
Attention-Guided Disentangled Feature Aggregation for Video Object Detection

 ,
,  ,
,  ,
, 
Abstract
:1. Introduction
- Motion Blur: Occurs due to the rapid or sudden movement of the objects, resulting in the object being blurry and losing its characteristics.
- Defocus: Occurs when the camera is not able to focus on the object in motion or when the imaging system itself is being moved. This results in unclear and out-of-focus frames.
- Occlusion: Occurs when the object is hidden behind other objects or elements in the environment. Occlusion results in a significant loss of information.
- Illumination Variance: Variation in the intensity of light can cause the object to have significantly different characteristics, such as losing colour information under a shadow.
- Scale Variance: The perceived size of the object changes as it moves towards or away from the camera and also when the camera zooms or moves with respect to the object.
- Spatial Variance: When the camera angle changes, it introduces different viewpoints, rotations or locations of the object, which may result in significantly different characteristics at different viewpoints.

- We highlight an important problem that naive attention-based feature aggregation is sub-optimal for video object detection. As a remedy, we follow the spirits of [18] in still images and propose to disentangle the representation first through refined spatial, scale and task-specific feature learning, which compliments inter-frame feature aggregation for video object detection.
- The proposed approach can be effortlessly integrated into any video object detection method to improve performance.
- Upon integrating our disentanglement head prior to feature aggregation in recent video object detection methods, we observe consistent and significant performance improvements. When our module is adopted into the recent state-of-the-art method TROI [16], we achieve a new state-of-the-art mAP of 80.3% on the ResNet-50 backbone network.
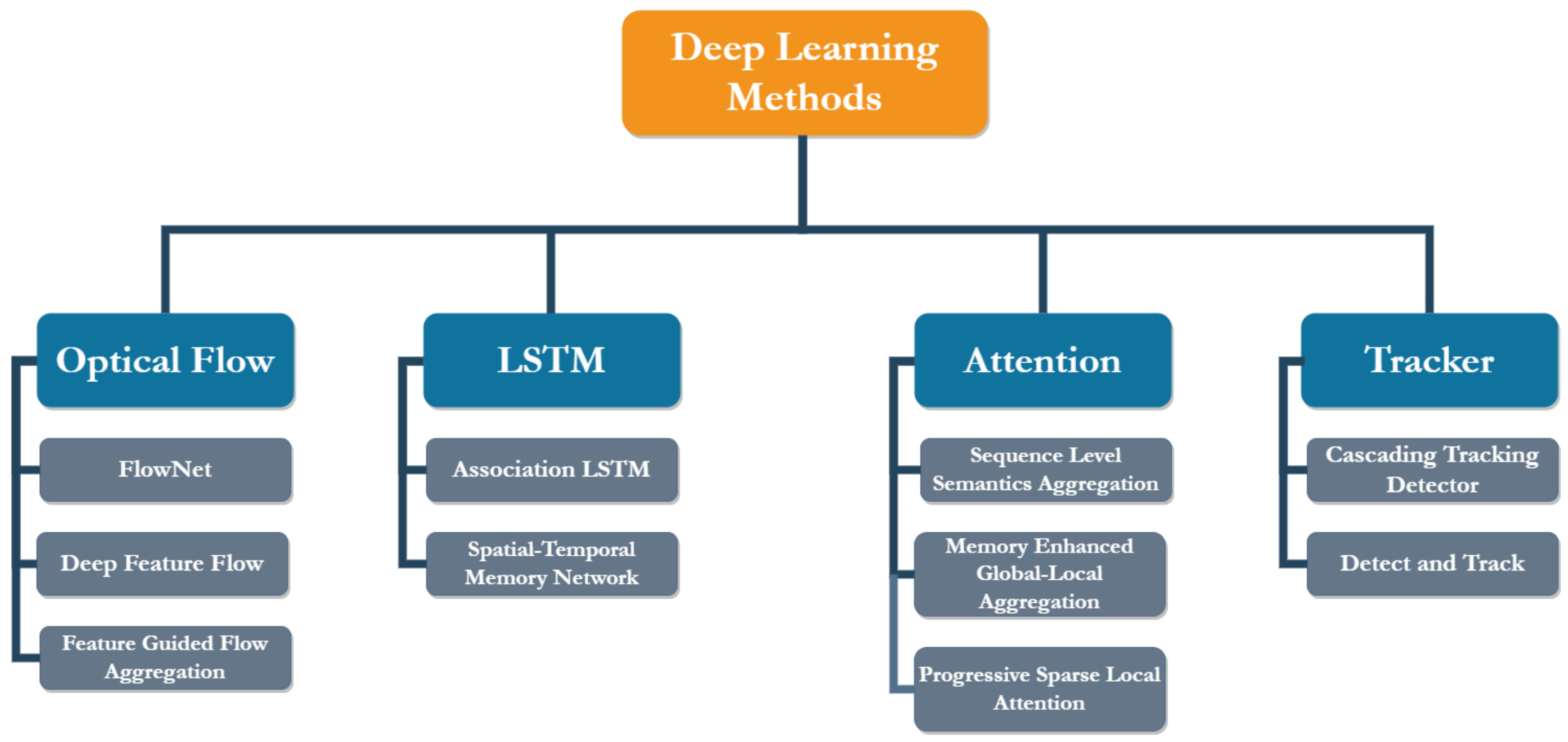
2. Background and Related Works
2.1. Optical Flow-Based Methods
2.2. LSTM-Based Methods
2.3. Attention-Based Methods
2.4. Tracking-Based Methods
2.5. Attention in Image Object Detection
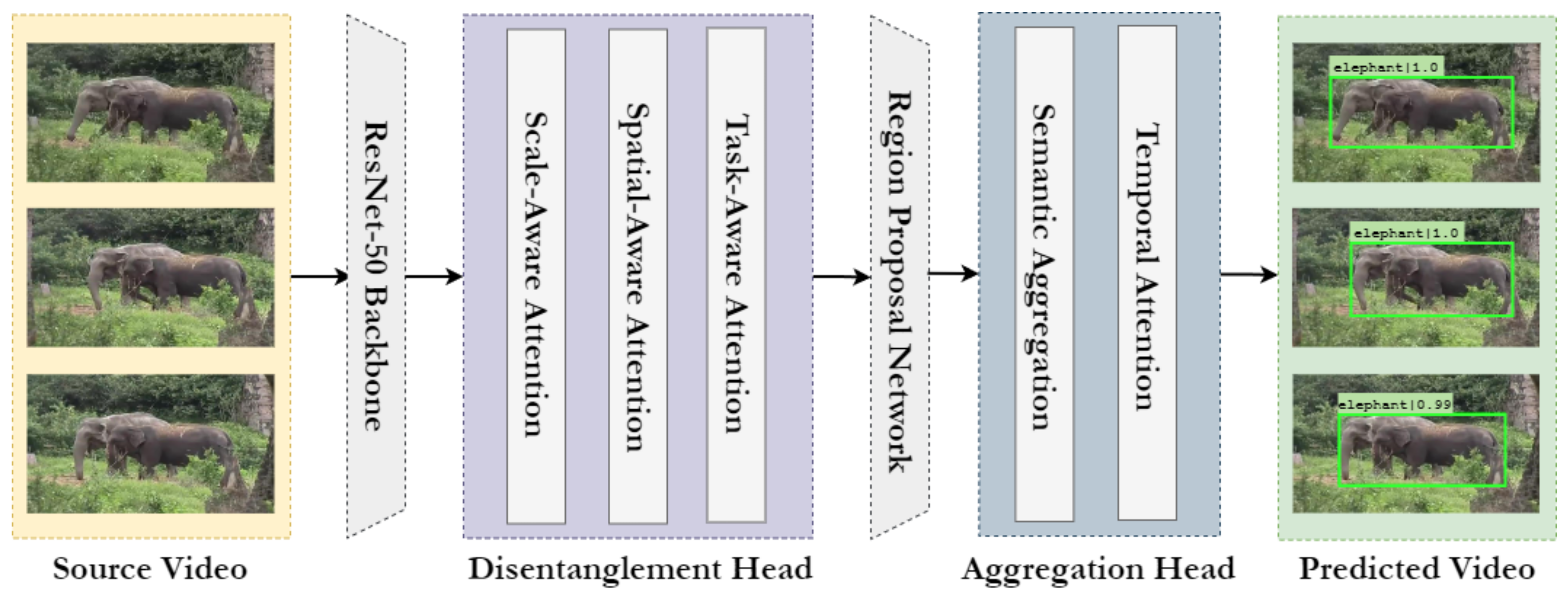
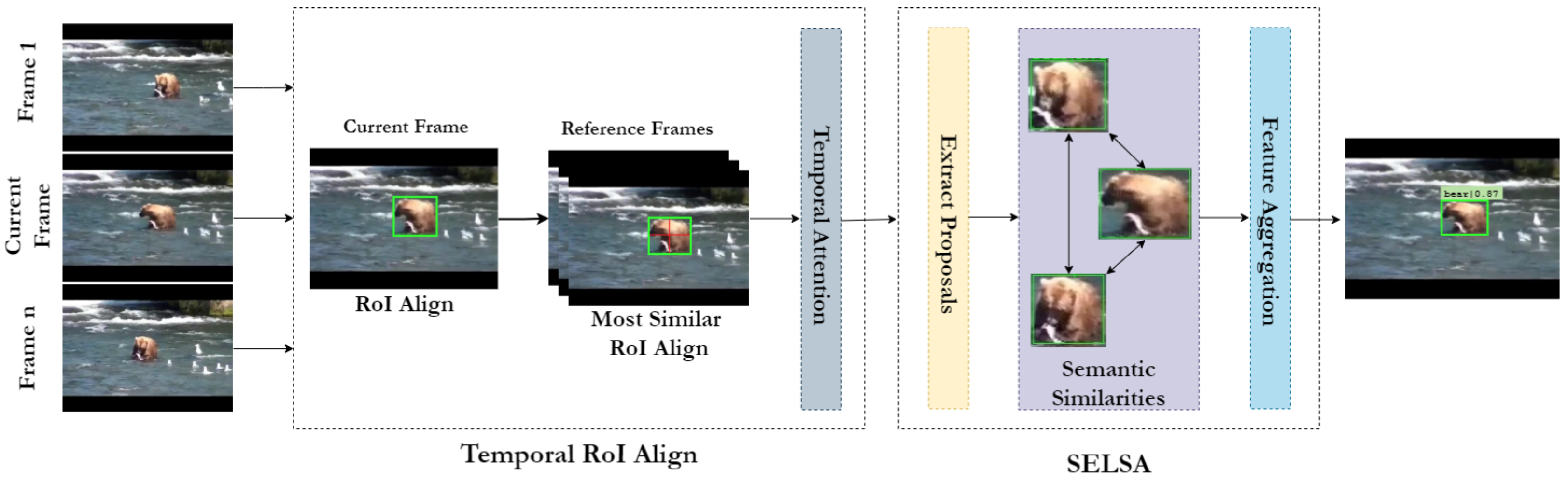
3. Method
3.1. Backbone
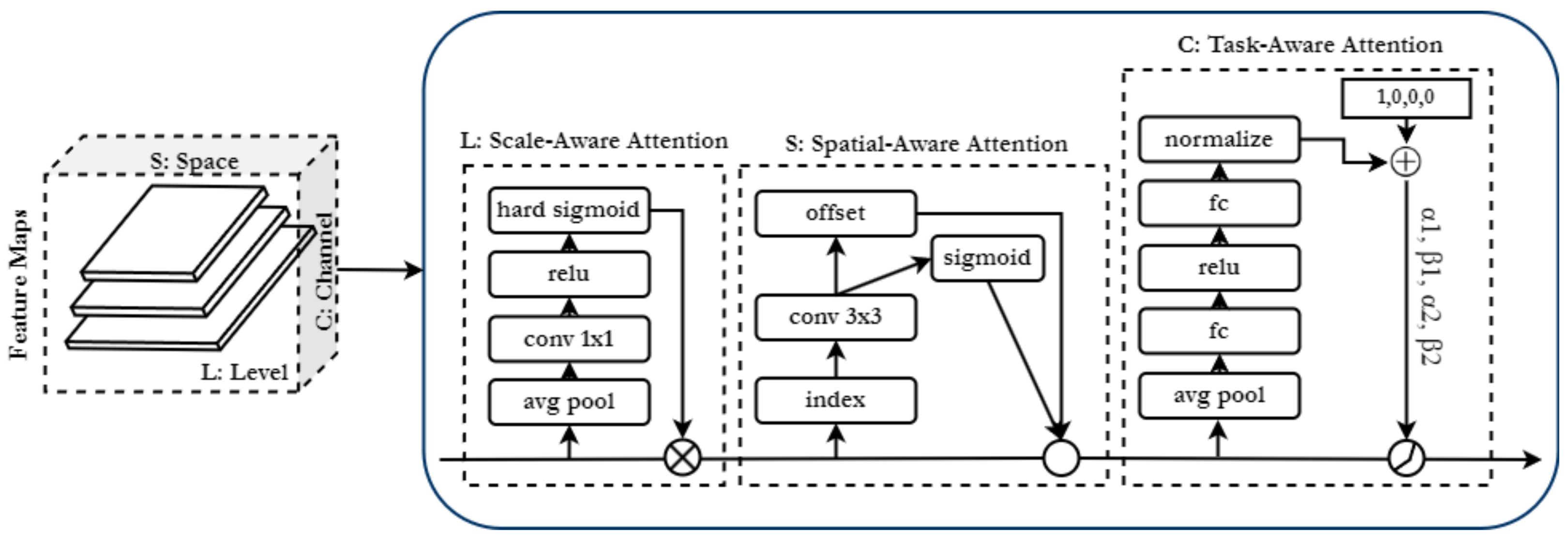
3.2. Disentangled Head
- Scale-aware attention is utilised on the level dimension, emphasizes the varying scales of the objects and dynamically fuses the features based on their semantic importance.
- Spatial-aware attention is deployed on the space dimension S and emphasizes on the location of the objects, it is applied to the fused features from the scale aware-attention.
- Task-aware attention is applied on the channels; it exploits the feature channels by dynamically switching on and off to favour specific tasks.

3.3. Region Proposal Network
3.4. Aggregation Head
4. Experimental Setup
4.1. Dataset and Evaluation Metrics
- Precision: Ratio of correctly predicted bounding boxes to all the predicted samples. It measures the model’s ability to identify only relevant objects.
- Recall: Ratio of correctly predicted bounding boxes to all ground truth bounding boxes. It measures the prediction of all relevant cases.
- Intersection over Union (IoU): Measure of the overlap between the predicted bounding box and the ground truth. The IoU threshold is used to classify detection; only if the overlapping area is greater than a threshold t, the detection is regarded as correct.
- Average Precision (AP): Interprets the precision–recall curve as the weighted mean of precisions at each threshold, with the increase in recall from the preceding threshold used as the weight.
- Mean Average Precision (mAP): Evaluates the accuracy of object detectors by averaging the average precision across all classes as shown below, where is the average precision of class and N is the number of classes.mAP is calculated at different IoU thresholds, mAP is the average mAP over 10 IoU thresholds from 0.5 to 0.95 with a step size of 0.05. mAP50 is the mAP at IoU = 0.5 and mAP75 is the mAP at IoU = 0.75.
4.2. Implementation Details
5. Experiments and Results
5.1. Ablation Study
5.1.1. Number of Attention Blocks
5.1.2. Number of Most Similar ROI Points
5.1.3. Number of Temporal Attention Blocks
5.1.4. Effectiveness of the Disentanglement Attention Module
5.2. Main Results
5.3. Qualitative Analysis
5.3.1. Visualising Detection Results
5.3.2. Robustness against Challenges in VOD
5.3.3. Failure Case Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Janai, J.; Güney, F.; Behl, A.; Geiger, A. Computer vision for autonomous vehicles: Problems, datasets and state of the art. Found. Trends Comput. Graph. Vis. 2020, 12, 1–308. [Google Scholar] [CrossRef]
- Xie, J.; Zheng, Y.; Du, R.; Xiong, W.; Cao, Y.; Ma, Z.; Cao, D.; Guo, J. Deep learning-based computer vision for surveillance in its: Evaluation of state-of-the-art methods. IEEE Trans. Veh. Technol. 2021, 70, 3027–3042. [Google Scholar] [CrossRef]
- Patrício, D.I.; Rieder, R. Computer vision and artificial intelligence in precision agriculture for grain crops: A systematic review. Comput. Electron. Agric. 2018, 153, 69–81. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.; Yang, Y.; Lin, P.; Park, D.S. Computer vision in healthcare applications. J. Healthc. Eng. 2018, 2018, 5157020. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Sultana, F.; Sufian, A.; Dutta, P. A review of object detection models based on convolutional neural network. In Intelligent Computing: Image Processing Based Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–16. [Google Scholar]
- Ahmed, M.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Survey and performance analysis of deep learning based object detection in challenging environments. Sensors 2021, 21, 5116. [Google Scholar] [CrossRef]
- Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Exploiting Concepts of Instance Segmentation to Boost Detection in Challenging Environments. Sensors 2022, 22, 3703. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, R.; Liu, F.; Yang, S.; Hou, B.; Li, L.; Tang, X. New Generation Deep Learning for Video Object Detection: A Survey. In IEEE Transactions on Neural Networks and Learning Systems; IEEE: Piscataway, NJ, USA, 2021; pp. 1–21. [Google Scholar] [CrossRef]
- Wu, H.; Chen, Y.; Wang, N.; Zhang, Z. Sequence Level Semantics Aggregation for Video Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Gong, T.; Chen, K.; Wang, X.; Chu, Q.; Zhu, F.; Lin, D.; Yu, N.; Feng, H. Temporal ROI Align for Video Object Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35. [Google Scholar]
- Hashmi, K.A.; Pagani, A.; Stricker, D.; Afzal, M.Z. BoxMask: Revisiting Bounding Box Supervision for Video Object Detection. arXiv 2022, arXiv:2210.06008. [Google Scholar]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic Head: Unifying Object Detection Heads With Attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–25 September 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. Brief: Binary robust independent elementary features. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 778–792. [Google Scholar]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. In Advances in Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 128–144. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Zhai, M.; Xiang, X.; Lv, N.; Kong, X. Optical flow and scene flow estimation: A survey. Pattern Recognit. 2021, 114, 107861. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Smagt, P.; Cremers, D.; Brox, T. FlowNet: Learning Optical Flow with Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2758–2766. [Google Scholar] [CrossRef]
- Zhu, X.; Xiong, Y.; Dai, J.; Yuan, L.; Wei, Y. Deep feature flow for video recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2349–2358. [Google Scholar]
- Zhu, X.; Wang, Y.; Dai, J.; Yuan, L.; Wei, Y. Flow-guided feature aggregation for video object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 408–417. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.c. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the 28th International Conference on Neural Information Processing Systems—Volume 1, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Lu, Y.; Lu, C.; Tang, C.K. Online Video Object Detection Using Association LSTM. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2363–2371. [Google Scholar] [CrossRef]
- Xiao, F.; Lee, Y.J. Video Object Detection with an Aligned Spatial-Temporal Memory. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. In Computational Visual Media; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–38. [Google Scholar]
- Chen, Y.; Cao, Y.; Hu, H.; Wang, L. Memory Enhanced Global-Local Aggregation for Video Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Guo, C.; Fan, B.; Gu, J.; Zhang, Q.; Xiang, S.; Prinet, V.; Pan, C. Progressive sparse local attention for video object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3909–3918. [Google Scholar]
- Mao, H.; Kong, T.; Dally, B. CaTDet: Cascaded Tracked Detector for Efficient Object Detection from Video. In Proceedings of the Machine Learning and Systems, Stanford, CA, USA, 31 March–2 April 2019; Volume 1, pp. 201–211. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Detect to track and track to detect. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3038–3046. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Li, W.; Liu, K.; Zhang, L.; Cheng, F. Object detection based on an adaptive attention mechanism. Sci. Rep. 2020, 10, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ying, X.; Wang, Q.; Li, X.; Yu, M.; Jiang, H.; Gao, J.; Liu, Z.; Yu, R. Multi-Attention Object Detection Model in Remote Sensing Images Based on Multi-Scale. IEEE Access 2019, 7, 94508–94519. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Dai, X.; Chen, Y.; Yang, J.; Zhang, P.; Yuan, L.; Zhang, L. Dynamic DETR: End-to-End Object Detection With Dynamic Attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 2988–2997. [Google Scholar]
- Wang, H.; Wang, Z.; Jia, M.; Li, A.; Feng, T.; Zhang, W.; Jiao, L. Spatial attention for multi-scale feature refinement for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 17–28 October 2019. [Google Scholar]
- Huang, Z.; Ke, W.; Huang, D. Improving object detection with inverted attention. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1294–1302. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Pan, Y.; Yao, T.; Zhou, W.; Li, H.; Mei, T. Relation distillation networks for video object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7023–7032. [Google Scholar]
- Hetang, C.; Qin, H.; Liu, S.; Yan, J. Impression Network for Video Object Detection. arXiv 2017, arXiv:1712.05896. [Google Scholar]
- Jiang, Z.; Liu, Y.; Yang, C.; Liu, J.; Gao, P.; Zhang, Q.; Xiang, S.; Pan, C. Learning where to focus for efficient video object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 18–34. [Google Scholar]
- Wang, S.; Zhou, Y.; Yan, J.; Deng, Z. Fully Motion-Aware Network for Video Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 542–557. [Google Scholar]
- Zhu, X.; Dai, J.; Yuan, L.; Wei, Y. Towards high performance video object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7210–7218. [Google Scholar]
- Bertasius, G.; Torresani, L.; Shi, J. Object detection in video with spatiotemporal sampling networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 331–346. [Google Scholar]
- Deng, H.; Hua, Y.; Song, T.; Zhang, Z.; Xue, Z.; Ma, R.; Robertson, N.; Guan, H. Object guided external memory network for video object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6678–6687. [Google Scholar]
- Shvets, M.; Liu, W.; Berg, A. Leveraging Long-Range Temporal Relationships Between Proposals for Video Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9755–9763. [Google Scholar] [CrossRef]
- Han, M.; Wang, Y.; Chang, X.; Qiao, Y. Mining Inter-Video Proposal Relations for Video Object Detection. In Proceedings of the Computer Vision—ECCV 2020, Virtual, 23–28 August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Zhou, P.; Zhou, C.; Peng, P.; Du, J.; Sun, X.; Guo, X.; Huang, F. NOH-NMS: Improving Pedestrian Detection by Nearby Objects Hallucination. In Proceedings of the 28th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2020. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Blocks | mAP | mAP50 | mAP75 |
|---|---|---|---|
| 1 | 0.484 | 0.780 | 0.515 |
| 2 | 0.495 | 0.797 | 0.537 |
| 3 | 0.485 | 0.771 | 0.521 |
| 4 | 0.485 | 0.770 | 0.518 |
| 5 | 0.477 | 0.756 | 0.509 |
| 6 | 0.451 | 0.732 | 0.476 |
| Points | mAP | mAP50 | mAP75 |
|---|---|---|---|
| 1 | 0.492 | 0.794 | 0.531 |
| 2 | 0.496 | 0.802 | 0.537 |
| 3 | 0.492 | 0.789 | 0.527 |
| 4 | 0.493 | 0.800 | 0.525 |
| 5 | 0.495 | 0.795 | 0.532 |
| 6 | 0.498 | 0.799 | 0.540 |
| Blocks | mAP | mAP50 | mAP75 |
|---|---|---|---|
| 1 | 0.497 | 0.797 | 0.544 |
| 2 | 0.494 | 0.791 | 0.538 |
| 4 | 0.493 | 0.800 | 0.525 |
| 8 | 0.487 | 0.781 | 0.522 |
| 16 | 0.489 | 0.775 | 0.518 |
| 32 | 0.484 | 0.782 | 0.518 |
| Method | mAP | mAP50 | mAP75 |
|---|---|---|---|
| SELSA | 0.487 | 0.784 | 0.531 |
| SELSA + Disentanglement Head | 0.490 | 0.788 | 0.536 |
| TROI | 0.485 | 0.798 | 0.523 |
| TROI + Disentanglement Head | 0.498 | 0.802 | 0.544 |
| Method | mAP | mAP50 | mAP75 |
|---|---|---|---|
| SELSA | 0.524 | 0.802 | 0.579 |
| SELSA + Disentanglement Head | 0.523 | 0.816 | 0.589 |
| TROI | 0.516 | 0.820 | 0.563 |
| TROI + Disentanglement Head | 0.525 | 0.824 | 0.577 |
| Method | Detector | Backbone | mAP |
|---|---|---|---|
| DFF [27] | R-FCN | ResNet-50 | 70.3 |
| FGFA [28] | R-FCN | ResNet-50 | 74.0 |
| D&T [36] | R-FCN | ResNet-50 | 76.5 |
| RDN [50] | Faster R-CNN | ResNet-101 | 76.7 |
| MEGA [33] | Faster R-CNN | ResNet-50 | 77.3 |
| SELSA [15] | Faster R-CNN | ResNet-50 | 78.4 |
| TROI [16] | Faster R-CNN | ResNet-50 | 79.8 |
| Ours | Faster R-CNN | ResNet-50 | 80.2 |
| Impression Net [51] | R-FCN | ResNet-101 | 74.2 |
| FGFA [28] | R-FCN | ResNet-101 | 76.3 |
| LSTS [52] | Faster R-CNN | ResNet-101 | 77.2 |
| MA-Net [53] | R-FCN | ResNet-101 | 78.1 |
| THP [54] | R-FCN | ResNet-101 | 78.6 |
| STSN [55] | R-FCN | ResNet-101 | 78.9 |
| OGEMN [56] | R-FCN | ResNet-101 | 79.3 |
| D&T [36] | R-FCN | ResNet-101 | 79.8 |
| PSLA [34] | R-FCN | ResNet-101 | 80.0 |
| SELSA [15] | Faster R-CNN | ResNet-101 | 80.25 |
| STMN [31] | R-FCN | ResNet-101 | 80.5 |
| LRT-RN [57] | Faster R-CNN | ResNet-101 | 81.0 |
| RDN [50] | Faster R-CNN | ResNet-101 | 81.8 |
| TROI [16] | Faster R-CNN | ResNet-101 | 82 |
| HVRNet [58] | Faster R-CNN | ResNet-101 | 83.2 |
| Ours | Faster R-CNN | ResNet-101 | 82.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muralidhara, S.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. Attention-Guided Disentangled Feature Aggregation for Video Object Detection. Sensors 2022, 22, 8583. https://doi.org/10.3390/s22218583
Muralidhara S, Hashmi KA, Pagani A, Liwicki M, Stricker D, Afzal MZ. Attention-Guided Disentangled Feature Aggregation for Video Object Detection. Sensors. 2022; 22(21):8583. https://doi.org/10.3390/s22218583
Chicago/Turabian StyleMuralidhara, Shishir, Khurram Azeem Hashmi, Alain Pagani, Marcus Liwicki, Didier Stricker, and Muhammad Zeshan Afzal. 2022. "Attention-Guided Disentangled Feature Aggregation for Video Object Detection" Sensors 22, no. 21: 8583. https://doi.org/10.3390/s22218583
APA StyleMuralidhara, S., Hashmi, K. A., Pagani, A., Liwicki, M., Stricker, D., & Afzal, M. Z. (2022). Attention-Guided Disentangled Feature Aggregation for Video Object Detection. Sensors, 22(21), 8583. https://doi.org/10.3390/s22218583