


Multi-Level Cycle-Consistent Adversarial Networks with Attention Mechanism for Face Sketch-Photo Synthesis
Abstract
:1. Introduction
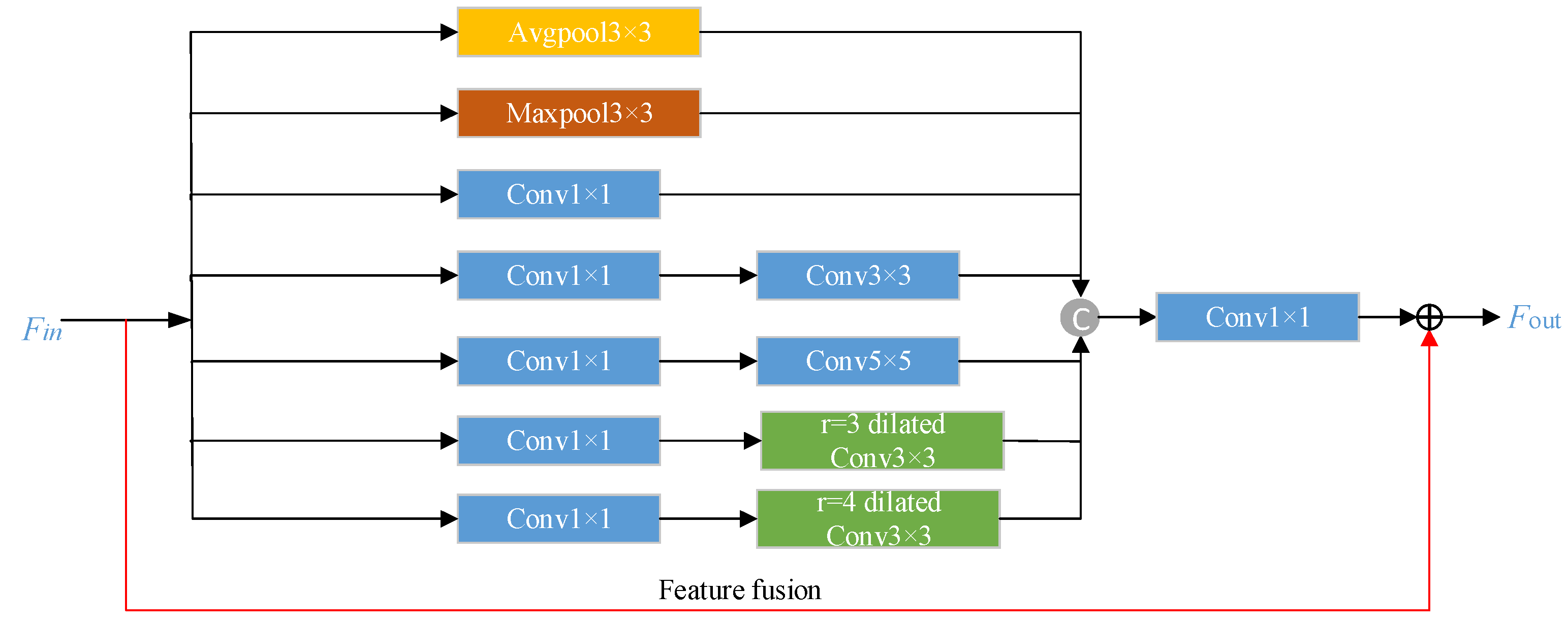
- Considering that sketches contain texture feature information of different scales, we add MFEM before the generator, enabling the network to extract multi-scale feature information.
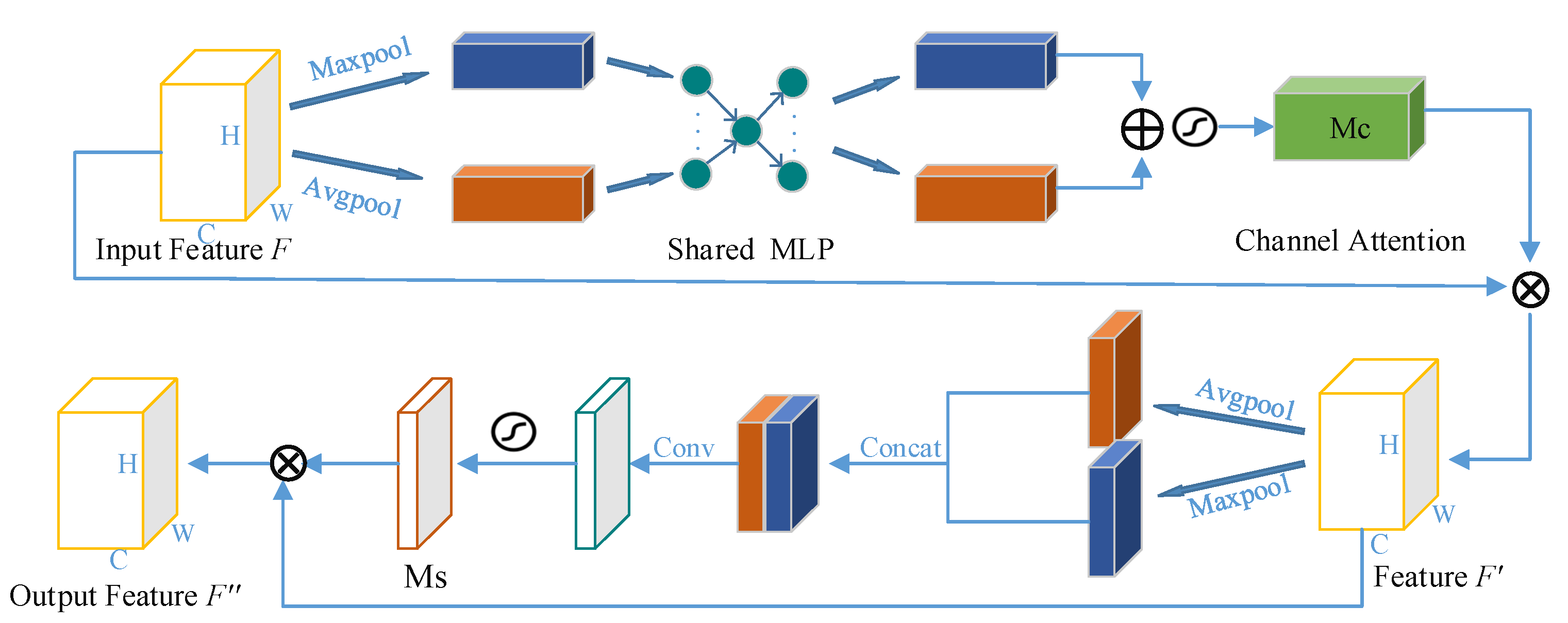
- We add CBAM to the residual block of the generator to improve the ability of the model to extract important feature information for better synthetic results.
- Based on the CycleGAN method, we construct multi-level cycle consistency loss to preserve the key facial features. Experimental results show that the photos synthesized by our method are more real and clear.
2. Related Work
2.1. Face Photo—Sketch Synthesis
2.2. Attention Mechanism
3. Proposed Method
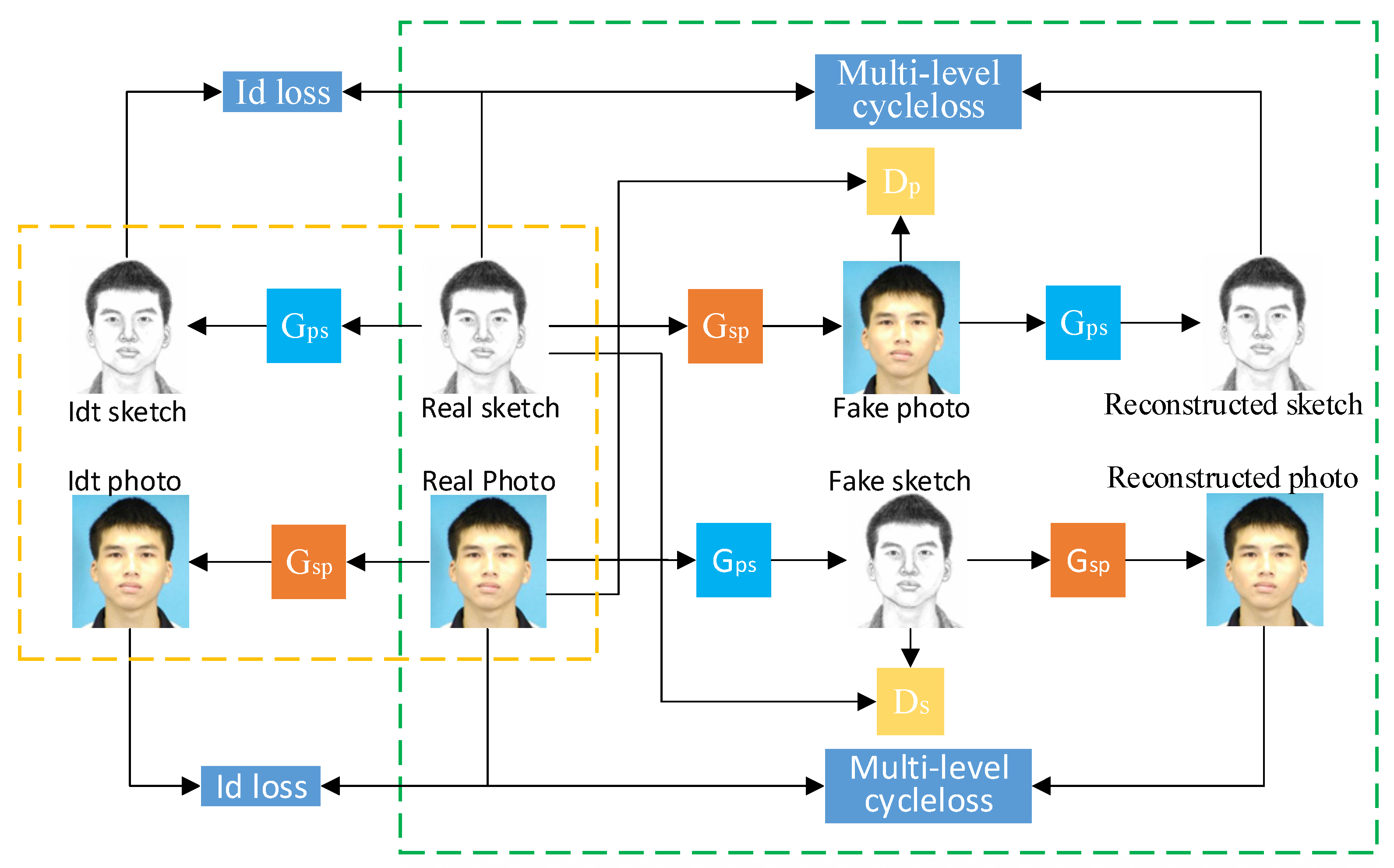
3.1. Framework
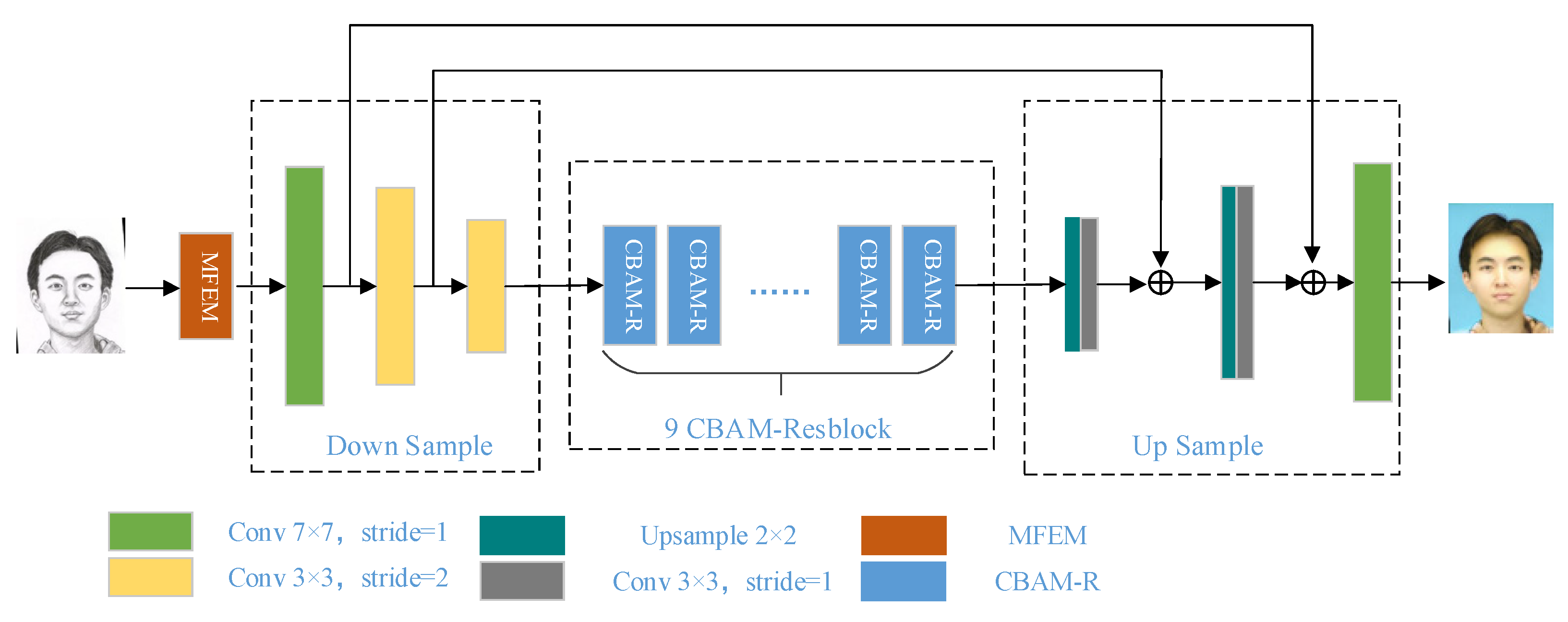
3.2. Network Structure
3.2.1. Generator Network Structure
3.2.2. Multi-Scale Feature Extraction Module
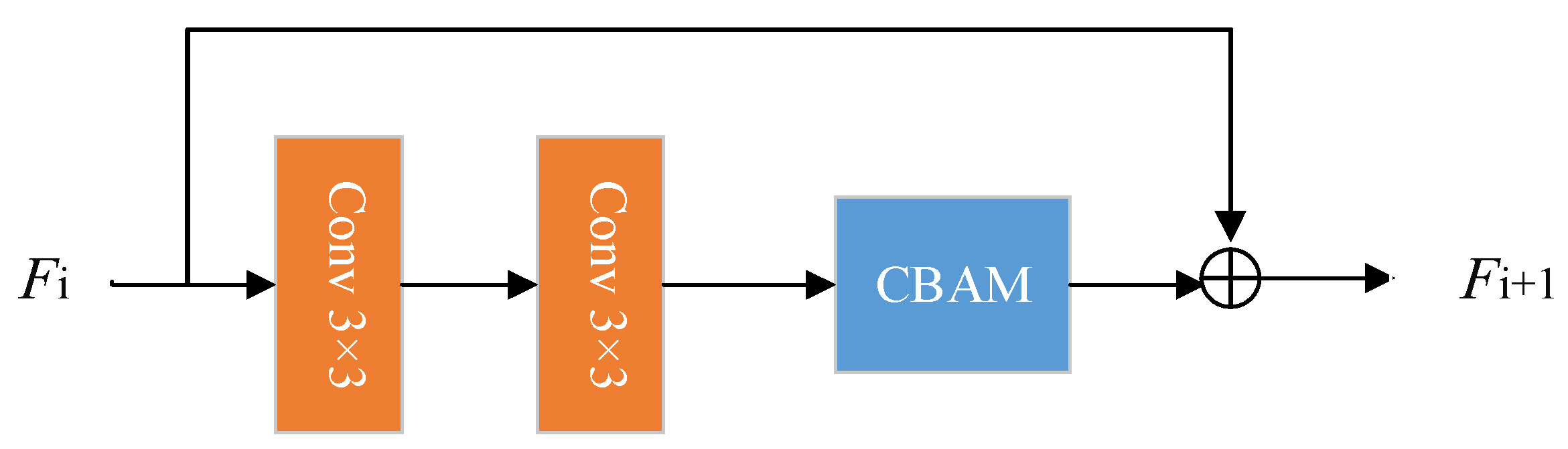
3.2.3. Convolution Attention Residual Block
3.3. Loss Function
3.3.1. Adversarial Loss
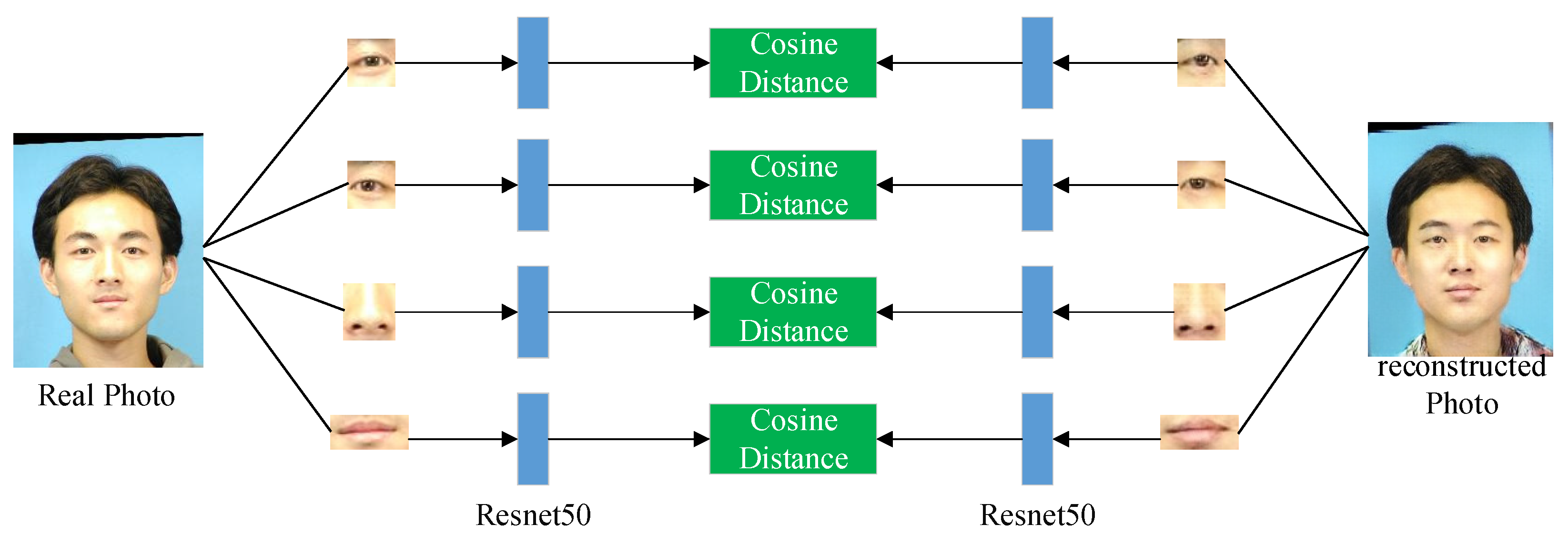
3.3.2. Identity Consistency Loss
3.3.3. Multi-Level Cycle Consistency Loss
4. Results
4.1. Datasets
4.2. Implementation Details
4.3. Comparative Analysis with Other Methods
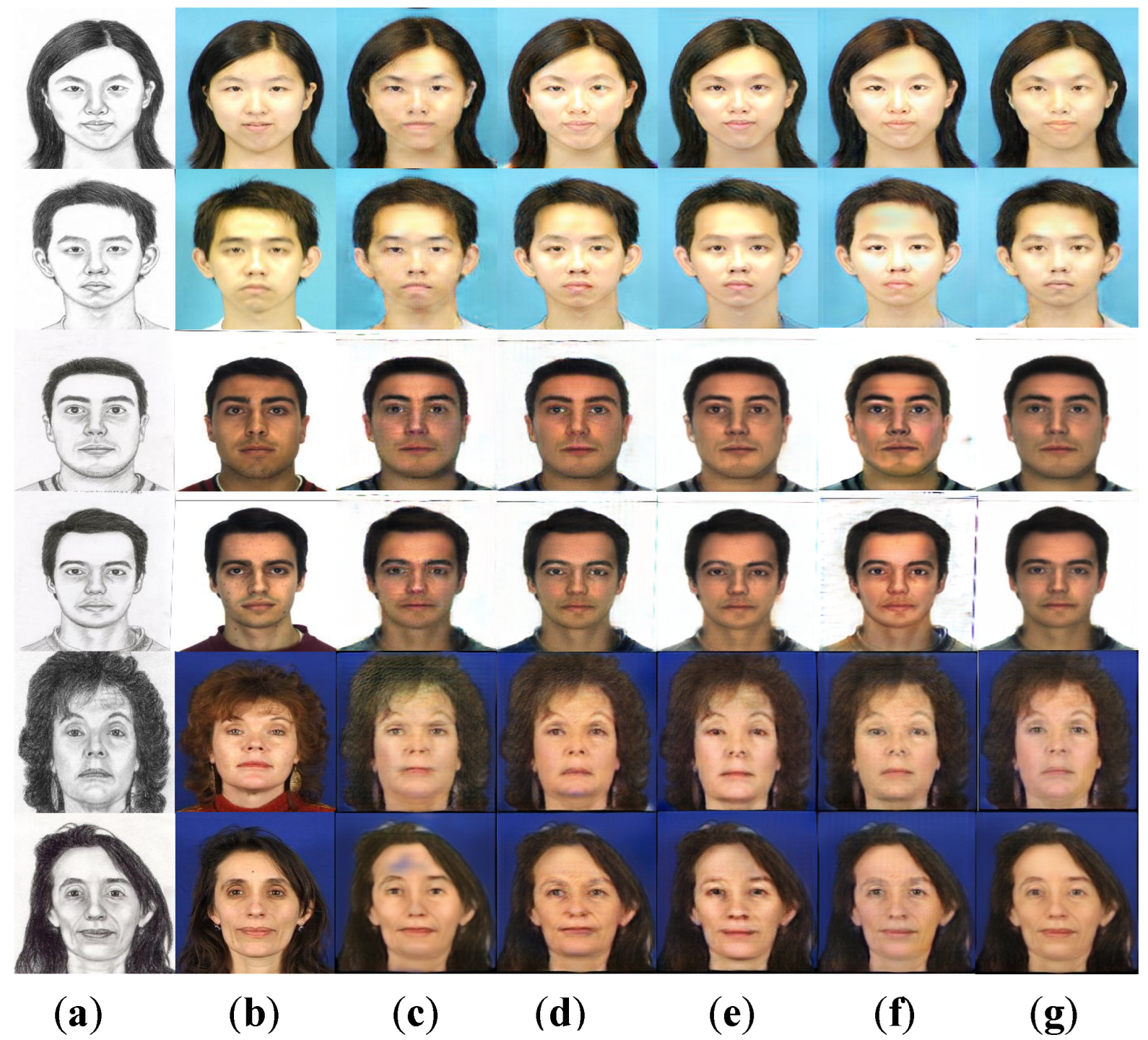
4.3.1. Qualitative Analysis
4.3.2. Quantitative Analysis
4.4. Ablation Experiment
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, N.; Gao, X.; Sun, L.; Li, J. Bayesian face sketch synthesis. IEEE Trans. Image Process. 2017, 26, 1264–1274. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Liu, Q.; Tang, X.; Jin, H.; Lu, H.; Ma, S. A nonlinear approach for face sketch synthesis and recognition. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 1005–1010. [Google Scholar]
- Wang, X.; Tang, X. Face photo-sketch synthesis and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 1955–1967. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Kuang, Z.; Wong, K.Y.K. Markov weight fields for face sketch synthesis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1091–1097. [Google Scholar]
- Zhang, S.; Gao, X.; Wang, N.; Li, J. Robust face sketch style synthesis. IEEE Trans. Image Process. 2015, 25, 220–232. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Lin, L.; Chen, T.; Wu, X.; Tan, W.; Izquierdo, E. Content-adaptive sketch portrait generation by decompositional representation learning. IEEE Trans. Image Process. 2016, 26, 328–339. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Wang, L.; Sindagi, V.; Patel, V. High-quality facial photo-sketch synthesis using multi-adversarial networks. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition, Xi’an, China, 15–19 May 2018; pp. 83–90. [Google Scholar]
- Fang, Y.; Deng, W.; Du, J.; Hu, J. Identity-aware CycleGAN for face photo-sketch synthesis and recognition. Pattern Recognit. 2020, 102, 107249. [Google Scholar] [CrossRef]
- Chao, W.; Chang, L.; Wang, X.; Cheng, J.; Deng, X.; Duan, F. High-fidelity face sketch-to-photo synthesis using generative adversarial network. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4699–4703. [Google Scholar]
- Zhu, M.; Li, J.; Wang, N.; Gao, X. A deep collaborative framework for face photo–sketch synthesis. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3096–3108. [Google Scholar] [CrossRef]
- Yu, J.; Xu, X.; Gao, F.; Shi, S.; Wang, M.; Tao, D.; Huang, Q. Toward Realistic Face Photo–Sketch Synthesis via Composition-Aided GANs. IEEE Trans. Cybern. 2020, 51, 4350–4362. [Google Scholar] [CrossRef] [PubMed]
- Yan, L.; Zheng, W.; Gou, C.; Wang, F.Y. IsGAN: Identity-sensitive generative adversarial network for face photo-sketch synthesis. Pattern Recognit. 2021, 119, 108077. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3146–3154. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Mao, X.D.; Li, Q.; Xie, H.R.; Lau, R.Y.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2813–2821. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Zhang, W.; Wang, X.; Tang, X. Coupled information-theoretic encoding for face photo-sketch recognition. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 20–25 June 2011; pp. 513–520. [Google Scholar]
- Liu, R.; Ge, Y.; Choi, C.L.; Wang, X.; Li, H. Divco: Diverse conditional image synthesis via contrastive generative adversarial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 10–17 March 2021; pp. 16377–16386. [Google Scholar]
- Xu, Y.; Xie, S.; Wu, W.; Zhang, K.; Gong, M.; Batmanghelich, K. Maximum Spatial Perturbation Consistency for Unpaired Image-to-Image Translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LO, USA, 19–23 June 2022; pp. 18311–18320. [Google Scholar]
- Martínez, A.; Benavente, R. The AR face database. Comput. Vis. Cent. 2007, 3, 5. [Google Scholar]
- Messer, K.; Matas, J.; Kittler, J.; Luettin, J.; Maitre, G. XM2VTSDB: The extended M2VTS database. In Proceedings of the Second International Conference on Audio and Video-Based Biometric Person Authentication, Washington, DC, USA, 22–24 March 1999; pp. 965–966. [Google Scholar]
- Phillips, P.J.; Wechsler, H.; Huang, J.; Rauss, P.J. The FERET database and evaluation procedure for face-recognition algorithms. Image Vis. Comput. 1998, 16, 295–306. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | CUHK | AR | XM2VATS | CUFSF |
|---|---|---|---|---|
| Training numbers | 100 | 80 | 100 | 200 |
| Testing numbers | 88 | 43 | 195 | 994 |
| Methods | CUHK | AR | XM2VTS | CUFSF |
|---|---|---|---|---|
| Pix2Pix | 0.647 | 0.676 | 0.548 | 0.529 |
| CycleGAN | 0.631 | 0.657 | 0.556 | 0.548 |
| PS2MAN | 0.653 | 0.689 | 0.562 | 0.583 |
| CA-GAN | 0.702 | 0.693 | 0.587 | 0.613 |
| DivCo | 0.657 | 0.635 | 0.590 | 0.547 |
| MSPC | 0.679 | 0.647 | 0.562 | 0.556 |
| Ours | 0.688 | 0.714 | 0.612 | 0.607 |
| Methods | CUHK | AR | XM2VTS | CUFSF |
|---|---|---|---|---|
| Pix2Pix | 16.588 | 17.212 | 18.233 | 16.436 |
| CycleGAN | 16.356 | 16.835 | 18.161 | 16.386 |
| PS2MAN | 17.688 | 17.032 | 18.483 | 16.695 |
| CA-GAN | 18.472 | 17.431 | 18.605 | 17.120 |
| DivCo | 16.836 | 17.223 | 18.602 | 16.431 |
| MSPC | 17.771 | 17.353 | 18.414 | 16.785 |
| Ours | 17.896 | 17.683 | 18.892 | 17.358 |
| Methods | CUHK | AR | XM2VTS | |||
|---|---|---|---|---|---|---|
| SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | |
| CycleGAN | 0.631 | 16.356 | 0.657 | 16.835 | 0.556 | 18.161 |
| CycleGAN w/MEFM | 0.647 | 16.751 | 0.679 | 17.235 | 0.568 | 18.327 |
| CycleGAN w/CBAM-R | 0.658 | 17.563 | 0.683 | 17.371 | 0.599 | 18.796 |
| CycleGAN w/Multilevel cycle loss | 0.663 | 17.458 | 0.696 | 16.897 | 0.593 | 18.463 |
| Ours | 0.688 | 17.896 | 0.714 | 17.683 | 0.612 | 18.892 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, D.; Yang, J.; Wei, Z. Multi-Level Cycle-Consistent Adversarial Networks with Attention Mechanism for Face Sketch-Photo Synthesis. Sensors 2022, 22, 6725. https://doi.org/10.3390/s22186725
Ren D, Yang J, Wei Z. Multi-Level Cycle-Consistent Adversarial Networks with Attention Mechanism for Face Sketch-Photo Synthesis. Sensors. 2022; 22(18):6725. https://doi.org/10.3390/s22186725
Chicago/Turabian StyleRen, Danping, Jiajun Yang, and Zhongcheng Wei. 2022. "Multi-Level Cycle-Consistent Adversarial Networks with Attention Mechanism for Face Sketch-Photo Synthesis" Sensors 22, no. 18: 6725. https://doi.org/10.3390/s22186725
APA StyleRen, D., Yang, J., & Wei, Z. (2022). Multi-Level Cycle-Consistent Adversarial Networks with Attention Mechanism for Face Sketch-Photo Synthesis. Sensors, 22(18), 6725. https://doi.org/10.3390/s22186725