1. Introduction
The goal of this work is to find the best matching photos for a given sketch in a face database, especially for software-generated composite sketches. An important application of such systems is to assist law enforcement agencies. In many cases, a face photo of a suspect is unavailable for criminal investigation. Instead, the only clue to identify suspect is a software-generated composite sketch or a hand-drawn forensic sketch based on a description by an eye-witness. Therefore, an automatic method that retrieves the best matching photos from a face database for a given sketch is necessary to quickly and accurately identify a suspect.
Successful photo-sketch matching depends on the solution to how to effectively deal with large modality gap between photo and sketch modalities. Moreover, the insufficiency of sketch samples for training makes photo-sketch recognition an extremely challenging task.
Regarding classical photo-sketch recognition, generative approaches [
1,
2,
3] bring both modalities into a single modality by transforming one of the modalities to the other (either a photo to a sketch, or vice versa) before matching. The main drawback of these methods is their dependency on the quality of the synthetic output, which most of the time suffers due to the large modality gap between photos and sketches. On the other hand, discriminative approaches attempt to extract modality-invariant features or learn a common subspace where both photo and sketch modalities are aligned [
4,
5,
6,
7,
8,
9,
10,
11,
12]. Although these methods formulate photo-sketch recognition through modality-invariant features or a common subspace, their performances are not satisfactory because (1) the distributions of the two modalities are not well aligned in the common feature space and (2) their feature vectors or common spaces fail to provide a rich representation capacity. Recent deep learning-based face photo-sketch recognition methods [
6,
9,
13,
14,
15,
16,
17,
18,
19] perform well compared to classical approaches. However, employing deep learning techniques for face photo-sketch recognition is very challenging because of insufficient training data.
Recently, Col-cGAN [
20] proposed a bidirectional face photo-sketch synthesis network. They generated synthetic outputs by using a middle latent domain between photo and sketch modalities. However, their middle latent domain does not provide enough representational power of both modalities. On the other hand, StyleGAN [
21] and its updated version, StyleGAN2 [
22], produces extremely realistic images by proposing a novel generator architecture. Instead of feeding the input latent code
directly into the generator, they first transform it into an intermediate latent space,
, via a mapping network. This disentangled intermediate latent space,
, offers the generator more control and representational capabilities. Noting the strong representation power of the latent code space of both StyleGAN and StyleGAN2 versions, we take advantage of their architecture in a bidirectional way to set up an intermediate latent space for our photo-sketch recognition problem.
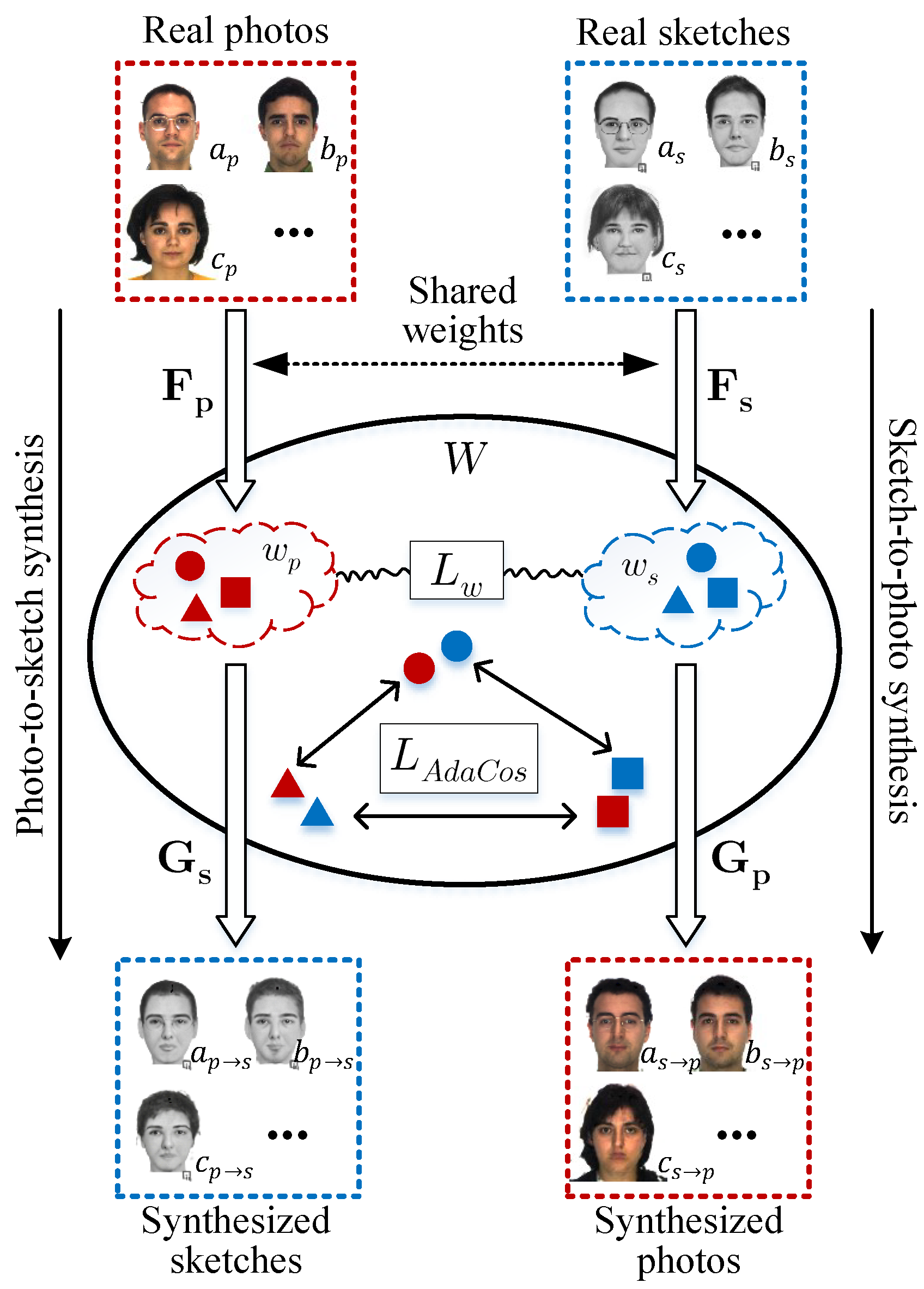
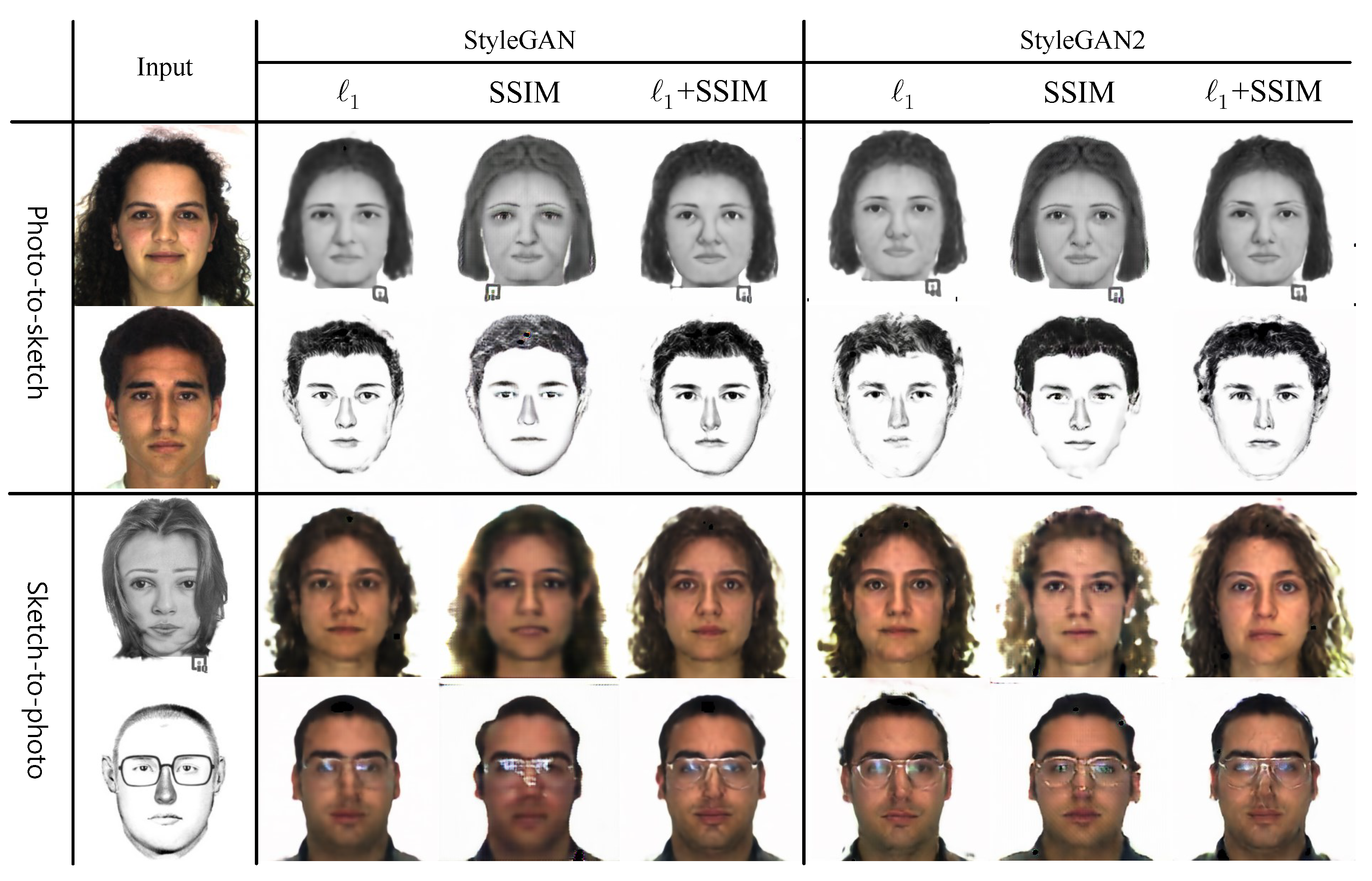
In this paper, we propose a novel method that exploits an intermediate latent space,
, between the photo and sketch modalities, as shown in
Figure 1. We employ a bidirectional collaborative synthesis network of the two modalities to set up the intermediate latent space where the distributions of those two modalities are effectively aligned. Additionally, the aforementioned StyleGAN-like architectures enable the intermediate latent space to have strong representational power to successfully match the two modalities. In an earlier version [
23] of this work, we only considered the StyleGAN generator. In this work, we extend our work to include StyleGAN2. While StyleGAN applies styles to an image by modulating mean and standard deviation using adaptive instance normalization (AdaIN), StyleGAN2 only modulates standard deviation with weight demodulation. We have experimented on StyleGAN2 in our network and compared it with the performance of StyleGAN.
In
Figure 1, the mapping networks,
and
, learn the intermediate latent codes
. To form a homogeneous intermediate space,
, we constrain the intermediate features to be more symmetrical using the
distance between the intermediate latent codes of the photo and the sketch. The intermediate latent space also makes use of feedback from the style generators that conduct translation from photo to sketch and from sketch to photo. This enables the intermediate latent space to have rich representational capacity for both the photo and the sketch that previous methods fail to provide. Once this intermediate latent space is successfully set up, we can then directly take advantage of any state-of-the-art face recognition methods. In our case, we employ AdaCos loss [
24].
Moreover, we use a three-step training scheme to resolve the problem of having a very limited number of training sketch samples. In the first step, we only learn image-to-image translation without AdaCos on paired photo-sketch samples. This serves the purpose of learning an initial intermediate latent space. Then, in the second step, we pre-train the photo mapping network,
, only with AdaCos, using a publicly available large photo dataset. This helps our model overcome the problem of insufficient sketch samples to train our deep network robustly for the target task. Lastly, we fine-tune the full network on a target photo/sketch dataset. More details of the model training are discussed in
Section 3.
The main contributions of our work are summarized as follows.
We propose a novel method for photo-sketch matching that exploits an intermediate latent space between the photo and sketch modalities;
- -
We set up the intermediate latent space through a bidirectional collaborative synthesis network;
- -
This latent space has rich representational power for photo/sketch recognition by employing StyleGAN-like architectures such as StyleGAN or StyleGAN2;
A three-step training scheme helps overcome the problem of insufficient sketch training samples;
Extensive evaluation on challenging publicly available composite face sketch databases shows the superior performance of our method compared with state-of-art methods.
2. Related Work
The face photo-sketch recognition problem has been extensively studied in recent years. Researchers have studied sketch recognition for various face sketch categories such as hand-drawn viewed sketches, hand-drawn semi-forensic sketches, hand-drawn forensic sketches, and software-generated composite sketches. Compared to hand-drawn viewed sketches, other sketch categories have much larger modality gaps due to the errors that come from forgetting (semi-forensic/forensic), understanding the description (forensic), or limitations of the components of the software (composite). Recent studies focus on more challenging composite and forensic sketches.
Trivial recognition methods can be categorized into generative and discriminative approaches.
Generative methods convert images from one modality into another modality, usually from a sketch to a photo, before matching. Then, a simple homogeneous face recognition method can be used for matching. Various techniques have been utilized for synthesis, such as a Markov random field model [
1], local linear embeding (LLE) [
2], and multi-task Gaussian process regression [
3]. However, the recognition performance of these approaches is strongly reliant on their synthesis results, which most of the time suffer due to the large modality gap between the two modalities.
Discriminative methods attempt to learn a common subspace or extract particular features in order to reduce the modality gap between photos and sketches of the same identity while increasing the gap between different identities. Representative methods in this category include partial linear squares (PLS) [
4,
5], coupled information-theoretic projection (CITP) [
6], local feature-based discriminant analysis (LFDA) [
7], canonical correlation analysis (CCA) [
8], and self-similarity descriptor (SSD) dictionary [
9]. Han et al. [
10] computed the similarity between a photo and composite sketch using a component-based representation technique. Multi-scale circular Weber’s local descriptor (MCWLD) was utilized in Bhatt et al. [
11] to solve the semi-forensic and forensic sketch recognition problem. Using graphical representation-based heterogeneous face recognition (G-HFR) [
12], the authors graphically represented heterogeneous image patches by employing Markov networks and designed a similarity metric for matching. These methods fail when the learned feature/common subspace do not have enough representational capacity for both photo and sketch modalities. In contrast, our method projects photos and sketches on a homogeneous intermediate space, where the distribution of the two modalities is better aligned with rich representational power.
Over the past few years, deep learning-based algorithms have been developed for face photo-sketch recognition [
6,
9,
13,
14,
15,
16,
17,
18]. Kazemi et al. [
13] and Iranmanesh et al. [
14] proposed attribute-guided approaches by introducing attribute-centered loss function and a joint loss function of identity and facial attribute classification, respectively. Liu et al. designed an end-to-end recognition network using a coupled attribute guided triplet loss (CAGTL). It plausibly eliminates defects of incorrectly estimated attributes [
15] during training. Iterative local re-ranking with attribute guided synthesis based on GAN was introduced in [
16]. Peng et al. proposed DLFace [
17], which is a local descriptor approach based on deep metric learning, while in [
18], a hybrid feature model was employed by fusing traditional HOG features with deep features. The largest obstacle to utilizing deep learning techniques for face photo-sketch recognition is the scarcity of sketch data. Even the largest publicly viewed sketch database [
6] has only 1194 pairs of sketches and photos, and the composite sketch database [
9] has photos and sketches of 123 identities. To overcome this problem, most approaches employ relatively shallow networks, data augmentation, or pre-training on a large-scale face photo database.
Recently, cosine-based softmax losses [
24,
25,
26,
27] have achieved great success in face photo recognition. SphereFace [
25] applied a multiplicative penalty to the angles between the deep features and their corresponding weights. Follow-up studies improved the performance by changing the penalising measure to an additive margin in cosine [
26] and angle [
27]. AdaCos [
24] outperforms previous cosine-based softmax losses by leveraging an adaptive scale parameter to automatically strengthen the supervision during training. However, the direct application of these methods to photo-sketch recognition is not satisfactory because they have not properly dealt with the modality gap.
3. Proposed Method
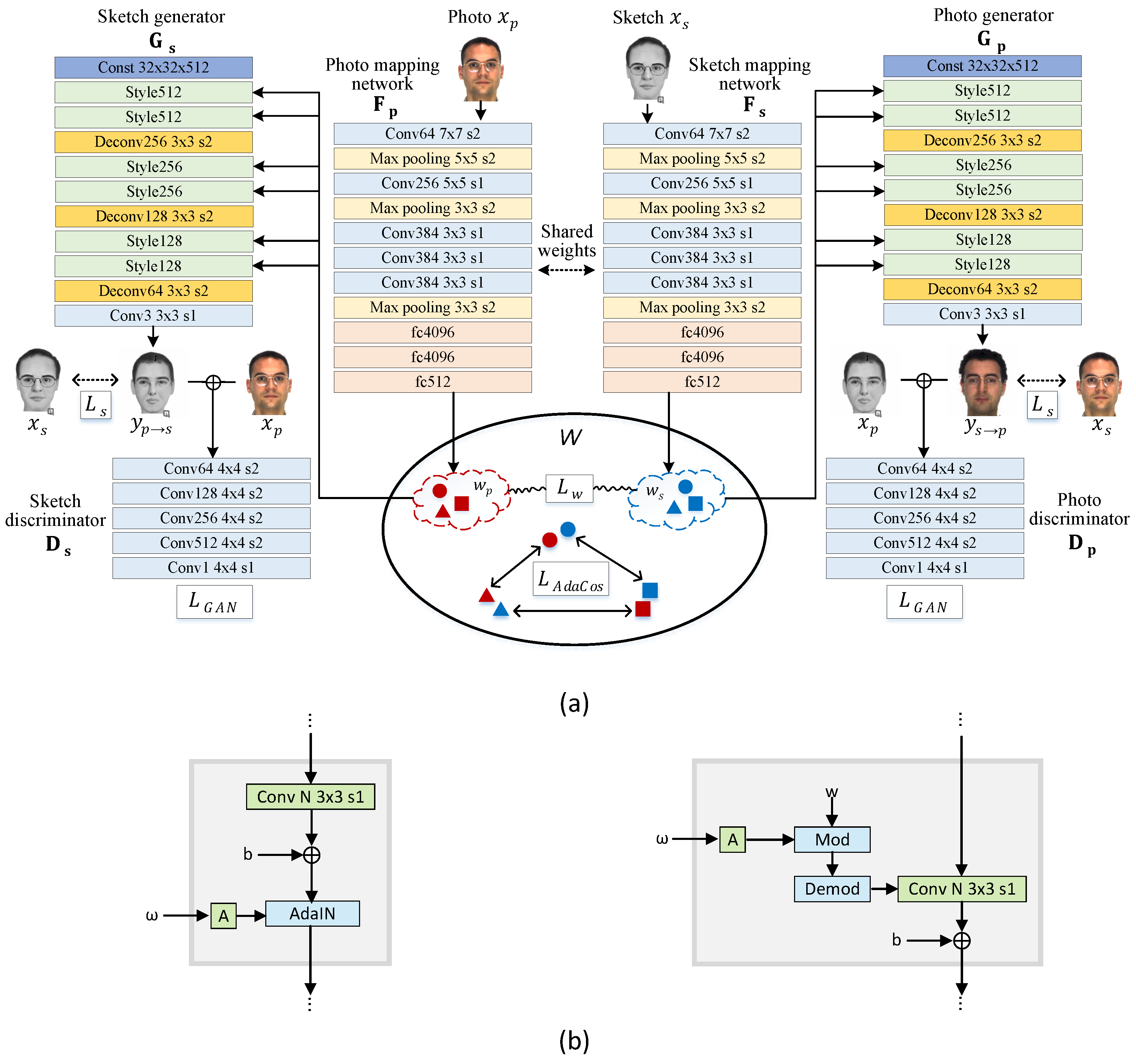
Our proposed framework takes advantage of a bidirectional photo/sketch synthesis network to set up an intermediate latent space as an effective homogeneous space for face photo-sketch recognition. The mutual interaction of the two opposite synthesis mappings occurs in the bidirectional collaborative synthesis network. The complete structure of our network is illustrated in
Figure 2a. Our network consists of mapping networks
and
, style generators
and
, and discriminators
and
.
and
share their weights.
The mapping networks,
and
, learn to encode photo and sketch images into their respective intermediate latent codes,
and
. Then,
and
are fed into the two opposite style generators
and
to perform photo-to-sketch and sketch-to-photo mapping, respectively. We employ a StyleGAN-like architecture to make the intermediate latent space be equipped with rich representational power. We also introduce a loss function to regularize the intermediate latent codes of two modalities, enabling them to learn a same feature distribution. Through this strategy, we learn a homogeneous intermediate feature space,
, that shares common information of the two modalities, thus producing the best results for heterogeneous face recognition. To enforce latent codes in
separable in the angular space, we learn AdaCos [
24] for the photo-sketch recognition task.
and
employ a simple encoder architecture that contains convolution, max pooling and fully connected layers. The style generators,
and
, consist of several style blocks and transposed convolution layers as in [
21]. StyleGAN [
21] and StyleGAN2 [
22] use different style block architectures, as shown in
Figure 2b. The details are described in
Section 3.1. The discriminators,
and
, distinguish generated photo/sketch and real samples by taking corresponding concatenated photo and sketch. We use a PatchGAN architecture [
28] of 70 × 70. Unlike the discriminator in [
20], our discriminator uses instance normalization instead of batch normalization.
3.1. StyleGAN and StyleGAN2 Generators
Both StyleGAN [
21] and StyleGAN2 [
22] transfer learned constant input to an output image by adjusting the style of an image at each style block using the latent code,
, as illustrated in
Figure 2. The difference between the two versions is in the internal structure of the style blocks.
The style block of our StyleGAN based ganerator is depicted on the left of
Figure 2b. The latent code defining a style is applied to an image through adaptive instance normalization (AdaIN). AdaIN first normalizes the feature maps, then modulates mean and standard deviation with the latent code. Unlike [
21], we do not use noise inputs and progressively growing architecture because the sole purpose of our style generators is to help the homogeneous intermediate latent space retain common representational information of the two modalities for reducing the modality gap between them. Our style generators are very light as compared to that of [
21] due to the limited number of training samples.
The StyleGAN2 version of our style block is shown on the right of
Figure 2b. StyleGAN2 [
22] replaces AdaIN with weight modulation to remove blob-shaped artifacts in the original StyleGAN. Weight demodulation, first, scales the weights of the convolution layer using latent code to modulate the standard deviation of the convolution outputs (mod block in
Figure 2b). Then, the outputs are scaled by the
norm of the corresponding weights before the next style block. This scaling is baked into the convolution weights directly (demod block in
Figure 2b). The crucial difference from the StyleGAN’s style block is that StyleGAN2 modulates standard deviation only. In StyleGAN2, mean of the feature maps is changed by bias after modulation.
Furthermore, ref. [
22] also proposes a skip connection-based generator and residual network discriminator with path length regularization in order to synthesize very clear high-resolution images (1024 × 1024). However, we do not use these techniques because our target image resolution is low (256 × 256), and the number of training data is very small.
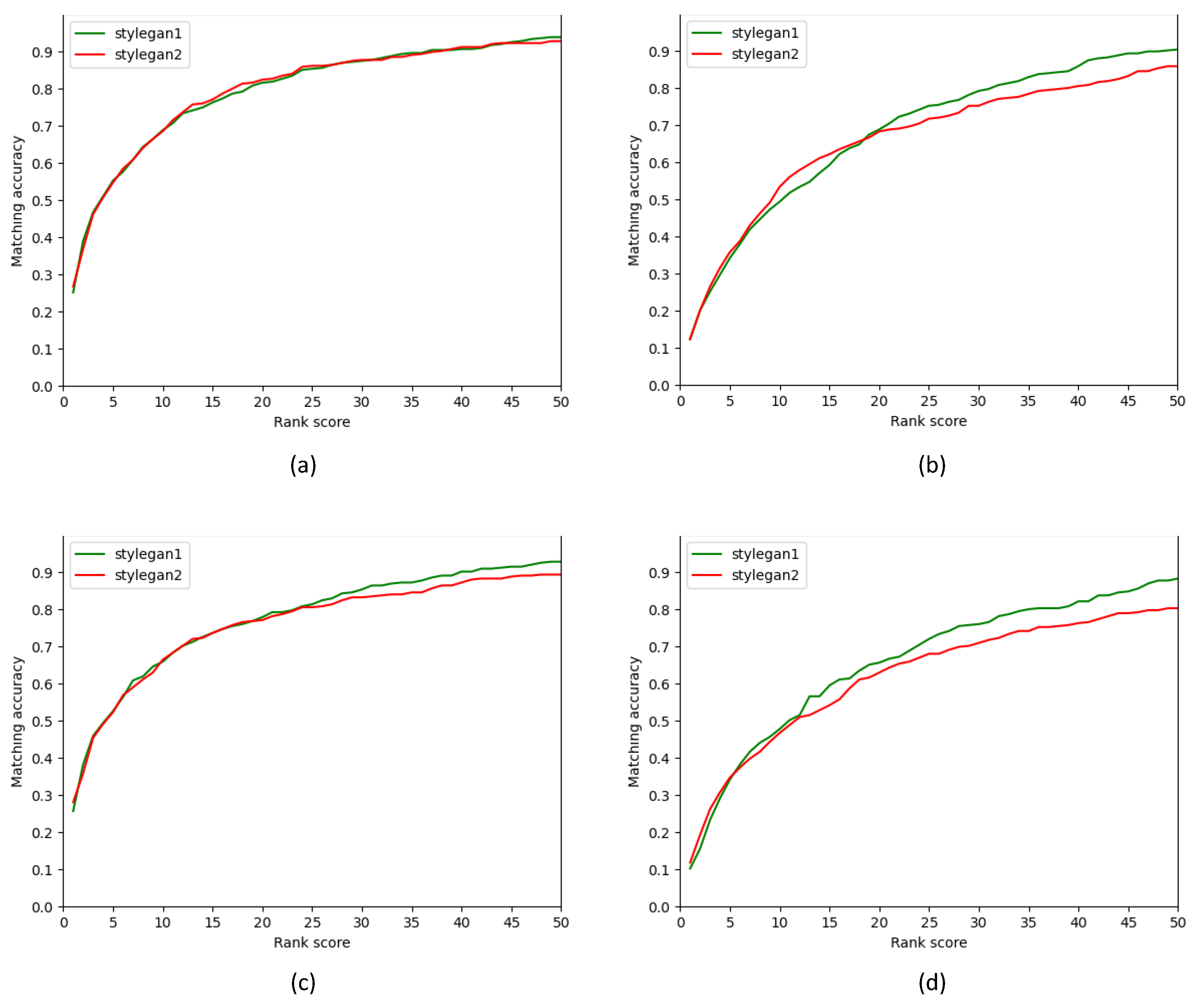
Both versions of the generator improve the recognition performance by providing more representation capacity to the intermediate latent space. We compare the StyleGAN and StyleGAN2 versions of our network in
Section 4.3.
3.2. Loss Functions
To learn the identity recognition, we use AdaCos loss [
24],
, which measures the angular distance in the
space. It minimizes the distance of intra-class features while maximizing the distance of inter-class features.
is defined as
where
is the corresponding label of the
i-th face image in the current mini-batch with size
N, and
C is the number of classes.
s is the adaptive scaling parameter. At the
t-th iteration of the training process, the scaling parameter is formulated as
where
is the median value of
in the current mini-batch.
To train the bidirectional photo/sketch synthesis part of the whole network, we use the GAN loss function,
[
29], along with the similarity loss,
, as follows.
helps to generate real and natural-looking synthetic outputs, while the similarity loss, , measures the pixel-wise distance between generated and real photo/sketch images.
In addition, to regularize and enforce the same distribution for a photo,
, and a sketch,
, in the intermediate latent space, we introduce a collaborative loss,
It minimizes the distance between and of the same identity.
Thus, the joint loss function used to train our network is as follows:
,
, and
in Equation (
6) control the relative importance of each loss function in the bidirectional photo/sketch synthesis task. We used
= 1,
= 10, and
= 1 in our experiments.
3.3. Training
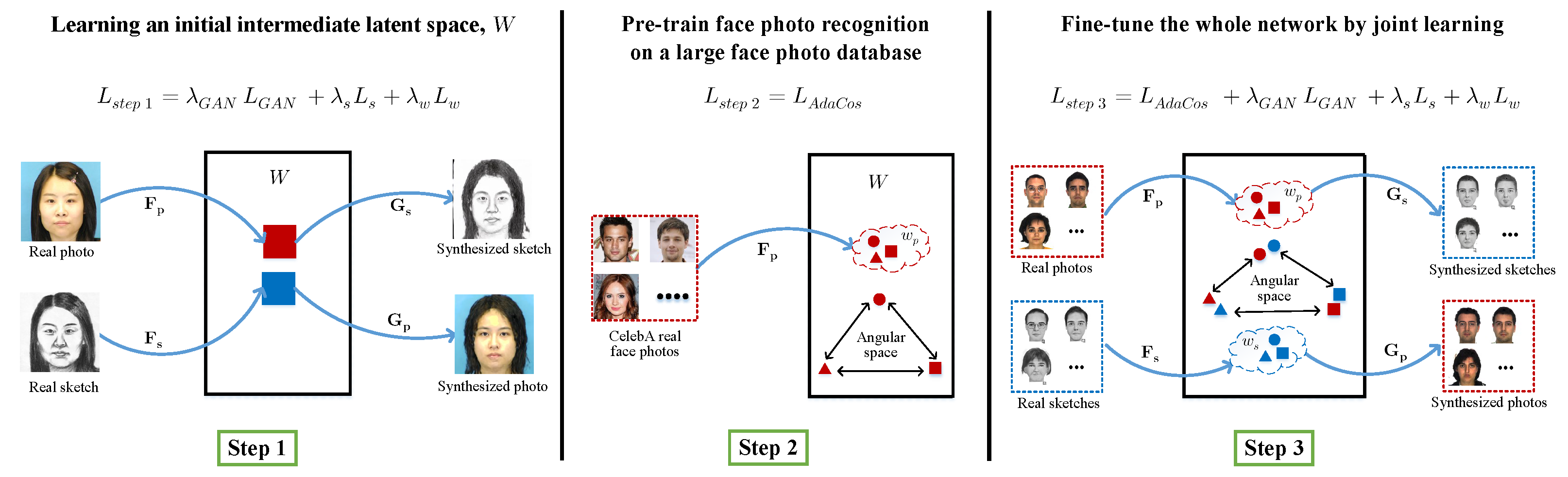
To overcome the problem of an insufficient amount of paired photo/sketch training data, we introduce a simple and effective three-step training scheme, as shown in
Figure 3. In step 1, we train the bidirectional photo/sketch synthesis network using paired photo-sketch training samples to set up an initial homogeneous intermediate latent space,
. We use our joint loss function in Equation (
6), excluding the AdaCos loss function,
. In step 2, we pre-train the photo mapping network,
, using AdaCos loss only on the publicly available large photo database CelebA [
30] to overcome the problem of insufficient sketch training samples. Then, we train our full network in step 3 using the whole joint loss function in Equation (
6) on target photo/sketch samples.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}