
Crosstalk Correction for Color Filter Array Image Sensors Based on Lp-Regularized Multi-Channel Deconvolution


Abstract
:1. Introduction
- The crosstalk problem is formulated as a multi-channel degradation model;
- A multi-channel deconvolution method based on the objective function with a hyper-Laplacian prior is designed. The proposed method utilizes regularization to achieve the estimated image with sharp edges and details, and it efficiently suppresses noise amplification for each color component. Concurrently, intercolor regularization is employed to smooth the color difference components and to encourage the homogeneity of the edges;
- An efficient algorithm based on alternating minimization is described. Experimental results validate that the proposed method is more robust than conventional methods.
2. Problem Formulation
3. Proposed Method
3.1. Multi-Channel Deconvolution
3.2. Constraints
3.3. Optimization
| Algorithm 1 Crosstalk Correction based on -regularized Multi-channel Deconvolution. |
Input: The observed image , the subsamling matrix , the crosstalk matrix , and the regularization parameters Output: The reconstructed image Initialization: Solve based on the demosaicing method () |
4. Experimental Results
4.1. Datasets
4.2. Compared Methods
4.3. Comparisons
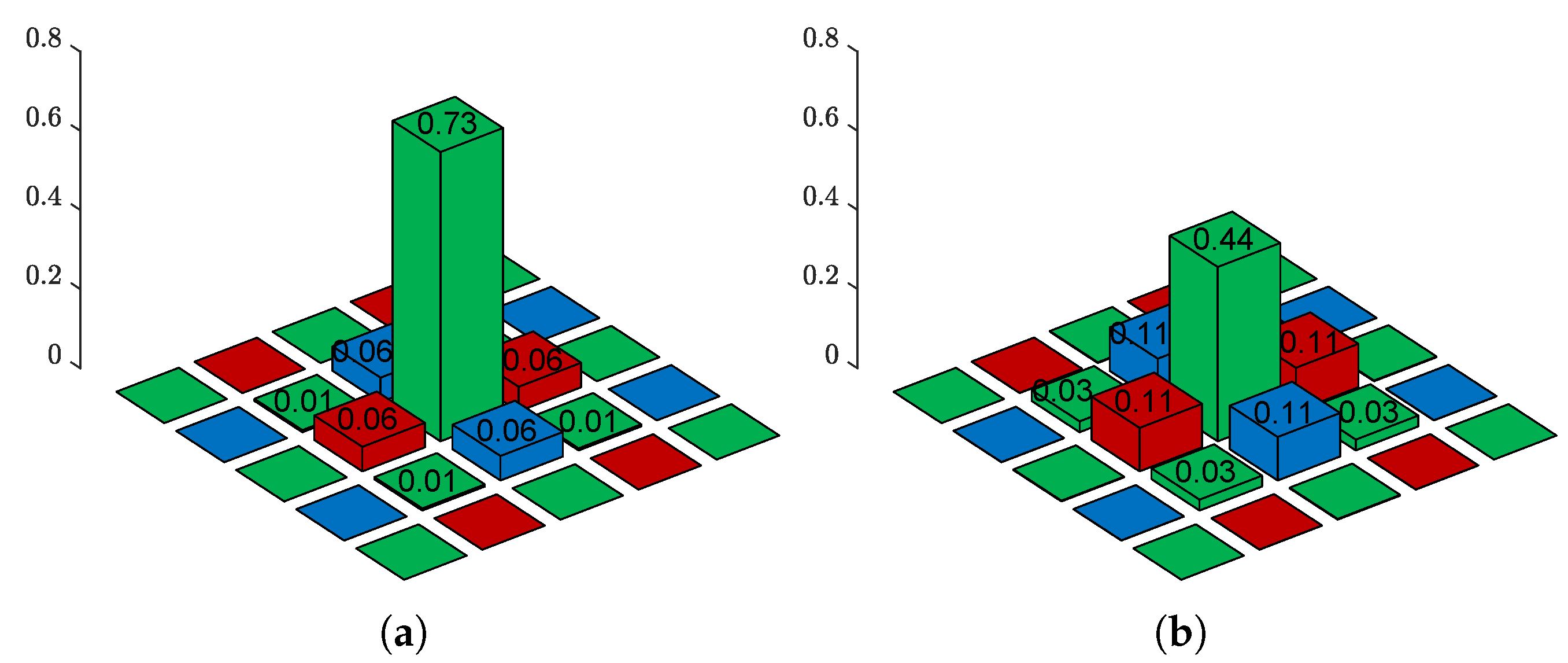
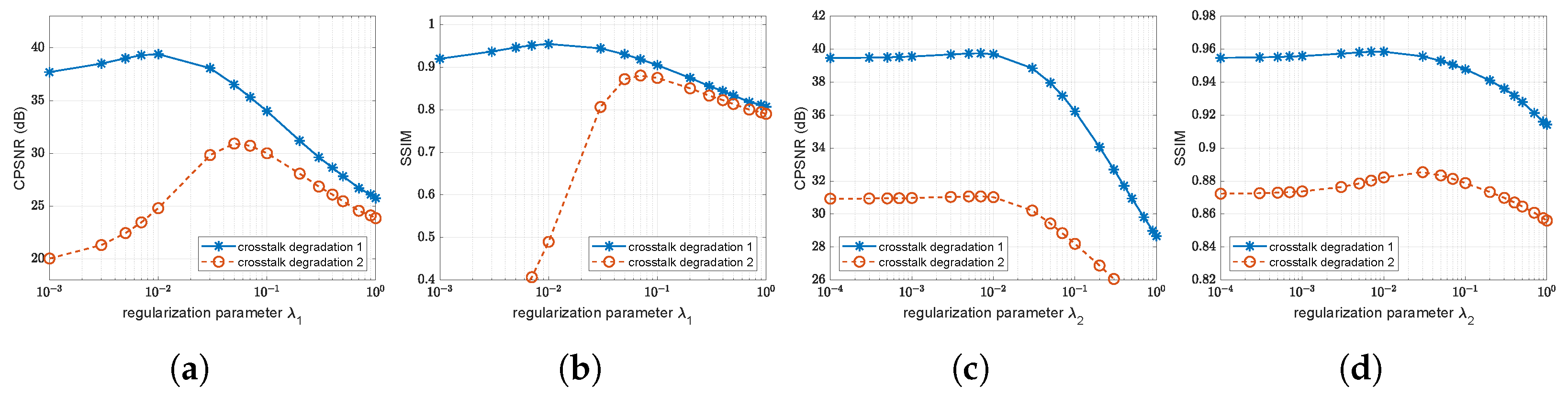
4.4. Influence of Parameters
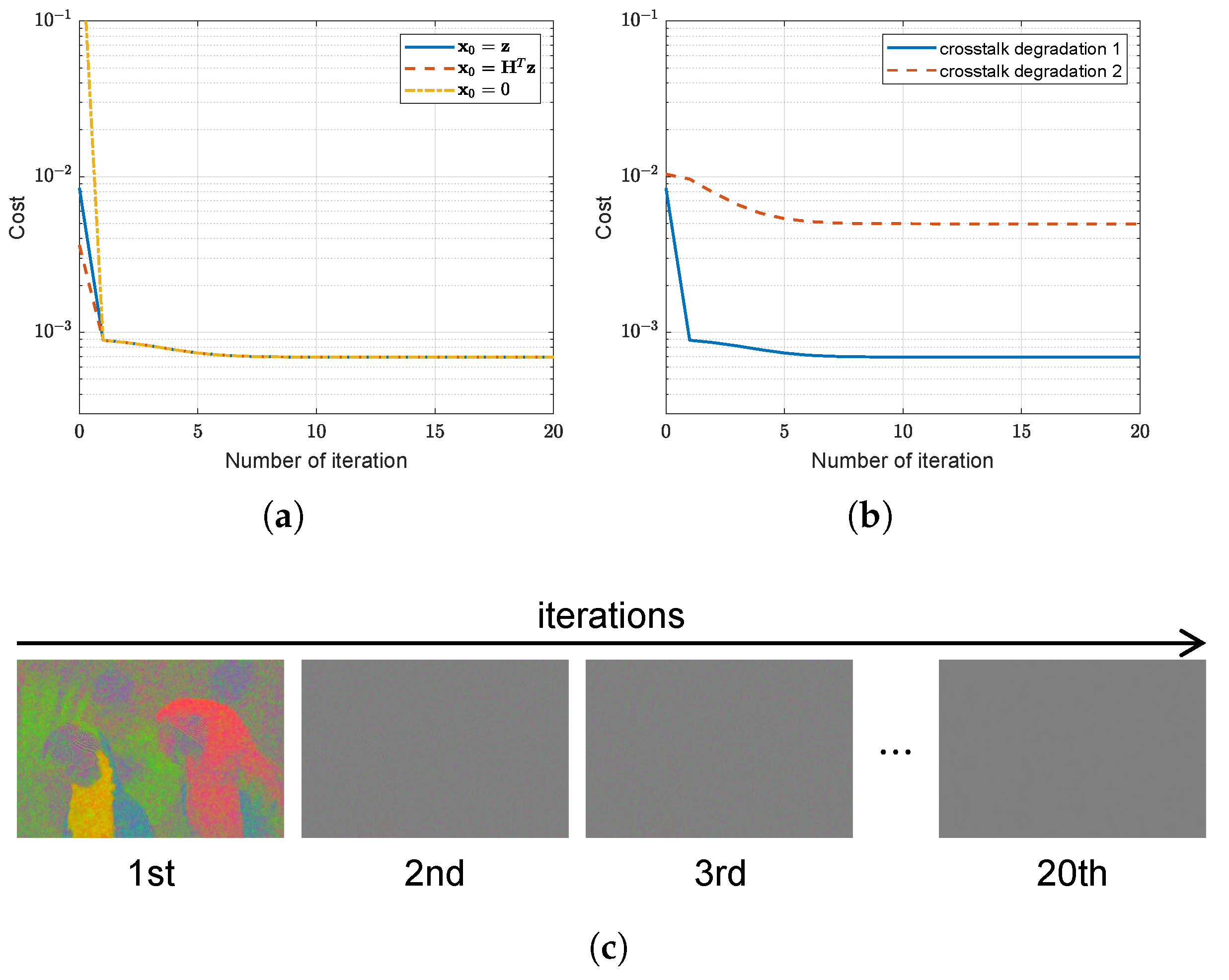
4.5. Convergence Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bayer, B.E. Color Imaging Array. U.S. Patent 3,971,065, 20 July 1976. [Google Scholar]
- Hirakawa, K.; Wolfe, P.J. Spatio-Spectral Color Filter Array Design for Optimal Image Recovery. IEEE Trans. Image Process. 2008, 17, 1876–1890. [Google Scholar] [CrossRef]
- Condat, L. A New Color Filter Array With Optimal Properties for Noiseless and Noisy Color Image Acquisition. IEEE Trans. Image Process. 2011, 20, 2200–2210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kimmel, R. Demosaicing: Image reconstruction from color CCD samples. IEEE Trans. Image Process. 1999, 8, 1221–1228. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pekkucuksen, I.; Altunbasak, Y. Multiscale Gradients-Based Color Filter Array Interpolation. IEEE Trans. Image Process. 2013, 22, 157–165. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Li, Y.; Wang, J.; Hao, P. Universal Demosaicking of Color Filter Arrays. IEEE Trans. Image Process. 2016, 25, 5173–5186. [Google Scholar] [CrossRef] [PubMed]
- Kiku, D.; Monno, Y.; Tanaka, M.; Okutomi, M. Beyond Color Difference: Residual Interpolation for Color Image Demosaicking. IEEE Trans. Image Process. 2016, 25, 1288–1300. [Google Scholar] [CrossRef] [PubMed]
- Monno, Y.; Kiku, D.; Tanaka, M.; Okutomi, M. Adaptive residual interpolation for color image demosaicking. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 3861–3865. [Google Scholar] [CrossRef]
- Farrell, J.; Xiao, F.; Kavusi, S. Resolution and light sensitivity tradeoff with pixel size. In Proceedings of the Digital Photography II, San Jose, CA, USA, 15–19 January 2006; Volume 6069, p. 60690N. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image Denoising by Sparse 3-D Transform-Domain Collaborative Filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Khashabi, D.; Nowozin, S.; Jancsary, J.; Fitzgibbon, A.W. Joint Demosaicing and Denoising via Learned Nonparametric Random Fields. IEEE Trans. Image Process. 2014, 23, 4968–4981. [Google Scholar] [CrossRef] [PubMed]
- Anzagira, L.; Fossum, E.R. Color filter array patterns for small-pixel image sensors with substantial cross talk. J. Opt. Soc. Am. A 2015, 32, 28–34. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hirakawa, K. Cross-talk explained. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 677–680. [Google Scholar] [CrossRef]
- Tian, H.; Sun, Q.; Li, J.; Domine, A. Crosstalk challenges cmos sensor design. Laser Focus World 2005, 41, 119–123. [Google Scholar]
- Lee, J.K.; Kim, A.; Kang, D.W.; Lee, B.Y. Efficiency enhancement in a backside illuminated 1.12 μm pixel CMOS image sensor via parabolic color filters. Opt. Express 2016, 24, 16027–16036. [Google Scholar] [CrossRef] [PubMed]
- Wu, X.; Zhang, X. Joint Color Decrosstalk and Demosaicking for CFA Cameras. IEEE Trans. Image Process. 2010, 19, 3181–3189. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zibulevsky, M.; Elad, M. L1-L2 Optimization in Signal and Image Processing. IEEE Signal Process. Mag. 2010, 27, 76–88. [Google Scholar] [CrossRef]
- Tikhonov, A.N. On the stability of inverse problems. Dokl. Akad. Nauk SSSR 1943, 39, 195–198. [Google Scholar]
- Rudin, L.I.; Osher, S. Total variation based image restoration with free local constraints. In Proceedings of the Proceedings of 1st International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994; Volume 1, pp. 31–35. [Google Scholar] [CrossRef]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear total variation based noise removal algorithms. Phys. D Nonlinear Phenom. 1992, 60, 259–268. [Google Scholar] [CrossRef]
- Krishnan, D.; Fergus, R. Fast Image Deconvolution using Hyper-Laplacian Priors. In Advances in Neural Information Processing Systems 22; Bengio, Y., Schuurmans, D., Lafferty, J.D., Williams, C.K.I., Culotta, A., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2009; pp. 1033–1041. [Google Scholar]
- Fergus, R.; Singh, B.; Hertzmann, A.; Roweis, S.T.; Freeman, W.T. Removing Camera Shake from a Single Photograph. In Proceedings of the ACM SIGGRAPH 2006 Papers; Association for Computing Machinery: New York, NY, USA, 2006; pp. 787–794. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, X.; Buades, A.; Li, X. Color demosaicking by local directional interpolation and nonlocal adaptive thresholding. J. Electron. Imaging 2011, 20, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Yang, J.; Yin, W.; Zhang, Y. A New Alternating Minimization Algorithm for Total Variation Image Reconstruction. SIAM J. Imaging Sci. 2008, 1, 248–272. [Google Scholar] [CrossRef]
- Zhou, W.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi Morel, M.L. Low-Complexity Single-Image Super-Resolution based on Nonnegative Neighbor Embedding. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012; BMVA Press: Surrey, UK, 2012; pp. 135.1–135.10. [Google Scholar] [CrossRef] [Green Version]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 711–730. [Google Scholar]
- Richardson, W.H. Bayesian-Based Iterative Method of Image Restoration. J. Opt. Soc. Am. 1972, 62, 55–59. [Google Scholar] [CrossRef]
- Zhang, K.; Zuo, W.; Gu, S.; Zhang, L. Learning Deep CNN Denoiser Prior for Image Restoration. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, J.; Pan, J.; Lai, W.S.; Lau, R.W.H.; Yang, M.H. Learning Fully Convolutional Networks for Iterative Non-Blind Deconvolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Gong, D.; Zhang, Z.; Shi, Q.; van den Hengel, A.; Shen, C.; Zhang, Y. Learning Deep Gradient Descent Optimization for Image Deconvolution. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5468–5482. [Google Scholar] [CrossRef] [PubMed] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kodak dataset | ||||||||||||||||
| CPSNR | SSIM | |||||||||||||||
| No. | CM1 | CM2 | CM3 | CM4 | CM5 | CM6 | CM7 | PM | CM1 | CM2 | CM3 | CM4 | CM5 | CM6 | CM7 | PM |
| 1 | 30.59 | 35.15 | 35.20 | 33.72 | 26.47 | 29.56 | 24.51 | 35.67 | 0.9527 | 0.9553 | 0.9568 | 0.9494 | 0.8497 | 0.9483 | 0.9223 | 0.9628 |
| 2 | 23.89 | 34.98 | 35.44 | 35.91 | 29.28 | 23.97 | 24.45 | 36.85 | 0.8992 | 0.8887 | 0.8918 | 0.9068 | 0.8428 | 0.7832 | 0.8429 | 0.9278 |
| 3 | 27.47 | 36.63 | 36.94 | 37.13 | 27.75 | 25.19 | 25.22 | 38.71 | 0.9165 | 0.9034 | 0.9120 | 0.9174 | 0.8731 | 0.8991 | 0.8797 | 0.9533 |
| 4 | 27.17 | 35.45 | 35.75 | 36.43 | 25.82 | 24.26 | 23.02 | 37.15 | 0.9259 | 0.9112 | 0.9153 | 0.9265 | 0.8355 | 0.8653 | 0.8745 | 0.9411 |
| 5 | 30.13 | 35.02 | 35.11 | 33.68 | 27.34 | 28.36 | 25.12 | 35.42 | 0.9549 | 0.9585 | 0.9603 | 0.9581 | 0.8937 | 0.9467 | 0.9283 | 0.9679 |
| 6 | 30.37 | 35.49 | 35.70 | 35.03 | 25.62 | 27.85 | 24.72 | 36.39 | 0.9484 | 0.9374 | 0.9413 | 0.9425 | 0.8444 | 0.9446 | 0.9114 | 0.9572 |
| 7 | 30.76 | 36.66 | 36.88 | 37.11 | 27.16 | 28.59 | 25.33 | 38.72 | 0.9417 | 0.9247 | 0.9306 | 0.9373 | 0.9226 | 0.9292 | 0.9073 | 0.9658 |
| 8 | 30.55 | 33.21 | 33.38 | 31.61 | 27.58 | 30.73 | 24.19 | 33.61 | 0.9543 | 0.9520 | 0.9550 | 0.9507 | 0.8951 | 0.9585 | 0.9257 | 0.9586 |
| 9 | 33.20 | 36.19 | 36.47 | 36.32 | 31.01 | 30.14 | 24.78 | 38.01 | 0.9318 | 0.8872 | 0.9028 | 0.9106 | 0.9180 | 0.9364 | 0.8796 | 0.9442 |
| 10 | 34.33 | 36.40 | 36.53 | 36.44 | 29.09 | 29.64 | 24.14 | 37.90 | 0.9379 | 0.9093 | 0.9177 | 0.9262 | 0.9140 | 0.9360 | 0.8880 | 0.9480 |
| 11 | 31.58 | 35.37 | 35.65 | 35.20 | 26.62 | 29.04 | 25.20 | 36.44 | 0.9406 | 0.9255 | 0.9320 | 0.9323 | 0.8241 | 0.9442 | 0.9014 | 0.9482 |
| 12 | 30.71 | 36.86 | 36.72 | 37.29 | 24.46 | 27.02 | 24.74 | 38.60 | 0.9345 | 0.9080 | 0.9133 | 0.9238 | 0.8388 | 0.9188 | 0.8824 | 0.9459 |
| 13 | 29.33 | 33.38 | 33.41 | 31.45 | 25.82 | 28.22 | 24.66 | 33.95 | 0.9481 | 0.9585 | 0.9598 | 0.9473 | 0.8135 | 0.9513 | 0.9278 | 0.9646 |
| 14 | 27.92 | 34.45 | 34.71 | 34.39 | 27.80 | 27.12 | 24.97 | 35.20 | 0.9391 | 0.9400 | 0.9441 | 0.9443 | 0.8538 | 0.9361 | 0.9085 | 0.9518 |
| 15 | 28.21 | 34.87 | 35.20 | 35.60 | 26.08 | 25.00 | 24.27 | 36.81 | 0.9194 | 0.8913 | 0.8968 | 0.9119 | 0.8485 | 0.8789 | 0.8699 | 0.9381 |
| 16 | 34.48 | 36.58 | 36.93 | 36.94 | 28.61 | 32.19 | 25.08 | 37.98 | 0.9435 | 0.9234 | 0.9307 | 0.9334 | 0.8822 | 0.9481 | 0.9037 | 0.9531 |
| 17 | 34.86 | 36.16 | 36.54 | 36.21 | 30.75 | 32.62 | 23.20 | 37.63 | 0.9419 | 0.9186 | 0.9286 | 0.9334 | 0.9025 | 0.9461 | 0.8905 | 0.9539 |
| 18 | 30.18 | 34.31 | 34.45 | 33.62 | 27.99 | 29.04 | 23.44 | 34.78 | 0.9348 | 0.9292 | 0.9355 | 0.9338 | 0.8450 | 0.9268 | 0.8977 | 0.9434 |
| 19 | 31.80 | 35.65 | 35.83 | 34.88 | 28.37 | 30.25 | 23.02 | 36.44 | 0.9382 | 0.9238 | 0.9306 | 0.9319 | 0.8526 | 0.9370 | 0.8905 | 0.9476 |
| 20 | 32.17 | 36.63 | 36.78 | 36.56 | 27.79 | 31.10 | 21.78 | 38.19 | 0.9367 | 0.9153 | 0.9218 | 0.9278 | 0.8861 | 0.9365 | 0.8730 | 0.9521 |
| 21 | 31.98 | 35.41 | 35.59 | 34.82 | 28.57 | 32.12 | 24.12 | 36.44 | 0.9382 | 0.9074 | 0.9133 | 0.9215 | 0.8921 | 0.9296 | 0.8926 | 0.9492 |
| 22 | 29.95 | 34.95 | 35.09 | 35.11 | 26.10 | 28.13 | 24.60 | 35.92 | 0.9305 | 0.9164 | 0.9229 | 0.9275 | 0.8106 | 0.9215 | 0.8946 | 0.9399 |
| 23 | 25.74 | 36.88 | 36.90 | 37.38 | 26.76 | 23.06 | 24.95 | 39.36 | 0.9135 | 0.8965 | 0.9044 | 0.9153 | 0.8902 | 0.8738 | 0.8706 | 0.9522 |
| 24 | 31.34 | 33.71 | 33.79 | 32.90 | 28.13 | 29.77 | 23.41 | 34.30 | 0.9488 | 0.9411 | 0.9451 | 0.9440 | 0.8937 | 0.9525 | 0.9177 | 0.9592 |
| Avg. | 30.36 | 35.43 | 35.63 | 35.24 | 27.54 | 28.46 | 24.29 | 36.69 | 0.9363 | 0.9218 | 0.9276 | 0.9314 | 0.8676 | 0.9229 | 0.8950 | 0.9511 |
| McMaster dataset | ||||||||||||||||
| CPSNR | SSIM | |||||||||||||||
| No. | CM1 | CM2 | CM3 | CM4 | CM5 | CM6 | CM7 | PM | CM1 | CM2 | CM3 | CM4 | CM5 | CM6 | CM7 | PM |
| 1 | 22.33 | 29.21 | 29.18 | 28.96 | 26.31 | 20.12 | 20.85 | 29.12 | 0.8460 | 0.8968 | 0.8967 | 0.8920 | 0.8195 | 0.8017 | 0.8329 | 0.8992 |
| 2 | 27.01 | 33.42 | 33.37 | 33.35 | 27.43 | 25.36 | 22.16 | 33.88 | 0.8754 | 0.8987 | 0.8994 | 0.9026 | 0.7900 | 0.8190 | 0.8291 | 0.9196 |
| 3 | 28.40 | 33.07 | 33.09 | 32.36 | 27.72 | 25.73 | 22.17 | 33.41 | 0.9245 | 0.9348 | 0.9378 | 0.9377 | 0.8910 | 0.9025 | 0.8764 | 0.9549 |
| 4 | 30.85 | 34.71 | 34.90 | 34.64 | 30.34 | 27.17 | 20.35 | 36.21 | 0.9516 | 0.9372 | 0.9425 | 0.9474 | 0.9504 | 0.9583 | 0.8993 | 0.9713 |
| 5 | 27.55 | 33.53 | 33.53 | 33.53 | 27.53 | 26.61 | 22.19 | 33.88 | 0.9077 | 0.9188 | 0.9208 | 0.9243 | 0.8568 | 0.8773 | 0.8752 | 0.9370 |
| 6 | 28.08 | 35.77 | 35.71 | 35.93 | 28.83 | 27.25 | 23.31 | 36.50 | 0.9045 | 0.9263 | 0.9279 | 0.9320 | 0.8500 | 0.8650 | 0.8806 | 0.9447 |
| 7 | 30.03 | 35.72 | 35.97 | 35.52 | 30.09 | 28.78 | 22.93 | 36.11 | 0.9254 | 0.9313 | 0.9342 | 0.9331 | 0.8348 | 0.9079 | 0.8610 | 0.9458 |
| 8 | 33.80 | 35.85 | 35.98 | 35.36 | 32.21 | 31.44 | 22.27 | 36.77 | 0.9132 | 0.9104 | 0.9146 | 0.9122 | 0.8891 | 0.9021 | 0.7697 | 0.9449 |
| 9 | 26.06 | 34.77 | 34.73 | 34.87 | 28.09 | 24.89 | 21.68 | 35.80 | 0.8841 | 0.9027 | 0.9036 | 0.9132 | 0.8431 | 0.8100 | 0.8424 | 0.9409 |
| 10 | 24.01 | 35.74 | 35.58 | 35.87 | 27.79 | 22.06 | 22.55 | 36.66 | 0.8582 | 0.9185 | 0.9181 | 0.9218 | 0.8137 | 0.7644 | 0.8305 | 0.9464 |
| 11 | 24.45 | 36.28 | 36.06 | 36.43 | 27.14 | 22.83 | 22.34 | 37.36 | 0.8150 | 0.9118 | 0.9075 | 0.9161 | 0.7336 | 0.7052 | 0.7810 | 0.9426 |
| 12 | 25.63 | 36.12 | 36.09 | 36.03 | 30.77 | 27.27 | 22.36 | 37.69 | 0.8938 | 0.8973 | 0.8988 | 0.9094 | 0.8624 | 0.8367 | 0.8471 | 0.9455 |
| 13 | 27.79 | 36.16 | 36.19 | 36.88 | 33.04 | 31.32 | 22.60 | 38.79 | 0.9015 | 0.8639 | 0.8675 | 0.8895 | 0.8838 | 0.8592 | 0.8435 | 0.9323 |
| 14 | 26.26 | 35.66 | 35.55 | 36.04 | 27.51 | 25.07 | 22.36 | 37.04 | 0.8740 | 0.8906 | 0.8924 | 0.9007 | 0.8084 | 0.8005 | 0.8248 | 0.9296 |
| 15 | 24.16 | 35.85 | 35.71 | 36.04 | 28.61 | 22.12 | 22.41 | 37.13 | 0.8509 | 0.8904 | 0.8902 | 0.8971 | 0.7458 | 0.7069 | 0.7838 | 0.9280 |
| 16 | 21.74 | 33.66 | 33.48 | 33.11 | 27.96 | 18.23 | 21.67 | 33.17 | 0.8098 | 0.9346 | 0.9332 | 0.9326 | 0.8141 | 0.7283 | 0.8265 | 0.9369 |
| 17 | 22.42 | 32.78 | 32.65 | 32.71 | 26.90 | 19.07 | 21.59 | 32.92 | 0.8137 | 0.9218 | 0.9202 | 0.9239 | 0.7896 | 0.6346 | 0.8147 | 0.9326 |
| 18 | 25.46 | 33.99 | 33.91 | 34.00 | 27.56 | 22.81 | 21.54 | 34.70 | 0.9103 | 0.9248 | 0.9257 | 0.9293 | 0.8581 | 0.8628 | 0.8593 | 0.9419 |
| Avg. | 26.45 | 34.57 | 34.54 | 34.53 | 28.66 | 24.90 | 22.07 | 35.40 | 0.8811 | 0.9117 | 0.9128 | 0.9175 | 0.8352 | 0.8190 | 0.8377 | 0.9386 |
| Kodak dataset | ||||||||||||||||
| CPSNR | SSIM | |||||||||||||||
| No. | CM1 | CM2 | CM3 | CM4 | CM5 | CM6 | CM7 | PM | CM1 | CM2 | CM3 | CM4 | CM5 | CM6 | CM7 | PM |
| 1 | 23.45 | 20.40 | 22.96 | 20.14 | 22.80 | 23.14 | 19.54 | 25.91 | 0.7248 | 0.4425 | 0.6344 | 0.4994 | 0.6268 | 0.7946 | 0.4642 | 0.7379 |
| 2 | 17.06 | 21.14 | 19.98 | 18.22 | 21.64 | 16.51 | 18.54 | 29.96 | 0.5310 | 0.2356 | 0.2662 | 0.1925 | 0.3376 | 0.5778 | 0.2390 | 0.7700 |
| 3 | 20.82 | 19.61 | 22.39 | 17.56 | 23.37 | 20.41 | 19.30 | 30.91 | 0.5760 | 0.1969 | 0.3985 | 0.1917 | 0.6379 | 0.7723 | 0.2364 | 0.8465 |
| 4 | 20.61 | 20.16 | 21.66 | 18.58 | 21.33 | 19.68 | 18.52 | 29.88 | 0.6019 | 0.2448 | 0.4159 | 0.2518 | 0.4217 | 0.7373 | 0.2706 | 0.7980 |
| 5 | 23.23 | 21.09 | 23.01 | 20.60 | 23.57 | 23.24 | 20.36 | 25.96 | 0.7426 | 0.5307 | 0.6606 | 0.5354 | 0.7330 | 0.8275 | 0.5539 | 0.8009 |
| 6 | 23.54 | 19.94 | 22.87 | 19.06 | 23.15 | 23.17 | 18.89 | 27.07 | 0.6732 | 0.3232 | 0.5541 | 0.3599 | 0.6241 | 0.8006 | 0.3622 | 0.7546 |
| 7 | 23.59 | 20.26 | 23.50 | 18.49 | 24.08 | 23.28 | 19.91 | 29.91 | 0.6542 | 0.3197 | 0.5078 | 0.3259 | 0.7194 | 0.8383 | 0.3575 | 0.8836 |
| 8 | 23.79 | 20.63 | 23.20 | 20.05 | 24.93 | 24.58 | 19.79 | 24.89 | 0.7587 | 0.5414 | 0.6901 | 0.5629 | 0.7924 | 0.8487 | 0.5709 | 0.7847 |
| 9 | 25.66 | 19.83 | 24.46 | 17.21 | 28.08 | 25.80 | 19.55 | 30.53 | 0.6207 | 0.2349 | 0.4672 | 0.2356 | 0.8367 | 0.8285 | 0.2810 | 0.8570 |
| 10 | 26.63 | 19.85 | 24.70 | 18.11 | 27.69 | 26.75 | 19.46 | 30.25 | 0.6299 | 0.2316 | 0.4837 | 0.2492 | 0.8225 | 0.8265 | 0.2868 | 0.8423 |
| 11 | 24.58 | 20.34 | 23.75 | 18.96 | 24.47 | 24.81 | 19.91 | 28.09 | 0.6435 | 0.3045 | 0.5264 | 0.3133 | 0.7058 | 0.7934 | 0.3507 | 0.7661 |
| 12 | 23.96 | 19.53 | 23.16 | 17.63 | 23.00 | 23.38 | 19.12 | 30.74 | 0.5995 | 0.1822 | 0.4279 | 0.1920 | 0.5484 | 0.7995 | 0.2405 | 0.8114 |
| 13 | 22.82 | 20.23 | 22.58 | 20.42 | 20.91 | 22.93 | 19.41 | 24.17 | 0.7306 | 0.4803 | 0.6695 | 0.5378 | 0.5656 | 0.7828 | 0.5030 | 0.7413 |
| 14 | 21.08 | 20.48 | 22.78 | 20.13 | 23.55 | 21.12 | 19.85 | 27.17 | 0.6743 | 0.3728 | 0.5626 | 0.4058 | 0.6492 | 0.7627 | 0.4063 | 0.7613 |
| 15 | 21.82 | 20.72 | 22.46 | 18.61 | 23.18 | 21.37 | 18.69 | 30.04 | 0.5925 | 0.2547 | 0.4325 | 0.2310 | 0.6755 | 0.7784 | 0.2741 | 0.8176 |
| 16 | 26.41 | 19.88 | 24.56 | 18.09 | 26.03 | 27.01 | 19.74 | 29.20 | 0.6289 | 0.2136 | 0.4885 | 0.2470 | 0.7383 | 0.8092 | 0.2794 | 0.7712 |
| 17 | 26.81 | 21.20 | 25.08 | 19.33 | 27.49 | 27.49 | 19.69 | 29.78 | 0.6445 | 0.3088 | 0.5096 | 0.2922 | 0.8143 | 0.8227 | 0.3360 | 0.8388 |
| 18 | 23.30 | 20.83 | 23.43 | 19.84 | 23.17 | 23.14 | 19.55 | 26.95 | 0.6713 | 0.3787 | 0.5639 | 0.3933 | 0.6648 | 0.7747 | 0.3963 | 0.7646 |
| 19 | 24.27 | 20.00 | 23.82 | 18.06 | 23.91 | 23.85 | 18.99 | 27.83 | 0.6524 | 0.2954 | 0.5207 | 0.3127 | 0.6986 | 0.8016 | 0.3348 | 0.7913 |
| 20 | 24.96 | 21.15 | 24.84 | 18.69 | 24.98 | 24.76 | 16.59 | 30.66 | 0.6653 | 0.2753 | 0.5221 | 0.2478 | 0.7380 | 0.8318 | 0.2708 | 0.8546 |
| 21 | 24.54 | 20.16 | 23.70 | 17.76 | 23.66 | 24.15 | 19.48 | 27.94 | 0.6579 | 0.3253 | 0.5118 | 0.3315 | 0.5943 | 0.8170 | 0.3606 | 0.8237 |
| 22 | 23.15 | 19.86 | 23.13 | 18.71 | 22.10 | 22.65 | 19.33 | 28.38 | 0.6355 | 0.2539 | 0.4939 | 0.2960 | 0.5215 | 0.7678 | 0.3037 | 0.7641 |
| 23 | 19.28 | 19.41 | 21.12 | 17.47 | 22.07 | 18.96 | 18.84 | 30.94 | 0.5742 | 0.2065 | 0.3795 | 0.1864 | 0.5709 | 0.7587 | 0.2428 | 0.8714 |
| 24 | 24.79 | 20.36 | 23.91 | 19.61 | 24.42 | 25.24 | 19.06 | 26.50 | 0.6924 | 0.3585 | 0.5861 | 0.3963 | 0.7359 | 0.8228 | 0.3959 | 0.7950 |
| Avg. | 23.34 | 20.29 | 23.21 | 18.81 | 23.90 | 23.23 | 19.26 | 28.49 | 0.6490 | 0.3130 | 0.5114 | 0.3245 | 0.6572 | 0.7906 | 0.3466 | 0.8020 |
| McMaster dataset | ||||||||||||||||
| CPSNR | SSIM | |||||||||||||||
| No. | CM1 | CM2 | CM3 | CM4 | CM5 | CM6 | CM7 | PM | CM1 | CM2 | CM3 | CM4 | CM5 | CM6 | CM7 | PM |
| 1 | 16.54 | 19.46 | 19.19 | 19.74 | 20.59 | 16.15 | 17.09 | 24.08 | 0.5966 | 0.4867 | 0.5371 | 0.4583 | 0.5732 | 0.6265 | 0.4650 | 0.7191 |
| 2 | 20.73 | 21.58 | 22.07 | 19.95 | 22.87 | 20.10 | 19.18 | 28.06 | 0.6010 | 0.4209 | 0.5022 | 0.3632 | 0.5880 | 0.6816 | 0.3957 | 0.7877 |
| 3 | 22.29 | 20.49 | 22.32 | 19.87 | 22.85 | 22.20 | 18.98 | 25.75 | 0.7010 | 0.5153 | 0.6205 | 0.5129 | 0.7628 | 0.8070 | 0.5175 | 0.8282 |
| 4 | 24.53 | 20.44 | 23.32 | 20.00 | 25.80 | 25.49 | 17.50 | 27.94 | 0.7179 | 0.4464 | 0.6171 | 0.4752 | 0.9138 | 0.8833 | 0.4815 | 0.9034 |
| 5 | 21.06 | 20.64 | 22.50 | 19.78 | 22.94 | 20.52 | 18.78 | 27.34 | 0.6360 | 0.3744 | 0.5187 | 0.3807 | 0.6086 | 0.7314 | 0.3943 | 0.8081 |
| 6 | 21.21 | 20.82 | 22.64 | 19.59 | 23.68 | 20.65 | 19.35 | 27.60 | 0.6042 | 0.3592 | 0.4870 | 0.3428 | 0.6010 | 0.7054 | 0.3705 | 0.7908 |
| 7 | 23.19 | 21.06 | 23.77 | 19.99 | 26.72 | 23.37 | 19.34 | 28.26 | 0.6592 | 0.3750 | 0.5559 | 0.3862 | 0.7465 | 0.7656 | 0.3786 | 0.7660 |
| 8 | 26.86 | 23.86 | 25.52 | 19.78 | 29.03 | 26.96 | 20.19 | 29.73 | 0.6351 | 0.4812 | 0.5268 | 0.3050 | 0.8459 | 0.7972 | 0.3622 | 0.8207 |
| 9 | 19.49 | 20.91 | 21.74 | 18.76 | 22.29 | 18.82 | 18.43 | 28.67 | 0.5837 | 0.3675 | 0.4495 | 0.3257 | 0.5174 | 0.6915 | 0.3559 | 0.8365 |
| 10 | 17.58 | 20.84 | 20.37 | 19.71 | 21.08 | 17.15 | 18.28 | 28.89 | 0.5541 | 0.3884 | 0.4367 | 0.3331 | 0.4784 | 0.6315 | 0.3529 | 0.8135 |
| 11 | 18.00 | 21.15 | 20.69 | 19.44 | 22.54 | 17.53 | 18.47 | 29.91 | 0.4969 | 0.3507 | 0.3809 | 0.2806 | 0.4837 | 0.5586 | 0.3051 | 0.7948 |
| 12 | 18.65 | 20.62 | 21.41 | 17.73 | 23.67 | 17.92 | 18.16 | 29.78 | 0.5728 | 0.3018 | 0.3751 | 0.2600 | 0.4956 | 0.6600 | 0.2940 | 0.8558 |
| 13 | 20.55 | 20.02 | 22.09 | 16.67 | 24.22 | 19.22 | 18.44 | 32.29 | 0.5653 | 0.1968 | 0.3062 | 0.1631 | 0.4607 | 0.6944 | 0.2216 | 0.8820 |
| 14 | 19.67 | 20.98 | 21.79 | 18.83 | 23.60 | 19.09 | 19.01 | 30.98 | 0.5502 | 0.3041 | 0.3959 | 0.2348 | 0.5872 | 0.6683 | 0.2850 | 0.8344 |
| 15 | 17.86 | 21.14 | 20.40 | 18.87 | 21.94 | 17.19 | 18.10 | 30.98 | 0.5047 | 0.3322 | 0.3683 | 0.2247 | 0.4392 | 0.5859 | 0.2777 | 0.8161 |
| 16 | 15.87 | 18.06 | 18.50 | 21.53 | 20.10 | 15.49 | 17.23 | 26.50 | 0.5825 | 0.4662 | 0.5222 | 0.4982 | 0.5267 | 0.6143 | 0.4585 | 0.7429 |
| 17 | 16.60 | 19.80 | 18.78 | 20.16 | 20.83 | 16.08 | 17.44 | 24.38 | 0.5013 | 0.4300 | 0.4568 | 0.4032 | 0.5088 | 0.5389 | 0.4069 | 0.7004 |
| 18 | 19.16 | 20.64 | 20.91 | 20.31 | 21.49 | 18.76 | 18.08 | 28.17 | 0.6560 | 0.4417 | 0.5272 | 0.4333 | 0.5850 | 0.7335 | 0.4382 | 0.7988 |
| Avg. | 19.99 | 20.69 | 21.56 | 19.48 | 23.12 | 19.59 | 18.45 | 28.30 | 0.5955 | 0.3910 | 0.4769 | 0.3545 | 0.5957 | 0.6875 | 0.3756 | 0.8055 |
| Crosstalk Degradation 1 ( and ) | ||||||||
| Kodak | McMaster | Set5 | Set14 | |||||
| Method | CPSNR | SSIM | CPSNR | SSIM | CPSNR | SSIM | CPSNR | SSIM |
| CM1 | 30.36 | 0.9363 | 26.45 | 0.8811 | 27.03 | 0.9060 | 27.09 | 0.8974 |
| CM2 | 35.43 | 0.9218 | 34.57 | 0.9117 | 34.95 | 0.9164 | 33.17 | 0.8972 |
| CM3 | 35.63 | 0.9276 | 34.54 | 0.9128 | 34.92 | 0.9186 | 33.21 | 0.9001 |
| CM4 | 35.24 | 0.9314 | 34.53 | 0.9175 | 35.00 | 0.9233 | 33.06 | 0.9034 |
| CM5 | 27.54 | 0.8676 | 28.66 | 0.8352 | 27.66 | 0.8575 | 27.51 | 0.8534 |
| CM6 | 28.46 | 0.9229 | 24.90 | 0.8190 | 25.94 | 0.8801 | 24.61 | 0.8654 |
| CM7 | 24.29 | 0.8950 | 22.07 | 0.8377 | 19.81 | 0.8353 | 19.90 | 0.7395 |
| PM | 36.69 | 0.9511 | 35.40 | 0.9386 | 35.42 | 0.9292 | 33.59 | 0.9098 |
| Crosstalk Degradation 2 ( and ) | ||||||||
| Kodak | McMaster | Set5 | Set14 | |||||
| Method | CPSNR | SSIM | CPSNR | SSIM | CPSNR | SSIM | CPSNR | SSIM |
| CM1 | 23.34 | 0.6490 | 19.99 | 0.5955 | 20.48 | 0.6541 | 20.66 | 0.6597 |
| CM2 | 20.29 | 0.3130 | 20.69 | 0.3910 | 20.69 | 0.4302 | 20.14 | 0.4139 |
| CM3 | 23.21 | 0.5114 | 21.56 | 0.4769 | 21.80 | 0.5260 | 21.50 | 0.5388 |
| CM4 | 18.81 | 0.3245 | 19.48 | 0.3545 | 19.88 | 0.4105 | 19.50 | 0.4171 |
| CM5 | 23.90 | 0.6572 | 23.12 | 0.5957 | 22.30 | 0.6064 | 22.11 | 0.5908 |
| CM6 | 23.23 | 0.7906 | 19.59 | 0.6875 | 19.77 | 0.7383 | 20.12 | 0.7395 |
| CM7 | 19.26 | 0.3466 | 18.45 | 0.3756 | 17.43 | 0.5693 | 18.04 | 0.4056 |
| PM | 28.49 | 0.8020 | 28.30 | 0.8055 | 28.67 | 0.8261 | 27.34 | 0.7879 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Jeong, K.; Kang, M.G. Crosstalk Correction for Color Filter Array Image Sensors Based on Lp-Regularized Multi-Channel Deconvolution. Sensors 2022, 22, 4285. https://doi.org/10.3390/s22114285
Kim J, Jeong K, Kang MG. Crosstalk Correction for Color Filter Array Image Sensors Based on Lp-Regularized Multi-Channel Deconvolution. Sensors. 2022; 22(11):4285. https://doi.org/10.3390/s22114285
Chicago/Turabian StyleKim, Jonghyun, Kyeonghoon Jeong, and Moon Gi Kang. 2022. "Crosstalk Correction for Color Filter Array Image Sensors Based on Lp-Regularized Multi-Channel Deconvolution" Sensors 22, no. 11: 4285. https://doi.org/10.3390/s22114285
APA StyleKim, J., Jeong, K., & Kang, M. G. (2022). Crosstalk Correction for Color Filter Array Image Sensors Based on Lp-Regularized Multi-Channel Deconvolution. Sensors, 22(11), 4285. https://doi.org/10.3390/s22114285