
Deep Reinforcement Learning Based Optical and Acoustic Dual Channel Multiple Access in Heterogeneous Underwater Sensor Networks


Abstract
:1. Introduction
- To improve the network performance of UWSNs, we construct a heterogeneous underwater sensor network framework that consists of hybrid optical and acoustic substructures. In the hybrid framework, source nodes can fulfill information interaction with the relay node via optical or acoustic channels. The two kinds of channels are jointly liable for their respective transmissions. Namely, the transmissions on each type of channel will not interfere with each other. As a result, the advantages of rapid transmission and high bandwidth of the optical mode and the stable and long-range transmission of the acoustic mode will be realized effectively.
- For the first time, we introduce the DRL technique into hybrid optical and acoustic dual-channel MAC design and propose a DRL-based MAC protocol for the constructed HOA-UWSN model, referred to as OA-DLMA, where a node applying the OA-DLMA protocol is regarded as an agent and the agent can learn to find an optimal access policy without preliminary knowledge of non-agent nodes. Consequently, the agent nodes can be trained through an effective training mechanism to capture and utilize the underutilized channels that are not entirely consumed by other nodes. It is revealed that the OA-DLMA protocol performs well even without additional prior information or handshake mechanism.
- To further improve the network performance, priority compensation for the optical channel is encouraged since the optical channel possess more data transmission capability. We set a distinguishing reward policy to differentiate the feedback of specific actions on optical and acoustic channels. Specifically, successful optical transmissions will gain larger rewards, while successful acoustic transmissions will obtain smaller rewards.
2. Related Work
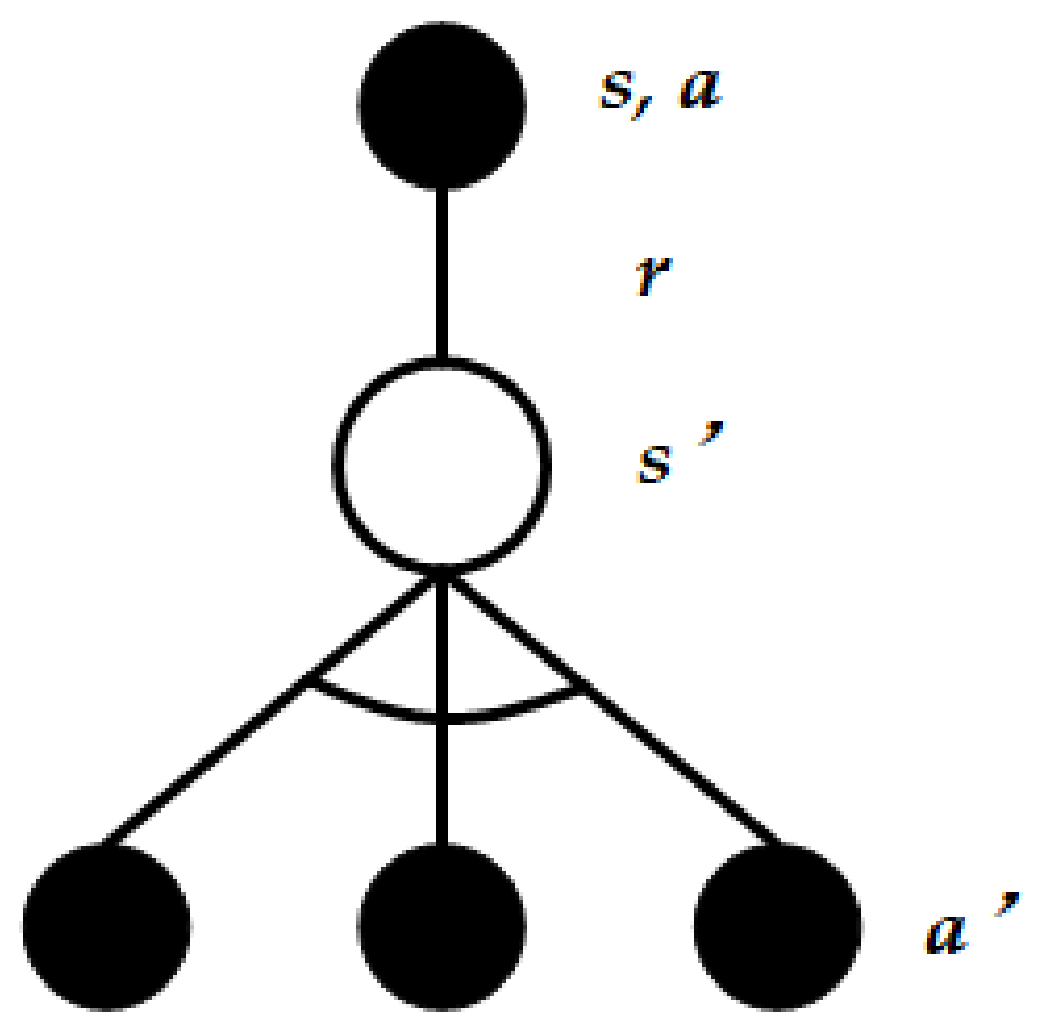
3. Model of DQN
3.1. Fundamental Q-Learning Model
3.2. Deep Q Learning
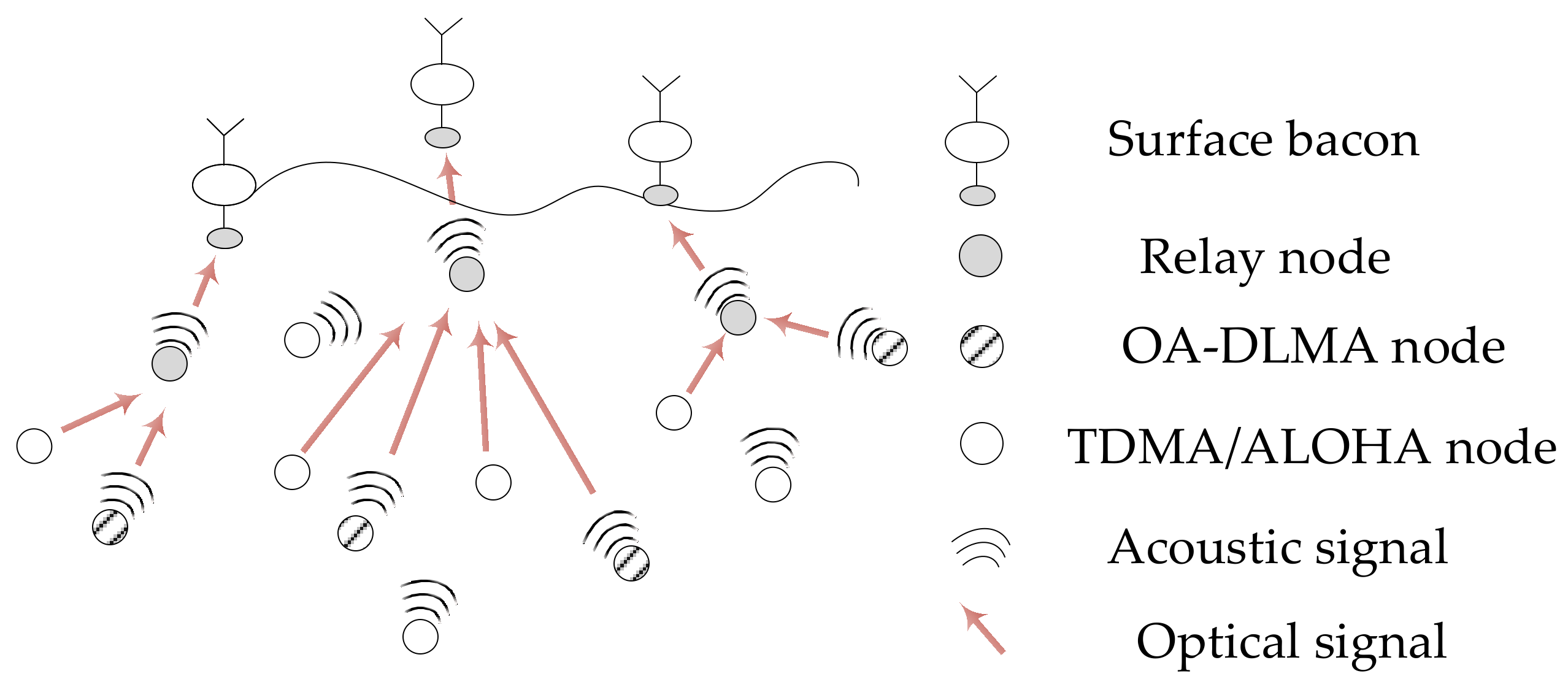
4. System Model
5. OA-DLMA Protocol
| Algorithm 1: Training process of the OA-DLMA protocol for heterogeneous UWSNs. |
| 1: Initialize α, γ, D, ε, F, M, NE //F is the update frequency of the target network |
| 2: Initialize Q-network and target-network with random weights θ, |
| 3: Initialize state randomly |
| 4: for each time slot t do |
| 5: Input current state st into Q-network and output Q value ; |
| 6: Select an action at using Equation (2); |
| 7: Get ot through collecting . |
| 8: for I = 1 to 2 do |
| 9: if then |
| 10: |
| 11: else |
| 12: if then |
| 13: . |
| 14: else if |
| 15: . |
| 16: else |
| 17: . |
| 18: end if |
| 19: end if |
| 20: Get the reward through collecting ; |
| 21: Generate the next state st+1 based on Equation (9); |
| 22: Store experience et = (at,st,rt,st+1) into replay memory D; |
| 23: end for |
| 24: Calculate the short-term average rewards as Equation (15); |
| 25: Calculate the channel utilization as Equation (16); |
| 26: Select random sample minibatch of experience tuples from D; |
| 27: Train Q-network; |
| 28: Compute loss function by Equation (12); |
| 29: Perform SGD to minimize loss function; |
| 30: Update θ; |
| 31: Every F time slots copy current Q-network to target-network: ; |
| 32: end for |
6. Performance Evaluation
6.1. Simulation Setup
6.2. Simulation Metrics
6.3. Simulation Results
6.3.1. The Coexistence of One OA-DLMA Node with One TDMA and One ALOHA Node
- (a)
- Acoustic TDMA and Optical ALOHA
- (b)
- Acoustic ALOHA and Optical TDMA
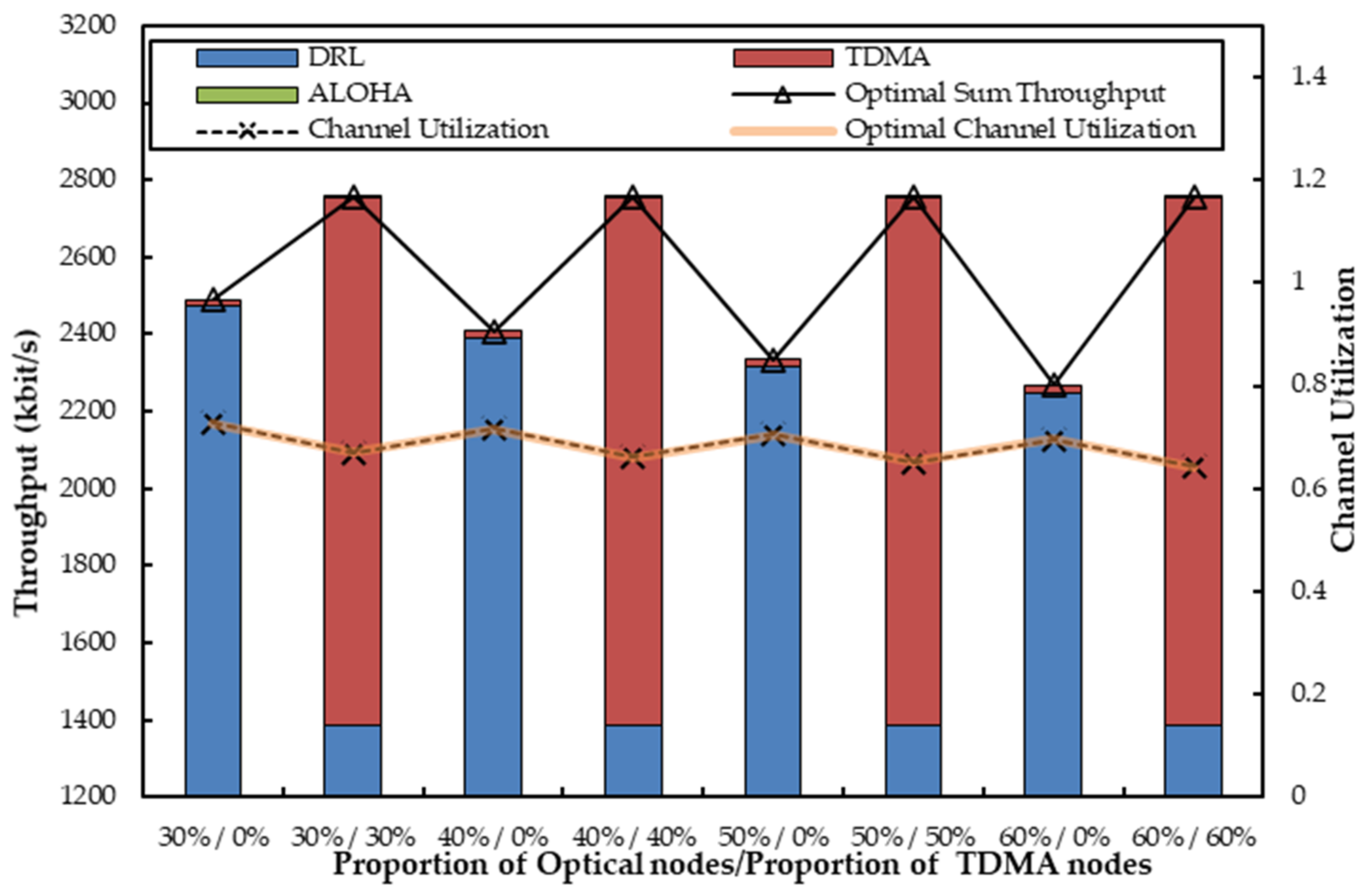
6.3.2. The Coexistence of Multiple OA-DLMA NODES with Multiple TDMA and ALOHA Nodes
6.3.3. OA-DLMA versus OA-CMAC/MC-DLMA Protocol
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviation | Description |
| DNN | Deep Neural Network |
| DQL | Deep Q Learning |
| DQN | Deep Q-Network |
| DRL | Deep Reinforcement Learning |
| HOA-UWSNs | Hybrid Optical and Acoustic Underwater Wireless Sensor Networks |
| IoUT | Internet of Underwater Things |
| MAC | Media Access Control |
| OA-UWSN | Optical-Acoustic hybrid Underwater Wireless Sensor Network |
| RF | Radio Frequency |
| RL | Reinforcement Learning |
| ROVs | Remotely Operated Vehicles |
| SGD | Stochastic Gradient Descent |
| TWSNs | Terrestrial Wireless Sensor Networks |
| UASN | Underwater Acoustic Sensor Network |
| UAVs | Unmanned Aerial Vehicles |
| UWSNs | Underwater Wireless Sensor Networks |
| WSNs | Wireless Sensor Networks |
Appendix A. Derivations of Optimal Throughput and Channel Utilization
Appendix A.1. One Model-Aware Node Coexists with One TDMA Node and One ALOHA Node
Appendix A.1.1. Throughput with One Acoustic TDMA Node and One Optical ALOHA Node
Appendix A.1.2. Throughput with One Acoustic ALOHA Node and One Optical TDMA Node
Appendix A.1.3. Channel Utilization with One Acoustic TDMA Node and One Optical ALOHA Node
Appendix A.1.4. Channel Utilization with One Acoustic ALOHA Node and One Optical TDMA Node
Appendix A.2. Y Model-Aware Nodes Coexist with Multiple Optical TDMA Nodes and Multiple Acoustic ALOHA Nodes
Appendix A.2.1. Throughput When the Number of Model-Aware Nodes Is Less than That of Optical Channels
Appendix A.2.2. Throughput When the Number of Model-Aware Nodes Is Greater than the Number of Optical Channels but Not More Than the Total Number of Optical and Acoustic Channels
Appendix A.2.3. Channel Utilization When the Number of Model-Aware Nodes Is Less than That of Optical Channels
Appendix A.2.4. Channel Utilization When the Number of Model-Aware Nodes is Greater than the Number of Optical Channels but Not More than the Total Number of Optical and Acoustic Channels
References
- Qiao, G.; Zhao, Y.J.; Liu, S.Z.; Ahmed, N. Doppler scale estimation for varied speed mobile frequency-hopped binary frequency-shift keying underwater acoustic communication. J. Acoust. Soc. Am. 2019, 146, 998–1004. [Google Scholar]
- Yang, J.M.; Qiao, G.; Hu, Q.; Zhang, J.R.; Du, G.B. A Dual Channel Medium Access Control (MAC) Protocol for Underwater Acoustic Sensor Networks Based on Directional Antenna. Symmetry 2020, 12, 878. [Google Scholar]
- Liang, H.T.; Fu, Y.F.; Gao, J. Bio-inspired self-organized cooperative control consensus for crowded UUV swarm based on adaptive dynamic interaction topology. Appl. Intell. 2021, 51, 4664–4681. [Google Scholar]
- Braca, P.; Goldhahn, R.; Ferri, G.; LePage, K.D. Distributed Information Fusion in Multistatic Sensor Networks for Underwater Surveillance. IEEE Sens. J. 2015, 16, 4003–4014. [Google Scholar]
- Secrieru, D.; Oaie, G.; Radulescu, V.; Voicaru, C. The Black Sea Security System—A New Early Warning and Environmental Monitoring System. In Sustainable Development of Sea-Corridors and Coastal Waters; Stylios, C., Floqi, T., Marinski, J., Damiani, L., Eds.; Springer: Cham, Switzerland, 2015; pp. 109–115. [Google Scholar]
- Chen, K.Y.; Ma, M.; Cheng, E.; Yuan, F.; Su, W. A Survey on MAC Protocols for Underwater Wireless Sensor Networks. IEEE Commun. Surv. Tutor. 2014, 16, 1433–1447. [Google Scholar]
- Kaushal, H.; Kaddoum, G. Underwater optical wireless communication. IEEE Access 2016, 4, 1518–1547. [Google Scholar]
- Wang, J.J.; Shi, W.; Xu, L.W.; Zhou, L.Y.; Niu, Q.N.; Liu, J. Design of optical-acoustic hybrid underwater wireless sensor network. J. Netw. Comput. Appl. 2017, 92, 59–67. [Google Scholar]
- Saeed, N.; Celik, A.; Al-Naffouri, T.Y.; Alouini, M.S. Underwater optical wireless communications, networking, and localization: A survey. Ad. Hoc. Netw. 2019, 94, 101935. [Google Scholar]
- Boukerche, A.; Sun, P. Design of Algorithms and Protocols for Underwater Acoustic Wireless Sensor Networks. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar]
- Badawy, M.; Khater, E.; Tolba, M.; Ibrahim, D.; El-Fishawy, N. A New Technique for Underwater Acoustic Wireless Sensor Network. In Proceedings of the 2020 15th International Conference on Computer Engineering and Systems (ICCES), Cairo, Egypt, 15–16 December 2020; pp. 1–5. [Google Scholar]
- Zhang, W.B.; Liu, Y.; Han, G.J.; Feng, Y.X.; Zhao, Y.T. An energy efficient and QoS aware routing algorithm based on data classification for industrial wireless sensor networks. IEEE Access 2018, 6, 46495–46504. [Google Scholar]
- Huang, W.K.; Liu, M.Q.; Zhang, S.L. SFAMA-MM: A slotted FAMA based MAC protocol for multi-hop underwater acoustic networks with a multiple reception mechanism. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 7315–7321. [Google Scholar]
- Yang, H. Propagation Delay Utilization and Data Concurrent Transmission MAC Protocol for Underwater Acoustic Communication Networks. Master’s Thesis, Zhejiang University, Hangzhou, China, 2019. [Google Scholar]
- Diamant, R.; Casari, P.; Campagnaro, F.; Kebkal, O.; Kebkal, V.; Zorzi, M. Fair and throughput-optimal routing in multimodal underwater networks. IEEE Trans. Wirel. Commun. 2018, 17, 1738–1754. [Google Scholar]
- Liu, Y.H.; Shang, T. Initialization of Hybrid Underwater Optical/Acoustic Network with Asymmetrical Duplex Link. In Proceedings of the 2018 20th International Conference on Transparent Optical Networks (ICTON), Bucharest, Romania, 1–5 July 2018; pp. 1–4. [Google Scholar]
- Frikha, M.S.; Gammar, S.M.; Lahmadi, A.; Andrey, L. Reinforcement and deep reinforcement learning for wireless Internet of Things: A survey. Comput. Commun. 2021, 178, 98–113. [Google Scholar]
- Park, S.H.; Mitchell, P.D.; Grace, D. Reinforcement Learning Based MAC Protocol (UW-ALOHA-Q) for Underwater Acoustic Sensor Networks. IEEE Access 2019, 7, 165531–165542. [Google Scholar]
- Ali, R.; Shahin, N.; Zikria, Y.B.; Kim, B.S.; Kim, S.W. Deep reinforcement learning paradigm for performance optimization of channel observation–based MAC protocols in dense WLANs. IEEE Access 2018, 7, 3500–3511. [Google Scholar]
- Kosunalp, S.; Chu, Y.; Mitchell, P.D.; Grace, D.; Clarke, T. Use of Q-learning approaches for practical medium access control in wireless sensor networks. Eng. Appl. Artif. Intell. 2016, 55, 146–154. [Google Scholar]
- Parker, L.E. Lifelong adaptation in heterogeneous multi-robot teams: Response to continual variation in individual robot performance. Auton. Robot. 2000, 8, 239–267. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Andrei, A.R.; Joel, V.; Marc, G.B.; Alex, G.; Martin, R.; Andreas, K.F.; Georg, O.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar]
- Ye, X.W.; Yu, Y.D.; FU, L.Q. Deep reinforcement learning based MAC protocol for underwater acoustic networks. IEEE Trans. Mob. Comput 2020, 21, 794–807. [Google Scholar]
- Geng, X.; Zheng, Y.R. MAC protocol for underwater acoustic networks based on deep reinforcement learning. In Proceedings of the International Conference on Underwater Networks & Systems, Atlanta, GA, USA, 23–25 October 2019; pp. 1–5. [Google Scholar]
- Alfouzan, F.; Shahrabi, A.; Ghoreyshi, S.M.; Boutaleb, T. An efficient scalable scheduling MAC protocol for underwater sensor networks. Sensors 2018, 18, 2806. [Google Scholar]
- Hwang, H.Y. Analysis of Throughput and Delay for an Underwater Multi-DATA Train Protocol with Multi-RTS Reception and Block ACK. Sensors 2020, 20, 6473. [Google Scholar]
- Zhao, R.Q.; Long, H.; Dobre, O.A.; Shen, X.H.; Ngatched, T.M.N.; Mei, H.D. Time Reversal Based MAC for Multi-Hop Underwater Acoustic Networks. IEEE Syst. J. 2019, 13, 2531–2542. [Google Scholar]
- Nguyen, C.T.; Nguyen, M.T.; Mai, V.V. Underwater optical wireless communication-based IoUT networks: MAC performance analysis and improvement. Opt. Switch. Netw. 2020, 37, 100570. [Google Scholar]
- Chirdchoo, N.; Soh, W.-S.; Chua, K.C. Aloha-Based MAC Protocols with Collision Avoidance for Underwater Acoustic Networks. In Proceedings of the IEEE INFOCOM 2007-26th IEEE International Conference on Computer Communications, Anchorage, AK, USA, 6–12 May 2007; pp. 2271–2275. [Google Scholar]
- Ma, R.T.B.; Misra, V.; Rubenstein, D. An analysis of generalized slotted-aloha protocols. IEEE ACM Trans. Netw. 2009, 17, 936–949. [Google Scholar]
- Casari, P.; Zorzi, M. Protocol design issues in underwater acoustic networks. Comput. Commun. 2011, 34, 2013–2025. [Google Scholar]
- Molins, M.; Stojanovic, M. Slotted FAMA: A MAC protocol for underwater acoustic networks. In Proceedings of the OCEANS 2006-Asia Pacific, Singapore, 16–19 May 2006; pp. 1–7. [Google Scholar]
- Syed, A.A.; Ye, W.; Heidemann, J. T-Lohi: A new class of MAC protocols for underwater acoustic sensor networks. In Proceedings of the IEEE INFOCOM 2008-The 27th Conference on Computer Communications, Phoenix, AZ, USA, 13–18 April 2008; pp. 231–235. [Google Scholar]
- Schirripa Spagnolo, G.; Cozzella, L.; Leccese, F. Underwater Optical Wireless Communications: Overview. Sensors 2020, 20, 2261. [Google Scholar]
- Duntley, S.Q. Light in the sea. J. Opt. Soc. Am. 1963, 53, 214–233. [Google Scholar]
- Cochenour, B.; Dunn, K.; Laux, A.; Mullen, L. Experimental measurements of the magnitude and phase response of high-frequency modulated light underwater. Appl. Opt. 2017, 56, 4019–4024. [Google Scholar]
- Farr, N.; Bowen, A.; Ware, J.; Pontbriand, C.; Tivey, M. An integrated, underwater optical/acoustic communications system. In Proceedings of the Oceans’10 Ieee Sydney, Sydney, Australia, 24–27 May 2010; pp. 1–6. [Google Scholar]
- Campagnaro, F.; Francescon, R.; Casari, P.; Diamant, R.; Zorzi, M. Multimodal underwater networks: Recent advances and a look ahead. In Proceedings of the International Conference on Underwater Networks & Systems, Halifax, NS, Canada, 6–8 November 2017; pp. 1–8. [Google Scholar]
- Wang, J.J.; Shen, J.; Shi, W.; Qiao, G.; Wu, S.E.; Wang, X.J. A novel energy-efficient contention-based MAC protocol used for OA-UWSN. Sensors 2019, 19, 183. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Park, S.H.; Mitchell, P.D.; Grace, D. Performance of the ALOHA-Q MAC protocol for underwater acoustic networks. In Proceedings of the 2018 International Conference on Computing, Electronics & Communications Engineering (iCCECE), Southend, UK, 16–17 August 2018; pp. 189–194. [Google Scholar]
- Qian, Y.; Fan, Y.C.; Hu, W.P.; Soong, F.K. On the training aspects of deep neural network (DNN) for parametric TTS synthesis. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 3829–3833. [Google Scholar]
- Gao, J.T.; Shen, Y.L.; Liu, J.; Ito, M.; Shiratori, N. Adaptive traffic signal control: Deep reinforcement learning algorithm with experience replay and target network. arXiv 2017, arXiv:1705.02755. [Google Scholar]
- Zeng, Z.Q.; Fu, S.; Zhang, H.H.; Dong, Y.; Cheng, J.L. A survey of underwater optical wireless communications. IEEE Commun. Surv. Tutor. 2017, 19, 204–238. [Google Scholar]
- Dugaev, D.; Peng, Z.; Luo, Y.; Pu, L. Reinforcement-Learning Based Dynamic Transmission Range Adjustment in Medium Access Control for Underwater Wireless Sensor Networks. Electronics 2020, 9, 1727. [Google Scholar]
- Yu, Y.D.; Wang, T.T.; Liew, S.C. Deep-reinforcement learning multiple access for heterogeneous wireless networks. IEEE J. Sel. Areas Commun. 2019, 37, 1277–1290. [Google Scholar]
- Ye, X.W.; Yu, Y.D.; Fu, L.Q. MAC Protocol for Multi-channel Heterogeneous Networks Based on Deep Reinforcement Learning. In Proceedings of the Globecom 2020–2020 IEEE Global Communications Conference, Taipei, China, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Mammeri, Z. Reinforcement learning based routing in networks: Review and classification of approaches. IEEE Access 2019, 7, 55916–55950. [Google Scholar]
- Lu, Y.J.; He, R.X.; Chen, X.J.; Lin, B.; Yu, C.Q. Energy-efficient depth-based opportunistic routing with q-learning for underwater wireless sensor networks. Sensors 2020, 20, 1025. [Google Scholar]
- Millán, J.D.R.; Posenato, D.; Dedieu, E. Continuous-action Q-learning. Mach. Learn. 2002, 49, 247–265. [Google Scholar]
- Fan, J.Q.; Wang, Z.R.; Xie, Y.C.; Yang, Z.R. A theoretical analysis of deep Q-learning. In Proceedings of the 2nd Conference on Learning for Dynamics and Control, Online Event, Berkeley, CA, USA, 11–12 June 2020; pp. 486–489. [Google Scholar]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar]
- Nair, A.; Srinivasan, P.; Blackwell, S.; Alcicek, C.; Fearon, R.; De Maria, A.; Panneershelvam, V.; Suleyman, M.; Beattie, C.; Petersen, S.; et al. Massively parallel methods for deep reinforcement learning. arXiv 2015, arXiv:1507.04296. [Google Scholar]
- Lin, L.J. Reinforcement Learning for Robots Using Neural Networks. Ph.D. Thesis, School of Computer Science, Carnegie-Mellon University, Pittsburgh, PA, USA, 1993. [Google Scholar]
- Zhang, S.T.; Sutton, R.S. A deeper look at experience replay. arXiv 2017, arXiv:1712.01275. [Google Scholar]
- Yin, H.Y.; Pan, S.J. Knowledge transfer for deep reinforcement learning with hierarchical experience replay. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1640–1646. [Google Scholar]
- Chen, Z.; Wang, J.J.; Wang, X.J.; Xu, L.W. A MAC protocol design for optical-acoustic hybrid underwater wireless sensor network. In Proceedings of the 11th EAI International Conference on Mobile Multimedia Communications (MOBIMEDIA’18), Qingdao, China, 21–23 June 2018; pp. 274–279. [Google Scholar]
- Song, Y.J.; Kong, P.Y. Optimizing design and performance of underwater acoustic sensor networks with 3D topology. IEEE Trans. Mob. Comput. 2020, 19, 1689–1701. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, J.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing: Birmingham, UK, 2017. [Google Scholar]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Ye, X.W.; Yu, Y.D.; Fu, L.Q. The optimal network throughputs when the model-aware node coexists with other nodes using different MAC protocols. arXiv 2020, arXiv:2008.11621. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research | Network | Communication Technique | Learning Algorithm | Channel Number | Main Contributions |
|---|---|---|---|---|---|
| Wang et al. [39] | UWSNs | Optical/Acoustic | N/A | Single Channel | Proposes an underwater optical and acoustic energy-efficient MAC protocol. |
| Park et al. [18] | UWSNs | Acoustic | RL | Single Channel | Proposes an underwater version of ALOHA-Q protocol with Q learning. |
| Geng et al. [24] | HetNets | Acoustic | DRL | Single Channel | Proposes an underwater DRL based MAC protocol and applies the protocol to both the synchronous and asynchronous time models. |
| Ye et al. [23] | HetNets | Acoustic | DRL | Single Channel | Provides a DR-DQN framework for proposing an DRL based MAC protocol for underwater HetNets. |
| Ye et al. [49] | HetNets | Radio | DRL | Multi-Channel | Proposes a DRL multi-channel MAC protocol for terrestrial HetNets. |
| Our study | HetNets | Optical/Acoustic | DRL | Dual Channel | Proposes a hybrid optical and acoustic DRL based MAC for underwater HetNets. To differentiate between the specific actions on the optical channel and the acoustic channel, a distinct reward policy is set for the two channels. |
| Hyper-Parameter | Value |
|---|---|
| The number of neurons per layer | 64 |
| Activation function | RELU |
| State history length M | 32 |
| Reward discount factor γ | 0.9 |
| Exploration probability ε | Decay from 1 to 0.01 |
| Experience buffer capacity D | 560 |
| Random samples NE | 32 |
| Optimizer of DQN | RMSProp |
| Learning rate α | 0.001 |
| Update frequency F of target-net | 480 |
| Smoothing window size Nw | 1600 |
| Parameter | Value |
|---|---|
| Acknowledgement time | 0.1 s |
| Acoustic bit rate | 10 kb/s |
| Optical bit rate | 1 Mb/s |
| Maximum distance between source node and the relay node | 30 m |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, E.; He, R.; Chen, X.; Yu, C. Deep Reinforcement Learning Based Optical and Acoustic Dual Channel Multiple Access in Heterogeneous Underwater Sensor Networks. Sensors 2022, 22, 1628. https://doi.org/10.3390/s22041628
Liu E, He R, Chen X, Yu C. Deep Reinforcement Learning Based Optical and Acoustic Dual Channel Multiple Access in Heterogeneous Underwater Sensor Networks. Sensors. 2022; 22(4):1628. https://doi.org/10.3390/s22041628
Chicago/Turabian StyleLiu, Enhong, Rongxi He, Xiaojing Chen, and Cunqian Yu. 2022. "Deep Reinforcement Learning Based Optical and Acoustic Dual Channel Multiple Access in Heterogeneous Underwater Sensor Networks" Sensors 22, no. 4: 1628. https://doi.org/10.3390/s22041628
APA StyleLiu, E., He, R., Chen, X., & Yu, C. (2022). Deep Reinforcement Learning Based Optical and Acoustic Dual Channel Multiple Access in Heterogeneous Underwater Sensor Networks. Sensors, 22(4), 1628. https://doi.org/10.3390/s22041628