
RUC-Net: A Residual-Unet-Based Convolutional Neural Network for Pixel-Level Pavement Crack Segmentation


Abstract
:1. Introduction
- We integrated the scSE attention mechanism in RUC-Net. This attention module correlated the global information of cracks, effectively improving the detection effect. In addition, we experimentally compared and investigated the difference of detection performance improvement by using various scSE attention module combinations in the encoder part (downsampling stage) and the decoder part (upsampling stage).
- We introduced the focal loss function, which could reduce the weight of easy-to-classify samples, to deal with the problem of class imbalance in crack segmentation.
2. Related Work
2.1. Convolutional Neural Network-Based Method
2.1.1. Classification
2.1.2. Object Detection
2.1.3. Pixel-Level Segmentation
2.2. Transformer-Based Method
3. Proposed Method
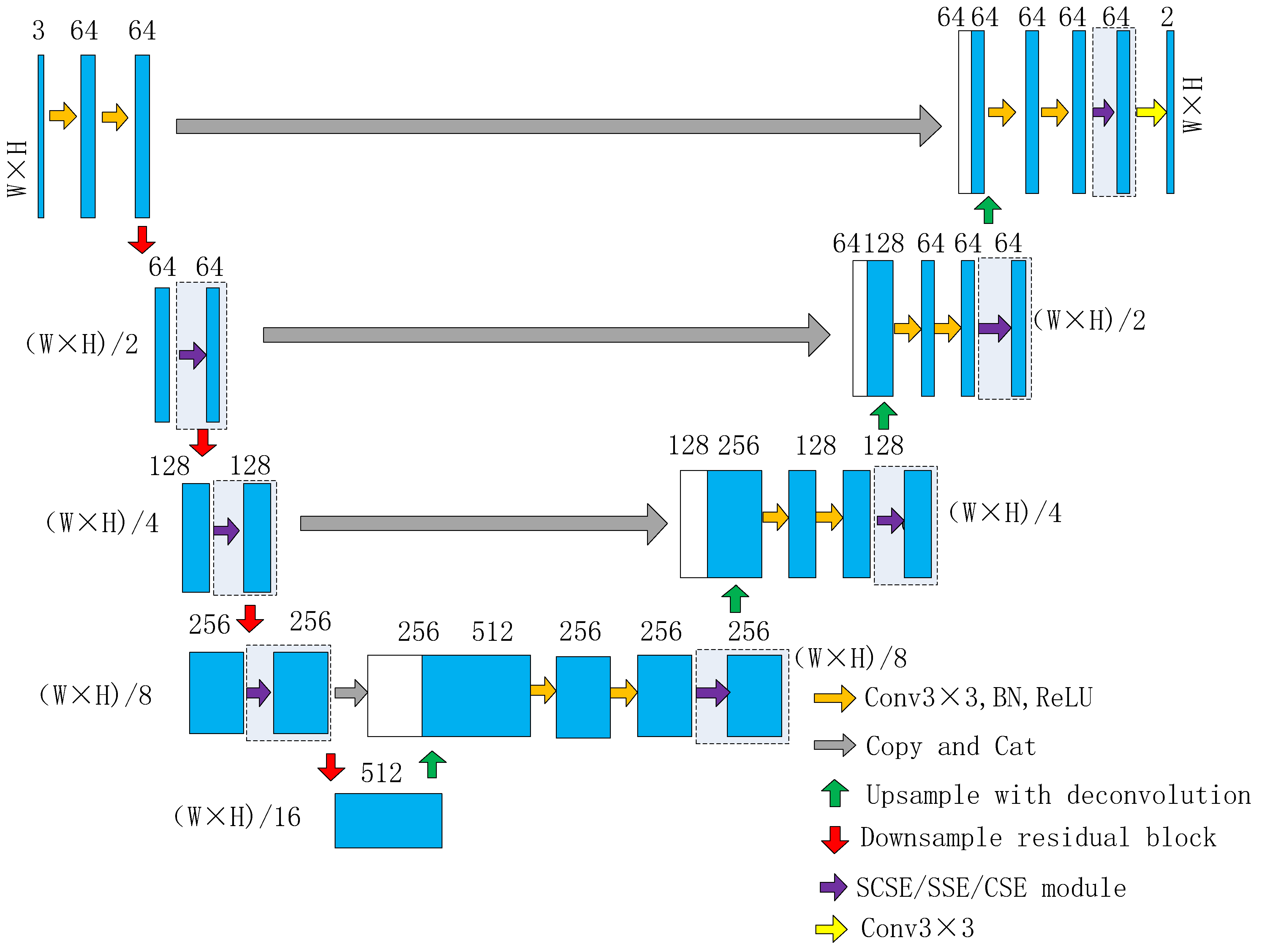
3.1. Network Architecture
- The 7 × 7 convolution layer and the max pool layer at the front part of Resnet18 were removed, and the two 3 × 3 convolution layers at the front part of Unet were retained to change the number of channels from three to 64.
- In the original Unet, after four downsamplings, the number of channels became 1024. In order to reduce the model parameters and computational complexity, unlike the original Unet, the final channel number of RUC-Net was 512 after four downsamplings. Therefore, the number of channels in the proposed network remained 64 after the first downsampling.
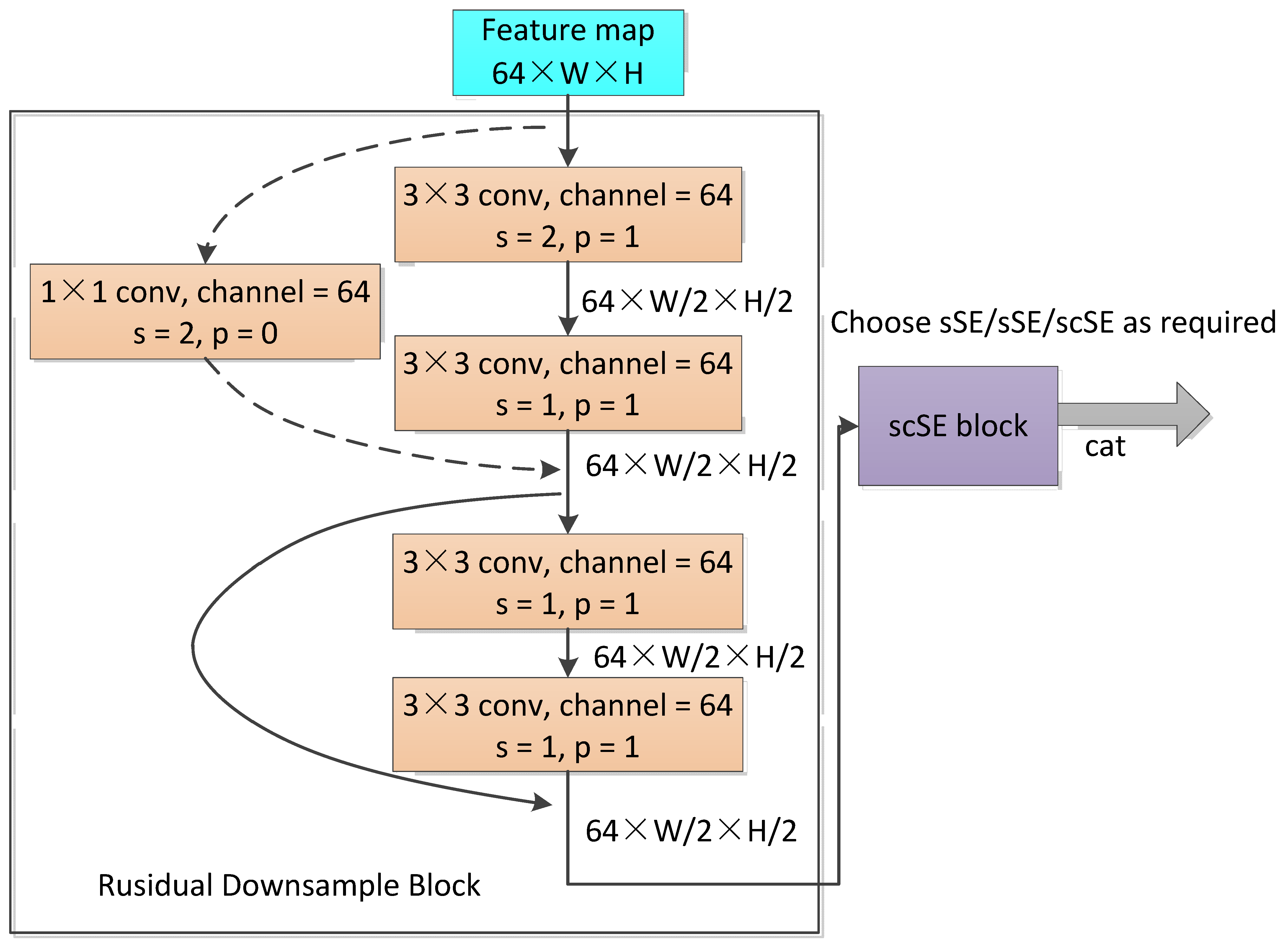
- The 2 × 2 max pooling layer, which was used for downsampling, and two 3 × 3 convolution layers of the original Unet network were replaced by the residual block, which is inspired by Resnet. As shown in Figure 2, each residual block contained two basic blocks. Each basic block contained two 3 × 3 convolutions and corresponding skip connections. In the first basic block, a 3 × 3 convolution with a stride of two was used for downsampling. A total of four residual blocks were used, and the last three residual blocks were equivalent to con3_x, con4_x, and con5_x in ResNet18. The first residual block, however, used 3 × 3 convolution with a stride of two for downsampling, which was different from conv2_x of the original ResNet18, which had no downsampling. After four times of downsampling, the resolution of the feature image changed to 1/16 of the original image.
3.2. scSE Module
- The sSE module. The original feature map was changed from [C, H, W] to [1, H, W] via a 1 × 1 convolution, then activated by a sigmoid to obtain the spatial attention map, which was applied to the original feature map to recalibrate the spatial information.
- The cSE module. The feature map was first changed from [C, H, W] to [C, 1, 1] by global average pooling, then converted to a C-dimension vector after twice performing 1 × 1 convolution operations. This vector was normalized by a sigmoid and was channelwise multiplied with the original feature map to obtain a feature map recalibrated by channel information.
- The scSE module. The scSE was the combination of the sSE and cSE modules, which was essentially the parallel connection of the two modules. Specifically, after the feature map was operated through the sSE and cSE modules, we added up the two outputs to recalibrate the feature map both spatially and channelwise.
3.3. Loss Function
3.4. Parameter Optimization
4. Experiment Result and Discussion
4.1. Implementation Details
4.2. Datasets
4.3. Evaluation Criteria
4.4. Experiment Results and Discussion
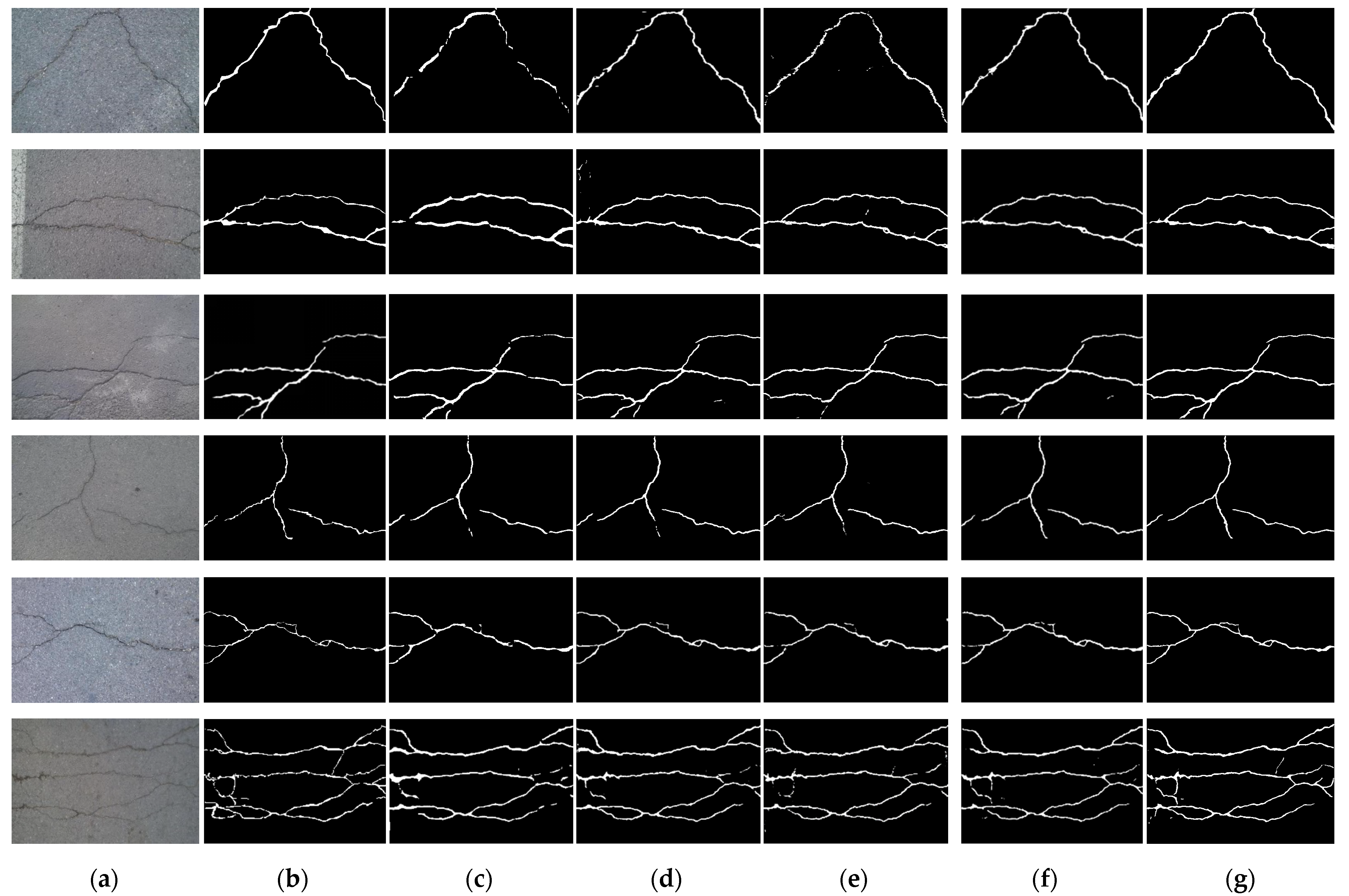
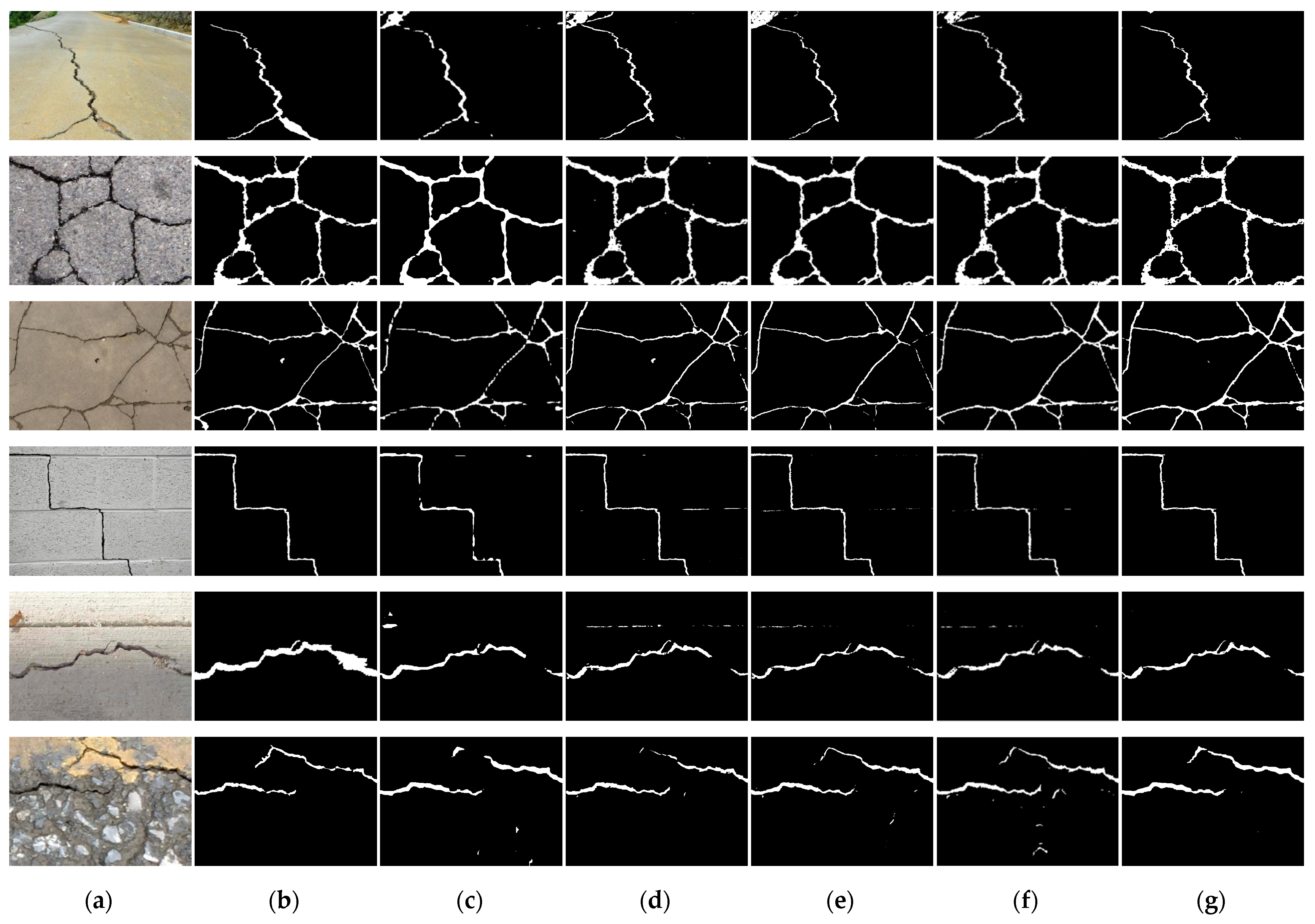
4.4.1. Results Using the CFD Dataset
4.4.2. Results Using the Crack500 Dataset
4.4.3. Results for the DeepCrack Dataset
5. Ablation Studies
5.1. Effect of Various scSE Modules and Their Combinations on Improving Detection Performance
5.2. Comparison of Various Parameters of the Focal Loss Function
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zakeri, H.; Nejad, F.M.; Fahimifar, A. Image Based Techniques for Crack Detection, Classification and Quantification in Asphalt Pavement: A Review. Arch. Comput. Methods Eng. 2017, 24, 935–977. [Google Scholar] [CrossRef]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A Deep Hierarchical Feature Learning Architecture for Crack Segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Fan, Z.; Wu, Y.; Lu, J.; Li, W. Automatic Pavement Crack Detection Based on Structured Prediction with the Convolutional Neural Network. arXiv 2018, arXiv:1802.02208. [Google Scholar]
- Oliveira, H.; Correia, P.L. Automatic Road Crack Segmentation Using Entropy and Image Dynamic Thresholding. In Proceedings of the 2009 17th European Signal Processing Conference, Glasgow, UK, 24–28 August 2009; pp. 622–626. [Google Scholar] [CrossRef]
- Li, P.; Wang, C.; Li, S.; Feng, B. Research on Crack Detection Method of Airport Runway Based on Twice-Threshold Segmentation. In Proceedings of the 5th International Conference on Instrumentation and Measurement, Computer, Communication and Control (IMCCC), Qinhuangdao, China, 18–20 September 2015; pp. 1716–1720. [Google Scholar] [CrossRef]
- Tsai, Y.C.; Kaul, V.; Mersereau, R.M. Critical Assessment of Pavement Distress Segmentation Methods. J. Transp. Eng. 2010, 136, 11–19. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Abudayyeh, O.; Kelly, M.E. Analysis of Edge-Detection Techniques for Crack Identification in Bridges. J. Comput. Civ. Eng. 2003, 17, 255–263. [Google Scholar] [CrossRef] [Green Version]
- Santhi, B.; Krishnamurthy, G.; Siddharth, S.; Ramakrishnan, P.K. Automatic Detection of Cracks in Pavements Using Edge Detection Operator. J. Theor. Appl. Inf. Technol. 2012, 36, 199–205. [Google Scholar]
- Nisanth, A.; Mathew, A. Automated Visual Inspection of Pavement Crack Detection and Characterization. Int. J. Technol. Eng. Syst. 2014, 6, 14–20. [Google Scholar]
- Yeum, C.M.; Dyke, S.J. Vision-Based Automated Crack Detection for Bridge Inspection. Comput. Civ. Infrastruct. Eng. 2015, 30, 759–770. [Google Scholar] [CrossRef]
- Cheng, H.D.; Chen, J.R.; Glazier, C.; Hu, Y.G. Novel Approach to Pavement Cracking Detection Based on Fuzzy Set Theory. J. Comput. Civ. Eng. 1999, 13, 270–280. [Google Scholar] [CrossRef]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic Pixel-Level Crack Detection and Measurement Using Fully Convolutional Network. Comput. Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Zhou, J. Wavelet-Based Pavement Distress Detection and Evaluation. Opt. Eng. 2006, 45, 027007. [Google Scholar] [CrossRef]
- Wu, S.; Liu, Y. A Segment Algorithm for Crack Dection. In Proceedings of the 2012 IEEE Symposium on Electrical & Electronics Engineering (EEESYM), Kuala Lumpur, Malaysia, 24–27 June 2012; pp. 674–677. [Google Scholar] [CrossRef]
- Nguyen, T.S.; Begot, S.; Duculty, F.; Avila, M. Free-Form Anisotropy: A New Method for Crack Detection on Pavement Surface Images. In Proceedings of the IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011. [Google Scholar]
- Amhaz, R.; Chambon, S.; Idier, J.; Baltazart, V. Automatic Crack Detection on Two-Dimensional Pavement Images: An Algorithm Based on Minimal Path Selection. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2718–2729. [Google Scholar] [CrossRef] [Green Version]
- Zou, Q.; Zhang, Z.; Li, Q.; Qi, X.; Wang, Q.; Wang, S. DeepCrack: Learning Hierarchical Convolutional Features for Crack Detection. IEEE Trans. Image Process. 2019, 28, 1498–1512. [Google Scholar] [CrossRef] [PubMed]
- Lee, B.J.; Lee, H.D. Position-Invariant Neural Network for Digital Pavement Crack Analysis. Comput. Civ. Infrastruct. Eng. 2004, 19, 105–118. [Google Scholar] [CrossRef]
- Moon, H.G.; Kim, J.H. Inteligent Crack Detecting Algorithm on the Concrete Crack Image Using Neural Network. In Proceedings of the 28th International Symposium on Automation and Robotics in Construction (ISARC), Seoul, Republic of Korea, 29 June–2 July 2011; pp. 1461–1467. [Google Scholar] [CrossRef] [Green Version]
- Gavilán, M.; Balcones, D.; Marcos, O.; Llorca, D.F.; Sotelo, M.A.; Parra, I.; Ocaña, M.; Aliseda, P.; Yarza, P.; Amírola, A. Adaptive Road Crack Detection System by Pavement Classification. Sensors 2011, 11, 9628–9657. [Google Scholar] [CrossRef]
- O’Byrne, M.; Schoefs, F.; Ghosh, B.; Pakrashi, V. Texture Analysis Based Damage Detection of Ageing Infrastructural Elements. Comput. Civ. Infrastruct. Eng. 2013, 28, 162–177. [Google Scholar] [CrossRef] [Green Version]
- Cha, Y.J.; You, K.; Choi, W. Vision-Based Detection of Loosened Bolts Using the Hough Transform and Support Vector Machines. Autom. Constr. 2016, 71, 181–188. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Cord, A.; Chambon, S. Automatic Road Defect Detection by Textural Pattern Recognition Based on AdaBoost. Comput. Civ. Infrastruct. Eng. 2012, 27, 244–259. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.B. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef] [PubMed]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Alipour, M.; Harris, D.K.; Miller, G.R. Robust Pixel-Level Crack Detection Using Deep Fully Convolutional Neural Networks. J. Comput. Civ. Eng. 2019, 33, 04019040. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Roy, A.G.; Navab, N.; Wachinger, C. Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks. arXiv 2018, arXiv:1803.02579v2. [Google Scholar]
- Qiao, W.; Liu, Q.; Wu, X.; Ma, B.; Li, G. Automatic Pixel-Level Pavement Crack Recognition Using a Deep Feature Aggregation Segmentation Network with a Scse Attention Mechanism Module. Sensors 2021, 21, 2902. [Google Scholar] [CrossRef]
- Cao, W.; Liu, Q.; He, Z. Review of Pavement Defect Detection Methods. IEEE Access 2020, 8, 14531–14544. [Google Scholar] [CrossRef]
- Ma, K.; Hoai, M.; Samaras, D. Large-Scale Continual Road Inspection: Visual Infrastructure Assessment in the Wild. In Proceedings of the British Machine Vision Conference 2017 (BMVC), London, UK, 4–7 September 2017. [Google Scholar] [CrossRef] [Green Version]
- Gopalakrishnan, K.; Khaitan, S.K.; Choudhary, A.; Agrawal, A. Deep Convolutional Neural Networks with Transfer Learning for Computer Vision-Based Data-Driven Pavement Distress Detection. Constr. Build. Mater. 2017, 157, 322–330. [Google Scholar] [CrossRef]
- Xu, H.; Su, X.; Xu, H.; Li, H. Autonomous Bridge Crack Detection Using Deep Convolutional Neural Networks. In Proceedings of the 3rd International Conference on Computer Engineering, Information Science & Application Technology, Chongqing, China, 30–31 May 2019. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Yang, F.; Daniel Zhang, Y.; Zhu, Y.J. Road Crack Detection Using Deep Convolutional Neural Network. In Proceedings of the International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar] [CrossRef]
- Pauly, L.; Peel, H.; Luo, S.; Hogg, D.; Fuentes, R. Deeper Networks for Pavement Crack Detection. In Proceedings of the 34th International Symposium on Automation and Robotics in Construction and Mining (ISARC), Taipei, Taiwan, 28 June–1 July 2017; pp. 479–485. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, N.T.H.; Le, T.H.; Perry, S.; Nguyen, T.T. Pavement Crack Detection Using Convolutional Neural Network. ACM Int. Conf. Proceeding Ser. 2018, 251–256. [Google Scholar] [CrossRef]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How Transferable Are Features in Deep Neural Networks? In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 3320–3328. [Google Scholar]
- Eisenbach, M.; Stricker, R.; Seichter, D.; Amende, K.; Debes, K.; Sesselmann, M.; Ebersbach, D.; Stoeckert, U.; Gross, H.M. How to Get Pavement Distress Detection Ready for Deep Learning? A Systematic Approach. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2039–2047. [Google Scholar] [CrossRef]
- Cha, Y.J.; Choi, W.; Büyüköztürk, O. Deep Learning-Based Crack Damage Detection Using Convolutional Neural Networks. Comput. Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Nie, M.; Wang, K. Pavement Distress Detection Based on Transfer Learning. In Proceedings of the 2018 5th International Conference on Systems and Informatics (ICSAI), Nanjing, China, 10–12 November 2018; pp. 435–439. [Google Scholar]
- Cha, Y.J.; Choi, W.; Suh, G.; Mahmoudkhani, S.; Büyüköztürk, O. Autonomous Structural Visual Inspection Using Region-Based Deep Learning for Detecting Multiple Damage Types. Comput. Civ. Infrastruct. Eng. 2018, 33, 731–747. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images. Comput. Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef] [Green Version]
- Mandal, V.; Uong, L.; Adu-gyamfi, Y. Automated Road Crack Detection Using Deep Convolutional Neural Networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5212–5215. [Google Scholar] [CrossRef]
- Hu, G.X.; Hu, B.L.; Yang, Z.; Huang, L.; Li, P. Pavement Crack Detection Method Based on Deep Learning Models. Wirel. Commun. Mob. Comput. 2021, 2021, 1–13. [Google Scholar] [CrossRef]
- Hsieh, Y.-A.; Tsai, Y.J. Machine Learning for Crack Detection: Review and Model Performance Comparison. J. Comput. Civ. Eng. 2020, 34, 04020038. [Google Scholar] [CrossRef]
- Huyan, J.; Li, W.; Tighe, S.; Xu, Z.; Zhai, J. CrackU-Net: A Novel Deep Convolutional Neural Network for Pixelwise Pavement Crack Detection. Struct. Control Health Monit. 2020, 27, e2551. [Google Scholar] [CrossRef]
- Zhang, A.; Wang, K.C.P.; Li, B.; Yang, E.; Dai, X.; Peng, Y.; Fei, Y.; Liu, Y.; Li, J.Q.; Chen, C. Automated Pixel-Level Pavement Crack Detection on 3D Asphalt Surfaces Using a Deep-Learning Network. Comput. Civ. Infrastruct. Eng. 2017, 32, 805–819. [Google Scholar] [CrossRef]
- Fei, Y.; Wang, K.C.P.; Zhang, A.; Chen, C.; Li, J.Q.; Liu, Y.; Yang, G.; Li, B. Pixel-Level Cracking Detection on 3D Asphalt Pavement Images through Deep-Learning- Based CrackNet-V. IEEE Trans. Intell. Transp. Syst. 2020, 21, 273–284. [Google Scholar] [CrossRef]
- Huang, H.-W.; Li, Q.-T.; Zhang, D.-M. Deep Learning Based Image Recognition for Crack and Leakage Defects of Metro Shield Tunnel. Tunn. Undergr. Sp. Technol. 2018, 77, 166–176. [Google Scholar] [CrossRef]
- Li, S.; Zhao, X.; Zhou, G. Automatic Pixel-Level Multiple Damage Detection of Concrete Structure Using Fully Convolutional Network. Comput. Civ. Infrastruct. Eng. 2019, 34, 616–634. [Google Scholar] [CrossRef]
- Cheng, J.; Xiong, W.; Chen, W.; Gu, Y.; Li, Y. Pixel-Level Crack Detection Using U-Net. In Proceedings of the IEEE Region 10 Annual International Conference TENCON 2019, Jeju, Republic of Korea, 28–21 October 2018; pp. 462–466. [Google Scholar] [CrossRef]
- Jenkins, M.D.; Carr, T.A.; Iglesias, M.I.; Buggy, T.; Morison, G. A Deep Convolutional Neural Network for Semantic Pixel-Wise Segmentation of Road and Pavement Surface Cracks. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 2120–2124. [Google Scholar] [CrossRef] [Green Version]
- Lau, S.L.H.; Chong, E.K.P.; Yang, X.; Wang, X. Automated Pavement Crack Segmentation Using U-Net-Based Convolutional Neural Network. IEEE Access 2020, 8, 114892–114899. [Google Scholar] [CrossRef]
- Bang, S.; Park, S.; Kim, H.; Kim, H. Encoder–Decoder Network for Pixel-Level Road Crack Detection in Black-Box Images. Comput. Civ. Infrastruct. Eng. 2019, 34, 713–727. [Google Scholar] [CrossRef]
- Yang, F.; Zhang, L.; Yu, S.; Prokhorov, D.; Mei, X.; Ling, H. Feature Pyramid and Hierarchical Boosting Network for Pavement Crack Detection. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1525–1535. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6877–6886. [Google Scholar] [CrossRef]
- Ju, X.; Zhao, X.; Qian, S. TransMF: Transformer-Based Multi-Scale Fusion Model for Crack Detection. Mathematics 2022, 10, 2354. [Google Scholar] [CrossRef]
- Qu, Z.; Li, Y.; Zhou, Q. CrackT-Net: A Method of Convolutional Neural Network and Transformer for Crack Segmentation. J. Electron. Imaging 2022, 31, 023040. [Google Scholar] [CrossRef]
- Wang, W.; Su, C. Automatic Concrete Crack Segmentation Model Based on Transformer. Autom. Constr. 2022, 139, 104275. [Google Scholar] [CrossRef]
- Liu, H.; Miao, X.; Mertz, C.; Xu, C.; Kong, H. CrackFormer: Transformer Network for Fine-Grained Crack Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3763–3772. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted | Crack | No Crack | |
|---|---|---|---|
| Ground Truth | |||
| Crack | True positive (TP) | False negative (FN) | |
| No crack | False positive (FP) | True negative (TN) | |
| Methods | Pr | Re | F1 | IoU |
|---|---|---|---|---|
| FCN | 0.6659 | 0.7483 | 0.7047 | 0.5441 |
| SegNet | 0.6799 | 0.7492 | 0.7129 | 0.5539 |
| Unet | 0.7008 | 0.7496 | 0.7244 | 0.5679 |
| TransUnet | 0.7058 | 0.7559 | 0.7300 | 0.5748 |
| Ours | 0.7125 | 0.7680 | 0.7392 | 0.5863 |
| Methods | Pr | Re | F1 | IoU |
|---|---|---|---|---|
| FCN | 0.6830 | 0.7206 | 0.7013 | 0.5400 |
| SegNet | 0.6893 | 0.7303 | 0.7092 | 0.5494 |
| Unet | 0.6852 | 0.7541 | 0.7180 | 0.5600 |
| TransUnet | 0.7025 | 0.7424 | 0.7219 | 0.5648 |
| Ours | 0.6988 | 0.7619 | 0.7290 | 0.5736 |
| Methods | Pr | Re | F1 | IoU |
|---|---|---|---|---|
| FCN | 0.8600 | 0.7737 | 0.8146 | 0.6871 |
| SegNet | 0.8632 | 0.7954 | 0.8279 | 0.7064 |
| Unet | 0.8810 | 0.7829 | 0.8291 | 0.7080 |
| TransUnet | 0.8730 | 0.7976 | 0.8336 | 0.7147 |
| Ours | 0.8833 | 0.8120 | 0.8461 | 0.7333 |
| Methods | Pr | Re | F1 | IoU |
|---|---|---|---|---|
| RUC-Net | 0.7136 | 0.7633 | 0.7375 | 0.5842 |
| RUC-Net+downcSE * | 0.7055 | 0.7596 | 0.7315 | 0.5767 |
| RUC-Net+downsSE | 0.7092 | 0.7699 | 0.7383 | 0.5851 |
| RUC-Net+upsSE | 0.7135 | 0.7643 | 0.7381 | 0.5849 |
| RUC-Net+upcSE | 0.7122 | 0.7676 | 0.7388 | 0.5858 |
| RUC-Net+downscSE | 0.7099 | 0.7691 | 0.7383 | 0.5852 |
| RUC-Net+upscSE | 0.7160 | 0.7657 | 0.7398 | 0.5871 |
| RUC-Net+fullscSE | 0.7064 | 0.7758 | 0.7395 | 0.5866 |
| Parameter Combination | Pr | Re | F1 | IoU | |
|---|---|---|---|---|---|
| γ | α | ||||
| 1.5 | 0.5 | 0.7353 | 0.7347 | 0.7349 | 0.5809 |
| 0.6 | 0.7160 | 0.7657 | 0.7398 | 0.5871 | |
| 0.7 | 0.7017 | 0.7747 | 0.7359 | 0.5822 | |
| 0.8 | 0.6704 | 0.8058 | 0.7318 | 0.5770 | |
| 2 | 0.5 | 0.7347 | 0.7289 | 0.7316 | 0.5768 |
| 0.6 | 0.7027 | 0.7776 | 0.7381 | 0.5850 | |
| 0.7 | 0.6840 | 0.7987 | 0.7369 | 0.5834 | |
| 0.8 | 0.6697 | 0.7999 | 0.7284 | 0.5729 | |
| 2.5 | 0.5 | 0.7337 | 0.7293 | 0.7315 | 0.5767 |
| 0.6 | 0.7062 | 0.7748 | 0.7389 | 0.5859 | |
| 0.7 | 0.6867 | 0.7924 | 0.7369 | 0.5834 | |
| 0.8 | 0.6805 | 0.7825 | 0.7279 | 0.5722 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, G.; Dong, J.; Wang, Y.; Zhou, X. RUC-Net: A Residual-Unet-Based Convolutional Neural Network for Pixel-Level Pavement Crack Segmentation. Sensors 2023, 23, 53. https://doi.org/10.3390/s23010053
Yu G, Dong J, Wang Y, Zhou X. RUC-Net: A Residual-Unet-Based Convolutional Neural Network for Pixel-Level Pavement Crack Segmentation. Sensors. 2023; 23(1):53. https://doi.org/10.3390/s23010053
Chicago/Turabian StyleYu, Gui, Juming Dong, Yihang Wang, and Xinglin Zhou. 2023. "RUC-Net: A Residual-Unet-Based Convolutional Neural Network for Pixel-Level Pavement Crack Segmentation" Sensors 23, no. 1: 53. https://doi.org/10.3390/s23010053
APA StyleYu, G., Dong, J., Wang, Y., & Zhou, X. (2023). RUC-Net: A Residual-Unet-Based Convolutional Neural Network for Pixel-Level Pavement Crack Segmentation. Sensors, 23(1), 53. https://doi.org/10.3390/s23010053