1. Introduction
The remaining useful life (RUL) prediction for rolling bearings is of great significant and practical value for the predictive maintenance of mechanical equipment and safe operation of industries [
1,
2]. In recent years, many scholars have studied and summarized RUL prediction methods [
3,
4,
5]. With the gradual accumulation of industrial condition monitoring data and the continuous improvement of computer computing power, data-driven RUL prediction methods have become the focus of prognostic and health management (PHM) research. Whereas, the rich condition monitoring data led to formidable challenges to traditional artificial intelligence methods [
6]. Deep learning methods have powerful information extraction capabilities and can quickly extract effective information from massive data. Therefore, RUL prediction methods based on deep learning are favored by an increasing number of scholars [
7,
8].
For RUL prediction, deep learning has been proven to have strong scalability and general-purpose capabilities to handle massive high-dimensional data, thereby realizing RUL prediction from such data [
9]. Ali et al. [
10] introduced the WD (Weibull distribution) to the SFAM (simplified fuzzy adaptive resonance theory mapping) neural network to predict the RUL of rolling bearings. Using an artificial neural network unit (ANN) with multiple hidden layers, Strušnik et al. [
11] constructed a simulation model to predict system performance based on real data. Kim et al. [
12] proposed a CNN-based (convolutional neural network, CNN) prediction model to reflect the correlation between RUL estimation and a health status detection process. Based on data trajectory expansion, a joint data-driven RUL prediction method using the AdaBoost regression model and the long-short term memory (LSTM) model was established by Zhu et al. [
13]. Liu et al. [
14] used stacked bidirectional LSTM to establish a data-based model to predict the RUL of supercapacitors. Kong et al. [
15] proposed a framework combining deep convolutional neutral network (DCNN) and two-layer LSTM, used for lithium-ion battery state-of-health (SOH) estimation and RUL prediction. Zheng et al. [
16] combined a multilayer LSTM unit with a standard feedforward layer to form a novel LSTM-based prediction model. At present, LSTM has attracted more and more attention for predicting the RUL of mechanical components due to the advantages of time series data modeling.
The above studies have verified the prospects of deep learning-based methods in RUL prediction. However, most of these methods are implemented with deterministic neural networks, which ultimately provide RUL point estimation. In practical applications, RUL prediction is affected by various types of prediction uncertainties, such as measurement uncertainty introduced by noise interference, model uncertainties related to the prediction model, and uncertainty conditions caused by the operation randomness [
17]. Uncertainty quantification is the basis of many key decisions. If the uncertainty is not quantified, the estimated value of the RUL prediction point has difficulty providing sufficient guidance value for the maintenance strategy in practical applications [
18,
19].
Liu et al. [
20] presented an incremental online learning strategy based on the relevance vector machine (RVM) algorithm, which achieved high prediction accuracy and considered the uncertainty. Tang et al. [
21] used a modeling method based on the truncated normal distribution (TND) to estimate the degradation state of lithium batteries, which can simultaneously obtain the distribution of drift parameters and the RUL distribution by considering measurement uncertainty. The above methods are based on mathematical statistics and quantify the uncertainty to an extent. Nonetheless, the quantification methods consume the resources and time, and the RUL prediction methods still have certain limitations. Therefore, to obtain an accurate RUL estimation while considering uncertainty, it is necessary to incorporate uncertainty features into deep-learning-based methods. Ghahramani [
22] stated that the Bayesian method is a promising measure of uncertainty, and Bayesian inference can be used as a learning tool to address uncertainty in deep learning. Additionally, Gal and Ghahramani [
23] theoretically and experimentally validated that, for quantifying the uncertainty, the dropout mechanism can be applied to obtain a Bayesian approximation in the deep learning field.
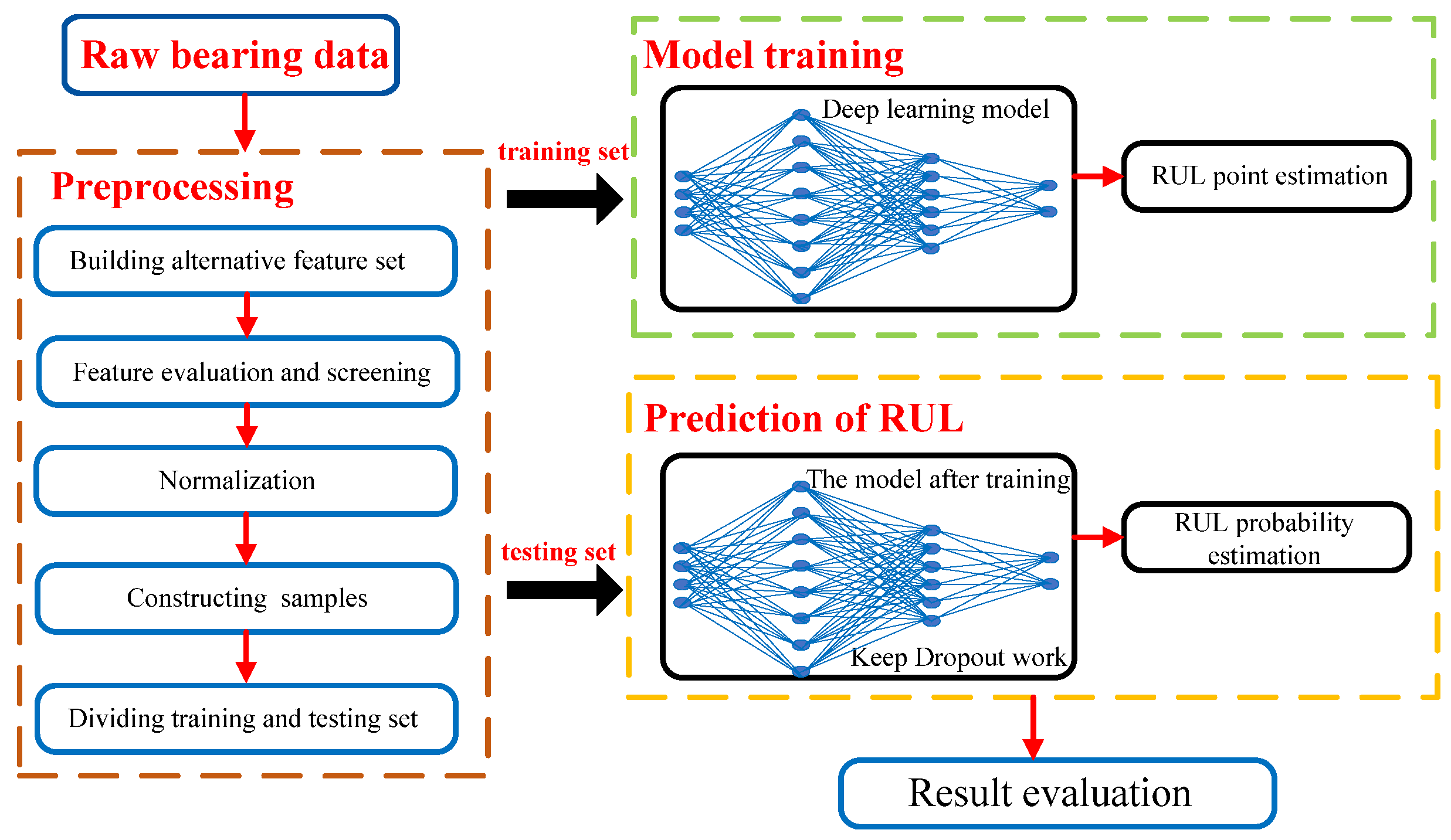
Based on the above analysis and summary, it can be found that the current RUL prediction is faced with the dual problems that traditional deep learning methods have difficulty measuring the uncertainty and common uncertainty measurement methods are limited to adapt to RUL prediction methods. To overcome these difficulties, this paper proposes a bearing RUL prediction method based on LSTM and uncertainty quantification. First, in the data preprocessing stage, the bearing degradation characteristics are screened according to correlation, monotonicity, and robustness to provide the bearing degradation information for model training. Second, in the prediction stage, by introducing dropout into the LSTM network model, the RUL point and the nonparametric kernel density distribution can be obtained. The RUL point estimation and nonparametric kernel density distribution are combined to make decisions based on uncertainty.
The paper is organized as follows. Following this introduction, the basic principle of LSTM are briefly presented in
Section 2. In
Section 3, the feature screening method and the proposed uncertainty-based RUL prediction model are introduced. Then, the verification and comparison of the proposed methods are carried out in
Section 4. Finally, the conclusions are drawn in
Section 5.
5. Conclusions
Traditional deep-learning-based RUL prediction methods often lack the ability to quantify related uncertainties in engineering practice. Considering this, this paper proposes a bearing RUL prediction method based on LSTM and uncertainty quantification. The uncertainty quantification is introduced by combining dropout and nonparametric kernel density estimation. The effectiveness and feasibility of the proposed prediction model is validated on the PHM2012 dataset, and based on the prediction result. Some conclusions are given:
(1) The prediction results on the PMH2012 dataset illustrate that the proposed prediction model can accurately and stably predict the bearing RUL. Especially in the stable degradation stage, it has excellent prediction performance, which has the significance in practical application.
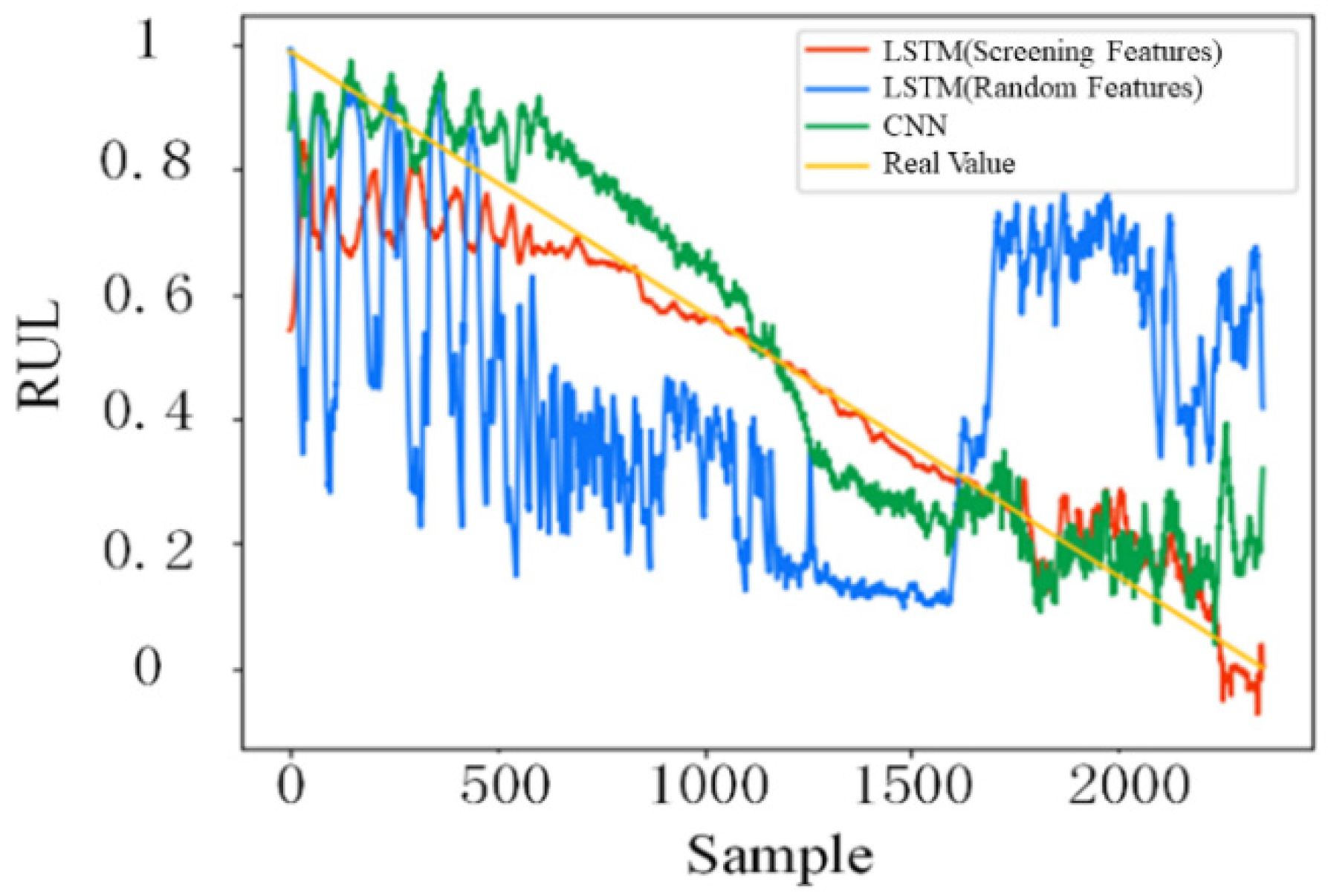
(2) The novel comprehensive evaluation index based on correlation, monotonicity, and robustness is proposed to improve the accuracy and stability of the prediction model. The process mainly focuses on evaluating and screening the features from the built alternative feature set to select the effective degradation features. Furthermore, the superiority of this strategy is perfectly validated by comparison with the LSTM-based prediction model trained with random features.
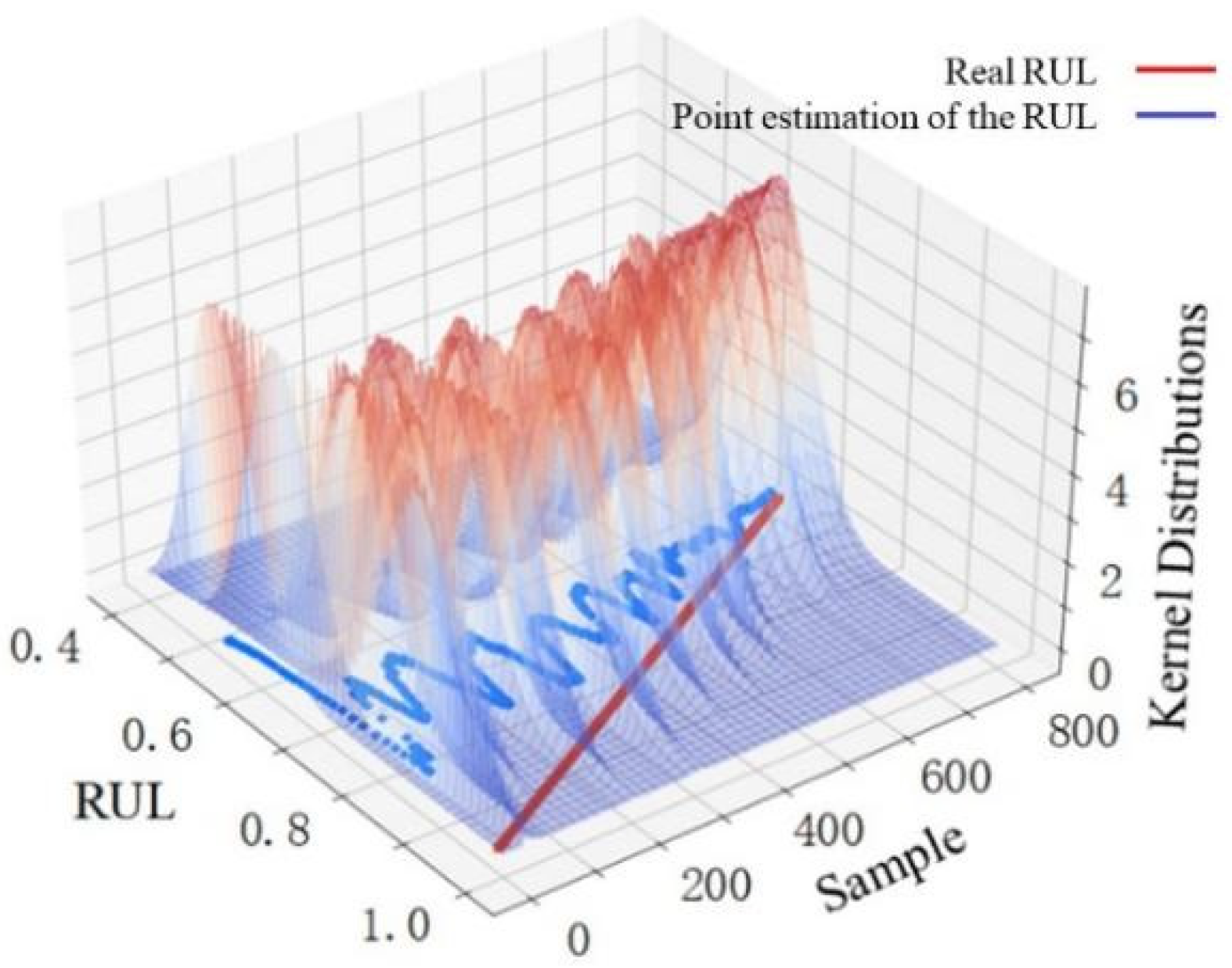
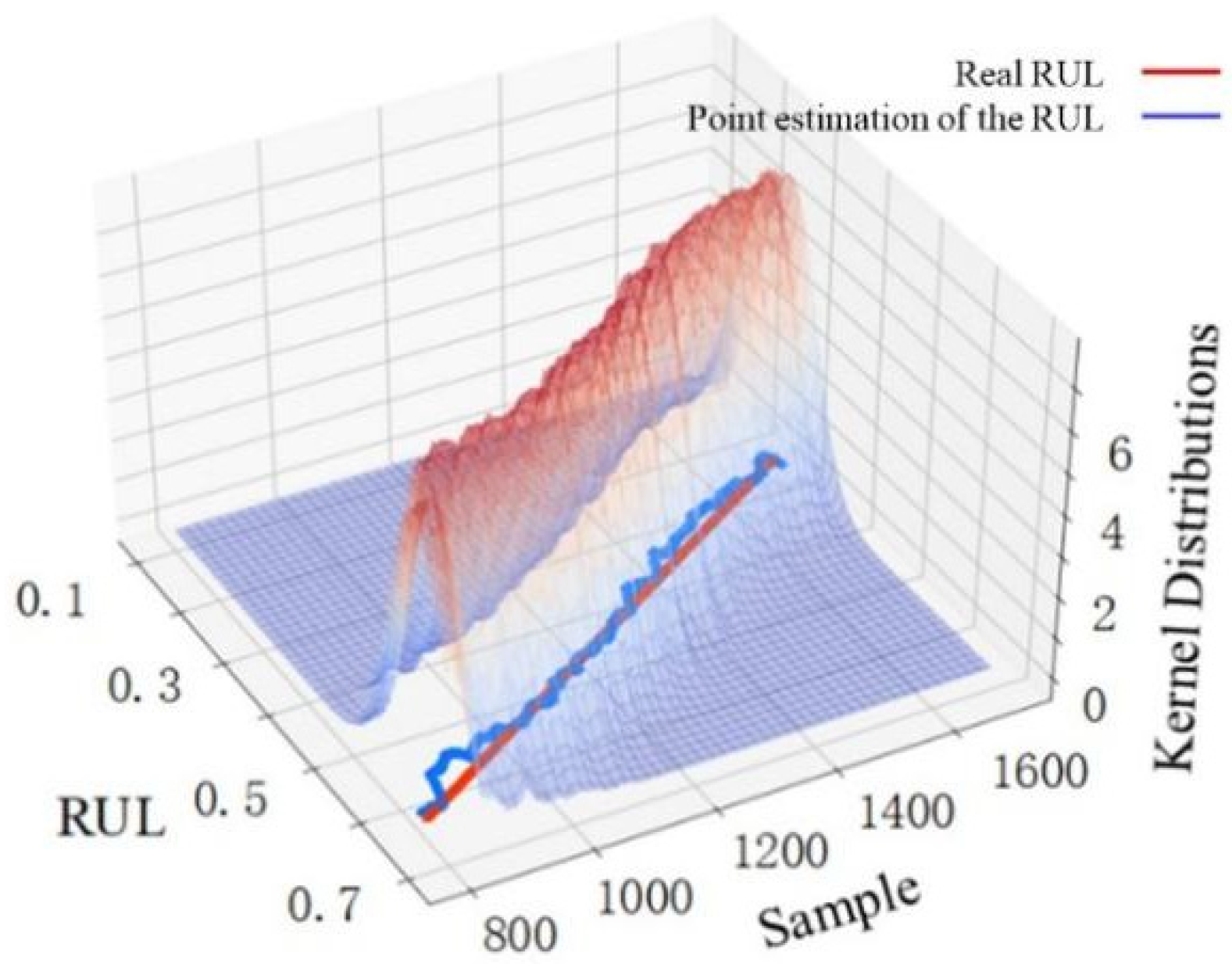
(3) The uncertainty existing in the actual prediction process is introduced by combining dropout and nonparametric kernel density estimation in this paper. The LSTM model with operating dropout can obtain RUL distribution result approximating Bayesian inference. These data are then processed using nonparametric kernel density estimation to obtain the kernel distribution that expresses uncertainty. As a result, the specific result and variation trend of point estimation and Gaussian kernel distribution of the bearing RUL can be observed on the basis of the proposed prediction model. It provides an important and scientific basis for uncertainty-based decisions.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}