
Pedestrian Origin–Destination Estimation Based on Multi-Camera Person Re-Identification



Abstract
:1. Introduction
- (1)
- We develop and test a novel pedestrian O–D estimation framework based on multi-camera pedestrian re-identification (re-ID). By identifying the same person in different camera views, the O–D of each identity can be generated.
- (2)
- We compare the state-of-the-art deep neural networks for pedestrian re-ID at different congestion levels and improve the accuracy in crowded scenarios by employing data augmentation techniques.
- (3)
- We generate an O–D matrix based on the trajectories and calculate the resident time, which provides recommendations for pedestrian facility improvement.
2. Related Work
3. Materials and Methods
3.1. Data
3.2. Methods
- (1)
- Frame extraction and synchronisation. The image frames named by frame number are extracted from the video footage. Frame synchronisation is to ensure that all of the videos are on the same timeline, so that we can associate the frames of the same time in different camera views.
- (2)
- Detection of candidate pedestrians. This step is a pre-process for pedestrian re-ID. In order to remove the cluttered background, the region-of-interest (ROI) of pedestrians are detected using the deformable part model (DPM) and pedestrian images are cropped from the image frames based on the bounding boxes. All of the pedestrian candidate images are collected in a gallery, which would be used for matching.
- (3)
- Pedestrian re-identification (re-ID). The purpose of this step is to classify the detections into different identities. The approach is to initially generate the trajectories in the same camera, calculate the averaged features for each trajectory, and then match the features across different cameras.
- (4)
- Mapping the image coordinates to world coordinates and generating the pedestrian O–D flows. The image coordinates of the pedestrian’s feet are converted to world coordinates to obtain all of the historical locations of the pedestrian. By organising the detection in a chronological order, pedestrian O–D flows can be calculated based on the accumulated trajectories.
3.2.1. Frame Extraction and Synchronisation
3.2.2. Pedestrian Detection and Generation of Gallery Images
3.2.3. Pedestrian Re-Identification
- Data augmentation at different congestion levels
- 2.
- Deep learning architectures for person re-ID
3.2.4. O–D Flow Generation
4. Results
4.1. Training Strategies
4.2. Model Evaluation
4.3. O–D Flow Estimation
5. Conclusions
- (1)
- The entire network for multi-view pedestrian re-ID can be designed in an end-to-end fashion. Since the pedestrian detection and the pedestrian re-ID were processed separately in this article, they may share the same backbone for feature extraction, which can make the framework more efficient when processed online. The extracted features can be used not only to generate the bounding box of a pedestrian, but also for subsequent matching.
- (2)
- An additional input channel can be applied, that is, the depth information collected by the depth sensors, and the information integrated into the current structure. The depth image contains information relating to the distance of the surfaces of pedestrians from a viewpoint from which the skeleton information and anthropometric measurements of the pedestrians can be extracted, which have been proven to be more robust than the appearance features extracted from RGB cameras in different camera environments.
- (3)
- State-of-the-art pedestrian re-ID techniques take the bounding boxes of pedestrians as inputs. Since the background is useless in the pedestrian re-id process, image segmentation can be combined with pedestrian detection to generate a more accurate pedestrian shape and completely remove the background.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Haghani, M.; Sarvi, M. Simulating pedestrian flow through narrow exits. Phys. Lett. A 2019, 383, 110–120. [Google Scholar] [CrossRef]
- Hnseler, S.F.; Molyneaux, N.A.; Bierlaire, M. Estimation of pedestrian origin-destination demand in train stations. Transp. Sci. 2017, 51, 981–997. [Google Scholar] [CrossRef]
- Alahi, A.; Ramanathan, V.; Li, F.-F. Socially-Aware Large-Scale Crowd Forecasting. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Li, Y.; Sarvi, M.; Khoshelham, K. Pedestrian origin-destination estimation in emergency scenarios. In Proceedings of the 2019 9th International Conference on Fire Science and Fire Protection Engineering (ICFSFPE), Chengdu, China, 18–20 October 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Soltsz, T.; Attila, A.; Miklós, B.; Miklós, K. PFS method for pedestrian origin-destination surveys of enclosed areas. Transp. Res. Procedia 2017, 27, 680–687. [Google Scholar] [CrossRef]
- Farooq, B.; Beaulieu, A.; Ragab, M.; Ba, V.D. Ubiquitous monitoring of pedestrian dynamics: Exploring wireless ad hoc network of multi-sensor technologies. In Proceedings of the 2015 IEEE SENSORS, Busan, Korea, 1–4 November 2015. [Google Scholar]
- Lesani, A.; Miranda-Moreno, L. Development and Testing of a Real-Time WiFi-Bluetooth System for Pedestrian Network Monitoring, Classification, and Data Extrapolation. IEEE Trans. Intell. Transp. Syst. 2018, 20, 1484–1496. [Google Scholar] [CrossRef]
- Pouke, M.; Goncalves, J.; Ferreira, D.; Kostakos, V. Practical simulation of virtual crowds using points of interest. Comput. Environ. Urban Syst. 2016, 57, 118–129. [Google Scholar] [CrossRef]
- Shlayan, N.; Kurkcu, A.; Ozbay, K. Exploring pedestrian Bluetooth and WiFi detection at public transportation terminals. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016. [Google Scholar]
- Chen, X.; Wu, S.; Shi, C.; Huang, Y.; Yang, Y.; Ke, R.; Zhao, J. Sensing data supported traffic flow prediction via denoising schemes and ANN: A comparison. IEEE Sens. J. 2020, 20, 14317–14328. [Google Scholar] [CrossRef]
- Yang, X.; Yin, H.; Wu, J.; Qu, Y.; Gao, Z.; Tang, T. Recognizing the Critical Stations in Urban Rail Networks: An Analysis Method Based on the Smart-Card Data. IEEE Intell. Transp. Syst. Mag. 2019, 11, 29–35. [Google Scholar] [CrossRef]
- Ma, X.; Xian, Z.; Xin, L.; Wang, X.; Xu, Z. Impacts of free-floating bikesharing system on public transit ridership. Transp. Res. Part D Transp. Environ. 2019, 76, 100–110. [Google Scholar] [CrossRef]
- Boltes, M.; Seyfried, A. Collecting pedestrian trajectories. Neurocomputing 2013, 100, 127–133. [Google Scholar] [CrossRef]
- Khan, S.D.; Stefania, B.; Saleh, B.; Giuseppe, V. Analyzing crowd behavior in naturalistic conditions: Identifying sources and sinks and characterizing main flows. Neurocomputing 2016, 177, 543–563. [Google Scholar] [CrossRef] [Green Version]
- Zaki, M.H.; Sayed, T. Automated Analysis of Pedestrian Group Behavior in Urban Settings. IEEE Trans. Intell. Transp. Syst. 2017, 19, 1880–1889. [Google Scholar] [CrossRef]
- Lui, A.K.-F.; Chan, Y.-H.; Leung, M.-F. Modelling of Destinations for Data-driven Pedestrian Trajectory Prediction in Public Buildings. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Widhalm, P.; Brandle, N. Learning Major Pedestrian Flows in Crowded Scenes. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010. [Google Scholar]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person re-identification: Past, present and future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Yang, L.; Jin, R. Distance Metric Learning: A Comprehensive Survey; Michigan State University: East Lansing, MI, USA, 2006; Volume 2, p. 4. [Google Scholar]
- Hermans, A.; Beyer, L.; Leibe, B. In defense of the triplet loss for person re-identification. arXiv 2017, arXiv:1703.07737. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Yu, Q.; Chang, X.; Song, Y.; Xiang, T.; Hospedales, T.M. The Devil is in the Middle: Exploiting Mid-level Representations for Cross-Domain Instance Matching. arXiv 2017, arXiv:1711.08106. [Google Scholar]
- Bai, X.; Yang, M.; Huang, T.; Dou, Z.; Yu, R.; Xu, Y. Deep-Person: Learning Discriminative Deep Features for Person Re-Identification. arXiv 2017, arXiv:1711.10658. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond part models: Person retrieval with refined part pooling (and a strong convolutional baseline). In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Lee, K.M. Part-Aligned Bilinear Representations for Person Re-identification. arXiv 2018, arXiv:1804.07094. [Google Scholar]
- Kalayeh, M.M.; Basaran, E.; Gokmen, M.; Kamasak, M.E.; Shah, M. Human Semantic Parsing for Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. In Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Si, J.; Zhang, H.; Li, C.-G.; Kuen, J.; Kong, X.; Kot, A.C.; Wan, G. Dual Attention Matching Network for Context-Aware Feature Sequence based Person Re-Identification. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Chang, X.; Hospedales, T.M.; Xiang, T. Multi-level factorisation net for person re-identification. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.S.; Cucchiara, R.; Tomasi, C. Performance Measures and a Data Set for Multi-Target, Multi-Camera Tracking. In Proceedings of the European Conference on Computer Vision Workshop on Benchmarking Multi-Target Tracking, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Hassen, Y.H.; Ayedi, W.; Ouni, T.; Jallouli, M. Multi-shot person re-identification approach based key frame selection. In Proceedings of the Eighth International Conference on Machine Vision (ICMV 2015), Tokyo, Japan, 18–22 May 2015; SPIE: Bellingham, WA, USA, 2015. [Google Scholar]
- Gao, C.; Wang, J.; Liu, L.; Yu, J.; Sang, N. Superpixel-Based Temporally Aligned Representation for Video-Based Person Re-Identification. Sensors 2019, 19, 3861. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2008), Anchorage, AK, USA, 24–26 June 2008. [Google Scholar]
- Fruin, J.J. Pedestrian Planning and Design. Ph.D. Thesis, The University of Michigan, Ann Arbor, MI, USA, 1971. [Google Scholar]
- Zhang, Z.; Wu, J.; Zhang, X.; Zhang, C. Multi-target, multi-camera tracking by hierarchical clustering: Recent progress on DukeMTMC Project. arXiv 2017, arXiv:1712.09531. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
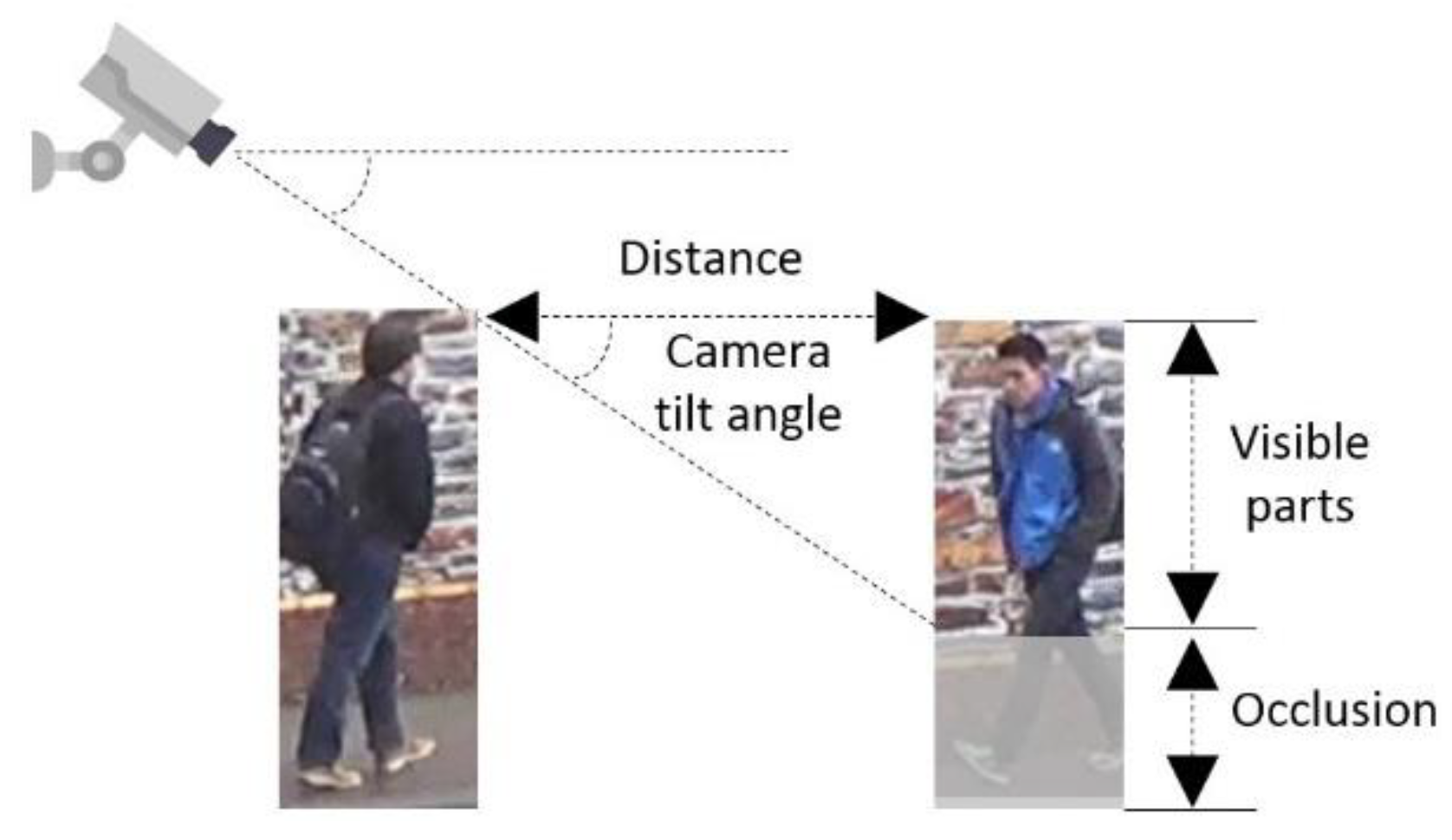
| LOS | Avg. Space (S, ft2/p) | Avg. Distance (D, Meter) | Visible Body Parts (P) |
|---|---|---|---|
| A | >35 | >1.803 | Whole body |
| B | 25–35 | 1.524–1.803 | >90% body |
| C | 15–25 | 1.180–1.524 | 70–90% body |
| D | 10–15 | 0.964–1.180 | 57–70% body |
| E | 5–10 | 0.682–0.964 | 40–57% body |
| F | <5 | <0.682 | <40% body |
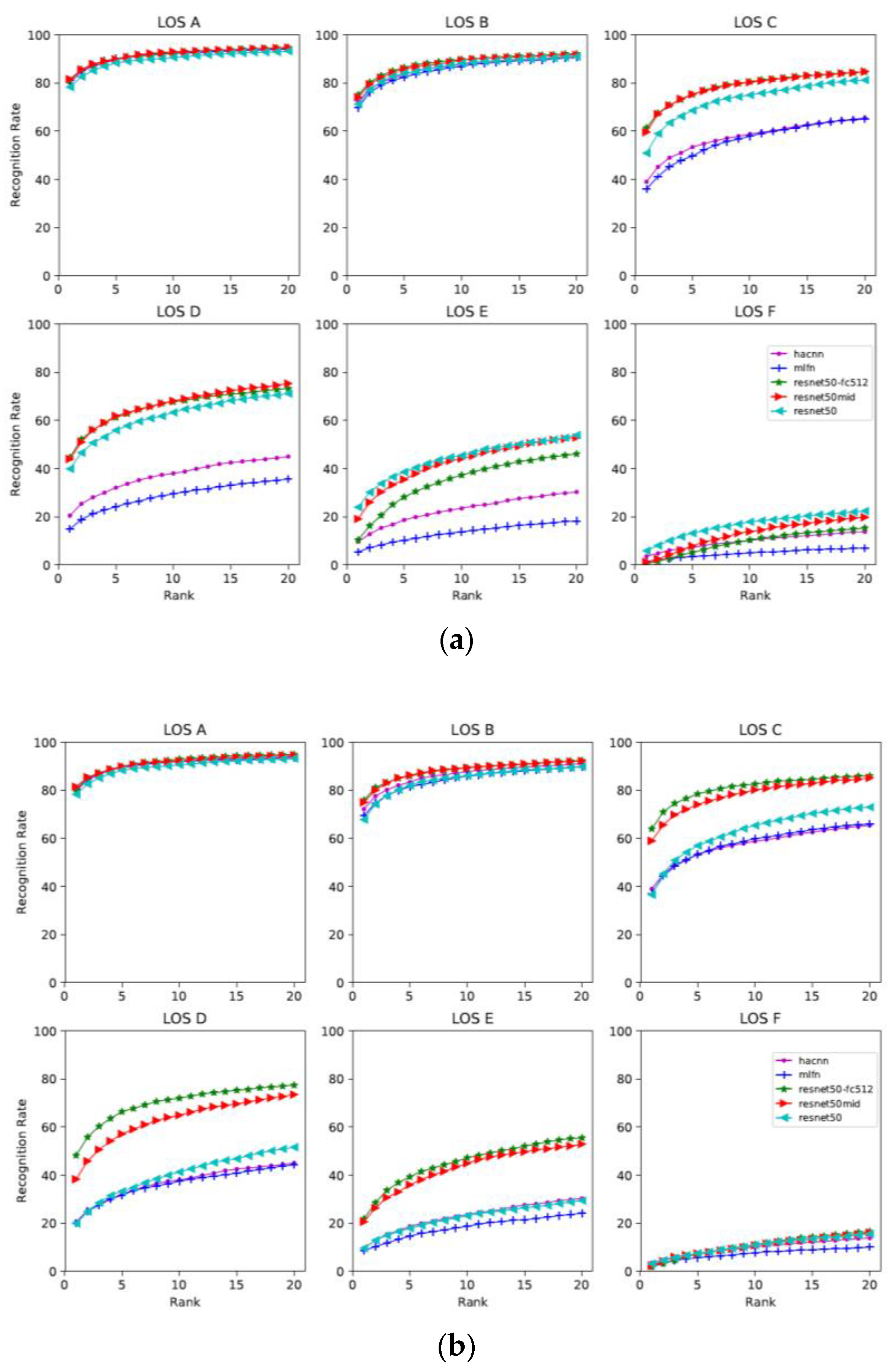
| Categories | Methods | LOS A | LOS B | LOS C | LOS D | LOS E | LOS F |
|---|---|---|---|---|---|---|---|
| Pair-wise network | |||||||
| Global | ResNet50 | 78.3 | 71.2 | 50.9 | 39.9 | 24.0 | 5.9 |
| ResNet-fc512 | 81.0 | 75.1 | 61.4 | 44.6 | 10.4 | 0.5 | |
| ResNet50-mid | 81.6 | 74.1 | 59.6 | 44.0 | 19.1 | 1.3 | |
| Local | HA-CNN | 80.1 | 72.2 | 39.0 | 20.5 | 9.7 | 3.6 |
| Attributes | MLFN | 81.1 | 69.7 | 36.0 | 14.9 | 5.4 | 1.3 |
| Triplet network | |||||||
| Global | ResNet50 | 77.7 | 67.8 | 36.6 | 19.9 | 9.6 | 3.2 |
| ResNet-fc512 | 80.5 | 75.9 | 64.0 | 48.2 | 21.8 | 1.9 | |
| ResNet50-mid | 81.5 | 75.0 | 59.0 | 38.3 | 20.6 | 2.4 | |
| Local | HA-CNN | 79.7 | 72.2 | 39.0 | 20.5 | 9.7 | 3.6 |
| Attributes | MLFN | 80.4 | 69.4 | 37.1 | 20.1 | 8.6 | 2.4 |
| Destination | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Cam1 | Cam2 | Cam3 | Cam4 | Cam5 | Cam6 | Cam7 | Cam8 | Sum | ||
| Origin | Cam1 | 0 | 336 | 0 | 0 | 12 | 0 | 4 | 24 | 376 |
| Cam2 | 310 | 0 | 166 | 0 | 144 | 0 | 2 | 15 | 637 | |
| Cam3 | 0 | 158 | 0 | 160 | 38 | 1 | 2 | 0 | 359 | |
| Cam4 | 0 | 1 | 147 | 0 | 7 | 0 | 0 | 0 | 155 | |
| Cam5 | 20 | 151 | 45 | 6 | 0 | 148 | 23 | 9 | 402 | |
| Cam6 | 0 | 0 | 0 | 0 | 161 | 0 | 174 | 0 | 335 | |
| Cam7 | 4 | 0 | 0 | 0 | 38 | 248 | 0 | 155 | 445 | |
| Cam8 | 113 | 9 | 0 | 0 | 10 | 0 | 213 | 0 | 345 | |
| Sum | 443 | 655 | 358 | 166 | 410 | 396 | 418 | 194 | 3040 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Sarvi, M.; Khoshelham, K.; Zhang, Y.; Jiang, Y. Pedestrian Origin–Destination Estimation Based on Multi-Camera Person Re-Identification. Sensors 2022, 22, 7429. https://doi.org/10.3390/s22197429
Li Y, Sarvi M, Khoshelham K, Zhang Y, Jiang Y. Pedestrian Origin–Destination Estimation Based on Multi-Camera Person Re-Identification. Sensors. 2022; 22(19):7429. https://doi.org/10.3390/s22197429
Chicago/Turabian StyleLi, Yan, Majid Sarvi, Kourosh Khoshelham, Yuyang Zhang, and Yazhen Jiang. 2022. "Pedestrian Origin–Destination Estimation Based on Multi-Camera Person Re-Identification" Sensors 22, no. 19: 7429. https://doi.org/10.3390/s22197429
APA StyleLi, Y., Sarvi, M., Khoshelham, K., Zhang, Y., & Jiang, Y. (2022). Pedestrian Origin–Destination Estimation Based on Multi-Camera Person Re-Identification. Sensors, 22(19), 7429. https://doi.org/10.3390/s22197429