
DFusion: Denoised TSDF Fusion of Multiple Depth Maps with Sensor Pose Noises



Abstract
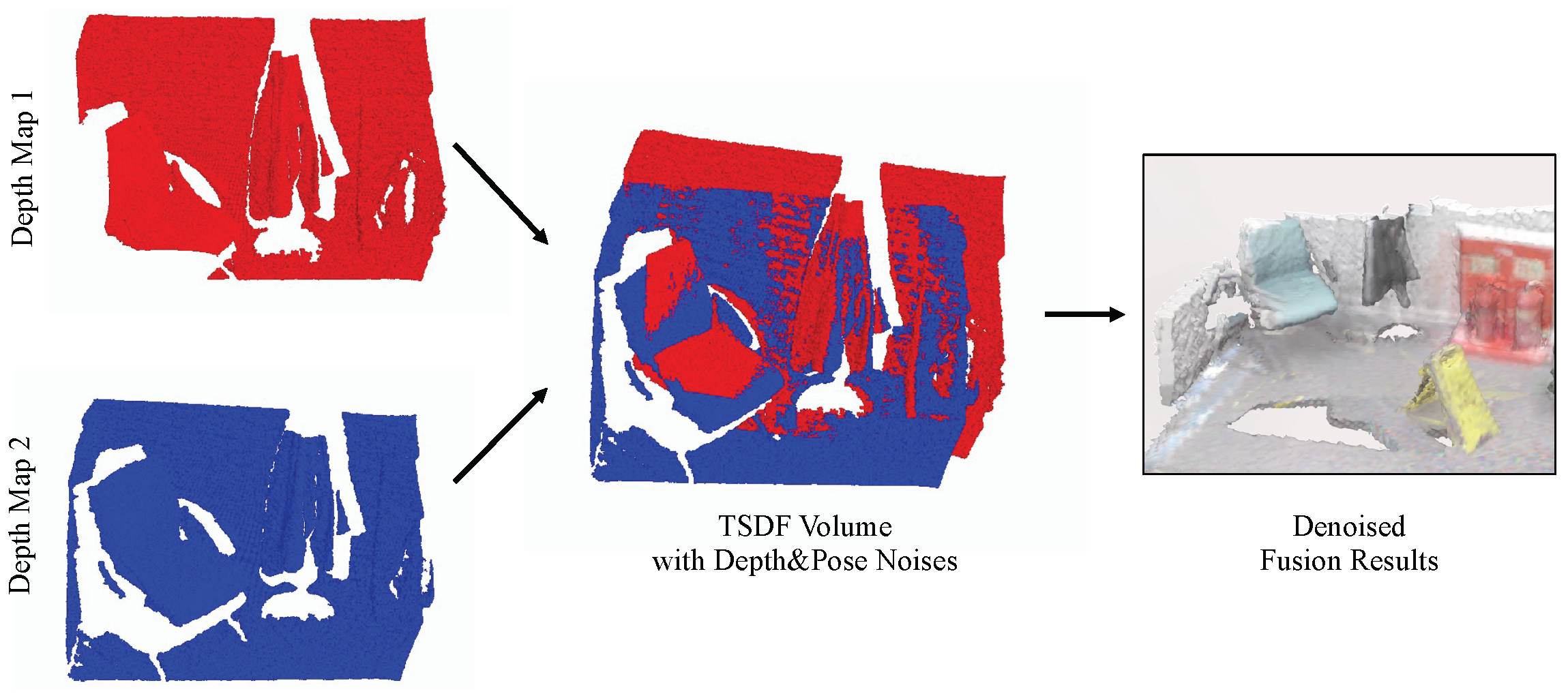
:1. Introduction
- We propose a new fusion network named DFusion, which considers both depth noises and pose noises in the fusion process. DFusion can avoid the performance drops caused by both types of noises, and conduct accurate and robust depth fusion.
- We design new fusion loss functions that focus on all the voxels while emphasizing the object and surface regions, which can improve the overall performance.
- The experiments are conducted on a synthetic dataset as well as a real scene dataset, measuring the actual noise levels with the real-world setting and demonstrating the denoising effects of the proposed method. The ablation study proves the effectiveness of the proposed loss function.
2. Related Works
2.1. Depth Fusion and Reconstruction
2.1.1. Classical Methods
2.1.2. Learning-Based Methods
2.2. Denoising/Noise Reduction
3. Methodology
3.1. TSDF Fusion
3.2. Network Architecture
3.3. Loss Functions
4. Experiments
4.1. Experimental Setup
4.2. Dataset and Noise Simulation
4.3. Evaluation Results
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Curless, B.; Levoy, M. A volumetric method for building complex models from range images. In Proceedings of the 23rd annual conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 303–312. [Google Scholar]
- Lefloch, D.; Weyrich, T.; Kolb, A. Anisotropic point-based fusion. In Proceedings of the 2015 18th International Conference on Information Fusion (Fusion), Washington, DC, USA, 6–9 July 2015; pp. 2121–2128. [Google Scholar]
- Dong, W.; Wang, Q.; Wang, X.; Zha, H. PSDF fusion: Probabilistic signed distance function for on-the-fly 3D data fusion and scene reconstruction. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 701–717. [Google Scholar]
- Weder, S.; Schonberger, J.; Pollefeys, M.; Oswald, M.R. RoutedFusion: Learning real-time depth map fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4887–4897. [Google Scholar]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Dai, A.; Nießner, M.; Zollhöfer, M.; Izadi, S.; Theobalt, C. BundleFusion: Real-time globally consistent 3D reconstruction using on-the-fly surface reintegration. ACM Trans. Graph. (ToG) 2017, 36, 1. [Google Scholar] [CrossRef]
- Nießner, M.; Zollhöfer, M.; Izadi, S.; Stamminger, M. Real-time 3D reconstruction at scale using voxel hashing. ACM Trans. Graph. (ToG) 2013, 32, 1–11. [Google Scholar] [CrossRef]
- Marniok, N.; Goldluecke, B. Real-time variational range image fusion and visualization for large-scale scenes using GPU hash tables. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 912–920. [Google Scholar]
- Zienkiewicz, J.; Tsiotsios, A.; Davison, A.; Leutenegger, S. Monocular, real-time surface reconstruction using dynamic level of detail. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 37–46. [Google Scholar]
- Keller, M.; Lefloch, D.; Lambers, M.; Izadi, S.; Weyrich, T.; Kolb, A. Real-time 3D reconstruction in dynamic scenes using point-based fusion. In Proceedings of the 2013 International Conference on 3D Vision-3DV 2013, Seattle, WA, USA, 29 June–1 July 2013; pp. 1–8. [Google Scholar]
- Schöps, T.; Sattler, T.; Pollefeys, M. SurfelMeshing: Online surfel-based mesh reconstruction. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2494–2507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stückler, J.; Behnke, S. Multi-resolution surfel maps for efficient dense 3D modeling and tracking. J. Vis. Commun. Image Represent. 2014, 25, 137–147. [Google Scholar] [CrossRef]
- Woodford, O.J.; Vogiatzis, G. A generative model for online depth fusion. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 144–157. [Google Scholar]
- Ulusoy, A.O.; Black, M.J.; Geiger, A. Patches, planes and probabilities: A non-local prior for volumetric 3D reconstruction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3280–3289. [Google Scholar]
- Yong, D.; Mingtao, P.; Yunde, J. Probabilistic depth map fusion for real-time multi-view stereo. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba Science City, Japan, 11–15 November 2012; pp. 368–371. [Google Scholar]
- Ulusoy, A.O.; Geiger, A.; Black, M.J. Towards probabilistic volumetric reconstruction using ray potentials. In Proceedings of the 2015 International Conference on 3D Vision (3DV), Lyon, France, 19–22 October 2015; pp. 10–18. [Google Scholar]
- Dai, A.; Nießner, M. 3DMV: Joint 3D-multi-view prediction for 3D semantic scene segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 October 2018; pp. 452–468. [Google Scholar]
- Dai, A.; Ritchie, D.; Bokeloh, M.; Reed, S.; Sturm, J.; Nießner, M. Scancomplete: Large-scale scene completion and semantic segmentation for 3d scans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4578–4587. [Google Scholar]
- Paschalidou, D.; Ulusoy, O.; Schmitt, C.; Van Gool, L.; Geiger, A. RayNet: Learning volumetric 3D reconstruction with ray potentials. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3897–3906. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Gkioxari, G.; Malik, J.; Johnson, J. Mesh R-CNN. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9785–9795. [Google Scholar]
- Murez, Z.; van As, T.; Bartolozzi, J.; Sinha, A.; Badrinarayanan, V.; Rabinovich, A. Atlas: End-to-end 3D scene reconstruction from posed images. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part VII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 414–431. [Google Scholar]
- Riegler, G.; Ulusoy, A.O.; Bischof, H.; Geiger, A. OctnetFusion: Learning depth fusion from data. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 57–66. [Google Scholar]
- Leroy, V.; Franco, J.S.; Boyer, E. Shape reconstruction using volume sweeping and learned photoconsistency. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 781–796. [Google Scholar]
- Zollhöfer, M.; Dai, A.; Innmann, M.; Wu, C.; Stamminger, M.; Theobalt, C.; Nießner, M. Shading-based refinement on volumetric signed distance functions. ACM Trans. Graph. (TOG) 2015, 34, 1–14. [Google Scholar] [CrossRef]
- Cherabier, I.; Schonberger, J.L.; Oswald, M.R.; Pollefeys, M.; Geiger, A. Learning priors for semantic 3D reconstruction. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 314–330. [Google Scholar]
- Duan, C.; Chen, S.; Kovacevic, J. 3D point cloud denoising via deep neural network based local surface estimation. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 March 2019; pp. 8553–8557. [Google Scholar]
- Rakotosaona, M.J.; La Barbera, V.; Guerrero, P.; Mitra, N.J.; Ovsjanikov, M. PointCleanNet: Learning to denoise and remove outliers from dense point clouds. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2020; Volume 39, pp. 185–203. [Google Scholar]
- Han, X.; Li, Z.; Huang, H.; Kalogerakis, E.; Yu, Y. High-resolution shape completion using deep neural networks for global structure and local geometry inference. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 85–93. [Google Scholar]
- Cao, Y.P.; Liu, Z.N.; Kuang, Z.F.; Kobbelt, L.; Hu, S.M. Learning to reconstruct high-quality 3D shapes with cascaded fully convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 616–633. [Google Scholar]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An information-rich 3D model repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Wasenmüller, O.; Meyer, M.; Stricker, D. CoRBS: Comprehensive RGB-D benchmark for SLAM using Kinect v2. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–7. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]
- Park, J.J.; Florence, P.; Straub, J.; Newcombe, R.; Lovegrove, S. DeepSDF: Learning continuous signed distance functions for shape representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 165–174. [Google Scholar]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Proceedings of the Sensor Fusion IV: Control Paradigms and Data Structures, International Society for Optics and Photonics, Munich, Germany, 12–15 November 1992; Volume 1611, pp. 586–606. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | MSE | MAD | ACC | IoU |
|---|---|---|---|---|
| DeepSDF [35] | 412.0 | 0.049 | 68.11 | 0.541 |
| OccupacyNetworks [23] | 47.5 | 0.016 | 86.38 | 0.509 |
| TSDF Fusion [1] | 10.9 | 0.008 | 88.07 | 0.659 |
| RoutedFusion [4] | 5.4 | 0.005 | 95.29 | 0.816 |
| DFusion (Ours) | 3.5 | 0.003 | 96.12 | 0.847 |
| Methods | MSE | MAD | ACC | IoU |
|---|---|---|---|---|
| DeepSDF [35] | 420.3 | 0.052 | 66.90 | 0.476 |
| OccupacyNetworks [23] | 108.6 | 0.037 | 77.34 | 0.453 |
| TSDF Fusion [1] | 43.4 | 0.020 | 80.45 | 0.582 |
| RoutedFusion [4] | 20.8 | 0.017 | 88.19 | 0.729 |
| DFusion (Ours) | 6.1 | 0.006 | 95.08 | 0.801 |
| Methods | Human | Desk | Cabinet | Car |
|---|---|---|---|---|
| KinectFusion [5] | 0.015 | 0.005 | 0.009 | 0.009 |
| ICP + RoutedFusion [4] | 0.014 | 0.005 | 0.008 | 0.009 |
| ICP + DFusion (Ours) | 0.012 | 0.004 | 0.006 | 0.007 |
| Methods | MSE | MAD | ACC | IoU |
|---|---|---|---|---|
| Without object loss | 8.3 | 0.007 | 92.11 | 0.744 |
| Without surface loss | 7.5 | 0.006 | 91.83 | 0.769 |
| Without object&surface loss | 16.3 | 0.015 | 90.87 | 0.740 |
| Original | 6.1 | 0.006 | 95.08 | 0.801 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niu, Z.; Fujimoto, Y.; Kanbara, M.; Sawabe, T.; Kato, H. DFusion: Denoised TSDF Fusion of Multiple Depth Maps with Sensor Pose Noises. Sensors 2022, 22, 1631. https://doi.org/10.3390/s22041631
Niu Z, Fujimoto Y, Kanbara M, Sawabe T, Kato H. DFusion: Denoised TSDF Fusion of Multiple Depth Maps with Sensor Pose Noises. Sensors. 2022; 22(4):1631. https://doi.org/10.3390/s22041631
Chicago/Turabian StyleNiu, Zhaofeng, Yuichiro Fujimoto, Masayuki Kanbara, Taishi Sawabe, and Hirokazu Kato. 2022. "DFusion: Denoised TSDF Fusion of Multiple Depth Maps with Sensor Pose Noises" Sensors 22, no. 4: 1631. https://doi.org/10.3390/s22041631
APA StyleNiu, Z., Fujimoto, Y., Kanbara, M., Sawabe, T., & Kato, H. (2022). DFusion: Denoised TSDF Fusion of Multiple Depth Maps with Sensor Pose Noises. Sensors, 22(4), 1631. https://doi.org/10.3390/s22041631