1. Introduction
Due to the good acquisition ability of target spectral information and image information, imaging spectrometers are widely used in remote sensing, medical, industrial, aerospace, and other fields. The first spectral detection was made by Isaac Newton, who used a triangular prism to divide sunlight into a rainbow-colored pattern. Traditional spectrometers are bulky, which has hindered them from achieving wider application in scenarios such as in satellites, drones, and handheld platforms. The computational spectroscopy technology based on the principle of compressed sensing (CS) was proposed [
1], and the spectrometer, which used wide spectral coding, became a hot topic in research because it could increase the signal-to-noise ratio (SNR). Many computational methods have been introduced into spectral detection. It has become possible to realize portable sensing systems [
2,
3].
Tao et al. proposed restricted isometry property (RIP) to guide the construction of the sensing matrix (i.e., the product of the measurement matrix of optical filters transmittance and the sparse basis matrix) [
1]. Based on RIP, scholars have successively improved the original algorithm and proposed OMP [
4], StOMP [
5], and TMP [
6]. Donoho proposed the non-correlation criterion of the measurement matrix constructed by the filter transmittance curve [
7], which supplies researchers with an easy way to construct the sensing matrix. The performance of the computational spectrometer is strongly related to the non-correlation of its encoding filters. However, there is a full-beam relationship between the transmittance curve and the filter structure design parameters. The mass-production and then try to select only a few of them that can meet the in non-correlation criterion is unacceptable. The low encoding efficiency also explains why the reconstruction accuracy of the spectrometer obtained by this method is largely limited.
Recently, deep neural networks are being applied to the field of spectral reconstruction [
8,
9,
10,
11], but a lightweight convolution neural network (CNN) has few been reported in this arena. Kulkarni pioneered work in the field of image reconstruction by using CNNs [
9]. Hao [
8] applied neural networks in computational spectroscopy, and it is worth noting that the architecture is featured with all fully connected (FC) layers. The work of these authors inspired us to propose a CNN with both filter-encoding and spectral reconstruction capabilities. A CNN is featured with a few parameters that can increase efficiency. In addition, its virtue of weighting parameter sharing and the use of sparse connections of local receptive fields enables the CNN to have better performance in the training consumption and recovery accuracy of computational spectral reconstruction. WER-Net uses an FC layer without offset to encode the incident spectrum and reconstruct the encoded information afterward by combining convolutional layers and FC layers. The training data for this network is obtained from CAVE [
10] and ICVL [
11], and the transmittance curve of a group of filters and its corresponding reconstruction network can be completed after training.
The rest of this paper is organized as follows. In
Section 2, we describe WER-Net’s architecture and methodology.
Section 3 describes WER-Net’s training procedure. Experiment results are reported in
Section 4. Finally,
Section 5 concludes the paper.
2. Methodology
Neurons are used as the basis of deep neural networks to simulate the working process of biological neural networks, and the most commonly used neuron model is the M-P neuron model proposed by McCulloch [
12]. Hopfield used neural networks to solve NP-hard problems for the first time [
13], which helped drive the rapid development of neural networks. After this, LeCun proposed LeNet-5, the standard CNN [
14], which greatly contributed to the development of the CNN. Since then, deep neural networks have flourished in a variety of fields. Among them, Kulkarni applied it to the field of image compression and reconstruction [
9], opening up the use of deep neural networks to solve CS problems. Zhang then applied feed-forward neural networks to the field of spectral reconstruction [
8].
WER-Net is composed of the encoding network and the reconstruction network. On the one hand, for the encoding network, because the spectral sampling process of the wide spectral encoding filter and the input operation process of the fully connected layer without bias are defined by matrix multiplication, a layer of fully connected layers without bias can be used to simulate the wide spectral coding filter and obtain the corresponding spectral transmittance curve. On the other hand, the reconstruction network simulates the process of solving the CS problem. According to the universal approximation theorem, the NP-hard problem of solving the CS problem can be solved by using more than three layers of neural networks. After adjusting the network structure to achieve the balance between solving accuracy and efficiency, we decided to use two layers of fully connected layers and three layers of a convolutional layer to realize the solving process.
The network architecture of WER-Net proposed in this paper is stated as follows. The first layer uses sampling of a fully connected layer without offset to simulate optical encoding filters, followed by spectral reconstruction by using two fully connected layers and three convolutional layers. Among them, except for the first and last layers, the ReLU function is used as the activation function. The above structure can also be described as: (FC without offset)-FC-Rule-(Conv-Rule)3-FC. To the best of our knowledge, this is the first-time convolutional layers are used in spectral reconstruction. The network structure diagram is shown in
Figure 1.
2.1. Engineered Loss-Function
The input and output of WER-Net are 400~700 nm@2nm spectral information matrix, and the training goal is
where
Θ represents the set of parameters in each layer of the neural network,
S is the spectral information matrix of the input, and
is the spectral reconstruction matrix of the output.
Equation (1) simply indicate the nature of the computational spectrometer. However, it has no regulating ability on the optical filters. After rounds of training, it ends up with an ideal spectral transmittance curve that fully complies with the non-correlation criterion. That brings us to a severe problem for the fabrication of optical filters because transmittance curves in the real world lack the spectral diversity of the ideal ones. That means researchers can never have the result they want so they adopt the random Gaussian matrix as the measurement matrix [
15,
16]. This may make for impressive performance with regard to reconstruction accuracy, but the overly random filters cannot be produced.
To address this problem, with the development of deep learning technology, many reverse design methods dedicated to achieving spectral responses have been presented [
17,
18,
19]. However, due to poor generalization, it is still difficult to achieve accurate reverse design for some extreme requirements. The good news is that as long as the spectral transmittance curve is smooth enough, the above methods can give good reverse design results. Therefore, in order to obtain filters that are characterized by technological feasibility while taking the requirements of Equation (1) into consideration, we make the weight parameters of the first FC layer as smooth as possible on each line. Consequently, we use the following loss function:
To circumvent the slow speed of the circulation operation, we take the values of the first to
nth columns of the weight matrix
W to form the matrix
W′, and take out the former n-1 columns of the
W to form the matrix
W″. The equivalent form of Equation (2) is shown in Equation (3):
The optical filter transmittance curve corresponding to the first FC layer without offsets trained in this way has good engineering characteristics and can be fabricated.
2.2. FC Layer in Encoding and Hierarchic Optimization
The structure of the M-P neuron model is shown in
Figure 2.
The neuronal model in
Figure 2 can be represented as the following equation:
where
represents the activation function,
for the weight value, and
for the input. For an FC layer composed of multiple neurons, it can be expressed as Equation (5) when the role of the activation function is not considered:
For wide-spectrum coding filters, the coding of spectra is as follows:
where
E represents the output of the filter encoded spectral signal,
T(
λ) represents the spectral transmittance of the filter, and
S(
λ) represents the incident spectral signal.
Discretize Equation (6), and we have
Discretize the incident spectral signal and the spectral transmittance, and the encoded spectral information can be described in matrix form:
If the incident spectral signal matrix S in Equation (8) is taken as the input X represented in Equation (5), and the offset term B is zeroed, then the output Y of Equation (5) equals E of Equation (8). In a nutshell, an FC layer without offset can simulate the process when incidental light passes through the optical filter, hence being encoded. In the proposed WER-Net, this method is used to design the wide-spectrum encoding filter.
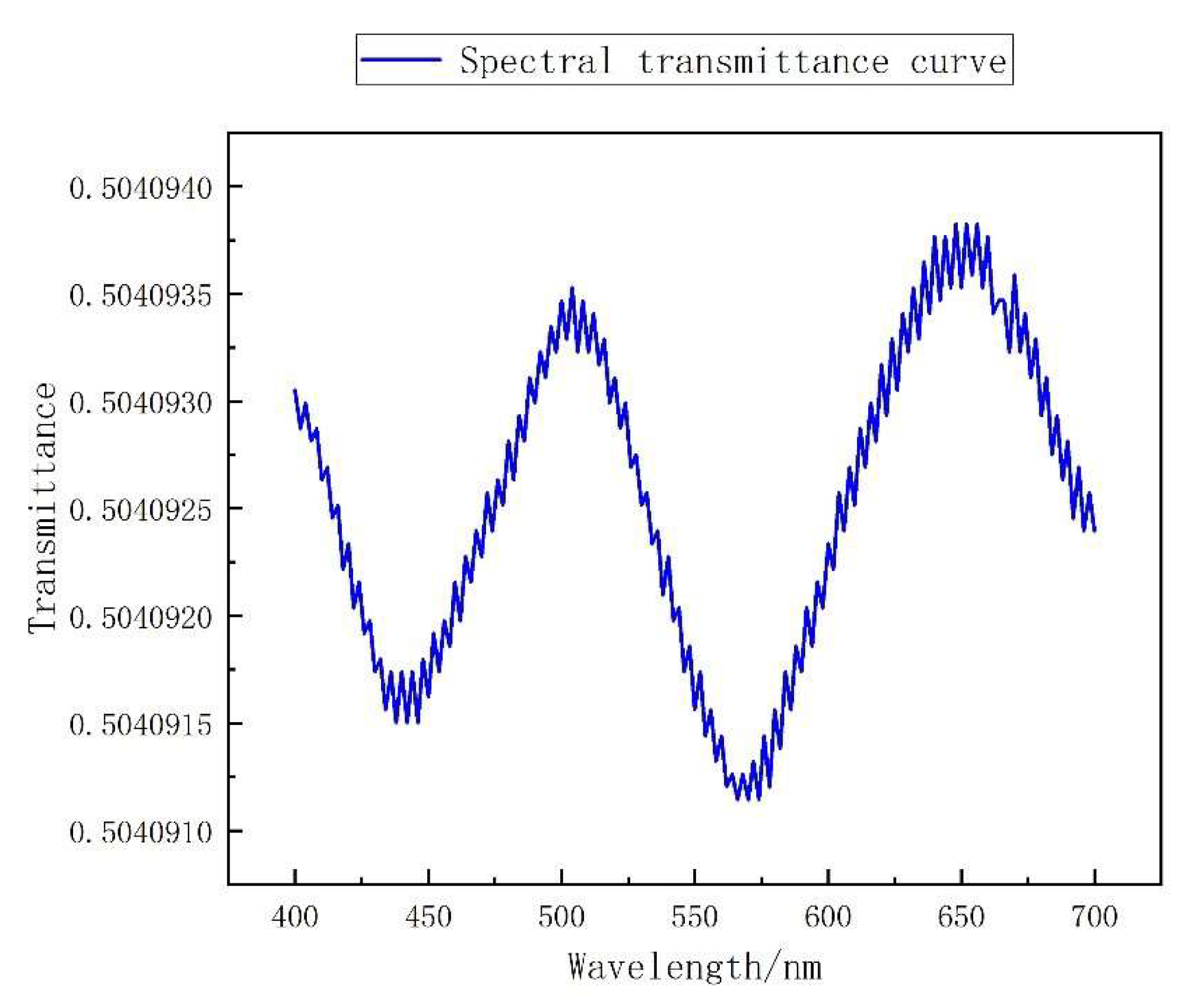
According to the principle of CS, the greater the non-correlation of the sampling matrix, the more object information can be obtained. Therefore, based on the aforementioned loss function, it can be judged that the training logic of the first FC layer without offset is to take into account the non-correlation and production process limitations. However, in the scenario following a certain number of training rounds, the spectral transmittance curve begins to jitter on the whole spectrum range, as shown in
Figure 3. It improves with non-correlation, but it brings great difficulties to the fabrication process of the filter.
Therefore, this paper proposes a hierarchical optimization method for WER-Net. Specifically, under the condition that the filter transmittance curve shows sufficient diversity, we stop the training of the first FC layer parameters, and retain it, and on this basis, the training of the full connection layer and convolutional layer parameters of the reconstruction part is continued. The hierarchical optimization method helps to maintain the technical feasibility of filter fabrication and also reduce the time and spatial complexity of training.
2.3. Spectral Reconstruction Using CNN
Deep neural networks have extremely powerful expression capabilities. They require only a single hidden layer and a small number of neural units to fit functions of any complexity with high precision [
20,
21,
22,
23]. To the best of our knowledge, some deep neural networks have been introduced into computational spectrometry [
8,
15,
16]. However, the application of CNNs in computational spectrometry is rarely reported. Moreover, this elucidates the major difference between WER-Net and other deep neural networks in spectrum reconstruction.
The structure of the convolutional layer can be expressed in Equation (9),
where
θ_(
i,j) represents the convolutional kernel element size of column
j in row
i, x_(
i,j) represents the element size of column
j in row
i, and
b is the deviation.
Although the common feedback-forward neural network in [
8] can be used to calculate the spectral reconstruction, severe challenges with regard to time and accuracy performance remain.
On the one hand, the feedback-forward neural network has a great number of parameters to be trained and stored. As a result, it needs a gigantic training dataset and becomes incompatible with embedded systems. If there are 100 hidden neurons in the first FC layer when applying neural networks for computational spectral reconstruction, thousands of weighting parameters would need to be updated in the first FC layer alone. This would lead to a drastic increase in both system storage demands and the training dataset volume. Otherwise, we have an inefficient decoding network which cannot be applied to scenarios like in situ measurement or real-time measurement. In addition, this bulky network cannot be easily embedded on many types of hardware.
On the other hand, the feedback-forward neural network lacks the ability to share its weighting parameters which would result in low efficiency in data fitting. Taking a random curve for instance, there could be a lot of diversities in this curve. It could be a high-order function, a random noise, an aperiodic impulse curve, etc. In order to match this curve, the feedback-forward neural network would perform a crude and time-consuming fitting process. However, in the real world, most of the spectral curves are demonstrating gradual changes. It means the neighboring wavelengths have a relatively good correlation property. Obtaining this property would benefit the neural network greatly. CNNs solve the above problems by virtue of their weighting parameter sharing and the use of sparse connections of local receptive fields [
14], which makes CNNs have better performance in the training consumption and recovery accuracy of computational spectral reconstruction.
2.4. Dataset Augmentation
To train the WER-Net, we used a total of 1,650,000 spectral data from the CAVE and ICVL. Both are 10-nm resolution data in the range of 400 to 700 nm.
In order to achieve the application of the network to a high-resolution spectrometer, this article conceives the idea to use some interpolation method to augment the 10-nm resolution database to a higher resolution one. For instance, to achieve 2-nm resolution, the least squares fitting is applied to augment the data of CAVE and ICVL, and the data of 31 × 1,650,000 is processed into 151 × 1,650,000 data. In the later experiment demonstration, the idea is verified.
2.5. Activation Function
At present, the mathematical principles of computational spectral algorithms, whether they are traditional GPSR [
24], or OMP [
4], or computational spectral algorithms based on deep learning, can be explained by CS theory.
Considering the signal
x∈R^N, the measurement process can be expressed as follows:
where the matrix
Φ∈R^(M × N) is called the measurement matrix, and
y∈R^M is the measurement vector. The encoding process is completed by the measurement process. The process of recovering the original signal from the measured value by means of a computational reconstruction is termed “reconstruction”. When
Φ∈R^(M × N), Equation (10) is an underdetermined entity. The linear inverse problem is a pathological problem. Solving a problem means recovering more information with less information, which is clearly inconsistent with Nyquist’s sampling theorem. Based on the CS theorem [
25,
26,
27], when both the signal and the measurement matrix meet certain conditions, even if M << N the original information can be recovered.
The process of solving the compressive perception is an NP-hard problem, instead of a simple linear problem. Referring to the universal approximation theorem, an activation function is needed to enable a neural network to fit a nonlinear problem. The nonlinearity of activation function needs delicate consideration.
It is widely acknowledged that the nonlinear performance of the ReLU function is superior to that of functions such as Tanh, as shown in
Figure 4, and the training error rate of a four-layer convolutional neural network by using the ReLU function reaches 25% faster than that of an equivalent network with a Tanh activation function [
28]. Therefore, the activation function used by WER-Net is the ReLU function.
5. Discussion
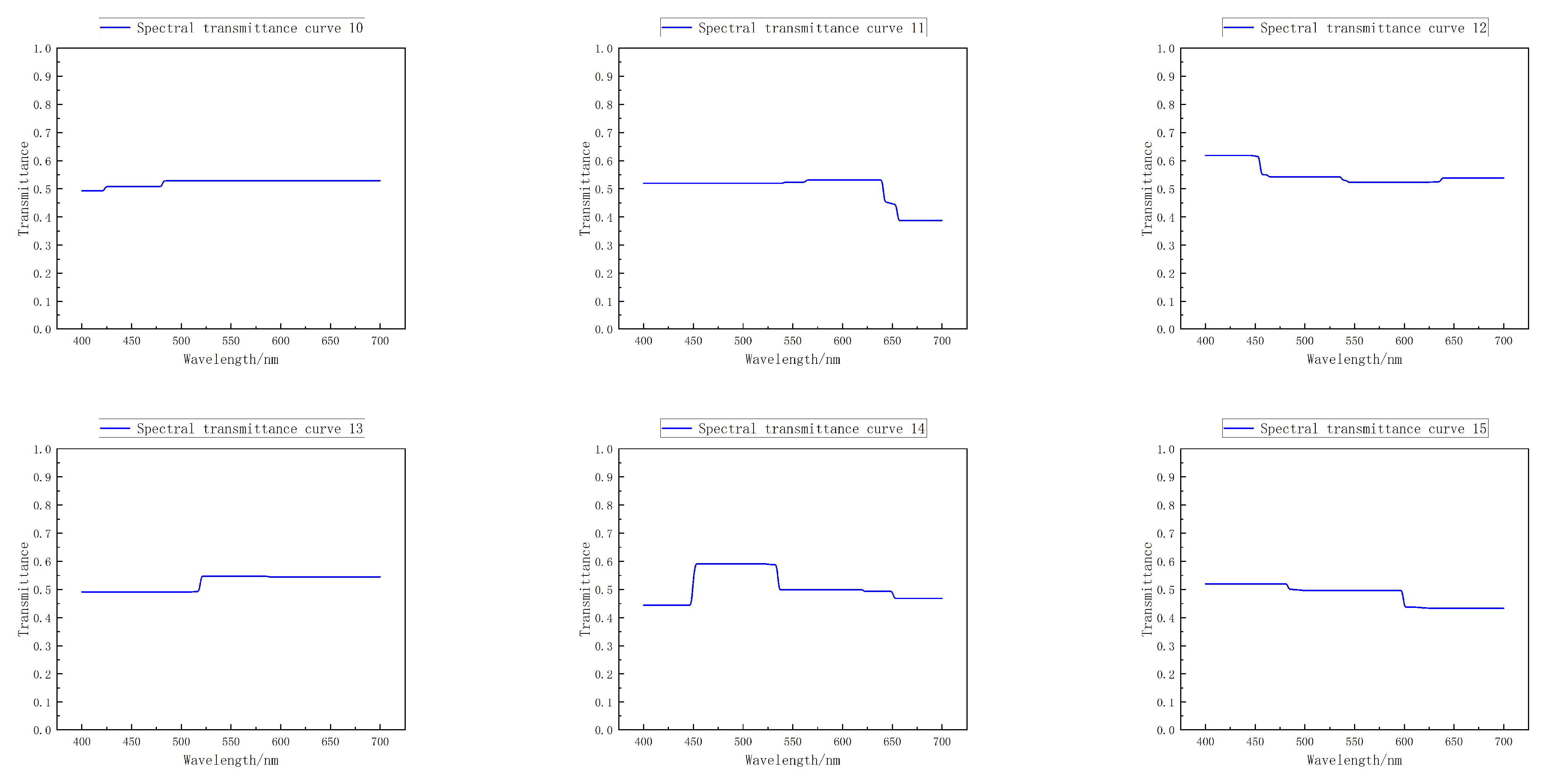
This paper presents a novel encoding and reconstruction artificial neural network called WER-Net, which is applied in a computational spectrum field. First, an FC layer without offset was constructed to simulate the encoding process of the spectrum, and then two FC layers and three convolution layers were architected to reconstruct the encoded spectrum. The open-source CAVE and ICVL database were then used for least square interpolation to obtain a virtual higher resolution training dataset. The database is used to train WER-Net to obtain the spectral transmittance and decoding network. In the encoding part, to acquire spectral transmittance, the regular terms and hierarchical optimization methods during training are used to make it more practical in engineering. In the reconstruction part, CNNs are used to reduce the network parameters and improve computational efficiency. Finally, experimental demonstration proves that the wide-spectrum encoding filter trained by WER-Net has universal applicability. The high-precision spectral reconstruction is successfully realized in traditional GPSR, OMP, and other algorithms. Moreover, the reconstruction accuracy of WER-Net is 208 times higher than GPSR, 38 times higher than OMP, and the reconstruction speed is only 0.48% of GPSR and 2.65% of OMP. WER-Net not only solves the drawbacks of high cost caused by the “mass production selection” tendencies of wide-spectrum encoding filters, but also greatly improves the reconstruction efficiency.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}