
A Thermal Infrared Pedestrian-Detection Method for Edge Computing Devices

 ,
,  ,
,
Abstract
:1. Introduction
- (1)
- We adjust the input size of the network, which reduces the calculation redundancy and alleviates the imbalanced number of small objects based on the self-built dataset.
- (2)
- Multi-scale mosaic data augmentation is proposed to extend object diversity in training, which simulates multiple objects, small objects, and occlusion objects scenarios.
- (3)
- To achieve effective feature fusion in the neck, we introduce the parameter-free attention mechanism to implement feature enhancement.
- (4)
- We accelerate the network inference using quantization technology on the edge device. To fully exploit hardware resources, multi-threading technology is utilized to realize multi-channel video detection tasks.
2. Proposed Method
2.1. Multi-Scale Mosaic
2.2. TIPYOLO Network Details
2.3. Video Processing Acceleration
3. Experiments and Results
3.1. Data Set and Experiment Setting
3.2. Evaluation Indexes
3.3. Analysis of Experimental Results
3.3.1. Ablation Study on the YDTIP Dataset
3.3.2. Comparison Experiments with Other Methods on the YDTIP Dataset
3.3.3. Comparison Experiments with Other Methods on the Public Dataset
3.3.4. Evaluation of Method Performance on Edge Computing Devices
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Maldague, X.; Galmiche, F.; Ziadi, A. Advances in pulsed phase thermography. Infrared Phys. Technol. 2002, 43, 175–181. [Google Scholar] [CrossRef]
- Bhadoriya, A.S.; Vegamoor, V.; Rathinam, S. Vehicle Detection and Tracking Using Thermal Cameras in Adverse Visibility Conditions. Sensors 2022, 22, 4567. [Google Scholar] [CrossRef]
- Pozzer, S.; De Souza, M.P.V.; Hena, B.; Hesam, S.; Rezayiye, R.K.; Azar, E.R.; Lopez, F.; Maldague, X. Effect of different imaging modalities on the performance of a CNN: An experimental study on damage segmentation in infrared, visible, and fused images of concrete structures. NDT E Int. 2022, 132, 102709. [Google Scholar] [CrossRef]
- Liu, Y.; Su, H.; Zeng, C.; Li, X. A robust thermal infrared vehicle and pedestrian detection method in complex scenes. Sensors 2021, 21, 1240. [Google Scholar] [CrossRef]
- Oluyide, O.M.; Tapamo, J.R.; Walingo, T.M. Automatic dynamic range adjustment for pedestrian detection in thermal (infrared) surveillance videos. Sensors 2022, 22, 1728. [Google Scholar] [CrossRef]
- Fang, Q.; Ibarra-Castanedo, C.; Maldague, X. Automatic defects segmentation and identification by deep learning algorithm with pulsed thermography: Synthetic and experimental data. Big Data Cogn. Comput. 2021, 5, 9. [Google Scholar] [CrossRef]
- Altay, F.; Velipasalar, S. The Use of Thermal Cameras for Pedestrian Detection. IEEE Sens. J. 2022, 22, 11489–11498. [Google Scholar] [CrossRef]
- El Maadi, A.; Maldague, X. Outdoor infrared video surveillance: A novel dynamic technique for the subtraction of a changing background of IR images. Infrared Phys. Technol. 2007, 49, 261–265. [Google Scholar] [CrossRef]
- Zhang, S.; Bauckhage, C.; Cremers, A.B. Informed haar-like features improve pedestrian detection. In Proceedings of the Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 947–954. [Google Scholar]
- Watanabe, T.; Ito, S. Two co-occurrence histogram features using gradient orientations and local binary patterns for pedestrian detection. In Proceedings of the Asian Conference on Pattern Recognition, Okinawa, Japan, 5–8 November 2013; pp. 415–419. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, B.; Nevatia, R. Pedestrian detection in infrared images based on local shape features. In Proceedings of the Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. Comput. Vis. Pattern Recognit. 2005, 1, 886–893. [Google Scholar]
- Torresan, H.; Turgeon, B.; Ibarra-Castanedo, C.; Hébert, P.; Maldague, X.P. Advanced surveillance systems: Combining video and thermal imagery for pedestrian detection. Thermosense XXVI 2004, 5405, 506–515. [Google Scholar]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared patch-image model for small target detection in a single image. IEEE Trans. Image Processing 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Chen, J.; Ran, X. Deep learning with edge computing: A review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 1314–1324. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Han, J.; Yang, Y. L-Net: Lightweight and fast object detector-based ShuffleNetV2. J. Real-Time Image Processing 2021, 18, 2527–2538. [Google Scholar] [CrossRef]
- Zheng, Y.; Wu, G. YOLOv4-Lite–Based Urban Plantation Tree Detection and Positioning with High-Resolution Remote Sensing Imagery. Front. Environ. Sci. 2022, 641, 756227. [Google Scholar] [CrossRef]
- Wang, Z.; Feng, J.; Zhang, Y. Pedestrian detection in infrared image based on depth transfer learning. Multimed. Tools Appl. 2022, 81, 1–20. [Google Scholar] [CrossRef]
- Hou, X.; Ma, J.; Zang, S. Airborne infrared aircraft target detection algorithm based on YOLOv4-tiny. J. Phys. Conf. Ser. 2021, 1865, 042007. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Yang, G.; Feng, W.; Jin, J.; Lei, Q.; Li, X.; Gui, G.; Wang, W. Face mask recognition system with YOLOV5 based on image recognition. In Proceedings of the International Conference on Computer and Communications, Ho Chi Minh City, Vietnam, 1–3 August 2020; pp. 1398–1404. [Google Scholar]
- Wu, Z.; Wang, X.; Chen, C. Research on lightweight infrared pedestrian detection model algorithm for embedded Platform. Secur. Commun. Netw. 2021, 2021, 1549772. [Google Scholar] [CrossRef]
- Li, X.; Wang, S.; Liu, B.; Chen, W.; Fan, W.; Tian, Z. Improved YOLOv4 network using infrared images for personnel detection in coal mines. J. Electron. Imaging 2022, 31, 013017. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Xue, M.; Chen, M.; Peng, D.; Guo, Y.; Chen, H. One Spatio-Temporal Sharpening Attention Mechanism for Light-Weight YOLO Models Based on Sharpening Spatial Attention. Sensors 2021, 21, 7949. [Google Scholar] [CrossRef] [PubMed]
- Xue, Y.; Ju, Z.; Li, Y.; Zhang, W. MAF-YOLO: Multi-modal attention fusion based YOLO for pedestrian detection. Infrared Phys. Technol. 2021, 118, 103906. [Google Scholar] [CrossRef]
- Gao, Z.; Dai, J.; Xie, C. Dim and small target detection based on feature mapping neural networks. J. Vis. Commun. Image Represent. 2019, 62, 206–216. [Google Scholar] [CrossRef]
- Lu, R.; Yang, X.; Li, W.; Fan, J.; Li, D.; Jing, X. Robust infrared small target detection via multidirectional derivative-based weighted contrast measure. IEEE Geosci. Remote Sens. Lett. 2020, 19, 7000105. [Google Scholar] [CrossRef]
- Zhu, Y.; Yang, J.; Deng, X.; Xiao, C.; An, W. Infrared pedestrian detection based on attention mechanism. J. Phys. Conf. Ser. 2020, 1634, 012032. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware faster R-CNN for robust multispectral pedestrian detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef]
- Takumi, K.; Watanabe, K.; Ha, Q.; Tejero-De-Pablos, A.; Ushiku, Y.; Harada, T. Multispectral object detection for autonomous vehicles. Themat. Workshops ACM Multimed. 2017, 2017, 35–43. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- González, A.; Fang, Z.; Socarras, Y.; Serrat, J.; Vázquez, D.; Xu, J.; López, A.M. Pedestrian detection at day/night time with visible and FIR cameras: A comparison. Sensors 2016, 16, 820. [Google Scholar] [CrossRef]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning 2021, Shenzhen, China, 26 February–1 March 2021; pp. 11863–11874. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Ning, C.; Menglu, L.; Hao, Y.; Xueping, S.; Yunhong, L. Survey of pedestrian detection with occlusion. Complex Intell. Syst. 2021, 7, 577–587. [Google Scholar] [CrossRef]
- He, X.; Cheng, R.; Zheng, Z.; Wang, Z. Small object detection in traffic scenes based on YOLO-MXANet. Sensors 2021, 21, 7422. [Google Scholar] [CrossRef] [PubMed]
- Jiang, C.; Ren, H.; Ye, X.; Zhu, J.; Zeng, H.; Nan, Y.; Sun, M.; Ren, X.; Huo, H. Object detection from UAV thermal infrared images and videos using YOLO models. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102912. [Google Scholar] [CrossRef]
- Roszyk, K.; Nowicki, M.R.; Skrzypczyński, P. Adopting the YOLOv4 architecture for low-latency multispectral pedestrian detection in autonomous driving. Sensors 2022, 22, 1082. [Google Scholar] [CrossRef] [PubMed]
- Cao, J.; Pang, Y.; Xie, J.; Khan, F.S.; Shao, L. From handcrafted to deep features for pedestrian detection: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4913–4934. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. Supplementary material for ‘ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the Computer Vision and Pattern Recognition 2020, Nanjing, China, 16–18 October 2020; pp. 13–19. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Li, W. Infrared Image Pedestrian Detection via YOLO-V3. Adv. Inf. Technol. Electron. Autom. Control Conf. 2021, 5, 1052–1055. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
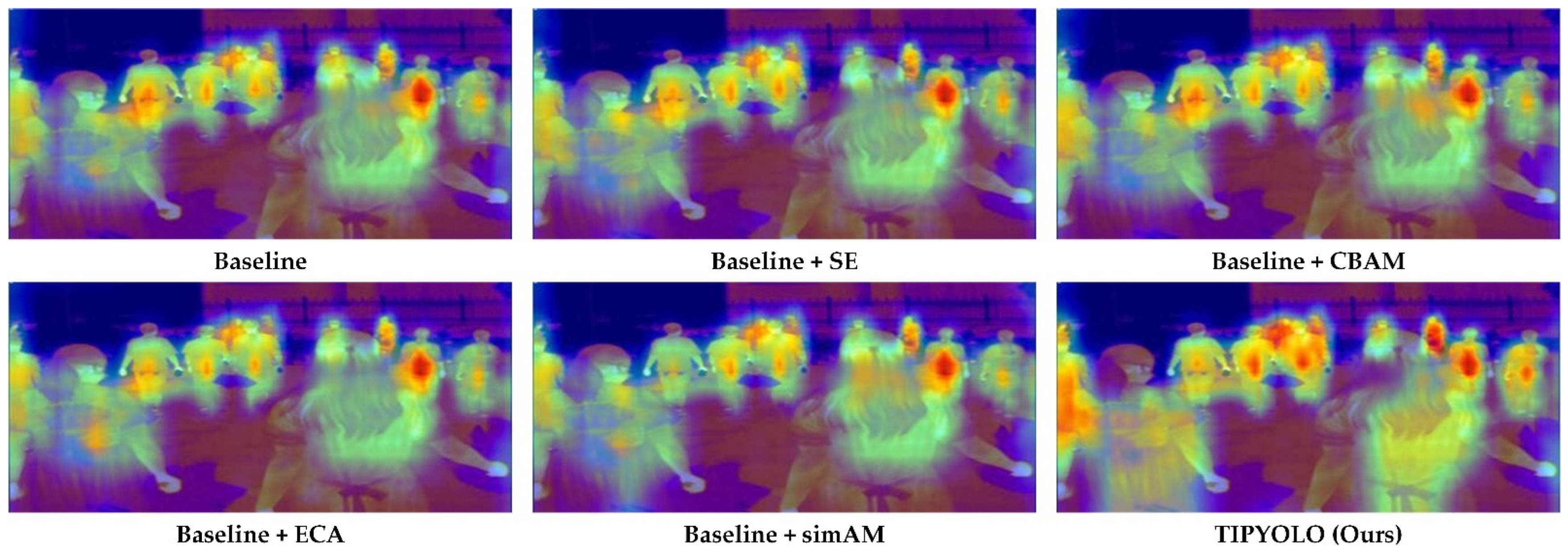{kind=link}
{kind=link}
{kind=link}
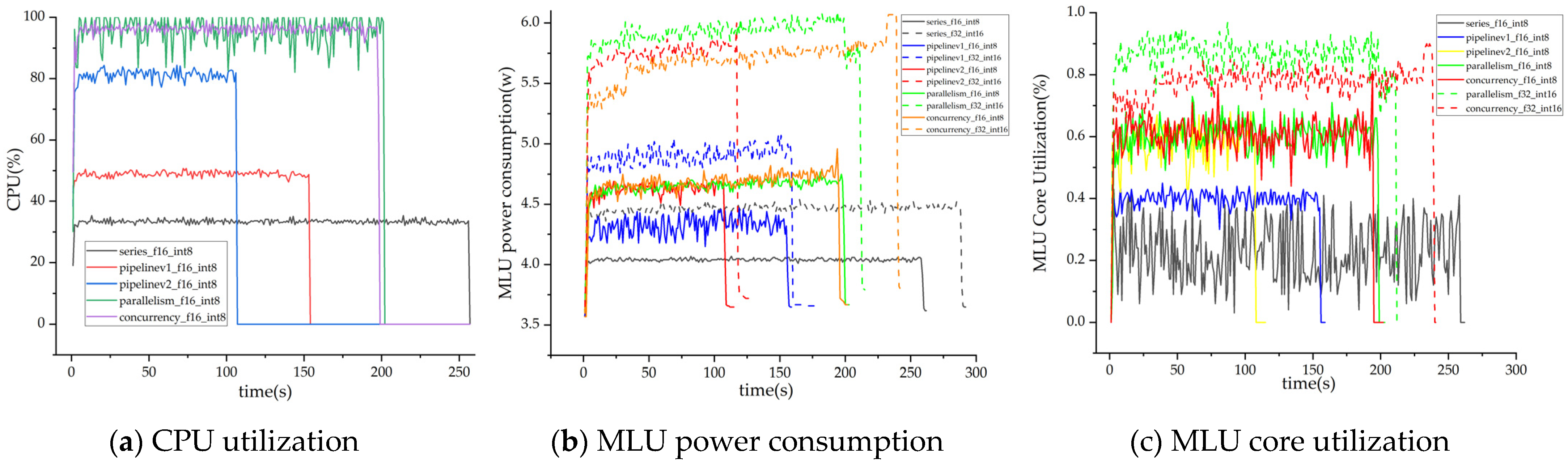{kind=link}
| Size | AP ↑ | AP50 ↑ | AP75 ↑ | APS ↑ | APM ↑ | APL ↑ |
|---|---|---|---|---|---|---|
| 640 × 640 | 0.701 | 0.959 | 0.785 | 0.413 | 0.722 | 0.869 |
| 416 × 416 | 0.654 | 0.950 | 0.721 | 0.494 | 0.773 | 0.895 |
| 416 × 192 | 0.657 | 0.951 | 0.726 | 0.501 | 0.772 | 0.895 |
| Method | Operators | Parameters | AP ↑ | AP50 ↑ | AP75 ↑ | APS ↑ | APM ↑ | APL ↑ |
|---|---|---|---|---|---|---|---|---|
| Baseline | - | - | 0.657 | 0.951 | 0.726 | 0.501 | 0.772 | 0.895 |
| + SE | GAP, FC, ReLU | 0.659 | 0.951 | 0.733 | 0.505 | 0.774 | 0.891 | |
| + CBAM | GAP, GMP, FC, ReLU, CAP, CMP, BN, C2D | 0.659 | 0.950 | 0.727 | 0.500 | 0.776 | 0.900 | |
| + ECA | GAP, C1D | 0.661 | 0.949 | 0.734 | 0.504 | 0.775 | 0.902 | |
| + simAM | , + | 0 | 0.659 | 0.951 | 0.731 | 0.502 | 0.776 | 0.893 |
| + Mosaic | - | 0 | 0.663 | 0.950 | 0.736 | 0.509 | 0.775 | 0.886 |
| + Multi-scale mosaic | - | 0 | 0.664 | 0.951 | 0.738 | 0.505 | 0.779 | 0.903 |
| + Multi-scale mosaic + simAM | , + | 0 | 0.663 | 0.951 | 0.736 | 0.509 | 0.778 | 0.897 |
| Method | Size | Parameters | AP ↑ | AP50 ↑ | AP75 ↑ | APS ↑ | APM ↑ | APL ↑ | MR−2 ↓ | FPS ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [48] | 416 × 416 | 157.75 M | 0.678 | 0.949 | 0.760 | 0.549 | 0.776 | 0.851 | 0.146 | 22.2 |
| Yolov4-tiny [25] | 416 × 416 | 22.57 M | 0.566 | 0.924 | 0.614 | 0.417 | 0.683 | 0.724 | 0.206 | 160.3 |
| Yolov4 [17] | 416 × 416 | 243.9 M | 0.645 | 0.952 | 0.724 | 0.51 | 0.747 | 0.806 | 0.146 | 41.2 |
| Yolov3 [51] | 416 × 416 | 234.69 M | 0.611 | 0.953 | 0.68 | 0.476 | 0.714 | 0.801 | 0.145 | 54.4 |
| Yolov4-lite [23] | 416 × 416 | 46.79 M | 0.576 | 0.939 | 0.629 | 0.434 | 0.678 | 0.755 | 0.193 | 56.1 |
| SSD [18] | 416 × 416 | 90.58 M | 0.573 | 0.917 | 0.613 | 0.405 | 0.693 | 0.734 | 0.275 | 63.1 |
| EfficientDet-D0 [26] | 512 × 512 | 14.6 M | 0.559 | 0.891 | 0.614 | 0.413 | 0.671 | 0.808 | 0.319 | 25.5 |
| Yolov5-S [27] | 416 × 416 | 26.95 M | 0.543 | 0.9 | 0.572 | 0.369 | 0.676 | 0.793 | 0.267 | 79.7 |
| Yolox-S [30] | 416 × 416 | 34.09 M | 0.654 | 0.95 | 0.721 | 0.494 | 0.773 | 0.895 | 0.153 | 76.6 |
| TIPYOLO (ours) | 416 × 192 | 34.09 M | 0.663 | 0.951 | 0.736 | 0.509 | 0.778 | 0.897 | 0.156 | 75.0 |
| Method | Size | Parameters | AP ↑ | AP50 ↑ | AP75 ↑ | APS ↑ | APM ↑ | APL ↑ | MR−2 ↓ | FPS ↑ |
|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [48] | 320 × 256 | 157.75 M | 0.539 | 0.884 | 0.588 | 0.452 | 0.673 | 0.733 | 0.27 | 19.6 |
| Yolov4-tiny [25] | 320 × 256 | 22.57 M | 0.352 | 0.677 | 0.346 | 0.222 | 0.573 | 0.651 | 0.447 | 162.5 |
| Yolov4 [17] | 320 × 256 | 243.9 M | 0.439 | 0.845 | 0.403 | 0.343 | 0.59 | 0.658 | 0.286 | 46.8 |
| Yolov3 [51] | 320 × 256 | 234.69 M | 0.42 | 0.842 | 0.375 | 0.322 | 0.574 | 0.669 | 0.296 | 65.8 |
| Yolov4-lite [23] | 320 × 256 | 46.79 M | 0.36 | 0.757 | 0.306 | 0.239 | 0.533 | 0.662 | 0.422 | 57.5 |
| SSD [18] | 320 × 320 | 90.58 M | 0.395 | 0.757 | 0.345 | 0.293 | 0.547 | 0.662 | 0.417 | 85.5 |
| EfficientDet-D0 [26] | 512 × 512 | 14.6 M | 0.366 | 0.676 | 0.357 | 0.278 | 0.528 | 0.59 | 0.537 | 25.9 |
| Yolov5-S [27] | 320 × 256 | 26.95 M | 0.401 | 0.756 | 0.38 | 0.299 | 0.586 | 0.67 | 0.46 | 78.3 |
| Yolox-S [30] | 320 × 256 | 34.09 M | 0.47 | 0.837 | 0.472 | 0.35 | 0.646 | 0.788 | 0.32 | 75.0 |
| TIPYOLO (ours) | 320 × 256 | 34.09 M | 0.484 | 0.848 | 0.481 | 0.369 | 0.65 | 0.78 | 0.298 | 70.6 |
| Method | AP ↑ | AP50 ↑ | AP75 ↑ | APS ↑ | APM ↑ | APL ↑ | MR−2 ↓ |
|---|---|---|---|---|---|---|---|
| Faster R-CNN [48] | 0.73/0.641 | 0.954/0.967 | 0.843/0.756 | 0.669/0.512 | 0.698/0.666 | 0.86/0.744 | 0.078/0.101 |
| Yolov4-tiny [25] | 0.464/0.45 | 0.92/0.83 | 0.395/0.448 | 0.296/0.267 | 0.439/0.566 | 0.617/0.633 | 0.217/0.298 |
| Yolov4 [17] | 0.543/0.563 | 0.963/0.972 | 0.565/0.605 | 0.417/0.45 | 0.536/0.587 | 0.666/0.655 | 0.063/0.097 |
| Yolov3 [51] | 0.591/0.567 | 0.971/0.969 | 0.663/0.619 | 0.437/0.457 | 0.58/0.592 | 0.706/0.662 | 0.058/0.111 |
| Yolov4-lite [23] | 0.529/0.526 | 0.957/0.954 | 0.514/0.543 | 0.385/0.366 | 0.499/0.563 | 0.662/0.624 | 0.103/0.148 |
| SSD [18] | 0.631/0.545 | 0.957/0.939 | 0.719/0.566 | 0.463/0.405 | 0.608/0.582 | 0.789/0.620 | 0.101/0.215 |
| EfficientDet-D0 [26] | 0.366/0.403 | 0.799/0.786 | 0.265/0.362 | 0.21/0.161 | 0.347/0.468 | 0.51/0.605 | 0.49/0.483 |
| Yolov5-S [27] | 0.323/0.51 | 0.728/0.911 | 0.21/0.512 | 0.169/0.322 | 0.311/0.553 | 0.455/0.662 | 0.538/0.283 |
| Yolox-S [30] | 0.595/0.552 | 0.924/0.92 | 0.655/0.599 | 0.389/0.391 | 0.646/0.636 | 0.806/0.747 | 0.162/0.206 |
| TIPYOLO(Ours) | 0.695/0.614 | 0.974/0.967 | 0.808/0.712 | 0.537/0.461 | 0.676/0.647 | 0.825/0.727 | 0.05/0.112 |
| Strategy | AP ↑ | AP50 ↑ | AP75 ↑ | APS ↑ | APM ↑ | APL ↑ | MR−2 ↓ |
|---|---|---|---|---|---|---|---|
| unquantified | 0.663 | 0.951 | 0.736 | 0.509 | 0.778 | 0.897 | 0.156 |
| (float32, float16) to (int16, int16) | 0.670 | 0.951 | 0.749 | 0.519 | 0.782 | 0.896 | 0.156 |
| (float32, float16) to (int8, int8) | 0.664 | 0.950 | 0.745 | 0.514 | 0.774 | 0.888 | 0.158 |
| (float32, float32) to (int16, int16) | 0.670 | 0.952 | 0.749 | 0.519 | 0.782 | 0.897 | 0.156 |
| (float32, float32) to(int8, int8) | 0.662 | 0.952 | 0.741 | 0.514 | 0.771 | 0.888 | 0.152 |
| Strategy | a | b | c | d | e | |
|---|---|---|---|---|---|---|
| (float32, float16) to (int16, int16) | 19.6 | 34.7 | 48.5 | 26.3 | 26.1 | 49.3 |
| (float32, float16) to (int8, int8) | 20.9 | 35.4 | 51.2 | 26.6 | 26.5 | 53.4 |
| (float32, float32) to (int16, int16) | 18.8 | 34.0 | 45.1 | 26.0 | 25.2 | 44.5 |
| (float32, float32) to (int8, int8) | 19.2 | 34.2 | 47.0 | 26.2 | 26.0 | 46.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, S.; Ji, Y.; Liu, S.; Mei, C.; Yao, X.; Feng, Y. A Thermal Infrared Pedestrian-Detection Method for Edge Computing Devices. Sensors 2022, 22, 6710. https://doi.org/10.3390/s22176710
You S, Ji Y, Liu S, Mei C, Yao X, Feng Y. A Thermal Infrared Pedestrian-Detection Method for Edge Computing Devices. Sensors. 2022; 22(17):6710. https://doi.org/10.3390/s22176710
Chicago/Turabian StyleYou, Shuai, Yimu Ji, Shangdong Liu, Chaojun Mei, Xiaoliang Yao, and Yujian Feng. 2022. "A Thermal Infrared Pedestrian-Detection Method for Edge Computing Devices" Sensors 22, no. 17: 6710. https://doi.org/10.3390/s22176710
APA StyleYou, S., Ji, Y., Liu, S., Mei, C., Yao, X., & Feng, Y. (2022). A Thermal Infrared Pedestrian-Detection Method for Edge Computing Devices. Sensors, 22(17), 6710. https://doi.org/10.3390/s22176710