
Few-Shot Fine-Grained Image Classification via GNN


Abstract
:1. Introduction
- We are the first to explore and use the information transfer of GNN for few-shot fine-grained image classification. The proposed method can better distinguish the nuances between different categories compared to other classification models.
- We optimize the embedding model. The initial embedding model is learned by the meta-learning method, which can make the feature extractor effective for both unknown and known test classes, and prevent it from falling into a local optimum.
2. Related Work
2.1. Few-Shot Learning
2.2. Fine-Grained Image Classification
2.3. FSL for Fine-Grained Classification
2.4. GNN-Based Methods in FSL
3. Materials and Methods
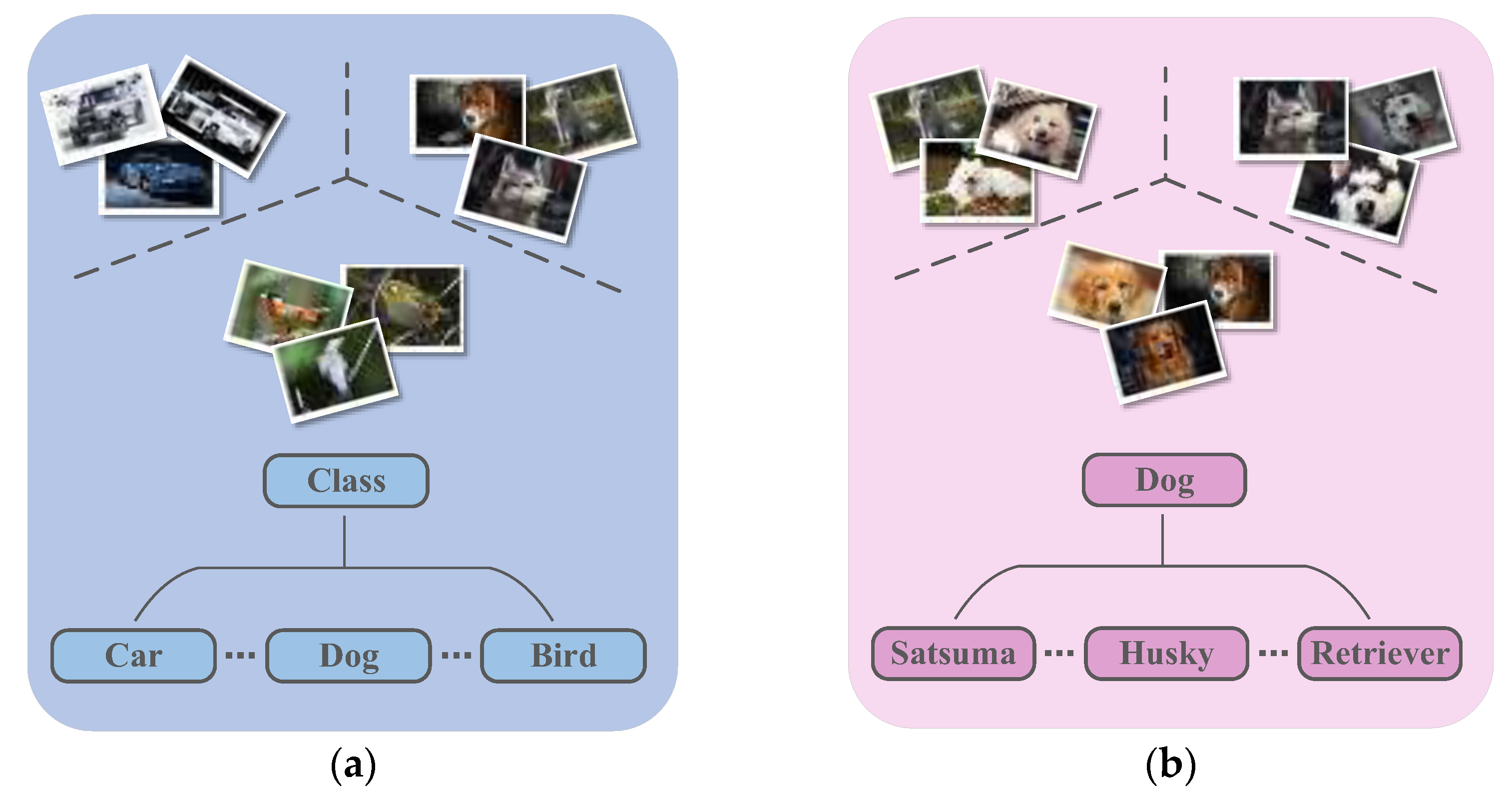
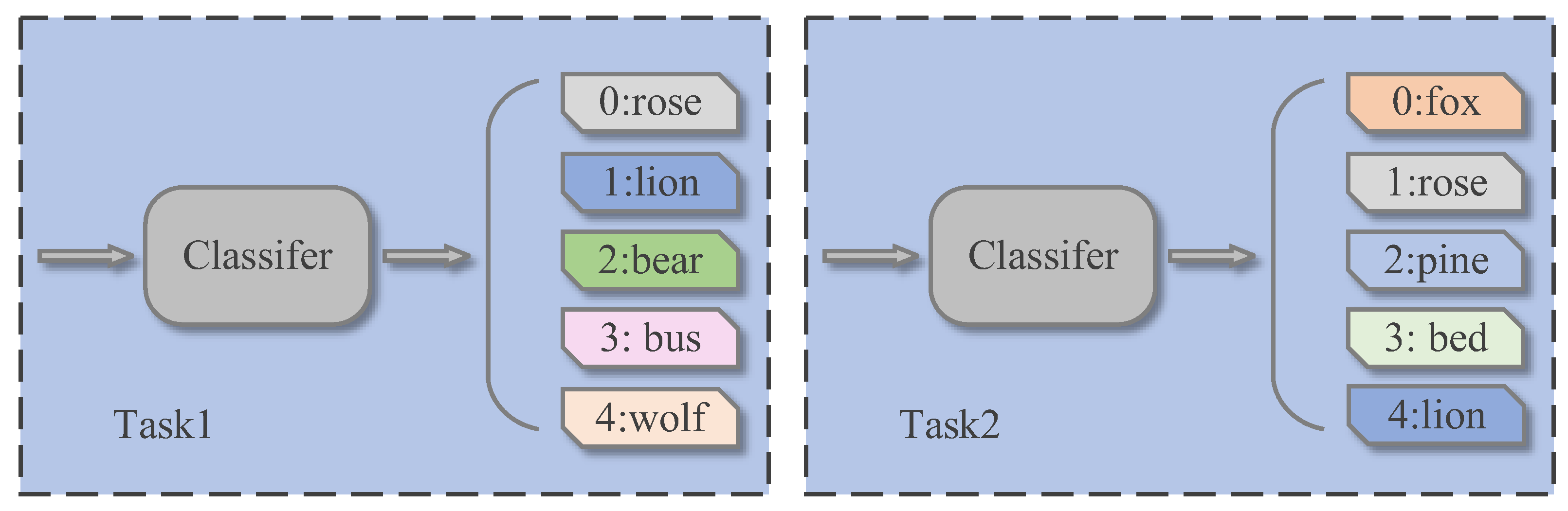
3.1. Data Organization and Definition of Task
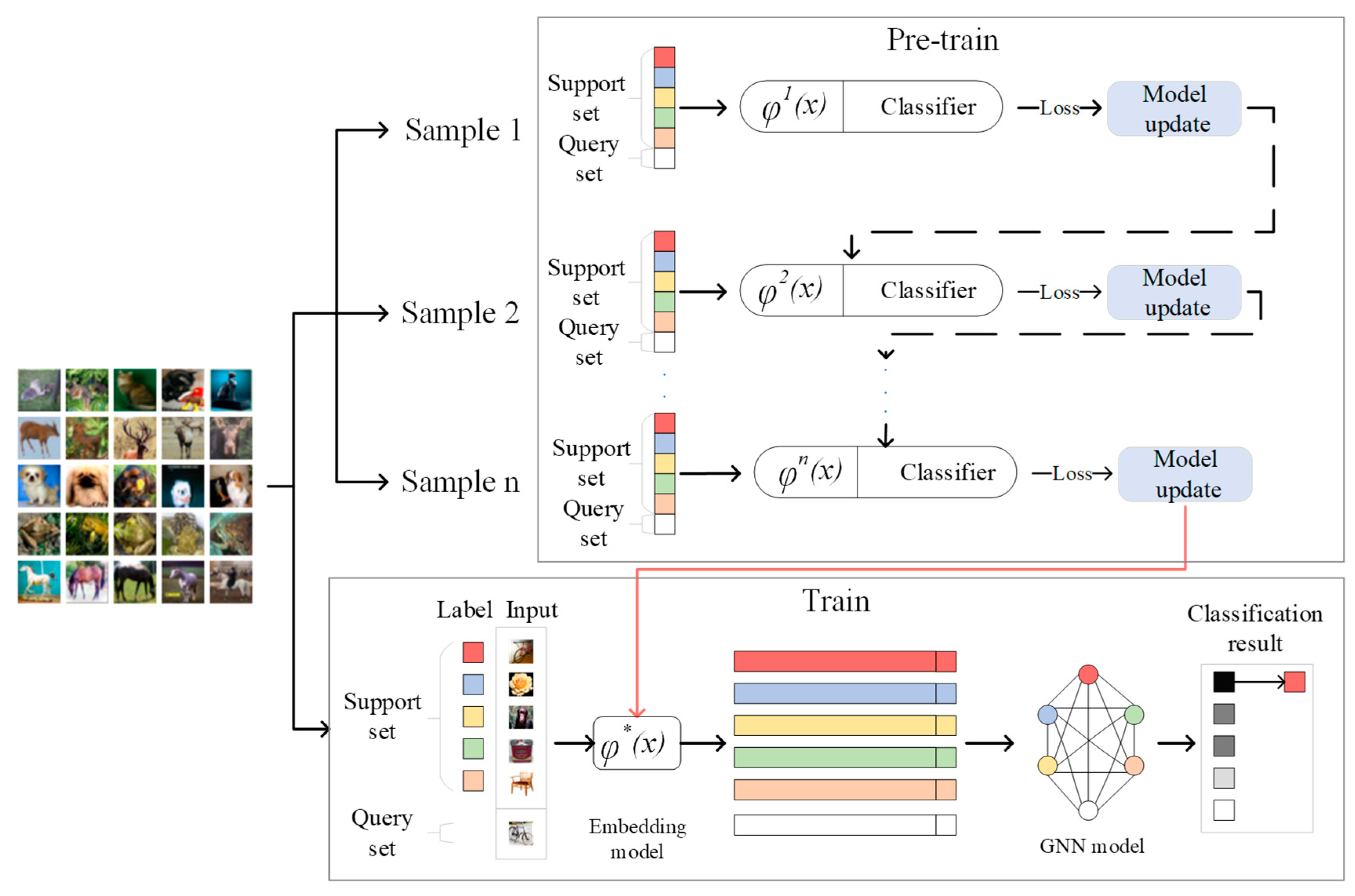
3.2. Model Design
3.3. Pre-Training Feature Extractor
| Algorithm 1. Pre-training feature extractor |
| Input: Meta-learner learning rate , the pre-training model , few-shot task distribution , the batch size |
| Output: good initialization parameters , learnable base-learner learning rate |
| 1: Randomly initialize , |
| 2: for do |
| 3: Sample tasks from ; |
| 4: for do |
| 5: ; |
| 6: Backward as ; |
| 7: ; |
| 8: ; |
| 10: end for |
| 11: Backward as ; |
| 12: Update ; |
| 13: end for |
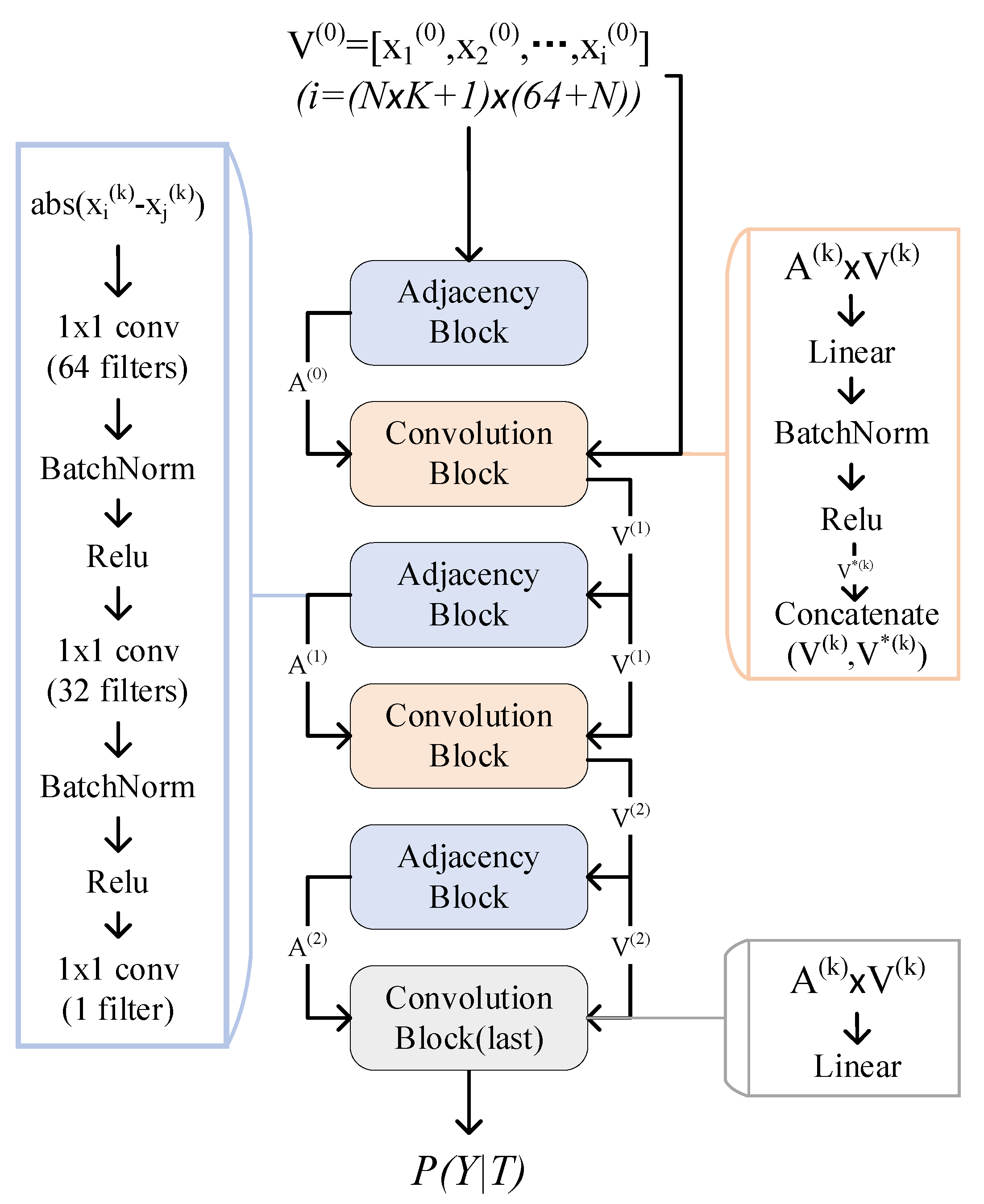
3.4. Formal Training
- Adjacency Block: The relationship between every two nodes is expressed as follows:where is a multi-layer neural network whose input is the Euclidian distance between two nodes. After obtaining all , adjacency matrix can be constructed.
- Convolution Block: The new nodes are obtained by a graph convolution neural network, which is formulated as follows:where is a nonlinear activation function, is a learned parameter, and is the matrix of features.
| Algorithm2. Formal training |
| Input: Meta-learner learning rate , the whole model (including embedding model with ), few-shot task distribution , the number of batches , the batch size , the number of iterations |
| Output: good parameters |
| 1: Randomly initialize other parameters ( refers to all the parameters of ); |
| 2: for do |
| 3: Sample tasks from ; |
| 4: for do |
| 5: Get nodes ; |
| 6: Get the initial matrix of features ; |
| 7: for do |
| 8: ; |
| 9: ; |
| 10: end for |
| 11: ; |
| 12: end for |
| 13: Backward as ; |
| 14: Update ; |
| 15: end for |
4. Experiment and Discussion
4.1. Dataset
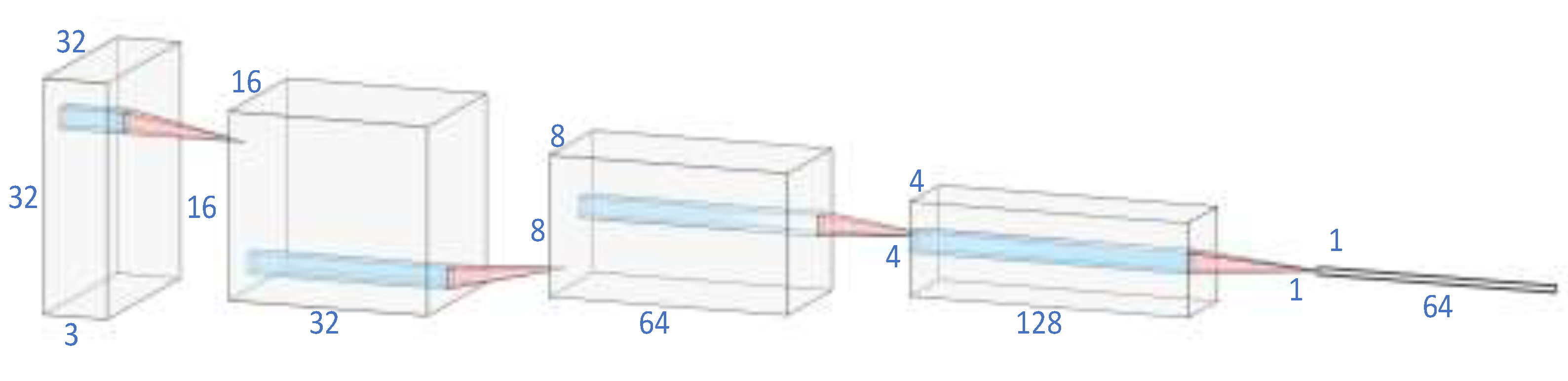
4.2. Network Structure Setting
4.3. Experimental Settings
4.4. Ablation Study
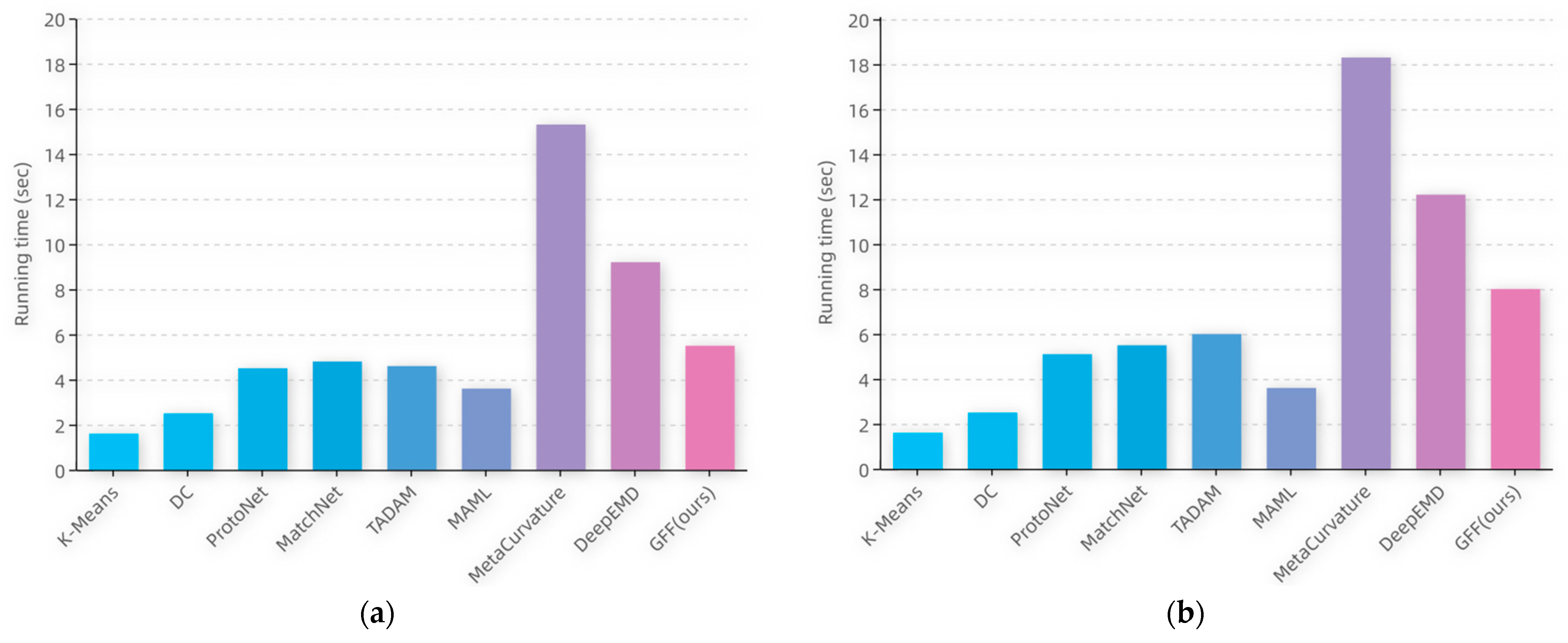
4.5. Performance and Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, T.; Kou, G.; Peng, Y.; Shi, Y. Classifying with adaptive hyper-spheres: An incremental classifier based on competitive learning. IEEE Trans. Syst. Man Cybern. Syst. 2017, 50, 1218–1229. [Google Scholar] [CrossRef]
- Gunduz, H. An efficient stock market prediction model using hybrid feature reduction method based on variational autoencoders and recursive feature elimination. Financ. Innov. 2021, 7, 1–24. [Google Scholar] [CrossRef]
- Fong, B. Analysing the behavioural finance impact of ’fake news’ phenomena on financial markets: A representative agent model and empirical validation. Financ. Innov. 2021, 7, 1–30. [Google Scholar] [CrossRef]
- Depren, Ö.; Kartal, M.T.; Kılıç Depren, S. Recent innovation in benchmark rates (BMR): Evidence from influential factors on Turkish Lira Overnight Reference Interest Rate with machine learning algorithms. Financ. Innov. 2021, 7, 1–20. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. A mask attention interaction and scale enhancement network for SAR ship instance segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar]
- Zhang, T.; Zhang, X. HTC+ for SAR Ship Instance Segmentation. Remote Sens. 2022, 14, 2395. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X. A polarization fusion network with geometric feature embedding for SAR ship classification. Pattern Recognit. 2022, 123, 108365. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, X.; Liu, C.; Shi, J.; Wei, S.; Ahmad, I. Balance learning for ship detection from synthetic aperture radar remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2021, 182, 190–207. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [Green Version]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Graves, A.; Wayne, G.; Danihelka, I. Neural turing machines. arXiv 2014, arXiv:1410.5401. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In International Conference on Machine Learning; PMLR: New York City, NY, USA, 2017; pp. 1126–1135. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-sgd: Learning to learn quickly for few-shot learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On first-order meta-learning algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. Adv. Neural Inf. Process. Syst. 2017, 30, 4080–4090. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation Network for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Zhang, N.; Donahue, J.; Girshick, R.; Darrell, T. Part-based R-CNNs for fine-grained category detection. In Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Lin, D.; Shen, X.; Lu, C.; Jia, J. Deep lac: Deep localization, alignment and classification for fine-grained recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1666–1674. [Google Scholar]
- Fu, J.; Zheng, H.; Mei, T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4438–4446. [Google Scholar]
- Sun, M.; Yuan, Y.; Zhou, F.; Ding, E. Multi-attention multi-class constraint for fine-grained image recognition. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 805–821. [Google Scholar]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear CNN models for fine-grained visual recognition. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 1449–1457. [Google Scholar]
- Gao, Y.; Beijbom, O.; Zhang, N.; Darrell, T. Compact bilinear pooling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 317–326. [Google Scholar]
- Chen, Y.; Bai, Y.; Zhang, W.; Mei, T. Destruction and construction learning for fine-grained image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5157–5166. [Google Scholar]
- Hu, T.; Qi, H.; Huang, Q.; Lu, Y. See better before looking closer: Weakly supervised data augmentation network for fine-grained visual classification. arXiv 2019, arXiv:1901.09891. [Google Scholar]
- Wei, X.S.; Wang, P.; Liu, L.; Shen, C.; Wu, J. Piecewise classifier mappings: Learning fine-grained learners for novel categories with few examples. IEEE Trans. Image Process. 2019, 28, 6116–6125. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Xu, J.; Huo, J.; Wang, L.; Gao, Y.; Luo, J. Distribution consistency based covariance metric networks for few-shot learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, January 27–February 1 2019; Volume 33, pp. 8642–8649. [Google Scholar]
- Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting local descriptor based image-to-class measure for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7260–7268. [Google Scholar]
- Hou, R.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Cross attention network for few-shot classification. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 4005–4016. [Google Scholar]
- Zhang, C.; Cai, Y.; Lin, G.; Shen, C. Deepemd: Differentiable earth mover’s distance for few-shot learning. arXiv 2020, arXiv:2003.06777. [Google Scholar]
- Garcia, V.; Bruna, J. Few-shot learning with graph neural networks. arXiv 2017, arXiv:1711.04043. [Google Scholar]
- Liu, Y.; Lee, J.; Park, M.; Kim, S.; Yang, Y. Transductive propagation network for few-shot learning. arXiv 2018, arXiv:1805.10002. [Google Scholar]
- Kim, J.; Kim, T.; Kim, S.; Yoo, C.D. Edge-labeling graph neural network for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11–20. [Google Scholar]
- Gidaris, S.; Komodakis, N. Generating classification weights with gnn denoising autoencoders for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 21–30. [Google Scholar]
- Yang, L.; Li, L.; Zhang, Z.; Zhou, X.; Zhou, E.; Liu, Y. Dpgn: Distribution propagation graph network for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13390–13399. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning multiple layers of features from tiny images. Handb. Syst. Autoimmune Dis. 2009, 1. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-Ucsd Birds-200—2011 Dataset; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Khosla, A.; Jayadevaprakash, N.; Yao, B.; Li, F. Novel dataset for fine-grained image categorization: Stanford dogs. In Proceedings of the CVPR Workshop, Long Beach, CA, USA, 16–20 June 2019; Volume 2. [Google Scholar]
- Jin, X.; Han, J. K-Means Clustering. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; pp. 563–564. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Park, E.; Oliva, J.B. Meta-curvature. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Oreshkin, B.; Rodríguez López, P.; Lacoste, A. Tadam: Task dependent adaptive metric for improved few-shot learning. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Chen, Z.; Fu, Y.; Wang, Y.X.; Ma, L.; Hebert, M. Image Deformation Meta-Networks for One-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 8680–8689. [Google Scholar]
- Afrasiyabi, A.; Lalonde, J.F.; Gagné, C. Mixture-based feature space learning for few-shot image classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 9041–9051. [Google Scholar]
- Rizve, M.N.; Khan, S.; Khan, F.S.; Shah, M. Exploring complementary strengths of invariant and equivariant representations for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 10836–10846. [Google Scholar]
- Zhong, X.; Gu, C.; Huang, W.; Li, L.; Chen, S.; Lin, C.W. Complementing representation deficiency in few-shot image classification: A meta-learning approach. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milano, Italy, 10–15 January 2021; pp. 2677–2684. [Google Scholar]
- Sun, Q.; Liu, Y.; Chua, T.S.; Schiele, B. Meta-transfer learning for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 403–412. [Google Scholar]
- Huang, H.; Zhang, J.; Zhang, J.; Wu, Q.; Xu, J. Compare more nuanced: Pairwise alignment bilinear network for few-shot fine-grained learning. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 91–96. [Google Scholar]
- Huang, H.; Zhang, J.; Zhang, J.; Xu, J.; Wu, Q. Low-rank pairwise alignment bilinear network for few-shot fine-grained image classification. IEEE Trans. Multimed. 2020, 23, 1666–1680. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Super Class | Classes |
|---|---|
| aquatic mammals | beaver, dolphin, otter, seal, whale |
| fish | aquarium fish, flatfish, ray, shark, trout |
| flowers | orchids, poppies, roses, sunflowers, tulips |
| food containers | bottles, bowls, cans, cups, plates |
| fruit and vegetables | apples, mushrooms, oranges, pears, sweet peppers |
| household electrical devices | clock, computer keyboard, lamp, telephone, television |
| household furniture | bed, chair, couch, table, wardrobe |
| insects | bee, beetle, butterfly, caterpillar, cockroach |
| large carnivores | bear, leopard, lion, tiger, wolf |
| large man-made outdoor things | bridge, castle, house, road, skyscraper |
| large natural outdoor scenes | cloud, forest, mountain, plain, sea |
| large omnivores and herbivores | camel, cattle, chimpanzee, elephant, kangaroo |
| medium-sized mammals | fox, porcupine, possum, raccoon, skunk |
| non-insect invertebrates | crab, lobster, snail, spider, worm |
| people | baby, boy, girl, man, woman |
| reptiles | crocodile, dinosaur, lizard, snake, turtle |
| small mammals | hamster, mouse, rabbit, shrew, squirrel |
| trees | maple, oak, palm, pine, willow |
| vehicles 1 | bicycle, bus, motorcycle, pickup truck, train |
| vehicles 2 | Lawn mower, rocket, streetcar, tank, tractor |
| Pre-Training | Cifar100 | CUB | DOGS | |
|---|---|---|---|---|
| 5-way 1-shot | - | 36.7 | 51.8 | 47.0 |
| √ | 49.2 (↑ 12.5) | 61.1 (↑ 9.3) | 49.8 (↑ 2.8) | |
| 5-way 5-shot | - | 62.3 | 73.7 | 63.3 |
| √ | 67.5 (↑ 5.2) | 78.6 (↑ 4.9) | 65.3 (↑ 2.0) |
| Method | 1-Shot | 5-Shot | 10-Shot |
|---|---|---|---|
| GNN (Raw, Baseline) | 36.7 | 62.3 | 69.3 |
| GNN + Pre-training (full classification) | 47.3 | 63.8 | 68.9 |
| GNN + Pre-training (meta-learning) | 49.2 | 67.5 | 72.5 |
| GNN + Pre-training (meta-learning) + Enhancement | 49.5 | 67.6 | 72.3 |
| Method | 1-Shot | 5-Shot |
|---|---|---|
| K-Means [40] | 38.5 ± 0.7 | 57.7 ± 0.8 |
| DC [41] | 42.0 ± 0.2 | 57.0 ± 0.2 |
| MAML [13] | 41.7 ± 0.6 | 56.2 ± 0.6 |
| MetaCurvature [42] | 41.1 ± 0.7 | 55.5 ± 0.8 |
| ProtoNet [16] | 41.5 ± 0.7 | 57.1 ± 0.8 |
| MatchNet [17] | 43.9 ± 0.7 | 57.1 ± 0.7 |
| TADAM [43] | 40.1 ± 0.4 | 56.1 ± 0.4 |
| DeepEMD [31] | 45.4 ± 0.4 | 61.5 ± 0.6 |
| IDeMe-Net [44] | 46.2 ± 0.8 | 64.1 ± 0.4 |
| MixtFSL [45] | 44.9 ± 0.6 | 60.7 ± 0.7 |
| IER [46] | 47.4 ± 0.8 | 64.4 ± 0.8 |
| MCRNet [47] | 41.0 ± 0.6 | 57.8 ± 0.6 |
| MTL [48] | 46.1 ± 0.8 | 61.4 ± 0.8 |
| GFF (ours) | 49.2 ± 0.8 | 67.5 ± 0.8 |
| Methods | CUB | Dog | ||
|---|---|---|---|---|
| 5-Way 1-Shot | 5-Way 5-Shot | 5-Way 1-Shot | 5-Way 5-Shot | |
| MatchNet [8] | 57.6 ± 0.7 | 70.6 ± 0.6 | 45.0 ± 0.7 | 60.6 ± 0.6 |
| ProtoNet [7] | 53.9 ± 0.7 | 70.8 ± 0.6 | 42.6 ± 0.6 | 59.5 ± 0.6 |
| RelationNet [9] | 58.9 ± 0.5 | 71.2 ± 0.4 | 43.3 ± 0.5 | 55.2 ± 0.4 |
| MAML [4] | 58.1 ± 0.4 | 71.5 ± 0.3 | 44.8 ± 0.3 | 58.6 ± 0.3 |
| DN4 [33] | 55.2 ± 0.9 | 74.9 ± 0.6 | 45.7 ± 0.8 | 66.3 ± 0.7 |
| PABN [49] | 61.1 ± 0.4 | 76.8 ± 0.2 | 45.6 ± 0.7 | 61.2 ± 0.6 |
| CovaMNet [32] | 58.5 ± 0.9 | 71.2 ± 0.8 | 49.1 ± 0.8 | 63.0 ± 0.6 |
| LRPABN [50] | 63.6 ± 0.8 | 76.1 ± 0.6 | 45.7 ± 0.8 | 60.9 ± 0.7 |
| GFF (ours) | 61.1 ± 0.4 | 78.6 ± 0.3 | 49.8 ± 0.8 | 65.3 ± 0.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Zhang, Y.; Wei, Q. Few-Shot Fine-Grained Image Classification via GNN. Sensors 2022, 22, 7640. https://doi.org/10.3390/s22197640
Zhou X, Zhang Y, Wei Q. Few-Shot Fine-Grained Image Classification via GNN. Sensors. 2022; 22(19):7640. https://doi.org/10.3390/s22197640
Chicago/Turabian StyleZhou, Xiangyu, Yuhui Zhang, and Qianru Wei. 2022. "Few-Shot Fine-Grained Image Classification via GNN" Sensors 22, no. 19: 7640. https://doi.org/10.3390/s22197640
APA StyleZhou, X., Zhang, Y., & Wei, Q. (2022). Few-Shot Fine-Grained Image Classification via GNN. Sensors, 22(19), 7640. https://doi.org/10.3390/s22197640