

AI-Based Detection of Aspiration for Video-Endoscopy with Visual Aids in Meaningful Frames to Interpret the Model Outcome

 , , and
, , and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Video Data and Annotation
2.2. Deep Neural Networks for Segmentation
2.3. Evaluation
2.4. Timeline for Interpretation of the Model Outcome
3. Results
3.1. Video Distribution across Data Sets and Annotated Frames
3.2. AI Training
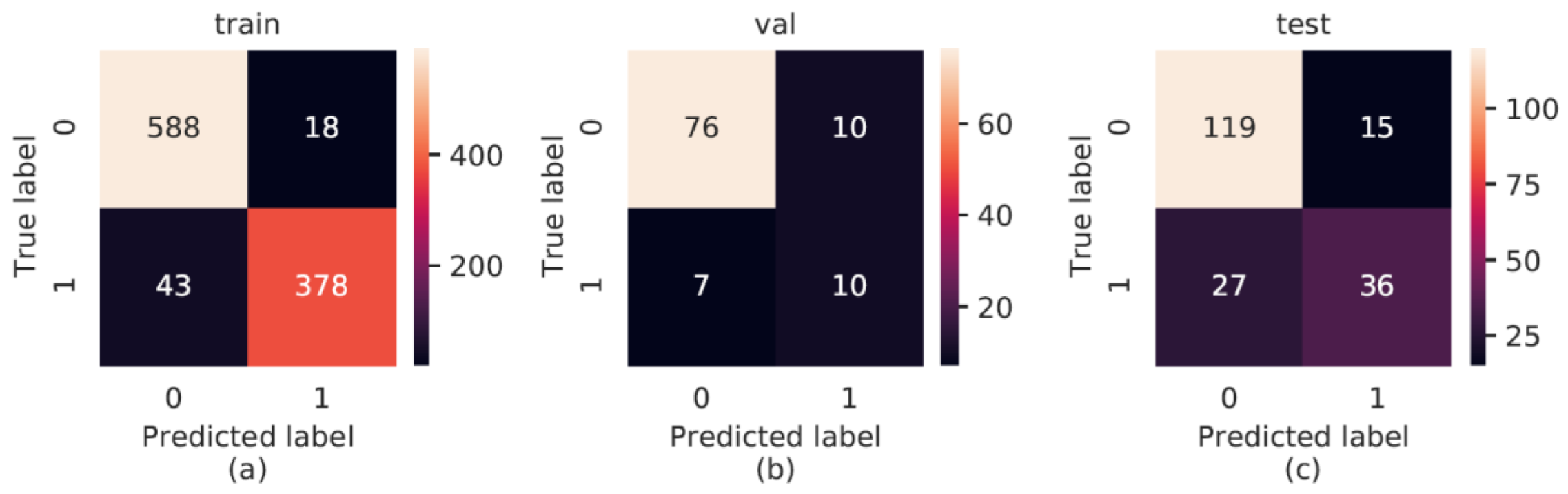
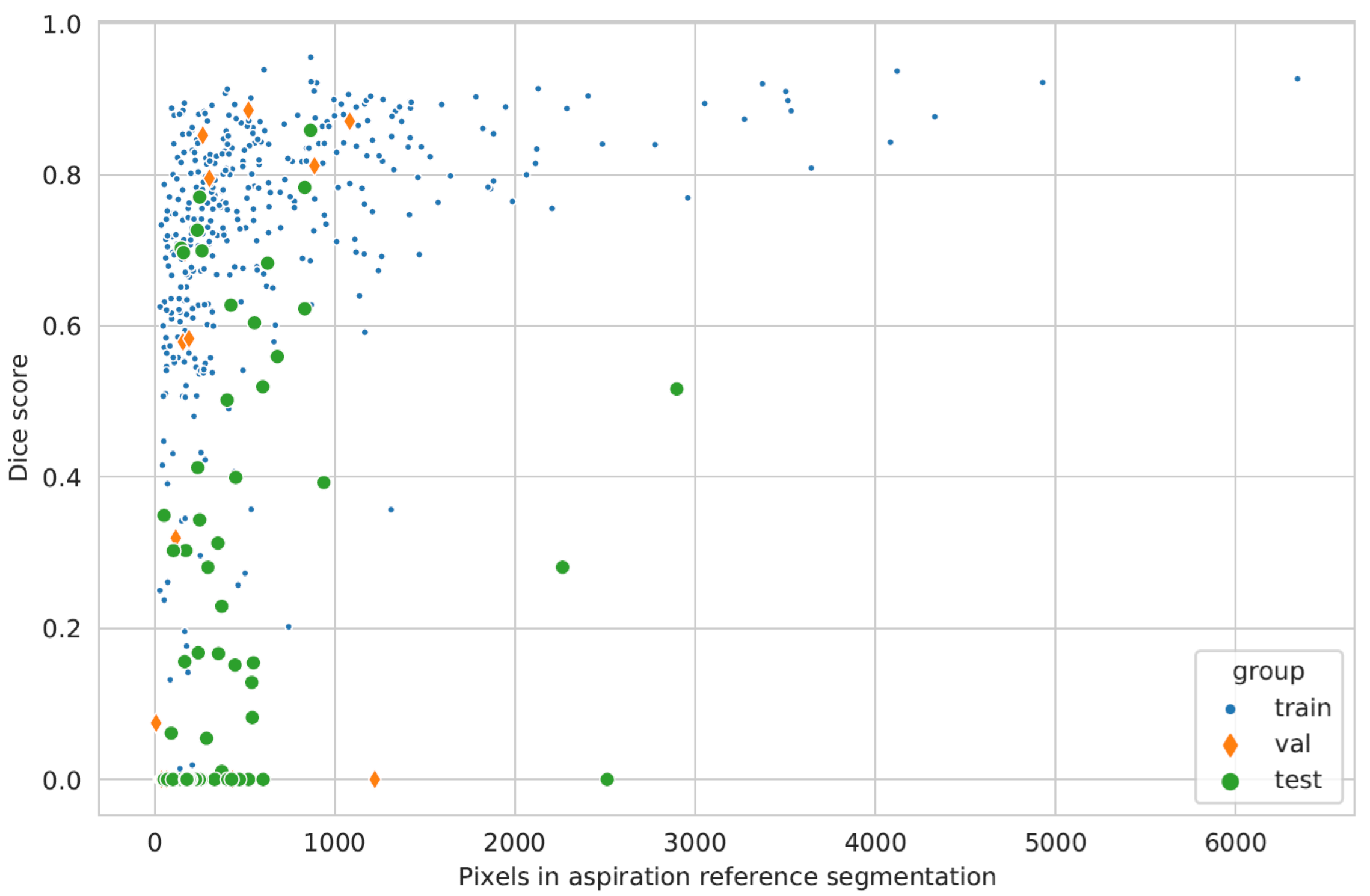
3.3. AI Performance
3.4. Interpretability by Identifying Meaningful Frames
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Muller, H.; Mayrhofer, M.; Van Veen, E.; Holzinger, A. The Ten Commandments of Ethical Medical AI" in Computer. Computer 2021, 54, 119–123. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Tjoa, E.; Guan, C. A Survey on Explainable Artificial Intelligence (XAI): Toward Medical XAI. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4793–4813. [Google Scholar] [CrossRef]
- Stepin, I.; Alonso, J.M.; Catala, A.; Pereira-Fariña, M. A Survey of Contrastive and Counterfactual Explanation Generation Methods for Explainable Artificial Intelligence. IEEE Access 2021, 9, 11974–12001. [Google Scholar] [CrossRef]
- Li, X.H.; Cao, C.C.; Shi, Y.; Bai, W.; Gao, H.; Qiu, L.; Wang, C.; Gao, Y.; Zhang, S.; Xue, X.; et al. A Survey of Data-Driven and Knowledge-Aware eXplainable AI. IEEE Trans. Knowl. Data Eng. 2020, 34, 29–49. [Google Scholar] [CrossRef]
- Dağlarli, E. Explainable Artificial Intelligence (xAI) Approaches and Deep Meta-Learning Models. In Advances and Applications in Deep Learning; Aceves-Fernandez, M.A., Ed.; IntechOpen: London, UK, 2020. [Google Scholar]
- Nazar, M.; Alam, M.M.; Yafi, E.; Su’ud, M.M. A Systematic Review of Human–Computer Interaction and Explainable Artificial Intelligence in Healthcare With Artificial Intelligence Techniques. IEEE Access 2021, 9, 153316–153348. [Google Scholar] [CrossRef]
- Ujwalla, G.; Kamal, H.; Yogesh, G. Deep Learning Approach to Key Frame Detection in Human Action Videos. In Recent Trends in Computational Intelligence; Ali, S., Tilendra Shishir, S., Eds.; IntechOpen: Rijeka, Croatia, 2020; Chapter 7. [Google Scholar]
- Yan, X.; Gilani, S.Z.; Feng, M.; Zhang, L.; Qin, H.; Mian, A. Self-Supervised Learning to Detect Key Frames in Videos. Sensors 2020, 20, 6941. [Google Scholar] [CrossRef]
- Bhattacharyya, N. The prevalence of dysphagia among adults in the United States. Otolaryngol.-Head Neck Surg. Off. J. Am. Acad. Otolaryngol. Head Neck Surg. 2014, 151, 765–769. [Google Scholar] [CrossRef]
- Attrill, S.; White, S.; Murray, J.; Hammond, S.; Doeltgen, S. Impact of oropharyngeal dysphagia on healthcare cost and length of stay in hospital: A systematic review. BMC Health Serv. Res. 2018, 18, 594. [Google Scholar] [CrossRef] [Green Version]
- Doggett, D.L.; Tappe, K.A.; Mitchell, M.D.; Chapell, R.; Coates, V.; Turkelson, C.M. Prevention of pneumonia in elderly stroke patients by systematic diagnosis and treatment of dysphagia: An evidence-based comprehensive analysis of the literature. Dysphagia 2001, 16, 279–295. [Google Scholar] [CrossRef]
- Rugiu, M.G. Role of videofluoroscopy in evaluation of neurologic dysphagia. Acta Otorhinolaryngol. Ital. 2007, 27, 306–316. [Google Scholar] [PubMed]
- Aviv, J.E.; Sataloff, R.T.; Cohen, M.; Spitzer, J.; Ma, G.; Bhayani, R.; Close, L.G. Cost-effectiveness of two types of dysphagia care in head and neck cancer: A preliminary report. Ear Nose Throat J. 2001, 80, 553–556, 558. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dziewas, R.; Glahn, J.; Helfer, C.; Ickenstein, G.; Keller, J.; Lapa, S.; Ledl, C.; Lindner-Pfleghar, B.; Nabavi, D.; Prosiegel, M.; et al. FEES für neurogene Dysphagien. Der. Nervenarzt. 2014, 85, 1006–1015. [Google Scholar] [CrossRef] [PubMed]
- Lüttje, D.; Meisel, M.; Meyer, A.-K.; Wittrich, A. Änderungsvorschlag für den OPS 2011. Bundesinstitut für Arzneimittel und Medizinprodukte. Available online: https://www.bfarm.de/DE/Kodiersysteme/Services/Downloads/OPS/_functions/ops-vorschlaege-2011.html?nn=841246&cms_gtp=1005398_list%253D5 (accessed on 18 October 2022).
- Bohlender, J. Fiberendoskopische Evaluation des Schluckens–FEES. Sprache Stimme Gehör 2017, 41, 216. [Google Scholar] [CrossRef] [Green Version]
- Hey, C.; Pluschinski, P.; Pajunk, R.; Almahameed, A.; Girth, L.; Sader, R.; Stöver, T.; Zaretsky, Y. Penetration–Aspiration: Is Their Detection in FEES® Reliable Without Video Recording? Dysphagia 2015, 30, 418–422. [Google Scholar] [CrossRef]
- Rosenbek, J.C.; Robbins, J.A.; Roecker, E.B.; Coyle, J.L.; Wood, J.L. A penetration-aspiration scale. Dysphagia 1996, 11, 93–98. [Google Scholar] [CrossRef]
- Colodny, N. Interjudge and Intrajudge Reliabilities in Fiberoptic Endoscopic Evaluation of Swallowing (Fees®) Using the Penetration–Aspiration Scale: A Replication Study. Dysphagia 2002, 17, 308–315. [Google Scholar] [CrossRef]
- Curtis, J.A.; Borders, J.C.; Perry, S.E.; Dakin, A.E.; Seikaly, Z.N.; Troche, M.S. Visual Analysis of Swallowing Efficiency and Safety (VASES): A Standardized Approach to Rating Pharyngeal Residue, Penetration, and Aspiration During FEES. Dysphagia 2022, 37, 417–435. [Google Scholar] [CrossRef]
- Butler, S.G.; Markley, L.; Sanders, B.; Stuart, A. Reliability of the Penetration Aspiration Scale With Flexible Endoscopic Evaluation of Swallowing. Ann. Otol. Rhinol. Laryngol. 2015, 124, 480–483. [Google Scholar] [CrossRef]
- Nienstedt, J.C.; Müller, F.; Nießen, A.; Fleischer, S.; Koseki, J.C.; Flügel, T.; Pflug, C. Narrow Band Imaging Enhances the Detection Rate of Penetration and Aspiration in FEES. Dysphagia 2017, 32, 443–448. [Google Scholar] [CrossRef]
- Stanley, C.; Paddle, P.; Griffiths, S.; Safdar, A.; Phyland, D. Detecting Aspiration During FEES with Narrow Band Imaging in a Clinical Setting. Dysphagia 2022, 37, 591–600. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.K.; Choo, Y.J.; Choi, G.S.; Shin, H.; Chang, M.C.; Park, D. Deep Learning Analysis to Automatically Detect the Presence of Penetration or Aspiration in Videofluoroscopic Swallowing Study. J. Korean Med. Sci. 2022, 37, e42. [Google Scholar] [CrossRef] [PubMed]
- Donohue, C.; Mao, S.; Sejdić, E.; Coyle, J.L. Tracking Hyoid Bone Displacement During Swallowing Without Videofluoroscopy Using Machine Learning of Vibratory Signals. Dysphagia 2021, 36, 259–269. [Google Scholar] [CrossRef]
- Kuramoto, N.; Ichimura, K.; Jayatilake, D.; Shimokakimoto, T.; Hidaka, K.; Suzuki, K. Deep Learning-Based Swallowing Monitor for Realtime Detection of Swallow Duration. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 20–24 July 2020; pp. 4365–4368. [Google Scholar]
- Lee, J.; Blain, S.; Casas, M.; Kenny, D.; Berall, G.; Chau, T. A radial basis classifier for the automatic detection of aspiration in children with dysphagia. J. Neuroeng. Rehabil. 2006, 3, 14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mao, S.; Zhang, Z.; Khalifa, Y.; Donohue, C.; Coyle, J.L.; Sejdic, E. Neck sensor-supported hyoid bone movement tracking during swallowing. R. Soc. Open Sci. 2019, 6, 181912. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feng, S.; Shea, Q.-T.-K.; Ng, K.-Y.; Tang, C.-N.; Kwong, E.; Zheng, Y. Automatic Hyoid Bone Tracking in Real-Time Ultrasound Swallowing Videos Using Deep Learning Based and Correlation Filter Based Trackers. Sensors 2021, 21, 3712. [Google Scholar] [CrossRef]
- Lee, J.C.; Seo, H.G.; Lee, W.H.; Kim, H.C.; Han, T.R.; Oh, B.M. Computer-assisted detection of swallowing difficulty. Comput. Methods Programs Biomed. 2016, 134, 79–88. [Google Scholar] [CrossRef]
- Zhang, Z.; Coyle, J.L.; Sejdić, E. Automatic hyoid bone detection in fluoroscopic images using deep learning. Sci. Rep. 2018, 8, 12310. [Google Scholar] [CrossRef] [Green Version]
- Frakking, T.T.; Chang, A.B.; Carty, C.; Newing, J.; Weir, K.A.; Schwerin, B.; So, S. Using an Automated Speech Recognition Approach to Differentiate Between Normal and Aspirating Swallowing Sounds Recorded from Digital Cervical Auscultation in Children. Dysphagia 2022, 37, 1482–1492. [Google Scholar] [CrossRef] [PubMed]
- Khalifa, Y.; Coyle, J.L.; Sejdić, E. Non-invasive identification of swallows via deep learning in high resolution cervical auscultation recordings. Sci. Rep. 2020, 10, 8704. [Google Scholar] [CrossRef] [PubMed]
- Steele, C.M.; Mukherjee, R.; Kortelainen, J.M.; Polonen, H.; Jedwab, M.; Brady, S.L.; Theimer, K.B.; Langmore, S.; Riquelme, L.F.; Swigert, N.B.; et al. Development of a Non-invasive Device for Swallow Screening in Patients at Risk of Oropharyngeal Dysphagia: Results from a Prospective Exploratory Study. Dysphagia 2019, 34, 698–707. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hadley, A.J.; Krival, K.R.; Ridgel, A.L.; Hahn, E.C.; Tyler, D.J. Neural Network Pattern Recognition of Lingual–Palatal Pressure for Automated Detection of Swallow. Dysphagia 2015, 30, 176–187. [Google Scholar] [CrossRef] [PubMed]
- Jayatilake, D.; Ueno, T.; Teramoto, Y.; Nakai, K.; Hidaka, K.; Ayuzawa, S.; Eguchi, K.; Matsumura, A.; Suzuki, K. Smartphone-Based Real-time Assessment of Swallowing Ability From the Swallowing Sound. IEEE J. Transl. Eng. Health Med. 2015, 3, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Jones, C.A.; Hoffman, M.R.; Lin, L.; Abdelhalim, S.; Jiang, J.J.; McCulloch, T.M. Identification of swallowing disorders in early and mid-stage Parkinson’s disease using pattern recognition of pharyngeal high-resolution manometry data. Neurogastroenterol. Motil. 2018, 30, e13236. [Google Scholar] [CrossRef] [PubMed]
- Kritas, S.; Dejaeger, E.; Tack, J.; Omari, T.; Rommel, N. Objective prediction of pharyngeal swallow dysfunction in dysphagia through artificial neural network modeling. Neurogastroenterol. Motil. Off. J. Eur. Gastrointest. Motil. Soc. 2016, 28, 336–344. [Google Scholar] [CrossRef]
- Lee, J.; Steele, C.M.; Chau, T. Swallow segmentation with artificial neural networks and multi-sensor fusion. Med. Eng. Phys. 2009, 31, 1049–1055. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.T.; Park, E.; Hwang, J.-M.; Jung, T.-D.; Park, D. Machine learning analysis to automatically measure response time of pharyngeal swallowing reflex in videofluoroscopic swallowing study. Sci. Rep. 2020, 10, 14735. [Google Scholar] [CrossRef] [PubMed]
- Sakai, K.; Gilmour, S.; Hoshino, E.; Nakayama, E.; Momosaki, R.; Sakata, N.; Yoneoka, D. A Machine Learning-Based Screening Test for Sarcopenic Dysphagia Using Image Recognition. Nutrients 2021, 13, 4009. [Google Scholar] [CrossRef]
- Roldan-Vasco, S.; Orozco-Duque, A.; Suarez-Escudero, J.C.; Orozco-Arroyave, J.R. Machine learning based analysis of speech dimensions in functional oropharyngeal dysphagia. Comput. Methods Programs Biomed. 2021, 208, 106248. [Google Scholar] [CrossRef] [PubMed]
- Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation) (Text with EEA relevance). OJ L 119 04.05.2016. p. 1. Available online: http://data.europa.eu/eli/reg/2016/679/oj (accessed on 18 October 2022).
- Holzinger, A.; Biemann, C.; Pattichis, C.S.; Kell, D.B. What Do We Need to Build Explainable AI Systems for the Medical Domain? arXiv 2017, arXiv:1712.09923v1. Available online: https://arxiv.org/pdf/1712.09923.pdf (accessed on 18 October 2022).
- Fehling, M.K.; Grosch, F.; Schuster, M.E.; Schick, B.; Lohscheller, J. Fully automatic segmentation of glottis and vocal folds in endoscopic laryngeal high-speed videos using a deep Convolutional LSTM Network. PLoS ONE 2020, 15, e0227791. [Google Scholar] [CrossRef]
- Laves, M.-H.; Bicker, J.; Kahrs, L.A.; Ortmaier, T. A dataset of laryngeal endoscopic images with comparative study on convolution neural network-based semantic segmentation. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 483–492. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Matava, C.; Pankiv, E.; Raisbeck, S.; Caldeira, M.; Alam, F. A Convolutional Neural Network for Real Time Classification, Identification, and Labelling of Vocal Cord and Tracheal Using Laryngoscopy and Bronchoscopy Video. J. Med. Syst. 2020, 44, 44. [Google Scholar] [CrossRef] [PubMed]
- Meine, H.; Moltz, J.H. SATORI. AI Collaboration Toolkit. Available online: https://www.mevis.fraunhofer.de/en/research-and-technologies/ai-collaboration-toolkit.html (accessed on 27 September 2022).
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Into Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for BiomedicalImage Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2015), Munich, Germany, 5–9 October 2015. [Google Scholar]
- Isensee, F.; Jaeger, P.F.; Kohl, S.A.A.; Petersen, J.; Maier-Hein, K.H. nnU-Net: A self-configuring method for deep learning-based biomedical image segmentation. Nat. Methods 2021, 18, 203–211. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. Proc. 32nd Int. Conf. Mach. Learn. 2015, 37, 448–456. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. 2015. Available online: https://arxiv.org/abs/1412.6980 (accessed on 18 October 2022).
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Powers, D.M.W. Evaluation: From Precision, Recall And F-Measure To Roc, Informedness, Markedness & Correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar] [CrossRef]
- Sasaki, Y. The Truth of the F-Measure. 2007. Available online: https://www.toyota-ti.ac.jp/Lab/Denshi/COIN/people/yutaka.sasaki/F-measure-YS-26Oct07.pdf (accessed on 18 October 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [Green Version]
- Inoue, K.; Yoshioka, M.; Yagi, N.; Nagami, S.; Oku, Y. Using Machine Learning and a Combination of Respiratory Flow, Laryngeal Motion, and Swallowing Sounds to Classify Safe and Unsafe Swallowing. IEEE Trans. Biomed. Eng. 2018, 65, 2529–2541. [Google Scholar] [CrossRef] [PubMed]
- O’Brien, M.K.; Botonis, O.K.; Larkin, E.; Carpenter, J.; Martin-Harris, B.; Maronati, R.; Lee, K.; Cherney, L.R.; Hutchison, B.; Xu, S.; et al. Advanced Machine Learning Tools to Monitor Biomarkers of Dysphagia: A Wearable Sensor Proof-of-Concept Study. Digit. Biomark. 2021, 5, 167–175. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AI Data Subset | Segmented Frames | Frames with Aspiration | Frames Not Showing Glottis |
|---|---|---|---|
| training | 1029 | 424 | 2220 |
| validation | 103 | 17 | 186 |
| test | 199 | 63 | 489 |
| Metrics | Training | Validation | Test |
|---|---|---|---|
| Precision | 0.955 | 0.500 | 0.706 |
| Recall | 0.898 | 0.588 | 0.571 |
| F1 score | 0.925 | 0.541 | 0.632 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Konradi, J.; Zajber, M.; Betz, U.; Drees, P.; Gerken, A.; Meine, H. AI-Based Detection of Aspiration for Video-Endoscopy with Visual Aids in Meaningful Frames to Interpret the Model Outcome. Sensors 2022, 22, 9468. https://doi.org/10.3390/s22239468
Konradi J, Zajber M, Betz U, Drees P, Gerken A, Meine H. AI-Based Detection of Aspiration for Video-Endoscopy with Visual Aids in Meaningful Frames to Interpret the Model Outcome. Sensors. 2022; 22(23):9468. https://doi.org/10.3390/s22239468
Chicago/Turabian StyleKonradi, Jürgen, Milla Zajber, Ulrich Betz, Philipp Drees, Annika Gerken, and Hans Meine. 2022. "AI-Based Detection of Aspiration for Video-Endoscopy with Visual Aids in Meaningful Frames to Interpret the Model Outcome" Sensors 22, no. 23: 9468. https://doi.org/10.3390/s22239468
APA StyleKonradi, J., Zajber, M., Betz, U., Drees, P., Gerken, A., & Meine, H. (2022). AI-Based Detection of Aspiration for Video-Endoscopy with Visual Aids in Meaningful Frames to Interpret the Model Outcome. Sensors, 22(23), 9468. https://doi.org/10.3390/s22239468