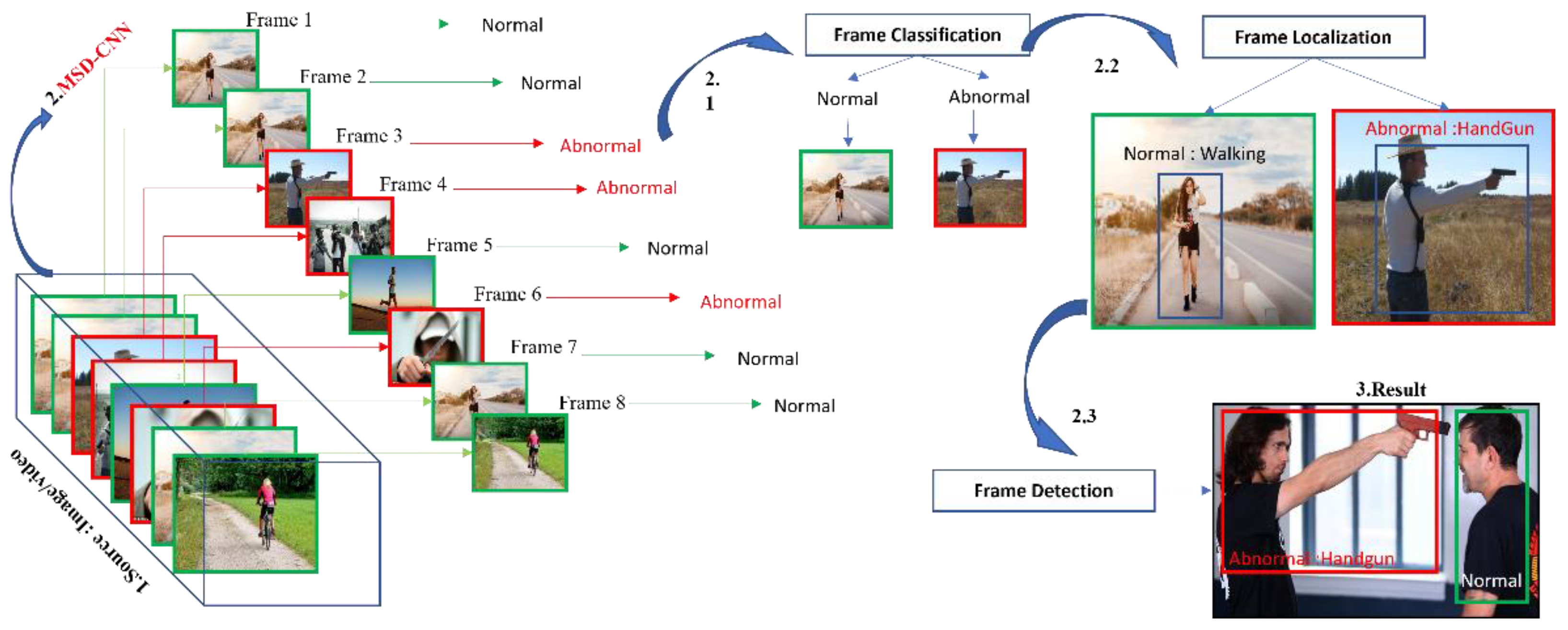
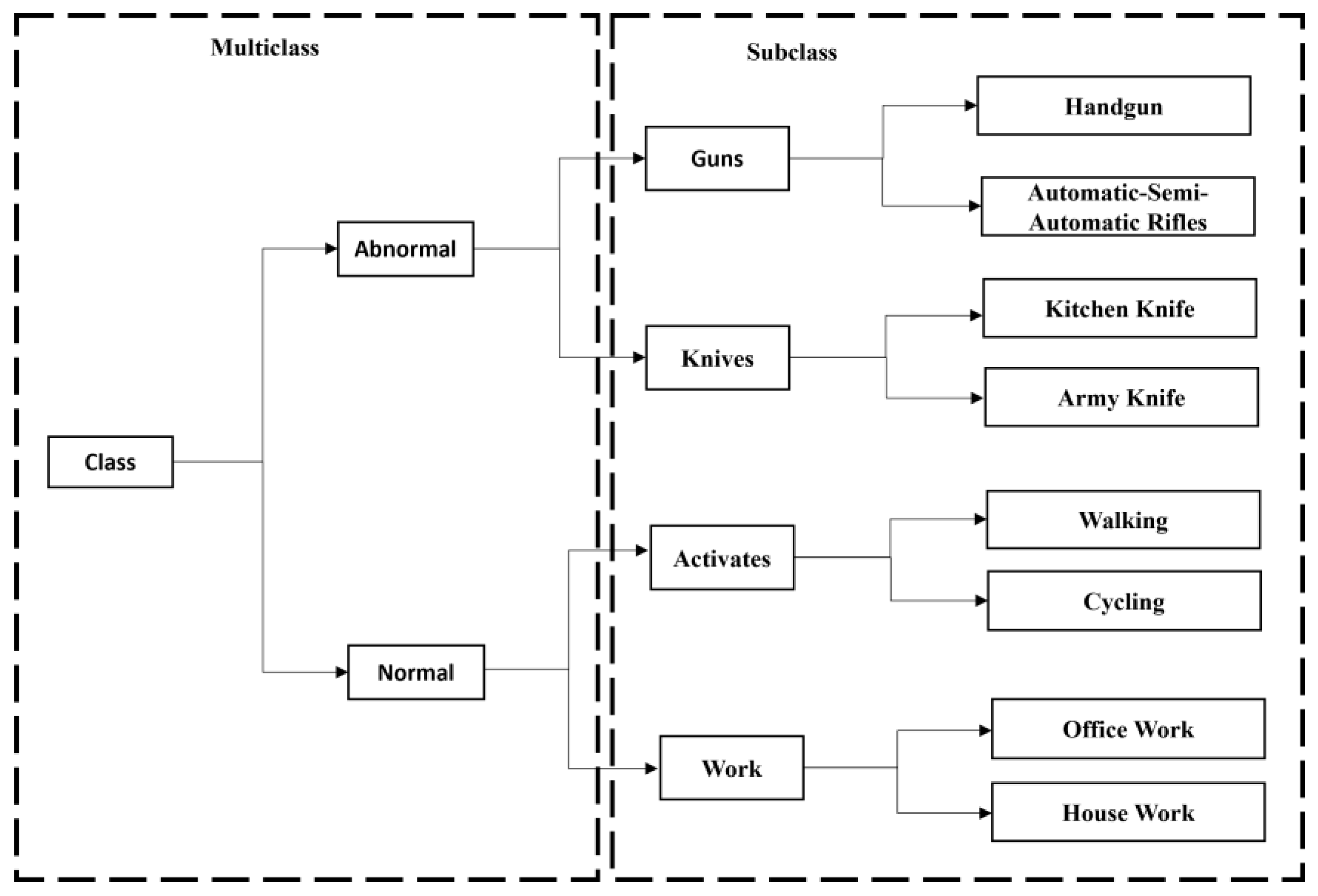
- Our study introduces a new lightweight multiclass-subclass detection CNN model to effectively and efficiently extract and detect abnormal features in a real-time scenario from both multiview and single view cameras;
- To facilitate the learning of the model for real-time detection, we constructed a custom dataset for training;
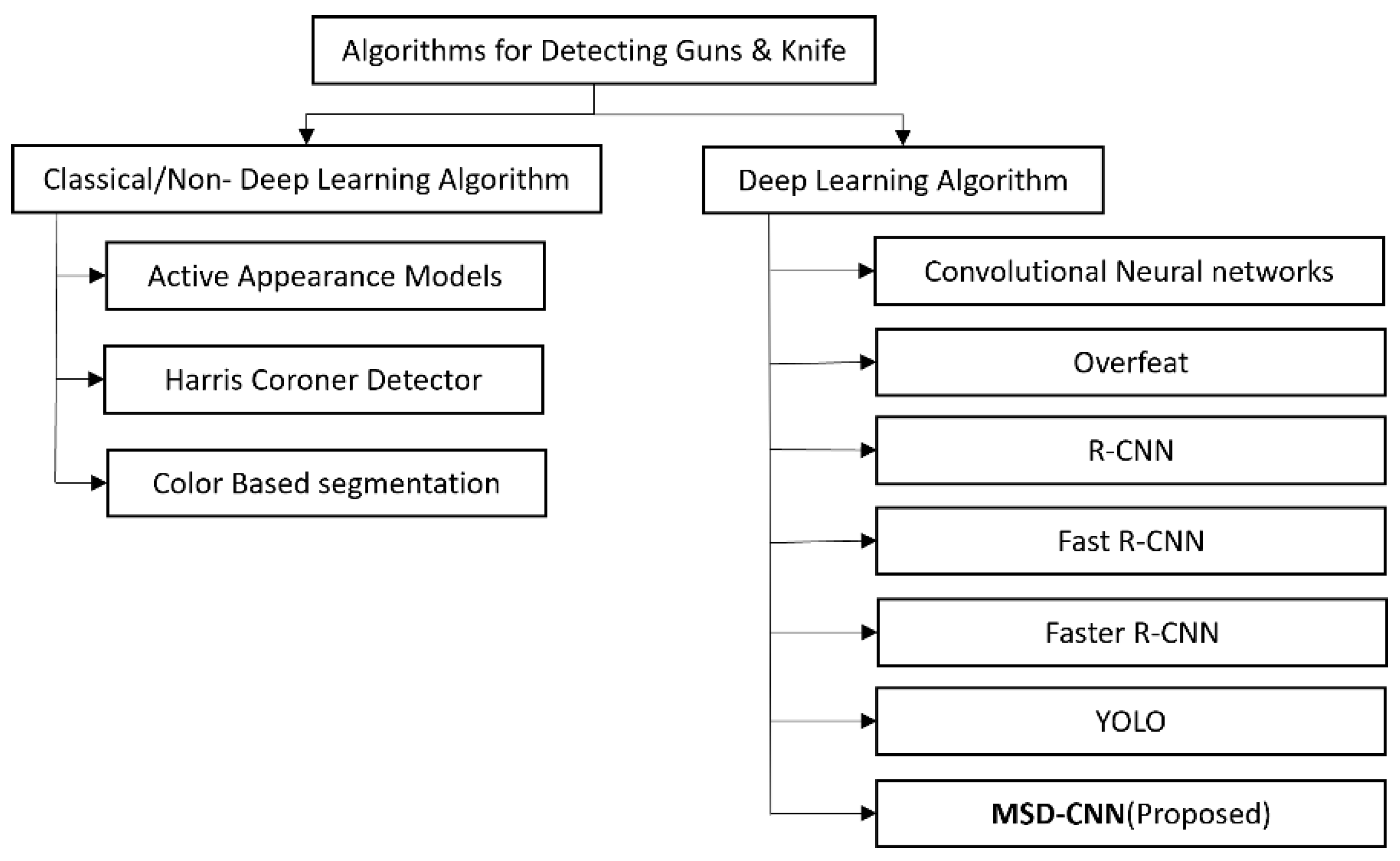
- We have summarized the insights of different algorithms used to detect handguns and knives and construct a taxonomy;
- We introduce a new evaluation method, Detection Time per Interval (DTpI), to evaluate an object’s emplacement concerning the multiclass evaluation real-time score in a multiview camera;
- The proposed model has achieved a better result than the state-of-the-art framework for detecting abnormal frames in real time.
2. Related Work
2.1. Gun and Knife Detection Using a Classical Algorithm
2.1.1. Active Appearance Model (AAM)
2.1.2. Harris Corner Detector (HCD)
2.1.3. Color-Based Segmentation (CBS)
2.2. Gun and Knife Detection Using Deep Neural Networks (DNNs)
2.2.1. Overfeat
2.2.2. CNN
2.2.3. R-CNN and Faster R-CNN
2.2.4. YOLO
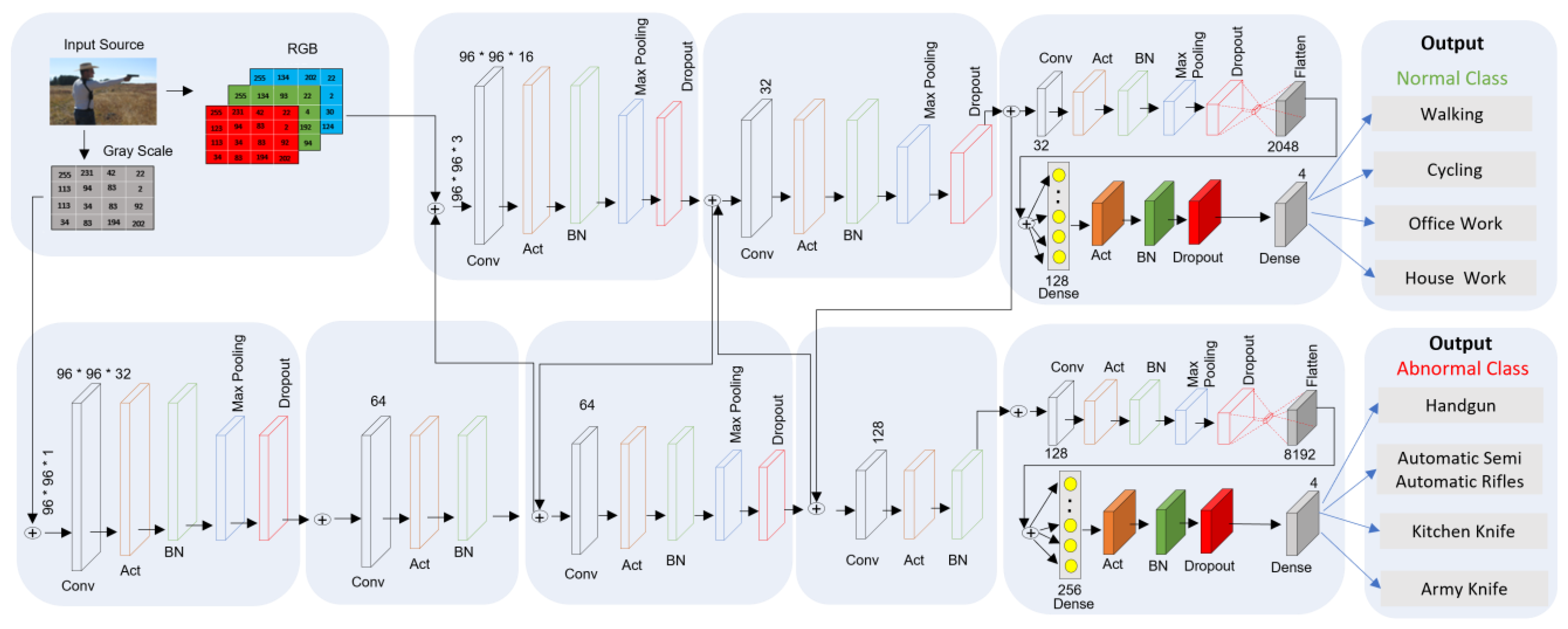
3. MSD-CNN
3.1. MSD-CNN Network
3.2. Architectural Flow
- First bullet Input: , with size
- Number of Filters:, where each has dimensions
- Activation Function:
- Output:, with size
- Filters with parameters
- Bias with (1 × 1 × 1) × parameters
- Weights with parameters
- Bias with parameters
| Algorithm 1. Detection in multiview cameras using GPU. |
| 1 2 3 4 Threads (videos) 5 Detected_frame_video_sequence_1= MSD-CNN applied on video_1 /* object classification and localization*/ 6 Detected_frame_video_sequence_n= MSD-CNN applied on video_n /* object classification and localization*/ |
4. Evaluation
4.1. Materials
4.1.1. Dataset for Training
- Flipping: Flipping an image is moving the image in a mirror-reversal horizontally or vertically;
- Shearing: Shearing an image is shifting part of an image;
- Scaling: Image scaling is the resizing of images.
4.1.2. Dataset for Testing
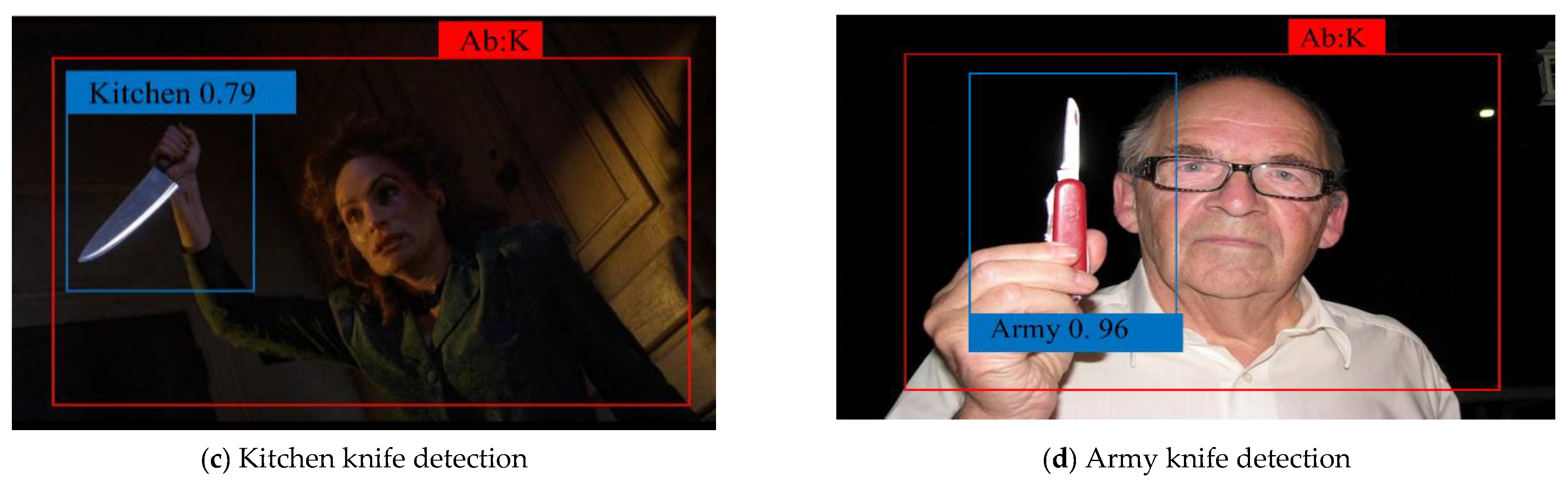
4.2. Comparison of Qualitative Results
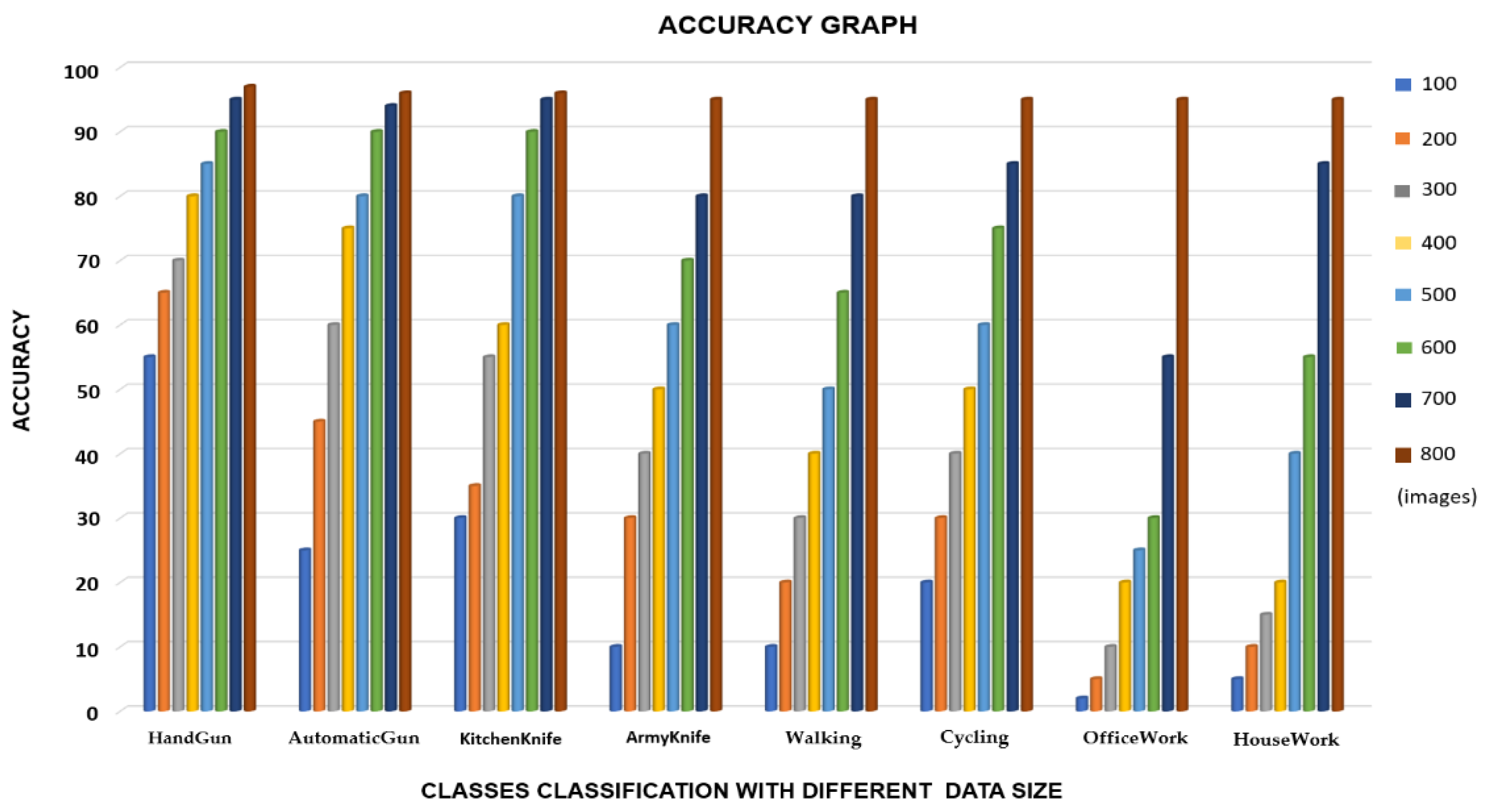
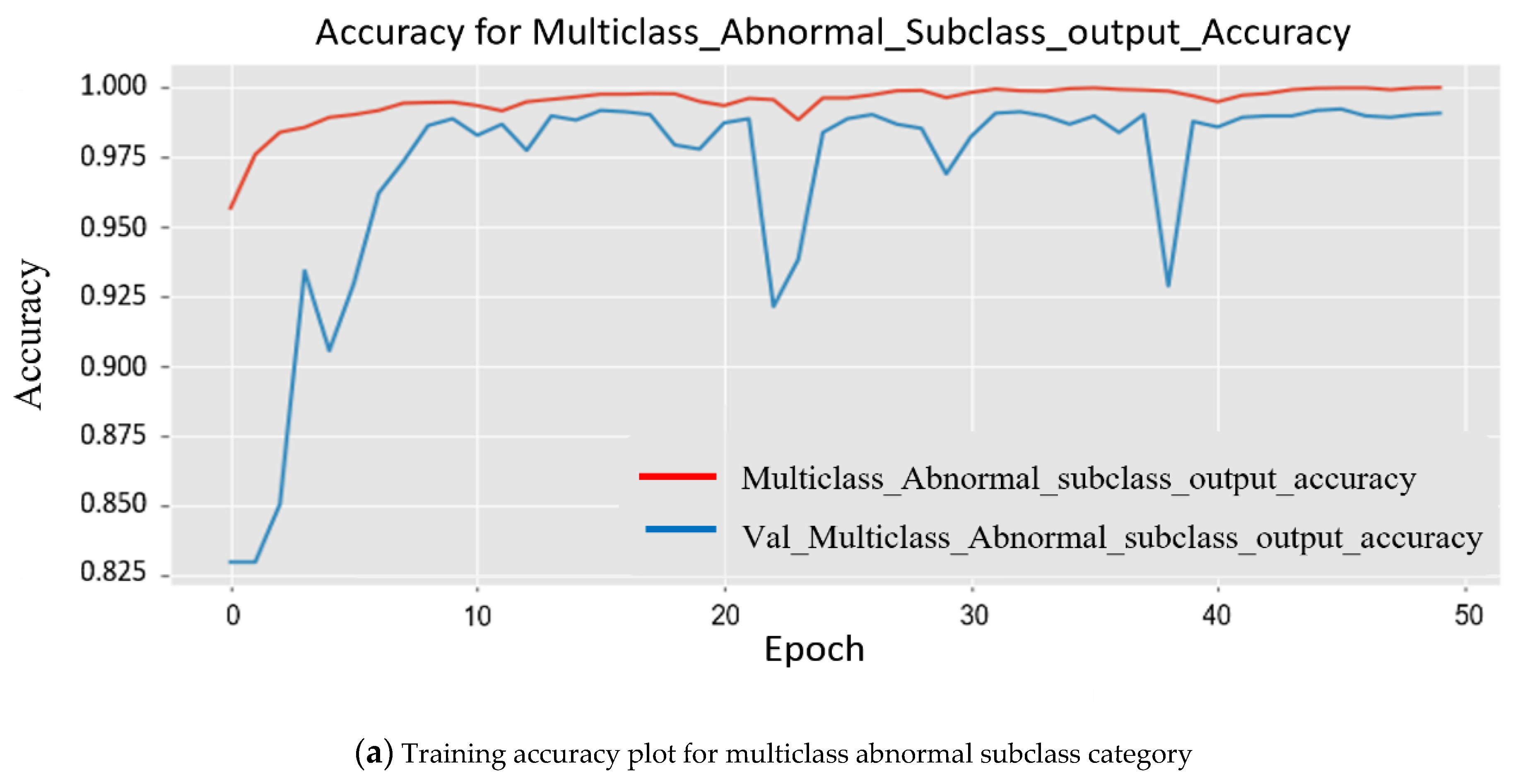
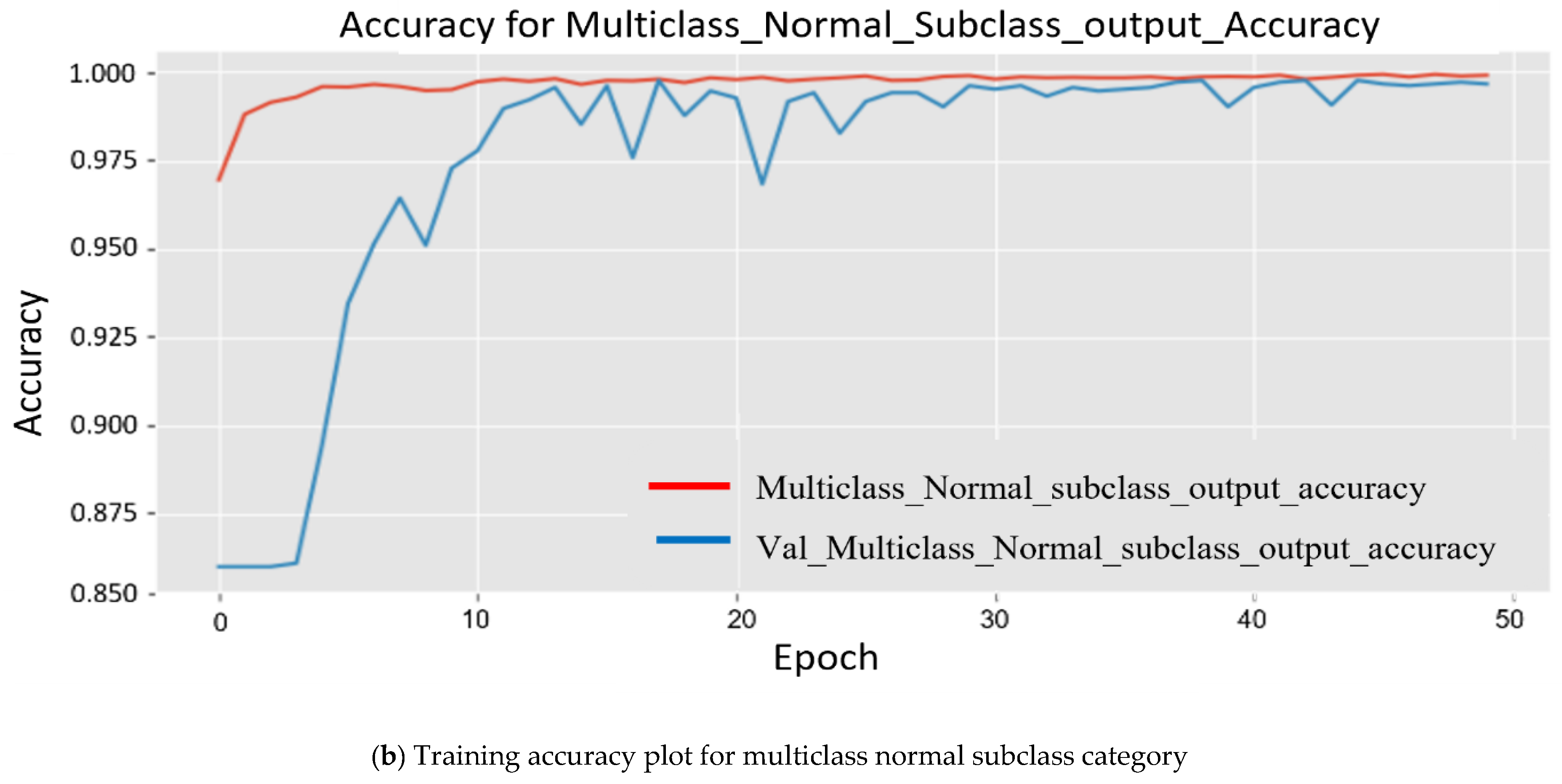
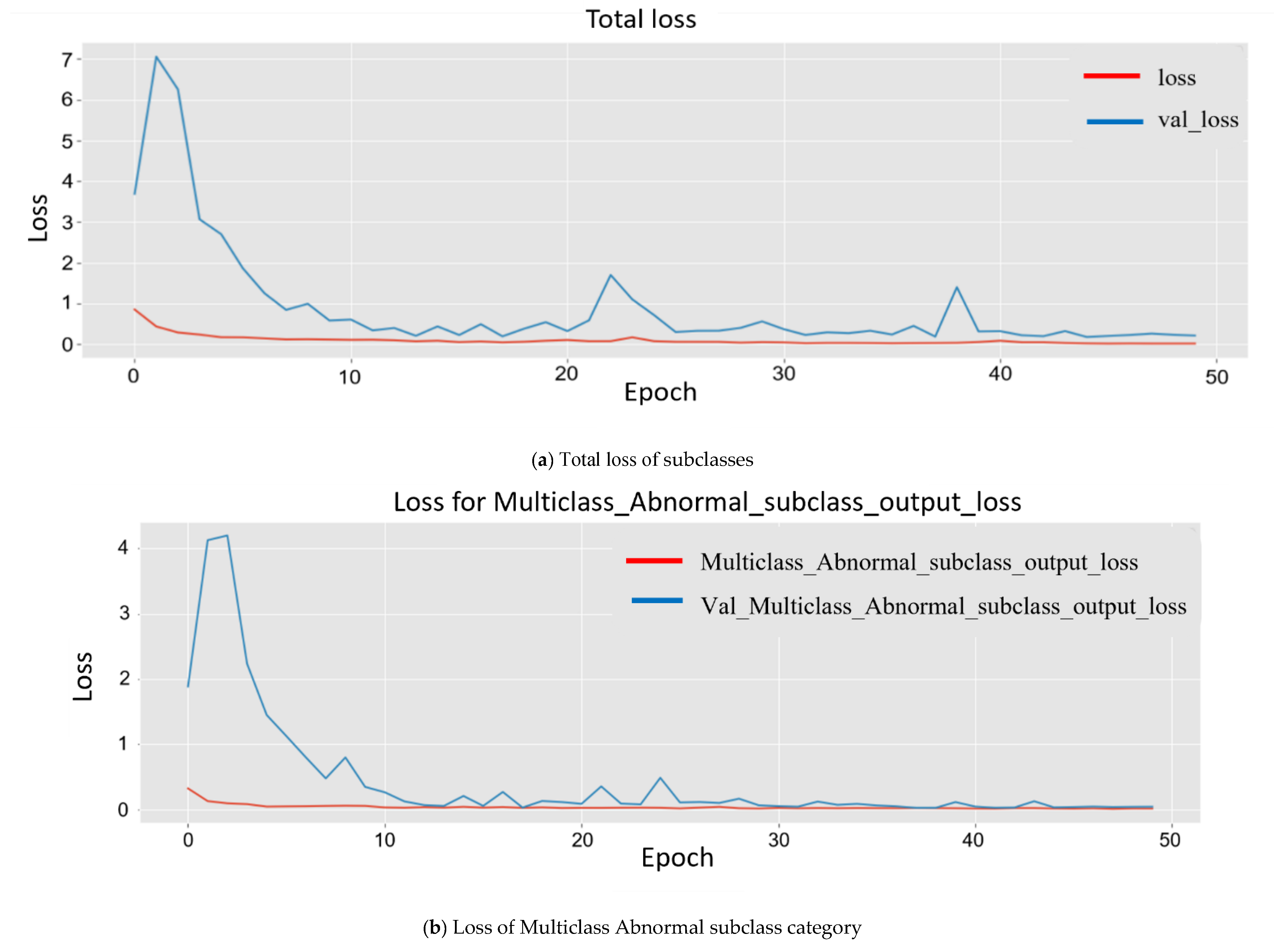
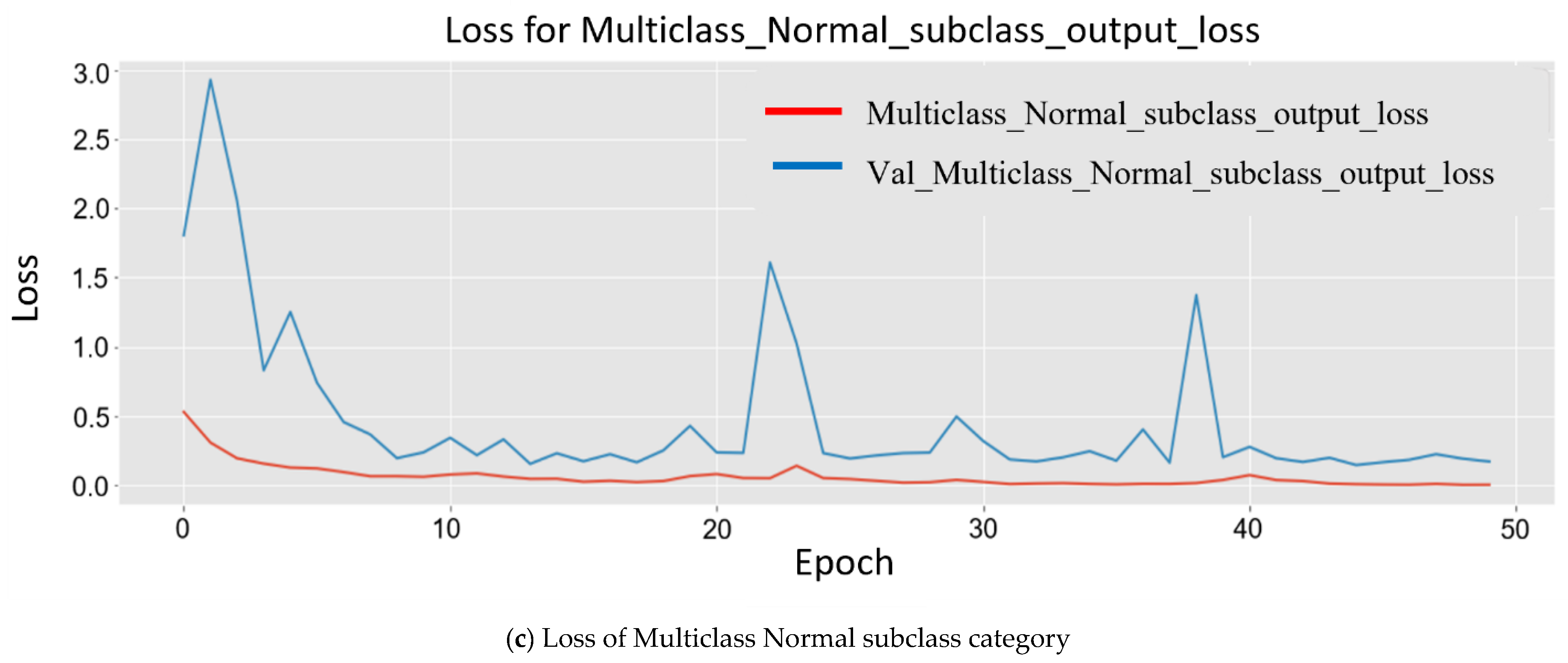
4.3. Quantitative Results Analysis
4.4. Detection Time Per Interval
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AAM | Active appearance model |
| CBS | Color-based segmentation |
| CNN | Convolutional neural network |
| COCO | Common object in context |
| DNN | Deep neural networks |
| GPU | Graphics processing unit |
| HCD | Harris corner detector |
| IMFDB | Internet movie firearm database |
| MSD-CNN | Multiclass subclass detection CNN |
| R-CNN | Region-based CNN |
| RELU | Rectified Linear Unit |
| SSD | Single shot multibox detector |
| UNODC | United Nations Office on Drugs and Crime |
| YOLO | You only look once |
References
- United Nations Office on Drugs and Crime (UNODC). Global Study on Homicide 2019. Data: UNODC Homicide Statistics 2019. Available online: https://www.unodc.org/documents/data-and-analysis/gsh/Booklet_5.pdf (accessed on 1 March 2022).
- Gesick, R.; Saritac, C.; Hung, C.C. Automatic image analysis process for the detection of concealed weapons. In Proceedings of the 5th Annual Workshop on Cyber Security and Information Intelligence Research: Cyber Security and Information Intelligence Challenges and Strategies, Oak Ridge, TN, USA, 13–15 April 2009; pp. 1–4. [Google Scholar]
- Flitton, G.; Breckon, T.P.; Megherbi, N. A comparison of 3D interest point descriptors with application to airport baggage object detection in complex C.T. imagery. Pattern Recognit. 2013, 46, 2420–2436. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Wang, L.; Su, Y. Visual place recognition: A survey from deep learning perspective. Pattern Recognit. 2021, 113, 107760. [Google Scholar] [CrossRef]
- Bai, X.; Wang, X.; Liu, X.; Liu, Q.; Song, J.; Sebe, N.; Kim, B. Explainable Deep Learning for Efficient and Robust Pattern Recognition: A Survey of Recent Developments. Pattern Recognit. 2021, 120, 108102. [Google Scholar] [CrossRef]
- Kim, J.U.; Ro, Y.M. Attentive Layer Separation for Object Classification and Object Localization in Object Detection. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–29 September 2019; pp. 3995–3999. [Google Scholar] [CrossRef]
- Nakib, M.; Khan, R.T.; Hasan, M. Crime Scene Prediction by Detecting Threatening Objects Using Convolutional Neural Network. Ph.D. Thesis, BRAC University, Dhak, Bangladesh, 2017. [Google Scholar]
- Halima, N.B.; Hosam, O. Bag of words-based surveillance system using support vector machines. Int. J. Secur. Appl. 2016, 10, 331–346. [Google Scholar] [CrossRef]
- Tiwari, R.K.; Verma, G.K. A computer vision-based framework for visual gun detection using SURF. In Proceedings of the 2015 International Conference on Electrical, Electronics, Signals, Communication and Optimization (EESCO), Visakhapatnam, India, 24–25 January 2015; pp. 1–5. [Google Scholar]
- Castillo, A.; Tabik, S.; Perez, F.; Olmos, R.; Herrera, F. Brightness guided preprocessing for automatic cold steel weapon detection in surveillance videos with deep learning. Neurocomputing 2018, 330, 151–161. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Duerig, T.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. arXiv 2018, arXiv:1811.00982. [Google Scholar] [CrossRef] [Green Version]
- Tang, P.; Wang, C.; Wang, X.; Liu, W.; Zeng, W.; Wang, J. Object Detection in Videos by High Quality Object Linking. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1272–1278. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bandara, K.; Hewamalage, H.; Liu, Y.H.; Kang, Y.; Bergmeir, C. Improving the accuracy of global forecasting models using time series data augmentation. Pattern Recognit. 2021, 120, 108148. [Google Scholar] [CrossRef]
- Sharma, K.U.; Thakur, N.V. A review and an approach for object detection in images. Int. J. Comput. Vis. Robot. 2017, 7, 196–237. [Google Scholar] [CrossRef]
- Tiwari, R.K.; Verma, G.K. A computer vision based framework for visual gun detection using harris interest point detector. Procedia Comput. Sci. 2015, 54, 703–712. [Google Scholar] [CrossRef] [Green Version]
- Pratihar, P.; Yadav, A.K. Detection techniques for human safety from concealed weapon and harmful EDS. Int. Rev. Appl. Eng. Res. 2014, 4, 71–76. [Google Scholar]
- Cootes, T.F.; Edwards, G.J.; Taylor, C.J. Active appearance models. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 681–685. [Google Scholar] [CrossRef] [Green Version]
- Glowacz, A.; Kmieć, M.; Dziech, A. Visual detection of knives in security applications using Active Appearance Models. Multimed. Tools Appl. 2015, 74, 4253–4267. [Google Scholar] [CrossRef] [Green Version]
- Sasikaladevi, V.; Mangai, V. Colour Based Image Segmentation Using Hybrid Kmeans with Watershed Segmentation. Int. J. Mech. Eng. Technol. 2018, 9, 1367–1377. [Google Scholar]
- Lai, J.; Maples, S. Developing a Real-Time Gun Detection Classifier. Tech. Rep. Available online: http://vision.stanford.edu/teaching/cs231n/reports/2017/pdfs/716.pdf (accessed on 1 March 2022).
- Asrith, M.J.N.V.S.K.; Reddy Prudhvi, K.; Sujihelen. Face Recognition and Weapon Detection from Very Low-Resolution Image. In Proceedings of the 2018 International Conference on Emerging Trends and Innovations in Engineering and Technological Research (ICETIETR), Ernakulam, India, 11–13 July 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Gelana, F.; Yadav, A. Firearm detection from surveillance cameras using image processing and machine learning techniques. In Smart Innovations in Communication and Computational Science; Springer: Singapore, 2019; pp. 25–34. [Google Scholar]
- Verma, G.K.; Dhillon, A. A handheld gun detection using faster r-cnn deep learning. In Proceedings of the 7th International Conference on Computer and Communication Technology, Allahabad, India, 24–26 November 2017; pp. 84–88. [Google Scholar]
- Kundegorski, M.E.; Akçay, S.; Devereux, M.; Mouton, A.; Breckon, T.P. On using feature descriptors as visual words for object detection within X-ray baggage security screening. In Proceedings of the 7th International Conference on Imaging for Crime Detection and Prevention (ICDP 2016), Madrid, Spain, 23–25 November 2016. [Google Scholar]
- Zhang, J.; Xing, W.; Xing, M.; Sun, G. Terahertz image detection with the improved faster region-based convolutional neural network. Sensors 2018, 18, 2327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Akcay, S.; Kundegorski, M.E.; Willcocks, C.G.; Breckon, T.P. Using deep convolutional neural network architectures for object classification and detection within x-ray baggage security imagery. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2203–2215. [Google Scholar] [CrossRef] [Green Version]
- Atto, A.M.; Benoit, A.; Lambert, P. Timed-image based deep learning for action recognition in video sequences. Pattern Recognit. 2020, 104, 107353. [Google Scholar] [CrossRef]
- de Azevedo Kanehisa, R.F.; de Almeida Neto, A. Firearm Detection using Convolutional Neural Networks. ICAART 2019, 2, 707–714. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. September. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Bhatti, M.T.; Khan, M.G.; Aslam, M.; Fiaz, M.J. Weapon detection in real-time cctv videos using deep learning. IEEE Access 2021, 9, 34366–34382. [Google Scholar] [CrossRef]
- Olmos, R.; Tabik, S.; Herrera, F. Automatic Handgun Detection Alarm in Videos Using Deep Learning. Neurocomputing 2018, 275, 66–72. [Google Scholar] [CrossRef] [Green Version]
- Nakib, M.; Khan, R.T.; Hasan, M.S.; Uddin, J. February. Crime Scene Prediction by Detecting Threatening Objects Using Convolutional Neural Network. In Proceedings of the 2018 International Conference on Computer, Communication, Chemical, Material and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 8–9 February 2018; pp. 1–4. [Google Scholar]
- Aversano, L.; Bernardi, M.L.; Cimitile, M.; Pecori, R. Deep Neural Networks Ensemble to detect COVID-19 from CT Scans. Pattern Recognit. 2021, 120, 108135. [Google Scholar] [CrossRef] [PubMed]
- Ha, I.; Kim, H.; Park, S.; Kim, H. Image retrieval using BIM and features from pretrained VGG network for indoor localization. Build. Environ. 2018, 140, 23–31. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Géron, A. Hands-On Machine Learning with Scikit-Learn, Keras, and Tensorflow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Baskurt, K.B.; Samet, R. Video synopsis: A survey. Comput. Vis. Image Underst. 2019, 181, 26–38. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Younis, A.; Shixin, L.; Jn, S.; Hai, Z. January. Real-Time Object Detection Using Pre-Trained Deep Learning Models MobileNet-SSD. In Proceedings of the 6th International Conference on Computing and Data Engineering, Almaty, Kazakhstan, 14–16 September 2020; pp. 44–48. [Google Scholar]
- Khokhlov, I.; Davydenko, E.; Osokin, I.; Ryakin, I.; Babaev, A.; Litvinenko, V.; Gorbachev, R. Tiny-YOLO object detection supplemented with geometrical data. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–5. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Quantity |
|---|---|
| ⴖH | height |
| ⴖw | width |
| ⴖC | number of channels |
| M | training examples |
| Mtrain | number of inputs for training |
| Mtest | number of test images |
| W | weights |
| b | bias |
| X/a | input |
| Y | output (predicated value) |
| Detection Type | Camera | Algorithm | Dataset | Evaluation Strategy | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Deployment | Different Types of Gun & Knife | Handgun | Knife | Single View Camera | Multiview Camera | Non-Deep Learning | Deep Learning | Training | Testing | Max mAP | Precision | Recall | F1 Measure | |
| Tiwari and Verma [15] | Off time | - | ✔ | - | ✔ | - | color-based segmentation and Harris interest point detector | - | CD | S | 84.26 | - | - | - |
| Glowacz et al. [18] | Off time | - | - | ✔ | ✔ | - | Harris Corner Detector | - | CD | S | 92.5 | - | - | - |
| Pratihar and Yadav [16] | Off time | - | ✔ | - | ✔ | - | Image Processing and the use of infrared rays | - | CD | S | - | - | - | - |
| Roberto Olmos [31] | Real time | - | ✔ | - | ✔ | - | - | Faster R-CNN | ID | S | 84 | - | 96 | 91 |
| Justin and Sydney [20] | Real time | - | ✔ | - | ✔ | - | - | Overfeat | ID | S | 89 | - | - | - |
| Verma and Dhillon [23] | Real time | - | ✔ | - | ✔ | - | - | Faster R-CNN | ID | S | 93 | - | - | - |
| Nakib et al. [32] | Off time | - | ✔ | ✔ | ✔ | - | - | CNN- Customized layer | ID | S | 90 | - | - | - |
| Kundergoski et al. [24] | Off time | - | ✔ | - | ✔ | - | - | RCNN, R-FCN, YOLOv2 | XD | S | 97 | - | - | - |
| Zhang et al. [25] | Off time | - | ✔ | - | ✔ | - | - | RCNN, R-FCN, YOLOv2 | HD | S | 69 | - | - | - |
| Bhatti et al. [30] | Real time | - | ✔ | - | ✔ | - | VGG16,YOLOv4 | CD | CD | 91 | 93 | 88 | 91 | |
| The present work | Real, off time | ✔ | ✔ | ✔ | ✔ | ✔ | - | CNN-Customized layer | ID | S,D | 97 | 90.7 | 86.3 | 95.7 |
| Dataset | TP | FP | FN | TN | Precision | Recall | F1 Measure |
|---|---|---|---|---|---|---|---|
| ImageNet, IMFDB, and OpenImage Net V4 | 2305 | 61 | 40 | 394 | 90.7% | 86.33% | 95.7% |
| Dataset | TP | FP | FN | TN | Precision | Recall | F1 Measure |
|---|---|---|---|---|---|---|---|
| Olmos | 473 | 32 | 25 | 78 | 93.4% | 94.66% | 93% |
| Training Set | Testing Set | Result (%) | ||
|---|---|---|---|---|
| Abnormal |  |  | Ab:G: handgun: 98 AbK: kitchen: 0.3 No:A: walking: 0.7 No:W: office: 0.1 | Ab:G: automatic: 18 Ab:K: army: 0.6 No:A: cycling: 0.22 No:W: house: 0.07 |
 |  | Ab:G: handgun: 10 Ab:K: kitchen: 0.5 No:A: walking: 0.4 No:W: office: 0.2 | Ab:G: automatic: 96.5 Ab:K: army: 0.3 No:A: cycling: 0.10 No:W: house: 1.0 | |
 |  | Ab:G: handgun: 6.2 Ab:K: kitchen: 98.54 No:A: walking: 1.7 No:W: office: 0.15 | Ab:G: automatic: 5.0 Ab:K: army: 30.5 No:A: cycling: 0.6 No:W: house: 0.1 | |
 |  | Ab:G: handgun: 0.3 Ab: K: kitchen: 11.1 No:A: walking: 0.32 No:W: office: 0.005 | Ab:G: automatic: 0.10 Ab:K: army: 96.01 No:A: cycling: 0.03 No:W: house: 0.02 | |
| Normal |  |  | Ab:G: handgun: 0.009 Ab:K: kitchen: 0.1 No:A: walking: 96.01 No:W: office: 0.57 | Ab:G: automatic: 2.4 Ab:K: army: 0.65 No:A: cycling: 0.36 No:W: house: 2.7 |
 |  | Ab:G: handgun: 0.26 Ab:K: kitchen: 0.21 No:A: walking: 0.63 No:W: office: 0.13 | Ab:G: automatic: 0.01 Ab:K: army: 0.45 No:A: cycling: 95.90 No:W: house: 0.35 | |
 |  | Ab:G: handgun: 0.18 Ab:K: kitchen: 0.17 No:A: walking: 0.78 No:W: office: 95.32 | Ab:G: automatic: 0.032 Ab:K: army: 0.444 No:A: cycling: 0.006 No:W: house: 8.00 | |
 |  | Ab:G: handgun: 0.54 Ab:K: kitchen: 0.16 No:A: walking: 0.01 No:W: office: 6.7 | Ab:G: automatic: 0.78 Ab:K: army: 0.09 No:A: cycling: 0.13 No:W: house: 95.20 | |
| YOLO [R1] | SSD [R2] | RFCN [R3] | RCNN [R4] | FRCNN [R5] | MSD-CNN | ||
|---|---|---|---|---|---|---|---|
| Abnormal Frame | handgun | 67.45 | 69.21 | 68.18 | 67.32 | 73.06 | 91.75 |
| automatic gun | 75.32 | 70.54 | 74.21 | 72.13 | 78.54 | 94.71 | |
| kitchen knife | 55.45 | 53.08 | 58.71 | 60.36 | 71.44 | 89.23 | |
| army knife | 34.84 | 45.05 | 46.47 | 45.53 | 60.18 | 83.24 | |
| Normal Frame | walking | 80.21 | 79.25 | 81.10 | 80.14 | 88.47 | 90.11 |
| cycling | 81.54 | 84.23 | 86.98 | 85.74 | 89.36 | 89.47 | |
| officework | 78.25 | 77.55 | 85.68 | 88.22 | 89.21 | 91.75 | |
| housework | 82.14 | 79.11 | 87.36 | 89.56 | 90.12 | 90.46 | |
| mAP | 70.01 | 69.5 | 73.58 | 73.57 | 80.47 | 90.02 |
| Mobile Net [T1] | Tiny-YOLO [T2] | MSD-CNN | ||||
|---|---|---|---|---|---|---|
| Loading | Inference | Loading | Inference | Loading | Inference | |
| Nvidia GeForce RTX 2060 (GPU) | 0.0083 | 0.0031 | 0.0015 | 0.0033 | 0.0057 | 0.0019 |
| PC-CPU | 0.5 | 0.19 | 0.091 | 0.2 | 0.46 | 0.15 |
| Raspberry Pi 4 | 2.97 | 2.31 | 0.6 | 3.0 | 1.86 | 2.10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ingle, P.Y.; Kim, Y.-G. Real-Time Abnormal Object Detection for Video Surveillance in Smart Cities. Sensors 2022, 22, 3862. https://doi.org/10.3390/s22103862
Ingle PY, Kim Y-G. Real-Time Abnormal Object Detection for Video Surveillance in Smart Cities. Sensors. 2022; 22(10):3862. https://doi.org/10.3390/s22103862
Chicago/Turabian StyleIngle, Palash Yuvraj, and Young-Gab Kim. 2022. "Real-Time Abnormal Object Detection for Video Surveillance in Smart Cities" Sensors 22, no. 10: 3862. https://doi.org/10.3390/s22103862
APA StyleIngle, P. Y., & Kim, Y. -G. (2022). Real-Time Abnormal Object Detection for Video Surveillance in Smart Cities. Sensors, 22(10), 3862. https://doi.org/10.3390/s22103862