
TraceBERT—A Feasibility Study on Reconstructing Spatial–Temporal Gaps from Incomplete Motion Trajectories via BERT Training Process on Discrete Location Sequences



Abstract
:1. Introduction
2. Methodology
- Trajectory pre-processing, defining the procedure of transforming the original raw trajectory recordings, continuous in time and space, into discrete location sequences;
- Location masking, reporting how the space–time information gaps are artificially created by masking a portion of elements in the sequences;
- BERT model training, describing how the derived incomplete traces are processed by the deep learning model, allowing the system to learn the underlying semantics of user mobility patterns;
- Location gap inference, characterizing the evaluation phase as an automatic generation of location data in correspondence of missing trajectory segments, turning incomplete input traces into complete output sequences.
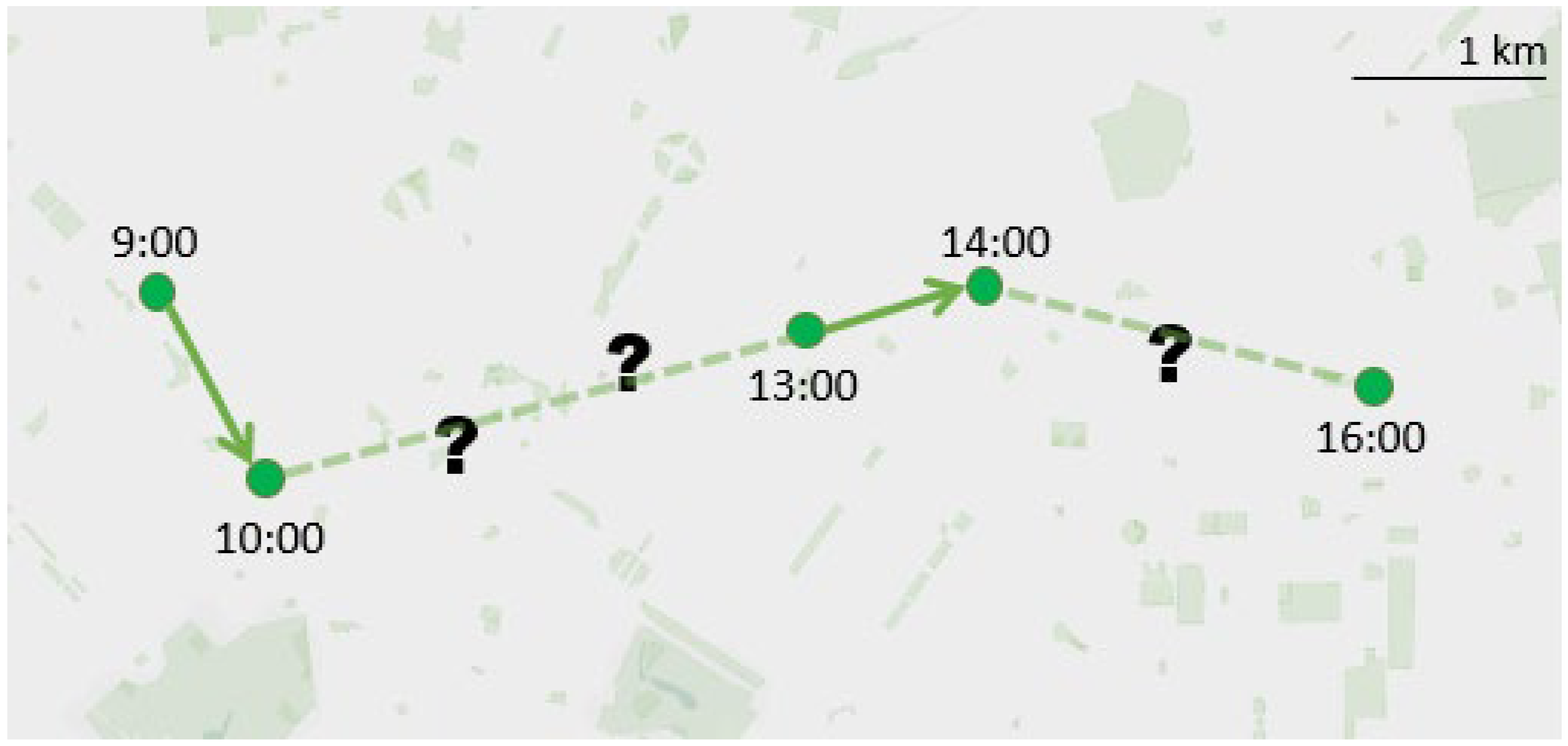
2.1. Trajectory Pre-Processing
2.2. Location Masking
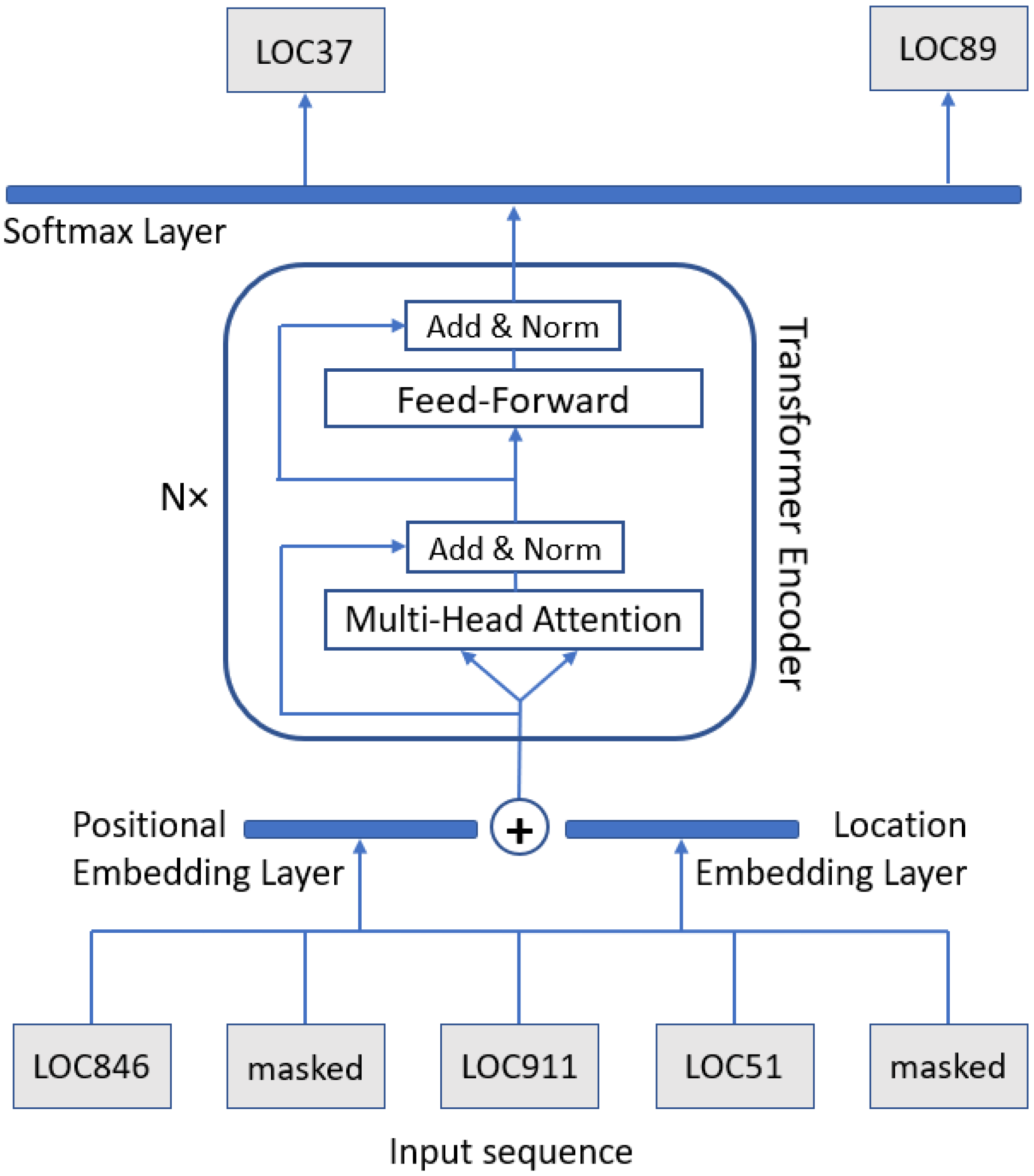
2.3. BERT Model Training
2.4. Location Gap Inference
3. Experiment
3.1. Dataset
3.2. Experimental Settings
- Personal Markov model (PMM). It focuses on separately modeling individual movement patterns. Locations are represented as states and movements between locations as state transitions. Transition probabilities are estimated by counting each single user’s transitions between unmasked locations, therefore building, for each individual user, a “personal” transition matrix. At inference time, masked locations are predicted as the ones sharing the highest transition probability, according to the user-specific transition matrix, with their neighboring unmasked locations along the sequence.
- Global Markov model (GMM). It focuses on modeling collective movement patterns. Probability distributions are estimated by counting the collective state transitions of all users together, generating one global transition matrix. At inference time, masked locations are predicted as the ones sharing the highest transition probability, according to the global transition matrix, with their neighboring unmasked locations along the sequence.
- Global location co-visits (GLC). It focuses on grouping locations that are often visited together within the same trajectory segment, investigating the general shared relatedness between co-visited places. The predicted location of a given trace in the test set is identified as the one sharing the highest number of co-visits with the known locations in the trace, according to the global motion behavior observed in the training set. The sequential order is not modeled; only the overall amount of inherent co-visits, within the whole segment’s time span, is taken into account to generate the prediction.
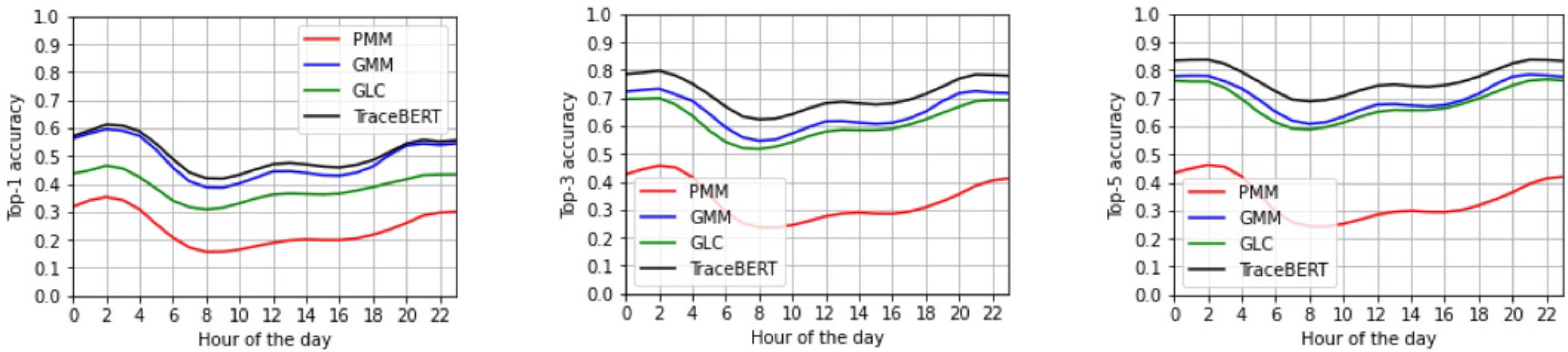
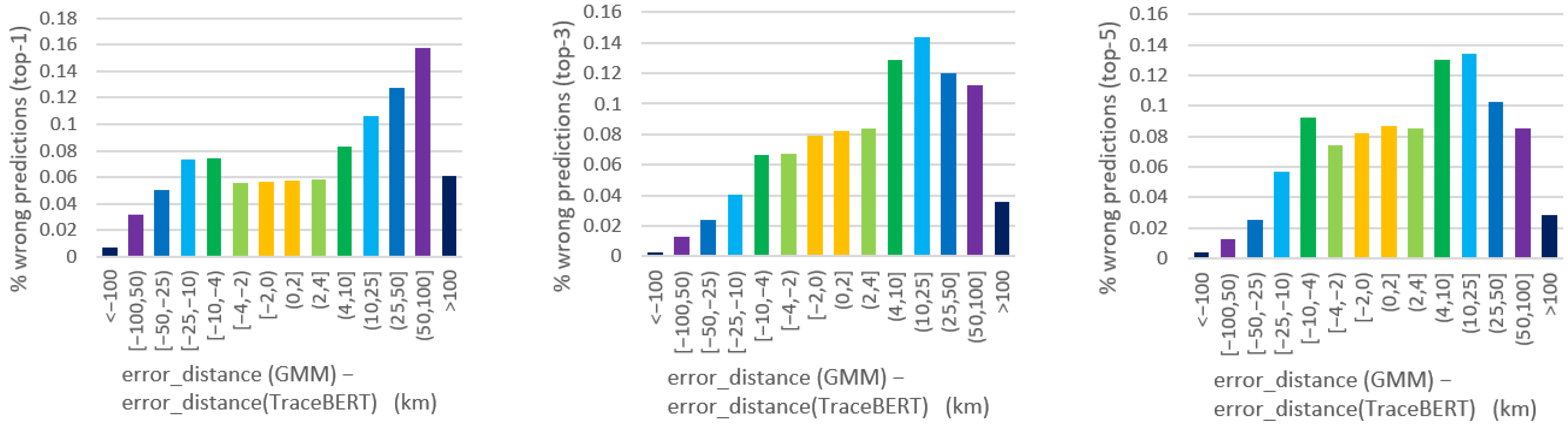
3.3. Results
3.4. Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gonzalez, M.C.; Hidalgo, C.A.; Barabasi, A.-L. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- Schneider, C.M.; Belik, V.; Couronné, T.; Smoreda, Z.; González, M.C. Unravelling daily human mobility motifs. J. R Soc. Interface 2013, 10, 20130246. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feng, Z.; Zhu, Y. A survey on trajectory data mining: Techniques and applications. IEEE Access 2016, 4, 2056–2067. [Google Scholar] [CrossRef]
- Jonietz, D.; Bucher, D. Continuous trajectory pattern mining for mobility behaviour change detection. In Proceedings of the LBS 2018: 14th International Conference on Location Based Services, Zurich, Switzerland, 15–17 January 2018; pp. 211–230. [Google Scholar]
- Mazimpaka, J.D.; Timpf, S. Trajectory data mining: A review of methods and applications. J. Spat. Inf. Sci. 2016, 2016, 61–99. [Google Scholar] [CrossRef]
- Zheng, Y. Trajectory data mining: An overview. ACM Trans. Intell. Syst. Technol. TIST 2015, 6, 1–41. [Google Scholar] [CrossRef]
- Bhargava, P.; Phan, T.; Zhou, J.; Lee, J. Who, what, when, and where: Multi-dimensional collaborative recommendations using tensor factorization on sparse user-generated data. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 130–140. [Google Scholar]
- Cheng, C.; Yang, H.; Lyu, M.R.; King, I. Where you like to go next: Successive point-of-interest recommendation. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Guo, Y.; Wang, S.; Zheng, L.; Lu, M. Trajectory Data Driven Transit-Transportation Planning. In Proceedings of the 2017 Fifth International Conference on Advanced Cloud and Big Data (CBD), Shanghai, China, 13–16 August 2017; pp. 380–384. [Google Scholar]
- Vander Laan, Z.; Franz, M.; Marković, N. Scalable Framework for Enhancing Raw GPS Trajectory Data: Application to Trip Analytics for Transportation Planning. J. Big Data Anal. Transp. 2021, 3, 119–139. [Google Scholar] [CrossRef]
- Enami, S.; Shiomoto, K. Spatio-temporal human mobility prediction based on trajectory data mining for resource management in mobile communication networks. In Proceedings of the 2019 IEEE 20th International Conference on High Performance Switching and Routing (HPSR), Xi’an, China, 26–29 May 2019; pp. 1–6. [Google Scholar]
- Yao, C.; Guo, J.; Yang, C. Achieving high throughput with predictive resource allocation. In Proceedings of the 2016 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Washington, DC, USA, 7–9 December 2016; pp. 768–772. [Google Scholar]
- Chen, M.; Liu, Y.; Yu, X. Nlpmm: A next location predictor with markov modeling. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Tainan, Taiwan, 13–16 May 2014; pp. 186–197. [Google Scholar]
- Cho, S.-B. Exploiting machine learning techniques for location recognition and prediction with smartphone logs. Neurocomputing 2016, 176, 98–106. [Google Scholar] [CrossRef]
- Lee, S.; Lim, J.; Park, J.; Kim, K. Next place prediction based on spatiotemporal pattern mining of mobile device logs. Sensors 2016, 16, 145. [Google Scholar] [CrossRef] [Green Version]
- Barlacchi, G.; Perentis, C.; Mehrotra, A.; Musolesi, M.; Lepri, B. Are you getting sick? Predicting influenza-like symptoms using human mobility behaviors. EPJ Data Sci. 2017, 6, 27. [Google Scholar] [CrossRef] [Green Version]
- Dabiri, S.; Heaslip, K. Inferring transportation modes from GPS trajectories using a convolutional neural network. Transp. Res. Part C Emerg. Technol. 2018, 86, 360–371. [Google Scholar] [CrossRef] [Green Version]
- Helbing, D.; Brockmann, D.; Chadefaux, T.; Donnay, K.; Blanke, U.; Woolley-Meza, O.; Moussaid, M.; Johansson, A.; Krause, J.; Schutte, S. Saving human lives: What complexity science and information systems can contribute. J. Stat. Phys. 2015, 158, 735–781. [Google Scholar] [CrossRef] [PubMed]
- Litman, T.; Colman, S.B. Generated traffic: Implications for transport planning. ITE J. 2001, 71, 38–46. [Google Scholar]
- Song, X.; Zhang, Q.; Sekimoto, Y.; Shibasaki, R. Prediction of human emergency behavior and their mobility following large-scale disaster. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 5–14. [Google Scholar]
- Gao, Q.-B.; Sun, S.-L. Trajectory-based human activity recognition using hidden conditional random fields. In Proceedings of the 2012 International Conference on Machine Learning and Cybernetics, Xi’an, China, 15–17 July 2012; pp. 1091–1097. [Google Scholar]
- Vail, D.L.; Veloso, M.M.; Lafferty, J.D. Conditional random fields for activity recognition. In Proceedings of the 6th International Joint Conference on Autonomous Agents and Multiagent Systems; Honolulu, HI, USA, 14–18 May 2007, pp. 1–8.
- Andrienko, G.; Andrienko, N.; Fuchs, G. Understanding movement data quality. J. Locat. Based Serv. 2016, 10, 31–46. [Google Scholar] [CrossRef]
- Graser, A. An exploratory data analysis protocol for identifying problems in continuous movement data. J. Locat. Based Serv. 2021, 15, 89–117. [Google Scholar] [CrossRef]
- Hwang, S.; VanDeMark, C.; Dhatt, N.; Yalla, S.V.; Crews, R.T. Segmenting human trajectory data by movement states while addressing signal loss and signal noise. Int. J. Geogr. Inf. Sci. 2018, 32, 1391–1412. [Google Scholar] [CrossRef] [Green Version]
- Iovan, C.; Olteanu-Raimond, A.-M.; Couronné, T.; Smoreda, Z. Moving and calling: Mobile phone data quality measurements and spatiotemporal uncertainty in human mobility studies. In Geographic Information Science at the Heart of Europe; Springer: Berlin/Heidelberg, Germany, 2013; pp. 247–265. [Google Scholar]
- Zhao, P.; Jonietz, D.; Raubal, M. Applying frequent-pattern mining and time geography to impute gaps in smartphone-based human-movement data. Int. J. Geogr. Inf. Sci. 2021, 35, 2187–2215. [Google Scholar] [CrossRef]
- Chen, G.; Hoteit, S.; Viana, A.C.; Fiore, M.; Sarraute, C. Enriching sparse mobility information in call detail records. Comput. Commun. 2018, 122, 44–58. [Google Scholar] [CrossRef] [Green Version]
- Meseck, K.; Jankowska, M.M.; Schipperijn, J.; Natarajan, L.; Godbole, S.; Carlson, J.; Takemoto, M.; Crist, K.; Kerr, J. Is missing geographic positioning system data in accelerometry studies a problem, and is imputation the solution? Geospat. Health 2016, 11, 403. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Song, T.; Kuang, R. Path segmentation for movement trajectories with irregular sampling frequency using space-time interpolation and density-based spatial clustering. Trans. GIS 2019, 23, 558–578. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Crivellari, A.; Beinat, E. From motion activity to geo-embeddings: Generating and exploring vector representations of locations, traces and visitors through large-scale mobility data. ISPRS Int. J. Geo-Inf. 2019, 8, 134. [Google Scholar] [CrossRef] [Green Version]
- Liu, K.; Gao, S.; Qiu, P.; Liu, X.; Yan, B.; Lu, F. Road2vec: Measuring traffic interactions in urban road system from massive travel routes. ISPRS Int. J. Geo-Inf. 2017, 6, 321. [Google Scholar] [CrossRef] [Green Version]
- Liu, K.; Yin, L.; Lu, F.; Mou, N. Visualizing and exploring POI configurations of urban regions on POI-type semantic space. Cities 2020, 99, 102610. [Google Scholar] [CrossRef]
- Yan, B.; Janowicz, K.; Mai, G.; Gao, S. From itdl to place2vec: Reasoning about place type similarity and relatedness by learning embeddings from augmented spatial contexts. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; pp. 1–10. [Google Scholar]
- Zhai, W.; Bai, X.; Shi, Y.; Han, Y.; Peng, Z.-R.; Gu, C. Beyond Word2vec: An approach for urban functional region extraction and identification by combining Place2vec and POIs. Comput. Environ. Urban Syst. 2019, 74, 1–12. [Google Scholar] [CrossRef]
- Crivellari, A.; Beinat, E. Trace2trace—A Feasibility Study on Neural Machine Translation Applied to Human Motion Trajectories. Sensors 2020, 20, 3503. [Google Scholar] [CrossRef]
- Li, F.; Gui, Z.; Zhang, Z.; Peng, D.; Tian, S.; Yuan, K.; Sun, Y.; Wu, H.; Gong, J.; Lei, Y. A hierarchical temporal attention-based LSTM encoder-decoder model for individual mobility prediction. Neurocomputing 2020, 403, 153–166. [Google Scholar] [CrossRef]
- Park, S.H.; Kim, B.; Kang, C.M.; Chung, C.C.; Choi, J.W. Sequence-to-Sequence Prediction of Vehicle Trajectory via LSTM Encoder-Decoder Architecture. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018; pp. 1672–1678. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Ashbrook, D.; Starner, T. Using GPS to learn significant locations and predict movement across multiple users. Pers. Ubiquitous Comput. 2003, 7, 275–286. [Google Scholar] [CrossRef]
- Feder, M.; Merhav, N.; Gutman, M. Universal prediction of individual sequences. IEEE Trans. Inf. Theory 1992, 38, 1258–1270. [Google Scholar] [CrossRef] [Green Version]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding with Unsupervised Learning; Technical Report; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the NAACL, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Cordonnier, J.; Loukas, A.; Jaggi, M. On the relationship between self-attention and convolutional layers. arXiv 2019, arXiv:1911.03584. [Google Scholar]
- Voita, E.; Talbot, D.; Moiseev, F.; Sennrich, R.; Titov, I. Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. arXiv 2019, arXiv:1905.09418. [Google Scholar]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- De Montjoye, Y.-A.; Quoidbach, J.; Robic, F.; Pentland, A. Predicting Personality Using Novel Mobile Phone-Based Metrics. In Proceedings of the International Conference on Social Computing, Behavioral-Cultural Modeling and Prediction, Washington, DC, USA, 2–5 April 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 48–55. [Google Scholar]
- Lu, X.; Bengtsson, L.; Holme, P. Predictability of population displacement after the 2010 Haiti earthquake. Proc. Natl. Acad. Sci. USA 2012, 109, 11576. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hawelka, B.; Sitko, I.; Kazakopoulos, P.; Beinat, E. Collective Prediction of Individual Mobility Traces for Users with Short Data History. PLoS ONE 2017, 12, e0170907. [Google Scholar] [CrossRef]
- Sundsøy, P.; Bjelland, J.; Reme, B.A.; Iqbal, A.M.; Jahani, E. Deep Learning Applied to Mobile Phone Data for Individual Income Classification. In Proceedings of the 2016 International Conference on Artificial Intelligence: Technologies and Applications, Bangkok, Thailand, 24–25 January 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Top-1 Accuracy | Top-3 Accuracy | Top-5 Accuracy | |
|---|---|---|---|
| PMM | 0.2050 | 0.2931 | 0.3012 |
| GMM | 0.4482 | 0.6198 | 0.6817 |
| GLC | 0.3658 | 0.5890 | 0.6613 |
| TraceBERT | 0.4745 | 0.6870 | 0.7492 |
| Traveled Distance = | ≤10 km | 10–25 km | 25–50 km | 50–100 km | ≥100 km |
|---|---|---|---|---|---|
| PMM | 0.4005 (0.5391) [0.5414] | 0.2644 (0.4027) [0.4153] | 0.1829 (0.2784) [0.2938] | 0.1321 (0.1931) [0.2040] | 0.0622 (0.0827) [0.0855] |
| GMM | 0.7039 (0.9227) [0.9582] | 0.5449 (0.7770) [0.8523] | 0.4458 (0.6273) [0.7143] | 0.3627 (0.5101) [0.5829] | 0.2237 (0.3191) [0.3686] |
| GLC | 0.5864 (0.9070) [0.9550] | 0.4642 (0.7648) [0.8559] | 0.3635 (0.6084) [0.7135] | 0.2903 (0.4791) [0.5659] | 0.1617 (0.2545) [0.3014] |
| TraceBERT | 0.7145 (0.9524) [0.9741] | 0.5604 (0.8441) [0.9069] | 0.4671 (0.7041) [0.7892] | 0.3916 (0.5792) [0.6586] | 0.2722 (0.4085) [0.4769] |
| ROG = | ≤3 km | 3–10 km | 10–32 km | ≥32 km |
|---|---|---|---|---|
| PMM | 0.3531 (0.5059) [0.5117] | 0.2190 (0.3279) [0.3428] | 0.1634 (0.2249) [0.2343] | 0.0705 (0.0908) [0.0931] |
| GMM | 0.6305 (0.8958) [0.9449] | 0.4885 (0.6709) [0.7598] | 0.4184 (0.5510) [0.6116] | 0.2401 (0.3347) [0.3823] |
| GLC | 0.5603 (0.8961) [0.9495] | 0.3981 (0.6649) [0.7722] | 0.3152 (0.4980) [0.5804] | 0.1709 (0.2637) [0.3099] |
| TraceBERT | 0.6509 (0.9360) [0.9679] | 0.4995 (0.7464) [0.8301] | 0.4430 (0.6139) [0.6810] | 0.2903 (0.4250) [0.4915] |
| # Masked Locations = | 1–2 Locations | 3–4 Locations | ≥5 Locations |
|---|---|---|---|
| PMM | 0.2732 (0.4043) [0.4201] | 0.1719 (0.2365) [0.2394] | 0.0370 0.0373 0.0374 |
| GMM | 0.4670 (0.6357) [0.6965] | 0.4426 (0.6155) [0.6778] | 0.3765 (0.5562) [0.6212] |
| GLC | 0.3691 (0.5977) [0.6722] | 0.3654 (0.5871) [0.6584] | 0.3495 (0.5505) [0.6166] |
| TraceBERT | 0.5017 (0.7177) [0.7789] | 0.4640 (0.6760) [0.7386] | 0.3875 (0.5830) [0.6471] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Crivellari, A.; Resch, B.; Shi, Y. TraceBERT—A Feasibility Study on Reconstructing Spatial–Temporal Gaps from Incomplete Motion Trajectories via BERT Training Process on Discrete Location Sequences. Sensors 2022, 22, 1682. https://doi.org/10.3390/s22041682
Crivellari A, Resch B, Shi Y. TraceBERT—A Feasibility Study on Reconstructing Spatial–Temporal Gaps from Incomplete Motion Trajectories via BERT Training Process on Discrete Location Sequences. Sensors. 2022; 22(4):1682. https://doi.org/10.3390/s22041682
Chicago/Turabian StyleCrivellari, Alessandro, Bernd Resch, and Yuhui Shi. 2022. "TraceBERT—A Feasibility Study on Reconstructing Spatial–Temporal Gaps from Incomplete Motion Trajectories via BERT Training Process on Discrete Location Sequences" Sensors 22, no. 4: 1682. https://doi.org/10.3390/s22041682
APA StyleCrivellari, A., Resch, B., & Shi, Y. (2022). TraceBERT—A Feasibility Study on Reconstructing Spatial–Temporal Gaps from Incomplete Motion Trajectories via BERT Training Process on Discrete Location Sequences. Sensors, 22(4), 1682. https://doi.org/10.3390/s22041682