




A Review of Multi-Modal Learning from the Text-Guided Visual Processing Viewpoint

 , , and
, , and
Abstract
:1. Introduction
- We comparatively analyze previous and new SOTA approaches over conventional evaluation criteria [11] and datasets by paying particular attention to the models missed by earlier studies.
- By critically examining different methodologies and their problem-solving approaches, we can set the stage for future research that can assist researchers in better understanding present limitations.
2. Foundation
2.1. Language and Vision AI
2.1.1. Language Models
2.1.2. Visual Models
2.2. Joint Representation
3. Text-Guided Visual-Output
4. Image (Static)
4.1. Energy-Based Models
4.2. Auto-Regressive Models
4.2.1. Generation
4.2.2. Manipulation
4.3. Variational Auto-Encoder (VAE)
4.4. Generative Adverserial Networks (GAN)
- First, we expand over the previous list by adding additional papers and categorizing them into the already given taxonomy.
- Second, we separate these models into generation or manipulation based on model input.
- Third, we not only consider the image as 2D but include studies beyond the 2D image, such as 3D images, stories, and videos.
4.4.1. Direct T2I
4.4.2. Supervised T2I
5. Story (Consistent)
5.1. GAN Model
5.2. Autoregressive Model
6. Video (Dynamic)
6.1. VAE Models
6.2. Auto-Regressive Models
6.2.1. Generation
6.2.2. Manipulation
6.3. GAN Models
6.3.1. Generation
6.3.2. Manipulation
7. Datasets
8. Evaluation Metrics and Comparisons
8.1. Automatic
8.1.1. T2I
8.1.2. T2S and T2V
8.2. Human Evaluation
9. Applications
Open-Source Tools
- Pytorch, TensorFlow, Keras, and Scikit-learn; for DL and ML;
- NumPy; for data analysis and high-performance scientific computing;
- OpenCV; for computer vision;
- NLTK, spaCy; for Natural Language Processing (NLP);
- SciPy; for advanced computing;
- Pandas; for general-purpose data analysis;
- Seaborn; for data visualization.
- Kaggle (https://www.kaggle.com, accessed on 30 May 2022);
- Google Dataset Search (https://datasetsearch.research.google.com, accessed on 30 May 2022);
- UCI Machine Learning Repository (https://archive.ics.uci.edu/ml/index.php, accessed on 30 May 2022);
- OpenML (https://www.openml.org, accessed on 30 May 2022);
- DataHub (https://datahubproject.io, accessed on 30 May 2022);
- Papers with Code (https://paperswithcode.com, accessed on 30 May 2022);
- VisualData (https://visualdata.io, accessed on 30 May 2022).
10. Existing Challenges
10.1. Data Limitations
10.2. High-Dimensionality
10.3. Framework Limitations
10.4. Misleading Evaluation
11. Discussion and Future Directions
11.1. Visual Tasks
11.2. Generative Models
11.3. Cross-Modal Datasets
11.4. Evaluation Techniques
- Evaluate the correctness between the image and caption;
- Evaluate the presence of defined objects in the image;
- Clarify the difference between the foreground and background;
- Evaluate the overall consistency between previous output and successive caption;
- Evaluate the consistency between the frames considering the spatio-temporal dynamics inherent in videos [415].
12. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kosslyn, S.M.; Ganis, G.; Thompson, W.L. Neural foundations of imagery. Nat. Rev. Neurosci. 2001, 2, 635–642. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Goldberg, A.; Eldawy, M.; Dyer, C.; Strock, B. A Text-to-Picture Synthesis System for Augmenting Communication; AAAI Press: Vancouver, BC, Canada, 2007; p. 1590. ISBN 9781577353232. [Google Scholar]
- Srivastava, N.; Salakhutdinov, R.R. Multimodal Learning with Deep Boltzmann Machines. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Mansimov, E.; Parisotto, E.; Ba, J.L.; Salakhutdinov, R. Generating Images from Captions with Attention. arXiv 2016, arXiv:1511.02793. [Google Scholar]
- Gregor, K.; Danihelka, I.; Graves, A.; Rezende, D.J.; Wierstra, D. DRAW: A Recurrent Neural Network For Image Generation. arXiv 2015, arXiv:1502.04623. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative Adversarial Text to Image Synthesis. arXiv 2016, arXiv:1605.05396. [Google Scholar]
- Wu, X.; Xu, K.; Hall, P. A Survey of Image Synthesis and Editing with Generative Adversarial Networks. Tsinghua Sci. Technol. 2017, 22, 660–674. [Google Scholar] [CrossRef]
- Huang, H.; Yu, P.S.; Wang, C. An Introduction to Image Synthesis with Generative Adversarial Nets. arXiv 2018, arXiv:1803.04469. [Google Scholar]
- Agnese, J.; Herrera, J.; Tao, H.; Zhu, X. A Survey and Taxonomy of Adversarial Neural Networks for Text-to-Image Synthesis. arXiv 2019, arXiv:1910.09399. [Google Scholar] [CrossRef]
- Frolov, S.; Hinz, T.; Raue, F.; Hees, J.; Dengel, A. Adversarial Text-to-Image Synthesis: A Review. arXiv 2021, arXiv:2101.09983. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- A Survey on Deep Multimodal Learning for Computer Vision: Advances, Trends, APPLICATIONS, and Datasets; Springer: Berlin/Heidelberg, Germany, 2021.
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal Machine Learning: A Survey and Taxonomy. arXiv 2017, arXiv:1705.09406. [Google Scholar] [CrossRef] [PubMed]
- Jurafsky, D.; Martin, J.H.; Kehler, A.; Linden, K.V.; Ward, N. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics and Speech Recognition; Amazon.com: Bellevue, WA, USA, 1999; ISBN 9780130950697. [Google Scholar]
- Weizenbaum, J. ELIZA—A computer program for the study of natural language communication between man and machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Khan, W.; Daud, A.; Nasir, J.A.; Amjad, T. A survey on the state-of-the-art machine learning models in the context of NLP. Kuwait J. Sci. 2016, 43, 95–113. [Google Scholar]
- Torfi, A.; Shirvani, R.A.; Keneshloo, Y.; Tavaf, N.; Fox, E.A. Natural Language Processing Advancements By Deep Learning: A Survey. arXiv 2020, arXiv:2003.01200. [Google Scholar]
- Krallinger, M.; Leitner, F.; Valencia, A. Analysis of Biological Processes and Diseases Using Text Mining Approaches. In Bioinformatics Methods in Clinical Research; Matthiesen, R., Ed.; Methods in Molecular Biology; Humana Press: Totowa, NJ, USA, 2010; pp. 341–382. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Hinton, G. Generating text with recurrent neural networks. In Proceedings of the 28th International Conference on International Conference on Machine Learning, ICML’11, Bellevue, WA, USA, 28 June–2 July 2011; Omnipress: Madison, WI, USA, 2011; pp. 1017–1024. [Google Scholar]
- Socher, R.; Lin, C.C.Y.; Ng, A.Y.; Manning, C.D. Parsing natural scenes and natural language with recursive neural networks. In Proceedings of the 28th International Conference on International Conference on Machine Learning, ICML’11, Bellevue, WA, USA, 28 June–2 July 2011; Omnipress: Madison, WI, USA, 2011; pp. 129–136, ISBN 9781450306195. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. arXiv 2014, arXiv:1405.4053. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level Convolutional Networks for Text Classification. In Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28, Available online: https://proceedings.neurips.cc/paper/2015/file/250cf8b51c773f3f8dc8b4be867a9a02-Paper.pdf (accessed on 30 May 2022).
- Harris, Z.S. Distributional Structure. WORD 1954, 10, 146–162. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Guy, L. Riemannian Geometry and Statistical Machine Learning; Illustrated, Ed.; Carnegie Mellon University: Pittsburgh, PA, USA, 2015; ISBN 978-0-496-93472-0. [Google Scholar]
- Leskovec, J.; Rajaraman, A.; Ullman, J.D. Mining of Massive Datasets, 2nd ed.; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. arXiv 2017, arXiv:1607.04606. [Google Scholar] [CrossRef]
- Zeng, G.; Li, Z.; Zhang, Y. Pororogan: An improved story visualization model on pororo-sv dataset. In Proceedings of the 2019 3rd International Conference on Computer Science and Artificial Intelligence, Normal, IL, USA, 6–8 December 2019; pp. 155–159. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D. StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks. arXiv 2017, arXiv:1612.03242. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D. StackGAN++: Realistic Image Synthesis with Stacked Generative Adversarial Networks. arXiv 2018, arXiv:1710.10916. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks. arXiv 2017, arXiv:1711.10485. [Google Scholar]
- Rumelhart, D.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Fukushima, K. Neocognitron. Scholarpedia 2007, 2, 1717. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Kalchbrenner, N.; Espeholt, L.; Simonyan, K.; Oord, A.v.d.; Graves, A.; Kavukcuoglu, K. Neural Machine Translation in Linear Time. arXiv 2017, arXiv:1610.10099. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional Sequence to Sequence Learning. arXiv 2017, arXiv:1705.03122. [Google Scholar]
- Reed, S.; Akata, Z.; Schiele, B.; Lee, H. Learning Deep Representations of Fine-grained Visual Descriptions. arXiv 2016, arXiv:1605.05395. [Google Scholar]
- Tang, G.; Müller, M.; Rios, A.; Sennrich, R. Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures. arXiv 2018, arXiv:1808.08946. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; Technical Report; OpenAI: San Francisco, CA, USA, 2018; p. 12. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners; OpenAI: San Francisco, CA, USA, 2019; Volume 1, p. 24. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Bengio, S.; Vinyals, O.; Jaitly, N.; Shazeer, N. Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks. arXiv 2015, arXiv:1506.03099. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; Association for Computational Linguistics: Ann Arbor, MI, USA, 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Keneshloo, Y.; Shi, T.; Ramakrishnan, N.; Reddy, C.K. Deep Reinforcement Learning For Sequence to Sequence Models. arXiv 2018, arXiv:1805.09461. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; Adaptive Computation and Machine Learning Series; A Bradford Book: Cambridge, MA, USA, 2018. [Google Scholar]
- Watkins, C.J.C.H.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Zaremba, W.; Sutskever, I. Reinforcement Learning Neural Turing Machines. arXiv 2015, arXiv:1505.00521. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Daumé, H.; Langford, J.; Marcu, D. Search-based Structured Prediction. arXiv 2009, arXiv:0907.0786. [Google Scholar] [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed]
- Neha, S.; Vibhor, J.; Anju, M. An Analysis of Convolutional Neural Networks for Image Classification—ScienceDirect. Procedia Comput. Sci. 2018, 132, 377–384. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Nasr Esfahani, S.; Latifi, S. Image Generation with Gans-based Techniques: A Survey. Int. J. Comput. Sci. Inf. Technol. 2019, 11, 33–50. [Google Scholar] [CrossRef]
- Li, Z.; Yang, W.; Peng, S.; Liu, F. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. arXiv 2020, arXiv:2004.02806. [Google Scholar] [CrossRef] [PubMed]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. arXiv 2015, arXiv:1512.00567. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2017, arXiv:1605.07146. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in Resnet: Generalizing Residual Architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. arXiv 2017, arXiv:1610.02357. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with Noisy Student improves ImageNet classification. arXiv 2020, arXiv:1911.04252. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules. arXiv 2017, arXiv:1710.09829. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A Survey of the Recent Architectures of Deep Convolutional Neural Networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar] [CrossRef]
- Wu, Y.N.; Gao, R.; Han, T.; Zhu, S.C. A Tale of Three Probabilistic Families: Discriminative, Descriptive and Generative Models. arXiv 2018, arXiv:1810.04261. [Google Scholar] [CrossRef]
- Goodfellow, I. NIPS 2016 Tutorial: Generative Adversarial Networks. arXiv 2017, arXiv:1701.00160. [Google Scholar]
- Oussidi, A.; Elhassouny, A. Deep generative models: Survey. In Proceedings of the 2018 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 2–4 April 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Fahlman, S.; Hinton, G.E.; Sejnowski, T. Massively Parallel Architectures for AI: NETL, Thistle, and Boltzmann Machines; AAAI: Washington, DC, USA, 1983; pp. 109–113. [Google Scholar]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; McClelland, J.L. Information Processing in Dynamical Systems: Foundations of Harmony Theory. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Foundations; MIT Press: Cambridge, MA, USA, 1987; pp. 194–281. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Salakhutdinov, R.; Hinton, G. Deep Boltzmann Machines. In Proceedings of the Twelth International Conference on Artificial Intelligence and Statistics, Hilton Clearwater Beach Resort, Clearwater Beach, FL, USA, 16–18 April 2009; Volume 5. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Ballard, D.H. Modular Learning in Neural Networks; AAAI Press: Seattle, WA, USA, 1987; pp. 279–284. [Google Scholar]
- Bayoudh, K.; Knani, R.; Hamdaoui, F.; Abdellatif, M. A survey on deep multimodal learning for computer vision: Advances, trends, applications, and datasets. Vis. Comput. 2022, 38, 5–7. [Google Scholar] [CrossRef] [PubMed]
- Xing, E.P.; Yan, R.; Hauptmann, A.G. Mining Associated Text and Images with Dual-Wing Harmoniums. arXiv 2012, arXiv:1207.1423. [Google Scholar]
- Srivastava, N.; Salakhutdinov, R. Multimodal Learning with Deep Boltzmann Machines. J. Mach. Learn. Res. 2014, 15, 2949–2980. [Google Scholar]
- Zitnick, C.L.; Parikh, D.; Vanderwende, L. Learning the Visual Interpretation of Sentences. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 1681–1688. [Google Scholar] [CrossRef]
- Sohn, K.; Shang, W.; Lee, H. Improved Multimodal Deep Learning with Variation of Information. In Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Oord, A.V.D.; Kalchbrenner, N.; Vinyals, O.; Espeholt, L.; Graves, A.; Kavukcuoglu, K. Conditional Image Generation with PixelCNN Decoders. arXiv 2016, arXiv:1606.05328. [Google Scholar]
- Reed, S. Generating Interpretable Images with Controllable Structure. 2017, p. 13. Available online: https://openreview.net/forum?id=Hyvw0L9el (accessed on 30 May 2022).
- Reed, S.; Oord, A.V.D.; Kalchbrenner, N.; Colmenarejo, S.G.; Wang, Z.; Belov, D.; de Freitas, N. Parallel Multiscale Autoregressive Density Estimation. arXiv 2017, arXiv:1703.03664. [Google Scholar]
- Kim, J.H.; Kitaev, N.; Chen, X.; Rohrbach, M.; Zhang, B.T.; Tian, Y.; Batra, D.; Parikh, D. CoDraw: Collaborative drawing as a testbed for grounded goal-driven communication. arXiv 2017, arXiv:1712.05558. [Google Scholar]
- Tan, F.; Feng, S.; Ordonez, V. Text2Scene: Generating Compositional Scenes from Textual Descriptions. arXiv 2019, arXiv:1809.01110. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-Shot Text-to-Image Generation. arXiv 2021, arXiv:2102.12092. [Google Scholar]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating Long Sequences with Sparse Transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Ding, M.; Yang, Z.; Hong, W.; Zheng, W.; Zhou, C.; Yin, D.; Lin, J.; Zou, X.; Shao, Z.; Yang, H.; et al. CogView: Mastering Text-to-Image Generation via Transformers. arXiv 2021, arXiv:2105.13290. [Google Scholar]
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 66–71. [Google Scholar] [CrossRef]
- Esser, P.; Rombach, R.; Blattmann, A.; Ommer, B. ImageBART: Bidirectional Context with Multinomial Diffusion for Autoregressive Image Synthesis. arXiv 2021, arXiv:2108.08827. [Google Scholar]
- Yuan, M.; Peng, Y. Text-to-image Synthesis via Symmetrical Distillation Networks. arXiv 2018, arXiv:1808.06801. [Google Scholar]
- Yuan, M.; Peng, Y. CKD: Cross-Task Knowledge Distillation for Text-to-Image Synthesis. IEEE Trans. Multimed. 2020, 22, 1955–1968. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge. arXiv 2016, arXiv:1609.06647. [Google Scholar] [CrossRef]
- Yan, X.; Yang, J.; Sohn, K.; Lee, H. Attribute2Image: Conditional Image Generation from Visual Attributes. arXiv 2016, arXiv:1512.00570. [Google Scholar]
- Zhang, C.; Peng, Y. Stacking VAE and GAN for Context-aware Text-to-Image Generation. In Proceedings of the 2018 IEEE Fourth International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Deng, Z.; Chen, J.; FU, Y.; Mori, G. Probabilistic Neural Programmed Networks for Scene Generation. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Andreas, J.; Rohrbach, M.; Darrell, T.; Klein, D. Deep Compositional Question Answering with Neural Module Networks. arXiv 2015, arXiv:1511.02799. [Google Scholar]
- Gu, S.; Chen, D.; Bao, J.; Wen, F.; Zhang, B.; Chen, D.; Yuan, L.; Guo, B. Vector Quantized Diffusion Model for Text-to-Image Synthesis. arXiv 2022, arXiv:2111.14822. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. arXiv 2020, arXiv:2006.11239. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis With Auxiliary Classifier GANs. arXiv 2017, arXiv:1610.09585. [Google Scholar]
- Dash, A.; Gamboa, J.C.B.; Ahmed, S.; Liwicki, M.; Afzal, M.Z. TAC-GAN - Text Conditioned Auxiliary Classifier Generative Adversarial Network. arXiv 2017, arXiv:1703.06412. [Google Scholar]
- Cha, M.; Gwon, Y.; Kung, H.T. Adversarial nets with perceptual losses for text-to-image synthesis. arXiv 2017, arXiv:1708.09321. [Google Scholar]
- Chen, K.; Choy, C.B.; Savva, M.; Chang, A.X.; Funkhouser, T.; Savarese, S. Text2Shape: Generating Shapes from Natural Language by Learning Joint Embeddings. arXiv 2018, arXiv:1803.08495. [Google Scholar]
- Fukamizu, K.; Kondo, M.; Sakamoto, R. Generation High resolution 3D model from natural language by Generative Adversarial Network. arXiv 2019, arXiv:1901.07165. [Google Scholar]
- Chen, Q.; Wu, Q.; Tang, R.; Wang, Y.; Wang, S.; Tan, M. Intelligent Home 3D: Automatic 3D-House Design From Linguistic Descriptions Only. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12625–12634. [Google Scholar] [CrossRef]
- Schuster, S.; Krishna, R.; Chang, A.; Fei-Fei, L.; Manning, C.D. Generating Semantically Precise Scene Graphs from Textual Descriptions for Improved Image Retrieval. In Proceedings of the Fourth Workshop on Vision and Language, Lisbon, Portugal, 18 September 2015; Association for Computational Linguistics: Lisbon, Portugal, 2015; pp. 70–80. [Google Scholar] [CrossRef]
- Tao, M.; Tang, H.; Wu, S.; Sebe, N.; Jing, X.Y.; Wu, F.; Bao, B. Df-gan: Deep fusion generative adversarial networks for text-to-image synthesis. arXiv 2020, arXiv:2008.05865. [Google Scholar]
- Bodla, N.; Hua, G.; Chellappa, R. Semi-supervised FusedGAN for Conditional Image Generation. arXiv 2018, arXiv:1801.05551. [Google Scholar]
- Zhang, Z.; Xie, Y.; Yang, L. Photographic Text-to-Image Synthesis with a Hierarchically-nested Adversarial Network. arXiv 2018, arXiv:1802.09178. [Google Scholar]
- Gao, L.; Chen, D.; Song, J.; Xu, X.; Zhang, D.; Shen, H.T. Perceptual Pyramid Adversarial Networks for Text-to-Image Synthesis. Proc. Aaai Conf. Artif. Intell. 2019, 33, 8312–8319. [Google Scholar] [CrossRef]
- Huang, X.; Wang, M.; Gong, M. Hierarchically-Fused Generative Adversarial Network for Text to Realistic Image Synthesis|IEEE Conference Publication|IEEE Xplore. In Proceedings of the 2019 16th Conference on Computer and Robot Vision (CRV), Kingston, QC, Canada, 29–31 May 2019; pp. 73–80. [Google Scholar] [CrossRef]
- Huang, W.; Xu, Y.; Oppermann, I. Realistic Image Generation using Region-phrase Attention. arXiv 2019, arXiv:1902.05395. [Google Scholar]
- Tan, H.; Liu, X.; Li, X.; Zhang, Y.; Yin, B. Semantics-enhanced adversarial nets for text-to-image synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10501–10510. [Google Scholar]
- Li, B.; Qi, X.; Lukasiewicz, T.; Torr, P.H.S. Controllable Text-to-Image Generation. arXiv 2019, arXiv:1909.07083. [Google Scholar]
- Mao, F.; Ma, B.; Chang, H.; Shan, S.; Chen, X. MS-GAN: Text to Image Synthesis with Attention-Modulated Generators and Similarity-Aware Discriminators. BMVC 2019, 150. Available online: https://bmvc2019.org/wp-content/uploads/papers/0413-paper.pdf (accessed on 30 May 2022).
- Li, L.; Sun, Y.; Hu, F.; Zhou, T.; Xi, X.; Ren, J. Text to Realistic Image Generation with Attentional Concatenation Generative Adversarial Networks. Discret. Dyn. Nat. Soc. 2020, 2020, 6452536. [Google Scholar] [CrossRef]
- Wang, Z.; Quan, Z.; Wang, Z.J.; Hu, X.; Chen, Y. Text to Image Synthesis with Bidirectional Generative Adversarial Network. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Liu, B.; Song, K.; Zhu, Y.; de Melo, G.; Elgammal, A. Time: Text and image mutual-translation adversarial networks. arXiv 2020, arXiv:2005.13192. [Google Scholar]
- Ruan, S.; Zhang, Y.; Zhang, K.; Fan, Y.; Tang, F.; Liu, Q.; Chen, E. Dae-gan: Dynamic aspect-aware gan for text-to-image synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 13960–13969. [Google Scholar]
- Cha, M.; Gwon, Y.L.; Kung, H.T. Adversarial Learning of Semantic Relevance in Text to Image Synthesis. arXiv 2019, arXiv:1812.05083. [Google Scholar] [CrossRef]
- Yin, G.; Liu, B.; Sheng, L.; Yu, N.; Wang, X.; Shao, J. Semantics Disentangling for Text-to-Image Generation. arXiv 2019, arXiv:1904.01480. [Google Scholar]
- Tan, H.; Liu, X.; Liu, M.; Yin, B.; Li, X. KT-GAN: Knowledge-transfer generative adversarial network for text-to-image synthesis. IEEE Trans. Image Process. 2020, 30, 1275–1290. [Google Scholar] [CrossRef] [PubMed]
- Mao, F.; Ma, B.; Chang, H.; Shan, S.; Chen, X. Learning efficient text-to-image synthesis via interstage cross-sample similarity distillation. Sci. China Inf. Sci. 2020, 64, 120102. [Google Scholar] [CrossRef]
- Nguyen, A.; Clune, J.; Bengio, Y.; Dosovitskiy, A.; Yosinski, J. Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space. arXiv 2017, arXiv:1612.00005. [Google Scholar]
- Dong, H.; Zhang, J.; McIlwraith, D.; Guo, Y. I2T2I: Learning Text to Image Synthesis with Textual Data Augmentation. arXiv 2017, arXiv:1703.06676. [Google Scholar]
- Qiao, T.; Zhang, J.; Xu, D.; Tao, D. MirrorGAN: Learning Text-to-image Generation by Redescription. arXiv 2019, arXiv:1903.05854. [Google Scholar]
- Chen, Z.; Luo, Y. Cycle-Consistent Diverse Image Synthesis from Natural Language. In Proceedings of the 2019 IEEE International Conference on Multimedia Expo Workshops (ICMEW), Shanghai, China, 8–12 July 2019; pp. 459–464. [Google Scholar] [CrossRef]
- Lao, Q.; Havaei, M.; Pesaranghader, A.; Dutil, F.; Di Jorio, L.; Fevens, T. Dual Adversarial Inference for Text-to-Image Synthesis. arXiv 2019, arXiv:1908.05324. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. DM-GAN: Dynamic Memory Generative Adversarial Networks for Text-to-Image Synthesis. arXiv 2019, arXiv:1904.01310. [Google Scholar]
- Miller, A.H.; Fisch, A.; Dodge, J.; Karimi, A.; Bordes, A.; Weston, J. Key-Value Memory Networks for Directly Reading Documents. arXiv 2016, arXiv:1606.03126. [Google Scholar]
- Liang, J.; Pei, W.; Lu, F. CPGAN: Full-Spectrum Content-Parsing Generative Adversarial Networks for Text-to-Image Synthesis. arXiv 2020, arXiv:1912.08562. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and VQA. arXiv 2017, arXiv:1707.07998. [Google Scholar]
- Ye, H.; Yang, X.; Takac, M.; Sunderraman, R.; Ji, S. Improving Text-to-Image Synthesis Using Contrastive Learning. arXiv 2021, arXiv:2107.02423. [Google Scholar]
- Zhang, H.; Koh, J.Y.; Baldridge, J.; Lee, H.; Yang, Y. Cross-Modal Contrastive Learning for Text-to-Image Generation. arXiv 2022, arXiv:2101.04702. [Google Scholar]
- Yuan, M.; Peng, Y. Bridge-GAN: Interpretable representation learning for text-to-image synthesis. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 4258–4268. [Google Scholar] [CrossRef]
- Souza, D.M.; Wehrmann, J.; Ruiz, D.D. Efficient Neural Architecture for Text-to-Image Synthesis. arXiv 2020, arXiv:2004.11437. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Stap, D.; Bleeker, M.; Ibrahimi, S.; ter Hoeve, M. Conditional Image Generation and Manipulation for User-Specified Content. arXiv 2020, arXiv:2005.04909. [Google Scholar]
- Zhang, Y.; Lu, H. Deep Cross-Modal Projection Learning for Image-Text Matching. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 707–723. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv 2018, arXiv:1812.04948. [Google Scholar]
- Rombach, R.; Esser, P.; Ommer, B. Network-to-network translation with conditional invertible neural networks. Adv. Neural Inf. Process. Syst. 2020, 33, 2784–2797. [Google Scholar]
- Liu, X.; Gong, C.; Wu, L.; Zhang, S.; Su, H.; Liu, Q. FuseDream: Training-Free Text-to-Image Generation with Improved CLIP+GAN Space Optimization. arXiv 2021, arXiv:2112.01573. [Google Scholar]
- Zhou, Y.; Zhang, R.; Chen, C.; Li, C.; Tensmeyer, C.; Yu, T.; Gu, J.; Xu, J.; Sun, T. LAFITE: Towards Language-Free Training for Text-to-Image Generation. arXiv 2022, arXiv:2111.13792. [Google Scholar]
- Zhang, P.; Li, X.; Hu, X.; Yang, J.; Zhang, L.; Wang, L.; Choi, Y.; Gao, J. VinVL: Making Visual Representations Matter in Vision-Language Models. arXiv 2021, arXiv:2101.00529. [Google Scholar]
- Joseph, K.J.; Pal, A.; Rajanala, S.; Balasubramanian, V.N. C4Synth: Cross-Caption Cycle-Consistent Text-to-Image Synthesis. arXiv 2018, arXiv:1809.10238. [Google Scholar]
- El, O.B.; Licht, O.; Yosephian, N. GILT: Generating Images from Long Text. arXiv 2019, arXiv:1901.02404. [Google Scholar]
- Wang, H.; Sahoo, D.; Liu, C.; Lim, E.; Hoi, S.C.H. Learning Cross-Modal Embeddings with Adversarial Networks for Cooking Recipes and Food Images. arXiv 2019, arXiv:1905.01273. [Google Scholar]
- Cheng, J.; Wu, F.; Tian, Y.; Wang, L.; Tao, D. RiFeGAN: Rich feature generation for text-to-image synthesis from prior knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 10911–10920. [Google Scholar]
- Yang, R.; Zhang, J.; Gao, X.; Ji, F.; Chen, H. Simple and Effective Text Matching with Richer Alignment Features. arXiv 2019, arXiv:1908.00300. [Google Scholar]
- Yang, Y.; Wang, L.; Xie, D.; Deng, C.; Tao, D. Multi-Sentence Auxiliary Adversarial Networks for Fine-Grained Text-to-Image Synthesis. IEEE Trans. Image Process. 2021, 30, 2798–2809. [Google Scholar] [CrossRef] [PubMed]
- Sharma, S.; Suhubdy, D.; Michalski, V.; Kahou, S.E.; Bengio, Y. ChatPainter: Improving Text to Image Generation using Dialogue. arXiv 2018, arXiv:1802.08216. [Google Scholar]
- El-Nouby, A.; Sharma, S.; Schulz, H.; Hjelm, D.; Asri, L.E.; Kahou, S.E.; Bengio, Y.; Taylor, G.W. Tell, draw, and repeat: Generating and modifying images based on continual linguistic instruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10304–10312. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Niu, T.; Feng, F.; Li, L.; Wang, X. Image Synthesis from Locally Related Texts. In Proceedings of the 2020 International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 145–153. [Google Scholar]
- Cheng, Y.; Gan, Z.; Li, Y.; Liu, J.; Gao, J. Sequential Attention GAN for Interactive Image Editing. arXiv 2020, arXiv:1812.08352. [Google Scholar]
- Frolov, S.; Jolly, S.; Hees, J.; Dengel, A. Leveraging Visual Question Answering to Improve Text-to-Image Synthesis. arXiv 2020, arXiv:2010.14953. [Google Scholar]
- Kazemi, V.; Elqursh, A. Show, Ask, Attend, and Answer: A Strong Baseline For Visual Question Answering. arXiv 2017, arXiv:1704.03162. [Google Scholar]
- Hinz, T.; Heinrich, S.; Wermter, S. Generating Multiple Objects at Spatially Distinct Locations. arXiv 2019, arXiv:1901.00686. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. arXiv 2015, arXiv:1506.02025. [Google Scholar]
- Hinz, T.; Heinrich, S.; Wermter, S. Semantic object accuracy for generative text-to-image synthesis. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1552–1565. [Google Scholar] [CrossRef] [PubMed]
- Sylvain, T.; Zhang, P.; Bengio, Y.; Hjelm, R.D.; Sharma, S. Object-Centric Image Generation from Layouts. arXiv 2020, arXiv:2003.07449. [Google Scholar]
- Goller, C.; Kuchler, A. Learning task-dependent distributed representations by backpropagation through structure. In Proceedings of the International Conference on Neural Networks (ICNN’96), Washington, DC, USA, 3–6 June 1996; Volume 1, pp. 347–352. [Google Scholar]
- Hong, S.; Yang, D.; Choi, J.; Lee, H. Inferring Semantic Layout for Hierarchical Text-to-Image Synthesis. arXiv 2018, arXiv:1801.05091. [Google Scholar]
- Ha, D.; Eck, D. A Neural Representation of Sketch Drawings. arXiv 2017, arXiv:1704.03477. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. arXiv 2015, arXiv:1506.04214. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Li, W.; Zhang, P.; Zhang, L.; Huang, Q.; He, X.; Lyu, S.; Gao, J. Object-driven Text-to-Image Synthesis via Adversarial Training. arXiv 2019, arXiv:1902.10740. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Qiao, T.; Zhang, J.; Xu, D.; Tao, D. Learn, imagine and create: Text-to-image generation from prior knowledge. Adv. Neural Inf. Process. Syst. 2019, 32, 3–5. [Google Scholar]
- Pavllo, D.; Lucchi, A.; Hofmann, T. Controlling Style and Semantics in Weakly-Supervised Image Generation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 482–499. [Google Scholar]
- Park, T.; Liu, M.; Wang, T.; Zhu, J. Semantic Image Synthesis with Spatially-Adaptive Normalization. arXiv 2019, arXiv:1903.07291. [Google Scholar]
- Wang, M.; Lang, C.; Liang, L.; Lyu, G.; Feng, S.; Wang, T. Attentive Generative Adversarial Network To Bridge Multi-Domain Gap For Image Synthesis. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2017, arXiv:1703.10593. [Google Scholar]
- Wang, M.; Lang, C.; Liang, L.; Feng, S.; Wang, T.; Gao, Y. End-to-End Text-to-Image Synthesis with Spatial Constrains. ACM Trans. Intell. Syst. Technol. 2020, 11, 47:1–47:19. [Google Scholar] [CrossRef]
- Johnson, J.; Gupta, A.; Fei-Fei, L. Image Generation from Scene Graphs. arXiv 2018, arXiv:1804.01622. [Google Scholar]
- Chen, Q.; Koltun, V. Photographic Image Synthesis with Cascaded Refinement Networks. arXiv 2017, arXiv:1707.09405. [Google Scholar]
- Mittal, G.; Agrawal, S.; Agarwal, A.; Mehta, S.; Marwah, T. Interactive Image Generation Using Scene Graphs. arXiv 2019, arXiv:1905.03743. [Google Scholar]
- Johnson, J.; Krishna, R.; Stark, M.; Li, L.J.; Shamma, D.A.; Bernstein, M.S.; Fei-Fei, L. Image retrieval using scene graphs. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3668–3678. [Google Scholar] [CrossRef]
- Li, B.; Zhuang, B.; Li, M.; Gu, J. Seq-SG2SL: Inferring Semantic Layout from Scene Graph Through Sequence to Sequence Learning. arXiv 2019, arXiv:1908.06592. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. arXiv 2016, arXiv:1602.07332. [Google Scholar] [CrossRef]
- Ashual, O.; Wolf, L. Specifying Object Attributes and Relations in Interactive Scene Generation. arXiv 2019, arXiv:1909.05379. [Google Scholar]
- Li, Y.; Ma, T.; Bai, Y.; Duan, N.; Wei, S.; Wang, X. PasteGAN: A Semi-Parametric Method to Generate Image from Scene Graph. arXiv 2019, arXiv:1905.01608. [Google Scholar]
- Vo, D.M.; Sugimoto, A. Visual-Relation Conscious Image Generation from Structured-Text. arXiv 2020, arXiv:1908.01741. [Google Scholar]
- Han, C.; Long, S.; Luo, S.; Wang, K.; Poon, J. VICTR: Visual Information Captured Text Representation for Text-to-Vision Multimodal Tasks. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 3107–3117. [Google Scholar] [CrossRef]
- Chen, D.; Manning, C. A Fast and Accurate Dependency Parser using Neural Networks. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 740–750. [Google Scholar] [CrossRef]
- Koh, J.Y.; Baldridge, J.; Lee, H.; Yang, Y. Text-to-image generation grounded by fine-grained user attention. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 237–246. [Google Scholar]
- Chen, J.; Shen, Y.; Gao, J.; Liu, J.; Liu, X. Language-Based Image Editing with Recurrent Attentive Models. arXiv 2018, arXiv:1711.06288. [Google Scholar]
- Shi, J.; Xu, N.; Bui, T.; Dernoncourt, F.; Wen, Z.; Xu, C. A Benchmark and Baseline for Language-Driven Image Editing. arXiv 2020, arXiv:2010.02330. [Google Scholar]
- Yu, L.; Lin, Z.; Shen, X.; Yang, J.; Lu, X.; Bansal, M.; Berg, T.L. MAttNet: Modular Attention Network for Referring Expression Comprehension. arXiv 2018, arXiv:1801.08186. [Google Scholar]
- Shi, J.; Xu, N.; Xu, Y.; Bui, T.; Dernoncourt, F.; Xu, C. Learning by Planning: Language-Guided Global Image Editing. arXiv 2021, arXiv:2106.13156. [Google Scholar]
- Dong, H.; Yu, S.; Wu, C.; Guo, Y. Semantic Image Synthesis via Adversarial Learning. arXiv 2017, arXiv:1707.06873. [Google Scholar]
- Kiros, R.; Salakhutdinov, R.; Zemel, R.S. Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models. arXiv 2014, arXiv:1411.2539. [Google Scholar]
- Nam, S.; Kim, Y.; Kim, S.J. Text-Adaptive Generative Adversarial Networks: Manipulating Images with Natural Language. arXiv 2018, arXiv:1810.11919. [Google Scholar]
- Günel, M.; Erdem, E.; Erdem, A. Language Guided Fashion Image Manipulation with Feature-wise Transformations. arXiv 2018, arXiv:1808.04000. [Google Scholar]
- Perez, E.; Strub, F.; de Vries, H.; Dumoulin, V.; Courville, A.C. FiLM: Visual Reasoning with a General Conditioning Layer. arXiv 2017, arXiv:1709.07871. [Google Scholar] [CrossRef]
- Zhu, D.; Mogadala, A.; Klakow, D. Image Manipulation with Natural Language using Two-sidedAttentive Conditional Generative Adversarial Network. arXiv 2019, arXiv:1912.07478. [Google Scholar]
- Mao, X.; Chen, Y.; Li, Y.; Xiong, T.; He, Y.; Xue, H. Bilinear Representation for Language-based Image Editing Using Conditional Generative Adversarial Networks. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2047–2051. [Google Scholar] [CrossRef]
- Li, B.; Qi, X.; Lukasiewicz, T.; Torr, P.H.S. ManiGAN: Text-Guided Image Manipulation. arXiv 2020, arXiv:1912.06203. [Google Scholar]
- Liu, Y.; De Nadai, M.; Cai, D.; Li, H.; Alameda-Pineda, X.; Sebe, N.; Lepri, B. Describe What to Change: A Text-guided Unsupervised Image-to-Image Translation Approach. arXiv 2020, arXiv:2008.04200. [Google Scholar]
- Liu, Y.; Nadai, M.D.; Yao, J.; Sebe, N.; Lepri, B.; Alameda-Pineda, X. GMM-UNIT: Unsupervised Multi-Domain and Multi-Modal Image-to-Image Translation via Attribute Gaussian Mixture Modeling. arXiv 2020, arXiv:2003.06788. [Google Scholar]
- Park, H.; Yoo, Y.; Kwak, N. MC-GAN: Multi-conditional Generative Adversarial Network for Image Synthesis. arXiv 2018, arXiv:1805.01123. [Google Scholar]
- Zhou, X.; Huang, S.; Li, B.; Li, Y.; Li, J.; Zhang, Z. Text Guided Person Image Synthesis. arXiv 2019, arXiv:1904.05118. [Google Scholar]
- Ma, L.; Sun, Q.; Georgoulis, S.; Gool, L.V.; Schiele, B.; Fritz, M. Disentangled Person Image Generation. arXiv 2017, arXiv:1712.02621. [Google Scholar]
- Li, B.; Qi, X.; Torr, P.H.S.; Lukasiewicz, T. Lightweight Generative Adversarial Networks for Text-Guided Image Manipulation. arXiv 2020, arXiv:2010.12136. [Google Scholar]
- Zhang, L.; Chen, Q.; Hu, B.; Jiang, S. Neural Image Inpainting Guided with Descriptive Text. arXiv 2020, arXiv:2004.03212. [Google Scholar]
- Patashnik, O.; Wu, Z.; Shechtman, E.; Cohen-Or, D.; Lischinski, D. StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery. arXiv 2021, arXiv:2103.17249. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. arXiv 2021, arXiv:2103.00020. [Google Scholar]
- Togo, R.; Kotera, M.; Ogawa, T.; Haseyama, M. Text-Guided Style Transfer-Based Image Manipulation Using Multimodal Generative Models. IEEE Access 2021, 9, 64860–64870. [Google Scholar] [CrossRef]
- Wang, H.; Williams, J.D.; Kang, S. Learning to Globally Edit Images with Textual Description. arXiv 2018, arXiv:1810.05786. [Google Scholar]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; Association for Computational Linguistics: Baltimore, MD, USA, 2014; pp. 55–60. [Google Scholar] [CrossRef]
- Chen, D.; Yuan, L.; Liao, J.; Yu, N.; Hua, G. StyleBank: An Explicit Representation for Neural Image Style Transfer. arXiv 2017, arXiv:1703.09210. [Google Scholar]
- Xia, W.; Yang, Y.; Xue, J.H.; Wu, B. TediGAN: Text-Guided Diverse Face Image Generation and Manipulation. arXiv 2021, arXiv:2012.03308. [Google Scholar]
- Anonymous. Generating a Temporally Coherent Image Sequence for a Story by Multimodal Recurrent Transformers. 2021. Available online: https://openreview.net/forum?id=L99I9HrEtEm (accessed on 30 May 2022).
- Li, Y.; Gan, Z.; Shen, Y.; Liu, J.; Cheng, Y.; Wu, Y.; Carin, L.; Carlson, D.; Gao, J. Storygan: A sequential conditional gan for story visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6329–6338. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Li, C.; Kong, L.; Zhou, Z. Improved-storygan for sequential images visualization. J. Vis. Commun. Image Represent. 2020, 73, 102956. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Song, Y.Z.; Rui Tam, Z.; Chen, H.J.; Lu, H.H.; Shuai, H.H. Character-Preserving Coherent Story Visualization. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 18–33. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. arXiv 2019, arXiv:1902.09212. [Google Scholar]
- Maharana, A.; Hannan, D.; Bansal, M. Improving generation and evaluation of visual stories via semantic consistency. arXiv 2021, arXiv:2105.10026. [Google Scholar]
- Lei, J.; Wang, L.; Shen, Y.; Yu, D.; Berg, T.L.; Bansal, M. MART: Memory-Augmented Recurrent Transformer for Coherent Video Paragraph Captioning. arXiv 2020, arXiv:2005.05402. [Google Scholar]
- Maharana, A.; Bansal, M. Integrating Visuospatial, Linguistic and Commonsense Structure into Story Visualization. arXiv 2021, arXiv:2110.10834. [Google Scholar]
- Bauer, L.; Wang, Y.; Bansal, M. Commonsense for Generative Multi-Hop Question Answering Tasks. arXiv 2018, arXiv:1809.06309. [Google Scholar]
- Koncel-Kedziorski, R.; Bekal, D.; Luan, Y.; Lapata, M.; Hajishirzi, H. Text Generation from Knowledge Graphs with Graph Transformers. arXiv 2019, arXiv:1904.02342. [Google Scholar]
- Yang, L.; Tang, K.D.; Yang, J.; Li, L. Dense Captioning with Joint Inference and Visual Context. arXiv 2016, arXiv:1611.06949. [Google Scholar]
- Gupta, T.; Schwenk, D.; Farhadi, A.; Hoiem, D.; Kembhavi, A. Imagine This! Scripts to Compositions to Videos. arXiv 2018, arXiv:1804.03608. [Google Scholar]
- Liu, Y.; Wang, X.; Yuan, Y.; Zhu, W. Cross-Modal Dual Learning for Sentence-to-Video Generation. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1239–1247. [Google Scholar] [CrossRef]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. arXiv 2017, arXiv:1705.02364. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Huq, F.; Ahmed, N.; Iqbal, A. Static and Animated 3D Scene Generation from Free-form Text Descriptions. arXiv 2020, arXiv:2010.01549. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 38–45. [Google Scholar] [CrossRef]
- Introduction—Blender Manual. Available online: https://www.blender.org/ (accessed on 30 May 2022).
- Mittal, G.; Marwah, T.; Balasubramanian, V.N. Sync-DRAW: Automatic video generation using deep recurrent attentive architectures. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1096–1104. [Google Scholar]
- Kiros, R.; Zhu, Y.; Salakhutdinov, R.; Zemel, R.S.; Torralba, A.; Urtasun, R.; Fidler, S. Skip-Thought Vectors. arXiv 2015, arXiv:1506.06726. [Google Scholar]
- Marwah, T.; Mittal, G.; Balasubramanian, V.N. Attentive Semantic Video Generation using Captions. arXiv 2017, arXiv:1708.05980. [Google Scholar]
- Li, Y.; Min, M.R.; Shen, D.; Carlson, D.; Carin, L. Video Generation From Text. arXiv 2017, arXiv:1710.00421. [Google Scholar] [CrossRef]
- Wu, C.; Huang, L.; Zhang, Q.; Li, B.; Ji, L.; Yang, F.; Sapiro, G.; Duan, N. GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions. arXiv 2021, arXiv:2104.14806. [Google Scholar]
- Pan, Y.; Qiu, Z.; Yao, T.; Li, H.; Mei, T. To Create What You Tell: Generating Videos from Captions. arXiv 2018, arXiv:1804.08264. [Google Scholar]
- Deng, K.; Fei, T.; Huang, X.; Peng, Y. IRC-GAN: Introspective Recurrent Convolutional GAN for Text-to-Video Generation. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, Macao, China, 10–16 August 2019; pp. 2216–2222. [Google Scholar] [CrossRef]
- Balaji, Y.; Min, M.R.; Bai, B.; Chellappa, R.; Graf, H.P. Conditional GAN with Discriminative Filter Generation for Text-to-Video Synthesis. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1995–2001. [Google Scholar] [CrossRef]
- Mazaheri, A.; Shah, M. Video Generation from Text Employing Latent Path Construction for Temporal Modeling. arXiv 2021, arXiv:2107.13766. [Google Scholar]
- Kim, D.; Joo, D.; Kim, J. TiVGAN: Text to Image to Video Generation with Step-by-Step Evolutionary Generator. arXiv 2021, arXiv:2009.02018. [Google Scholar] [CrossRef]
- Fu, T.J.; Wang, X.E.; Grafton, S.T.; Eckstein, M.P.; Wang, W.Y. M3L: Language-based Video Editing via Multi-Modal Multi-Level Transformers. arXiv 2022, arXiv:2104.01122. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lafferty, J.D.; McCallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning, San Francisco, CA, USA, 28 June–1 July 2001; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; pp. 282–289. [Google Scholar]
- van den Oord, A.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel Recurrent Neural Networks. arXiv 2016, arXiv:1601.06759. [Google Scholar]
- van den Oord, A.; Vinyals, O.; Kavukcuoglu, K. Neural Discrete Representation Learning. In Advances in Neural Information Processing Systems; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2018; Volume 30, Available online: https://proceedings.neurips.cc/paper/2017/file/7a98af17e63a0ac09ce2e96d03992fbc-Paper.pdf (accessed on 30 May 2022).
- Sohl-Dickstein, J.; Weiss, E.A.; Maheswaranathan, N.; Ganguli, S. Deep Unsupervised Learning using Nonequilibrium Thermodynamics. arXiv 2015, arXiv:1503.03585. [Google Scholar]
- Hu, Y.; He, H.; Xu, C.; Wang, B.; Lin, S. Exposure: A White-Box Photo Post-Processing Framework. arXiv 2017, arXiv:1709.09602. [Google Scholar] [CrossRef]
- Park, J.; Lee, J.; Yoo, D.; Kweon, I.S. Distort-and-Recover: Color Enhancement using Deep Reinforcement Learning. arXiv 2018, arXiv:1804.04450. [Google Scholar]
- Shinagawa, S.; Yoshino, K.; Sakti, S.; Suzuki, Y.; Nakamura, S. Interactive Image Manipulation with Natural Language Instruction Commands. arXiv 2018, arXiv:1802.08645. [Google Scholar]
- Laput, G.P.; Dontcheva, M.; Wilensky, G.; Chang, W.; Agarwala, A.; Linder, J.; Adar, E. PixelTone: A Multimodal Interface for Image Editing. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris France, 27 April–2 May 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 2185–2194. [Google Scholar] [CrossRef]
- Denton, E.L.; Chintala, S.; Szlam, A.; Fergus, R. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks. arXiv 2015, arXiv:1506.05751. [Google Scholar]
- Lin, Z.; Feng, M.; dos Santos, C.N.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A Structured Self-attentive Sentence Embedding. arXiv 2017, arXiv:1703.03130. [Google Scholar]
- Li, S.; Bak, S.; Carr, P.; Wang, X. Diversity Regularized Spatiotemporal Attention for Video-based Person Re-identification. arXiv 2018, arXiv:1803.09882. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Wang, X.; Chen, Y.; Zhu, W. A Comprehensive Survey on Curriculum Learning. arXiv 2020, arXiv:2010.13166. [Google Scholar]
- Hadsell, R.; Chopra, S.; LeCun, Y. Dimensionality Reduction by Learning an Invariant Mapping. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 2, pp. 1735–1742. [Google Scholar] [CrossRef]
- Nguyen, A.M.; Dosovitskiy, A.; Yosinski, J.; Brox, T.; Clune, J. Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. arXiv 2016, arXiv:1605.09304. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and Tell: A Neural Image Caption Generator. arXiv 2014, arXiv:1411.4555. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial Feature Learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]
- Dumoulin, V.; Belghazi, I.; Poole, B.; Mastropietro, O.; Lamb, A.; Arjovsky, M.; Courville, A. Adversarially Learned Inference. arXiv 2016, arXiv:1606.00704. [Google Scholar]
- Saunshi, N.; Ash, J.; Goel, S.; Misra, D.; Zhang, C.; Arora, S.; Kakade, S.; Krishnamurthy, A. Understanding Contrastive Learning Requires Incorporating Inductive Biases. arXiv 2022, arXiv:2202.14037. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Dinh, L.; Krueger, D.; Bengio, Y. NICE: Non-linear Independent Components Estimation. arXiv 2014, arXiv:1410.8516. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using Real NVP. arXiv 2016, arXiv:1605.08803. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and Improving the Image Quality of StyleGAN. arXiv 2019, arXiv:1912.04958. [Google Scholar]
- Das, A.; Kottur, S.; Gupta, K.; Singh, A.; Yadav, D.; Lee, S.; Moura, J.M.F.; Parikh, D.; Batra, D. Visual Dialog. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1242–1256. [Google Scholar] [CrossRef] [PubMed]
- Johnson, J.; Hariharan, B.; Van Der Maaten, L.; Hoffman, J.; Fei-Fei, L.; Lawrence Zitnick, C.; Girshick, R. Inferring and executing programs for visual reasoning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2989–2998. [Google Scholar]
- Ben-younes, H.; Cadène, R.; Cord, M.; Thome, N. MUTAN: Multimodal Tucker Fusion for Visual Question Answering. arXiv 2017, arXiv:1705.06676. [Google Scholar]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. arXiv 2016, arXiv:1612.00837. [Google Scholar]
- Zhao, B.; Meng, L.; Yin, W.; Sigal, L. Image Generation from Layout. arXiv 2018, arXiv:1811.11389. [Google Scholar]
- Sun, W.; Wu, T. Image Synthesis From Reconfigurable Layout and Style. arXiv 2019, arXiv:1908.07500. [Google Scholar]
- Sun, W.; Wu, T. Learning Layout and Style Reconfigurable GANs for Controllable Image Synthesis. arXiv 2020, arXiv:2003.11571. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.B. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A Comprehensive Survey on Graph Neural Networks. arXiv 2019, arXiv:1901.00596. [Google Scholar] [CrossRef] [PubMed]
- Pont-Tuset, J.; Uijlings, J.; Changpinyo, S.; Soricut, R.; Ferrari, V. Connecting vision and language with localized narratives. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 647–664. [Google Scholar]
- Pose-Normalized Image Generation for Person Re-identification. arXiv 2017, arXiv:1712.02225.
- Adorni, G.; Di Manzo, M. Natural Language Input for Scene Generation. In Proceedings of the First Conference of the European Chapter of the Association for Computational Linguistics, Pisa, Italy, 1–2 September 1983; Association for Computational Linguistics: Pisa, Italy, 1983. [Google Scholar]
- Coyne, B.; Sproat, R. WordsEye: An automatic text-to-scene conversion system. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques—SIGGRAPH ’01, Los Angeles, CA, USA, 12–17 August 2001; ACM Press: New York, NY, USA, 2001; pp. 487–496. [Google Scholar] [CrossRef]
- Chang, A.X.; Eric, M.; Savva, M.; Manning, C.D. SceneSeer: 3D Scene Design with Natural Language. arXiv 2017, arXiv:1703.00050. [Google Scholar]
- Häusser, P.; Mordvintsev, A.; Cremers, D. Learning by Association—A versatile semi-supervised training method for neural networks. arXiv 2017, arXiv:1706.00909. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 214–223. Available online: https://proceedings.mlr.press/v70/arjovsky17a.html (accessed on 30 May 2022).
- Kim, G.; Moon, S.; Sigal, L. Joint photo stream and blog post summarization and exploration. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3081–3089. [Google Scholar] [CrossRef]
- Kim, G.; Moon, S.; Sigal, L. Ranking and retrieval of image sequences from multiple paragraph queries. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1993–2001. [Google Scholar] [CrossRef]
- Ravi, H.; Wang, L.; Muniz, C.M.; Sigal, L.; Metaxas, D.N.; Kapadia, M. Show Me a Story: Towards Coherent Neural Story Illustration. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7613–7621. [Google Scholar] [CrossRef]
- Chen, J.; Chen, J.; Yu, Z. Incorporating Structured Commonsense Knowledge in Story Completion. arXiv 2018, arXiv:1811.00625. [Google Scholar] [CrossRef]
- Ma, M.; Mc Kevitt, P. Virtual human animation in natural language visualisation. Artif. Intell. Rev. 2006, 25, 37–53. [Google Scholar] [CrossRef]
- Åkerberg, O.; Svensson, H.; Schulz, B.; Nugues, P. CarSim: An Automatic 3D Text-to-Scene Conversion System Applied to Road Accident Reports. In Proceedings of the Research Notes and Demonstrations of the 10th Conference of the European Chapter of the Association of Computational Linguistics, Budapest, Hungary, 12–17 April 2003; Association of Computational Linguistics: Stroudsburg, PA, USA, 2003; pp. 191–194. [Google Scholar]
- Krishnaswamy, N.; Pustejovsky, J. VoxSim: A Visual Platform for Modeling Motion Language. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: System Demonstrations, Osaka, Japan, 11–16 December 2016; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 54–58. [Google Scholar]
- Hayashi, M.; Inoue, S.; Douke, M.; Hamaguchi, N.; Kaneko, H.; Bachelder, S.; Nakajima, M. T2V: New Technology of Converting Text to CG Animation. ITE Trans. Media Technol. Appl. 2014, 2, 74–81. [Google Scholar] [CrossRef]
- El-Mashad, S.Y.; Hamed, E.H.S. Automatic creation of a 3D cartoon from natural language story. Ain Shams Eng. J. 2022, 13, 101641. [Google Scholar] [CrossRef]
- Miech, A.; Zhukov, D.; Alayrac, J.; Tapaswi, M.; Laptev, I.; Sivic, J. HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips. arXiv 2019, arXiv:1906.03327. [Google Scholar]
- Saito, M.; Matsumoto, E.; Saito, S. Temporal Generative Adversarial Nets with Singular Value Clipping. arXiv 2017, arXiv:1611.06624. [Google Scholar]
- Tulyakov, S.; Liu, M.; Yang, X.; Kautz, J. MoCoGAN: Decomposing Motion and Content for Video Generation. arXiv 2017, arXiv:1707.04993. [Google Scholar]
- Gavrilyuk, K.; Ghodrati, A.; Li, Z.; Snoek, C.G.M. Actor and Action Video Segmentation from a Sentence. arXiv 2018, arXiv:1803.07485. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Clark, A.; Donahue, J.; Simonyan, K. Efficient Video Generation on Complex Datasets. arXiv 2019, arXiv:1907.06571. [Google Scholar]
- Xian, Y.; Lampert, C.H.; Schiele, B.; Akata, Z. Zero-Shot Learning—A Comprehensive Evaluation of the Good, the Bad and the Ugly. arXiv 2017, arXiv:1707.00600. [Google Scholar] [CrossRef] [Green Version]
- Lampert, C.H.; Nickisch, H.; Harmeling, S. Learning to detect unseen object classes by between-class attribute transfer. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 951–958. [Google Scholar] [CrossRef]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J. StarGAN v2: Diverse Image Synthesis for Multiple Domains. arXiv 2019, arXiv:1912.01865. [Google Scholar]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading Digits in Natural Images with Unsupervised Feature Learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 16–17 December 2011. [Google Scholar]
- Gonzalez-Garcia, A.; van de Weijer, J.; Bengio, Y. Image-to-image translation for cross-domain disentanglement. arXiv 2018, arXiv:1805.09730. [Google Scholar]
- Eslami, S.M.A.; Heess, N.; Weber, T.; Tassa, Y.; Kavukcuoglu, K.; Hinton, G.E. Attend, Infer, Repeat: Fast Scene Understanding with Generative Models. arXiv 2016, arXiv:1603.08575. [Google Scholar]
- Nilsback, M.E.; Zisserman, A. Automated Flower Classification over a Large Number of Classes. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics Image Processing, Bhubaneswar, India, 16–19 December 2008; pp. 722–729. [Google Scholar] [CrossRef]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. Technical Report CNS-TR-2011-001; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Finn, C.; Goodfellow, I.J.; Levine, S. Unsupervised Learning for Physical Interaction through Video Prediction. arXiv 2016, arXiv:1605.07157. [Google Scholar]
- Abolghasemi, P.; Mazaheri, A.; Shah, M.; Bölöni, L. Pay attention!—Robustifying a Deep Visuomotor Policy through Task-Focused Attention. arXiv 2018, arXiv:1809.10093. [Google Scholar]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; Technical Report 07-49; University of Massachusetts: Amherst, MA, USA, 2007. [Google Scholar]
- Berg, T.; Berg, A.; Edwards, J.; Maire, M.; White, R.; Teh, Y.W.; Learned-Miller, E.; Forsyth, D. Names and faces in the news. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; Volume 2, pp. 2–4. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. arXiv 2014, arXiv:1411.7766. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deep Learning Face Representation by Joint Identification-Verification. arXiv 2014, arXiv:1406.4773. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OI, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar] [CrossRef]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual Question Answering. arXiv 2015, arXiv:1505.00468. [Google Scholar]
- Zhang, P.; Goyal, Y.; Summers-Stay, D.; Batra, D.; Parikh, D. Yin and Yang: Balancing and Answering Binary Visual Questions. arXiv 2015, arXiv:1511.05099. [Google Scholar]
- Salvador, A.; Hynes, N.; Aytar, Y.; Marin, J.; Ofli, F.; Weber, I.; Torralba, A. Learning Cross-Modal Embeddings for Cooking Recipes and Food Images. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3068–3076. [Google Scholar] [CrossRef]
- Zitnick, C.L.; Parikh, D. Bringing Semantics into Focus Using Visual Abstraction. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3009–3016. [Google Scholar] [CrossRef]
- Kim, J.; Parikh, D.; Batra, D.; Zhang, B.; Tian, Y. CoDraw: Visual Dialog for Collaborative Drawing. arXiv 2017, arXiv:1712.05558. [Google Scholar]
- Johnson, J.; Hariharan, B.; van der Maaten, L.; Fei-Fei, L.; Zitnick, C.L.; Girshick, R.B. CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning. arXiv 2016, arXiv:1612.06890. [Google Scholar]
- Gwern, B.; Anonymous; Danbooru Community. Danbooru2019 Portraits: A Large-Scale Anime Head Illustration Dataset. 2019. Available online: https://www.gwern.net/Crops#danbooru2019-portraits (accessed on 30 May 2022).
- Anonymous; Danbooru Community; Gwern, B. Danbooru2021: A Large-Scale Crowdsourced and Tagged Anime Illustration Dataset. Available online: https://www.gwern.net/Danbooru2021 (accessed on 30 May 2022).
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2007/workshop/index.html (accessed on 30 May 2022).
- Guillaumin, M.; Verbeek, J.; Schmid, C. Multimodal semi-supervised learning for image classification. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 902–909. [Google Scholar] [CrossRef]
- Huiskes, M.J.; Lew, M.S. The MIR Flickr Retrieval Evaluation. In Proceedings of the 1st ACM International Conference on Multimedia Information Retrieval, Vancouver, BC, Canada, 30–31 October 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 39–43. [Google Scholar] [CrossRef]
- Huiskes, M.J.; Thomee, B.; Lew, M.S. New Trends and Ideas in Visual Concept Detection: The MIR Flickr Retrieval Evaluation Initiative. In Proceedings of the International Conference on Multimedia Information Retrieval, Philadelphia, PA, USA, 29–31 March 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 527–536. [Google Scholar] [CrossRef] [Green Version]
- Bosch, A.; Zisserman, A.; Munoz, X. Image Classification using Random Forests and Ferns. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Modeling the Shape of the Scene: A Holistic Representation of the Spatial Envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Manjunath, B.; Ohm, J.R.; Vasudevan, V.; Yamada, A. Color and texture descriptors. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 703–715. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Fellbaum, C. (Ed.) WordNet: An Electronic Lexical Database; Language, Speech, and Communication; A Bradford Book: Cambridge, MA, USA, 1998. [Google Scholar]
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop. arXiv 2016, arXiv:1506.03365. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. Available online: http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html (accessed on 30 May 2022).
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. SUN database: Large-scale scene recognition from abbey to zoo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar] [CrossRef]
- Thomee, B.; Shamma, D.A.; Friedland, G.; Elizalde, B.; Ni, K.; Poland, D.; Borth, D.; Li, L. The New Data and New Challenges in Multimedia Research. arXiv 2015, arXiv:1503.01817. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Caesar, H.; Uijlings, J.R.R.; Ferrari, V. COCO-Stuff: Thing and Stuff Classes in Context. arXiv 2016, arXiv:1612.03716. [Google Scholar]
- Sharma, P.; Ding, N.; Goodman, S.; Soricut, R. Conceptual Captions: A Cleaned, Hypernymed, Image Alt-text Dataset For Automatic Image Captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 2556–2565. [Google Scholar] [CrossRef]
- Chambers, C.; Raniwala, A.; Perry, F.; Adams, S.; Henry, R.R.; Bradshaw, R.; Weizenbaum, N. FlumeJava: Easy, Efficient Data-Parallel Pipelines. In Proceedings of the 31st ACM SIGPLAN Conference on Programming Language Design and Implementation, London, UK, 15–20 June 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 363–375. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.R.R.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Duerig, T.; et al. The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. arXiv 2018, arXiv:1811.00982. [Google Scholar] [CrossRef]
- Schuhmann, C.; Vencu, R.; Beaumont, R.; Kaczmarczyk, R.; Mullis, C.; Katta, A.; Coombes, T.; Jitsev, J.; Komatsuzaki, A. LAION-400M: Open Dataset of CLIP-Filtered 400 Million Image-Text Pairs. arXiv 2021, arXiv:2111.02114. [Google Scholar]
- Common Crawl. Available online: https://commoncrawl.org/ (accessed on 30 May 2022).
- Chang, A.X.; Funkhouser, T.A.; Guibas, L.J.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Kazemzadeh, S.; Ordonez, V.; Matten, M.; Berg, T. ReferItGame: Referring to Objects in Photographs of Natural Scenes. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 787–798. [Google Scholar] [CrossRef]
- Grubinger, M.; Clough, P.; Müller, H.; Deselaers, T. The IAPR TC12 Benchmark: A New Evaluation Resource for Visual Information Systems. In Proceedings of the International Workshop ontoImage, Genova, Italy, 22 May 2006; Volume 2. [Google Scholar]
- Escalante, H.J.; Hernández, C.A.; Gonzalez, J.A.; López-López, A.; Montes, M.; Morales, E.F.; Enrique Sucar, L.; Villaseñor, L.; Grubinger, M. The Segmented and Annotated IAPR TC-12 Benchmark. Comput. Vis. Image Underst. 2010, 114, 419–428. [Google Scholar] [CrossRef] [Green Version]
- Zhu, S.; Fidler, S.; Urtasun, R.; Lin, D.; Loy, C.C. Be Your Own Prada: Fashion Synthesis with Structural Coherence. arXiv 2017, arXiv:1710.07346. [Google Scholar]
- Bychkovsky, V.; Paris, S.; Chan, E.; Durand, F. Learning Photographic Global Tonal Adjustment with a Database of Input/Output Image Pairs. In Proceedings of the Twenty-Fourth IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Yu, A.; Grauman, K. Fine-Grained Visual Comparisons with Local Learning. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OI, USA, 23–28 June 2014; pp. 192–199. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Qiu, S.; Wang, X.; Tang, X. DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1096–1104. [Google Scholar] [CrossRef]
- Zhopped—The First, Free Image Editing Community. Available online: http://zhopped.com/ (accessed on 30 May 2022).
- Reddit—Dive into Anything. Available online: https://www.reddit.com/ (accessed on 30 May 2022).
- Huang, T.H.K.; Ferraro, F.; Mostafazadeh, N.; Misra, I.; Agrawal, A.; Devlin, J.; Girshick, R.; He, X.; Kohli, P.; Batra, D.; et al. Visual Storytelling. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 1233–1239. [Google Scholar] [CrossRef]
- Kim, K.; Heo, M.; Choi, S.; Zhang, B. DeepStory: Video Story QA by Deep Embedded Memory Networks. arXiv 2017, arXiv:1707.00836. [Google Scholar]
- Smeaton, A.; Over, P. TRECVID: Benchmarking the Effectiveness of Information Retrieval Tasks on Digital Video. In Proceedings of the International Conference on Image and Video Retrieval, Urbana-Champaign, IL, USA, 24–25 July 2003; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2728. [Google Scholar] [CrossRef]
- Chen, D.; Dolan, W. Collecting Highly Parallel Data for Paraphrase Evaluation. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; Association for Computational Linguistics: Portland, OR, USA, 2011; pp. 190–200. [Google Scholar]
- Xu, J.; Mei, T.; Yao, T.; Rui, Y. MSR-VTT: A Large Video Description Dataset for Bridging Video and Language. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5288–5296. [Google Scholar] [CrossRef]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The Kinetics Human Action Video Dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Damen, D.; Doughty, H.; Farinella, G.M.; Fidler, S.; Furnari, A.; Kazakos, E.; Moltisanti, D.; Munro, J.; Perrett, T.; Price, W.; et al. Scaling Egocentric Vision: The EPIC-KITCHENS Dataset. arXiv 2018, arXiv:1804.02748. [Google Scholar]
- Girdhar, R.; Ramanan, D. CATER: A diagnostic dataset for Compositional Actions and TEmporal Reasoning. arXiv 2019, arXiv:1910.04744. [Google Scholar]
- Materzynska, J.; Berger, G.; Bax, I.; Memisevic, R. The Jester Dataset: A Large-Scale Video Dataset of Human Gestures. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 2874–2882. [Google Scholar] [CrossRef]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OI, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar] [CrossRef]
- Reed, S.; Akata, Z.; Mohan, S.; Tenka, S.; Schiele, B.; Lee, H. Learning What and Where to Draw. arXiv 2016, arXiv:1610.02454. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; Volume 3, pp. 32–36. [Google Scholar] [CrossRef]
- Aifanti, N.; Papachristou, C.; Delopoulos, A. The MUG facial expression database. In Proceedings of the 11th International Workshop on Image Analysis for Multimedia Interactive Services WIAMIS 10, Garda, Italy, 12–14 April 2010; pp. 1–4. [Google Scholar]
- Clark, E.A.; Kessinger, J.; Duncan, S.E.; Bell, M.A.; Lahne, J.; Gallagher, D.L.; O’Keefe, S.F. The Facial Action Coding System for Characterization of Human Affective Response to Consumer Product-Based Stimuli: A Systematic Review. Front. Psychol. 2020, 11, 920. [Google Scholar] [CrossRef] [PubMed]
- Reddy, K.K.; Shah, M. Recognizing 50 Human Action Categories of Web Videos. Mach. Vision Appl. 2013, 24, 971–981. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Hsieh, S.H.; Xiong, C.; Corso, J.J. Can humans fly? Action understanding with multiple classes of actors. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2264–2273. [Google Scholar] [CrossRef]
- McIntosh, B.; Duarte, K.; Rawat, Y.S.; Shah, M. Multi-modal Capsule Routing for Actor and Action Video Segmentation Conditioned on Natural Language Queries. arXiv 2018, arXiv:1812.00303. [Google Scholar]
- Li, S.; Xiao, T.; Li, H.; Zhou, B.; Yue, D.; Wang, X. Person Search with Natural Language Description. arXiv 2017, arXiv:1702.05729. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. DeepReID: Deep Filter Pairing Neural Network for Person Re-identification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OI, USA, 23–28 June 2014; pp. 152–159. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Bu, J.; Tian, Q. Person Re-identification Meets Image Search. arXiv 2015, arXiv:1502.02171. [Google Scholar]
- Xiao, T.; Li, S.; Wang, B.; Lin, L.; Wang, X. End-to-End Deep Learning for Person Search. arXiv 2016, arXiv:1604.01850. [Google Scholar]
- Gray, D.; Brennan, S.; Tao, H. Evaluating appearance models for recognition, reacquisition, and tracking. In Proceedings of the IEEE International Workshop on Performance Evaluation for Tracking and Surveillance, Rio de Janeiro, Brazil, 14 October 2007; Volume 3, pp. 1–7. [Google Scholar]
- Li, W.; Zhao, R.; Wang, X. Human Reidentification with Transferred Metric Learning. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 31–44. [Google Scholar] [CrossRef]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Klambauer, G.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Nash Equilibrium. arXiv 2017, arXiv:1706.08500. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. arXiv 2018, arXiv:1801.03924. [Google Scholar]
- Unterthiner, T.; van Steenkiste, S.; Kurach, K.; Marinier, R.; Michalski, M.; Gelly, S. Towards Accurate Generative Models of Video: A New Metric & Challenges. arXiv 2018, arXiv:1812.01717. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. arXiv 2017, arXiv:1711.11248. [Google Scholar]
- Im, D.J.; Kim, C.D.; Jiang, H.; Memisevic, R. Generating images with recurrent adversarial networks. arXiv 2016, arXiv:1602.05110. [Google Scholar]
- Turner, R.E.; Sahani, M. Two problems with variational expectation maximisation for time-series models. In Bayesian Time Series Models; Barber, D., Cemgil, T., Chiappa, S., Eds.; Cambridge University Press: Cambridge, UK, 2011; Chapter 5; pp. 109–130. [Google Scholar]
- Cremer, C.; Li, X.; Duvenaud, D. Inference Suboptimality in Variational Autoencoders. arXiv 2018, arXiv:1801.03558. [Google Scholar]
- Bond-Taylor, S.; Leach, A.; Long, Y.; Willcocks, C.G. Deep Generative Modelling: A Comparative Review of VAEs, GANs, Normalizing Flows, Energy-Based and Autoregressive Models. arXiv 2021, arXiv:2103.04922. [Google Scholar] [CrossRef] [PubMed]
- Balint, J.; Allbeck, J.M.; Hieb, M.R. Automated Simulation Creation from Military Operations Documents. 2015, p. 12. Available online: https://www.semanticscholar.org/paper/Automated-Simulation-Creation-from-Military-Balint-Allbeck/a136c984169c3423a6f0bc7a1f50e419d75298a7 (accessed on 30 May 2022).
- Huang, H.; Li, Z.; He, R.; Sun, Z.; Tan, T. IntroVAE: Introspective Variational Autoencoders for Photographic Image Synthesis. arXiv 2018, arXiv:1807.06358. [Google Scholar]
- Hinton, G.; Krizhevsky, A.; Wang, S. Transforming Auto-Encoders. In Proceedings of the International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6791, pp. 44–51. [Google Scholar] [CrossRef]
- Menick, J.; Kalchbrenner, N. Generating High Fidelity Images with Subscale Pixel Networks and Multidimensional Upscaling. arXiv 2018, arXiv:1812.01608. [Google Scholar]
- Razavi, A.; van den Oord, A.; Vinyals, O. Generating Diverse High-Fidelity Images with VQ-VAE-2. arXiv 2019, arXiv:1906.00446. [Google Scholar]
- Barua, S.; Ma, X.; Erfani, S.M.; Houle, M.E.; Bailey, J. Quality Evaluation of GANs Using Cross Local Intrinsic Dimensionality. arXiv 2019, arXiv:1905.00643. [Google Scholar]
- Zhao, S.; Song, J.; Ermon, S. Towards Deeper Understanding of Variational Autoencoding Models. arXiv 2017, arXiv:1702.08658. [Google Scholar]
- Fan, A.; Lavril, T.; Grave, E.; Joulin, A.; Sukhbaatar, S. Accessing Higher-level Representations in Sequential Transformers with Feedback Memory. arXiv 2020, arXiv:2002.09402. [Google Scholar]
- Su, J.; Wu, G. f-VAEs: Improve VAEs with Conditional Flows. arXiv 2018, arXiv:1809.05861. [Google Scholar]
- Ravuri, S.V.; Vinyals, O. Classification Accuracy Score for Conditional Generative Models. arXiv 2019, arXiv:1905.10887. [Google Scholar]
- MNIST Handwritten Digit Database, Yann LeCun, Corinna Cortes and Chris Burges. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 30 May 2022).
- Blandfort, P.; Karayil, T.; Borth, D.; Dengel, A. Image Captioning in the Wild: How People Caption Images on Flickr. In Proceedings of the Workshop on Multimodal Understanding of Social, Affective and Subjective Attributes, Mountain View, CA, USA, 27 October 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 21–29. [Google Scholar] [CrossRef]
- Computer Vision and Image Understanding—Journal—Elsevier. Available online: https://www.journals.elsevier.com/computer-vision-and-image-understanding (accessed on 30 May 2022).
- Ronquillo, N.; Harguess, J. On Evaluating Video-based Generative Adversarial Networks (GANs). In Proceedings of the 2018 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 9–11 October 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.J.; Chang, K.W. VisualBERT: A Simple and Performant Baseline for Vision and Language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Zhou, S.; Gordon, M.L.; Krishna, R.; Narcomey, A.; Morina, D.; Bernstein, M.S. HYPE: Human eYe Perceptual Evaluation of Generative Models. arXiv 2019, arXiv:1904.01121. [Google Scholar]












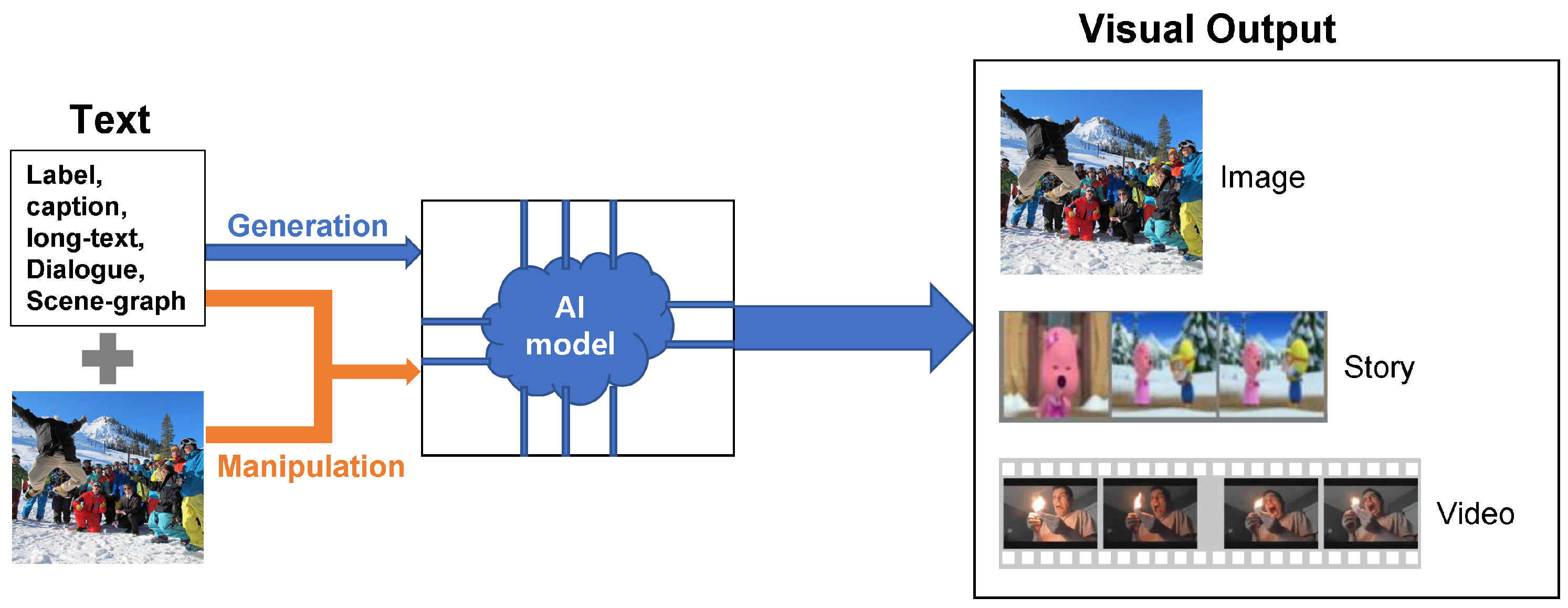{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Venue | Acronym | Selected Publications |
|---|---|---|
| Computer Vision and Pattern Recognition | CVPR | 46 |
| International Conference on Computer Vision | ICCV | 11 |
| Advances in Neural Information Processing Systems | NeurIPS | 12 |
| AAAI Conference on Artificial Intelligence | AAAI | 5 |
| International Conference on Machine Learning | ICML | 5 |
| European Conference on Computer Vision | ECCV | 9 |
| International Joint Conferences on Artificial Intelligence | IJCAI | 2 |
| International Conference on Learning Representations | ICLR | 5 |
| Model | Abbreviation | Year (Final-Version) | Characteristics | Modalities 1. Input 2. Output | Neural Networks 1. Text Model 2. Visual Model | ||
|---|---|---|---|---|---|---|---|
| Static (Image) | Generation | Energy-based | |||||
| [92] | MATDH | 2005 | Multi-wing harmonium based on 2-layer random fields, contrastive divergence, and variational algorithm for learning | label, text image | Poisson model + bag-of-words Color-histogram by Guassian model | ||
| [93] | MLDBM | 2012 | Bi-modal DBM as a generative model for learning joint representation of multimodal data | label, text image | text-DBM image-DBM | ||
| [94] | LVIS | 2013 | Conditional Random Field for generating scenes by handling 2 nouns and 1 relation, Abstract Scene dataset through MTurk | caption image | Sentence parsing Conditional Random-Field | ||
| [95] | MDRNN | 2014 | RBM with contrastive divergence and multi-prediction training, Minimize variation of information, Recurrent encoding structure for finetuning | label image | text-RBM image-RBM | ||
| Autoregressive | |||||||
| [96] | PixelCNN | 2016 | Multi-conditioning (label, latent embeddings), work as Image autoencoder, gated-CNN layer | label image | one-hot encoding Gated-CNN | ||
| [97] | PixelCNN-spatial | 2017 | PixelCNN for T2I with controllable object location using segmentation masks or keypoints | caption+segmentation-map/ keypoint-map image | char-CNN-GRU CNN (for seg/keypoint), modified PixelCNN | ||
| [98] | Multiscale PixelCNN | 2017 | Parallel PixelCNN through conditionally independent pixel groups, multiscale image generation, multiple tasks (label-image, T2I, action-video) | caption + keypoint-map, label, action-video image: 512 × 512, video-frame: GRP | char-CNN-GRU ResNet+PixelCNN, Conv-LSTM (for video) | ||
| [99] | CoDraw | 2019 | Collaborative image drawing game for CoDraw dataset, Multiple AI models for depicting Tell-Draw game | caption+previous-image abstract scene | LSTM-attention BiLSTM, Reinforcement learning | ||
| [100] | Text2Scene | 2019 | Seq2seq framework, ConvGRU for recurrent drawing, 2 attention-based decoders, unified framework for 3 generation tasks (cartoon, semantic layout, image) | caption+ previous-image=>layout image: 256 × 256 | BiGRU CNN+ConvGRU (for previous) | ||
| [101] | DALL-E | 2021 | Large pre-trained Autoregressive transformer, zero-shot learning, generates 512 images/caption and selects 1 through CLIP | caption image: 256 × 256 | 256-BPE+CLIP discrete-VAE+ResNet+Transformer [102] | ||
| [103] | CogView | 2021 | Large pre-trained GPT-transformer with VQ-VAE, caption-loss evaluation metric, PB-relaxation and Sandwich-LN to stablize training, zero-shot generation, self-reranking to avoid CLIP | captions image: 256 × 256 | {SentencePiece [104] VQ-VAE}=>GPT | ||
| [105] | ImageBART | 2021 | The hierarchical bidirectional contextualized into autoregressive transformer model, inverting multinomial diffusion by Markov chain, addressing unidirectional and single-scale limitations | caption, label, previous-image image: 256 × 256, 300 × 1800 | CLIP CNN+Markov-Chain + Transformer [39] | ||
| Knowledge Distillation | |||||||
| [106] | SDN | 2018 | T2I using a Distillation network with VGG19 as a teacher and a similar student generative model, 2-stage training with different distillation | caption+real-image image: 224 × 224 | char-CNN-GRU VGG19 | ||
| [107] | CKD | 2019 | Transfer knowledge from image classifier and captioning model, a multi-stage distillation paradigm to adapt to multiple source models | caption+real-image=>caption image: 299 × 299 | Captioning model [108], Text-encoder [43] Inception-v3, VGG19 | ||
| Variational Auto-encoder | |||||||
| [5] | CwGAN | 2016 | Conditional alignDRAW model with soft attention mechanism, post-processing by LAPGAN | caption image: 32 × 32 | BiLSTM-attention LSTM-VAE | ||
| [109] | disCVAE | 2016 | Attribute to Image model, General energy minimization algorithm for posterior inference, separate image foreground, and background with layered VAE | visual attributes image: 64 × 64 | multi-dimension vectors VAE | ||
| [110] | CVAE-cGAN | 2018 | Context-aware stacked cross-model (CVAE, cGAN) framework, CVAE decouples foreground and background while cGAN refines it | caption image:256 × 256 | char-CNN-GRU + CA CVAE-cGAN | ||
| [111] | PNP-Net | 2018 | PNP-Net, a generic canonical VAE T2I framework, with zero-shot learning neural modules for modifying visual appearance of objects | tree-structure description image: 128 × 128 | NMN + LSTM [112] VAE | ||
| [113] | VQ-Diffusion | 2022 | Non-autoregressive Vector-quantized diffusion, VQ-VAE with denoising diffusion model, eliminates unidirectional bias and adds mask-replace diffusion to remove error accumulation | caption, label image: 256 × 256 | BPE-encoding [114] + CLIP (ViT-B) VQ-VAE + Diffusion-transformer [115] | ||
| GAN-based | |||||||
| Direct | |||||||
| Simple | |||||||
| [4] | Conditional GAN | 2014 | Introduction of conditional GAN, unimodal task of class2image, and multimodal task of image-tagging | label, tag image: 28 × 28 | Skip-gram [25], one-hot-vector deep-CNN | ||
| [116] | ITTGAN | 2016 | Solutions to unstable training of GAN, focuses on 2 applications of GAN, introduces IS evaluation metric and human evaluation through MTurk | label image: 128 × 128 | one-hot encoder cGAN | ||
| [7] | GAN-INT-CLS | 2016 | Introduction to GAN model for T2I, matching-aware discriminator, manifold interpolation regularizer for text in generator, showed style-transfer | caption image: 64 × 64 | char-CNN-LSTM DC-GAN | ||
| [117] | AC-GAN | 2017 | Improved training of T2I GAN, label-prediction discriminator, higher-resolution, introduces MS-SSIM evaluation metric, identify GAN issues | label image: 128 × 128, 64 × 64; class-label | one-hot vector AC-GAN | ||
| [118] | TAC-GAN | 2017 | Improving perceptual quality, the generator optimizes contextual and perceptual loss | caption image: 64 × 64 | char-CNN-RNN DC-GAN | ||
| [119] | Perceptual-GAN | 2017 | AC-GAN for T2I | caption, label image: 128 × 128 | Skip-thought DCGAN | ||
| [120] | Text2Shape | 2018 | End-to-End framework for text-to-3D Shape, joint representation for retrieval, generation with conditional wassertein GAN, 2 datasets as Primitives and ShapeNetCore | description voxels: 32 × 32 × 32 | CNN-RNN (GRU) 3D-CNN + Wassertian-GAN | ||
| [121] | HR3D-GAN | 2019 | 2-stage high-resolution GAN model for voxels, critic-net for multiple roles, multiple indices for comparison | description voxels: 64 × 64 × 64 | Text2Shape | ||
| [122] | Intelligent-3DH | 2020 | House-plan-generative model (HPGM), new dataset as Text-to-3D house model, 2-subtasks (floor-plan by GC-LPN, interior textures by LCT-GAN), | description=>scene-graph texture-images: 160 × 160; floor-plan: drawings | Scene-graph-parser [123] Graph-conv-net + Bounding box-regression + text-image-GAN | ||
| [124] | DF-GAN | 2021 | 1-stage T2I for high-resolution, text-image fusion block, skip-z with truncation, target-aware discriminator having matching-aware–gradient-penalty (MA-GP) | caption image: 256 × 256 | Bi-LSTM-Inception-v3 (DAMSM) + CA unconditional GAN (Geometric-GAN) | ||
| Stacked | |||||||
| [32] | StackGAN | 2017 | Stacked-GAN for high-resolution T2I, introduces conditioning augmentation for text, improved details, and diversity | caption image: 256 × 256 | char-CNN-RNN (pre-train) + CA residual-CNN | ||
| [33] | StackGAN++ | 2018 | Multi-stage tree-like GAN design, the t-SNE algorithm used for identifying mode-collapse, stability by multiscale image distribution, and conditional–unconditional joint distribution | caption image: 256 × 256 | char-CNN-RNN (pre-train) + CA residual-CNN | ||
| [125] | FusedGAN | 2018 | 2-fused generators (conditional, unconditional), sampling images with controlled diversity, semi-supervised data for training, avoids additional intermediate information | caption image: 64 × 64 | char-CNN-RNN + CA DC-GAN | ||
| [126] | HDGAN | 2018 | Depth-wise adversarial learning using one hierarchical generator and multiple discriminators, higher resolution, multi-purpose adversarial loss, introduces the VSSM evaluation metric | caption image: 512 × 512 | char-CNN-RNN (pre-train) + CA res-CNN | ||
| [127] | PPAN | 2019 | 1-pyramid generator with 3 discriminators for feed-forward coarse-to-fine generation, perceptual loss for semantic similarity, multi-purpose discriminator for consistency and invariance | caption image: 256 × 256 | char-RNN (pre-train) + CA residual-CNN | ||
| [128] | HfGAN | 2019 | Hierarchically fused GAN with 1 discriminator, generator fuses features based on residual learning, local–global feature separation, skip connection to avoid degradation problem | caption image: 256 × 256 | DAMSM + CA DC-GAN | ||
| Attention | |||||||
| [34] | AttnGAN | 2017 | Attention model for T2I with multi-stage attentional-generative-network (AGN), deep-attentional-multimodal-similarity-model (DAMSM) for image–text matching loss | caption image: 256 × 256 | DAMSM + CA Attn-GAN | ||
| [129] | RIGRA | 2019 | Shows regular-grid region with word-attention causes problems, introduces true-grid attention regions by auxiliary bounding boxes and phrases, considered word phrases | caption image: 256 × 256 | DAMSM + phrase-LSTM + CA Attn-GAN | ||
| [130] | SEGAN | 2019 | Semantic-consistency module (SCM) for image consistency, sliding loss to replace contrastive loss, Attention-competition module (ACM) for adaptive attention weights, Siamese net with 2 semantic similarities | caption image: 256 × 256 | DAMSM + Cross-modal-similarity (ACM) + CA Attn-GAN | ||
| [131] | Control-GAN | 2019 | High quality, controlled part generation, word-level spatial and channel-wise attention-driven generator, word-level discriminator, adoption of perceptual loss | caption image: 256 × 256 | DAMSM + CA AttnGAN | ||
| [132] | MS-GAN | 2019 | Multi-stage attention-modulated generators (AMG), similarity-aware discriminators (SAD) | caption image: 256 × 256 | DAMSM + CA 3-stage GAN | ||
| [133] | ACGAN | 2020 | Attentional concatenation with multilevel cascaded structure, higher resolution, minibatch discrimination for discriminator to increase diversity | caption image: 1024 × 1024 | DAMSM + CA Residual-CNN | ||
| [134] | TVBi-GAN | 2020 | Consistency by 2 semantic-enhanced modules, Semantic-enhanced attention (SEAttn) for realism, Semantic-enhanced batch normalization (SEBN) to balance consistency and diversity | caption image: 256 × 256 | DAMSM + CA Deep-CNN | ||
| [135] | TIME | 2020 | Avoiding pre-trained models by end-to-end Transformer training, and sentence-level text features are 2 unnecessary techniques (2D positional, hinge loss) for better attention and learning paces | caption image: 256 × 256 | Transformer Transformer-modified + AttnGAN | ||
| [136] | DAE-GAN | 2021 | Multiple granuality text representation (sentence, word, aspect), Aspect-aware Dynamic Re-drawer (ADR), ADR from Attended Global Refinement (AGR), and Aspect-aware Local Refinement (ALR) | caption image: 256 × 256 | (LSTM+DAMSM+CA) + NLTK (POS-tagging) Inception_v3 | ||
| Siamese | |||||||
| [137] | Text-SEGAN | 2019 | Focused text semantics by 2 components, Siamese mechanism in discriminator for high-level semantics, semantic-conditioned-batch-normalization for low-level semantics | caption image: 256 × 256 | Bi-LSTM Semantic-Conditioned Batch Normalization (SCBN) | ||
| [138] | SD-GAN | 2019 | Avoids mode-collapse, AC-GAN discriminator measuring semantic relevance instead of class prediction, training triplet with positive–negative sampling to improve training | caption image: 64 × 64 | char-CNN-RNN GAN-INT-CLS | ||
| Knowledge Distillation | |||||||
| [139] | KT-GAN | 2020 | Semantic distillation mechanism (SDM) for teaching text-encoder in T2I through image-encoder in I2I, Attention-transfer mechanism updates word and subregions attention weights | caption image: 256 × 256 | BiLSTM+DAMSM+CA AttnGAN + AATM + SDM-(I2I+T2I) | ||
| [140] | ICSDGAN | 2021 | Interstage knowledge distillation, cross-sample similarity distillation (CSD) blocks | caption image: 256 × 256 | Bi-LSTM [34] MS-GAN [132] | ||
| Cycle Consistency | |||||||
| [141] | PPGN | 2017 | Prior on latent improves quality and diversity, unified probabilistic interpretation of related methods, shows multi-condition generation, improves inpainting, modality-agnostic approach | caption, label, latent image: 227 × 227 | 2-layer LSTM AlexNet DNN, MFV | ||
| [142] | I2T2I | 2017 | Novel training method by T2I-I2T for T2I, 3-module network (image-captioning, image-text mapping, GAN), textual data augmentation by image-captioning module | caption image: 64 × 64 | LSTM Inception_v3 + GAN-CLS | ||
| [143] | MirrorGAN | 2019 | Semantic text-embedding module (STEM), global–local attentive cascaded module (GLAM), semantic text regeneration and alignment module (STREAM), Cross-entropy-based loss | caption image: 256 × 256; caption | DAMSM+CA Attn-GAN, CNN-RNN | ||
| [144] | SuperGAN | 2019 | Adoption of the cycle-GAN framework, 2 main components (synthesis and captioning), cycle-consistent adversarial loss and training strategy, new color-histogram evaluation metric | caption image: 128 × 128; caption | Skip-thought StackGAN, AlexNet-LSTM | ||
| [145] | Dual-GAN | 2019 | Introduction of latent space disentangling of content and style, dual inference mechanism, content learned in a supervised and unsupervised way, style only unsupervised | caption=>latent-space image: 64 × 64 | char-CNN-RNN + CA HDGAN, BiGAN | ||
| Memory | |||||||
| [146] | DM-GAN | 2019 | Dynamic memory-based model for high-quality images when initial image is fuzzy, memory writing gate for selecting relevant word, response gate to fuse image–memory information | caption image: 256 × 256 | parameter-fix-DAMSM + CA KV-MemNN [147] + GAN | ||
| [148] | CPGAN | 2020 | Memory structure to parse textual content during encoding, Memory-Attented Text encoder, Object-aware Image encoder, Fine-grained conditional discriminator | memory+caption image: 256 × 256 | Bi-LSTM + DAMSM + (Yolo_v3+BUTD)=>memory Yolo-v3 + AttnGAN [149] | ||
| Contrastive learning | |||||||
| [150] | Improving-T2I | 2021 | Contrastive learning for semantically consistent visual–textual representation, synthetic image consistency in GAN, flexible to be fitted in previous methods | caption image: 256 × 256 | BiLSTM + DAMSM + contrastive-learning Inception_v3 + (AttnGAN, DMGAN) | ||
| [151] | XMC-GAN | 2022 | Single-stage GAN with several contrastive losses, benchmark on OpenImages dataset | caption image: 256 × 256 | BERT conditional-GAN + VGG | ||
| Unconditional | |||||||
| [152] | Bridge-GAN | 2019 | Transitional space as a bridge for content-consistency, 2 subnetworks (Transitional mapping and GAN), ternary mutual information objective function for optimizing transitional space | caption image: 256 × 256 | char-CNN-RNN Transitional-mapping + GAN | ||
| [153] | ENAT2I | 2020 | Single-stage architecture with 1 G/D using residual net, text image editing via arithmetic operations, sentence interpolation technique for smooth conditional space, and augmentation | caption image: 256 × 256 | modified-DAMSM (BiGRU with global-vector only) + Sentence-Interpolation (SI) Bi-GAN-deep [154] | ||
| [155] | textStyleGAN | 2020 | Unifying pipeline (generation manipulation), a new dataset of CelebTD-HQ with faces and descriptions, pre-trained weight manipulation of textStyleGAN for facial image manipulation | caption, attribute image (T2I and A2I): 256 × 256, 1024 × 1024 | pre-train a Bi-LSTM-CNN-CMPM-CMPC [156] + CA StyleGAN [157] | ||
| [158] | N2NTCIN | 2020 | Reuse of expert model for multimodality, a flexible conditionally invertible-domain-translation-network (cINN), computationally affordable synthesis, and generic domain transfer | caption, attribute image (T2I and A2I): 256 × 256 | BERT BigGAN | ||
| [159] | FuseDream | 2021 | CLIP+GAN space, zero-shot learning, 3-techniques to improve (AugCLIP score, initialization strategy, bi-level optimization) | caption image: 512 × 512 | CLIP + AugCLIP BiGAN | ||
| [160] | LAFITE | 2022 | T2I in various settings (Language-free, zero-shot, and supervised), VinVL [161] as image captioning for T2I, reduced model size | caption image: 256 × 256 | CLIP StyleGAN2 + ViT | ||
| Supervised | |||||||
| Multiple descriptions | |||||||
| [162] | C4Synth | 2018 | Introduced multi-caption T2I, 2 models as C4Synth and Recrrenct-C4Synth, Recurrent model removes caption limitation, also tested for image style transfer | multi-captions image: 256 × 256 | char-CNN-RNN + CA CycleGAN + RecurrentGAN | ||
| [163] | GILT | 2019 | Introduced indirect long-text T2I, comparing 2 embedding types (no-regularize and regularize), NOREG for image generation, REG for classification | sentences (instructions+ingredients) image: 256 × 256 | ACME [164] StackGAN-v2 | ||
| [165] | RiFeGAN | 2020 | Attention-based caption-matching model to avoid conflicts and enrich from prior knowledge, self-attentional embedding mixtures (SAEM) for features from enriching captions, high quality | multi-captions image: 256 × 256 | RE2 [166] + BiLSTM + CA + SAEM + MultiCap-DAMSM AttnGAN | ||
| [167] | MA-GAN | 2021 | Captures semantic correlation between sentences, progressive negative sample selection mechanism (PNSS), single-sentence generation and multi-sentence discriminator module (SGMD) | multi-senteces image: 256 × 256 | AttnGAN + CA AttnGAN | ||
| Dialog | |||||||
| [168] | Chat-Painter | 2018 | High quality using VisDial dialogues and MS-COCO captions, highlights GAN problems (object-centric, mode-collapse, unstable, no end-to-end training) | caption+dialogue image: 256 × 256 | char-CNN-RNN (caption), Skip-Thought-BiLSTM (dialogue) StackGAN | ||
| [169] | GeNeVA | 2019 | Recurrent-GAN architecture~Generative Neural Visual Artist (GeNeVA), new i-CLEVR dataset, new relationship similarity evaluation metric | sequential-text+prev-image image: computer-graphics | GloVe [170] + BiGRU shallow-residual-CNN | ||
| [171] | VQA-GAN | 2020 | Introduced QA with locally related text for T2I, new Visual-QA accuracy evaluation metric, 3-module model (heirarchical QA encoder, QA-conditional GAN, external VQA loss) | Visual-QA+layout+label image: 128 × 128 | 2-level-BiLSTM + CA + DAMSM AttnGAN-EVQA (Global-local pathway) | ||
| [172] | SeqAttnGAN | 2020 | Introduced interactive image editing with sequential multi-turn textual commands, Neural state tracker for previous images and text, 2 new datasets such as Zap-Seq and DeepFashion-Seq | image, sequential-interaction image: 64 × 64 | Bi-LSTM + RNN-GRU + DAMSM modified-AttnGAN (multi-scale joint G-D) | ||
| [173] | VQA-T2I | 2020 | Combining AttnGAN with VQA [174] to improve quality and image–text alignment, utilizing VQA 2.0 dataset, create additional training samples by concatenating QA pairs | caption+QA image: 256 × 256 | Bi-LSTM + DAMSM AttnGAN + VQA [174] | ||
| Layout | |||||||
| [43] | GAWWN | 2016 | Text-location control T2I for high-resolution, text-conditional object part completion model, new dataset for pose-conditional text–human image synthesis | caption+Bounding box/ keypoint image: 128 × 128 | char-CNN-GRU (average of 4 captions) Global-local pathway | ||
| [175] | GMOSDL | 2019 | Fine-grained layout control by iterative object pathway in generator and discriminator, only bounding box and label used for generation, added discriminator for semantic location | (caption+label)=>layout image: 256 × 256 | char-CNN-RNN + one-hot vector + CA (StackGAN+AttnGAN) + STN [176] | ||
| [177] | OP-GAN | 2020 | Model having object-global pathways for complex scenes, new evaluation metric called Semantic object accuracy (SOA) based on pre-trained object detector | (caption+label)=>layout image: 256 × 256 | RNN-encoder + DAMSM AttnGAN | ||
| [178] | OC-GAN | 2020 | Scene-graph similarity module (SGSM) improves layout fidelity, mitigates spurious objects and merged objects, conditioning instance boundaries generates sharp objects, new SceneFID evaluation metric | scene-graph+boundry-map +layout image: 256 × 256 | GCN [179] + Inception-v3 SGSM | ||
| Semantic-map | |||||||
| [180] | ISLHT2I | 2018 | Heirarchical approach for T2I inferring semantic layout, improves image–text semantics, sequential 3-step image generation (bbox-layout-image) | caption=>(label+bbox)=>mask image: 128 × 128 | char-CNN-RNN LSTM with GMM [181], Bi-convLSTM [182], Generative-model [183] | ||
| [184] | Obj-GAN | 2019 | Object-centered T2I with layout-image generation, object-driven attentive generator, new fast R-CNN-based object-wise discriminator, improved complex scenes | caption=>(label+bbox) =>shape image: 256 × 256 | Bi-LSTM + DAMSM + GloVe attentive-seq2seq [185], Bi-convLSTM, 2-Stage GAN | ||
| [186] | LeicaGAN | 2019 | Textual–visual co-embedding network (TVE) containing text–image and text–mask encoder, mulitple prior aggregation net (MPA), cascaded attentative generator (CAG) for local–global features | caption=>mask image: 299 × 299 | Bi-LSTM Inception-v3 | ||
| [187] | CSSW | 2020 | Introduced weakly supervised approach, 3 inputs (maps, text, labels), foreground–background generation, resolution-independent attention module, semantic-map to label maps by the object detector | caption+attributes +semantic-map image: 256 × 256 | BERT, bag-of-embeddings (class+attribute) SPADE [188] | ||
| [189] | AGAN-CL | 2020 | Model to improve realism, the generator has 2 sub-nets (contextual net for generating contours, cycle transformation autoencoder for contour-to-images), injection of contour in image generation | caption=>contour image: 128 × 128 | CNN-RNN VGG16, Cycle-transformation-autoencoder ([190] + ResNet) | ||
| [191] | T2ISC | 2020 | End-to-End T2I framework with spatial constraints targetting multiple objects, synthesis module taking semantic and spatial information to generate an image | caption=>layout image: 256 × 256 | BiLSTM Multi-stage GAN | ||
| Scene-graph | |||||||
| [192] | Sg2Im | 2018 | Introduced Scene-graph-to-image, graph-convolution net for processing input, generates layout by Bounding box and segmentation mask, cascaded-refinement net for layout-to-image | scene-graph=>layout image: 64 × 64, 128 × 128 | Scene-graph [123] Graph-convolution-Net (GCN) + Layout-prediction-Net (LPN) + Cascaded-refinement-net(CRN) [193] | ||
| [194] | IIGSG | 2019 | Interactive image generation from incrementally growing scene-graph, recurrent architecture for Sg2Im generation, no–intermediate supervision required | expanding-scene-graph =>layout image: 64 × 64 | Scene-graph [195] Recurrent (GCN + LPN + CRN) | ||
| [196] | Seq-SG2SL | 2019 | Transformer-based model to transduce scene-graph and layout, Scene-graph for semantic-fragments, brick-action code segments (BACS) for semantic-layout, new SLEU evaluation metric | scene-graph => SF semantic-layout | Scene-graph [197] (SF+BACS => layout ) + Transformer | ||
| [198] | SOAR | 2019 | Dual embedding (layout–appearance) for complex scene-graphs, diverse images controllable by user, 2 control modes per object, new architecture and loss-terms | scene-graph=>mask=>layout image: 256 × 256 | Scene-graph [195] Autoencoder | ||
| [199] | PasteGAN | 2019 | Object-level image manipulation through scene-graph and image-crop as input, Crop-Reining-Net and Object–Image Fuser for object interactions, crop-selector for compatible crops | scene-graph=>object-crops image: 64 × 64 | Scene-graph [195] GCN + Crop-selector + crop-refining-net + object-image-fuser + CRN | ||
| [200] | stacking-GAN | 2020 | Visual-relation layout module using 2 methods (comprehensive and individual), 3-pyramid GAN conditioned on layout, subject–predicate–object relation for localizing Bounding boxes | scene-graph=>layout image: 256 × 256 | Scene-graph [195] GCN + comprehensive-usage-subnet + RefinedBB2Layout + conv-LSTM + GAN (CRN) | ||
| [201] | VICTR | 2020 | Example of text-to-scene Graph, new visual–text representation information for T2I, text representation also for T2Vision multimodal task | caption=>scene-graph image: 256 × 256 | Parser [202] + GCN AttnGAN, StackGAN, DMGAN | ||
| Mouse-traces | |||||||
| [203] | TReCS | 2021 | Sequential model using grounding (mouse-traces), segmentation image generator for the final image, descriptions retrieve segmentation masks and predict labels aligned with grounding | mouse-traces+segmentation- mask + narratives image: 256 × 256 | BERT Inception-v3 | ||
| Static (Image) | Manipulation | Autoregressive | |||||
| [204] | LBIE | 2018 | Generic framework for text-image editing (segmentation and colorization), recurrent attentive models, region-based termination gate for fusion process, new CoSaL dataset | image+description image: 512 × 512, 256 × 256 | Bi-LSTM (GRU-cells) VGG, CNN | ||
| [205] | LDIE | 2020 | Language-request (vague, detailed) image editing task for local and global, new GIER dataset, baseline algorithm with CNN-RNN-MAttNet | image+description image: 128 × 128 (training), variable | Bi-LSTM ResNet18 + MattNet [206] | ||
| [207] | T2ONet | 2021 | Model for interpretable global editing operations, operation planning algorithm for operations and sequence, new MA5k-Req dataset, the relation of pixel supervision and Reinforcement Learning (RL) | image+description image: 128 × 128 (training), variable | GloVe + BiLSTM ResNet18 | ||
| GAN-based | |||||||
| Local | |||||||
| Direct | |||||||
| [208] | SISGAN | 2017 | Image manipulation using GAN (realistic, text-only changes), end–end architecture with adversarial learning, a training strategy for GAN learning | image+caption image: 64 × 64 | OxfordNet-LSTM [209] + CA VGG | ||
| [210] | TAGAN | 2018 | Text-adaptive discriminator for word-level local discriminators of text-attributes | image+caption image: 128 × 128 | training BiGRU + CA + fastText [30] SISGAN | ||
| [211] | FiLMedGAN | 2018 | cGAN model (FiLMedGAN) using Feature-wise Linear Modulation (FiLM [212]), feature transformations and skip-connections with regularization | image+caption image: 128 × 64 | fastText + GRU VGG-16, SISGAN | ||
| [213] | TEA-cGAN | 2019 | Two-sided attentive cGAN architecture with fine-grained attention on G/D, 2-scale generator, high resolution, Attention-fusion module | image+caption image: 256 × 256 | BiLSTM + fastText AttnGAN | ||
| [214] | LBIE-cGAN | 2019 | Language-based image editing (LBIE) with cGAN, conditional Bilinear Residual Layer (BRL), highlights representation learning issue for 2-order correlation between 2 conditioning vectors in cGAN | caption+caption image: 64 × 64 | OxfordNet-LSTM [209] VGG, SISGAN | ||
| [215] | ManiGAN | 2020 | 2 key modules (ACM and DCM), ACM correlates text-relevant image regions, DCM rectifies mismatch attributes and completes missing ones, new manipulative-precision evaluation metric | image+caption image: 256 × 256 | RNN (TAGAN, AttnGAN) Inception-v3 + ControlGAN | ||
| [216] | DWC-GAN | 2020 | Textual command for manipulation, 3 advantages of commands (flexible, automatic, avoid need-to-know-all), disentangle content and attribute, new command annotation for CelebA and CUB | text-command+image image: 128 × 128 | LSTM + Skip-gram-fastText GMM-UNIT [217] | ||
| Intermediate supervision | |||||||
| [218] | MC-GAN | 2018 | Image manipulation as foreground–background by generating a new object, introduces synthesis block | image+caption+mask image: 128 × 128 | char-CNN-RNN + CA StackGAN | ||
| [219] | TGPIS | 2019 | Text-guided GAN-based pose inference net, new VQA-perceptual-score evaluation metric, 2-stage framework (pose-to-image) using attention-upsampling and multi-modal loss | image+pose+caption image: 256 × 256 | BiLSTM Pose-encoder [220], CNN | ||
| [221] | LWGAN | 2020 | Word-level discriminator for image manipulation, word-level supervisory labels, lightweight model with few parameters | image+caption image: 256 × 256 | BiLSTM + CA + ACM + attention (spatial-channel) + PoS-tagging Inception-v3 + VGG-16 | ||
| [222] | TDANet | 2021 | Text-guided dual attention model for image inpainting, inpainting scheme for different text to obtain pularistic outputs | corrupt-image+caption image: 256 × 256 | GRU (AttnGAN) ResNet | ||
| Latent space | |||||||
| [223] | StyleCLIP | 2021 | 3-techinques for CLIP+StyleGAN (text-guided latent-optimizer, latent-residual-mapper, global-mapper) | image+caption/attribute image: 256 × 256 | CLIP + prompt-engineering [224] StyleGAN | ||
| Cyclic | |||||||
| [225] | TGST-GAN | 2021 | Style transfer-based manipulation from 3 components (captioning, style generation, style-transfer net), module-based generative model | image+caption=>caption =>style-image image: - | LSTM + AttnGAN ResNet101 + AttnGAN + VGG19 | ||
| Global | |||||||
| [226] | LGEIT | 2018 | Global image editing with text, 3 different models (hand-crafted bucket-based, pure ended-end, filter-bank), Graph-RNN for T2I, a new dataset | image+caption image: - | GloVe + BiGRU, Graph-GRU [227] cGAN, GAN-INT-CLS, StyleBank [228] | ||
| Both | |||||||
| [229] | TediGAN | 2021 | A unified framework for generation and manipulation, a new Multi-modal Celeb-HQ dataset, GAN-inversion for multi-modalities (text, sketch, segmentation-map) | caption, sketch, segmentation-mask, image image: 1024 × 1024 | Text-encoder (RNN) + Visual-linguistic-similarity StyleGAN | ||
| Consistent (Stories) | Generation | Autoregressive | |||||
| [230] | C-SMART | 2022 | Introduced a Bidirectional generative model using multi-modal self-attention on long-text and image as input, cyclically generated pseudo-text for training (text–image–text), high resolution | story (sequence-of-sentences) +image image-sequences: 128 × 128 | Transformer VQ-VAE + Recurrent-transformer (with gated memory) | ||
| GAN-based | |||||||
| Basic | |||||||
| [231] | StoryGAN | 2019 | Sequential-GAN consists of 3 components (story-encoder, RNN-based context encoder, GAN), Text2Gist module, 2 new datasets (Pororo-SV and CLEVR-SV) | story image-sequences: 64 × 64 | (USE [232])-story_level + (MLP + CA + GRU + Text2Gist)-sentence_level RNN-(Text2Gist) + Seq-GAN (2-discriminators as story and image) | ||
| [31] | PororoGAN | 2019 | Aligned sentence encoder (ASE) and attentional word encoder (AWE), image patches discriminator | story image-sequences: 64 × 64 | StoryGAN | ||
| [233] | Improved-StoryGAN | 2020 | Weighted activation degree (WAD) in discriminator for local–global consistency, dilated convolution for the limited receptive field, gated convolution for initial story encoding with BiGRU | story image-sequences: 64 × 64 | USE-Gated_convolution (story-level) + BiGRU-Text2Gist (sentence-level) Dilated-convolution [234] | ||
| Supervised | |||||||
| [235] | CP-CSV | 2020 | Character preserving framework for StoryGAN, 2 text-encoders for sentence and story-level input, 3 discriminators (story, image, figure segmentation), new FSD evaluation metric | story=>segmentation-maps image-sequences: 64 × 64 | StoryGAN + Object-detection-model [236] | ||
| Captioning | |||||||
| [237] | DUCO-StoryGAN | 2021 | Dual learning via video redescription for semantic alignment, copy transform for a consistent story, memory augmented recurrent transformer, Evaluation metrics (R-precision, BLEU, F1-score) | story image-sequences: 64 × 64 | CA + (MART [238] + GRU)~context-encoder 2-stage GAN + copy-transform | ||
| [239] | VLC-StoryGAN | 2021 | Model using text with commonsense, dense-captioning for training, intra-story contrastive loss between image regions and words, new FlintstonesSV dataset | story image-sequences: 64 × 64 | GloVe + (MARTT+CA) + (ConceptNet [240] + Transformer-graph [241]) 2-stage GAN + Video-captioning [242] | ||
| Dynamic (Video) | Generation | Autoregressive (Retrival, dual-learning) | |||||
| [243] | CRAFT | 2018 | Sequential training of Composition-Retrival-and-Fusion net (CRAFT), 3-part model (layout composer, entity retriever, background retriever), new dataset of FlintStones | caption=>layout =>entity-background retrival video: 128 × 128; frames: 8 | BiLSTM CNN, MLP | ||
| [244] | CMDL | 2019 | End-to-End crossmodal dual learning, dual mapping structure for bidirectional relation as text–video–text, multi-scale text-visual feature encoder for global and local representations | description=>video=> decription video: - | LSTM, (GloVe + BiLSTM [245]) 3D-CNN [246] + VGG19 | ||
| [247] | SA3D | 2020 | 2-stage pipeline for static and animated 3D scenes from text, new IScene dataset, new multi-head decoder to extract multi-object features | description=>Layout video: computer-graphics | TransformerXL [248] (LSTM + Attn-BLock) + Blender [249] | ||
| Variational Auto-Encoder | |||||||
| [250] | Sync-DRAW | 2017 | Introduced T2V task by attentive recurrent model, 3 components (read-mechanism, R-VAE, write-mechanism), a new dataset of Bouncing MNIST video with captions, and KTH with captions | caption, prev-frame video: 64 × 64, 120 × 120; frames: 10, 32 | Skip-thought [251] LSTM+VAE | ||
| [252] | ASVG | 2017 | Text–video generation from long-term and short-term video contexts, selectively combining information with attention | caption, prev-frame video: 64 × 64, 120 × 120; frames: 10, 15 | BiLSTM-attention ConvLSTM+VAE | ||
| [253] | T2V | 2017 | Hybrid text–video generation framework with CVAE and GAN, a new dataset from Youtube, intermediate gist generation helps static background, Text2Filter for dynamic motion information | caption video: 64 × 64; frames: 32 | Skip-thought CVAE+GAN | ||
| [254] | GODIVA | 2021 | Large text–video pretrained model with 3-dimensional sparse attention mechanism, new Relative matching evaluation metric, zero-shot learning, auto-regressive prediction | caption video: 64 × 64, 128 × 128; frames: 10 | positional-text-embeddings VQ-VAE | ||
| GAN-based | |||||||
| [255] | TGANs-c | 2018 | Temporal GAN conditioned on the caption (TGAN-c), 3-discriminators (video, frame, motion), training at video-level and frame-level with temporal coherence loss | description video: 48 × 48; frames: 16 | BiLSTM-words + LSTM-sentence Deconv-cGAN (3-discriminators: video, frame, motion) | ||
| [256] | IRC-GAN | 2019 | Recurrent transconvolutional generator (RTG) having LSTM cells with 2D transConv net, Mutual-information introspection (MI) for semantic similarity in 2 stages | description video: 64 × 64; frames: 16 | one-hot-vector + BiLSTM + LSTM-encoder LSTM + TransConv2D + cGAN | ||
| [257] | TFGAN | 2019 | Multi-scale text-conditioning on the discriminative convolutional filter, a new synthetic dataset for text–video modality | description video: 128 × 128; frames: 16 | CNN + GRU-recurrent modified-MoCoGAN | ||
| [258] | Latent-Path | 2021 | Introduced T2V generation on a real dataset, discriminator with single-frame (2D-Conv) and multi-frame (3D-Conv), and Stacked-pooling block for generating frames from latent representations | description video: 64 × 64; frames: 6, 16 | BERT 2D/3D-CNN + stacked-upPooling | ||
| [259] | TiVGAN | 2021 | Text-to-image-to-video GAN (TiVGAN) framework, 2-stage model (T2I and frame-by-frame generation), training stabilization techniques (independent sample pairing, 2-branch discriminator) | description=>image video: 128 × 128; frames: 22 | Skip-thought+PCA GAN-INT-CLS+GRU | ||
| Manipulation | GAN-based | ||||||
| [260] | M3L | 2022 | Introduced language-based video editing task (LBVE), Multi-modal multi-level transformer for text–video editing, 3 new datasets (E-MNIST, E-CLEVR, E-JESTER) | description+video video: 128 × 128; frames: 35 | RoBERTa [261] 3D ResNet | ||
| Name | Year | Designed for | Source | Stats | Annotations | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Approx. Size (GB) | Quantity | Quality | ||||||||
| Training | Validation | Testing | Total | Approx. Resolution (px) | ||||||
| Image data | ||||||||||
| Animal datasets | ||||||||||
| AwA2 [316] | 2018 | Transfer-learning | AwA [317], Internet (Flicker, Wikipedia) | 13 | 20,142 | 9698 | 7460 | 37,300 | - | 85 binary-continuous class attributes |
| AFHQ [318] | 2021 | Image-to-Image translation | Flicker, Pixabay | 0.3 | 13,500 | - | 1500 | 15,000 | 512 × 512 | 3-domain (cat, dog, wildlife), breed information |
| Digit datasets | ||||||||||
| SVHN [319] | 2011 | Object-recognition, Text–natural_image learning | Google Street View | 2.3 | 604,388 | - | 26,032 | 630,420 | 32 × 32 | 10 classes, character-level Bounding box, multi-digit representation |
| MNIST [63] | 1998 | Pattern-recognition | NIST | 0.1 | 60,000 | - | 10,000 | 70,000 | 28 × 28 | 0–9 labels, 1 digit/image |
| MNIST-CB [320] | 2018 | Pattern-recognition | MNIST | - | 50,000 | - | 10,000 | 60,000 | 256 × 256 | 0–9 labels, 1 digit/image |
| Color-MNIST [111] | 2018 | MNIST | - | 8000 | - | 8000 | 16,000 | 256 × 256 | 2 digits/image, 2 sizes, 6 colors, 4 relations | |
| Multi-MNIST [175] | 2019 | MNIST, AIR [321] | 0.202 | 50,000 | - | 10,000 | 60,000 | 256 × 256 | 3 digits/image, labels, layout-encoding, split_digits | |
| Object-centric datasets | ||||||||||
| Oxford-102 [322] | 2009 | Image-Classification, Fine-grain Recognition | Internet | 0.5 | 7034 | - | 1155 | 8189 | - | 102 categories, chi2-distance, labels, segmentation-mask, low-level (color, gradient-histogram, SIFT), 10 captions/image [43] |
| CUB-2010 [323] | 2010 | Subordinate categorization | Flicker | 0.7 | 3000 | - | 3033 | 6033 | - | Bounding Box, Rough Segmentation, Attributes, labels, 10 captions/image [43] |
| black CUB-2011 [323] | 2011 | 1.2 | 8855 | - | 2933 | 11,788 | - | 200-categories, 15 Part Locations, 312 Binary Attributes, 1 Bounding Box, labels, 10 captions/image [43], text commands [216] | ||
| Application datasets | ||||||||||
| GRP [324] | 2016 | Real-world interaction learning | Ten 7-DOF robot arms pushing | 137 | 54,000 | 1500 | 1500 | 57,000 | 640 × 512, 256 × 256 | Robot joint-angle, gripper-pose, commanded gripper-pose, measured torques, images, 3–5 sec videos |
| Robotic-videos [325] | 2018 | Visuomotor policies | Camera recordings, commands | 4.7 | - | - | - | 10,003 | - | 10 fps, avg. 20 sec videos, 3 angles, 3 cameras, attention map, pick–push task |
| Facial datasets | ||||||||||
| LFW [326] | 2007 | Face-recognition | Faces-in-the-wild [327], Viola-Jones [328] | 1.5 | 2200 | - | 1000 | 13,233 ~total | 250 × 250 | 4 categories (original, 3 aligned), labels, names |
| CelebA [329] | 2015 | Facial-attribute learning | CelebFaces [330] | 23 | 160,000 | 20,000 | 20,000 | 200,000 | Original, 218 × 178 | Bounding boxes, Landmarks, Attributes, Identity, text commands [216] |
| CelebA-HQ [281] | 2018 | High-quality Facial-learning | CelebA | 28 | - | - | - | 30,000 | 1024 × 1024 | + high quality |
| FFHQ [157] | 2019 | Facial-learing | Flicker, MFA-ERT [331] | 1280 | 60,000 | 10,000 | - | 70,000 | Original, 1024 × 1024, 128 × 128 | unsupervised high-level face attributes |
| CelebTD-HQ [155] | 2020 | Text-to-faces | Celeb-HQ | - | 24,000 | - | 6000 | 30,000 | 1024 × 1024 | + 10 descriptions/image |
| Multi-modal CelebA-HQ [229] | 2021 | Text-guided Multi-modal generation | 20 | 24,000 | - | 6000 | 30,000 | 1024 × 1024, 512 × 512 | + 10 descriptions/image, label map, sketches | |
| Long-text datasets | ||||||||||
| VQA [332] | 2015 | Visual-reasoning | MS-COCO, Abstract-Scenes | - | 102,783 | 50,504 | 101,434 | 254,721 | - | 5 captions, 3 questions/image, 10 answers/image |
| VQA-2.0 [288] | 2017 | MS-COCO, Abstract-Scenes, Binary-Abstract-Scenes [333] | - | 443,000 | 214,000 | 453,000 | 1,110,000 | - | + 3 question/image, 10 answer/question, image–question–answer pair | |
| Recipe1M [334] | 2017 | High-capacity Multi-modal learning | ~24 cooking websites | 135 | 619,508 | 133,860 | 134,338 | 887,706 | - | 1M recipes (ingredients + instructions), title, labels |
| Synthetic datasets | ||||||||||
| Abstract Scenes [335] | 2013 | Semantic-information (vision-language) | 58-category clip-arts | 0.8 | 8016 | - | 2004 | 10,020 | - | 58 classes, person attributes, co-occurrence, absolute spatial location, relative spatial location, depth ordering |
| CoDraw [336] | 2019 | Goal-driven human–machine interaction | Abstract-Scenes, LViS [94], VisDial [285] | 1 | 7989 | 1002 | 1002 | 9993 | - | + dialogues, utterance–snapshot pairs |
| CLEVR [337] | 2016 | Visual-reasoning | Computer-generated CLEVR-universe | 19 | 70,000 | 15,000 | 15,000 | 100,000 | 224 × 224 ~unclear | Q-A, Scene-graphs, Functional-program |
| i-CLEVR [169] | 2019 | 10 | 30,000 | 10,000 | 10,000 | 50,000 | - | + sequence of 5 image–instruction pairs | ||
| CLEVR-G [111] | 2018 | CLEVR-(256 × 256) images | 0.06 | 10,000 | - | 10,000 | 20,000 | 256 × 256 | + still images | |
| CLEVR-SV [231] | 2019 | Text-to-visual story | CLEVR | - | 10,000 | - | 3000 | 13,000 | 320 × 240 | 4 objects/story, metallic/rubber objects, 8 colors, 2 sizes, 3 shapes |
| Anime [338] | 2021 | Machine-learning | DANBOORU-2021 [339] | 265 | - | - | - | 1,213,000 | 512 (w,h) | hand Bounding boxes, faces, figures, hand |
| Real-world datasets | ||||||||||
| PASCAL-VOC2007 [340] | 2007 | Object-detection, Classification, Segmentation | Flicker | 1 | 2501 | 2510 | 5011 | 10,022 | 2 classes, viewpoint, Bounding box, occlusion/truncation, difficult, segmentation (class, object), person layout, user tags [341] | |
| black MIR-Flicker25k [342] | 2008 | Classification, Retrival | 3 | 15,000 | - | 10,000 | 25,000 | Original | multi-level labels, manual tags, EXIF | |
| MIR-Flicker-1M [343] | 2010 | 12 | - | - | - | 100,000 | Original, 256 × 256 | + “user-tags”, Pyramid histogram of words [344], GIST [345], MPEG-7 descriptors [346] | ||
| black CIFAR-10 [347] | 2009 | Image generation | Internet (Google, Flicker, Altavista), WordNet [348] | 0.2 | 50,000 | - | 10,000 | 60,000 | 32 × 32 | 10 classes, labels |
| LSUN [349] | 2015 | Google-images, Amazon-Mechanical-Turk (AMT), PASCAL-VOC-2012 [350], SUN [351] | 1736 | - | - | - | 60,000,000 | 256 (w,h) | 10 scenes, 20 objects, labels | |
| YFCC100M [352] | 2016 | Computer vision | Flicker | 15 | - | - | - | 99,206,564 (image), 793,436 (video) | - | user tags, pictures, and videos, geographic location, extraction timespan, camera info |
| black ILSVRC: ImageNet [353] | 2017 | Classification, Retrival, Detection, Feature extraction | Internet, WordNet [348] | 166 | 1,281,167 | 50,000 | 100,000 | 14,197,122 ~total | 400 × 350 | Bounding boxes, SIFT features, labels, synets |
| MS-COCO [354] | 2015 | Detection, segmentation | Flickr | 25 | 165,482 | 81,208 | 81,434 | 328,124 | - | Pixel-level segmentation, 91 object classes, 5 descriptions, panoptic, Instance spotting, Bounding boxes, Keypoint detection, dense pose, VisDial dialogue, Scene graphs |
| COCO-stuff [355] | 2018 | Background in computer vision | MS-COCO | 21 | 118,490 | 5400 | 40,900 | 164,790 | - | + stuff_labels |
| LN-COCO [294] | 2020 | Multimodal tasks (vision–language), image captioning | 7 | 134,272 | 8573 | - | 142,845 | - | captions, speech, groundings (mouse-trace) | |
| CC3M [356] | 2018 | Image-captioning | Flumejava [357] | 0.6 | 3,318,333 | 28,000 | 22,500 | 3,368,833 | 400 (w,h) | image–caption pair, labels, |
| VG [197] | 2017 | Cognitive-task | MS-COCO, YFCC100M | 15 | - | - | - | 108,077 | 500~width | Region-descriptions, Objects, Attributes, Relationships, Region-graphs, Scene-graphs, Q-A pairs |
| black VG+ [187] | 2020 | VG | - | - | - | - | 217,000 | - | - | |
| OpenImages [358] | 2020 | Image classification | Flicker | 565 | 9,011,219 | 41,620 | 125,436 | 9,178,275 | 1600 × 1200, 300,000-px | Class-labels, image-labels, Bounding boxes, visual relation annotation |
| LN-OpenImages [294] | 2020 | Multimodal tasks (vision-language) | OpenImages | 21 | 507,444 | 41,691 | 126,020 | 675,155 | - | captions, speech, groundings (mouse-trace) |
| LAION-400M [359] | 2021 | Multi-modal Lanuage-vision learning | Common-Crawl [360] | 11,050 | - | - | - | 413,000,000 | 1024, 512, 256 | image–caption pair |
| 3D datasets | ||||||||||
| Primitive Shapes [120] | 2018 | Text-to-3D_shape | Voxilizing 6-type primitives | 0.05 | 6048 | 756 | 756 | 7560 | 32 × 32 | synthetic 255 descriptions/primitive, 6 shape labels, 14 colors, 9 sizes |
| ShapeNetCore [120] | ShapeNet [361], AMT | 11 | 12,032 | 1503 | 1503 | 15,038 | 32 × 32, 256 × 256, 128 × 128 | 5 descriptions/shape, color voxelization (suface, solid), 2 categories (table, chair) | ||
| Text–to–3D House Model [122] | 2020 | House-planning | - | 1 | 1600~houses, 503~textures | - | 400~houses, 370~textures | 2000~houses, 873~textures | avg. 6 rooms/house, 1 description, textures_images | |
| IScene [247] | 2020 | Text-to-3D video generation | Computer generated | - | 100,000~static 100,000~animated | 5000~static 5000~animated | 6400~static 6400~animated | 1,300,000~static 1,400,000~animated | - | 13 captions/static scene, 14 captions/animated |
| Editing datasets | ||||||||||
| ReferIt [362] | 2014 | Natural language referring the expression | ImageCLEF IAPR [363], SAIAPR TC-12 [364] | 3 | 10,000 | - | 9894 | 19,894 | - | 238 object categories, avg. of 7 descriptions/image, labels, segmenation maps, object attributes |
| black Fashion-synthesis [365] | 2017 | Text-based image editing | DeepFashion | 8 | 70,000 | 8979 | 78,979 | 256 × 256 | descriptions, labels (gender, color, sleeve, category attributes), segmentation maps, Bounding boxes, dense pose, landmark | |
| CoSaL [204] | 2018 | Language-Based Image Editing | Computer-generated | - | 50,000 | - | 10,000 | 60,000 | - | 9 shapes, descriptions (direct, relational) |
| Global-edit-Data [226] | 2018 | Global Image editing | AMT, MIT-Adobe-5K [366] | - | 1378 | 252 | 252 | 1882 | - | original edit pair, transformation rating, phrase description of transformation |
| Zap-Seq [172] | 2020 | Interactive image editing | UT-Zap50K [367] | - | - | - | - | 8734 | - | 3–5 image sequences, shoes, attributes, multi-captions |
| DeepFashion-Seq [172] | 2020 | Deepfashion [368] | - | - | - | - | 4820 | - | clothes, attributes, 3-5 image sequences, multi-captions | |
| GIER [205] | 2020 | Language-Based Image Editing | Zhopped.com [369], Reddit.com [370], AMT, Upwork | 7.5 | 4934 | 618 | 618 | 6170 | 128 × 128, 300 × 500 | 5 language_requests, 23 editing operations, masks |
| MA5k-Req [207] | 2021 | Image editing | AMT, MIT-Adobe-5K [366] | 9.5 | 17,325 | 2475 | 4950 | 24,750 | - | 5 edits/image, 1 description/image |
| Story datasets | ||||||||||
| VIST [371] | 2016 | Sequential vision-to-language | YFCC100M, AMT, Stanford CoreNLP [227] | 320 | 40,108 | 5013 | 5013 | 50,136~stories | - | 5-image/story, 1-caption/image |
| PororoQA [372] | 2017 | Visual question answering | Pororo, AMT | 11.5 | 103~episodes, 5521~QA | 34~episodes, 1955~QA | 34~episodes, 1437~QA | 171~episodes, 8913~QA | - | 40-s video/story (408-movies), multi-captions/1-s video, multi-QA/story, 13-characters |
| black Pororo-SV [231] | 2019 | Text-to-visual story | PororoQA | - | 13,000 | - | 2336 | 15,336 | - | 1-description/story, 5-image/story |
| Video datasets | ||||||||||
| TRECVID’03 news [373] | 2003 | Video information retrieval | ABC World News Tonight, CNN headline news, C-SPAN programs | - | 127~h | - | 6~h | 133~h | - | Story segmentation, 17 features, shot separations, (1894 binary word/ video-shot, 166 HSV color correlogram [92]) |
| black FlintstonesSV [239] | 2021 | Sequential vision-to-language | FlintStones Dataset | 5 | 20,132 | 2071 | 2309 | 24,512 | - | + 7 characters, 5 images/story |
| FlintStones Dataset [243] | 2018 | Video caption perceptual reasoning, semantic scene generation | Flintstones, AMT | 128 | 20,148 | 2518 | 2518 | 25,184 | - | 3 sec clip (75 frames), Bounding boxes, segmentation maps, 1-4 sentence descriptions/video, clean background, labels |
| MSVD [374] | 2011 | Machine paraphrasing | Youtube, AMT | 1.7 | 1773 | - | 197 | 1970 | - | avg. 40 descriptions/video, 4–10 sec video, multi-lingual descriptions |
| MSR-VTT [375] | 2016 | Text–video embedding | Internet, AMT | 6 | 6513 | 497 | 2990 | 10,000 | original, 320 × 240 | 30 fps, 20 captions/video, 41.2 h video, 20 categories |
| Text-to-video-dataset [253] | 2017 | Youtube, KHAV [376] | - | 2800 | 400 | 800 | 4000 | original, 256 × 256 | SIFT-keypoints, 25 fps, 10 categories, 400 videos/category, title and description | |
| Epic-Kitchen [377] | 2018 | Egocentric Vision | Camera recordings, AMT, Youtube caption tool | 740 | 272 | - | 106~seen, 54~unseen | 432 | 1920 ×1080 | 60 fps, object bounding boxes, action segmentation, multi-lingual sound recordings, 1–55 min variable duration |
| Howto100M [310] | 2019 | Text–video embedding | Youtube, WikiHow | 785 | - | - | - | 1,220,000 | original, 256 (w,h) | caption, avg. 110 clip–caption pairs/video, 12 categories |
| Moving Shapes (v1,v2) [257] | 2019 | Computer-generated | - | 129,200 | - | 400 | 129,600 | 256 × 256 | 3 shapes, 5 colors, 2 sizes, 3 motion types, 16 frames/video, 1 caption/video | |
| Bouncing MNIST [250] | 2017 | Text–video generation | Bouncing MNIST | - | 10,000 | 2000 | - | 12,000 | 256 × 256 | single-digit, 2-digit, labels, caption, 10 frames/video |
| Video editing datasets | ||||||||||
| E-CLEVR [260] | 2022 | Text-based video editing | CLEVR, CATER [378] | - | 10,133 | - | 729 | 10,862 | 128 × 128 | 20 fps, avg. 13 words/caption, source target video |
| E-JESTER [260] | 2022 | 20BN-JESTER [379], AMT | - | 14,022 | - | 885 | 14,907 | 100 × 176 | 4 fps, 27 classes, avg. 10 words/caption | |
| E-MNIST [260] | 2022 | moving-MNIST | - | 11,070 | - | 738 | 11,808 | 256 × 256 | Source target video, 2 types (S-MNIST, D-MNIST), 30 fps, avg. 5.5 word/caption, | |
| Human action datasets | ||||||||||
| MHP [380] | 2014 | Pose estimation | YouTube videos | 13 | 28,821 | - | 11,701 | 40,522 | - | body–joint positions, torso–head 3D orientations, joint and body part occlusion labels, 491 activity labels, 3 captions/image [381] |
| black KTH-Action [382] | 2004 | Action recognition | Camera recordings | - | 770 | 766 | 855 | 2391 | 160 × 120 | 6 actions, 25 people, 25 fps, 4 sec video, 4 scenarios, caption-SyncDRAW [250], caption-KTH-4 [256] |
| black MUG [383] | 2010 | Facial understanding | Camera images | 38 | - | - | - | 204,242 | 896 × 896 | 86 subjects, 80 facial landmarks, 7 emotions, 19 fps, direct emotions FACS [384], video induced emotions |
| black UCF-101 [314] | 2012 | Human action recognition | UCF50 [385], YouTube | 127 | 13,320 | 2104 | 5613 | 21,037 | 320 × 240 | 101 classes in 5 types, STIP features, 7.2 sec video avg., 25 fps, 25 groups/action, dynamic background, Bounding boxes, class attributes |
| black A2D [386] | 2015 | Youtube | 20 | 3036 | - | 746 | 3782 | - | avg. 136 frames, 7 actors, 8 actions, instance-level segmentation, descriptions [313], frame-level BBox [387] | |
| black KHAV [376] | 2017 | Youtube, AMT | - | 253,540 | 17,804 | 34,901 | 306,245 | variable | 400 classes, min 400 videos/class, avg. 10 sec video | |
| CUHK-PEDES [388] | 2017 | Person searching (video surveillance) | CUHK03 [389], Market-1501 [390], AMT, SSM [391], VIPER [392], CUHK01 [393], | - | 34,054 | 3078 | 3074 | 40,206 | - | 2- descriptions/image, attribute labels, orientation phrase [219] |
| Evaluation Metrics | ||||||||
|---|---|---|---|---|---|---|---|---|
| Quality | Semantics | |||||||
| Model (Categories of image models) | Datasets: (1) Oxford (2) CUB (3) MS-COCO; COCO-stuff (4) CoDraw/Abstract-Scenes (5) Conceptual captions | (6) FFHQ; CelebTD-HQ; CelebA-HQ; CelebA; MM-Celeb-HQ (7) ImageNet (8) CIFAR-10 (9) Visual-genome (10) Fashion-data (Zap-seq; DeepFashion-seq; Fashion-synthesis) | (11) Pororo (12) 3D-houses (13) LN-data (COCO; OpenImages) (14) VQA 2.0 (15) CLEVR | (16) Editing-data (GIER; MA5k-Req; MIT-Adobe5k) (17) CUHK-PEDES (18) Video-generation (KTH; MSVD; MSR-VTT; Kinetics, MUG; UCF-101; A2D) | ||||
| IS (higher-better) | FID, SceneFID (low-better) | SSIM (higher-better) | LPIPS (High-better) | SOA-c, SOA-i % (High-better) | VS-Similarity (High-better) | R-precision % (High-better) | Captioning metrics (BLEU, METEOR, ROUGE_L, CIDEr, SPICE, CapLoss) (High-better) | |
| [100] | (3) 24.77 ± 1.59 | (3) (0.614, 0.426, 0.300, 0.218), 0.201, 0.457, 0.656, 0.130 | ||||||
| [101] | (2) 1.35 ± 0.25 (3) 17.9 ± 0.15 | (2) 56.10 (3) 27.50 | ||||||
| [103] | (3) 18.2 | (3) 23.6 | (3) -, -, -, -, -, 2.43 | |||||
| [105] | (5) 15.27± 0.59 (6) 4.49 ± 0.05 | (5) 22.61 (6) 10.81 (7) 21.19 | (6) (CLIP: 0.23 ± 0.03) | |||||
| [106] | (1) 4.28 ± 0.09 (2) 6.89 ± 0.06 | (1) 0.2174 (2) 0.3160 | ||||||
| [107] | (1) 4.66 ± 0.07 (2) 7.94 ± 0.12 | (1) 0.2186 (2) 0.3176 | ||||||
| [5] | (3) 0.156 ± 0.11 | |||||||
| [110] | (1) 4.21 ± 0.06 (2) 4.97 ± 0.03 | |||||||
| [113] | (1) 14.1 (2) 10.32 (3) 13.86 (6) 6.33 (7) 11.89 | |||||||
| [116] | (8) 8.09 ± 0.07 | |||||||
| [7] | (1) 4.17 ± 0.07 (2) 5.08 ± 0.08 (3) 7.88 ± 0.07 | (1) 79.55 (2) 68.79 (3) 60.62 | (1) 0.1948 (2) 0.2934 (15) 0.596 | (2) 0.082 ± 0.147 | (3) 0.077, 0.122, -, 0.160 | |||
| [117] | (8) 8.25 ± 0.07 | (12) 220.18 | ||||||
| [118] | 3.45 ± 0.05 | |||||||
| [122] | (12) 145.16 | |||||||
| [124] | (2) 5.10 | (2) 14.81 (3) 21.42 (6) -; -; -; -; 137.60 | (6) -; -; -; -; 0.581 | (3) (CLIP: 66.42 ± 1.49) | (3) -, -, -, -, -, 3.09 | |||
| [32] | (1) 3.20 ± 0.01 (2) 3.70 ± 0.04 (3) 8.45 ± 0.03; 8.4 ± 0.2 (7) 8.84 ± 0.08 (9) 7.39 ± 0.38 (10) 7.88; 6.24 | 1) 55.28 (2) 51.89 (3) 74.05; 78.19 (7) 89.21 (9) 77.95 (10) 60.62; 65.62 | (1) 0.1837 (2) 0.2812 (10) 0.437; 0.316 | (1) 0.278 ± 0.134 (2) 0.228 ± 0.162 | (2) 10.37 ± 5.88 | (3) 0.089, 0.128, -, 0.195; 0.062, 0.095, -, 0.078 | ||
| [33] | (1) 3.26 ± 0.01 (2) 4.04 ± 0.05 (3) 8.30 ± 0.10 (6) -; -; -; 1.444 (7) 9.55 ± 0.11 | 2) 15.30 (3) 81.59 (6) -; -; -; 285.48 (7) 44.54 (12) 188.15 | (2) 0.028 ± 0.009 (6) -; -; -; 0.292 ± 0.053 | (2) 45.28 ± 3.72 (3) 72.83 ± 3.17 | ||||
| [125] | (2) 3.00 ± 0.03 | |||||||
| [126] | (1) 3.45 ± 0.07 (2) 4.15 ± 0.05 (3) 11.86 ± 0.18; 11.9 ± 0.2 | (1) 40.02 ± 0.55 (2) 18.23 (3) 75.34 | (1) 0.1886 (2) 0.2887 | (1) 0.296 ± 0.131 (2) 0.246 ± 0.157 (3) 0.199 ± 0.183 | ||||
| [127] | (1) 3.52 ± 0.02 (2) 4.38 ± 0.05 | (1) 0.297 ± 0.136 (2) 0.290 ± 0.149 | ||||||
| [128] | (1) 3.57 ± 0.05 (2) 4.48 ± 0.04 (3) 27.53 ± 0.25 | (1) 0.303 ± 0.137 (2) 0.253 ± 0.165 (3) 0.227 ± 0.145 | ||||||
| [34] | (1) 3.55 ± 0.06 (2) 4.36 ± 0.03 (3) 25.89 ± 0.47; 25.9 ± 0.5 (9) 8.20 ± 0.35 (10) 9.79; 8.28 (13) 20.80; 15.3 (14) 20.53 ± 0.36 (17) 3.726 ± 0.123 | (2) 23.98 (3) 35.49; 35.49 (6) -; -; -; -; 125.98 (9) 72.11 (10) 48.58; 55.76 (13) 51.80; 56.6 (14) 44.35 | (1) 0.1873 (2) 0.3129 (10) 0.527; 0.405 (17) 0.298 ± 0.126 | (6) -; -; -; -; 0.512 | (3) 25.88, 38.79 | (2) 0.279 (3) 0.071 | (1) 20.3 ± 1.5 (2) 67.82 ± 4.43 (3) 85.47 ± 3.69 (CLIP: 65.66 ± 2.83) (13) 43.88 | (3) -, -, -, 0.695 ± 0.005, -, 3.01; 0.087, 0.105, -, 0.251 |
| [129] | (3) 23.74 ± 0.36 | (3) 34.52 | (3) 86.44 ± 3.38 | |||||
| [130] | (2) 4.67 ± 0.04 (3) 27.86 ± 0.31 | (2) 18.167 (3) 32.276 | (2) 0.302 (3) 0.089 | |||||
| [131] | (2) 4.58 ± 0.09 (3) 24.06 ± 0.60 | (6) -; -; -; -; 116.32 | (6) -; -; -; -; 0.522 | (3) 25.64, - | (2) 69.33 ± 3.23 (3) 82.43 ± 2.43 | |||
| [132] | (2) 4.56 ± 0.05 (3) 25.98 ± 0.04 | (2) 10.41 (3) 29.29 | ||||||
| [133] | (1) 3.98 ± 0.05 (2) 4.48 ± 0.05 | |||||||
| [134] | (2) 5.03 ± 0.03 (3) 31.01 ± 0.34 | (2) 11.83 (3) 31.97 | ||||||
| [135] | (2) 4.91 ± 0.03 (3) 30.85 ± 0.7 | (2) 14.3 (3) 31.14 | (3) 32.78, - | (2) 71.57 ± 1.2 (3) 89.57 ± 0.9 | (3) 0.381, -, -, -, - | |||
| [136] | (2) 4.42 ± 0.04 (3) 35.08 ± 1.16 | (2) 15.19 (3) 28.12 | (2) 85.45 ± 0.57 (3) 92.61 ± 0.50 | |||||
| [137] | (1) 3.65 ± 0.06 | |||||||
| [138] | (2) 4.67 ± 0.09 (3) 35.69 ± 0.50; 35.7 ± 0.5 | (3) 29.35 | (3) 51.68 | |||||
| [139] | (2) 4.85 ± 0.04 (3) 31.67 ± 0.36 | (2) 17.32 (3) 30.73 | ||||||
| [140] | (1) 3.87 ± 0.05 (2) 4.66 ± 0.04 | (1) 32.64 (2) 9.35 | ||||||
| [141] | (7) 60.6 ± 1.6 | |||||||
| [143] | (2) 4.56 ± 0.05 (3) 26.47 ± 0.41; 26.5 ± 0.4 | (2) 18.34 (3) 34.71 | (3) 27.52, - | (2) 60.42 ± 4.39 (3) 80.21 ± 0.39 | ||||
| [145] | (1) 2.90 ± 0.03 (2) 3.58 ± 0.05 (3) 8.94 ± 0.20 | (1) 37.94 ± 0.39 (2) 18.41 ± 1.07 (3) 27.07 ± 2.55 | ||||||
| [146] | (2) 4.75 ± 0.07 (3) 30.49 ± 0.57; 30.5 ± 0.6 | (2) 16.09 (3) 32.64; 32.64 (6) -; -; -; -; 131.05 | (6) -; -; -; -; 0.544 | (3) 33.44, 48.03 | (1) 19.9 ± 1.4 (2) 72.31 ± 0.91 (3) 88.56 ± 0.28 (CLIP: 65.45 ± 2.18) | (3) -, -, -, 0.823 ± 0.002, -, 2.87 | ||
| [148] | (3) 52.73 ± 0.61 | (3) 55.82 | (3) 77.02, 84.55 | (3) 93.59 | ||||
| [150] (AttnGAN, DM-GAN) | (2) 4.42 ± 0.05, 4.77 ± 0.05 (3) 25.70 ± 0.62, 33.34 ± 0.51 | (2) 16.34, 14.38 (3) 23.93, 20.79 | (2) 69.64 ± 0.63, 78.99 ± 0.66 (3) 86.55 ± 0.51, 93.40 ± 0.39 | |||||
| [151] | (3) 30.45 (13) 28.37; 24.90 | (3) 9.33 (13) 14.12; 26.91 | (3) 50.94, 71.33 (13) 36.76, 48.14 | (3) 71.00 (13) 66.92; 57.55 | ||||
| [152] | (2) 4.74 ± 0.04 (3) 16.40 ± 0.30 | (2) 0.298 ± 0.146 | ||||||
| [153] | (1) 3.71 ± 0.06 (2) 4.23 ± 0.05 | (1) 16.47 (2) 11.17 | ||||||
| [155] | (2) 4.78 ± 0.03 (3) 33.0 ± 0.31 | (6) -; 5.08 ± 0.07 | (2) 79.56 (3) 88.23 | |||||
| [158] | (3) -; 34.7 ± 0.3 | (3) -; 30.63 | ||||||
| [159] | (3) 32.88 ± 0.93 | (3) 25.24 | (3) 63.80 ± 1.12 (CLIP: 98.44 ± 0.15) | |||||
| [160] | (2) 5.97 (3) 32.34 (6) -; -; 2.93 (13) 26.32 | (2) 10.48 (3) 8.12 (6) -; -; 12.54 (13) 11.78 | (3) 61.09, 74.78 | |||||
| [162] | (1) 3.52 ± 0.15 (2) 4.07 ± 0.13 | |||||||
| [165] | (1) 4.53 ± 0.05 (2) 5.23 ± 0.09 | (1) 26.7 ± 1.6 (2) 23.8 ± 1.5 | ||||||
| [167] | (1) 4.09 ± 0.08 (2) 4.76 ± 0.05 | (1) 41.85 (2) 21.66 | ||||||
| [168] | (3) 9.74 ± 0.02 | |||||||
| [169] | (16) 87.0128; 33.7366 | (16) 0.7492; 0.7772 | ||||||
| [171] | (14) 21.92 ± 0.25 | (14) 41.7 (15) 36.14 | ||||||
| [172] | (10) 9.58; 8.41 | (10) 50.31; 53.18 | (10) 0.651; 0.498 | |||||
| [173] | (3) 26.64 | (3) 25.38 | (3) 84.79 | |||||
| [43] | (2) 3.62 ± 0.07 | (2) 67.22 | (2) 0.237 | (2) 0.114 ± 0.151 | ||||
| [175] (StackGAN, AttnGAN) | (3) 12.12 ± 0.31, 24.76 ± 0.43 | (3) 55.30 ± 1.78, 33.35 ± 1.15 | ||||||
| [177] | (3) 27.88 ± 0.12 | (3) 24.70 ± 0.09 | (3) 35.85, 50.47 | (3) 89.01 ± 0.26 | (3) -, -, -, 0.819 ± 0.004 | |||
| [178] | (3) -; 17.0 ± 0.1 (9) 14.4 ± 0.6 | (3) -; 45.96, 16.76 (9) 39.07, 9.63 | ||||||
| [180] | (3) 11.46 ± 0.09; 11.46 ± 0.09 | (3) -; 0.122, 0.154, -, 0.367 | ||||||
| [184] | (3) 32.79 ± 0.21 (13) 16.5 | (3) 21.21 (13) 66.5 | (3) 27.14, 41.24 | (3) 93.39 ± 2.08 | (3) -, -, -, 0.783 ± 0.002 | |||
| [186] | (1) 3.92 ± 0.02 (2) 4.62 ± 0.06 | (1) 85.81 (2) 85.28 | ||||||
| [187] | (3) -; 32.31 (9) 20.83 | |||||||
| [189] | (1) 4.72 ± 0.1 (2) 4.97 ± 0.21 (3) 29.87 ± 0.09 | (1) 74.32 (2) 63.78 (3) 79.57 | ||||||
| [191] | (2) 5.06 ± 0.21 (3) 29.03 ± 0.15 | (2) 16.87 (3) 20.06 | (2) 99.8 (3) 95.0 | |||||
| [192] | (3) -; 7.3 ± 0.1 (9) 6.3 ± 0.2 | (3) -; 67.96 (9) 74.61 | (3) -; 0.29 ± 0.10 (9) 0.31 ± 0.08 | (3) 0.107, 0.141, -, 0.238 | ||||
| [194] | (3) -; 4.14 | |||||||
| [198] | (3) -; 14.5 ± 0.7 | (3) -; 81.0 | (3) -; 0.67 ± 0.05 | |||||
| [199] | (3) -; 10.2 ± 0.2 (9) 8.2 ± 0.2 | (3) -; 38.29 (9) 35.25 | (3) -; 0.32 ± 0.09 (9) 0.29 ± 0.08 | |||||
| [200] | (3) -; 14.78 ± 0.65 (9) 12.03 ± 0.37 | (3) -; 26.32 (9) 27.33 | (3) -; 0.52 ± 0.09 (9) 0.56 ± 0.06 | (3) 0.139, 0.157, -, 0.325 | ||||
| [201] (StackGAN, AttnGAN, DM-GAN) | (3) 10.38 ± 0.2, 28.18 ± 0.51, 32.37 ± 0.31 | (3) -, 29.26, 32.37 | (3) -, 86.39 ± 0.0039, 90.37 ± 0.0063 | |||||
| [203] | (13) 21.30; 14.7 | (13) 48.70; 61.9 | (13) 37.88 | |||||
| [207] | (16) 49.2049; 6.7571 | (16) 0.8160; 0.8459 | ||||||
| [208] | (1) 5.03 ± 0.62 (2) 1.92 ± 0.05 (10) -; -; 8.65 ± 1.33 (17) 3.790 ± 0.182 | (10) 22.86 (16) 140.1495; 30.9877 | (16) 0.7300; 0.7938 (17) 0.239 ± 0.106 | (2) 0.045 (3) 0.077 | ||||
| [210] | (2) 4.451 (6) -; -; -; 1.178 (10) 9.83; 8.26 | (2) 50.51 (6) -; -; -; 421.84 (10) 47.25; 56.49 (16) 112.4168; 43.9463 | (10) 0.512; 0.428 (16) 0.5777; 0.5429 | (2) 0.060 ± 0.024 (6) -; -; -; 0.024 ± 0.012 | (2) 0.048 (3) 0.089 | |||
| [211] | (1) 4.83 ± 0.48 (2) 2.59 ± 0.11 (10) -; -; 8.78 ± 1.43 | (10) -; -; 10.72 | ||||||
| [213] | ||||||||
| [214] | (1) 6.26 ± 0.44 (2) 2.76 ± 0.08 (10) -; -; 11.63 ± 2.15 | (16) 214.7331; 102.1330 | (16) 0.4395; 0.4988 | |||||
| [215] | (2) 8.47 (3) 14.96 | (2) 11.74 (3) 25.08 (6) 143.39; -; -; -; 117.89 | (2) 0.001 ± 0.000 | (2) 10.1 (3) 8.7 | ||||
| [216] | (2) 4.599 (6) -; -; -; 3.069 | (2) 2.96 (6) -; -; -; 32.14 | (2) 0.081 ± 0.001 (6) -; -; -; 0.152 ± 0.003 | |||||
| [219] | (17) 4.218 ± 0.195 | (17) 0.364 ± 0.123 | ||||||
| [221] | (2) 8.02 (3) 12.39 | |||||||
| [222] | (2) 0.0547 (3) 0.0709 | |||||||
| [226] | (16) 74.7761; 14.5538 | (16) 0.7293; 0.7938 | ||||||
| [229] (generation, manipulation) | (6) (-, 135.47); -; -; -; (106.37, 107.25) | (6) -; -; -; -; 0.456 | ||||||
| Model | Evaluation Metrics | ||||||||||||||
| Quality | |||||||||||||||
| Datasets: (1) Pororo (2) CLEVR (3) Flintstones (4) KTH (5) MSVD (6) MSR-VTT (7) Kinetics (8) MUG | (9) UCF-101 (10) A2D (11) IScene (12) MNIST (1-digit; 2-digit) (13) Text-Video-data (14) Robotic-dataset (15) Video-manipulation (E-MNIST; E-CLEVR; E-JESTER) | ||||||||||||||
| IS (Frame, Video) (higher-better) | FID (low-better) | FSD (low-better) | FVD (low-better) | SSIM (higher-better) | VAD (Low-better) | GAM (low-diverse) | Accuracy (Object, Gesture, Frame) (High-better) | Char. F1 (High-better) | CA (High-better) | NLL (Low-better) | R-precision % (High-better) | RM (High-better) | CLIP-sim (High-better) | BLEU (High-better) | |
| [230] | (1) 50.24 | (1) 30.40 | (1) -, -, 28.06 | (1) 58.11 | 58.11 | (1) 5.30/2.34 | |||||||||
| [231] | (1) 49.27 | (91) 111.09 | (1) 274.59 | (1) 0.481 (2) 0.672 | (1) 27.0 | (1) 1.51 ± 0.15 | (1) 3.24/1.22 | ||||||||
| [31] | (1) 0.509 | (1) 25.7 | |||||||||||||
| [233] | (1) 0.521 | (1) 38.0 | |||||||||||||
| [235] | (1) 40.56 | (1) 71.51 | (1) 190.59 | (1) 1.76 ± 0.04 | (1) 3.25/1.22 | ||||||||||
| [237] | (1) 34.53 | (1) 171.36 | (1) -, -, 13.97 | (1) 38.01 | (1) 3.56 ± 0.04 | (1) 3.68/1.34 | |||||||||
| [239] | (1) 18.09 | (1) -, -, 17.36 | (1) 43.02 | (1) 3.28 ± 0.00 | (1) 3.80/1.44 | ||||||||||
| [243] | (3) 7.636 | ||||||||||||||
| [244] | (4) 2.077 ± 0.299, 1.280 ± 0.024 (5) 2.580 ± 0.125, 1.141 ± 0.013 | ||||||||||||||
| [247] (static, animated) | (11) 0.812, 0.849 | ||||||||||||||
| [250] | (12) 340.39; 639.71 | ||||||||||||||
| [252] | (4) 70.95 | ||||||||||||||
| [253] | (7) 82.13, 14.65 | (7) 42.6 (13) 42.6 | |||||||||||||
| [254] | (6) 98.34 | (6) 24.02 | |||||||||||||
| [255] | (4) 1.937 ± 0.134, 1.005 ± 0.002 (5) 1.749 ± 0.031, 1.003 ± 0.001 (7) -, 4.87 (8) -, 4.65 (9) -, 3.95 ± 0.19 (10) -, 3.84 ± 0.12 (14) -, 2.97 ± 0.21 | (4) 69.92 (9) 51.64 (10) 31.56 (14) 6.59 | (5) 0.96 | (14) 70.4 | (9) 0.19 (10) 0.31 | ||||||||||
| [256] | (4) 0.667 (12) 0.673; 0.687 | ||||||||||||||
| [257] | (7) 31.76, 7.19 | (7) 76.2 | |||||||||||||
| [258] | (9) -, 7.01 ± 0.36 (10) -, 4.85 ± 0.16 (14) -, 3.36 ± 0.15 | (9) 51.64 (10) 25.91 (14) 3.79 | (14) 76.6 | (9) 0.43 (10) 0.39 | |||||||||||
| [259] | (7) -, 5.55 (8) -, 5.34 | (4) 47.34 | (7) 77.8 | ||||||||||||
| [260] | (15) 1.90; 1.96; 1.44 | (15) 93.2; 84.5; -, 89.3 | |||||||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ullah, U.; Lee, J.-S.; An, C.-H.; Lee, H.; Park, S.-Y.; Baek, R.-H.; Choi, H.-C. A Review of Multi-Modal Learning from the Text-Guided Visual Processing Viewpoint. Sensors 2022, 22, 6816. https://doi.org/10.3390/s22186816
Ullah U, Lee J-S, An C-H, Lee H, Park S-Y, Baek R-H, Choi H-C. A Review of Multi-Modal Learning from the Text-Guided Visual Processing Viewpoint. Sensors. 2022; 22(18):6816. https://doi.org/10.3390/s22186816
Chicago/Turabian StyleUllah, Ubaid, Jeong-Sik Lee, Chang-Hyeon An, Hyeonjin Lee, Su-Yeong Park, Rock-Hyun Baek, and Hyun-Chul Choi. 2022. "A Review of Multi-Modal Learning from the Text-Guided Visual Processing Viewpoint" Sensors 22, no. 18: 6816. https://doi.org/10.3390/s22186816
APA StyleUllah, U., Lee, J. -S., An, C. -H., Lee, H., Park, S. -Y., Baek, R. -H., & Choi, H. -C. (2022). A Review of Multi-Modal Learning from the Text-Guided Visual Processing Viewpoint. Sensors, 22(18), 6816. https://doi.org/10.3390/s22186816