


A Self-Learning Mechanism-Based Approach to Helicopter Entry and Departure Recognition


Abstract
:1. Introduction
- The lightweight YOLOv5s algorithm is applied for the fast detection of helicopter video, using the detection bounding box to calculate the relative position of the helicopter, thus generating a collection of raw image data as input to the self-learning mechanism;
- The self-learning mechanism constructed in this paper can select and update the image classification module, which establishes a dynamic cycle of overall self-learning of the algorithm, and promotes the cyclic optimization of model learning. Taking the helicopter entry and departure state as an example, the self-learning mechanism built in this paper has a certain capacity for generalization and can solve the entry and departure recognition problem of most relatively rigid bodies in a fixed area.
- Building an Automatic Selector of Data (Auto-SD) and Adjustment Evaluator of Data Bias (Ad-EDB) to automatically label the helicopter motion state with the original data set generated from a priori knowledge and object detection. The algorithm combines a priori knowledge and the original data set generated from object detection to automatically annotate the helicopter motion status, adjust and evaluate the accuracy of the labels, select the best matching image classification module for training, and finally achieve the status recognition of helicopter entry and exit positions.
2. Related Work
2.1. Object Detection
2.2. Image Classification
2.3. Helicopter Landing and Take-Off Operating Rules
3. Self-Learning Mechanism-Based Entry and Departure Recognition Model
3.1. The Lightweight YOLOv5s Algorithm (YOLOv5s-RMV3S)
3.2. Training Algorithm for Entry and Departure Recognition Models
| Algorithm 1 Entry and Departure Model Training Algorithm |
|
|
3.3. Automatic Selector of Data (Auto-SD)
3.4. Adjustment Evaluator of Data Bias (Ad-EDB)
4. Experimental Results and Analysis
4.1. Data Set and Experimental Environment
4.2. Comparison of Experimental Results
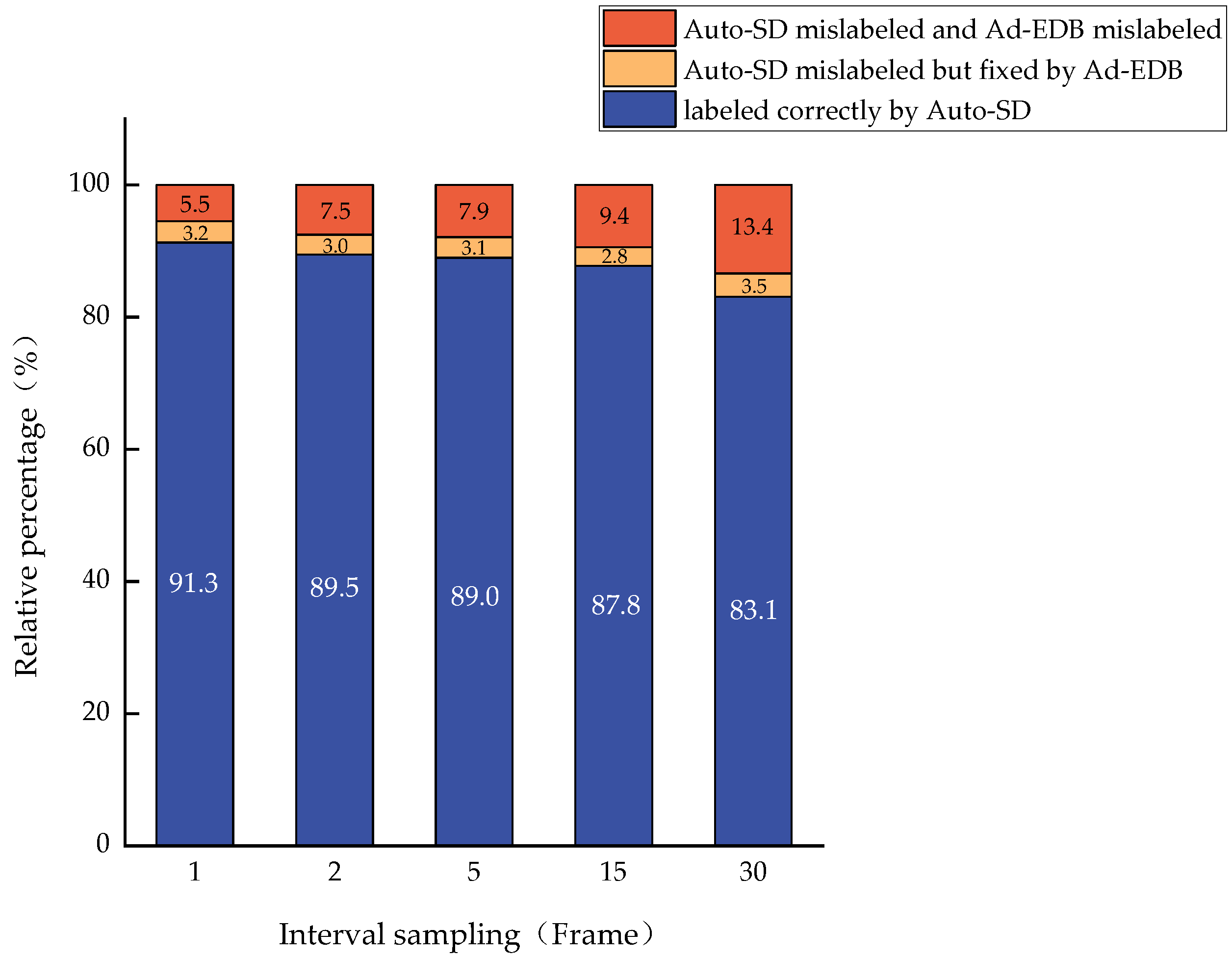
4.2.1. Experimental Results on Self-Learning Mechanisms
4.2.2. Experimental Results of the Overall Algorithm
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Q.; Mott, J.H. Development of a Reliable Method for General Aviation Flight Phase Identification. IEEE Trans. Intell. Transp. Syst. 2022, 23, 11729–11738. [Google Scholar] [CrossRef]
- Farhadmanesh, M.; Rashidi, A. General Aviation Aircraft Identification at Non-Towered Airports Using a Two-Step Computer Vision-Based Approach. IEEE Access 2022, 10, 48778–48791. [Google Scholar] [CrossRef]
- Trainelli, L.; Salucci, F. Optimal Sizing and Operation of Airport Infrastructures in Support of Electric-Powered Aviation. Aerospace 2021, 8, 40. [Google Scholar] [CrossRef]
- Zheng, Y.; Miao, J. Intelligent Airport Collaborative Decision Making (A-CDM) System. In Proceedings of the 2019 IEEE 1st International Conference on Civil Aviation Safety and Information Technology, Kunming, China, 17–19 October 2019; pp. 616–620. [Google Scholar]
- Wu, J.; Sun, C. Deep clustering variational network for helicopter regime recognition in HUMS. Aerosp. Sci. Technol. 2022, 124, 1270. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, X. Dynamical Analysis of Rotor Loads in Helicopter Circling Flight Condition. In Proceedings of the 2021 Asia-Pacific International Symposium on Aerospace Technology, Jeju Island, Korea, 3–6 November 2021; p. 912. [Google Scholar]
- Jiao, L. Challenges and thinking of the next generation of artificial intelligence. CAAI Trans. Intell. Syst. 2020, 15, 1185–1187. [Google Scholar]
- Xu, Z. Ten fundamental problems for artificial intelligence: Mathematical and physical aspects. Sci. Sin. Inf. 2021, 51, 1967–1978. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, X. Multi-focus image fusion with a self-learning fusion rule. J. Image Graph. 2020, 25, 1637–1648. [Google Scholar]
- Xiong, B.; Liu, Y. Recognition of helicopter flight condition based on support vector machine. J. Appl. Sci. 2016, 34, 469–474. [Google Scholar]
- Wang, J.; Xiong, B. Recognition method of helicopter flight condition based on random forest. Comput. Eng. Appl. 2017, 53, 149–152. [Google Scholar]
- Gao, J. Helicopter flight status recognition based on BP Neural Network. Helicopter Tech. 2022, 1, 25–28. [Google Scholar]
- Li, S.; Wang, J. Helicopter flight status recognition based on pre-classification mechanism and GRNN. Aeronaut. Sci. Technol. 2021, 32, 18–23. [Google Scholar]
- Li, F. Aircraft Landing Gear Status Monitoring Based on Deep Learning. Master’s Thesis, Chinese Academy of Sciences, Changchun, China, 2022. [Google Scholar]
- Feng, W. Helicopter flight status recognition method based on airborne vibration monitoring system. Foreign Electron. Meas. Technol. 2020, 39, 133–136. [Google Scholar]
- Lopac, N.; Jurdana, I. Application of Laser Systems for Detection and Ranging in the Modern Road Transportation and Maritime Sector. Sensors 2022, 22, 5946. [Google Scholar] [CrossRef]
- Wang, C.; Di, J. Processing of laser scanning data in aircraft parking systems. Laser Technol. 2015, 39, 357–360. [Google Scholar]
- Yang, J.; Wu, J. Aircraft Target Detection in Remote Sensing Image Based on Multi-scale Circle Frequency Filter and Convolutional Neural Network. J. Electron. Inf. Technol. 2021, 43, 1397–1404. [Google Scholar]
- Grichick, R.; Donahue, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, K.; Feng, X. Overview of deep convolutional neural networks for image classification. J. Image Graph. 2021, 26, 2305–2325. [Google Scholar]
- Ge, Y.; Liu, H. Survey on Deep Learning Image Recognition in Dilemma of Small Samples. J. Softw. 2022, 33, 193–210. [Google Scholar]
- He, K.; Zhang, X. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lyu, Z.; Chen, L. SA-FRCNN: An Improved Object Detection Method for Airport Apron Scenes. Trans. Nanjing Univ. Aeronaut. Astronaut. 2021, 38, 571–586. [Google Scholar]
- Siswariya, S.; Micro-Doppler, J.V. Signature based Helicopter Identification and Classification through Machine Learning. Int. J. Comput. 2021, 15, 23–29. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | P/% | R/% | mAP/% | Parameters/M | Computation/G | Size/MB |
|---|---|---|---|---|---|---|
| YOLOv5s | 97.4 | 97.1 | 97.4 | 7.1 | 16.4 | 13.7 |
| YOLOv5s-RMV3S | 96.3 | 96.1 | 96.3 | 3.5 | 6.3 | 6.8 |
| Selection Accuracy/% | |
|---|---|
| 0.92 | 90.31 |
| 0.93 | 90.53 |
| 0.94 | 91.13 |
| 0.95 | 91.32 |
| 0.96 | 90.55 |
| 0.97 | 90.37 |
| Method | Entry False Detection Rate/% | Departure False Detection Rate/% | Recognition Accuracy/% | Availability of Self-Study |
|---|---|---|---|---|
| SVM-based method | 7.12 | 4.15 | 88.73 | No |
| Random Forest-based method | 6.03 | 4.01 | 89.96 | No |
| YOLOv5s (generating bounding boxes) | 5.15 | 3.53 | 91.32 | No |
| Laser method (application sensors) | 3.15 | 1.50 | 95.35 | No |
| Optical flow method (determining propeller motion) | 9.43 | 7.36 | 83.21 | No |
| Lightweight Object Detection + Auto-SD + ResNet18 | 2.94 | 1.35 | 95.71 | No |
| Lightweight Object Detection + Auto-SD + ResNet18 + Ad-EDB | 1.15 | 1.02 | 97.83 | Yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyu, Z.; Chang, X.; An, W.; Yu, T. A Self-Learning Mechanism-Based Approach to Helicopter Entry and Departure Recognition. Sensors 2022, 22, 7852. https://doi.org/10.3390/s22207852
Lyu Z, Chang X, An W, Yu T. A Self-Learning Mechanism-Based Approach to Helicopter Entry and Departure Recognition. Sensors. 2022; 22(20):7852. https://doi.org/10.3390/s22207852
Chicago/Turabian StyleLyu, Zonglei, Xuepeng Chang, Wei An, and Tong Yu. 2022. "A Self-Learning Mechanism-Based Approach to Helicopter Entry and Departure Recognition" Sensors 22, no. 20: 7852. https://doi.org/10.3390/s22207852
APA StyleLyu, Z., Chang, X., An, W., & Yu, T. (2022). A Self-Learning Mechanism-Based Approach to Helicopter Entry and Departure Recognition. Sensors, 22(20), 7852. https://doi.org/10.3390/s22207852