
Inertial-Measurement-Unit-Based Novel Human Activity Recognition Algorithm Using Conformer


Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
3.1. Dataset Description and Preprocessing
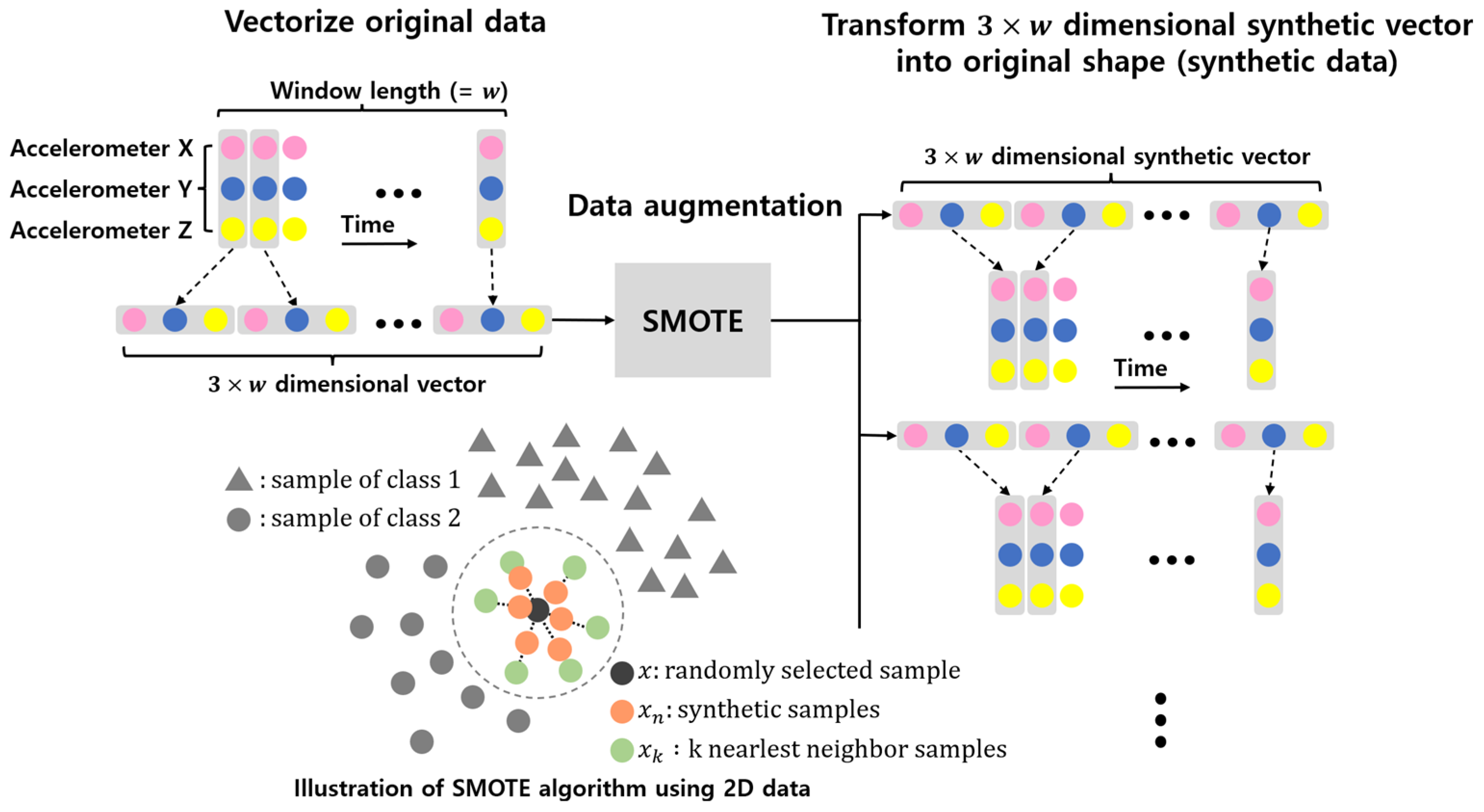
3.2. Data Augmentation
- The class set was . The number of samples, k, with the closest Euclidean distance to a random sample, , which are windowed data, is . was obtained using the k-nearest neighbor algorithm [27].
- The number of new samples between and is , and the rule for generating is expressed in Equation (1):
- Steps 1 and 2 are repeated such that the amount of class data in each class ) becomes N.
- , , and were applied using the augmentation process.
3.3. Proposed Model
3.3.1. Conformer-Based HAR Model
3.3.2. Training and Evaluation
- Actual positives that are correctly predicted are called true positives (TP).
- Actual positives that are wrongly predicted negatives are called false negatives (FN).
- Actual negatives that are correctly predicted are called true negatives (TN).
- Actual negatives that are wrongly predicted are called false positives (FP).
4. Results and Discussion
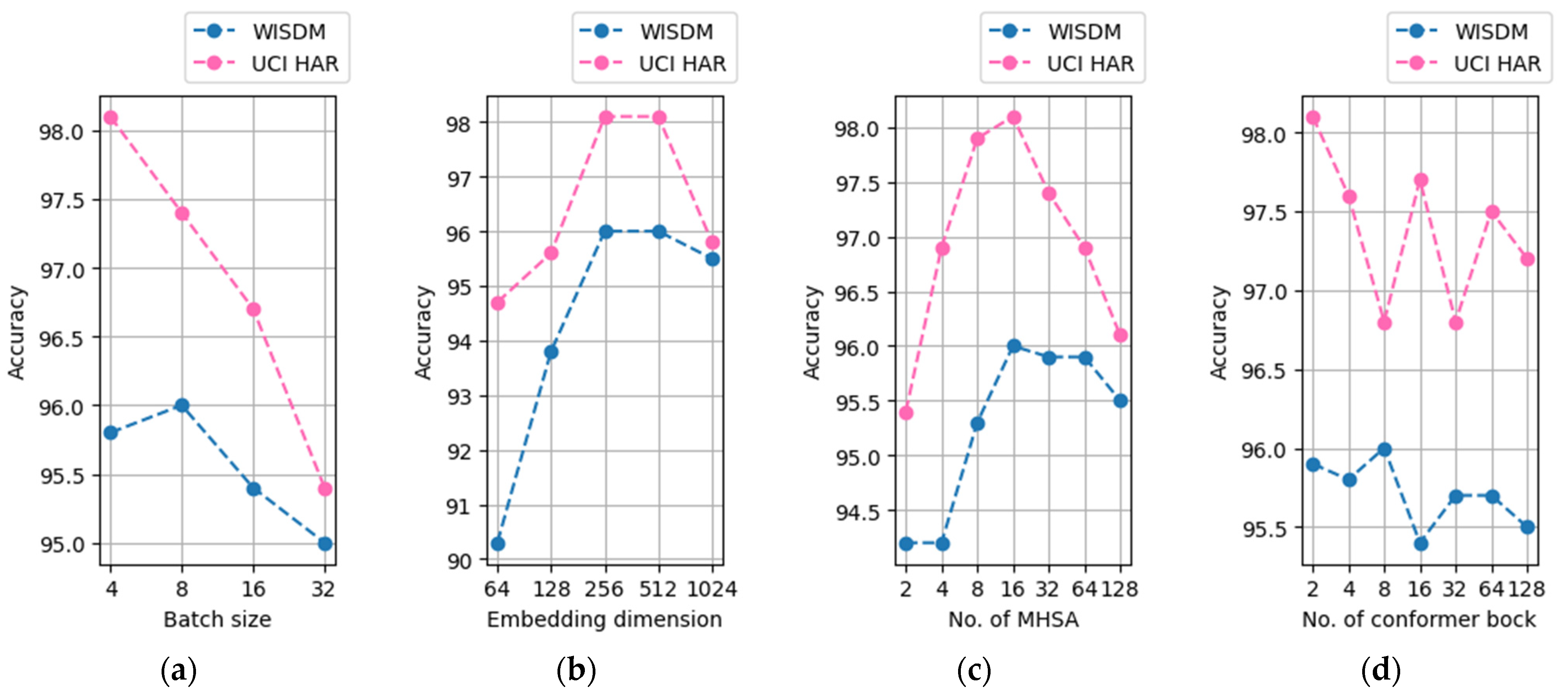
4.1. Hyperparameter Parameter Optimization for the Model
4.2. Evaluation of Proposed Algorithm
4.2.1. Effect of Data Augmentation and Comparison of Proposed Model with Baseline Model
4.2.2. Performance Comparison of the Proposed Algorithm with Baseline Models
4.2.3. Comparison of Proposed Algorithm with Previous Studies
4.2.4. Verification of the Generality of the Proposed Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. (CSUR) 2014, 46, 1–33. [Google Scholar] [CrossRef]
- Demrozi, F.; Pravadelli, G.; Bihorac, A.; Rashidi, P. Human activity recognition using inertial, physiological and environmental sensors: A comprehensive survey. IEEE Access 2020, 8, 210816–210836. [Google Scholar] [CrossRef] [PubMed]
- Sousa Lima, W.; Souto, E.; El-Khatib, K.; Jalali, R.; Gama, J. Human activity recognition using inertial sensors in a smartphone: An overview. Sensors 2019, 19, 3213. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, R.; Yan, D.; Peng, H.; Yang, T.; Sha, X.; Zhao, Y.; Liu, L. Basketball movements recognition using a wrist wearable inertial measurement unit. In Proceedings of the 2018 IEEE 1st International Conference on Micro/Nano Sensors for AI, Healthcare, and Robotics (NSENS), Shenzhen, China, 5–7 December 2018; IEEE: New York, NY, USA, 2018; pp. 73–76. [Google Scholar]
- Wang, Z.; Shi, X.; Wang, J.; Gao, F.; Li, J.; Guo, M.; Qiu, S. Swimming motion analysis and posture recognition based on wearable inertial sensors. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), 6–9 October 2019; IEEE: New York, NY, USA, 2019; pp. 3371–3376. [Google Scholar]
- Kim, Y.W.; Joa, K.L.; Jeong, H.Y.; Lee, S. Wearable IMU-based human activity recognition algorithm for clinical balance assessment using 1D-CNN and GRU ensemble model. Sensors 2021, 21, 7628. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Zhang, F.; Xu, Z.; Wei, J. The Diverse Gait Dataset: Gait segmentation using inertial sensors for pedestrian localization with different genders, heights and walking speeds. Sensors 2022, 22, 1678. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2012, 15, 1192–1209. [Google Scholar] [CrossRef]
- Kim, Y.W.; Cho, W.H.; Joa, K.L.; Jung, H.Y.; Lee, S. A new auto-Scoring algorithm for bance assessment with wearable IMU device based on nonlinear model. J. Mech. Med. Biol. 2020, 20, 2040011. [Google Scholar] [CrossRef]
- Chen, Z.; Qingchang, Z.; Yeng, C.S.; Le, Z. Robust human activity recognition using smartphone sensors via CT-PCA and online SVM. IEEE Trans. Ind. Inform. 2017, 13, 3070–3080. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef] [Green Version]
- Khan, N.S.; Ghani, M.S. A survey of deep learning-based models for human activity recognition. Wirel. Pers. Commun. 2021, 120, 1593–1635. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Mekruksavanich, S.; Jitpattanakul, A. Smartwatch-based human activity recognition using hybrid lstm network. In Proceedings of the 2020 IEEE Sensors, Virtual Conference, Virtual, Rotterdam, The Netherlands, 25–28 October 2020; IEEE: New York, NY, USA, 2020; pp. 1–4. [Google Scholar]
- Mukherjee, D.; Mondal, R.; Singh, P.K.; Sarkar, R.; Bhattacharjee, D. EnsemConvNet: A deep learning approach for human activity recognition using smartphone sensors for healthcare applications. Multimed. Tools Appl. 2020, 79, 31663–31690. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; Volume 3058. [Google Scholar]
- Lim, B.; Arık, S.Ö.; Loeff, N.; Pfister, T. Temporal fusion transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef]
- Ruan, L.; Jin, Q. Survey: Transformer based video-language pre-training. AI Open 2022, 3, 1–13. [Google Scholar] [CrossRef]
- Mazzia, V.; Angarano, S.; Salvetti, F.; Angelini, F.; Chiaberge, M. Action Transformer: A self-attention model for short-time pose-based human action recognition. Pattern Recognit. 2022, 124, 108487. [Google Scholar] [CrossRef]
- Shavit, Y.; Klein, I. Boosting inertial-based human activity recognition with transformers. IEEE Access 2021, 9, 53540–53547. [Google Scholar] [CrossRef]
- Dirgová Luptáková, I.; Kubovčík, M.; Pospíchal, J. Wearable sensor-based human activity recognition with transformer model. Sensors 2022, 22, 1911. [Google Scholar] [CrossRef]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented Transformer for Speech Recognition. In Proceedings of the INTERSPEECH 2020, Shanghai, China, 25–29 October 2020; ISCA: Baixas, France, 2020; pp. 5036–5040. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; IEEE: New York, NY, USA, 2021; pp. 367–376. [Google Scholar]
- Chen, S.; Wu, Y.; Chen, Z.; Wu, J.; Li, J.; Yoshioka, T.; Wang, C.; Liu, S.; Zhou, M. Continuous speech separation with conformer. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: New York, NY, USA, 2021; pp. 5749–5753. [Google Scholar]
- Chawla, N.; VBowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Okai, J.; Paraschiakos, S.; Beekman, M.; Knobbe, A.; de Sá, C.R. Building robust models for human activity recognition from raw accelerometers data using gated recurrent units and long short term memory neural networks. In Proceedings of the 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), 23–27 July 2019; IEEE: New York, NY, USA, 2019; pp. 2486–2491. [Google Scholar]
- Zebin, T.; Sperrin, M.; Peek, N.; Casson, A.J. Human activity recognition from inertial sensor time-series using batch normalized deep LSTM recurrent networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 17–21 July 2018; IEEE: New York, NY, USA, 2018; pp. 1–4. [Google Scholar]
- Kuang, X.; He, J.; Hu, Z.; Zhou, Y. Comparison of deep feature learning methods for human activity recognition. Appl. Res. Comput. 2018, 35, 2815–2817. [Google Scholar]
- Teng, Q.; Wang, K.; Zhang, L.; He, J. The layer-wise training convolutional neural networks using local loss for sensor-based human activity recognition. IEEE Sens. J. 2020, 20, 7265–7274. [Google Scholar] [CrossRef]
- Ha, S.; Yun, J.M.; Choi, S. Multi-modal convolutional neural networks for activity recognition. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Hong Kong, China, 9–12 October 2015; IEEE: New York, NY, USA, 2015; pp. 3017–3022. [Google Scholar]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. ACM SigKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the 21th International European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Ghate, V. Hybrid deep learning approaches for smartphone sensor-based human activity recognition. Multimed. Tools Appl. 2021, 80, 35585–35604. [Google Scholar] [CrossRef]
- Xu, H.; Li, J.; Yuan, H.; Liu, Q.; Fan, S.; Li, T.; Sun, X. Human activity recognition based on Gramian angular field and deep convolutional neural network. IEEE Access 2020, 8, 199393–199405. [Google Scholar] [CrossRef]
- Khan, Z.N.; Ahmad, J. Attention induced multi-head convolutional neural network for human activity recognition. Appl. Soft Comput. 2021, 110, 107671. [Google Scholar] [CrossRef]
- Johnson, J.M.; Khoshgoftaar, T.M. Survey on deep learning with class imbalance. J. Big Data 2019, 6, 1–54. [Google Scholar] [CrossRef]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time series data augmentation for deep learning: A survey. arXiv 2020, arXiv:2002.12478. [Google Scholar]
- Moreno-Barea, F.J.; Jerez, J.M.; Franco, L. Improving classification accuracy using data augmentation on small data sets. Expert Syst. Appl. 2020, 161, 113696. [Google Scholar] [CrossRef]
- Rok, B.; Lusa, L. SMOTE for high-dimensional class-imbalanced data. BMC Bioinform. 2013, 14, 106. [Google Scholar]
- Boin, J.B.; Roth, N.; Doshi, J.; Llueca, P.; Borensztein, N. Multi-class segmentation under severe class imbalance: A case study in roof damage assessment. arXiv 2020, arXiv:2010.07151. [Google Scholar]
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–12 June 2012; IEEE: New York, NY, USA, 2012; pp. 108–109. [Google Scholar]
- Liu, T.; Wang, S.; Liu, Y.; Quan, W.; Zhang, L. A lightweight neural network framework using linear grouped convolution for human activity recognition on mobile devices. J. Supercomput. 2022, 78, 6696–6716. [Google Scholar] [CrossRef]
- Cheng, X.; Zhang, L.; Tang, Y.; Liu, Y.; Wu, H.; He, J. Real-time human activity recognition using conditionally parametrized convolutions on mobile and wearable devices. IEEE Sens. J. 2022, 22, 5889–5901. [Google Scholar] [CrossRef]
- Abedin, A.; Rezatofighi, H.; Ranasinghe, D.C. Guided-GAN: Adversarial Representation Learning for Activity Recognition with Wearables. arXiv 2021, arXiv:2110.05732. [Google Scholar]
- Son, M.; Jung, S.; Jung, S.; Hwang, E. BCGAN: A CGAN-based over-sampling model using the boundary class for data balancing. J. Supercomput. 2021, 77, 10463–10487. [Google Scholar] [CrossRef]
- Chowdhury, S.S.; Boubrahimi, S.F.; Hamdi, S.M. Time Series Data Augmentation using Time-Warped Auto-Encoders. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Pasadena, CA, USA, 13–15 December 2021; IEEE: New York, NY, USA, 2021; pp. 467–470. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Parameter | WISDM | UCI-HAR |
|---|---|---|
| Latent sequence embedding dimension | 256 | 256 |
| Number of MHSA heads | 16 | 16 |
| Number of blocks | 8 | 2 |
| Feed-forward expansion factor | 2 | 2 |
| Convolution expansion factor | 2 | 2 |
| Dropout rates (%) | 10 | 10 |
| Dataset | Metric | Conformer | Transformer | 1D-CNN | |||
|---|---|---|---|---|---|---|---|
| Original | Augmented | Original | Augmented | Original | Augmented | ||
| WISDM | Accuracy (%) | 96.0 | 98.1 | 95.5 | 97.9 | 85.7 | 89.1 |
| Macro F1 score (%) | 94.6 | 98.1 | 94.2 | 97.9 | 80.3 | 88.9 | |
| Epoch time (s) | 115.1 | 285.3 | 100.5 | 243.5 | 22.8 | 53.6 | |
| Test time (s) | 157.0 | 392.9 | 62.9 | 148.4 | 35.0 | 79.0 | |
| UCI-HAR | Accuracy (%) | 98.1 | 99.3 | 97.5 | 98.9 | 93.0 | 96.0 |
| Macro F1 score (%) | 98.2 | 99.3 | 97.7 | 98.9 | 93.1 | 96.0 | |
| Epoch time (s) | 63.8 | 134.5 | 76.6 | 159.6 | 18.8 | 38.6 | |
| Test time (s) | 24.5 | 52.1 | 24.2 | 47.1 | 13.6 | 27.6 | |
| Dataset | Metric | Conformer (No. of Conformer Block = 2) | |
|---|---|---|---|
| Original | Augmented | ||
| WISDM | Accuracy (%) | 95.9 | 98.1 |
| Macro F1 score (%) | 94.5 | 98.1 | |
| Epoch time (s) | 87.99 | 205.3 | |
| Test time (s) | 67.7 | 160.1 | |
| Algorithm | WISDM | UCI-HAR |
|---|---|---|
| Accuracy (%) | Accuracy (%) | |
| Proposed algorithm | 98.1 | 99.3 |
| DeepCNN-RF [36] | 97.7 | 98.2 |
| Fusion-Mdk-ResNet [37] | 96.8 | 89.5 |
| attention-based multi-head [38] | 98.2 | 95.4 |
| Dataset | Metric | Conformer for WISDM | Transformer | ||
|---|---|---|---|---|---|
| Original | Augmented | Original | Augmented | ||
| PAMAP2 | Accuracy (%) | 99.1 | 99.7 | 98.7 | 99.3 |
| Macro F1 score (%) | 99.0 | 99.7 | 98.6 | 99.3 | |
| Epoch time (s) | 118.2 | 237.2 | 140.7 | 283.3 | |
| Test time (s) | 95.7 | 191.8 | 91.1 | 182.4 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.-W.; Cho, W.-H.; Kim, K.-S.; Lee, S. Inertial-Measurement-Unit-Based Novel Human Activity Recognition Algorithm Using Conformer. Sensors 2022, 22, 3932. https://doi.org/10.3390/s22103932
Kim Y-W, Cho W-H, Kim K-S, Lee S. Inertial-Measurement-Unit-Based Novel Human Activity Recognition Algorithm Using Conformer. Sensors. 2022; 22(10):3932. https://doi.org/10.3390/s22103932
Chicago/Turabian StyleKim, Yeon-Wook, Woo-Hyeong Cho, Kyu-Sung Kim, and Sangmin Lee. 2022. "Inertial-Measurement-Unit-Based Novel Human Activity Recognition Algorithm Using Conformer" Sensors 22, no. 10: 3932. https://doi.org/10.3390/s22103932
APA StyleKim, Y. -W., Cho, W. -H., Kim, K. -S., & Lee, S. (2022). Inertial-Measurement-Unit-Based Novel Human Activity Recognition Algorithm Using Conformer. Sensors, 22(10), 3932. https://doi.org/10.3390/s22103932