
Cross-Modal Object Detection Based on a Knowledge Update

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- Multimodal encoder
- (2)
- GCN inference module
- (3)
- Knowledge update
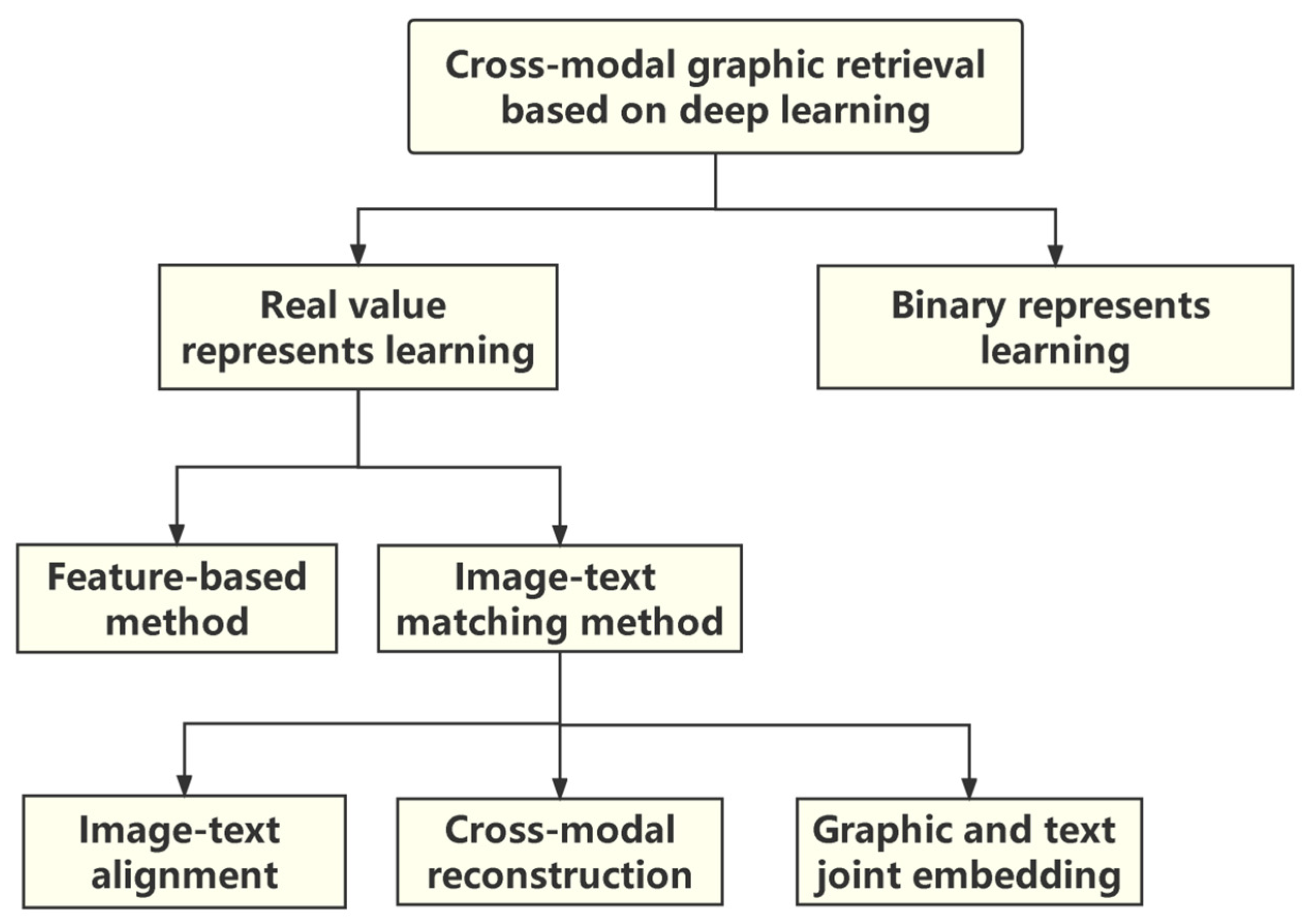
2. Related Works
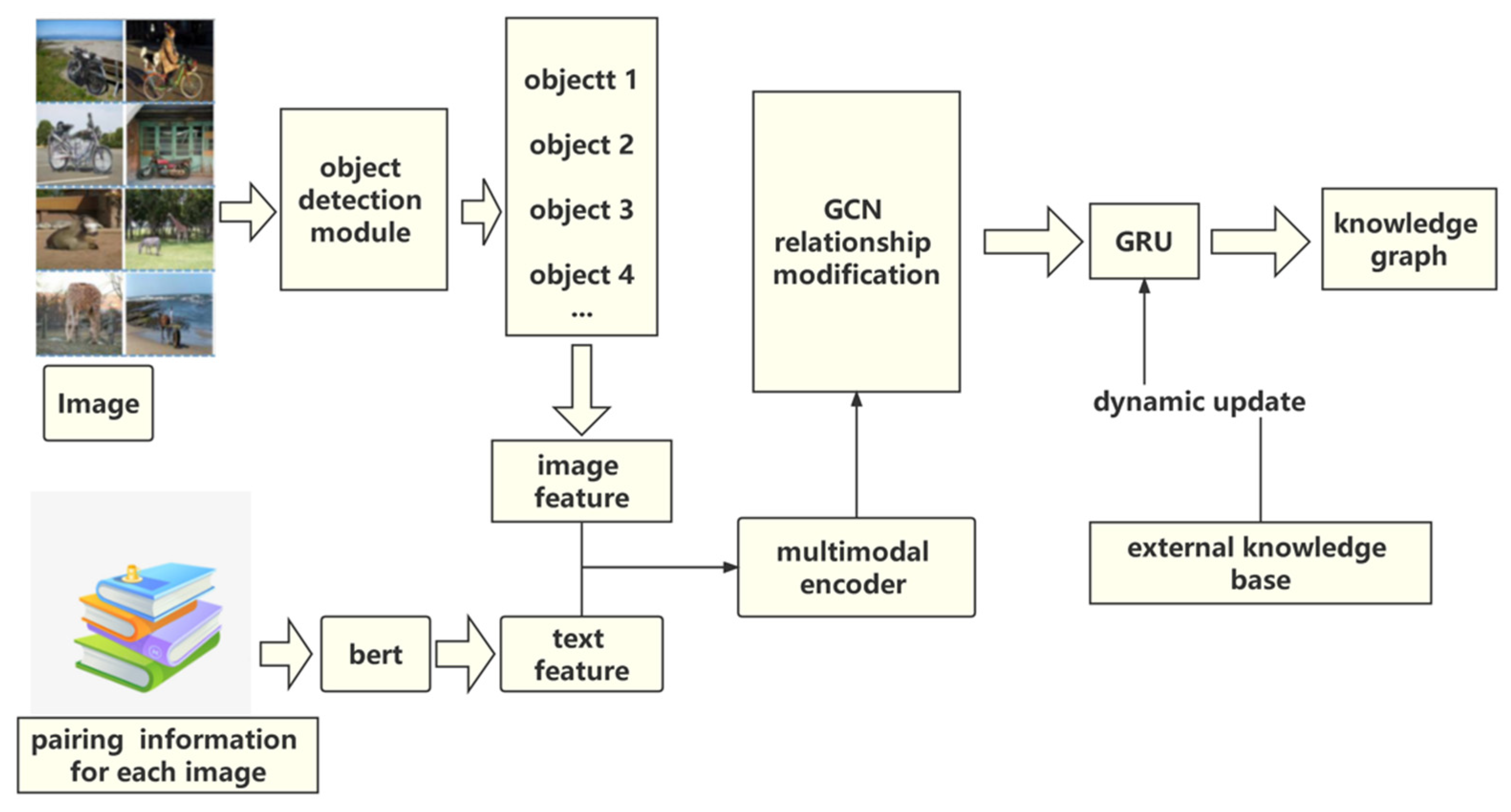
3. Method
3.1. Object Detection Module
3.2. Multimodal Encoder
3.3. GCN Relationship Modification
3.4. GRU (Gated Recurrent Unit)
4. Experimental Evaluations
4.1. Data Set
4.2. Experimental Details
4.3. Display of Results
4.4. Effect Display of Adding the GCN Inference Module
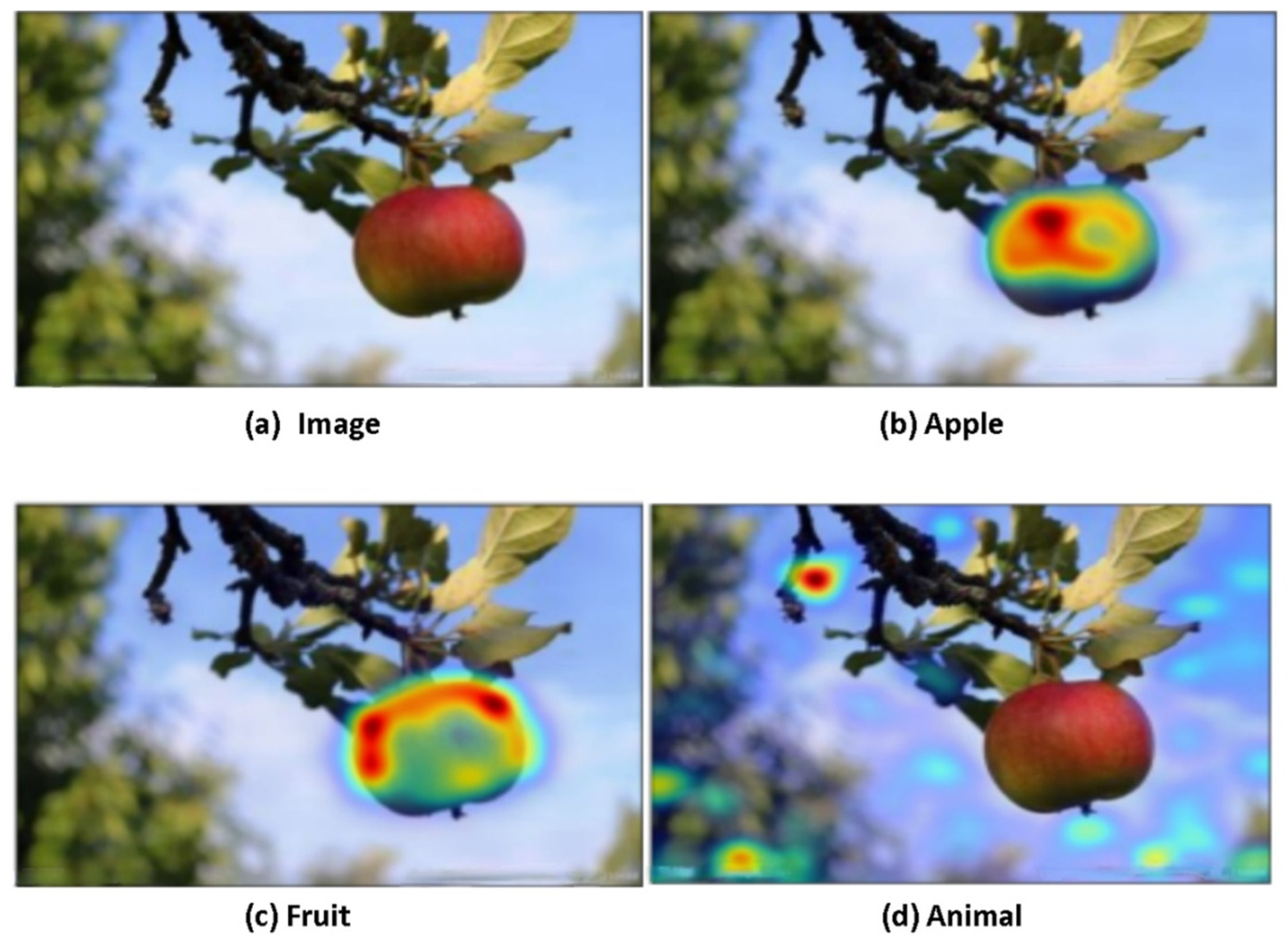
4.4.1. The Comparison Heat Map of the Generalized Category Detection of the Object
4.4.2. Detection of Behavioral Information
4.4.3. This Model Has the Function of Further Reasoning
5. Summary
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
References
- Ramachandram, D.; Taylor, G.W. Deep multi-modal learning: A survey on recent advances and trends. IEEE Signal Processing Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Otto, C.; Springstein, M.; Anand, A.; Ewerth, R. Characterization and classification of semantic image-text relations. Int. J. Multimed. Inf. Retr. 2020, 9, 31–45. [Google Scholar] [CrossRef] [Green Version]
- Harold, H. Relations between two sets of variates. Biometrika 1936, 28, 321–377. [Google Scholar]
- Li, D.; Dimitrova, N.; Li, M.; Sethi, I.K. Multimedia content processing through cross-modal association. In Proceedings of the Eleventh ACM International Conference on Multimedia, Berkeley, CA, USA, 2–8 November 2003; pp. 604–611. [Google Scholar]
- Sha, A.; Wang, B.; Wu, X.; Zhang, L.; Hu, B.; Zhang, J.Q. Semi-Supervised Classification for Hyperspectral Images Using Edge-Conditioned Graph Convolutional Networks. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 2690–2693. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Wang, K.; Yin, Q.; Wang, W.; Wu, S.; Wang, L. A comprehensive survey on cross-modal retrieval. arXiv 2016, arXiv:1607.06215. [Google Scholar]
- Mitchell, M.; Dodge, J.; Goyal, A.; Yamaguchi, K.; Stratos, K.; Han, X.; Mensch, A.; Berg, A.; Berg, T.; Daumé, H. Midge: Generating image descriptions from computer vision detections. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012; pp. 747–756. [Google Scholar]
- Farhadi, A.; Hejrati, M.; Sadeghi, M.A.; Young, P.; Rashtchian, C.; Hockenmaier, J.; Forsyth, D. Every picture tells a story: Generating sentences from images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2010; pp. 15–29. [Google Scholar]
- Li, S.; Kulkarni, G.; Berg, T.; Berg, A.; Choi, Y. Composing simple-image descriptions using web-scale ngrams. In Proceedings of the Fifteenth Conference on Computational Natural Language Learning, Portland, OR, USA, 23–24 June 2011; pp. 220–228. [Google Scholar]
- Hodosh, M.; Young, P.; Hockenmaier, J. Framingimage description as a ranking task: Data, models and evaluation metrics. J. Artif. Intell. Res. 2013, 47, 853–899. [Google Scholar] [CrossRef] [Green Version]
- Mao, J.; Xu, W.; Yang, Y.; Wang, J.; Yuille, A.L. Explain images with multimodal recurrent neural networks. arXiv 2014, arXiv:1410.1090. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern-Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Wang, S.; Song, G.; Huang, Q. Learning fragment self-attention embeddings for image-text matching. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2088–2096. [Google Scholar]
- Wang, Y.; Yang, H.; Qian, X.; Ma, L.; Lu, J.; Li, B.; Fan, X. Position focused attention network for image-text matching. arXiv 2019, arXiv:1907.09748. [Google Scholar]
- Li, K.; Zhang, Y.; Li, K.; Li, Y.; Fu, Y. Visual semantic reasoning for image-text matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 4654–4662. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Processing Syst. 2017, 30, 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Tandon, N.; De Melo, G.; Suchanek, F.; Weikum, G. Webchild: Harvesting and organizing commonsense knowledge from the web. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; pp. 523–532. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A nucleus for a web of open data. In Proceedings of the 6th International the Semantic Web and 2nd Asian Conference on Asian Semantic Web Conference, Busan, Korea, 11–15 November 2007; pp. 722–735. [Google Scholar]
- Speer, R.; Chin, J.; Havasi, C. Concept Net 5.5: An open multilingual graph of general knowledge. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4444–4451. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Berlin, Germany, 2014; pp. 740–755. [Google Scholar]
- Available online: https://www.sohu.com/a/420471132_100062867 (accessed on 1 February 2022).
- Available online: http://www.mianfeiwendang.com/doc/f4560357b98ac18802bcd855/5 (accessed on 1 February 2022).







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Y.; Zhou, H.; Chen, L.; Shen, Y.; Guo, C.; Zhang, X. Cross-Modal Object Detection Based on a Knowledge Update. Sensors 2022, 22, 1338. https://doi.org/10.3390/s22041338
Gao Y, Zhou H, Chen L, Shen Y, Guo C, Zhang X. Cross-Modal Object Detection Based on a Knowledge Update. Sensors. 2022; 22(4):1338. https://doi.org/10.3390/s22041338
Chicago/Turabian StyleGao, Yueqing, Huachun Zhou, Lulu Chen, Yuting Shen, Ce Guo, and Xinyu Zhang. 2022. "Cross-Modal Object Detection Based on a Knowledge Update" Sensors 22, no. 4: 1338. https://doi.org/10.3390/s22041338
APA StyleGao, Y., Zhou, H., Chen, L., Shen, Y., Guo, C., & Zhang, X. (2022). Cross-Modal Object Detection Based on a Knowledge Update. Sensors, 22(4), 1338. https://doi.org/10.3390/s22041338