
Reinforcement-Learning-Based Robust Resource Management for Multi-Radio Systems



Abstract
:1. Introduction
2. Methodology
2.1. Multi-Radio Environment Model
2.2. Multi-Objective Reinforcement Learning
2.3. Simulation Environment and Analytical Framework
3. The Proposed Solution
3.1. State and Action Spaces
3.2. Reward-Function Design
- Positive rewards are only given for actions that result in a successful link between MN and SN.
- In the event that no link can be established on any transceiver, the agent should choose not to transmit.
3.2.1. Objective 1. Maximised Bit Rate
3.2.2. Objective 2. Minimised Power Consumption
3.3. WAMO-SARSA Algorithm with Adaptive Exploration
| Algorithm 1: Weighted Adaptive Multi-Objective SARSA (WAMO-SARSA). |
 |
4. Results
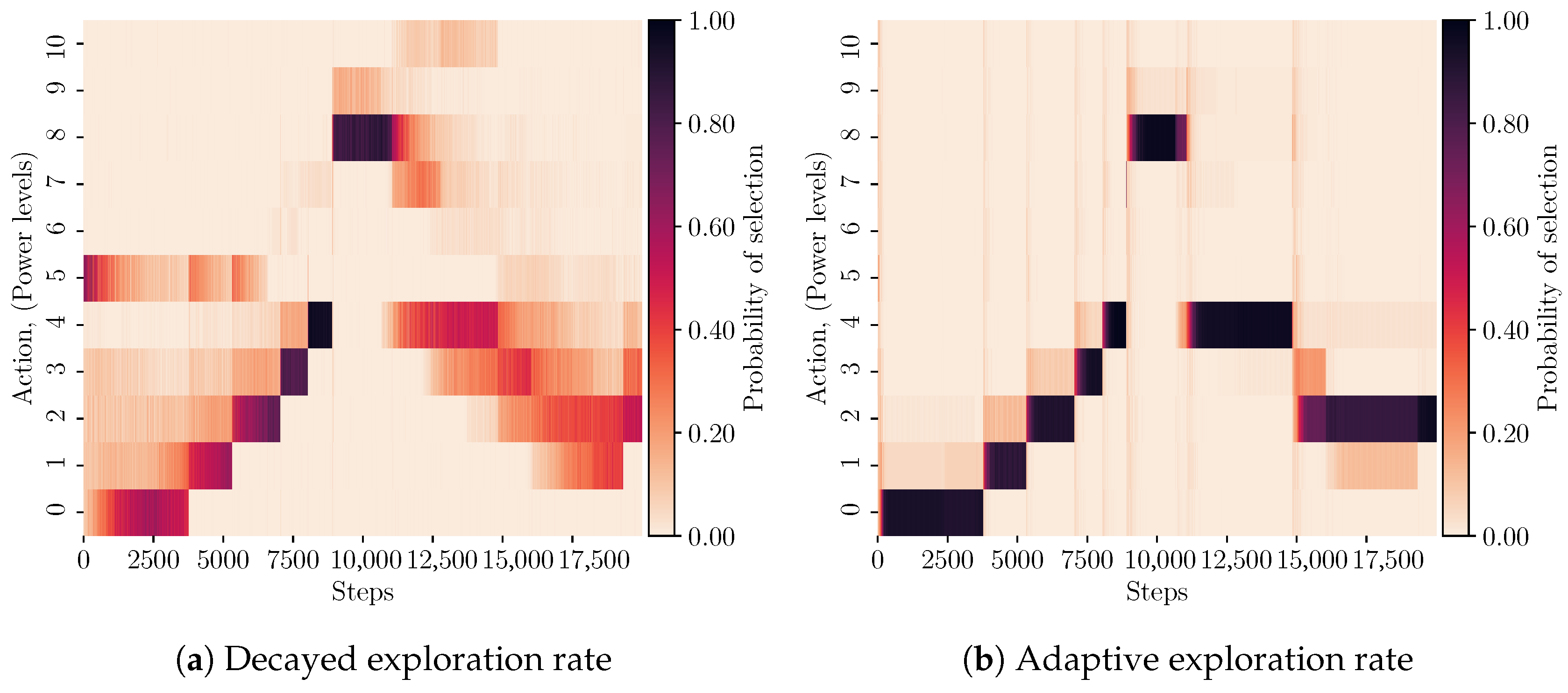
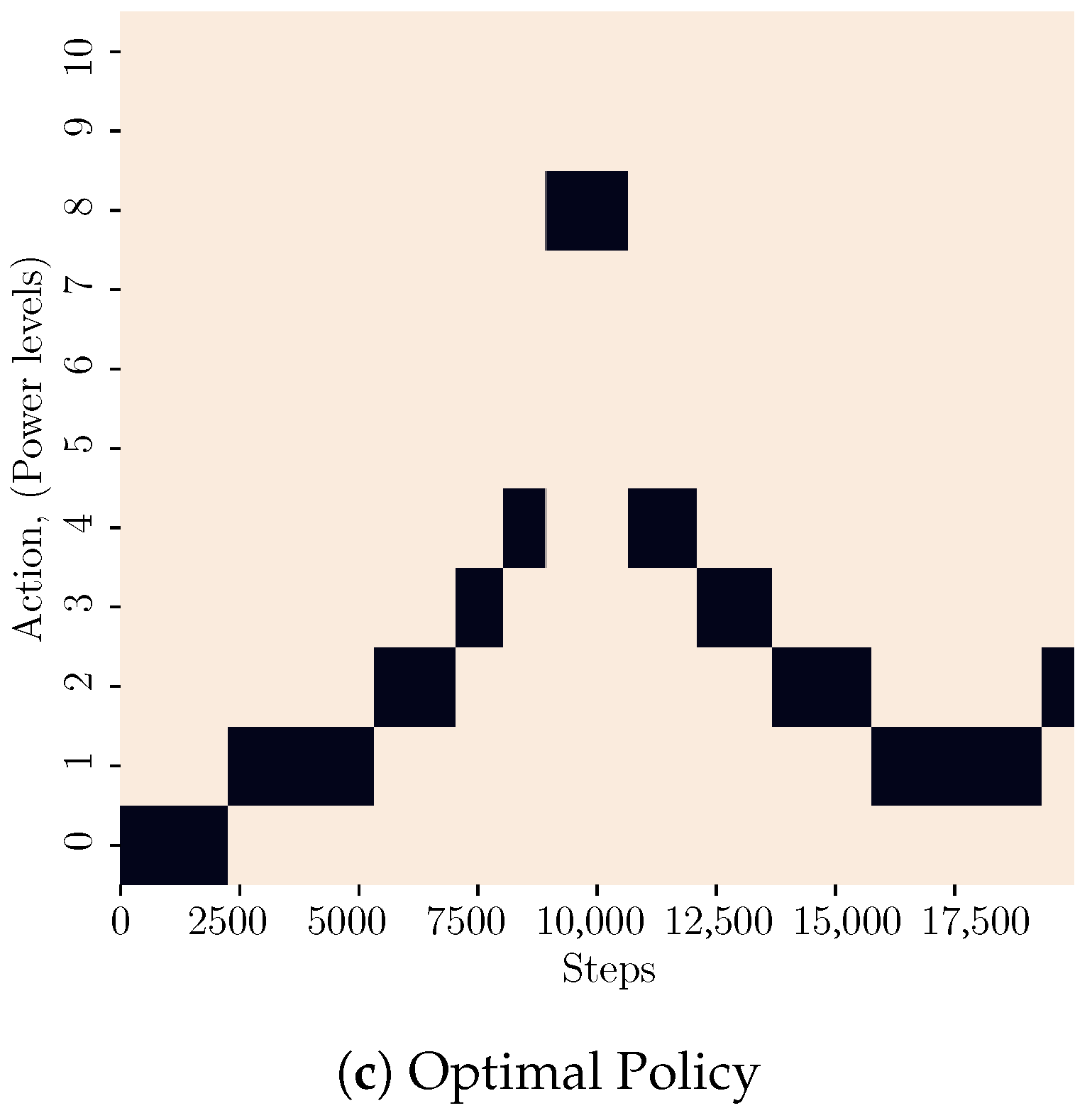
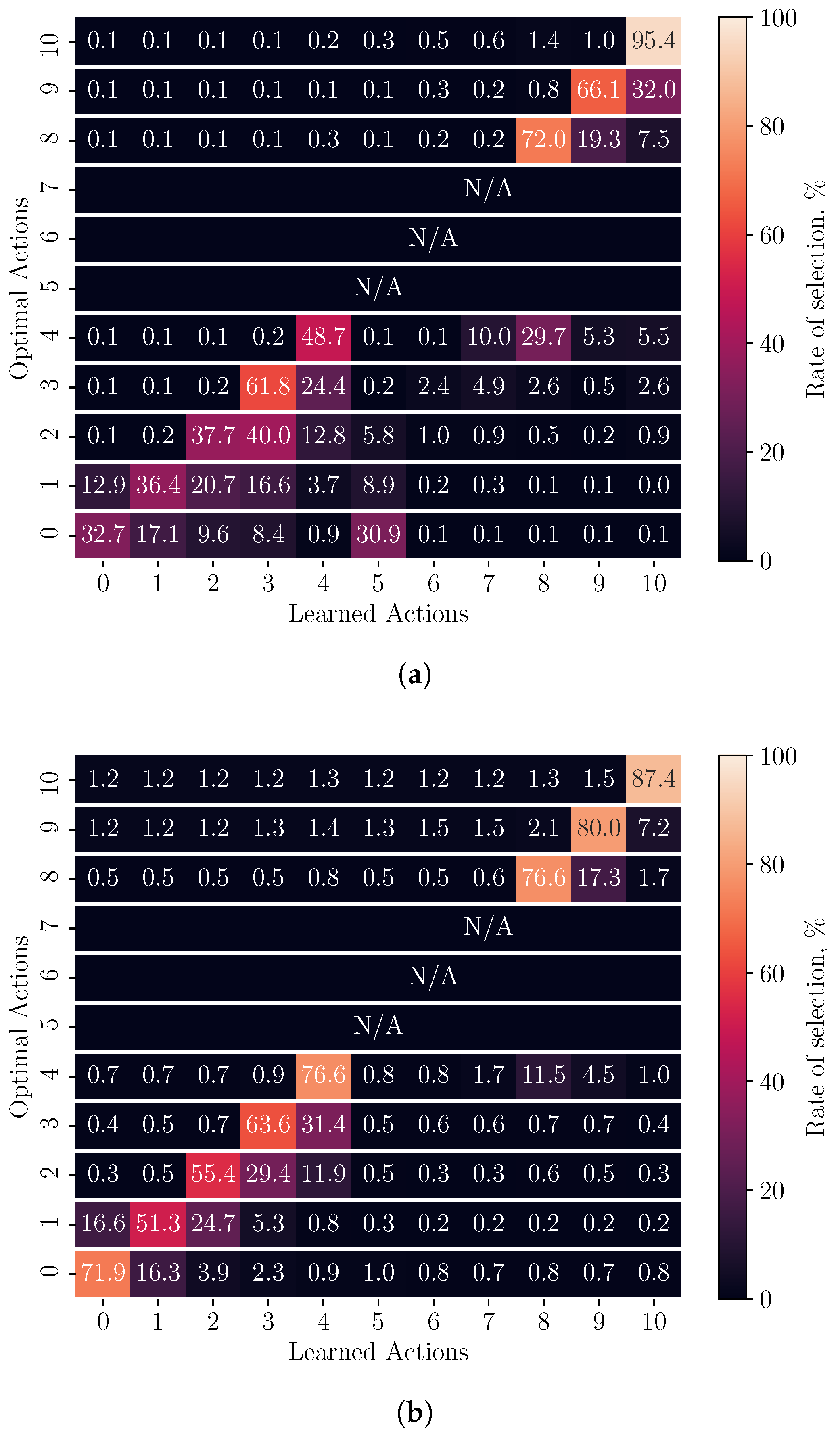
4.1. Adaptive Exploration Policy Evaluation
4.2. Adaptive Exploration Performance Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BPSK | Binary Phase Shift Keying |
| GM-SARSA | Greatest-Mass Multiple-Goal Reinforcement Learning with Modular SARSA |
| IoT | Internet of Things |
| MN(s) | Mobile Node(s) |
| MORL | Multi-Objective Reinforcement Learning |
| Multi-RAT | Multi-Radio Access Technology |
| QPSK | Quadrature Phase Shift Keying |
| RL | Reinforcement Learning |
| SARSA | State–Action–Reward–State–Action |
| SN(s) | Stationary Node(s) |
| TD | Temporal Difference |
| VDBE | Value-Difference-Based -greedy Exploration |
| WAMO-SARSA | Weighted Adaptive Multi-Objective SARSA |
| WSN(s) | Wireless Sensor Network(s) |
| WTDE | Weighted TD-Error |
References
- Chae, S.H.; Kim, T.; Hong, J.P. Distributed Multi-Radio Access Control for Decentralized OFDMA Multi-RAT Wireless Networks. IEEE Commun. Lett. 2021, 25, 1303–1307. [Google Scholar] [CrossRef]
- Hassan, W.; Farag, T. Adaptive Allocation Algorithm for Multi-Radio Multi-Channel Wireless Mesh Networks. Future Internet 2020, 12, 127. [Google Scholar] [CrossRef]
- Pérez, E.; Parada, R.; Monzo, C. Global Emergency System Based on WPAN and LPWAN Hybrid Networks. Sensors 2022, 22, 7921. [Google Scholar] [CrossRef] [PubMed]
- Ligios, M.; Delgado, M.T.; Conzon, D.; Rossini, R.; Sottile, F.; Pastrone, C. Cognitive-Based Multi-Radio Prototype for Industrial Environment. Ann. Telecommun. 2018, 73, 665–676. [Google Scholar] [CrossRef]
- Roy, A.; Chaporkar, P.; Karandikar, A. Optimal Radio Access Technology Selection Algorithm for LTE-WiFi Network. IEEE Trans. Veh. Technol. 2018, 67, 6446–6460. [Google Scholar] [CrossRef]
- Yan, M.; Feng, G.; Zhou, J.; Qin, S. Smart Multi-RAT Access Based on Multiagent Reinforcement Learning. IEEE Trans. Veh. Technol. 2018, 67, 4539–4551. [Google Scholar] [CrossRef]
- Chincoli, M.; Liotta, A. Self-Learning Power Control in Wireless Sensor Networks. Sensors 2018, 18, 375. [Google Scholar] [CrossRef] [PubMed]
- Gummeson, J.; Ganesan, D.; Corner, M.; Shenoy, P. An Adaptive Link Layer for Heterogeneous Multi-Radio Mobile Sensor Networks. IEEE J. Sel. Areas Commun. 2010, 28, 1094–1104. [Google Scholar] [CrossRef]
- Wang, X.; Li, J.; Wang, L.; Yang, C.; Han, Z. Intelligent User-Centric Network Selection: A Model-Driven Reinforcement Learning Framework. IEEE Access 2019, 7, 21645–21661. [Google Scholar] [CrossRef]
- Liu, C.; Xu, X.; Hu, D. Multiobjective Reinforcement Learning: A Comprehensive Overview. IEEE Trans. Syst. Man Cybern. Syst. 2015, 45, 385–398. [Google Scholar] [CrossRef]
- Camp, T.; Boleng, J.; Davies, V. A Survey of Mobility Models for Ad Hoc Network Research. Wirel. Commun. Mob. Comput. 2002, 2, 483–502. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Wes McKinney. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 56–61. [Google Scholar] [CrossRef]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. Openai gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- ANSI/IEEE Std 802.11; Standard for Information Technology—Telecommunications and Information Exchange between Systems—Local and Metropolitan Area Networks—Specific Requirements—Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications. IEEE: Piscataway, NJ, USA, 1998; pp. 1–512.
- IEEE Std 802.15.4-2006; IEEE Standard for Information Technology—Local and Metropolitan Area Networks—Specific Requirements—Part 15.4: Wireless Medium Access Control (MAC) and Physical Layer (PHY) Specifications for Low Rate Wireless Personal Area Networks (WPANs). IEEE: Piscataway, NJ, USA, 2006; pp. 1–320.
- Grześ, M.; Kudenko, D. Online Learning of Shaping Rewards in Reinforcement Learning. Neural Netw. 2010, 23, 541–550. [Google Scholar] [CrossRef] [PubMed]
- Tokic, M. Adaptive ϵ-Greedy Exploration in Reinforcement Learning Based on Value Differences. In Proceedings of the Annual Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2010; pp. 203–210. [Google Scholar]
- Sprague, N.; Ballard, D. Multiple-Goal Reinforcement Learning with Modular Sarsa(O). In Proceedings of the 18th International Joint Conference on Artificial Intelligence, IJCAI’03, San Francisco, CA, USA,, 12–14 May 2003; pp. 1445–1447. [Google Scholar]
- Tokic, M.; Palm, G. Value-Difference Based Exploration: Adaptive Control between Epsilon-Greedy and Softmax. In KI 2011: Advances in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7006, pp. 335–346. [Google Scholar]
- Sokolova, M.; Lapalme, G. A Systematic Analysis of Performance Measures for Classification Tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | IEEE802.11b [16] | IEEE802.15.4 [17] |
|---|---|---|
| Operating voltage (V) | 3.3 | 3.3 |
| Frequency (MHz) | 2400 | 915 |
| Bandwidth (MHz) | 20 | 2 |
| Bitrate (Kbps) | 11,000 | 250 |
| Modulation | BPSK | QPSK |
| Receiver sensitivity (dBm) | −97 | −110 |
| MTU (bytes) | 2346 | 127 |
| Decayed | Adaptive | |
|---|---|---|
| Precision | 0.62 | 0.72 |
| Recall | 0.56 | 0.70 |
| F1-score | 0.59 | 0.71 |
| Environment | Data Tx, MB | PLR, % | Power, Wh | |||
|---|---|---|---|---|---|---|
| Decayed | Adaptive | Decayed | Adaptive | Decayed | Adaptive | |
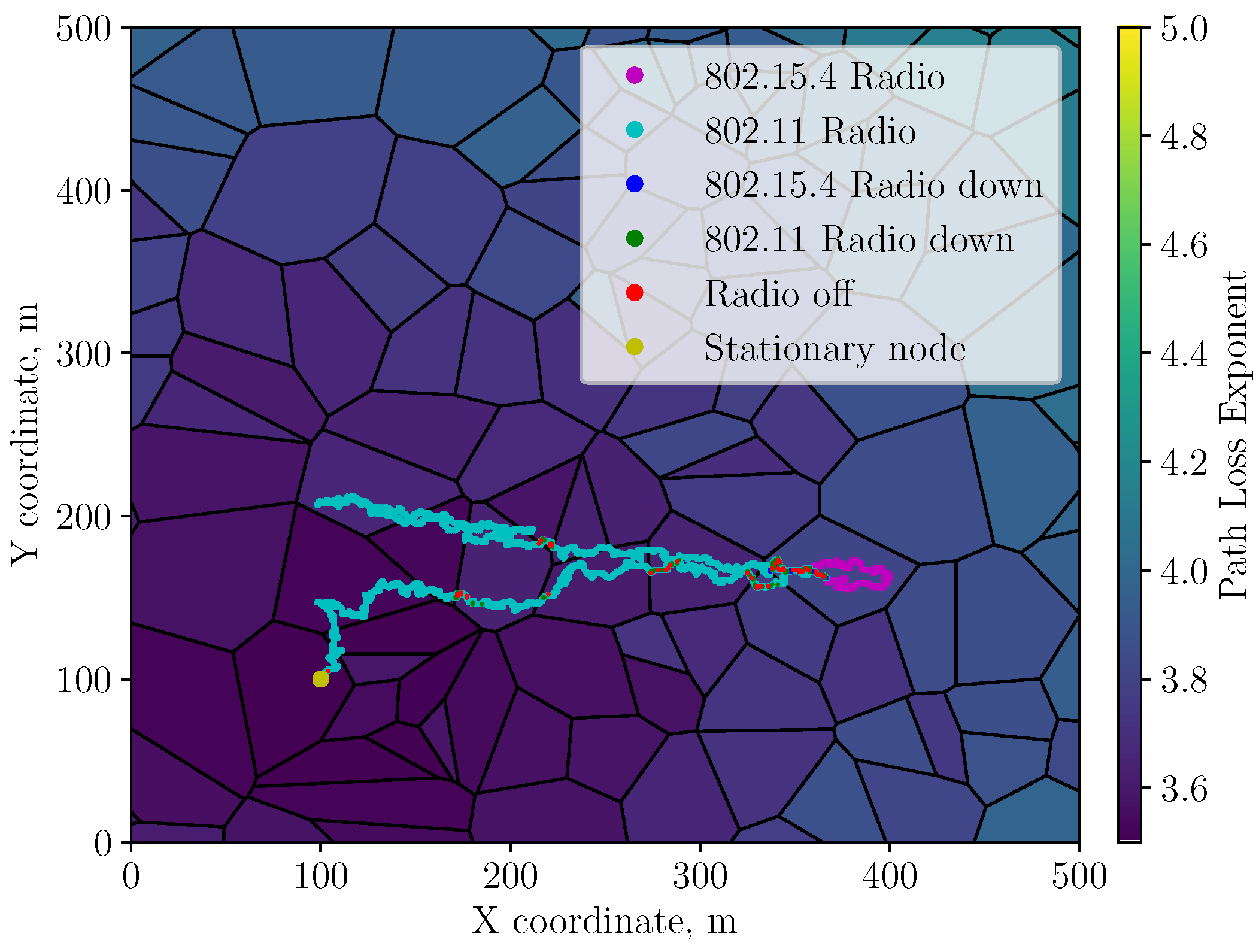
| Linear return (Figure 1) | 103.04 | 110.21 | 15.77 | 3.40 | 0.50 | 0.58 |
| Far boundary | 64.82 | 75.42 | 25.31 | 11.21 | 0.24 | 0.32 |
| Near return | 112.85 | 116.42 | 7.25 | 1.57 | 0.58 | 0.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Delaney, J.; Dowey, S.; Cheng, C.-T. Reinforcement-Learning-Based Robust Resource Management for Multi-Radio Systems. Sensors 2023, 23, 4821. https://doi.org/10.3390/s23104821
Delaney J, Dowey S, Cheng C-T. Reinforcement-Learning-Based Robust Resource Management for Multi-Radio Systems. Sensors. 2023; 23(10):4821. https://doi.org/10.3390/s23104821
Chicago/Turabian StyleDelaney, James, Steve Dowey, and Chi-Tsun Cheng. 2023. "Reinforcement-Learning-Based Robust Resource Management for Multi-Radio Systems" Sensors 23, no. 10: 4821. https://doi.org/10.3390/s23104821
APA StyleDelaney, J., Dowey, S., & Cheng, C. -T. (2023). Reinforcement-Learning-Based Robust Resource Management for Multi-Radio Systems. Sensors, 23(10), 4821. https://doi.org/10.3390/s23104821