1. Introduction
A social relationship, as a key concept in sociology, describes the interaction between people. It has been proved to have both short-term and long-term effects on human health [
1]. Understanding the social relationships among people is thus essential for identifying the link between social relationships and health outcomes. In addition, effective social relation recognition (SRR) can also provide valuable interactive information for other related tasks, such as an activity analysis [
2] and group emotion detection [
3], which further benefits more comprehensive tasks, such as smart city design [
4] and social sustainability [
5].
Meanwhile, with the development of the Internet and multimedia, various platforms, e.g., Facebook, Twitter and TikTok, are generating huge amounts of social data with great application values [
6]. Specifically, the different types of social data, including social network information (positioning information [
7,
8] and network graph structure [
9]), text [
10,
11], image [
12] and video [
13,
14], contain abundant interactive information between users and are conducive to understanding social relationships. Among these different forms of data, visual data reflect the relationship between individuals more intuitively than textual and social network information. Furthermore, compared with video, images show less complexity and are easier to be processed. In other words, recognizing social relationships based on images balances the intuitiveness and the complexity.
Existing methods for SRR based on images have their own paradigm, which contains three key parts: (1) feature extraction, (2) feature fusion and (3) classification and optimization. In terms of the scale of features, different features can be divided into intra-relation features, inter-relation features and scene features. A detailed classification of these features will be given in the related work.
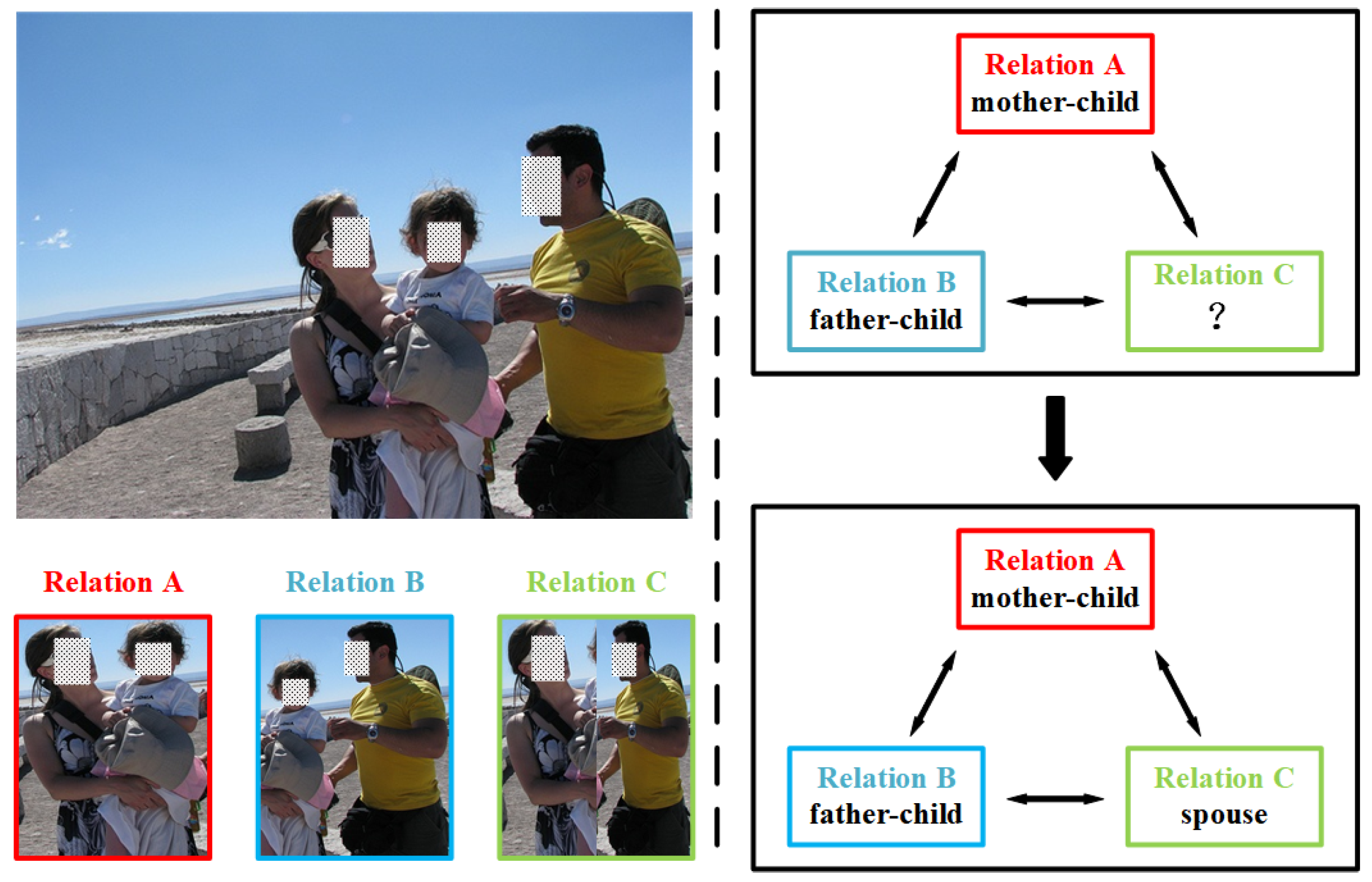
For feature fusion, early attempts concatenate intra-relation features and scene features [
15] or design simple feature selection methods to fuse them [
12,
16]. Recent works further exploit the inter-relation features (logical constraints, illustrated in
Figure 1) by concatenating intra-relation features to generate relation nodes and introducing a gated graph neural network (GGNN) or a graph convolutional network (GCN) to propagate the messages among these nodes or to extract the topological information [
17,
18,
19]. However, the above methods cannot effectively fuse the intra-relation feature to better represent social relationships because they ignore the varying degrees of importance of different features to a particular relationship. In addition, the updating mechanism of a GGNN and GCN inadequately considers the different influences of all the other neighbor nodes, namely the message-passing method among nodes is unreasonable when exploiting logical constraints for SRR.
For classification and optimization, using standard cross-entropy (CE) to train the multi-layer perceptron (MLP) or fully-connected layer (FC) is the mainstream [
12,
16,
17,
18,
19]. However, the benchmark datasets for SRR have imbalanced sample numbers across different classes, which means the dominant classes will overwhelm the training process and thus cause low accuracy of classes with fewer samples. In addition, samples from different specific classes have similar visual clues, e.g., samples from the class ‘
friend’ and samples from the class ‘
couple’. High inter-class similarity leads to serious confusion between these similar classes, which can be found in the confusion matrixes in [
17,
18]. The above methods show the absence of consideration for the bad effect caused by imbalanced data and high inter-class similarity.
In this paper, we propose a Multi-level Transformer-Based Social Relation Recognition model (MT-SRR), which introduces a transformer into the feature extraction module and feature fusion module in different ways, as well as design a new loss function for relation classification. Specifically, the vision transformer (ViT) [
20] is adopted to globally extract the visual features of persons. An intra-relation transformer (Intra-TRM) is then introduced to fuse intra-relation features and scene features to generate more rational social relationship representations. Then, an inter-relation transformer (Inter-TRM) is designed to enhance inter-relation features by attentionally aggregating similar social relationship representations in the same image, which has logical constraints among them. Finally, margins related to sample similarity and sample numbers are added to the standard CE in order to adaptively increase the distance between different classes with consideration of the imbalanced data.
Our contributions can be summarized as follows:
A new transformer-based feature fusion block (Intra-TRM) is proposed to carefully fuse the intra-relation features and scene features in order to generate better social relation representation. The designed module dynamically fuses these extracted features, which give different features weights related to their similarity to the key features of a specific relationship.
A new transformer-based inter-relation feature enhancement block (Inter-TRM) is employed to enhance the representation of similar relationships in one image and exploit the logical constraints among them. This module attentionally aggregates similar relation representations in the same image, which can solve the problem caused by the unweighted updating mechanism of a commonly used graph-reasoning network for SRR.
A new margin is designed to mitigate the negative effect caused by imbalanced data. The new margin is related with inter-class similarity and influenced by the sample numbers, which can adaptively adjust the distance between different classes with different sample numbers.
Our proposed MT-SRR achieves the state-of-the-art results on two public benchmark datasets for SRR, i.e., the People in Social Context (PISC) [
12] and the People in Photo Album (PIPA) [
21]. Extensive ablation results further demonstrate the effectiveness of the Intra-TRM, Inter-TRM and the newly designed loss function.
The rest of the paper is organized as follows.
Section 2 reviews the related work about SRR and the applications of a transformer in computer vision.
Section 3 elaborates the details of our proposed MT-SRR. The detailed experimental results are described in
Section 4.
Section 5 gives the conclusion of this paper.
2. Related Work
In this section, we give a holistic view of social relation recognition to describe the tendency of its development, followed by a literature review of a transformer used in computer vision, which can be introduced to better orchestrate the intra-relation features, inter-relation features and scene features for SRR.
2.1. Social Relationship Recognition
Social relationship recognition is now a field of growing interest to the research community. In this subsection, we will brief the SRR in terms of the three key parts of the paradigm, as mentioned in
Section 1.
Through years of researchers’ persistent efforts, the specific categories of features have been richly extended, as shown in
Table 1. In detail, earlier attempts tend to manually design face features, e.g., the colors of skin and hair [
22] and appearance [
23], to recognize simple kinship relationships. With the increasing demand for detailed relation recognition and the development of a deep learning network, researchers began to use complex neural networks to extract face features for detailed relation recognition. Gao et al. [
24] introduced a higher-order graph neural network to find the connection between two faces. After the publications of the PISC datasets [
12] and the PIPA datasets [
21], researchers began to pay more attention to extracting whole body features and scene features. Li et al. [
12] adopted a convolutional neural network (CNN) to extract body features from cropped individual regions and union regions as well as extract visual scene clues from cropped contextual objects. Zhang et al. [
25] further utilized the pose key points to enhance the body features and extract scene information from the whole image. Goel [
15] recognized age and gender clues and extended SRR to a multi-task framework. Since then, the performance of intra-relation features extraction was close to a saturation point and subsequent works started to take inter-relation features into consideration. Li et al. [
19], Qing et al. [
17] and Li et al. [
18] successively constructed different graph structures to generate the logical constraints among different types of social relationships.
For feature fusion, most works focus on the fusion of concatenated intra-relation features and scene features. Li et al. [
12] adopted the traditional attention mechanism to fuse the concatenated intra-relation features and contextual object clues. Wang et al. [
29] introduced a gated graph neural network (GGNN) to pass messages between intra-relation features and contextual objects. Few methods try to better fuse the intra-relation features but neglect the fusion of inter-relation features, e.g., Wang et al. [
16] learned a sparse weighting matrix to select optimal feature subsets in order to reduce the noises and redundancy caused by high-dimension multi-source attributes. Recent methods employ different variants of a graph neural network (GNN) to grasp the inter-relation features and fuse them (provided within the GNN itself), e.g., Li et al. [
18] designed a new weighted-GGNN to attentionally fuse inter-relation features and scene features. Qing et al. [
17] simultaneously utilized a GGNN and graph convolutional network (GCN) to fuse the global and local information among inter-relation features.
The aforementioned SRR methods have validated the effectiveness of features on different scales and have achieved some progress on the fusion of concatenated intra-relation features, inter-relation features and scene features. However, few works take the effective fusion of intra-relation into account. Moreover, the updating mechanism of existing social relationship graph-reasoning methods [
17,
18,
19] still inadequately considers the different influences of all the other neighbor nodes, although Li et al. [
18] have introduced different weights between the scene node and relation nodes. Furthermore, existing works rarely attempt to alleviate the problem caused by imbalanced data and high inter-class similarity.
2.2. Transformer for Visual Tasks
Significant success has been achieved by the transformer in computer vision led by the ViT. Firstly, various transformer-based backbones greatly improve the performance of feature extraction. The great improvement is credited to multi-head self-attention (MSA) because this structure can simultaneously calculate self-attention among all the patches and thus fuse the global feature of the whole images. Subsequent methods integrate the design philosophy of a CNN into a transformer structure and a series of variations [
30,
31,
32] of ViT have been proposed as the backbones for feature extraction.
Secondly, the transformer structure also benefits a large number of downstream tasks, e.g., semantic segmentation [
33], remote sensing image classification [
34,
35,
36] and behavior analysis [
37,
38,
39]. However, in tasks such as semantic segmentation and remote sensing image classification, the contribution of a transformer structure is still limited to its advantage in visual features extraction. On the contrary, in behavior analysis, due to the similarity between video frames and image patches (both are parts of the whole video stream or image), the transformer structure is introduced to exploit the temporal information among these video frames [
38]. Similarly, a transformer is also employed to exploit the features from the pose skeleton in order to recognize human actions [
39].
The above applications of the transformer structure have proved its potential capacities for feature extraction and feature interpretation. In terms of SRR, using a transformer-based backbone can exploit more global information hidden in images compared with CNN-based backbones, which contain the important interactive information between individuals. MSA, as the core of the transformer structure, also enables the transformer to attentionally fuse intra-relation features and inter-relation features, when the input is various features and relation representations, respectively. To this end, we first introduce the ViT as the feature extraction module. Intra-TRM is then employed to attentionally fuse intra-features with the ability of MSA. Finally, Inter-TRM is designed to enhance the representation of a similar relationship in one image for more rational social relation recognition.
3. Methods
In this section, we elaborate on the proposed MT-SRR. We give a general view of the whole framework with a brief introduction of the design process, followed by a detailed description of three key parts in our model, namely (1) feature extraction, (2) feature fusion and (3) classification and optimization.
3.1. Overall Framework of Model
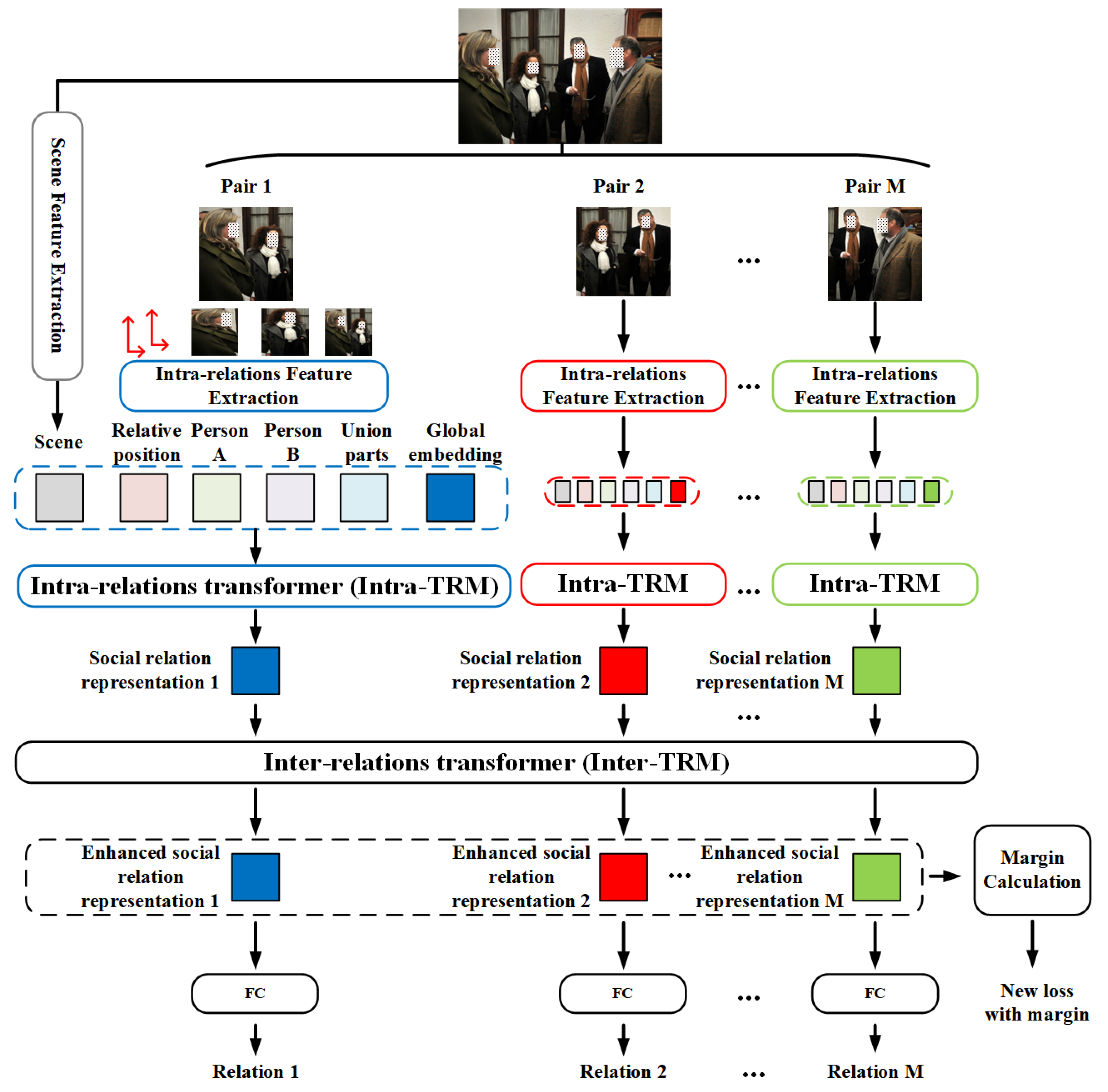
Similar to the general paradigm for SRR [
12,
17,
18,
19,
25], the proposed MT-SRR pays more attention to recognizing pair-wise relationships, whose overall framework is depicted in
Figure 2. Specially, we adopt two transformer-based feature fusion models on two levels: one is used to fuse the intra-relation features and scene features, and the other is utilized to fuse the inter-relation features to enhance the representation of a similar relationship in one image. Briefly speaking, for an image with
N individuals, there are
different relationships (‘
no relation’ is treated as a special kind of relationship in this paper). For each social relationship, we first adopt pretrained ViTs to extract different intra-relation features for its capacity of globally exploiting the visual clues and employ a ResNet50 pretrained on Places365-Standard [
40] especially for scene recognition. Then, Intra-TRM is used to attentionally fuse the output of the feature extraction module, namely the intra-relation features and scene features, and generate a well-designed relation representation. Next, Inter-TRM is employed to enhance the relation representations with inter-relation features by attentionally fusing similar relationship in the same image and generating a new relation representation. Finally, the outputs of Inter-TRM are fed to the classification module. At the same time, we accumulate the sample numbers of different relationships and calculate the average cosine similarity among the outputs of Inter-TRM. A dynamic margin related to the sample numbers and average cosine similarity is then added to standard CE in order to alleviate the bad effect caused by data imbalance.
3.2. Feature Extraction
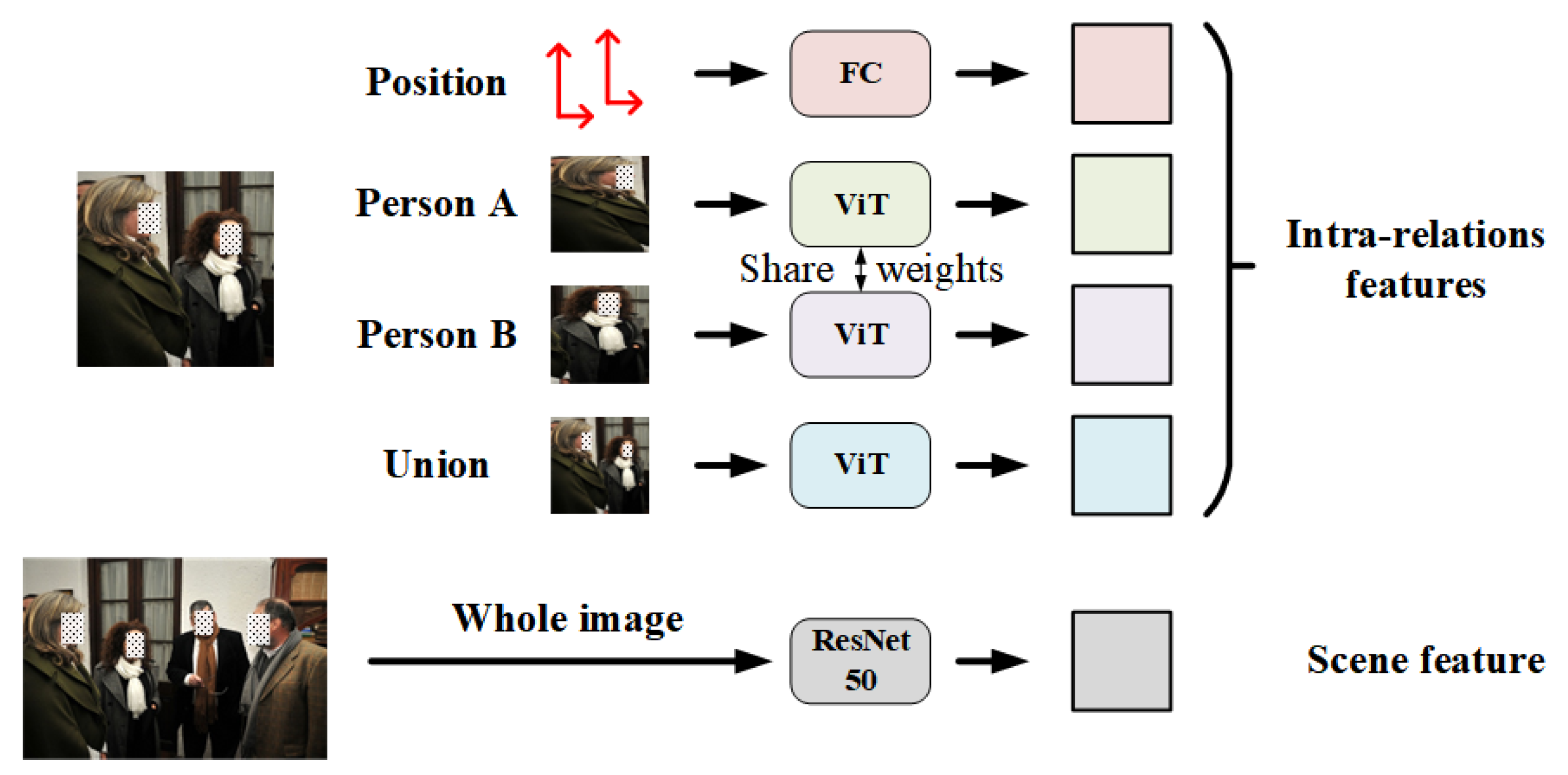
For a specific relationship in an image with
N individuals, we extract four different intra-relation features and one scene feature by five channels, as sketched in
Figure 3. Specially, we first crop the image with the bounding boxes information provided by the labels and generate two individual regions and a union region of two individuals. Individual regions contain the visual clues of a single person, e.g., face, clothing and pose, while the union region implies the interactive information between two individuals. These cropped regions, along with the whole images for scene feature extraction, are uniformly resized to
as the input of specific feature extraction networks. Relative position information, including the coordinates and areas of two individual bounding boxes, are also fed to the feature extraction module.
Different from recent SRR methods [
17,
18], we introduce fine-tuned ViT pretrained on ImageNet [
41] to extract intra-relation features. Compared with CNN, ViT divides the image into small patches and employs multi-head self-attention (MSA) to more globally integrate the features from different patches, which pays more attention to the global interactive information and thus benefits the social relation representation. In our framework, the output dimension of the last MLP layer in ViT is changed from 1000 to 2048 and the parameters of MLP layer are fine-tuned during the training process to adapt to our tasks. Scene feature is still extracted from the whole image by a ResNet50 pretrained on Place365-Standard dataset and we change the output dimension of ResNet50 to 2048 by removing the last classification layer and the first pooling layer. Here, we do not use the ViT as a scene feature extraction network because the scene information is relatively simple and Place365-Standard dataset is specially proposed for scene recognition, which provides pretrained models using ResNet50 as the backbone. In addition, an FC, whose output is a vector with the size of
, is adopted to extract the relative position information. Finally, we obtain four
intra-relation features and one
scene feature for each relationship in the image, which are fed to subsequent feature fusion module.
3.3. Transformer-Based Feature Fusion
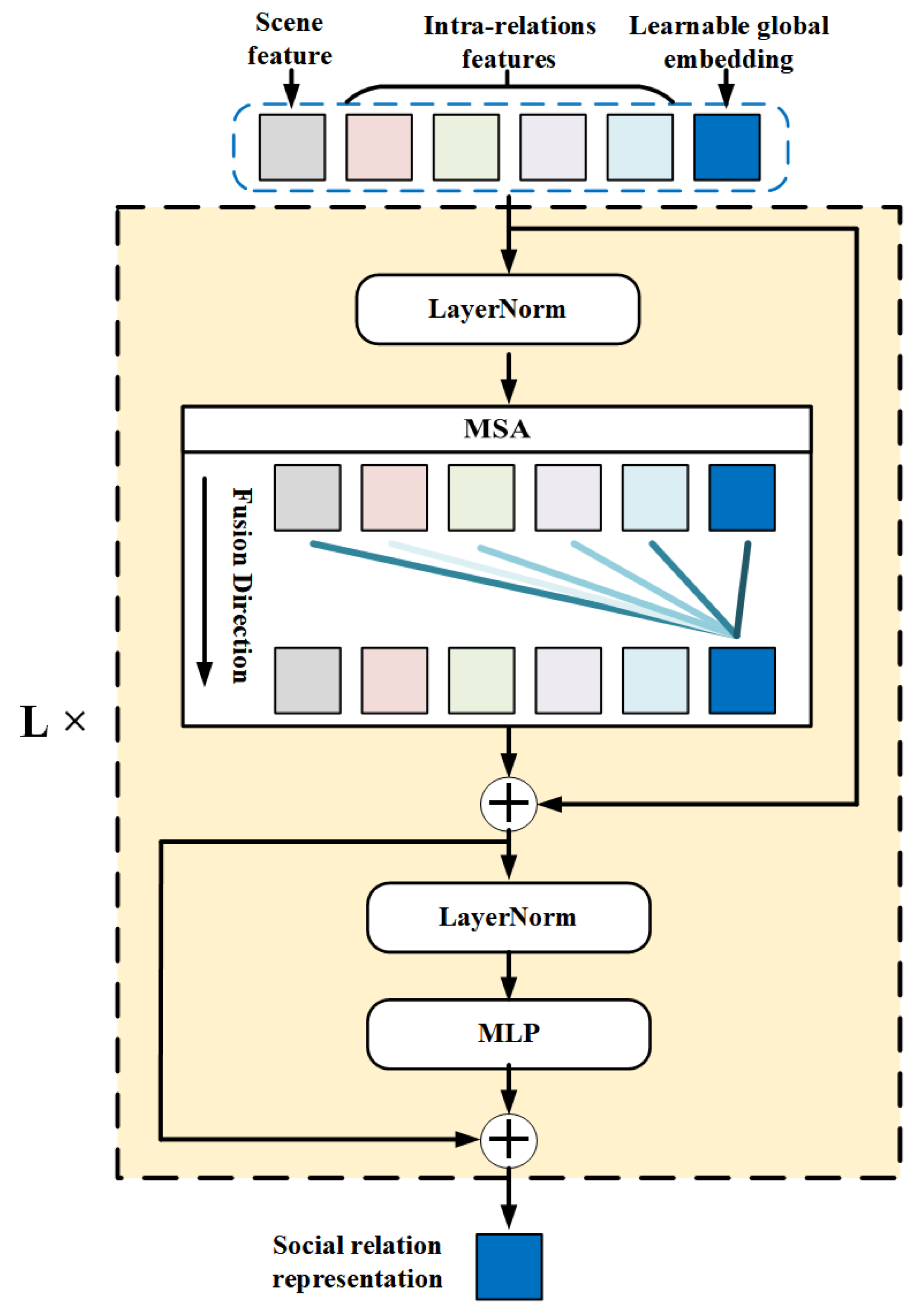
Next in the pipeline is the features fusion module. We first design a transformer-based feature fusion module, namely Intra-TRM, to dynamically fuse all the features fed by the feature extraction module and generate more rational social relation representations for each relationship in an image. Then, another transformer-based feature fusion module, i.e., Inter-TRM, is introduced to enhance the social relation representation generated by Intra-TRM, which utilizes MSA to attentionally aggregate similar social relation representation in the same image. The details of the whole module are elaborated as follows in terms of Intra-TRM and Inter-TRM.
For Intra-TRM, the inputs are the intra-relation features and scene features in previous steps. Inspired by the application of transformer structure in Natural Language Processing (NLP) [
42], we add an extra global embedding
with the same dimension as those extracted features to the input, for globally fusing all the extracted features for each relationship in one image. The whole input of Intra-TRM (
) can be expressed as:
where
,
,
,
,
are the features extracted from two individual regions, one union region, relative position and the whole image, respectively.
M is the number of relationships in an image with
N individuals, as mentioned in
Section 3.1.
Then, we utilize a stacked transformer to globally fuse the intra-features and scene features for more rational social relationship representations. In addition, residual connections are added before and after every block, respectively. The whole process can be described by the following formula:
where
L is the number of stacked blocks, which is set as 12, referring to [
42].
denotes the outputs of the
l-th block, while
has similar meaning. MSA is extended by standard self-attention, which runs several self-attention operations (called ‘heads’) in different vector space in parallel and concatenates their output for subsequent processing. LN is the abbreviation of layer normalization.
Stacked transformer blocks ensure that the extra learnable global embedding can effectively fuse the intra-relation features and scene features with dynamic weights. For each relationship, we use the global embedding within the output of final transformer block as the social relation representation
r. The illustration of whole Intra-TRM is shown in
Figure 4.
For Inter-TRM, we use
M social relation representations in one image as the inputs
, expressed as,
Similar to Intra-TRM, a stacked transformer structure is constructed with Equations (
2) and (
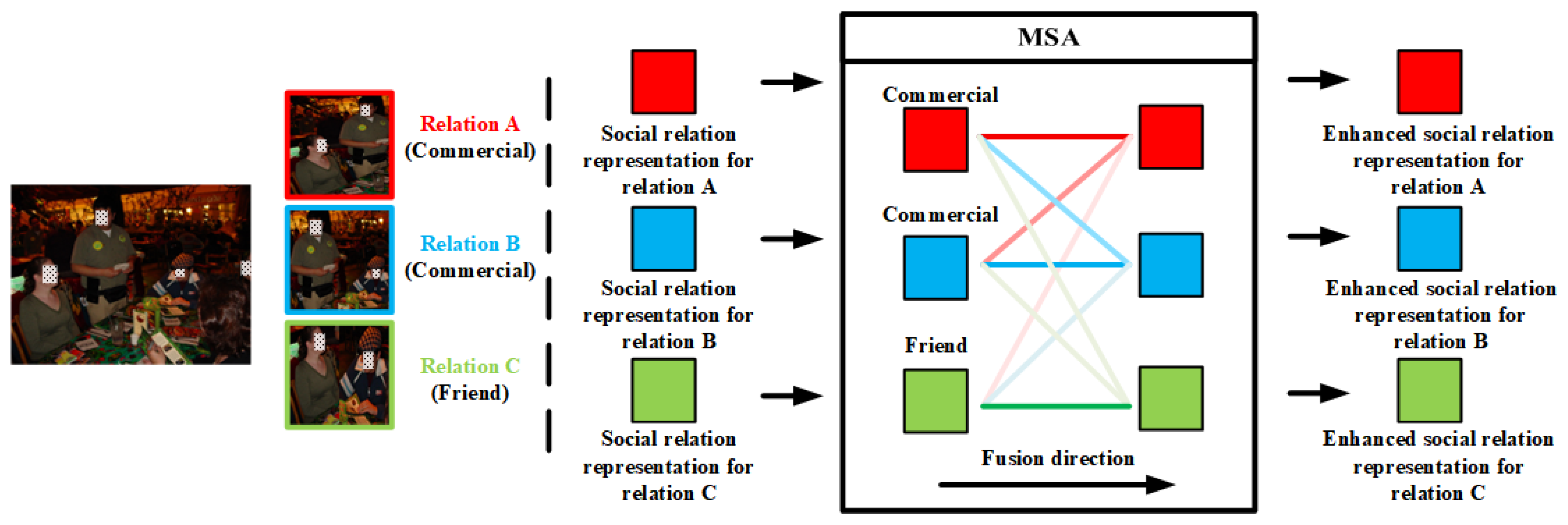
3), which utilizes the MSA mechanism to enhance similar social relation representations in the same image. MSA mechanism enables these social relation representations to attentionally aggregate the similar representations and thus generate enhanced social relation representations, which benefits the inter-relation feature fusion for SRR. For example, as illustrated in the left part of
Figure 5, there are three different relations in the image, namely two pairs of ‘
commercial’ and one pair of ‘
friend’. In MSA blocks of Intra-TRM, the input representations aggregate all the representations based on the similarity among them. To be specific, the similarity between one social relation representation and itself is most likely to be the largest, followed by the similarity between social relation representations of the same class, while the similarity between social relation representations of different classes is the lowest. The different similarity enables the block to attentionally aggregate the similar social relation representations, as the different gradations of colors in
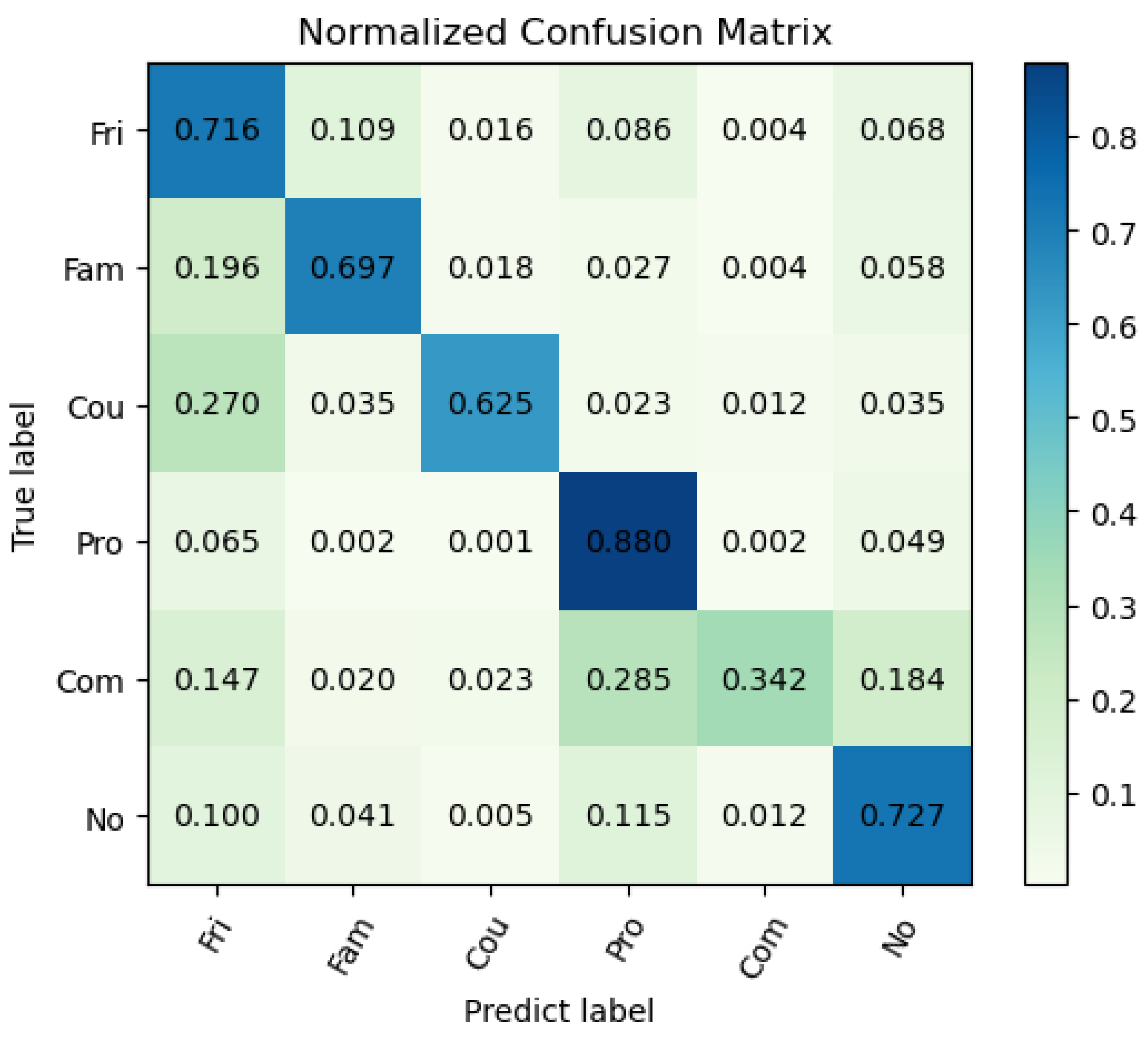
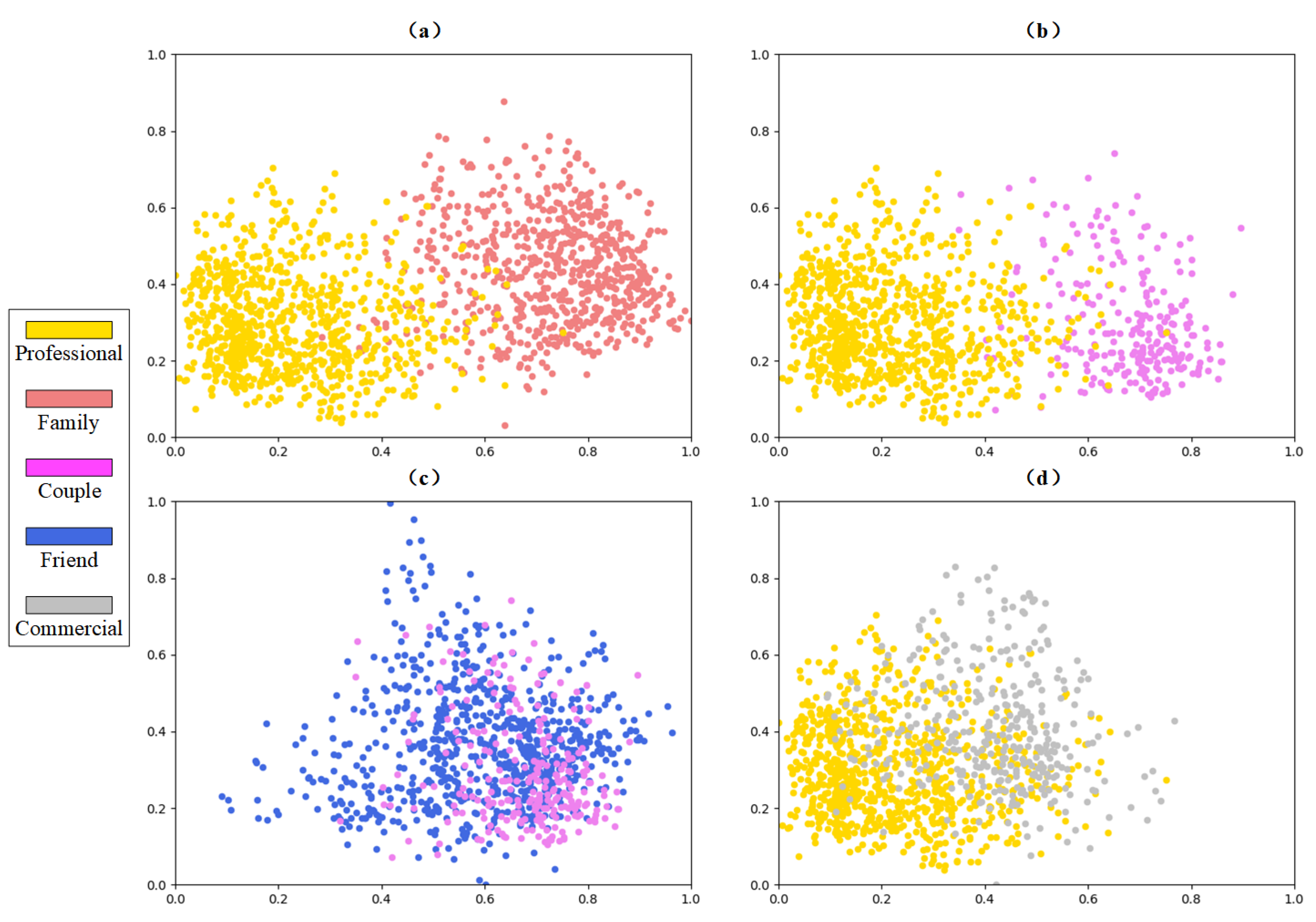
Figure 5. However, such a method will be affected by the problem of high inter-class similarity, which may increase the confusion between similar classes. To tackle the problem, we further design a new loss function, which is elaborated in the next section.
3.4. Classification and Optimization
The aforementioned Inter-TRM outputs are the final social relation representations
, which are used to calculate the per-class probability
with a soft-max function, expressed as:
where
is the probability of the
j-th class.
m denotes the number of classes in different SRR tasks (3, 6 and 16 for PISC-C, PISC-F and PIPA, respectively).
means the final classification results with the max probability of the
i-th sample.
In order to further optimize our model to alleviate the bad effect caused by imbalanced data, we add an adaptive margin
related to the sample numbers and the inter-class similarity to standard CE, inspired by [
43]. The margin should satisfy the following two properties: (1) the more similar the two classes are, the larger it should be; (2) between two similar classes, the margin of the dominant class (class with more samples) should be smaller than that of the minority class in order to enlarge the suppression of minority class over dominant class. Therefore, for a sample of class
y, the new loss function with margin is designed as follows,
where
and
are the output of class
y and class
after FC in Equation (
5).
The adaptive margin
can be calculated as follows,
where
is the maximum sample number of different classes in training data,
is the sample number of class
y.
means the average cosine similarity between samples in class
y and samples in class
.
5. Conclusions
In this paper, we focus on the design of the feature fusion module, which orchestrates the intra-relation features, inter-relation features and scene feature in order to generate more rational social relation representation for a deeper understanding of SRR. Specially, two transformer-based feature fusion modules, namely Intra-TRM and Inter-TRM, are introduced to dynamically fuse all the features for social relation representations generation and attentionally enhance the representations of similar social relationships in the same image, respectively. We also add a newly designed margin to standard CE in order to mitigate the bad effect caused by imbalanced data. The new margin can be potentially used in different tasks which have the same problem, e.g., emotion recognition and activity recognition in a public space.
In total, the two transformer-based modules boost the performance with absolute 9.5%, 8.1% and 4.6% for PISC-C (mAP), PISC-F (mAP) and PIPA (Acc) over the ablation baseline, which demonstrates that our MT-SRR can efficiently orchestrate the features on different scales. The comparison between Inter-TRM and graph-based networks further proves that Inter-TRM is the better choice for exploiting the logical constraints. In addition, the ablation results also prove that the newly designed margin can alleviate the bad effect caused by imbalanced data and improve the recognition accuracy on three tasks with only 0.5% deterioration on PISC-F (mAP). In general, our proposed MT-SRR significantly outperforms the state-of-the-art methods by absolute 2.0%, 1.3% and 6.4% for PISC-C (mAP), PISC-F (mAP) and PIPA (Acc), which illustrates the effectiveness of our proposed MT-SRR.
However, some classes with highly similar visual clues still suffer from low recognition accuracy. To address the problem, how to comprehensively utilize multimodal social data (text, audio, etc.) to distinguish the highly confused classes and achieve more accurate recognition is thus a key issue in the future. In addition, how to apply SRR to higher-level social scene understanding and further benefit more complex social intelligence systems, such as a city-scale public administration system, is another key issue for future research.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}