1. Introduction
Deep learning is evolving rapidly, and it has not only revolutionized computer vision, but many fields of engineering, medicine [
1], and business analytics [
2]. However, there still is a long way to go in order to effectively deploy deep networks in the real world to assist humans in their daily workloads in diverse aspects. Humans have the capability to adapt to any environment and excel in it where such evolution is not limited or defined by the finite dataset or pre-defined tasks for any particular domain (application). Rather, it is a lifelong learning process that evolves over time. This poses major limitations to the performance of deep neural networks.
To overcome such limitations, researchers have proposed different knowledge distillation strategies [
3], end-to-end learning [
4], learning without forgetting [
5], expert gating [
6], indefinitely long-term learning (iCaRL) [
7], and hierarchical incremental learning [
8]. More recently, Tian et al. [
9] analyzed the shortcomings of the Kullback–Leibler (KL) divergence in learning structured representative knowledge that exhibits complex dimensional interdependencies for which the KL divergence turned out to be undefined. Furthermore, they proposed a contrastive representative objective that captures the higher correlation and output dependencies of representational data for different knowledge transfer tasks.
Mirzadeh et al. [
10] proposed a multi-stage knowledge distillation strategy involving intermediate models to bridge the gap between teacher–student networks by showing that a student of a fixed size with an arbitrarily large teacher network results in a significant reduction in performance. The researchers emphasized the fact that such a topology is beneficial for mitigating the loss of information during the drastic model compression that happens when such a model is employed in resource-constrained edge devices and embedded sensor nodes. Reference [
11] proposed a similar knowledge distillation approach where the backbone and the final classification layers were treated separately with the primary focus on the backbone knowledge transfer to the student. This allowed for the termination of the loss weight as the task head of the student can be trained independently afterwards. Son et al. [
12] exploited multi-stage knowledge distillation by using multiple teacher and teacher’s assistant networks at each stage and introduced stochastic teaching for the student network by randomly dropping one of the many teacher and teacher assistant networks, thus regularizing the learning of the student network in the process.
An information-theoretic framework encompassing variational information maximization for knowledge transfer between a teacher and a student was presented in [
13] that maximizes the mutual information between both networks to alleviate the problems associated with the knowledge distillation and transfer learning tasks. This technique bypasses the need for manual matching of the network’s activations. However, large accurate teacher networks do not necessarily generate accurate student networks as the growth capacity of the teacher is often absent in the student. This results in a failure by the student to emulate the teacher network’s performance, resulting in the increase of the training loss [
14]. In such scenarios, early stopping of the teacher network can be an effective solution in contrast to multi-stage knowledge distillation steps that allow the student to converge its training loss [
14]. Yaun et al. [
15] exploited the fact that a teacher network with significantly less performance than the student can still effectively improve the student network due to the inherent property of knowledge distillation acting as a type of label-smoothing regularization. Thus, they proposed a teacher-free knowledge distillation strategy that allows the student network to learn from itself in the absence of any strong teacher networks while still achieving comparable results without any computational overhead.
Lee et al. [
16] presented a scheme to overcome catastrophic forgetting by leveraging large, unlabeled, and easily accessible data through confidence-based sampling by which the new model instance learns the prior and current task by distilling knowledge from three sources: its previously trained instance, the newly trained teacher, as well as their ensemble. Reference [
17] proposed a novel technique to combat the effects of catastrophic forgetting by first training a separate model for the new classes and then combining the old and the newly trained model using a novel double-distillation approach that relies on publicly available unlabeled data, thus mitigating the effects of the original data being unavailable. GEM (2017) [
18] is another replay-based method that is composed of a memory component that stores a few dataset samples from the previous tasks, and it optimizes them by determining the direction of the change of weights. However, the optimization comes at the cost of excessive computational power and time (because the number of tasks increases over time). To mitigate these shortcomings, A-GEM (2019) was proposed in [
19].
Srinidhi Hegde et al. [
20] introduced a new loss term for knowledge distillation as the variational loss function, which optimizes based on four different parameters: likelihood, hint from the teacher, variational term, and block sparse regularization for transferring sparsity from the teacher to student network. It uses Bayesian neural networks, based on the principle of the determination of random variables of the parameters, which are used with the weight terms in the propagation. Contrary to the existing literature, we found three main aspects that have not been thoroughly addressed before in the context of continual learning.
The first one is the scarcity of incremental learning systems for multimodal analysis. There are frameworks that incrementally learn the data representations from similar datasets. However, the true objective of developing an incremental learning system is to identify similar data representations even from entirely different types of input, which is a hallmark of human learning. For example, a doctor can confirm a diagnosis from different data across different modalities. In fact, such an approach increases the reliability of the diagnosis. However, one hurdle in such a scheme for multimodal analysis is that such an analysis cannot be performed at the same time as the data from the different modalities become gradually available over time.
The second aspect that is addressed in this paper is the development of a system that effectively learns about unrelated tasks across different applications. During transfer learning, we fine-tuned the model that had already been trained on another dataset for our desired application. However, the fine-tuned model may no longer perform well on the previous task even if the last classification layer remains unchanged. This problem arises due to the limitation of deep learning models to catastrophically forget the old knowledge. In contrast, we humans can adapt to any environment without losing prior knowledge. Solutions have been developed that have yielded promising results to overcome catastrophic forgetting while incrementally learning the newer, related tasks [
9,
16,
18,
19]. However, to the best of our knowledge, there is no literature available to date in which the effects of catastrophic forgetting are minimized for entirely different tasks belonging to entirely different applications, for example diagnosing a disease, detecting a contraband item, detecting a cat in a picture, etc.
The third area that is explored in this paper is the analysis of the transferability of incremental learning systems on related inter- and intra-modality tasks. To summarize, the major highlights of the paper are as follows.
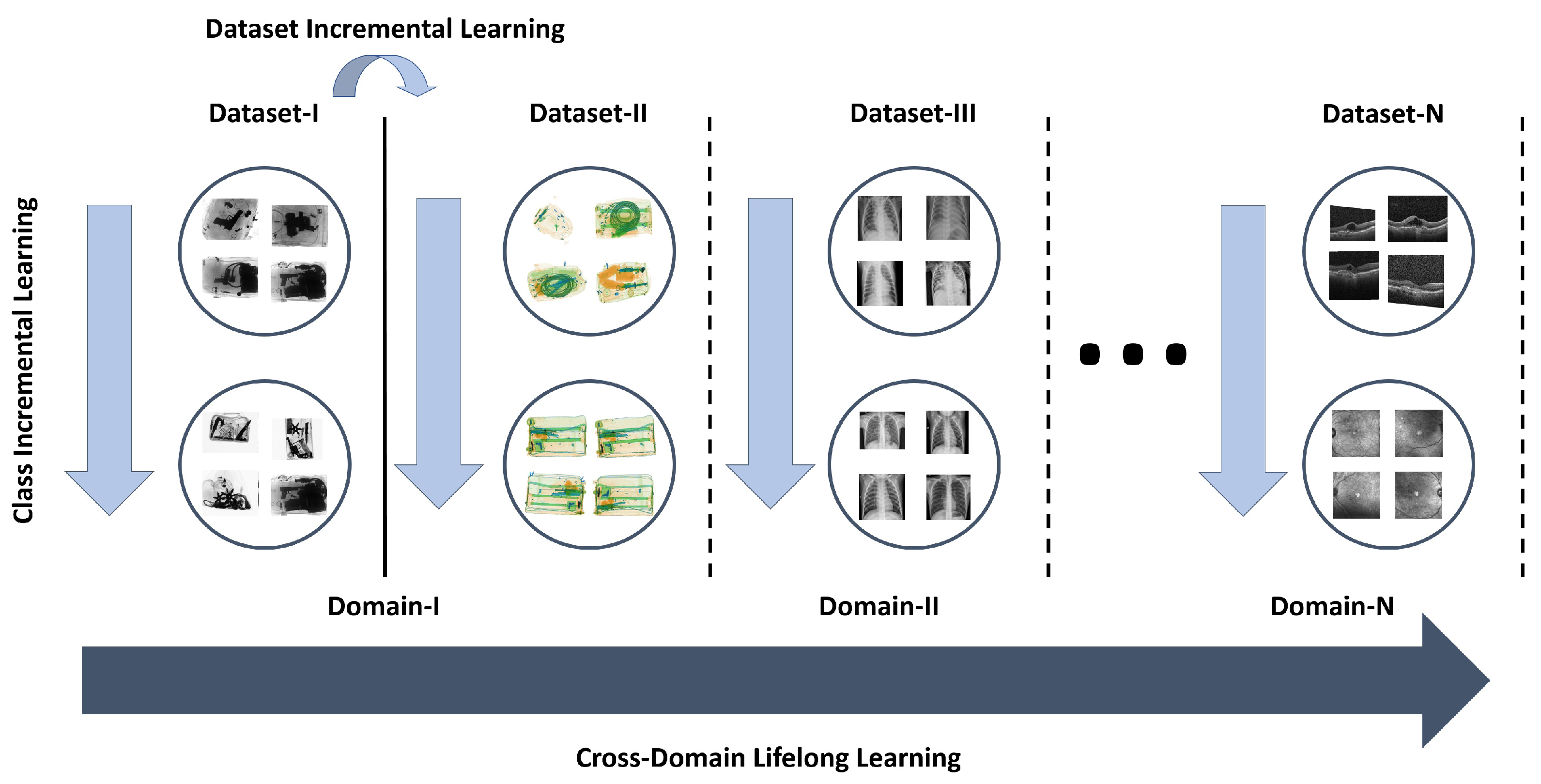
3. Proposed Framework
The block diagram of the proposed framework is shown in
Figure 2. Inspired by iCaRL [
7], we also present a decision support system that learns indefinitely from representational data over time. However, compared to [
7], the proposed framework is not only limited to class incremental learning. Instead, it can learn about new tasks from a multimodal dataset spanning different applications without forgetting the prior knowledge. This is achieved by jointly optimizing two objectives collectively termed the mutual distillation loss. The first objective allows the framework to remember prior knowledge, while the second objective allows the framework to learn about new tasks with the assumption that in real life, all the tasks have an interdependence on each other irrespective of their nature. We tried to exploit that mutual information in order to make the deep neural network learn more as humans do. The mutual distillation loss was further utilized along with the independent representation of older and newer knowledge in a continual learning objective. The detailed formulation of mutual distillation and continual learning loss is presented below.
3.1. Mutual Distillation Loss
Mutual distillation loss () is a combination of two objectives that jointly optimize the deep network to effectively learn new information from a small dataset without forgetting prior learned knowledge. Contrary to all the knowledge distillation frameworks in the literature that handle catastrophic forgetting by optimizing prior and new knowledge simultaneously, but independently of each other, we assumed that real-life events have complex relationships and dependencies on each other. We tried to exploit and maximize that mutual information for effective learning.
For any deep network having an input x where (the superset of all samples from all applications), is computed by jointly optimizing two objectives, which are derived from the joint distributions and where (old knowledge soft representation) and (soft representation of newer knowledge).
These distributions ensure that the network learns and understands the complex relationship between older and newly acquired knowledge and can effectively perform well on each task without losing its past knowledge or capping its capacity to learn new experiences. Adding the notion of classes in the above definitions of the joint distribution yields:
where
w represents the total number of classes. Afterwards, the posterior for each class
is computed through Bayes’ rule:
and:
where
represents the number of events having outcome
,
denotes the total events, and the prior is computed as:
. Moreover, the likelihood of the representational data is modeled through a multivariate Gaussian distribution:
where
y∈ [
],
d denotes the multivariate dimension, and
and
represent the mean and covariance of the distribution, respectively. Taking the log on both sides yields:
Afterwards,
for outcome
is defined by minimizing
and
:
where
denotes the temperature and
and
denote the number of old and new training samples, respectively. We can see here that Equation (
8) can also be interpreted as a combination of the categorical cross-entropy loss.
3.2. Continual Learning Loss
bridges the gap between new and prior knowledge by exploiting their representational dependencies. Furthermore, to make the network aware of their exclusive characteristics, we jointly optimized two more objectives such that:
where:
and:
where
denotes the batch size. From Equations (
10) and (
11), we can see that
is simply a categorical cross-entropy loss and
is a KL divergence loss.
5. Results
We evaluated the proposed framework for three different applications involving nine publicly available datasets. While ResNet101 provided the best results for all the different datasets, the proposed framework was also evaluated with MobileNet [
36], ResNet50 [
37], and VGG-16 [
38]. In addition, the fine-tuning comparisons were performed with ResNet101, as it was the best-performing model in the group.
We started with training the classification model on the GDXray dataset in which we incrementally added each suspicious class with the small training dataset. We continued the same process for the SIXray dataset and then for different applications. Our motivation here was to make the classification model effectively learn the complex relationships between different tasks during the knowledge distillation process. For that, we used our proposed continual learning loss, which explicitly uses the mutual distillation objective to resolve the dependencies between the prior knowledge and the new information. Furthermore, as other knowledge distillation frameworks, also retains the past knowledge by minimizing and effectively learns new tasks through . We also compared with other popular loss functions such as the KL divergence and multi-category cross-entropy to see how effectively it learns the newer knowledge while retaining the already learned task. The evaluations on each dataset individually and then on the combined dataset are presented below.
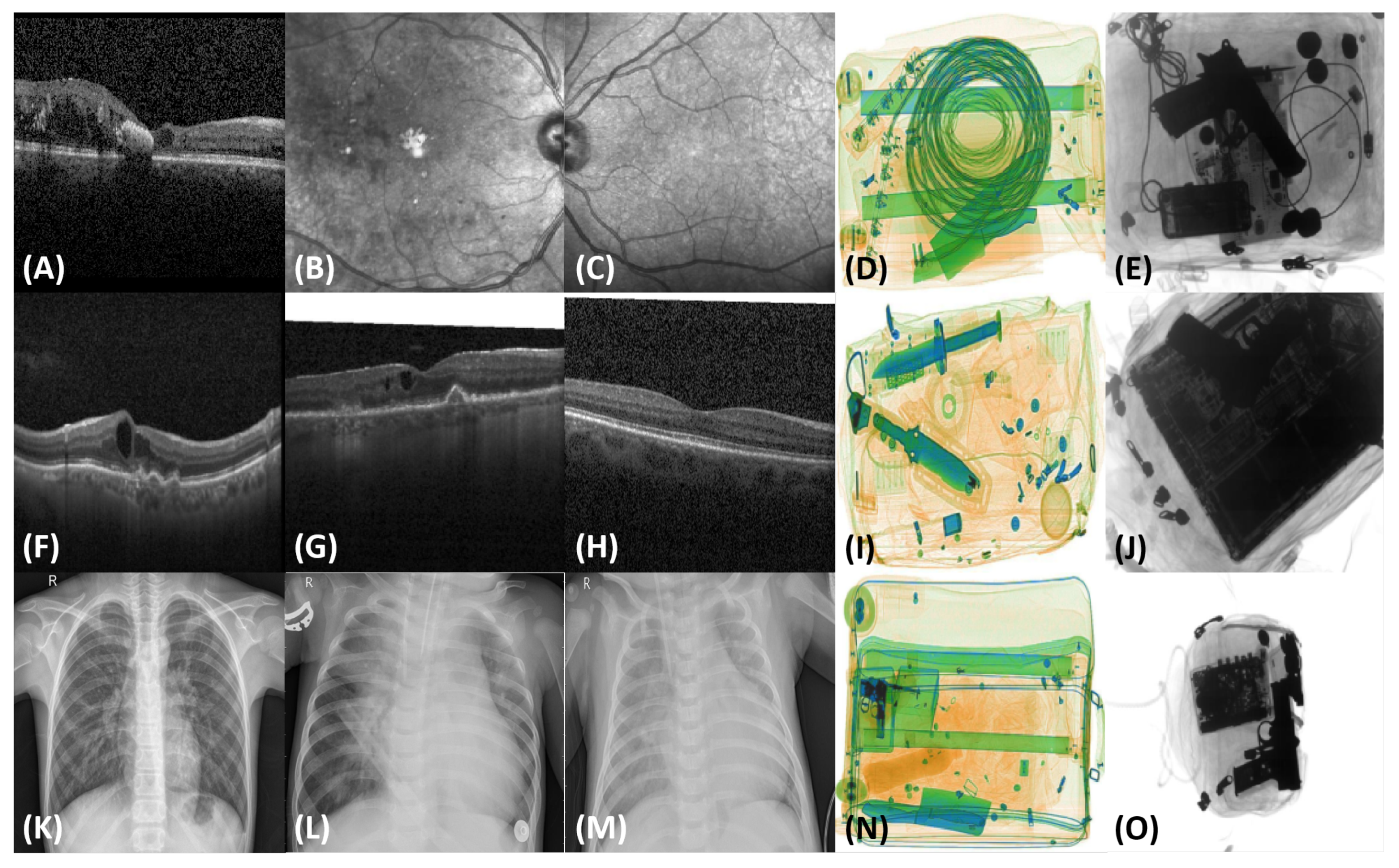
5.1. Evaluations on the GDXray Dataset
The baggage scans in the GDXray dataset contain all the suspicious items, so for the first training iteration, the model was just trained for predicting whether a grayscale scan contains a gun or not. Afterwards, in each successive iteration, contraband items such as knives, shurikens, and razors were added.
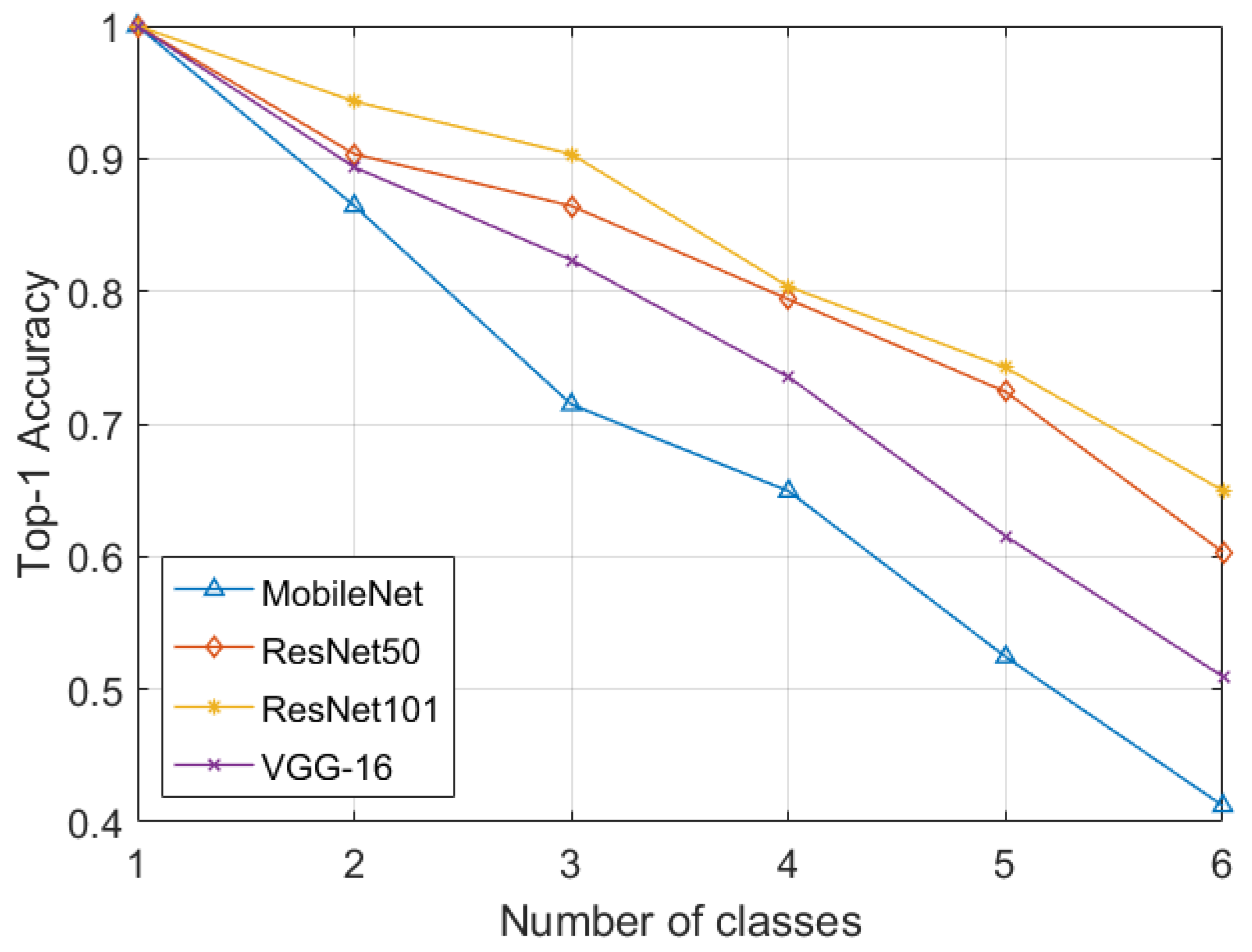
Furthermore, to correctly classify scans containing miscellaneous and normal items such as springs, paperclips, etc., within the GDXray dataset, we added a separate normal class. In some images, the suspicious items may occur in groups. Therefore, a “multiple” class was added for such cases, bringing the total number of classes to six. The performance on GDXray in each iteration was measured through accuracy, sensitivity, specificity, precision, and F1-scores. From
Table 1, it can be observed that the proposed framework had an accuracy of 0.6498% and an F1-score of 0.7462 for the six6-class suspicious item classification when employing ResNet101. we can observe that the proposed framework accurately recognized the suspicious item scans with an accuracy of 0.6498% and an F1-score of 0.7462 using ResNet101. Moreover, we also computed the classification results through ResNet101-based transfer learning on GDXray and compared its classification performance with the proposed incremental learning strategy. In order to fine-tune ResNet101 on the GDXray dataset, we used the cross-entropy loss function as the proposed objective function was designed for continual learning schemes. It can be observed from
Table 1 that the proposed framework lagged only 5.72% from the transfer learning approach in terms of the F1-score. Moreover, the performance of class incremental learning can be observed in
Figure 3, where we can observe how effectively the proposed objective function retained the prior knowledge and produced classification results extremely comparable to the fine-tuning approach.
5.2. Evaluations on the SIXray Dataset
After training and evaluation on GDXray, we incrementally trained the proposed framework on SIXray to identify suspicious items from colored X-ray scans.
At first, the deep learning models were trained to recognize the scans containing guns. In the next iterations, the models were incrementally trained to recognize the knives, wrenches, pliers, scissors, and hammers. In a similar manner to the GDXray dataset, for the scans containing multiple suspicious items, we added a separate class for them, namely “multiple”. In the last iteration, the deep learning models were trained to identify negative (normal) scans that did not contain any suspicious items. It should be noted here that the SIXray dataset is highly imbalanced (i.e., it contains 8929 suspicious scans and 1,050,302 normal scans). Moreover,
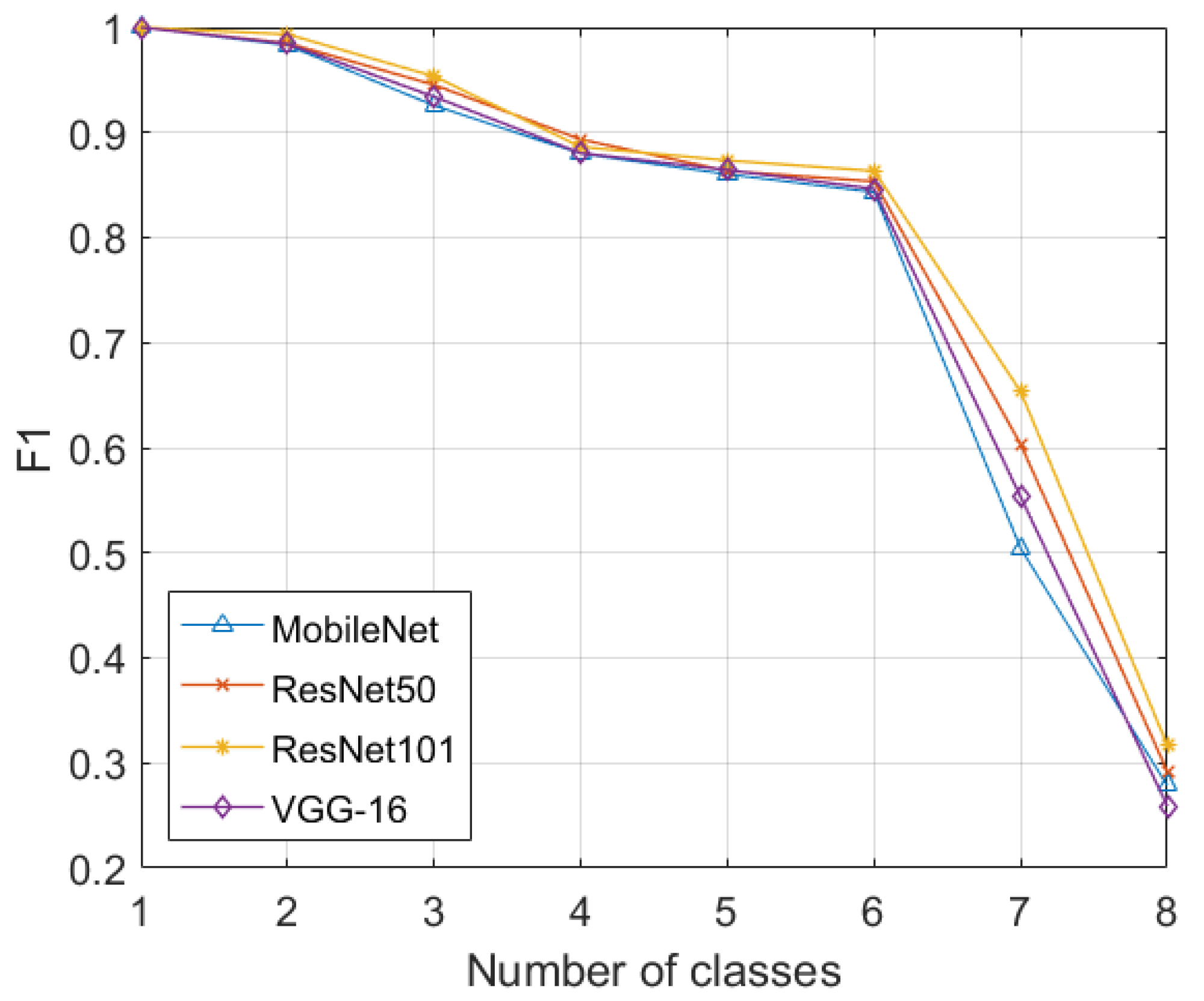
Table 2 shows the classification performance of the proposed framework on the SIXray dataset, where it can be observed that the proposed framework achieved an accuracy of 0.9663 and an F1-score of 0.3167. The significant difference in these scores is due to the fact that SIXray dataset is extremely imbalanced. The imbalanced nature of the SIXray dataset can be further seen in
Figure 4, where the classification performance of the deep model (in terms of the F1-score) drastically decreased while learning the negative samples (in the eighth iteration). Apart from this, we can also observe the sudden decrease in the classification performance in the seventh iteration. This is because the number of scans containing individual items is extremely low as compared to those scans that contain multiple suspicious items (i.e., there are around 8905 out of 8929 positive scans within the SIXray dataset that contain multiple suspicious items), thus creating a class imbalance situation, yielding the significant decrease in the classification performance. However, even the fine-tuning approach suffered from such an imbalance, as we can observe the 17.77% decrease from the sixth to seventh iteration in
Figure 4.
Furthermore, we evaluated all the deep learning models on SIXray10, SIXray100, and SIXray1000 using the proposed objective function, and it lagged by 32.14% on SIXray10, 49.47% on SIXray100, and 50.93% on SIXray1000 from the transfer learning approach in terms of the F1-scores, as evident from
Table 3. These results again should be analyzed with the fact that the SIXray dataset is highly imbalanced.
5.3. Evaluations on the Zhang Chest X-ray Dataset
For the Zhang chest X-ray dataset, we trained the deep learning models on healthy chest X-ray scans first and then incrementally trained them to identify the pneumonia-affected scans. We also computed the results through the transfer learning approach on the Zhang chest X-ray dataset using ResNet101 and multi-category cross-entropy. From
Table 4, we can see that the proposed framework lagged from the transfer learning approach only by 2.26% in terms of the accuracy while using a significantly smaller training dataset at one time in memory.
5.4. Evaluations on the Rabbani Dataset
For the third application, we trained the deep learning models first on the Rabbani dataset. It is one of the few datasets that allows retinal examination and screening of retinal subjects based on multimodal imagery. First of all, the proposed framework was trained on healthy OCT and fundus scans. In the subsequent iterations, it was trained on OCT and fundus scans of the DME and AMD pathologies, respectively. The classification performance of the proposed framework on the Rabbani dataset is shown in
Table 5, where we can see that the proposed objective had a gap of only 4.65% (in terms of accuracy) to bridge the gap between the incremental learning and transfer learning approach.
5.5. Evaluations on the BIOMISA Dataset
BIOMISA is one of the recently published datasets containing retinal fundus and OCT images of healthy and retinopathy-affected subjects. The scans within the BIOMISA dataset were acquired by the Topcon 3D OCT 2000 machine. The performance of the proposed framework on the BIOMISA dataset is shown in
Table 6, where it can be observed that the best performance was achieved for the ResNet101 model where it only lagged from fine-tuning by 1.008% in terms of the F1-score.
5.6. Evaluations on the Duke Datasets
To evaluate the proposed framework on the Duke datasets, we first merged Duke-I and Duke-II together because Duke-I only contains AMD and normal pathologies, whereas Duke-II only contains DME pathologies. Therefore, training the system solely on Duke-II for classifying only the DME subjects would not have been appropriate. Apart from this, we evaluated Duke-III separately since it contains scans from all three pathologies. The classification performance of the proposed framework on the Duke datasets is shown in
Table 7 and
Table 8. From
Table 7 and
Table 8, we can observe that the proposed framework was able to achieve an F1-score of 0.9537 on the Duke-I and Duke-II datasets and an F1-score of 0.9584 on the Duke-III dataset using the ResNet101 model.
5.7. Evaluations on the Zhang OCT Dataset
The last dataset on which the proposed framework was evaluated is the Zhang OCT dataset. In total, 1000 scans were used for the evaluation purposes (250 scans per pathology) as per the dataset standard, and the proposed framework was able to achieve an accuracy of 0.9260 using ResNet101, as evident from
Table 9. Moreover, it can also be noted from
Table 9 that the proposed framework only lagged from the fine-tuning approach by 3.44%, which is less significant especially considering the fact that the proposed framework drastically reduces the memory and data requirements for training as compared to the fine-tuning approach.
5.8. Evaluations on Combined Dataset
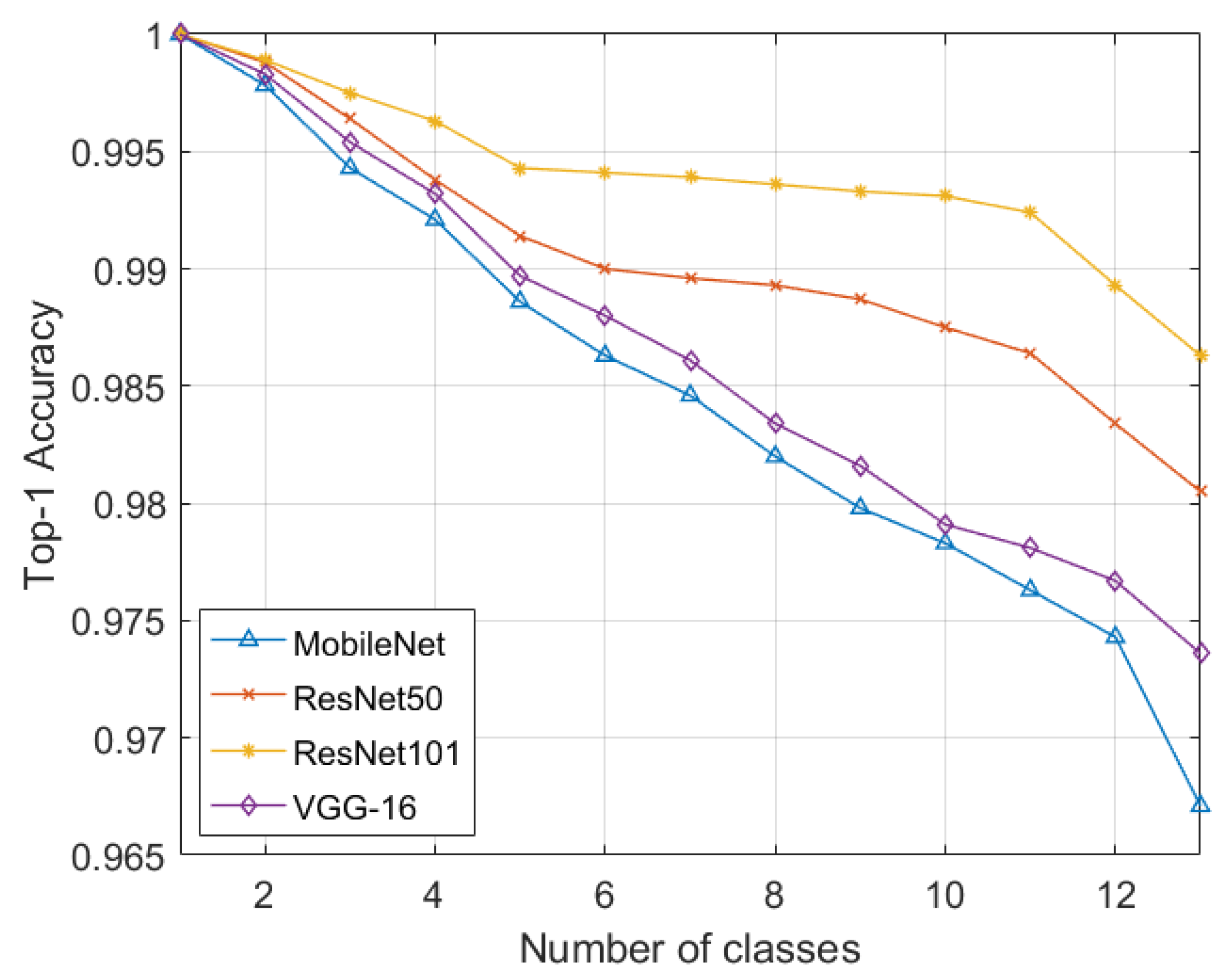
Apart from evaluating the proposed objective function individually on each dataset, we trained the deep learning models on the combined dataset with 13 classes, namely guns, knives, shurikens, razors, pliers, scissors, hammers, wrenches, normal, multiple items, pneumonia, AMD, and DME, where the proposed objective function was utilized in making the models effectively learn new classes for different tasks across different domains.
Table 10 shows the classification performance of the deep learning models encompassing the proposed objective function for effectively learning different classification tasks. It can be observed that with the ResNet101 model, the proposed objective was able to achieve the top-1 test accuracy of 0.9863, which lagged by the transfer learning approach with only a 0.0045% difference in terms of accuracy. It should be further noted that while achieving a comparable classification performance, the incremental learning scheme (powered by the proposed objective function) resulted in a 90.63% decrease in the dataset at one time in memory for training as compared to the transfer learning approach. Moreover,
Figure 5 further shows the incremental training performance of the deep learning models. We also compared the performance of the proposed loss function with the multi-category cross-entropy loss and KL divergence loss, as shown in
Table 11. All these loss functions were utilized during the incremental training, where the proposed continual incremental loss was able to produce 15.88% better results in terms of accuracy on the combined dataset as compared to the categorical cross entropy.
Apart from this, we also performed an intra-domain transferability analysis to further examine the generalization capacity of the deep learning models trained using our proposed objective function. It can be observed from
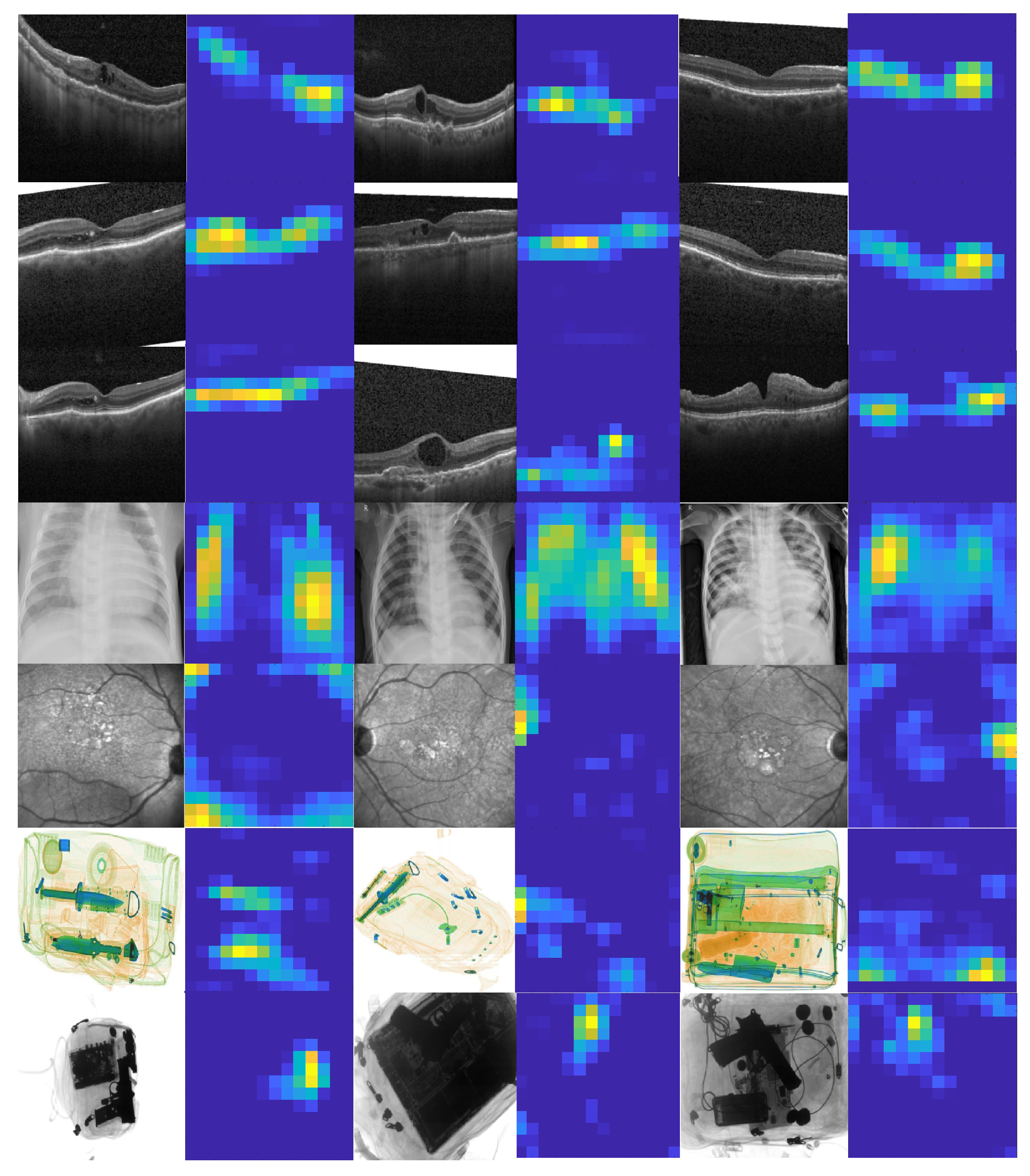
Table 12 that the incrementally trained models achieved good transferability performance for the retinal image datasets. However, for the SIXray and GDXray datasets, the performance was on the lower bounds. This is because of the significant variability in the image features (as, for instance, GDXray X-ray scans are grayscale in nature, whereas SIXray scans are colored). We did not include the Zhang chest X-ray dataset in this experiment since it was a single dataset for the pneumonia classification domain in the proposed study. Moreover, we did not evaluate inter-domain transferability since such experiment would be less valuable (e.g., it would not be meaningful if the model trained to identify suspicious baggage items predicts retinal diseases). In addition to this, we display the final probability maps of the random scans (from the nine publicly available datasets) in
Figure 6 to analyze how effectively the ResNet101 model (trained using the proposed objective function) interpreted them. It can be observed from
Figure 6 how robustly the ResNet101 model retained the important representations for the correct classifications irrespective of the scan type, scan modality, or scan acquisition machinery. Furthermore, it can be analyzed how well the learning was achieved over the totally unrelated tasks across different domains.
5.9. Ablation Study
The proposed study involved two ablative aspects, which are as follows.
5.9.1. Impact of Mutual Distillation Loss
The backbone of the proposed
is the mutual distillation loss
, which is minimized during the training of the deep learning. Mutual distillation loss is crucial for learning complex knowledge representations, which avoids catastrophic forgetting by understanding the complex relationships between old and new knowledge. We trained the ResNet101 model incrementally, and during the training, we excluded the mutual distillation loss to see its adverse effects. It can be observed from
Table 11 that on each dataset, there was a significant performance degradation if the complex dependencies between old and new knowledge (especially on the same dataset) were not analyzed.
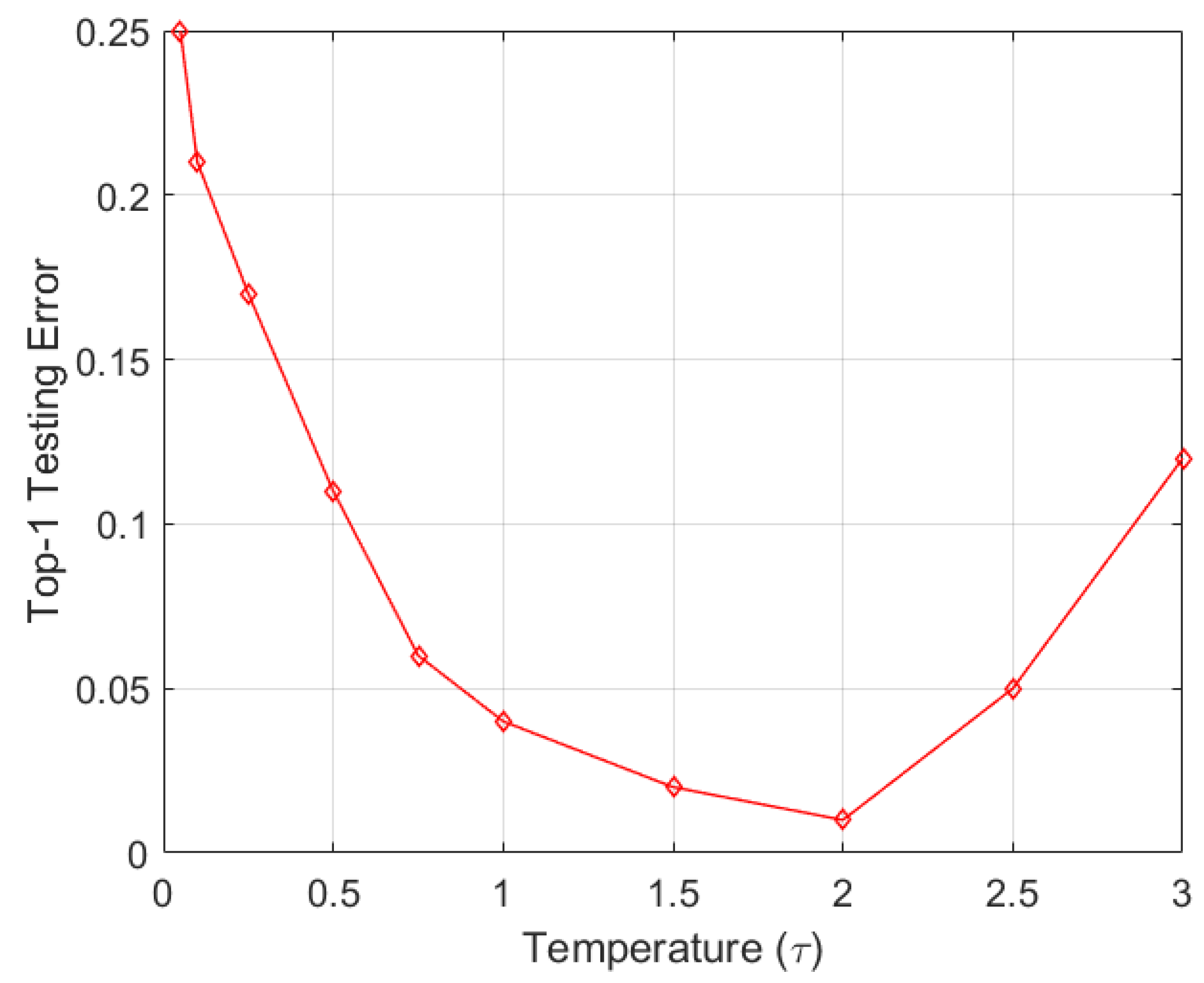
5.9.2. Dependency on Temperature
In order to have a trained model that retains its ability to keep its prior knowledge, soft probabilities are useful. They also greatly help in diversifying deep learning models to learn new representations. The second ablative aspect of the proposed study was to vary the temperature to see its effects on the overall learning. The temperature
was used to scale the values of a layer before the Softmax activation was applied to obtain probabilistic outputs from the model.
Figure 7 shows the experiment results for the ResNet101 model on the combined dataset, where we can observe that the best learning was achieved for
. It can be seen that scaling of the values should not be too lenient or too aggressive, which results in performance degradation. The temperature is, of course, dataset dependent and should be computed separately for each dataset empirically, as the values may differ. Here, we can analyze that a temperature ranging from 1.5–2 is ideal for effective learning on the combined dataset.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}