1. Introduction
With the wide application of multi-view video and free-view television, virtual view synthesis technology has developed rapidly [
1,
2]. The virtual multi-view synthesis technology interacts with texture and depth images from different viewpoints to generate new viewpoints, of which the depth-image-based rendering (DIBR) algorithm is the most commonly used and recognized [
3,
4]. In practice, distortions may occur in the acquisition, compression, and transmission of texture and depth images, which affect the image quality of view synthesis [
5]. As a result, it is necessary to give a corresponding quality evaluation to measure and optimize the effect of view synthesis [
6].
Image quality assessment (IQA) is divided into full-reference (FR), reduced-reference (RR), and no-reference (NR) [
7]. FR-IQA methods require reference to the original distortion-free image for scoring. Typical FR-IQA methods include Structural Similarity (SSIM) [
8], Information Fidelity Criterion (IFC) [
9], and Visual Information Fidelity (VIF) [
10]. RR-IQA methods use only a small amount of edge information extracted from the original distortion-free image as a reference for scoring [
11,
12]. However, in practical applications, the original image of the distorted image rarely exists. Hence, it is more practical to use the NR-IQA method, which does not require any information from the original distortion-free image to be referenced for scoring [
13]. Traditional NR-IQA methods include the Blind Image Quality Index (BIQI) [
14], the Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE) [
15], and the Natural Image Quality Evaluator (NIQE) [
16]. With the development of deep learning in recent years, Kang et al. [
17] first proposed an NR-IQA model using a Convolutional Neural Network (CNN) to extract image features. After that, some deep-learning-based NR-IQA models were also proposed [
18,
19]. Although the above IQA models have outstanding performance in the quality assessment of natural scene images, their application in view synthesis is very limited. This is because there are also local geometric distortions generated by the depth images and DIBR process in the view synthesis, which cannot be handled by the general IQA model [
6].
In this case, view synthesis quality metrics have been proposed [
20,
21,
22] to evaluate the image quality after DIBR-based view synthesis. However, the DIBR process is computationally expensive and time-consuming. For this reason, it is very meaningful and valuable to predict the image quality after view synthesis from pre-synthesis texture and depth images [
23,
24,
25]. Nevertheless, current quality evaluation methods for view synthesis basically use hand-designed features. The performance improvement of traditional methods is relatively slow because of the shallow feature extraction of hand-designed methods [
26]. In contrast, CNN has a strong expressive ability and is widely used in the field of quality evaluation of natural scene images [
17]. Therefore, we consider applying deep learning in quality prediction for view synthesis.
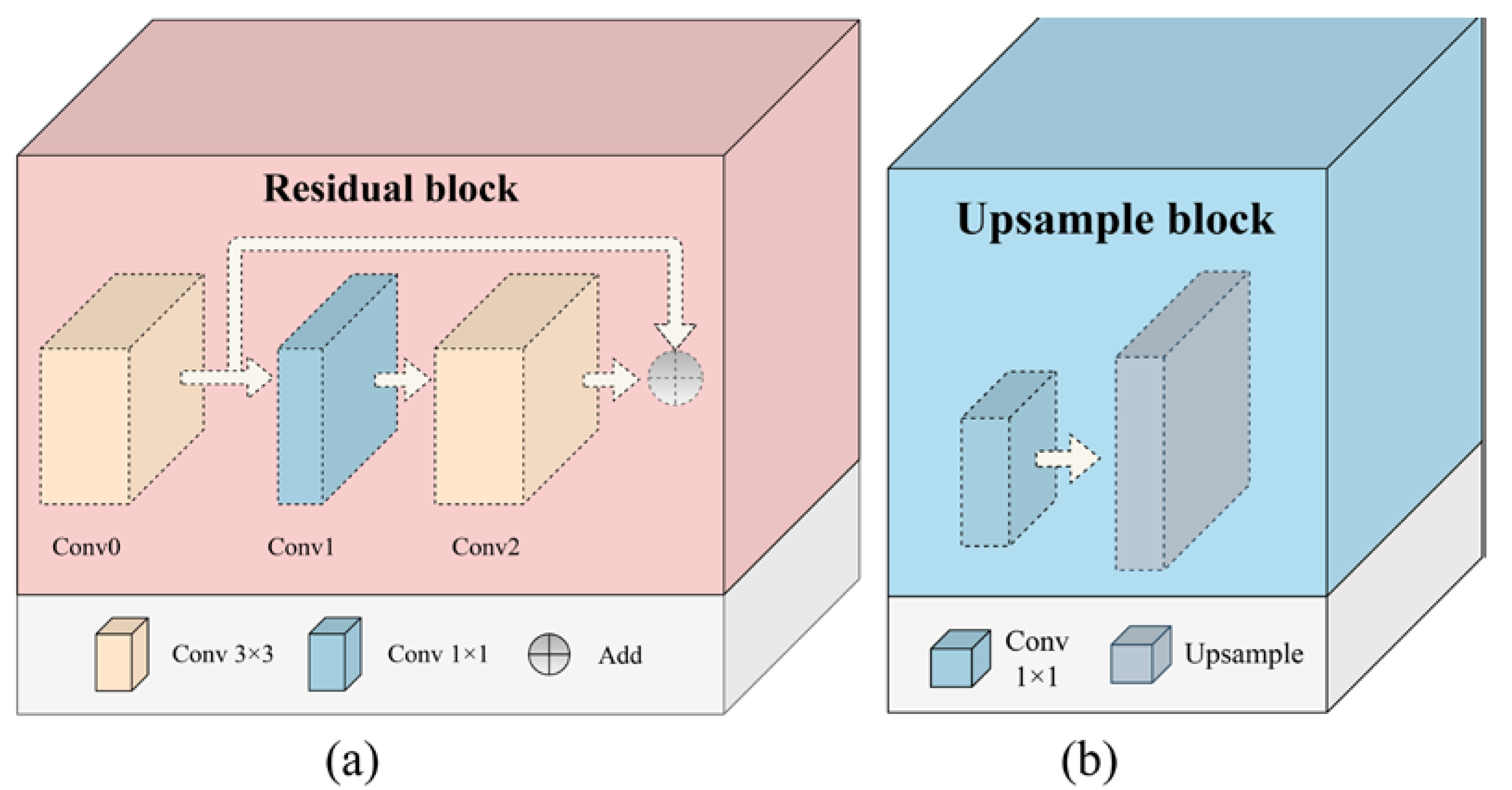
This paper proposes a blind quality prediction model based on HEterogeneous DIstortion Perception (HEDIP), which predicts the image quality of view synthesis from pre-synthesis texture and depth images. The distortions of texture and depth images usually lead to traditional and geometric distortions [
25], i.e., heterogeneous distortions, in the DIBR-synthesized images. To obtain more edge information, the proposed model is designed as a Two-Channel Convolutional Neural Network (TCCNN) structure, which can extract features in the image spatial and gradient domain, respectively. Among them, the edge features extracted by the gradient channel can effectively reflect the geometric distortions. Furthermore, to better describe the geometric distortions, we add a Contextual Multi-Level Feature Fusion (CMLFF) module, which can fuse shallow detail features and deep semantic features. At the input of the proposed HEDIP model, the texture and depth images are fused by Discrete Cosine Transform (DCT) [
27] to imitate the distortions of DIBR-synthesized images. The fused images are then fed to the TCCNN to extract features in the spatial and gradient domains. Additionally, a fully connected layer linearly regresses the extracted features into a quality score. Considering the presence of non-uniform distortions in the view synthesis image [
25], the ground-truth score of the source image cannot effectively represent the labels of each image patch during training. Therefore, we design a Heterogeneous Distortion Perception (HDP) module with the help of the classic BRISQUE [
15] metric and combine it with the ground-truth score of the source image to provide effective training labels for each image patch. The advantage of the proposed HEDIP model is demonstrated through extensive experiments and comparisons. The contributions of this paper are as follows.
We propose a deep-learning-based blind quality prediction model for view synthesis, a two-channel convolutional neural network structure based on the spatial-gradient domain, which operates end-to-end via input texture and depth images.
A heterogeneous distortion perception module is designed to provide effective training labels for each image patch.
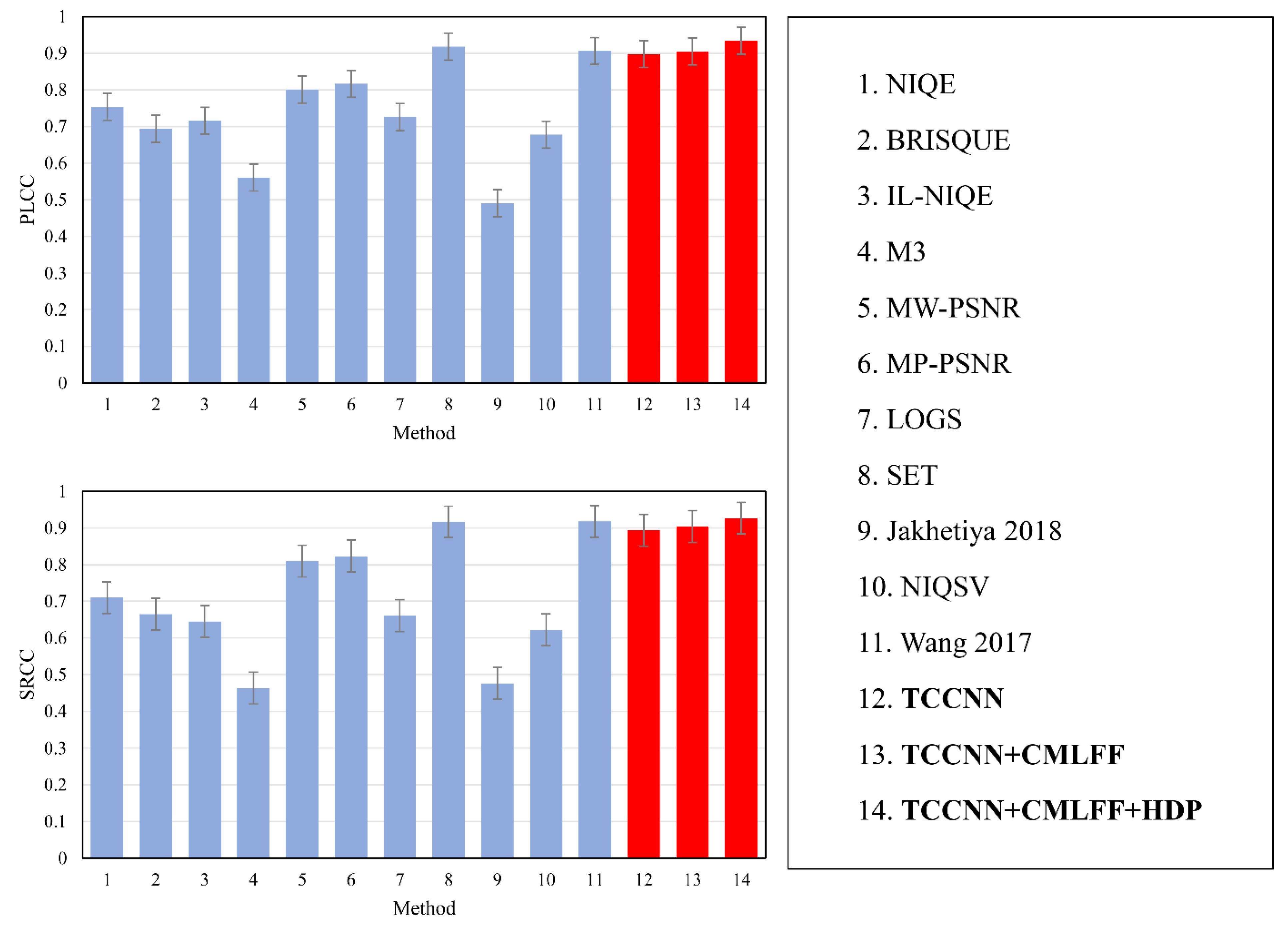
Extensive experiments on different databases show that our proposed model achieves state of the art.
2. Related Work
Existing view synthesis quality metrics basically adopt hand-designed methods to extract features. Tian et al. [
20] proposed a NIQSV metric by quantifying the distortions of synthesized images based on morphological and edge operations. Furthermore, they also proposed NIQSV+ [
21] metric on this basis to evaluate blurred regions, holes, and stretching distortions. Gu et al. [
22] first generated reconstructed images using the autoregression (AR) model and then measured the geometric distortions based on the error between the AR-reconstructed image and the corresponding DIBR-synthesized image. In [
28], a No-Reference Morphological Wavelet with Threshold (NR-MWT) metric first obtained high-frequency information based on morphological wavelet and then mapped the high-frequency information to the quality score. Gu et al. [
29] reported a Multiscale Natural Scene Statistical analysis (MNSS) method, which inferred the image quality mainly based on the degree of self-similarity impairment and major structure degradation at different scales. Zhou et al. [
30] addressed a blind view composite quality metric, which used Difference-of-Gaussian features to measure edge degradation and texture unnaturalness. Wang et al. [
31] decomposed the DIBR-synthesized images by using discrete wavelet transform and then calculated the quality score of the synthesized image based on the geometric distortions and global sharpness of the low-frequency and high-frequency sub-bands. Recently, Li et al. [
32] reported a view synthesis quality metric based on local Instance DEgradation and global Appearance (IDEA). This model used discrete orthogonal moments and superpixels to measure local and global distortions, respectively.
The above works are all about quality evaluation of the images after view synthesis. The DIBR-based view synthesis process includes the acquisition, compression, transmission, and decompression of texture and depth images, as well as deformation and rendering in the DIBR process. In practical applications, different types and degrees of distortions may occur in each link of view synthesis. Moreover, the DIBR process is computationally intensive and complex To avoid unnecessary distortions and calculations, it is worth considering predicting the quality of view synthesis based on texture and depth images, which can make the view synthesis system more flexible. Currently, only a few studies have investigated quality prediction for view synthesis. Wang et al. [
23] advised a novel FR quality prediction model, which utilized the classic SSIM [
8] method to compute two quality indication maps between distorted images and reference images for texture and depth. The overall quality is calculated based on the two quality indication maps. Shao et al. [
24] recommended a High-Efficiency View Synthesis Quality Prediction (HEVSQP) method with the help of sparse representation. They first achieved Color-Involved View Synthesis Quality Prediction (CI-VSQP) and Depth-Involved View Synthesis Quality Prediction (DI-VSQP), and then predicted the quality score of the synthesized view through the metrics of CI-VSQP and DI-VSQP models. Li et al. [
25] put forward a prediction model based on color-depth image fusion, which fused the input texture and depth images through wavelet transform to imitate the synthesized images. The statistical features of the fused images are then mapped to quality scores.
5. Discussion
The current quality assessment methods for view synthesis basically use hand-designed features. Due to the shallow feature extraction of hand-designed methods, the performance improvement of traditional methods is relatively slow. Inspired by the above efforts, we proposed a blind quality prediction model based on heterogeneous distortion perception, which predicts the image quality of view synthesis from pre-synthesis texture and depth images. The proposed deep learning model is a two-channel architecture that can extract features in the spatial and gradient domains. Furthermore, due to the presence of local distortion in the view synthesis image, we address a heterogeneous distortion perception module to provide effective training labels for each image patch. The experimental results demonstrate the effectiveness of the proposed model.
The quality prediction model can make the view synthesis system more flexible, considering that if the input color/depth images cannot generate satisfactory synthesized viewpoint (by prediction), their quality can be adjusted before sending to the time-consuming DIBR process. The current quality assessment methods for view synthesis basically use hand-designed features, while convolutional neural networks can learn more effective features, which may promote the development of quality assessment technology for view synthesis. Although our model achieves very high performance in predicting the quality of view synthesis, we believe that further improvements to the backbone network in future work may still have the potential to improve the overall performance of the model. The work in this paper mainly evaluates the quality of view synthesis of images. With the demand for high-quality visuals, evaluating the view synthesis quality of videos is a very promising direction. Therefore, in following work, we may extend from the two-dimensional quality evaluation to the three-dimensional quality evaluation; of course, this will be challenging.
6. Conclusions
The quality of synthesized images affects the development and application of DIBR-based view synthesis technology. Most of the current view synthesis quality metrics evaluate the image quality after DIBR-based view synthesis and use hand-crafted methods to extract features. On the one hand, the DIBR process is computationally expensive. On the other hand, shallower hand-crafted features may affect the performance improvement. To tackle these problems, we have proposed a blind quality prediction model based on heterogeneous distortion perception, which predicts the image quality of view synthesis from pre-synthesis texture and depth images. To the best of our knowledge, the proposed model is the first to apply deep learning in the field of view synthesis quality assessment, while predicting the synthesized images without the complex DIBR process. The proposed model has been designed as a two-channel convolutional neural network structure, which can extract spatial and gradient domain features separately. Furthermore, we have designed a heterogeneous distortion perception module, which can provide effective training labels for image patches in source images. Extensive experiments have been conducted on two public view synthesis image databases. The experimental results have demonstrated the superior performance of the proposed model.
The work of this paper is to predict the image quality after view synthesis without DIBR-based view synthesis, which will make the view synthesis system more sensitive. If the predicted synthesis quality is low before synthesis, it can be adjusted in time to avoid complex calculations. In future work, improving the backbone network of the proposed model can optimize the quality prediction performance. Due to the strong ability of deep learning to learn features, the wider application of convolutional neural networks in the field of quality evaluation of view synthesis may promote the development of this field.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}